1. Introduction
Reliable and regularly updated land use/land cover (LULC) maps at medium to coarse spatial resolution are required for various modeling and monitoring purposes. At continental to global scale, accurate LULC data are for example needed for modeling energy, water and carbon flux exchanges of terrestrial ecosystem components [
1,
2]. At regional scale, prominent applications range from vegetation dynamics and land change monitoring to urbanization and policy development [
3–
5].
Available (global) LULC maps show large differences in the number and definitions of LULC classes depending on satellite data type, foreseen application as well as the specific objectives of the map developers [
6]. For example, the Global Land Cover Map 2000 (GLC2000) [
7] is based on 22 land cover classes described through the United Nations (UN) Land Cover Classification System (LCCS) [
8]. The GlobCover 2009 map [
9] (Version 2.3 available for the year 2009), hereafter GlobCover, is also labeled according to the LCCS. However, a different cartographic and thematic aggregation is performed. The Moderate-resolution Imaging Spectroradiometer (MODIS) Land Cover Type product (MCD12Q1, version 5) [
10] includes five different global classification systems, among which the 17-class system described through the International Geosphere Biosphere Programme (IGBP).
For map production, usually spectral or spectro-temporal features are used with classifiers ranging from decision trees to parametric (maximum likelihood) classifiers. For example, GLC2000 was derived at 1-km spatial resolution using an unsupervised clustering approach and daily observations acquired between 1999 and 2000 from SPOT-VEGETATION. MODIS LC was derived at 500-m spatial resolution using a supervised decision tree classifier with yearly average of nadir BRDF-adjusted reflectance, enhanced vegetation index (EVI) and land surface temperature (LST) values. At 300-m spatial resolution, GlobCover was derived using supervised classification and unsupervised clustering of spectral and temporal information from bi-monthly composites of ENVISAT-MERIS acquisitions (reflectance and minimum and maximum NDVI values).
Besides the mentioned differences regarding input features, compositing period, spatial resolution and classification algorithms, existing (global) LULC products also differ in map projection and reference time. These issues make an accuracy assessment and a map inter-comparison difficult. Generally, however, it is agreed that overall classification accuracies of global products are only in the range between ∼65% and ∼75% [
6]. For example, GLC2000 demonstrated an overall accuracy of 68.6% using stratified random sampling of Landsat data with 544 homogeneous samples points [
7,
11]. GlobCover was validated using various satellite data sources at fine spatial resolution (e.g., image data from Google Earth), temporal profiles and annual composites of medium and coarse resolution satellite data (such as ENVISAT-MERIS and SPOT-VEGETATION). The product achieved an overall accuracy weighted by the class area of 67.5% [
9]. MODIS LC was validated using the training dataset with a 10-fold cross-validation analysis. This product reported an overall accuracy of 74.8%. However, a high variability in the class-specific accuracies was observed [
10].
Over the last years, various studies have focused on datasets harmonization and inter-comparison and have found significant inconsistencies between existing products. For instance, [
6] found that GLC2000, GlobCover (Version 2.1 for the year 2005) and MODIS LC (Version 5 IGBP) maps show large differences in the total surface classified as cropland and forest land cover. For the pair GlobCover-GLC2000, these differences were found as high as 28.4% of the average surface classified as cropland. Further results of map comparisons and relative quality assessment can be found in [
6,
11–
14].
Despite the known discrepancies between existing products [
11], little emphasis has been placed on examining the disagreements between existing products. Such a focus could help improve the overall accuracy of future land cover products [
15].
With this study we present a preliminary analysis of MODIS 250-m NDVI (10 years of 16-day composites) time series data to derive LULC maps. We focus on six broad vegetation classes and one additional non-vegetated class (Urban/Built-up). The approach involves the use of a Least Square Support Vector Machine (LS-SVM) algorithm trained on reference samples obtained through visual interpretation of Google Earth (GE) high resolution imagery. The core of the LS-SVM training process is based on repeated random splits of the training dataset to select a small set of suitable support vectors optimizing class separability. Independent validation samples spread over three contrasting regions in Europe (Eastern Austria, Macedonia and Southern France) are used to assess the accuracy of the LS-SVM NDVI-derived classification and of two existing LC products: GLC2000 and GlobCover. The three regions of interest are characterized by different climatic conditions and patterns in land use and land cover.
Two main research questions are addressed in this study:
Is it feasible to outperform overall classification accuracies of existing (global) land cover products (GLC2000 and GlobCover) using LS-SVM fed with MODIS NDVI time series and additional climatic indicators?
Are there any systematic patterns in classification performance (e.g., classification accuracy of the LS-SVM for samples where existing maps agree/disagree; class specific performance differences between LS-SVM and existing products)?
In addition, the paper explores some key issues associated with the collection of reference data and the training of the classification algorithm. We investigate the possibility to minimize sampling efforts through guided sampling using ancillary information from intersection of two existing land cover products (GLC2000 and GlobCover). It will be shown that higher classification accuracy can be achieved using only points of agreement.
The paper discusses these questions together with the results, and gives some recommendations to improve the accuracy of existing products, with a focus on areas of disagreement.
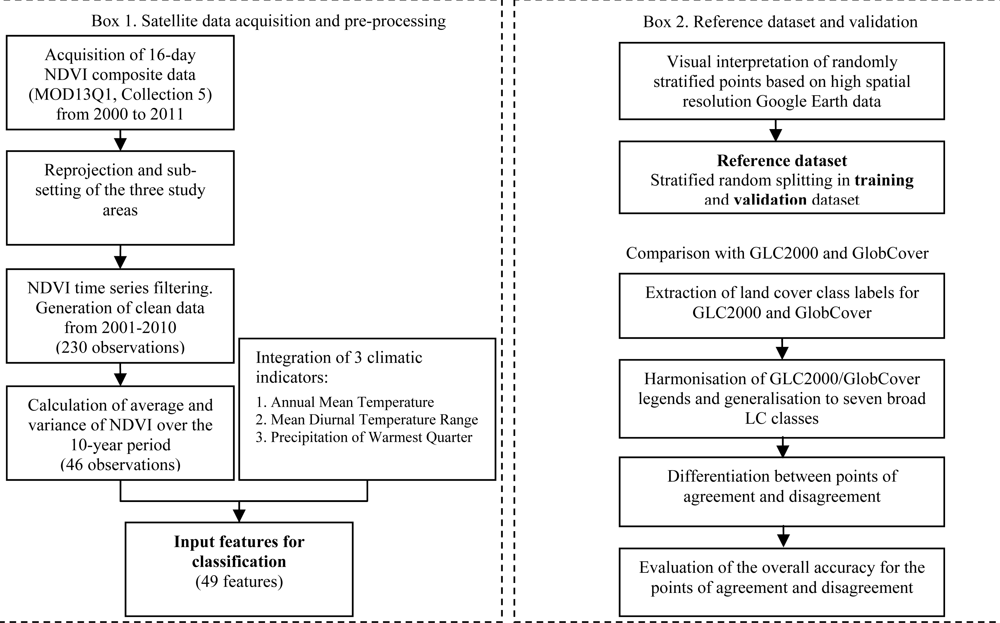
2. Materials and Methods
2.1. Overview
A methodology is described for producing reliable land cover maps focusing on broad (here seven) LC classes. Only a few broad LC classes were chosen (1) to provide a practical separation between managed vegetation and natural vegetation, and (2) to keep some flexibility and not preclude the possibility of comparisons with other LC schemes. The LC definitions used in this study and corresponding GlobCover and GLC2000 class codes are provided in
Table 1.
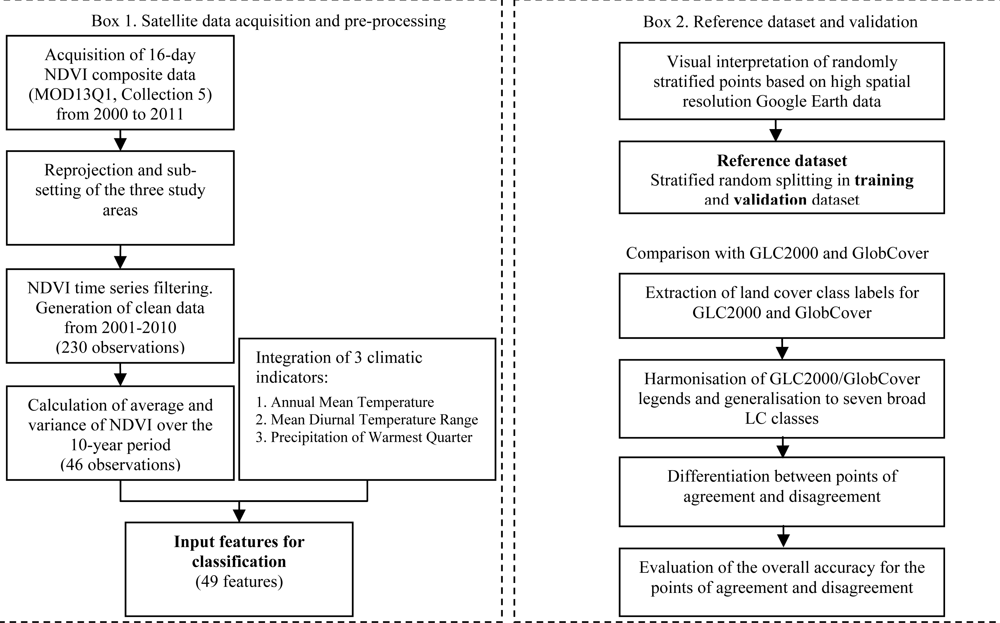
Multi-temporal datasets such as the MODIS product provide a cost-effective means to develop and to deliver regularly updated land cover products over large geographic regions [
16–
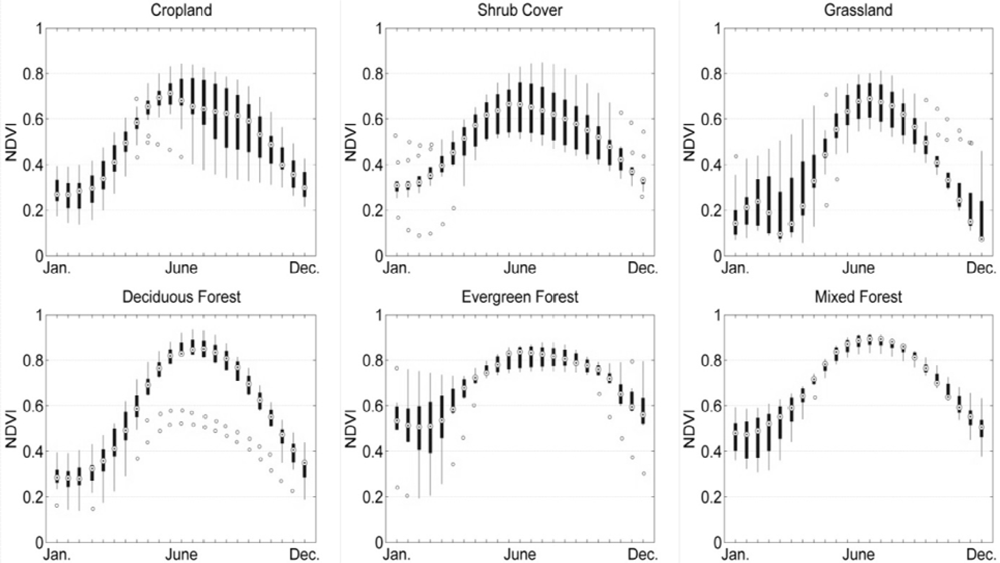
18]. Here we used as input features time series of 16-day NDVI composites from MODIS satellite sensor data (MOD13Q1) for the classification. For each of the 23 compositing periods, the average and the variance was derived from the full time series. The profile of average NDVI reflects the basic growth curves of different vegetation types. The variance reflects the class-specific reactivity to inter-annual changes in climatic driving variables (e.g., temperature, precipitation). Three climatic features were added to the NDVI-based features to facilitate large scale classifications with a common set of support vectors. The overall workflow is schematized in
Figure 1.
To reduce the efforts required for collecting ground truth information, reference data were derived through visual interpretation of high resolution images. For this purpose a Matlab (MathWorks) tool was developed making efficient use of GE data.
For the classification a Least Square Support Vector Machine (LS-SVM) algorithm, developed by Suykens
et al. [
19], was implemented. LS-SVM represents a variant of the original SVM formulation [
20] with similar classification performance, reduced complexity and enhanced processing power [
21]. We selected a SVM-based algorithm, as this method is used in various remote sensing classification problems and achieves good accuracy compared to other classification algorithms (e.g., maximum likelihood, discriminant analysis or decision trees). A comprehensive review is available in [
22]. The classification performance of SVM with MODIS time series was assessed in [
23]. The authors investigated, among other issues, the impact of training samples size and confirmed the superior generalization power even with small number of training samples (20 pixels per class). They also explored the variability in the overall accuracy using multiple randomly selected subsets of training samples, for a given training sample size.
In our study, we trained the LS-SVM algorithm with repeated random splits of the training dataset to select a small set of suitable support vectors optimizing class separability [
24,
25].
For comparison of our LS-SVM LC map with existing land cover products, validation focused on an independent dataset not used during the training phase. Class-specific and overall classification accuracies were calculated. Special attention was paid to those samples, where existing maps disagreed.
2.2. Satellite Data and Pre-Processing
The data used in this study consisted of 16-day NDVI composites from MODIS/Terra with a 250-m pixel size. The MODIS 16-day NDVI composite is a Level 3 product (MOD13Q1), calculated from the Level 2 daily surface reflectance product (MOD09 series) [
26]. Data were aggregated using the Constrained View angle-Maximum Value Composite (CV-MVC) compositing method in a 16-day interval [
27].
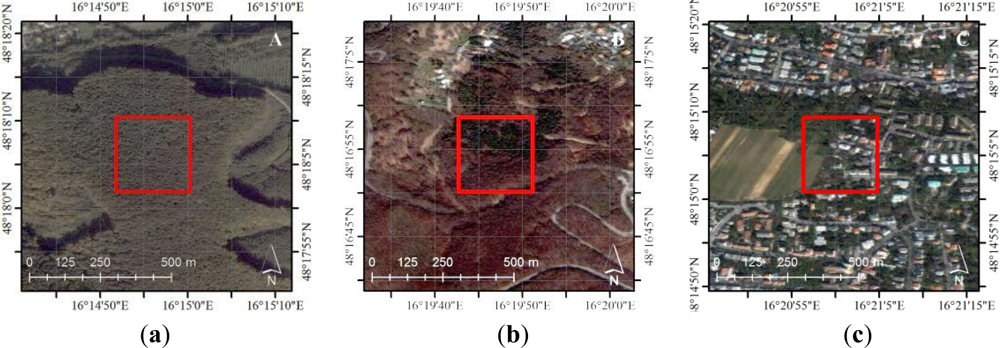
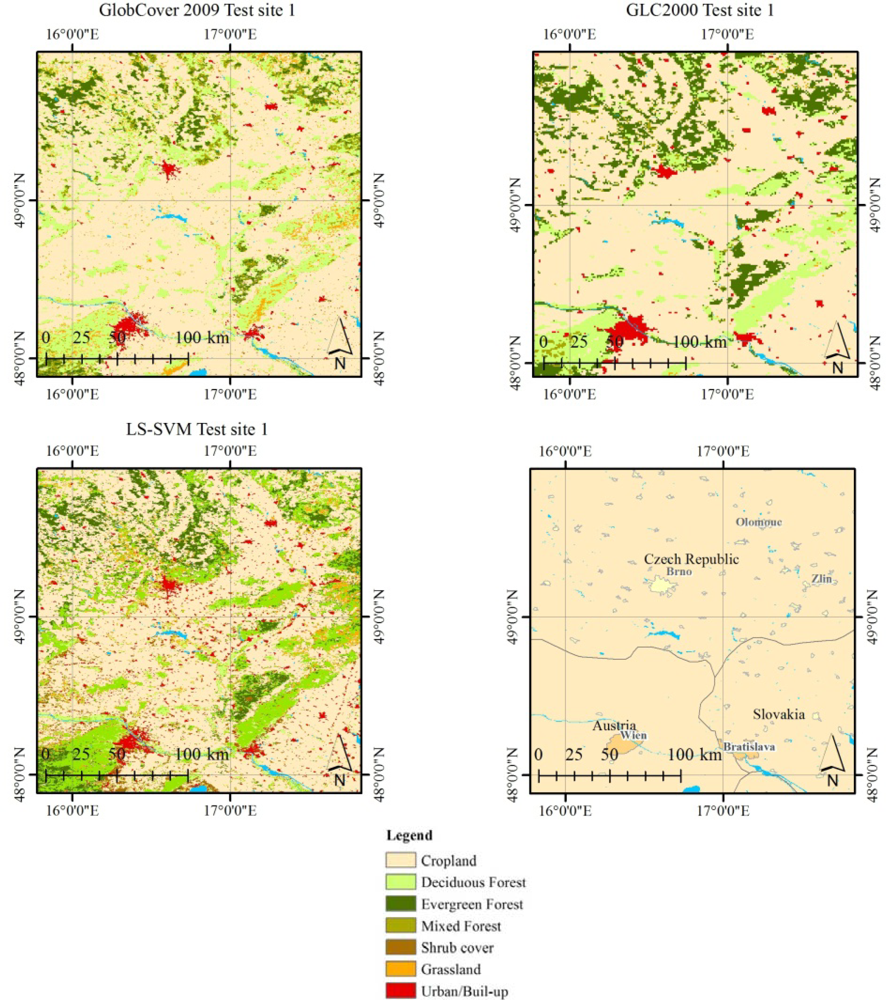
MODIS NDVI data spanning from February 2000 to mid-2011 were downloaded for three experimental test sites (
Table 2). The test sites were selected to cover a variety of land cover types and climatic conditions in Europe.
MOD13Q1 image frames (here h18v04 and h19v04) were reprojected from the Sinusoidal to UTM projection with map datum WGS 84. This coordinate transformation was achieved using the MODIS data Reprojection Tool (MRT) with nearest neighbor resampling. The sub-setting of the three test sites was performed on the reprojected data. Images were consequently stacked to produce the time series dataset. One important requirement for multi-temporal analysis is the co-registration of the various acquisitions in the time series. According to the MODIS team, the geolocation accuracy is approximately 50 m at nadir [
28]. Taking into account both nadir and off-nadir pixels, [
17] reported an error of about 113 m that is considered acceptable for the purpose of the analysis.
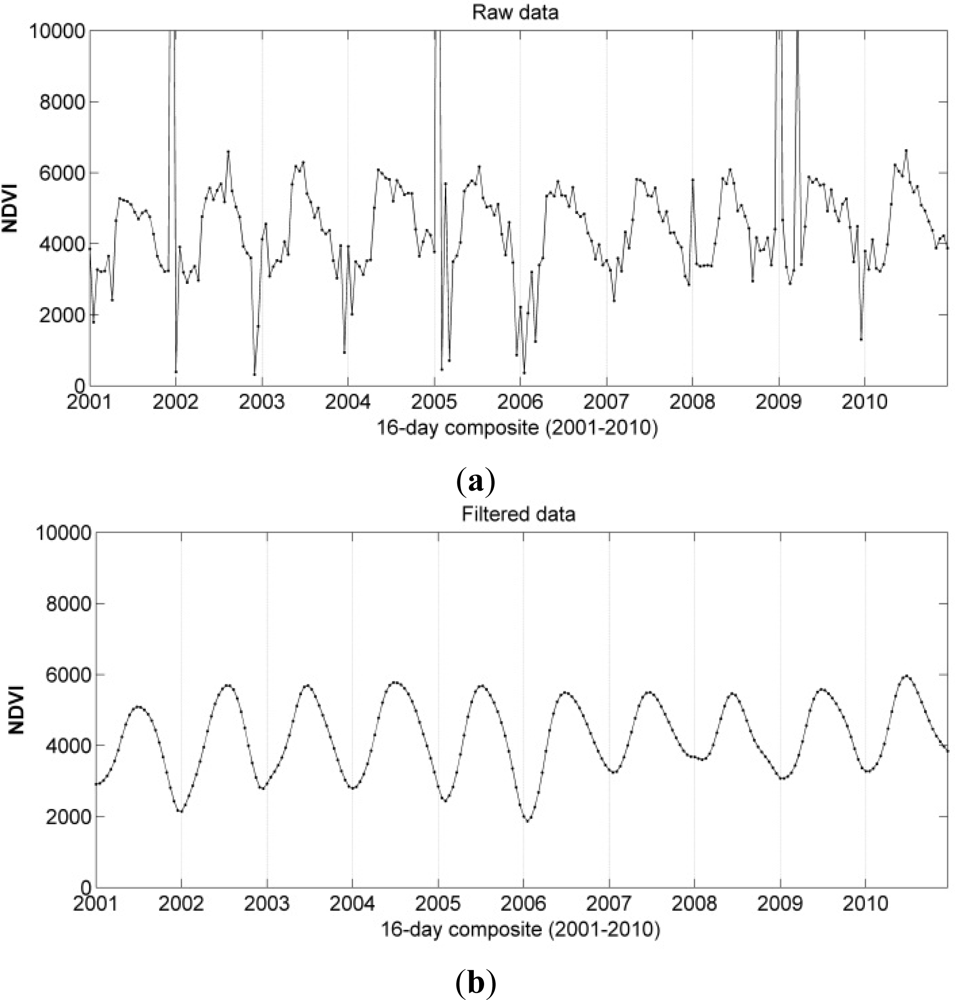
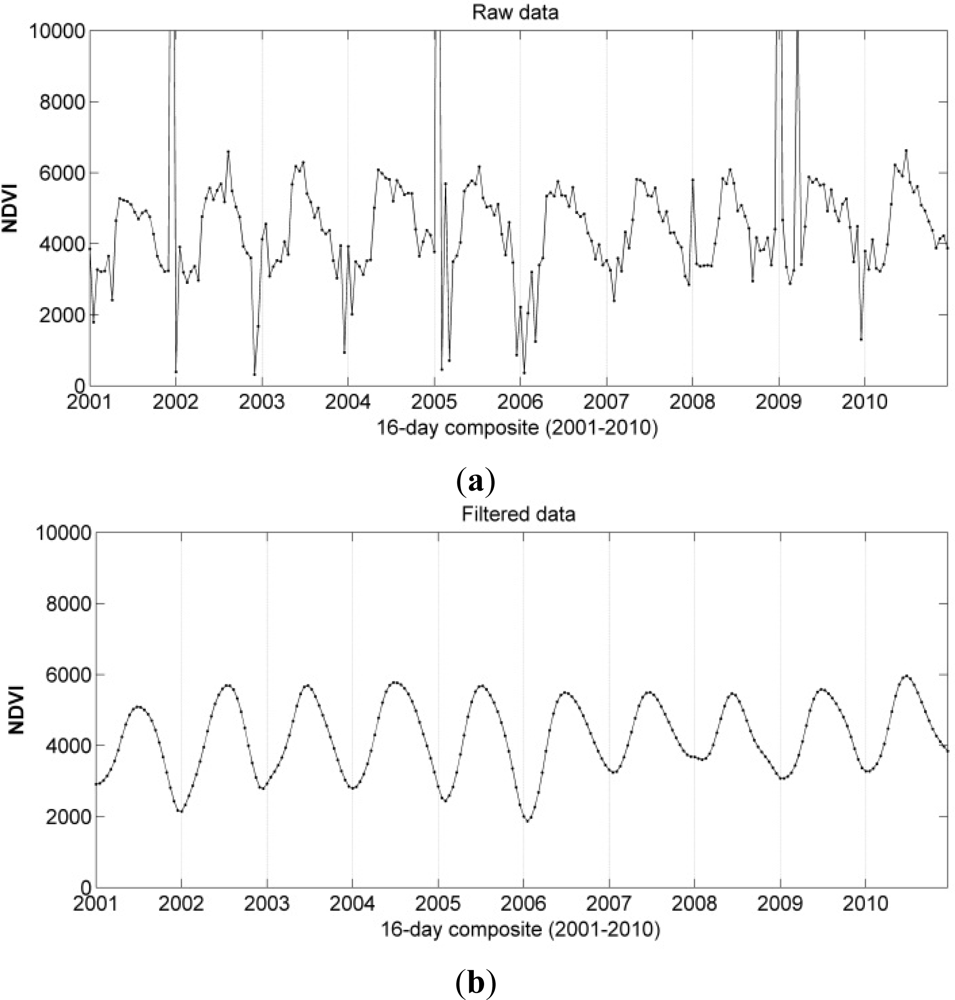
To fill data gaps, and to remove undesired effects of undetected clouds and poor atmospheric conditions, the time series data were filtered. The generation of the filtered dataset was based on a smoothing technique described in [
29]. Data smoothing was achieved continuously from year 2000 to 2011. The employed Whittaker smoother [
30] balances fidelity to the observations with the roughness of the smoothed curve. The algorithm is extremely fast, gives continuous control over smoothness with only one parameter, and interpolates automatically missing data. For further details the reader is referred to [
29,
31,
32]. An example of NDVI time series before and after the filtering is presented in
Figure 2.
The filtered time series consisted of 230 NDVI data values (10 years of data, 23 acquisitions per year, 1 observation every 16 days) from the start of 2001 to the end of 2010 (first and last complete year). The 230 NDVI data values were summarized to provide 16-day inter-annual averages (n = 23) and the corresponding variances (n = 23) for the period 2001–2010. The final NDVI dataset used in our study thus consisted of 46 observations representing the inter-annual averages and variances. A positive effect of using multi-annual data was shown by [
33] where the effect of data compositing and length of the observation period on the LC accuracy was investigated.
As a consequence of the multi-annual data compositing, changes in land use and land cover may be expected to produce artefacts in the inter-annual averages (and variances) of the NDVI values. In this study, we assumed that LULC changes would have only a minimal impact on our European dataset. The rate of land cover changes for 36 European countries was estimated by [
34] being 1.3% of the total land surface for the period 2000–2006, with average annual change rates of 0.08% for Austria, 0.14% for Macedonia and 0.11% for France.
Three climatic indicators were included as LS-SVM input features so that the classifier receives information concerning the respective climatic conditions of each sample: the Annual Mean Temperature, the Mean Diurnal Temperature Range, and the Precipitation of Warmest Quarter calculated at 1-km spatial resolution. These three indicators were selected from the global climate layers of the WorldClim [
35] dataset summarizing annual and seasonal trends of monthly temperature and rainfall values. Temperature and precipitation are important drivers of crop/vegetation growth and phenology. They are thus responsible for inter-annual and spatial variability of NDVI profiles.
The data values of the 49 features dataset were normalized using the standard score and constituted the input for the multi-temporal land cover (LS-SVM) classification.
2.3. Reference Dataset
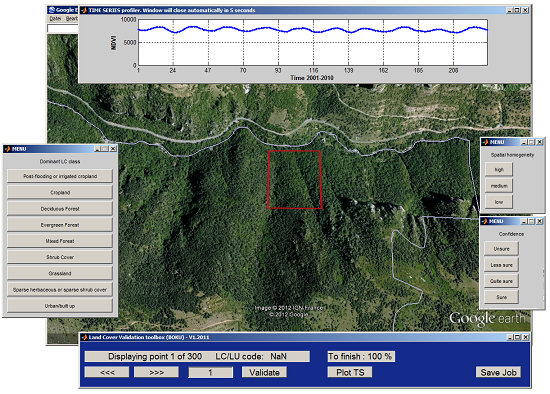
Reference LC information is required to train the LS-SVM, and to determine the quality of the established map in the accuracy assessment process. Visual interpretation of high spatial resolution images represents a time- and cost-saving alternative to traditional field surveys for ground truthing, and the only practical solution at regional and global scales [
36,
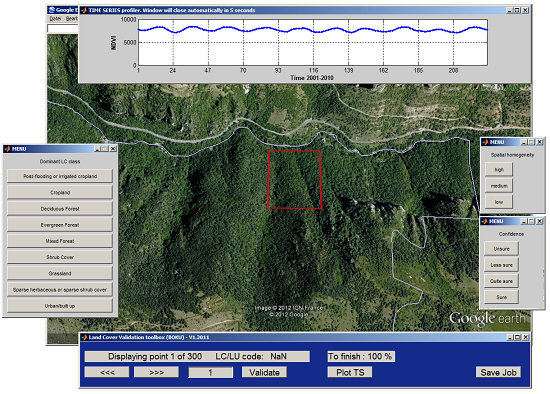
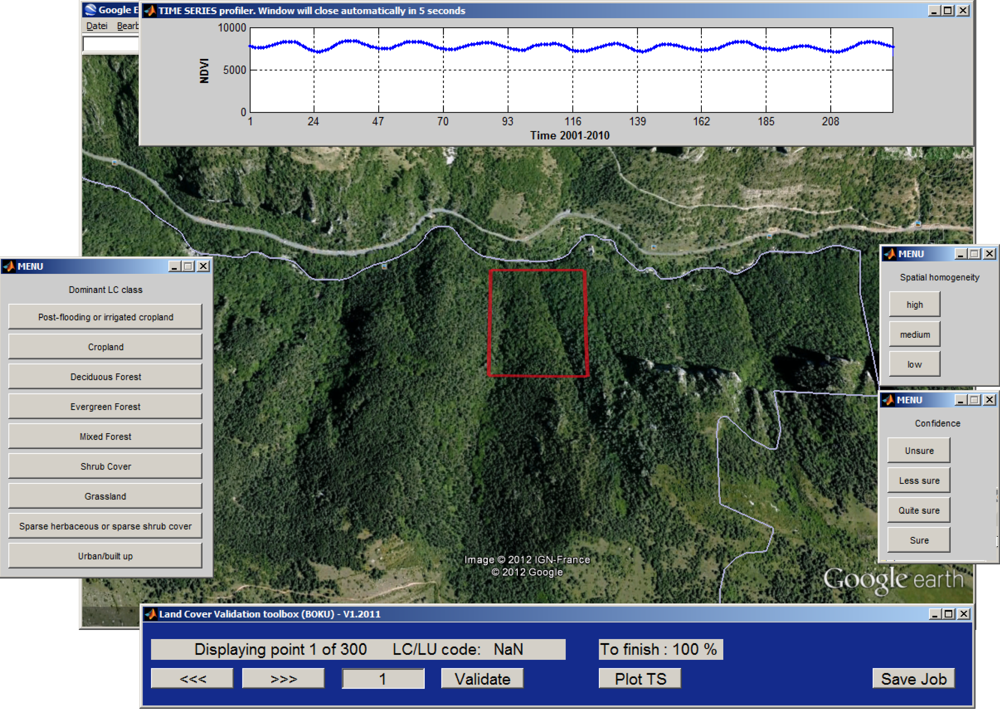
37]. For this purpose, a software toolbox was developed under Matlab to assist the display of satellite images available in GE and to add the visually determined LC label to each of the surveyed point. The NDVI time series corresponding to the MODIS 250-m pixel under validation was used to assess the consistency of the interpreted LC type with the temporal characteristics and to cross-check for changes that may have occurred during the 10 years. The main interface of the software toolbox is presented in
Figure 3.
Two quality indicators were also assigned: (i) the confidence of interpretation, and (ii) the homogeneity of the area under interpretation. The first index categorizes the uncertainties arising while interpreting the high spatial resolution images. Four levels were distinguished: ‘Sure’, ‘Quite sure’, ‘Less sure’ and ‘Unsure’. The second index expresses the level of pixel homogeneity observed in the GE high spatial resolution images. We defined three possible categories based on the number and proportion of land cover types covering the MODIS 250-m pixel footprint and in its neighborhood area (about half a pixel to account for possible geolocation errors) (
Figure 4):
‘High’ for homogeneous pixels containing only one land cover type (a);
‘Medium’ for mixed pixels with a clear predominance of one land cover type (b);
‘Low’ for mixed pixels with more than one land cover type without a clear majority (c). Note that despite this low homogeneity a (single) LC label was assigned.
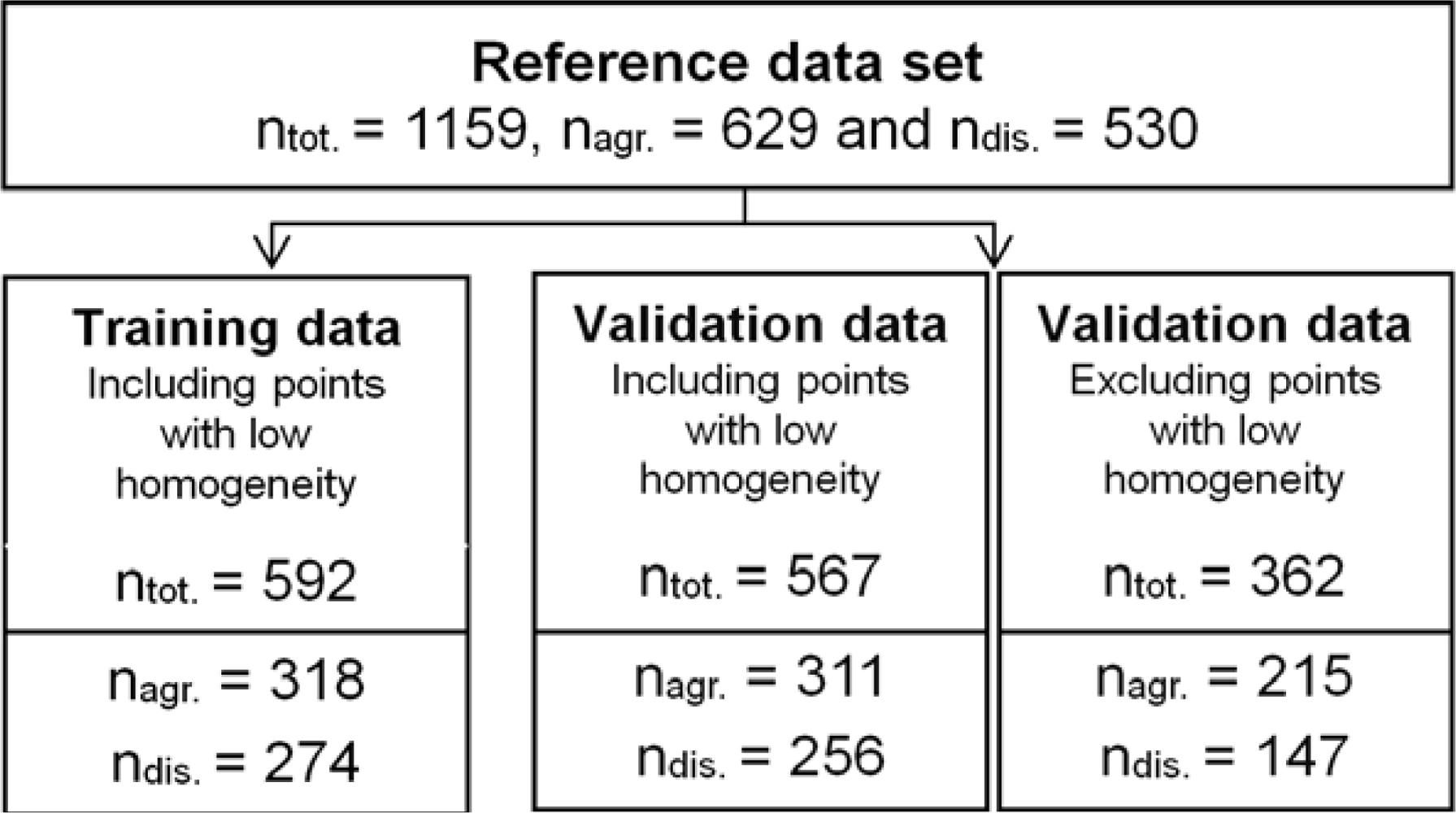
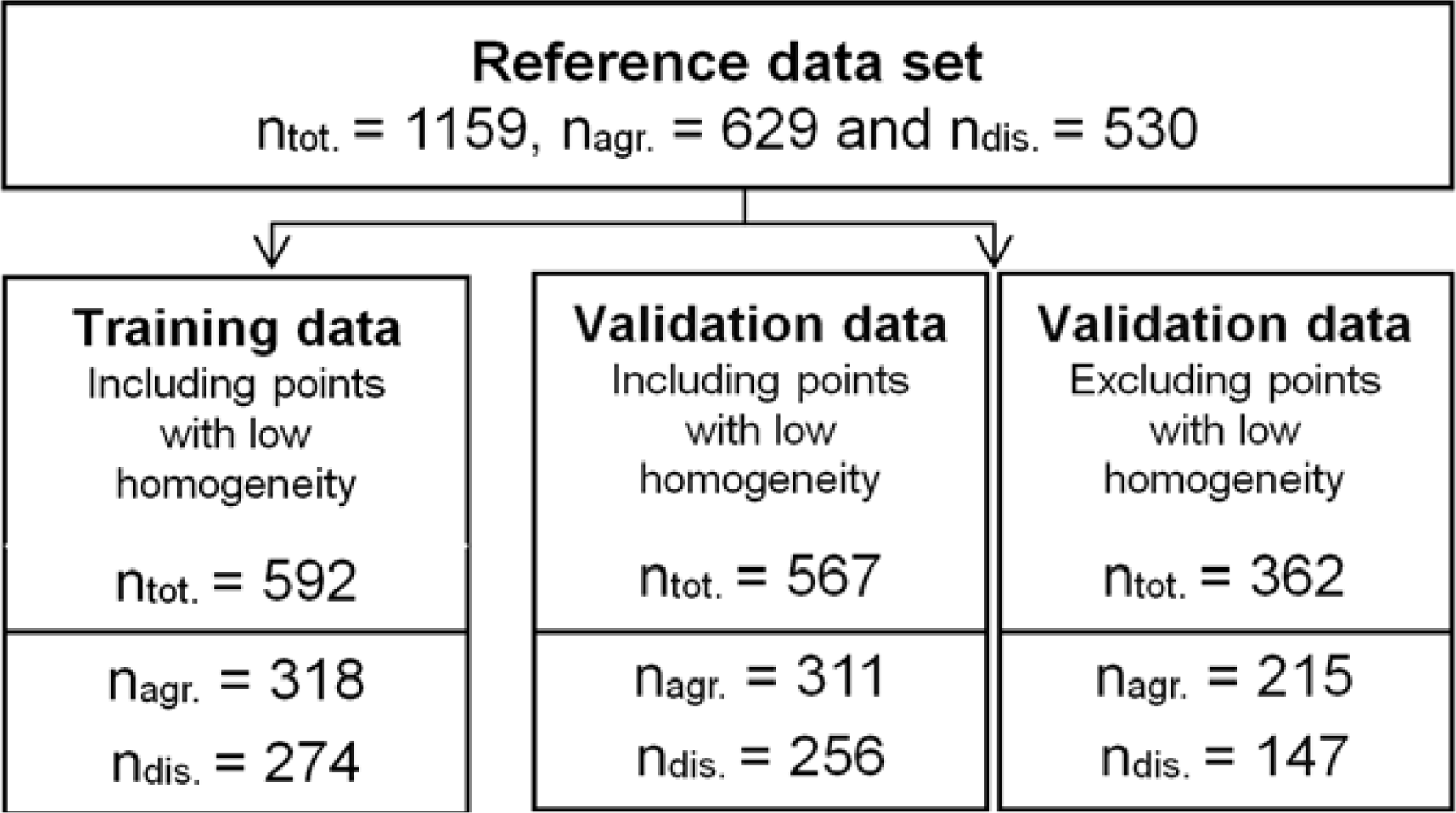
Using this approach, we visually interpreted a total number of 1,235 points randomly selected, of which 76 were qualified as ‘Unsure’. To reduce thematic errors in the reference dataset caused by the visual interpretation, these 76 points were excluded from further analysis.
The final dataset (ntot = 1,159) was randomly split into two sub-samples (training and validation). For the optimization of the LS-SVM algorithm, only the training samples were used. The validation samples were used only for the classification performance assessment. Accuracy measures were calculated for different levels of pixel homogeneity: (1) first for medium to high homogeneity levels (n = 362), and (2) subsequently including all levels of pixel homogeneity (n = 567) .
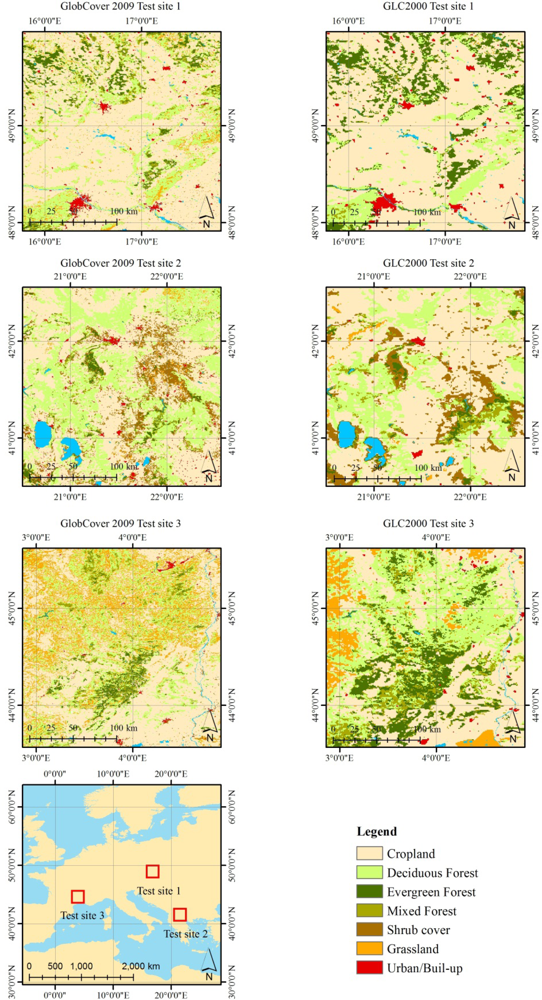
2.4. Comparison with Existing LC Products
The classification performance of the LS-SVM was compared to two existing LC products (GLC2000 and GlobCover). The LC class codes were extracted based on the exact location of the reference dataset points for GLC2000 (1-km pixel size). For GlobCover (300-m pixel size) a 3 × 3 neighborhood majority rule was used. In case where no class met the majority threshold, the center value was taken. A prerequisite to compare land cover data from existing LC products is the harmonization of the different classification legends. Processing aspects and recommendations for LC harmonization are described in [
38]. Although GLC2000 and GlobCover are based on different mixed unit definitions and LC legends, both consider 22 LC classes according to the United Nations (UN) Land Cover Classification System (LCCS) [
8]. Various methodologies have been proposed to aggregate and compare LC maps obtained from different satellite sensor data and mapping projects [
37]. In our study, the LC legends of GLC2000 and GlobCover were first cross-related using a crisp approach [
12]. This permits comparing class descriptions between the two mapping projects. Subsequently, the LC classes of the two legends were translated to a third system and thematically aggregated into seven LC classes (see
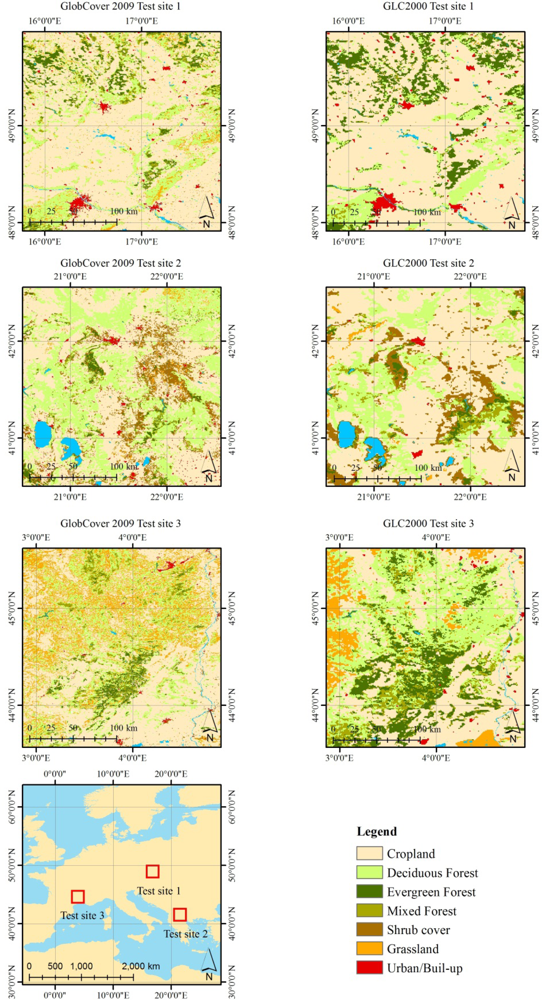
Table 1). This yields two new LC maps with harmonized legends (
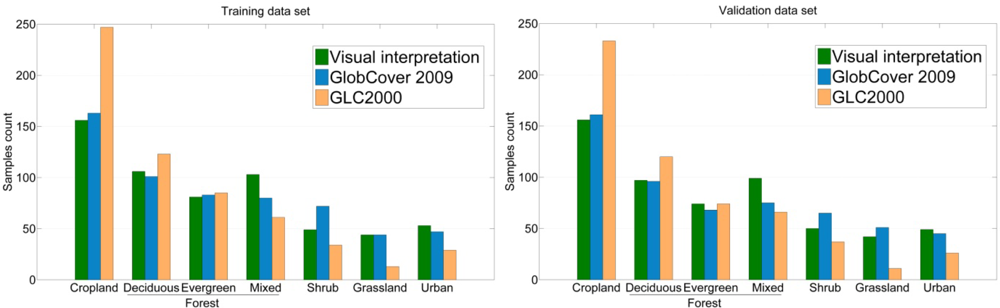
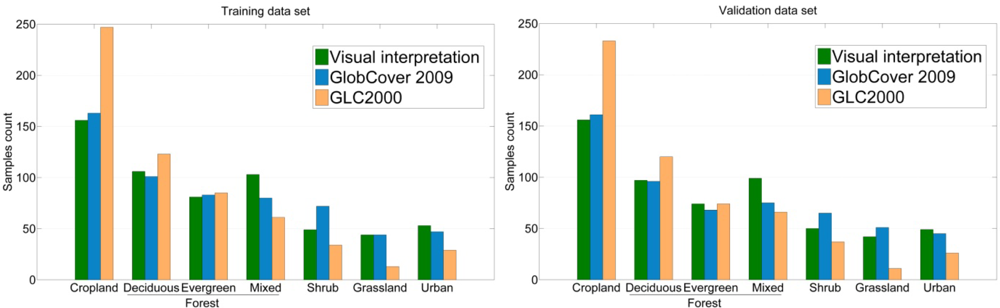
Figure 5). After harmonization and aggregation of legends, the areas of agreement (‘agr.’) and of disagreement (‘dis.’) between the two recoded LC products were derived. The distribution and the number of samples in the training and validation datasets are provided in
Figure 6 and in
Figure 7, respectively.
2.5. Classification Algorithm and Training Strategy
The image classification was performed by a non-linear SVM classifier [
20]. The algorithm uses a kernel function to transform the training samples from the input space to a feature space of higher dimension. This results in a linearly separable dataset—normally non-linearly separable in the original input space—that can be separated by a linear classifier [
39]. In this high-dimensional space, the algorithm finds an optimal separating hyperplane between two classes of training samples. The optimal hyperplane is constructed by maximizing the distance (margin) to the closest data points from the plane. The orientation of the plane is determined only by the training points that lie on the class boundaries, the so-called ‘support vectors’ [
40].
SVMs are intrinsically binary classifiers and different strategies have been proposed to solve the multi-class problem [
41,
42]. However, various studies found that the performance of one approach compared to another depends on the dataset used and on the specific classification problem [
43]. In this study, the multi-class classification problem was decomposed into multiple binary classifications using the one-against-one coding scheme, which provides good accuracy and is usually more suitable for practical use [
44] compared to other coding schemes. This approach was also selected in similar studies dealing with land cover classification [
45]. Regarding SVM algorithm and kernel function settings, we used a Least Square-SVM (LS-SVM) classifier with a Radial Basis Function (RBF) kernel. LS-SVM is a particular case of SVMs proposed by
Suykens and
Vandewalle [
19,
46]. The original formulation was revised to use a set of linear equations instead of quadratic programming problems and therefore to reduce the complexity and to improve the computing power [
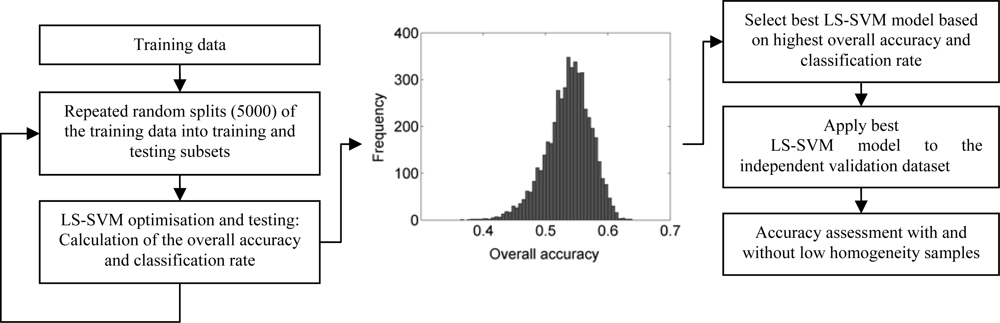
21]. The algorithm has two tuning parameters, namely the regularization parameter and the scaling factor of the kernel function. For the purpose of our study, the two tuning parameters and the optimum set of support vectors were optimized concurrently in a computational loop (5,000 iterations). In a first step, the training dataset was randomly split into subsets of training (candidate support vectors) and testing datasets. Based on these candidate support vectors (subset of training samples), a model optimization was performed to identify the best performing parameter combination for our classification problem. For this purpose, we used a grid-search method, as recommended by [
47]. Each parameter combination was checked using a leave-one-out cross-validation, and the parameter pair with best cross-validation accuracy was selected. For each split, the LS-SVM model was optimized with the candidate support vectors, and the overall accuracy and the classification rate were assessed using the testing dataset. The number of candidate support vectors (80) was given by the minimum number of samples that each class has in the training set. This optimization was repeated 5,000 times using random splits of the training dataset into multiple subsets of training (candidate support vectors) and testing datasets. The best LS-SVM model of the 5,000 iterations was selected based on the highest overall accuracy and classification rate and it was applied to the independent validation dataset. Since random splitting was applied, some samples may never be selected, whereas others may be selected more than once. The schematization of the training, testing and validation process is presented in
Figure 8. With this approach, we selected the most informative training samples that were likely to be good support vectors for the entire study region. The importance of small but informative training samples was also highlighted in previous studies dealing with intelligent selection of reference data for SVM classification in the spectral domain [
24,
25].
2.6. Accuracy Assessment and Accuracy Target
The classification performance evaluation was based on common statistical measures [
48] derived from the classification error matrix. Only the validation dataset was used for this purpose. The selected statistical measures included the Overall Accuracy (OA), the Producer’s Accuracy (PA), the User’s Accuracy (UA), and the Cohen’s Kappa coefficient (κ). The two-side confidence intervals (CI) for the OA were calculated at 95% confidence level using the normal approximation method [
49] with the continuity correction.
The performance of the LS-SVM classifier for the entire validation dataset is reported and distinguishing between ‘agr.’ and ‘dis.’ validation samples. Similarly, we report the accuracy of GlobCover and GLC2000. In benchmarking the LS-SVM performance, we refer to the classification accuracy achieved with GlobCover and GLC2000. We report the increase/decrease of the OA of LS-SVM classifier as percentage of the OA for GlobCover and for GLC2000. The statistical significance of the differences between the pairs LS-SVM-GlobCover and LS-SVM-GLC2000 was evaluated with the McNemar’s test with the continuity correction [
50].
5. Conclusions and Recommendations
This work evaluated the land cover (LC) classification performance of a least square support vector machine (LS-SVM) algorithm using Moderate-resolution Imaging Spectroradiometer (MODIS) 250 m Normalized Difference Vegetation Index (NDVI) time series. The classification performance was compared to the overall accuracies of two existing LC products (GlobCover and GLC2000). In particular, results were evaluated with respect to points in agreement and disagreement between GlobCover and GLC2000 using a harmonized legend with seven land cover classes. This disjoint analysis was performed to evaluate possible improvements in classification accuracy where existing maps are inconsistent (disagree).
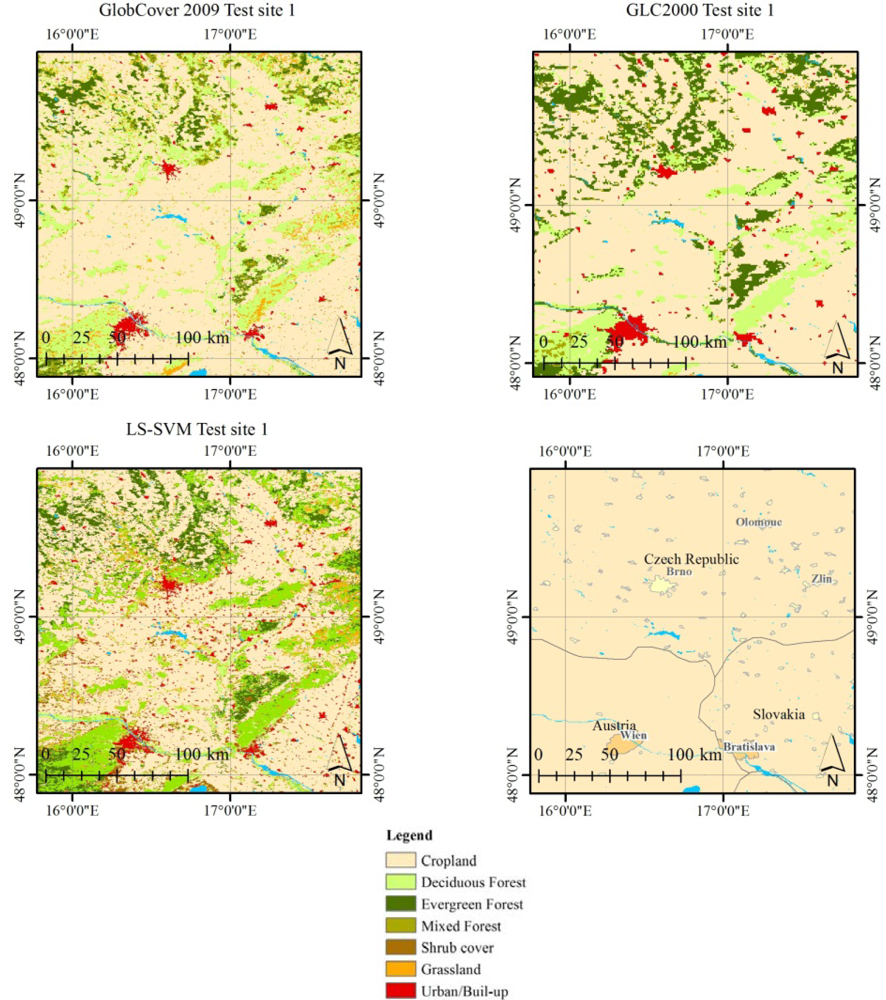
The LS-SVM NDVI-derived LC map achieved an overall accuracy of 70% and it resulted 14% and 18% more accurate compared to GlobCover and GLC2000, respectively. The LS-SVM map was as accurate as existing LC maps in points of agreement (71–75% in our assessment), while classification accuracy was significantly improved (from 36–41% to 68%) in points of disagreement. This improvement was as high as 68% considering a similar minimum mapping unit such as LS-SVM at 250-m and GlobCover at 300-m. Results showed that there is a high potential to significantly improve the accuracy for areas where existing products disagree. Within our 3 test sites, areas of disagreement represent roughly 35% of the total area. This opens new possibilities to revise existing LC maps (e.g., by focusing on areas of disagreement).
Additionally, we investigated the possibility to reduce the effort for visual interpretation. This can be done by selecting and interpreting only points of agreement. Points of disagreement could be excluded a-priori from the visual interpretation and from the training dataset because these points can be considered of low quality and little help for classification. In training the classification algorithm, one can exclusively rely on training samples extracted over points of agreement, thus reducing the effort required for visual interpretation (saving man power and time). In future studies, sampling effort can thus be reduced focusing only on areas of agreement.
Given the currently available global datasets, the users of LC products should in our opinion focus on combining existing maps and identify areas of agreement and disagreement. The accuracy of areas of spatial disagreement could then be improved based for example on the methodology proposed in this study. The proposed methodology can be easily generalized to different legend definitions or levels of land cover detail. This will help maximizing the overall accuracy of the resulting final land cover map as confirmed by our study.
Similar to several other studies [
6,
12,
13,
15], our work confirmed that there is no clear preference of one LC product compared to others. A selection will always have to be based on a specific purpose or application. Steps to further improve the accuracy of land cover maps include, for instance, ensembles of different algorithms for map production based on multi-source datasets [
55]. Subsequently, these maps can be combined and synthetized in one product based on decision fusion rules [
56,
57].





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}