1. Introduction
Driven by rapid technological advancements, the remote sensing imagery domain is undergoing unprecedented growth, demonstrating remarkable progress across multiple dimensions [
1,
2,
3]. Remote sensing is closely connected to disciplines such as geomatics and surveying technology, computer science, earth sciences, and optoelectronic information. It is widely applied in military intelligence [
4], urban planning [
5], resource exploration [
6], and other areas. Furthermore, object detection in remote sensing imagery is now an indispensable technology, drawing widespread interest from multiple fields. Object detection aims to identify specific targets within visual data while precisely localizing their spatial coordinates and semantic categories, enabling efficient extraction of actionable intelligence through localized region-of-interest analysis [
7,
8,
9].
Deep-learning-based approaches for remote sensing object detection are broadly categorized into single-stage and two-stage architectures. Single-stage object detection algorithms do not explicitly generate regions of interest (ROIs) but instead formulate the detection task as a unified regression problem applied to the entire image. Representative single-stage detection algorithms include Single Shot MultiBox Detector (SSD) [
10], You Only Look Once (YOLO) [
11], and CenterNet [
12]. In contrast, two-stage frameworks decompose the task into sequential phases: region proposal generation and target classification with localization. In the first phase, a Region Proposal Network (RPN) or a similar mechanism generate candidate regions by sliding predefined anchor boxes over feature maps, leveraging saliency analysis and spatial likelihood to identify potential target areas. These proposals undergo preliminary classification and bounding box regression. During the second phase, dedicated classification and regression subnetworks—integrated within the convolutional architecture—refine the candidate regions by extracting discriminative features to output precise target categories and spatial coordinates. The R-CNN series, including R-CNN [
13], Fast R-CNN [
14], Faster R-CNN [
15], and Mask R-CNN [
16], represents the canonical two-stage detection paradigm. While these methods excel on natural image benchmarks dominated by large objects against uncluttered backgrounds, their direct application to remote sensing imagery faces distinct challenges. The prevalence of small targets, extreme scale variations, and complex spatial contexts necessitates specialized architectural adaptations beyond conventional frameworks optimized for natural imagery.
However, remote sensing imagery presents unique challenges due to extreme variations in imaging altitudes, leading to substantial scale disparities across different object categories. Even for objects within the same category, significant intra-class scale diversity is frequently observed in aerial scenes. This pronounced scale discrepancy imposes severe constraints on feature extraction in convolutional neural networks (CNNs). While deep CNN layers capture contextual information to infer environmental context and coarse object outlines, they inevitably discard localized details critical for characterizing multi-scale targets. Consequently, relying solely on these high-level features fails to comprehensively represent objects with drastic scale variations, often resulting in missed detections that severely impact detection accuracy. These objects exhibit limited pixel coverage, indistinct feature representations, and scarce positive samples. Simultaneously, their precise localization poses substantial challenges as most deep learning architectures struggle to extract discriminative features from such minimal pixel footprints. Progressive down-sampling operations in conventional networks exacerbate this issue, causing progressive degradation of small object features into blurred and indistinguishable representations. Additionally, the structurally complex backgrounds of remote sensing images—containing redundant non-target objects with visual similarities to true targets—frequently induce false positives. This complexity also hinders precise edge feature extraction from imagery and complicates foreground–background separation, presenting a significant obstacle for reliable detection systems.
To address these challenges, we innovatively propose the MCRS-YOLO network for object detection in remote sensing images. This paper introduces a detection model based on YOLOv11 [
17], which enhances information flow and reduces object information loss through a multi-branch aggregation network. By reconstructing the feature pyramid via dynamic interpolation and multi-feature fusion, the model’s multiscale feature representation capability is further improved, and spatial semantic information is enriched. The introduction of a large depth-wise separable kernel module effectively leverages contextual information, expands the effective receptive field, and enhances detection performance for small objects. Additionally, the integration of NWD [
18] improves the model’s ability to recognize targets in complex backgrounds. The experimental results demonstrate that these optimization strategies significantly enhance the performance of object detection in remote sensing images.
The main contributions of this paper are as follows:
The MBA is designed in this paper. Multiple convolutional variants such as bypass convolution and depth-wise separable convolution (DSConv) are synergistically integrated into the deeper layers of the backbone network. In the neck network, we further combined convolutional operations with gating mechanisms. This design effectively enhances the diversity of visual features and improves information flow, thereby strengthening the network’s ability to model dense spatial transformations and mitigating the challenges caused by insufficient object information;
The MFRFPN is designed for spatial feature reconstruction and multi-scale pyramid context extraction. It captures the global context in both horizontal and vertical directions, obtaining the axial global context to explicitly model rectangular critical regions, effectively integrates hierarchical feature information, and enhances the model’s contextual awareness. Through dynamic interpolation and multi-feature fusion, the network further improves multi-scale feature representation capabilities and strengthens the model’s ability to recognize targets in complex backgrounds;
The LDSK is proposed in this paper. This module achieves an expanded effective receptive field by decomposing the 2D kernels of depth-wise convolution and dilated depth-wise convolution into two cascaded 1D separable kernels. By integrating multi-scale receptive field information and establishing long-range dependencies, it enhances feature extraction capabilities to improve small object perception;
The NWD is introduced into hybrid loss training, where a novel metric is utilized to measure the similarity of bounding boxes. It mitigates the sensitivity of conventional metrics to positional deviations in small objects, enhances the saliency of small target features, and suppresses background noise.
The remainder of this paper is organized as follows:
Section 2 reviews related work in the field.
Section 3 elaborates on the proposed methodology in detail.
Section 4 evaluates and analyzes the method through ablation studies, comparative experiments, and visualization analyses to validate its efficacy. Finally,
Section 5 concludes this study and outlines potential directions for future research.
3. Methods
Compared to previous versions, YOLOv11 stands out with an enhanced model structure. Its optimized gradient paths and modular design boost feature extraction while keeping the model lightweight. This suits it well for remote sensing images with complex backgrounds and multi-scale targets. YOLOv11 also has lower computational complexity than other YOLO versions. With GPU optimization and architectural improvements, YOLOv11 achieves faster inference speed than other YOLO variants, which is crucial for real-time processing of remote sensing imagery.
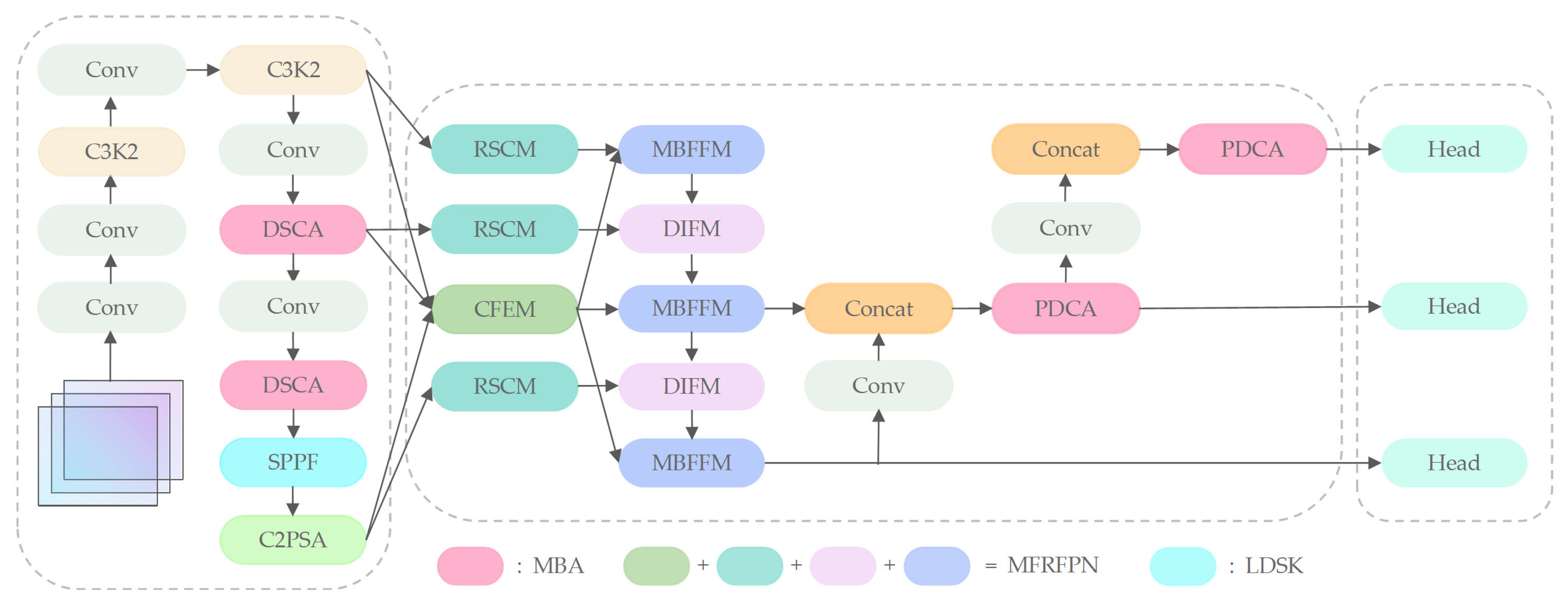
The YOLOv11 architecture comprises three core components: the backbone, neck, and head. The backbone network—incorporating modules like C3K2, SPPF, and C2PSA—serves as the primary feature extractor. In YOLOv11, the C3K2 module extracts features via stacked standard convolutional layers. However, it lacks multi-branch convolutions and local-–lobal feature interaction mechanisms, making it hard to retain fine-grained information of small targets. The SPPF module expands the receptive field through fixed-kernel-size pooling operations, but this leads to insufficient modeling of long-range dependencies for small targets. Additionally, the neck uses a traditional feature pyramid structure without adequately modeling the axial global context; so, it struggles to handle complex spatial relationships in remote sensing images. The loss function in YOLOv11 relies on the traditional IoU metric, which is highly sensitive to positional deviations in small object detection. Boundary box prediction errors for small objects are easily amplified, increasing both false positive and false negative rates. Therefore, we propose MCRS-YOLO, a network architecture specifically optimized for small object detection in remote sensing imagery. The overall framework is illustrated in
Figure 1.
Given the diminutive size and limited informational content of small objects, backbone networks struggle to capture their discriminative features. To address this, we propose the Depth-wise Separable Aggregation (DSCA) network in the deeper layers of the backbone, enhancing semantic depth and foundational feature extraction capabilities. Concurrently, we introduce the LDSK within the backbone’s feature extraction pipeline to expand the effective receptive field. The processed features from three distinct scales are then propagated to the neck network. Recognizing the pronounced scale variability of targets in remote sensing imagery, we observe that conventional neck designs inadequately leverage contextual guidance for multi-scale feature fusion, limiting spatial fidelity. The MFRFPN is proposed within the neck to resolve this issue through enhanced spatial feature reconstruction and multi-scale context aggregation. Additionally, the Partial Depth-wise Context Aggregation (PDCA) network is integrated to strengthen global perception of multi-scale targets. These innovations synergistically mitigate information degradation during feature transmission while enriching spatial–semantic representations and enabling more effective cross-scale integration. Further addressing the challenge of spatial sensitivity in small object detection—where complex background interference frequently introduces localization noise—we implement a hybrid loss training strategy that reduces IoU metric sensitivity to positional deviations. This approach suppresses background interference through adaptive weighting of localization confidence and semantic discriminability, ultimately enhancing overall detection robustness.
MBA’s DSCA replaces the C3K2 module in the deep layers of the backbone, and its PDCA is integrated into the neck network. MBA serves as the foundation of the network, providing enhanced features for subsequent modules like MFRFPN, LDSK, and NWD. Its enriched feature diversity improves MFRFPN’s multi-scale feature fusion, offers a stronger basis for LDSK’s context extraction, and aids NWD in accurately measuring bounding box similarity. MFRFPN relies on high-quality features from MBA for multi-scale feature reconstruction and fusion. LDSK’s ability to capture wide-ranging context features complements MFRFPN’s integration of features across scales. MFRFPN’s output is also a key basis for NWD’s bounding box similarity calculations. LDSK expands the receptive field to capture broader context information, working with MFRFPN to provide detailed local features and rich global context. The context features extracted by LDSK also inform NWD’s calculations. NWD optimizes the model’s prediction results based on high-quality features from preceding modules like MBA, MFRFPN, and LDSK. Improvements in these modules enhance NWD’s effectiveness.
3.1. Multi-Branch Aggregation Network
For the purpose of enhancing the diversity of visual characteristics and improve information flow, strengthen the network’s capability in modeling spatial transformations, and mitigate challenges caused by insufficient object feature representation, we propose the MBA. The MBA is not a single monolithic block, but rather a distributed design integrated at two strategic locations within the network architecture. As illustrated in the overall framework of
Figure 1 in this paper, the MBA module primarily corresponds to the following two components. The DSCA is embedded deep within the backbone network, aiming to enhance feature extraction capability and semantic depth. The PDCA is integrated into the neck network, designed to strengthen global perception and multi-scale feature fusion. Specifically, DSCA replaces the original C3K2 module in the backbone, while PDCA is incorporated into the neck structure. These two components together constitute the MBA module, which is strategically placed across the core processing pipeline of the detection framework—from the backbone to the neck.
3.1.1. Convolutional Backbone Network
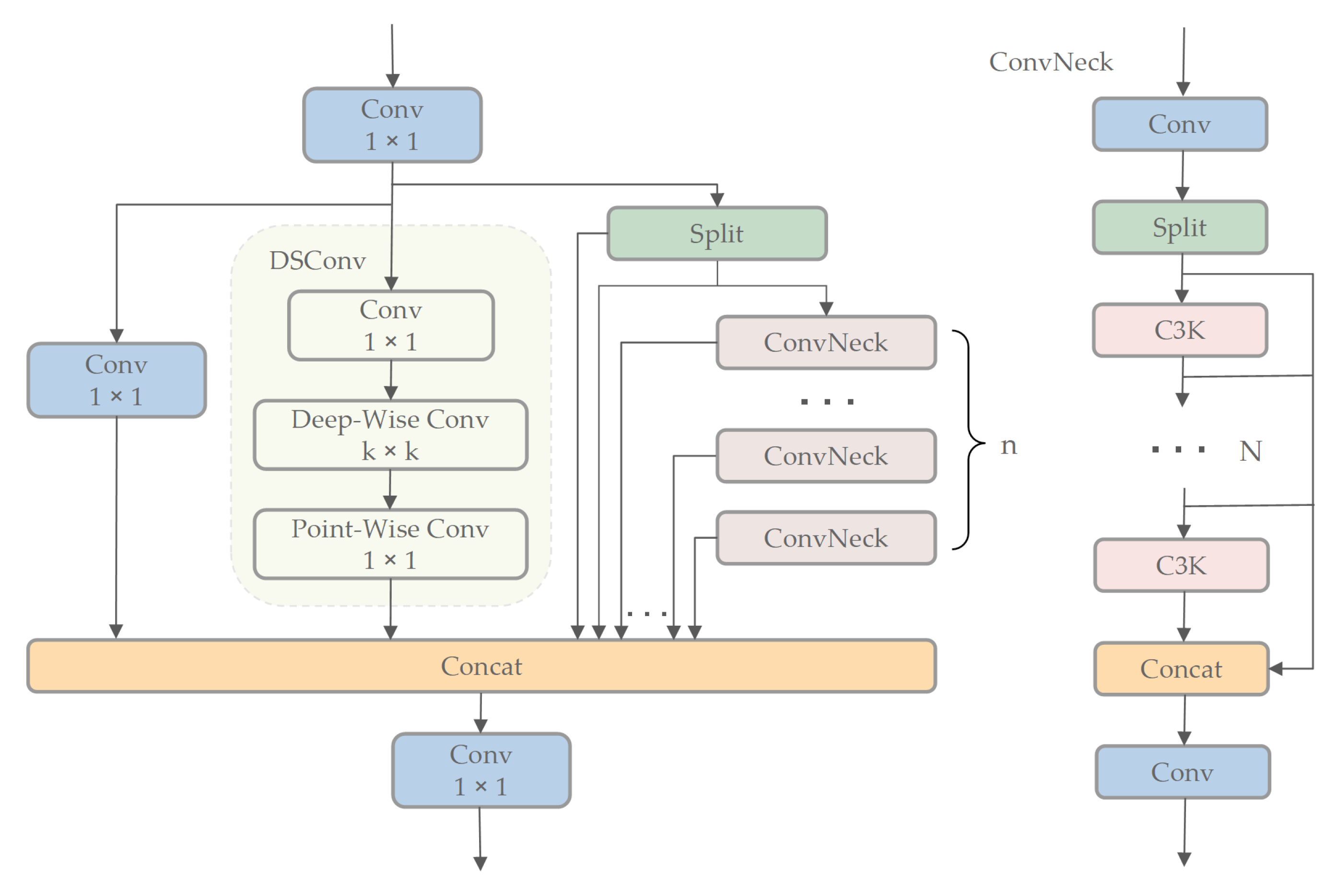
For enhancing the feature extraction performance of the MCRS-YOLO backbone in deeper layers, the DSCA is developed. The objective of DSCA is to synergize diverse convolutional operations—including depth-wise separable convolutions, bypass convolutions, and hierarchical feature recalibration—thereby improving feature discriminability, strengthening gradient propagation, and enhancing multi-level feature representation and semantic depth. The architecture of DSCA is depicted in
Figure 2.
DSCA combines three convolutional variants—1 × 1 bypass convolution for channel-wise feature recalibration, DSConv for efficient spatial processing, and the C3K2 module for enhanced hierarchical integration—to improve the information flow. This integration generates a more diverse and enriched gradient flow during training, significantly enhancing the semantic depth of foundational features while effectively enriching contextual information. We apply batch normalization (BN) after each Conv operation in the DSCA module to maintain feature diversity and achieve lower latency. BN can be merged into adjacent Conv layers, stabilizing training and improving inference efficiency. This is crucial for ensuring compatibility among multi-branch convolutional paths and maintaining inter-layer gradient flow. The method BN is applied. A notable advantage of BN is its capability to be incorporated into nearby convolutional layers, leading to improved inference efficiency. The DSCA architecture is formulated as follows:
The channel number of
is 2c. The channel count for
is c. Finally, we fuse and compress the three features through concatenation, followed by a 1 × 1 convolution to generate the output
with a channel number of 2c, as shown below:
3.1.2. Convolutional Neck Network
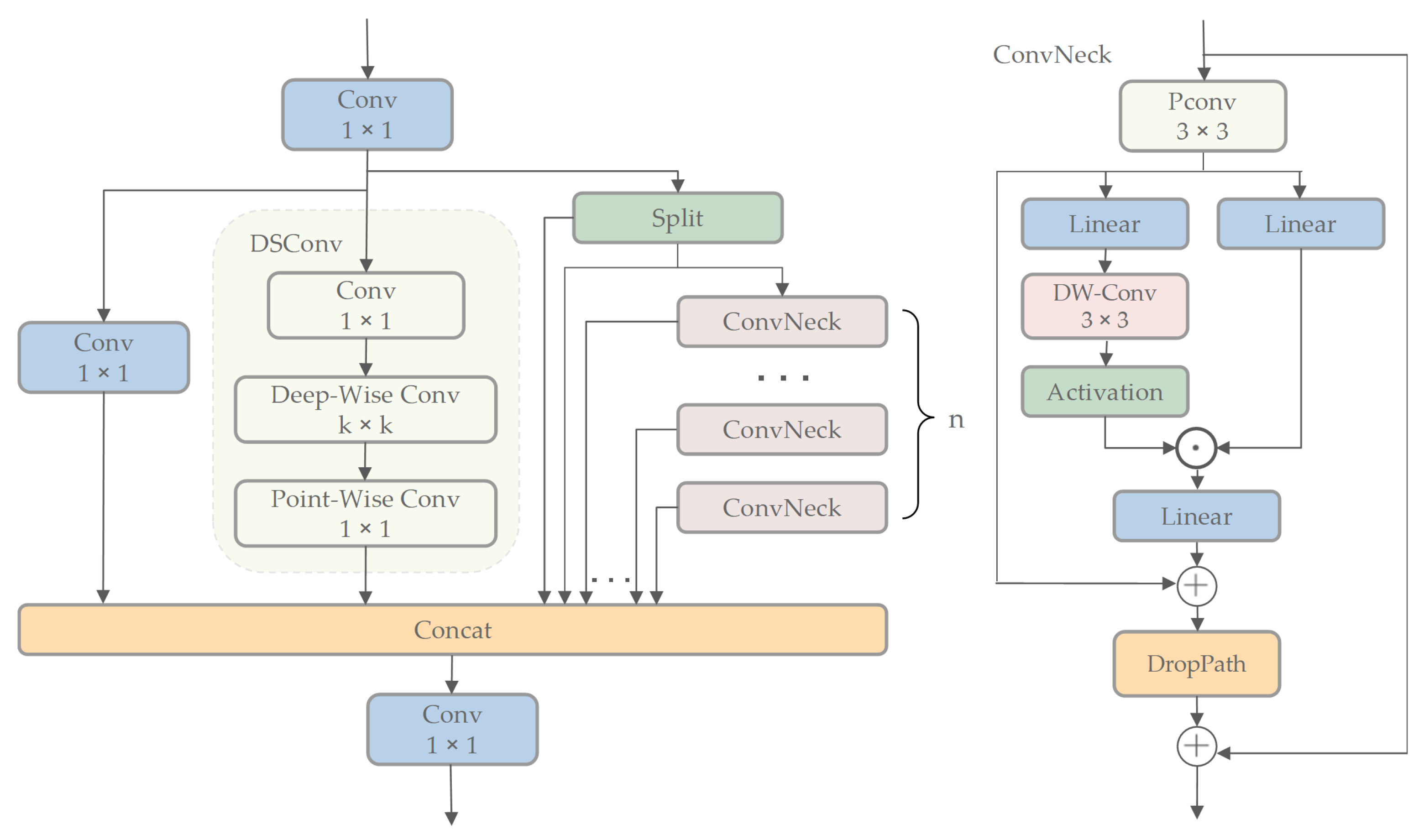
The neck network is typically used to combine feature maps from various hierarchical stages, generating multi-scale feature representations to improve object detection accuracy. To achieve this, we further enhance DSCA and propose PDCA. Specifically, we redesign the ConvNeck component in DSCA by incorporating partial convolutions and depth-wise convolutions.
The ConvNeck in PDCA comprises partial convolution (PConv), depth-wise convolution, linear transformations, activation functions, and regularization operations. The input is processed through PConv, where spatial features are captured by performing standard convolutional operations to a selected channel subset, while others retain their original values without computation. For efficient memory access, contiguous channels at the start or end are selected as computational representatives. The process then splits into dual paths: the left branch sequentially applies linear transformation, depth-wise convolution, and gated activation, while the right branch directly applies linear transformation. The outputs from both branches are merged through element-wise multiplication to enhance discriminative features, with a subsequent linear transformation applied for dimensionality adjustment. The depth-wise convolution implicitly captures positional information from zero-padding, acting as conditional positional encoding. The result is added to the PConv-processed input, regularized via DropPath to maintain information flow and prevent overfitting, and finally merged with the original input via residual addition to generate the fused output. This design leverages depth-wise convolution to refine gating signals using local features, enhancing model performance. The architecture is illustrated in
Figure 3.
3.2. Reconstructed Feature Pyramid
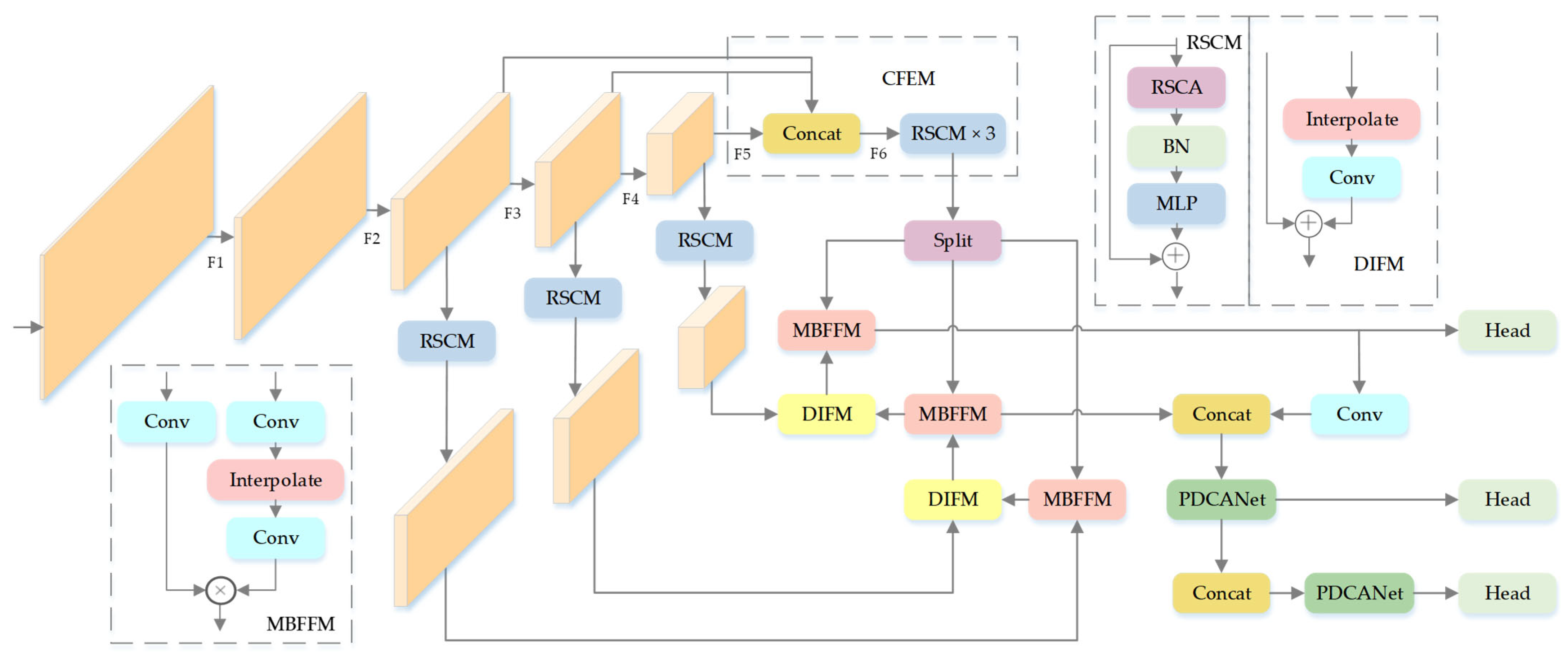
Aiming to merge and synthesize contextual information across multi-scale feature maps to enhance the model’s performance for target detection in complex remote sensing scenarios, we propose MFRFPN for feature pyramid reconstruction. MFRFPN is shown in
Figure 4.
A Rectangular Self-Calibration Module (RSCM) is developed to mitigate interference from cluttered backgrounds in remote sensing images and improve foreground feature saliency. In this framework, horizontal and vertical pooling operations are integrated to aggregate multi-scale pyramid features, thereby enabling axial-aware global context modeling. The RSCM consists of three components: Rectangular Self-Calibration Attention (RSCA), BN, and Multi-Layer Perceptron (MLP). RSCA implements hybrid attention by merging multi-scale spatial context modeling and channel-wise feature reweighting, which jointly mitigates semantic conflicts to boost discriminative power. Additionally, the RSCM employs an MLP to further strengthen feature representation.
The RSCA mechanism captures axial global contexts through horizontal and vertical pooling operations, generating two distinct directional feature vectors. These vectors undergo broadcast addition to effectively model ROIs. A shape self-calibration function aligns these regions with foreground objects using large-kernel strip convolutions decoupled along horizontal and vertical axes. Horizontal strip convolution with k × 1 kernel adjusts row-wise features to approximate object boundaries, with BN and ReLU activation applied subsequently. Vertical strip convolution with 1 × k kernel then performs complementary column-wise calibration. This dual-axis architecture adapts flexibly to arbitrary object geometries, formally expressed as follows:
Here, the symbol denotes the large-kernel strip convolution, and represents the kernel size of the strip convolution. The symbol corresponds to BN followed by the ReLU activation function. and represent horizontal pooling and vertical pooling, respectively. Notably, the numeral δ is used here to denote the Sigmoid function. The symbol denotes the output feature of the RSCA mechanism.
Additionally, a hybrid fusion framework merges augmented attention features and raw inputs, leveraging 3 × 3 depthwise convolutional kernels to preserve structural details while suppressing redundant activations. Refined input features and calibrated attention vectors are combined through Hadamard product, which enhances discriminative feature propagation while preserving computational efficiency.
Here, the operator denotes depth-wise convolution with a 3 × 3 kernel, and represents the attention features obtained from the preceding step. The symbol indicates the Hadamard product.
BN and MLP are incorporated after RSCA to refine the features. Finally, residual connections are embedded to strengthen gradient flow and feature propagation. The schematic of RSCM depicted in
Figure 4 is mathematically expressed as follows:
Here, denotes broadcast addition. represents the feature fusion function that integrates depth-wise convolution and the Hadamard product to enhance discriminative features. The attention feature is fused with the original feature through depth-wise separable convolution and element-wise multiplication, enabling dynamic feature weighting. This process strengthens salient features while suppressing irrelevant ones. The symbol denotes a composite operation consisting of BN and an MLP. It is applied to the fused feature for normalization and nonlinear transformation, thereby enhancing the semantic representation capability.
To extract contextual information, enrich semantic features, and enhance model performance, the feature pyramid is redesigned through multi-scale integration, while the Contextual Feature Extraction Module (CFEM) is introduced to enhance cross-level dependency modeling. The backbone generates feature maps with multiple scales
at different stages, with resolutions [
×
,
×
,
×
,
×
,
×
], which are utilized for subsequent detection and segmentation tasks. To ensure computational efficiency, the large-scale features F
1 and F
2 are discarded. The lower-scale features F
3, F
4 and F
5 are down-sampled to
×
via average pooling and then combined via concatenation to construct the pyramid feature F
6. Subsequently, F
6 is fed into a series of stacked RSCM modules for further processing. The RSCM module captures axial global contextual information by integrating multi-scale pyramid features, thereby enhancing the saliency of foreground features. Subsequent to pyramidal feature fusion, the consolidated features are split and reconstructed via adaptive up-sampling, thereby recovering their original scales. This process is formulated as follows:
where
denotes average pooling with a down-sampling factor
applied to feature F, and P represents the feature with pyramid context.
The Dynamic Interpolation Fusion Module (DIFM) is engineered to fuse feature maps across multiple scales by dynamically integrating low-resolution features with processed high-resolution features. The module takes two inputs: a low-resolution feature map and a high-resolution feature map. First, the high-resolution feature map is adaptively scaled via bilinear interpolation to align spatial resolutions with the low-resolution counterpart. Spatially up-sampled high-resolution features undergo 1 × 1 convolution-based channel adaptation, ensuring dimensional consistency with low-resolution feature hierarchies. Finally, the processed high-resolution features are element-wise summed with the low-resolution features to generate the fused output.
The MBFFM focuses on local feature refinement through nonlinear transformations and Hadamard products, effectively suppressing background noise while enhancing discriminative patterns. The DIFM emphasizes dynamic scale calibration, integrating multi-scale features using bilinear interpolation and channel-wise adaptation. MBFFM operates at the branch level within the feature pyramid, emphasizing nonlinear interactions between branches to suppress redundant activations and enhance key feature regions. DIFM, on the other hand, addresses the dynamic alignment of cross-scale features during global reconstruction, ensuring complementarity among multi-scale information.
The Multi-Branch Feature Fusion Module (MBFFM) integrates feature maps of different resolutions through convolution operations and activation functions. The module takes two inputs: a low-resolution feature map and a high-resolution feature map. First, the high-resolution feature map undergoes convolution followed by an h-sigmoid activation function for nonlinear transformation. It is then up-sampled via bilinear interpolation to align with the spatial resolution of the low-resolution features. Finally, the processed high-resolution features are element-wise multiplied with the convolved low-resolution features. This mechanism suppresses feature responses in irrelevant regions while enhancing critical semantic representations, enabling dynamic feature selection through hierarchical fusion.
The MFRFPN integrates low-level spatial and high-level semantic features across corresponding scales. The CFEM module is utilized to reconstruct fused features. The RSCM captures axial global context to model bounding boxes of interest, while the shape self-calibration function refines attention maps toward foreground objects. A feature pyramid guides the spatial feature reconstruction, ensuring multi-scale awareness in the reconstructed features.
3.3. Efficient Feature Enhancement Strategy
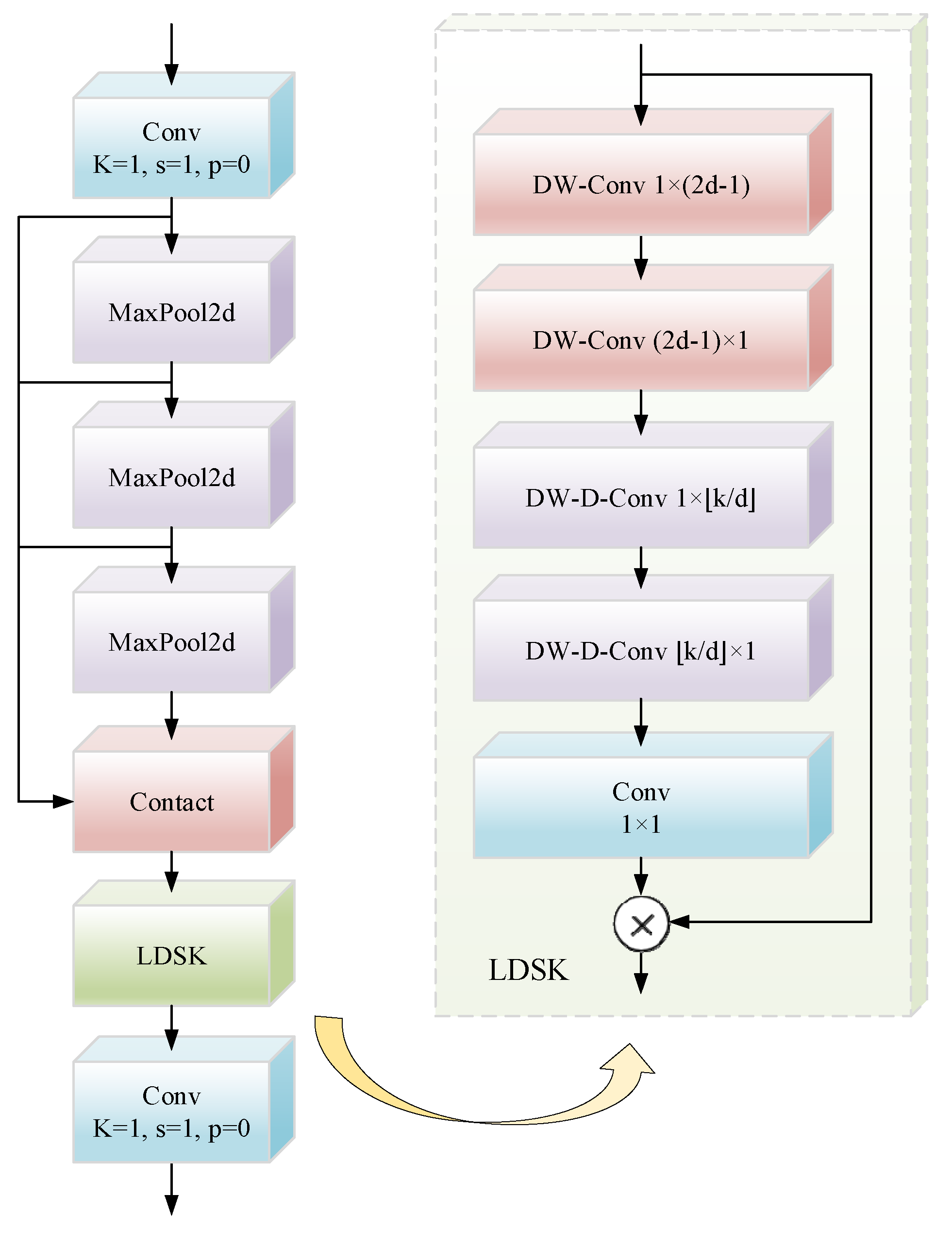
The SPPF module undertakes the tasks of feature extraction and encoding at multiple scales. This enables the integration of multi-scale features, with the aim of enhancing the semantic representations of feature maps. To enhance the architecture’s feature augmentation capability, we proposed LDSK, as depicted in
Figure 5. The LDSK significantly improves the SPPF’s ability to aggregate features across scales. By leveraging large depth-separable kernels and dilated spatial convolutions, the LDSK captures broad contextual information from images, generates attention maps, and uses these maps to adaptively weight the original features. This mechanism strengthens the network’s focus on discriminative patterns, thereby improving model performance.
Traditional dilated convolution enhances feature extraction by expanding the receptive field, but it often leads to a significant increase in parameter count. Attention mechanisms typically rely on global pooling and fully connected layers to generate channel-wise or spatial attention weights, introducing additional computational overhead. In contrast, LDSK employs 1D separable convolutions to reduce the number of parameters and avoid the complex weight generation process, thereby significantly improving computational efficiency. Moreover, conventional dilated convolution tends to suffer from sparse sampling under large dilation rates, resulting in the loss of local details. Although attention mechanisms focus on key regions through learned weights, they involve complex computations. The LDSK module addresses these issues by decomposing convolution kernels to achieve implicit axial global context modeling. Its adaptive dilation rate design extends the receptive field while preserving local continuity, making it particularly effective for capturing contextual patterns in remote sensing images with complex structures.
The LDSK’s structure and function are categorized into three essential steps: initialization convolution layer, spatially dilated convolution layer, and attention fusion/application. Initialization Convolution layer: LDSK decomposes 2D convolution kernels into horizontal and vertical 1D kernels. These two convolutional layers separately extract horizontal and vertical directional features from input feature maps, enabling the model to enhance saliency localization. The LDSK module employs dilated convolutions with multi-scale dilation rates in its dedicated layer to refine features extracted from preliminary attention maps. Spatially dilated convolution layer: After obtaining preliminary attention maps, LDSK uses spatially dilated convolutions with varying dilation rates to further extract features. Through cascaded 1D convolution kernels, LDSK simultaneously captures both local and global contextual information. These layers expand receptive fields to aggregate extensive contextual features while processing horizontal and vertical directions independently, enhancing spatial relationship understanding. Attention fusion and application: Following the convolution operations, the LDSK integrates features via the terminal convolutional layer to produce optimized attention maps. These maps undergo element-wise multiplication with the original input features, dynamically weighting significant features while suppressing irrelevant ones. The output is derived as follows:
Given an input feature map , where denotes the number of input channels, and represent the height and width, is the dilation rate, indicates the maximum receptive field of the kernel, and ⌊⋅⌋ denotes the floor operation. The symbols ∗ and represent convolution and Hadamard product, respectively. denotes the output of the depth-wise convolution. represents the output of the dilated depth-wise convolution. A 1 × 1 convolution refines the outputs of the dilated depth-wise convolution, producing the attention map . The output is obtained via the Hadamard product between and the input feature map .
The choice of hyper parameters in the LDSK module is based on the need to balance receptive field expansion and computational efficiency while addressing the unique challenges of remote sensing images. Thus, we selected k = 11 and d = 2. In the LDSK module, the convolutional kernel size is set to K = 11. This is because in feature extraction, the kernel size needs to cover the typical scale of small targets. The large kernel matches small target clusters in remote sensing images and aligns with SPPF output features to avoid disconnection. For computational efficiency, the kernel is decomposed into two 1D kernels, reducing parameters while maintaining spatial modeling ability and receptive field. The dilation rate in the LDSK module is set to d = 2. Remote sensing images often have dense small targets. This rate ensures sufficient context coverage and avoids over-smoothing. It prevents overfitting in cascaded layers and captures multi-scale contexts. This design adapts to the large scale variations of targets in remote sensing images. The rate expands the receptive field without increasing kernel size or causing aliasing artifacts. It also aligns with the feature pyramid levels of MFRFPN. A d = 2 rate balances global context capture and training stability.
3.4. Hybrid Loss
Unlike natural imagery, remote sensing imagery demonstrates a higher density of small-scale objects. However, traditional IoU metrics are inherently prone to positional variations in small objects, which makes it challenging to provide sufficient high-quality samples for object detectors and degrades detection performance. A hybrid loss training strategy is introduced to optimize small-scale target discriminability.
To enhance object detection performance, NWD is adopted to quantify the distribution between bounding boxes. This metric is then converted into a similarity measure and trained alongside the original IoU. NWD smooths positional deviations and better characterizes the weight distribution of different pixels within bounding boxes. More importantly, it remains scale-insensitive and is better suited for assessing similarity among tiny objects. By modeling bounding box
and bounding box
as 2D Gaussian distributions, we derive the squared Wasserstein distance
. Nevertheless, since
is unsuitable for direct use as a similarity measure, an exponential normalization is applied to obtain NWD:
where
is a dataset-specific constant. The bounding box loss functions are formulated as follows:
Here, serves as a modulation coefficient.
The hybrid loss function integrates NWD and IoU metrics via a dynamic weighting mechanism, with each loss component’s contribution modulated by a predefined IoU ratio parameter. Based on ablation experiments on the NWPU-VHR10 and VEDAI datasets, setting this ratio at 0.5 achieves the best balance between localization accuracy and robustness to positional deviations. This setting balances IoU’s sensitivity to boundary alignment with NWD’s scale-invariant similarity measurement. Lower values reduce background noise suppression, while higher values degrade performance due to overemphasis on strict IoU alignment—particularly problematic for small objects with sparse pixel coverage. NWD’s robustness to scale changes reduces the scale sensitivity of IoU, making it ideal for detecting small objects with amplified positional deviations. A 50% weight ensures NWD dominates gradient updates for small targets, while IoU’s localization sensitivity provides strong gradients for precise boundary alignment, complementing NWD’s global similarity measurement. This 50% weighting also ensures adequate localization refinement for larger objects or cases with clear spatial boundaries.
5. Conclusions
In this paper, a novel small object detection method for remote sensing imagery is proposed, which is termed MCRS-YOLO. Detecting small objects in such images is particularly challenging due to limited object details and complex backgrounds. Conventional operations like pooling, sampling convolutions, and multi-scale feature fusion often lead to a significant loss of spatial information, severely degrading detection accuracy. To mitigate these limitations, we introduce MCRS-YOLO, a model incorporating three key modules: MBA, MFRFPN, and LDSK. Each module uniquely contributes to improving detection performance. MBA enhances feature diversity and information flow through synergistic multi-convolution operations, mitigating insufficient object information. MFRFPN integrates spatially rich multi-scale features to preserve spatial and semantic details. LDSK captures broad contextual information via large-kernel convolutions, expanding the effective receptive field to prioritize critical features. A hybrid loss training strategy combines NWD with IoU loss, reducing sensitivity to positional deviations in small objects while suppressing background noise.
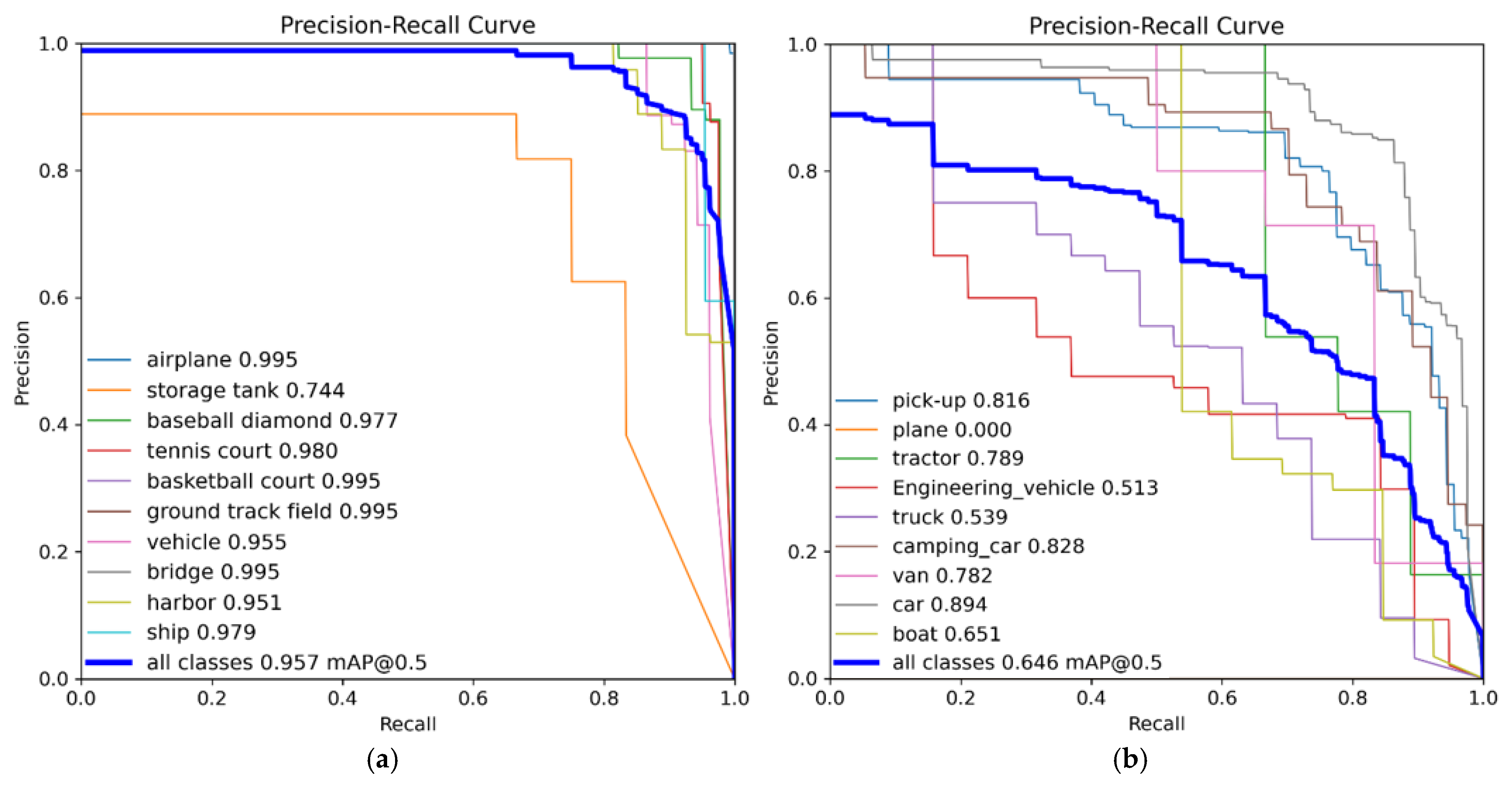
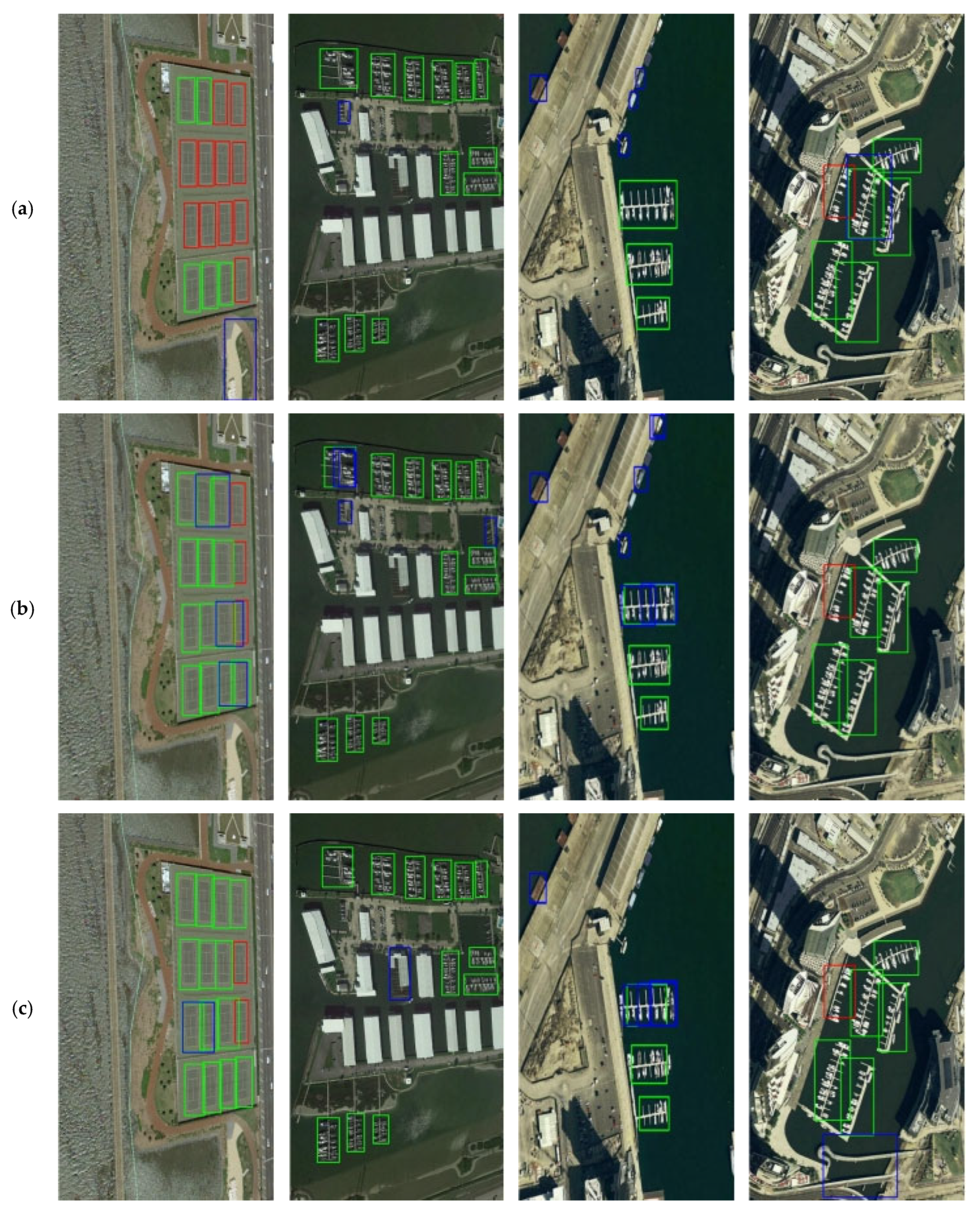
Evaluations on the NWPU-VHR10 and VEDAI datasets reveal that MCRS-YOLO effectively avoids false positives and missed detections when handling significant variations in object scales, dense small targets and cluttered scenes, thereby elevating the accuracy of remote sensing image object detection. Compared to other mainstream models, MCRS-YOLO exhibits superior performance while providing a more efficient and accurate methodology. Future studies will prioritize resolving persisting limitations to strengthen MCRS-YOLO’s adaptability and reliability, targeting algorithm refinements for small object detection in remote sensing imagery and enabling reliable detection capabilities across broader applications and scenarios.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}