
Long-Tailed Effect Study in Remote Sensing Semantic Segmentation Based on Graph Kernel Principles

 ,
,
Abstract
1. Introduction
- A mechanism for representing the structural features of tail classes is proposed for the first time. By recognizing and extracting the eigenstructures of tail classes objects as supplementary information, the information imbalance between tail and head classes is alleviated.
- To further optimize the model’s training process, graph kernel is incorporated into our model, which dynamically adjusts the effect of graph structure information within the loss function, avoiding excessive suppression of head class objects and the information imbalance between head and tail classes.
- A remote sensing image semantic segmentation model based on graph kernel principles and graph neural networks (GKNNs) is designed on the basis of the aforementioned contributions to address the challenge of recognizing specific remote sensing objects of importance that are scarce and small in scale.
2. Related Work
2.1. Long-Tailed Visual Recognition
2.2. Graph Kernel
3. Materials and Methods
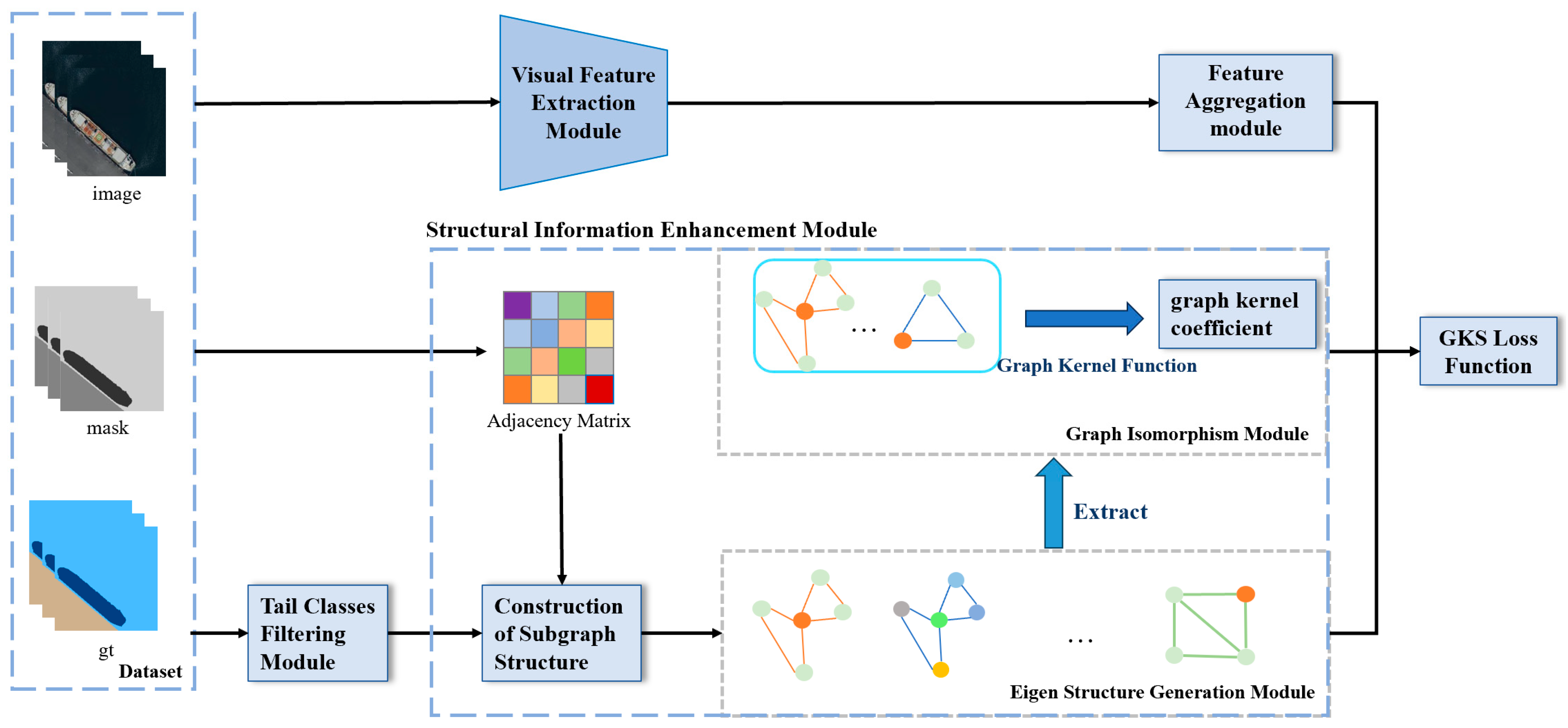
3.1. The GKNNs Model Architecture
3.2. Structural Information Enhancement Module
3.2.1. The Eigenstructure Generation Algorithm
| Algorithm 1 Generating Eigenstructures for Tail Class |
| Input: Dataset . Set of all Tail Classes |
| ▷ Sample Ground Truth: . Adjacency Matrix: . Object Mask: |
Output:
|
| ▷ Retrieve the first-order neighboring nodes of the target object along with their adjacency relationships |
|
| ▷ Extracting the subgraph of the tail class object |
|
|
|
|
3.2.2. The Graph Isomorphism Algorithm of Subgraph Structure
3.3. Structural Loss Function
3.3.1. Class-Balanced Structural Loss
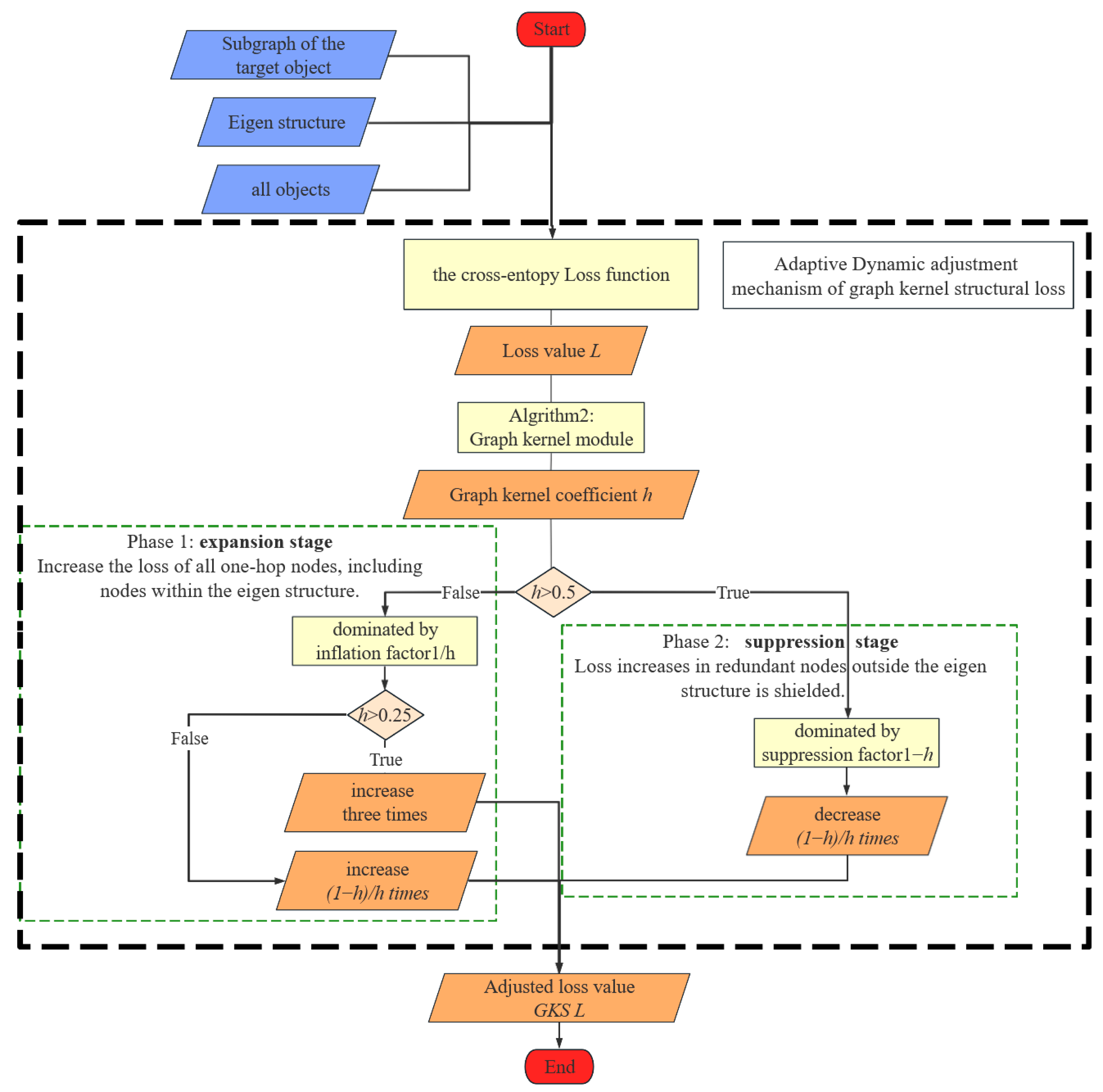
3.3.2. Graph Kernel Structural Loss
| Algorithm 2 Isomorphism between Eigenstructures and Neighborhood Subgraphs of Tail Classes |
| Input: Subgraph . Eigenstructure ▷ Adjacency Matrix: . Target Node Class: . eigenstructure edges: . eigenstructure edges frequency: Output: kernel coefficient h
|
| ▷ Convert the subgraph neighborhood into edge-based computation |
|
4. Results
4.1. Experiment Settings
- (1)
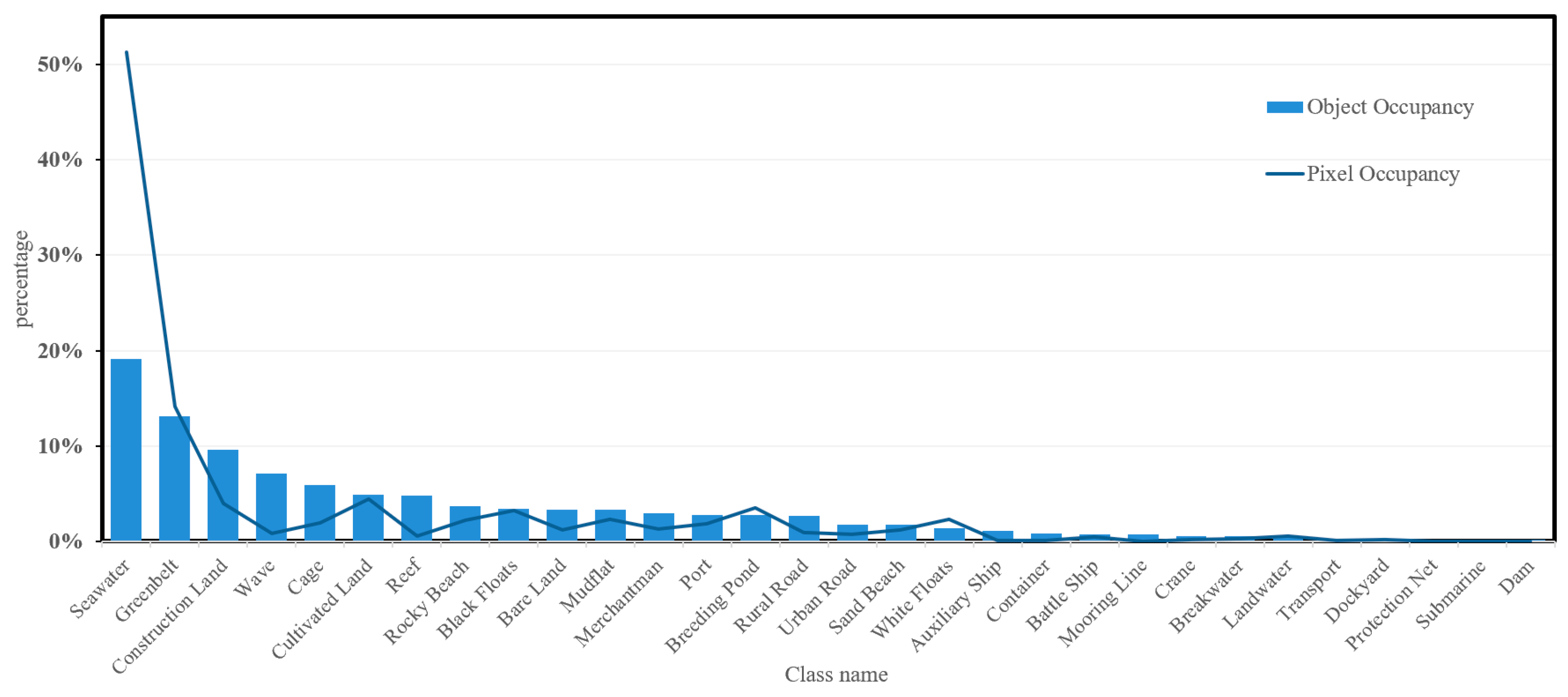
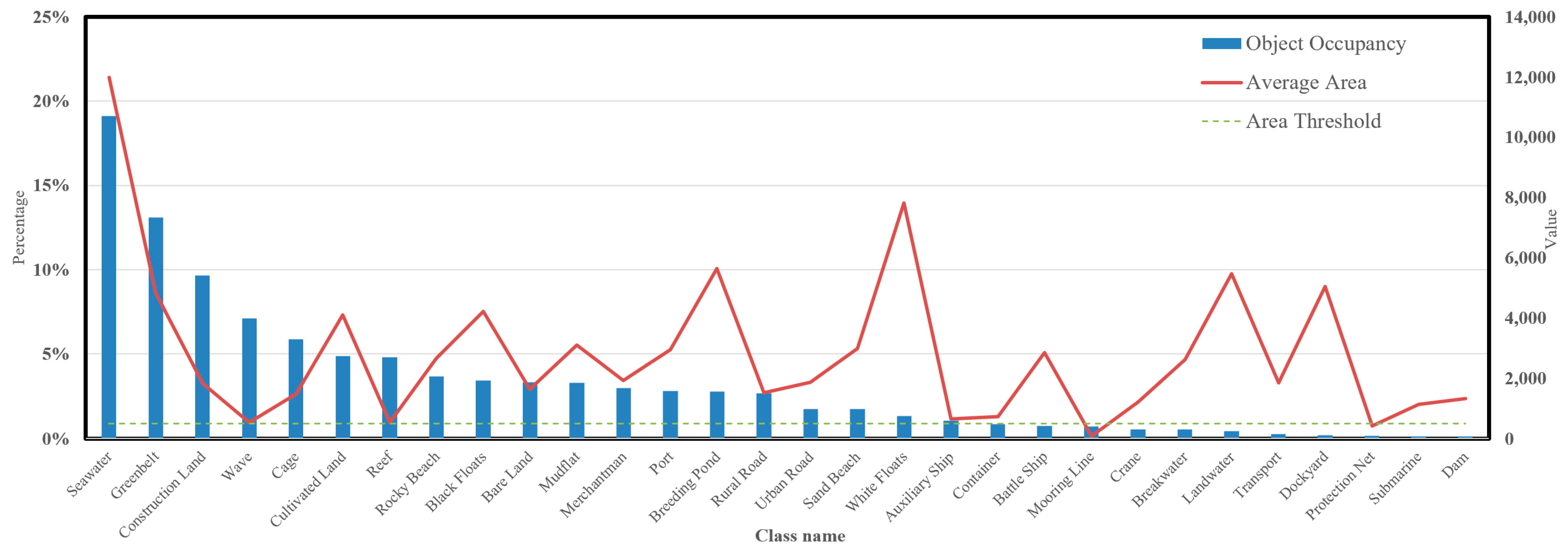
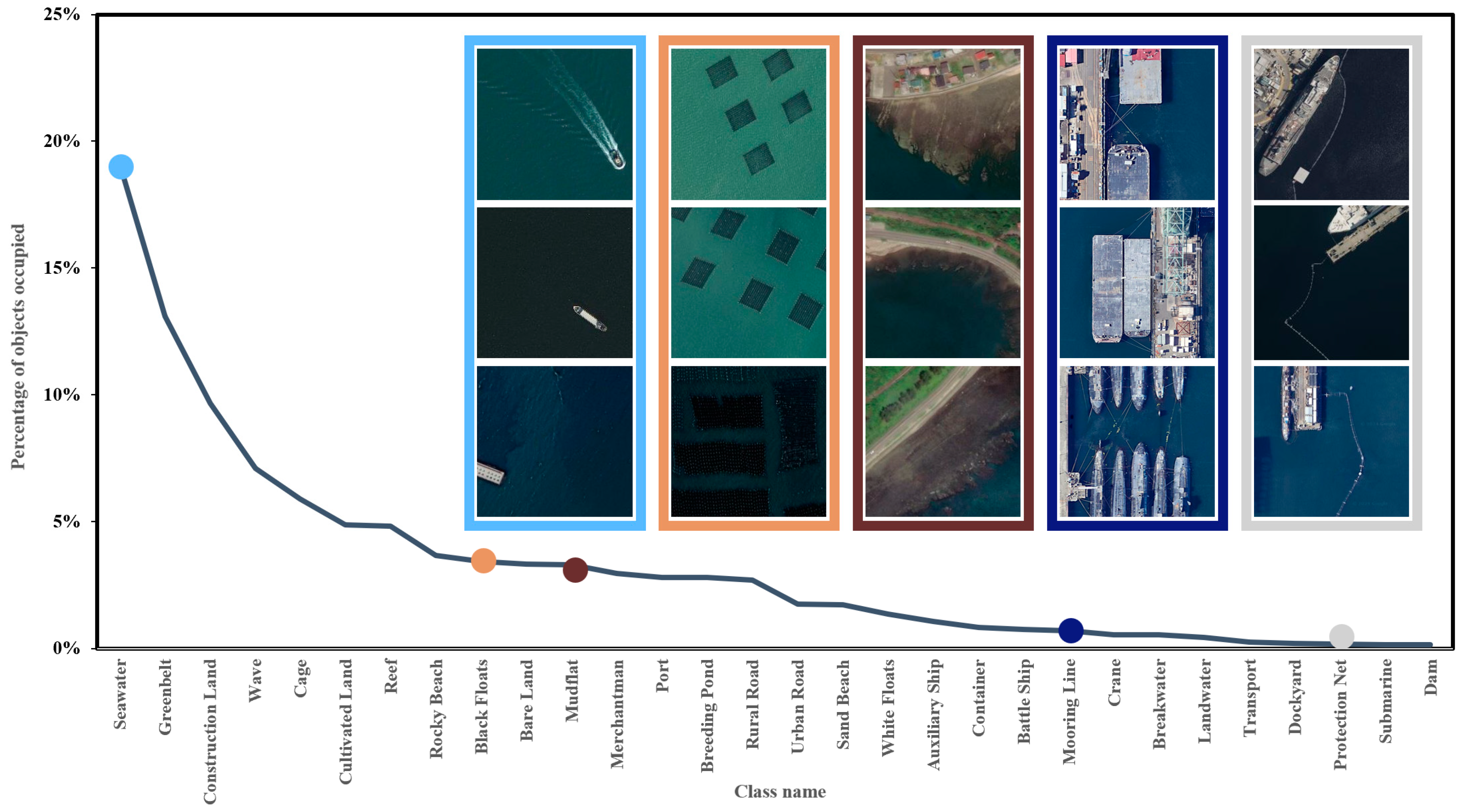
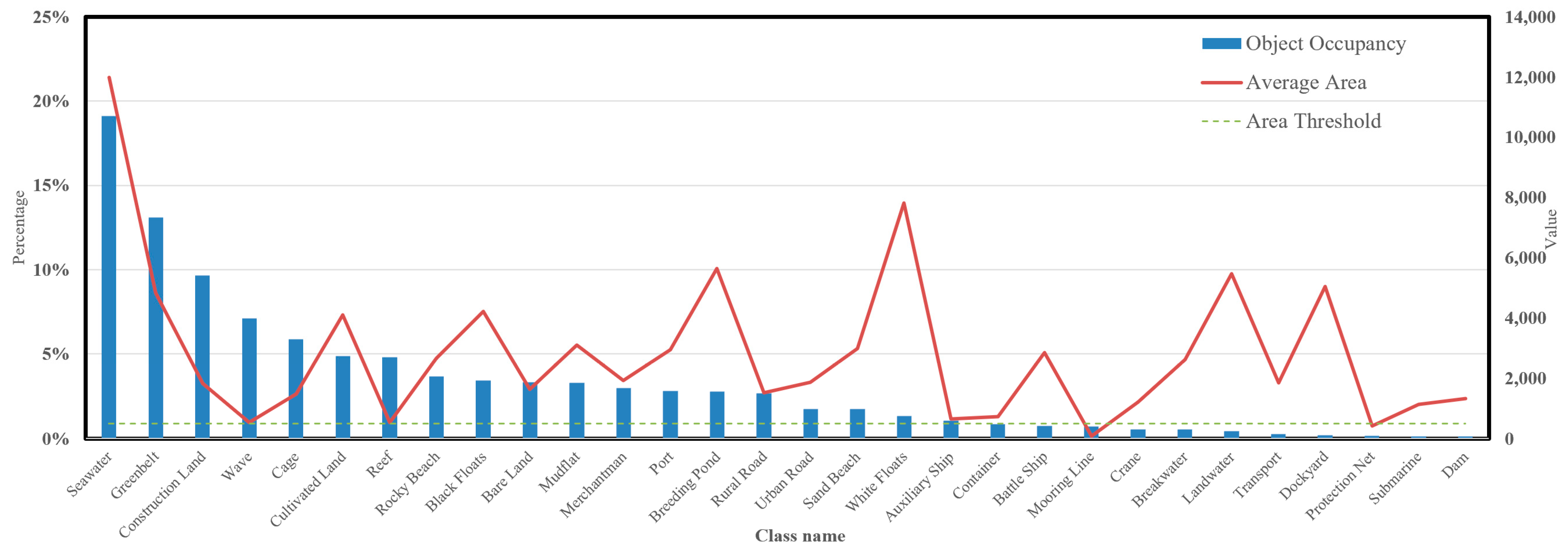
- Dataset and long-tailed effect analysis
- (2)
- Implementation Details
4.2. Training Loss Analysis
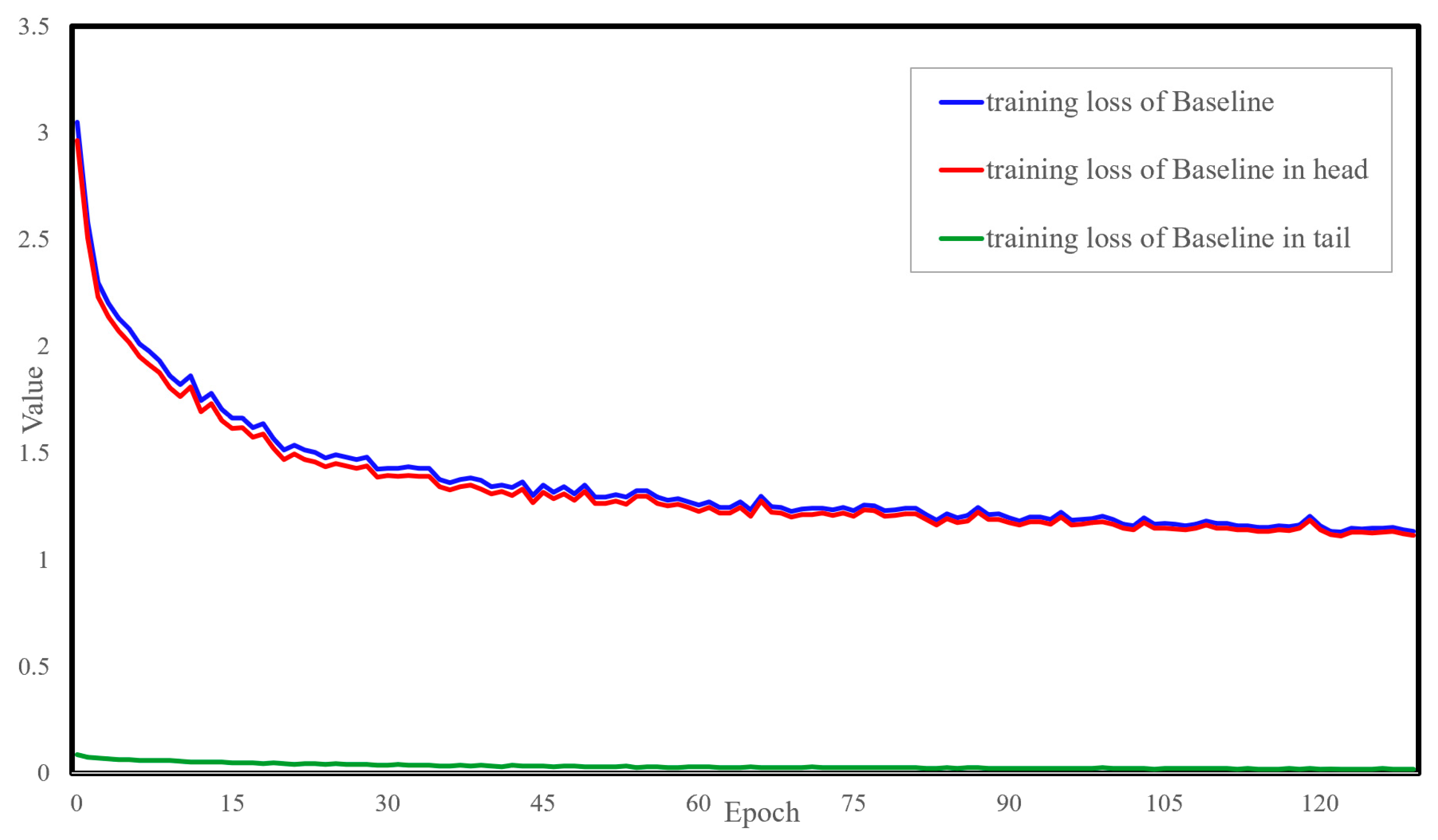
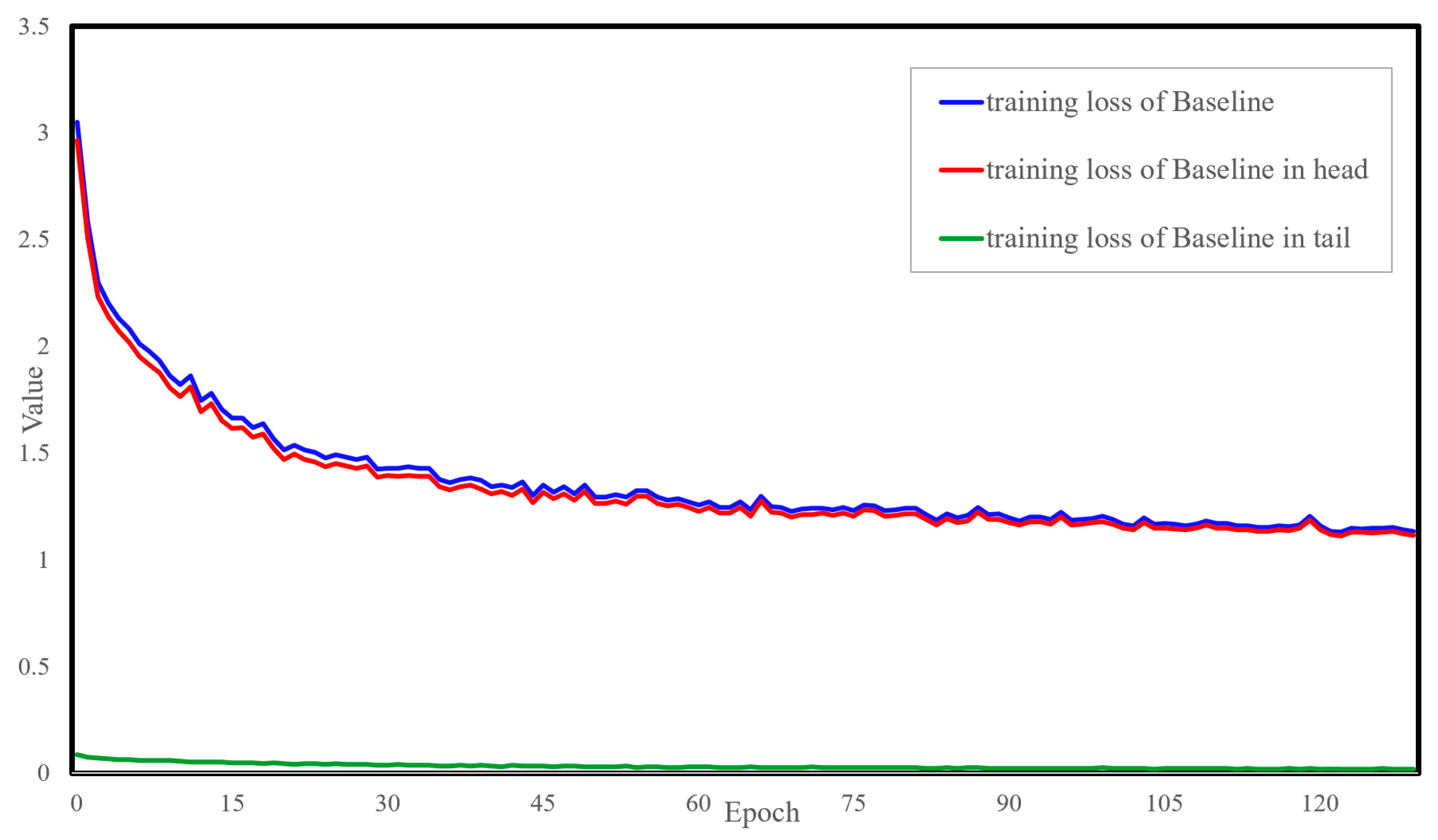
4.2.1. Training Loss of the Baseline Model
4.2.2. Tail Loss Comparative Analysis of the Models
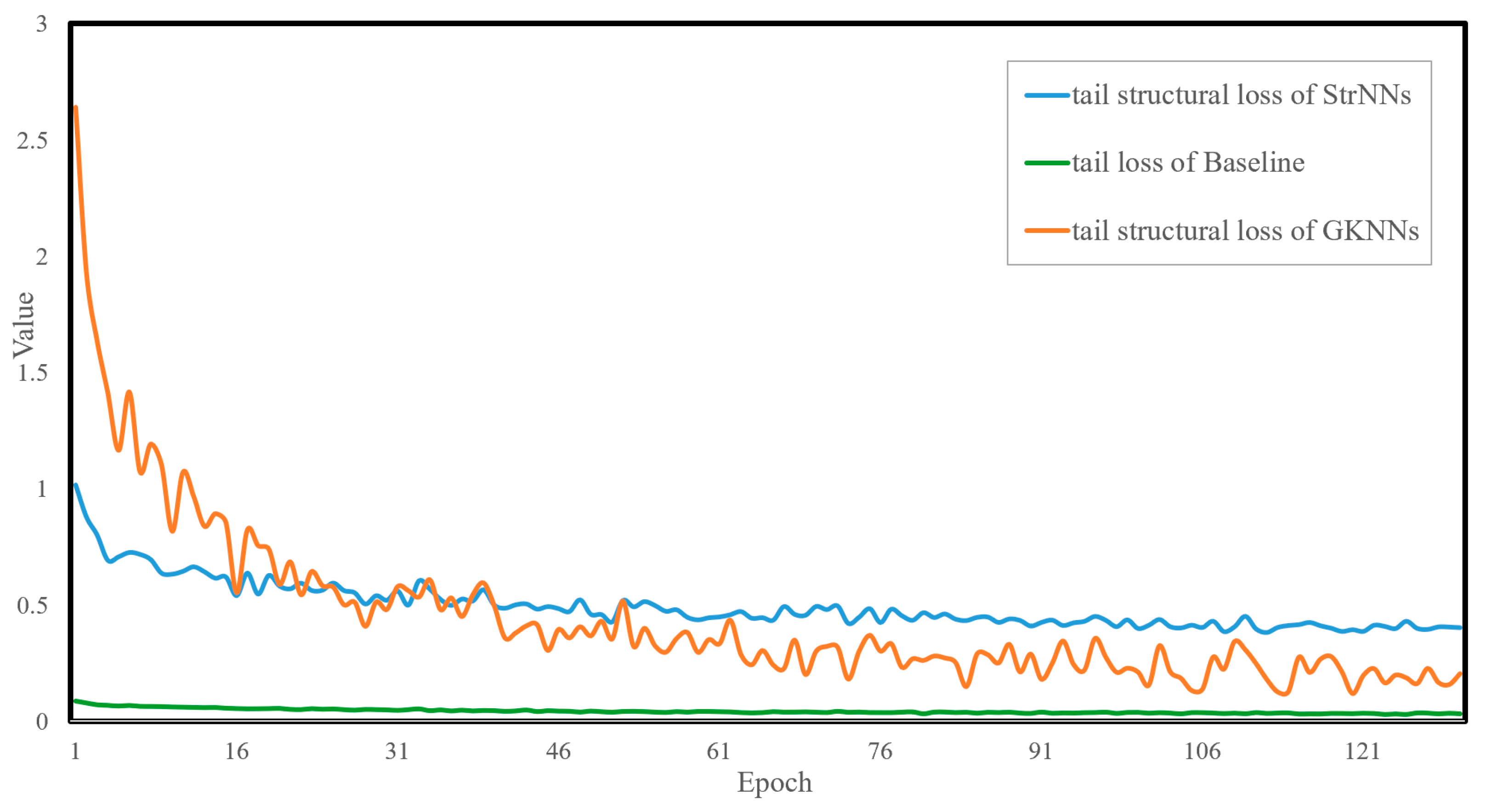
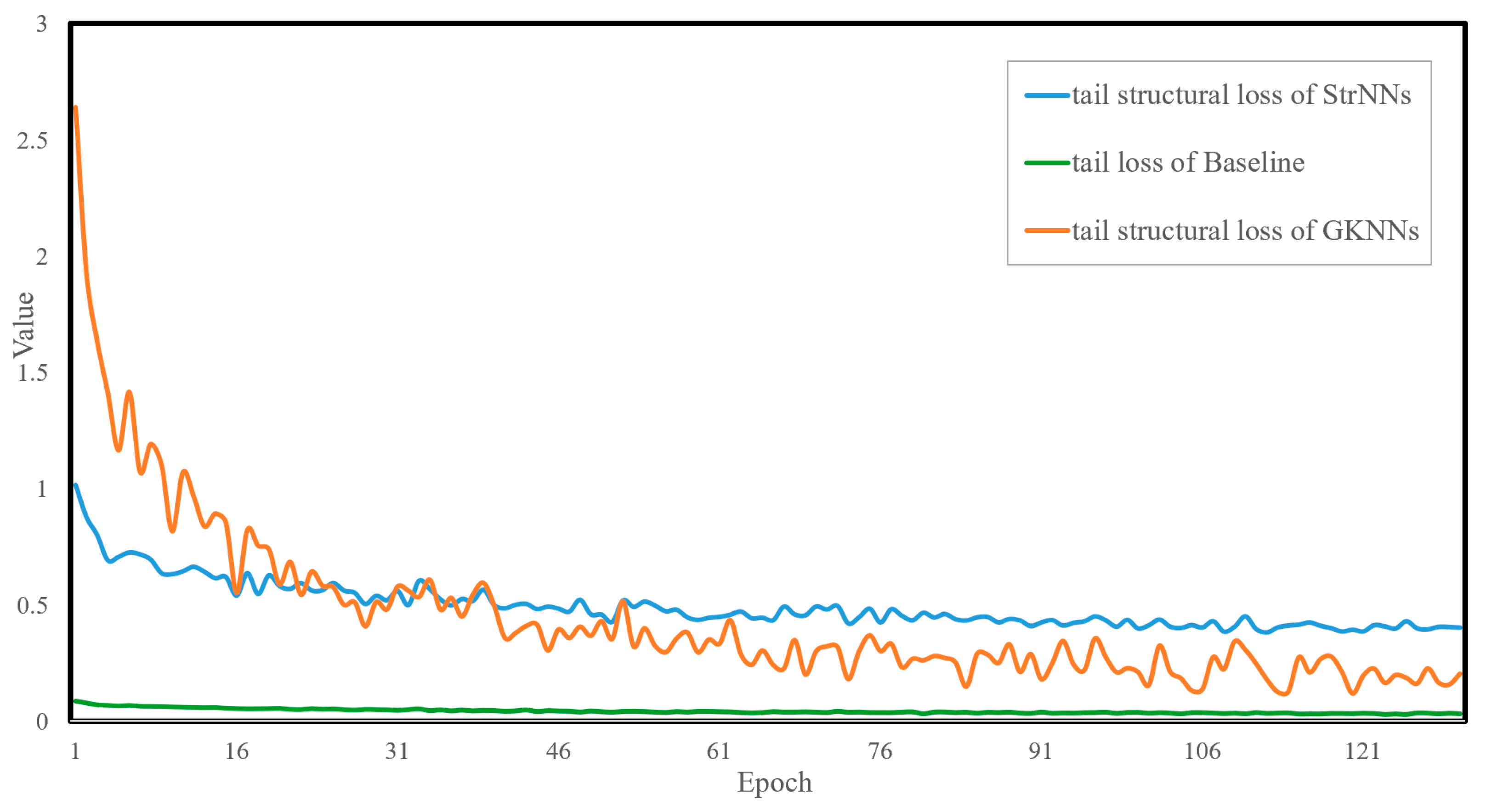
- Both the StrNNs model and the GKNNs model exhibit significant improvements in attention to tail classes. It can be observed from the figure that the tail loss curve of the baseline model consistently remains below the other two loss curves.
- Compared to the StrNNs model, the GKNNs model can achieve dynamic and adaptive adjustments of attention to tail classes. The tail structural loss value of the StrNNs model is initially around 1, while that of the GKNNs model, under the expansion effect of inflation factor, starts higher, at around 2.6. The tail structural loss curve of the GKNNs model experiences rapid descent initially, reaching parity with the StrNNs model around the 17th epoch. Subsequently, due to the dynamic suppression effect of the suppression factor, tail structural loss of the GKNNs model gradually decreases and becomes lower than that of the StrNNs model.
4.2.3. Training Loss of the GKNNs Model
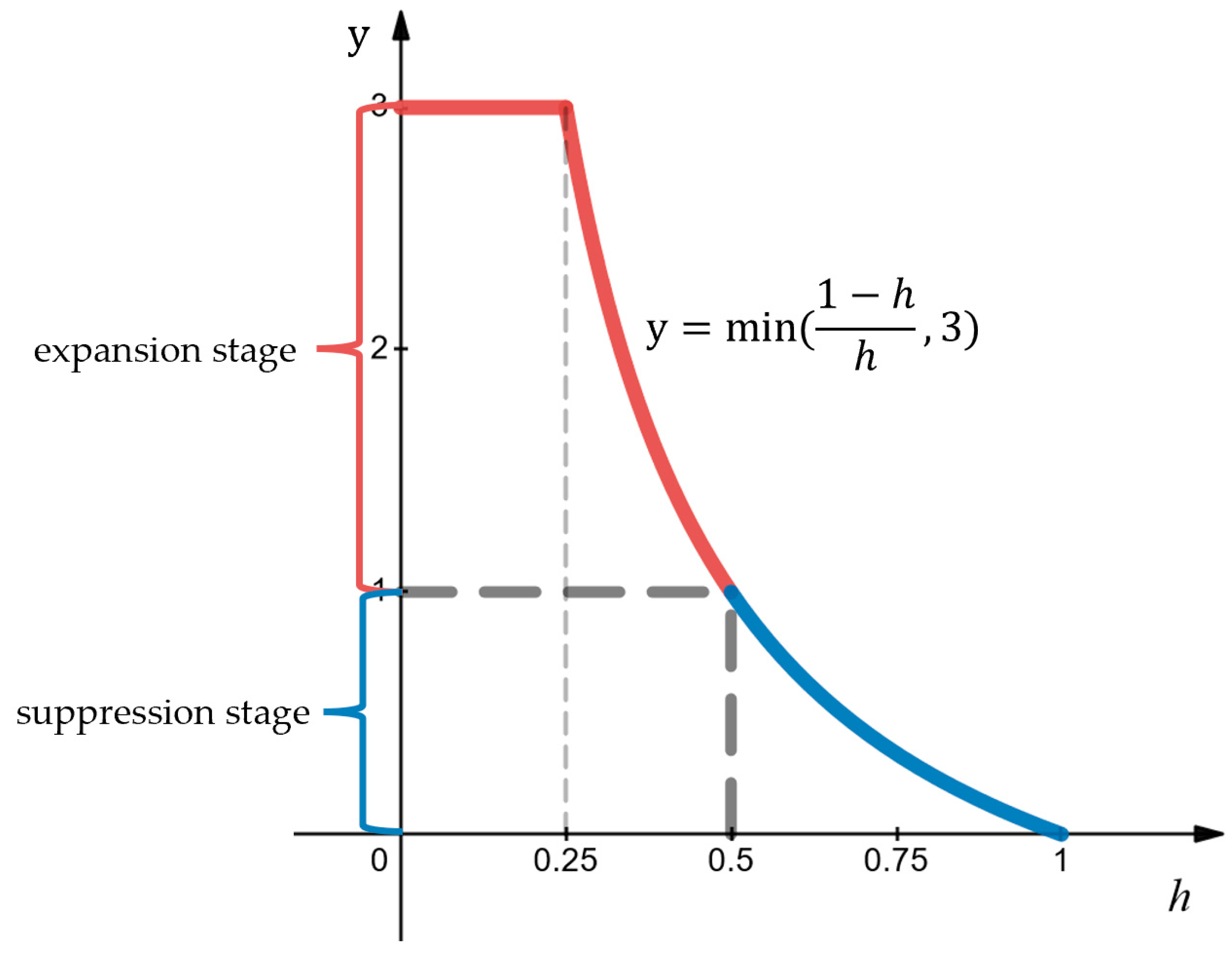
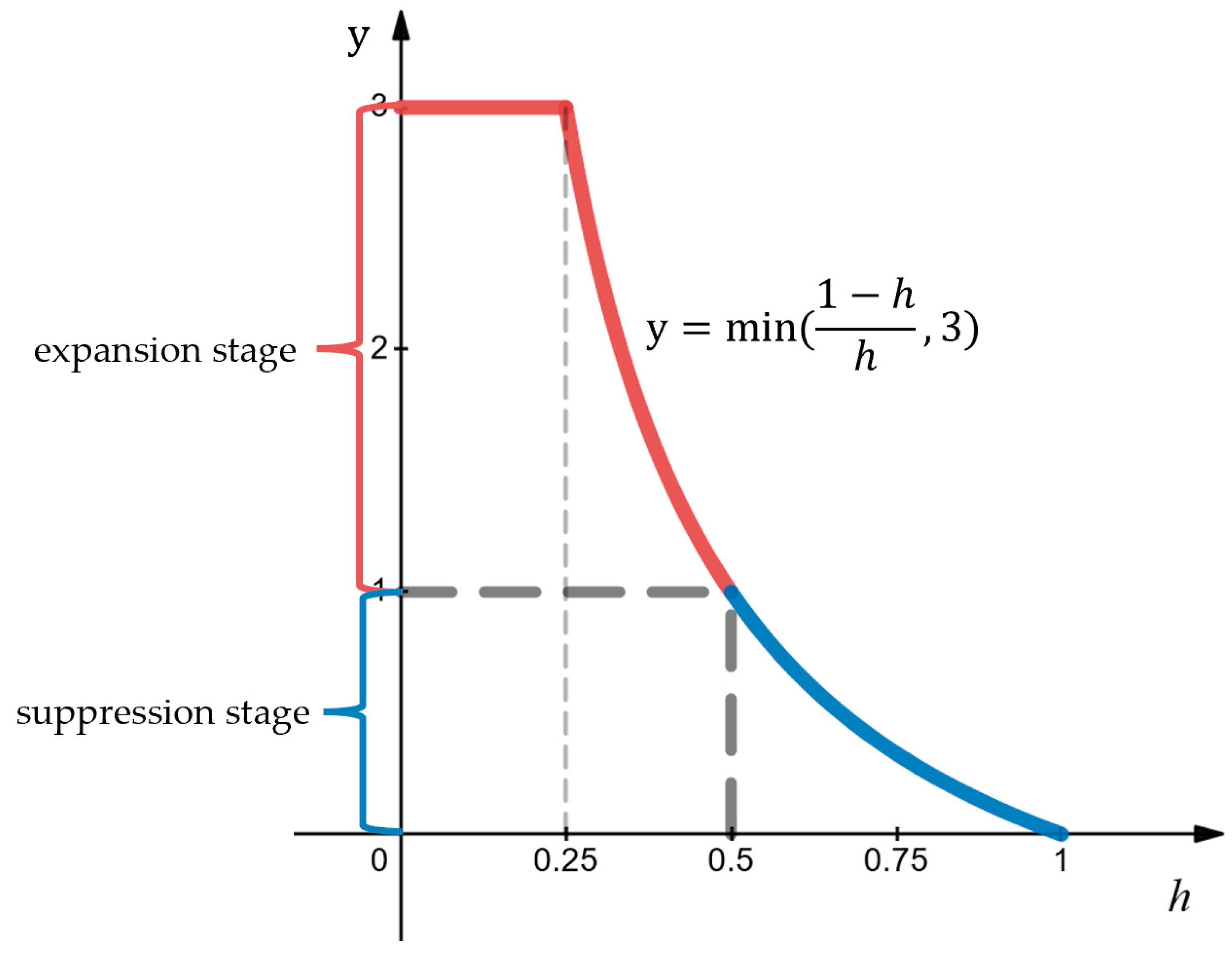
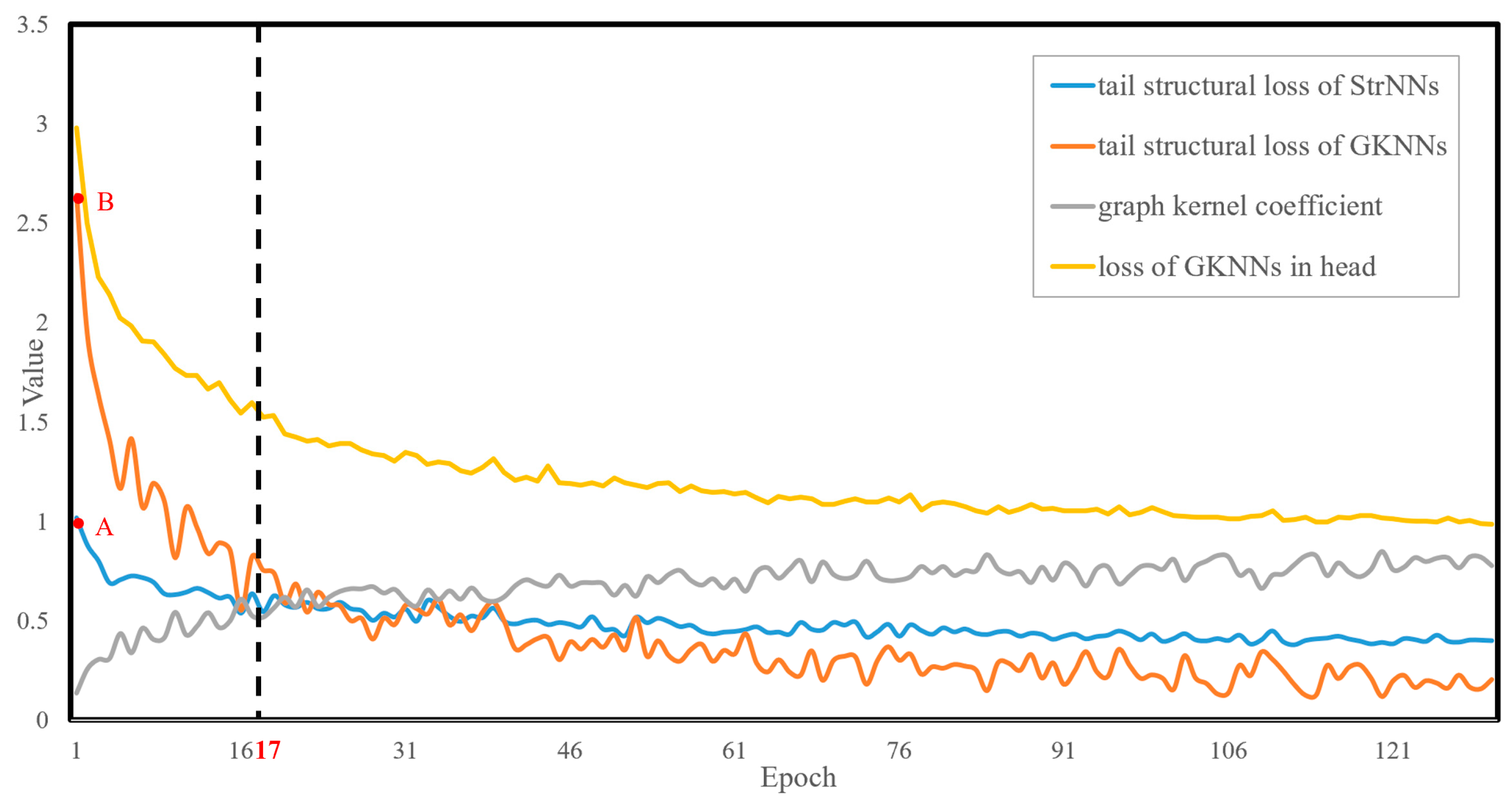
- Expansion stage: In the initial stages, the tail structural loss values of GKNNs and StrNNs are 2.6 (red point B in Figure 10) and 1.0 (red point A in Figure 10), while the loss of head classes is 2.9. By effect of the inflation factor, the initial tail structural loss is increased from 1.0 to 2.6, reaching the same order of magnitude as the head classes. This ensures that the tail class objects receive sufficient training. As the model continues to train, the graph kernel coefficient rapidly increases from 0 to 0.5, resulting in a simultaneous swift decline in the tail loss value of GKNNs. Around the 17th epoch, the graph kernel coefficient stabilizes around 0.5. Under the combined influence of the suppression and inflation factors, the tail structural loss value of GKNNs remains consistent with that of the StrNNs model.
- Suppression stage: After the 17th epoch, the graph kernel coefficient gradually approaches 1. Due to the dynamic suppression effect of the suppression factor, the tail structural loss of the GKNNs model gradually decrease and becomes lower than that of the StrNNs model for tail classes. Therefore, GKNNs can maintain the advantage of head classes without affecting the model’s focus on them.
4.3. Model Classification Precision Analysis
- (1)
- Comparison of Overall Metrics
- (2)
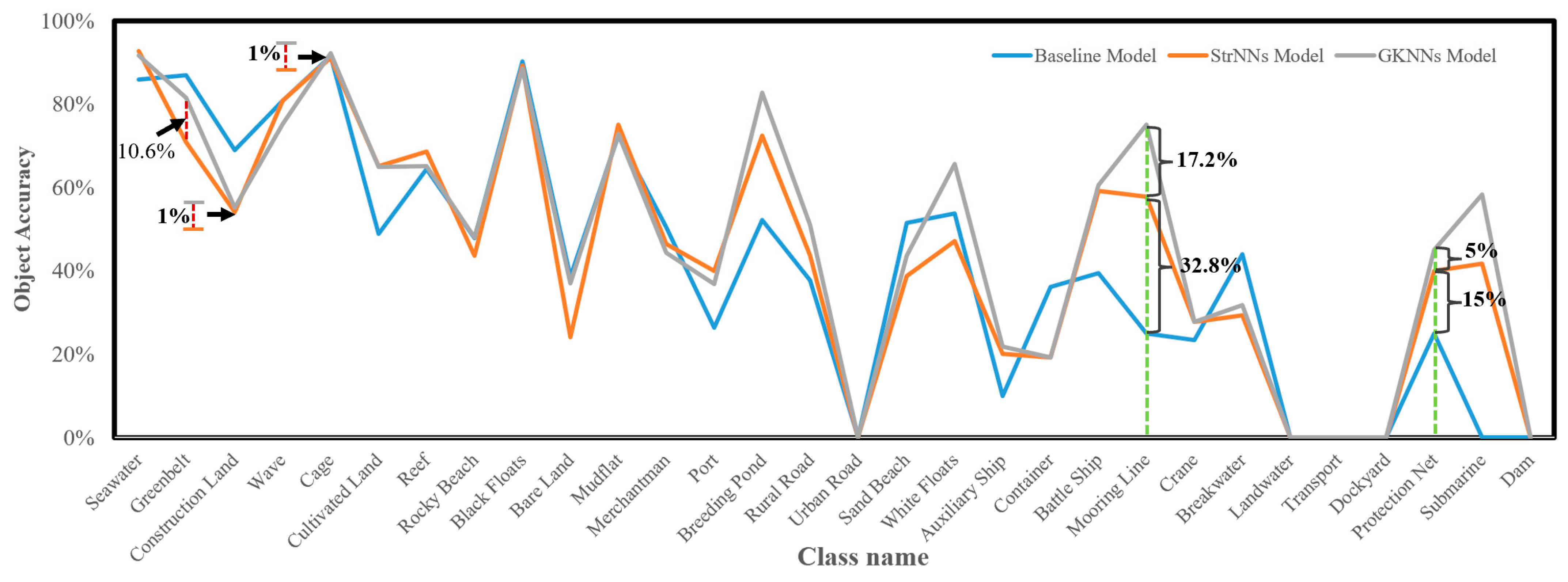
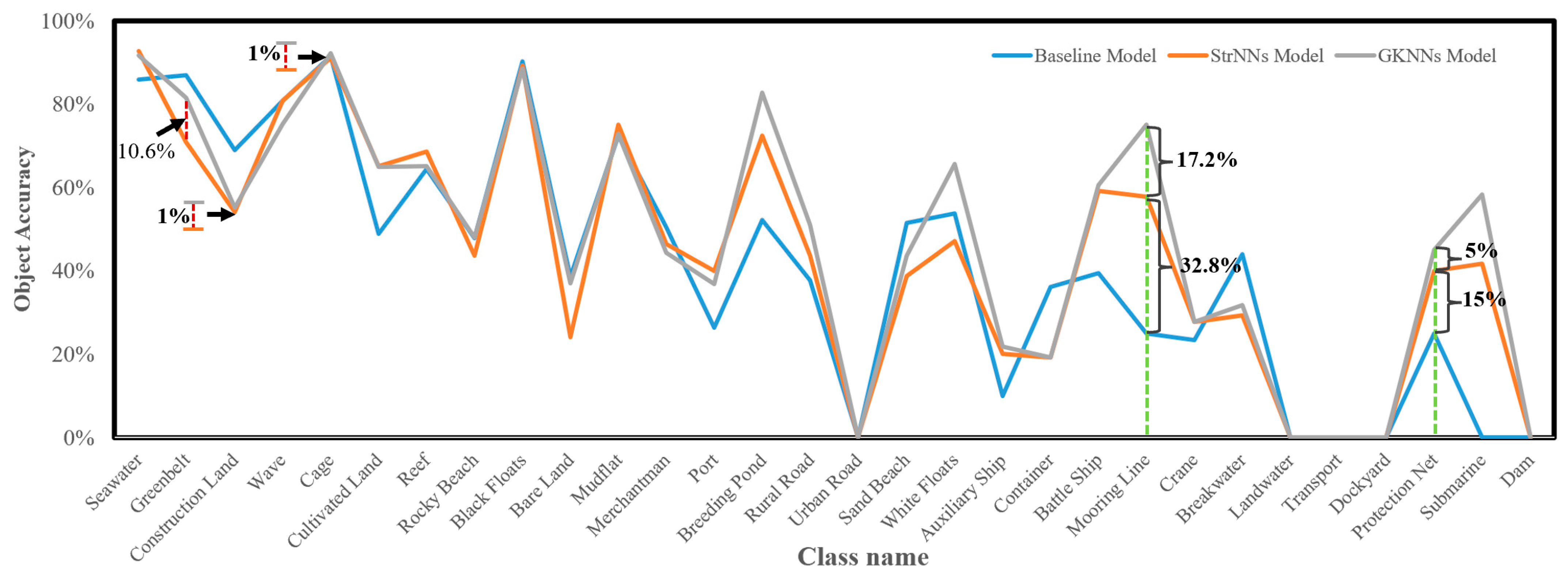
- Comparison of Class Object Accuracy
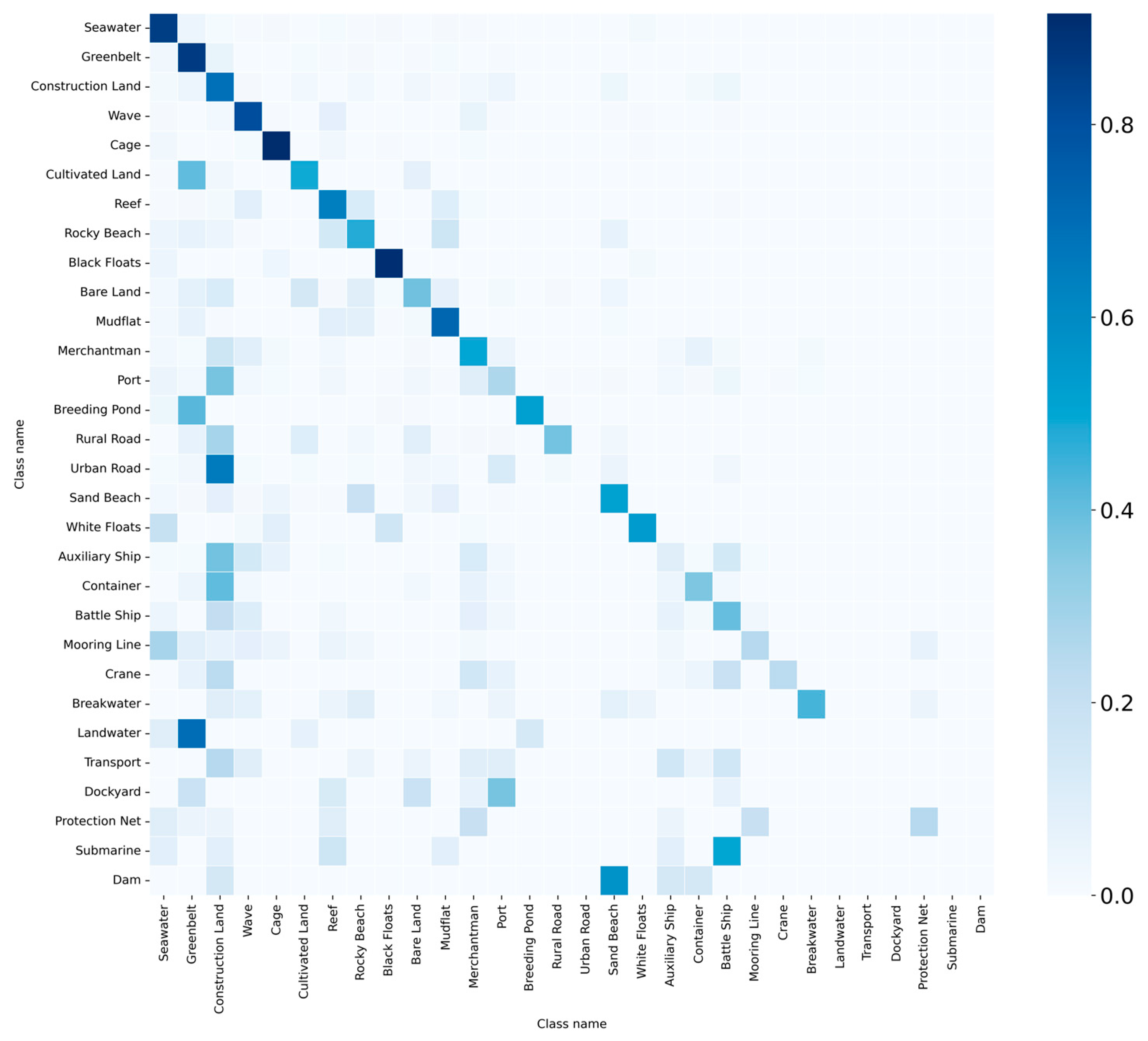
- Significant improvements of 32.8% and 15% are observed for the target tail classes, mooring line and protection net, respectively, compared to the baseline.
- As class 1 (seawater) is a crucial class in the eigenstructure of target tail classes, both StrNNs and GKNNs exhibit a 6% improvement in OA(object).
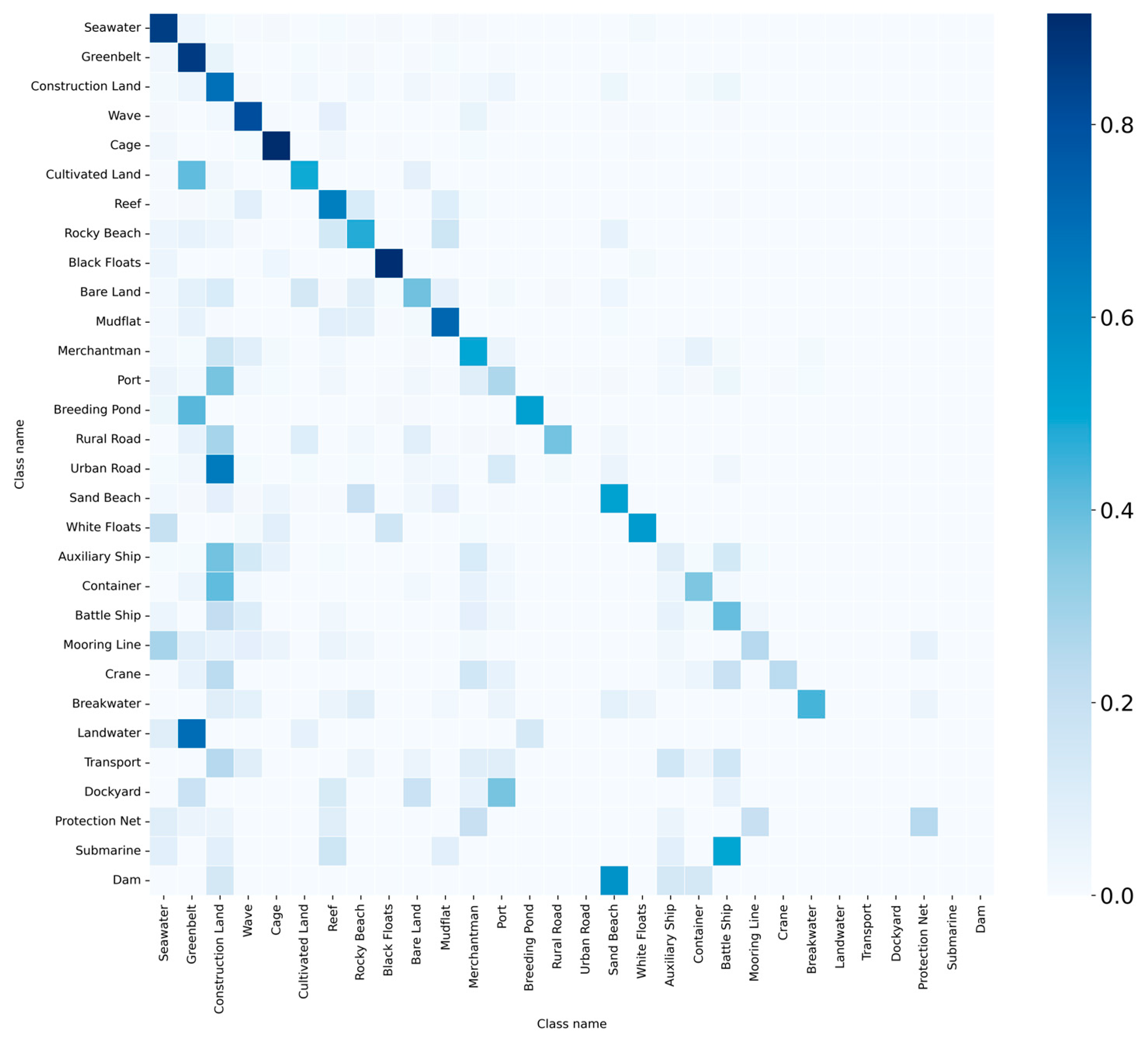
- However, excessive emphasis on target tail classes by StrNNs, aiming to balance training information between tail and head classes, slightly influences the recognition of some head classes (e.g., greenbelt, construction land, cage). Based on the situation above, an adaptive dynamic adjustment mechanism is introduced in GKNNs built upon StrNNs.
4.4. Backbone Model Analysis
- The ResNet34-112 × 112 backbone architecture employed in GKNNs exhibits relatively good performance in identifying target tail classes.
- Regarding the effectiveness for target tail classes, particularly for the morning line class with the smallest average object area, it can be observed that deep networks are prone to confusing features of small objects, while feature maps from shallower networks demonstrate better recognition accuracy for tail classes [41].
- Considering both the extraction performance of target tail classes and the computational efficiency of the model, we opted for ResNet34-112 × 112 as the backbone network for GKNNs.
4.5. Instance Analysis
4.5.1. Analyzing Instances with the Structural Loss in Tail Classes
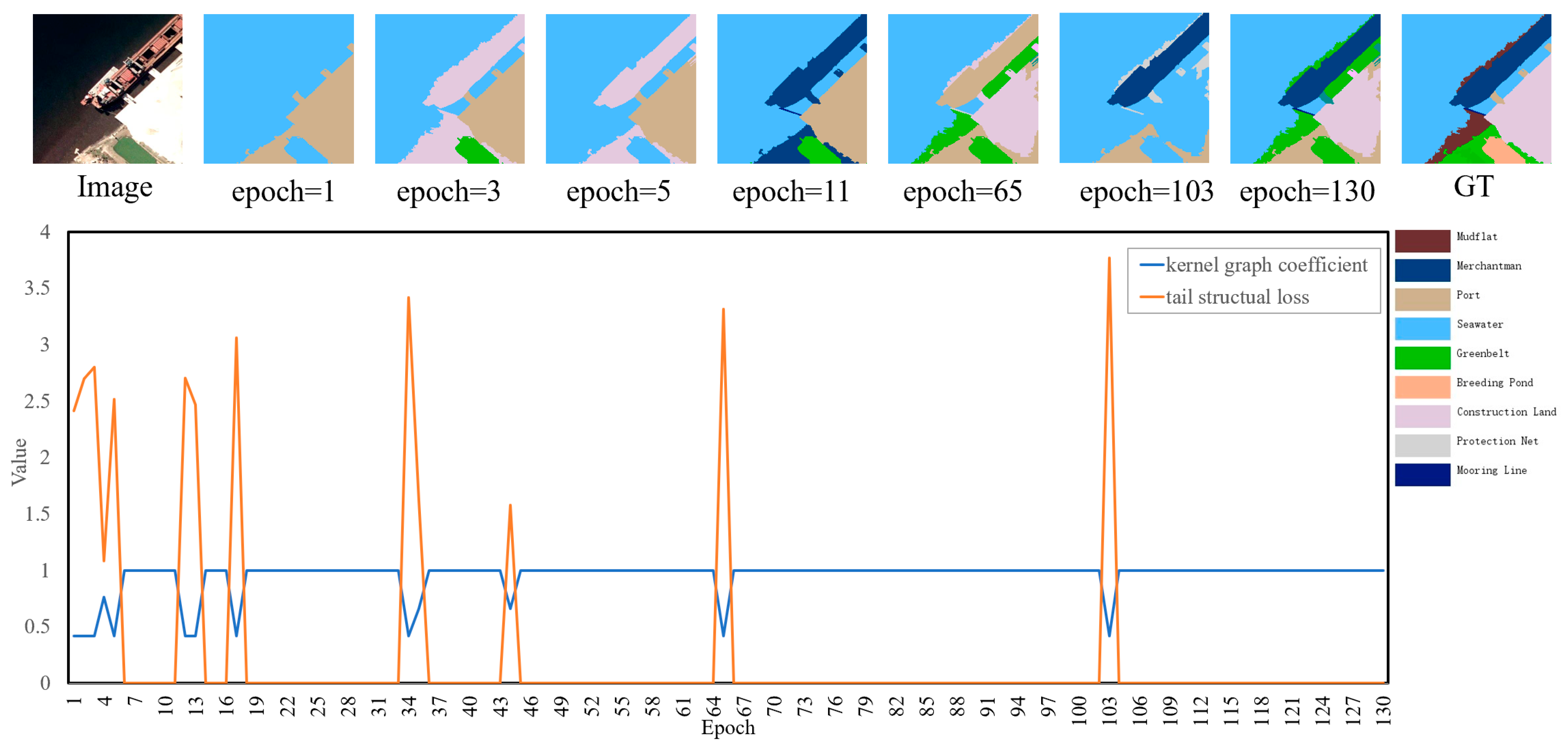
- Expansion stage: Before the fifth epoch, the graph kernel coefficient is less than 0.5, and the tail structural loss values of Sample 1 are magnified by the inflation factor. The tail structural loss decreases rapidly as the graph kernel coefficient increases.
- Suppression stage: After the fifth epoch, the graph kernel coefficient is greater than 0.5 and gradually approaches 1, and the tail structural loss enters a suppression stage. The kernel graph coefficient exhibits fluctuation during training, specifically dipping below 0.5 in epochs 27, 31, and 43.
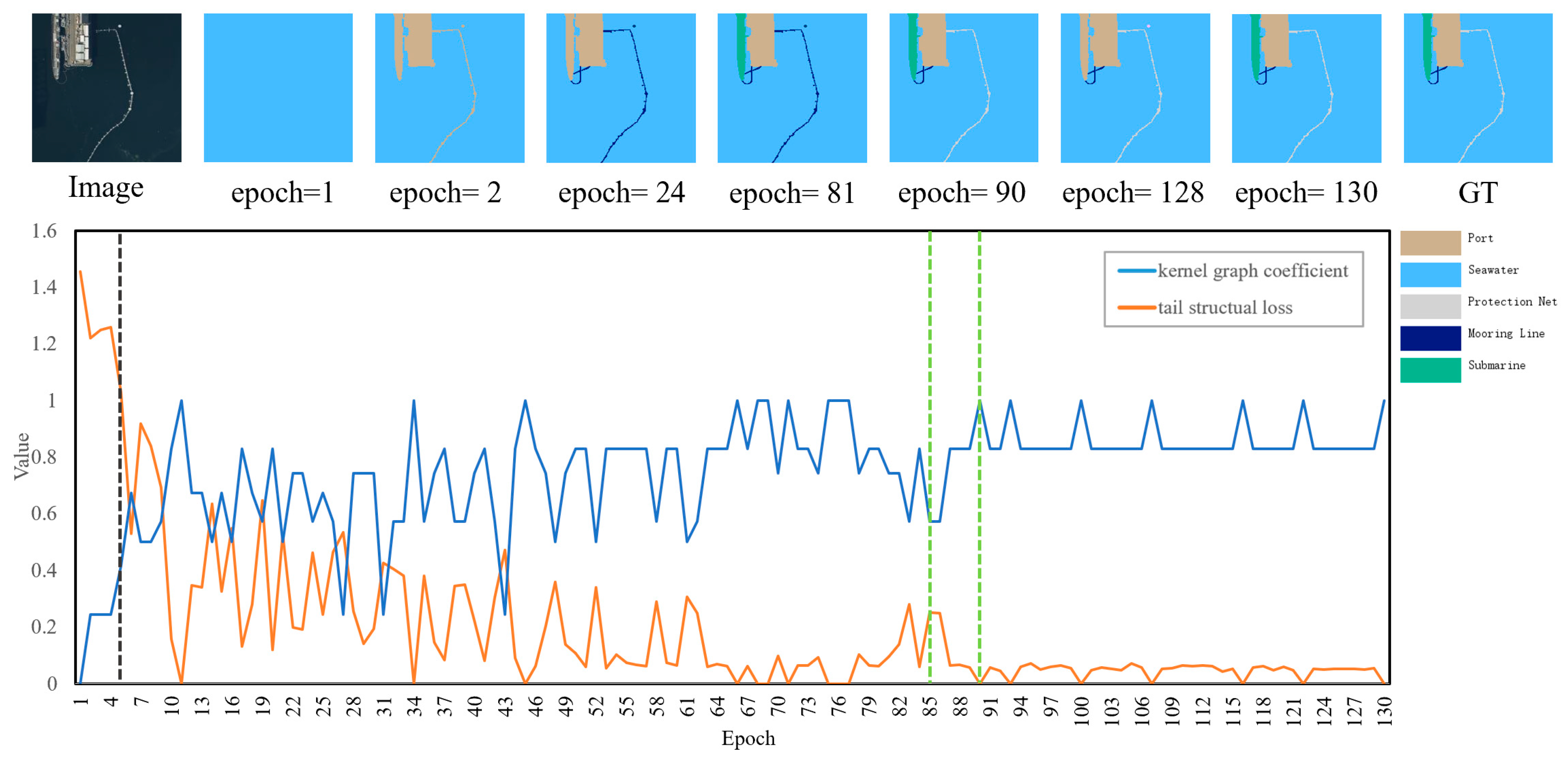
- The local analysis of the adaptive dynamic adjustment mechanism: From the 85th epoch to the 90th epoch (as shown by green lines in Figure 12), it can be observed that when the eigenstructure objects of the tail classes are correctly predicted step by step, the graph kernel coefficient increases from 0.57 to 1 accordingly, and the corresponding tail structural loss decreases from 0.25 to 0. This causes the model to no longer pay more attention to the tail classes, thereby preserving the performance advantage of the head classes. By the 90th epoch, both mooring line and protection net objects, together with their respective eigenstructures, are correctly predicted and the graph kernel coefficient reaches 1, achieving adaptive dynamic adjustment of the tail structural loss.
4.5.2. Analysis of Multiple Model Prediction Results for Typical Examples
5. Discussion and Conclusions
- This study introduces an effective mechanism for representing the structural features based on graph kernel principles to represent the structural features of tail classes and quantitatively describe the learning effectiveness of eigenstructure information. This mechanism leverages the eigenstructure information of tail class objects, in conjunction with basic visual features, to supplement and enhance the information of tail class objects, thereby partially compensate for the imbalance between tail and head class object information.
- Implemented with adaptive dynamic adjustment of the loss based on graph kernels, our designed inflation and suppression factors can dynamically control the strength of the enhancement information for tail classes. The results demonstrate that this mechanism ensures sufficient information for the recognition of tail classes while avoiding adverse impacts on the recognition of head classes.
- The experimental results show that the accuracy of target tail classes such as protection net and mooring line were improved by 20% and 50%, respectively, compared to the baseline model. Moreover, the average accuracy of object classes was increased by 6.16%. Experimental results demonstrate that the GKNNs model effectively addresses the recognition problem of minority and small targets, partially mitigates the phenomenon of foreign objects with similar spectra to tail objects, and improves its generalization ability and the semantic segmentation performance in remote sensing.
- The representation method for eigenstructure can be improved. In this research, the environmental information and eigenstructure of target tail classes objects are supplemented as background knowledge. The selection of eigenstructure depends on expert systems and simultaneously requires a certain amount of training samples. In the future, it is contemplated to use graph embedding models to better represent the eigenstructure, thereby enhancing the generalization of the model.
- More information of tail classes needs to be considered. Currently, the supplementary information for tail classes includes the visual and spatial features of target tail class objects. In subsequent work, more enriched attributes information such as the contours, areas, and the effect of corresponding geographical scene of tail classes can be embedded in the form of knowledge graph to supplement object information and balance the information gap between head and tail classes.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Yu, F.; Liu, Y.; Yumna, Z.; Gui, G.; Tao, M.; Qiang, S.; Jun, G. Long-tailed visual recognition with deep models: A methodological survey and evaluation. Neurocomputing 2022, 509, 290–309. [Google Scholar]
- Gupta, A.; Dollár, P.; Girshick, R. LVIS: A Dataset for Large Vocabulary Instance Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5351–5359. [Google Scholar]
- Wei, X. Image recognition of long-tail distribution: Pathways and progress. China Basic Sci. 2023, 25, 48–55. [Google Scholar]
- Buda, M.; Maki, A.; Mazurowski, M.A. A systematic study of the class imbalance problem in convolutional neural networks. Neural Netw. 2018, 106, 249–259. [Google Scholar] [CrossRef] [PubMed]
- Drummond, C.; Holte, R. C4.5, Class Imbalance, and Cost Sensitivity: Why Under-sampling Beats Oversampling. In Proceedings of the ICML Workshop on Learning from Imbalanced Data Sets, Washington, DC, USA, 21 August 2003; pp. 1–8. [Google Scholar]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Philip Kegelmeyer, W. SMOTE: Synthetic minority over 2 sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Kang, B.; Xie, S.; Rohrbach, M.; Yan, Z.; Gordo, A.; Feng, J.; Kalantidis, Y. Decoupling representation and classifier for long-tailed recognition. In Proceedings of the International Conference on Learning Representations (ICLR), Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- He, H.; Bai, Y.; Garcia, E.; Li, S. Adaptive synthetic sampling approach for imbalanced learning. In Proceedings of the IEEE International Joint Conference on Neural Networks (IEEE World Congress on Computational Intelligence), Hong Kong, China, 1–8 June 2008. [Google Scholar]
- Mahajan, D.; Girshick, R.; Ramanathan, V.; He, K.; Paluri, M.; Li, Y.; Bharambe, A.; Van Der Maaten, L. Exploring the limits of weakly supervised pretraining. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 181–196. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollar, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Cui, Y.; Jia, M.; Lin, T.Y.; Song, Y.; Belongie, S. Class-balanced loss based on effective number of samples. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 9268–9277. [Google Scholar]
- Wang, Y.; Ramanan, D.; Hebert, M. Learning to model the tail. In Proceedings of the 31st Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Liu, B.; Li, H.; Kang, H.; Hua, G.; Vasconcelos, N. GistNet: A geometric structure transfer network for long-tailed recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 8209–8218. [Google Scholar]
- Zhang, Y.; Cheng, D.Z.; Yao, T.; Yi, X.; Hong, L.; Chi, E.H. A model of two tales: Dual transfer learning framework for improved long-tail item recommendation. In Proceedings of the Web Conference 2021, Ljubljana, Slovenia, 19–23 April 2021; pp. 2220–2231. [Google Scholar]
- Cui, Y.; Song, Y.; Sun, C.; Howard, A.; Belongie, S. Large scale fine-grained categorization and domain-specific transfer learning. In Proceedings of the IEEE conference on computer vision and pattern recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4109–4118. [Google Scholar]
- Hu, X.; Jiang, Y.; Tang, K.; Chen, J.; Miao, C.; Zhang, H. Learning to segment the tail. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 14045–14054. [Google Scholar]
- Liu, J.; Sun, Y.; Han, C.; Dou, Z.; Li, W. Deep representation learning on long-tailed data: A learnable embedding augmentation perspective. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 2970–2979. [Google Scholar]
- Taha, A.Y.; Tiun, S.; Abd Rahman, A.H.; Sabah, A. Multilabel Over-Sampling and under-Sampling with Class Alignment for Imbalanced Multilabel Text Classification. J. Inf. Commun. Technol. 2021, 20, 423–456. [Google Scholar] [CrossRef]
- Zhou, B.; Cui, Q.; Wei, X.S.; Chen, Z.M. BBN: Bilateral-branch network with cumulative learning for long-tailed visual recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 9719–9728. [Google Scholar]
- Cao, K.; Wei, C.; Gaidon, A.; Aréchiga, N.; Ma, T. Learning imbalanced datasets with label-distribution-aware margin loss. In Proceedings of the Neural Information Processing Systems (NeurIPS), Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Cui, W.; He, X.; Yao, M.; Wang, Z.; Hao, Y.; Li, J.; Wu, W.; Zhao, H.; Xia, C.; Li, J. Knowledge and Spatial Pyramid Distance-Based Gated Graph Attention Network for Remote Sensing Semantic Segmentation. Remote Sens. 2021, 13, 1312. [Google Scholar] [CrossRef]
- Cui, W.; Hao, Y.; Xu, X.; Feng, Z.; Zhao, H.; Xia, C.; Wang, J. Remote Sensing Scene Graph and Knowledge Graph Matching with Parallel Walking Algorithm. Remote Sens. 2022, 14, 4872. [Google Scholar] [CrossRef]
- Zhong, Z.; Cui, J.; Liu, S.; Jia, J. Improving calibration for long-tailed recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 16489–16498. [Google Scholar]
- Han, H.; Wang, W.Y.; Mao, B.H. Borderline-SMOTE: A New Over-Sampling Method in Imbalanced Data Sets Learning. In Proceedings of the International Conference on Advances in Intelligent Computing, Hefei, China, 23–26 August 2005; pp. 878–887. [Google Scholar]
- Chang, N.; Yu, Z.; Wang, Y.X.; Anandkumar, A.; Fidler, S.; Alvarez, J.M. Image-Level or Object-Level? A Tale of Two Resampling Strategies for Long-Tailed Detection. In Proceedings of the International Conference on Machine Learning, Vienna, Austria, 18–24 July 2021; pp. 1463–1472. [Google Scholar]
- Wei, H.; Tao, L.; Xie, R.; Feng, L.; An, B. Open-Sampling: Exploring out-of-Distribution Data for Re-Balancing Long-Tailed Datasets. In Proceedings of the International Conference on Machine Learning, Baltimore, MD, USA, 17–23 July 2022; pp. 23615–23630. [Google Scholar]
- Yu, H.; Du, Y.; Wu, J. Reviving Undersampling for Long-Tailed Learning. Available online: https://arxiv.org/abs/2401.16811 (accessed on 30 January 2024).
- Wei, F.; Stolfo, J.S.; Zhang, J.; Chan, P.K. AdaCost: Misclassification cost- sensitive boosting. In Proceedings of the 16th International Conference on Machine Learning, SanMateo, USA, 27–30 June 1999. [Google Scholar]
- Khan, S.H.; Hayat, M.; Bennamoun, M.; Sohel, F.A.; Togneri, R. Cost-Sensitive Learning of Deep Feature Representations from Imbalanced Data. IEEE Trans. Neural Netw. Learn. Syst. 2017, 29, 3573–3587. [Google Scholar] [PubMed]
- Fernando, K.R.M.; Tsokos, C.P. Dynamically Weighted Balanced Loss: Class Imbalanced Learning and Confidence Calibration of Deep Neural Networks. IEEE Trans. Neural Netw. Learn. Syst. 2021, 33, 2940–2951. [Google Scholar] [CrossRef] [PubMed]
- Dong, Q.; Gong, S.; Zhu, X. Class Rectification Hard Mining for Imbalanced Deep Learning. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1851–1860. [Google Scholar]
- Xiang, L.; Ding, G.; Han, J. Learning from multiple experts: Self-paced knowledge distillation for long-tailed classification. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; pp. 247–263. [Google Scholar]
- Haussler, D. Convolution Kernels on Discrete Structures; UCS-CRL-99-10; University of California at Santa Cruz: Santa Cruz, CA, USA, 1999. [Google Scholar]
- Gärtner, T. A survey of kernels for structured data. ACM SIGKDD Explor. Newsl. 2003, 5, 49–58. [Google Scholar] [CrossRef]
- Gärtner, T.; Flach, P.; Wrobel, S. On graph kernels: Hardness results and efficient alternatives. Learn. Theory Kernel Mach. 2013, 2777, 129–143. [Google Scholar]
- Shervashidze, N.; Vishwanathan, S.V.N.; Petri, T.; Mehlhorn, K.; Borgwardt, K. Efficient graphlet kernels for large graph comparison. In Proceedings of the 22nd International Conference on Artificial Intelligence and Statistics, Naha, Okinawa, Japan, 16–18 April 2009; pp. 488–495. [Google Scholar]
- Shervashidze, N.; Schweitzer, P.; Leeuwen, E.J.V.; Mehlhorn, K.; Borgwardt, K.M. Weisfeiler-lehman graph kernels. J. Mach. Learn. Res. 2011, 12, 2539–2561. [Google Scholar]
- Nikolentzos, G.; Meladianos, P.; Tixier, A.J.P.; Skianis, K.; Vazirgiannis, M. Kernel graph convolutional neural networks. In Proceedings of the 27th International Conference on Artificial Neural Networks, Rhodes, Greece, 4–7 October 2018; pp. 22–32. [Google Scholar]
- Du, S.S.; Hou, K.; Póczos, B.; Salakhutdinov, R.; Wang, R.; Xu, K. Graph neural tangent kernel: Fusing graph neural networks with graph kernels. In Proceedings of the Neural Information Processing Systems (NeurIPS), Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Feng, A.; You, C.; Wang, S.; Tassiulas, L. KerGNNs: Interpretable graph neural networks with graph kernels. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, Canada, 22–28 February 2022; pp. 6614–6622. [Google Scholar]
- Luo, W.; Li, Y.; Urtasun, R.; Zemel, R. Understanding the effective receptive field in deep convolutional neural networks. In Proceedings of the 30th Conference on Neural Information Processing Systems (NIPS 2016), Barcelona, Spain, 5–10 December 2016. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | OA (Object) | OA (Pixel) | Kappa | AA (Object) |
|---|---|---|---|---|
| GAT | 67.06% | 84.84% | 0.6366 | 41.69% |
| StrNNs | 66.89% | 84.18% | 0.6364 | 44.60% |
| GKNNs | 68.82% | 86.02% | 0.6567 | 47.85% |
| Resnet34-112 × 112 (Ours) | Resnet34-56 × 56 | Resnet34-28 × 28 | |
|---|---|---|---|
| Protection net OA(object) | 45.00% | 60.00% | 45.00% |
| Mooring line OA(object) | 75.00% | 37.50% | 23.44% |
| AA(object) of target tail classes | 60.00% | 48.75% | 34.22% |
| OA(object) of all classes | 68.82% | 72.23% | 71.56% |
| Params | 122,925 | 344,877 | 1,460,293 |
| Memory(MB) | 9002 | 9704 | 9776 |
| Time (second/iteration) | 18.16 | 22.44 | 22.93 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cui, W.; Feng, Z.; Chen, J.; Xu, X.; Tian, Y.; Zhao, H.; Wang, C. Long-Tailed Effect Study in Remote Sensing Semantic Segmentation Based on Graph Kernel Principles. Remote Sens. 2024, 16, 1398. https://doi.org/10.3390/rs16081398
Cui W, Feng Z, Chen J, Xu X, Tian Y, Zhao H, Wang C. Long-Tailed Effect Study in Remote Sensing Semantic Segmentation Based on Graph Kernel Principles. Remote Sensing. 2024; 16(8):1398. https://doi.org/10.3390/rs16081398
Chicago/Turabian StyleCui, Wei, Zhanyun Feng, Jiale Chen, Xing Xu, Yueling Tian, Huilin Zhao, and Chenglei Wang. 2024. "Long-Tailed Effect Study in Remote Sensing Semantic Segmentation Based on Graph Kernel Principles" Remote Sensing 16, no. 8: 1398. https://doi.org/10.3390/rs16081398
APA StyleCui, W., Feng, Z., Chen, J., Xu, X., Tian, Y., Zhao, H., & Wang, C. (2024). Long-Tailed Effect Study in Remote Sensing Semantic Segmentation Based on Graph Kernel Principles. Remote Sensing, 16(8), 1398. https://doi.org/10.3390/rs16081398