Abstract
Hyperspectral images are typically composed of hundreds of narrow and contiguous spectral bands, each containing information regarding the material composition of the imaged scene. However, these images can be affected by various sources of noise, distortions, or data loss, which can significantly degrade their quality and usefulness. This paper introduces a convergent guaranteed algorithm, LRS-PnP-DIP(1-Lip), which successfully addresses the instability issue of DHP that has been reported before. The proposed algorithm extends the successful joint low-rank and sparse model to further exploit the underlying data structures beyond the conventional and sometimes restrictive unions of subspace models. A stability analysis guarantees the convergence of the proposed algorithm under mild assumptions, which is crucial for its application in real-world scenarios. Extensive experiments demonstrate that the proposed solution consistently delivers visually and quantitatively superior inpainting results, establishing state-of-the-art performance.
1. Introduction
Hyperspectral remote sensing has found widespread application in numerous fields such as astronomy, agriculture, environmental monitoring, and Earth observation. Hyperspectral images (HSIs) are often captured via satellite or airborne sensors, each presenting samples at different time slots, using push-broom strategies along the flying pathway [1]. The nature of the HSI acquisition system makes the HSI a high-resolution 3D data cube that covers hundreds or thousands of narrow spectral bands, conveying a wealth of spatio-spectral information. However, due to instrumental errors, imperfect navigation and atmospheric variations, practical HSIs can suffer from noise, and missing pixels or even entire lines of pixels (an example of this type of missing data can be found in the recently released Earth Surface Mineral Dust Source Investigation (EMIT) hyperspectral dataset, developed by NASA’s Jet Propulsion Laboratory and launched on 14 July 2022 [2]). These issues can severely impact the accuracy and reliability of subsequent analyses, making HSI inpainting a critical task in the field of remote sensing and Earth observation.
1.1. Hyperspectral Image Inpainting
Hyperspectral image inpainting refers to the restoration of missing or corrupted data in acquired HS images. Unlike RGB images, for which inpainting involves filling a single pixel value (red, green, and blue channels), HSI inpainting requires filling in a complex vector that contains extensive spectral information. This additional complexity makes the already challenging task of HSI inpainting even more difficult. The primary objective of HSI inpainting is to create visually convincing structures while ensuring that the texture of the missing regions is spectrally coherent. The inpainting of HS images typically involves two main steps: (a) estimating the missing or corrupted data by leveraging information from the neighboring spectral bands and spatially adjacent pixels and (b) refining the estimated data to ensure consistency with the overall spectral and spatial properties of the HS image. Traditional approaches, such as those proposed by [3], assume that the spectral vectors of the HSI always exist in some unknown low-dimensional subspaces, and the missing regions are estimated through projections. However, the performance of such techniques deteriorates significantly when large portions of the image are missing, and they may even fail when all spectral bands are absent. Another line of research involves the tensor completion process to restore incomplete observations [4,5,6]. These methods leverage the spatio-spectral correlations of the hyperspectral data cube, offering potential improvements over subspace-based techniques.
Over the past decade, the success of deep learning has brought new opportunities for solving HSI inpainting tasks. In [7,8], the authors proposed transformer-based frameworks to effectively capture both local and global contextual information in 3D images, demonstrating the potential of attention modules in exploring relationships between missing pixels and background pixels. In [9], the authors showed that missing pixels can be predicted using generative neural networks. However, this approach has two key limitations: (1) it requires training the networks on extensive datasets to achieve the desired performance, and (2) the inpainted areas often suffer from over-smoothing, resulting in the loss of critical information, such as abrupt changes in the surface materials. More recently, researchers discovered that the network’s structure itself may serve as a good inductive bias for regularizing image reconstruction tasks, such as image inpainting [10]. A deep image prior (DIP) enables the learning of priors directly from the image without the need for extensive training datasets, which was further developed and successfully applied to hyperspectral (HS) images [11]. Following [11], subsequent works [12,13,14,15,16,17,18] have shown that certain trained or untrained neural networks can be directly incorporated into iterative solvers to improve the reconstruction accuracy, i.e., as the regularizer. More recently, the authors of [19] introduced a self-supervised framework that leverages the powerful learning capabilities of diffusion models and sets new state-of-the-art benchmarks across several HSI reconstruction tasks. However, as it was reported in our preliminary report [20], as well as in a series of DIP-related works [13,21,22,23], the DIP may not always be the ideal solution, despite promising empirical results. On the practical side, this is because a DIP works by directly fitting a neural network to the corrupted HS image; in the absence of regularization or explicit denoising mechanisms, a DIP tends to overfit, which will eventually capture the noise in the image. On the theoretical side, a DIP lacks a strong theoretical foundations to explain its performance, and its convergence is highly sensitive to random initialization of the neural network. Different initializations could potentially lead to poor results. Although subsequent works [12,13,24] have attempted to mitigate this issue by introducing a plug-and-play (PnP) denoiser into the training of a DIP, they require either a suitable early stopping criterion or the manual control of the learning rate. As a result, there remains a need for a new HSI inpainting algorithm that combines the strengths of both PnP and DIP methods while offering convergence guarantees.
1.2. Sparsity and Low Rankness in HSIs
Despite the high dimensionality, HS images exhibit intrinsic sparse and low-rank structures due to the high correlation between spatial pixels and spectral channels. This property has made sparse representation—(SR) and low rank—(LR) based methods popular for the processing of HSIs [25,26,27]. SR relies on the key assumption that the spectral signatures of the pixels approximately lie in a low-dimensional subspace spanned by representative pixels from the same class. With a given dictionary, SR allows for sparse decomposition of HSIs into a linear combination of several atoms, thus exploiting the spatial similarity of HSIs (It is worth mentioning that, when the dictionary is not given, we can manually use the end-members of some pixels with pure spectra and build the dictionary, or learn the dictionary [28] in an unsupervised manner, using sparsity as a regularizer). This assumption about the underlying structures has been effectively applied in various HSI tasks, including HSI classification [29], denoising [30], and unmixing [31].
LR is another widely used regularizer in HSI processing, which assumes that pixels in the clean HSI image have high correlations in the spectral domain, thus capturing both the spectral similarity and global structure of HSIs. LR allows for the modeling of the HSI as a low-rank matrix; thus, the missing and corrupted information in the HSIs can be effectively reconstructed by leveraging the underlying low-rank structure. In many state-of-the-art HSI reconstruction algorithms, LR is often used in parallel with SR to achieve better reconstruction accuracy [30,32]. By combining the two priors together, algorithms can better handle missing data, noise, and corruption while maintaining the overall structure and spectral integrity of the image. For more detailed information on LR and SR of hyperspectral images, we refer readers to the review work in [33].
However, a notable limitation with such an LR or SR model is that the real HS data do not exactly follow the sparse and/or low-dimension assumptions.; e.g., there are long trails (numerous small but non-zero elements) in the descending sorted absolute sparse coefficients and singular values, where overly-restrictive assumptions on these coefficients could lead to under-fitting. In conclusion, both LR and SR rely on some predefined mathematical models that assume certain properties of the HS image, such as low-dimensional manifolds (low-rankness) or sparse representations in specific domains. While these models are useful, they struggle to capture more complex patterns in the real HS data, such as non-linear relationships and complex spatio-spectral dependencies. Moreover, when a significant percentage of the data are corrupted or entire spectral bands of pixels are missing, these methods often fail [3]. The question of how deep neural models can address this issue by exploiting more data-adaptive, low-dimensional models in a self-supervised learning framework is the main topic of this study.
In this paper, we start by giving a brief overview of the LRS-PnP-DIP algorithm [20]; we replaced the denoising/thresholding step with the PnP denoiser, and we used a DIP to replace the low-rank component of the formulation. Since there remains a lack of comprehensive theoretical analysis of the DIP and its extensions that can guarantee the convergence, we demonstrate both theoretically and empirically that small modifications can ensure the convergence of LRS-PnP and LRS-PnP-DIP, while the original algorithms in [20] may diverge. We propose a variant of the LRS-PnP-DIP algorithm dubbed LRS-PnP-DIP(1-Lip), which not only outperforms existing learning-based methods but also resolves the instability issue of a DIP in an iterative algorithm.
1.3. Contributions
This paper presents a novel HS inpainting algorithm that leverages the learning capability of deep networks while providing insights into the convergence behavior of such complex algorithms. Through rigorous mathematical analysis, we derive sufficient conditions for stability and fixed-point convergence and show that these conditions are satisfied by slightly modified algorithms. Our approach offers several key contributions, including the following:
- This paper explores the LRS-PnP and LRS-PnP-DIP algorithm in more depth by showing the following: (1) The sparsity and low-rank constraints are both important to the success of the methods in [20]. (2) DIP can better explore the low-rank subspace compared to conventional subspace models such as singular value thresholding (SVT).
- Under some mild assumptions, a fixed-point convergence proof is provided for the LRS-PnP-DIP algorithm (see Theorem 1). We introduce a variant to the LRS-PnP-DIP called LRS-PnP-DIP(1-Lip), which effectively resolves the instability issue of the algorithm by slightly modifying both the DIP and PnP denoiser.
- To the best of our knowledge, this is the first time the theoretical convergence of PnP with DIP replaced the low-rank prior being analyzed under an iterative framework.
- Extensive experiments were conducted on real-world data to validate the effectiveness of the enhanced LRS-PnP-DIP(1-Lip) algorithm with a convergence certificate. The results demonstrate the superiority of the proposed solution over existing learning-based methods in both stability and performance.
The remainder of this paper is organized as follows: Section 2 provides an introduction to our approach, and Section 3 describes our main convergence theory for the proposed LRS-PnP-DIP(1-Lip) algorithm. Section 4 provides the implementation details and discusses the experimental results. Section 5 concludes the paper with a brief discussion of potential future directions.
2. Proposed Methods
Mathematical Formulations
The task of HSI inpainting can be formulated as reconstructing the clean image, X, from a noisy and incomplete measurement, Y, where an additive noise, N, and a masking operator, M, are present:
The clean image (where ), with and representing the spatial dimensions of the image, and represents the total number of spectral bands. The operator is a binary mask, where zero represents the missing pixels, and one represents the observed and valid pixels. Thus, the masking operator can be represented as a diagonal square matrix. N is the additive Gaussian noise of appropriate size. Usually, M is provided, and the formulation (1) describes a linear system, which can be expressed as follows:
In this equation, , , and represent the vectorized forms of X, Y, and N, respectively, and is a diagonal matrix. We obtain the recovered, i.e., inpainted, image, , by applying sparse representation to each image patch, . Here, the operator extracts the i-th patch from image , where each patch may consist of only valid pixels or a combination of valid and missing pixels, depending on the size of . The inpainted image can be obtained by solving the following optimization problem:
The objective in the expression above consists of three terms. The first term is the data fidelity term, weighted by the parameter . Since estimating from is inherently ill-posed, i.e., with more unknown variables than equations, the solution is non-unique. To address this, we introduce two additional “priors” to regularize the inpainting problem: low-rank and sparsity constraints. The second term penalizes solution to be low-rank, which is typically employed as a surrogate for rank minimization. The third term restricts the missing pixels to be generated from the subspace approximated by the valid pixels. These terms are weighted by parameters and , respectively. The sparse representation problem is solved using a given dictionary, . Specifically, can be constructed either by using the end-members of some pixels with pure spectra or by learning from the noisy pixels in the observations. It is here exclusively learned from noisy pixels in the observations using online dictionary learning [28]. By adopting the augmented Lagrangian and introducing the auxiliary variable [34], problem (3) can be rewritten as follows:
The Lagrangian multiplier and penalty terms are denoted as and , respectively. Using the alternating direction method of multipliers (ADMM), we can sequentially update the three variables , , and to solve problem (4):
(1) Fixing and , and updating α:
The problem in Equation (5) is a patch-based, sparse coding problem that can be solved using iterative solvers. Let us denote the first term on the right-hand side of Equation (5) as and the second term as while dropping the subscript for simplicity. Problem (5) can be represented as a constrained optimization problem:
By introducing an auxiliary variable, , and a multiplier, , the augmented Lagrangian of (6) becomes the following:
Then, ADMM finds solutions by breaking the constrained optimization problem (6) into several sub-problems and updating them separately in an iterative fashion. The pseudocode is provided in Algorithm 1.
The sub-problem can be solved by the proximal operator [35]. The authors in [36] realized that can be treated as a “noisy” version of , and can be seen as a regularization term. Then, the whole process resembles a denoising operation applying to the intermediate results, which can be simply replaced with the PnP denoisers such as BM3D and the non-local mean (NLM) denoiser. In our approach, we employed PnP-ISTA [36] as an alternative solution for solving problem (5). We denote the gradient of f as and I as an Identity matrix with an appropriate shape. The entire process can then be replaced with an off-the-shelf denoiser , operating on [36]. Each iteration takes the following form:
PnP-ISTA can significantly improve the reconstruction quality over traditional ISTA [37] due to the following reasons: (1) it enables the integration of state-of-the-art denoisers to handle different noise patterns and different types of images, which is particularly flexible, as one can apply any off-the-shelf denoiser without massively changing the existing framework; and (2) it allows the use of denoisers tailored to different problems (e.g., a denoiser that promotes sparsity or smoothness, or even a denoising neural network that encodes more complex priors).
| Algorithm 1 Pseudocode of ADMM for solving problem (6). |
| Initialization . while Not Converged do . . . end while |
(2) We can update in this setting by:
where and are the corresponding Lagrangian multiplier and penalty term, respectively, which we use subscripts to distinguish between and in step (4). The problem can be solved using the singular value thresholding (SVT) algorithm [38] as follows:
Specifically, denote as , matrix as , and the soft thresholding operator as follows:
where is an operator taking the positive part of its input. Applying (11) to the singular values of promotes low-rankness:
In the proposed LRS-PnP-DIP algorithm [20], this step is substituted with a deep image prior (DIP) , where denotes the network parameters that need to be updated, and the input is set to ; i.e., the latent image from the previous iterations:
(3) Fixing α and , and updating :
A closed-form solution for exists as follows:
In the expression above, the patch selection operator is rewritten in its matrix form . To calculate in practice, we can leverage the fact that, for the HSI inpainting task, both and are diagonal matrices. As a results, the matrix inversion of can be simply implemented as an element-wise division. This trick significantly reduces the computational cost of the inversion, making the proposed algorithm more scalable for practical use.
(4) The Lagrangian and penalty terms are updated as follows:
The LRS-PnP-DIP algorithm proposed in [20] is summarized in Algorithm 2.
| Algorithm 2 (LRS-PnP-DIP) algorithm. |
| Require: masking matrix: , noisy and incomplete HSI: , learned dictionary: . denoiser: . max iteration: . DIP: Output: inpainted HSI image . Initialization DIP parameters , . while Not Converged do for do: update DIP parameters , with target: and intermediate results: as input. update by (15). update Lagrangian parameters and penalty terms. end while |
- Remarks. In contrast to its original form, it is here proposed to replace the conventional PnP denoiser in (8) with an averaged NLM denoiser, as introduced in [39]. Additionally, we modify the in (13) to obtain Lipschitz continuity with Lipschitz constant 1. The averaged NLM denoiser is a variant of NLM denoiser whose weight is designed to be a doubly symmetric matrix, ensuring that both the columns and rows sum to 1. With this doubly symmetric property, the spectral norm of the weight matrix is bounded by 1, meaning the averaged NLM denoiser is by design, non-expansive. (We refer the reader to [39] for detailed structures of the averaged NLM denoiser).
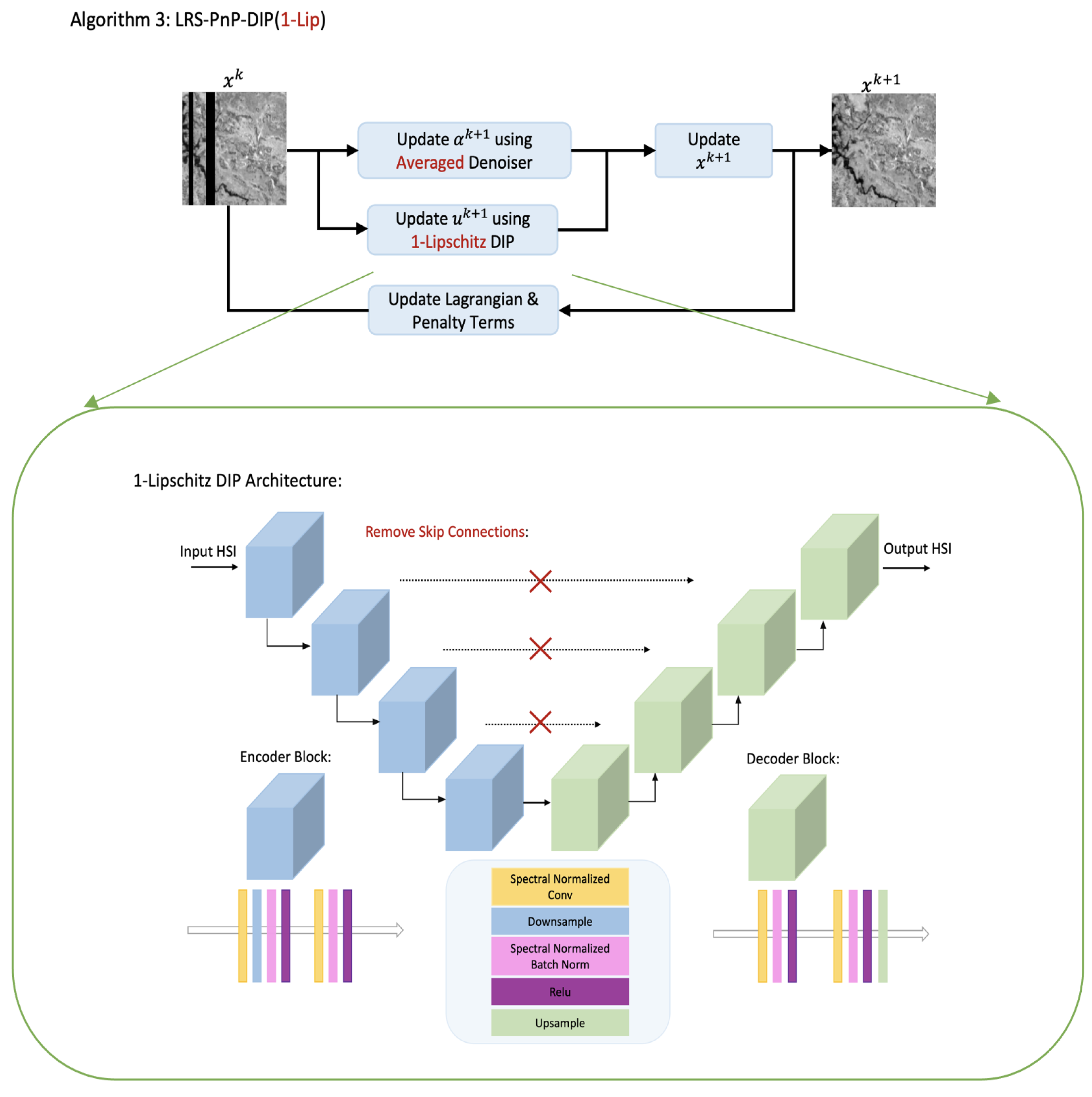
The enhanced algorithm is denoted as LRS-PnP-DIP(1-Lip), which is shown in Algorithm 3, and its flow chart is provided in Figure 1.
| Algorithm 3 LRS-PnP-DIP(1-Lip) algorithm. |
| Require: masking matrix: , noisy and incomplete HSI: , learned dictionary: . averaged NLM Denoiser: . max iteration: . 1-Lipschitz DIP: Output: inpainted HSI image . Initialization DIP parameters , . while Not Converged do for do: update DIP parameters , with target: and intermediate results: as input. update by (15). update Lagrangian parameters and penalty terms. end while |
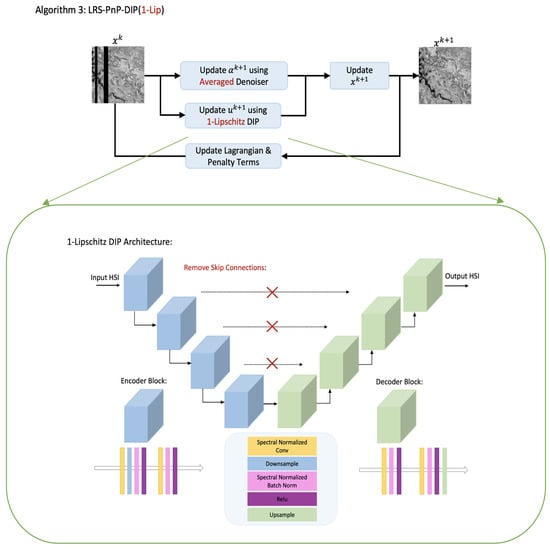
Figure 1.
Flow chart of the proposed LRS-PnP-DIP(1-Lip) algorithm. At each iteration, and are sequentially updated. The 1-Lipschitz DIP is implemented by imposing Lipschitz constraints on all layers. We use red color to highlight the differences between this work and the LRS-PnP-DIP algorithm [20]. The detailed design of the 1-Lipschitz DIP is placed in Appendix A.1.
3. Convergence Analysis
In this section, we describe the fixed-point convergence of the proposed LRS-PnP-DIP(1-Lip) algorithm under mild assumptions. Fixed-point convergence refers to the type of convergence wherein the algorithm asymptotically enters a steady state. To establish our main theorem, we need the following results:
Definition 1
(Non-expansive operator). An operator, , is said to be non-expansive if, for any , the following applies:
Definition 2
(-averaged). An operator, , is said to be θ-averaged with some if there exists a non-expansive operator, R, such that we can write .
Lemma 1.
Let be θ-averaged for some . Then, for any , the following applies:
Proof of this lemma can be found in [[40], Lemma 6.1].
Definition 3
(Fixed point). We say that is a fixed point of the operator if . We denote the set of fixed points as fix(T).
Definition 4
(-smoothed). Let be differentiable; we say that f is β-smooth if there exists , such that for any .
Definition 5
(Strong convexity). A differentiable function, f, is said to be strongly convex with modulus if is convex.
Lemma 2
(Property of strong convexity). Let f be strongly convex with modulus . Then, for any , the following applies:
Proof of this Lemma can be found in [41].
- We made the following assumptions:
Assumption 1.
We assume that (1) the denoiser used in the sparse coding step is linear and θ-averaged for some , (2) the function is β-smoothed, and (3) .
- Remarks. The -averaged property is a subset of the non-expansive operator that most of the existing PnP frameworks have worked with [39,42]. In fact, the non-expansive assumption is found to be easily violated for denoisers such as BM3D and NLM denoisers when used in practice. Nevertheless, the convergence of PnP methods using such denoisers can still be empirically verified. In the experiments, we adopted the modified NLM denoiser whose spectral norm is bounded by 1. Hence, it satisfies the -averaged property by design [39].
Lemma 3
(Fixed-point convergence of PnP sparse coding). If Assumption 1 holds, then, for any α, and , the sequence generated via step (8) converges to some .
Proof of this Lemma can be found in [[40], Theorem 3.5].
Assumption 2.
We assume that the DIP function is L-Lipschitz-bounded:
for any x, y, and .
- Remarks. In the above assumption, the smallest constant L that makes the inequality hold is called the Lipschitz constant. The Lipschitz constant is expressed as the maximum ratio between the absolute change in the output and the input. It quantifies how much the function output changes with respect to the input perturbations or, roughly speaking, how robust the function is. In deep learning, it. Assumption 2 guarantees that the trained DIP has a Lipschitz constant, , which is a desirable feature so that a network does not vary drastically in response to minuscule changes in its input. In the experiments, this can be achieved by constraining the spectral norm of each layer of the neural network during training.
We are now ready to state our main theorem.
Theorem 1
(Convergence of LRS-PnP-DIP(1-Lip) in the Lyapunov Sense). If both Assumptions 1 and 2 hold, with penalty μ, and with an L-Lipschitz constrained DIP (), then there exists a non-increasing function, , such that all trajectories generated via LRS-PnP-DIP(1-Lip) are bounded, and that as , , , and ; i.e., even if the equilibrium states of , α, and are perturbed, they will finally converge to , , and , respectively. The proposed LRS-PnP-DIP(1-Lip) algorithm is, thus, asymptotically stable.
- We placed the detailed proof of Theorem 1 in Appendix A.2.
4. Experimental Results
4.1. Implementation Details
We evaluate the proposed inpainting model on two publicly available hyperspectral datasets:
- The Chikusei airborne hyperspectral dataset [43] (the link to the Chikusei dataset can be found at https://naotoyokoya.com/Download.html, accessed on 4 January 2025); the test HS image consists of 192 channels, and it was cropped to 36 × 36 pixels in size.
- The Indian Pines dataset from AVIRIS sensor [44]; the test HS image consisted of 200 spectral bands, and it was cropped to 36 × 36 pixels size.
For each dataset, we trained the dictionary with a size of 1296 × 2000, using only noisy and incomplete HSI images (the size of the test HS image and the dictionary were chosen to match the practical use case where the proposed inpainting algorithms were to be mounted on each nano-satellite to process different small image tiles in parallel [45]), this is a necessary step if we do not have access to pure spectra. If a standard spectral dataset exists, learning can be performed in the form of a pre-training step. However, we used the input HS image for this task to demonstrate that the proposed algorithms operate in a self-supervised setting. Additionally, we introduced Gaussian noise with noise level to the cropped HS images. Since the main focus of this paper is image inpainting, instead of denoising, was kept fixed across all experiments. We applied mask to all the spectral bands in the given region, which represents the most challenging case. For the choice of the PnP denoiser, we used both the BM3D and modified NLM denoisers [39]; the latter is an averaged denoiser, which enjoys a non-expansive property that is crucial to convergence analysis.
Our implementation of the deep image prior model follows the same structure as in the deep hyperspectral prior [11]. During the training of 1-Lipschitz DIP, we applied Lipschitz regularization to all layers, as in [46]. In each iteration, we fed the DIP with the latent image from the previous iteration, rather than the random signal, as suggested by [11]. We did not perturb the input to support our convergence analysis, which is different from the canonical DIP. To eliminate the need for manually selecting the total number of iterations for the DIP model, we adopted the early stopping criterion proposed in [47] with a fixed window size of 20 and a patience number of 100, which detects the near-peak MPSNR point using windowed moving variance (WMV). Note that, for the training of conventional DIP, the early-stopping strategy is often employed to prevent it from fitting to random noise after certain iterations. However, the proposed LRS-PnP-DIP(1-Lip) algorithm mitigates the over-fitting issue due to the imposed constraint. The early-stopping criterion is applied primarily to optimize the algorithm’s runtime so that one does not have to wait for the algorithm to reach the maximum number of iterations. In our formulation, the low-rank and sparsity constraints in the equation were weighted with parameters and , respectively, while the data fidelity term was weighted with . Initially, we set to 1 and to 0.5. Notably, the choice of is highly dependent on the noise level of the observed image. If the noise level is low, the recovered image, X, should be similar to the noisy observation, Y, parameter should be large, and vice versa. The Adam optimizer was used, and the learning rate was set to 0.1. Finally, we used three widely used metrics, namely the mean signal-to-noise ratio (MPSNR), mean structural similarity (MSSIM), and mean spectral angle mapper (MSAM), to evaluate the performance of the model in all experiments.
4.2. Low-Rank vs. Sparsity
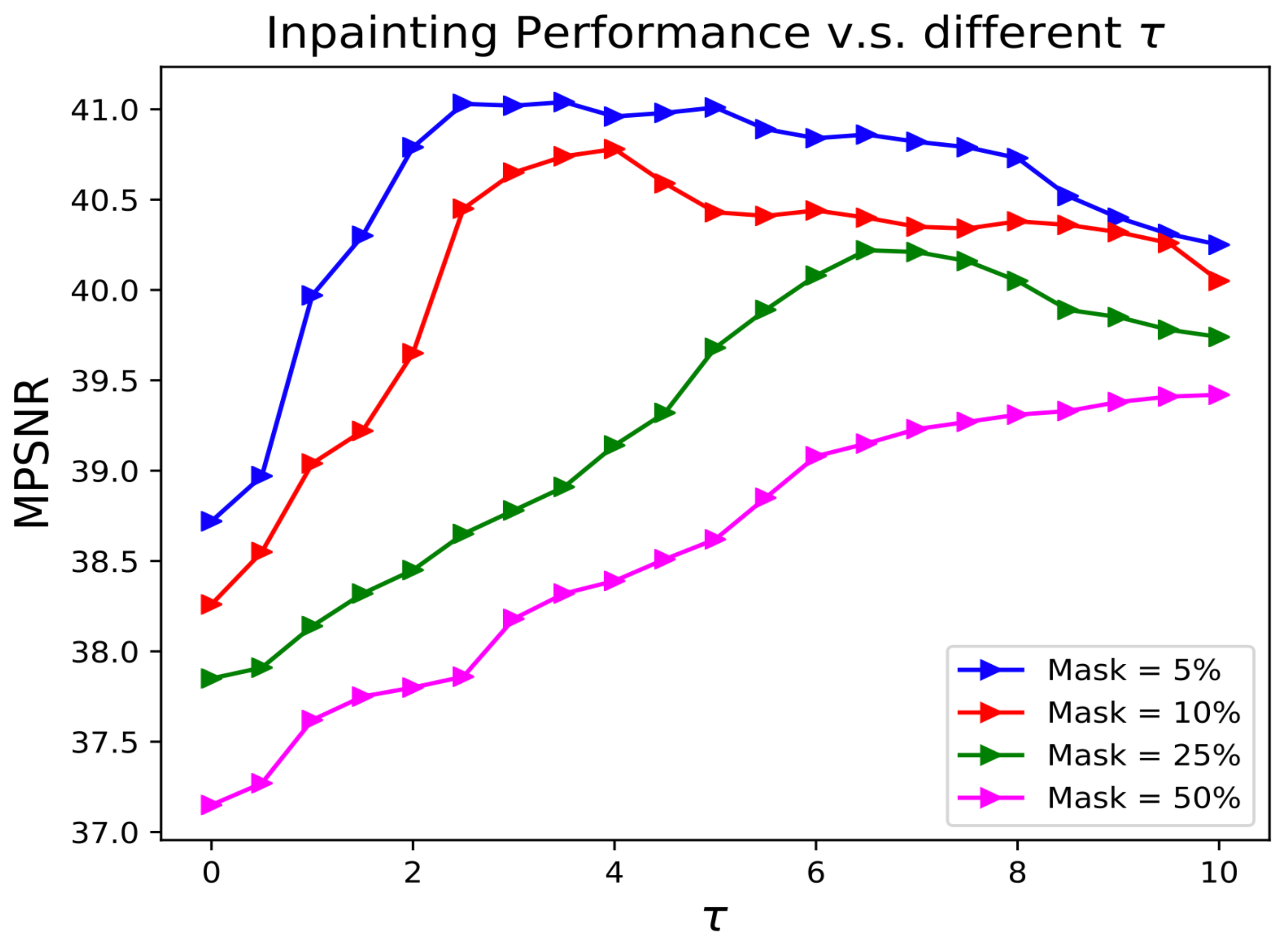
In this section, we examine the effectiveness of both sparsity and low-rank constraints in our proposed LRS-PnP algorithm. Figure 2 shows the inpainting performance of LRS-PnP over different for different masks (in percentages), where is defined as the ratio of the weight of the sparsity constraint and the low-rank constraint. For example, means that the sparsity constraint is disabled, and mask = 50% means that 50% of the pixels are missing. We can conclude from the results that (1) the LRS-PnP algorithm works better with both low-rank and sparsity constraints, as using either an overwhelming sparsity constraint or a low-rank constraint alone tends to reduce inpainting performance, and (2) when the percentage of missing pixels increases, more weight should be placed on the sparsity constraint in order to achieve high-quality reconstruction. On the one hand, approximation errors may be introduced in the sparse coding step; i.e., step (5) in Algorithms 2 and 3. These errors can potentially be suppressed by the constraint of low rank. On the other hand, the sparsity constraint exploits the spectral correlations; i.e., the performance will be enhanced if spatial information is considered.
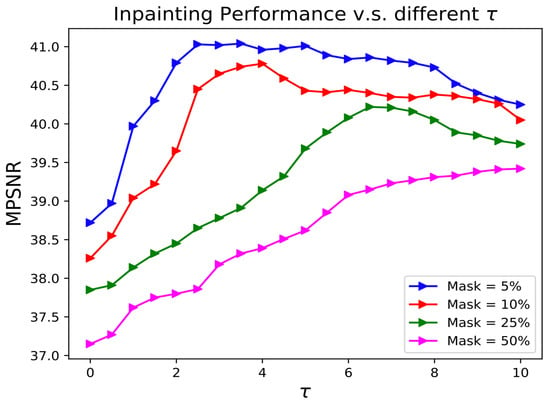
Figure 2.
Comparison of MPSNR value of LRS-PnP among different () under different masks.
4.3. Low Rankness Due to DIP
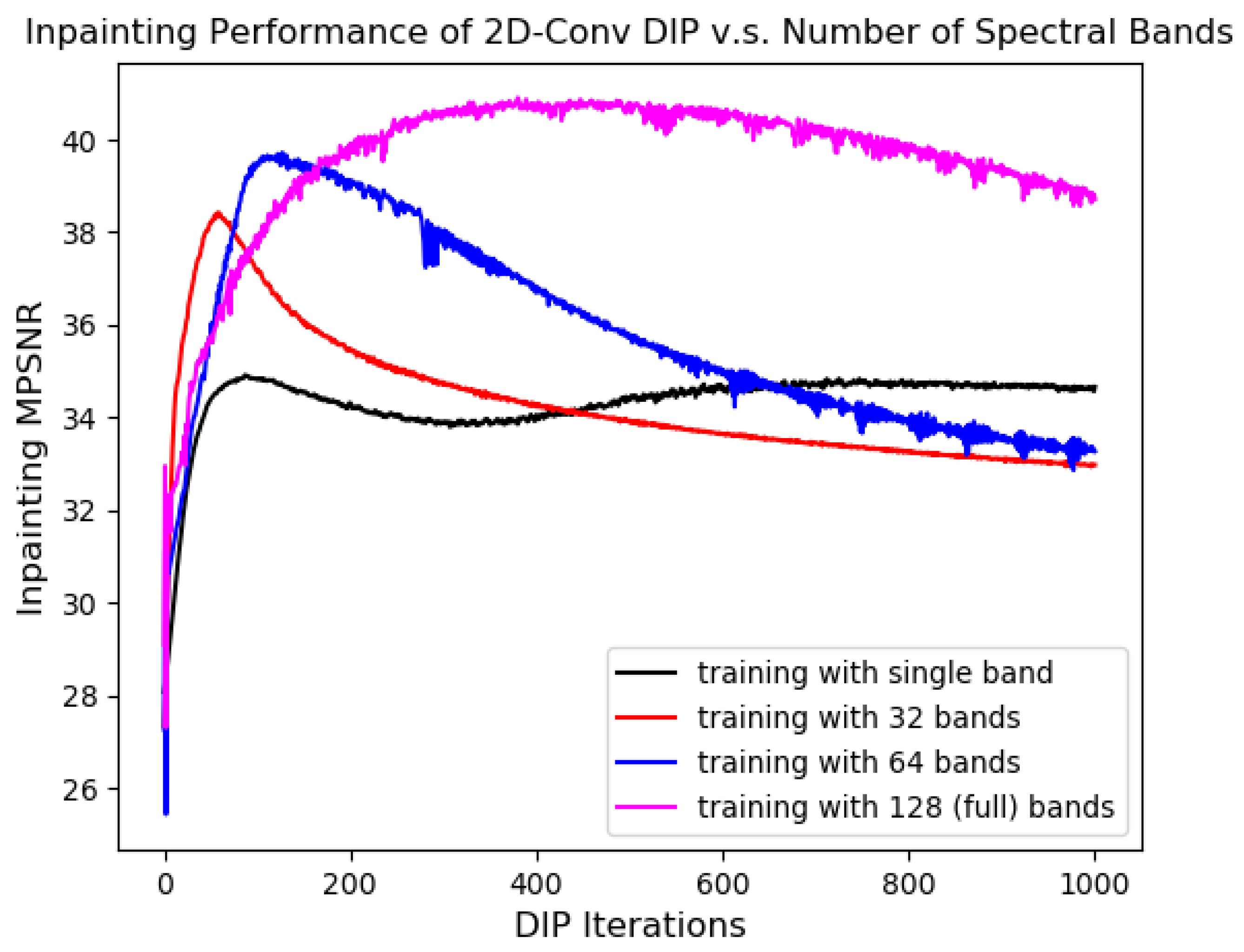
In the original LRS-PnP-DIP Algorithm [20], we propose solving the low-rank minimization problem using DIP instead of the traditional SVT projection. A natural question arises: does the DIP (e.g., the architecture proposed in Figure 1) effectively capture the redundancies in the spectral domain? This is empirically justified in Figure 3, where we trained DIP on the corrupted HS image with varying numbers of spectral bands as input and output. The results show that the inpainting performance of DIP improved substantially when more spectral bands were utilized during training; the peak MPSNR was obtained when the neural network saw the entire 128 bands of the input HS images, rather than each single band individually. This finding is counterintuitive since DIP with 2D convolution is generally expected to handle only the spatial correlation of input HSIs. Similar observations have been reported in [10,48], where the authors confirmed that DIP with 2D convolution implicitly explored the channel correlations, possibly due to the upsampling layers in the decoder part that manipulates the HSI channels in the spectral domain.
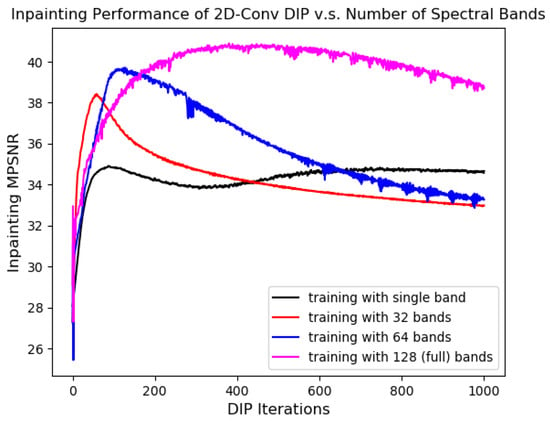
Figure 3.
Learning capability of DIP vs. number of input and output channels. Training is conducted with a single-band HS image, meaning that the input HSIs are processed; there is no correlation in the spectral domain. There is a significant performance gain when there are more input bands, indicating that the DIP with 2D convolution has the ability to exploit the correlation between channels.
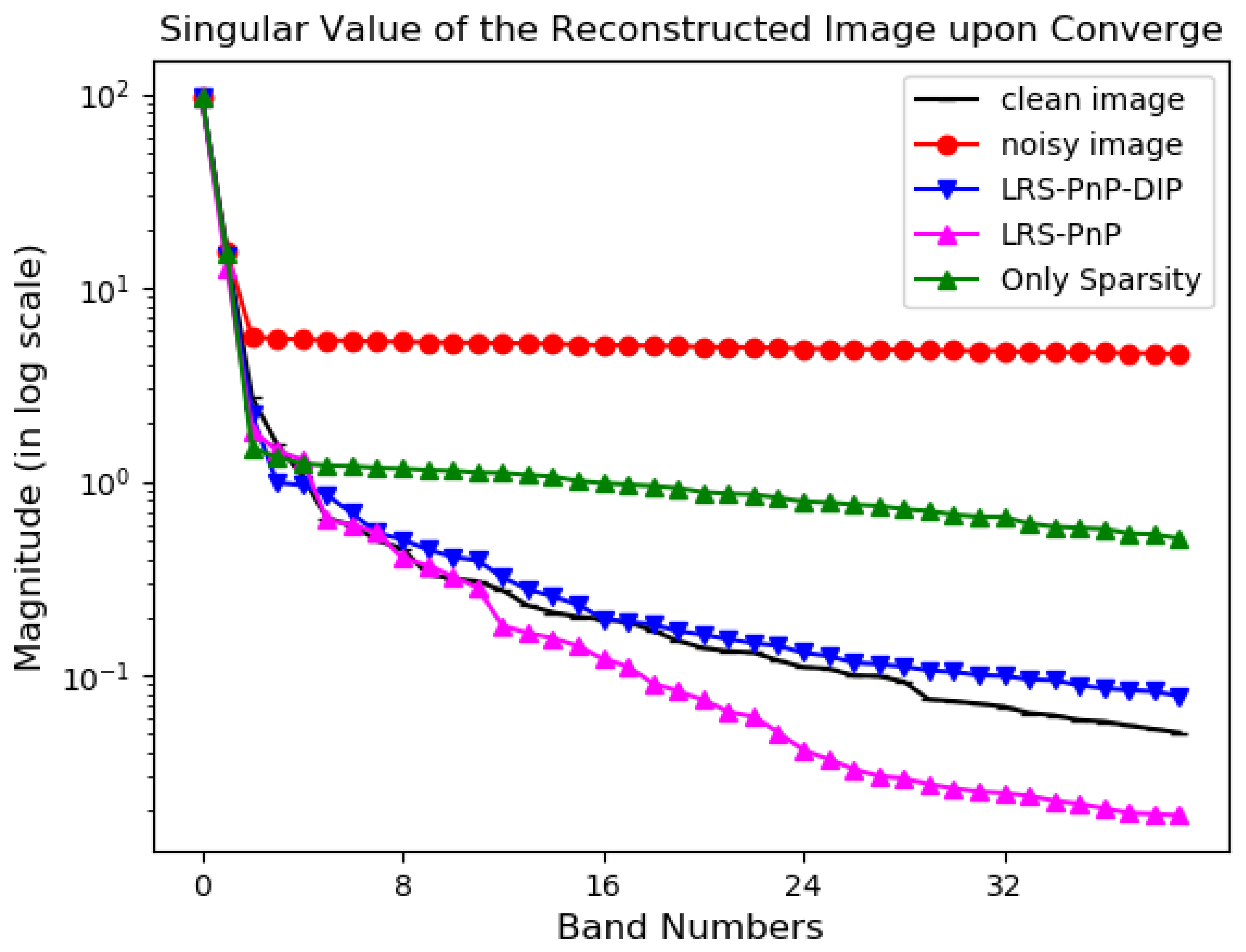
In Figure 4, we sort the singular values of the inpainted image of LRS-PnP (the pink line), LRS-PnP-DIP [20] (the blue line), and PnP sparse coding without a low-rank constraint (green line), in descending order. Among these algorithms, LRS-PnP performs singular value projection to promote low rankness, while it is replaced with DIP in LRS-PnP-DIP. It is observed that using a well-trained DIP alone was sufficient to capture these low-rank details. Thus, we suggest replacing the conventional SVT process with DIP. Although there is no theoretical evidence on how DIP mimics the SVT, we show through experiments that the DIP can well preserve some small yet important singular values that would otherwise be discarded via SVT projection. Hence, it has the ability to better exploit the low-rank subspace in a data-driven fashion, possibly owing to its highly non-linear network structures and inductive bias.
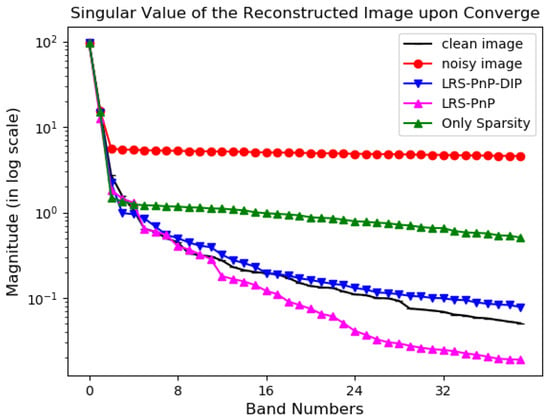
Figure 4.
The amplitude of the singular value of the reconstructed image upon converge. The important singular values are captured and preserved via the 2D-convolution DIP, which is even more accurate than the traditional SVT projection.
4.4. Convergence
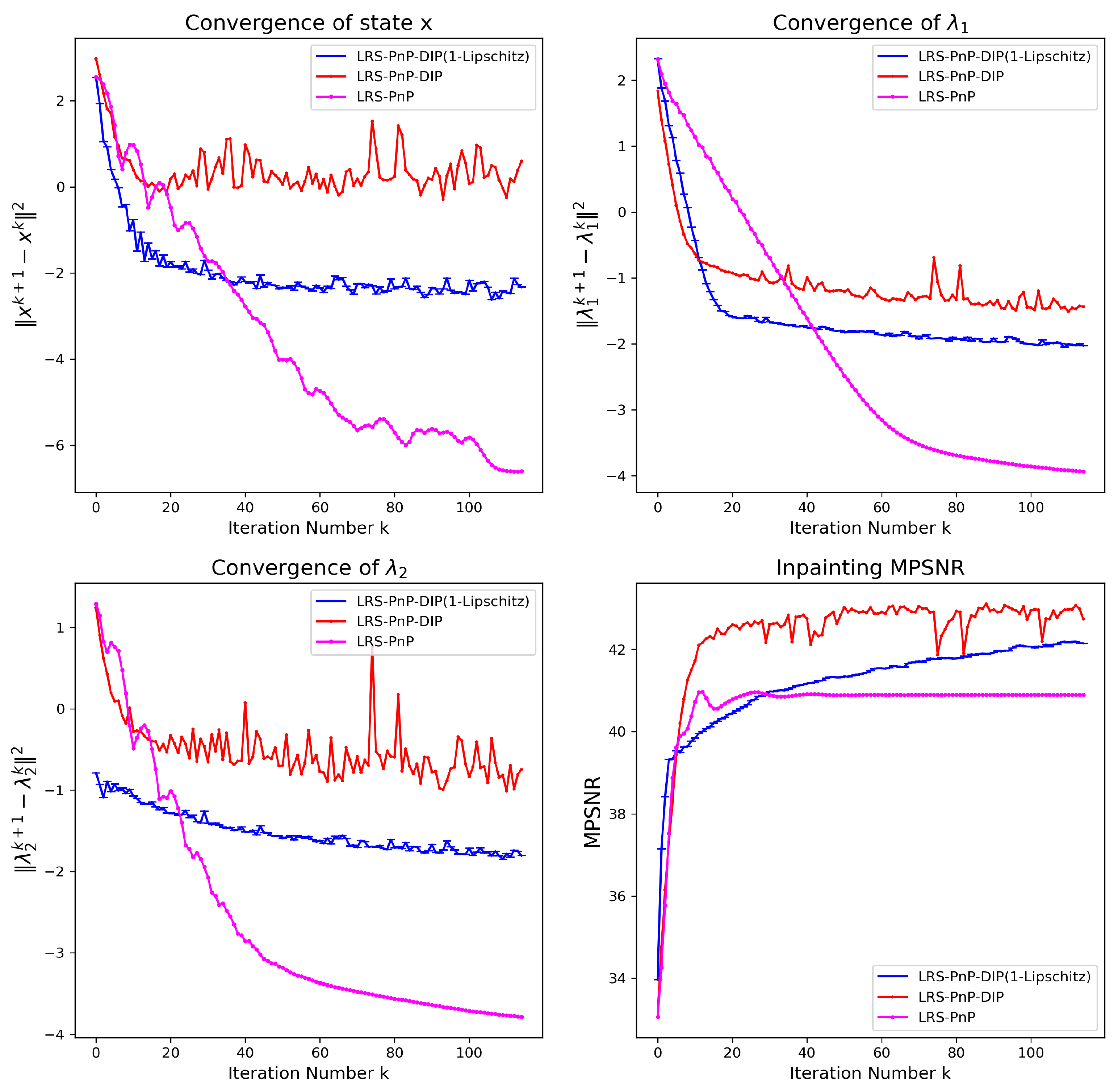
The use of the PnP denoiser and DIP in the context of HSIs has been recently investigated in [12,13]. However, theoretical evidence of the stability of the algorithm is still lacking. To bridge this gap, we verify the convergence of LRS-PnP-DIP(1-Lip). In Figure 5, the top left, top right, and bottom left figures represent the successive differences of each state on a log scale, and the bottom right figure represents the inpainting performance. For LRS-PnP-DIP, we used the BM3D denoiser and DIP without constraints. For LRS-PnP-DIP(1-Lip), we used the modified NLM denoiser and the 1-Lipschitz constraint DIP. The latter automatically satisfies Assumptions 1 and 2; thus, the fixed-point convergence can be guaranteed. Interestingly, we noticed that LRS-PnP-DIP with BM3D and conventional DIP still works pretty well in practice even though there are fluctuations in state , as can be seen in the top right and bottom left plots in Figure 5. We deduced that such instability mainly comes from the process of solving DIP sub-problems, rather than the denoising sub-problems, as the primal variable smoothly converges with BM3D denoisers as well.
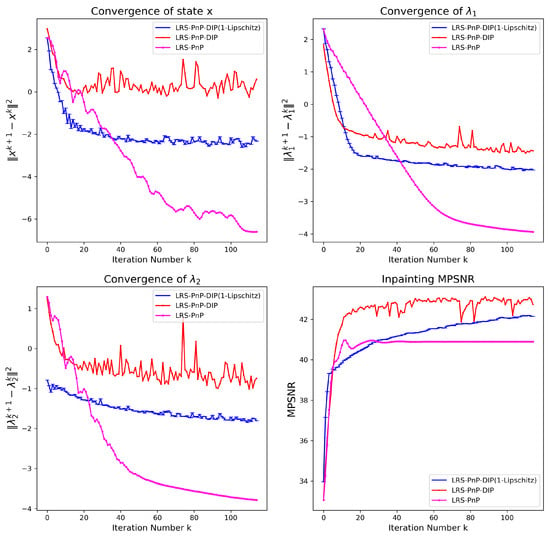
Figure 5.
Empirical converge of LRS-PnP-DIP(1-Lip) with modified NLM denoiser and non-expansive/1-Lipschitz DIP. Top left, top right, and bottom left: successive difference of , , and in the log scale, respectively. Bottom right: the inpainting MPSNR vs. the number of iterations.
From the bottom right plot, we observed that the best results are obtained with LRS-PnP-DIP in terms of reconstruction quality, and the LRS-PnP-DIP(1-Lip) is only slightly lower than its unconstrained counterpart. Our observations on the reduced performance of Lipschitz DIP are in agreement with existing works [46,49], where imposing the Lipschitz constraint during training does hurt the capacity and expressivity of the neural network.
4.5. Comparison with State of the Art
The proposed algorithms were compared with learning-based algorithms: DHP [11], GLON [4], R-DLRHyIn [16], DeepRED [22], PnP-DIP [24], DeepHyIn [50], and DDS2M [19]. To ensure the fairness of comparison, we employed the same U-net as the backbone for DHP, DeepRED, R-DLRHyIn, PnP-DIP, and LRS-PnP-DIP(1-Lip) and the attention-based U-net with the same complexity for DeepHyIn and DDS2M. For GLON, we replaced its original FFDNet with the one trained on the hyperspectral dataset [51] and kept the others intact. (The reason for making this adaption is that the neural network proposed in GlON [4] was trained on RGB/grayscale images. It was found to be beneficial to use an FFDNet, e.g., in [51], trained on the HSI dataset.) For DeepHyIn, we used the end members extracted from the clean image patch. For DDS2M, we fine-tuned the diffusion-related parameters, as suggested in [19]. The statistical results of each test sample are averaged over 20 experiments to account for the effect of random seeds during training.
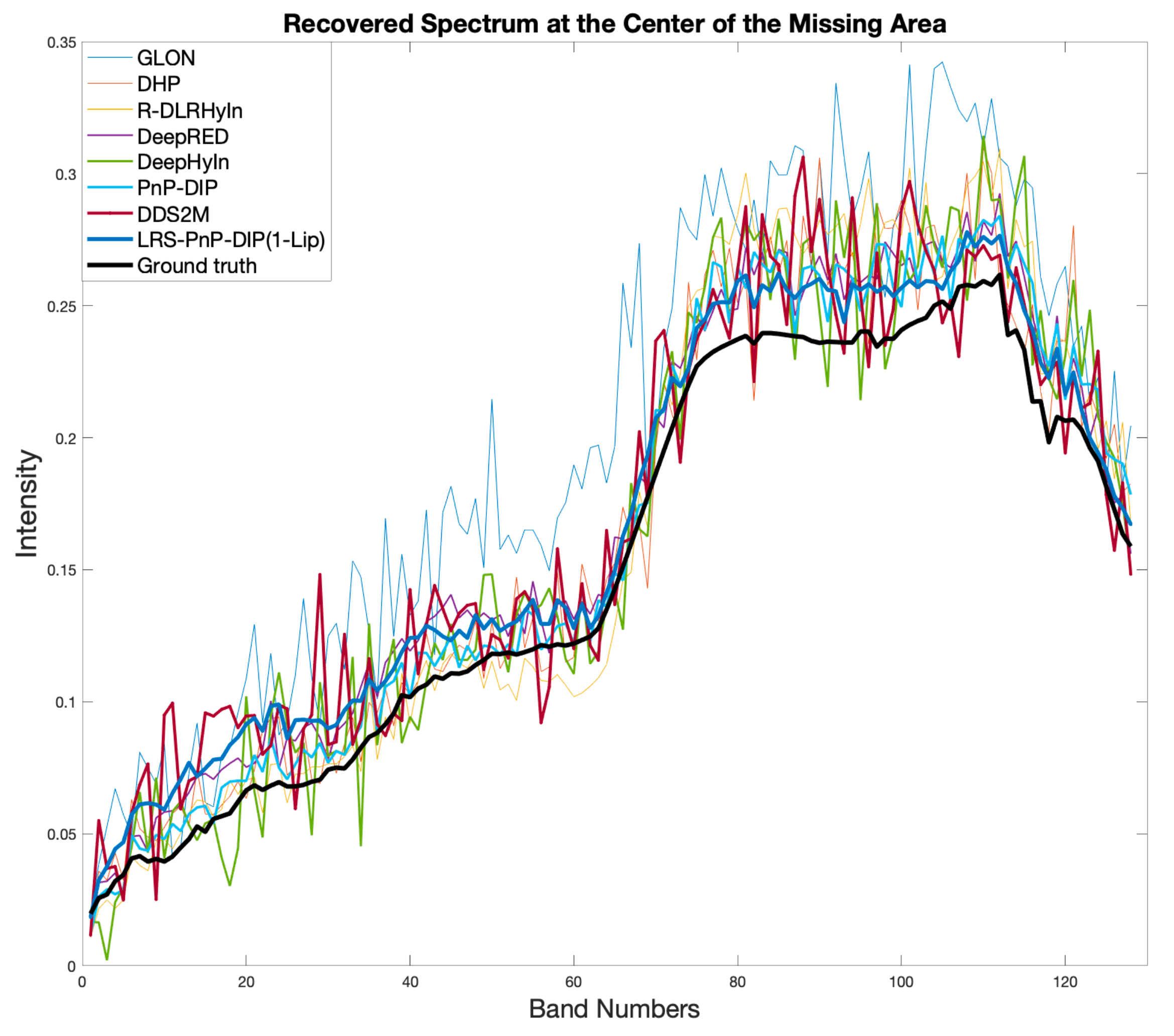
In Figure 6, we plot the recovered spectrum of the center of the missing area of LRS-PnP-DIP(1-Lip) for each method. It can be seen that LRS-PnP-DIP(1-Lip) produces a more consistent and realistic spectrum in the missing region compared to methods such as GLON, DHP, DeepRED, R-DLRHyIn, DDS2M, and DeepHyIn. We present the visual inpainting results for each method on the Chikusei dataset and the Indian Pines dataset, as depicted in Figure 7 and Figure 8, respectively. The quantitative statistical results for each dataset, evaluated under various mask shapes, are summarized in Table 1 for the Chikusei dataset and Table 2 for the Indian Pines dataset.
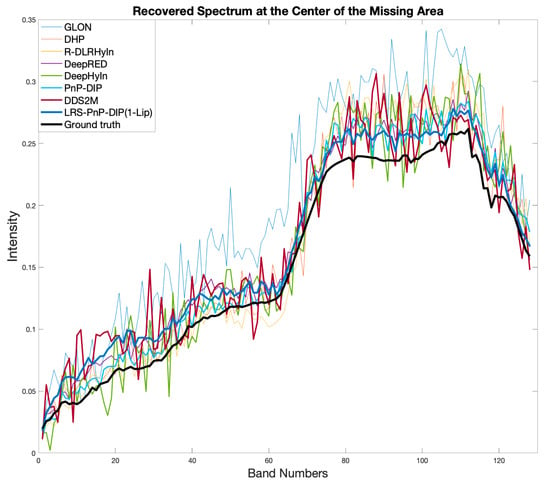
Figure 6.
Different algorithms and their recovered spectrum of the center pixel with the assumption that the whole spectrum bands are missing. MPSNR increases from the thin line to the thick line.

Figure 7.
Comparison between the proposed algorithm and other learning-based inpainting algorithms on the Chikusei dataset. From top to bottom: (1) clean image, (2) input image, (3) GLON, (4) DHP, (5) R-DLRHyIn, (6) DeepRED, (7) DeepHyIn, (8) PnP-DIP, (9) DDS2M, and (10) LRS-PnP-DIP(1-Lip). All images are visualized at band 80.

Figure 8.
Comparison between the proposed algorithm and other learning-based inpainting algorithms on the Indian Pines dataset. From top to bottom: (1) clean image, (2) input image, (3) GLON, (4) DHP, (5) R-DLRHyIn, (6) DeepRED, (7) DeepHyIn, (8) PnP-DIP, (9) DDS2M, and (10) LRS-PnP-DIP(1-Lip). All images are visualized at band 150.

Table 1.
Comparison between the proposed algorithm and other learning-based inpainting algorithms on the Chikusei dataset: the mean and variance over 20 samples are shown here. During the experiments, four different mask shapes were used, which are depicted in the first four columns of Figure 7. The best results are underlined for each type of mask. For the metrics MPSNR and MSSIM, higher values indicate better performance. Conversely, for the MSAM metric, the lower the better.
Table 2.
Comparison between the proposed algorithm and other learning-based inpainting algorithms on the Indian Pines dataset: The mean and variance over 20 samples are shown here. During the experiments, four different mask shapes were used, which are depicted in the first four columns of Figure 7. The best results are underlined for each type of mask.
It is shown that LRS-PnP-DIP(1-Lip) can effectively suppress noise compared to methods such as R-DLRHyIn, DeepHyIn, and DDS2M. Moreover, it alleviates the over-smoothing phenomenon of the DeepRED and PnP-DIP algorithms by preserving more details in the non-missing region; this is clear for the last two test samples in Figure 7 and for the first four test samples in Figure 8. From Table 1 and Table 2, it can be seen that LRS-PnP-DIP(1-Lip) almost always demonstrates the highest inpainting performance on both the Chikusei and Indian Pines datasets compared to other methods. The second best is established via DDS2M, which is the closest method to ours in terms of inpainting quality. This is possibly due to its ability to leverage inductive bias from hierarchical diffusion structures. However, as is evident in Figure 7 and Figure 8, DDS2M and other DIP-based extensions occasionally exhibit limitations, such as producing noisy backgrounds or failing to effectively inpaint missing strips. It is important to note that these methods utilize conventional DIP as backbones; hence, they are susceptible to the instability issue of DIP where the algorithm may eventually fit into pure noise without proper constraints. In contrast, LRS-PnP-DIP(1-Lip) is superior, as it not only harvests the strong learning capability of DHP but also enjoys a stability guarantee. For the HSI inpainting task, we anticipate that some information, from the background/non-missing pixels to be carried to the deeper layers, there is a performance loss when removing the skip connections between the encoder and the decoder. Nevertheless, LRS-PnP-DIP(1-Lip) mutes these layers to trade performance for convergence, and it is empirically found that, even if LRS-PnP-DIP(1-Lip) is highly restricted due to layer-wise spectral normalization, it can preserve more textures and produce less noisy results than DDS2M. This observation leads to the conclusion that the proposed LRS-PnP-DIP(1-Lip) algorithm would be preferable for solving practical inpainting tasks compared to existing solutions. It has the ability to yield faithful reconstructions while ensuring stability and robustness.
5. Conclusions
The LRS-PnP algorithm, along with its variant LRS-PnP-DIP proposed in the previous work [20], are innovative hyperspectral inpainting methods designed to address the challenge of missing pixels in noisy and incomplete HS images. These techniques can better handle the challenging situations in practical HSI acquisition systems where the entire spectral band may be absent. Through experiments, we show that both sparsity and the low-rank priors can be effectively integrated as constraints during the training of DIP; the resulting LRS-PnP-DIP algorithm leverages the strong learning capability of the powerful generative DIP model and is able to exploit spectral and spatial redundancies inherent to HSIs. Because the proposed methods do not require any training data, they are particularly attractive for practical hyperspectral inpainting tasks, where only the observed corrupted image is available for reference. However, the LRS-PnP-DIP algorithm suffers from instability issues and may occasionally diverge due to the DIP. In this paper, this long-lasting issue was effectively addressed through the proposed LRS-PnP-DIP(1-Lip) algorithm. Experimental results on real datasets demonstrate that the LRS-PnP-DIP(1-Lip) algorithm not only resolves the instability issue but also delivers results competitive with the state-of-the-art HSI inpainting algorithms. Unlike previous works where the convergence of the algorithm is either missing or only empirically verified, such as [12,13,14,24,52], this work has provided theoretical evidence and established convergence guarantees under non-expansiveness and Lipschitz continuity assumptions on the PnP denoiser and the DIP neural network. However, the performance of DIP has been observed to be sensitive to the network structure [11] and to the training parameters, such as the number of iterations and the learning rate. When the proposed LRS-PnP-DIP(1-Lip) algorithm is given an insufficient number of iterations to learn, DIPs may not work as expected. In future work, we would like to explore the inductive bias of DHPs, as well as a broader variety of deep learning models, such as transformers (the transformer has recently been explored in the remote sensing community [53]) to exploit their potential in solving HSI inpainting problems. Additionally, the extension of the proposed methods to other HSI processing tasks, such as self-supervised HSI denoising, unmixing, and deblurring, is left to a future investigation.
Author Contributions
Conceptualization, S.L. and M.Y.; methodology, S.L. and M.Y.; software, S.L.; validation, S.L. and M.Y.; formal analysis, S.L. and M.Y.; investigation, S.L. and M.Y.; resources, S.L.; data curation, S.L.; writing—original draft preparation, S.L; writing—review and editing, S.L. and M.Y.; visualization, S.L. and M.Y.; supervision, M.Y. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
The code for reproducing results is available at https://github.com/shuoli0708/LRS-PnP-DIP, accessed on 14 January 2025. The data presented in this study are available upon request from the corresponding author.
Conflicts of Interest
The authors declare no conflicts of interest.
Appendix A
Appendix A.1. On the Design of 1-Lipschitz DIP
In the proposed LRS-PnP-DIP(1-Lip) algorithm, we redesigned the DIP to have a Lipschitz constant of 1. To do so, we started by taking a deeper look at how the Lipschitz constant is calculated for each layer; then, we showed that the Lipschitz constraint can be enforced to construct a 1-Lipschitz DIP.
Appendix A.1.1. Convolutional Layer
The convolutional layer works by performing the convolutional operation on the input to extract the features. The output of the convolution operation can be expressed as follows:
where is a double-block circular matrix. Substituting (A1) into the definition of the Lipschitz constant, we have the following:
It follows that
The above expression reveals the fact that the spectral norm of is bounded by the Lipschitz constant L. Hence, regularizing the convolutional layer to have Lipschitz continuity boils down to constraining the matrix ; e.g., in our case, is expected to have all of its singular values be at most 1, meaning that is 1-Lipschitz. To design such a matrix, , we adopted the power iteration method, as suggested in [46]. The power iteration method works iteratively and approximates the largest singular value of . Given a sufficient number of iterations, it converges to the true spectral norm of with almost negligible errors. In practice, this can be achieved with only a few iterations, which is quite efficient compared to the SVD method.
Appendix A.1.2. Skip Connection Layer
The DIP has skip connections between the encoder and the decoder. These skip/residual connections ensure anuninterrupted gradient flow, which can effectively tackle the vanishing gradient problem. Moreover, it allows some previous features to be reused later in the network. In particular, for our HSI inpainting problem, we expect some information about the clean pixels from the background to be carried to the next layers.
- The skip connections take the following form:
Applying the triangular inequality to the norm, we have the following:
Furthermore, the right-hand side of inequality (A6) can be bounded by the Lipschitz constant of functions and as follows:
We can conclude that the Lipschitz constant of is bounded by the sum of the Lipschitz constants of and . Therefore, for the skip connections defined in (A4), the Lipschitz constant is bounded by , with a non-negative . Because the skip connections would have a Lipschitz constant exceeding 1, we removed them from the implementation of the 1-Lipschitz DIP.
Appendix A.1.3. Pooling Layer
The pooling layer works by dividing the input image into a set of sub-image patches and converting them to a single value. We used max-pooling in the encoder to extract feature maps from the input HSIs. Max pooling takes the maximum values of the neurons and discards the rest:
where n denotes the number of image patches. The expression above can be seen as an affine transformation with a fixed weight; i.e.,
The gradient of is 1 for the neurons with the maximum value and 0 otherwise; the latter does not participate in the propagation. Hence, by definition, the max pooling layer is Lipschitz-continuous with a Lipschitz constant of 1.
Appendix A.1.4. Activation Layer
The Lipschitz constant of the activation layer is trivial, as most activation functions such as ReLu, Leaky-ReLu, Tanh, and Sigmoid have Lipschitz constants of 1.
Appendix A.1.5. Batch Normalization Layer
The batch normalization layer works by scaling and normalizing the inputs so as to mitigate issues related to internal covariance shifts. It is defined as follows:
In the above formulation, is the mini-batch mean, and is the mini-batch variance. f is normalized, scaled by , and shifted with respect to the bias b. and b are two learned parameters during training, which forces the network to also learn the identity transformation and the ability to make a decision on how to balance them. From (A10), it is evident that is an affine transform with the transformation matrix being as follows:
Therefore, similar to the analysis of the convolutional layers, the Lipschitz constant of the batch normalization layer is the spectral norm of . However, typically normalizes its input by the variance and scales it by the factor ; this would inevitably destroy the Lipschitz continuity. Hence, we propose a variant to the batch normalization layer as follows:
The modified BN operator centers its input by subtracting the mean, which is quite different from its original form, (A10). In the experiments, we observed that such an adaptation did not affect the performance of the DIP.
Appendix A.1.6. Lipschitz Constant of the Full Network
Consider a neural network, , which is a composition of n independent sub-networks, , each of which has its own Lipschitz constant, :
Then, the Lipschitz constant of can be upper-bounded by the following:
Hence, we can tackle the Lipschitz constant of each layer independently and combine them to construct the upper bound of the entire network. We note that the bound certified in (A14) is not tight and that there are spaces for establishing a tighter bound by considering the network as a whole, which we will leave for future work.
Appendix A.1.7. Enforcing Lipschitz Constraint
Inspired by the work in [46], we introduce an extra projection step after each weight update as follows:
where L stands for the desired Lipschitz constant, particularly for 1-Lipschitz DIP. This step aims to project the weight matrix, W, back to the feasible set for those layers that violate the Lipschitz constraint.
Appendix A.2. Proof of Theorem 1
The proof relies on the Lyapunov stability theory, which is the heart of the dynamic system analysis [54]. Lyapunov stability theory can be categorized into (a) the indirect method, which analyzes the convergence through the system state equation, and (b) the direct method, which explicitly describes the behavior of the system’s trajectories and its convergence by making use of the Lyapunov function. We refer the reader to [55] for a more detailed definition of the Lyapunov function (specifically, Theorem 1.2 and Theorem 3.3). In some contexts, it is also known as an energy or dissipative function [56]. Compared to the former, the direct method is more appealing, as the convergence can be established by only showing the existence of such a function. In this proof, we begin by defining a function for our proposed LRS-PnP-DIP(1-Lip) algorithm, and we prove its validity. That is, we construct an energy function, , that describes the behaviors of each states in Algorithm 3, and to prove that is a non-increasing function as iteration proceeds; hence, the total energy of the dynamic system established via Algorithm 3 is conservative and stable.
- Let , for a non-zero .
- Remarks. This design follows similar structures as in the original convergence proof of the ADMM algorithm [34] and in a recent work [57]. Here, is a function of the system’s state change, which is, by design, non-negative. The first two assumptions in Theorem 1.2 [55] automatically hold. Thus, we only need to show that the proposed candidate is a non-increasing function in order to be a valid Lyapunov function. More specifically, we will show that is a decreasing function, which satisfies the following:
Firstly, recall that the LRS-PnP-DIP(1-Lip) algorithm takes the following update steps:
We define , , , , and in the subsequent proof for simplicity. This results in the following:
We take Equation (A19) as our starting point and denote the first term, , as . The first-order optimality of equation (A19) implies the following:
The critical point satisfies, i.e., :
Due to the strong convexity of , using Lemma 2 with and yields the following:
Secondly, using Assumption 2, the DHP is L-Lipschitz with and , ; we get the following:
Thirdly, using Assumption 1 and the resulting Lemma 1, suggesting that the operator used in the updating step (A17) is -averaged, and , , we have the following:
Now, we multiply (A26) on both sides by , and we gather the resulting inequality with (A27) and (A28):
We put inside the left-hand side of the first inequality, and we add them to give the following:
which can be written as:
After rearrangement, we get the following:
Recall that
It can be seen that the left-hand side of inequality (A32) recovers exactly . To make a non-increasing function, we require the entire right-hand side to be non-negative; it is thus sufficient to show that the last two terms, , are non-negative. This is straightforward to show if we plug into the first line of (A29) to get the following:
Now, if we add both sides of (A33), from to , it follows that
We can conclude that sequences , and are all bounded sequences due to the Lyapunov theorem. That is, as :
Thus, the iterations generated via the LRS-PnP-DIP(1-Lip) algorithm converge to the critical points () with a sufficiently large k, and all the trajectories are bounded. LRS-PnP-DIP(1-Lip) is also asymptotically stable according to Theorem 3.3 [55].
Appendix A.3. Parameters Tuning and Ablation Tests
Appendix A.3.1. Sensitivity Analysis and Hyperparameters Selections
In this section, we provide the detailed selection of hyperparameters for the proposed LRS-PnP-DIP(1-Lip) algorithm in the experiments. In Table A2, we provide the inpainting performance of LRS-PnP-DIP(1-Lip) with the weights of low-rank constraint and sparsity constraints varying within the range of 0.1 to 1. It can be seen that the optimal performance is obtained when both low-rank and sparsity constraints are present, as long as there is no overwhelming of either or . This indicates that LRS-PnP-DIP(1-Lip) is insensitive to the precise value of the low-rank constraint or sparsity constraints , which is different from the LRS-PnP algorithm [20] discussed in Section 4.2. Therefore, we set both and to 1 across all experiments.
Table A1.
The selection of hyperparameters for the proposed LRS-PnP-DIP(1-Lip) algorithm.
Table A1.
The selection of hyperparameters for the proposed LRS-PnP-DIP(1-Lip) algorithm.
| Parameters | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| 200 | 1/2 | 1 | 1 | 1/2 | 1/2 | 0 | 0 | 0.12 | |
| Parameters | |||||||||
| 0.1 | 0 | 1 | 50 | 0.1 |
Table A2.
Inpainting MPSNR of LRS-PnP-DIP(1-Lip) algorithm with varying and . Using either overwhelming or could deteriorate the inpainting results.
Table A2.
Inpainting MPSNR of LRS-PnP-DIP(1-Lip) algorithm with varying and . Using either overwhelming or could deteriorate the inpainting results.
| 0 | 0.1 | 0.25 | 0.5 | 0.75 | 1 | ||
|---|---|---|---|---|---|---|---|
| 0 | 30.692 | 37.479(±0.63) | 38.121(±0.46) | 38.475(±0.48) | 38.686(±0.52) | 38.884(±0.31) | |
| 0.1 | 37.004 | 40.849(±0.31) | 39.107(±0.35) | 39.321(±0.37) | 39.443(±0.30) | 39.812(±0.34) | |
| 0.25 | 37.211 | 40.355(±0.29) | 40.798(±0.36) | 40.266(±0.29) | 39.770(±0.23) | 39.906(±0.31) | |
| 0.5 | 37.592 | 39.766(±0.27) | 40.807(±0.24) | 40.831(±0.26) | 40.532(±0.25) | 40.245(±0.32) | |
| 0.75 | 37.663 | 39.897(±0.37) | 40.373(±0.33) | 40.565(±0.27) | 40.807(±0.30) | 40.780(±0.26) | |
| 1 | 37.957 | 38.591(±0.46) | 39.248(±0.31) | 39.848(±0.25) | 39.902(±0.25) | 40.835(±0.28) | |
Appendix A.3.2. Computational Efficiency
Table A3 provides per-iteration running time and the total running time upon converge for each method discussed in Section 4.5. To ensure a fair comparison, all methods, except for GLON [4], which uses a pre-trained FFDNet, were implemented with the same DIP backbone. All experiments were conducted in Python with PyTorch 1.13 using the NVIDIA GeForce RTX 3090 GPU. It can be seen that GLON suggests the fastest inference time, but at the cost of sub-optimal inpainting performance. DHP [11], R-DLRHyIn [16], and DeepHyIn [50] share similar computational complexity; these are followed by DDS2M [19], which typically requires a large number of diffusion steps in order to yield faithful reconstruction. On the other hand, methods such as DeepRED [22], PnP-DIP [24] and LRS-PnP-DIP(1-Lip) are computationally more expensive, which is mainly due to the use of PnP denoisers as regularizers at each iteration. Although LRS-PnP-DIP(1-Lip) introduces extra computation complexity to solve the sparsity-constrained problem (5), its overall running time is competitive with that of the DeepRED and PnP-DIP methods, This is mainly because LRS-PnP-DIP(1-Lip) enjoys a stability guarantee, which makes it converge faster with fewer iterations.
Table A3.
Different algorithms and their running times on both the Chikusei and Indian Pines datasets.
Table A3.
Different algorithms and their running times on both the Chikusei and Indian Pines datasets.
| Dataset | Cost | GLON [4] | DHP [11] | R-DLRHyIn [16] | DeepHyIn [50] | DDS2M [19] | DeepRED [22] | PnP-DIP [24] | LRS-PnP-DIP(1-Lip) |
|---|---|---|---|---|---|---|---|---|---|
| Chikusei | per-iteration | 0.138 | 0.083 | 0.089 | 0.102 | 0.114 | 2.412 | 2.542 | 3.622 |
| all iterations | 69.302 | 89.596 | 106.855 | 95.351 | 382.027 | 482.985 | 473.064 | 394.601 | |
| Indian Pines | per-iteration | 0.104 | 0.109 | 0.115 | 0.136 | 0.149 | 2.732 | 2.967 | 3.905 |
| all iterations | 74.741 | 97.215 | 115.541 | 103.344 | 401.654 | 494.088 | 474.156 | 425.601 |
Appendix A.3.3. Effect of the Lipschitz Constraint DIP
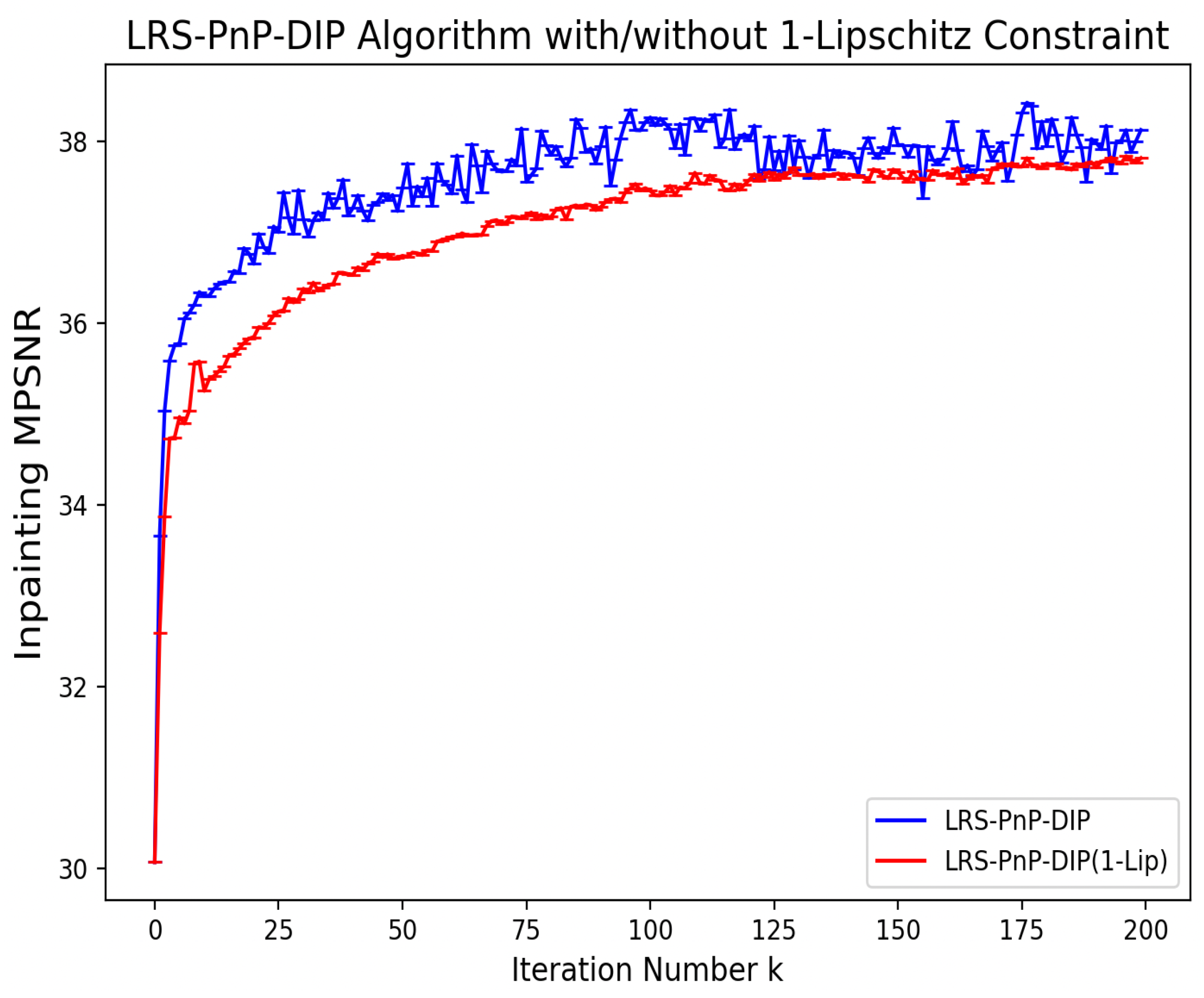
As an extension to the LRS-PnP-DIP algorithm, LRS-PnP-DIP(1-Lip) enforces the Lipschitz continuity (A14) of DIP by applying the Lipschitz constraint to each layer of the neural network independently with Lipschitz constant . In the proposed LRS-PnP-DIP(1-Lip) algorithm, we remove the residual connections from the DIP (as was discussed in Appendix A.1.2). However, changing from Skip-Net to U-Net may potentially lead to reduced performance, which is part of the trade-off with the convergence. In Figure A1, we provide an ablation test comparing the performance of LRS-PnP-DIP with/without 1-Lipschitz constraint. It can be seen that 1-Lipschitz constraint promotes the stability of the reconstruction process, ensuring the convergence of the algorithm. This improvement comes at the cost of only a slight reduction in inpainting performance.
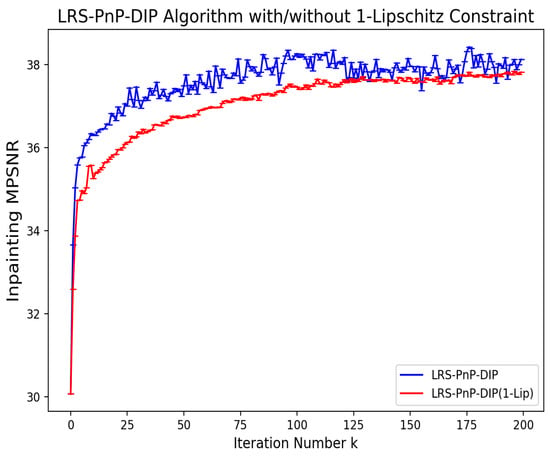
Figure A1.
Inpainting performance of LRS-PnP-DIP algorithm with/without 1-Lipschitz constraint.
Figure A1.
Inpainting performance of LRS-PnP-DIP algorithm with/without 1-Lipschitz constraint.
Appendix A.3.4. Effect of the Averaged Denoiser
Compared to the conventional NLM denoiser, the averaged property of the modified NLM denoiser imposes a significantly more restrictive condition. Such a modification also raises the question as to whether it will damage the performance of the original one. In Table A4, we record the inpainting MPSNR and MSSIM of the LRS-PnP-DIP algorithm [20] with different PnP denoisers; the LRS-PnP-DIP with averaged NLM denoiser achieves almost the same performance as with the BM3D or the conventional NLM denoiser.
Table A4.
Inpainting performance of LRS-PnP-DIP algorithm with different PnP denoisers, under noise level , respectively. The mean and variance over 20 samples are shown here. The best results are highlighted in bold.
Table A4.
Inpainting performance of LRS-PnP-DIP algorithm with different PnP denoisers, under noise level , respectively. The mean and variance over 20 samples are shown here. The best results are highlighted in bold.
| Method | Metric | Input | BM3D Denoiser | NLM Denoiser | Averaged NLM Denoiser |
|---|---|---|---|---|---|
| MPSNR ↑ | 31.76 | 41.23(±0.25) | 41.25(±0.30) | 41.22(±0.13) | |
| MSSIM ↑ | 0.304 | 0.920(±0.01) | 0.918(±0.01) | 0.920(±0.01) | |
| MPSNR ↑ | 30.38 | 39.55(±0.29) | 39.60(±0.22) | 39.55(±0.220) | |
| MSSIM ↑ | 0.247 | 0.913(±0.01) | 0.915(±0.01) | 0.914(±0.01) | |
| MPSNR ↑ | 28.75 | 37.68(±0.32) | 37.65(±0.35) | 37.67(±0.24) | |
| MSSIM ↑ | 0.229 | 0.904(±0.01) | 0.903(±0.01) | 0.903(±0.01) |
Appendix A.3.5. Effect of the DIP Network Architectures
As was reported in a series of DIP-related works [10,11,24,50], the performance of DIP is sensitive to the structure of the neural networks. Table A5 provides a comparative analysis of several network architectures, including ResNet 2D/3D, U-Net 2D/3D, and Skip-Net 2D/3D. Empirical results indicate that Skip-Net 2D (i.e., a U-Net architecture with skip connections and 2D convolution layers) achieves the best performance for the HSI inpainting task. Hence, Skip-Net 2D was selected and implemented as the backbone architecture for the proposed LRS-PnP-DIP, LRS-PnP-DIP(1-Lip), and all other competing methods in the comparative analysis. Furthermore, it was found that ResNet architectures yield inferior results within the proposed framework, highlighting the importance of network design choices for achieving optimal inpainting performance. We left the exploration and identification of the most suitable DIP network structure for HSI inpainting as a future research direction.
Table A5.
On the choice of different DIP network architectures in the proposed LRS-PnP-DIP algorithm. For the metrics MPSNR and MSSIM, higher values indicate better performance. The best results are highlighted in bold.
Table A5.
On the choice of different DIP network architectures in the proposed LRS-PnP-DIP algorithm. For the metrics MPSNR and MSSIM, higher values indicate better performance. The best results are highlighted in bold.
| Methods | MPSNR↑ | MSSIM↑ |
|---|---|---|
| Input | 22.582 | 0.178 |
| ResNet 2D | 30.975(±0.62) | 0.610(±0.02) |
| ResNet 3D | 29.661(±1.20) | 0.589(±0.03) |
| UNet 2D | 35.963(±0.42) | 0.882(±0.02) |
| UNet 3D | 35.438(±0.56) | 0.868(±0.01) |
| Skip-Net 2D | ||
| Skip-Net 3D | 37.050(±0.32) | 0.890(±0.01) |
References
- Ortega, S.; Guerra, R.; Diaz, M.; Fabelo, H.; López, S.; Callico, G.M.; Sarmiento, R. Hyperspectral push-broom microscope development and characterization. IEEE Access 2019, 7, 122473–122491. [Google Scholar] [CrossRef]
- EMIT L1B At-Sensor Calibrated Radiance and Geolocation Data 60 m V001. Available online: https://search.earthdata.nasa.gov/search/granules?p=C2408009906-LPCLOUD&pg[0][v]=f&pg[0][gsk]=-start_date&q=%22EMIT%22&tl=1711560236!3!! (accessed on 27 August 2024).
- Zhuang, L.; Bioucas-Dias, J.M. Fast hyperspectral image denoising and inpainting based on low-rank and sparse representations. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 730–742. [Google Scholar] [CrossRef]
- Zhao, X.L.; Yang, J.H.; Ma, T.H.; Jiang, T.X.; Ng, M.K.; Huang, T.Z. Tensor completion via complementary global, local, and nonlocal priors. IEEE Trans. Image Process. 2021, 31, 984–999. [Google Scholar] [CrossRef]
- Li, B.Z.; Zhao, X.L.; Wang, J.L.; Chen, Y.; Jiang, T.X.; Liu, J. Tensor completion via collaborative sparse and low-rank transforms. IEEE Trans. Comput. Imaging 2021, 7, 1289–1303. [Google Scholar] [CrossRef]
- Luo, Y.S.; Zhao, X.L.; Jiang, T.X.; Chang, Y.; Ng, M.K.; Li, C. Self-supervised nonlinear transform-based tensor nuclear norm for multi-dimensional image recovery. IEEE Trans. Image Process. 2022, 31, 3793–3808. [Google Scholar] [CrossRef]
- Wu, Y.; Liu, J.; Gong, M.; Liu, Z.; Miao, Q.; Ma, W. MPCT: Multiscale point cloud transformer with a residual network. IEEE Trans. Multimed. 2023, 26, 3505–3516. [Google Scholar] [CrossRef]
- Yuan, Y.; Wu, Y.; Fan, X.; Gong, M.; Ma, W.; Miao, Q. EGST: Enhanced geometric structure transformer for point cloud registration. IEEE Trans. Vis. Comput. Graph. 2023, 30, 6222–6234. [Google Scholar] [CrossRef] [PubMed]
- Wong, R.; Zhang, Z.; Wang, Y.; Chen, F.; Zeng, D. HSI-IPNet: Hyperspectral imagery inpainting by deep learning with adaptive spectral extraction. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 4369–4380. [Google Scholar] [CrossRef]
- Ulyanov, D.; Vedaldi, A.; Lempitsky, V. Deep image prior. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 9446–9454. [Google Scholar]
- Sidorov, O.; Yngve Hardeberg, J. Deep hyperspectral prior: Single-image denoising, inpainting, super-resolution. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Meng, Z.; Yu, Z.; Xu, K.; Yuan, X. Self-supervised neural networks for spectral snapshot compressive imaging. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 2622–2631. [Google Scholar]
- Lai, Z.; Wei, K.; Fu, Y. Deep Plug-and-Play Prior for Hyperspectral Image Restoration. Neurocomputing 2022, 481, 281–293. [Google Scholar] [CrossRef]
- Wu, Z.; Yang, C.; Su, X.; Yuan, X. Adaptive Deep PnP Algorithm for Video Snapshot Compressive Imaging. arXiv 2022, arXiv:2201.05483. [Google Scholar] [CrossRef]
- Gan, W.; Eldeniz, C.; Liu, J.; Chen, S.; An, H.; Kamilov, U.S. Image reconstruction for mri using deep cnn priors trained without groundtruth. In Proceedings of the 2020 54th Asilomar Conference on Signals, Systems, and Computers, Pacific Grove, CA, USA, 1–4 November 2020; pp. 475–479. [Google Scholar]
- Niresi, K.F.; Chi, C.Y. Robust Hyperspectral Inpainting via Low-Rank Regularized Untrained Convolutional Neural Network. IEEE Geosci. Remote Sens. Lett. 2023, 20, 1–5. [Google Scholar] [CrossRef]
- Hong, D.; Yao, J.; Li, C.; Meng, D.; Yokoya, N.; Chanussot, J. Decoupled-and-coupled networks: Self-supervised hyperspectral image super-resolution with subpixel fusion. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5527812. [Google Scholar] [CrossRef]
- Yao, J.; Hong, D.; Chanussot, J.; Meng, D.; Zhu, X.; Xu, Z. Cross-attention in coupled unmixing nets for unsupervised hyperspectral super-resolution. In Proceedings of the Computer Vision—ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Part XXIX 16. pp. 208–224. [Google Scholar]
- Miao, Y.; Zhang, L.; Zhang, L.; Tao, D. Dds2m: Self-supervised denoising diffusion spatio-spectral model for hyperspectral image restoration. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–6 October 2023; pp. 12086–12096. [Google Scholar]
- Li, S.; Yaghoobi, M. Self-Supervised Hyperspectral Inpainting with the Optimisation inspired Deep Neural Network Prior. In Proceedings of the 2023 31st European Signal Processing Conference (EUSIPCO), Helsinki, Finland, 4–8 September 2023; pp. 471–475. [Google Scholar]
- Heckel, R.; Hand, P. Deep decoder: Concise image representations from untrained non-convolutional networks. arXiv 2018, arXiv:1810.03982. [Google Scholar]
- Mataev, G.; Milanfar, P.; Elad, M. DeepRED: Deep image prior powered by RED. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Liu, J.; Sun, Y.; Xu, X.; Kamilov, U.S. Image restoration using total variation regularized deep image prior. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 7715–7719. [Google Scholar]
- Sun, Z.; Latorre, F.; Sanchez, T.; Cevher, V. A plug-and-play deep image prior. In Proceedings of the ICASSP 2021—2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, Canada, 6–11 June 2021; pp. 8103–8107. [Google Scholar]
- Chen, Y.; Nasrabadi, N.M.; Tran, T.D. Hyperspectral image classification using dictionary-based sparse representation. IEEE Trans. Geosci. Remote Sens. 2011, 49, 3973–3985. [Google Scholar] [CrossRef]
- Zhang, H.; He, W.; Zhang, L.; Shen, H.; Yuan, Q. Hyperspectral image restoration using low-rank matrix recovery. IEEE Trans. Geosci. Remote Sens. 2013, 52, 4729–4743. [Google Scholar] [CrossRef]
- Li, C.; Zhang, B.; Hong, D.; Yao, J.; Chanussot, J. LRR-Net: An Interpretable Deep Unfolding Network for Hyperspectral Anomaly Detection. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–12. [Google Scholar] [CrossRef]
- Mairal, J.; Bach, F.; Ponce, J.; Sapiro, G. Online dictionary learning for sparse coding. In Proceedings of the 26th Annual International Conference on Machine Learning, Montreal, QC, Canada, 14–18 June 2009; pp. 689–696. [Google Scholar]
- Peng, J.; Sun, W.; Du, Q. Self-paced joint sparse representation for the classification of hyperspectral images. IEEE Trans. Geosci. Remote Sens. 2018, 57, 1183–1194. [Google Scholar] [CrossRef]
- Zhao, Y.Q.; Yang, J. Hyperspectral image denoising via sparse representation and low-rank constraint. IEEE Trans. Geosci. Remote Sens. 2014, 53, 296–308. [Google Scholar] [CrossRef]
- Iordache, M.D.; Bioucas-Dias, J.M.; Plaza, A. Sparse unmixing of hyperspectral data. IEEE Trans. Geosci. Remote Sens. 2011, 49, 2014–2039. [Google Scholar] [CrossRef]
- Xue, J.; Zhao, Y.; Liao, W.; Kong, S.G. Joint spatial and spectral low-rank regularization for hyperspectral image denoising. IEEE Trans. Geosci. Remote Sens. 2017, 56, 1940–1958. [Google Scholar] [CrossRef]
- Ma, G.; Huang, T.Z.; Huang, J.; Zheng, C.C. Local low-rank and sparse representation for hyperspectral image denoising. IEEE Access 2019, 7, 79850–79865. [Google Scholar] [CrossRef]
- Boyd, S.; Parikh, N.; Chu, E.; Peleato, B.; Eckstein, J. Distributed optimization and statistical learning via the alternating direction method of multipliers. Found. Trends® Mach. Learn. 2011, 3, 1–122. [Google Scholar]
- Parikh, N.; Boyd, S. Proximal algorithms. Found. Trends® Optim. 2014, 1, 127–239. [Google Scholar] [CrossRef]
- Venkatakrishnan, S.V.; Bouman, C.A.; Wohlberg, B. Plug-and-play priors for model based reconstruction. In Proceedings of the 2013 IEEE Global Conference on Signal and Information Processing, Austin, TX, USA, 3–5 December 2013; pp. 945–948. [Google Scholar]
- Daubechies, I.; Defrise, M.; De Mol, C. An iterative thresholding algorithm for linear inverse problems with a sparsity constraint. Commun. Pure Appl. Math. J. Issued Courant Inst. Math. Sci. 2004, 57, 1413–1457. [Google Scholar] [CrossRef]
- Cai, J.F.; Candès, E.J.; Shen, Z. A singular value thresholding algorithm for matrix completion. SIAM J. Optim. 2010, 20, 1956–1982. [Google Scholar] [CrossRef]
- Sreehari, S.; Venkatakrishnan, S.V.; Wohlberg, B.; Buzzard, G.T.; Drummy, L.F.; Simmons, J.P.; Bouman, C.A. Plug-and-play priors for bright field electron tomography and sparse interpolation. IEEE Trans. Comput. Imaging 2016, 2, 408–423. [Google Scholar] [CrossRef]
- Nair, P.; Gavaskar, R.G.; Chaudhury, K.N. Fixed-point and objective convergence of plug-and-play algorithms. IEEE Trans. Comput. Imaging 2021, 7, 337–348. [Google Scholar] [CrossRef]
- Ekeland, I.; Temam, R. Convex Analysis and Variational Problems; SIAM: Philadelphia, PA, USA, 1999. [Google Scholar]
- Ryu, E.; Liu, J.; Wang, S.; Chen, X.; Wang, Z.; Yin, W. Plug-and-play methods provably converge with properly trained denoisers. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 5546–5557. [Google Scholar]
- Yokoya, N.; Iwasaki, A. Airborne Hyperspectral Data over Chikusei; SAL-2016-05-27; University of Tokyo: Tokyo, Japan, 2016. [Google Scholar]
- Baumgardner, M.F.; Biehl, L.L.; Landgrebe, D.A. 220 band AVIRIS hyperspectral image data set: June 12, 1992 Indian Pine test site 3. Purdue Univ. Res. Repos. 2015, 10, 991. [Google Scholar]
- Denby, B.; Lucia, B. Orbital edge computing: Nanosatellite constellations as a new class of computer system. In Proceedings of the Twenty-Fifth International Conference on Architectural Support for Programming Languages and Operating Systems, Lausanne, Switzerland, 16–20 March 2020; pp. 939–954. [Google Scholar]
- Gouk, H.; Frank, E.; Pfahringer, B.; Cree, M.J. Regularisation of neural networks by enforcing lipschitz continuity. Mach. Learn. 2021, 110, 393–416. [Google Scholar] [CrossRef]
- Wang, H.; Li, T.; Zhuang, Z.; Chen, T.; Liang, H.; Sun, J. Early Stopping for Deep Image Prior. arXiv 2021, arXiv:2112.06074. [Google Scholar]
- Nguyen, H.V.; Ulfarsson, M.O.; Sigurdsson, J.; Sveinsson, J.R. Deep sparse and low-rank prior for hyperspectral image denoising. In Proceedings of the IGARSS 2022–2022 IEEE International Geoscience and Remote Sensing Symposium, Kuala Lumpur, Malaysia, 17–22 July 2022; pp. 1217–1220. [Google Scholar]
- Miyato, T.; Kataoka, T.; Koyama, M.; Yoshida, Y. Spectral normalization for generative adversarial networks. arXiv 2018, arXiv:1802.05957. [Google Scholar]
- Rasti, B.; Ghamisi, P.; Gloaguen, R. Unsupervised deep hyperspectral inpainting using a new mixing model. In Proceedings of the IGARSS 2022–2022 IEEE International Geoscience and Remote Sensing Symposium, Kuala Lumpur, Malaysia, 17–22 July 2022; pp. 1221–1224. [Google Scholar]
- Maffei, A.; Haut, J.M.; Paoletti, M.E.; Plaza, J.; Bruzzone, L.; Plaza, A. A single model CNN for hyperspectral image denoising. IEEE Trans. Geosci. Remote Sens. 2019, 58, 2516–2529. [Google Scholar] [CrossRef]
- Cascarano, P.; Sebastiani, A.; Comes, M.C. ADMM DIP-TV: Combining Total Variation and Deep Image Prior for image restoration. arXiv 2020, arXiv:2009.11380. [Google Scholar]
- Jiao, L.; Zhang, X.; Liu, X.; Liu, F.; Yang, S.; Ma, W.; Li, L.; Chen, P.; Feng, Z.; Guo, Y.; et al. Transformer meets remote sensing video detection and tracking: A comprehensive survey. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 16, 1–45. [Google Scholar] [CrossRef]
- Shevitz, D.; Paden, B. Lyapunov stability theory of nonsmooth systems. IEEE Trans. Autom. Control 1994, 39, 1910–1914. [Google Scholar] [CrossRef]
- Bof, N.; Carli, R.; Schenato, L. Lyapunov theory for discrete time systems. arXiv 2018, arXiv:1809.05289. [Google Scholar]
- Hill, D.; Moylan, P. The stability of nonlinear dissipative systems. IEEE Trans. Autom. Control 1976, 21, 708–711. [Google Scholar] [CrossRef]
- Zhang, T.; Shen, Z. A fundamental proof of convergence of alternating direction method of multipliers for weakly convex optimization. J. Inequal. Appl. 2019, 2019, 128. [Google Scholar] [CrossRef] [PubMed]


Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).