
STIDNet: Spatiotemporally Integrated Detection Network for Infrared Dim and Small Targets

Abstract
1. Introduction
1.1. Related Works
1.1.1. Single-Frame Infrared Dim and Small Target Detection
1.1.2. Multiframe Infrared Dim and Small Target Detection
1.2. Motivation
- (1)
- The spatial and temporal dimensions were integrated into a multiframe IRDST detection network. The salient airspace features and time-domain motion characteristics of the target were incorporated into a unified network architecture based on 3D convolution, which achieved multiframe IRDST detection via an end-to-end network.
- (2)
- According to the consistency of the short-term moving direction of the IRDST, its multiscale three-dimensional motion features with fixed weights were convolved to synchronously enhance the temporal and spatial significance of the target and inhibit random clutter and noise, which improved the detectability of IRDSTs with low SCRs.
- (3)
- The spatiotemporal characteristics of five parallel and independent optimization strategies were incorporated into the designed spatiotemporal feature fusion-based processing module, which successfully mapped spatiotemporal tensors to target multiframe probability maps.
- (4)
- Compared with the current methods, the proposed strategy exhibited better detection performance, especially for IRDSTs with low SCRs.
2. Methods
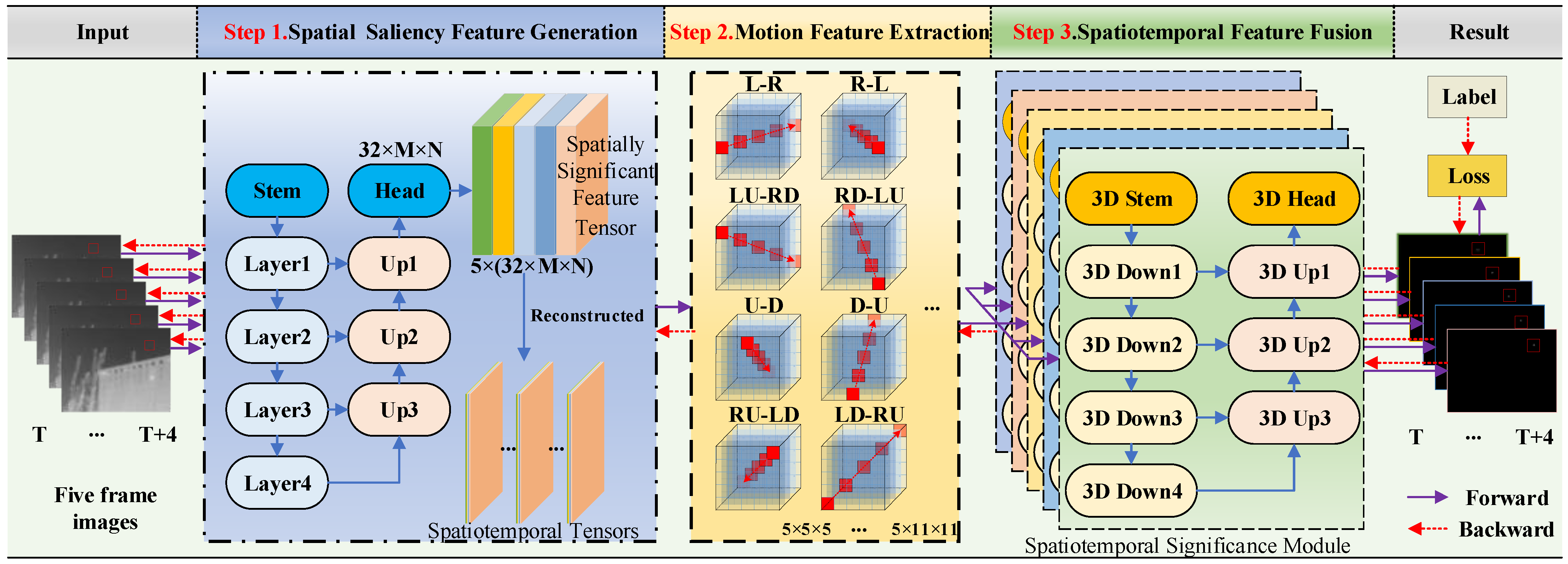
2.1. Overall Architecture
2.2. Spatial Saliency Feature Generation Module
2.3. Motion Feature Extraction Module
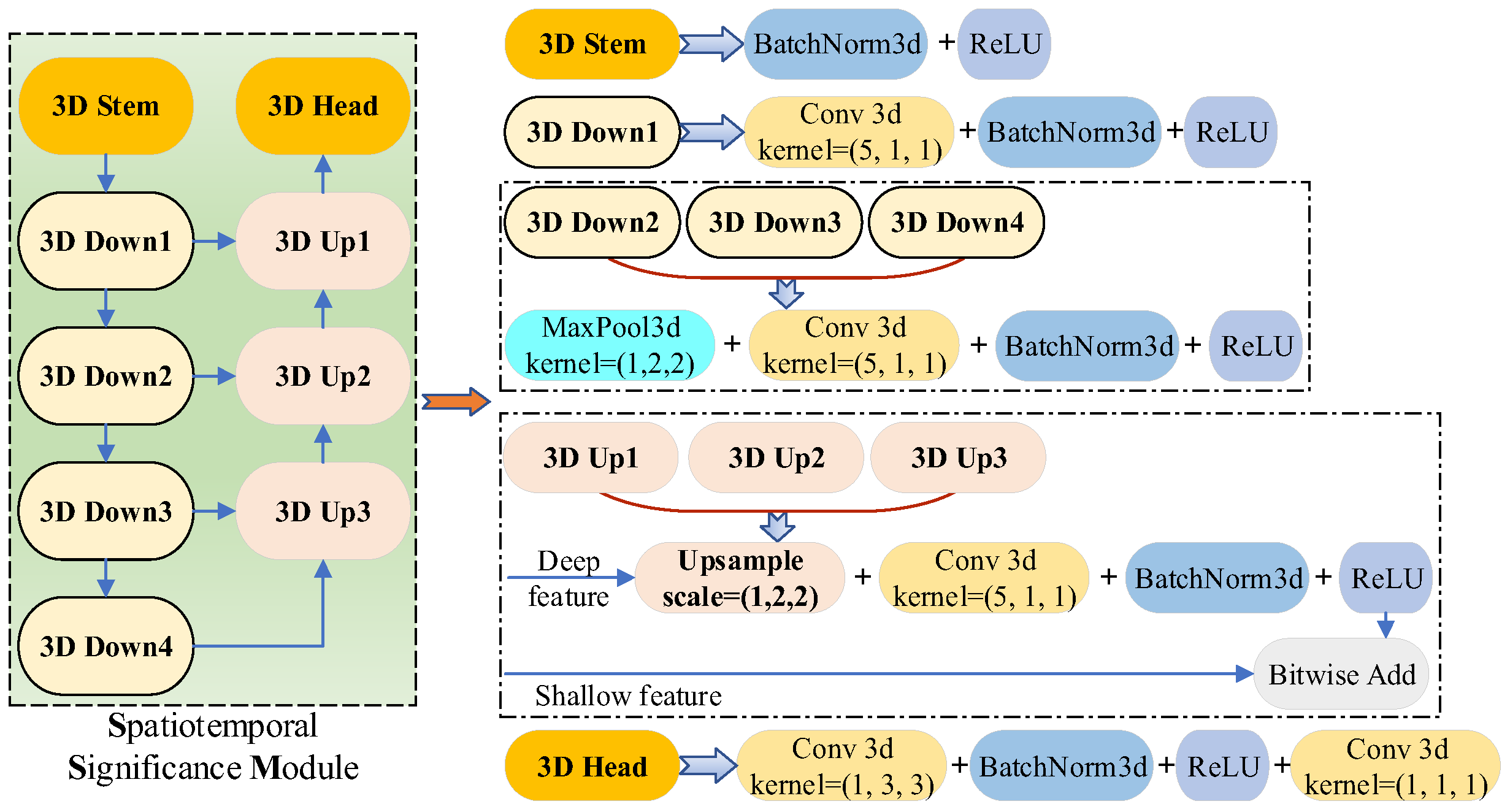
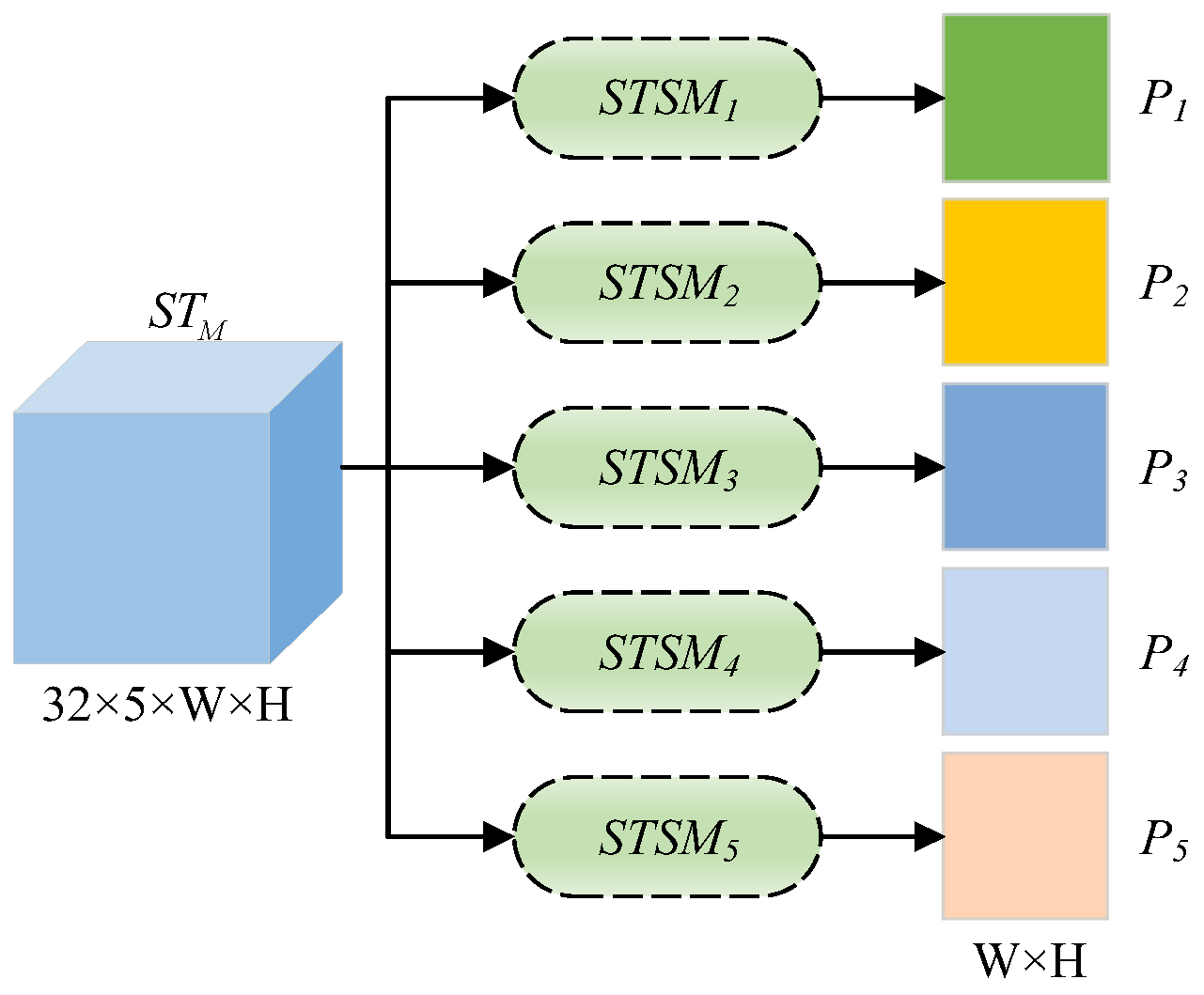
2.4. Spatiotemporal Feature Fusion Module
2.5. Loss Function
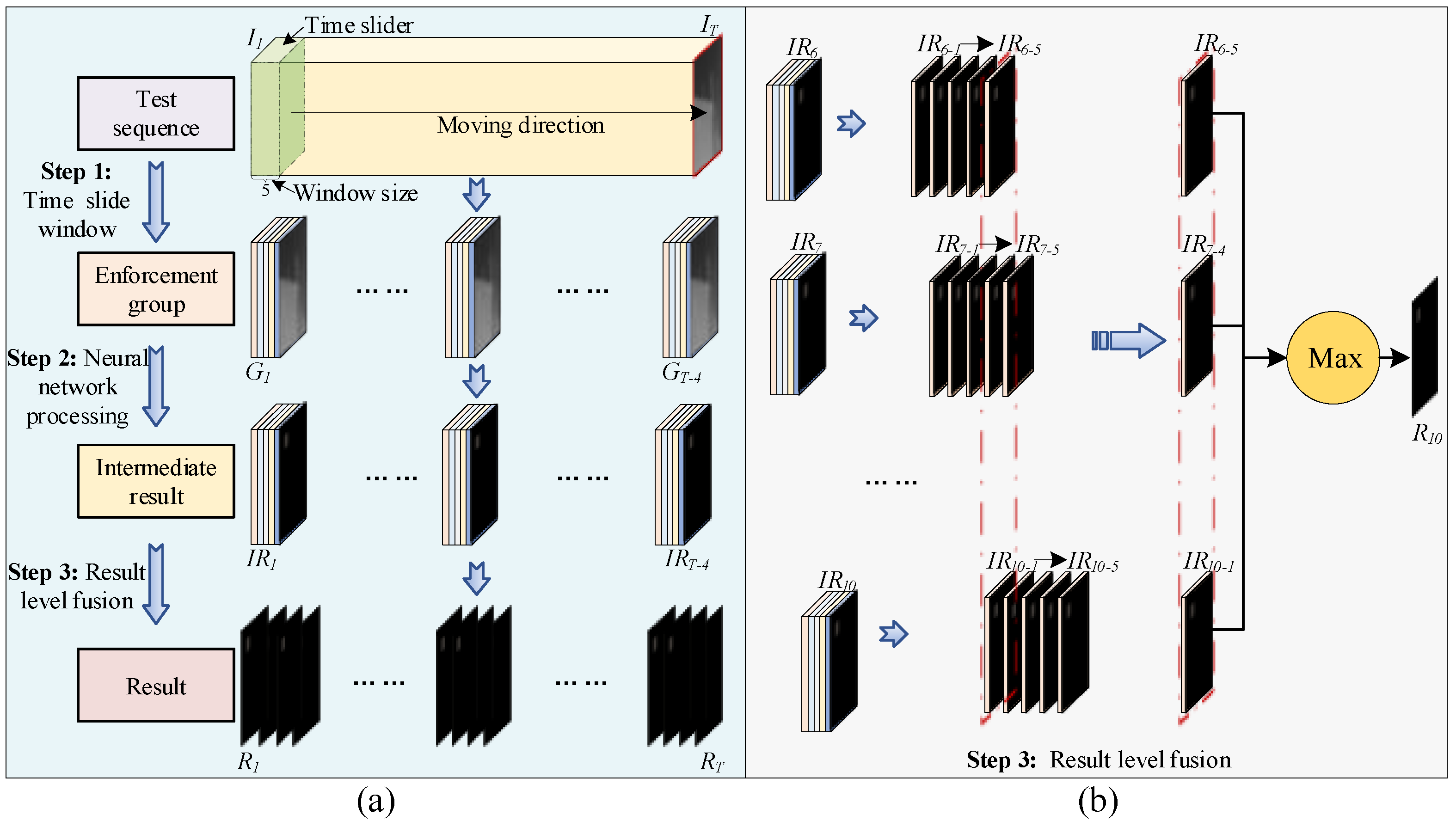
2.6. Result-Level Fusion in the Implementation
3. Experiments and Results
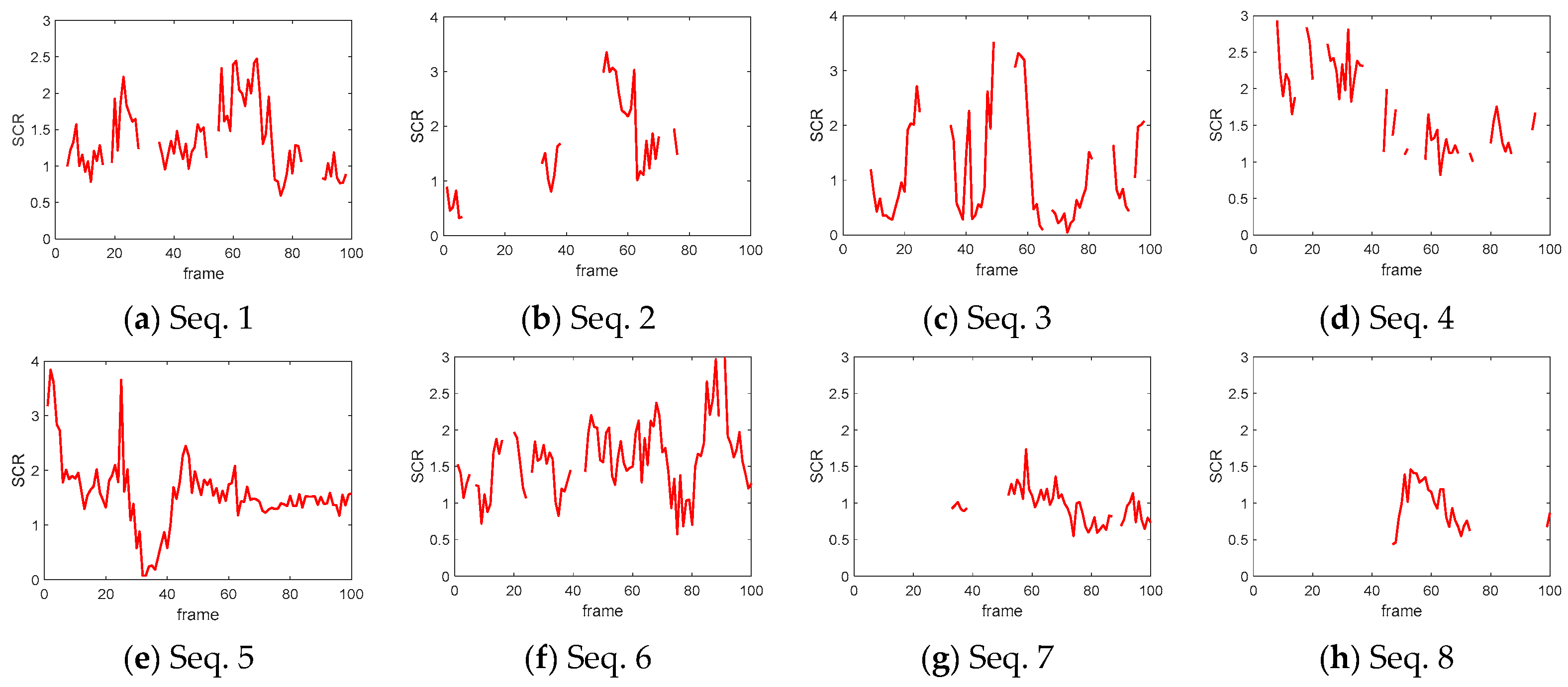
3.1. Dataset
3.2. Performance Evaluation Indices
3.3. Network Training
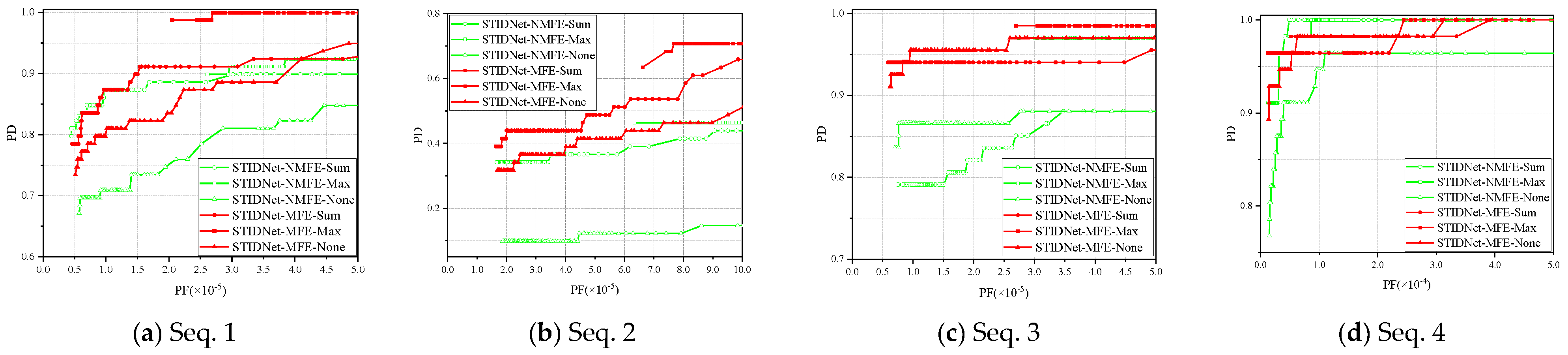
3.4. Ablation Study
- (1)
- The AUC achieved on the test set by the network with motion feature extraction was better than that of the network without motion feature extraction. Motion feature extraction can significantly improve the ability to detect IRDSTs.
- (2)
- Fusion processing was superior to non-fusion processing. After conducting a comparison, the AUC of the maximum value fusion method was the highest.
3.5. Visual Analysis of Feature Maps
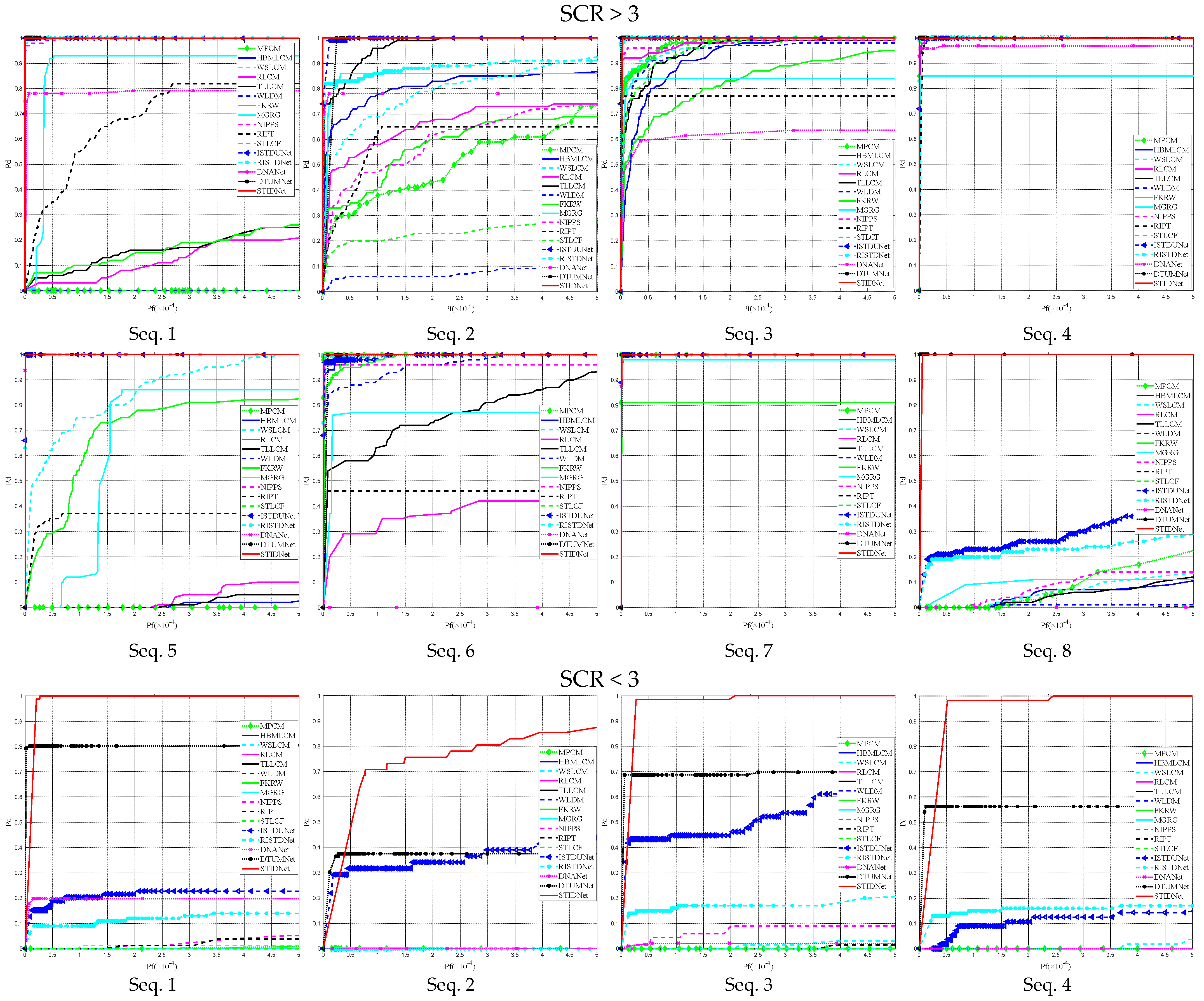
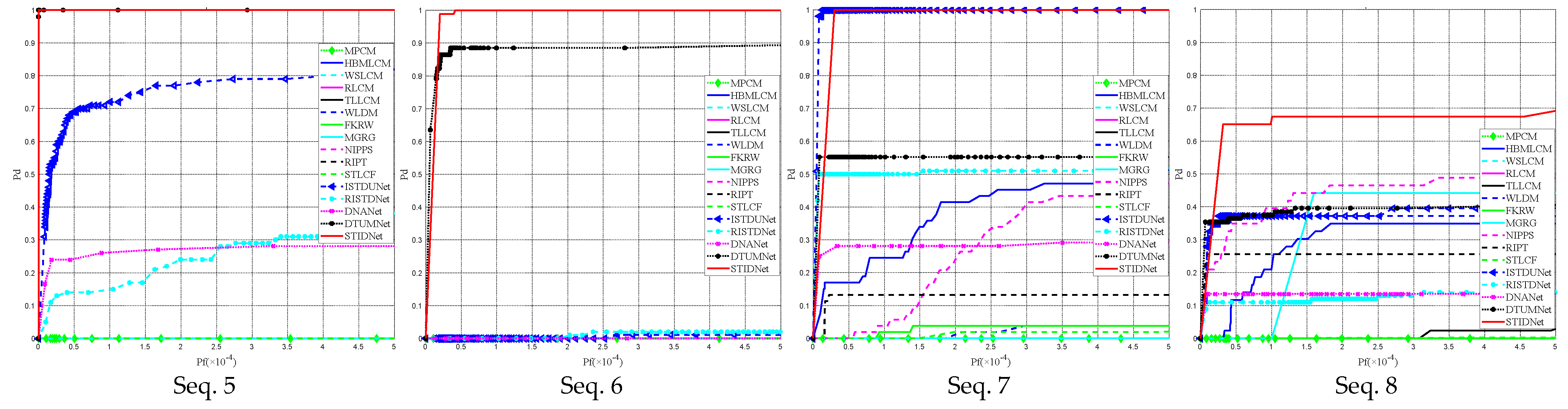
3.6. Comparison Experiments
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Kim, S.; Lee, J. Scale invariant small target detection by optimizing signal-to-clutter ratio in heterogeneous background for infrared search and track. Pattern Recognit. 2012, 45, 393–406. [Google Scholar] [CrossRef]
- Zhao, M.J.; Li, W.; Li, L.; Hu, J.; Ma, P.G.; Tao, R. Single-Frame Infrared Small-Target Detection: A Survey. IEEE Geosci. Remote Sens. Mag. 2022, 10, 87–119. [Google Scholar] [CrossRef]
- Deshpande, S.D.; Er, M.H.; Ronda, V.; Chan, P. Max-Mean and Max-Median filters for detection of small-targets. In Proceedings of the Signal and Data Processing of Small Targets, SPIE’s International Symposium on Optical Science Engineering, and Instrumentation, Denver, CO, USA, 4 October 1999; pp. 74–83. [Google Scholar]
- Han, J.H.; Liu, S.B.; Qin, G.; Zhao, Q.; Zhang, H.H.; Li, N.N. A Local Contrast Method Combined With Adaptive Background Estimation for Infrared Small Target Detection. IEEE Geosci. Remote Sens. Lett. 2019, 16, 1442–1446. [Google Scholar] [CrossRef]
- Bae, T.W.; Lee, S.H.; Sohng, K.I. Small target detection using the Bilateral Filter based on Target Similarity Index. IEICE Electron. Expr. 2010, 7, 589–595. [Google Scholar] [CrossRef]
- Bai, X.Z.; Zhou, F.G. Analysis of new top-hat transformation and the application for infrared dim small target detection. Pattern Recognit. 2010, 43, 2145–2156. [Google Scholar] [CrossRef]
- Zhang, S.F.; Huang, X.H.; Wang, M. Background Suppression Algorithm for Infrared Images Based on Robinson Guard Filter. In Proceedings of the 2nd International Conference on Multimedia and Image Processing (ICMIP), Wuhan, China, 17–19 March 2017; IEEE: New York, NY, USA, 2017; pp. 250–254. [Google Scholar]
- Chen, C.L.P.; Li, H.; Wei, Y.T.; Xia, T.; Tang, Y.Y. A Local Contrast Method for Small Infrared Target Detection. IEEE Trans. Geosci. Remote Sens. 2014, 52, 574–581. [Google Scholar] [CrossRef]
- Han, J.H.; Ma, Y.; Zhou, B.; Fan, F.; Liang, K.; Fang, Y. A Robust Infrared Small Target Detection Algorithm Based on Human Visual System. IEEE Geosci. Remote Sens. Lett. 2014, 11, 2168–2172. [Google Scholar] [CrossRef]
- Wei, Y.T.; You, X.G.; Li, H. Multiscale patch-based contrast measure for small infrared target detection. Pattern Recognit. 2016, 58, 216–226. [Google Scholar] [CrossRef]
- Han, J.H.; Liang, K.; Zhou, B.; Zhu, X.Y.; Zhao, J.; Zhao, L.L. Infrared Small Target Detection Utilizing the Multiscale Relative Local Contrast Measure. IEEE Geosci. Remote Sens. Lett. 2018, 15, 612–616. [Google Scholar] [CrossRef]
- Yao, S.K.; Chang, Y.; Qin, X.J. A Coarse-to-Fine Method for Infrared Small Target Detection. IEEE Geosci. Remote Sens. Lett. 2019, 16, 256–260. [Google Scholar] [CrossRef]
- Han, J.H.; Moradi, S.; Faramarzi, I.; Liu, C.Y.; Zhang, H.H.; Zhao, Q. A Local Contrast Method for Infrared Small-Target Detection Utilizing a Tri-Layer Window. IEEE Geosci. Remote Sens. Lett. 2020, 17, 1822–1826. [Google Scholar] [CrossRef]
- Gao, C.; Meng, D.; Yang, Y.; Wang, Y.; Zhou, X.; Hauptmann, A.G. Infrared patch-image model for small target detection in a single image. IEEE Trans Image Process. 2013, 22, 4996–5009. [Google Scholar] [CrossRef] [PubMed]
- Dai, Y.M.; Wu, Y.Q.; Song, Y.; Guo, J. Non-negative infrared patch-image model: Robust target-background separation via partial sum minimization of singular values. Infrared Phys. Technol. 2017, 81, 182–194. [Google Scholar] [CrossRef]
- Dai, Y.M.; Wu, Y.Q. Reweighted Infrared Patch-Tensor Model With Both Nonlocal and Local Priors for Single-Frame Small Target Detection. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 3752–3767. [Google Scholar] [CrossRef]
- Hou, Q.Y.; Wang, Z.P.; Tan, F.J.; Zhao, Y.; Zheng, H.L.; Zhang, W. RISTDnet: Robust Infrared Small Target Detection Network. IEEE Geosci. Remote Sens. Lett. 2022, 19. [Google Scholar] [CrossRef]
- Tong, X.Z.; Sun, B.; Wei, J.Y.; Zuo, Z.; Su, S.J. EAAU-Net: Enhanced Asymmetric Attention U-Net for Infrared Small Target Detection. Remote Sens. 2021, 13, 3200. [Google Scholar] [CrossRef]
- Li, B.Y.; Xiao, C.; Wang, L.G.; Wang, Y.Q.; Lin, Z.P.; Li, M.; An, W.; Guo, Y.L. Dense Nested Attention Network for Infrared Small Target Detection. IEEE Trans. Image Process. 2023, 32, 1745–1758. [Google Scholar] [CrossRef]
- Dai, Y.M.; Wu, Y.Q.; Zhou, F.; Barnard, K. Attentional Local Contrast Networks for Infrared Small Target Detection. IEEE Trans. Geosci. Remote Sens. 2021, 59, 9813–9824. [Google Scholar] [CrossRef]
- Zuo, Z.; Tong, X.Z.; Wei, J.Y.; Su, S.J.; Wu, P.; Guo, R.Z.; Sun, B. AFFPN: Attention Fusion Feature Pyramid Network for Small Infrared Target Detection. Remote Sens. 2022, 14, 3412. [Google Scholar] [CrossRef]
- Wang, K.W.; Du, S.Y.; Liu, C.X.; Cao, Z.G. Interior Attention-Aware Network for Infrared Small Target Detection. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5002013. [Google Scholar] [CrossRef]
- Wu, X.; Hong, D.F.; Chanussot, J. UIU-Net: U-Net in U-Net for Infrared Small Object Detection. IEEE Trans. Image Process. 2023, 32, 364–376. [Google Scholar] [CrossRef] [PubMed]
- Deng, L.Z.; Zhu, H.; Tao, C.; Wei, Y.T. Infrared moving point target detection based on spatial-temporal local contrast filter. Infrared Phys. Technol. 2016, 76, 168–173. [Google Scholar] [CrossRef]
- Zhu, H.; Guan, Y.S.; Deng, L.Z.; Li, Y.S.; Li, Y.J. Infrared moving point target detection based on an anisotropic spatial-temporal fourth-order diffusion filter. Comput. Electr. Eng. 2018, 68, 550–556. [Google Scholar] [CrossRef]
- Sun, Y.; Yang, J.G.; An, W. Infrared Dim and Small Target Detection via Multiple Subspace Learning and Spatial-Temporal Patch-Tensor Model. IEEE Trans. Geosci. Remote Sens. 2021, 59, 3737–3752. [Google Scholar] [CrossRef]
- Wojke, N.; Bewley, A.; Paulus, D. Simple Online and Realtime Tracking with a Deep Association Metric. In Proceedings of the 24th IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; IEEE: New York, NY, USA, 2017; pp. 3645–3649. [Google Scholar]
- Zhang, T.; Zhao, D.F.; Chen, Y.S.; Zhang, H.L.; Liu, S.L. DeepSORT with siamese convolution autoencoder embedded for honey peach young fruit multiple object tracking. Comput. Electron. Agric. 2024, 217, 108583. [Google Scholar] [CrossRef]
- Bertinetto, L.; Valmadre, J.; Henriques, J.F.; Vedaldi, A.; Torr, P.H.S. Fully-Convolutional Siamese Networks for Object Tracking. In Proceedings of the Computer Vision ECCV 2016 Workshops, PT II, Amsterdam, The Netherlands, 8–10 and 15–16 October 2016; Springer: Berlin, Germany, 2016; pp. 850–865. [Google Scholar]
- Mei, Y.P.; Yan, N.; Qin, H.X.; Yang, T.; Chen, Y.Y. SiamFCA: A new fish single object tracking method based on siamese network with coordinate attention in aquaculture. Comput. Electron. Agric. 2024, 216, 108542. [Google Scholar] [CrossRef]
- Liu, X.; Li, X.Y.; Li, L.Y.; Su, X.F.; Chen, F.S. Dim and Small Target Detection in Multi-Frame Sequence Using Bi-Conv-LSTM and 3D-Conv Structure. IEEE Access 2021, 9, 135845–135855. [Google Scholar] [CrossRef]
- Li, R.J.; An, W.; Xiao, C.; Li, B.Y.; Wang, Y.Q.; Li, M.; Guo, Y.L. Direction-Coded Temporal U-Shape Module for Multiframe Infrared Small Target Detection. IEEE Trans. Neural Networks Learn. Syst. 2023, 36, 555–568. [Google Scholar] [CrossRef]
- Hou, Q.Y.; Zhang, L.W.; Tan, F.J.; Xi, Y.Y.; Zheng, H.L.; Li, N. ISTDU-Net: Infrared Small-Target Detection U-Net. IEEE Geosci. Remote Sens. Lett. 2022, 19, 7506205. [Google Scholar] [CrossRef]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollar, P. Focal Loss for Dense Object Detection. IEEE Trans. Neural Networks Learn. Syst. 2020, 42, 318–327. [Google Scholar] [CrossRef] [PubMed]
- Shi, Y.F.; Wei, Y.T.; Yao, H.; Pan, D.H.; Xiao, G.R. High-Boost-Based Multiscale Local Contrast Measure for Infrared Small Target Detection. IEEE Geosci. Remote Sens. Lett. 2018, 15, 33–37. [Google Scholar] [CrossRef]
- Han, J.H.; Moradi, S.; Faramarzi, I.; Zhang, H.H.; Zhao, Q.; Zhang, X.J.; Li, N. Infrared Small Target Detection Based on the Weighted Strengthened Local Contrast Measure. IEEE Geosci. Remote Sens. Lett. 2021, 18, 1670–1674. [Google Scholar] [CrossRef]
- Deng, H.; Sun, X.P.; Liu, M.L.; Ye, C.H.; Zhou, X. Small Infrared Target Detection Based on Weighted Local Difference Measure. IEEE Trans. Geosci. Remote Sens. 2016, 54, 4204–4214. [Google Scholar] [CrossRef]
- Qin, Y.; Bruzzone, L.; Gao, C.Q.; Li, B. Infrared Small Target Detection Based on Facet Kernel and Random Walker. IEEE Trans. Geosci. Remote Sens. 2019, 57, 7104–7118. [Google Scholar] [CrossRef]
- Huang, S.Q.; Peng, Z.M.; Wang, Z.R.; Wang, X.Y.; Li, M.H. Infrared Small Target Detection by Density Peaks Searching and Maximum-Gray Region Growing. IEEE Geosci. Remote Sens. Lett. 2019, 16, 1919–1923. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Methods | Motion Feature Extraction | Fusion Method |
|---|---|---|---|
| 1 | STIDNet-NMFE-Sum | ✘ | SUM |
| 2 | STIDNet-NMFE-Max | ✘ | MAX |
| 3 | STIDNet-NMFE-None | ✘ | ✘ |
| 4 | STIDNet-MFE-Sum | ✓ | SUM |
| 5 | STIDNet-MFE-Max | ✓ | MAX |
| 6 | STIDNet-MFE-None | ✓ | ✘ |
| No. | STIDNet-NMFE-Sum | STIDNet-NMFE-Max | STIDNet-NMFE-None | STIDNet-MFE-Sum | STIDNet-MFE-Max | STIDNet-MFE-None |
|---|---|---|---|---|---|---|
| Seq. 1 | 0.99906 | 0.99916 | 0.99907 | 0.99921 | 0.99921 | 0.99916 |
| Seq. 2 | 0.95076 | 0.96522 | 0.92476 | 0.99832 | 0.99904 | 0.9945 |
| Seq. 3 | 0.99909 | 0.99906 | 0.99889 | 0.99912 | 0.99912 | 0.99913 |
| Seq. 4 | 0.99878 | 0.99876 | 0.99866 | 0.99877 | 0.99876 | 0.99878 |
| Seq. 5 | 0.99885 | 0.99885 | 0.99885 | 0.99885 | 0.99885 | 0.99885 |
| Seq. 6 | 0.99849 | 0.99881 | 0.99871 | 0.99889 | 0.99888 | 0.99889 |
| Seq. 7 | 0.99931 | 0.9993 | 0.99931 | 0.99931 | 0.9993 | 0.99931 |
| Seq. 8 | 0.9653 | 0.9695 | 0.94587 | 0.98699 | 0.98974 | 0.9888 |
| Mean | 0.988705 | 0.9910825 | 0.983015 | 0.9974325 | 0.9978625 | 0.9971775 |
| Methods | Publication | Parameter Settings | Params (M) | FPS |
|---|---|---|---|---|
| MPCM [10] | Pattern Recognit. 2016 | L = 3; Window size = [3, 5, 7, 9] | - | 36.331 |
| HBMLCM [35] | IEEE Geosci. Remote Sens. Lett. 2018 | External window size = 15 × 15; target size = [3, 5, 7, 9] | - | 126.098 |
| WSLCM [36] | IEEE Geosci. Remote Sens. Lett. 2021 | Gauss_krl = [1, 2, 1; 2, 4, 2; 1, 2, 1]./16; Scs = [5, 7, 9, 11] | - | 0.801 |
| RLCM [11] | IEEE Geosci. Remote. Sens. Lett. 2018 | Scale = 3; k1 = [2, 5, 9]; k2 = [4, 9, 16] | - | 1.024 |
| TLLCM [13] | IEEE Geosci. Remote. Sens. Lett. 2019 | GS = [1/16, 1/8, 1/16; 1/8, 1/4, 1/8; 1/16, 1/8, 1/16] | - | 1.533 |
| NIPPS [15] | Infr. Phys. Technol. 2017 | PatchSize = 50; SlideStep = 10; LambdaL = 2; RatioN = 0.005 | - | 0.249 |
| RIPT [16] | IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens. 2017 | PatchSize = 30; SlideStep = 10; LambdaL = 0.7; MuCoef = 5; h = 1 | - | 1.238 |
| WLDM [37] | IEEE Trans. Geosci. Remote Sens. 2016 | L = 9 | - | 0.389 |
| FKRW [38] | IEEE Trans. Geosci. Remote Sens. 2019 | L = [−4, −1, 0, −1, −4; −1, 2, 3, 2, −1; 0, 3, 4, 3, 0;−1, 2, 3, 2, −1; −4, −1, 0, −1, −4] | - | 9.034 |
| MGRG [39] | IEEE Geosci. Remote. Sens. Lett. 2019 | numSeeds = 20; tarRate = 0.01 × 0.15 | - | 1.422 |
| STLCF [25] | Computers and Electrical Engineering. 2018 | tspan_rng = 2; swind_rng = 7 | - | 2.749 |
| ISTDUNet [33] | IEEE Trans. Geosci. Remote Sens. Lett. 2022 | hyperparameter of channel = 2 | 2.761 | 23.027 |
| RISTDNet [17] | IEEE Trans. Geosci. Remote Sens. Lett. 2022 | - | 0.763 | 4.723 |
| DNANet [19] | IEEE Trans. Image Process. 2023 | - | 1.134 | 20.747 |
| DTUMNet [32] | IEEE Trans. on Neural Networks and Learning Systems. 2023 | Res-Unet | 0.298 | 9.494 |
| STIDNet | - | - | 4.874 | 5.945 |
| Seq. | WSLCM | RLCM | TLLCM | NIPPS | RIPT | STLCF | ISTDUNet | RISTDNet | DNANet | DTUMNet | STIDNet | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| S C R > 3 | 1 | 0.9987 | 0.9972 | 0.9979 | 0.9987 | 0.9087 | 0.9833 | 0.9987 | 0.9987 | 0.9727 | 0.9987 | 0.99865 |
| 2 | 0.9689 | 0.9713 | 0.9990 | 0.8690 | 0.8241 | 0.9926 | 0.9990 | 0.9972 | 0.9890 | 0.9990 | 0.99901 | |
| 3 | 0.9989 | 0.9989 | 0.9989 | 0.9939 | 0.8840 | 0.9989 | 0.9989 | 0.9989 | 0.9775 | 0.9989 | 0.9989 | |
| 4 | 0.9989 | 0.9989 | 0.9989 | 0.9989 | 0.9989 | 0.9989 | 0.9989 | 0.9989 | 0.9984 | 0.9989 | 0.99885 | |
| 5 | 0.9981 | 0.9933 | 0.9965 | 0.9982 | 0.6837 | 0.9844 | 0.9982 | 0.9982 | 0.9982 | 0.9982 | 0.9982 | |
| 6 | 0.9987 | 0.9930 | 0.9985 | 0.9787 | 0.7290 | 0.9987 | 0.9987 | 0.9987 | 0.5054 | 0.9987 | 0.99866 | |
| 7 | 0.9990 | 0.9936 | 0.9990 | 0.9990 | 0.9990 | 0.9990 | 0.9990 | 0.9990 | 0.9990 | 0.9990 | 0.99903 | |
| 8 | 0.9501 | 0.9577 | 0.9957 | 0.5691 | 0.4993 | 0.9823 | 0.9954 | 0.9641 | 0.7676 | 0.9987 | 0.99873 | |
| 9 | 0.9881 | 0.9959 | 0.9981 | 0.9426 | 0.4994 | 0.9871 | 0.9987 | 0.9983 | 0.9362 | 0.9989 | 0.99889 | |
| 10 | 0.9982 | 0.9959 | 0.9983 | 0.9979 | 0.5940 | 0.9952 | 0.9984 | 0.9985 | 0.4848 | 0.9985 | 0.99845 | |
| 11 | 0.9780 | 0.9249 | 0.9983 | 0.8885 | 0.6490 | 0.9965 | 0.9985 | 0.9978 | 0.9438 | 0.9985 | 0.99853 | |
| 12 | 0.9990 | 0.9989 | 0.9990 | 0.9989 | 0.9989 | 0.9983 | 0.9990 | 0.9990 | 0.9989 | 0.9989 | 0.99895 | |
| Mean | 0.98955 | 0.98496 | 0.99818 | 0.93612 | 0.77233 | 0.99293 | 0.99845 | 0.99561 | 0.88096 | 0.99874 | 0.99874 | |
| S C R < 3 | 1 | 0.51761 | 0.50963 | 0.87721 | 0.72535 | 0.51833 | 0.97573 | 0.95366 | 0.7933 | 0.78389 | 0.98842 | 0.99921 |
| 2 | 0.5213 | 0.7861 | 0.9832 | 0.4996 | 0.4993 | 0.7348 | 0.9933 | 0.5819 | 0.4579 | 0.7737 | 0.99904 | |
| 3 | 0.5505 | 0.5343 | 0.8537 | 0.5589 | 0.5509 | 0.8941 | 0.9962 | 0.9319 | 0.6491 | 0.9834 | 0.99912 | |
| 4 | 0.5436 | 0.4658 | 0.8897 | 0.4994 | 0.4989 | 0.6392 | 0.9900 | 0.8321 | 0.5795 | 0.9053 | 0.99876 | |
| 5 | 0.5274 | 0.5913 | 0.9778 | 0.6923 | 0.4981 | 0.7893 | 0.9979 | 0.9772 | 0.8919 | 0.9989 | 0.99885 | |
| 6 | 0.5042 | 0.4859 | 0.9244 | 0.5091 | 0.4993 | 0.8581 | 0.9833 | 0.9037 | 0.6659 | 0.9975 | 0.99888 | |
| 7 | 0.4992 | 0.4780 | 0.5788 | 0.7351 | 0.5656 | 0.9789 | 0.9993 | 0.8576 | 0.7410 | 0.8156 | 0.9993 | |
| 8 | 0.4989 | 0.7642 | 0.9202 | 0.7658 | 0.6277 | 0.9287 | 0.9217 | 0.7248 | 0.8154 | 0.9285 | 0.98974 | |
| Mean | 0.52034 | 0.57690 | 0.87563 | 0.62319 | 0.53227 | 0.84985 | 0.97942 | 0.82531 | 0.69807 | 0.92392 | 0.99786 | |
| Seq. | WSLCM | RLCM | TLLCM | NIPPS | RIPT | STLCF | ISTDUNet | RISTDNet | DNANet | DTUMNet | STIDNet | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| S C R > 3 | 1 | 38.6 | 5.6 | 9.14 | 278.3 | 32.5 | 2.1 | 1358.4 | 278.3 | 5.7 | 1365.3 | 2251.7 |
| 2 | 988.5 | 7.2 | 9.59 | 524.6 | 1860.2 | 2.9 | 240.3 | 47.6 | 1.3 | 588.3 | 1711.0 | |
| 3 | 2109.6 | 15.4 | 64.0 | 257.9 | 1046.1 | 5.9 | 746.3 | 204.1 | 7.1 | 795.7 | 1848.9 | |
| 4 | 20.3 | 3.0 | 6.4 | 11.2 | 8.1 | 2.3 | 52.4 | 8.4 | 2.7 | 1300.9 | 1557.6 | |
| 5 | 14.2 | 1.4 | 2.6 | 15.2 | 19.5 | 1.3 | 13.7 | 11.5 | 0.9 | 529.6 | 935.2 | |
| 6 | 18.5 | 3.4 | 6.8 | 11.0 | 24.3 | 2.2 | 43.5 | 39.4 | 1.6 | 534.5 | 1484.5 | |
| 7 | 23.1 | 1.3 | 3.4 | 6.4 | 9.8 | 1.1 | 8.1 | 14.9 | 0.3 | 196.0 | 410.6 | |
| 8 | 13.7 | 1.3 | 2.3 | 7.3 | 619.7 | 1.4 | 52.4 | 21.2 | 0.6 | 509.5 | 598.9 | |
| 9 | 688.2 | 5.3 | 14.5 | 55.1 | 28.6 | 2.1 | 589.5 | 114.6 | 3.0 | 652.3 | 1131.9 | |
| 10 | 28.7 | 10.3 | 21.9 | 17.8 | 28.4 | 4.3 | 44.2 | 14.3 | 8.3 | 1392.9 | 2205.1 | |
| 11 | 21.0 | 6.2 | 10.5 | 35.1 | 55.0 | 1.8 | 765.7 | 340.9 | 4.2 | 630.0 | 1814.0 | |
| 12 | 2.8 | 2.3 | 2.3 | 37.1 | 82.6 | 1.2 | 126.5 | 29.9 | 8.1 | 467.4 | 1445.0 | |
| S C R < 3 | 1 | 25.5 | 4.9 | 26.4 | 51.0 | 46.4 | 2.6 | 33.5 | 12.5 | 4.9 | 708.6 | 1163.0 |
| 2 | 22.5 | 8.0 | 9.3 | 42.2 | 20.5 | 1.4 | 147.9 | 29.2 | 5.2 | 1910.9 | 887.6 | |
| 3 | 22.2 | 4.0 | 5.6 | 17.5 | 7.2 | 1.6 | 56.6 | 31.0 | 1.4 | 501.0 | 1045.2 | |
| 4 | 15.1 | 2.7 | 6.9 | 24.5 | 6.4 | 1.5 | 13.0 | 16.1 | 1.8 | 965.8 | 1164.4 | |
| 5 | 137.5 | 2.1 | 3.3 | 39.0 | 8.7 | 1.4 | 96.7 | 11.1 | 1.6 | 352.3 | 545.8 | |
| 6 | 84.7 | 8.7 | 16.5 | 32.1 | 26.5 | 2.1 | 204.6 | 27.3 | 4.4 | 487.7 | 1768.7 | |
| 7 | 104.9 | 4.7 | 6.7 | 74.7 | 622.7 | 2.3 | 414.8 | 74.7 | 3.6 | 857.6 | 1687.2 | |
| 8 | 1054.4 | 6.0 | 12.7 | 85.8 | 38.9 | 2.2 | 624.2 | 502.9 | 4.1 | 1341.5 | 1629.2 | |
| Seq. | WSLCM | RLCM | TLLCM | NIPPS | RIPT | STLCF | ISTDUNet | RISTDNet | DNANet | DTUMNet | STIDNet | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| S C R > 3 | 1 | 1313.7 | 1.0 | 277.2 | 1518.3 | 614.1 | 3.4 | 578.4 | 24.9 | 1.1 | 1022.4 | 1241.5 |
| 2 | 2194.1 | 1.5 | 1492.1 | 1746.6 | 951.8 | 2.4 | 68.9 | 5.3 | 0.1 | 659.4 | 1127.2 | |
| 3 | 2806.6 | 1.6 | 1718.9 | 1239.0 | 1391 | 4.0 | 919.3 | 1053.9 | 1.8 | 1133.9 | 1817.0 | |
| 4 | 0.0 | 0.3 | 182.7 | 14.8 | 0.0 | 5.8 | 256.8 | 88.0 | 2.3 | 9490.6 | 6081.9 | |
| 5 | 45.9 | 1.4 | 3.5 | 16.4 | 0.0 | 1.2 | 33.9 | 8.6 | 0.3 | 1430.9 | 1620.5 | |
| 6 | 753.0 | 1.4 | 819.3 | 190.1 | 0.0 | 1.3 | 4.4 | 5.5 | 0.2 | 438.7 | 221.8 | |
| 7 | 535.6 | 1.2 | 882.4 | 61.6 | 26.1 | 1.0 | 8.3 | 4.5 | 0.1 | 422.4 | 203.1 | |
| 8 | 793.9 | 0.7 | 1352.1 | 918.6 | 421.3 | 1.6 | 27.9 | 14.1 | 0.2 | 1141.4 | 651.4 | |
| 9 | 1664.2 | 1.2 | 149.6 | 1107.8 | 1235 | 2.2 | 417.1 | 56.0 | 1.0 | 1004.7 | 1381.4 | |
| 10 | 0.4 | 0.1 | 7.1 | 5.2 | 0.0 | 2.0 | 6.0 | 28.2 | 0.7 | 5321.5 | 2736.5 | |
| 11 | 0.0 | 0.1 | 145.3 | 666.2 | 633.2 | 4.3 | 683.0 | 215.7 | 3.0 | 2859.4 | 2466.1 | |
| 12 | 0.0 | 0.0 | 232214 | 58.0 | 1571 | 1412.7 | 25336.6 | 18766.9 | 2130.7 | 7416719 | 398266 | |
| S C R < 3 | 1 | 20.8 | 0.6 | 12.3 | 18.8 | 5.0 | 2.9 | 131.9 | 39.9 | 0.8 | 3263.6 | 3281.2 |
| 2 | 0.8 | 0.8 | 2.9 | 0.0 | 0.0 | 1.1 | 251.7 | 1.1 | 1.1 | 6947.3 | 4837.8 | |
| 3 | 6.6 | 0.6 | 18.1 | 231.9 | 141.4 | 3.1 | 360.2 | 73.3 | 1.6 | 4968.6 | 10788 | |
| 4 | 1.5 | 0.00 | 36.0 | 0.0 | 0.0 | 2.1 | 16.5 | 6.6 | 0.6 | 4408.6 | 4652.2 | |
| 5 | 1094.3 | 0.8 | 27.7 | 1085.5 | 549.2 | 1.4 | 20.6 | 15.3 | 0.7 | 593.1 | 847.8 | |
| 6 | 832.5 | 1.6 | 112.5 | 485.3 | 789.3 | 1.2 | 65.0 | 105.0 | 0.9 | 454.4 | 1340.9 | |
| 7 | 1275.7 | 1.1 | 23.8 | 890.2 | 961.4 | 1.3 | 64.8 | 89.0 | 0.6 | 715.6 | 566.5 | |
| 8 | 1440.6 | 0.9 | 68.4 | 1053.6 | 1117.3 | 2.1 | 72.4 | 487.7 | 1.0 | 1235.3 | 1101.9 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, L.; Zhou, Z.; Xi, Y.; Tan, F.; Hou, Q. STIDNet: Spatiotemporally Integrated Detection Network for Infrared Dim and Small Targets. Remote Sens. 2025, 17, 250. https://doi.org/10.3390/rs17020250
Zhang L, Zhou Z, Xi Y, Tan F, Hou Q. STIDNet: Spatiotemporally Integrated Detection Network for Infrared Dim and Small Targets. Remote Sensing. 2025; 17(2):250. https://doi.org/10.3390/rs17020250
Chicago/Turabian StyleZhang, Liuwei, Zhitao Zhou, Yuyang Xi, Fanjiao Tan, and Qingyu Hou. 2025. "STIDNet: Spatiotemporally Integrated Detection Network for Infrared Dim and Small Targets" Remote Sensing 17, no. 2: 250. https://doi.org/10.3390/rs17020250
APA StyleZhang, L., Zhou, Z., Xi, Y., Tan, F., & Hou, Q. (2025). STIDNet: Spatiotemporally Integrated Detection Network for Infrared Dim and Small Targets. Remote Sensing, 17(2), 250. https://doi.org/10.3390/rs17020250