MFACNet: A Multi-Frame Feature Aggregating and Inter-Feature Correlation Framework for Multi-Object Tracking in Satellite Videos



Abstract
1. Introduction
- Remote-sensing video satellites provide wide-field imaging, resulting in large frame sizes with a high proportion of background pixels. Additionally, video sequences are affected by satellite platform motion and atmospheric refraction, leading to image jitter. Cloud clusters, ground reflections, and the preprocessing of standard video sequence products also contribute to background noise. A sample of objects in remote-sensing images and video satellite sequences is shown in Figure 1;
- Video sequences contain numerous objects with dense spatial distributions and complex dynamics. Furthermore, due to the limited resolution of video sequences, individual objects are represented by dozens of pixels and lack fine texture details, which results in significant challenges in object detection and low discriminability between different objects. A sample of objects in video satellite sequences, along with their pixel statistics, is shown in Figure 2;
- When video satellites capture videos with a tiny off-nadir angle, the resulting video sequences can be approximated as being captured in a near-vertical manner. Compared with nature scenarios, the object sizes are relatively consistent, and fewer occlusions occur between objects. The motion patterns of objects are similar, and their trajectories tend to be linear. Additionally, unlike conventional remote-sensing imagery, remote-sensing video satellites capture imagery with high frame rates, which results in high scene overlap in the captured landscapes and significant overlap of the same object between adjacent frames.
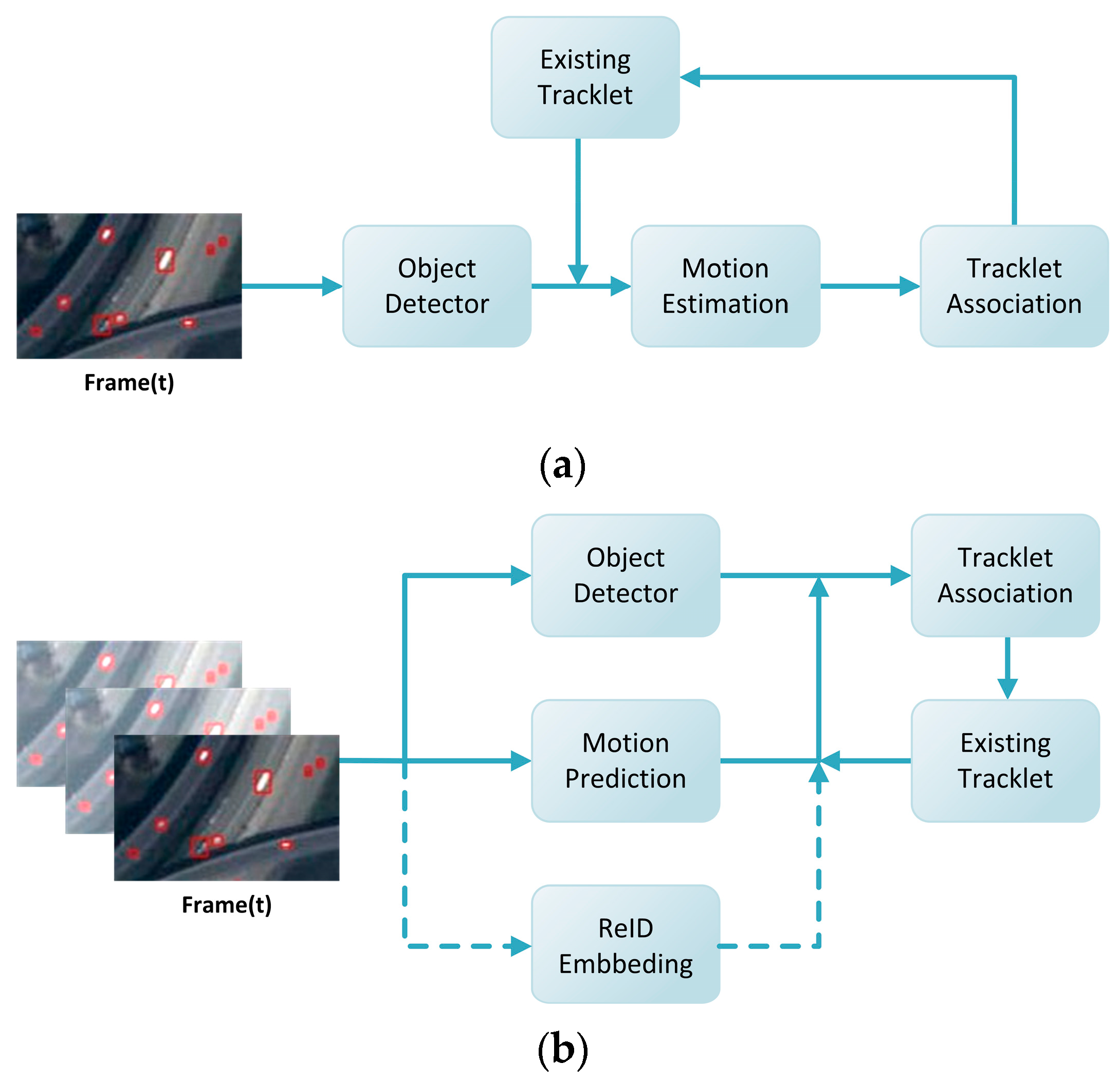
- We proposed an end-to-end JDT framework called the MFACNet, which extracts the static features of man-made objects in video sequences while effectively integrating dynamic cues from consecutive frames. This framework significantly enhances the detection and tracking performance of the network;
- For detection, we devised a lightweight feature aggregation wrapper (FAW) module, which utilizes sets of deformable convolutions (DCN) [41] to extract correlated information in different channel dimensions from the feature groups of multiple frames. All of the information is then employed to enhance the feature representation of the current frame. For tracking, we employed an end-to-end learnable feature-mapping motion estimation (FMME) module to estimate the displacement of individual objects. Regarding object-trajectory matching, we designed an IoU-prioritized cascaded matching scheme that effectively utilizes both localization and appearance information to generate and manage object trajectories;
- We conducted the training and validation of our model on a video satellite object tracking dataset, which was constructed from the video sequences captured by the Jilin-1 video satellite and GF-3 high-resolution video satellite. The experimental results demonstrated that the proposed model achieves state-of-the-art performance on the experimental dataset methods in terms of tracking accuracy and robustness, which highlight the potential of precisely utilizing deep features from video sequences.
2. Materials and Methods
2.1. Feature Aggregation Wrapper Module
2.1.1. Feature Propagation
2.1.2. Feature Enhancement
2.2. Feature-Mapping Motion Estimation Module
2.2.1. ReID Sub-Network
2.2.2. Displacement Prediction
2.3. IoU-Prior Cascade Matching
2.4. Tracklet Management and Training Strategy
3. Experiments
3.1. Experimental Data
3.2. Implementation Details
3.3. Evaluation Metrics
3.4. Number of Preceding Features Input
3.5. Comparison with Existing Methods
4. Discussion
4.1. Effectiveness of the FMME
4.2. Effectiveness of the FAW Module
4.3. Effectiveness of IoU-Prior Cascade Matching
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Keck, M.; Galup, L.; Stauffer, C. Real-time tracking of low-resolution vehicles for wide-area persistent surveillance. In Proceedings of the 2013 IEEE Workshop on Applications of Computer Vision (WACV), Clearwater Beach, FL, USA, 15–17 January 2013; pp. 441–448. [Google Scholar]
- Karimi Nejadasl, F.; Gorte, B.G.H.; Hoogendoorn, S.P. Optical flow based vehicle tracking strengthened by statistical decisions. ISPRS J. Photogramm. Remote Sens. 2006, 61, 159–169. [Google Scholar] [CrossRef]
- Zhang, J.; Jia, X.; Hu, J.; Tan, K. Satellite Multi-Vehicle Tracking under Inconsistent Detection Conditions by Bilevel K-Shortest Paths Optimization. In Proceedings of the 2018 Digital Image Computing: Techniques and Applications (DICTA), Canberra, Australia, 10–13 December 2018; pp. 1–8. [Google Scholar]
- Zhang, J.; Zhang, X.; Tang, X.; Huang, Z.; Jiao, L. Vehicle Detection and Tracking in Remote Sensing Satellite Vidio based on Dynamic Association. In Proceedings of the 2019 10th International Workshop on the Analysis of Multitemporal Remote Sensing Images (MultiTemp), Shanghai, China, 5–7 August 2019; pp. 1–4. [Google Scholar]
- Ahmadi, S.A.; Ghorbanian, A.; Mohammadzadeh, A. Moving vehicle detection, tracking and traffic parameter estimation from a satellite video: A perspective on a smarter city. Int. J. Remote Sens. 2019, 40, 8379–8394. [Google Scholar] [CrossRef]
- Ao, W.; Fu, Y.W.; Hou, X.Y.; Xu, F. Needles in a Haystack: Tracking City-Scale Moving Vehicles From Continuously Moving Satellite. Ieee Trans. Image Process. 2020, 29, 1944–1957. [Google Scholar] [CrossRef]
- Wei, J.; Sun, J.; Wu, Z.; Yang, J.; Wei, Z. Moving Object Tracking via 3-D Total Variation in Remote-Sensing Videos. IEEE Geosci. Remote Sens. Lett. 2022, 19, 3506405. [Google Scholar] [CrossRef]
- Piccardi, M. Background subtraction techniques: A review. In Proceedings of the 2004 IEEE International Conference on Systems, Man and Cybernetics (IEEE Cat. No. 04CH37583), The Hague, The Netherlands, 10–13 October 2004; pp. 3099–3104. [Google Scholar]
- Bruhn, A.; Weickert, J.; Schnörr, C. Lucas/Kanade meets Horn/Schunck: Combining local and global optic flow methods. Int. J. Comput. Vis. 2005, 61, 211–231. [Google Scholar] [CrossRef]
- Singla, N. Motion detection based on frame difference method. Int. J. Inf. Comput. Technol. 2014, 4, 1559–1565. [Google Scholar]
- Shao, J.; Du, B.; Wu, C.; Yan, P. PASiam: Predicting Attention Inspired Siamese Network, for Space-Borne Satellite Video Tracking. In Proceedings of the 2019 IEEE International Conference on Multimedia and Expo (ICME), Shanghai, China, 8–12 July 2019; pp. 1504–1509. [Google Scholar]
- Yang, T.; Wang, X.; Yao, B.; Li, J.; Zhang, Y.; He, Z.; Duan, W. Small moving vehicle detection in a satellite video of an urban area. Sensors 2016, 16, 1528. [Google Scholar] [CrossRef] [PubMed]
- Barnich, O.; Droogenbroeck, M.V. ViBe: A Universal Background Subtraction Algorithm for Video Sequences. IEEE Trans. Image Process. 2011, 20, 1709–1724. [Google Scholar] [CrossRef]
- Yin, Q.; Hu, Q.; Liu, H.; Zhang, F.; Wang, Y.; Lin, Z.; An, W.; Guo, Y. Detecting and tracking small and dense moving objects in satellite videos: A benchmark. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5612518. [Google Scholar] [CrossRef]
- He, Q.; Sun, X.; Yan, Z.; Li, B.; Fu, K. Multi-object tracking in satellite videos with graph-based multitask modeling. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5619513. [Google Scholar] [CrossRef]
- Li, S.; Zhou, Z.; Zhao, M.; Yang, J.; Guo, W.; Lv, Y.; Kou, L.; Wang, H.; Gu, Y. A Multi-task Benchmark Dataset for Satellite Video: Object Detection, Tracking, and Segmentation. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5611021. [Google Scholar]
- Wang, Q.; Zheng, Y.; Pan, P.; Xu, Y. Multiple object tracking with correlation learning. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 3876–3886. [Google Scholar]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. Yolox: Exceeding yolo series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 2023, Vancouver, BC, Canada, 17–24 June 2023; pp. 7464–7475. [Google Scholar]
- Maher, A.; Taha, H.; Zhang, B. Realtime multi-aircraft tracking in aerial scene with deep orientation network. J. Real-Time Image Process. 2018, 15, 495–507. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar]
- Bewley, A.; Ge, Z.; Ott, L.; Ramos, F.; Upcroft, B. Simple online and realtime tracking. In Proceedings of the 2016 IEEE international conference on image processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 3464–3468. [Google Scholar]
- Kalman, R.E. A New Approach to Linear Filtering and Prediction Problems. J. Basic Eng. 1960, 82, 35–45. [Google Scholar] [CrossRef]
- Wang, Y.; Cheng, H.; Zhou, X.; Luo, W.; Zhang, H. Moving Ship Detection and Movement Prediction in Remote Sensing Videos. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2020, 43, 1303–1308. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Xiao, C.; Yin, Q.; Ying, X.; Li, R.; Wu, S.; Li, M.; Liu, L.; An, W.; Chen, Z. DSFNet: Dynamic and static fusion network for moving object detection in satellite videos. IEEE Geosci. Remote Sens. Lett. 2021, 19, 3510405. [Google Scholar] [CrossRef]
- Li, Y.; Jiao, L.; Tang, X.; Zhang, X.; Zhang, W.; Gao, L. Weak Moving Object Detection In Optical Remote Sensing Video With Motion-Drive Fusion Network. In Proceedings of the IGARSS 2019—2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; pp. 5476–5479. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]
- Ben-David, S.; Blitzer, J.; Crammer, K.; Kulesza, A.; Pereira, F.; Vaughan, J.W. A theory of learning from different domains. Mach. Learn. 2010, 79, 151–175. [Google Scholar] [CrossRef]
- Feng, J.; Zeng, D.; Jia, X.; Zhang, X.; Li, J.; Liang, Y.; Jiao, L. Cross-frame keypoint-based and spatial motion information-guided networks for moving vehicle detection and tracking in satellite videos. ISPRS J. Photogramm. Remote Sens. 2021, 177, 116–130. [Google Scholar] [CrossRef]
- Law, H.; Deng, J. CornerNet: Detecting Objects as Paired Keypoints. Int. J. Comput. Vis. 2018, 128, 642–656. [Google Scholar] [CrossRef]
- Shi, X.; Chen, Z.; Wang, H.; Yeung, D.Y.; Wong, W.-K.; Woo, W.-C. Convolutional LSTM Network: A Machine Learning Approach for Precipitation Nowcasting. In Proceedings of the Neural Information Processing Systems 2015, Montreal, QC, Canada, 7–12 December 2015. [Google Scholar]
- Date, K.; Nagi, R. GPU-accelerated Hungarian algorithms for the linear assignment problem. Parallel Comput. 2016, 57, 52–72. [Google Scholar] [CrossRef]
- Zhang, Y.; Sun, P.; Jiang, Y.; Yu, D.; Weng, F.; Yuan, Z.; Luo, P.; Liu, W.; Wang, X. Bytetrack: Multi-object tracking by associating every detection box. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23 October 2022; pp. 1–21. [Google Scholar]
- Dai, Y.; Hu, Z.; Zhang, S.; Liu, L. A survey of detection-based video multi-object tracking. Displays 2022, 75, 102317. [Google Scholar] [CrossRef]
- Cao, J.; Pang, J.; Weng, X.; Khirodkar, R.; Kitani, K. Observation-centric sort: Rethinking sort for robust multi-object tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 2023, Vancouver, BC, Canada, 18–22 June 2023; pp. 9686–9696. [Google Scholar]
- Wang, Y.; Kitani, K.; Weng, X. Joint Object Detection and Multi-Object Tracking with Graph Neural Networks. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an China, 30 May–5 June 2021; pp. 13708–13715. [Google Scholar]
- Zhang, Y.; Wang, C.; Wang, X.; Zeng, W.; Liu, W. Fairmot: On the fairness of detection and re-identification in multiple object tracking. Int. J. Comput. Vis. 2021, 129, 3069–3087. [Google Scholar] [CrossRef]
- Zhou, X.; Koltun, V.; Krähenbühl, P. Tracking objects as points. In Proceedings of the 16th European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 474–490. [Google Scholar]
- Wu, J.; Cao, J.; Song, L.; Wang, Y.; Yang, M.; Yuan, J. Track to detect and segment: An online multi-object tracker. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 12352–12361. [Google Scholar]
- Dai, J.; Qi, H.; Xiong, Y.; Li, Y.; Zhang, G.; Hu, H.; Wei, Y. Deformable Convolutional Networks. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 764–773. [Google Scholar]
- Zhou, X.; Wang, D.; Krähenbühl, P. Objects as points. arXiv 2019, arXiv:1904.07850. [Google Scholar]
- Yu, F.; Wang, D.; Darrell, T. Deep Layer Aggregation. In Proceedings of the Default Cover Image 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 2403–2412. [Google Scholar]
- Perreault, H.; Bilodeau, G.-A.; Saunier, N.; Héritier, M. FFAVOD: Feature fusion architecture for video object detection. Pattern Recognit. Lett. 2021, 151, 294–301. [Google Scholar] [CrossRef]
- Qiu, H.; Ma, Y.; Li, Z.; Liu, S.; Sun, J. BorderDet: Border Feature for Dense Object Detection. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Scharstein, D.; Szeliski, R. A taxonomy and evaluation of dense two-frame stereo correspondence algorithms. Int. J. Comput. Vis. 2002, 47, 7–42. [Google Scholar] [CrossRef]
- Chang, J.-R.; Chen, Y.-S. Pyramid stereo matching network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5410–5418. [Google Scholar]
- Yang, J.; Mao, W.; Álvarez, J.M.; Liu, M. Cost Volume Pyramid Based Depth Inference for Multi-View Stereo. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 4876–4885. [Google Scholar]
- Im, S.; Jeon, H.-G.; Lin, S.; Kweon, I.-S. DPSNet: End-to-end Deep Plane Sweep Stereo. arxiv, 2019; arXiv:1905.00538. [Google Scholar]
- Laga, H.; Jospin, L.V.; Boussaid, F.; Bennamoun, M. A survey on deep learning techniques for stereo-based depth estimation. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 44, 1738–1764. [Google Scholar] [CrossRef]
- Teed, Z.; Deng, J. RAFT: Recurrent All-Pairs Field Transforms for Optical Flow. In Proceedings of the 16th European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Dendorfer, P.; Osep, A.; Milan, A.; Schindler, K.; Cremers, D.; Reid, I.D.; Roth, S.; Leal-Taixé, L. MOTChallenge: A Benchmark for Single-Camera Multiple Target Tracking. Int. J. Comput. Vis. 2020, 129, 845–881. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arxiv, 2014; arXiv:1412.6980. [Google Scholar]
- Bernardin, K.; Stiefelhagen, R. Evaluating Multiple Object Tracking Performance: The CLEAR MOT Metrics. EURASIP J. Image Video Process. 2008, 2008, 246309. [Google Scholar] [CrossRef]
- Ristani, E.; Solera, F.; Zou, R.; Cucchiara, R.; Tomasi, C. Performance measures and a data set for multi-target, multi-camera tracking. In Proceedings of the 13th European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2016; pp. 17–35. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Pseudo-code of IoU-prior cascade matching |
 |
| T Frames | MOTA ↑ | IDF1 ↑ | FP ↓ | FN ↓ | IDS ↓ |
|---|---|---|---|---|---|
| 1 | 27.2 | 45.1 | 119,084 | 405,698 | 5683 |
| 2 | 28.4 | 43.3 | 75,495 | 438,956 | 6809 |
| 3 | 27.6 | 41.0 | 69,564 | 450,244 | 7408 |
| 4 | 26.5 | 38.8 | 67,934 | 458,443 | 8863 |
| Method | Year | Joint | MOTA ↑ | IDF1 ↑ | MT ↑ | ML ↓ | FP ↓ | FN ↓ | IDS ↓ |
|---|---|---|---|---|---|---|---|---|---|
| SORT | 2016 | 30.6 | 43.6 | 22.9 | 36.7 | 46,459 | 212,073 | 3461 | |
| ByteTrack | 2021 | 31.1 | 51.2 | 30.9 | 31.9 | 64,455 | 190,420 | 3360 | |
| OC-SORT | 2022 | 26.8 | 43.6 | 14.0 | 52.8 | 14,334 | 258,921 | 1093 | |
| FairMOT | 2020 | ✔ | 17.5 | 37.2 | 15.9 | 55.3 | 135,991 | 117,260 | 56,706 |
| CenterTrack | 2020 | ✔ | 28.2 | 53.6 | 27.9 | 28.0 | 111,206 | 151,189 | 6925 |
| TraDes | 2021 | ✔ | 27.3 | 53.8 | 28.0 | 27.6 | 99,521 | 167,834 | 5270 |
| MFACNet (ours) | 2023 | ✔ | 33.1 | 55.4 | 31.9 | 31.0 | 52,792 | 189,089 | 1743 |
| Baseline | FMME | FAW | IoU CM | MOTA ↑ | IDF1 ↑ | FN ↓ | MT ↑ | IDS ↓ |
|---|---|---|---|---|---|---|---|---|
| ✔ | ✔ | 26.6 | 42.9 | 502,392 | 30.1 | 8882 | ||
| ✔ | ✔ | ✔ | 28.4 | 43.2 | 438,951 | 33.8 | 6866 | |
| ✔ | ✔ | ✔ | ✔ | 28.4 | 43.3 | 438,956 | 34.3 | 6809 |
| CenterTrack | 26.3 | 42.7 | 511,462 | 31.0 | 11,741 | |||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, H.; Shen, Y.; Wang, Z.; Zhang, Q. MFACNet: A Multi-Frame Feature Aggregating and Inter-Feature Correlation Framework for Multi-Object Tracking in Satellite Videos. Remote Sens. 2024, 16, 1604. https://doi.org/10.3390/rs16091604
Zhao H, Shen Y, Wang Z, Zhang Q. MFACNet: A Multi-Frame Feature Aggregating and Inter-Feature Correlation Framework for Multi-Object Tracking in Satellite Videos. Remote Sensing. 2024; 16(9):1604. https://doi.org/10.3390/rs16091604
Chicago/Turabian StyleZhao, Hu, Yanyun Shen, Zhipan Wang, and Qingling Zhang. 2024. "MFACNet: A Multi-Frame Feature Aggregating and Inter-Feature Correlation Framework for Multi-Object Tracking in Satellite Videos" Remote Sensing 16, no. 9: 1604. https://doi.org/10.3390/rs16091604
APA StyleZhao, H., Shen, Y., Wang, Z., & Zhang, Q. (2024). MFACNet: A Multi-Frame Feature Aggregating and Inter-Feature Correlation Framework for Multi-Object Tracking in Satellite Videos. Remote Sensing, 16(9), 1604. https://doi.org/10.3390/rs16091604