1. Introduction
Synthetic Aperture Radar (SAR) is an active remote sensing imaging technology that uses radar signals and signal processing techniques to acquire surface images [
1,
2]. SAR has the characteristics of being influenced little by the weather and light conditions, being able to strongly penetrate hidden targets and being able to perform all-weather work. As a result, the detection of ships at sea using SAR imagery has been widely studied.
In maritime monitoring, ship detection and classification are very important tasks. Accurate positioning and identification make it easier for relevant departments to carry out proper planning and resource allocation in terms of the military, transportation and maintenance of order. However, the cloudy and rainy weather at sea and the characteristics of SAR imagery make the detection and classification of ships using SAR images a major challenge. At present, there are many methods of ship detection for SAR imagery that aim to meet this challenge. Traditional ship detection methods mainly include CFAR [
3], template matching, and trailing edge detection. These methods are based on manually designed features for ship detection in SAR images with limited robustness. For example, the Constant False Alarm Rate (CFAR) estimates the statistical data of background clutter, adaptively calculates the detection threshold and maintains a constant false alarm probability. However, its disadvantage is that the determination of the detection threshold depends on the distribution of sea clutter. The template matching and trailing edge detection [
4,
5] algorithm is too complex and has poor stability, which is not suitable for wide application.
Convolutional Neural Network (CNN)-based methods have shown great potential in computer vision tasks in recent years [
6,
7,
8,
9,
10,
11,
12,
13]. Therefore, in order to improve the stability of SAR ship detection methods in complex scenes, deep learning methods have gradually become the focus of SAR image detection research. The YOLO [
6,
11] series of one-stage detection algorithms are widely used in SAR image detection due to their high speed and accuracy. For example, Sun et al. [
14] proposed a YOLO framework that fuses a new bi-directional feature fusion module (bi-DFM) for detecting ships in high-resolution SAR imagery. A SAR ship detector called DB-YOLO [
15] was proposed by Zhu et al. The network enhances information fusion by improving the cross-stage submodule to achieve the accurate detection of small targets. Guo et al. [
16] proposed a SAR ship detection method based on YOLOX, which was verified by a large number of experimental results in order to effectively and accurately detect ships in cruise. In summary, since most of the objects in SAR images are characterized by a dense arrangement, an arbitrary angle and multiple scales, this brings three major challenges to SAR image ship detection and classification based on the YOLO method. Although there has been much research on CNN-based SAR ship detection and classification, we still need to solve the following challenges.
(1) The first challenge is the difficulty of detecting densely arranged ship targets. The distribution of ships in complex scenarios, especially in-shore scenarios, is not random and they tend to be highly concentrated in certain areas. Vaswani et al. [
17] confirmed that multi-head self-attention (MHSA) captures relationships between targets. Naseer et al. [
18] demonstrated that MHSA is also effective in reducing the interference of background noise and some occlusions. Therefore, modelling each part of the image and the relationships between them using attentional mechanisms is crucial for ship detection. Zhu et al. [
19] introduced MHSA into the backbone network and detection head of YOLO. Li et al. [
20] designed an MHSA that makes full use of contextual information. Aravind et al. [
21] proposed a new bottleneck module by replacing the 3 × 3 convolution with an MHSA module. The cross-stage partial (CSP) bottleneck transformer module was proposed by Feng et al. [
22] to model the relationships between vehicles in UAV images. Yu et al. [
23] proposed a transformer module in the backbone network to improve the performance of detectors in sonar images. However, most of these detectors do not take into account the spatial distribution characteristics of ships.
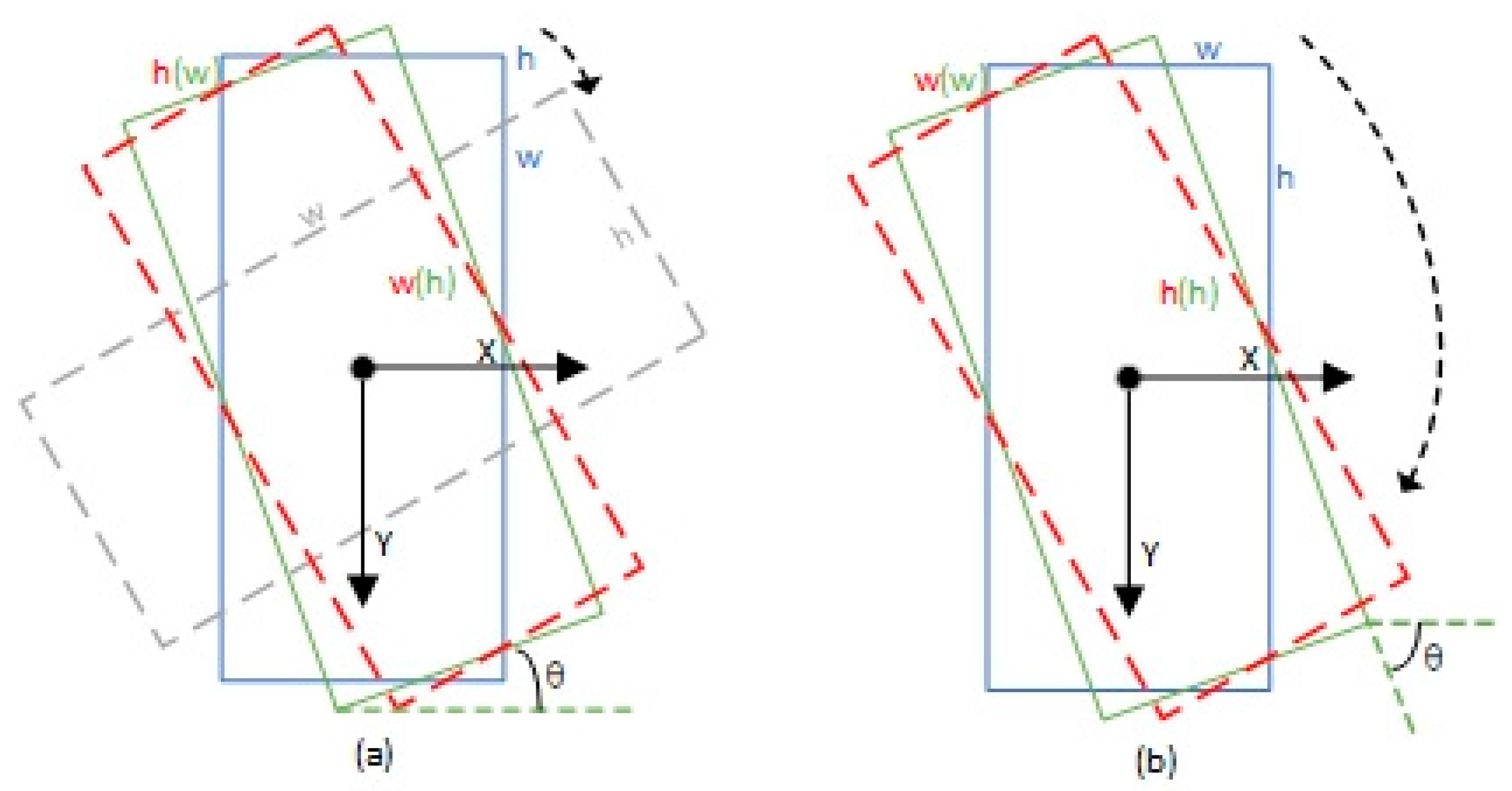
(2) The second challenge is the rotated bounding box. The orientation of the ship leads us to the need to predict angle information. There are three methods commonly used to define a rotated bounding box, namely the opencv definition method, the long-edge definition method and the ordered quadrilateral definition method.
Figure 1 illustrates the definition details. The opencv method and the long-edge method are both five-parameter
definition methods, where
are the coordinates of the centre and
are the length and width of the rotated bounding box. The difference is that the angle
in the opencv method is the acute angle made by the box with the x-axis, and this side of the box is denoted as
, and the other side is denoted as
, so that the angle is expressed in the range
. The angle
in the long-side method is the angle made by the long side
of the box with the x-axis, so the angle is expressed in the range
. The ordered quadrilateral definition method
takes the leftmost point as the starting point and orders the other points counterclockwise. The periodicity of angular (PoA) and the exchangeability of edges (EoE) can lead to angle predictions outside of our defined range. As a result, a large loss value is generated, triggering the boundary discontinuity problem, which affects training. These different methods share the same boundary problem. Since targets with large aspect ratios, such as ships, are very sensitive to changes in angle, it is of great interest to study the boundary problem.
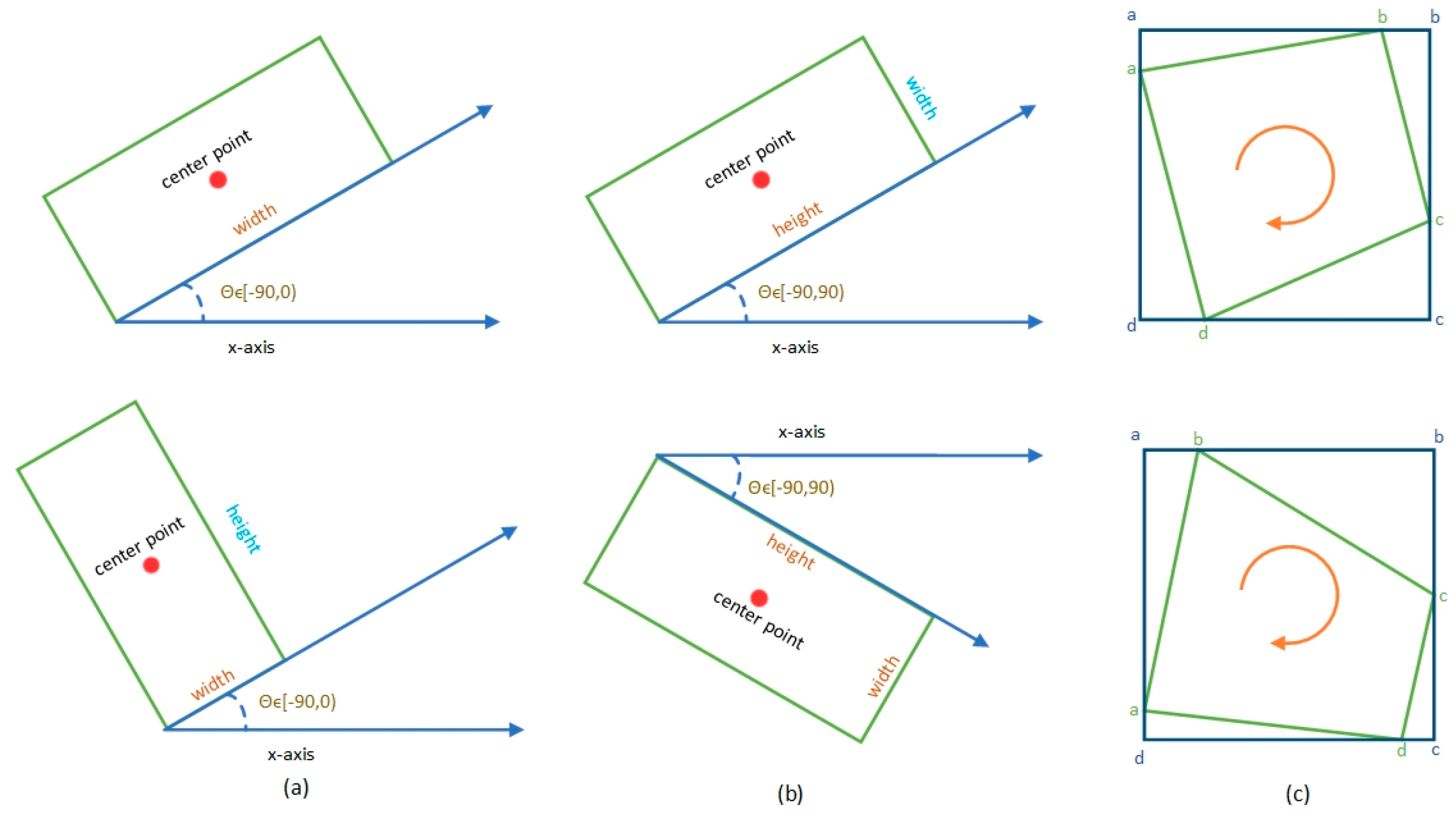
Figure 2 shows the boundary problem for the opencv method and the long-edge method. The ideal angle regression path in the opencv method is a counter-clockwise rotation from the blue box to the red box. However, there are two problems with PoA and EoE in the opencv-based approach due to the definition of
and
. These two problems can lead to very high losses following this regression. Therefore, the model is only regressed in a clockwise direction. This regression method definitely increases the difficulty of the regression. The long-edge method can also be affected by PoA, resulting in a sudden increase in the loss value. To solve these problems, Yang et al. [
24] proposed the Circular Label Smoothing (CSL) method, which turns angles into 180 categories for training. CSL was then further developed into the Densely Coded Label (DCL) method [
25]. The DCL method mainly improves the number of prediction layers and the performance in square-like target detection. However, at the same time, the authors also point out that converting angles to classifications leads to an increase in theoretical errors and the number of model parameters. Subsequently, the Gaussian Wasserstein Distance (GWD) method was proposed by Yang et al. [
26]. This method converts the rotating bounding box into a two-dimensional Gaussian distribution and uses the GWD to calculate the distance between the two Gaussian distributions. The authors use this distance value to reflect the similarity between two rotating bounding boxes, thus solving the problem of the Rotating Intersection-over-Unions (RIoU) not being differentiable. Yang et al. [
26] proposed the use of Kullback–Leibler Divergence (KLD) instead of GWD to calculate the distance. Unlike Smooth L1 Loss and GWD Loss, KLD Loss is scale invariant and its center is not slightly displaced, allowing high-precision rotation detection. M. Llerena et al. [
27] proposed a new loss function, the Probabilistic Intersection-over-Union (ProbIoU) loss function, which uses the Hellinger distance to measure the similarity of targets. Yang et al. [
28] proposed the Kalman Filtering Intersection-over-Unions (KFIoU), which uses the idea of Gaussian multiplication to solve the problem of inconsistency between the metric and the loss function. Calculating the RIoU between two rotating bounding boxes has become the most important problem in rotation ship detection.
(3) The third challenge is that there are still few methods to solve the problem of simultaneous SAR ship detection and SAR ship classification. Zhang et al. [
29] proposed a polarization fusion network with geometric feature embedding (PFGFE-Net) to alleviate the problem of polarization, insufficient utilization and traditional feature abandonment. Zhang et al. [
30] proposed a multitask learning framework. The framework achieves better deep-feature extraction by integrating the dense convolutional networks. Zhang et al. [
31] proposed a pyramid network with dual-polarization feature fusion for ship classification in SAR images. The network uses the attention mechanism to balance the features and performs dual-polarization feature fusion to effectively improve the ship classification performance. Zhang et al. [
32] incorporated the traditional histogram of oriented gradient (HOG) feature into the ship classification network. The method fully exploits the potential of mature handcrafted features and global self-attention mechanisms, and achieves excellent results on the OpenSARShip dataset. All of these networks achieve the classification of SAR ships, but do not enable SAR ship detection. Part of the reason for this phenomenon is that SAR images contain a large amount of complex background information and multi-scale feature targets, making ship detection and classification extremely difficult. Another reason is the lack of a suitable dataset. Most of the existing research methods are based on ship detection datasets such as SSDD [
33], AirSARship [
34], HRSID [
35] and LS-SSDD-v1.0 [
36]. These datasets have limitations in terms of data quality and target labelling. The development of ship detection and classification is hampered by these conditions. Lei et al. [
37] published a high-resolution SAR ship detection dataset (SRSDD). The dataset contains six categories of ships in complex scenarios and can be used for rotating target detection and category detection. Jiang et al. [
38] proposed a feature extraction module, a feature context aggregation module, and a multi-scale feature fusion module. These modules improve the detection of small objects in complex backgrounds via the fusion of multi-scale features and contextual information mining, and have achieved good performance on the SRSDD. Zhang et al. [
39] proposed a YOLOV5s-based ship detection method for SAR images. This network attempts to incorporate frequency domain information into the channel attention mechanism to improve the detection and classification performance. Shao et al. [
40] proposed RBFA-Net for the rotational detection and classification of ships in SAR images. Although the above methods have made some progress in integrating ship detection and classification research, there is still room for improvement in terms of model performance and model size.
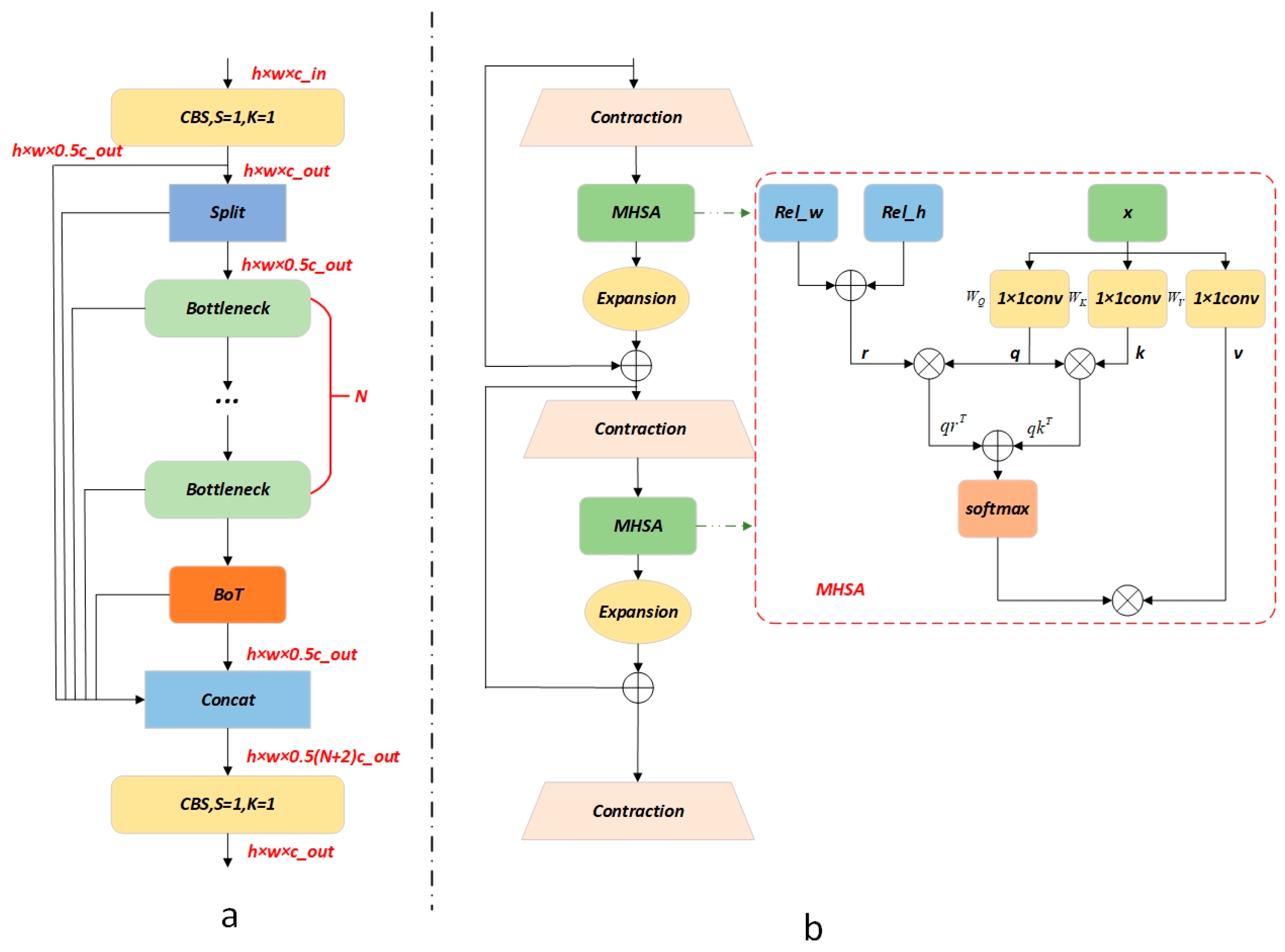
In order to address the above problems, a YOLOV8-based oriented ship detection and classification method for SAR images is proposed with lightweight receptor field feature convolution, bottleneck transformers and probabilistic intersection-over-union network (R-LRBPNet). The main objective of the network is to achieve the accurate detection and classification of ships while keeping the network lightweight. Firstly, our proposed C2fBT module is able to better extract integrated channel and global spatial features. Secondly, the R-LRBPNet presents an angle-decoupling module. In R-LRBPNet, the input feature maps are tuned for regression and classification tasks, respectively. The fast and accurate regression of angles is achieved using the ProbIoU + Distribution Focal Loss (DFL) [
41] approach at the decoupling head. Finally, in the feature fusion stage, our proposed lightweight receptor field feature convolution (LRFConv) is used to improve the sensitivity of the network to multi-scale targets and its ability to discriminate between complex and detailed information, thus improving the network’s ability to classify ships.
The main contributions are as follows:
A feature fusion module C2FBT is proposed. The module uses global spatial information to alleviate the problem of difficult detection due to the high density of ships. R-LRBPNet is proposed for SAR ship detection and classification.
A separate angle-decoupling head and ProbIoU + DFL angle loss function are proposed. The model is effective in achieving accurate angle regression and reducing the imbalance between the angle regression task and other tasks.
The LRFConv is proposed in R-LRBPNet. This module improves the network’s sensitivity to multi-scale targets and its ability to extract important detailed information.
A large number of experiments on the SRSDD dataset show that our R-LRBPNet is able to accurately detect and classify ships compared to 13 other networks.
The remainder of this paper is organized as follows. In
Section 2, we propose the overall framework of the model and introduce the methodology. The experiments are described in
Section 3. In
Section 4, we analyze the results of the comparison experiment and ablation experiment. Finally,
Section 5 summarizes the paper.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}