1. Introduction
Precipitation is a crucial component of the water cycle [
1,
2]. Accurate and reliable precipitation observations help to better understand and simulate hydrometeorological processes, aiding in informed decision-making and risk assessment for natural and human environments [
3,
4,
5,
6].
Methods for precipitation observations include ground observations, radar monitoring, and satellite retrieval [
7,
8,
9], and each method has strengths and weaknesses. Ground stations provide accurate precipitation data at the point scale but have limited spatial coverage depending on the distribution of stations [
10,
11]. In contrast, satellite and radar data cover larger areas and better represent spatial distributions but have accuracy limitations due to cloud cover, surface conditions, and algorithm limitations [
12,
13,
14]. Various precipitation datasets have been developed based on these observations, such as the Global Historical Climatology Network (GHCN), which includes data from more than 100,000 stations across 180 countries [
15]; the Global Precipitation Climatology Centre (GPCC), which provides gridded data based on observations [
16]; the Tropical Rainfall Measuring Mission (TRMM), which combines multiple sensors [
17]; and the ERA5 reanalysis precipitation products [
18]. These datasets serve as valuable tools for research and operational applications; however, many studies have revealed that bias still exists in precipitation datasets [
19,
20,
21].
To further improve the accuracy and reliability of precipitation datasets, one promising approach is to integrate different information to better utilize the advantages of multisource precipitation, i.e., precipitation merging [
22,
23,
24,
25]. Many scholars have researched multisource precipitation merging technologies and have proposed various new methods [
26,
27]. Conventional approaches, such as objective analysis [
28] and optimal interpolation [
29,
30], achieve multisource precipitation merging by correcting the constructed initial fields. Other merging methods, such as geographically weighted regression [
31,
32] and kriging interpolation [
33], incorporate auxiliary information from the underlying surface. However, most conventional methods rely on strong assumptions [
34], such as the assumption that the data are stationary on a global or local scale and that the relationship between the data is linear [
35,
36,
37]. In operational applications, when real conditions do not conform to these assumptions, the performance of these conventional methods is reduced [
38,
39].
Machine learning technologies can learn complex patterns and relationships between different data, making them preferable for data merging [
40,
41,
42,
43]. With the development of machine learning technologies, many studies have attempted to leverage the powerful feature extraction and learning capabilities of machine learning algorithms for multisource precipitation merging. Nguyen et al. used a random forest algorithm to merge multiple satellite precipitation products in South Korea [
44], Kumar et al. employed various machine learning algorithms, including support vector machine (SVM), to integrate station and satellite observational data [
45], and Wehbe et al. used artificial neural networks (ANNs) to merge multiple precipitation products from the Arabian Peninsula [
46]. To account for the spatial and temporal characteristics of precipitation, some scholars have further utilized neural networks such as convolutional neural networks (CNNs) [
47,
48] and long short-term memory (LSTM) neural networks [
49,
50] for multisource precipitation merging. Among neural network algorithms, the ConvLSTM network inherits the advantages of both CNNs and LSTMs, enabling it to capture the spatiotemporal features of precipitation data simultaneously. Many studies have applied ConvLSTM to multisource precipitation merging, and their merged results also show that fully considering the spatiotemporal relationship of precipitation can improve the accuracy of merged precipitation data [
39,
51,
52,
53].
However, the above methods do not consider the precipitation identification error, which is also one of the significant sources of precipitation bias. For example, Tian et al. and Lei et al. conducted error analysis on grid precipitation data and reported that missed and misreported precipitation errors are important components of precipitation errors [
54,
55]. Moreover, errors in precipitation identification affect the identification of the spatial location and scope of precipitation [
56], the length of the dry/wet moment, and the statistics of the start/end time [
57]. Accurately determining whether precipitation events occur is crucial for improving the performance of grid-observed precipitation. Therefore, some studies have introduced separate identification modules for multisource precipitation merging. For example, Lei et al. constructed a precipitation identification module using various methods, such as gradient boosting decision tree (GBDT), extreme gradient boosting (XGBoost), and random forest (RF) [
56]. Zhang et al. used methods such as SVM, RF, ANN, and extreme learning machine (ELM) for precipitation identification [
58]. Lyu et al. used XGBoost for precipitation identification [
59], and Li et al. identified precipitation by constructing a gridded precipitation probability estimation model [
57]. The inclusion of these precipitation identification modules further reduced the errors in precipitation merging.
However, the precipitation identification modules constructed using these methods usually require stretching and dimensionality reduction to convert two-dimensional spatial data into one-dimensional data before they are input into the model for calculation, which can compromise the spatial characteristics of precipitation [
60,
61]. ConvLSTM can directly utilize two-dimensional spatial data, allowing for a more comprehensive consideration of the spatiotemporal characteristics of precipitation. To the best of our knowledge, current studies that use ConvLSTM for multisource precipitation merging have not considered precipitation identification. Additionally, for machine learning, the distribution of sample data can significantly affect model performance [
62,
63,
64]. Moreover, most current studies that use machine learning for multisource precipitation data merging have explored only the impact of sample dataset size on model performance, without analyzing how various distributions of precipitation sample data influence the merged results [
56,
57]. These limitations affect the accuracy of precipitation merging.
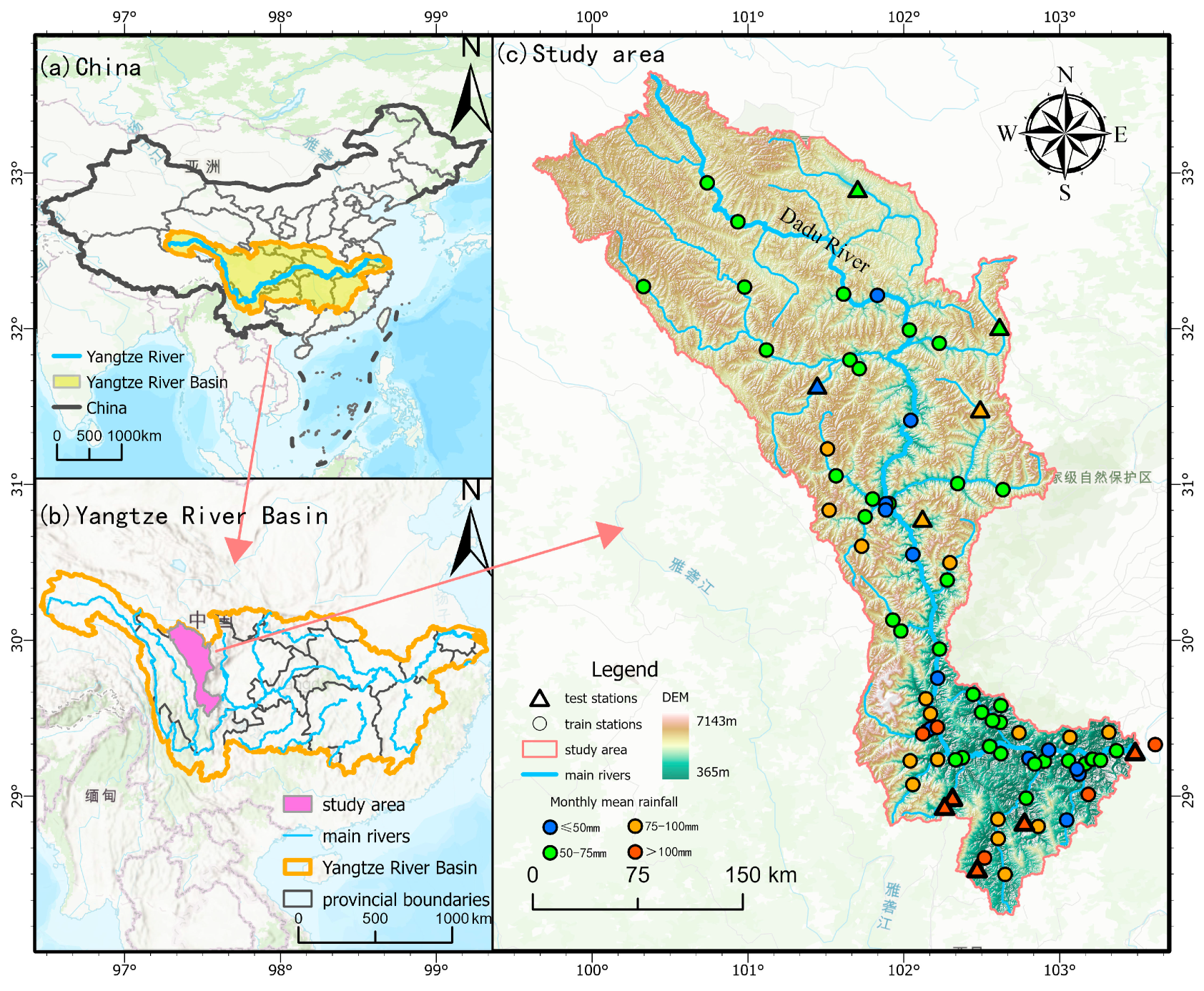
To address these limitations, we propose a dual-layer neural network based on ConvLSTM (D-ConvLSTM) for merging ground station and gridded precipitation data. The first layer is the precipitation identification ConvLSTM module, which comprehensively considers the spatial distribution characteristics of precipitation and uses cross-entropy [
65] as the loss function to achieve a dry‒wet classification. The second layer uses the mean absolute error (MAE) as the loss function to correct precipitation values during wet periods. It is applied to the Dadu River Basin in China and compared with the traditional optimal interpolation method and single-layer ConvLSTM, verifying the effectiveness and advantages of D-ConvLSTM. Additionally, we change the ratio of dry to wet data in the training set of the precipitation identification network (ConvLSTM-identify) and the ratio of overestimated or underestimated CMPAS precipitation values compared to station observation values in the training set of the precipitation correction network (ConvLSTM-correct) to explore the impact of the training data distribution on the performance of the neural network merging model.
3. Methods
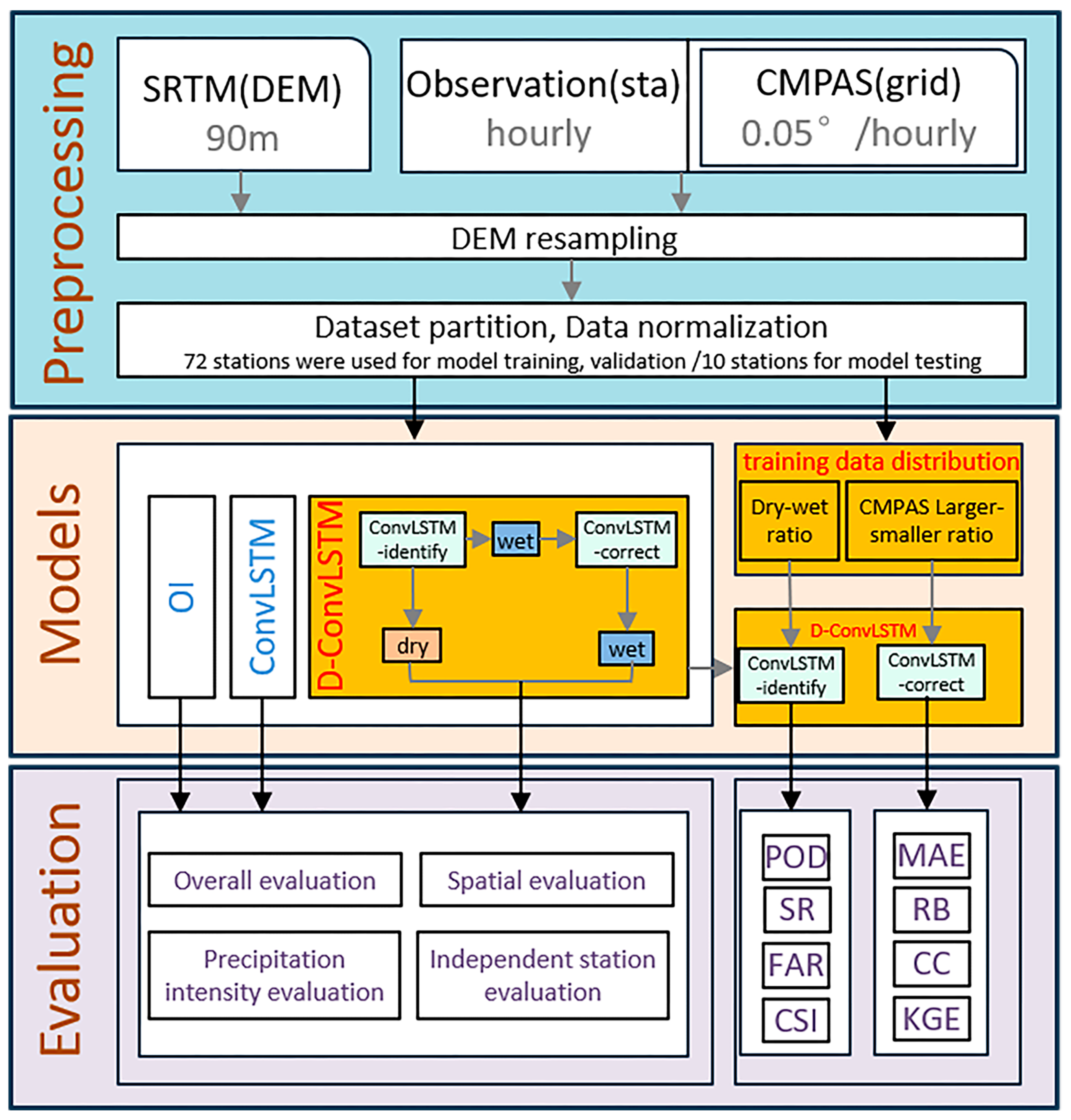
The flowchart of this study is presented in
Figure 3. This study proposes the D-ConvLSTM model to integrate observed precipitation data from DDR stations with CMPAS gridded precipitation data, addressing both precipitation classification and value estimation errors. The performance of D-ConvLSTM is assessed using multiple evaluation metrics and compared against the results of the OI and ConvLSTM to demonstrate its overall improvement. Furthermore, the study examines the impact of different training data distributions on the D-ConvLSTM merging model by changing the ratio of dry to wet data in the training data and the proportion of overestimation or underestimation of gridded precipitation compared with station observations. Finally, classification and statistical indicators, including overall evaluation, independent station evaluation, precipitation intensity evaluation, spatial evaluation, and evaluation of D-ConvLSTM model performance with different training data distributions, are used to evaluate different types of merged precipitation.
3.1. ConvLSTM and D-Convlstm
ConvLSTM is a deep learning model that integrates convolutional neural networks (CNNs) and long short-term memory (LSTM) networks. ConvLSTM considers both the temporal correlation of precipitation sequences and the spatial distribution characteristics of precipitation, making it particularly suitable for multisource precipitation data merging [
51,
52]. Its structure is similar to that of LSTM [
75]. To reduce the complexity of the network structure, this paper adopts a simplified ConvLSTM, which has the same structure as LSTM but replaces the Hadamard product in LSTM with convolution operations from neural networks, as shown in
Figure 4.
Its internal calculation formula is as follows:
where
is the sigmoid activation function;
is another activation function;
is the Hadamard product;
is the convolution operation in the neural network;
is the input at time
;
is the hidden state at time
;
,
,
, and
are the input gate, forgetting gate, status gate, and output gate, respectively; and
and
are the weights and bias, respectively.
Based on the work of Lei et al. [
56], Zhang et al. [
58], and Lyu et al. [
59], this study proposes an improved D-ConvLSTM model based on ConvLSTM for the merging of grid precipitation and station-observed precipitation, with the internal structure shown in
Figure 5. D-ConvLSTM has two layers. The first layer, ConvLSTM-identify, is used for dry (precipitation = 0) and wet (precipitation > 0) identification. The second layer, ConvLSTM-correct, is used for correcting precipitation values during wet periods. Different loss functions are applied to the two layers mentioned above.
The first layer employs the cross-entropy loss function, which is defined in Equation (2):
where
is the total number of samples;
is the category to which sample
belongs; and
is the predicted value for sample
, represented as a probability value.
The second layer employs the mean absolute error loss function, which is defined as Equation (3):
where
is the total number of samples;
is the category to which sample
belongs; and
is the predicted value for sample
.
Several hyperparameters need to be determined for training the D-ConvLSTM model. In this study, after multiple adjustments of batch size, hidden size, and learning rate, we found that changes in these three hyperparameters had a minimal impact on the merged results. Considering computer performance, model complexity, and training time, this study used the following parameters: batchSize = 10,000, hiddenSize = 32, and learningRate = 0.01. For
n and seqLenth,
n was set to (7,9,11,13,15), and seqLenth was set to (4,5,6,7,8), with repeated experiments conducted to select the most suitable hyperparameters. The hyperparameters used by ConvLSTM and D-ConvLSTM are shown in
Table 1. The computational environment used in this study is configured as follows: the processor is a 12th Gen Intel(R) Core(TM) i7-12700 with 12 cores and 20 threads; the memory is 32 GB; the GPU is an NVIDIA RTX A4000 with 16 GB of VRAM; the operating system is Windows 11; and the deep learning framework used is PyTorch. Training the D-ConvLSTM model for 100 epochs using this environment takes 54 min, while calculating the precipitation for 2881 grids and 36,148 time steps takes 56 min.
3.2. Optimal Interpolation (OI)
Optimal interpolation (OI) is a conventional approach for grid and station precipitation merging and is widely used in many operational systems. The OI is an objective analysis method based on the optimal interpolation theory proposed by Eliassen in 1954 [
29]. In this study, we also use the OI as a benchmark for comparison. For each grid point, the OI calculates the analysis value by adding the initial estimate of the grid point to the correction value. The correction value is obtained by weighting the deviations of the observed values from surrounding stations relative to the initial estimate at the station’s location [
76]. In this study, when the OI is used for merging, stations located on the interpolated grid are not considered. The calculation principles and formulas can be found in
Appendix A.1.
In areas with a dense distribution of study sites, the distances between the nearest neighboring stations range from 5 to 15 km. In this study, when determining the parameters of the OI model, r was set to (5,10,15,20,25), and s was set to (50,75,100,125,150), with repeated experiments conducted.
Table 2 presents the parameters utilized for the OI model in this study.
3.3. Training Data Selection Strategies
This study also aims to investigate the impact of the training data distribution on the merging performance. For ConvLSTM-identify (1st layer), the strategy is to change the ratio of dry to wet data in the training set. For wet samples, considering that the number of dry samples far exceeds that of wet samples, we make no adjustments to wet samples and use all the data for training. For dry samples, we adjust the samples for training from 2.5% to 100%, increasing by 2.5% each time.
For ConvLSTM-correct (2nd layer), the strategy is to change the ratio of CMPAS precipitation values that are overestimated or underestimated compared with station-observed values. Owing to the samples in this study where precipitation exceeds 5 mm, the CMPAS is generally overestimated, whereas for samples below 5 mm, the CMPAS is typically underestimated. To focus the model more on samples with greater precipitation, no adjustments are made to the samples where CMPAS precipitation values are underestimated during training; all of them are included in model training. For samples with overestimated CMPAS precipitation values, the amounts are increased sequentially from 2.5% to 100%, in increments of 2.5% each time. The specific change strategies are shown in
Table 3.
3.4. Evaluation Metrics
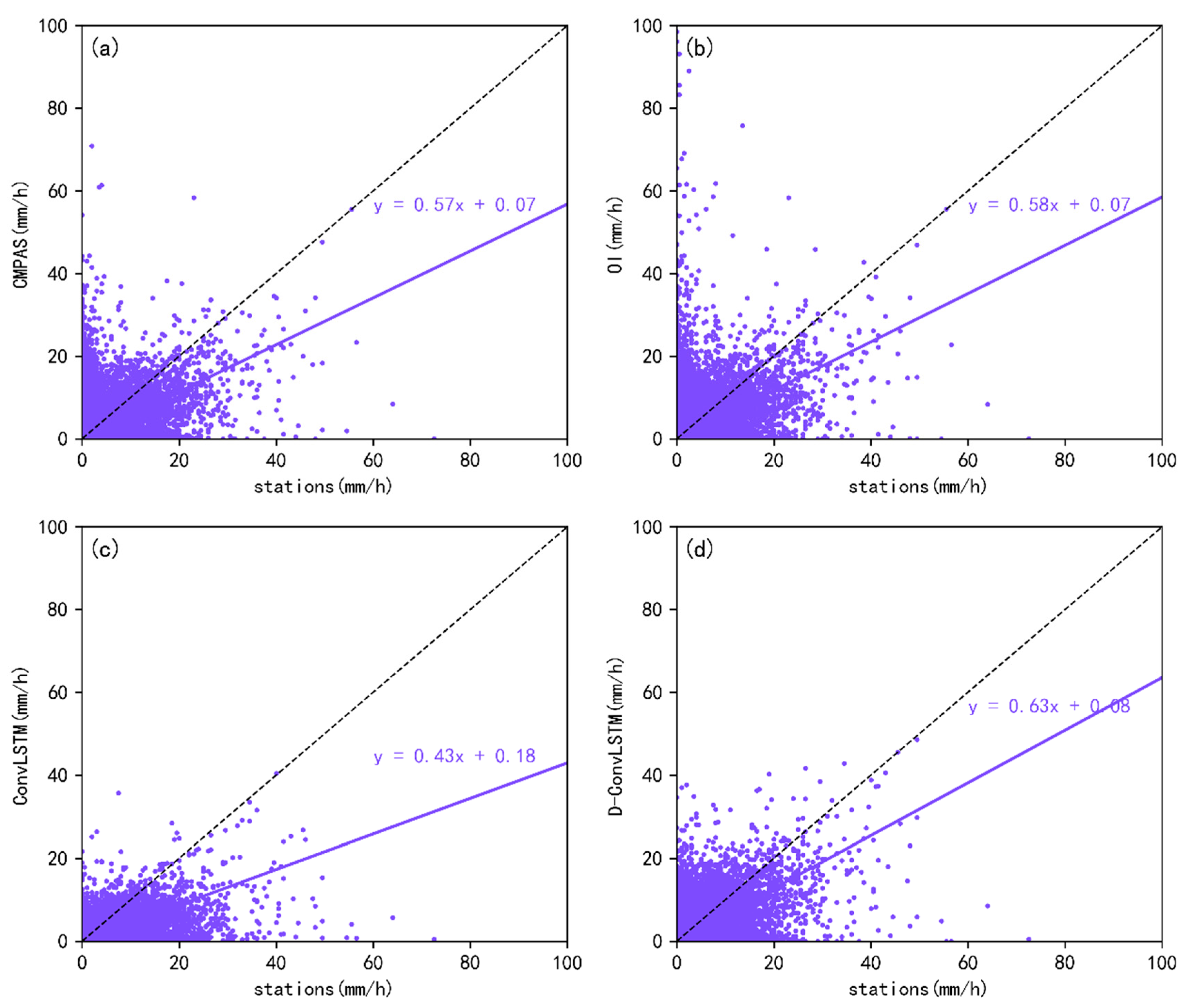
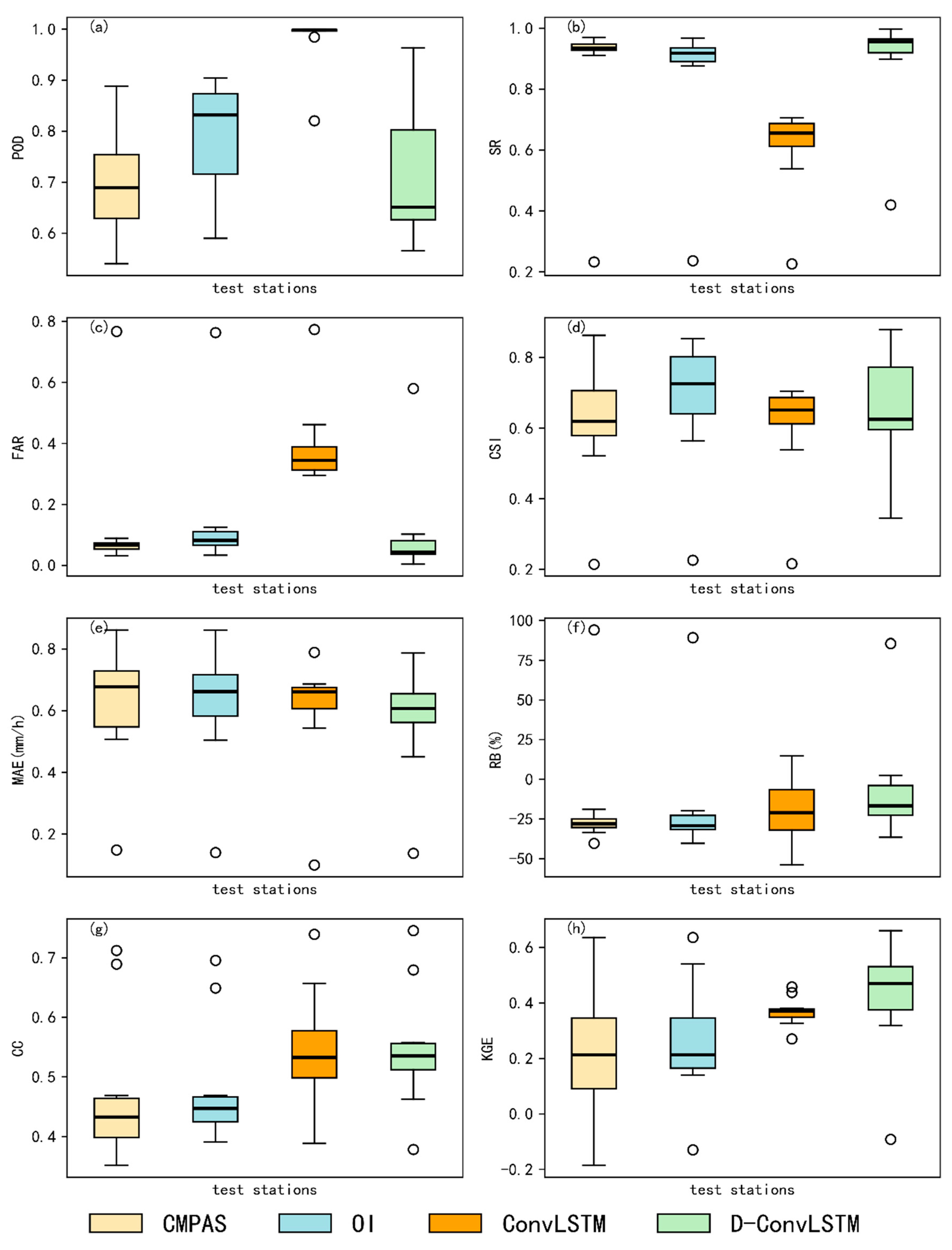
We employ different metrics to evaluate the performance of D-ConvLSTM and investigate the influence of training data selection. We also compare the results of D-ConvLSTM with those of ConvLSTM and the OI to identify the strengths and weaknesses of D-ConvLSTM. We calculate the following metrics using station precipitation observations and corresponding grid-merging precipitation values.
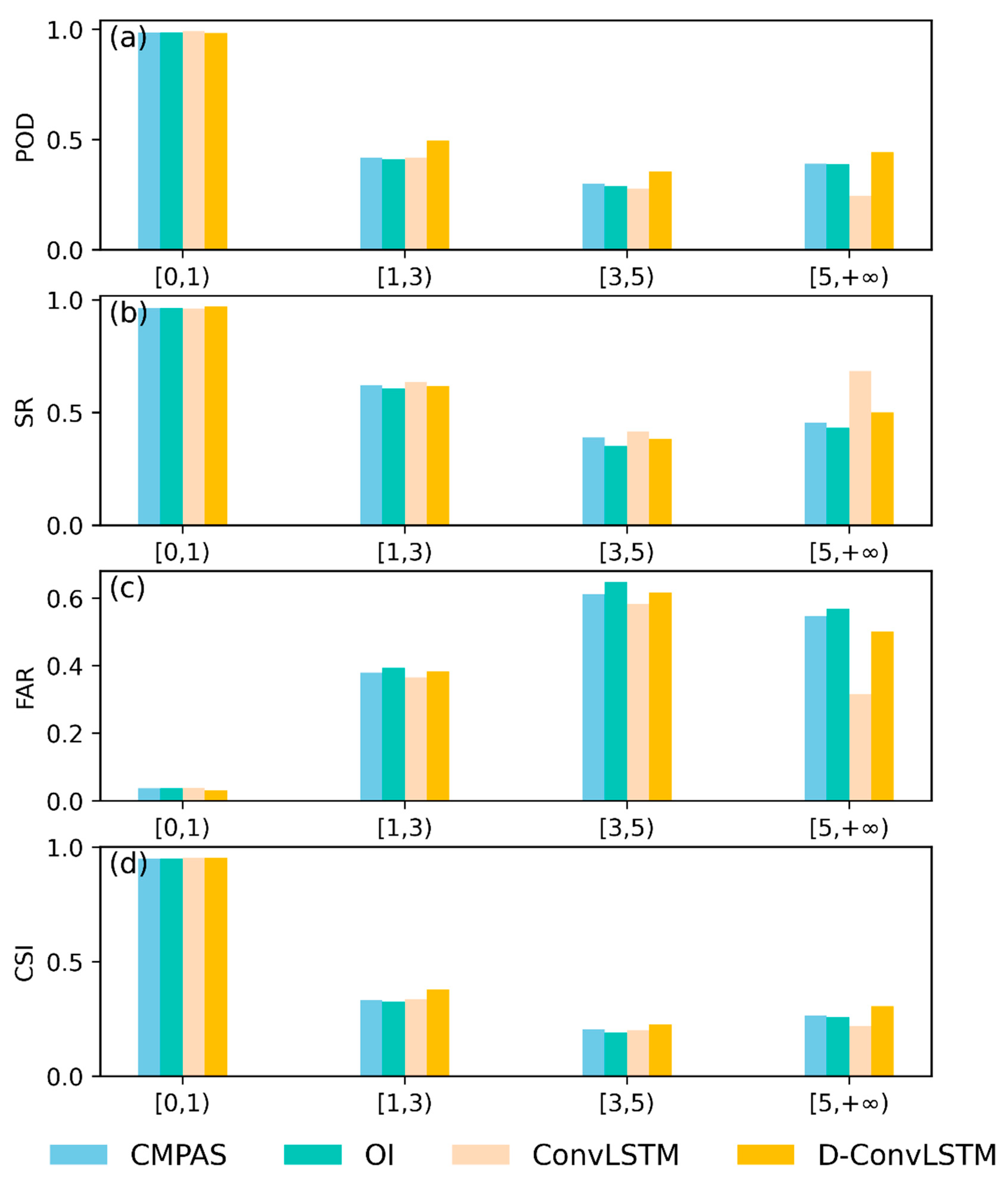
The evaluation metrics include classification metrics and statistical metrics. This study uses classification metrics, including the probability of detection (POD), success ratio (SR), false alarm ratio (FAR), and critical success index (CSI), to assess the model’s precipitation identification capability. The POD indicates the ability to correctly detect precipitation events. The SR and FAR represent the ratios of correctly detected precipitation periods and incorrectly detected precipitation periods to the total detected precipitation periods, respectively. The CSI combines the POD and FAR, serving as a comprehensive indicator of precipitation identification capability. The optimal value of the POD, SR, and CSI is 1, whereas the FAR is 0.
They are defined in Equation (4):
where
is the number of periods where precipitation was observed and correctly detected as precipitation;
is the number of periods where precipitation was not observed but incorrectly detected as precipitation; and
is the number of periods where precipitation was observed but incorrectly detected as not occurring.
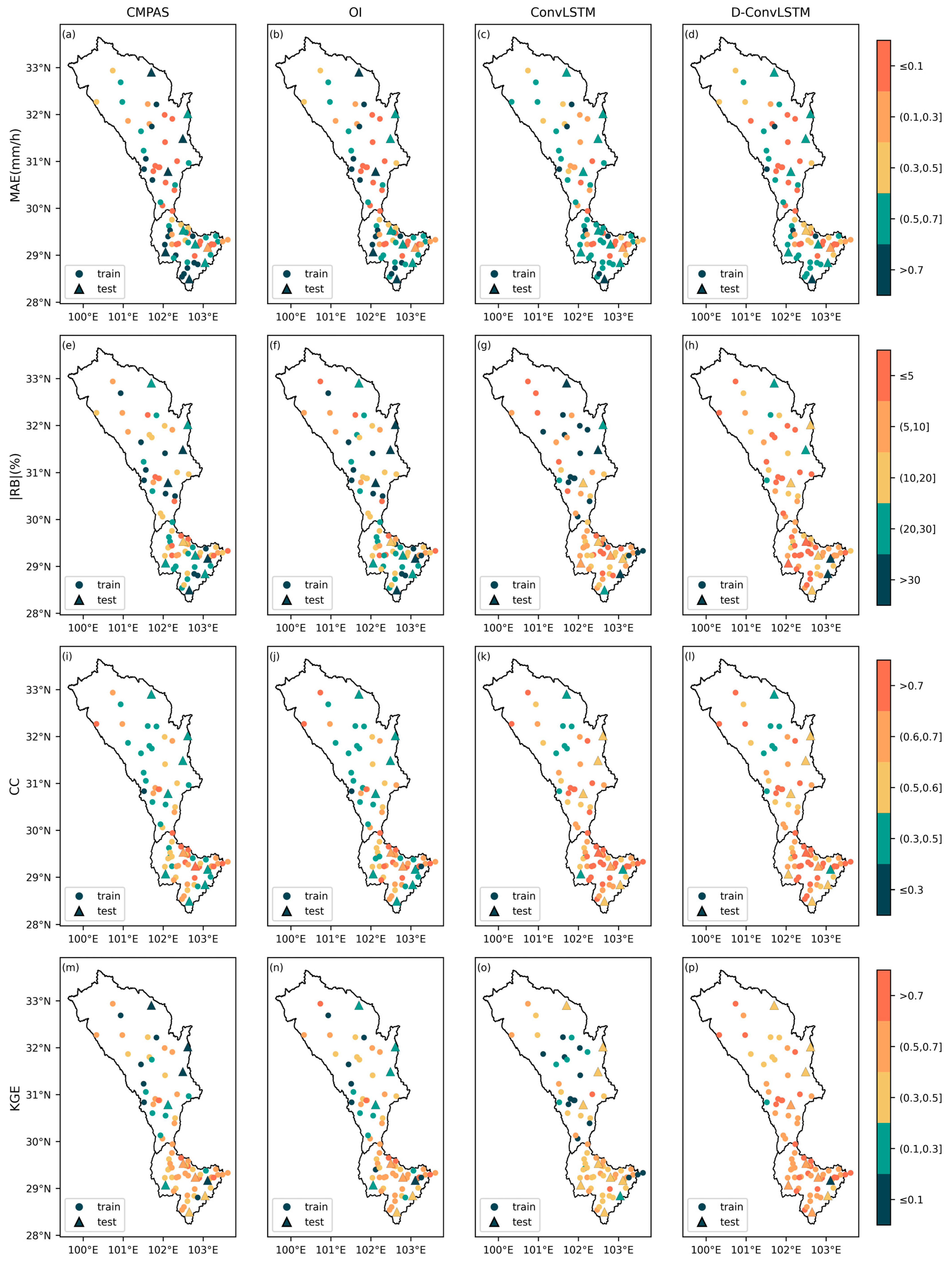
This study uses statistical metrics to assess the estimation errors of merged precipitation values and their alignment with station-observed precipitation. These metrics include the mean absolute error (MAE), relative bias (RB), Pearson correlation coefficient (CC), and Kling–Gupta efficiency (KGE). The MAE quantifies the error between merged precipitation and observed values over short time intervals, whereas the RB captures the cumulative error across extended periods. The CC measures the degree of correlation between merged precipitation and observed values, whereas the KGE evaluates the overall goodness of fit between these two datasets. The optimal value of the CC and KGE is 1, whereas the values of the MAE and RB are 0.
They are defined in Equation (5):
where
is the number of periods;
is the station observation at time
;
is the merged precipitation at time
;
is the mean precipitation in the entire evaluation period;
is the deviation ratio;
is the variation rate;
is the mean precipitation in the evaluation period; and
is the standard deviation of precipitation in the evaluation period.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}