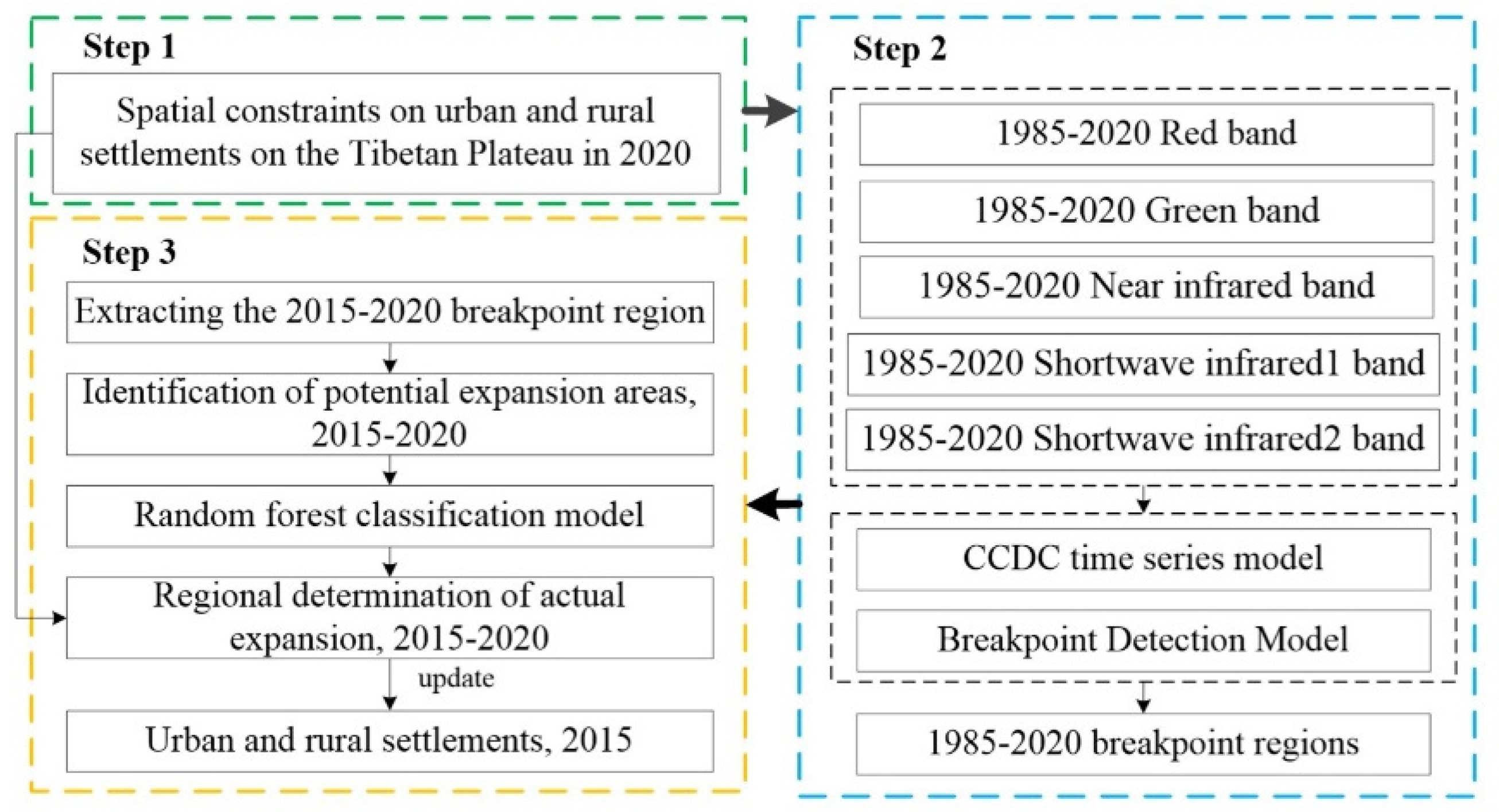
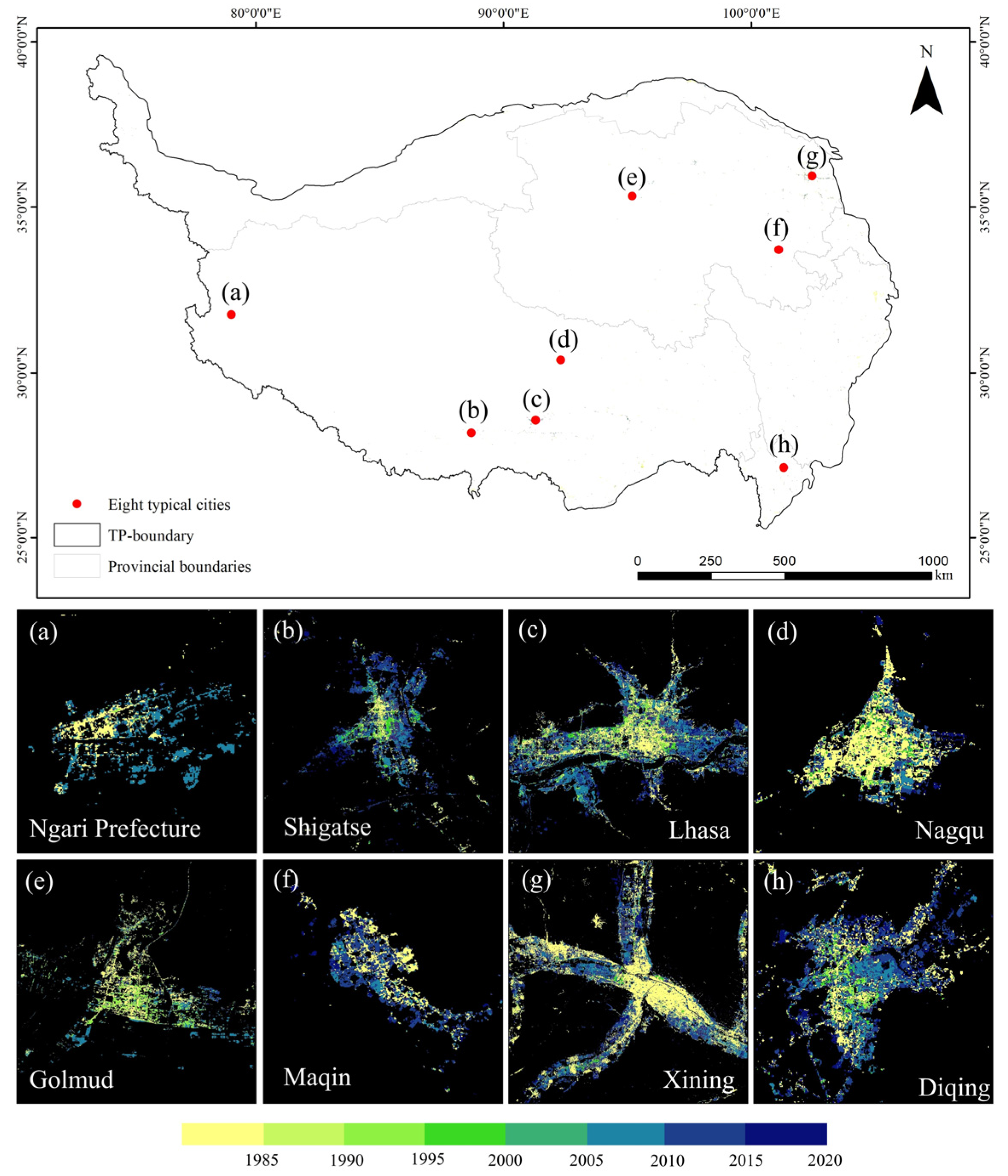
4.2.2. Physical Expansion Areas
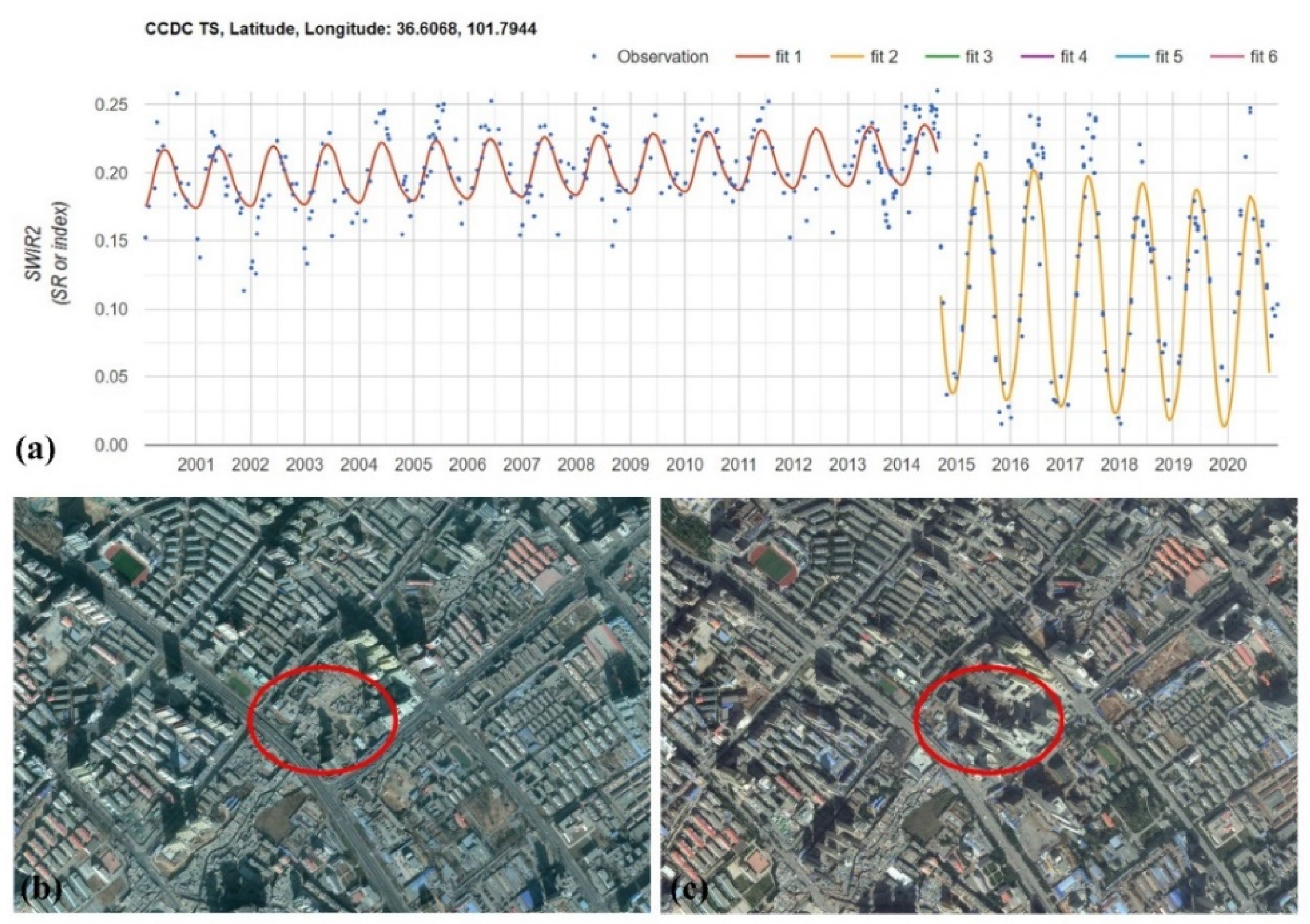
Urban demolition, reconstruction, and surface transformation activities can significantly alter the spectral characteristics of a region, leading to the detection of breakpoint areas. However, these changes do not necessarily indicate a change in land use types. Taking the urban renovation of a certain area as an example (
Figure 9), from the high-resolution Google Earth imagery, it can be observed that in early 2014, the area was predominantly composed of low-rise residential buildings. By the end of 2015, high-rise buildings had been completed, indicating that the area underwent rapid building renewal within a short period. We can easily detect spectral abrupt changes through the CCDC algorithm and breakpoint detection algorithm. However, the update of buildings did not actually increase the area or extent of the city and should not be defined as urban expansion. Therefore, further identification of potential expansion areas is required.
Based on the random forest classification model, the potential expansion areas were further classified to extract the actual expansion regions. The classification results for part of the potential expansion areas in Lhasa and Xining between 2015 and 2020 are shown (
Figure 10). In the northwest of Lhasa’s Chengguan District, farmland (yellow area) was converted into URSs dominated by blue-roofed buildings between 2015 and 2020. Similarly, farmland in Xining (yellow area) was converted into URSs dominated by high-rise buildings during the same period, indicating that the classification results accurately extracted the actual expansion areas between 2015 and 2020. According to the classification accuracy statistics (
Table 4), the overall accuracy between 2015 and 2020 reached 0.96, with a kappa coefficient of 0.92, indicating that the random forest model can accurately extract the actual changes within the potential expansion areas. Overall, for the seven time periods from 1985 to 2020, the overall accuracy exceeded 0.86, suggesting relatively high classification accuracy. The kappa values were all above 0.80, indicating that the classification results are generally reliable. In most time periods, both producer and user accuracies remained high, demonstrating good recognition capability across all categories. The classification accuracy between 1985 and 1990 was lower compared to other years, which could be attributed to the lower quality of Landsat imagery from 1985. In conclusion, the random forest classification model can accurately extract actual expansion areas.
4.2.3. Update of URSs and Their Boundary Extraction
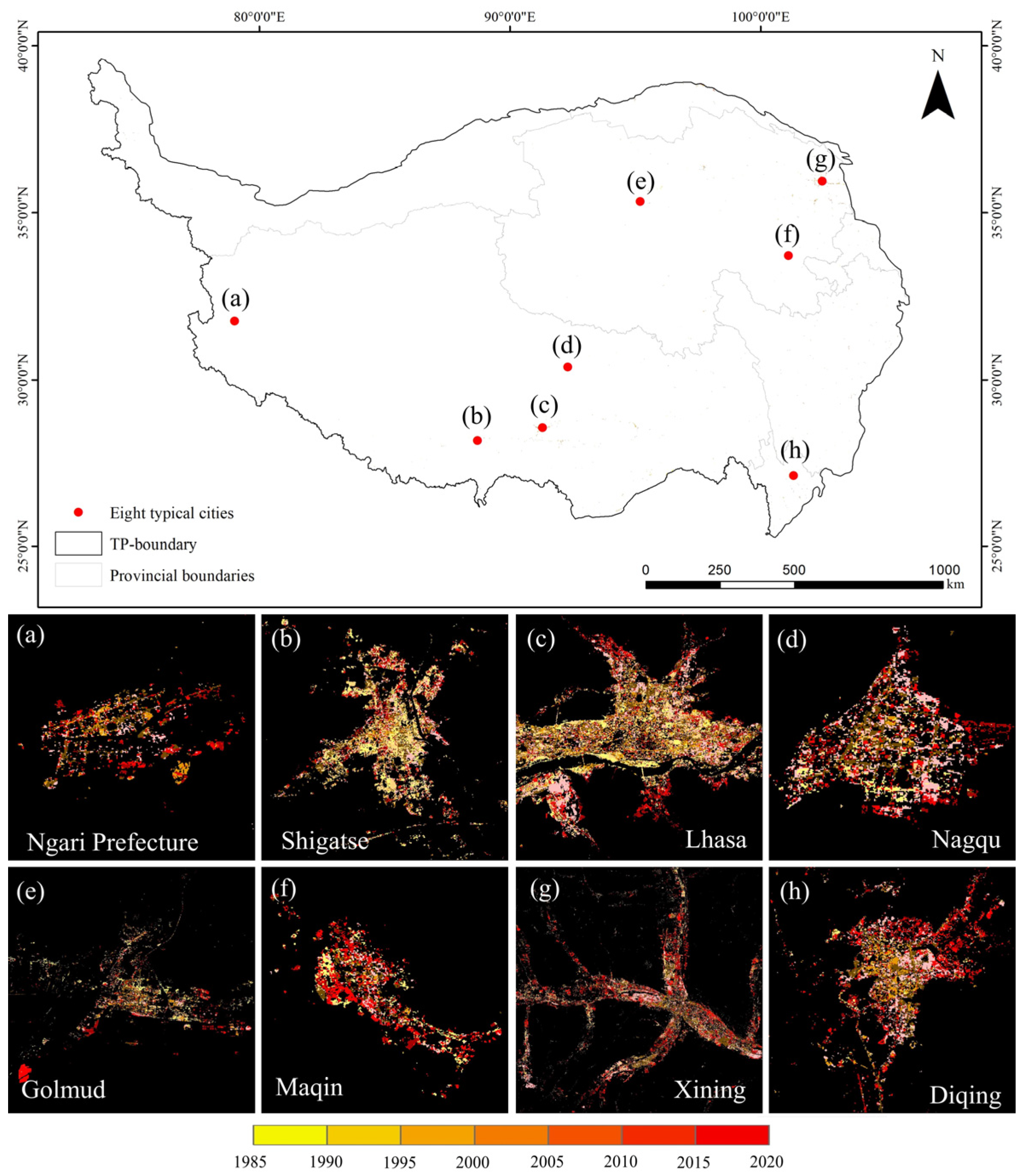
Based on the extraction results of the actual expansion areas, the URSs on the Qinghai–Tibet Plateau from 1985 to 2020 were updated (
Figure 11), effectively reflecting the urbanization process over the past 35 years. Bright yellow and deep blue represent the spatial distribution of URS in the early 1980s and the late 2020s, respectively, and the gradient of colors shows the dynamic process of urban expansion. In 1985, URSs were mainly concentrated in city centers, after which rapid expansion began outward from the urban core. Particularly, in recent years, the acceleration of urbanization has led to more significant urban area growth. In the expanded areas, the blue tone dominates, indicating that most of the urban expansion occurred after 2010. For example, Lhasa expanded rapidly to the east and west after 2005, while Nagqu is relatively unique, with a smaller urban area and a dominance of yellow, indicating that the expansion of Nagqu has been relatively slow in recent decades.
The URSBs were extracted based on mathematical morphology and pixel-based statistical methods, with an optimal morphological structural element radius of 13 [
40]. Natural spatial features within the city were removed, and the URSBs on the Qinghai–Tibet Plateau from 1985 to 2020 were drawn and overlaid on Landsat satellite imagery.
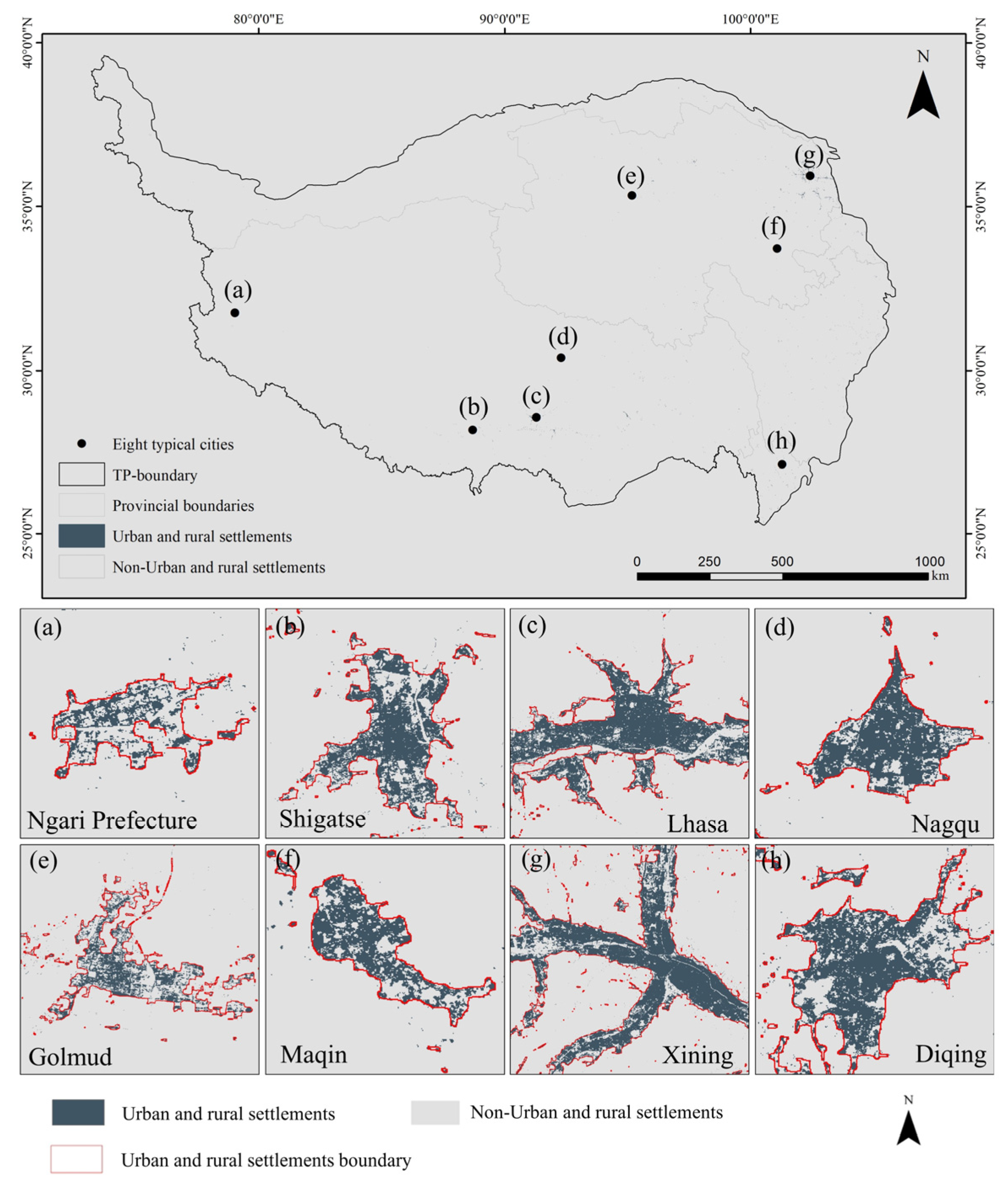
Figure 12 shows the boundary spatial patterns of eight typical cities, including Lhasa and Xining, for the years 1985, 1995, 2005, and 2015. The extracted boundary results closely align with the actual spatial extent of URSs, effectively separating URSs from other land use types, with continuous and complete boundaries. The migration of these boundaries reflects the urban expansion process, particularly between 2005 and 2015, where significant changes in boundary shape correspond to the rapid urbanization during that period.
4.2.4. Accuracy Evaluation
Based on the optimal RF classification model, the URS information of the Qinghai–Tibet Plateau for 2015 was extracted. A total of 1940 samples were used, with about 30% of the samples involved in accuracy validation. The random forest classification achieved an overall accuracy of 0.96, kappa value of 0.90, producer accuracy of 0.91, and user accuracy of 0.96, indicating high classification precision and reliable results, which can serve as baseline data.
(1) Area Matching Accuracy.
The closer the area matching S is to 100%, the higher the degree of matching and accuracy. The area matching accuracy for the entire Qinghai–Tibet Plateau, and eight representative regions such as Ngari Prefecture and Shigatse, was calculated (
Table 5). The overall area matching accuracy for the Qinghai–Tibet Plateau reached 97.79%, indicating a high level of consistency between the datasets. The area matching degree for Shigatse was 83.79%, which may be due to errors caused by misclassification of bare soil in the random forest classification. For other cities, the area matching error was less than 8%, demonstrating relatively high matching accuracy at the city scale.
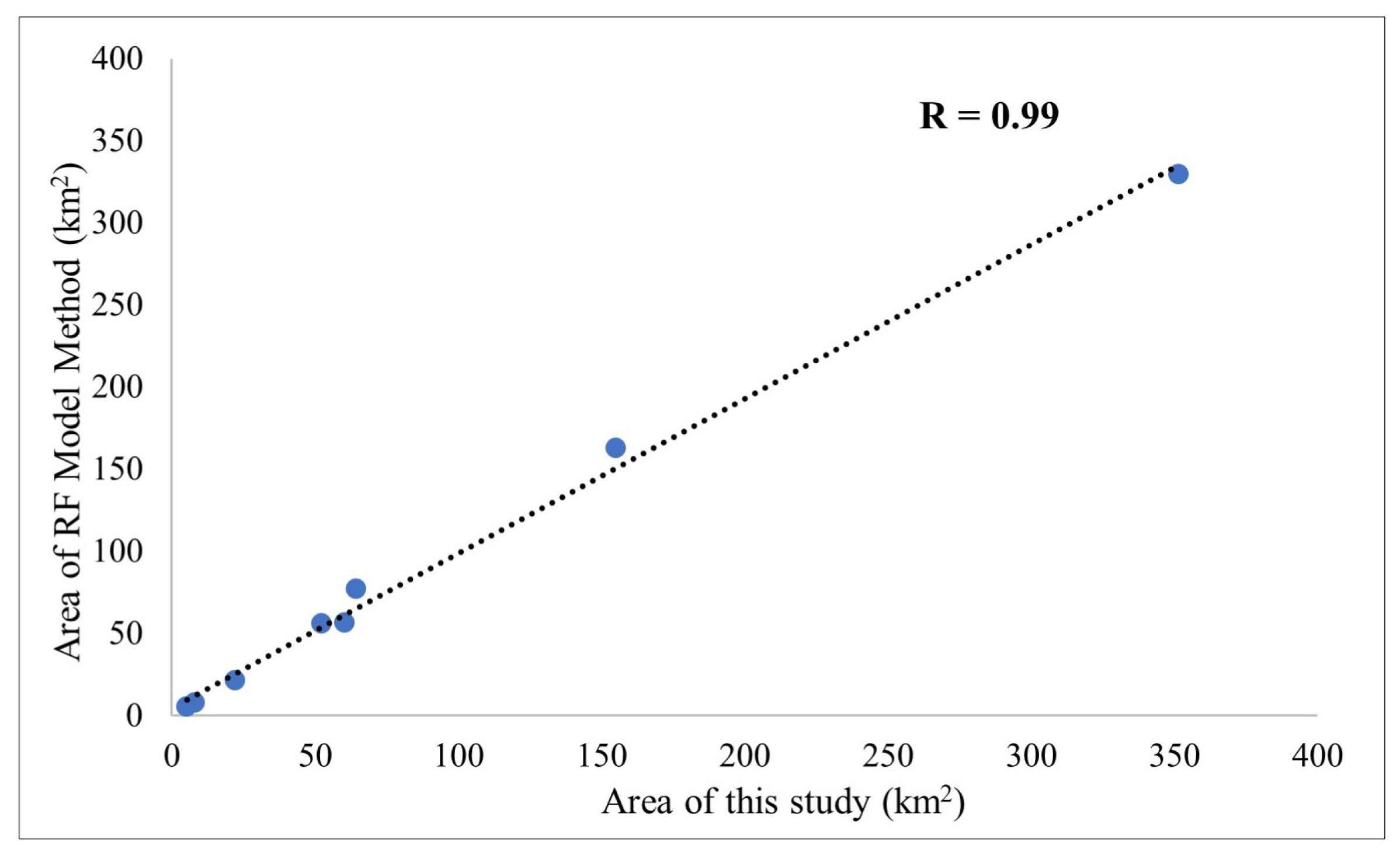
This study evaluated the accuracy of extracted areas through correlation analysis.
Figure 13 presented a scatter plot with the areas extracted by this study’s method on the
x-axis and those extracted by the “optimal random forest algorithm based on multi-source data” on the
y-axis, including area data from eight typical cities. The results showed that the Pearson correlation coefficient between the two sets of data was as high as 0.99 (significance level
p < 0.001), indicating a very strong correlation and consistency between the areas extracted by this study’s method and the reference areas, thus fully validating the accuracy and reliability of the method.
(2) Confusion Matrix Accuracy Validation
Based on the 1940 samples from the 2015 random forest classification, approximately 30% of the samples were randomly selected as validation samples to assess the accuracy of the URS extraction in this study. The results showed that the overall accuracy was 98.33%, with a kappa value of 0.96. For the “URS” class, the producer accuracy was 98.45%, and the user accuracy was 99.21%.
(3) Comparison with other products.
The validation sample of this study is based on the available GURS, GAIA, and GISD30 datasets, and the confusion matrix accuracy showed that the average overall accuracy of the URSs was 93.25% with a kappa coefficient of 0.89 (
Table 6). Specifically, in eight years (1985, 1990, 1995, 2000, 2005, 2010, 2015, and 2020), the overall accuracy is more than 90% and the kappa coefficient is more than 0.85. The overall presentation showed that the earlier the year, the lower the overall accuracy and the kappa coefficient, which may be due to the poor quality of Landsat imagery in the early years.
In addition to the quantitative evaluation described above, we selected four representative cities on the Tibetan Plateau (Lhasa, Xining, Nagqu, and Diqing Tibetan Autonomous Prefecture) to compare these datasets (
Figure 14). The comparison reveals two main differences between URSs and other products. First, the ability to represent the spatial extent details of URSs was different. URSs have a high degree of consistency with the other products in terms of URSs in the urban subjects, and GURSs in particular exhibit a high degree of spatial accuracy. Due to the limitation of spatial resolution, GURSs (100 m resolution) have obvious jagged data, and the details of urban and rural settlements are slightly poorer. GAIA and GISD30 both have a spatial resolution of 30 m, but some rural settlements are missing, which makes the mapping ability weaker in rural areas. The ability of GURSs to show the details can more accurately reflect the dynamics of the urban sprawl. Second, the phenomenon of overestimation and underestimation of URSs. Taking Lhasa as an example, GURSs ignored low-density urban and rural settlements; GAIA misclassified bare land as URSs and overestimated the actual extent, which may be due to the fact that URSs have similar spectral characteristics to bare land and the classification process only considered the spectral characteristics of URS; GISD30 greatly underestimated URSs; and the product of the present study greatly mitigated the problem of misclassification and omission, and was in line with the actual situation maintain high consistency and high classification accuracy. The same phenomenon was found in other typical cities.
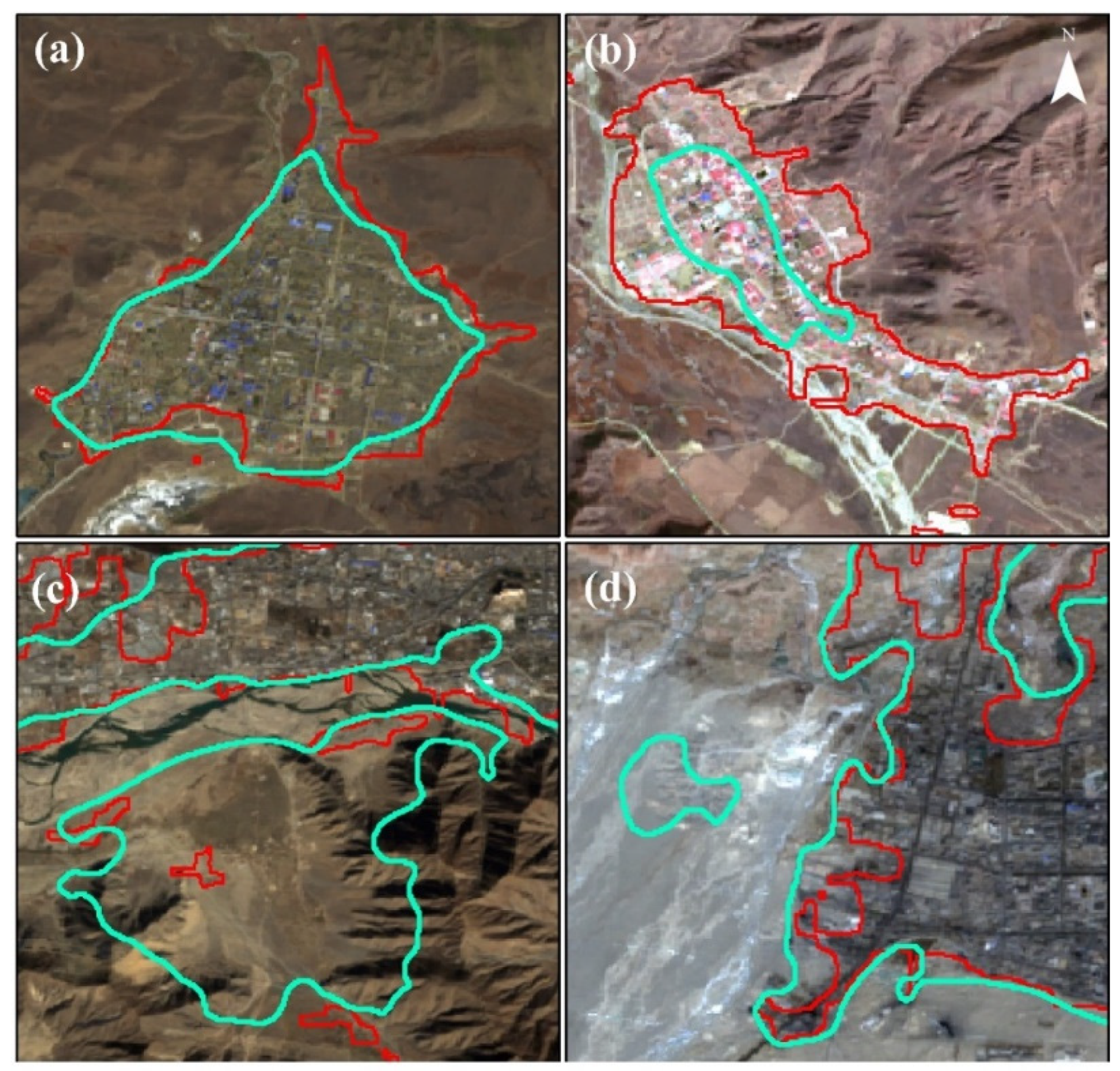
There are two main areas of difference between URSBs and GUBs in the comparison of urban and rural settlement boundaries (
Figure 15). The first is the difference in the extent of the city. Although the extent in the core urban areas is highly consistent, the GUB product clearly overestimates or underestimates the urban boundaries to varying degrees. For example, in
Figure 15a,b, the GUB underestimates the actual urban extent by overlooking the buildings in the surrounding areas. In
Figure 15c, the southern part of Lhasa in 1995 had not been developed and was mainly covered by bare land and grassland, yet the GUB incorrectly extracted the urban range. The overestimation of the urban boundary may be due to the similar spectral characteristics of bare land and URSs.
Figure 15d also showed an incorrect estimation of the urban boundary, as the western part of Golmud in 2005 was a river alluvial fan with no human habitation traces. URSB and URS product mapping ideas are similar; both are based on the secondary processing of urban and rural settlements to generate maps. That is, URSB is based on URS data, and GUB is based on GAIA products; however, GAIA products only consider spectral characterization indexes in the non-arid areas, so GUBs will be wrongly scored and omitted. Second, the level of detail of the boundaries was different. Both the URSB and the GUB datasets have a spatial resolution of 30 m. As shown in
Figure 15a,b, the boundaries in this study effectively identify Non-URS areas, with the boundary shape being more irregular, while the GUBs were relatively smoother.



 ,
, 



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}