
U-MGA: A Multi-Module Unet Optimized with Multi-Scale Global Attention Mechanisms for Fine-Grained Segmentation of Cultivated Areas

Abstract
1. Introduction
- (1)
- Similarity between arable and non-arable land areas, and insufficient multi-scale and fine-grained feature extraction: Convolutional Neural Networks (CNNs) are particularly effective at extracting local features, allowing them to capture detailed information in arable land imagery. However, since arable land not only includes local details but also requires global contextual information for improved segmentation accuracy, this study uses the U-Net network as the backbone model. Although U-Net performs well in feature extraction, it has certain limitations in multi-scale information fusion and texture detail extraction, particularly in handling complex boundaries and fine-grained features. To address this, the previous literature has proposed combining channel and spatial attention mechanisms, which effectively enhance network performance in complex scenarios. Inspired by these approaches, we introduce a novel attention mechanism—Multi-Scale Adaptive Segmentation (MSAS)—which integrates SEBlock (Squeeze-and-Excitation Block) [42], CBAM (Convolutional Block Attention Module) [43], and multi-scale feature fusion techniques, enhancing the model’s ability to extract multi-scale contextual and fine-grained features.
- (2)
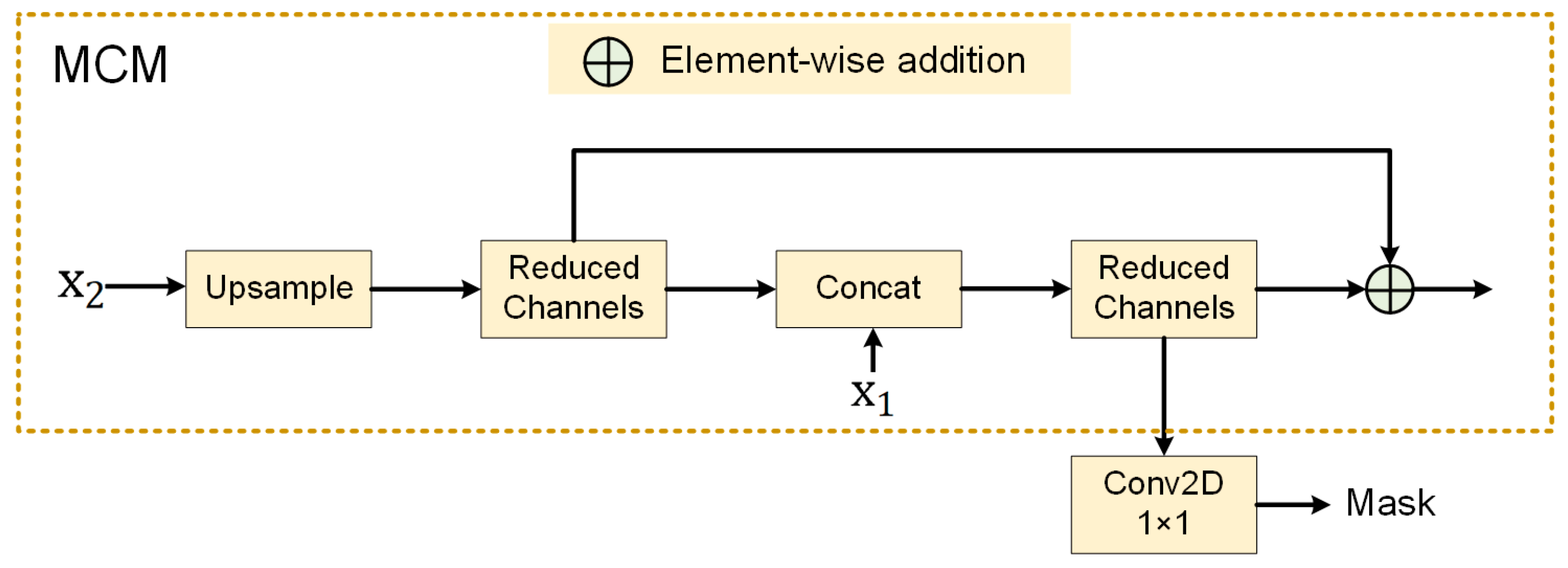
- Insufficient utilization of multi-scale information: During feature extraction, the extracted feature information often exhibits multi-scale distribution, with boundary and texture features of arable land appearing at different scales (e.g., small plots and large-scale agricultural areas coexisting). Therefore, the model must fully exploit multi-scale contextual information and extract key discriminative features. Traditional encoders may not efficiently utilize this information. To effectively address this, we introduce the Multi-Scale Contextual Module (MCM) [44], which employs upsampling, channel dimensionality reduction, inter-layer concatenation, and stepwise feature refinement to improve the model’s ability to use multi-scale features and enhance its adaptability to complex boundaries and diverse regions.
- (3)
- Insufficient extraction and utilization of fine-grained features: In remote sensing imagery, arable land often contains small, sparse areas with highly complex boundary details and texture features, which vary under different image resolutions. Small features such as ridges and furrows in arable land are often overlooked in low-resolution imagery, while in high-resolution imagery, some fine features may be overemphasized due to noise, leading to the insufficient utilization of detailed information. Due to the complexity of these boundary and texture features, conventional decoder methods often struggle to effectively leverage these fine-grained details. Therefore, we incorporate the Group Aggregation Bridge (GAB) module [45], which combines grouped convolutions and multi-scale dilated convolutions to integrate feature information from different resolutions while capturing texture detail information across various scales, improving the model’s ability to model complex boundaries and fine details.
- (1)
- Considering the high spectral and textural similarity between cultivated and non-cultivated areas in remote sensing imagery, we propose a novel attention mechanism module—MSAS. This module integrates SEBlock, CBAM, and multi-scale image features to not only reinforce the extraction of local features in farmland regions but also incorporate global contextual information, thereby enhancing the model’s sensitivity to farmland texture and boundary details.
- (2)
- To address the challenge of exploiting features from regions at different scales in farmland imagery, we introduce the MCM. Through upsampling, channel dimensionality reduction, cross-layer concatenation, and progressive feature refinement, this module enhances the model’s ability to capture farmland boundaries, plot morphology, and spatial distribution, enabling it to better accommodate the scale variations between small, scattered fields and large contiguous farmlands.
- (3)
- To tackle the issue of insufficient feature extraction in small and sparse farmland regions within remote sensing images, we propose the GAB module. By combining grouped convolutions with multi-scale dilated convolutions, this module effectively aggregates feature information from different resolutions, thereby improving the model’s capability to recognize small farmland targets.
2. Materials and Methods
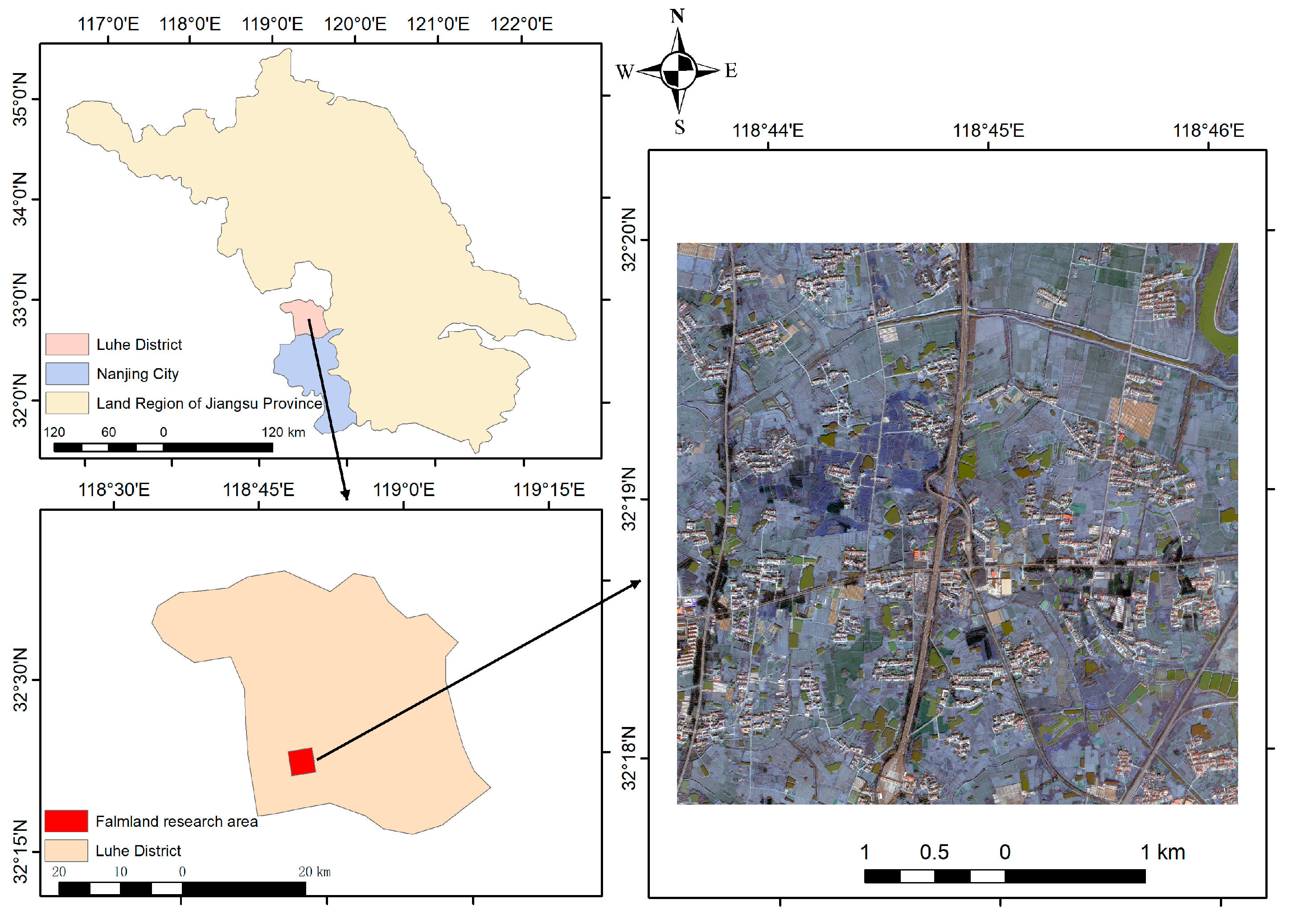
2.1. Overview of the Study Areas
2.2. Data Sources
2.3. Data Preprocessing
2.3.1. Study Area 1: Liuhe District, Nanjing
2.3.2. Study Area 2: Public Dataset
2.3.3. Image Enhancement
3. Methods
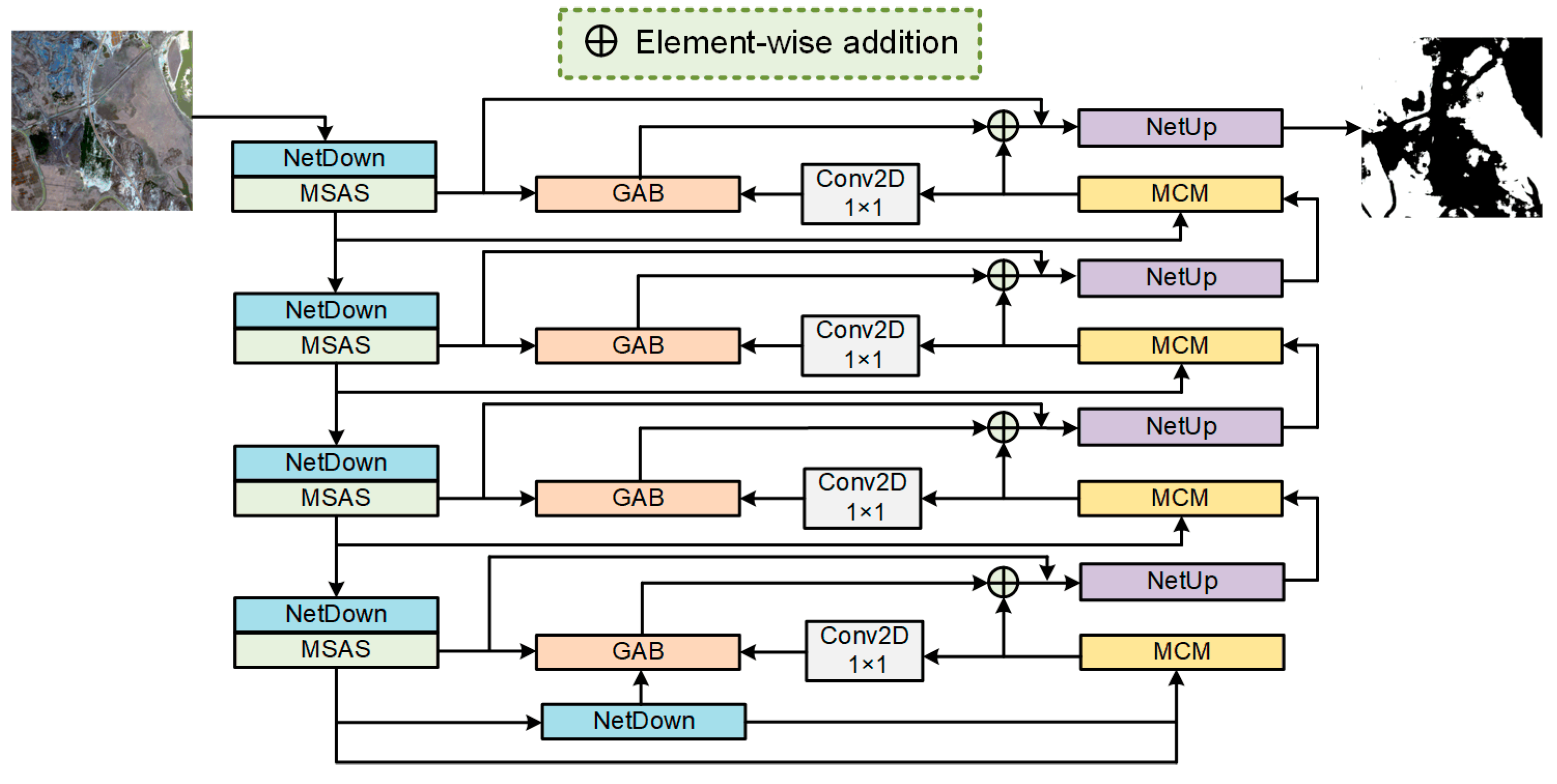
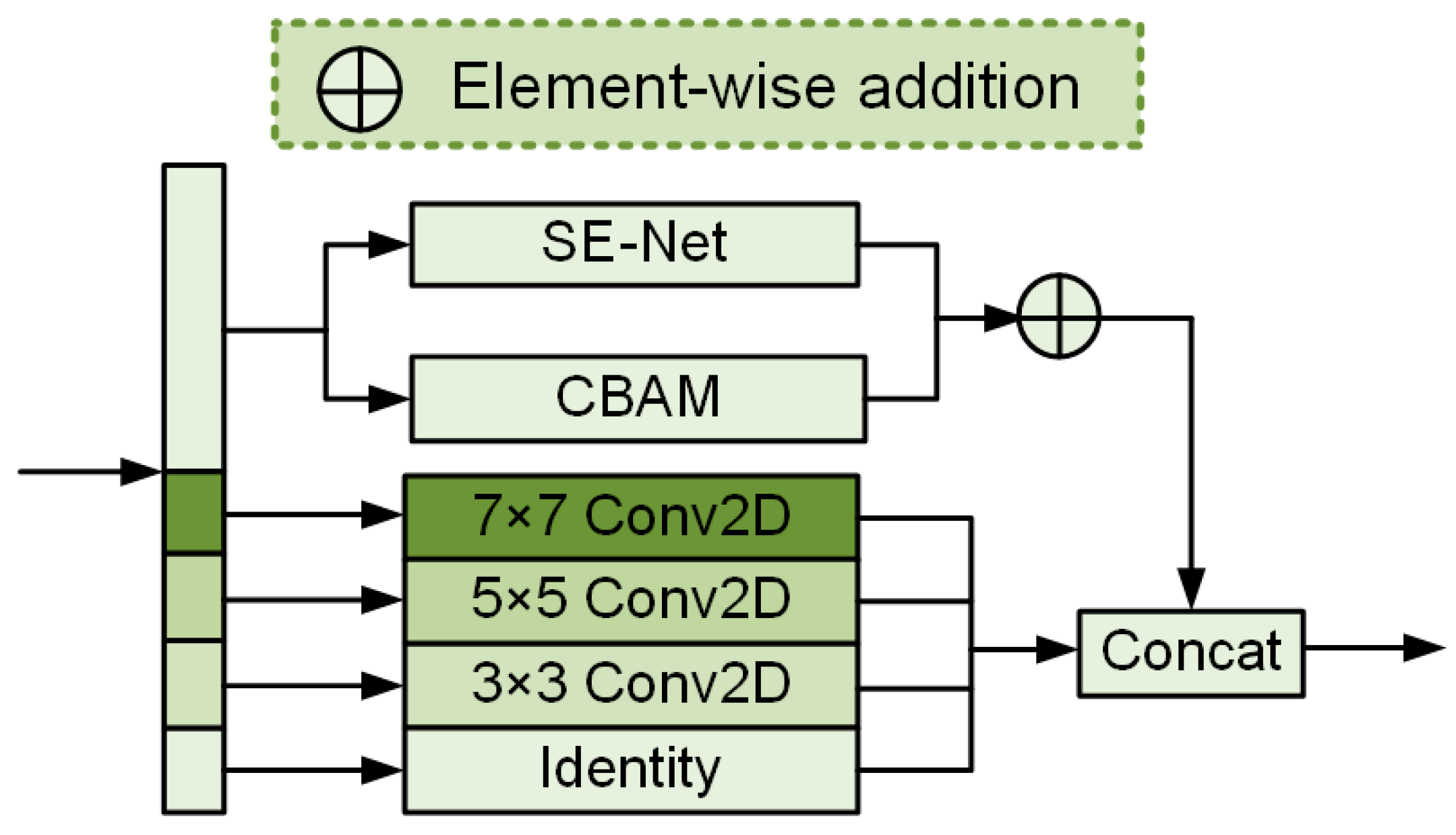
3.1. Multi-Scale Adaptive Segmentation (MSAS)
- (1)
- SE Module: The SE module performs global average pooling to compute global information for each channel:
- (2)
- CBAM Module (Convolutional Block Attention Module): Spatial Attention Calculation: The feature map undergoes both max-pooling and average-pooling:
- (3)
- Multi-Scale Branch Module: Different convolution kernels process different parts of the feature map to capture features at multiple scales: .
3.2. Multi-Level Convolution Module (MCM)
3.3. Group Aggregation Bridge (GAB)
4. Results
4.1. Ablation Experiments
4.2. Comparative Experiments
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Chen, A.; He, H.; Wang, J.; Li, M.; Guan, Q.; Hao, J. A study on the arable land demand for food security in China. Sustainability 2019, 11, 4769. [Google Scholar] [CrossRef]
- Liao, Y.; Lu, X.; Liu, J.; Huang, J.; Qu, Y.; Qiao, Z.; Xie, Y.; Liao, X.; Liu, L. Integrated Assessment of the Impact of Cropland Use Transition on Food Production Towards the Sustainable Development of Social–Ecological Systems. Agronomy 2024, 14, 2851. [Google Scholar] [CrossRef]
- Zhao, S.; Yin, M. Change of urban and rural construction land and driving factors of arable land occupation. PLoS ONE 2023, 18, e0286248. [Google Scholar] [CrossRef]
- Sun, X.; Xiang, P.; Cong, K. Research on early warning and control measures for arable land resource security. Land Use Policy 2023, 128, 106601. [Google Scholar] [CrossRef]
- Wang, S.; Han, W.; Huang, X.; Zhang, X.; Wang, L.; Li, J. Trustworthy remote sensing interpretation: Concepts, technologies, and applications. ISPRS J. Photogramm. Remote Sens. 2024, 209, 150–172. [Google Scholar] [CrossRef]
- Turker, M.; Ozdarici, A. Field-based crop classification using SPOT4, SPOT5, IKONOS and QuickBird imagery for agricultural areas: A comparison study. Int. J. Remote Sens. 2011, 32, 9735–9768. [Google Scholar] [CrossRef]
- Yang, C.; Everitt, J.H.; Murden, D. Evaluating high resolution SPOT 5 satellite imagery for crop identification. Comput. Electron. Agric. 2011, 75, 347–354. [Google Scholar] [CrossRef]
- Tehrany, M.S.; Pradhan, B.; Jebuv, M.N. A comparative assessment between object and pixel-based classification approaches for land use/land cover mapping using SPOT 5 imagery. Geocarto Int. 2014, 29, 351–369. [Google Scholar] [CrossRef]
- Zhao, B.; Ma, N.; Yang, J.; Li, Z.; Wang, Q. Extracting features of soil and water conservation measures from remote sensing images of different resolution levels: Accuracy analysis. Bull. Soil Water Conserv. 2012, 32, 154–157. [Google Scholar]
- Agnoletti, M.; Cargnello, G.; Gardin, L.; Santoro, A.; Bazzoffi, P.; Sansone, L.; Pezza, L.; Belfiore, N. Traditional landscape and rural development: Comparative study in three terraced areas in northern, central and southern Italy to evaluate the efficacy of GAEC standard 4.4 of cross compliance. Ital. J. Agron. 2011, 6, e16. [Google Scholar] [CrossRef]
- Martínez-Casasnovas, J.A.; Ramos, M.C.; Cots-Folch, R. Influence of the EU CAP on terrain morphology and vineyard cultivation in the Priorat region of NE Spain. Land Use Policy 2010, 27, 11–21. [Google Scholar] [CrossRef]
- Sofia, G.; Bailly, J.-S.; Chehata, N.; Tarolli, P.; Levavasseur, F. Comparison of pleiades and LiDAR digital elevation models for terraces detection in farmlands. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 9, 1567–1576. [Google Scholar] [CrossRef]
- Zhang, C.; Pan, X.; Li, H.; Gardiner, A.; Sargent, I.; Hare, J.; Atkinson, P.M. A hybrid MLP-CNN classifier for very fine resolution remotely sensed image classification. ISPRS J. Photogramm. Remote Sens. 2018, 140, 133–144. [Google Scholar] [CrossRef]
- Bascoy, P.G.; Garea, A.S.; Heras, D.B.; Argüello, F.; Ordóñez, A. Texture-based analysis of hydrographical basins with multispectral imagery. In Proceedings of the Remote Sensing for Agriculture, Ecosystems, and Hydrology XXI, Strasbourg, France, 9–11 September 2019; pp. 225–234. [Google Scholar]
- Zhu, W.; Rezaei, E.E.; Nouri, H.; Sun, Z.; Li, J.; Yu, D.; Siebert, S. UAV flight height impacts on wheat biomass estimation via machine and deep learning. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 16, 7471–7485. [Google Scholar] [CrossRef]
- Hofmann, P.; Blaschke, T.; Strobl, J. Quantifying the robustness of fuzzy rule sets in object-based image analysis. Int. J. Remote Sens. 2011, 32, 7359–7381. [Google Scholar] [CrossRef]
- Diaz-Varela, R.A.; Zarco-Tejada, P.J.; Angileri, V.; Loudjani, P. Automatic identification of agricultural terraces through object-oriented analysis of very high resolution DSMs and multispectral imagery obtained from an unmanned aerial vehicle. J. Environ. Manag. 2014, 134, 117–126. [Google Scholar] [CrossRef] [PubMed]
- Eckert, S.; Ghebremicael, S.T.; Hurni, H.; Kohler, T. Identification and classification of structural soil conservation measures based on very high resolution stereo satellite data. J. Environ. Manag. 2017, 193, 592–606. [Google Scholar] [CrossRef] [PubMed]
- Han, W.; Zhang, X.; Wang, Y.; Wang, L.; Huang, X.; Li, J.; Wang, S.; Chen, W.; Li, X.; Feng, R. A survey of machine learning and deep learning in remote sensing of geological environment: Challenges, advances, and opportunities. ISPRS J. Photogramm. Remote Sens. 2023, 202, 87–113. [Google Scholar] [CrossRef]
- He, C.; Liu, Y.; Wang, D.; Liu, S.; Yu, L.; Ren, Y. Automatic extraction of bare soil land from high-resolution remote sensing images based on semantic segmentation with deep learning. Remote Sens. 2023, 15, 1646. [Google Scholar] [CrossRef]
- Voelsen, M.; Lauble, S.; Rottensteiner, F.; Heipke, C. Transformer Models for Multi-Temporal Land Cover Classification Using Remote Sensing Images. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2023, 10, 981–990. [Google Scholar] [CrossRef]
- Singh, N.J.; Nongmeikapam, K. Semantic segmentation of satellite images using deep-unet. Arab. J. Sci. Eng. 2023, 48, 1193–1205. [Google Scholar] [CrossRef]
- Chang, Z.; Li, H.; Chen, D.; Liu, Y.; Zou, C.; Chen, J.; Han, W.; Liu, S.; Zhang, N. Crop Type Identification Using High-Resolution Remote Sensing Images Based on an Improved DeepLabV3+ Network. Remote Sens. 2023, 15, 5088. [Google Scholar] [CrossRef]
- Jiang, J.; Lyu, C.; Liu, S.; He, Y.; Hao, X. RWSNet: A semantic segmentation network based on SegNet combined with random walk for remote sensing. Int. J. Remote Sens. 2020, 41, 487–505. [Google Scholar] [CrossRef]
- Tao, Y.; Xu, M.; Lu, Z.; Zhong, Y. DenseNet-based depth-width double reinforced deep learning neural network for high-resolution remote sensing image per-pixel classification. Remote Sens. 2018, 10, 779. [Google Scholar] [CrossRef]
- Wang, M.; Zhang, X.; Niu, X.; Wang, F.; Zhang, X. Scene classification of high-resolution remotely sensed image based on ResNet. J. Geovisualization Spat. Anal. 2019, 3, 16. [Google Scholar] [CrossRef]
- Sun, W.; Zhou, R.; Nie, C.; Wang, L.; Sun, J. Farmland segmentation from remote sensing images using deep learning methods. In Proceedings of the Remote Sensing for Agriculture, Ecosystems, and Hydrology XXII, online, 21–25 September 2020; pp. 51–57. [Google Scholar]
- Sun, Y.; Li, Z.-L.; Luo, J.; Wu, T.; Liu, N. Farmland parcel-based crop classification in cloudy/rainy mountains using Sentinel-1 and Sentinel-2 based deep learning. Int. J. Remote Sens. 2022, 43, 1054–1073. [Google Scholar] [CrossRef]
- Han, W.; Feng, R.; Wang, L.; Cheng, Y. A semi-supervised generative framework with deep learning features for high-resolution remote sensing image scene classification. ISPRS J. Photogramm. Remote Sens. 2018, 145, 23–43. [Google Scholar] [CrossRef]
- Hu, L.; Qin, M.; Zhang, F.; Du, Z.; Liu, R. RSCNN: A CNN-based method to enhance low-light remote-sensing images. Remote Sens. 2020, 13, 62. [Google Scholar] [CrossRef]
- Tian, T.; Li, L.; Chen, W.; Zhou, H. SEMSDNet: A multiscale dense network with attention for remote sensing scene classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 5501–5514. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhao, H.; Ma, G.; Xie, D.; Geng, S.; Lu, H.; Tian, W.; Lim Kam Sian, K.T.C. MAAFEU-NET: A novel land use classification model based on mixed attention module and adjustable feature enhancement layer in remote sensing images. ISPRS Int. J. Geo-Inf. 2023, 12, 206. [Google Scholar] [CrossRef]
- Lv, N.; Zhang, Z.; Li, C.; Deng, J.; Su, T.; Chen, C.; Zhou, Y. A hybrid-attention semantic segmentation network for remote sensing interpretation in land-use surveillance. Int. J. Mach. Learn. Cybern. 2023, 14, 395–406. [Google Scholar] [CrossRef]
- Popel, M.; Bojar, O. Training tips for the transformer model. arXiv 2018, arXiv:1804.00247. [Google Scholar] [CrossRef]
- Dosovitskiy, A. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Thisanke, H.; Deshan, C.; Chamith, K.; Seneviratne, S.; Vidanaarachchi, R.; Herath, D. Semantic segmentation using Vision Transformers: A survey. Eng. Appl. Artif. Intell. 2023, 126, 106669. [Google Scholar] [CrossRef]
- Chen, J.; Lu, Y.; Yu, Q.; Luo, X.; Adeli, E.; Wang, Y.; Lu, L.; Yuille, A.L.; Zhou, Y. Transunet: Transformers make strong encoders for medical image segmentation. arXiv 2021, arXiv:2102.04306. [Google Scholar]
- Omia, E.; Bae, H.; Park, E.; Kim, M.S.; Baek, I.; Kabenge, I.; Cho, B.-K. Remote sensing in field crop monitoring: A comprehensive review of sensor systems, data analyses and recent advances. Remote Sens. 2023, 15, 354. [Google Scholar] [CrossRef]
- Song, C.; Chen, J.M.; Hwang, T.; Gonsamo, A.; Croft, H.; Zhang, Q.; Dannenberg, M.; Zhang, Y.; Hakkenberg, C.; Li, J. Ecological characterization of vegetation using multi-sensor remote sensing in the solar reflective spectrum. In Remote Sensing Handbook, Volume IV; CRC Press: Boca Raton, FL, USA, 2024; pp. 249–308. [Google Scholar]
- Zhai, Y.; Zhou, L.; Qi, H.; Gao, P.; Zhang, C. Application of visible/near-infrared spectroscopy and hyperspectral imaging with machine learning for high-throughput plant heavy metal stress phenotyping: A review. Plant Phenomics 2023, 5, 0124. [Google Scholar] [CrossRef] [PubMed]
- Li, L.; Mu, X.; Jiang, H.; Chianucci, F.; Hu, R.; Song, W.; Qi, J.; Liu, S.; Zhou, J.; Chen, L. Review of ground and aerial methods for vegetation cover fraction (fCover) and related quantities estimation: Definitions, advances, challenges, and future perspectives. ISPRS J. Photogramm. Remote Sens. 2023, 199, 133–156. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Zhong, M.; Sun, J.; Ren, P.; Wang, F.; Sun, F. MAGNet: Multi-scale Awareness and Global fusion Network for RGB-D salient object detection. Knowl.-Based Syst. 2024, 299, 112126. [Google Scholar] [CrossRef]
- Ruan, J.; Xie, M.; Gao, J.; Liu, T.; Fu, Y. Ege-unet: An efficient group enhanced unet for skin lesion segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Vancouver, BC, Canada, 8–12 October 2023; pp. 481–490. [Google Scholar]
- Hu, M.; Li, Y.; Fang, L.; Wang, S. A2-FPN: Attention aggregation based feature pyramid network for instance segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 15343–15352. [Google Scholar]
- Xie, E.; Wang, W.; Yu, Z.; Anandkumar, A.; Alvarez, J.M.; Luo, P. SegFormer: Simple and efficient design for semantic segmentation with transformers. Adv. Neural Inf. Process. Syst. 2021, 34, 12077–12090. [Google Scholar]
- Wang, L.; Li, R.; Zhang, C.; Fang, S.; Duan, C.; Meng, X.; Atkinson, P.M. UNetFormer: A UNet-like transformer for efficient semantic segmentation of remote sensing urban scene imagery. ISPRS J. Photogramm. Remote Sens. 2022, 190, 196–214. [Google Scholar] [CrossRef]
- Wang, L.; Li, R.; Duan, C.; Zhang, C.; Meng, X.; Fang, S. A novel transformer based semantic segmentation scheme for fine-resolution remote sensing images. IEEE Geosci. Remote Sens. Lett. 2022, 19, 6506105. [Google Scholar] [CrossRef]
- Chen, J.; Mei, J.; Li, X.; Lu, Y.; Yu, Q.; Wei, Q.; Luo, X.; Xie, Y.; Adeli, E.; Wang, Y. TransUNet: Rethinking the U-Net architecture design for medical image segmentation through the lens of transformers. Med. Image Anal. 2024, 97, 103280. [Google Scholar] [CrossRef] [PubMed]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Load | Spatial Resolution | Spectral Range | Observation Width | Revisit Period |
|---|---|---|---|---|
| PMS (panchromatic and multispectral) sensor | 1 m | 450–900 nm | 45 km | 5 days |
| 4 m | 450–520 nm | |||
| 520–590 nm | ||||
| 630–690 nm | ||||
| 770–890 nm |
| Base | MCM | GAB | MSAS | OA | Precision | Recall | |
|---|---|---|---|---|---|---|---|
| No. 1 | √ | 85.76 ± 2.29 | 86.28 ± 1.89 | 86.55 ± 1.91 | |||
| No. 2 | √ | √ | 87.99 ± 1.75 | 87.75 ± 1.90 | 87.88 ± 1.85 | ||
| No. 3 | √ | √ | √ | 88.07 ± 2.09 | 88.22 ± 2.01 | 87.52 ± 2.71 | |
| No. 4 | √ | √ | √ | √ | 89.95 ± 1.55 | 89.71 ± 1.70 | 89.94 ± 1.54 |
| Base | MCM | GAB | MSAS | OA | Precision | Recall | |
|---|---|---|---|---|---|---|---|
| No. 1 | √ | 84.79 ± 2.86 | 84.20 ± 3.44 | 83.58 ± 3.82 | |||
| No. 2 | √ | √ | 86.49 ± 2.27 | 86.06 ± 2.70 | 85.45 ± 2.86 | ||
| No. 3 | √ | √ | √ | 87.41 ± 1.64 | 87.34 ± 2.34 | 85.53 ± 4.46 | |
| No. 4 | √ | √ | √ | √ | 89.30 ± 1.57 | 89.39 ± 1.60 | 87.64 ± 3.52 |
| OA (%) | Precision (%) | Recall (%) | F1 (%) | IoU (%) | Kappa (%) | Parameters (M) | |
|---|---|---|---|---|---|---|---|
| U-MGA (ours) | 89.95 ± 1.55 | 89.71 ± 1.70 | 89.94 ± 1.54 | 89.80 ± 1.63 | 81.56 ± 2.67 | 79.61 ± 3.26 | 13.616 |
| Unet | 85.76 ± 2.29 | 86.28 ± 1.89 | 86.55 ± 1.91 | 85.70 ± 2.30 | 75.06 ± 3.54 | 71.65 ± 4.41 | 12.705 |
| A2FPN | 85.71 ± 1.31 | 86.65 ± 1.35 | 84.79 ± 1.57 | 85.17 ± 1.49 | 74.31 ± 2.21 | 70.52 ± 2.93 | 11.596 |
| Segformer | 67.15 ± 2.43 | 74.40 ± 2.45 | 69.66 ± 1.57 | 66.04 ± 2.33 | 49.65 ± 2.60 | 37.10 ± 3.40 | 3.54 |
| FTUnetformer | 86.09 ± 2.39 | 87.02 ± 2.14 | 85.04 ± 3.02 | 85.50 ± 2.81 | 74.90 ± 4.17 | 71.17 ± 5.50 | 91.531 |
| DCSwin | 84.29 ± 2.09 | 84.28 ± 2.22 | 83.81 ± 2.23 | 83.93 ± 2.24 | 72.45 ± 3.33 | 67.90 ± 4.46 | 113.419 |
| TransUnet | 86.44 ± 2.09 | 87.08 ± 2.01 | 85.65 ± 2.52 | 85.96 ± 2.39 | 75.55 ± 3.59 | 72.06 ± 4.71 | 387.698 |
| OA (%) | Precision (%) | Recall (%) | F1 (%) | IoU (%) | Kappa (%) | Parameters (M) | |
|---|---|---|---|---|---|---|---|
| U-MGA (ours) | 89.30 ± 1.57 | 89.39 ± 1.60 | 87.64 ± 3.52 | 88.24 ± 2.52 | 79.25 ± 3.76 | 76.53 ± 4.98 | 13.616 |
| Unet | 84.79 ± 2.86 | 84.20 ± 3.44 | 83.58 ± 3.82 | 83.58 ± 3.77 | 72.25 ± 5.33 | 67.29 ± 7.45 | 12.705 |
| A2FPN | 84.51 ± 2.90 | 85.01 ± 2.44 | 82.55 ± 4.18 | 82.92 ± 3.68 | 71.37 ± 5.16 | 66.19 ± 7.14 | 11.596 |
| Segformer | 71.18 ± 7.12 | 70.66 ± 7.66 | 71.39 ± 7.38 | 70.18 ± 8.13 | 54.95 ± 9.30 | 41.22 ± 15.47 | 3.54 |
| FTUnetformer | 84.18 ± 2.82 | 84.14 ± 3.99 | 81.63 ± 6.29 | 82.10 ± 5.46 | 70.54 ± 6.82 | 64.51 ± 10.70 | 91.531 |
| DCSwin | 82.99 ± 3.14 | 82.98 ± 2.95 | 81.02 ± 4.33 | 81.34 ± 3.88 | 69.14 ± 5.36 | 62.98 ± 7.54 | 113.419 |
| TransUnet | 82.90 ± 5.67 | 81.61 ± 6.76 | 81.58 ± 6.82 | 81.54 ± 6.79 | 69.73 ± 9.04 | 63.10 ± 13.57 | 387.698 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, Y.; Xie, Y.; Yao, W.; Zhang, Y.; Wang, X.; Yang, Y.; Tang, L. U-MGA: A Multi-Module Unet Optimized with Multi-Scale Global Attention Mechanisms for Fine-Grained Segmentation of Cultivated Areas. Remote Sens. 2025, 17, 760. https://doi.org/10.3390/rs17050760
Chen Y, Xie Y, Yao W, Zhang Y, Wang X, Yang Y, Tang L. U-MGA: A Multi-Module Unet Optimized with Multi-Scale Global Attention Mechanisms for Fine-Grained Segmentation of Cultivated Areas. Remote Sensing. 2025; 17(5):760. https://doi.org/10.3390/rs17050760
Chicago/Turabian StyleChen, Yun, Yiheng Xie, Weiyuan Yao, Yu Zhang, Xinhong Wang, Yanli Yang, and Lingli Tang. 2025. "U-MGA: A Multi-Module Unet Optimized with Multi-Scale Global Attention Mechanisms for Fine-Grained Segmentation of Cultivated Areas" Remote Sensing 17, no. 5: 760. https://doi.org/10.3390/rs17050760
APA StyleChen, Y., Xie, Y., Yao, W., Zhang, Y., Wang, X., Yang, Y., & Tang, L. (2025). U-MGA: A Multi-Module Unet Optimized with Multi-Scale Global Attention Mechanisms for Fine-Grained Segmentation of Cultivated Areas. Remote Sensing, 17(5), 760. https://doi.org/10.3390/rs17050760