
Underwater Sonar Image Classification with Image Disentanglement Reconstruction and Zero-Shot Learning


Abstract
1. Introduction
- We disentangle the images to integrate the structure vectors of optical images and the texture vectors of sonar images to generate a realistic pseudo-sonar image.
- We use the pseudo-sonar images to train the zero-shot classifier, aiming to enhance the detection performance of the classification model on unseen sonar images.
- We conducted comprehensive testing and analysis on the image generation and zero-shot classification, and the experimental results demonstrate the method we propose has good performance in underwater sonar image classification.
2. Related Work
2.1. Sonar Image Object Classification
2.2. Sonar Image Augmentation
2.3. Zero-Shot Learning
3. Proposed Method
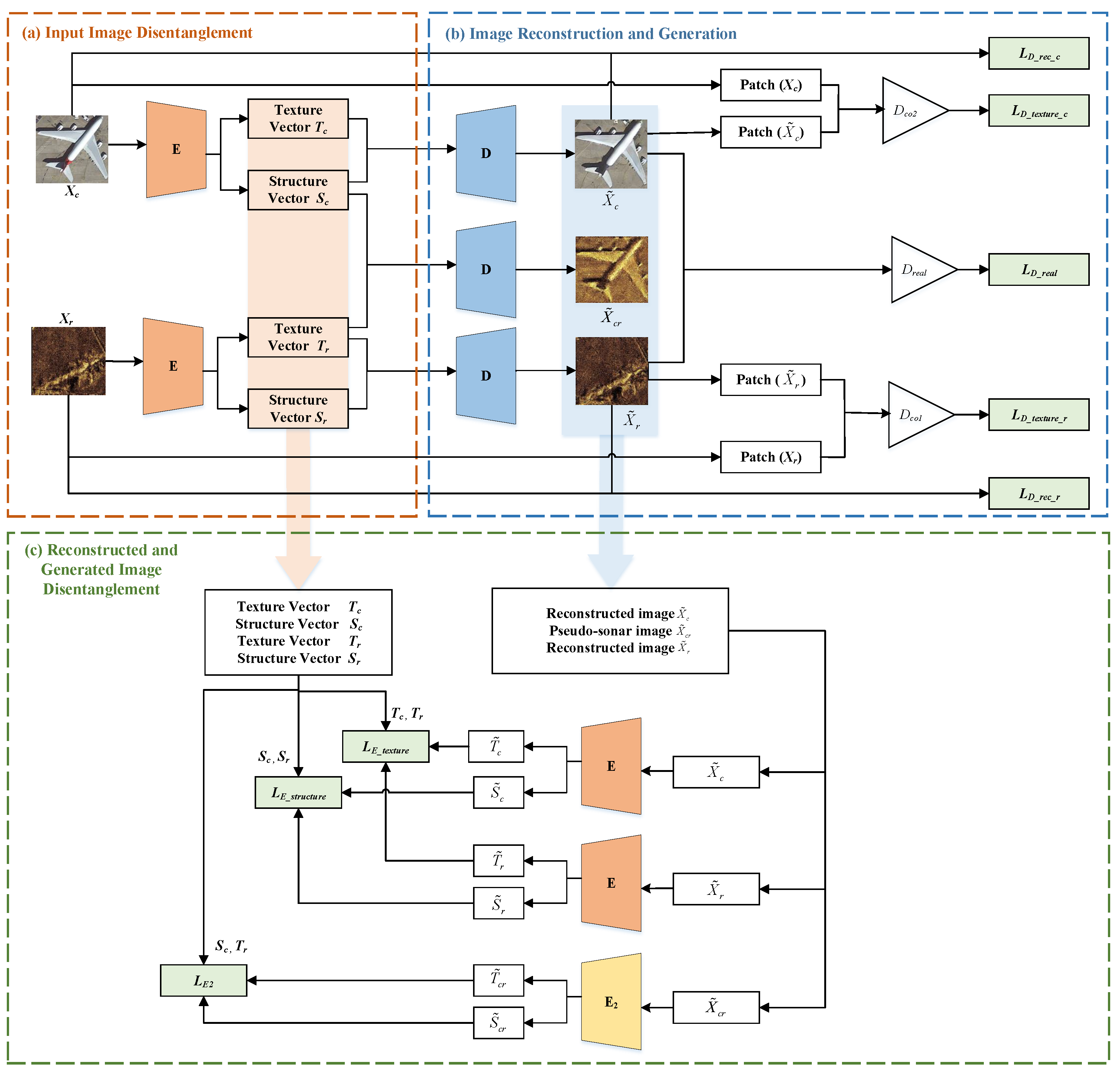
3.1. Framework Overview
3.2. Image Disentanglement Reconstruction
3.2.1. Input Image Disentanglement
3.2.2. Image Reconstruction and Generation
3.2.3. Reconstructed and Generated Image Disentanglement
3.3. Zero-Shot Classification
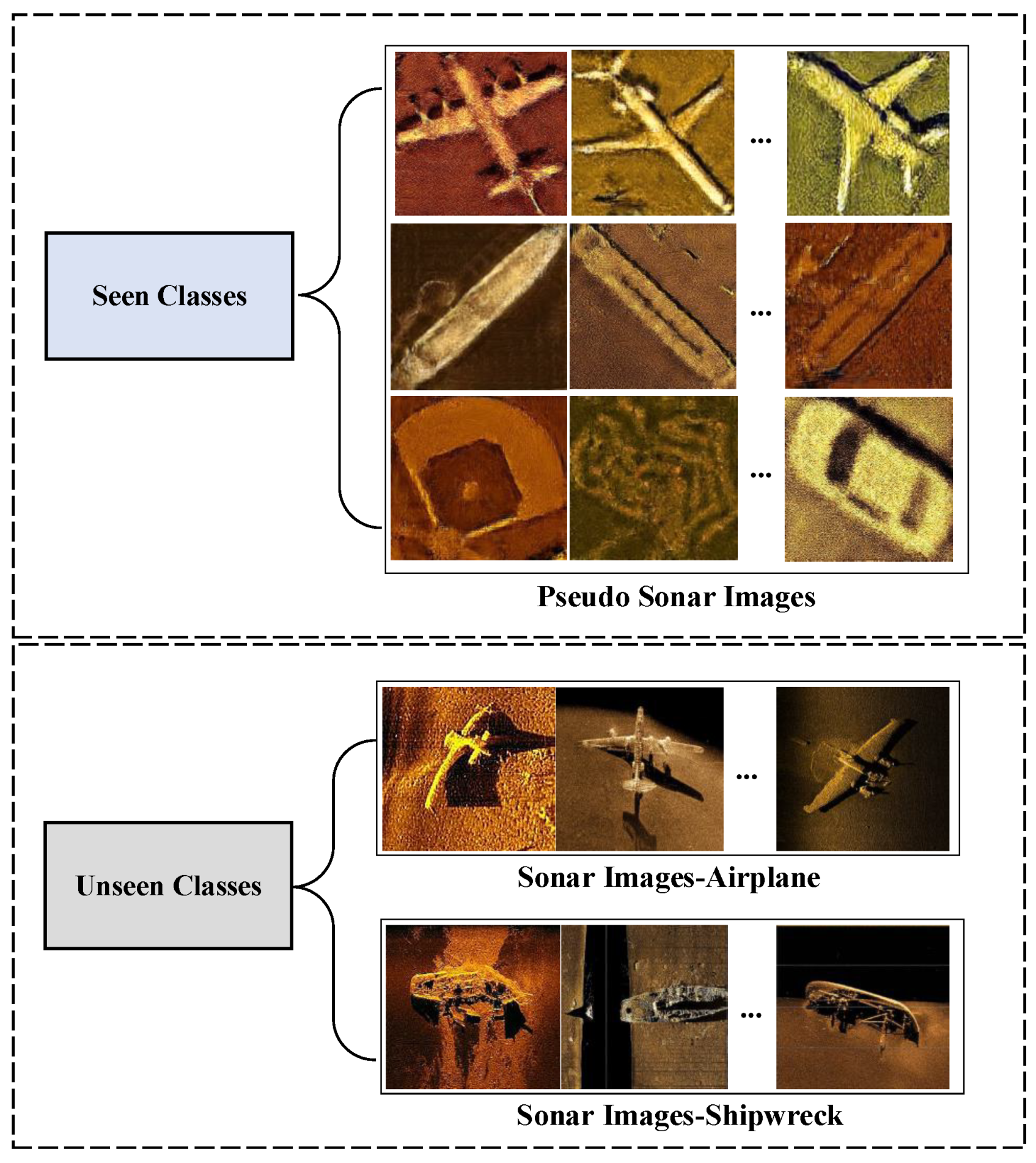
3.3.1. Data Preparation
3.3.2. Algorithm of Zero-Shot Learning
| Algorithm 1 The algorithm of zero-shot learning. |
| Input: epoch, trained IDR model, , , KLSG and SCTD Output: Accuracy
|
4. Experiment
4.1. Experiment Setup
4.2. Image Disentanglement Reconstruction
4.3. Pseudo-Sonar Image Generation
4.4. Quantitative Evaluation of Pseudo-Sonar Image Quality
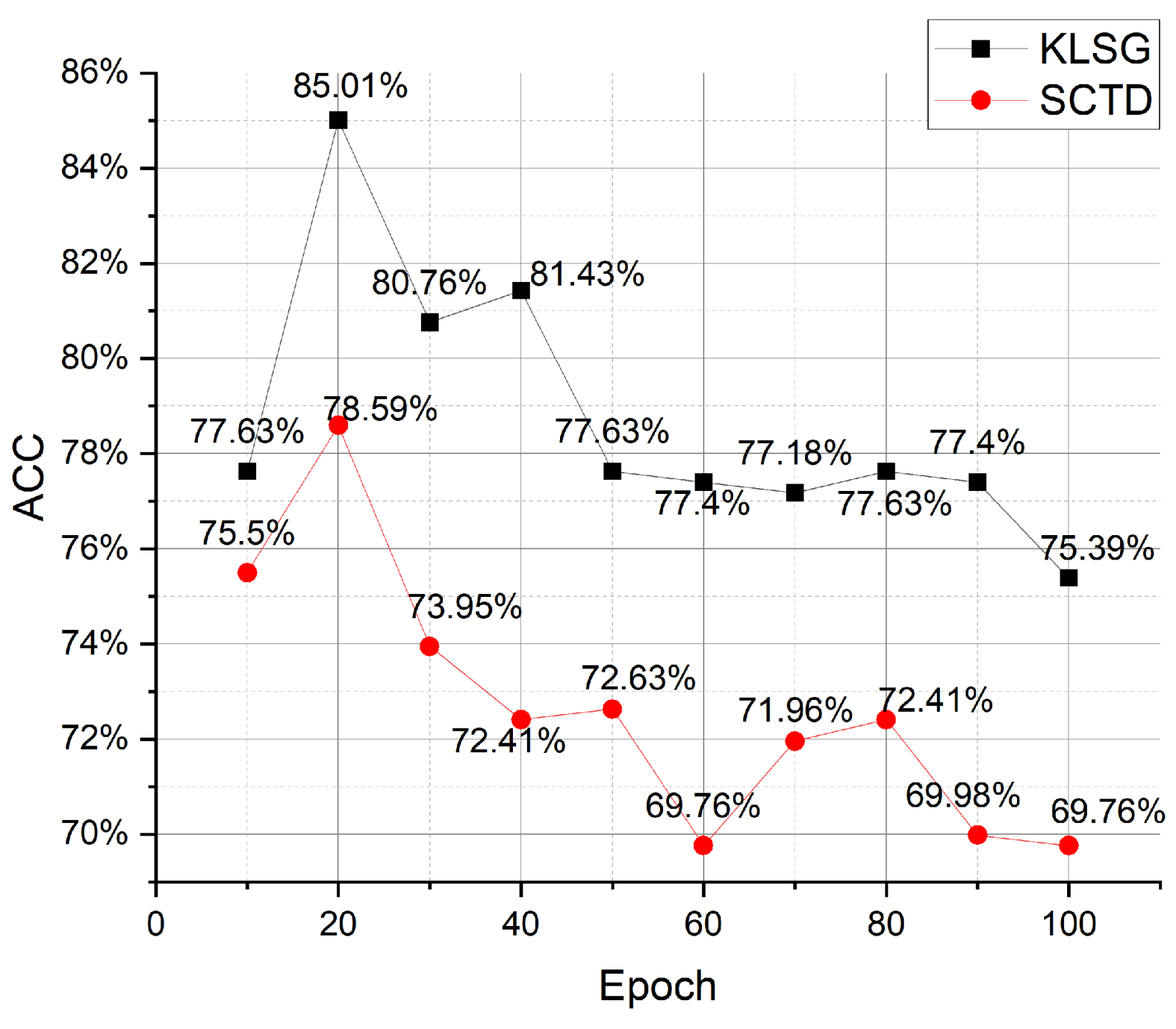
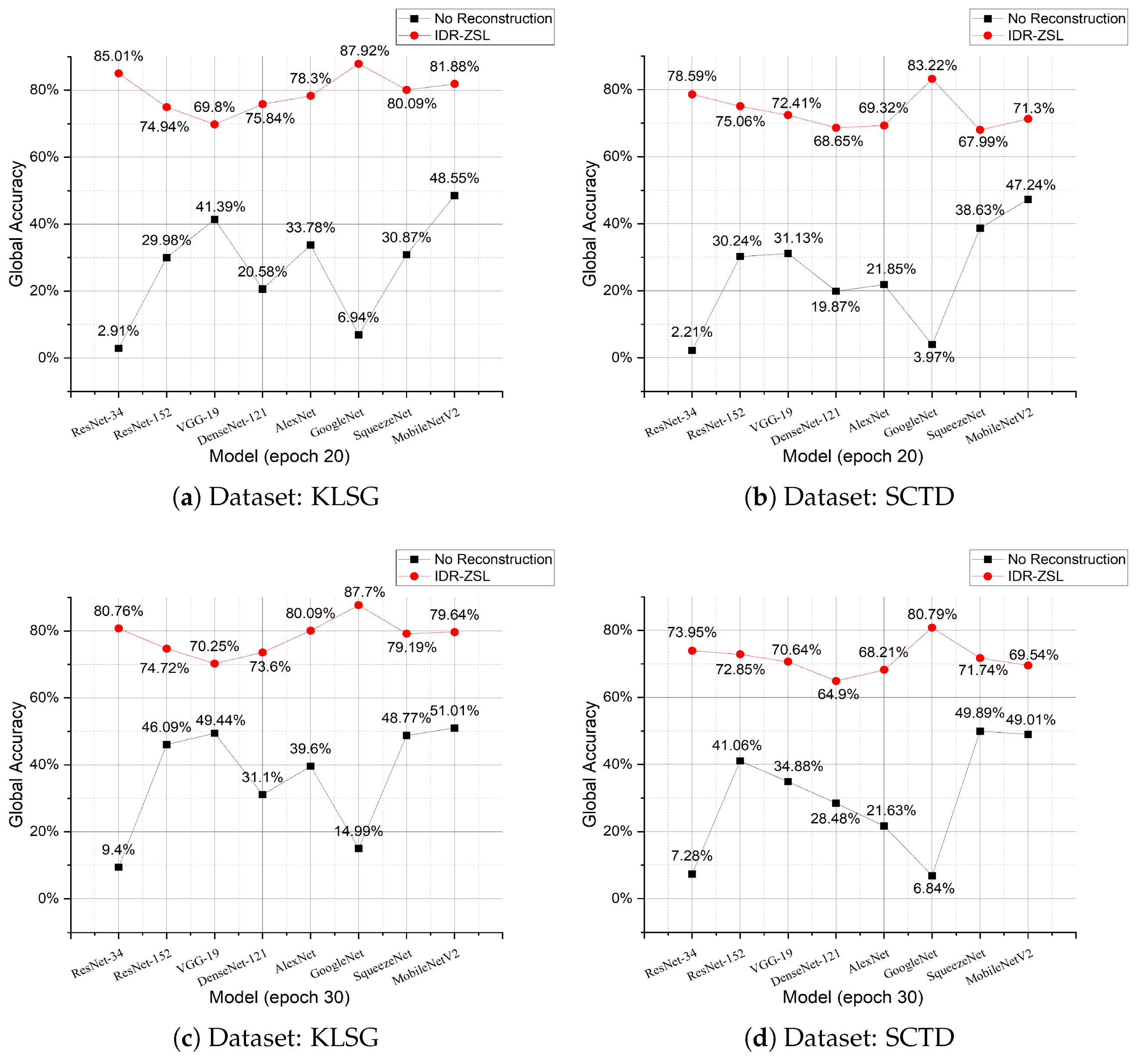
4.5. Evaluation of Zero-Shot Classification Performance
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Xi, Z.; Zhao, J.; Zhu, W. Side-Scan Sonar Image Simulation Considering Imaging Mechanism and Marine Environment for Zero-Shot Shipwreck Detection. IEEE Trans. Geosci. Remote Sens. 2023, 61, 4209713. [Google Scholar] [CrossRef]
- Jones, R.E.; Griffin, R.A.; Unsworth, R.K. Adaptive Resolution Imaging Sonar (ARIS) as a tool for marine fish identification. Fish. Res. 2021, 243, 106092. [Google Scholar] [CrossRef]
- Ødegård, Ø.; Hansen, R.E.; Singh, H.; Maarleveld, T.J. Archaeological use of Synthetic Aperture Sonar on deepwater wreck sites in Skagerrak. J. Archaeol. Sci. 2018, 89, 1–13. [Google Scholar] [CrossRef]
- Steiniger, Y.; Kraus, D.; Meisen, T. Survey on Deep Learning Based Computer Vision for Sonar Imagery. Eng. Appl. Artif. Intell. 2022, 114, 105157. [Google Scholar] [CrossRef]
- Doan, V.S.; Huynh-The, T.; Kim, D.S. Underwater Acoustic Target Classification Based on Dense Convolutional Neural Network. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1500905. [Google Scholar] [CrossRef]
- Kong, W.; Hong, J.; Jia, M.; Yao, J.; Cong, W.; Hu, H.; Zhang, H. YOLOv3-DPFIN: A Dual-Path Feature Fusion Neural Network for Robust Real-Time Sonar Target Detection. IEEE Sens. J. 2020, 20, 3745–3756. [Google Scholar] [CrossRef]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A Simple Way to Prevent Neural Networks from Overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Shorten, C.; Khoshgoftaar, T.M. A Survey on Image Data Augmentation for Deep Learning. J. Big Data 2019, 6, 60. [Google Scholar] [CrossRef]
- Huo, G.; Wu, Z.; Li, J. Underwater Object Classification in Sidescan Sonar Images Using Deep Transfer Learning and Semisynthetic Training Data. IEEE Access 2020, 8, 47407–47418. [Google Scholar] [CrossRef]
- Huang, C.; Zhao, J.; Zhang, H.; Yu, Y. Seg2Sonar: A Full-Class Sample Synthesis Method Applied to Underwater Sonar Image Target Detection, Recognition, and Segmentation Tasks. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5909319. [Google Scholar] [CrossRef]
- Zhou, J.; Li, Y.; Qin, H.; Dai, P.; Zhao, Z.; Hu, M. Sonar Image Generation by MFA-CycleGAN for Boosting Underwater Object Detection of AUVs. IEEE J. Ocean Eng. 2024, 49, 905–919. [Google Scholar] [CrossRef]
- Lampert, C.H.; Nickisch, H.; Harmeling, S. Attribute-Based Classification for Zero-Shot Visual Object Categorization. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 453–465. [Google Scholar] [CrossRef] [PubMed]
- Xian, Y.; Lampert, C.H.; Schiele, B.; Akata, Z. Zero-Shot Learning—A Comprehensive Evaluation of the Good, the Bad and the Ugly. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 2251–2265. [Google Scholar] [CrossRef] [PubMed]
- Romera-Paredes, B.; Torr, P.H.S. An Embarrassingly Simple Approach to Zero-Shot Learning. In Proceedings of the 32nd International Conference on Machine Learning, ICML Lille, France, 6–11 July 2015; Feris, R.S., Lampert, C., Parikh, D., Eds.; Volume 3, pp. 11–30. [Google Scholar] [CrossRef]
- Socher, R.; Ganjoo, M.; Manning, C.D.; Ng, A.Y. Zero-Shot Learning through Cross-Modal Transfer. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 5–8 December 2013. [Google Scholar]
- Han, Z.; Fu, Z.; Chen, S.; Yang, J. Contrastive Embedding for Generalized Zero-Shot Learning. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 2371–2381. [Google Scholar] [CrossRef]
- Preciado-Grijalva, A.; Wehbe, B.; Firvida, M.B.; Valdenegro-Toro, M. Self-Supervised Learning for Sonar Image Classification. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), New Orleans, LA, USA, 19–20 June 2022; pp. 1498–1507. [Google Scholar] [CrossRef]
- Gerg, I.D.; Monga, V. Structural Prior Driven Regularized Deep Learning for Sonar Image Classification. IEEE Trans. Geosci. Remote Sens. 2022, 60, 4200416. [Google Scholar] [CrossRef]
- Wang, X.; Jiao, J.; Yin, J.; Zhao, W.; Han, X.; Sun, B. Underwater Sonar Image Classification Using Adaptive Weights Convolutional Neural Network. Appl. Acoust. 2019, 146, 145–154. [Google Scholar] [CrossRef]
- Yang, Z.; Zhao, J.; Yu, Y.; Huang, C. A Sample Augmentation Method for Side-Scan Sonar Full-Class Images That Can Be Used for Detection and Segmentation. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5908111. [Google Scholar] [CrossRef]
- Huang, C.; Zhao, J.; Yu, Y.; Zhang, H. Comprehensive Sample Augmentation by Fully Considering SSS Imaging Mechanism and Environment for Shipwreck Detection Under Zero Real Samples. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5906814. [Google Scholar] [CrossRef]
- Chen, S.; Hou, W.; Khan, S.; Khan, F.S. Progressive Semantic-Guided Vision Transformer for Zero-Shot Learning. In Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 16–22 June 2024; pp. 23964–23974. [Google Scholar] [CrossRef]
- Li, Y.; Luo, Y.; Wang, Z.; Du, B. Improving Generalized Zero-Shot Learning by Exploring the Diverse Semantics from External Class Names. In Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 16–22 June 2024; pp. 23344–23353. [Google Scholar] [CrossRef]
- Hou, W.; Chen, S.; Chen, S.; Hong, Z.; Wang, Y.; Feng, X.; Khan, S.; Khan, F.S.; You, X. Visual-Augmented Dynamic Semantic Prototype for Generative Zero-Shot Learning. In Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 16–22 June 2024; pp. 23627–23637. [Google Scholar] [CrossRef]
- Li, C.; Ye, X.; Cao, D.; Hou, J.; Yang, H. Zero Shot Objects Classification Method of Side Scan Sonar Image Based on Synthesis of Pseudo Samples. Appl. Acoust. 2021, 173, 107691. [Google Scholar] [CrossRef]
- Liu, X.; Ma, Z.; Ma, J.; Zhang, J.; Schaefer, G.; Fang, H. Image Disentanglement Autoencoder for Steganography without Embedding. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 2293–2302. [Google Scholar] [CrossRef]
- Karras, T.; Laine, S.; Aittala, M.; Hellsten, J.; Lehtinen, J.; Aila, T. Analyzing and Improving the Image Quality of StyleGAN. arXiv 2020, arXiv:1912.04958. [Google Scholar]
- Park, T.; Zhu, J.Y.; Wang, O.; Lu, J.; Shechtman, E.; Efros, A.A.; Zhang, R. Swapping Autoencoder for Deep Image Manipulation. Adv. Neural Inf. Process. Syst. 2020, 33, 7198–7211. [Google Scholar]
- Li, K.; Wan, G.; Cheng, G.; Meng, L.; Han, J. Object Detection in Optical Remote Sensing Images: A Survey and a New Benchmark. ISPRS J. Photogramm. Remote Sens. 2020, 159, 296–307. [Google Scholar] [CrossRef]
- Zhang, P.; Tang, J.; Zhong, H.; Ning, M.; Liu, D.; Wu, K. Self-Trained Target Detection of Radar and Sonar Images Using Automatic Deep Learning. IEEE Trans. Geosci. Remote Sens. 2022, 60, 4701914. [Google Scholar] [CrossRef]
- Salimans, T.; Goodfellow, I.; Zaremba, W.; Cheung, V.; Radford, A.; Chen, X. Improved Techniques for Training GANs. arXiv 2016, arXiv:1606.03498. [Google Scholar]
- Heusel, M.; Ramsauer, H.; Unterthiner, T.; Nessler, B.; Hochreiter, S. GANs Trained by a Two Time-Scale Update Rule Converge to a Local Nash Equilibrium. arXiv 2018, arXiv:1706.08500. [Google Scholar]
- Bińkowski, M.; Sutherland, D.J.; Arbel, M.; Gretton, A. Demystifying MMD GANs, arXiv 2021. arXiv:1801.01401. [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015—Conference Track Proceedings, San Diego, CA, USA, 7–9 May 2015; pp. 1–14. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2261–2269. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of the Advances in Neural Information Processing Systems 25 (NIPS 2012), Lake Tahoe, NV, USA, 3–6 December 2012. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar] [CrossRef]
- Iandola, F.N.; Han, S.; Moskewicz, M.W.; Ashraf, K.; Dally, W.J.; Keutzer, K. SqueezeNet: AlexNet-level Accuracy with 50x Fewer Parameters and <0.5 MB Model Size. arXiv 2016, arXiv:1602.07360. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. MobileNetV2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notation | Description |
|---|---|
| E | The encoder of content image and reference sonar image |
| The encoder of pseudo-sonar image | |
| D | The decoder |
| The co-occurrence discriminator of sonar image | |
| The co-occurrence discriminator of optical content image | |
| The discriminator that identifies the authenticity of the input image | |
| S | The image structure vector extracted by the encoder |
| T | The image texture vector extracted by the encoder |
| The optical content image | |
| The reconstructed optical content image | |
| The reference sonar image | |
| The reconstructed reference sonar image | |
| The generated pseudo-sonar images | |
| The real sonar images |
| Stage | Dataset | Describe | Category | Number | Total |
|---|---|---|---|---|---|
| Pseudo-sonar image generation stage | [29] | The optical content images provide structured vectors for the subsequent generation. | Aircraft | 1000 | 3800 |
| Ship | 1000 | ||||
| Others | 1800 | ||||
| (SCTD) [30] | The reference sonar images provide texture vectors for the subsequent generation. | Human | 44 | 110 | |
| Background | 66 | ||||
| Real sonar image testing stage | KLSG [9] | Real sonar images for testing the zero-shot classifier. | Aircraft | 62 | 447 |
| Shipwreck | 385 | ||||
| SCTD [30] | Real sonar images for testing the zero-shot classifier. | Aircraft | 90 | 453 | |
| Shipwreck | 363 |
| Image | Image Category | IS ↑ | FID ↓ | KID ↓ |
|---|---|---|---|---|
| Ship | 3.0442 | 109.8039 | 0.0983 | |
| Airplane | 5.2340 | 118.0901 | 0.0615 | |
| Others | 4.2403 | 114.5206 | 0.0504 | |
| AVG | 4.1728 | 114.1382 | 0.0701 | |
| Human | 3.9668 | 109.8945 | 0.0133 | |
| Background | 3.4383 | 89.5107 | 0.0050 | |
| AVG | 3.7026 | 99.7026 | 0.0092 |
| Model | E | D | ||||
|---|---|---|---|---|---|---|
| RM1 () | √ | √ | √ | √ | ||
| RM2 () | √ | √ | √ | √ | ||
| RM3 () | √ | √ | √ | √ | ||
| IDR | √ | √ | √ | √ | √ | √ |
| Method | Image Category | IS ↑ | FID ↓ | KID ↓ |
|---|---|---|---|---|
| RM1 () | Ship | 3.6922 | 220.2140 | 0.1538 |
| Airplane | 3.1686 | 266.6832 | 0.2143 | |
| Others | 3.7733 | 251.2810 | 0.1840 | |
| AVG | 3.5447 | 246.0594 | 0.1840 | |
| RM2 () | Ship | 4.3136 | 270.0884 | 0.1949 |
| Airplane | 3.0738 | 314.0999 | 0.2704 | |
| Others | 4.1380 | 288.2377 | 0.2017 | |
| AVG | 3.8418 | 290.8087 | 0.2223 | |
| RM3 () | Ship | 4.8751 | 172.9161 | 0.0936 |
| Airplane | 4.3153 | 201.1329 | 0.1572 | |
| Others | 4.0854 | 183.2955 | 0.0947 | |
| AVG | 4.4253 | 185.7815 | 0.1152 | |
| IDR | Ship | 4.9114 | 170.4028 | 0.0984 |
| Airplane | 4.5830 | 186.0565 | 0.1246 | |
| Others | 4.3683 | 187.7052 | 0.0856 | |
| AVG | 4.6209 | 181.3882 | 0.1029 |
| Dataset | Model | Global Accuracy | Average Accuracy | ||
|---|---|---|---|---|---|
| No Reconstruction | IDR-ZSL | No Reconstruction | IDR-ZSL | ||
| KLSG | ResNet-34 | 2.91% | 85.01% | 7.78% | 63.56% |
| ResNet-152 | 29.98% | 74.94% | 26.20% | 63.13% | |
| VGG-19 | 41.39% | 69.80% | 30.12% | 60.14% | |
| DenseNet-121 | 20.58% | 75.84% | 16.68% | 62.97% | |
| AlexNet | 33.78% | 78.30% | 20.29% | 57.63% | |
| GoogleNet | 6.94% | 87.92% | 11.47% | 72.01% | |
| SqueezeNet | 30.87% | 80.09% | 18.60% | 60.03% | |
| MobileNetV2 | 48.55% | 81.88% | 35.62% | 63.09% | |
| SCTD | ResNet-34 | 2.21% | 78.59% | 3.88% | 59.06% |
| ResNet-152 | 30.24% | 75.06% | 20.54% | 60.20% | |
| VGG-19 | 31.13% | 72.41% | 24.02% | 58.13% | |
| DenseNet-121 | 19.87% | 68.65% | 14.07% | 52.45% | |
| AlexNet | 21.85% | 69.32% | 13.64% | 51.61% | |
| GoogleNet | 3.97% | 83.22% | 5.82% | 66.55% | |
| SqueezeNet | 38.63% | 67.99% | 24.10% | 49.53% | |
| MobileNetV2 | 47.24% | 71.30% | 29.89% | 51.18% | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Peng, Y.; Li, H.; Zhang, W.; Zhu, J.; Liu, L.; Zhai, G. Underwater Sonar Image Classification with Image Disentanglement Reconstruction and Zero-Shot Learning. Remote Sens. 2025, 17, 134. https://doi.org/10.3390/rs17010134
Peng Y, Li H, Zhang W, Zhu J, Liu L, Zhai G. Underwater Sonar Image Classification with Image Disentanglement Reconstruction and Zero-Shot Learning. Remote Sensing. 2025; 17(1):134. https://doi.org/10.3390/rs17010134
Chicago/Turabian StylePeng, Ye, Houpu Li, Wenwen Zhang, Junhui Zhu, Lei Liu, and Guojun Zhai. 2025. "Underwater Sonar Image Classification with Image Disentanglement Reconstruction and Zero-Shot Learning" Remote Sensing 17, no. 1: 134. https://doi.org/10.3390/rs17010134
APA StylePeng, Y., Li, H., Zhang, W., Zhu, J., Liu, L., & Zhai, G. (2025). Underwater Sonar Image Classification with Image Disentanglement Reconstruction and Zero-Shot Learning. Remote Sensing, 17(1), 134. https://doi.org/10.3390/rs17010134