
Multi-Scale Long- and Short-Range Structure Aggregation Learning for Low-Illumination Remote Sensing Imagery Enhancement

 , ,
, ,
Abstract
1. Introduction
- We present a novel structure aggregation learning network which is able to simultaneously exploit long-range and short-range structures in the input LI images for quality enhancement. Moreover, different from most existing methods that mainly focus on those general structures shared by different images, the proposed network can exploit the specific structure for each image, thus being flexible to restore images with various contents and illumination conditions.
- We establish the proposed network in a multi-scale manner, which is able to sufficiently exploit the structures concealed across different scales of the input IL image.
2. Related Work
2.1. Deep Learning Based LI Image Enhancement
2.1.1. Mapping-Based Method
2.1.2. Generating Exposure Stack-Based Method
2.2. Dynamic Neural Networks
2.2.1. Attention Mechanisms
2.2.2. Vision Transformer
3. The Proposed Method
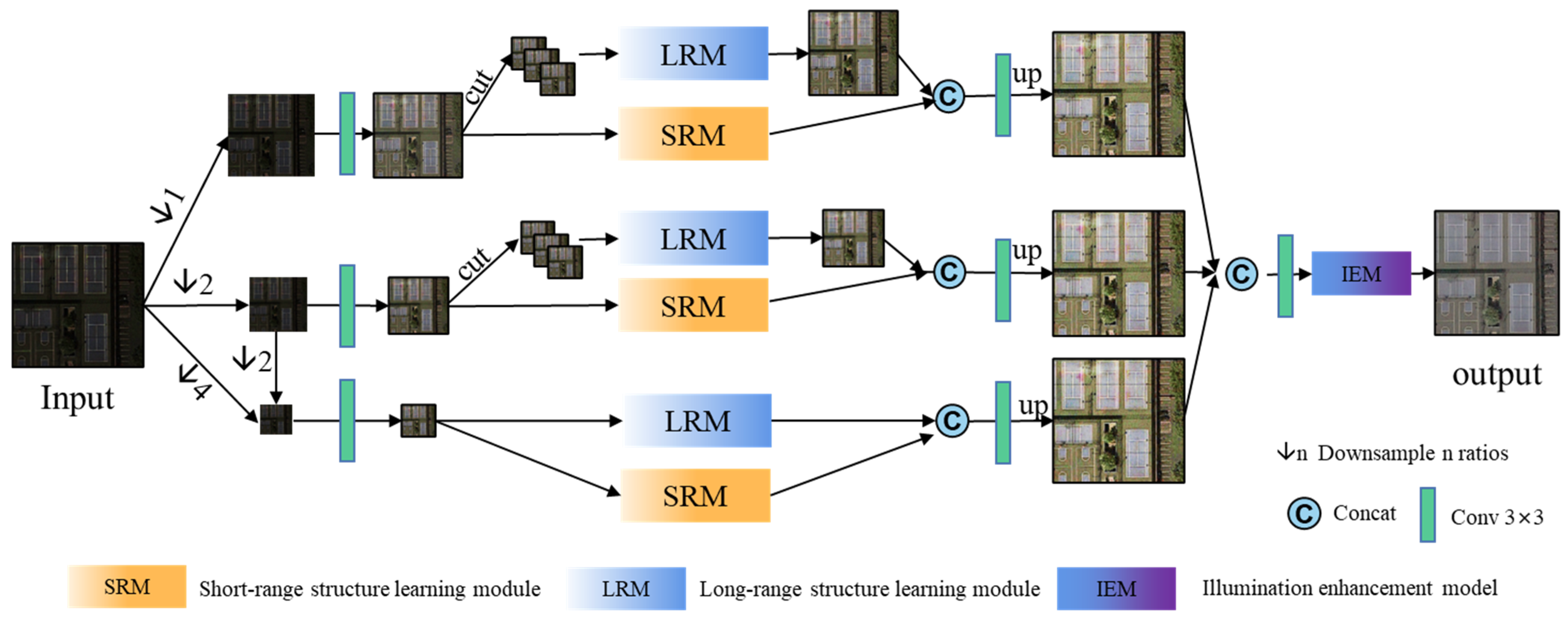
3.1. Problem Definition and Framwork
3.2. Short-Range Structure Learning Module
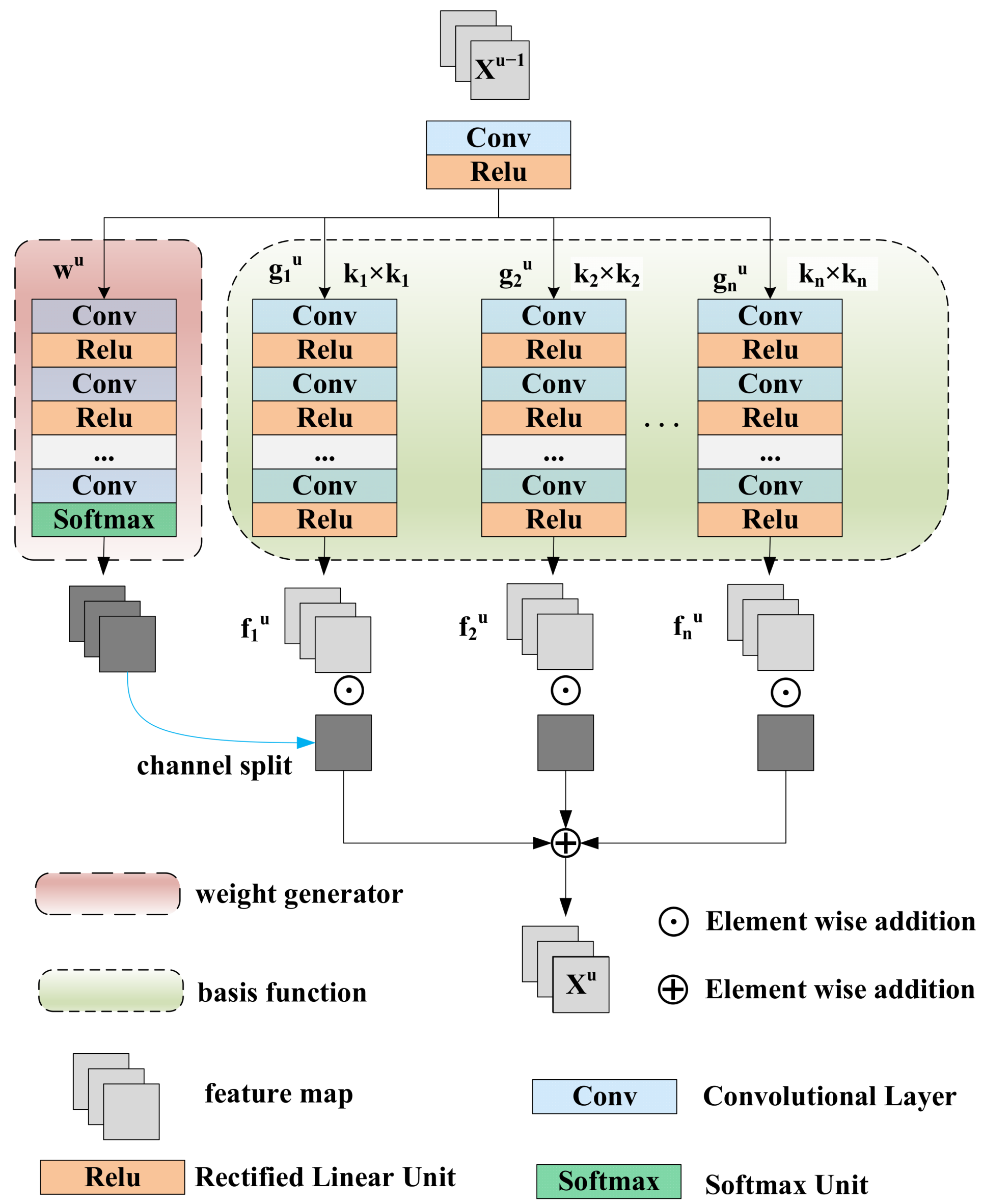
3.3. Long-Range Structure Learning Module
3.4. Fine-Grained Illumination Enhancement Module
3.5. Multi-Scale Aggregation
4. Experiments
4.1. Experimental Setting
4.1.1. Datasets
4.1.2. Comparison Methods
4.1.3. Evaluation Metrics
4.1.4. Implementation Details
4.2. Performance Evaluation
4.3. Ablation Study
4.3.1. Short-Range Structure Learning Module
4.3.2. Long-Range Structure Learning Module
4.3.3. Multi-Scale Structure with Different Scales
4.4. Evaluation on the Real World Data
4.5. Limitations and Future Directions
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Li, X.; Wang, L.; Cheng, Q.; Wu, P.; Gan, W.; Fang, L. Cloud removal in remote sensing images using nonnegative matrix factorization and error correction. ISPRS J. Photogramm. Remote Sens. 2019, 148, 103–113. [Google Scholar] [CrossRef]
- Han, W.; Zhang, X.; Wang, Y.; Wang, L.; Huang, X.; Li, J.; Wang, S.; Chen, W.; Li, X.; Feng, R.; et al. A survey of machine learning and deep learning in remote sensing of geological environment: Challenges, advances, and opportunities. ISPRS J. Photogramm. Remote Sens. 2023, 202, 87–113. [Google Scholar] [CrossRef]
- Deng, Z.; Sun, H.; Zhou, S.; Zhao, J.; Lei, L.; Zou, H. Multi-scale object detection in remote sensing imagery with convolutional neural networks. ISPRS J. Photogramm. Remote Sens. 2018, 145, 3–22. [Google Scholar] [CrossRef]
- Fuentes-Peñailillo F, Gutter K, Vega R; et al. Transformative technologies in digital agriculture: Leveraging Internet of Things, remote sensing, and artificial intelligence for smart crop management. J. Sens. Actuator Netw. 2024, 13, 39. [Google Scholar] [CrossRef]
- Eilertsen, G.; Kronander, J.; Denes, G.; Mantiuk, R.K.; Unger, J. HDR image reconstruction from a single exposure using deep CNNs. ACM Trans. Graph. (TOG) 2017, 36, 1–15. [Google Scholar] [CrossRef]
- Liu, Y.-L.; Lai, W.-S.; Chen, Y.-S.; Kao, Y.-L.; Yang, M.-H.; Chuang, Y.-Y.; Huang, J.-B. Single-image HDR reconstruction by learning to reverse the camera pipeline. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 1651–1660. [Google Scholar]
- Raipurkar, P.; Pal, R.; Raman, S. HDR-cGAN: Single LDR to HDR image translation using conditional GAN. In Proceedings of the Twelfth Indian Conference on Computer Vision, Graphics and Image Processing, Jodhpur, India, 19–22 December 2021; pp. 1–9. [Google Scholar]
- Vaswani, A. Attention is all you need. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Alexey, D. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Chen, H.; Wang, Y.; Guo, T.; Xu, C.; Deng, Y.; Liu, Z.; Ma, S.; Xu, C.; Xu, C.; Gao, W. Pre-trained image processing transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 12299–12310. [Google Scholar]
- Cai, Y.; Lin, J.; Hu, X.; Wang, H.; Yuan, X.; Zhang, Y.; Timofte, R.; Van Gool, L. Mask-guided spectral-wise transformer for efficient hyperspectral image reconstruction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 17502–17511. [Google Scholar]
- Zhang, Z.; Jiang, Y.; Jiang, J.; Wang, X.; Luo, P.; Gu, J. Star: A structure-aware lightweight transformer for real-time image enhancement. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 4106–4115. [Google Scholar]
- Zhang, Y.; Li, K.; Li, K.; Zhong, B.; Fu, Y. Residual non-local attention networks for image restoration. arXiv 2019, arXiv:1903.10082. [Google Scholar]
- Gu, J.; Dong, C. Interpreting super-resolution networks with local attribution maps. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 9199–9208. [Google Scholar]
- Lim, B.; Son, S.; Kim, H.; Nah, S.; Mu Lee, K. Enhanced deep residual networks for single image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 24–26 July 2017; pp. 136–144. [Google Scholar]
- Lee, S.; An, G.H.; Kang, S.-J. Deep chain hdri: Reconstructing a high dynamic range image from a single low dynamic range image. IEEE Access 2018, 6, 49913–49924. [Google Scholar] [CrossRef]
- Santos, M.S.; Ren, T.I.; Kalantari, N.K. Single image HDR reconstruction using a CNN with masked features and perceptual loss. arXiv 2020, arXiv:2005.07335. [Google Scholar] [CrossRef]
- Moriwaki, K.; Yoshihashi, R.; Kawakami, R.; You, S.; Naemura, T. Hybrid loss for learning single-image-based HDR reconstruction. arXiv 2018, arXiv:1812.07134. [Google Scholar]
- Jung, S.-W.; Son, D.-M.; Kwon, H.-J.; Lee, S.-H. Regional weighted generative adversarial network for LDR to HDR image conversion. In Proceedings of the 2020 International Conference on Artificial Intelligence in Information and Communication (ICAIIC), Fukuoka, Japan, 19–21 February 2020; pp. 697–700. [Google Scholar]
- Marnerides, D.; Bashford-Rogers, T.; Hatchett, J.; Debattista, K. Expandnet: A deep convolutional neural network for high dynamic range expansion from low dynamic range content. Comput. Graph. Forum 2018, 37, 37–49. [Google Scholar] [CrossRef]
- Iglesias, G.; Talavera, E.; Díaz-Álvarez, A. A survey on GANs for computer vision: Recent research, analysis and taxonomy. Comput. Sci. Rev. 2023, 48, 100553. [Google Scholar]
- Zhu, J.-Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- Li, Z.; Wang, Y.; Zhang, J. Low-light image enhancement with knowledge distillation. Neurocomputing 2023, 518, 332–343. [Google Scholar] [CrossRef]
- Kim, J.; Lee, S.; Kang, S.-J. End-to-end differentiable learning to HDR image synthesis for multi-exposure images. In Proceedings of the AAAI Conference on Artificial Intelligence, Online, 2–9 February 2021; pp. 1780–1788. [Google Scholar]
- Liang, B.; Weng, D.; Bao, Y.; Tu, Z.; Luo, L. Reconstructing hdr image from a single filtered ldr image base on a deep hdr merger network. In Proceedings of the 2019 IEEE International Symposium on Mixed and Augmented Reality Adjunct (ISMAR-Adjunct), Beijing, China, 10–19 October 2019; pp. 257–258. [Google Scholar]
- Wang, W.; Yan, D.; Wu, X.; He, W.; Chen, Z.; Yuan, X.; Li, L. Low-light image enhancement based on virtual exposure. Signal Process. Image Commun. 2023, 118, 117016. [Google Scholar] [CrossRef]
- Zhang, L.; Lang, Z.; Wang, P.; Wei, W.; Liao, S.; Shao, L.; Zhang, Y. Pixel-aware deep function-mixture network for spectral super-resolution. Proc. AAAI Conf. Artif. Intell. 2020, 34, 12821–12828. [Google Scholar] [CrossRef]
- Yan, Q.; Gong, D.; Shi, Q.; Hengel, A.v.d.; Shen, C.; Reid, I.; Zhang, Y. Attention-guided network for ghost-free high dynamic range imaging. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 1751–1760. [Google Scholar]
- Lee, J.; Toutanova, K. Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Han, K.; Wang, Y.; Chen, H.; Chen, X.; Guo, J.; Liu, Z.; Tang, Y.; Xiao, A.; Xu, C.; Xu, Y. A survey on vision transformer. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 87–110. [Google Scholar] [CrossRef] [PubMed]
- Zamir, S.W.; Arora, A.; Khan, S.; Hayat, M.; Khan, F.S.; Yang, M.H. Restormer: Efficient transformer for high-resolution image restoration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 5728–5739. [Google Scholar]
- Chen, H.; Qi, Z.; Shi, Z. Remote sensing image change detection with transformers. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5607514. [Google Scholar] [CrossRef]
- Hong, D.; Han, Z.; Yao, J.; Gao, L.; Zhang, B.; Plaza, A.; Chanussot, J. SpectralFormer: Rethinking hyperspectral image classification with transformers. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5518615. [Google Scholar] [CrossRef]
- He, X.; Zhou, Y.; Zhao, J.; Zhang, D.; Yao, R.; Xue, Y. Swin transformer embedding UNet for remote sensing image semantic segmentation. IEEE Trans. Geosci. Remote Sens. 2022, 60, 4408715. [Google Scholar] [CrossRef]
- Chen, L.; Lu, X.; Zhang, J.; Chu, X.; Chen, C. Hinet: Half instance normalization network for image restoration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 182–192. [Google Scholar]
- Wang, Q.; Li, B.; Xiao, T.; Zhu, J.; Li, C.; Wong, D.F.; Chao, L.S. Learning deep transformer models for machine translation. arXiv 2019, arXiv:1906.01787. [Google Scholar]
- Guo, C.; Li, C.; Guo, J.; Loy, C.C.; Hou, J.; Kwong, S.; Cong, R. Zero-reference deep curve estimation for low-light image enhancement. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 1780–1789. [Google Scholar]
- Ren, S.; Zhou, D.; He, S.; Feng, J.; Wang, X. Shunted self-attention via multi-scale token aggregation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 10853–10862. [Google Scholar]
- Wang, R.; Zhang, Q.; Fu, C.-W.; Shen, X.; Zheng, W.-S.; Jia, J. Underexposed photo enhancement using deep illumination estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 6849–6857. [Google Scholar]
- Wei, C.; Wang, W.; Yang, W.; Liu, J. Deep retinex decomposition for low-light enhancement. arXiv 2018, arXiv:1808.04560. [Google Scholar]
- Cheng, G.; Han, J.; Zhou, P.; Guo, L. Multi-class geospatial object detection and geographic image classification based on collection of part detectors. ISPRS J. Photogramm. Remote Sens. 2014, 98, 119–132. [Google Scholar] [CrossRef]
- Cheng, G.; Han, J. A survey on object detection in optical remote sensing images. ISPRS J. Photogramm. Remote Sens. 2016, 117, 11–28. [Google Scholar] [CrossRef]
- Cheng, G.; Zhou, P.; Han, J. Learning rotation-invariant convolutional neural networks for object detection in VHR optical remote sensing images. IEEE Trans. Geosci. Remote Sens. 2016, 54, 7405–7415. [Google Scholar] [CrossRef]
- Li, K.; Wan, G.; Cheng, G.; Meng, L.; Han, J. Object detection in optical remote sensing images: A survey and a new benchmark. ISPRS J. Photogramm. Remote Sens. 2020, 159, 296–307. [Google Scholar] [CrossRef]
- Debevec, P.E.; Malik, J. Recovering high dynamic range radiance maps from photographs. Semin. Graph. Pap. Push. Boundaries 2023, 2, 643–652. [Google Scholar]
- Endo, Y.; Kanamori, Y.; Mitani, J. Deep reverse tone mapping. ACM Trans. Graph. 2017, 36, 177. [Google Scholar] [CrossRef]
- Yuan, L.; Chen, Y.; Wang, T.; Yu, W.; Shi, Y.; Jiang, Z.-H.; Tay, F.E.; Feng, J.; Yan, S. Tokens-to-token vit: Training vision transformers from scratch on imagenet. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 558–567. [Google Scholar]
- Paszke, A.; Gross, S.; Chintala, S.; Chanan, G.; Yang, E.; DeVito, Z.; Lin, Z.; Desmaison, A.; Antiga, L.; Lerer, A. Automatic differentiation in pytorch. In Proceedings of the NIPS 2017 Workshop Autodiff, Long Beach, CA, USA, 9 December 2017. [Google Scholar]
- Kingma, D.P. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| I1 | I2 | I3 | L1 | L2 | L3 | ||
|---|---|---|---|---|---|---|---|
| DeepUpe [45] | PSNR | 33.341 | 31.68 | 29.75 | 33.20 | 32.57 | 29.84 |
| SSIM | 0.9608 | 0.9476 | 0.9300 | 0.9381 | 0.9123 | 0.8532 | |
| RetineNet [46] | PSNR | 34.47 | 32.99 | 31.25 | 33.99 | 32.45 | 30.97 |
| SSIM | 0.9587 | 0.9467 | 0.9351 | 0.9191 | 0.893 | 0.8524 | |
| FMB [27] | PSNR | 32.02 | 30.30 | 28.17 | 34.17 | 32.61 | 30.41 |
| SSIM | 0.9536 | 0.9370 | 0.9163 | 0.9202 | 0.8945 | 0.8418 | |
| DCE [37] | PSNR | 35.53 | 33.23 | 31.36 | 34.20 | 32.65 | 30.86 |
| SSIM | 0.9633 | 0.9515 | 0.9335 | 0.9116 | 0.8964 | 0.8529 | |
| STAR [12] | PSNR | 35.28 | 33.14 | 31.62 | 33.09 | 32.41 | 30.55 |
| SSIM | 0.9622 | 0.9490 | 0.9344 | 0.9178 | 0.8929 | 0.8477 | |
| ours | PSNR | 36.45 | 34.71 | 32.04 | 34.22 | 32.73 | 30.99 |
| SSIM | 0.9639 | 0.9518 | 0.9354 | 0.9204 | 0.8965 | 0.8529 |
| I1 | I2 | I3 | L1 | L2 | L3 | ||
|---|---|---|---|---|---|---|---|
| DeepUpe [45] | PSNR | 30.33 | 29.50 | 26.89 | 33.77 | 32.57 | 30.43 |
| SSIM | 0.9509 | 0.9334 | 0.9080 | 0.9307 | 0.9123 | 0.8801 | |
| RetineNet [46] | PSNR | 31.41 | 30.18 | 28.42 | 35.40 | 34.10 | 32.32 |
| SSIM | 0.9434 | 0.9310 | 0.9112 | 0.9351 | 0.9161 | 0.8809 | |
| FMB [27] | PSNR | 32.19 | 30.64 | 28.22 | 35.71 | 34.35 | 32.36 |
| SSIM | 0.9549 | 0.9397 | 0.9186 | 0.9364 | 0.9186 | 0.8811 | |
| DCE [37] | PSNR | 32.02 | 30.45 | 28.37 | 35.46 | 34.35 | 32.26 |
| SSIM | 0.9550 | 0.9398 | 0.9101 | 0.936 | 0.9195 | 0.8839 | |
| STAR [12] | PSNR | 31.97 | 29.85 | 28.30 | 34.99 | 33.66 | 30.67 |
| SSIM | 0.9553 | 0.9394 | 0.9199 | 0.9342 | 0.9152 | 0.8742 | |
| ours | PSNR | 33.18 | 31.27 | 29.07 | 35.75 | 34.44 | 32.48 |
| SSIM | 0.9564 | 0.9409 | 0.9186 | 0.9367 | 0.9185 | 0.8820 |
| VHR-10 | |||||||
|---|---|---|---|---|---|---|---|
| I1 | I2 | I3 | L1 | L2 | L3 | ||
| w/o long-range module | PSNR | 35.87 | 33.2 | 31.00 | 34.18 | 32.67 | 30.44 |
| SSIM | 0.9637 | 0.9502 | 0.9340 | 0.9201 | 0.8952 | 0.8530 | |
| w/o short-range dynamic module | PSNR | 35.49 | 34.55 | 32.04 | 34.20 | 32.61 | 30.80 |
| SSIM | 0.9636 | 0.9526 | 0.9375 | 0.9202 | 0.8945 | 0.8503 | |
| w/o dynamic | PSNR | 36.36 | 34.56 | 31.81 | 34.19 | 32.59 | 30.29 |
| SSIM | 0.9643 | 0.9545 | 0.9394 | 0.9207 | 0.8938 | 0.8505 | |
| two branches (2*) | PSNR | 36.30 | 34.05 | 31.93 | 34.14 | 32.72 | 30.88 |
| SSIM | 0.9650 | 0.9518 | 0.9350 | 0.9196 | 0.8965 | 0.852 | |
| two branches (4*) | PSNR | 36.03 | 33.82 | 31.68 | 34.11 | 32.73 | 30.77 |
| SSIM | 0.9627 | 0.9506 | 0.9339 | 0.9201 | 0.8964 | 0.8494 | |
| one branch | PSNR | 35.94 | 33.68 | 31.40 | 34.06 | 32.54 | 30.7 |
| SSIM | 0.9621 | 0.9496 | 0.9334 | 0.9188 | 0.8932 | 0.8484 | |
| ours | PSNR | 36.45 | 34.71 | 32.04 | 34.22 | 32.73 | 30.89 |
| SSIM | 0.9639 | 0.9518 | 0.9354 | 0.9204 | 0.8965 | 0.8519 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cao, Y.; Tian, Y.; Su, X.; Xie, M.; Hao, W.; Wang, H.; Wang, F. Multi-Scale Long- and Short-Range Structure Aggregation Learning for Low-Illumination Remote Sensing Imagery Enhancement. Remote Sens. 2025, 17, 242. https://doi.org/10.3390/rs17020242
Cao Y, Tian Y, Su X, Xie M, Hao W, Wang H, Wang F. Multi-Scale Long- and Short-Range Structure Aggregation Learning for Low-Illumination Remote Sensing Imagery Enhancement. Remote Sensing. 2025; 17(2):242. https://doi.org/10.3390/rs17020242
Chicago/Turabian StyleCao, Yu, Yuyuan Tian, Xiuqin Su, Meilin Xie, Wei Hao, Haitao Wang, and Fan Wang. 2025. "Multi-Scale Long- and Short-Range Structure Aggregation Learning for Low-Illumination Remote Sensing Imagery Enhancement" Remote Sensing 17, no. 2: 242. https://doi.org/10.3390/rs17020242
APA StyleCao, Y., Tian, Y., Su, X., Xie, M., Hao, W., Wang, H., & Wang, F. (2025). Multi-Scale Long- and Short-Range Structure Aggregation Learning for Low-Illumination Remote Sensing Imagery Enhancement. Remote Sensing, 17(2), 242. https://doi.org/10.3390/rs17020242