1. Introduction
The problem of detecting a distributed target in sea clutter has been widely studied in the maritime radar field during these years [
1,
2]. The generalized likelihood ratio test [
3] (GLRT) was first utilized to construct the adaptive detectors. Other criteria like Rao and Wald tests have been investigated subsequently over time.
The design of an adaptive detector is closely tied to the clutter model. Therefore, an accurate and appropriate model can substantially improve detection performance. The clutter obtained by high-resolution radar usually shows spikiness, implying that the probability density function (PDF) of the clutter power shows heavy-tailed, which is different from the Rayleigh distribution [
4]. To characterize the non-Rayleigh clutter, the compound-Gaussian (CG) model is commonly adopted. Under the CG model, the clutter can be decomposed into two quantities, named texture and speckle component. The former varies gradually over time and can be considered approximately constant within a coherent processing interval at each range cell [
5].
The gamma texture was first investigated for describing the sea clutter [
6]. However, in some scenarios, the gamma texture was found to be mismatched and resulted in performance loss. Therefore, other textures such as lognormal texture [
7], generalized inverse Gaussian texture [
8], and inverse Gaussian (IG) texture have been proposed. Moreover, in [
1], the authors proved that the IG texture can fit the sea clutter better than the other texture distributions in most situations.
In contrast to the texture component, the speckle component is a random vector obeying zero-mean complex Gaussian distribution with an unknown covariance matrix (CM). The estimation of the speckle CM is of great significance in adaptive detection. An accurate estimation of the CM can be used to suppress the clutter efficiently, hence raising the probability of detection (PD) [
9]. To estimate the CM, a secondary dataset, located around the testing data, is employed. However, in some scenarios, the training data may be insufficient. Thus, investigating the estimate of the speckle CM with limited training data is meaningful in improving the detection performance in practice.
Many approaches have been proposed to estimate the clutter CM. Traditional methods contain the sample covariance matrix (SCM) estimator [
3], the normalized sample covariance matrix (NSCM) estimator [
10], the constrained approximate maximum likelihood (constrained AML) estimator [
11,
12], and the CM estimator based on geometry barycenters [
13]. When the environment is homogeneous or partially homogeneous, the structure of the CMs in cells under test (CUTs) and reference cells are the same, the above methods can estimate the CM accurately and result in acceptable performance of the detectors. However, in some situations, the homogeneous clutter environment model may not be suitable [
12,
14]. In this case, the structure of the clutter CM in each range cell may be different, resulting in insufficient training data and great performance degradation of the mentioned estimators. To overcome this, some efficient methods have been studied. Aboutanios derived a hybrid detection approach and proposed the use of the generalized inner product as a heterogeneity measure [
15]. In [
16], Aubry gave an approach for CM estimation based on the geometric diagram. Additionally, in [
17], the authors regarded the CM as a random quantity obeying inverse complex Wishart distribution [
18], and utilizing Bayesian theory to construct an adaptive detector for a point-like target with limited training data. Subsequently, Bandiera [
19] proposed a range-distributed target detector based on the GLRT for CG clutter with gamma texture, and the experiments indicated that the detectors showed better performance than the other detectors. Xue [
20] investigated knowledge-aided detection in IG texture CG clutter and assessed the detection performance via simulated and measured data experiments. Guo [
21] considered the detection of rank-one distributed target embedded in lognormal texture CG clutter and proposed several Bayesian detectors that can work with limited training data or even no training data by incorporating the maximum a posteriori (MAP)-estimated speckle CM and texture component.
The detectors discussed are primarily designed for point-like or range-distributed targets in the absence of interference. However, in real-world detection scenarios, radar echoes are often contaminated by interference from sources such as civil broadcasting systems or electronic countermeasures, in addition to clutter and target signals [
22,
23]. The interference received by radar will lead to false alarm points and seriously degrade the detection performance [
24]. By utilizing the electronic support measures [
25], prior information on the interference can be obtained. In this case, the interference can be called subspace interference.
Considering the existence of subspace interference, motivated by the Bayesian approach, in this paper, we aim to detect the range-distributed targets under subspace interference in IG texture CG clutter. Additionally, the speckle CM is assumed to be random and obeys the complex inverse Wishart distribution. The innovations and contributions of this article are as follows:
- (1)
We derive six Bayesian interference-canceling detectors under CG clutter with inverse Gaussian texture. The first GLRT-based detector can work in the absence of training data while the others combine prior information on the speckle CM and training data to obtain higher estimate precision of the CM to enhance the performance.
- (2)
The Bayesian interference-canceling detectors for range-distributed targets embedded in CG clutter with IG texture and subspace interference are first proposed.
- (3)
Simulated and IPIX radar-measured data are utilized to confirm the effectiveness of the proposed detectors and their superiority to the competitors in most situations.
The rest of the article is organized as follows. We give the problem formulation and declaration of signal, interference, and clutter models in
Section 2. Then, we derive six Bayesian interference-canceling detectors in
Section 3. The effectiveness of the proposed detectors is carried out in
Section 4 throughout experiments. Finally, we conclude this article in
Section 5.
Notations: Matrices/vectors are written in uppercase/lowercase bold letters. , and represents conjugate, transpose, and conjugate transpose, respectively. , , and denotes the inverse, square root, and inverse square root of a square matrix. denotes the Kronecker product. denotes the trace. represents the natural logarithm. denotes the determinant. is the absolute value of a scalar. denotes the 2-norm of a column vector. denotes the complex inverse Wishart distribution. denotes the statistical expectation. and means “is proportional to” and “is distributed as”, is the Euler’s gamma function. is the diagonal matrix. denotes the dimensional zero matrix.
2. Problem Formula
There exists an
complex matrix
representing the testing data collected by a radar system with
pulses across
range cells (also called CUT). The echo of the distributed target is with a known steering vector but unknown amplitudes, having the form
, where the
complex vector
is the target steering vector, and
complex vector
denotes the complex amplitudes of the target in different range cells. The clutter component is represented by
. Each column of
is modeled as CG clutter. Thus, we have
where
is a diagonal matrix with non-zero elements being the texture components corresponding to a specific range cell.
In this article, the texture component in range cells is regarded as obeying the IG distribution [
26], i.e.,
where
and
denote the shape and scale parameter in
-th range cell, respectively.
In addition, each column of , named speckle component, is independent and identically Gaussian distributed with an CM and zero mean. To estimate the speckle CM , the clutter-only training data matrix with length is usually assumed available.
However, when the training data is insufficient, the estimate precision of
may degrade seriously. To settle this problem, the CM
is considered to obey the complex inverse Wishart distribution with degree of freedom (DoF)
and a scaled matrix
(
), i.e.,
. The PDF of
is given by [
19,
27]:
where
and
can be regarded as the prior information for the speckle CM
. In this article,
is estimated from the previously scanned data and
is assumed known. Moreover, the DoF
measures the distance between
and
. Specifically,
is closer to
as
gets larger.
Besides the target and clutter, we also consider the existence of subspace interference. Specifically, the interference can be represented by , where is an complex matrix which can be taken as the interference steering matrix, is an complex matrix representing the coordinates of the interference.
Through the above discussion, the detection problem of rank-one distributed targets with subspace interference can be represented by the binary hypotheses test as follows:
For the above detection problem, the conditional PDFs of
under two hypotheses are found to be:
where
,
,
is the
-th column of
,
is the
-th column of
,
is the
-th element of
,
is the
-th column of
, and
represents the texture component in
-th range cell.
3. Bayesian Interference-Canceling Detectors Design
In this section, we first propose a GLRT-based Bayesian interference-canceling detector that can work without training data. After that, we combine the training data, the DoF and the scaled matrix to construct the interference-canceling detectors by the two-step GLRT, the Rao, Wald, Gradient, and Durbin tests, respectively.
3.1. BICGLRT-DT Detector
Combining the prior information of
and
, we can write the GLRT [
3,
21] for the detection problem in (4) as:
where
stands for the detecting threshold judged by a pre-assigned probability of false alarm (PFA). After some algebra and maximization, the maximized numerator and denominator of (7) is given as:
where the detailed derivation can be seen in
Appendix A,
, and
.
To estimate
, we denote the following function:
Then, calculating the partial derivative of
with respect to (w.r.t.)
and nulling the result, we get:
After some algebra, the equation for
under
hypothesis can be written as:
The roots of (11) can be given as [
28]:
It has been proved in [
28] that there is only one positive root for (11). Thus, we select the positive root
in (12) as the MAP estimate of
under
.
Substituting the MAP estimate
into (8) leads to
Similar to (13), the maximized PDF under
hypothesis is written as:
where
, and
is the positive root of the following equation:
Finally, combining (13) and (14) with (7), after some algebra, we obtain the Bayesian interference-canceling GLRT detector for distributed target (BICGLRT-DT) as follows:
3.2. TD-BICGLRT-DT Detector
In this subsection, the DoF
, scaled matrix
, and training data are adopted simultaneously to derive the interference-canceling detector based on two-step GLRT [
29]. We first assume the
and
are known, and the GLRT for (4) can be written as:
where
Next, by calculating the partial derivative of (18) w.r.t.
and nulling the result, we get the maximum likelihood estimate (MLE) of
under
:
where
,
and
. Taking the derivative of (20) w.r.t.
, the MLE of
is given as:
where
.
Inserting (20) and (21) into (17), we yield:
where
, and
.
Similar to (22), we get
where
.
Combining (22) and (23) with (17) leads to:
Next, we estimate
and
. Taking the similar manner as (11), (12), and (15), the MAP of estimate of
and
is the positive root of the following two equations, respectively.
Combining (22), (23) and the estimated
,
with (24), we obtain the detecting statistic:
After that, to estimate
, the MAP approach is utilized. For the training data, the posterior PDF of
and
is:
where
is the column of
. After taking the partial derivative of (28) w.r.t.
, we find that the MAP estimated
is the positive root of the equation as follows:
Then, substituting
into (28), taking the logarithm of (28) and calculating the partial derivative of it w.r.t.
, the result is expressed as:
Combining (29) with (31), we obtain
Inserting (31) and (32) into (30), after some algebra, we yield the MAP estimate of
:
It can be seen that
is the function of itself and
, and
is related to
. Therefore,
needs to be solved by an iteration procedure. The initial matrix
is constructed by the NSCM as follows:
Moreover, to ensure
(where
denotes the number of operated iterations) at the end of each iteration, the following process should be operated:
For the -th iteration, the procedure can be listed as follows:
- (1)
Calculating by and (29).
- (2)
Calculating based on and (33).
- (3)
Normalizing by (35).
After the iterations, we can obtain the
as the MAP estimate of speckle CM
. Finally, inserting the estimated
into (27), we obtain the statistic of training-data-based Bayesian interference-canceling GLRT detector for distributed target (TD-BICGLRT-DT):
where
,
,
,
,
,
,
.
and
are the positive root of the following equations, respectively.
3.3. TD-BICRao-DT Detector
Assume
is the parameter set and has the form:
where
and
, where
and
. The Fisher information matrix (FIM) w.r.t.
is:
For convenience, partition the FIM as:
The complex parameter Rao test [
30] for (4) can be written as:
where
denotes the detecting threshold,
is the MLE of
under
hypothesis, and
is the value of:
at
. Taking the partial derivative of logarithm of (6) w.r.t.
and its conjugate leads to
Substituting (44) and (45) into (40) yields:
Calculating the partial derivative of (45) w.r.t.
and taking the expectation, we obtain:
Similar to (47), taking the partial derivative of (45) w.r.t.
and calculating the expectation, i.e.,
Therefore, we have .
Next, to obtain the
, we first take the partial derivative of (6) w.r.t.
and
, respectively:
From (49) and (50) we can easily derive the following:
Combining the above three equalities, we obtain:
Inserting
, (46) and (55) into (43) results in:
Besides, we notice that
under
hypothesis and
. In the second step, inserting (44), (45), (56), the estimated
in (38), and the estimated
in (33) into (42), we obtain the statistic of training-data-based Bayesian interference-canceling Rao detector for distributed target (TD-BICRao-DT):
3.4. TD-BICWald-DT Detector
The complex parameter Wald test [
30] for (4) is given by:
where
is the detecting threshold,
is the MLE of
under
, and
is the MLE of
under
.
Inserting (56) and (21) into (58), ignoring the constant yields:
After that, inserting the estimated
in (37) and the estimated
in (33) into (59), we obtain the statistic of training-data-based Bayesian interference-canceling Wald detector for distributed target (TD-BICWald-DT):
3.5. TD-BICGradient-DT Detector
The complex value Gradient test [
31] for (4) is given as follows:
where
is the detecting threshold. Therefore, by inserting (21), (44),
,
in (38) and the estimated
into (61), we get the statistic of training-data-based Bayesian interference-canceling Gradient detector for distributed target (TD-BICGradient-DT):
which is found to be the same as the TD-BICRao-DT in (57).
3.6. TD-BICDurbin-DT Detector
The complex value Durbin test [
31] for (4) is denoted as:
where
is the detecting threshold,
is the MLE of
under
with
,
is the MLE of
under
. Consequently, we have
And
is given by:
Plugging (46), (56), (65),
in (38) and the estimated
into (63) results in the statistic of training-data-based Bayesian interference-canceling Durbin detector for distributed target (TD-BICDurbin-DT):
which is the same as both (57) and (62).
In summary, the TD-BICRao-DT, TD-BICGradient-DT, and TD-BICDurbin-DT are equivalent to each other. Therefore, we only discuss the BICGLRT-DT, TD-BICGLRT-DT, TD-BICRao-DT, and TD-BICWald-DT in the following.
4. Complexity Analysis
In this section, the computational complexity of the proposed detectors and the existing detectors is analyzed in detail, including time complexity and space complexity.
4.1. Time Complexity
Since matrix multiplication is much more complex than addition, we only consider the former in this subsection.
We first discuss the time complexity of the BICGLRT-DT in (16). It can be noted that the calculation of and occupy the most time consumption. For the , we can rewrite it as . Obviously, the calculation of mainly involves an inversion of matrix with complexity , an inversion of matrix with complexity , and times multiplication to obtain and . For , we can recast it as . Since the inverse of is executed before, there only remains some multiplications with low-magnitude complexity for calculating . To sum up, the time complexity of the BICGLRT-DT for each CUT is . For all the CUTs, since each CUT shares the same , the inversion of need to be executed only once, the complexity is also .
Then, we consider the complexity of the TD-BICGLRT-DT in (36). Due to the iteration steps, the estimate of contributes greatly to the time complexity. For the iteration step 1 (29), an inversion of matrix with complexity is executed during each iteration. For the step 2 (33), the factor shares the same as that in (29), therefore, there’s no three-order complexity operation in step 3. The step 3 in (35) only contains a trace operation and a multiplication, thus, the complexity can be ignored. Moreover, it can be seen from (34) that the complexity of the calculation of the is . In summary, during each iteration, the complexity is . Denote the times of iteration by , then the complexity of estimating is . After the iterations, to obtain and , the complexity is , where the analysis is similar to that of and . In summary, the time complexity of the TD-BICGLRT-DT for all the CUTs is . For the other TD-detectors, the time complexity is the same.
For comparison, we chose the GLRT-
detector in [
19] as the competitor. The test statistic of the GLRT-
is given by:
where
. Obviously, the computational complexity of the GLRT-
is
.
4.2. Space Complexity
In this subsection, we discuss the space complexity based on the size of the data, i.e., size of a matrix. The discussion of space complexity is similar to that of time complexity, for the statistic of the BICGLRT-DT, the matrix is with the space complexity , and the complexity of the matrix is . Therefore, the space complexity of the BICGLRT-DT can be approximately regarded as . For the TD-BICGLRT-DT, we can easily deduce that the space complexity is also by taking in a similar manner the analysis of the BICGLRT-DT. And the complexity of the GLRT- is .
For an intuitive comparison, we summarize the time and space complexity of our proposed detectors and the competitor in
Table 1.
5. Performance Assessment
In this section, numerical experiments are carried out to investigate the performance of the Bayesian interference-canceling detectors by exploiting simulated and measured sea clutter data, respectively. The detection threshold and the probability of detection (PD) are obtained by and 104 independent Monte Carlo trails, respectively. The PFA is set to be . During the experiments, the GLRT- detector is selected as the comparison detector.
For the elements in the scaled matrix
, we define
, where
. The target steering vector is represented as
, where
is the normalized target Doppler frequency with range
. Similarly, the
-th column of interference steering matrix
is defined as
, where
represents the normalized interference Doppler frequency in the
-th column of
. The signal-to-clutter ratio (SCR) and interference-to-clutter ratio (ICR) are defined as
If no special declaration, we set , , , ICR = 15 dB, for any . For target component, is set to be 0.3, for subspace interference, we set , . We choose the DoF and the number of iterations for the estimate of to be 4. For the subspace interference, the coordinate is randomly generated at the beginning of each experiment. During the simulated data and measured data experiments, the frequencies of the interference are fixed.
Moreover, for the distributed target, we provide some signal models with different energy distributions according to [
32] and the models are listed in
Table 2, where
can be regarded as the proportion of signal energy in
-th range cell of the CUT.
5.1. Simulated Data Results
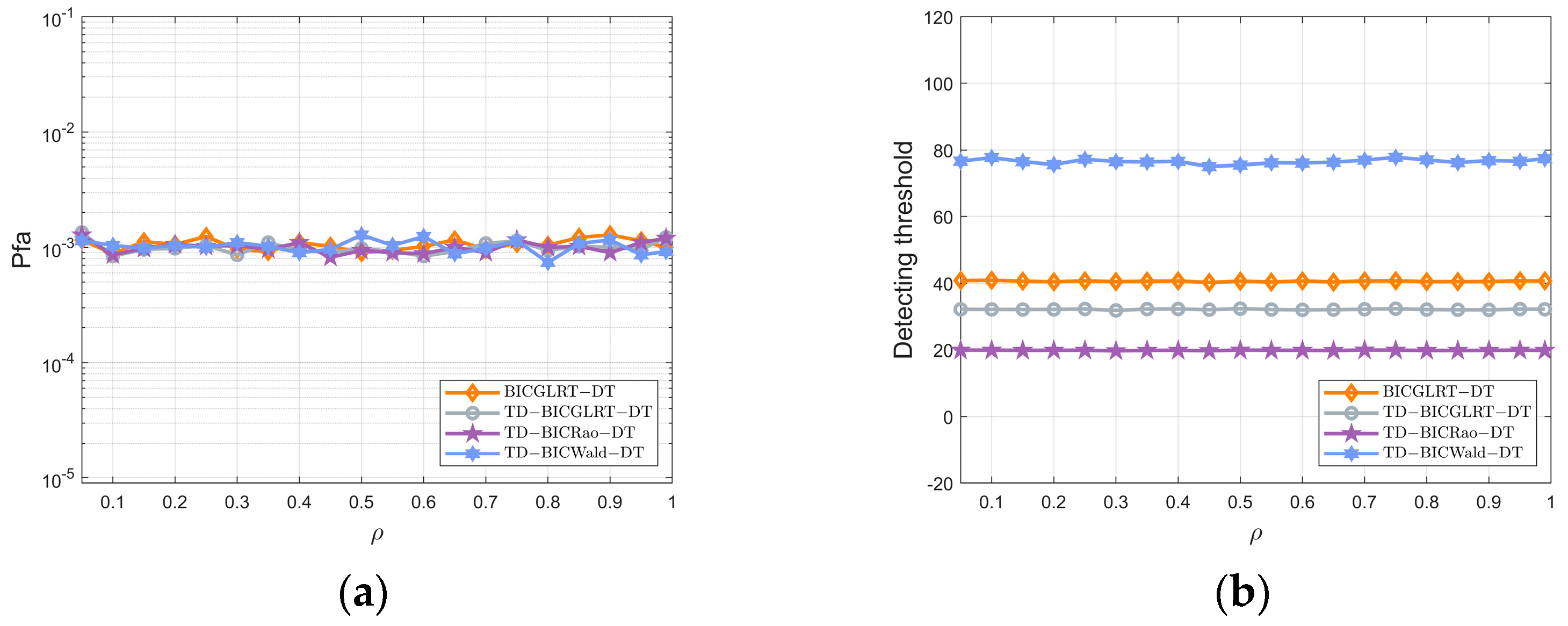
Figure 1 displays the PFA and detecting thresholds of the proposed detectors (BICGLRT-DT, TD-BICGLRT-DT, TD-BICRao-DT, and TD-BICWald-DT) versus one-lag coefficients without training data. In this case, we have
.
The above figure shows that the curves of the PFA and detecting thresholds fluctuate slowly with the change of . Therefore, the proposed Bayesian interference-canceling detectors hold CFAR property w.r.t. the scaled matrix .
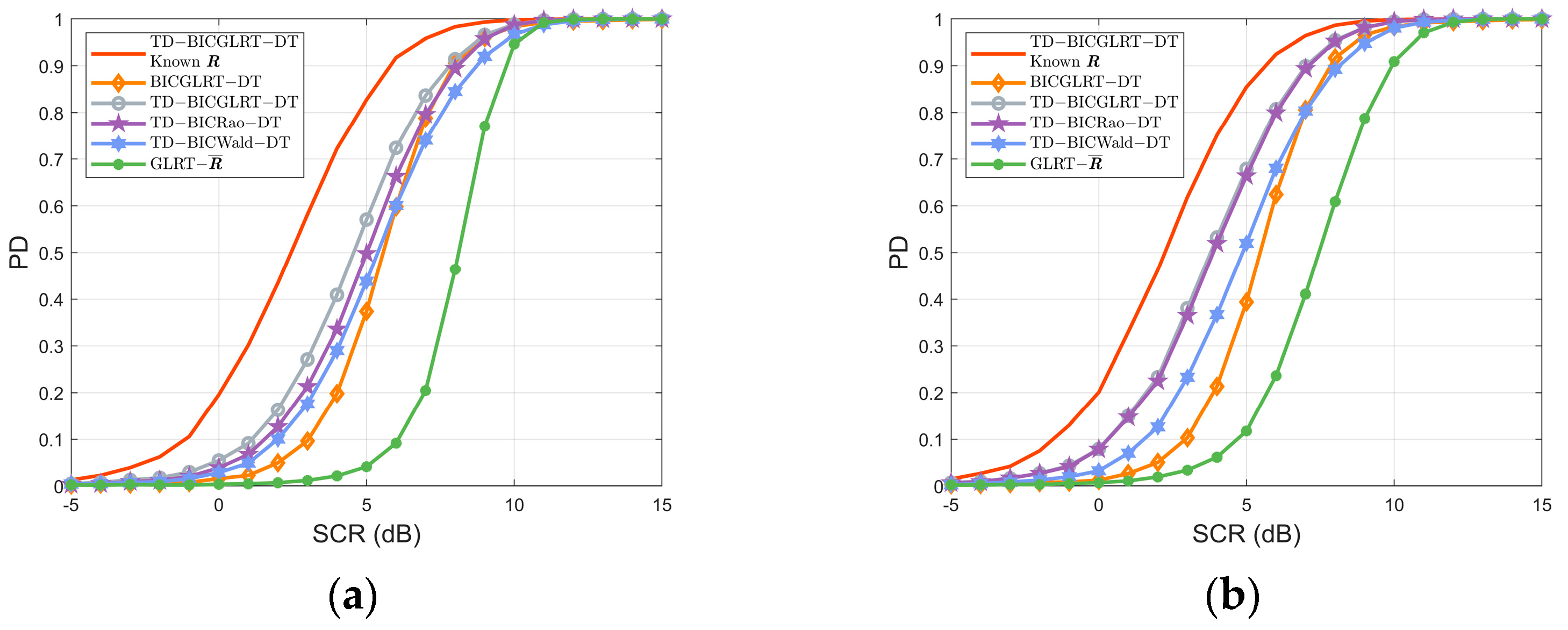
Figure 2 plots the PDs of the detectors versus SCR with the
under different signal energy models. The curves show that the Bayesian interference-canceling detectors attain better performance than the GLRT-
, the reason being that the GLRT-
does not take the existence of subspace interference into consideration. As a matter of fact, the presence of interference will raise the detecting threshold of GLRT-
, therefore leading to performance degradation. By exploiting the training data, the proposed TD-BICGLRT-DT, TD-BICRao-DT, and TD-BICWald-DT outperform the BICGLRT-DT. Moreover, as discussed in
Section 4, the TD-detectors achieve better performance than the BICGLRT-DT at the cost of high time complexity. Additionally, it can be seen that the TD-BICGLRT-DT has the highest PD when the signal energy is distributed uniformly. The performance of the TD-BICRao-DT degrades seriously as the signal energy gradually concentrates in a specific range cell in the CUT, indicating that the TD-BICRao-DT is sensitive to the energy distribution. In contrast, the TD-BICWald-DT is the most robust as energy distribution varies. The detailed analysis of the influence of the signal energy model can be seen in
Appendix B.
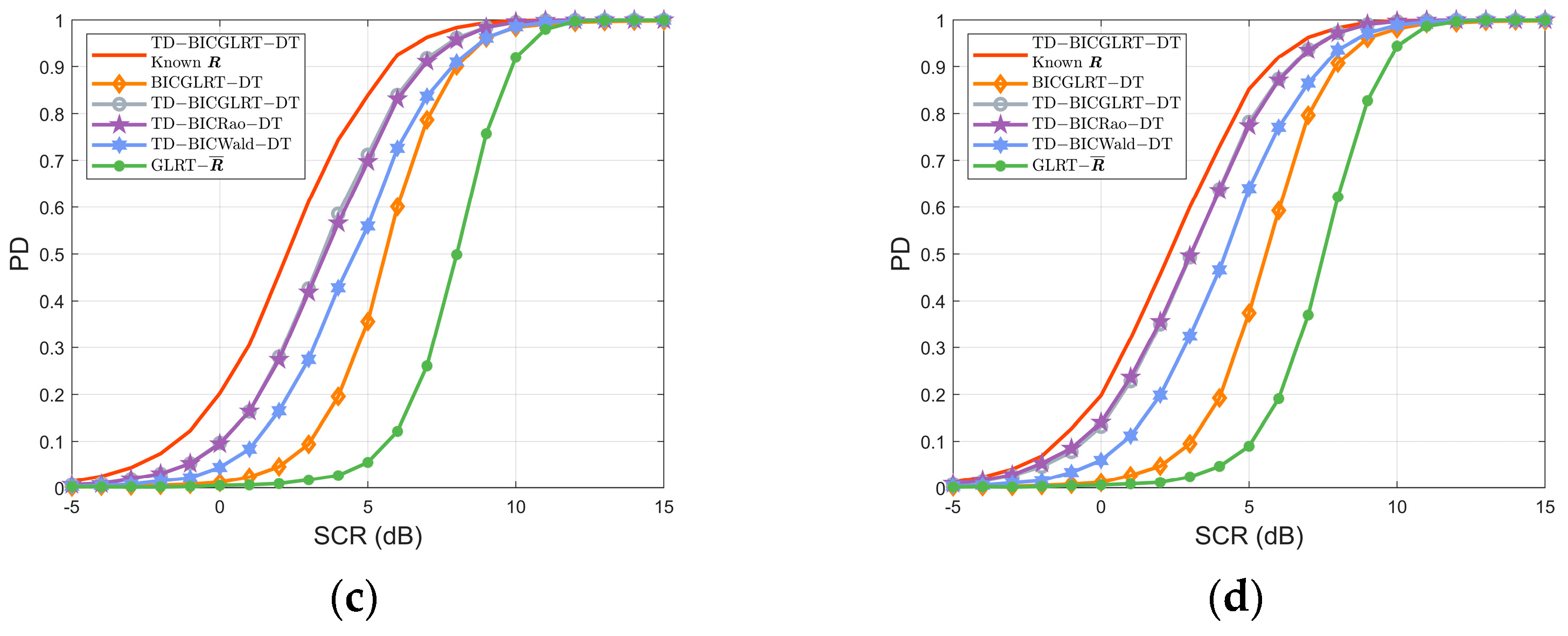
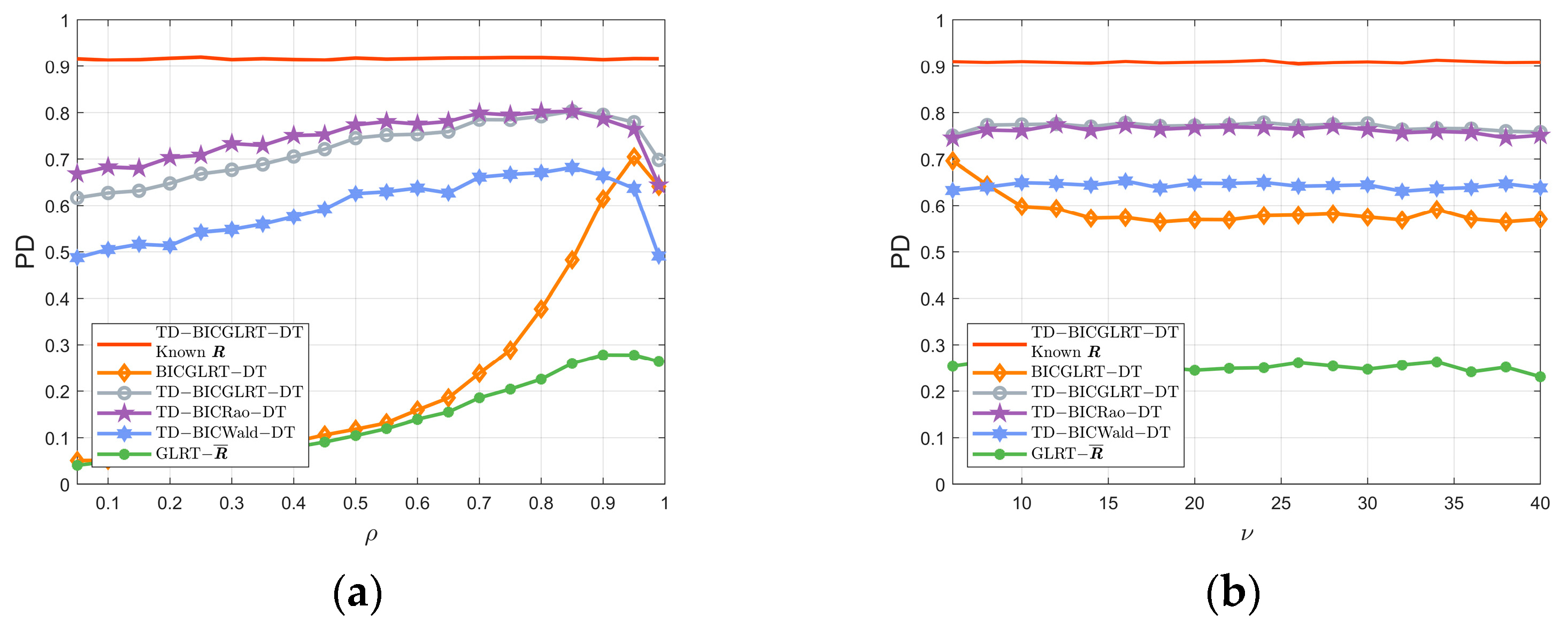
In
Figure 3, we investigate the detection performance of the detectors with different numbers of training data under signal energy model 1. As shown in
Figure 3a, the curve of the BICGLRT-DT is nearly consistent with that of the TD-BICGLRT-DT and TD-BICRao-DT when SCR is higher than 7 dB. As
gets larger, the performance of proposed TD-BICGLRT-DT, TD-BICRao-DT, and TD-BICWald-DT gradually approaches that of the TD-BICGLRT-DT with known
. The reason is that the increase in
will make the estimated
closer to the true
, therefore improving the detection performance.
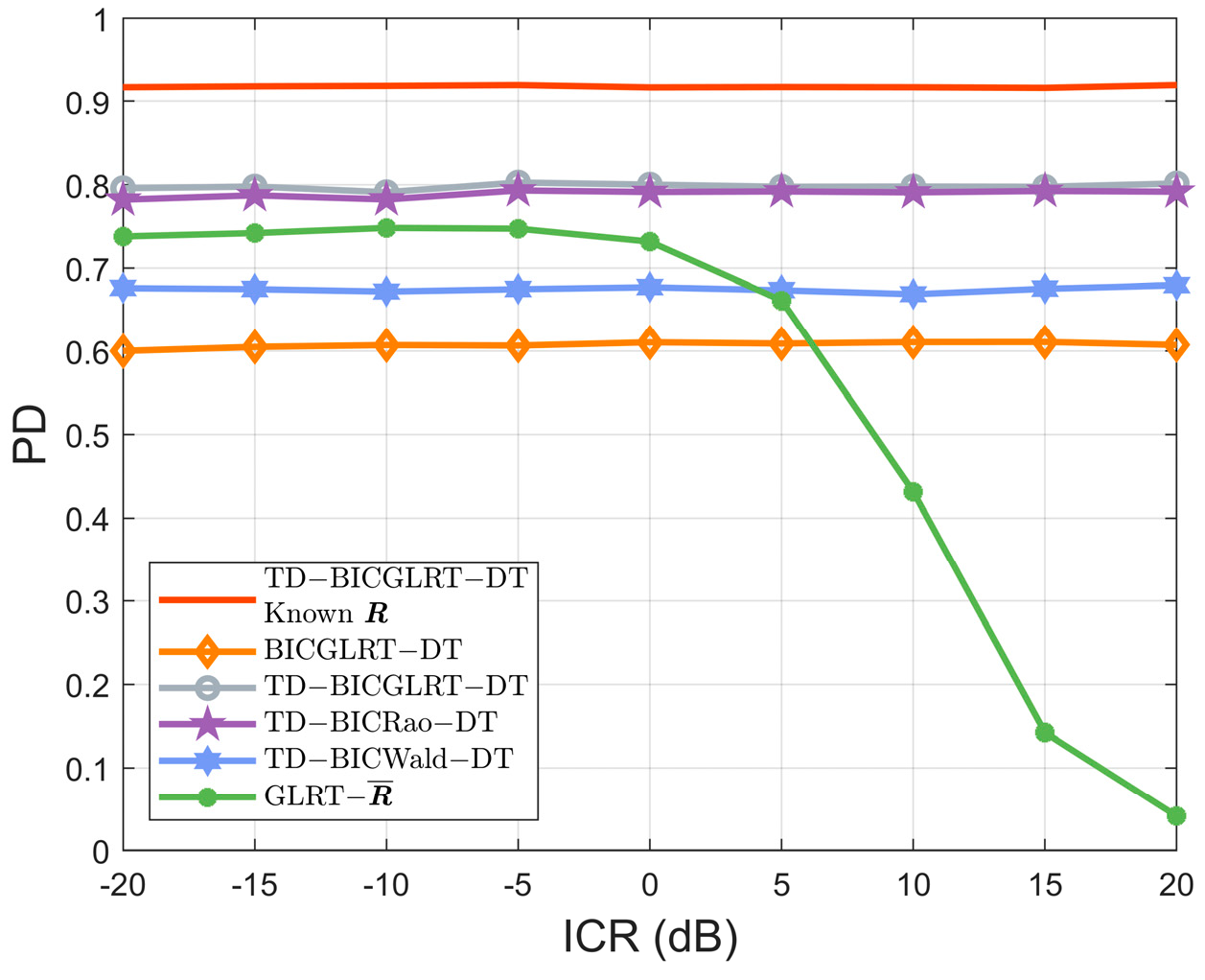
The performance comparison of the proposed BICGLRT-DT, TD-BICGLRT-DT, TD-BICRao-DT, TD-BICWald-DT, and the existing GLRT-
under different ICRs are displayed in
Figure 4. As shown by the curves, the PDs of the proposed interference-canceling detectors almost stay unchanged with different ICRs, implying that the performance of the BICGLRT-DT, TD-BICGLRT-DT, TD-BICRao-DT, and TD-BICWald-DT are not influenced by the power of the subspace interference.
Figure 5 shows the PDs of the detectors when there exists a prior information mismatch. Specifically, we consider the mismatch of the one-lag coefficient
in
Figure 5a. The actual
is set to be 0.9, and the curves indicate that the proposed detectors degrade when the presumed
deviates from the actual
. Moreover, the TD-BICGLRT-DT, TD-BICRao-DT, and TD-BICWald-DT show better robustness than the proposed BICGLRT-DT since these three detectors utilize the training data to estimate the true
. In
Figure 5b, we chose
as the actual value of DoF. The results demonstrate that the performance of the TD-BICGLRT-DT, TD-BICRao-DT, and TD-BICWald-DT are almost not influenced by the value of actual
.
5.2. Measured Data Results
The detection performance of the Bayesian interference-canceling detectors is evaluated based on measured sea clutter data in this subsection. The sea clutter data collected by IPIX radar in 1998 is selected in this subsection [
33].
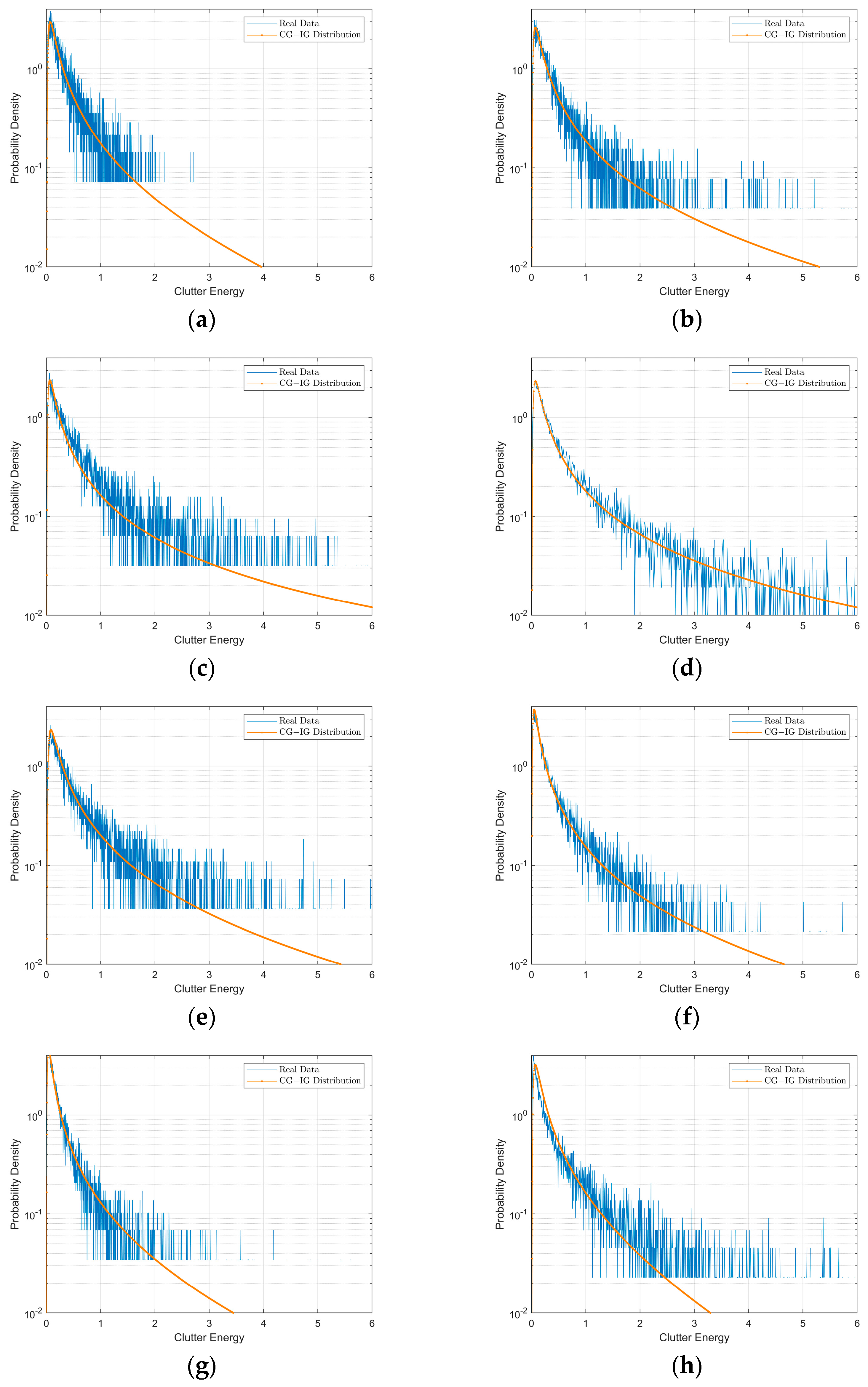
Specifically, we chose data in HH polarization in IPIX file 83 and file 84. The range–pulse spectrum of the data is shown in
Figure 6. The data in file 83 and 84 contain 60,000 pulses and 34 range cells and we chose the 12th cell to the 15th cell as the CUT, meaning that
. The training data is collected from both sides of the range cells adjacent to the CUT uniformly.
To estimate the clutter shape and scale parameter, we adopt the method of fractional moments and the Nelder–Mead searching algorithm [
34]. The estimated results are listed in
Table 3. The energy PDFs based on the measured data and estimate clutter parameter in the CUT are displayed in
Figure 7.
As we can see in
Figure 7, the measured clutter data can be fitted well by utilizing the IG distribution.
Due to the limited size of measured data,
is adopted. The clutter data from range cells different from CUT is utilized to estimate the scaled matrix
as clarified in [
20].
To assess the effectiveness of our proposed Bayesian interference-canceling detectors, we add the simulated target component and subspace interference to the CUT. As shown in
Figure 8, the results indicate that the Bayesian interference-canceling detectors achieve more than 5 dB SCR gain than the GLRT-
when the signal energy is distributed uniformly. As the signal energy concentrates into one specific range cell, the BICGLRT-DT, TD-BICGLRT-DT, and TD-BICWald-DT can still maintain better performance than the competitor. Thus, the measured data experiments demonstrate that the proposed interference-canceling detectors outperform the competitor in CG clutter environments with subspace interference.
6. Conclusions
The problem of Bayesian detection for distributed target under subspace interference and CG clutter with IG texture was investigated in this article. Based on the Bayesian theory, we designed six interference-canceling detectors. The first detector, named BICGLRT-DT, was constructed by eliminating the speckle CM through integration and can work without training data. Based on the two-step GLRT, complex parameter Rao, Wald, Gradient, and Durbin tests, we derived the other five detectors, which estimated the speckle CM by an iteration algorithm with limited training data. The space and time complexity of the proposed detectors were analyzed theoretically. Through the experiments, we confirmed the effectiveness of the proposed Bayesian interference-canceling detectors and pointed out the tradeoff between the time complexity and the detection performance. The experimental results based on simulated and measured sea clutter data demonstrated that the proposed TD-BICGLRT-DT, TD-BICRao-DT, and TD-BICWald-DT can achieve better performance than the proposed BICGLRT-DT since the former ones utilized the training data, leading to a higher estimate precision of . Moreover, the proposed BICGLRT-DT, TD-BICGLRT-DT, and TD-BICWald-DT performed better than the existing GLRT- with any signal energy distributions.


 ,
, 





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}