
Synthesizing Remote Sensing Images from Land Cover Annotations via Graph Prior Masked Diffusion


Abstract
1. Introduction
- We propose a novel graph-prior masked diffusion-based remote sensing image synthesis framework using the guidance of a semantic map. The model encodes the semantic map using a graph transformer, which effectively captures the spatial dependencies and contextual relationships between different land cover classes, thus enhancing the fidelity and consistency of the generated results.
- We propose a scene-aware guidance strategy to enhance the diversity of the generated images by leveraging the semantic context of similar scenes.
- Our method achieves state-of-the-art performance on the OpenEarthMap dataset.
2. Related Work
2.1. Diffusion Models
2.2. Semantic Image Synthesis
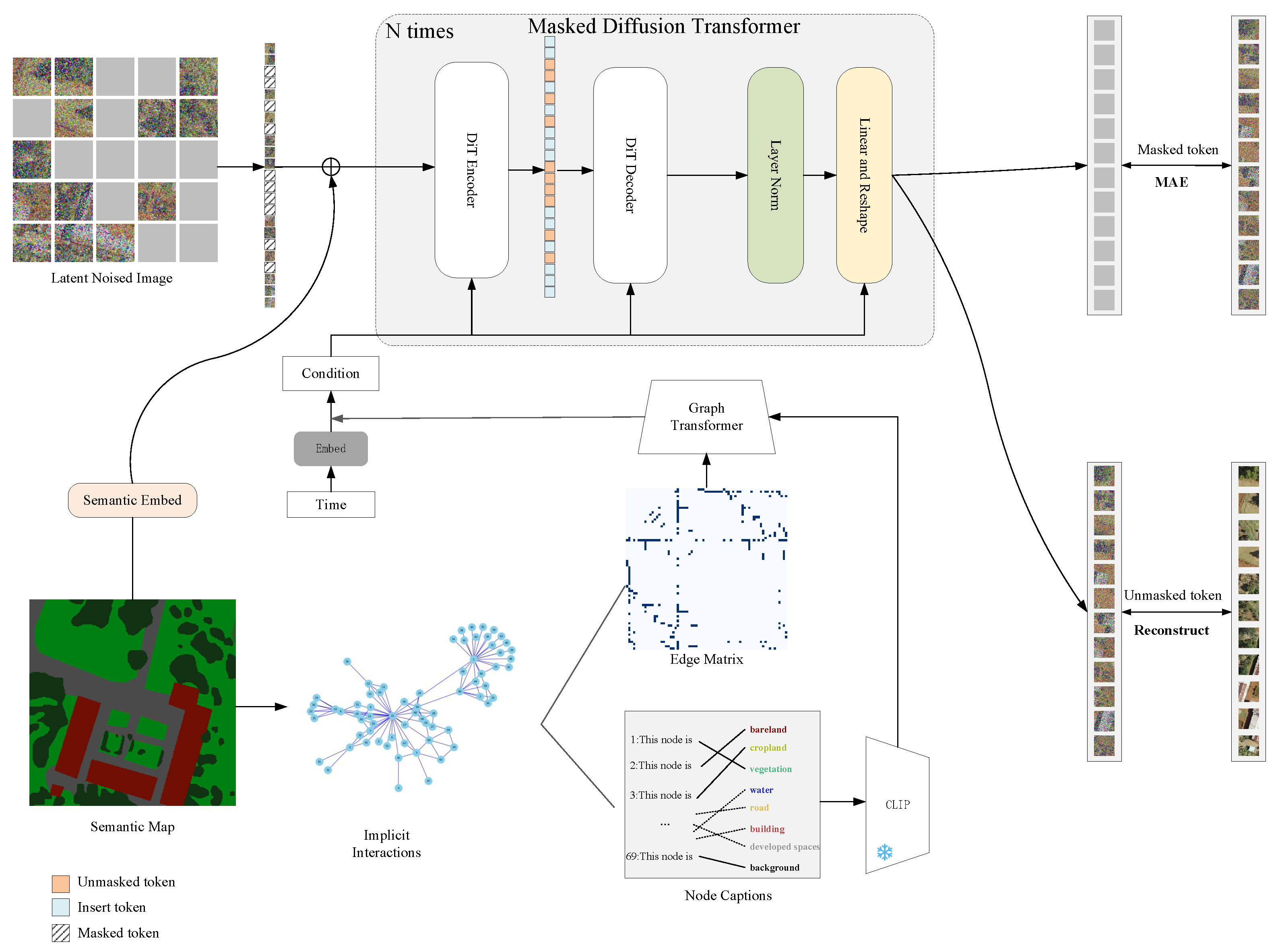
3. Method
3.1. Preliminary
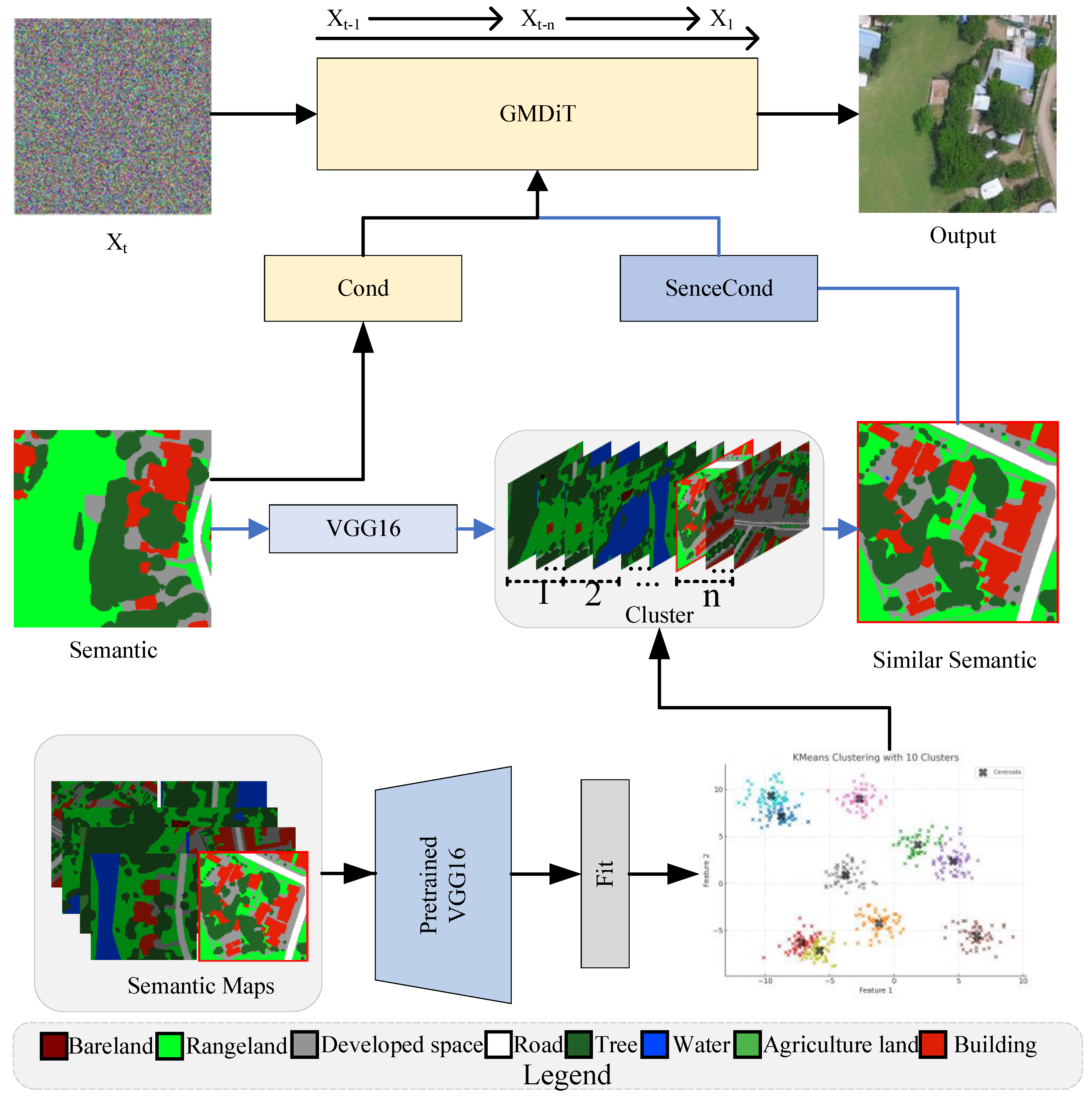
3.2. Semantic Graph Construction
3.3. Graph Transformer
3.4. Graph-Masked Diffusion Transformer Framework
3.5. Loss Function
3.6. Scene-Aware Guidance
4. Experiment Setups
4.1. Dataset
4.2. Comparison with SOTA Models
4.3. Ablation Study
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- Liu, X.; Yin, G.; Shao, J.; Wang, X.; Li, H. Learning to Predict Layout-to-image Conditional Convolutions for Semantic Image Synthesis. arXiv 2019, arXiv:1910.06809. [Google Scholar]
- Park, T.; Liu, M.Y.; Wang, T.C.; Zhu, J.Y. Semantic Image Synthesis With Spatially-Adaptive Normalization. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 2332–2341. [Google Scholar]
- Wang, T.C.; Liu, M.Y.; Zhu, J.Y.; Tao, A.; Kautz, J.; Catanzaro, B. High-Resolution Image Synthesis and Semantic Manipulation with Conditional GANs. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Dhariwal, P.; Nichol, A. Diffusion models beat gans on image synthesis. Adv. Neural Inf. Process. Syst. 2021, 34, 8780–8794. [Google Scholar]
- Zheng, H.; Nie, W.; Vahdat, A.; Anandkumar, A. Fast Training of Diffusion Models with Masked Transformers. arXiv 2023, arXiv:2306.09305. [Google Scholar]
- Rombach, R.; Blattmann, A.; Lorenz, D.; Esser, P.; Ommer, B. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 10684–10695. [Google Scholar]
- Alharmi, G.; Al-Khazraji, A. Generative adversarial networks: A recent survey. In Proceedings of the 6th Smart Cities Symposium (SCS 2022), Bahrain, 6–8 December 2022; IET: Singapore, 2022; Volume 2022, pp. 547–552. [Google Scholar]
- Song, J.; Meng, C.; Ermon, S. Denoising Diffusion Implicit Models. arXiv 2022, arXiv:2010.02502. [Google Scholar]
- Peebles, W.; Xie, S. Scalable diffusion models with transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–6 October 2023; pp. 4195–4205. [Google Scholar]
- Gao, S.; Zhou, P.; Cheng, M.M.; Yan, S. Masked diffusion transformer is a strong image synthesizer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–6 October 2023; pp. 23164–23173. [Google Scholar]
- Wang, H.; Wang, J.; Wang, J.; Zhao, M.; Zhang, W.; Zhang, F.; Xie, X.; Guo, M. GraphGAN: Graph Representation Learning with Generative Adversarial Nets. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Tseng, A.M.; Diamant, N.; Biancalani, T.; Scalia, G. GraphGUIDE: Interpretable and Controllable Conditional Graph Generation with Discrete Bernoulli Diffusion. arXiv 2023, arXiv:2302.03790. [Google Scholar]
- Vignac, C.; Krawczuk, I.; Siraudin, A.; Wang, B.; Cevher, V.; Frossard, P. DiGress: Discrete Denoising Diffusion for Graph Generation. arXiv 2022, arXiv:2209.14734. [Google Scholar]
- Sohl-Dickstein, J.N.; Weiss, E.A.; Maheswaranathan, N.; Ganguli, S. Deep Unsupervised Learning using Nonequilibrium Thermodynamics. arXiv 2015, arXiv:1503.03585. [Google Scholar]
- Nichol, A.; Dhariwal, P.; Ramesh, A.; Shyam, P.; Mishkin, P.; McGrew, B.; Sutskever, I.; Chen, M. Glide: Towards photorealistic image generation and editing with text-guided diffusion models. arXiv 2021, arXiv:2112.10741. [Google Scholar]
- Ramesh, A.; Dhariwal, P.; Nichol, A.; Chu, C.; Chen, M. Hierarchical text-conditional image generation with clip latents. arXiv 2022, arXiv:2204.06125. [Google Scholar]
- Wang, W.; Bao, J.; Zhou, W.; Chen, D.; Chen, D.; Yuan, L.; Li, H. Semantic image synthesis via diffusion models. arXiv 2022, arXiv:2207.00050. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. Adv. Neural Inf. Process. Syst. 2014, 27, 2672–2680. [Google Scholar]
- <i>Heusel, M.; Ramsauer, H.; Unterthiner, T.; Nessler, B.; Hochreiter, S. Gans trained by a two time-scale update rule converge to a local nash equilibrium. Adv. Neural Inf. Process. Syst. 2017, 30, 6629–6640. [Google Scholar]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1125–1134. [Google Scholar]
- Karras, T.; Aittala, M.; Aila, T.; Laine, S. Elucidating the Design Space of Diffusion-Based Generative Models. In Proceedings of the 36th International Conference on Neural Information Processing Systems, New Orleans, LA, USA, 28 November–9 December 2022. [Google Scholar]
- Kirillov, A.; Mintun, E.; Ravi, N.; Mao, H.; Rolland, C.; Gustafson, L.; Xiao, T.; Whitehead, S.; Berg, A.C.; Lo, W.Y.; et al. Segment anything. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–6 October 2023; pp. 4015–4026. [Google Scholar]
- Xue, H.; Huang, Z.; Sun, Q.; Song, L.; Zhang, W. Freestyle Layout-to-Image Synthesis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 18–22 June 2023. [Google Scholar]
- Lv, Z.; Wei, Y.; Zuo, W.; Wong, K.Y.K. PLACE: Adaptive Layout-Semantic Fusion for Semantic Image Synthesis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024. [Google Scholar]
- Sastry, S.; Khanal, S.; Dhakal, A.; Jacobs, N. GeoSynth: Contextually-Aware High-Resolution Satellite Image Synthesis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 460–470. [Google Scholar]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning transferable visual models from natural language supervision. In Proceedings of the International Conference on Machine Learning, Virtual, 18–24 July 2021; pp. 8748–8763. [Google Scholar]
- Kingma, D.P. Auto-encoding variational bayes. arXiv 2013, arXiv:1312.6114. [Google Scholar]
- Song, Y.; Sohl-Dickstein, J.; Kingma, D.P.; Kumar, A.; Ermon, S.; Poole, B. Score-based generative modeling through stochastic differential equations. arXiv 2020, arXiv:2011.13456. [Google Scholar]
- Lou, C.; Al-qaness, M.A.; AL-Alimi, D.; Dahou, A.; Abd Elaziz, M.; Abualigah, L.; Ewees, A.A. Land use/land cover (LULC) classification using hyperspectral images: A review. Geo-Spat. Inf. Sci. 2024, 28, 345–386. [Google Scholar] [CrossRef]
- Yang, J.; Liu, Z.; Xiao, S.; Li, C.; Lian, D.; Agrawal, S.; Singh, A.; Sun, G.; Xie, X. Graphformers: Gnn-nested transformers for representation learning on textual graph. Adv. Neural Inf. Process. Syst. 2021, 34, 28798–28810. [Google Scholar]
- Ho, J.; Salimans, T. Classifier-free diffusion guidance. arXiv 2022, arXiv:2207.12598. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Loshchilov, I. Decoupled weight decay regularization. arXiv 2017, arXiv:1711.05101. [Google Scholar]
- Xia, J.; Yokoya, N.; Adriano, B.; Broni-Bediako, C. Openearthmap: A benchmark dataset for global high-resolution land cover mapping. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 2–7 January 2023; pp. 6254–6264. [Google Scholar]
- MacQueen, J. Some methods for classification and analysis of multivariate observations. In Proceedings of the Fifth Berkeley Symposium on Mathematical Statistics and Probability, Volume 1: Statistics; University of California Press: Oakland, CA, USA, 1967; Volume 5, pp. 281–298. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | TYPE | FID ↓ | Inference Time (S) ↓ |
|---|---|---|---|
| Pix2PixHD | GAN | 51.74 | 0.007 |
| SPADE | GAN | 44.56 | 0.010 |
| SDM | Diffusion | 101.46 | 7.86 |
| PLACE | Diffusion | 49.51 | 8.87 |
| Freestyle | Diffusion | 30.28 | 7.46 |
| LDM | Diffusion | 29.19 | 2.59 |
| GeoSynth | Diffusion | 26.43 | 2.05 |
| GMDiT(Ours) | Diffusion | 23.15 | 2.01 |
| Type | FID ↓ |
|---|---|
| Without Graph Prior | 26.41 |
| With Graph Prior | 23.15 |
| Number of Clusters (K) | FID ↓ |
|---|---|
| 0 (cfg) | 26.83 |
| 5 | 24.65 |
| 10 | 23.15 |
| 15 | 23.78 |
| 20 | 24.12 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Deng, K.; Wei, S.; Pang, S.; Jiang, H.; Su, B. Synthesizing Remote Sensing Images from Land Cover Annotations via Graph Prior Masked Diffusion. Remote Sens. 2025, 17, 2254. https://doi.org/10.3390/rs17132254
Deng K, Wei S, Pang S, Jiang H, Su B. Synthesizing Remote Sensing Images from Land Cover Annotations via Graph Prior Masked Diffusion. Remote Sensing. 2025; 17(13):2254. https://doi.org/10.3390/rs17132254
Chicago/Turabian StyleDeng, Kai, Siyuan Wei, Shiyan Pang, Huiwei Jiang, and Bo Su. 2025. "Synthesizing Remote Sensing Images from Land Cover Annotations via Graph Prior Masked Diffusion" Remote Sensing 17, no. 13: 2254. https://doi.org/10.3390/rs17132254
APA StyleDeng, K., Wei, S., Pang, S., Jiang, H., & Su, B. (2025). Synthesizing Remote Sensing Images from Land Cover Annotations via Graph Prior Masked Diffusion. Remote Sensing, 17(13), 2254. https://doi.org/10.3390/rs17132254