Abstract
Estimating forest area at a national scale within the United Nations program of Reducing Emissions from Deforestation and Forest Degradation (REDD) is primarily based on land cover information using remote sensing technologies. Timely delivery for a country of a size like Mexico can only be achieved in a standardized and cost-effective manner by automatic image classification. This paper describes the operational land cover monitoring system for Mexico. It utilizes national-scale cartographic reference data, all available Landsat satellite imagery, and field inventory data for validation. Seven annual national land cover maps between 1993 and 2008 were produced. The classification scheme defined 9 and 12 classes at two hierarchical levels. Overall accuracies achieved were up to 76%. Tropical and temperate forest was classified with accuracy up to 78% and 82%, respectively. Although specifically designed for the needs of Mexico, the general process is suitable for other participating countries in the REDD+ program to comply with guidelines on standardization and transparency of methods and to assure comparability. However, reporting of change is ill-advised based on the annual land cover products and a combination of annual land cover and change detection algorithms is suggested.1. Introduction
“At present, REDD pilot projects are sprouting up in communities around the tropics, often using government funds or in some cases carbon credits that have been issued on voluntary carbon markets. As helpful as these individual projects might be for improving people’s livelihoods and preserving local biodiversity, however, it’s not clear that they measurably reduce global-warming emissions. To realize the full promise of REDD—and to tap into the much larger flows of private money expected in future carbon markets—nations must ultimately manage their forests on a national scale” [1].
During the 16th session of the Conference of the Parties of the United Nations Framework Convention on Climate Change (UNFCCC) in Cancun in November 2010, Mexico presented its envisaged national strategy for the United Nations program of Reducing Emissions from Deforestation and Forest Degradation (REDD+). Mexico is going to use its National Forest and Soils Inventory (INFyS) and satellite-based remote sensing technologies as instruments for developing a robust national Measuring, Reporting, and Verification (MRV) system in which the state and change of land cover plays a key role for activity data (AD) monitoring. The specific requirements for a MRV system in Mexico with one hectare reporting units limit the available satellite data sources to establish a historic record to the Landsat system with 30 m spatial resolution and wall-to-wall national coverage with systematic image acquisitions.
The state and change of the land cover in Mexico has been characterized by several regional studies utilizing Landsat data and applying different class schemes, e.g., in Southern Mexico [2], eastern Coastal Mexico [3], Northwestern coastal Mexico [4], Southern Yucatan [5], the states of Campeche [6], or Chihuahua [7]. Only a few studies attempted mapping at the national level. The North American Landscape Characterization mapped 12 classes with Landsat Multispectral Scanner (MSS) and Thematic Mapper (TM) triplicates at 60 m spatial resolution but classification accuracy of 60% to 67% was too low for spatially explicit change detection [8]. Continental studies map or monitor the land cover of Mexico using 250 m MODIS [9–11] and 500 m MODIS [12,13] but the spatial resolution is too coarse for MRV systems. The Mexican National Institute of Statistics and Geography (Instituto Nacional de Estadística y Geografía, INEGI) provided several national vegetation type maps at a scale 1:250,000 with about 70 classes [14,15]. In addition to an inappropriate scale for a MRV system, mapping inconsistencies due to differences in geometry and class definitions, as well as mapping sources make change detection from map to map comparison not recommendable. The full potential of the entire Landsat archive for automated wall-to-wall land cover mapping and change monitoring of Mexico has up to date not been explored. One of the aims of the MRV-AD monitoring system is to provide standardized annual wall-to-wall land cover products. Timely delivery for a country of a size like Mexico with two million km2 can only be achieved in a standardized and cost-beneficial manner by automatic classification of remote sensing imagery.
The paper presents the MAD-MEX system (Monitoring Activity Data for the Mexican REDD+ program) for automatic wall-to-wall baseline land cover mapping. It is the aim of the MAD-MEX system to deliver, standardized national land cover products in timely and transparent fashion at a given reported classification accuracy. This will serve as the prime base product for further (visual) interpretation and enhanced land cover class assignment. We deem this the only feasible method to frequently update national land cover and land use products at a production scale of 1:100,000.
For the historical baseline mapping the complete Landsat archive containing all imagery recorded over Mexico utilizing ETM+ and TM sensor data are used. The classification process follows an object-oriented “Map-to-Image” approach, i.e., utilizing existing cartographic land use information at high thematic resolution as base information for classification training. All available Landsat data are used that meet the defined quality criteria, which is currently a maximum cloud cover threshold of ten percent. However, the cloud coverage threshold has only been applied for the classifications for the years 1993 to 2000. Multi-temporal metrics are calculated on pre-processed Landsat scenes for a given year. Image objects are derived by image segmentation and object features are extracted from the multi-temporal metrics. Initial thematic mapping against the base land use map is done and forms the basis for classificatory training. Subsequent decision tree classification is performed using the object features. Final product validation and class aggregation is done on independent field inventory data. National land cover products have been processed for the years 1993, 1995, 1997, 2000, 2002, 2005, and 2008.
2. Data
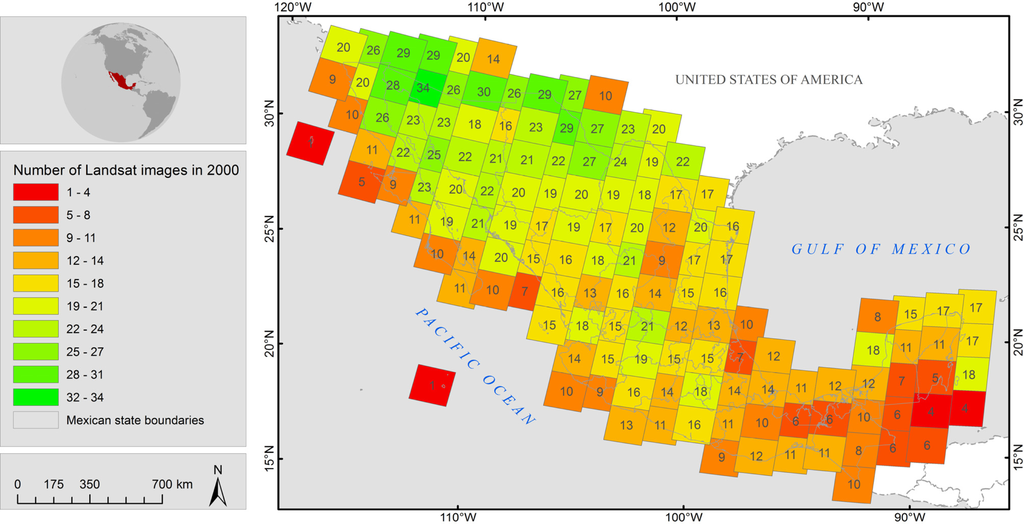
All available Landsat7 ETM+ and Landsat5 TM L1T data acquired over Mexico in the respective years with cloud cover less than 10 percent have been used. For the years 2002, 2005, and 2008, the cloud threshold has been neglected. A wall-to-wall coverage of the whole country requires 135 distinct tiles (path/row). For the years 1993, 1995, 1997, 2000, 2002, 2005, and 2008, a total of 1081, 964, 1005, 2173, 2518, 3696, 5706 images, respectively, were employed. Figure 1 displays the quantitative distribution of Landsat scenes for the year 2000 indicating unequal distribution of the number of image acquisitions that meet the given cloud coverage criteria. Naturally, the number of available scenes is lower in southern regions dominated by frequent cloud coverage during rainy season.
A national Digital Elevation Model (DEM) dataset has been provided by INEGI. The Continuous Mexican Elevation Dataset (Continuo Mexicano de Elevaciones CEM versión 2.0) is based on the interpolation of elevation contours at 1:50,000, geodetic points, and also the hydrographic network and water bodies at a scale of 1:50,000. Its final version 2.0 has been produced in 2010 and data are available continuously for the whole country as raster datasets with approximately 30 m pixel size. In addition to the actual elevation values we derived slope and aspect values.
The National Institute of Statistics and Geography of Mexico (INEGI) create and publish vegetation type maps (uso de suelo y vegetación, USV) for the national level at a scale of 1:250,000 using a 25 hectare minimum mapping unit. Those maps differentiate about 70 thematic classes including different vegetation types and areas devoted to agriculture, livestock, and forestry. They also include specific information on representative plant species vegetation classes. Four map series have been published, in brackets the years of reference satellite data used for the respective products are given: USV I (1979–1991), USV II (1993–1999), USV III (2002–2004) [14], USV IV (2005–2007) [15], and an update to USV V has been released by INEGI as of October, 2013. For generating a national land cover reference dataset we utilized INEGI USV series II, III, and IV.
INEGI’s map production process includes (i) manual preliminary interpretation and on-screen digitizing of available satellite imagery (Landsat, SPOT); (ii) field verification in selected information sites, whereby for the so called “checkpoints” detailed information is measured and for the “observation” points only qualitative information on vegetation type and land use is collected. Verification is either done in-field or supported by helicopters in remote areas; (iii) reinterpretation based on field verification results and comparative analysis with the previous map series; (iv) analysis and integration of information to object polygons; and finally; (v) the map edition yielding in a vector map comprising different information layers on vegetation types, vegetation ecosystems, agricultural usage and others, such as urban areas or water bodies.
Sample data from different national inventories have been used to assess the classification accuracy of land cover products. Forestry samples were provided by the National Forestry Commission (Comisión Nacional Forestal) [16]. The Colegio de Posgraduados (COLPOS) and the Secretaría de la Reforma Agraria (SRA) provided samples for grassland and agricultural land use [17,18] and INEGI for urban areas [19].
3. Classification Scheme
A hierarchical national land cover classification scheme at two levels has been defined. The initial classification scheme of 13 designated land cover classes has been defined by INEGI, CONAFOR, the National Commission for Knowledge and Use of Biodiversity (Comisión Nacional para el Conocimiento y Uso de la Biodiversidad, CONABIO), and the National Institute of Ecology and Climate Change (Instituto Nacional de Ecología y Cambio Climático, INECC) [20]. Additionally a level one classification scheme was defined with ten classes. Since a “snow and ice” class is not available in the reference maps and only occurs on some vulcan mountain tops, this class has been eliminated. This led to a final classification scheme of 9 and 12 classes at two levels, respectively (Table 1).

4. Methods
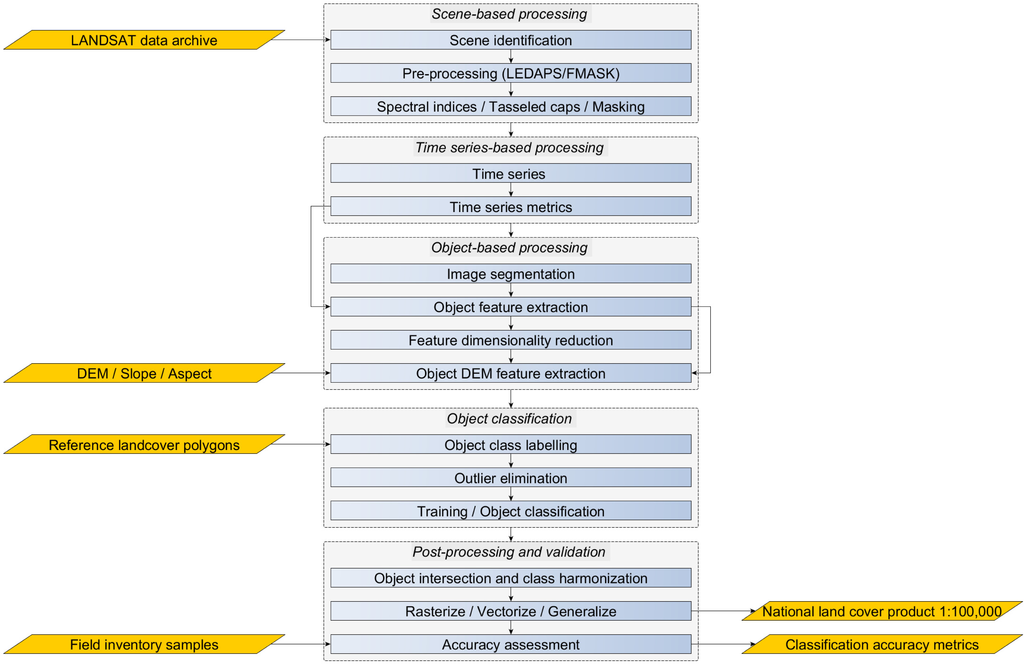
Due to varying numbers of available Landsat images per path/row at different times of a given year, processing was performed on frame stacks with the available Landsat imagery. Figure 2 provides an overview of the individual processes grouped in five general steps. The methodology applies all available satellite imagery over only a few clear observations or even country mosaics to benefit from the full multi-temporal measurements and not to lose that information by temporal aggregation.
4.1. Data Processing
Frame-based (path/row) processing includes the identification and extraction of all Landsat scenes from the data archive followed by several preprocessing steps. Each Landsat scene was radiometrically calibrated to top-of-atmosphere (TOA) and surface reflectance using the Landsat Ecosystem Disturbance Adaptive Processing System (LEDAPS) [21–23]. The FMASK algorithm [24] masks pixels which are classified as cloud, shadow, water, and no-data. The Normalized Difference Vegetation Index (NDVI), Enhanced Vegetation Index (EVI), Simple Ratio Index (SR), and Atmospherically Resistant Vegetation Index (ARVI) were calculated from surface reflectance images. Based on the TOA reflectance the 6 Tasseled Cap components (TC1-TC6) were calculated using the transformation coefficients described in [25,26].
Once all scenes for one path/row were preprocessed we formed ten annual time series (TS) of NDVI, EVI, SR, ARVI, and the six Tasseled Cap components As suggested by several other studies [9,27,28] simple temporal metrics (minimum, maximum, range, average, and standard deviation) were calculated from the ten time series. This calculation was only applied to pixels with valid observations (not flagged by FMASK as cloud or shadow) and has the potential to mitigate the effect of remaining erroneous data. The temporal feature set yields 50 dimensions (five multi-temporal metrics applied to ten time series).
Image segmentation [29,30] was performed on the multi-temporal NDVI metrics using the Berkeley Image Segmentation software. From empirical tests the respective segmentation parameter compactness was set to 0.5, shape to 0.5, and the iteration threshold to 5. NDVI metrics proved sufficient to represent seasonal variations during the course of the year. For each image segment a simple set of object metrics (minimum, maximum, average, and standard deviation) were computed from temporal features (the five multi-temporal metrics applied from the ten time series), resulting in a set of image samples represented by 200 attributes/features.
Principal component analysis was subsequently applied on the beforehand extracted object features in order to reduce information redundancy in the feature metrics by reducing the feature space to a dimension in which only statistically significant features are condensed. Principal components were ranked according to their explanatory power. Only those principal components were chosen for further analysis where the cumulative explained variability of the top principal components reached a threshold of 95%.
In addition, we introduced information from the digital elevation model to the object feature space. For each image segment, descriptive statistics (minimum, maximum, average, and standard deviation) from the DEM, the derived slope and aspect raster images were calculated, respectively. For doing so DEM and derived images were transformed on-the-fly to fit to the current Landsat frame map properties and image dimensions.
4.2. Training Dataset Generation
The thematic class from the INEGI USV reference map objects has been assigned to all image objects which geometry were spatially completely within that USV map object. This step is critical because these reference maps do also provide errors mainly due to the degree of manual interpretation and the cartographic generalization resulting in discrepancies due to labeling errors and positional errors [31]. In order not to propagate such errors into the classification training process (i) a persistency analysis on the INEGI USV series II to IV; and (ii) an outlier elimination as described below were performed. For persistency analysis all INEGI USV map series II to IV were intersected against each other and new objects having new geometries were generated by conserving their respective original attributes. Finally, only those objects were kept, which land use attributes have been constant over all three map series. Land cover information according to the defined scheme at all levels has finally been assigned to each object. CONAFOR and INEGI have delivered the translation of INEGI USV land use and vegetation type classes to the designated classification scheme. The scale of INEGI USV is 1:250,000 with a MMU of 25 hectare while a 30 m Landsat-based land cover map results in a conservative scale of 1:100,000 [32] (following the rule of thumb “Scale = Resolution (in meters) × 2 × 1000”). Thus, many of the object samples are being labeled with a potentially wrong thematic class because a map object of INEGI USV consists of many segmented image objects that should be labeled to different classes. We do recognize this as a source of error. However, INEGI USVs are the only available spatially-explicit and thematically-detailed data source at the national level at a rather high percentage of accurately labeled objects at its given scale and mapping unit. To identify erroneous object samples subsequently to be excluded from classification training an outlier analysis was performed. In order to do this, iterative histogram trimming over the first three features (principal components) over all image object samples and all land cover classes was applied. The concept of iterative trimming has been utilized by Radoux and Defourny for the object based detection of forest changes [33,34]. However, the approach is also suitable in order to produce “pure” image-objects as basis for classification training. The hypothesis behind iterative trimming is that objects belonging to the same class share the same distribution over their describing features. The distribution is described by the probability density function calculated by the non-parametric Kernel Density Estimation (KDE). Outliers were excluded based on a probability density threshold and the new parameters of the distribution were reprocessed until all objects showed to be above the threshold. We chose a rather strict initial probability threshold. The threshold has been dynamically calculated as the probability value which scored at the 25% histogram percentile value. This will cause an initial reduction to only those 75% percent of objects which are most probable and then iteratively further reduces the objects until all of the remainder are above the threshold.
4.3. Classification
Training of the classifier utilized only those objects remaining after outlier elimination. Classification was performed with supervised C5.0 decision tree algorithms [35,36], which are robust, non-parametric, do not suffer the curse of dimensionality as they only focus on the important features, are resource efficient, and work well on noisy data. For each Landsat frame a ten-folded C5.0 decision tree was trained from the training object samples and applied to the entire set of image objects.
Resulting classified objects amounted in average to 40,000,000 for the whole country. Since the Landsat frame system provides an overlap over neighboring frames, many objects intersect spatially. Objects from overlapping classifications have subsequently been intersected to new geometries by preserving their origin attributes, namely the predicted class and the C5.0 classification confidence value. Each object’s predicted class has been relabeled to the class that had been predicted at higher confidence. To speed up subsequent geo-processing and to support meaningful data distribution classified vector polygons were converted to raster representation and mosaicked to a 30 m national raster dataset. Finally, small objects below the minimum mapping unit were removed by applying morphological image closing.
4.4. Validation
Results from object classification for the year 2000 were validated against point samples from the different field inventories. All annual land cover products were validated, however, the year 2000 land cover dataset was chosen as a reference data set because of the best satellite data availability from the Landsat TM and still intact (until the 2003 scanline failure) ETM+ sensors.
Due to a too small number of samples for each path/row (Landsat frame) validation was performed at the national level. Utilizing all available reference points from the forest inventory (INFyS) would have introduced an error which will negatively propagate into the validation results. This error is primarily based on the scale difference between image classification and field inventory size. The four sub-plots (of app. 400 m2 each) representing one permanent inventory plot of approximately one hectare do not necessarily feature one land use class. Therefore, only those forest inventory reference points were employed for validation which sub-plots feature the same land cover class. Plots which meet this criterion are represented by only one point which is the centroid of the four sub-plot reference points.
Random area-weighted stratified sampling was performed by using the land cover classes from the INEGI USV reference map as strata. The validation procedure followed the protocol described by Olofsson et al. [37]. For stratified sampling a total of 5000 (#1) and 10,000 (#2) points to be used for validation were defined and have been randomly extracted for each class with respect to the class area weight Wi (see Table 2) calculated as Wi = Am,i/Atot with Am,i being the mapped area of class i and Atot being the total area mapped, both calculated from the official INEGI USV III map. The final samples per class have then simply been calculated as Si = Wi × Stot, with Si being the samples per class and Stot the assigned maximum number of samples. The sampling was done in five independent iterations in order to analyze stability of validation results over different combinations and number of sample points. In addition, validation utilizing all available point samples was done. Validation was done for all the annual land cover products, even if the years of field sample acquisition do not correspond. However, they are the only sources available on a national scale and one can assume that actual land cover change rates over the years are very small so that the majority of the sample points preserve their land cover label. Validation delivered overall accuracies for each land cover product over the different sample sizes and classification schemes. For the year 2000, class based producers and users accuracies were derived from the error matrix as also from the error-adjusted area estimates along with their confidence intervals. Finally, comparisons of the resulting year 2000 national map against the respective INEGI map series with respect to the area proportion of each class were performed.
5. Results
We used persistent areas calculated from the INEGI series II to IV as initial reference objects. This reduced the national USV dataset of approximately 1,950,000 km2 by 23% to 1,500,000 km2. Subsequent outlier elimination generated the final training objects representing approximately 780,000 km2 (area derived from the year 2000 classification). The final training dataset represents 40% of the whole country (Figure 3).
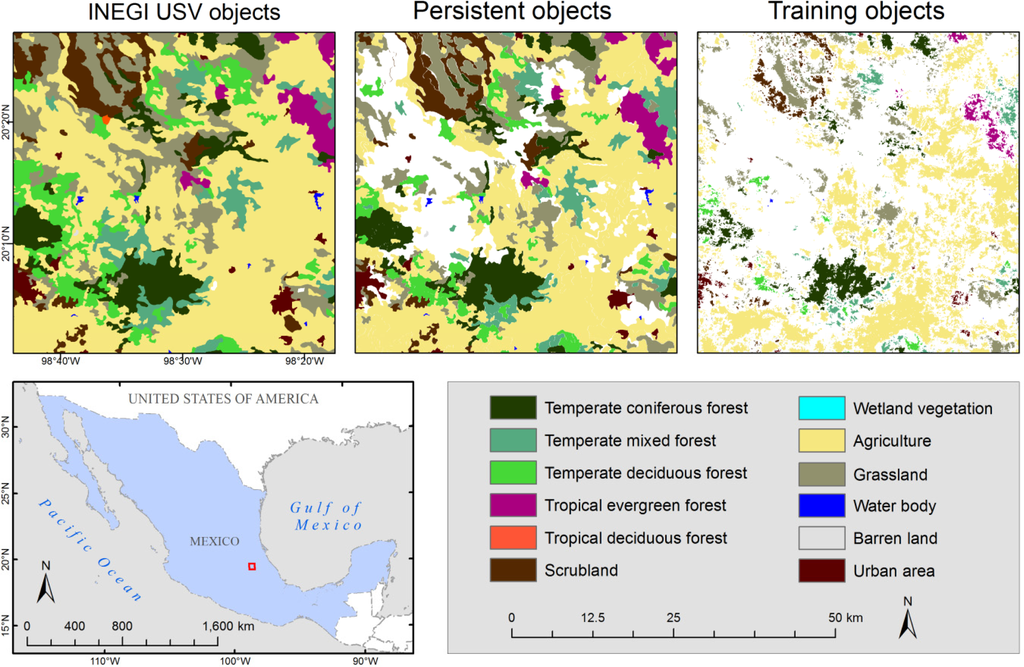
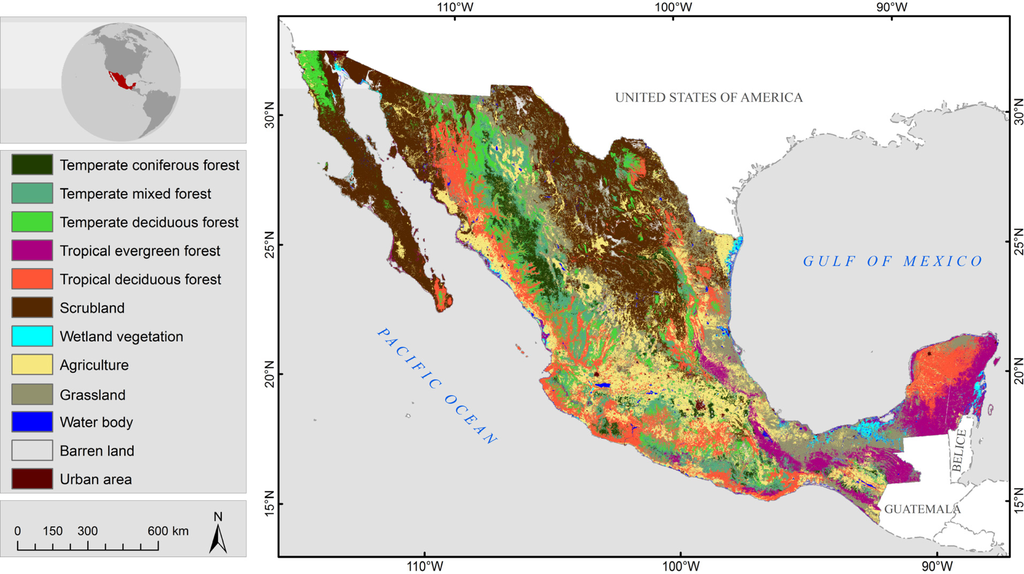
National land cover products for the years 1993, 1995, 1997, and 2000 have been processed at the Mexican National Commission for Knowledge and Use of Biodiversity (CONABIO). Products for 2002, 2005, and 2008 were processed at the Woods Hole Research Center (WHRC). Utilizing a processing cluster of 20 processing nodes at CONABIO and 14 nodes at WHRC full processing of one year land cover map took at longest one week. As an example a map showing the national land cover product for the year 2000 is given in Figure 4 with the classes labeled to level 2. Figure 5 shows a comparison of the MAD-MEX land cover products 1993, 1995, and 2000 against the INEGI USV series III product highlighting the higher scale and geometric detail of objects in the land cover classification products.

Overall accuracy for the validations of the 1993, 1995, and 2000 land cover products is given in Table 3. This result is based on five iterations over 5000 and 9321 randomly selected samples and also one validation utilizing all available sample data. Utilizing 5000 sample points overall accuracies at level 2 rate 70% to 72% for all years. For the 9321 sample points similar accuracies between 69% and 71% were achieved. When validating against level 1 overall accuracies increase to 75%–77%. Comparing values retrieved for using either 5000 or 9321 sample points exhibit no apparent difference in calculated accuracies. The overall accuracies derived from using all available sample points, however, are lower, rating between 62% and 66%. These are very much influenced by the unequal and non-stratified distribution of samples available per class especially with disproportionate amount of samples in the grassland class.
Class based producers and users accuracies for the validations of the year 2000 land cover product using 9321 randomly sampled validation points against level 1 and 2 of the classification scheme derived from the error matrix are given in Table 4. Good agreements of classification results with validation data have been found for tropical evergreen forest (74.9%–78.8%), scrubland (80.7%), agriculture (75.4%–78.5%), and barren land (72.0%–88.0%). Only moderate results were achieved for tropical deciduous forest (68.5%–70.1%), wetland vegetation (64.8%–68.5%), urban areas (64.1%–73.4%), and water bodies (59.5%–68.9%) as also for the grassland class (61.6%–68.9%). The temperate forest classes in general were classified poorly ranging roughly 50% to 60%. At level 1 the aggregated class for temperate forests rates very high with producers accuracies between 78.8% and 82.1%. The respective class representing the tropical forests also yields in high accuracies (76.2%–77.5%).
Table 5 shows the error matrix for the validation against the 9321 points retrieved for the first iteration of the validation of the MAD-MEX land cover 2000 map along with sample accuracies calculated from the estimated area proportions. Among the temperate forests one can observe the majority of confusions taking place between these three classes with 16.8% of actual temperate coniferous forest samples classified as temperate mixed forest; 12.7% of temperate deciduous forest wrongly classified as temperate mixed forest, and 27.2% and 9.6% of actual temperate mixed forest classified to temperate coniferous forest and temperate deciduous forest, respectively. We can also find 9.3% of temperate deciduous forest samples misclassified to tropical deciduous forest. Vice versa, 5.7% of tropical deciduous forest is classified as temperate deciduous forest. This can be explained with similar phenological patterns for these two broad-leaved forest types. Tropical deciduous forest further confuses with the evergreen forest class (5.2%), scrubland at a rate of 5.5% as also to grassland (5.5%). The latter can be explained by confusions of secondary woody and herbaceous forests to scrublands. With that, confusions to scrubland and grassland are likely to occur. Scrubland rates very high with major confusion of 5.4% to grassland. Barren land gets classified at an accuracy of 72.0% with the majority of errors (12.0%) towards scrubland. Wetland vegetation confuses with grassland with an error rate of 18.5%. This class is defined by Popal and Tular vegetation, which are herbaceous aquatic vegetation types in marshy places and the coastal plains. Having similar structure and being evergreen confusion with grassland is likely. Over almost all classes misclassifications to agriculture can be observed, especially and surprisingly for urban areas (25.0%). Major confusions of agriculture samples are found with the grassland class (13.8%) and vice versa with 18% of grassland samples classified as agriculture. Grassland further confuses with tropical evergreen and deciduous forests at rates of 5.5% and 6.6%. This might occur because the grassland samples received from COLPOS also assign livestock which often takes place within the tropical forests. Surprisingly, the relatively easy class of Water bodies confuses especially with Barren land. Reasons can be the availability of both permanent and non-permanent water bodies in the reference dataset and/or the under- and/or over representation of the water class in the INEGI USV training dataset in some regions. With respect to the confidence values standard errors above 15% in either produces or users accuracy are observed for water bodies, barren land, urban areas, and wetland vegetation. Those classes are mostly overestimated as can be seen by the poor Users accuracies values. However, all of those classes represent only very small area portions summing up to approximately 1% of the country area.
The national land cover classification for the year 2000 was compared to the INEGI USV III map. The total areas per class are presented in Table 6 with the areas being directly calculated from the INEGI USV map and the MAD-MEX 2000 product. In addition the area ranges as retrieved from the area adjusted error matrix and the standard errors in Table 5 are listed.
The total classified area shows clear discrepancies in between the MAD-MEX land cover map extend (1943.56 × 103 km2) and the INEGI map extend (1957.22 × 103 km2). This can be explained in two ways: (1) A country mask preserving only land information over Mexico was applied. To do this, we applied a buffer of 300 m to the vector dataset representing the Mexican national territory in order to account for generalization effects in the polygon dataset which was available at a scale of 1:250,000. The result of this is that we also classified coastal and boundary objects outside Mexico; (2) For individual years of classification, some areas could not be classified due to only one observation or a total lack of Landsat imagery, a phenomenon that occurred mainly over some small islands.
The total area of forest resulting from aggregating the areas of temperate and tropical forest types rates 761.04 × 103 km2 and 734.27 × 103 km2 in INEGI USV map and the MAD-MEX product, respectively. Other published statistics indicate a much lower forest area. For example the Global forest assessments by the Food and Agriculture Organization of the United Nations (FAO) reported 677,000–678,000 km2 for 1990, 2000, and 2010, respectively [38]. Other numbers are given by Mas et al. who reported a forest area of appr. 640,000 km2 for the year 2000 [31]. The MAD-MEX results disagree with those numbers with approximately 10% overestimation. However, the definition of the tropical deciduous forest class includes also subtropical and submontane scrub land and (tropical) mezquite woodland. This is actually in line with the current forest definition of Mexico which defines forests as plant communities, mainly of woody composition with 5 m height and 10% cover density (over ground) and of a minimum area of 0.5 ha. Moreover, subtropical scrubs are defined as a community of shrubs or small deciduous trees that grow in a transition zone between temperate forests, tropical deciduous forests and scrub. They represent a successive stage of the lower tropical deciduous forest (Selva baja caducifolia) [39]. Submontane scrubland is a community of sometimes very dense thorny or deciduous shrub species developing among the arid scrubland, oak forests and deciduous tropical forest with tree heights up to 5 m [39]. Likewise, mesquite trees reach a height of 20 m and can occur very dense especially the tropic mesquites. In the INEGI USV series III map that sum up to an area of 71,000 km2 which very well describes that overestimation.
Scrutinizing individual class based area proportions we find discrepancies between the MAD-MEX land cover maps and the respective USV map within their estimated error margins. Highest differences are observed for water bodies, barren land, urban areas, and wetland vegetation as already indicated by the error matrices. Measured and estimated total forest areas agree very well with the measured area in the reference INEGI map and the estimated error margin of only 5% that represent an area of about 40 × 103 km2 which is about 2% of the whole country.
6. Discussion
The applied standardized methodology and technical implementation provides robust and fast processing of thousands of Landsat data sets. The methodology is transparent, transferable, has a reported accuracy margin and delivers timely national land cover products. Within one week a wall-2-wall land cover map was produced. With respect to annual official national land cover production and reporting duties of INEGI and CONAFOR the automatic generation of the MAD-MEX may serve as the principal component of a future high frequency production chain sporting as well elements of visual interpretation over specific areas and classes.
The classification methodology applied relies on the availability of Landsat time series for a given path/row. This is a considerable constraint of the applied methodology. Having said this, we do recognize the overall difficulty in obtaining data, be it of active and passive sensors for large area coverage year round in the tropics.
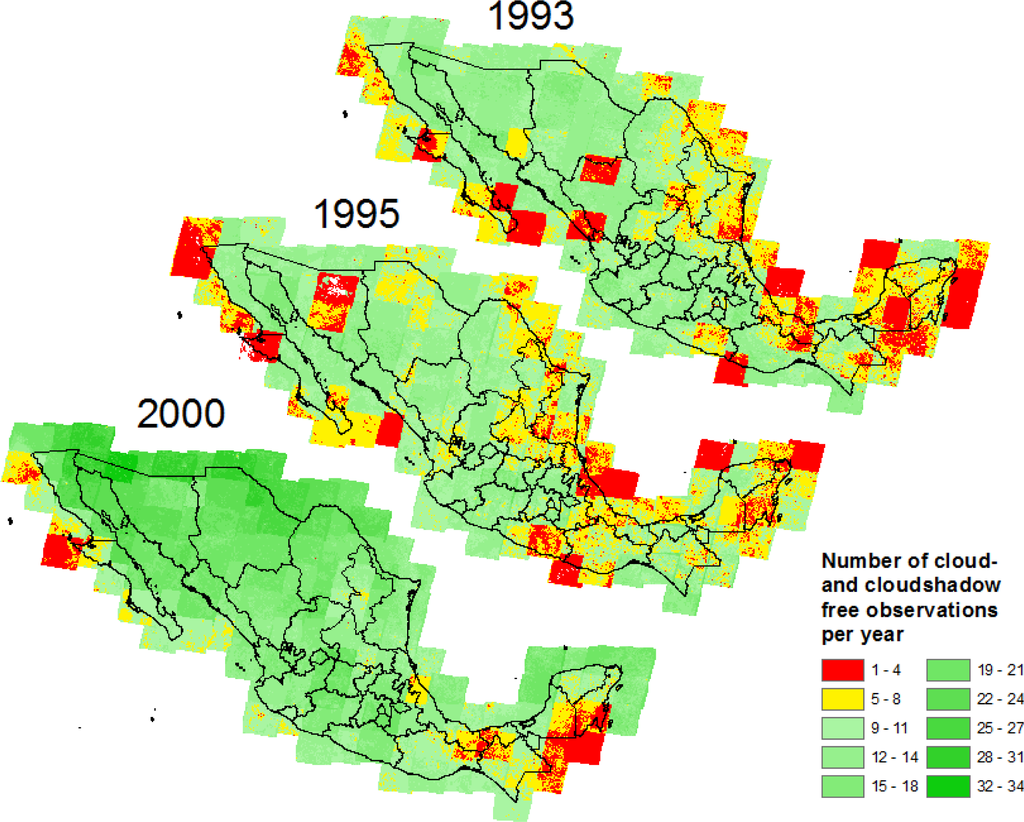
On top of scene availability the availability of pixels not obscured by cloud or cloud shadow is of outmost importance. Those must be well distributed over time in order to capture eventual land cover dynamics on the ground as related for example to agriculture patterns or vegetation phenology. The effects of insufficient availability of multi-temporal information will propagate errors starting with the time-series metrics calculation to the image segmentation and feature extraction (which is based on the metrics of the time series) to the final object classification. This might limit the applicability of the here-proposed method to countries on the outer margins of the inner tropics precisely not featuring very high precipitation levels. On the other hand, it might result in limited options of the inner tropical countries to produce multi-year composites of land cover sets instead of annual products such as we propose for Mexico. Figure 6 visualizes the number of clear pixels, i.e., not masked by FMASK as clouds or shadows, available for the years 1993, 1995, and 2000. In red we highlighted those pixels having fewer than five clear observations. In yellow we visualized those having five to eight clear observations. Comparing the maps one can easily see that for the years 1993 and 1995 many pixels might be underrepresented in a multi-temporal space. Many others can be described as critical having at maximum eight observations. Still the situation is not perfect in the year 2000; however, it appears to be the optimal year for generating the Mexican national reference land cover dataset.
The calculated maps provided very good classification results at the national scale when representing 9 distinct land cover classes. Classifying into the next higher land cover classification level representing 12 classes delivered unsatisfying results especially for the temperate forest classes. The numbers derived by product validation make obvious the weakness of the applied methodology to discriminate between the temperate forest types. In addition, the thematic depth especially over the forest types is very little. However, the full potential of what land cover classes can actually be derived with the given data and methodology has so far not fully been explored. We will, therefore, focus on a data driven class separability analysis also employing the available sample data plus expert knowledge to potentially derive an optimized national land cover classification scheme.
Main target of REDD+ is measuring and reporting deforestation and forest degradation which requires change analysis. The use of discrete land cover products as sole source is limited. It will propagate classification errors into the change products and derived change metrics. Our maps have a distinct error margin for each class. Even if we classified for some classes with very high accuracy, the error will always be greater than the rate of change for this specific class. Thus, a reporting of changes based on comparing discrete land cover maps is ill-advised. We therefore propose the combination of data driven change detection algorithms in combination with the land cover products for final assignation of the qualitative change i.e., the actual change class.
7. Conclusions
We presented the MAD-MEX system supporting automatic wall-2-wall land cover classification using the full Landsat data archive. The system is developed against open source technology with the Berkeley Image Segmentation being the only commercial product. The system makes use of existing cluster infrastructures and over that supports parallel processing. It is stable and fast as it can process a national land cover map for Mexico with an area of two million square kilometers in a few days. MAD-MEX is easily configurable and transferable to other institutions hardware systems.
The methodology applied for land cover classification relies on the availability of multiple Landsat acquisitions per year with as many as possible cloud- and shadow free pixels. In addition, it requires a national reference dataset at a defined thematic scheme. The implemented outlier elimination allows for the integration of generalized reference dataset as in the case of Mexico with the INEGI USV maps at 1:250,000.
We calculated six national land cover products at defined 9 and 12 classes at a scale of 1:100,000 for years from 1993 to 2008. The maps are in very well agreement with other national products. Validation was done on available field samples providing moderate to high classification accuracies. The results stimulate further investigations on the definition of a national land cover legend using feature- and validation driven class separability analysis.
The Landsat-based land cover products calculated by MAD-MEX serve as the principal products in Activity Data Monitoring in the Mexican REDD-MRV activities. They source not only the baseline estimation but will also be processed for future annual monitoring at the respective 1:100,000 map scale. Given the fact, that MAD-MEX—transparently and standardized—produces a map with standardized thematic scheme and reported classification accuracies in within a few days, manual post-processing steps including error removal, assignation of higher thematic detail, enhanced validation, and final product publication are easily achievable in within one year.
Acknowledgments
The authors thank the Mexican Ministry of Environment and the Norwegian Ministry of Foreign Affairs for the funding of the project “Reinforcing REDD+ and South-South Cooperation” and the Centre for International Migration and Development (CIM) for providing resource funding.
Author Contributions
The research has been designed by Steffen Gebhardt, Thilo Wehrmann, and Michael Schmidt. The MAD-MEX system has been designed and implemented at the National Commission for the Knowledge and Use of Biodiversity (CONABIO) by Thilo Wehrmann, Steffen Gebhardt, Matthias Schramm, and Rene Kopeinig. Data processing at CONABIO was primarily conducted by Steffen Gebhardt. System installation and data processing at Woods Hole Research Center (WHRC) has been performed by Jesse Bishop, Oliver Cartus, and Josef Kellndorfer. Validation data collection and preparation was done by Miguel Angel Muñoz Ruiz and Pedro Maeda. Product validation was done by Steffen Gebhardt with support of Pedro Maeda in result interpretation. Rainer Ressl, Lucio Andrés Santos and Michael Schmidt have been responsible for project management and scientific advisory. The manuscript has been authored by Steffen Gebhardt, Josef Kellndorfer, and Michael Schmidt.
Conflicts of Interest
The authors declare no conflict of interest.
References
- On the road to REDD. Nature 2009, 462, 11.
- Vaca, R.A.; Golicher, D.J.; Cayuela, L.; Hewson, J.; Steininger, M. Evidence of incipient forest transition in southern Mexico. PLoS One 2012, 7. [Google Scholar] [CrossRef]
- Crews-Meyer, K.A.; Hudson, P.F.; Colditz, R.R. Landscape complexity and remote classification in eastern coastal Mexico: Applications of Landsat-7 ETM+ data. Geocarto Int 2004, 19, 45–56. [Google Scholar]
- Alatorre, L.C.; Sánchez-Andrés, R.; Cirujano, S.; Beguería, S.; Sánchez-Carrillo, S. Identification of mangrove areas by remote sensing: The ROC curve technique applied to the northwestern Mexico coastal zone using Landsat imagery. Remote Sens 2011, 3, 1568–1583. [Google Scholar]
- Schmook, B.; Palmerj Dickson, R.; Sangermano, F.; Vadjunec, J.M.; Eastman, J.R.; Rogan, J. A step-wise land-cover classification of the tropical forests of the Southern Yucatan, Mexico. Int. J. Remote Sens 2011, 32, 1139–1164. [Google Scholar]
- Soto-Galera, E.; Piera, J.; López, P. Spatial and temporal land cover changes in Terminos Lagoon Reserve, Mexico. Rev. Biol. Trop 2010, 58, 565–575. [Google Scholar]
- Currit, N. Development of a remotely sensed, historical land-cover change database for rural Chihuahua, Mexico. Int. J. Appl. Earth Obs. Geoinf 2005, 7, 232–247. [Google Scholar]
- Lunetta, R.S.; Ediriwickrema, J.; Johnson, D.M.; Lyon, J.G.; McKerrow, A. Impacts of vegetation dynamics on the identification of land-cover change in a biologically complex community in North Carolina, USA. Remote Sens. Environ 2002, 82, 258–270. [Google Scholar]
- Clark, M.L.; Aide, T.M.; Riner, G. Land change for all municipalities in Latin America and the Caribbean assessed from 250-m MODIS imagery (2001–2010). Remote Sens. Environ 2012, 126, 84–103. [Google Scholar]
- Colditz, R.R.; López Saldaña, G.; Maeda, P.; Espinoza, J.A.; Tovar, C.M.; Hernández, A.V.; Benítez, C.Z.; Cruz López, I.; Ressl, R. Generation and analysis of the 2005 land cover map for Mexico using 250 m MODIS data. Remote Sens. Environ 2012, 123, 541–552. [Google Scholar]
- Latifovic, R.; Zhu, Z.L.; Cihlar, J.; Giri, C.; Olthof, I. Land cover mapping of north and central America—Global land cover 2000. Remote Sens. Environ 2004, 89, 116–127. [Google Scholar]
- Blanco, P.D.; Colditz, R.R.; López Saldaña, G.; Hardtke, L.A.; Llamas, R.M.; Mari, N.A.; Fischer, A.; Caride, C.; Aceñolaza, P.G.; del Valle, H.F.; et al. A land cover map of Latin America and the Caribbean in the framework of the SERENA project. Remote Sens. Environ 2013, 132, 13–31. [Google Scholar]
- Giri, C.; Jenkins, C. Land cover mapping of greater Mesoamerica using MODIS data. Can. J. Remote Sens 2005, 31, 274–282. [Google Scholar]
- INEGI Conjunto de Datos Vectoriales de la Carta de Uso del Suelo y Vegetación, Escala 1:250,000, Serie III (Continuo Nacional); Instituto Nacional de Estadística y Geografía (INEGI): Aguascalientes, Ags., México, 2005.
- INEGI Conjunto de Datos Vectoriales de la Carta de Uso del Suelo y Vegetación, Escala 1:250,000, Serie IV (Continuo Nacional); Instituto Nacional de Estadística y Geografía (INEGI): Aguascalientes, Ags., México, 2008.
- CONAFOR Inventario Nacional Forestal y de Suelos (INFyS 2004–2007); Comisión Nacional Forestal (CONAFOR): Zapopan, Jalisco, Mexico, 2007.
- COLPOS Classification of Agricultural Lands of Mexico; Colegio de Posgraduados (COLPOS), Segretaría de Agricultura, Ganadería, Desarrollo Rural, Pesca y Alimentacion de Mexico (SAGARPA): Texcoco, Estado de México, México, 2008.
- PROCEDE Registro Agrario Nacional (RAN)—Data from 1992 to 2006; Programa de Certificacion de Derechos Ejidales y Solares Urbanos (PROCEDE), Secretaría de la Reforma Agraria (SRA), Procuraduría Agraria (PA); Instituto Nacional de Estadística y Geografía (INEGI): Aguascalientes, Ags., México, 2006.
- INEGI Localidades de la República Mexicana, 2000; Instituto Nacional de Estadística y Geografía (INEGI): Aguascalientes, Ags., México, 2005.
- Avanzan en la Estandarización de Las Clases de Vegetación, Observador Forestal; 2013; Available online: http://www.mrv.mx/images/Observador_Forestal_02_Enero_2013.pdf (accessed on 17 April 2014).
- Masek, J.G.; Vermote, E.F.; Saleous, N.; Wolfe, R.; Hall, F.G.; Huemmrich, F.; Gao, F.; Kutler, J.; Lim, T.K. A Landsat surface reflectance dataset for north America, 1990–2000. IEEE Geosci. Remote Sens. Lett 2006, 3, 68–72. [Google Scholar]
- Masek, J.G.; Vermote, E.F.; Saleous, N.; Wolfe, R.; Hall, F.G.; Huemmrich, F.; Gao, F.; Kutler, J.; Lim, T.K. LEDAPS Landsat Calibration, Reflectance, Atmospheric Correction Preprocessing Code, Model Product; Oak Ridge National Laboratory Distributed Active Archive Center: Oak Ridge, TN, USA, 2012. [Google Scholar]
- Feng, M.; Huang, C.; Channan, S.; Vermote, E.F.; Masek, J.G.; Townshend, J.R. Quality assessment of Landsat surface reflectance products using MODIS data. Comput. Geosci 2012, 38, 9–22. [Google Scholar]
- Zhu, Z.; Woodcock, C.E. Object-based cloud and cloud shadow detection in Landsat imagery. Remote Sens. Environ 2012, 118, 83–94. [Google Scholar]
- Crist, E.P. A TM tasseled cap equivalent transformation for reflectance factor data. Remote Sens. Environ 1985, 17, 301–306. [Google Scholar]
- Huang, C.; Wylie, B.; Yang, L.; Homer, C.; Zylstra, G. Derivation of a tasselled cap transformation based on Landsat 7 at-satellite reflectance. Int. J. Remote Sens 2002, 23, 1741–1748. [Google Scholar]
- De Fries, R.S.; Hansen, M.; Townshend, J.R.G.; Sohlberg, R. Global land cover classifications at 8 km spatial resolution: The use of training data derived from Landsat imagery in decision tree classifiers. Int. J. Remote Sens 1998, 19, 3141–3168. [Google Scholar]
- Hansen, M.C.; Defries, R.S.; Townshend, J.R.G.; Sohlberg, R. Global land cover classification at 1 km spatial resolution using a classification tree approach. Int. J. Remote Sens 2000, 21, 1331–1364. [Google Scholar]
- Berkeley Image Segmentation; Berkeley Environmental Technology International, LLC.: Long Beach, CA, USA. Available online: http://www.imageseg.com/ (accessed on 17 April 2014).
- Clinton, N.; Holt, A.; Scarborough, J.; Yan, L.; Gong, P. Accuracy assessment measures for object-based image segmentation goodness. Photogramm. Eng. Remote Sens 2010, 76, 289–299. [Google Scholar]
- Mas, J.-F.; Velázquez, A.; Díaz-Gallegos, J.R.; Mayorga-Saucedo, R.; Alcántara, C.; Bocco, G.; Castro, R.; Fernández, T.; Pérez-Vega, A. Assessing land use/cover changes: A nationwide multidate spatial database for Mexico. Int. J. Appl. Earth Obs. Geoinf 2004, 5, 249–261. [Google Scholar]
- Chuvieco, E.; Huete, A. Fundamentals of Satellite Remote Sensing; CRC Press: Boca Raton, FL, USA, 2010. [Google Scholar]
- Radoux, J.; Defourny, P. Image-to-Map Conflict Detection Using Iterative Trimming : Application to Forest Change. Proceedings of the International Society for Photogrammetry and Remote Sensing XXXVIII (4/C1), Calgary, Alberta, Canada, 5–8 August 2008; Available online: http://www.isprs.org/proceedings/xxxviii/4-c1/sessions/Session6/6731_Radoux_pap.pdf (accessed on 17 April 2014).
- Radoux, J.; Defourny, P. Automated image-to-map discrepancy detection using iterative trimming. Photogramm. Eng. Remote Sens 2010, 76, 173–181. [Google Scholar]
- Quinlan, J.R. C4.5: Programs for Machine Learning (Morgan Kaufmann Series in Machine Learning), 1st ed; Morgan Kaufmann Publishers Inc.: San Mateo, CA, USA, 1992. [Google Scholar]
- Hodge, V.; Austin, J. A survey of outlier detection methodologies. Artif. Intell. Rev 2004, 22, 85–126. [Google Scholar]
- Olofsson, P.; Foody, G.M.; Stehman, S.V.; Woodcock, C.E. Making better use of accuracy data in land change studies: Estimating accuracy and area and quantifying uncertainty using stratified estimation. Remote Sens. Environ 2013, 129, 122–131. [Google Scholar]
- FAO Global Forest Resources Assessment 2010, FAO For. Pap. 163; Food and Agriculture Organization of the United Nations: Rome, Italy, 2010; Available online: http://www.fao.org/docrep/013/i1757e/i1757e.pdf (accessed on 17 April 2014).
- INEGI. Guía Para la Interpretación de Cartografía Uso del Suelo y Vegetación: Escala 1:250 000 Serie III; Instituto Nacional de Estadística y Geografía (INEGI): Aguascalientes, Ags., México, 2009. Available online: http://www.inegi.org.mx/prod_serv/contenidos/espanol/bvinegi/productos/geografia/publicaciones/guias-carto/sueloyveg/1_250_III/Suelo_Vegeta.pdf (accessed on 17 April 2014).
© 2014 by the authors; licensee MDPI, Basel, Switzerland This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/3.0/).