1. Introduction
Wildland fires burn with varying intensity, which may be measured as flame height, heat, rate of spread, or total energy released. The resulting ecological effects depend on the interaction of intensity, duration and landscape characteristics, and are commonly referred to as fire severity, a broad term which encompasses mortality of vegetation as well as change in cover, effects on soil, and other factors. One field measurement of burn severity which is applicable across a wide range of vegetation types and has gained relatively widespread acceptance is composite burn index (CBI). CBI rating comprises the condition and color of soil, amount of vegetation consumed, scorch of trees, and presence of sprouting and/or new colonizing vegetation [
1]. While useful, estimates of severity are not generally sufficient to make stand-level forest management decisions about post-fire response. Forest managers in particular have a need for information about fire effects and the spatial distribution of tree mortality following wildfire, but direct assessment from the field is time-consuming and costly. Remote sensing may be used to estimate varying levels of mortality and provide a more efficient, timely, scalable, and potentially more cost-effective means for post-fire assessment. The changes to the structure and color of aboveground vegetation and the color of soil following wildfire result in changes in the signal returned by both active and passive remote sensing systems. In particular, discrete-return light detection and ranging (LiDAR) and digital orthophotography (imagery) are commonly used to assess the condition of vegetation, including change detection following disturbance events such as wildland fire.
Between the two technologies, the use of imagery to detect and characterize tree mortality and severity of forest fires has a more well-developed and robust research history. CBI was developed for the purpose of relating ground-based estimates of burn severity to estimates derived from 30 m resolution Landsat TM/ETM imagery [
1]. Common image processing methods used to characterize burn severity include linear transformations, univariate image differencing, and supervised, unsupervised, and hybrid classification; the most commonly used strategies are methods of univariate image differencing [
2]. Commonly used indices based on band ratios are the normalized burn ratio (NBR) and the normalized difference vegetation index (NDVI), and the differenced versions, dNBR and dNDVI. Although dNBR may be more sensitive to changes caused by wildland fire, dNDVI can be calculated from more commonly available color infrared imagery, which may also be available at finer spatial and temporal scales than Landsat imagery. Comparison of NDVI, NBR, dNDVI, and dNBR from Landsat TM/ETM+ scenes across four wildfire burn sites in Alaska to CBI found that NDVI performed similarly to NBR (|r| of 0.72
vs. 0.77) and dNDVI similarly to dNBR (|r| of 0.67
vs. 0.70) [
3]. Assessment of fire severity across three fires in pine, oak, and eucalyptus forests in Spain found that NDVI performed similarly to NBR, dNDVI similarly to dNBR, and that single-scene indices outperformed multi-temporal indices at describing severity within burned areas, while multi-temporal indices were more accurate at distinguishing between burned and unburned areas [
4]. With any method based on imagery, accuracy can be an issue, as “countervailing post-fire factors often lead to spectral confusion” [
5].
The combination of LiDAR data and imagery may offer the ability to improve on assessments based on imagery alone. The distribution of LiDAR returns reflected from vegetation offers additional structural information about the size, density, and possibly condition of that vegetation. Although this strategy has not been widely exploited as yet, Kane
et al. [
6] used LiDAR data to characterize vertical and horizontal canopy structure, and combined structural variables with an adjusted dNBR calculated from Landsat data to characterize the effects of fire severity on forest structure.
The use of LiDAR alone to model forest structure is widely accepted and used across a variety of forest types and operational settings. A number of strategies have been used to model stand-level vegetation metrics based on attributes of LiDAR data. In a Douglas-fir/grand fir forest in Oregon, LiDAR data with average first-return density of 10 points/m
2 was used to estimate Basal Area (BA), Lorey’s mean height, volume, density, quadratic mean DBH, and crown width using both area-based and single-tree approaches. Area-based models performed as well or better than single-tree models except for Lorey’s mean height. LiDAR metrics used in best models included the max, mean, percentiles, and interquartile distances of canopy heights; a variety of normalized point densities within height bins; and median, maximum, and percentiles of intensity data [
7].
Thematic classification of stands has also been attempted using LiDAR data. A random forest algorithm was used with LiDAR data (density of 0.26 returns/m
2) to classify a multi-species conifer forest in Idaho by forest successional stage. In one model, with 7 classes, having overall accuracy of 90.12%, canopy cover and mean height were the most important predictors, followed by the density in two height strata from 1–2.5 m to 20–30 m, median height, 25th percentile height, modal height, and density in the 10–20 m height stratum. In another model, with 6 classes, having overall accuracy of 95.54%, canopy cover and mean height were the most important predictors, followed by maximum height, median height, and density of the 20–30 m height stratum [
8]. Similarly, LiDAR data has been used to detect the presence or absence of particular conditions in forested environments. The presence of understory vegetation in a diverse deciduous forest, for example, was detected by filtering leaf-on and leaf-off LiDAR data based on probable height to crown base by species of overstory tree cover, with 77% accuracy using both datasets, and 72% accuracy using only leaf-off data [
9]. The distribution (presence/absence) of shrub understory was mapped with 83% accuracy in a mixed conifer forest in Idaho using percent ground returns, percent of returns between 1 and 2.5m, and plot slope multiplied by the cosine of aspect, and the distribution (presence/absence) of snags was mapped with 72%–80% accuracy using a variety of topographic and canopy height metrics derived from LiDAR [
10]. In a forest with a relatively high component of standing dead trees, on the North Rim of the Grand Canyon, LiDAR percentile heights and high/low intensity peak frequency data was used to distinguish between live and standing dead biomass and estimate volume of each with R
2 of 0.76 for live biomass, and 0.62 for dead [
11].
While LiDAR has been used more extensively to characterize forest stand conditions in general, relatively few studies have used LiDAR data to describe or quantify damage resulting from forest fires. Canopy height (first return − bare earth) changes from LiDAR data gathered before and after the Hayman Fire in Colorado revealed areas where vegetation was consumed, but errors in repeated measurement confounded quantification of vegetation lost [
12]. Angelo
et al. [
13] explored the use of vertical vegetation profiles derived using LiDAR point cloud data to predict time since fire in an oak scrub landscape. LiDAR point data binned into 1 m slices served as input for a Support Vector Machine (SVM) classifier, which provided a reliable map of structural vegetation differences. While suitable classification accuracy could be achieved with a relatively small training dataset, mapped outputs were generated at the relatively coarse 320 m × 320 m “mesoscale”. In sagebrush vegetation, damage was estimated from change in height of first return. Accuracy of classification by this method ranged from 64% to 96%, and was superior to classification by dNBR, which ranged from 32% to 85% [
14]. The combination or fusion of imagery with LiDAR techniques discussed above has been used for a similar variety of purposes. These strategies may be as simple as utilizing information from both datasets (sometimes referred to as “stacking”), but often involves linear transformations of combined data, machine-learning algorithms, supervised classification, or some hybrid combination of any of the preceding methods. A variety of fuel metrics (canopy height, basal area, canopy cover, shrub cover, shrub height) were modeled in a Sierra Nevada mixed conifer forest with R
2 between 0.59 and 0.87 using principal component analysis of NAIP 1 m CIR imagery and heights, percentiles, and densities from LiDAR data having average pulse density of 9 pulses/m
2 [
15]. Surface fuels were modeled with 87.2% accuracy in pine-hardwood forestland including areas of brush and grass in east Texas using fusion of QuickBird 2.5 m CIR imagery with LiDAR-derived canopy cover, canopy height model variance, and normalized point density in four 0.5 m height bins [
16].
There is a dearth of information regarding the variable mortality of trees following wildfire, and whether or not it can be modelled, using remotely sensed data, with sufficient accuracy to make management decisions, or to model the effects of fires on nutrient and carbon cycling. There are also few studies in the literature regarding the combination of imagery and LiDAR to characterize the effects of fire, whether in terms of mortality or some index of severity.
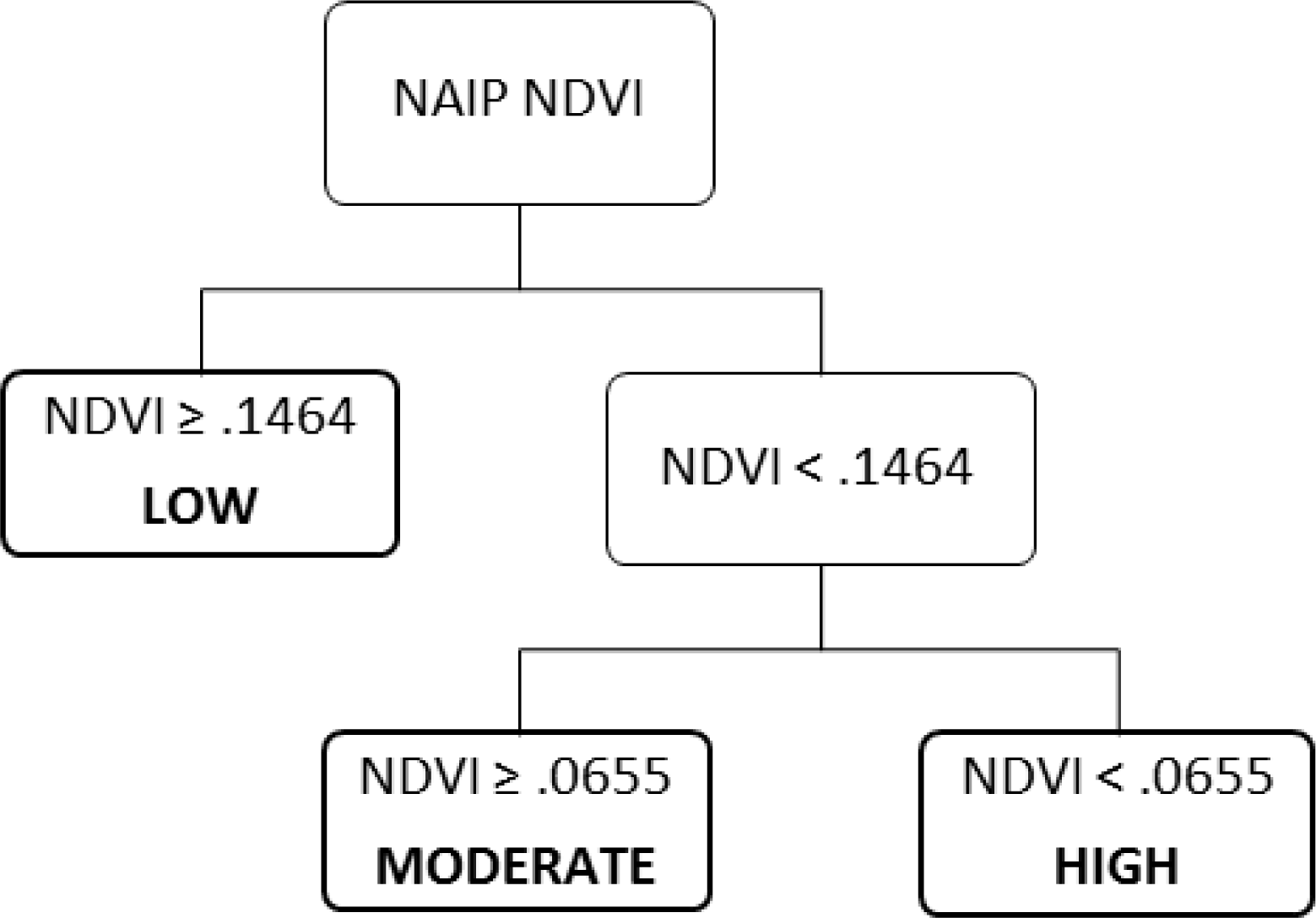
In this study, we combined NDVI from NAIP 1 m CIR imagery with a variety of metrics from pre- and post-fire LiDAR data to estimate the level of mortality of trees of all species at a plot scale, roughly equivalent to 0.08 ha (1/5 ac) plots. Three levels of mortality were defined based on plot percent mortality of trees 25.4 cm (10′′) DBH and greater. Estimates made using a Classification Analysis and Regression Tree (CART) approach with NDVI alone were compared to estimates made using NDVI in combination with post-fire only and with differenced pre- and post-fire LiDAR to assess whether gains in accuracy would result from the addition of LiDAR data. We had two objectives: first, to determine the accuracy that could be obtained using imagery alone, and compare any gains in accuracy that could be made by adding LiDAR data, and second, to demonstrate generation of wall-to-wall mortality estimates using imagery and LiDAR data.
4. Discussion
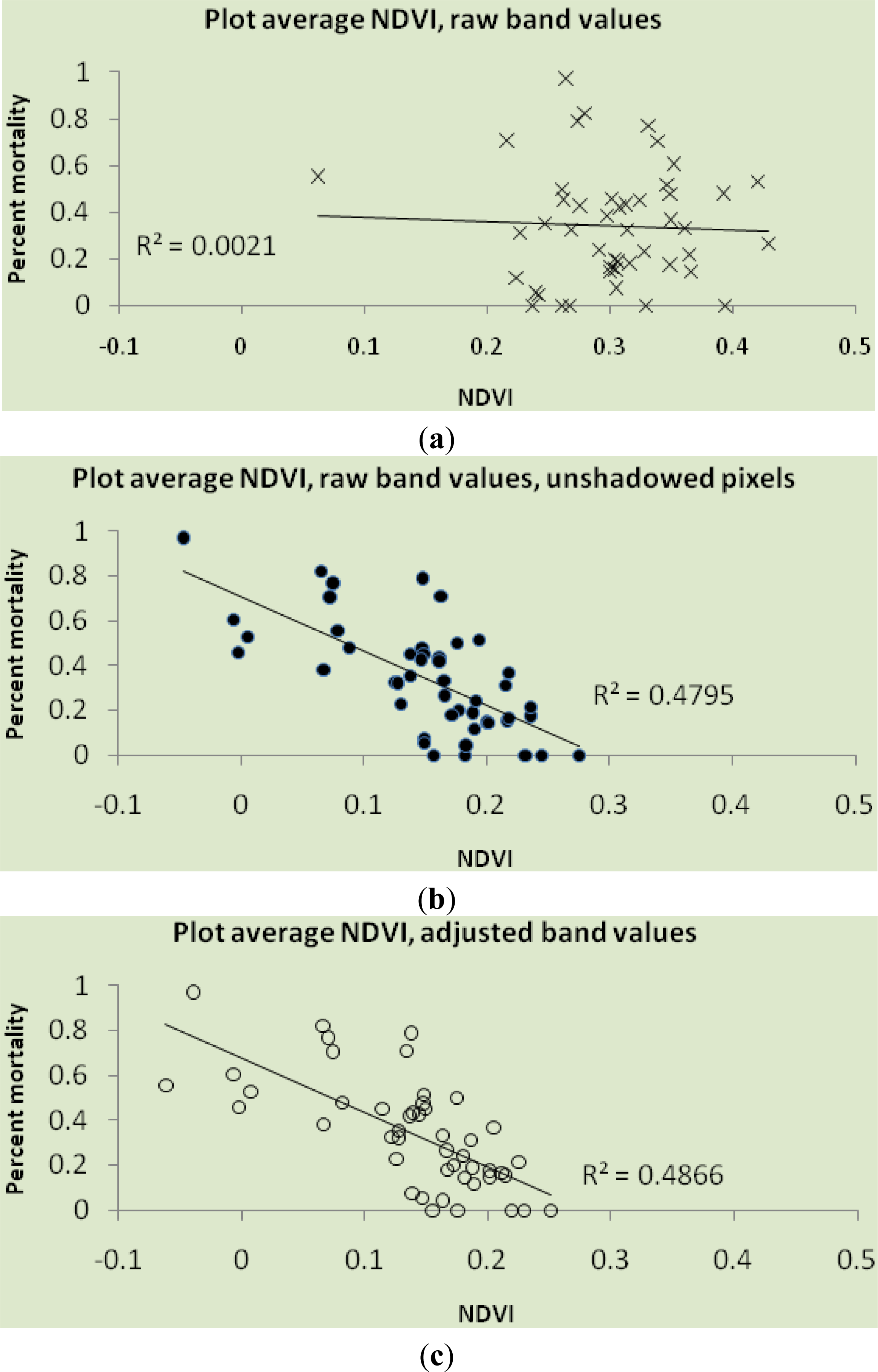
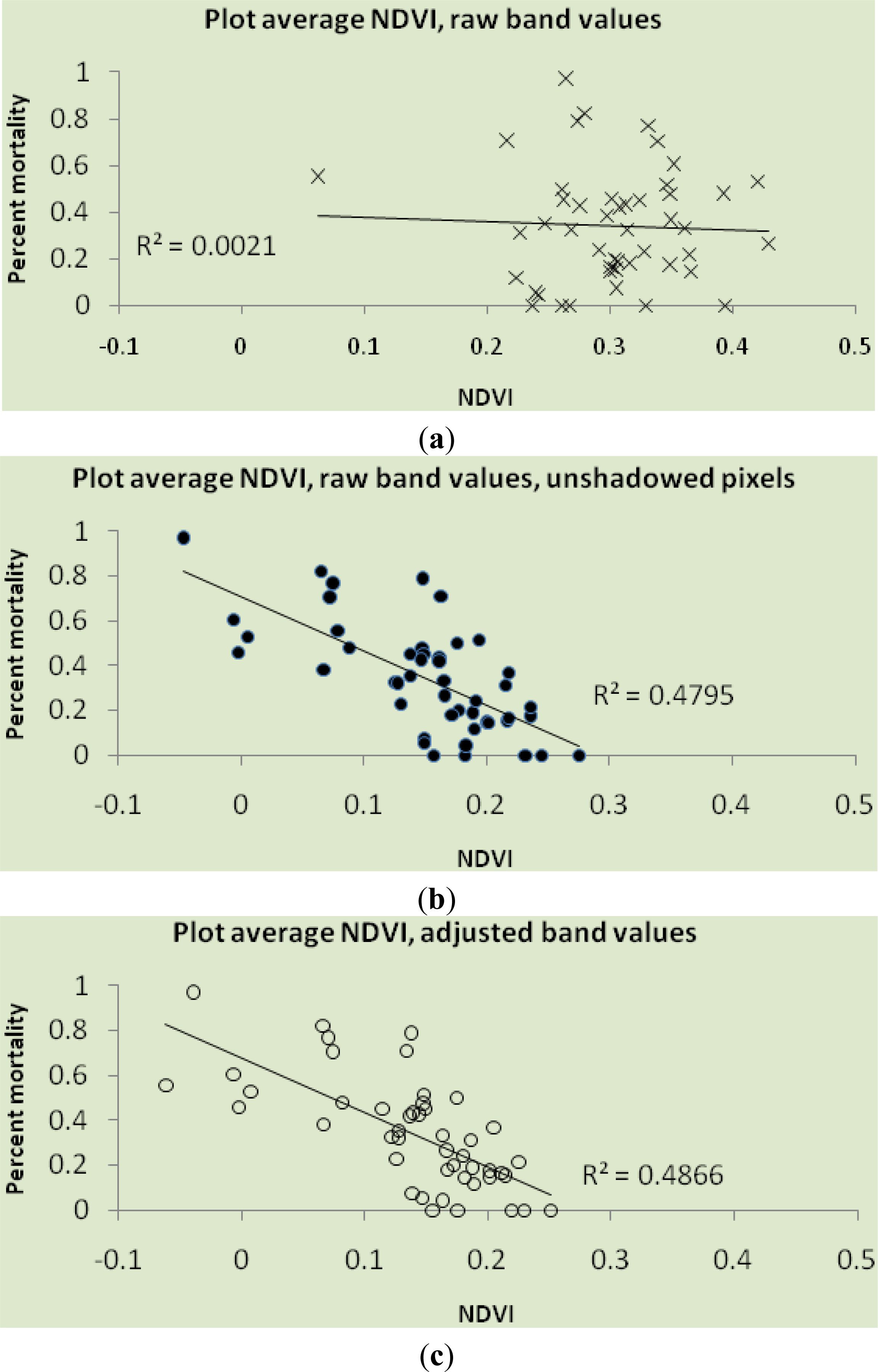
We presented a comparison of the accuracy of imagery-only, imagery fused with post-fire LiDAR, and imagery fused with differenced (pre- and post-fire) LiDAR in estimating plot-level mortality resulting from a wildfire in a typical second-growth coast redwood forest. We presented the percent accuracy of each method across 47 field plots. Using a single, freely available post-fire image (model A), mortality classes were estimated with 74% accuracy. Our results are similar to other studies which have used NDVI to estimate severity, although it is difficult to compare severity to mortality [
3–
5]. Although approximately 40% of plots in the higher two mortality classes were misclassified, importantly, no plots with high mortality (>50%) were classified as low mortality (<25%), or
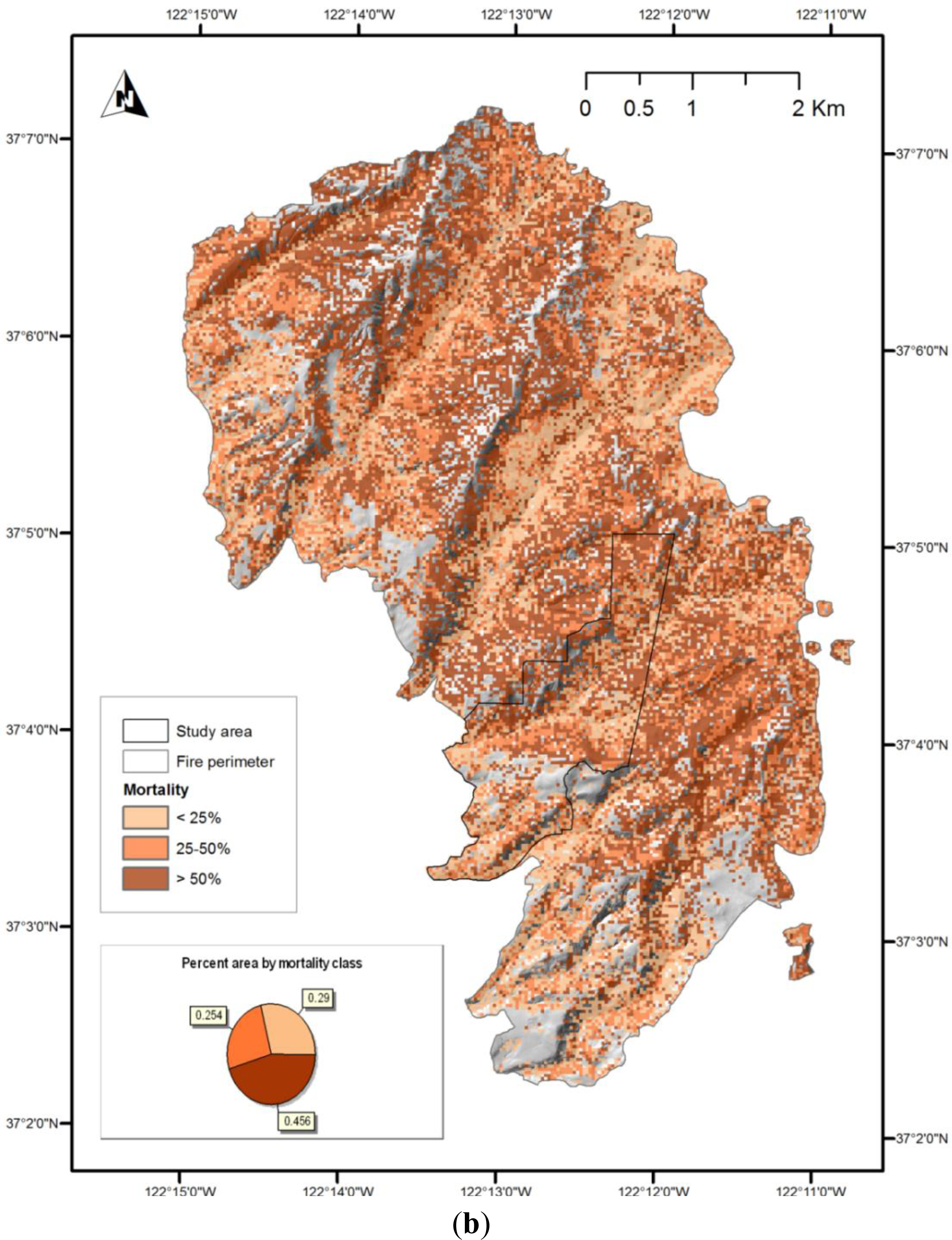
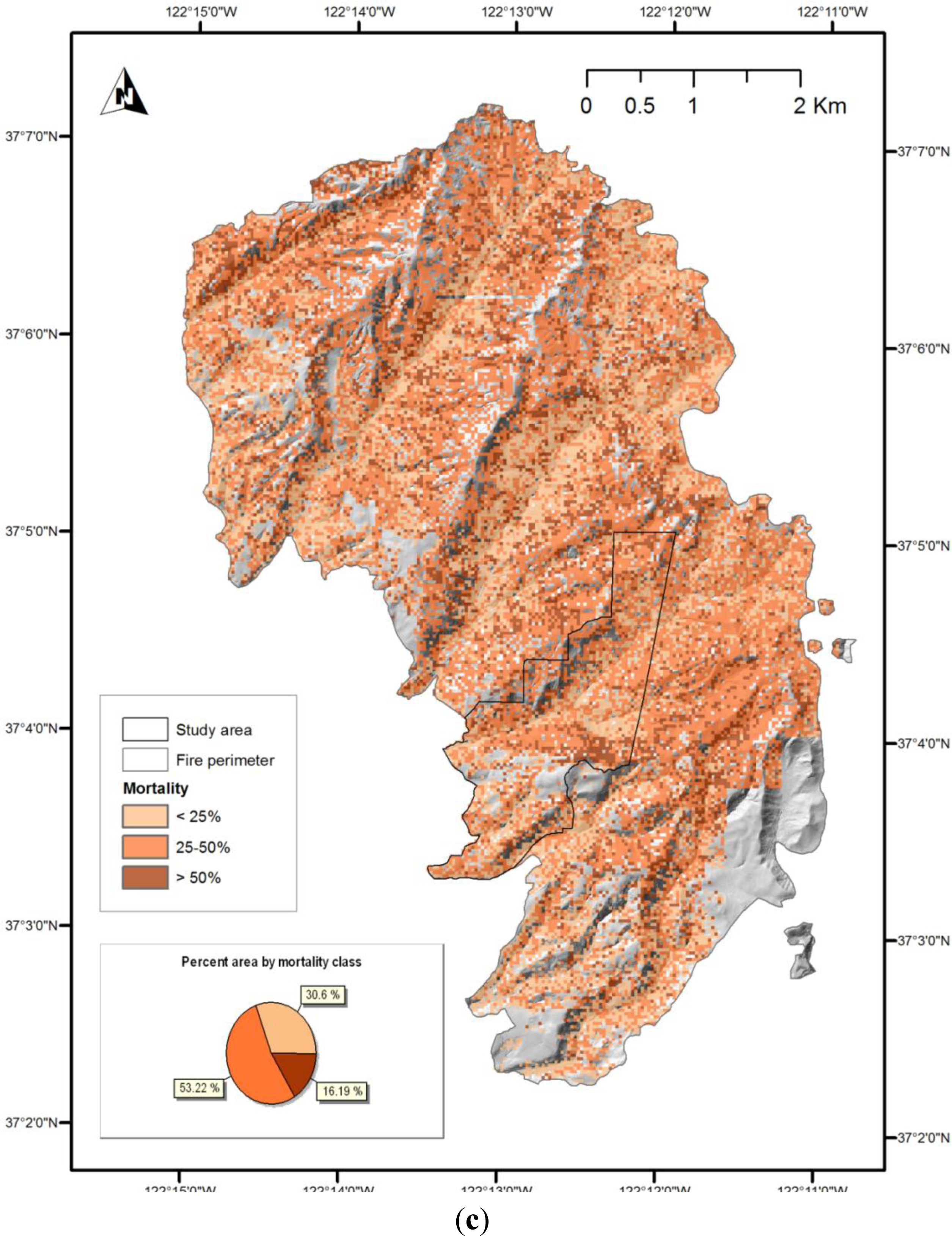
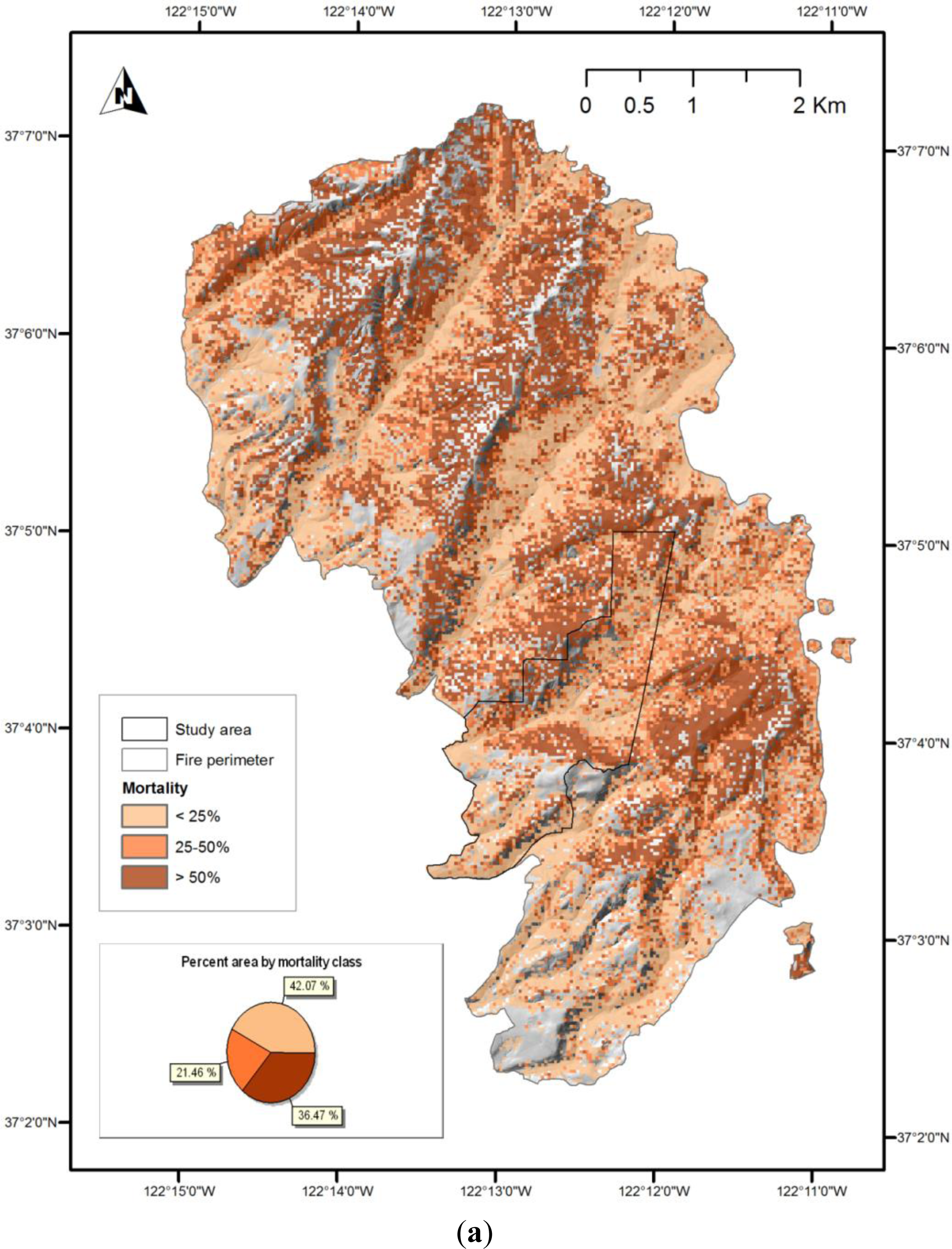
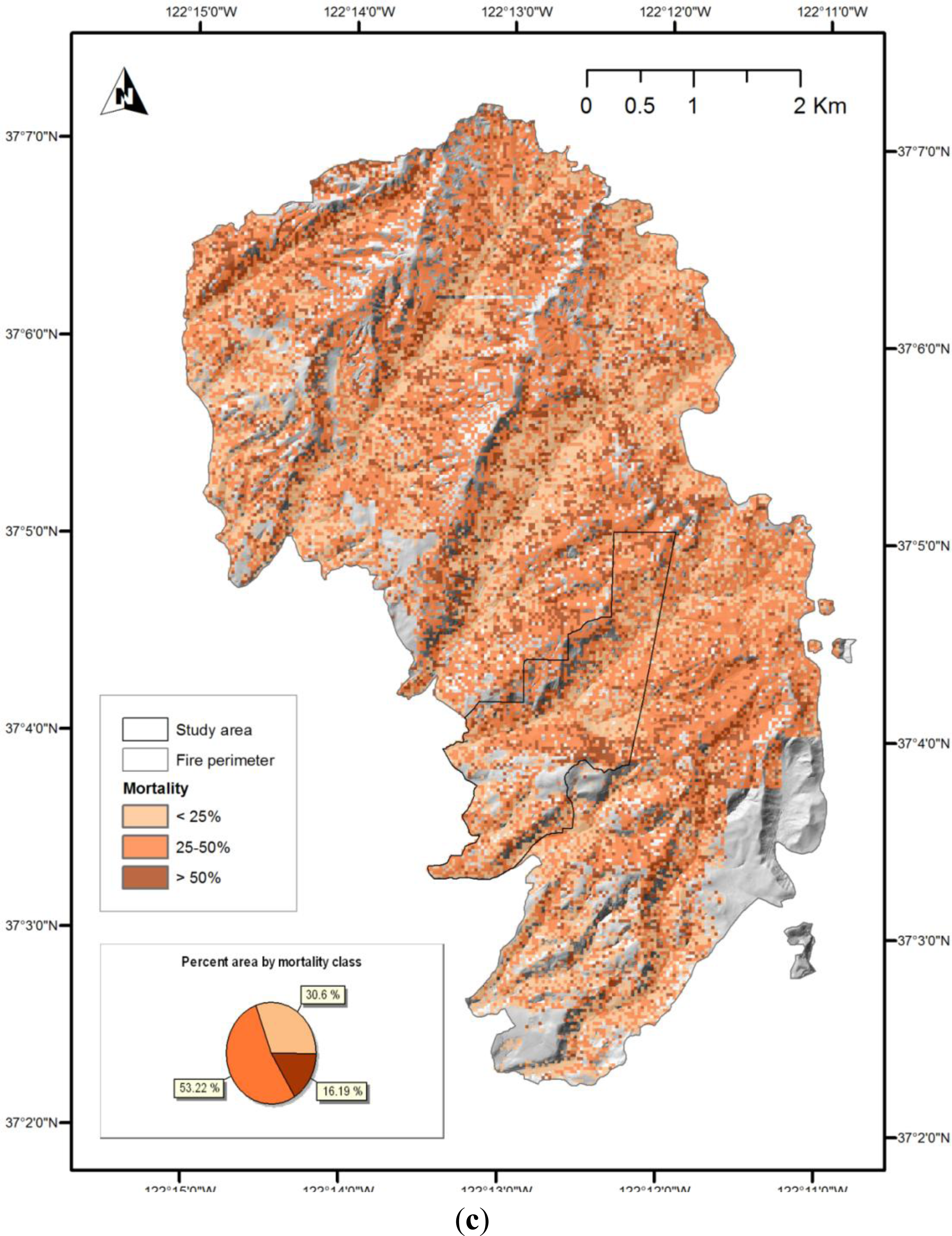
vice-versa. In addition, we generated maps of estimated mortality across the entire fire area, for demonstration purposes. These maps should not be considered accurate, as the models they use are based on a limited sample, which does not represent all the forest types present across the fire area. However, they are likely to be as accurate in areas of similar forest type outside the study area as they are within it. Examination of the map of the model A prediction for the entire fire area, shown in
Figure 8a, suggests that too much area was classified as low-mortality by this method; the confusion matrix suggests that some of this area should have been classified as moderate.
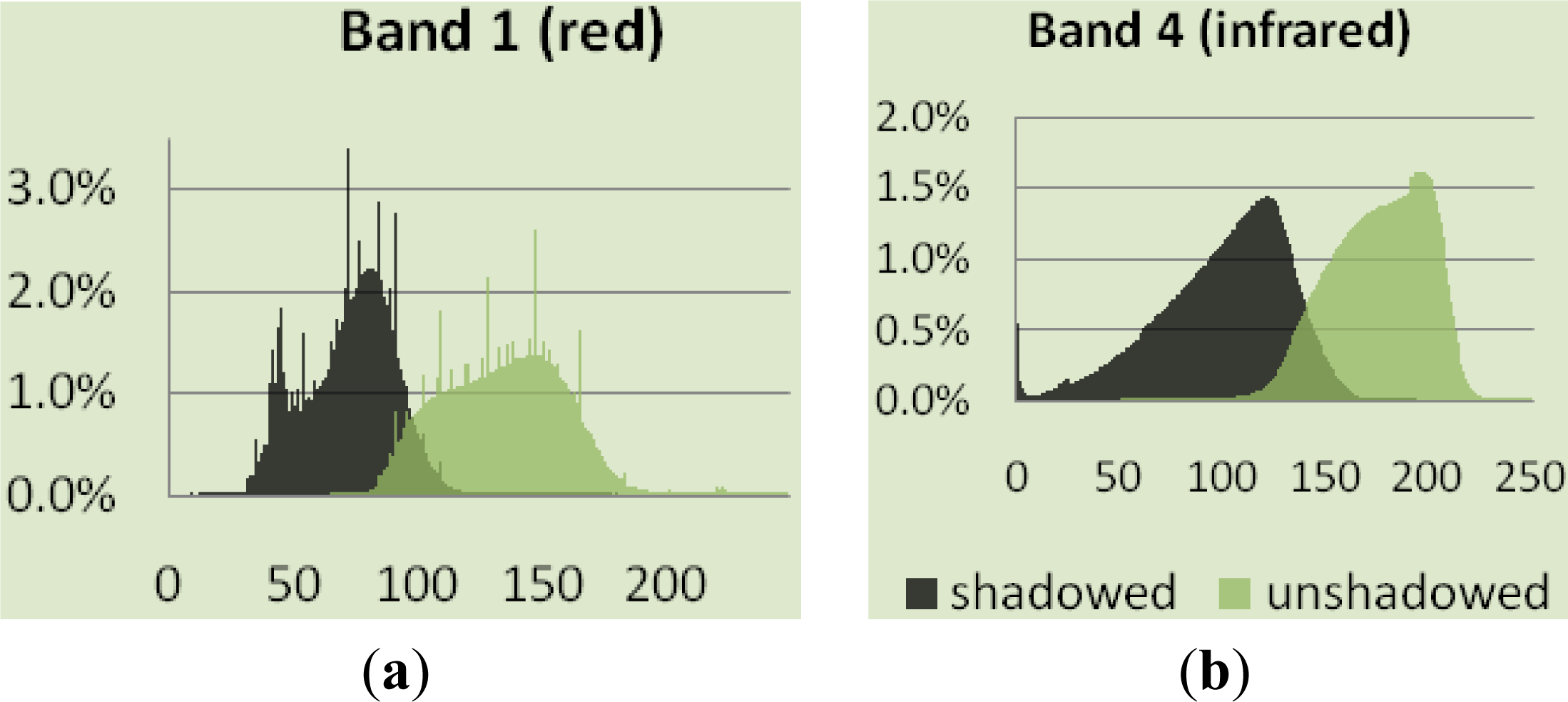
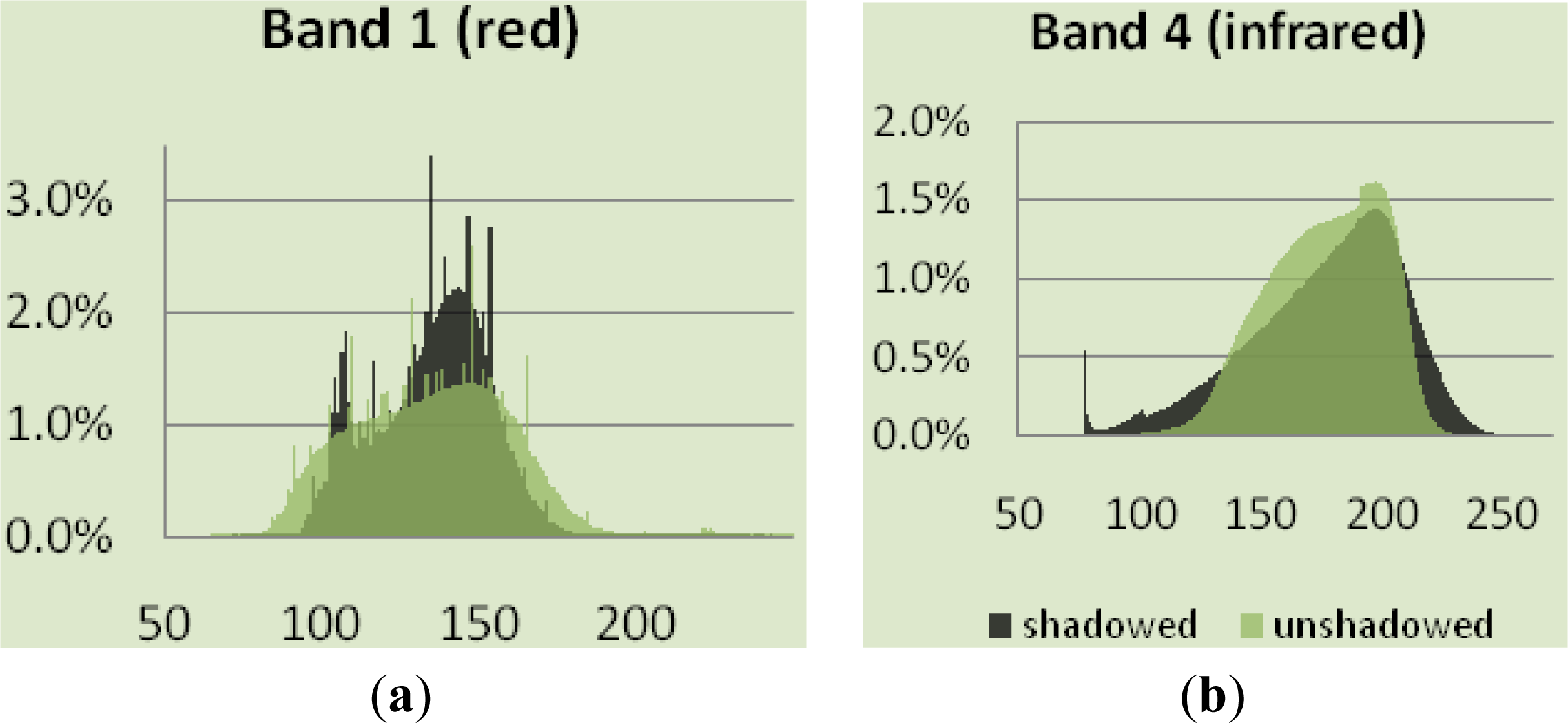
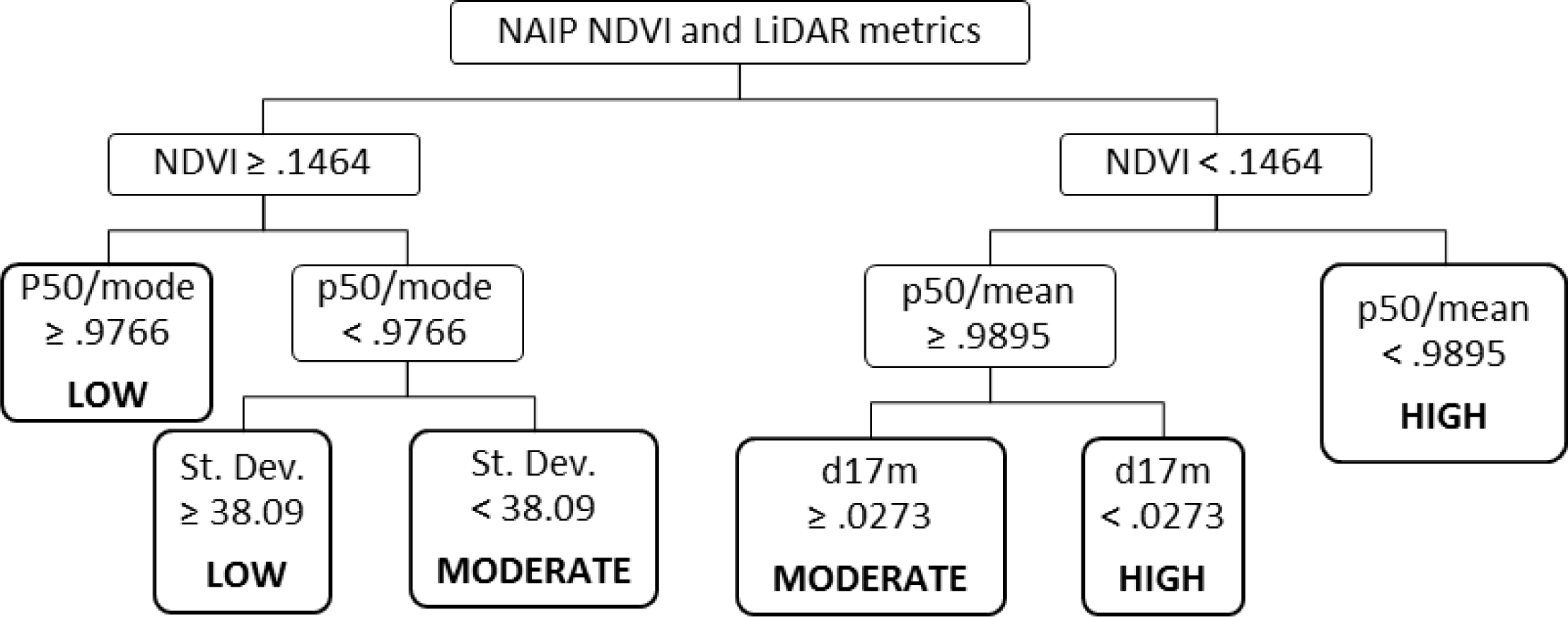
The combination of imagery with post-fire LiDAR data improved overall accuracy from 74% to 85%, compared to imagery alone. Most of the improvement can be attributed to plots which were incorrectly classified as low-mortality and which are in fact moderate-mortality. On the other hand, classification using post-fire LiDAR is less accurate when it comes to low-mortality plots, and classifies one of these plots as high-mortality, which is one of only two plots which were misclassified across two classes—the other being in the unshadowed NDVI classification.
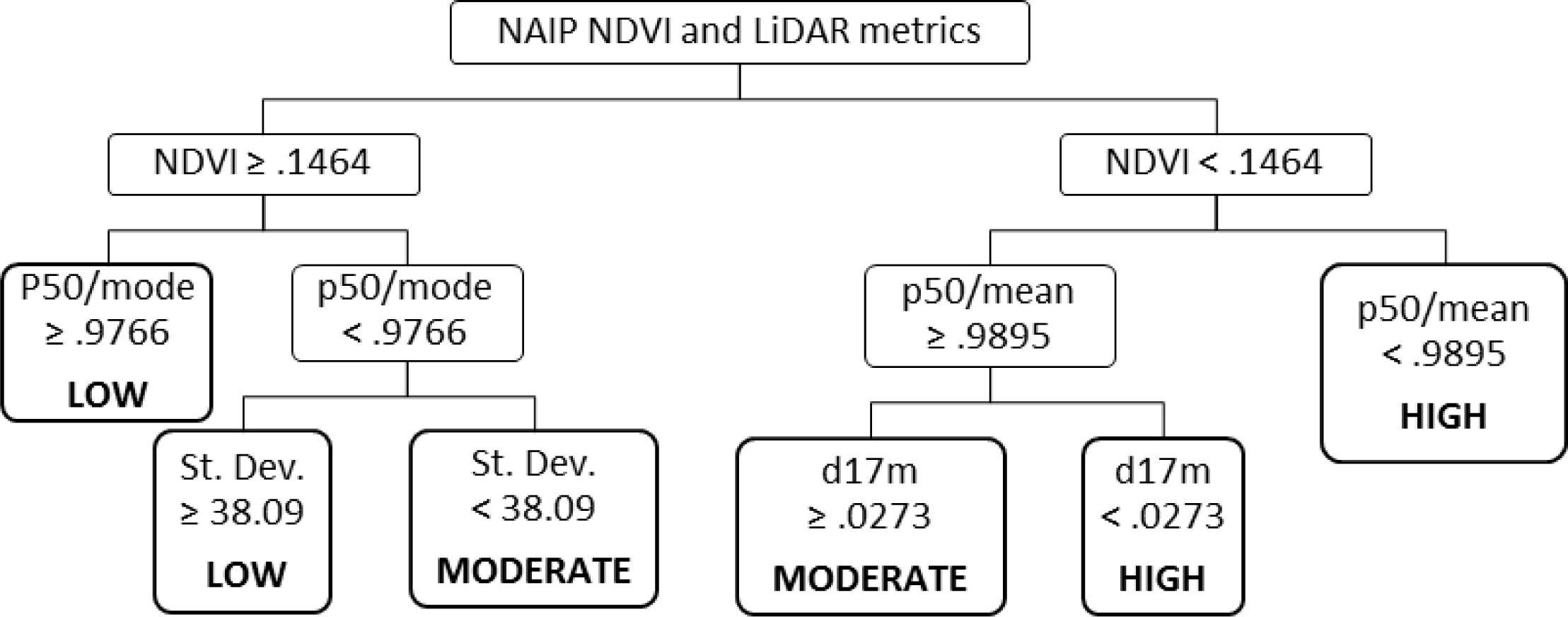
Two of the LiDAR variables selected, the p50/mean and p50/mode, describe the skew in the data. The standard deviation is used in combination with p50/mode—where both are low, mortality is higher. Where both values are higher, there are a greater number of returns higher in the canopy, which presumably corresponds with greater vegetative structure, and lower mortality. Similarly, where the ratio of p50/mean is low, mortality is high, as it is where p50/mean is higher but the percentage of returns from 16 to 17 m is low. To state this another way, for similar values of NDVI, mortality is lower where p50/mean and d17 are high—where there are more returns higher in the canopy, by two different measures.
The addition of LiDAR data for post fire assessment is associated with substantial additional cost, though the data may be gathered for other purposes such as watershed or other risk assessments. At present, the question for land managers considering the use of LiDAR data for predicting mortality or characterizing fire severity will be whether this extra cost is justified by increased accuracy. As more uses are developed for the data, however, collection becomes more economically feasible. In addition, anecdotally, it appears that the extent of LiDAR acquisitions is increasing, and the future will likely bring more widely available, higher quality inexpensive or free LiDAR data.
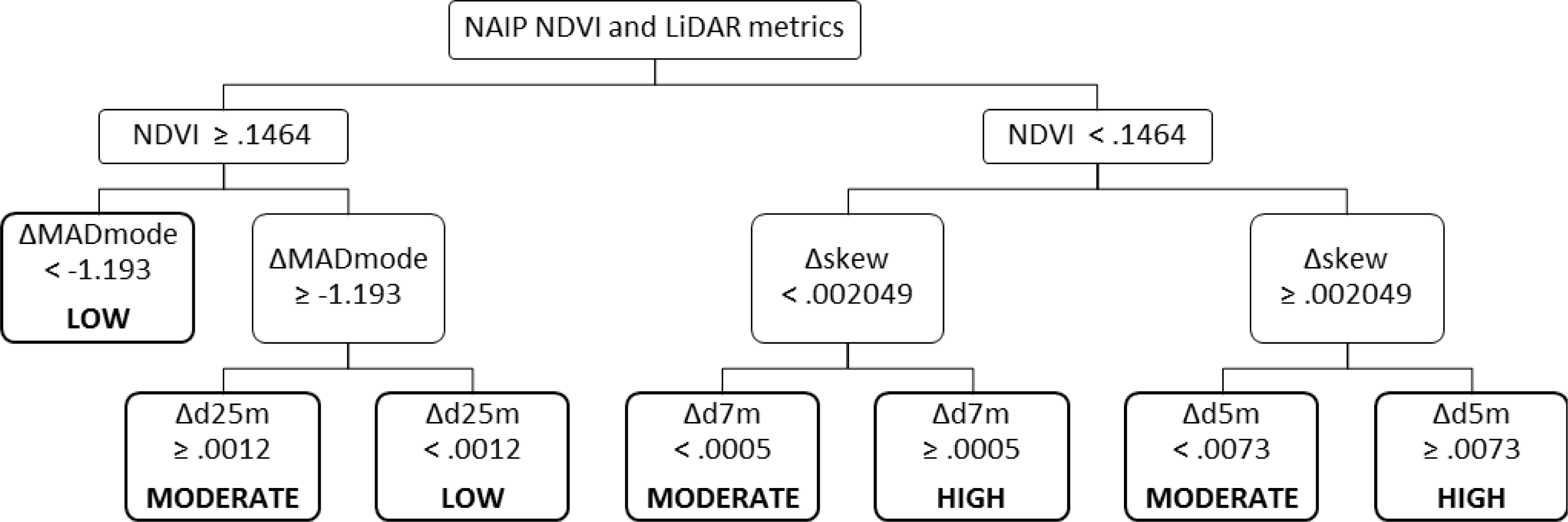
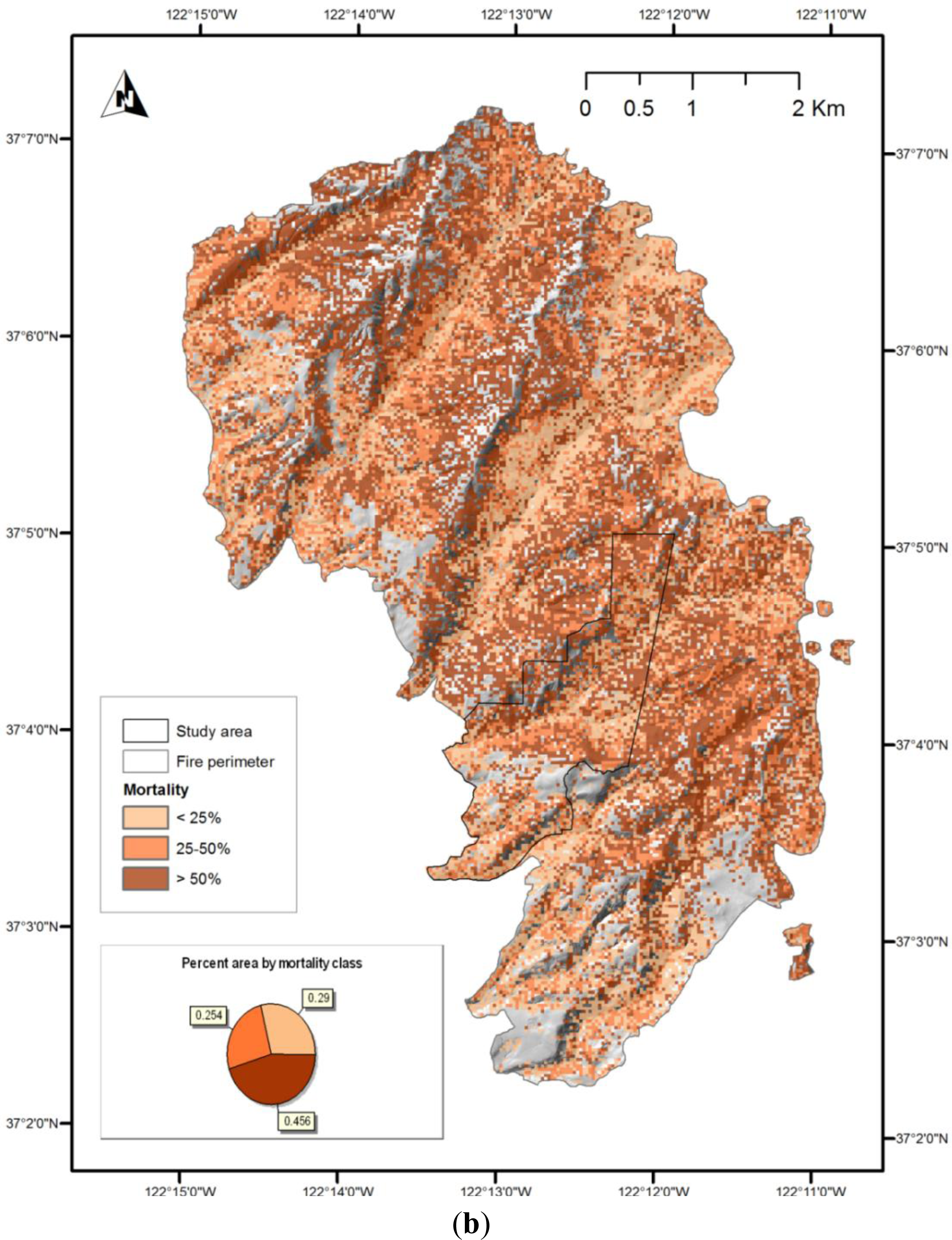
The combination of imagery with both pre- and post-fire LiDAR in a change-detection approach did not improve classification in this study. There was a slight decrease in overall accuracy compared to the post-fire LiDAR and imagery model, and this strategy yielded the lowest accuracy in the highest-mortality class of all strategies explored. Half of the plots with mortality greater than 50% were misclassified as moderate-mortality.
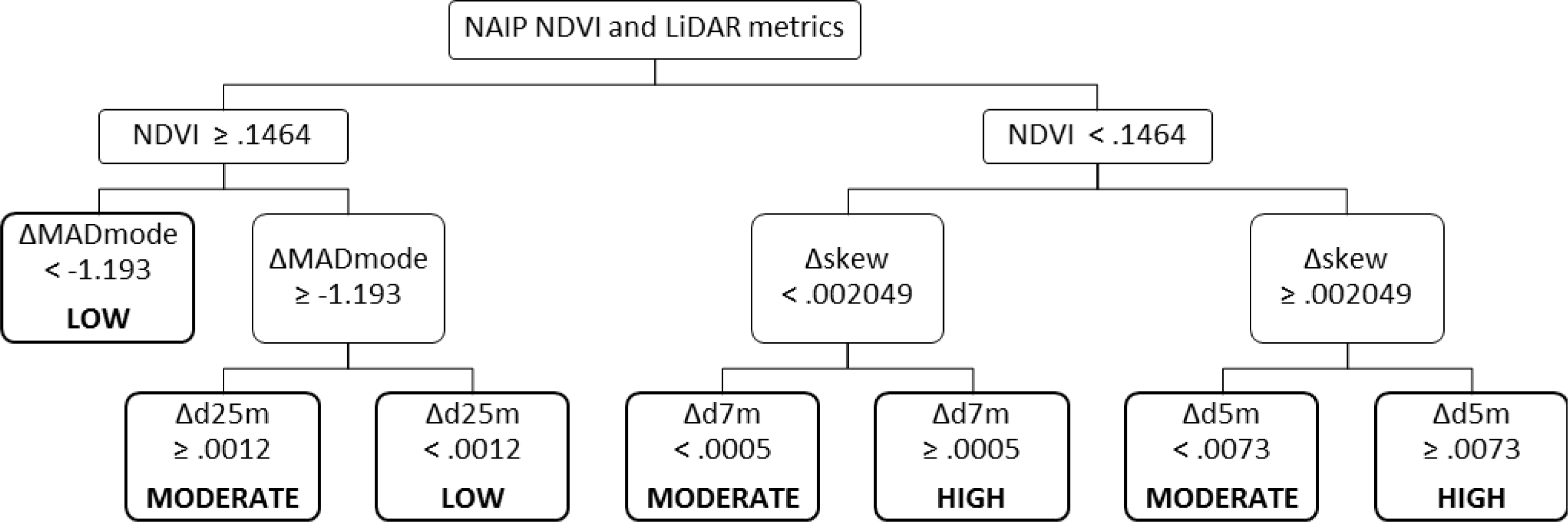
Similarly to model B, this model used variables describing the skew and variation in the data set—in this case, Δskew and ΔMADmode—and change in normalized densities in three height bins, from 4–5, 6–7, and 24–25 m. Where ΔMADmode was higher (positive or only slightly negative), and Δd25m was positive, mortality was higher, which seems counterintuitive—these characteristics indicate that LiDAR returns are more broadly distributed through the canopy, and that there is more structure high in the canopy. It may be, however, that this is only due to an absence of structure below 25 m. Where Δd7m and Δd5m were negative, mortality was lower, which seems reasonable if the change was due to more returns higher in the canopy, but this is not certain—it could also be due to a higher proportion of returns below those thresholds.
Unless pre- and post-fire data collections are made with differencing in mind, they will likely differ in density, which affects both DEM generation and canopy metrics in complex ways, interacting with slope and cover. These effects likely confound the relationships between metrics and actual aboveground structure, making relationships with mortality (or other attributes) difficult to detect. Similar problems were discovered by Kaufmann
et al. [
12]. It is possible that thinning the post-fire LiDAR point cloud to more closely match the pre-fire data would have provided better results. In addition, data sets may have been separated into files of manageable sizes using different grids, as was the case in this study. Differences in density and in gridding make calculation of differenced metrics much more complex and time-consuming than metrics from a single dataset. As a result, in most cases, differencing would have to yield a significant improvement in accuracy to justify the additional time and effort.
The Lockheed Fire began at the northern end of the fire area (shown in
Figure 8) and was initially wind-driven, jumping from ridge to ridge in a south-east direction, and backing down to the drainages between. The fire was generally most intense on the ridge-tops, and least intense in drainages. All three methods used to map estimated mortality highlight a pattern which is generally consistent with this pattern of intensity, although model C (
Figure 8c) shows only a weak pattern related to topography.
Field measurements used in this study are limited to diameter and status (live or dead). Field survey crews were trained in proper procedures, and mortality was assessed three separate times over three years [
17]. However, it is possible that there are errors in the field data used.
The LiDAR vendor for the data used in this study stated the vertical accuracy of the data was 18.3 cm at 95% confidence, and 15.2 cm at 90% confidence, and the 1σ horizontal accuracy as 30 cm. These accuracies are based on measurements made under better than average conditions across the study area. The accuracy is likely lower in areas with dense forest canopy, especially in the pre-fire data.
The field plots used in this study were originally established on a 152.4 m (500′) grid, based on a variety of control points, using a staff compass and cloth tape. Coordinate locations for these plots were collected with a Garmin 60 csx GPS, which is a consumer-grade unit. While their ultimate accuracy is lower than that of mapping-grade units, personal experience working in the study area has demonstrated that currently available mapping-grade units will not establish a position in many plot locations. Horizontal positional accuracy of these locations is estimated to be within 10–15 m, though an independent accuracy assessment has not been conducted. However, a similar unit, deployed in forested conditions, had average RMSE of 16.88 m, with the authors calculating 95th percentile RMSE to be 29.22 m [
20]. Using these values, the average plot would have an error representing approximately 64% of the plot area—this is the proportion of the remote sensing data that is outside the field plot. The 95% error stated is nearly equal to the plot diameter—only 3% of the remote sensing data sampled would be from the actual area of the field plot. The consequences of errors in plot locations are probably less than might be suggested by the percentages stated, given that some area immediately outside plots will contain canopies of trees which are in fact located within those plots, while a similar area which is in fact part of the plot will contain canopies of trees which are outside the plot. In addition, the mortality of larger trees is not expected to be drastically different over the space of a few meters. In general, plots nearer to control points had locations closer to the original grid, while those further from control points appear to have more error, as would be expected if the actual locations of plots conform less to the grid as the distance from control increases, and the GPS points are more accurate.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}