Abstract
Riverbank sand overexploitation is threatening the ecology and shipping safety of rivers. The rapid identification of riverbank sand mining areas from satellite images is extremely important for ecological protection and shipping management. Image segmentation methods based on AI technology are gradually becoming popular in academia and industry. However, traditional neural networks have complex structures and numerous parameters, making them unsuitable for meeting the needs of rapid extraction in large areas. To improve efficiency, we proposed a lightweight multi-scale network (LMS Net), which uses a lightweight multi-scale (LMS) block in both the encoder and decoder. The lightweight multi-scale block combines parallel computing and depthwise convolution to reduce the parameters of the network and enhance its multi-scale extraction ability. We created a benchmark dataset to validate the accuracy and efficiency improvements of our network. Comparative experiments and ablation studies proved that our LMS Net is more efficient than traditional methods like Unet and more accurate than typical lightweight methods like Ghostnet and other more recent methods. The performance of our proposed network meets the requirements of river management.
1. Introduction
River sand is a non-metallic mineral produced by the repeated collision and friction of natural stones under the action of water [1]. It has become an important building material due to its high quality, easy mining and low cost. However, there have been frequent occurrences of excessive sand mining on riverbanks in recent years, leading to instability of the river and damage to the environment, affecting the safety of bridges and shipping. Therefore, it is vital to obtain the real-time statuses of sand mining areas on riverbanks and prevent excessive sand mining.
River management departments need a distribution map of the sand mining areas on the riverbank that meets the following specific requirements. First, the sand mining areas need to be automatically acquired by a computer. Second, the overall accuracy (OA) rate needs to be above 93% and no large sand mining areas must be left out. Third, the extracted areas need clear boundaries, without blurring or fragmentation. Lastly, the method needs to be fast and use little memory so that it can run on mobile devices such as laptops and tablets, making it convenient for managers to acquire the information. The traditional way to capture this information is field measurement, which faces difficulty in meeting real-time requirements.
Recently, remote sensing and satellite imaging technology has greatly promoted earth observation [2]. Compared with manual methods, remote sensing technology has obvious advantages in its ability to facilitate the continuous monitoring of riverbank sand mining [3], and high-resolution satellite images enable the necessary quick extraction of riverbank sand mining areas. Semantic segmentation is an important method in remote sensing imaging; it enables the pixel-level classification of images and suits the monitoring of riverbank sand mining areas.
Traditional methods of semantic segmentation are mainly based on simple features of images such as points and values. For example, segmentation based on a gray value uses thresholds and gradation to detect different categories of objects [4]. Edge detection algorithms use detection operators to obtain the edges of objects [5,6]. However, these methods ignore the spatial features and texture and color information of the images, and the improper selection of thresholds can lead to mistakes. For images with complex pixel changes, these methods perform relatively poorly. There are also methods based on the structures of structured regression forest (SRF) [7] or support vector machine (SVM) [8], but many parameters, such as the kernel function, need to be repeatedly adjusted in these methods. These parameters significantly impact the results; setting them improperly may lead to poor performance. Therefore, it is difficult to meet the accuracy requirements using traditional methods.
Recently, AI technology has attracted attention from many scholars [9]. Image segmentation methods based on AI technology have been commonly used in many kinds of tasks, including satellite images, due to their excellent precision [10,11]. Fully convolutional networks (FCNs) [12] have shown favorable results in remote sensing image segmentation tasks [13], such as Unet [14], Unet++ [15], Deeplab series [16] and HRnet [17]. However, these networks have too many parameters, which seriously reduces the efficiency of segmentation, especially for large-scale remote sensing images. The method should be improved to adapt to the real-time monitoring of sand mining behavior on riverbanks.
Feature information in the images is mainly extracted by the encoder in deep neural networks. There are two main structures of encoders: the convolutional structure and Transformer structure. The traditional fully convolutional structure is used in numerous models for semantic segmentation tasks, and some scholars have proposed adding plug-and-play modules into the model to improve the precision of feature extraction and prevent the loss of key features [18]. However, the method of adding modules leads to limited improvements in accuracy and also adds many parameters to the model, resulting in a decrease in computational efficiency. In recent years, models using Transformer based on self-attention have found more usage in image segmentation tasks [19]. Although Transformer can handle more complex data to generate accurate output, it also brings computational and storage challenges, requiring a large amount of computing resources and optimization algorithms to support its training and inference processes. The number of parameters in this structure even exceeds that of the entire fully convolutional neural network, making it unsuitable for riverbank sand mining area segmentation. Therefore, it is necessary to make lightweight improvements to convolutional neural networks to reduce the numbers of parameters and improve the efficiency.
In addition, due to the different areas of sand mining, the varying sizes of targets should also be considered. The network should consider targets of different sizes and be better able to extract multi-scale features.
Generalizable and real-time models are essential for the analysis of riverbank sand mining areas. Current models encounter challenges in computational demands and in multi-scale feature extraction [20]. To conquer these problems, in our study, we propose a lightweight multi-scale network (LMS Net) for quick results based on segmentation with high-resolution satellite images for a riverbank sand mining area.
Our research makes the following contributions:
- The use of LMS Net is proposed to improve the efficiency of detecting sand mining areas on the riverbank. The parameters of the network were reduced in number to at least 1/10 compared to the results obtained using typical networks like Unet, while maintaining similar accuracy.
- An LMS block was designed and added into our network. It enhances the multi-scale feature extraction ability and has shown good performance in multi-scale sand mining area segmentation.
- Compared to other lightweight networks, our network greatly improves segmentation accuracy while improving a few parameters, achieving a balance between computational resources and segmentation performance.
We introduce our research from the following aspects. Section 2 summarizes the existing lightweight semantic segmentation networks. In the third section, we discuss the overall architecture of the LMS network and the detailed structure of the LMS block. The fourth section presents the results of comparative experiments and an ablation study using tables and images. The last two sections draw conclusions and discuss the experimental results.
2. Related Works
This section summarizes and elaborates on the advantages and disadvantages of lightweight image segmentation networks proposed by previous researchers.
The core of lightweight networks is to modify the network from both the volume and speed perspectives while maintaining accuracy as much as possible. Several successful lightweight networks have emerged and been applied in remote sensing image processing.
SqueezeNet is an early lightweight network [21]. It uses the Fire module for parameter compression. Although it is not as widely used as other lightweight networks, its architectural ideas and experimental conclusions are still worth learning from.
The MobileNet model is a classic and widely used lightweight network. The core of the first generation of MobileNet is a depthwise separable convolution module, which is composed of both depthwise convolution and pointwise convolution [22]. MobileNet v2 uses linear bottlenecks and inverted residuals to reduce information loss [23]. MobileNet v3 introduced a squeeze-and-excitation module and hard-swish activation function to reduce the computational complexity [24].
The ShuffleNet series is also very important in lightweight networks. ShuffleNet v1 uses a pointwise group convolution module to accelerate calculation and shuffles the channels to boost the information flow between the feature channels [25]. ShuffleNet v2 introduced a channel split to further reduce the parameters [26].
GhostNet was designed for solving the problem of redundancy in feature maps [27]. It uses a ghost module with an identity mapping operation to expand the dimensions of the feature map, which is a cost-efficient way to generate more features.
In recent years, some scholars have conducted studies on the lightweight segmentation of satellite images, which is partially related to the segmentation of riverbank sand-mining areas. Chen et al. [3] proposed an improved DeepLabv3+ lightweight neural network, combining the MobileNetv2 backbone, a hybrid dilated convolution (HDC) module and a trip pooling module (SPN) to alleviate the gridding effect. Inuwa et al. [28] proposed a lightweight and memory-efficient network that can be deployed on resource-constrained devices and is suitable for real-time remote sensing applications. Bo et al. [29] proposed an ultra-lightweight network (ULN) to reduce the amount of calculation and improve the computation speed. This network achieved competitive results with fewer parameters. He et al. [30] proposed an enhanced end-to-end lightweight segmentation network dedicated to satellite imagery, where a superpixel segmentation pooling module is added to improve the accuracy. Wang et al. [31] explored a cost-effective multimodal sensing semantic segmentation model, which employed multiple lightweight modality-specific experts, an adaptive multimodal matching module and a feature extraction pipeline to improve the efficiency. Luo et al. [32] combined the advantages of convolutional neural networks and Transformer to propose the FSegNet network, introducing FasterViT and utilizing its efficient hierarchical attention to mitigate the surge in self-attention computation of the remote sensing images. Wang et al. [33] proposed a novel lightweight edge-supervised neural network for optical remote sensing images, where the backbone is lightened by a feature encoding subnet to achieve better performance compared with some typical methods. Yan et al. [34] introduced a lightweight network based on multi-scale asymmetric convolutional neural networks with an attention mechanism (MA-CNN-A) for ship-radiated noise classification. Wang et al. [35] proposed a multi-scale graph encoder–decoder network (MGEN) for multimodal data classification. Song et al. [36] employed a convolutional neural network model named DeeperLabC for the semantic segmentation of corals.
In summary, these networks mentioned above were all designed for general tasks in the segmentation of remote sensing images. Lightweight modifications were made to the networks to balance computational speed and accuracy. However, these general networks perform poorly in the special scenario of detecting sand mining behavior from riverbank images. Thus, it is vital to build a specific lightweight network dedicated to the task of evaluating riverbank sand mining area segmentation.
In our research, we propose a brand-new method of achieving riverbank sand mining area segmentation using high-resolution satellite images. Our method demonstrates lightweight improvements compared with traditional networks and also considers multi-scale feature extraction. The following sections introduce the detailed structure and experimental results of the model.
3. Materials and Methods
3.1. Image Dataset and Preprocessing
We proposed an image dataset to test the accuracy and efficiency of our network. The experimental data products are from the Gaofen-2 (GF-2) Satellite, which has an orbital altitude of 631 km and a 5-day revisit period. The resolution of the panchromatic band in its image is 1 m and the resolution of the multispectral bands (RGB and near-infrared) is 4 m. The wavelengths of each band are 450–520 nm in blue, 520–590 nm in green, 630–690 nm in red and 770–890 nm in near-infrared [30].
The dataset for our research was from 5 sets of satellite image products. Four of them were taken over Shulan, Jilin Province, China. These were acquired on 4 November 2022, 14 June 2023, 27 August 2023 and 15 October 2023. The other one was taken over Changsha, Hunan Province, China, on 20 July 2023. We selected 20 regions in these 5 images and marked all the sand mining areas at the riverbank as the ground-truth labels. All these images and corresponding labels were clipped to a size of 256 × 256. We used random rotations, shifts, blurring, salt and pepper noise and horizontal and vertical flips to expand the dataset and a ±0–5% random brightness jitter in the RGB bands for data augmentation. The augmented dataset was then divided into a training dataset, validation dataset and testing dataset at an approximate 8:1:1 ratio. Each dataset contained images with and without riverbank sand mining areas. The types and quantities of the images in each dataset are shown in Table 1, and Figure 1 uses 3 typical scenarios as examples to show the images in the dataset. We have already made part of this dataset open source. The 4 images taken over Shulan and the corresponding labels can be downloaded at https://pan.baidu.com/s/1symaNsAmXzamDR2Ljf7nlQ?pwd=uafb (accessed on 4 January 2025).

Table 1.
Types and quantities of images in the dataset.

Figure 1.
Examples of the benchmark dataset.
3.2. Overall Architecture of LMS Net
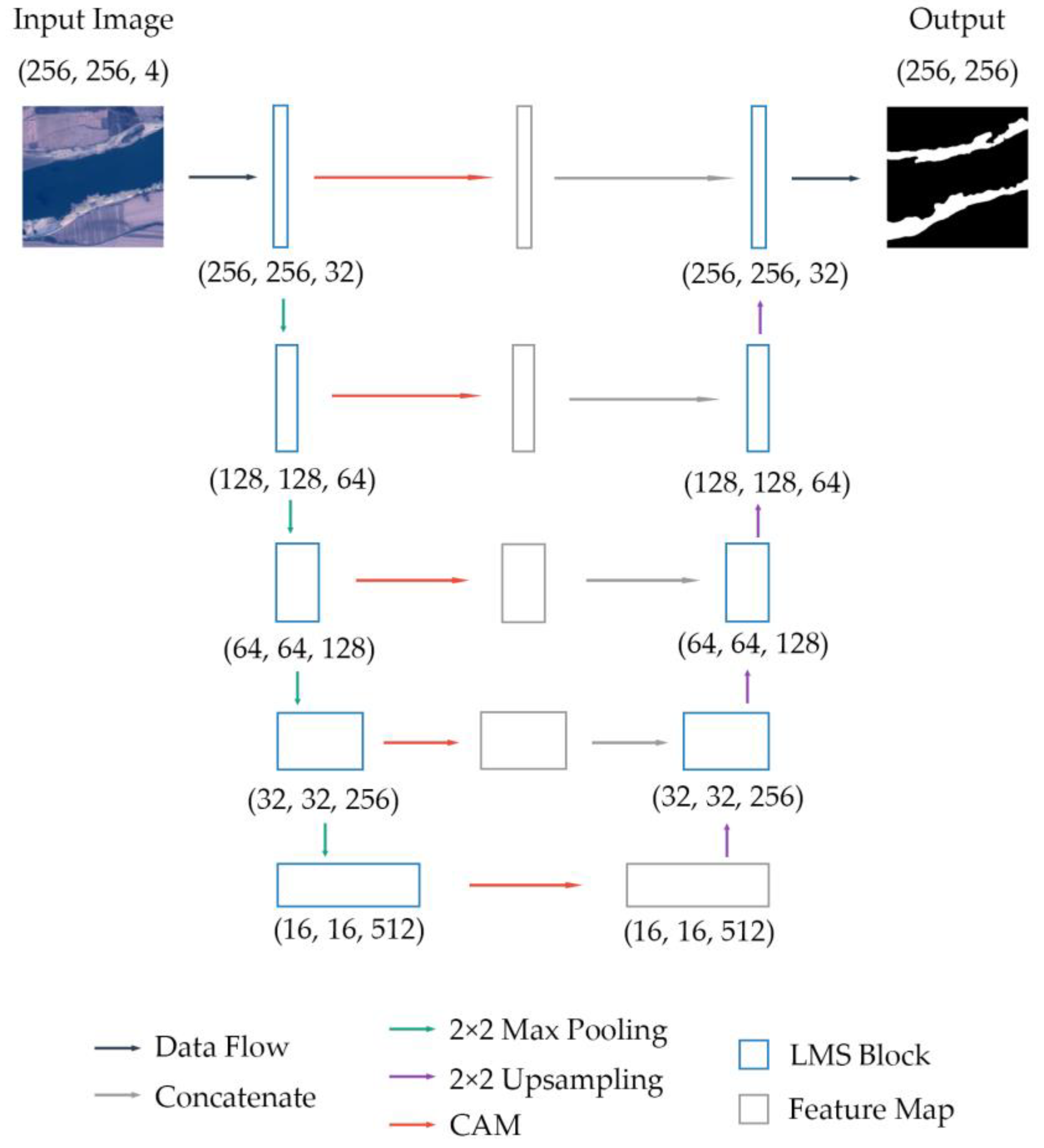
Figure 2 shows the overall architecture of our LMS Net. The numbers in the figure represent the sizes of the images or features. As shown in the figure, the LMS network has 5 levels from shallow to deep. In the first level, the original image was input to the LMS block, and the output was . This process can be represented by the following formula:
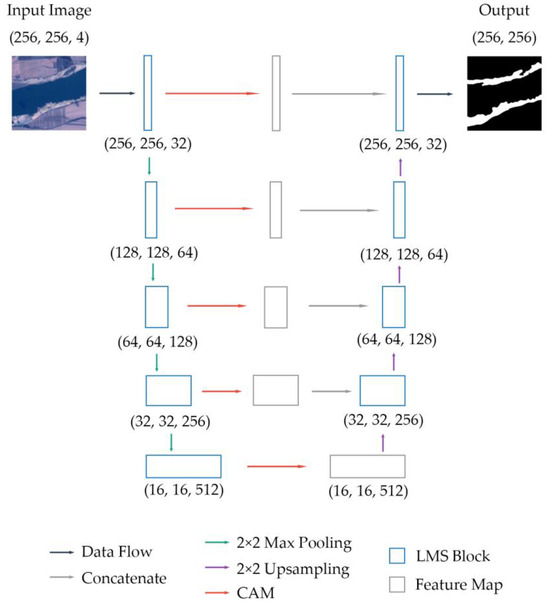
Figure 2.
Overall architecture of LMS Net.
Starting from the second level, the output features from the previous level were 2 × 2 maximum-pooled and then input to another LMS block. This step can be formulated as follows:
The output features of the LMS block at each level were input into a channel attention module (CAM), which is defined in Section 3.4. The output feature was . This can be described as follows:
In the decoding process, first, was upsampled through a 2 × 2 bilinear interpolation and then concatenated with by channel to form the feature .
Then, was input to the LMS block and upsampled through a 2 × 2 bilinear interpolation before being concatenated with in the last stage. The features returned to the previous level. These operations were then repeated in each level until the features returned to the first level.
At the end of the network, was calculated through a 3 × 3 convolutional layer and a channel number adjustment was obtained. Finally, the output result was obtained.
3.3. Detailed Structure of LMS Block
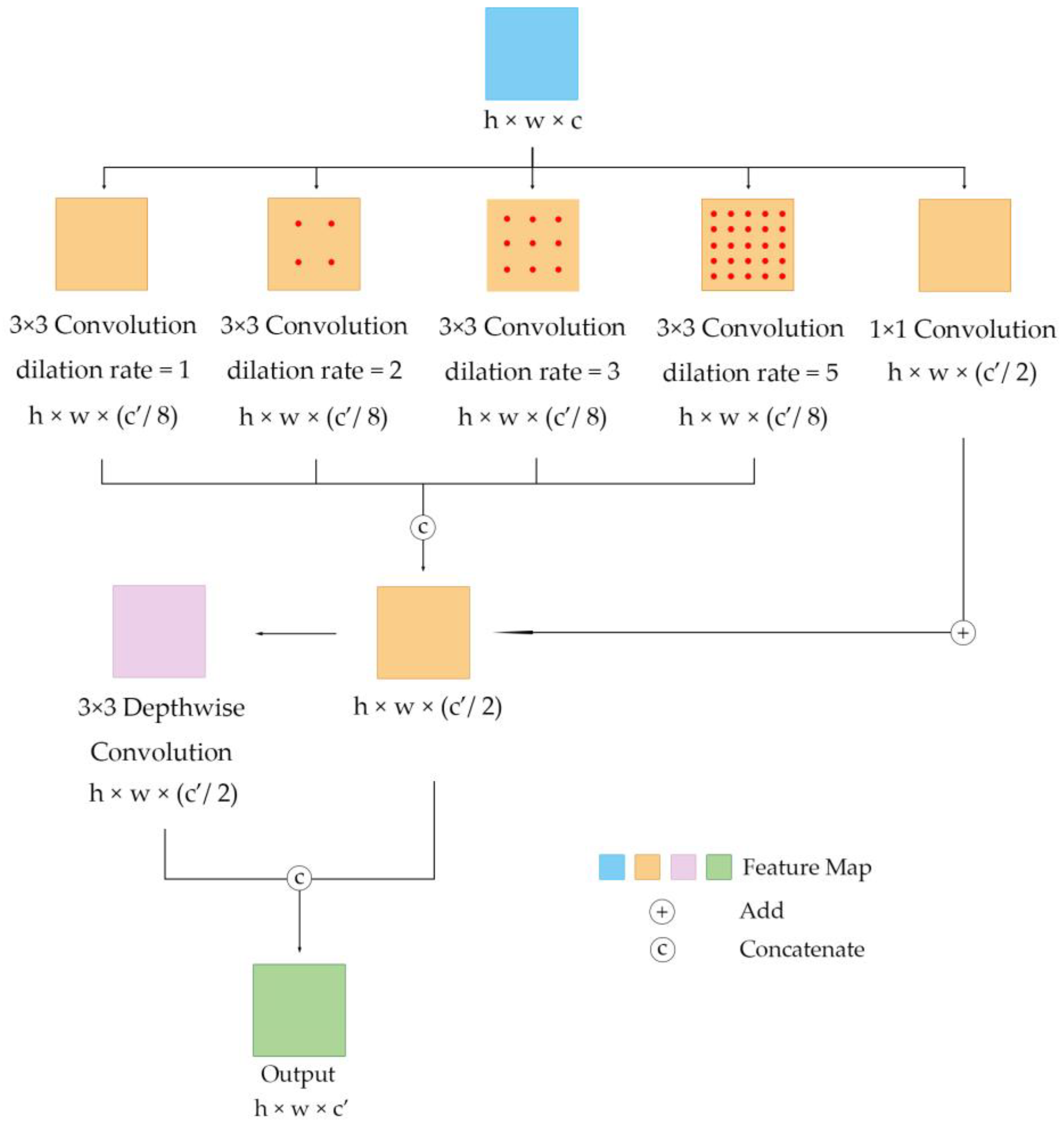
In our lightweight multi-scale network, we propose a new module for the encoder and decoder, a lightweight multi-scale (LMS) block, which is important for the quick extraction of the multi-scale features of the sand mining area from satellite images. This section shows the detailed structure of the LMS block.
The input of this module is from satellite images or feature maps from the middle levels. The input matrix was first calculated through 5 parallel convolutional layers. The first 4 of the 5 convolutional layers have a kernel size of 3; a stride of 1; and dilation rates of 1, 2, 3 and 5, respectively. These 4 parallel modules use different dilation rates to extract image features of different scales. The output matrices of these 4 layers are , , and , which have the same length and width and 1/8 the number of channels as the output matrix. Then, these four matrices are concatenated along the channel dimension to form a new feature, , which has half the number of channels compared to the output matrix.
Next, undergoes a depthwise convolution and the output matrix is . These two matrices are concatenated by channel and finally form the output matrix . This final step can be described as follows:
The detailed architecture of our LMS block is shown in Figure 3.
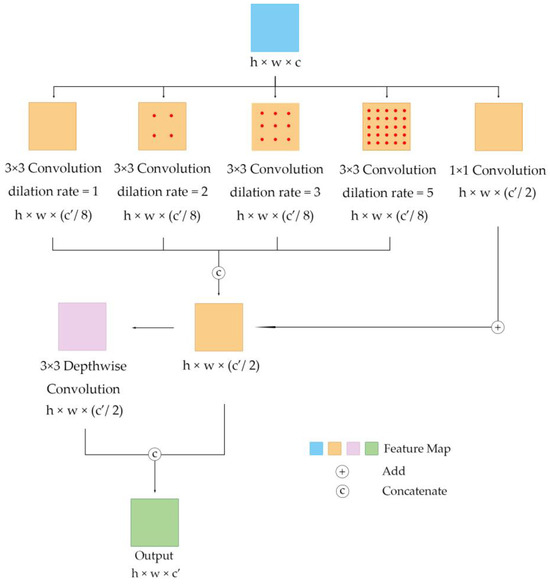
Figure 3.
Detailed architecture of LMS block.
3.4. Channel Attention Module
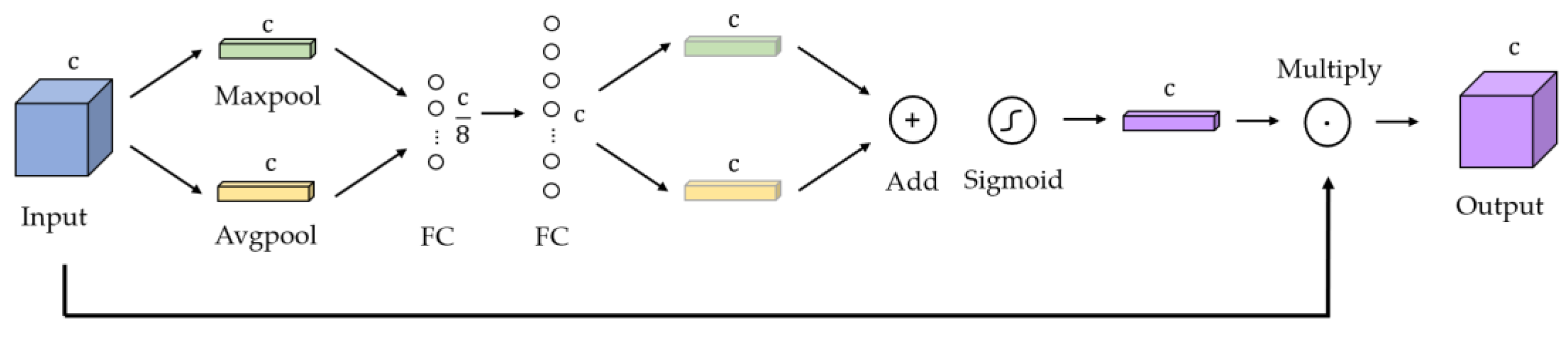
A channel attention module (CAM) [37] is used in our network to selectively emphasize the informative features in the images while suppressing features that are less informative. Figure 4 shows the detailed architecture of this module.
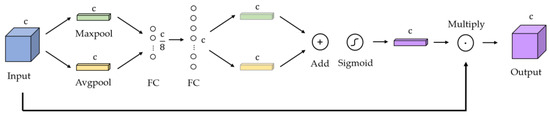
Figure 4.
Detailed architecture of channel attention module.
First, the input feature map containing channels is compressed in the dimension of the channel to form two 1 × 1 matrices, and . uses max pooling and uses average pooling. Then, and go through two fully connected layers, the first of which has nodes and the second of which has nodes. After this step, we can obtain two matrices with weights. Next, these two matrices are added to form one new vector. This vector is calculated with a sigmoid function . Finally, it is multiplied with the input feature map, and the output result is . This mechanism can be described as follows:
3.5. Experimental Design and Criteria
All the experiments in our research were deployed with Tensorflow 2.10.1 on an NVIDIA 4070 Graphics Processing Unit (GPU) manufactured by the MSI company in Kunshan, Jiangsu Province, China. To accelerate the training process, CUDA toolkit 11.2 and cuDNN library 8.1 were used.
Our LMS network was compared with Deeplab V3+ [16], MobileNet V2 [23], ShuffleNet V2 [26], SqueezeNet [21], GhostNet [27], Enet [38], Ultra-lightweight Net [29] and FSegNet [32]. All the networks were trained with an Adam optimizer. We set the hyperparameter to 0.9, to 0.999 and the initial learning rate to 0.0001. The networks were trained for 100 iterations, and the batch size was 10. We adopted the early stopping strategy, which terminates training when the loss does not decrease after 20 iterations of training. We used the CrossEntropy function to calculate the loss of all these networks, which is formulated as follows. All the network experiments were 9-fold cross-validated and averaged.
We also designed an ablation study to compare the performance before and after network improvement. Three networks, UNet, Unet-half and our LMS Net, were trained to verify the improvement in performance. Unet-half reduces the number of channels in each convolution layer by half, based on Unet. The optimizer, hyperparameters and early stopping strategy were the same in the ablation study and in the contrast experiment. The ablation experiment was also 9-fold cross-validated and averaged.
The output pixels of the results are composed of 4 kinds: True positive (TP) is the term used for pixels that are correctly segmented as sand mining areas. False positive (FP) is the term for those that are segmented as sand mining areas but are labeled as background. True negative (TN) is the term for those that are correctly segmented as background and false negative (FN) is the term for those that are segmented as background but are labeled as sand mining areas.
We evaluated the results of the experiment from the following perspectives. The overall accuracy (OA) refers to the ratio of TP and TN to the total number of output pixels. The precision (P), recall (R), mean intersection over union (mIoU), F1-score (F1) and Kappa are formulated as follows.
In addition, we also compared the number of parameters (Params), floating-point operation speed (Floating-Point Operations Per Second, FLOPS), output frame rate (Frame Per Second, FPS) and prediction time of each model.
4. Results
4.1. Network Training
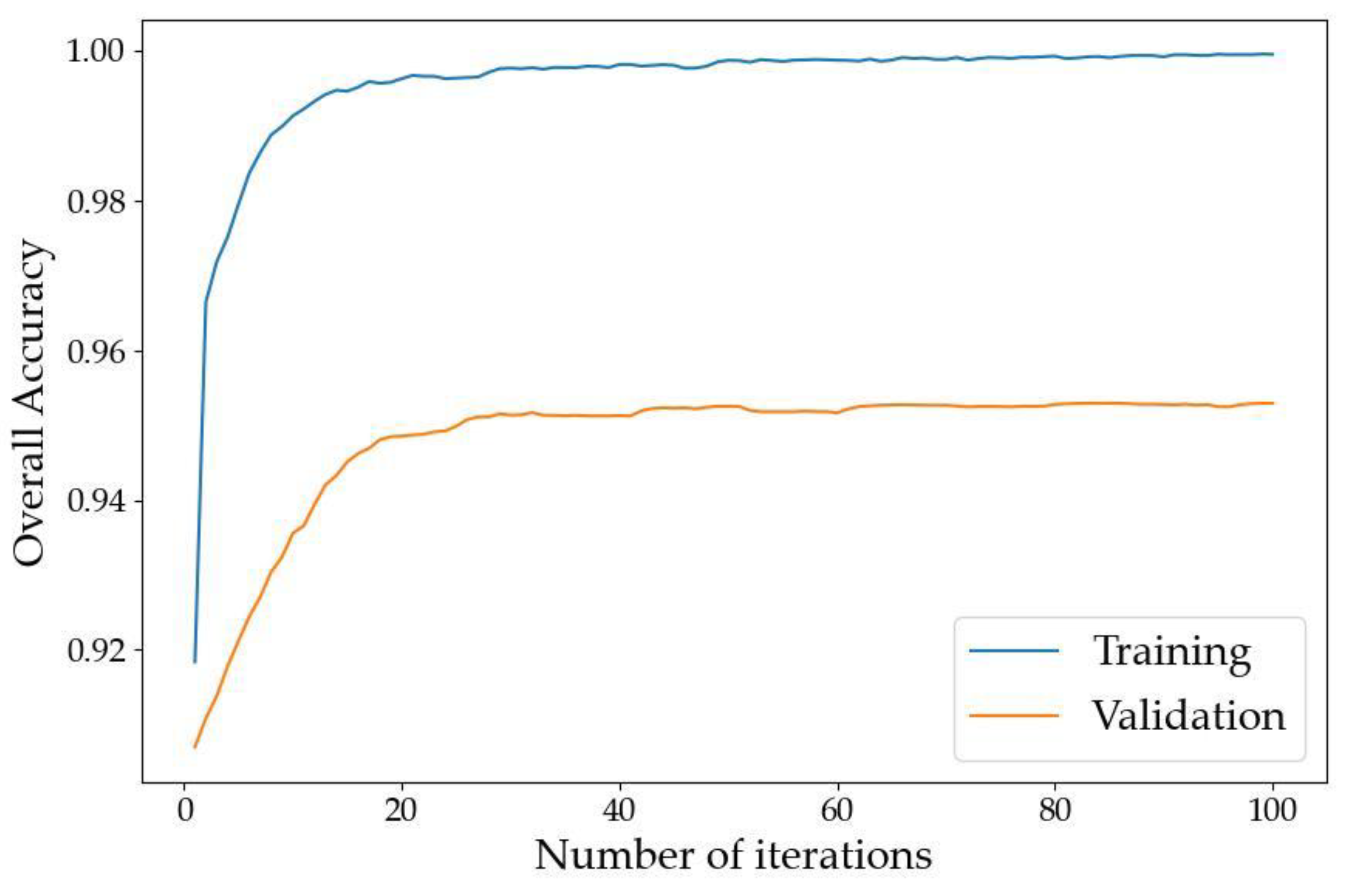
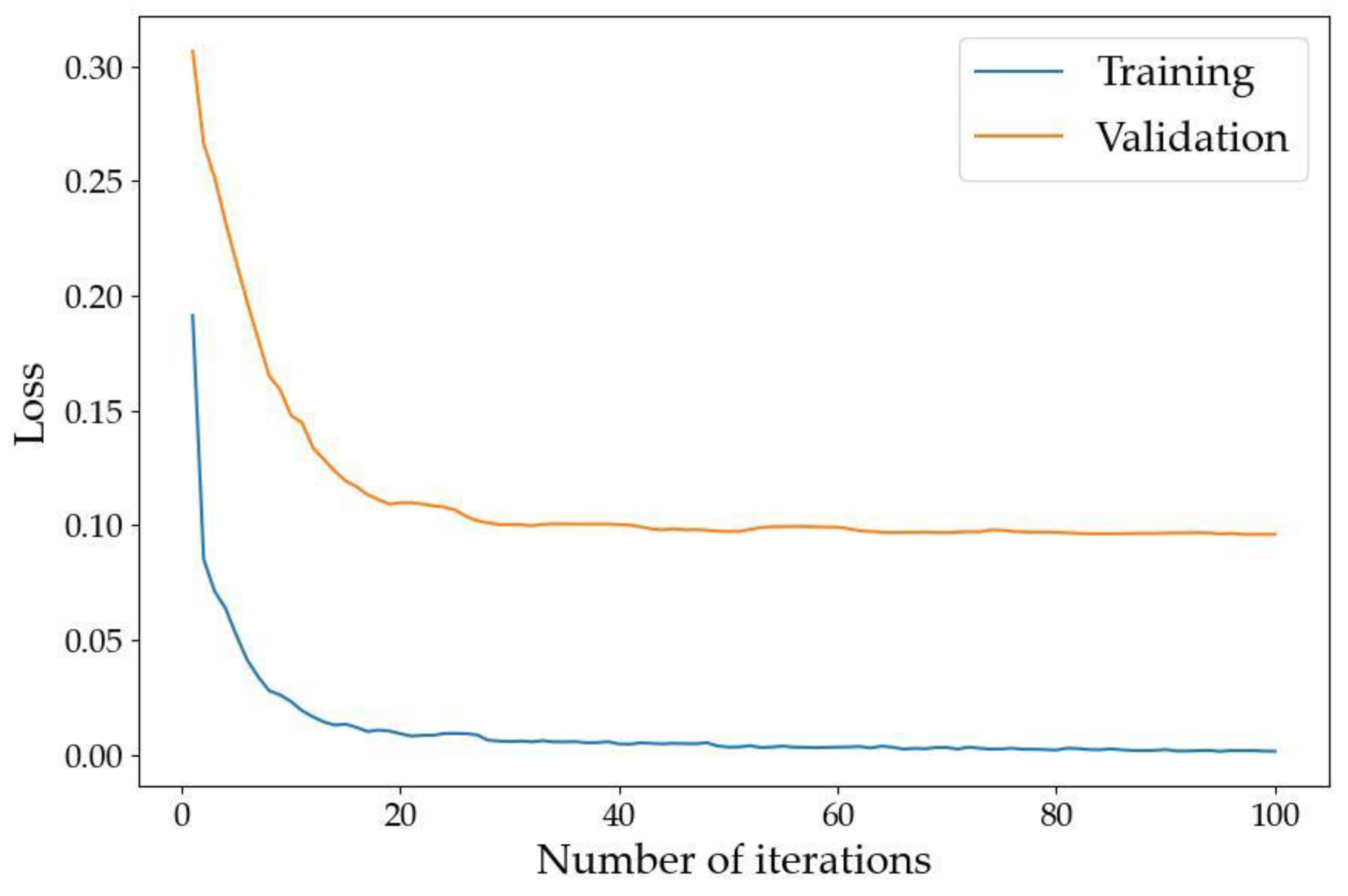
The overall accuracy (OA) curves of our LMS Net on both the training dataset and validation dataset are shown in Figure 5. The loss curves on the training dataset and validation dataset are shown in Figure 6.
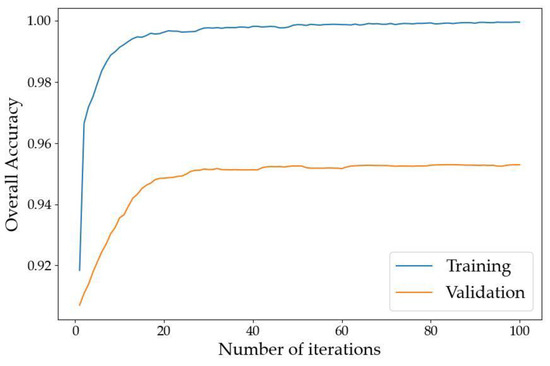
Figure 5.
Overall accuracy curves of LMS Net.
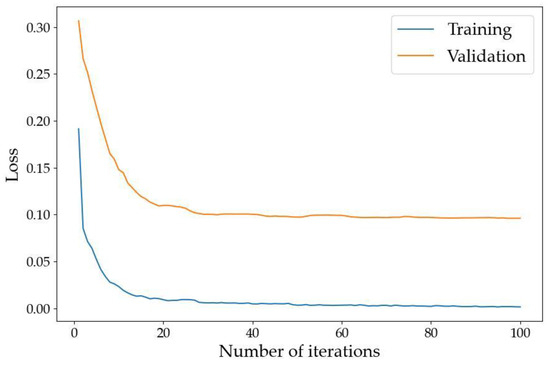
Figure 6.
Loss curves of LMS Net.
The two figures above show that the model converged after training on our benchmark dataset for 100 epochs.
4.2. Contrast Experiment
The quantitative results of the contrast experiment on our test dataset are shown below. The performance is shown in Table 2 and Table 3. The efficiency is shown in Table 4 and Table 5.
Table 2.
OA, precision and recall on benchmark dataset using different networks.
Table 3.
MIoU, F1 and Kappa on benchmark dataset using different networks.
Table 4.
Parameters, memory footprint and FLOPS on benchmark dataset using different networks.
Table 5.
FPS and prediction time on benchmark dataset using different networks.
We obtained the following results through experiments. First, compared to networks with fewer than 1M parameters, such as Deeplab V3+ [16], MobileNet V2 [23], ShuffleNet V2 [26] and SqueezeNet [21], our LMS Net had an mIoU increase of at least 18.19%, an F1-score increase of at least 13.97% and a Kappa increase of at least 26.56%. Second, compared to networks with more than 1M parameters, such as GhostNet [27], ENet [38] and ultra-lightweight net [29], our LMS Net had an mIoU increase of at least 5.92%, an F1-score increase of at least 2.71% and a Kappa increase of at least 2.62%. Third, the output frame rates of all networks were not significantly different except for MobileNet V2 [23]. Fourth, the number of parameters of FSegNet [32] is enormous compared to the number of parameters of the other networks. Although it showed the best precision among these networks, it takes about twice the time for prediction as other networks and consumes a larger amount of computing resources. The improvement in precision is also limited. Lastly, GhostNet [27], ENet [38], ultra-lightweight net [29] and our LMS Net require more floating-point operations, but the improvement in accuracy is significant.
We selected four typical scenarios as examples to show the results of sand mining area segmentation. The input images, ground truth and output segmentation results for Deeplab V3+ [16], MobileNet V2 [23], ShuffleNet V2 [26], SqueezeNet [21], GhostNet [27], ENet [38], ultra-lightweight net [29], FSegNet [32] and our LMS Net are shown in Figure 7.


Figure 7.
Examples of sand miming area segmentation results obtained using different networks.
Figure 7 shows that the segmentation performance of the networks with fewer than 1M parameters is relatively poor. The shapes of the results are incorrect, and the boundaries are not clear. In some scenarios, there are also serious errors and omissions in extraction. GhostNet [27], ENet [38] and ultra-lightweight net [29] perform much better, but there are still unclear areas in boundary extraction. However, FSegNet [32] and our LMS Net showed good performance. In all these scenarios, the output results of these two networks are closer to the true value and the boundary is clearer. The segmentation of sand mining areas at different scales is basically accurate.
4.3. Ablation Study
Table 6, Table 7, Table 8 and Table 9 present the quantitative results of our ablation study in terms of performance and efficiency, and examples are shown in Figure 8.
Table 6.
OA, precision and recall of ablation study.
Table 7.
MIoU, F1 and Kappa of ablation study.
Table 8.
Parameters, memory footprint and FLOPS of ablation study.
Table 9.
FPS and prediction time of ablation study.

Figure 8.
Examples of results in ablation study.
The quantitative results indicate that, compared to the Unet [14] and Unet-half, the improvements for LMS Net in terms of the OA, mIoU, F1 and Kappa were not obvious. However, our LMS Net decreased the parameters by at least 91.24%, decreased the FLOPS by at least 88.69% and increased the FPS by 42.84%, showing an obvious improvement in efficiency.
Figure 8 shows that the output segmentation results of Unet [14] have a certain degree of fragmentation, especially in the first image. In the Unet-half network, the fragmentation phenomenon has been alleviated to some extent. The performance of the LMS network is relatively better.
5. Discussion
From the results of the comparative experiment, we can divide the networks used for comparison into four categories. The performance of networks with fewer than 1M parameters, including Deeplab V3+ [16], MobileNet V2 [23], ShuffleNet V2 [26] and SqueezeNet [21], was relatively poor. Ultra-lightweight net [29] and LMS Net had fewer than 1M parameters more than those four networks but showed greatly improved accuracy. The performance of ENet [38] and Ghostnet [27] fell between that of the two categories above. FSegNet [32] consumed the most computational resources among these networks because of the usage of Transformer, and its improvement in segmentation quality was limited.
Considering that ultra-lightweight net [29] and LMS Net have more complex decoder designs compared to other networks, we can speculate that the rationality of decoder design greatly affects the segmentation accuracy. Although the number of network parameters in the other two categories is different, their decoder designs are very simple. Therefore, an increase in the number of parameters can bring a slight improvement in accuracy, but this improvement is far inferior to that achieved with a more reasonable decoder design for the network.
From the results of the ablation experiment, it can be seen that the LMS network can greatly reduce the number of parameters and improve computational speed while maintaining accuracy that is not significantly different from that of complex networks like Unet. The LMS network is even better than Unet in extracting targets of different sizes. These results indicate that our LMS network achieves the goal of lightweight and multi-scale object extraction.
In future research, we will focus on the design of decoder structures in lightweight networks and how to balance the number of parameters between encoders and decoders. We will seek new methods to optimize encoder parameters and design suitable lightweight segmentation decoders.
6. Conclusions
There are considerable challenges in the rapid segmentation of sand mining areas with satellite images of the riverbank. In our study, LMS Net was proposed for the quick segmentation of sand mining areas to improve efficiency while maintaining accuracy. LMS blocks were applied to replace the traditional convolutional blocks in our network. The LMS block combined branches of dilated convolutional layers and depthwise convolution, which reduced the number of parameters and enhanced the multi-scale feature extraction ability. To reduce the feature loss and further improve the multi-scale segmentation accuracy, a channel attention module was added into the network.
Our contrast experiment and ablation study validated the performance and efficiency of our proposed LMS network by comparing it with typical lightweight segmentation networks and different improved network stages. The results indicate that our network meets the requirements of river management in terms of segmentation efficiency and accuracy.
Author Contributions
Conceptualization, H.Z. and S.L.; methodology, H.Z.; software, H.Z.; validation, H.Z.; formal analysis, H.Z.; investigation, H.Z.; resources, H.L.; data curation, H.Z.; writing—original draft preparation, H.Z.; writing—review and editing, S.L.; visualization, H.Z.; supervision, S.L.; project administration, S.L.; funding acquisition, S.L. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Aerospace Information Research Institute (E3BD111704).
Data Availability Statement
Data are contained within the article.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Sundaralingam, K.; Peiris, A.; Sathiparan, N. Manufactured Sand as River Sand Replacement for Masonry Binding Mortar. In Proceedings of the 2021 Moratuwa Engineering Research Conference (MERCon), Moratuwa, Sri Lanka, 27–29 July 2021; pp. 403–408. [Google Scholar]
- He, C.; Liu, Y.; Wang, D.; Liu, S.; Yu, L.; Ren, Y. Automatic Extraction of Bare Soil Land from High-Resolution Remote Sensing Images Based on Semantic Segmentation with Deep Learning. Remote Sens. 2023, 15, 1646. [Google Scholar] [CrossRef]
- Chen, H.; Qin, Y.; Liu, X.; Wang, H.; Zhao, J. An improved DeepLabv3+ lightweight network for remote-sensing image semantic segmentation. Complex Intell. Syst. 2024, 10, 2839–2849. [Google Scholar] [CrossRef]
- Aouat, S.; Ait-hammi, I.; Hamouchene, I. A new approach for texture segmentation based on the Gray Level Co-occurrence Matrix. Multimed. Tools Appl. 2021, 80, 24027–24052. [Google Scholar] [CrossRef]
- Tian, X.; Chen, L.; Zhang, X. Classifying tree species in the plantations of southern China based on wavelet analysis and mathematical morphology. Comput. Geosci. 2021, 151, 104757. [Google Scholar] [CrossRef]
- Li, D.; Zhang, G.; Wu, Z.; Yi, L. An Edge Embedded Marker-Based Watershed Algorithm for High Spatial Resolution Remote Sensing Image Segmentation. IEEE Trans. Image Process. 2010, 19, 2781–2787. [Google Scholar] [CrossRef]
- Wang, X.; Zhai, S.; Niu, Y. Automatic Vertebrae Localization and Identification by Combining Deep SSAE Contextual Features and Structured Regression Forest. J. Digit. Imaging 2019, 32, 336–348. [Google Scholar] [CrossRef]
- Rao, C.S.; Karunakara, K. Efficient Detection and Classification of Brain Tumor using Kernel based SVM for MRI. Multimed. Tools Appl. 2022, 81, 7393–7417. [Google Scholar] [CrossRef]
- Wang, L.; Shoulin, Y.; Alyami, H.; Laghari, A.A.; Rashid, M.; Almotiri, J.; Alyamani, H.J.; Alturise, F. A novel deep learning-based single shot multibox detector model for object detection in optical remote sensing images. Geosci. Data J. 2024, 11, 237–251. [Google Scholar] [CrossRef]
- Ma, L.; Liu, Y.; Zhang, X.; Ye, Y.; Yin, G.; Johnson, B.A. Deep learning in remote sensing applications: A meta-analysis and review. ISPRS J. Photogramm. Remote Sens. 2019, 152, 166–177. [Google Scholar] [CrossRef]
- Zhang, J.X.; Yang, T.; Chai, T. Neural network control of underactuated surface vehicles with prescribed trajectory tracking performance. IEEE Trans. Neural Netw. Learn. Syst. 2022, 99, 1–14. [Google Scholar] [CrossRef] [PubMed]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. arXiv 2017, arXiv:1411.4038. [Google Scholar]
- Yin, Y.; Luo, S.; Zhou, J.; Kang, L.; Chen, C.Y.-C. LDCNet: Lightweight dynamic convolution network for laparoscopic procedures image segmentation. Neural Netw. 2024, 170, 441–452. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Springer: Berlin, Germany, 2015; pp. 234–241. [Google Scholar]
- Zhou, Z.; Rahman Siddiquee, M.M.; Tajbakhsh, N.; Liang, J. UNet++: A Nested U-Net Architecture for Medical Image Segmentation. In Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support: Third International Workshop, DLMIA 2017, and 7th International Workshop, ML-CDS 2017, Held in Conjunction with MICCAI 2017, Québec City, QC, Canada, 14 September 2017; Springer: Cham, Switzerland, 2018; pp. 3–11. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic image segmentation with deep convolu-tional nets, atrous convolution, and fully connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef]
- Sun, K.; Xiao, B.; Liu, D.; Wang, J. Deep high-resolution representation learning for human pose estimation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 5686–5696. [Google Scholar]
- Zhang, S.; Zhang, C. Modified U-Net for plant diseased leaf image segmentation. Comput. Electron. Agric. 2023, 204, 107511. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems 30 (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Tong, L.; Li, T.; Zhang, Q.; Zhang, Q.; Zhu, R.; Du, W.; Hu, P. LiViT-Net: A U-Net-like, lightweight Transformer network for retinal vessel segmentation. Comput. Struct. Biotechnol. J. 2024, 24, 213–224. [Google Scholar] [CrossRef]
- Iandola, F.N.; Han, S.; Moskewicz, M.W.; Ashraf, K.; Dally, W.J.; Keutzer, K. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5MB model size. arXiv 2016, arXiv:1602.07360. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. MobileNetV2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Howard, A.; Sandler, M.; Chen, B.; Wang, W.; Chen, L.C.; Tan, M.; Chu, G.; Vasudevan, V.; Zhu, Y.; Pang, R.; et al. Searching for MobileNetV3. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1314–1324. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6848–6856. [Google Scholar]
- Ma, N.; Zhang, X.; Zheng, H.-T.; Sun, J. ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design. In Proceedings of the Computer Vision—ECCV 2018, 15th European Conference, Munich, Germany, 8–14 September 2018; Springer: Cham, Switzerland; pp. 122–138. [Google Scholar]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C.; Xu, C. GhostNet: More Features from Cheap Operations. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 1577–1586. [Google Scholar]
- Inuwa, M.B.; Zhang, K.; Wang, J.; Haoyu, L. Lightweight multiscale framework for segmentation of high-resolution remote sensing imagery. J. Appl. Remote Sens. 2021, 15, 034508. [Google Scholar] [CrossRef]
- Li, B.; Lv, P.; Zhong, Y.; Zhang, L. High Resolution Remote Sensing Image Semantic Segmentation Based on Ultra-Lightweight Fully Convolution Neural Network. In Proceedings of the IGARSS 2022—2022 IEEE International Geoscience and Remote Sensing Symposium, Kuala Lumpur, Malaysia, 17–22 July 2022; pp. 3175–3178. [Google Scholar]
- Dong, H.; Yu, B.; Wu, W.; He, C. Enhanced Lightweight End-to-End Semantic Segmentation for High-Resolution Remote Sensing Images. IEEE Access 2022, 10, 70947–70954. [Google Scholar] [CrossRef]
- Wang, Q.; Chen, W.; Huang, Z.; Tang, H.; Yang, L. MultiSenseSeg: A Cost-Effective Unified Multimodal Semantic Segmentation Model for Remote Sensing. IEEE Trans. Geosci. Remote Sens. 2024, 62, 1–24. [Google Scholar] [CrossRef]
- Luo, W.; Deng, F.; Jiang, P.; Dong, X.; Zhang, G. FSegNet: A Semantic Segmentation Network for High-Resolution Remote Sensing Images That Balances Efficiency and Performance. IEEE Geosci. Remote Sens. Lett. 2024, 21, 1–5. [Google Scholar] [CrossRef]
- Wang, L.; Long, C.; Li, X.; Tang, X.; Bai, Z.; Gao, H. CSFFNet: Lightweight cross-scale feature fusion network for salient object detection in remote sensing images. IET Image Process. 2024, 18, 602–614. [Google Scholar] [CrossRef]
- Yan, C.; Yan, S.; Yao, T.; Yu, Y.; Pan, G.; Liu, L.; Wang, M.; Bai, J. A Lightweight Network Based on Multi-Scale Asymmetric Convolutional Neural Networks with Attention Mechanism for Ship-Radiated Noise Classification. J. Mar. Sci. Eng. 2024, 12, 130. [Google Scholar] [CrossRef]
- Wang, F.; Du, X.; Zhang, W.; Nie, L.; Wang, H.; Zhou, S.; Ma, J. Remote Sensing LiDAR and Hyperspectral Classification with Multi-Scale Graph Encoder–Decoder Network. Remote Sens. 2024, 16, 3912. [Google Scholar] [CrossRef]
- Song, H.; Mehdi, S.R.; Zhang, Y.; Shentu, Y.; Wan, Q.; Wang, W.; Raza, K.; Huang, H. Development of Coral Investigation System Based on Semantic Segmentation of Single-Channel Images. Sensors 2021, 21, 1848. [Google Scholar] [CrossRef] [PubMed]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. CBAM: Convolutional block attention module. In Computer Vision—ECCV 2018, Proceedings of the 15th European Conference, Munich, Germany, 8–14 September 2018; Springer: Cham, Switzerland, 2018; pp. 3–19. [Google Scholar]
- Paszke, A.; Chaurasia, A.; Kim, S.; Culurciello, E.J.A. ENet: A Deep Neural Network Architecture for Real-Time Semantic Segmentation. arXiv 2017, arXiv:1606.02147. [Google Scholar]




Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).