
ASS-CD: Adapting Segment Anything Model and Swin-Transformer for Change Detection in Remote Sensing Images



Abstract
1. Introduction
- (1)
- A novel CD network called ASS-CD is proposed, which is the first work to combine two pre-trained foundation models (FastSAM and Swin-Transformer) and transfer their general knowledge to the CD task through the adapter module. It also represents the first adapter framework to effectively fuse local and global information through a cross-attention mechanism in the remote sensing domain. By training a small number of parameters, the proposed ASS-CD achieves high-precision CD results.
- (2)
- To address the challenge of background interference and multi-scale change targets, our work first integrates CBAM into the skip connections of the U-Net architecture, which consists of channel and spatial attention blocks.
- (3)
- The HDSM is designed to impose deep supervision on multi-scale feature maps generated by the decoder and computes the Dice loss. This innovative design helps to address the class imbalance between positive and negative samples in CD datasets, which also promotes the model to learn more discriminative features.
2. Related Works
2.1. Deep Learning-Based CD Methods
2.2. PEFT for PVFMs
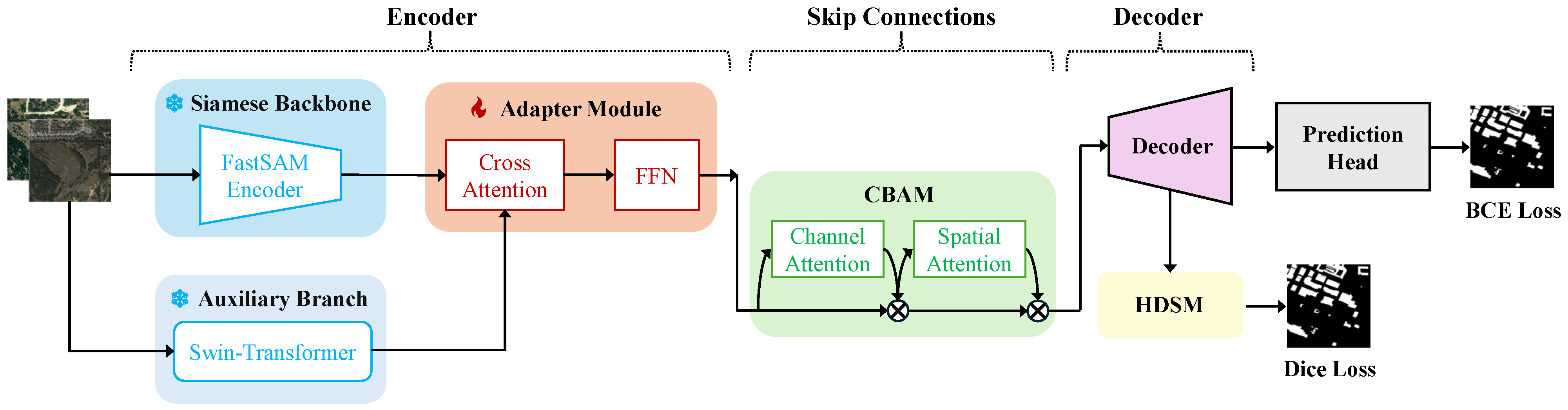
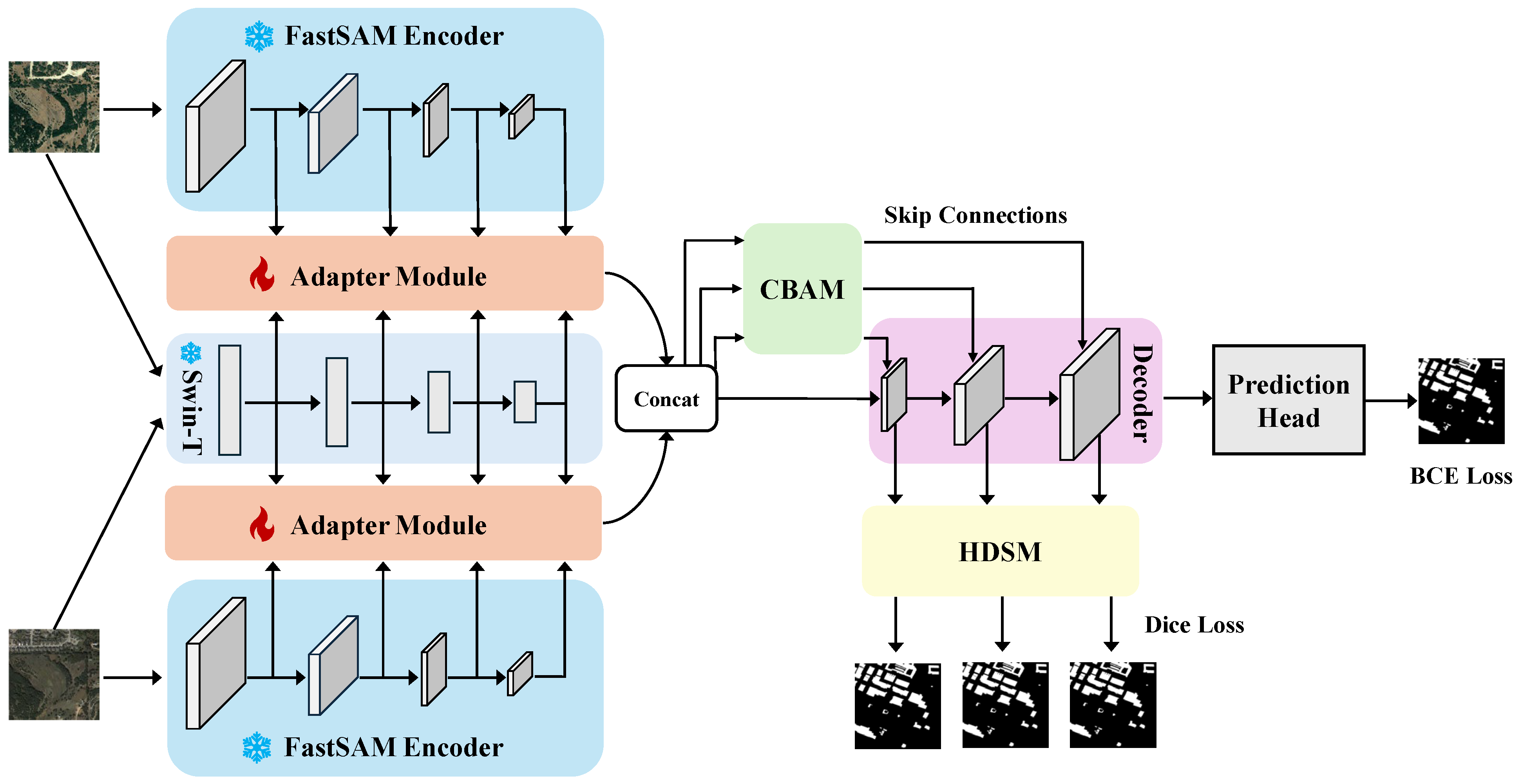
3. Proposed Method
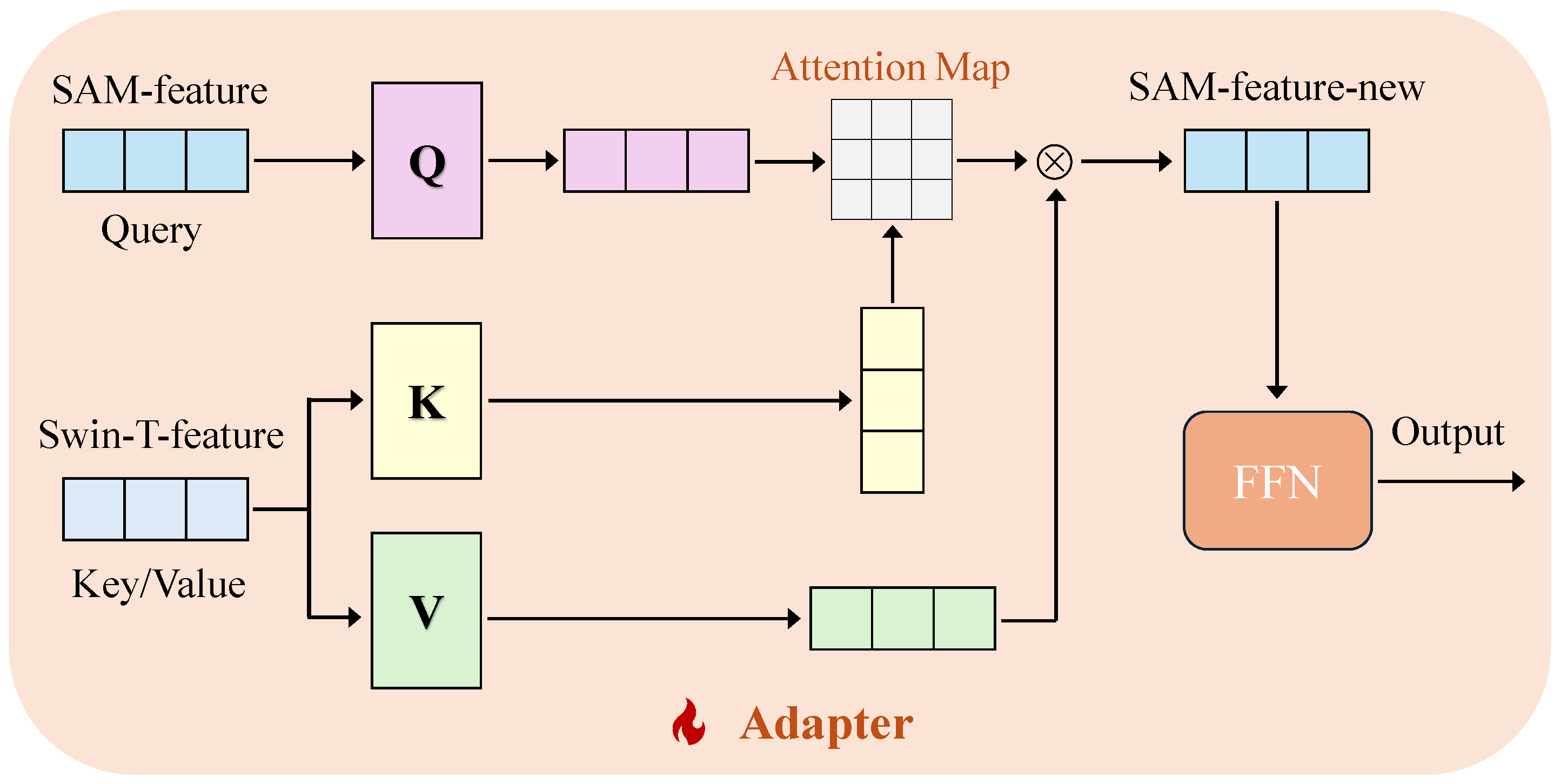
3.1. Adapter Module
3.2. CBAM
3.3. HDSM
3.4. Loss Function
4. Experimental Results and Analysis
4.1. Dataset Description
- (1)
- LEVIR-CD [20]: This dataset is employed for CD, consisting of 637 bi-temporal high-resolution Google Earth image pairs with dimensions of 1024 × 1024 pixels and a spatial resolution of 0.5 m. These images capture substantial land-use changes, particularly building development and demolition, over time periods ranging from 5 to 14 years. To accommodate the input size requirements of the PVFMs and address GPU memory limitations, we cropped the images into 256 × 256 patches. The final dataset was split into 7120, 1024, and 2048 image pairs for the training, validation, and test sets, respectively. The dataset can be obtained from https://justchenhao.github.io/LEVIR/ accessed on 10 October 2022.
- (2)
- WHU-CD [59]: This high-resolution aerial imagery dataset is utilized for building change detection tasks, focusing on the Christchurch region in New Zealand, where it captures changes between 2012 and 2016 due to post-earthquake reconstruction efforts following the 2011 earthquake. The original aerial images have a resolution of 0.2 m per pixel and cover a large area of 32,507 × 15,354 pixels. For practical use, the images were cropped into 256 × 256 patches. The dataset was divided into 6096, 762, and 762 image pairs for the training, validation, and test sets, respectively. The dataset can be obtained from https://gpcv.whu.edu.cn/data/building_dataset.html accessed on 1 October 2023.
- (3)
- DSIFN-CD [21]: This is a dataset specifically designed for change detection, with data sourced from Google Earth covering six cities (i.e., Beijing, Chengdu, Shenzhen, Chongqing, Wuhan, and Xi’an) in China. DSIFN-CD includes various types of change objects, such as roads, buildings, farmlands, and water bodies. In this paper, the default 512 × 512 samples were cropped into 256 × 256 image patches. The dataset was randomly divided into training, validation, and test sets, containing 14,400, 1360, and 192 RSI pairs, respectively. The dataset can be obtained from https://paperswithcode.com/dataset/dsifn-cd accessed on 15 December 2023.
4.2. Implementation Details and Evaluation Metrics
4.3. Comparison Experiments
4.4. Ablation Study
- Baseline: U-Net + FastSAM;
- Model_a: U-Net + FastSAM + Adapter;
- Model_b: U-Net + FastSAM + Adapter + CBAM;
- Model_c: U-Net + FastSAM + Adapter + HDSM;
- ASS-CD: U-Net + FastSAM + Adapter + CBAM + HDSM.
5. Discussion
- (1)
- We fuse two PVFMs, FastSAM and Swin-Transformer, to adapt the general knowledge of image semantic understanding to the specific CD task for RSIs, which allows our method to benefit from both local and global information from the pre-trained model.
- (2)
- By integrating the CBAM and HDSM modules, the model’s ability to extract multi-scale varying objects, especially local details, is significantly improved, and these modules also effectively reduce the interference of irrelevant background information in RSIs.
- (3)
- The introduction of Dice loss helps to overcome the category imbalance problem in the CD dataset, thereby improving the stability of model training.
- (1)
- Adaptability to more advanced pre-trained models. In recent years, with the rapid advancement of large-scale model technology, more sophisticated PVFMs have emerged. For instance, the highly acclaimed vision Mamba model has achieved remarkable results in various computer vision tasks. Given this, we might explore the latest visual models to further enhance CD accuracy without altering the hierarchical architecture of ASS-CD.
- (2)
- Deployment complexity on hardware devices. As mentioned in the complexity analysis subsection, although ASS-CD only updates a small number of parameters, the frozen parameters from FastSAM and Swin-Transformer lead to significant storage requirements when deploying the model on hardware devices. This underscores the necessity of employing model lightweighting techniques such as model pruning and knowledge distillation to reduce complexity while selecting appropriate PVFMs.
- (3)
- Balance between model complexity and performance gain. Although we adopt an adapter tuning strategy to ensure that the number of parameters updated during training are minimal, the architecture of the proposed ASS-CD remains relatively complex due to the use of two large pre-trained models to learn general knowledge. In addition, the introduction of other modules like deep supervision also adds an extra computational burden and training complexity. We should explore more lightweight methods to supervise intermediate layers and simplify the parameters of HDSM, which are important factors during model implementation. In future work, we plan to simplify the model while maintaining its performance. This may involve reducing the number of adapters, using lighter pre-trained models, or optimizing other modules to strike a balance between model complexity and performance gain.
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Cheng, G.; Huang, Y.; Li, X.; Lyu, S.; Xu, Z.; Zhao, H.; Zhao, Q.; Xiang, S. Change Detection Methods for Remote Sensing in the Last Decade: A Comprehensive Review. Remote Sens. 2024, 16, 2355. [Google Scholar] [CrossRef]
- Coppin, P.R.; Jonckheere, I.G.C.; Nackaerts, K.; Muys, B.; Lambin, E.F. Digital Change Detection Methods in Ecosystem Monitoring: A Review. Int. J. Remote Sens. 2004, 25, 1565–1596. [Google Scholar] [CrossRef]
- Bruzzone, L.; Prieto, D.F. Automatic Analysis of the Difference Image for Unsupervised Change Detection. IEEE Trans. Geosci. Remote Sens. 2000, 38, 1171–1182. [Google Scholar] [CrossRef]
- Feranec, J.; Hazeu, G.W.; Christensen, S.; Jaffrain, G. Corine Land Cover Change Detection in Europe (case studies of the Netherlands and Slovakia). Land Use Policy 2007, 24, 234–247. [Google Scholar] [CrossRef]
- Shi, S.; Zhong, Y.; Zhao, J.; Lv, P.; Liu, Y.; Zhang, L. Land-Use/Land-Cover Change Detection Based on Class-Prior Object-Oriented Conditional Random Field Framework for High Spatial Resolution Remote Sensing Imagery. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–16. [Google Scholar] [CrossRef]
- Qiao, H.; Wan, X.; Wan, Y.; Li, S.; Zhang, W. A Novel Change Detection Method for Natural Disaster Detection and Segmentation from Video Sequence. Sensors 2020, 20, 5076. [Google Scholar] [CrossRef] [PubMed]
- Yu, Q.; Zhang, M.; Yu, L.; Wang, R.; Xiao, J. SAR Image Change Detection Based on Joint Dictionary Learning with Iterative Adaptive Threshold Optimization. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 5234–5249. [Google Scholar] [CrossRef]
- Amitrano, D.; Guida, R.; Iervolino, P. Semantic Unsupervised Change Detection of Natural Land Cover with Multitemporal Object-Based Analysis on SAR Images. IEEE Trans. Geosci. Remote Sens. 2021, 59, 5494–5514. [Google Scholar] [CrossRef]
- Wang, L.; Wang, L.; Wang, Q.; Atkinson, P.M. SSA-SiamNet: Spatial-Wise Attention-Based Siamese Network for Hyperspectral Image Change Detection. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5510018. [Google Scholar] [CrossRef]
- Luo, F.; Zhou, T.; Liu, J.; Guo, T.; Gong, X.; Ren, J. Multiscale Diff-Changed Feature Fusion Network for Hyperspectral Image Change Detection. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5502713. [Google Scholar] [CrossRef]
- Khelifi, L.; Mignotte, M. Deep Learning for Change Detection in Remote Sensing Images: Comprehensive Review and Meta-Analysis. IEEE Access 2020, 8, 126385–126400. [Google Scholar] [CrossRef]
- Ertürk, S. Fuzzy Fusion of Change Vector Analysis and Spectral Angle Mapper for Hyperspectral Change Detection. In Proceedings of the IGARSS 2018, Valencia, Spain, 22–27 July 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 5045–5048. [Google Scholar]
- Celik, T. Unsupervised Change Detection in Satellite Images Using Principal Component Analysis and k-Means Clustering. IEEE Geosci. Remote Sens. Lett. 2009, 6, 772–776. [Google Scholar] [CrossRef]
- Wu, C.; Du, B.; Zhang, L. Hyperspectral Change Detection Based on Independent Component Analysis. Int. J. Remote Sens. 2012, 16, 545–561. [Google Scholar]
- Zheng, Z.; Du, S.; Taubenböck, H.; Zhang, X. Remote Sensing Techniques in The Investigation of Aeolian Sand Dunes: A Review of Recent Advances. Remote Sens. Environ. 2022, 271, 112913. [Google Scholar] [CrossRef]
- Daudt, R.C.; Le Saux, B.; Boulch, A. Fully Convolutional Siamese Networks for Change Detection. In Proceedings of the 2018 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; pp. 4063–4067. [Google Scholar]
- Fang, S.; Li, K.; Shao, J.; Li, Z. SNUNet-CD: A Densely Connected Siamese Network for Change Detection of VHR Images. IEEE Geosci. Remote Sens. Lett. 2021, 19, 1–5. [Google Scholar] [CrossRef]
- Zheng, Z.; Ma, A.; Zhang, L.; Zhong, Y. Change is Everywhere: Single-Temporal Supervised Object Change Detection in Remote Sensing Imagery. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 15173–15182. [Google Scholar]
- Fang, S.; Li, K.; Li, Z. Changer: Feature Interaction is What You Need for Change Detection. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–11. [Google Scholar] [CrossRef]
- Chen, H.; Shi, Z. A Spatial-Temporal Attention-Based Method and a New Dataset for Remote Sensing Image Change Detection. Remote Sens. 2020, 12, 1662. [Google Scholar] [CrossRef]
- Zhang, C.; Yue, P.; Tapete, D.; Jiang, L.; Shangguan, B.; Huang, L.; Liu, G. A Deeply Supervised Image Fusion Network for Change Detection in High Resolution Bi-temporal Remote Sensing Images. ISPRS J. Photogramm. Remote Sens. 2020, 166, 183–200. [Google Scholar] [CrossRef]
- Feng, Y.; Jiang, J.; Xu, H.; Zheng, J. Change Detection on Remote Sensing Images Using Dual-Branch Multilevel Intertemporal Network. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–15. [Google Scholar] [CrossRef]
- Han, C.; Wu, C.; Guo, H.; Hu, M.; Chen, H. HANet: A Hierarchical Attention Network for Change Detection with Bitemporal Very-High-Resolution Remote Sensing Images. IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens. 2023, 16, 3867–3878. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S. An Image Is Worth 16x16 Words: Transformers for Image Recognition at Scale. In Proceedings of the International Conference on Learning Representations (ICLR), Virtual, 3–7 May 2021. [Google Scholar]
- Bandara, W.G.C.; Patel, V.M. A Transformer-Based Siamese Network for Change Detection. In Proceedings of the IGARSS 2022—2022 IEEE International Geoscience and Remote Sensing Symposium, Kuala Lumpur, Malaysia, 17–22 July 2022; pp. 207–210. [Google Scholar]
- Zhang, C.; Wang, L.; Cheng, S.; Li, Y. SwinSUNet: Pure Transformer Network for Remote Sensing Image Change Detection. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–13. [Google Scholar] [CrossRef]
- Wang, Q.; Jing, W.; Chi, K.; Yuan, Y. Cross-Difference Semantic Consistency Network for Semantic Change Detection. IEEE Trans. Geosci. Remote Sens. 2024, 62, 1–12. [Google Scholar] [CrossRef]
- Chen, H.; Qi, Z.; Shi, Z. Remote Sensing Image Change Detection with Transformers. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–14. [Google Scholar] [CrossRef]
- Li, W.; Xue, L.; Wang, X.; Li, G. ConvTransNet: A CNN–Transformer Network for Change Detection with Multiscale Global–Local Representations. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–15. [Google Scholar] [CrossRef]
- Tang, X.; Zhang, T.; Ma, J.; Zhang, X.; Liu, F.; Jiao, L. WNet: W-Shaped Hierarchical Network for Remote-Sensing Image Change Detection. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–14. [Google Scholar] [CrossRef]
- Cui, Y.; Chen, H.; Dong, S.; Wang, G.; Zhuang, Y. U-Shaped CNN-ViT Siamese Network with Learnable Mask Guidance for Remote Sensing Building Change Detection. IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens. 2024, 17, 11402–11418. [Google Scholar] [CrossRef]
- Gao, Y.; Pei, G.; Sheng, M.; Sun, Z.; Chen, T.; Yao, Y. Relating CNN-Transformer Fusion Network for Remote Sensing Change Detection. In Proceedings of the 2024 IEEE International Conference on Multimedia and Expo (ICME), Niagara Falls, ON, Canada, 15–19 July 2024; pp. 1–6. [Google Scholar]
- Sun, X.; Wang, P.; Lu, W.; Zhu, Z.; Lu, X.; He, Q.; Li, J.; Xuee, R.; Yang, Z.; Chang, H.; et al. RingMo: A Remote Sensing Foundation Model with Masked Image Modeling. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–22. [Google Scholar] [CrossRef]
- Wang, D.; Zhang, Q.; Xu, Y.; Zhang, J.; Du, B.; Tao, D.; Zhang, L. Advancing Plain Vision Transformer Toward Remote Sensing Foundation Model. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–15. [Google Scholar] [CrossRef]
- Hong, D.; Zhang, B.; Li, X.; Li, Y.; Li, C.; Yao, J.; Yokoya, N.; Li, H.; Ghamisi, P.; Jia, X.; et al. SpectralGPT: Spectral Remote Sensing Foundation Model. IEEE Trans. Pattern Anal. Mach. Intell. 2024, 46, 5227–5244. [Google Scholar] [CrossRef] [PubMed]
- Xin, Y.; Luo, S.; Zhou, H.; Du, J.; Liu, X.; Fan, Y.; Li, Q.; Du, Y. Parameter-Efficient Fine-Tuning for Pre-trained Vision Models: A Survey. arXiv 2024, arXiv:2402.02242. [Google Scholar]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning Transferable Visual Models from Natural Language Supervision. In Proceedings of the International Conference on Machine Learning, Virtual, 1 July 2021; pp. 8748–8763. [Google Scholar]
- Kirillov, A.; Mintun, E.; Ravi, N.; Mao, H.; Rolland, C.; Gustafson, L.; Xiao, T.; Whitehead, S.; Berg, A.C.; Lo, W.-Y.; et al. Segment Anything. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–6 October 2023; pp. 4015–4026. [Google Scholar]
- Zhu, L.; Liao, B.; Zhang, Q.; Wang, X.; Liu, W.; Wang, X. Vision Mamba: Efficient Visual Representation Learning with Bidirectional State Space Model. arXiv 2024, arXiv:2401.09417. [Google Scholar]
- Chen, T.; Zhu, L.; Ding, C.; Cao, R.; Wang, Y.; Li, Z.; Sun, L.; Mao, P.; Zang, Y. SAM Fails to Segment Anything?—SAM-Adapter: Adapting SAM in Underperformed Scenes: Camouflage, Shadow, Medical Image Segmentation, and More. arXiv 2023, arXiv:2304.09148. [Google Scholar]
- Reed, C.J.; Gupta, R.; Li, S.; Brockman, S.; Funk, C.; Clipp, B.; Keutzer, K.; Candido, S.; Uyttendaele, M.; Darrell, T. Scale-MAE: A Scale-Aware Masked Autoencoder for Multiscale Geospatial Representation Learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–6 October 2023; pp. 4088–4099. [Google Scholar]
- Pu, X.; Jia, H.; Zheng, L.; Wang, F.; Xu, F. Classwise-SAM-Adapter: Parameter Efficient Fine-Tuning Adapts Segment Anything to Sar Domain for Semantic Segmentation. arXiv 2024, arXiv:2401.02326. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the Medical Image Computing and Computer-assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Zhao, X.; Ding, W.; An, Y.; Du, Y.; Yu, T.; Li, M.; Tang, M.; Wang, J. Fast Segment Anything. arXiv 2023, arXiv:2306.12156. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Sudre, C.H.; Li, W.; Vercauteren, T.; Ourselin, S.; Jorge Cardoso, M. Generalised Dice Overlap as A Deep Learning Loss Function for Highly Unbalanced Segmentations. In Proceedings of the Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support: Third International Workshop, DLMIA 2017, and 7th International Workshop, ML-CDS 2017, Held in Conjunction with MICCAI 2017, Québec City, QC, Canada, 14 September 2017; pp. 240–248. [Google Scholar]
- Zhou, Z.; Rahman Siddiquee, M.M.; Tajbakhsh, N.; Liang, J. UNet++: A Nested U-Net Architecture for Medical Image Segmentation. In Proceedings of the Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support: 4th International Workshop, DLMIA 2018, and 8th International Workshop, ML-CDS 2018, Held in Conjunction with MICCAI 2018, Granada, Spain, 20 September 2018; pp. 3–11. [Google Scholar]
- Li, Z.; Yan, C.; Sun, Y.; Xin, Q. A Densely Attentive Refinement Network for Change Detection Based on Very-High-Resolution Bitemporal Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–18. [Google Scholar] [CrossRef]
- Wang, S.; Wu, W.; Zheng, Z.; Li, J. CTST: CNN and Transformer-Based Spatio-Temporally Synchronized Network for Remote Sensing Change Detection. IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens. 2024, 17, 16272–16288. [Google Scholar] [CrossRef]
- Li, J.; Meng, Y.; Tao, C.; Zhang, Z.; Yang, X.; Wang, Z.; Wang, X.; Li, L.; Zhang, W. ConvFormerSR: Fusing Transformers and Convolutional Neural Networks for Cross-Sensor Remote Sensing Imagery Super-Resolution. IEEE Trans. Geosci. Remote Sens. 2024, 62, 1–15. [Google Scholar] [CrossRef]
- He, K.; Chen, X.; Xie, S.; Li, Y.; Dollár, P.; Girshick, R. Masked Autoencoders are Scalable Vision Learners. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 16000–16009. [Google Scholar]
- Li, K.; Cao, X.; Meng, D. A New Learning Paradigm for Foundation Model-Based Remote-Sensing Change Detection. IEEE Trans. Geosci. Remote Sens. 2024, 62, 1–12. [Google Scholar] [CrossRef]
- Chen, Z.; Duan, Y.; Wang, W.; He, J.; Lu, T.; Dai, J.; Qiao, Y. Vision Transformer Adapter for Dense Predictions. arXiv 2022, arXiv:2205.08534. [Google Scholar]
- Ding, L.; Zhu, K.; Peng, D.; Tang, H.; Yang, K.; Bruzzone, L. Adapting Segment Anything Model for Change Detection in VHR Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2024, 62, 1–11. [Google Scholar] [CrossRef]
- Chen, K.; Liu, C.; Li, W.; Liu, Z.; Chen, H.; Zhang, H.; Zou, Z.; Shi, Z. Time Travelling Pixels: Bitemporal Features Integration with Foundation Model for Remote Sensing Image Change Detection. In Proceedings of the IGARSS 2024—2024 IEEE International Geoscience and Remote Sensing Symposium, Athens, Greece, 7–12 July 2024; pp. 8581–8584. [Google Scholar]
- Liu, Z.; Hu, H.; Lin, Y.; Yao, Z.; Xie, Z.; Wei, Y.; Ning, J.; Cao, Y.; Zhang, Z.; Dong, L.; et al. (Eds.) Swin Transformer V2: Scaling Up Capacity and Resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 11999–12009. [Google Scholar]
- Li, R.; Wang, X.; Huang, G.; Yang, W.; Zhang, K.; Gu, X.; Tran, S.N.; Garg, S.; Alty, J.; Bai, Q. A Comprehensive Review on Deep Supervision: Theories and Applications. arXiv 2022, arXiv:2207.02376. [Google Scholar]
- Ji, S.; Wei, S.; Lu, M. Fully Convolutional Networks for Multisource Building Extraction from an Open Aerial and Satellite Imagery Data Set. IEEE Trans. Geosci. Remote Sens. 2019, 57, 574–586. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Pre | Rec | F1 | IoU | OA |
|---|---|---|---|---|---|
| FC-Siam-conc [16] | 88.79 | 86.57 | 87.67 | 78.04 | 98.75 |
| FC-Siam-diff [16] | 89.25 | 82.62 | 85.81 | 75.14 | 98.46 |
| STANet [20] | 90.68 | 87.70 | 89.17 | 80.45 | 98.91 |
| SNUNet [17] | 91.25 | 85.55 | 88.30 | 79.06 | 98.85 |
| HANet [23] * | 91.21 | 89.36 | 90.28 | 82.27 | 99.02 |
| Changeformer [25] | 91.85 | 87.88 | 89.82 | 81.52 | 98.99 |
| SwinSUNet [26] | 90.76 | 86.92 | 88.80 | 79.85 | 98.88 |
| BIT [28] | 91.74 | 88.25 | 89.96 | 81.76 | 99.00 |
| ConvTransNet [29] | 92.64 | 88.58 | 90.56 | 82.75 | 99.06 |
| WNet [30] * | 91.16 | 90.18 | 90.67 | 82.93 | 99.06 |
| ASS-CD (Ours) | 93.78 | 90.85 | 92.29 | 85.69 | 99.14 |
| Methods | Pre | Rec | F1 | IoU | OA |
|---|---|---|---|---|---|
| FC-Siam-conc [16] | 83.42 | 86.15 | 84.76 | 73.56 | 98.77 |
| FC-Siam-diff [16] | 86.55 | 85.01 | 85.77 | 75.09 | 98.88 |
| STANet [20] | 89.40 | 87.10 | 88.23 | 78.95 | 99.07 |
| SNUNet [17] | 90.25 | 87.46 | 88.83 | 79.91 | 99.09 |
| HANet [23] * | 88.30 | 88.01 | 88.16 | 78.82 | 99.16 |
| Changeformer [25] | 95.35 | 83.83 | 89.22 | 80.54 | 99.19 |
| SwinSUNet [26] | 91.35 | 87.42 | 89.34 | 80.74 | 99.20 |
| BIT [28] | 93.16 | 88.74 | 90.90 | 83.31 | 99.29 |
| ConvTransNet [29] | 92.66 | 91.57 | 92.11 | 85.38 | 99.38 |
| WNet [30] * | 92.37 | 90.15 | 91.25 | 83.91 | 99.31 |
| ASS-CD (Ours) | 93.88 | 92.70 | 93.29 | 87.42 | 99.45 |
| Methods | Pre | Rec | F1 | IoU | OA |
|---|---|---|---|---|---|
| FC-Siam-conc [16] * | 66.45 | 54.21 | 59.71 | 42.56 | 87.57 |
| FC-Siam-diff [16] * | 59.67 | 65.71 | 62.54 | 45.50 | 86.63 |
| STANet [20] * | 67.71 | 61.68 | 64.56 | 47.66 | 88.49 |
| SNUNet [17] * | 60.60 | 72.89 | 66.18 | 49.45 | 87.34 |
| HANet [23] * | 56.52 | 70.33 | 62.67 | 45.64 | 85.76 |
| Changeformer [25] | 73.61 | 75.28 | 74.44 | 59.28 | 89.10 |
| SwinSUNet [26] | 67.50 | 71.45 | 69.42 | 53.16 | 88.65 |
| BIT [28] * | 68.36 | 70.18 | 69.26 | 52.97 | 89.41 |
| ConvTransNet [29] | 66.30 | 68.74 | 67.50 | 50.94 | 88.20 |
| WNet [30] | 68.71 | 70.52 | 69.60 | 53.38 | 88.66 |
| ASS-CD (Ours) | 75.20 | 78.35 | 76.74 | 62.26 | 90.29 |
| Methods | Params (M) | FLOPs (G) |
|---|---|---|
| FC-Siam-conc [16] | 1.55 | 5.33 |
| FC-Siam-diff [16] | 1.35 | 4.73 |
| STANet [20] | 16.93 | 13.16 |
| SNUNet [17] | 12.03 | 54.83 |
| Changeformer [25] | 20.75 | 21.18 |
| BIT [28] | 3.50 | 10.63 |
| ConvTransNet [29] | 7.13 | 30.53 |
| ASS-CD (trainable only) | 5.30 | 12.72 |
| +FastSAM (frozen) | +68 | |
| +Swin-Transformer (frozen) | +88 |
| Methods | Adapter | CBAM | HDSM | LEVIR-CD | WHU-CD | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Pre | Rec | F1 | IoU | OA | Pre | Rec | F1 | IoU | OA | ||||
| Pure U-Net | 81.29 | 78.68 | 79.96 | 66.62 | 97.96 | 79.55 | 78.10 | 78.82 | 65.04 | 98.13 | |||
| Baseline | 86.62 | 84.35 | 85.47 | 74.63 | 98.50 | 83.27 | 81.33 | 82.29 | 69.91 | 98.45 | |||
| Model_a | √ | 91.34 | 87.55 | 89.40 | 80.84 | 98.95 | 90.81 | 88.67 | 89.73 | 81.37 | 99.17 | ||
| Model_b | √ | √ | 92.55 | 89.25 | 90.87 | 83.27 | 99.10 | 91.90 | 90.10 | 90.99 | 83.47 | 99.28 | |
| Model_c | √ | √ | 92.67 | 89.70 | 91.16 | 83.76 | 99.11 | 92.54 | 91.05 | 91.79 | 84.82 | 99.36 | |
| ASS-CD | √ | √ | √ | 93.78 | 90.85 | 92.29 | 85.69 | 99.14 | 93.88 | 92.70 | 93.29 | 87.42 | 99.45 |
| Dataset | BCE | Dice | Pre | Rec | F1 | IoU | OA |
|---|---|---|---|---|---|---|---|
| √ | 92.55 | 89.25 | 90.87 | 83.27 | 99.10 | ||
| LEVIR-CD | √ | 93.13 | 88.87 | 90.95 | 83.40 | 99.10 | |
| √ | √ | 93.78 | 90.85 | 92.29 | 85.69 | 99.14 | |
| √ | 91.90 | 90.10 | 90.99 | 83.47 | 99.28 | ||
| WHU-CD | √ | 92.60 | 89.76 | 91.16 | 83.75 | 99.30 | |
| √ | √ | 93.88 | 92.70 | 93.29 | 87.42 | 99.45 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wei, C.; Wu, X.; Wang, B. ASS-CD: Adapting Segment Anything Model and Swin-Transformer for Change Detection in Remote Sensing Images. Remote Sens. 2025, 17, 369. https://doi.org/10.3390/rs17030369
Wei C, Wu X, Wang B. ASS-CD: Adapting Segment Anything Model and Swin-Transformer for Change Detection in Remote Sensing Images. Remote Sensing. 2025; 17(3):369. https://doi.org/10.3390/rs17030369
Chicago/Turabian StyleWei, Chenlong, Xiaofeng Wu, and Bin Wang. 2025. "ASS-CD: Adapting Segment Anything Model and Swin-Transformer for Change Detection in Remote Sensing Images" Remote Sensing 17, no. 3: 369. https://doi.org/10.3390/rs17030369
APA StyleWei, C., Wu, X., & Wang, B. (2025). ASS-CD: Adapting Segment Anything Model and Swin-Transformer for Change Detection in Remote Sensing Images. Remote Sensing, 17(3), 369. https://doi.org/10.3390/rs17030369