
Three-Dimensional Point Cloud Object Detection Based on Feature Fusion and Enhancement

 ,
, 
Abstract
1. Introduction
- In Section 1, we delve into the current state of research in 3D point cloud object detection, identifying key challenges in the field. One notable issue is the difficulty of feature extraction when using bird’s eye view representations. Furthermore, we discuss the limitations posed by the uneven data distribution in point clouds, exacerbated by the significant scanning depth of light detection and ranging (LiDAR) technology. This leads to sparser data in deeper space sectors, challenging the effectiveness of existing detection methods.
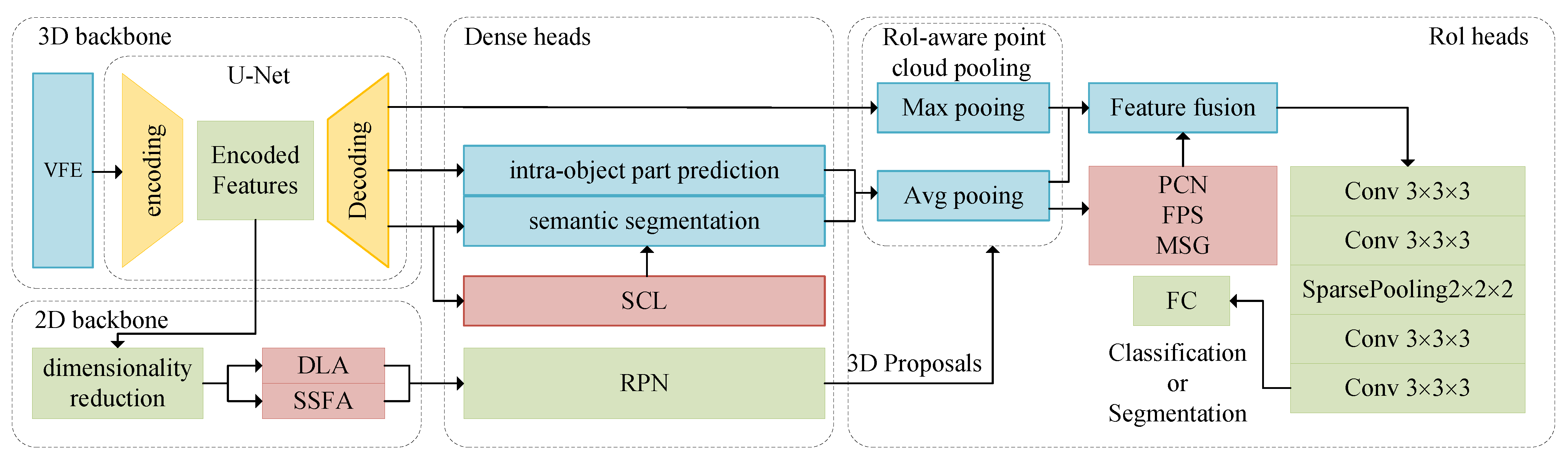
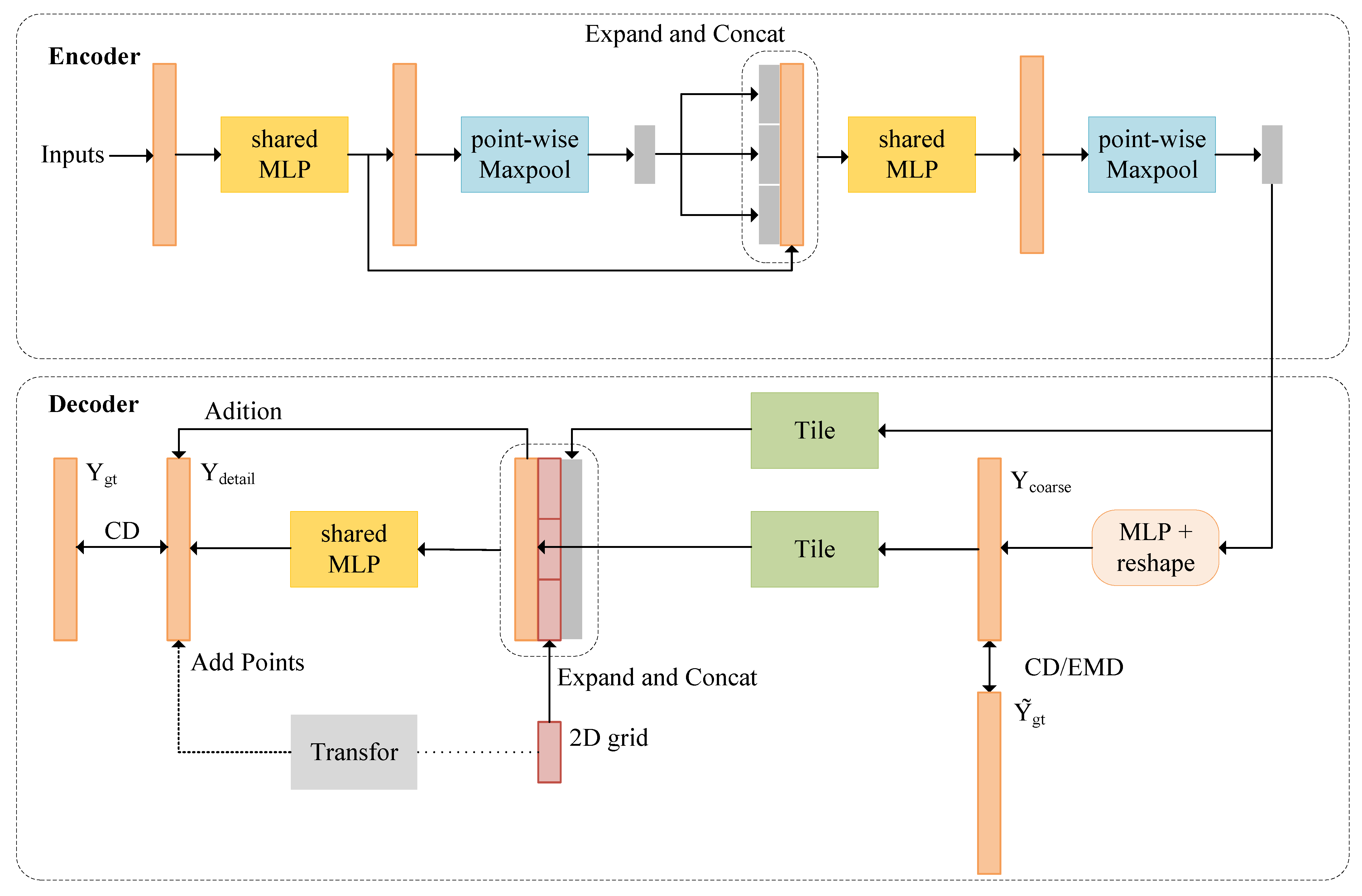
- Section 2 provides a comprehensive overview of our proposed network. We introduce a detailed schematic of the network structure, focusing on its innovative components: the SSFA, SCL, and PCN modules. Each element is meticulously described, illustrating its specific role and contribution to enhancing the network’s performance in 3D object detection tasks.
- In Section 3, we present the experimental framework, outcomes, and a detailed analysis of our research. The KITTI dataset serves as the primary basis for our experimentation. We conduct extensive comparative and ablation studies to validate the feasibility and effectiveness of our proposed model. Through these methodologies, our objective is to elucidate the capabilities of the model and explore its applicability in practical, real-world environments.
2. Method
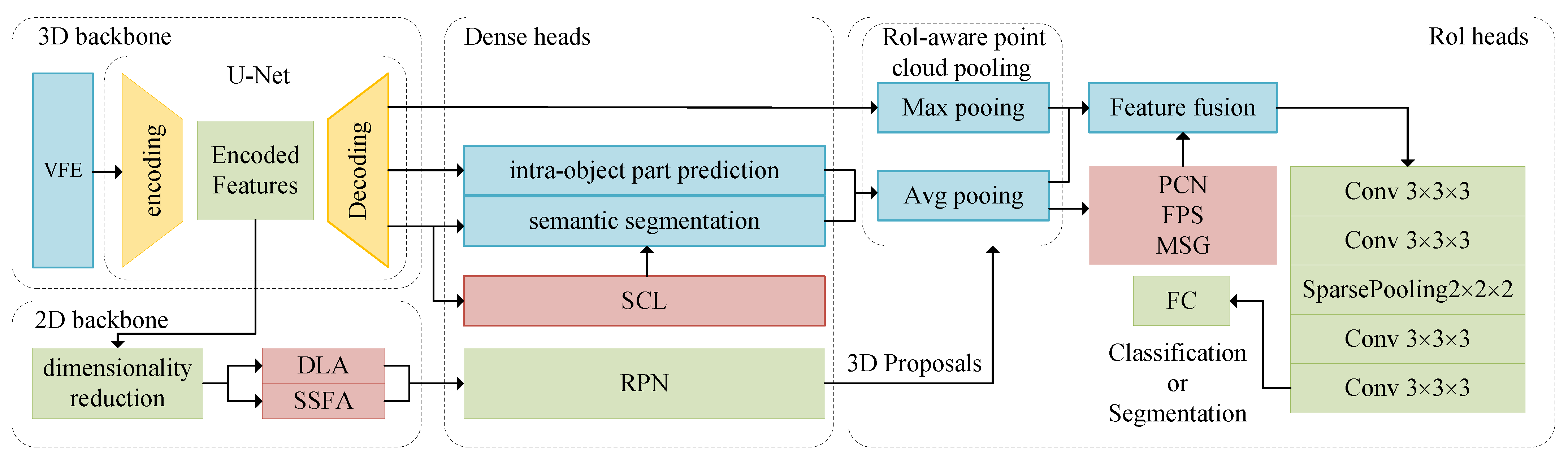
2.1. Architecture
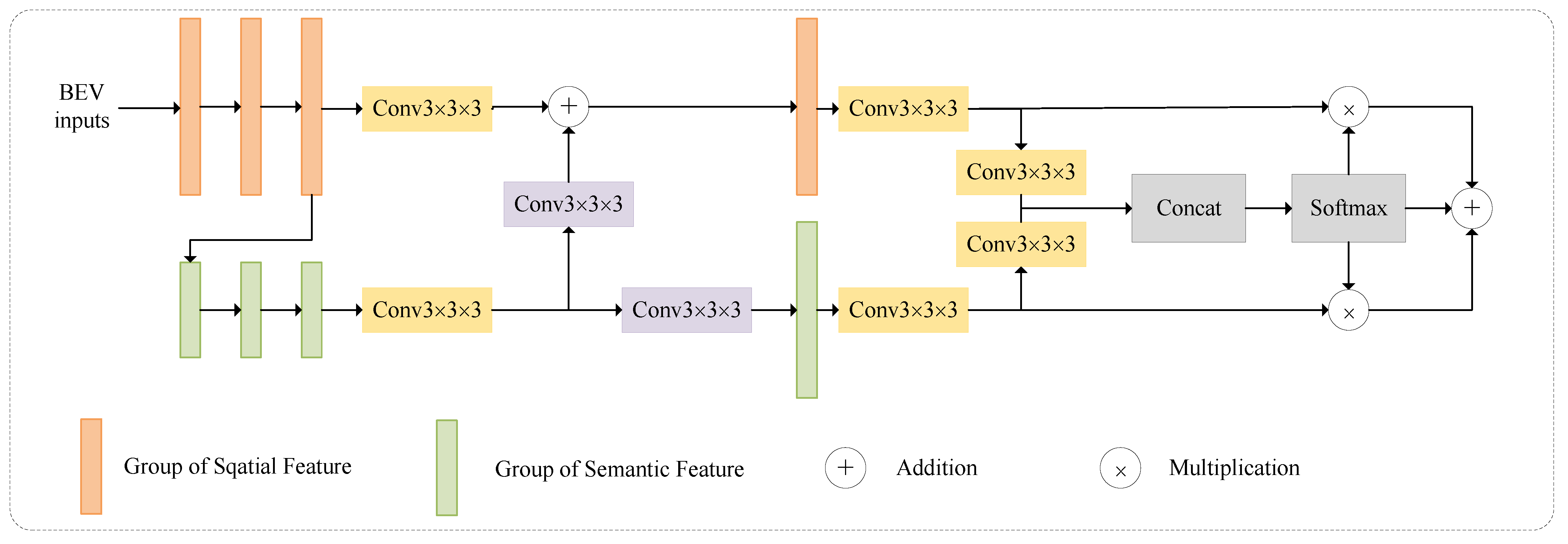
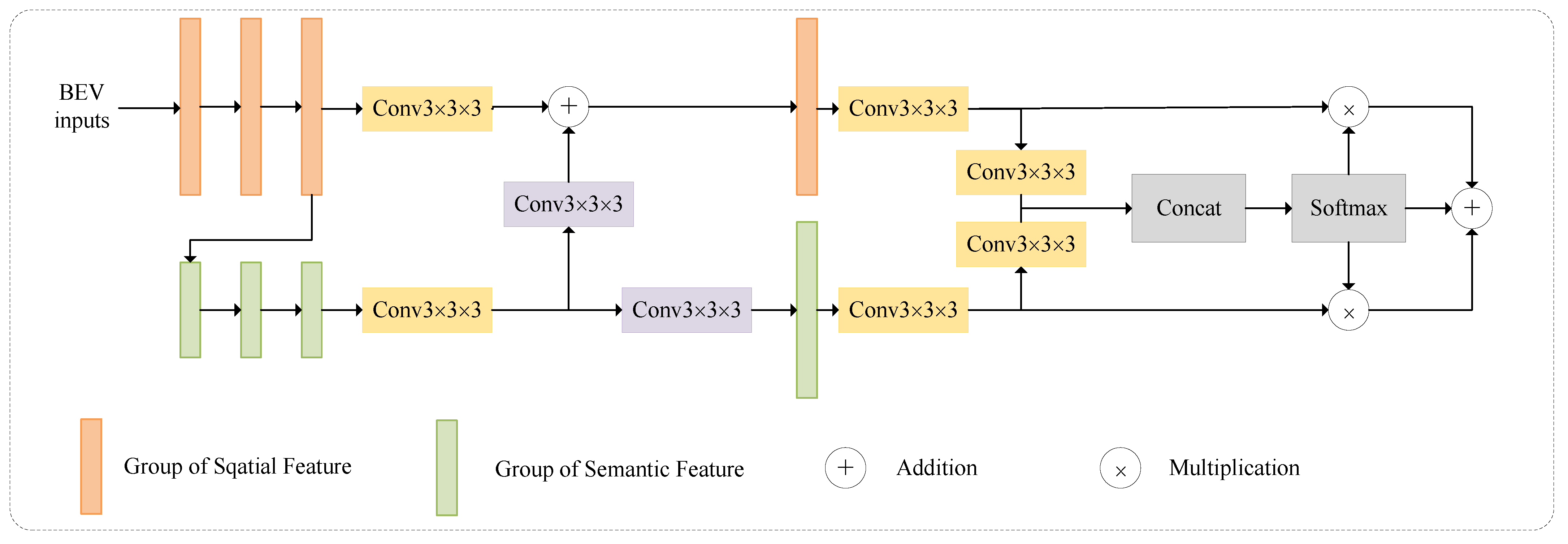
2.2. Spatial–Semantic Feature Aggregation
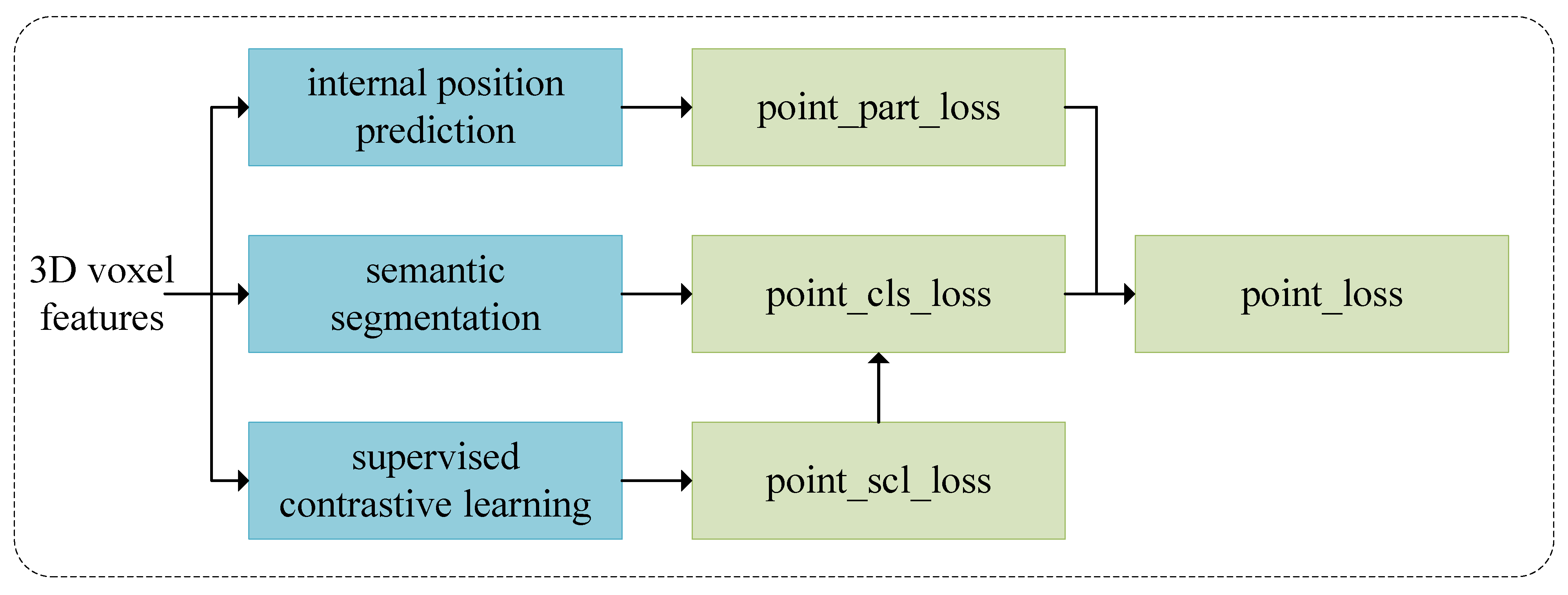
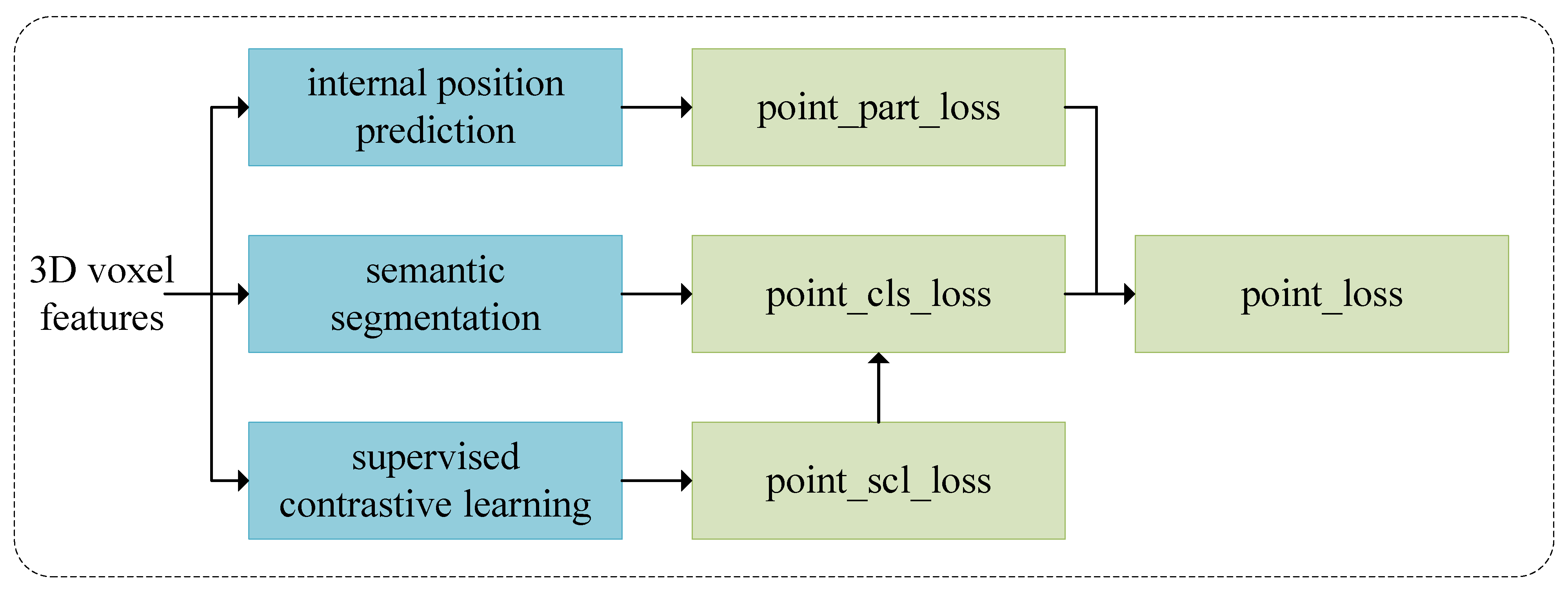
2.3. Supervised Contrastive Learning for Semantic Segmentation
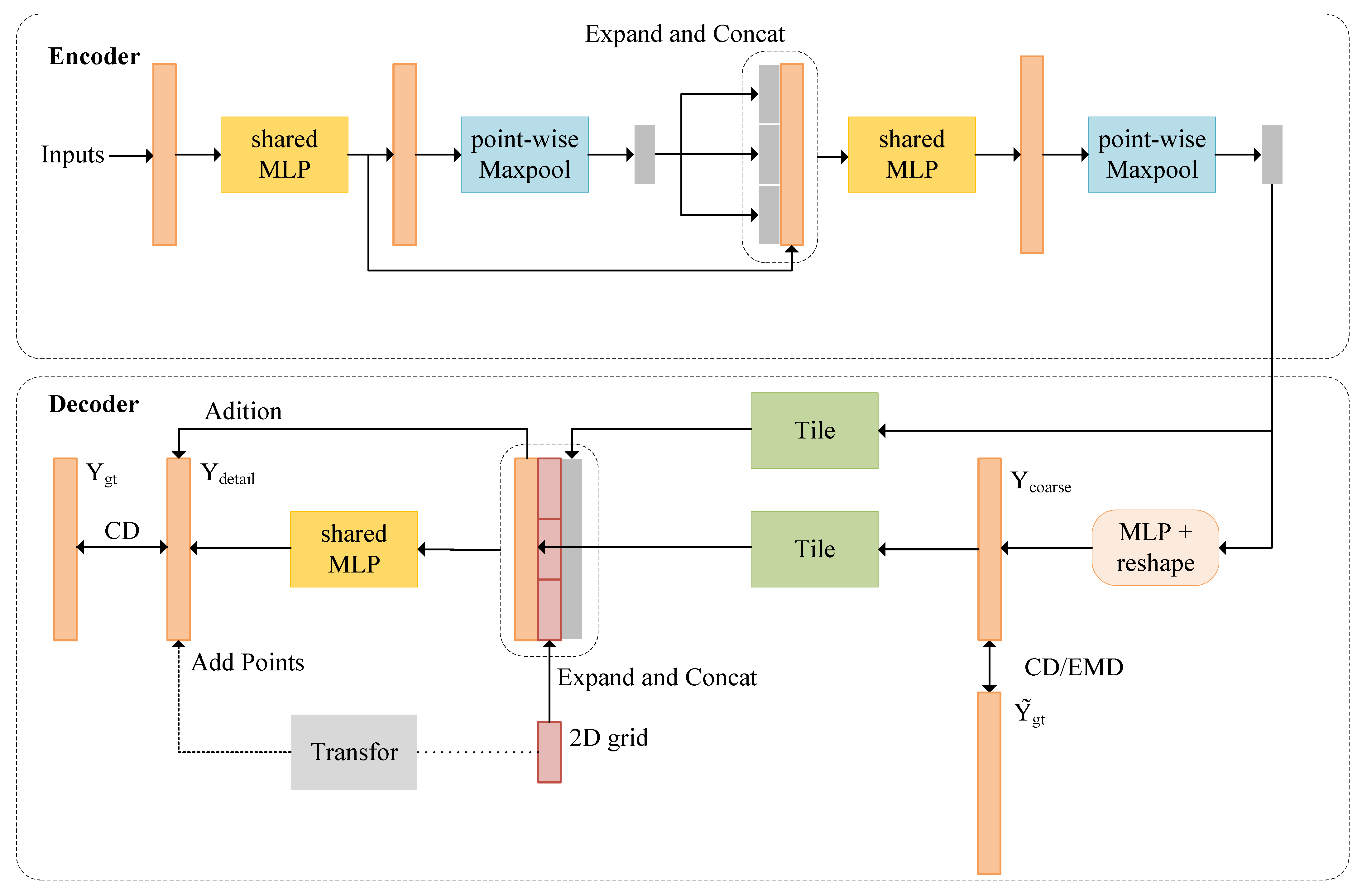
2.4. Point Completion Network
3. Experimental Setup and Results Analysis
3.1. KITTI Dataset Introduction
3.2. Evaluation Metrics
- bbox—accuracy of the 2D detection box;
- BEV—accuracy within the bird’s eye view (BEV) perspective;
- Three-dimensional—accuracy of the 3D detection box;
- AOS—accuracy in detecting the target’s rotational angle.
3.3. Experimental Setup
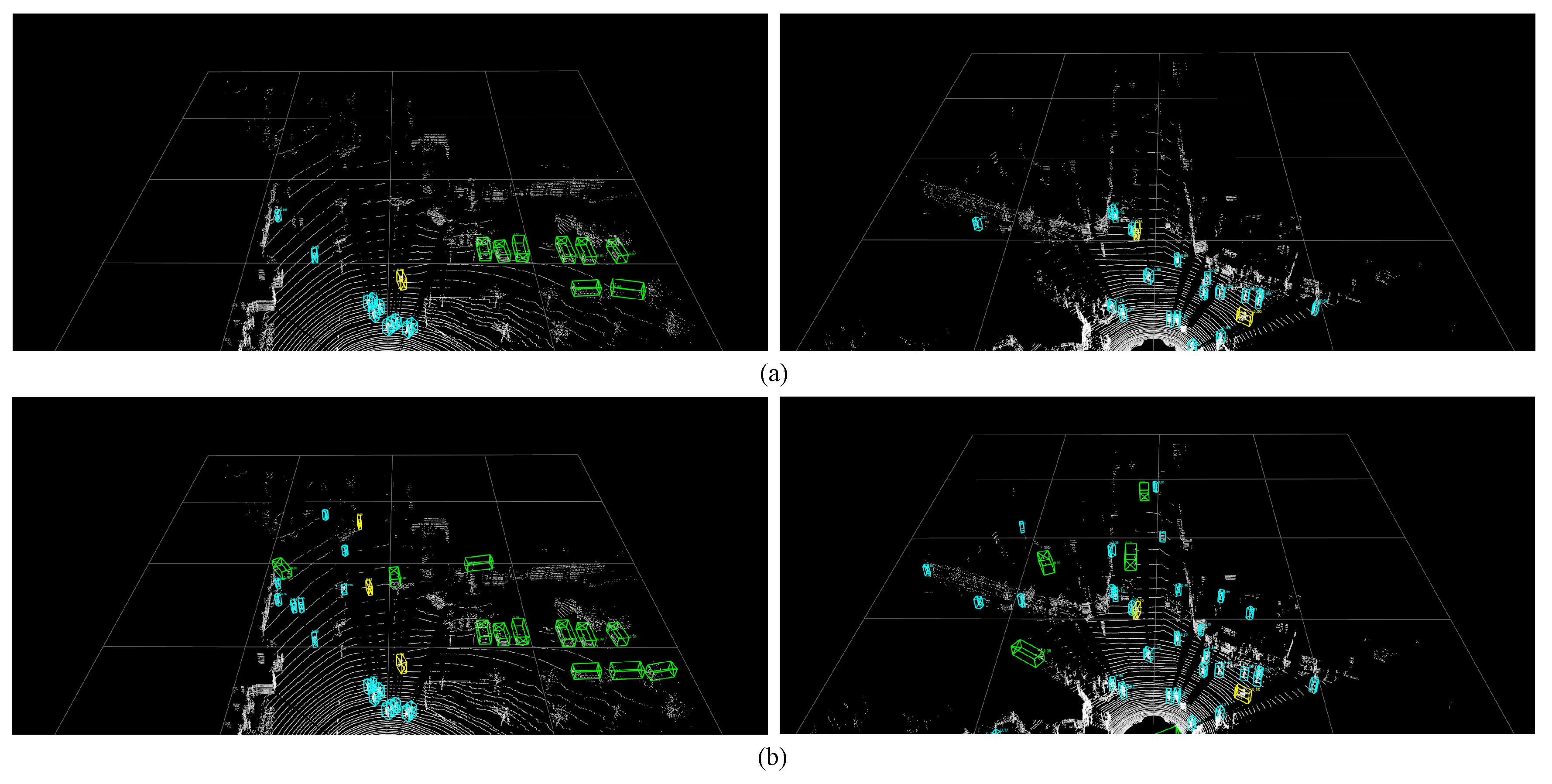
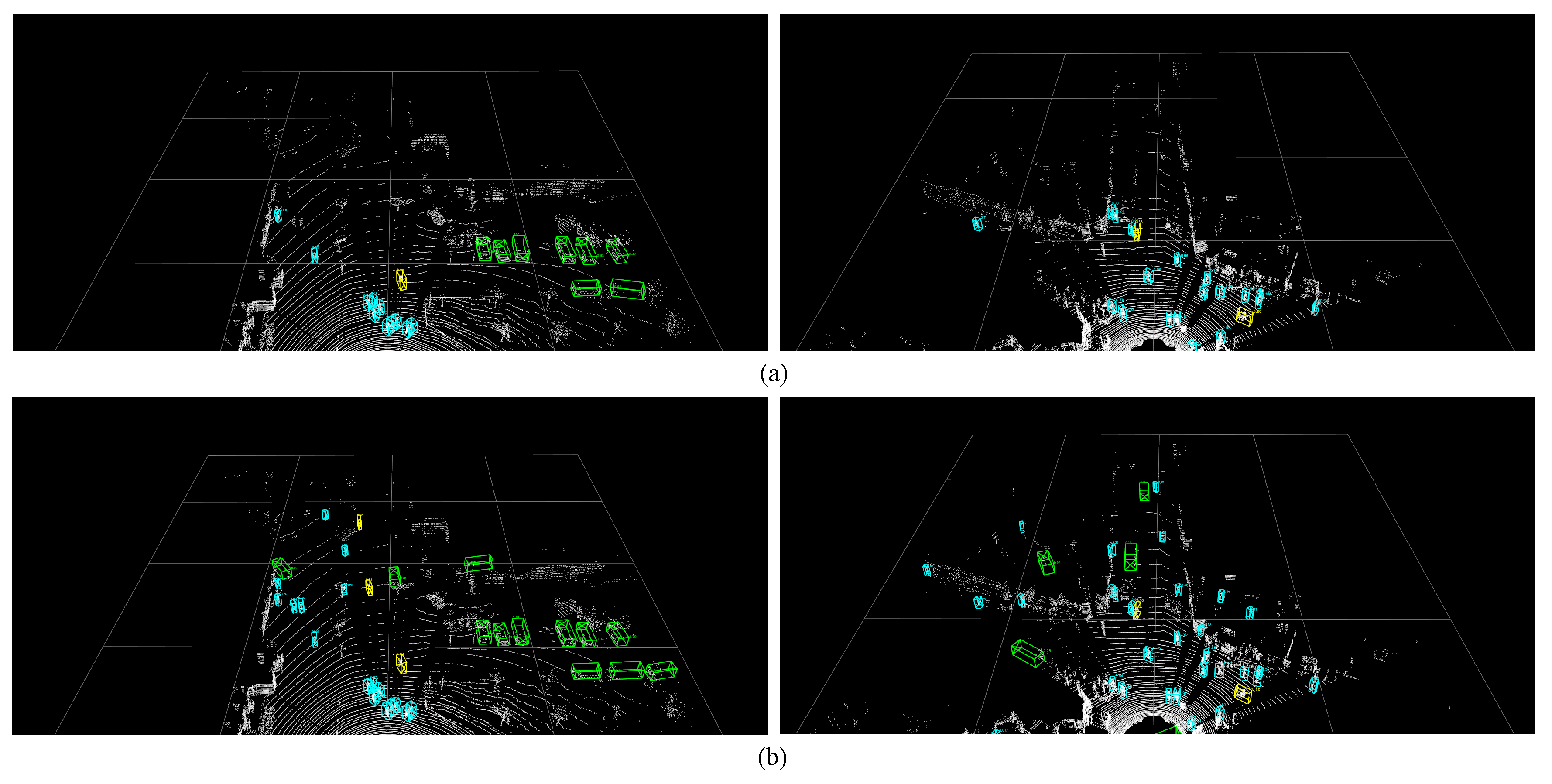
3.4. Experimental Results
3.5. Results Analysis
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| supervised contrastive losses | |
| b | description of b |
| the loss with the ith data | |
| i | the ith data |
| I | the set of data |
| the set of positive samples | |
| the number of positive samples | |
| p | one of the positive sample |
| the set of negative samples | |
| a | one of the negative samples |
| temperature | |
| loss in PCN | |
| output of course | |
| output of detail | |
| ground truth | |
| subsample ground | |
| distance function | |
| distance function | |
| a hyperparameter for trading off and | |
| AP accuracy | |
| with point number N, the AP accuracy | |
| N | point numbers |
| r | the recall |
| the accuracy of recall |
References
- Arnold, E.; Al-Jarrah, O.Y.; Dianati, M.; Fallah, S.; Oxtoby, D.; Mouzakitis, A. A Survey on 3D Object Detection Methods for Autonomous Driving Applications. IEEE Trans. Intell. Transport. Syst. 2019, 20, 3782–3795. [Google Scholar] [CrossRef]
- Ku, J.; Mozifian, M.; Lee, J.; Harakeh, A.; Waslander, S.L. Joint 3D Proposal Generation and Object Detection from View Aggregation. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 1–8. [Google Scholar]
- Zeng, Y.; Hu, Y.; Liu, S.; Ye, J.; Han, Y.; Li, X.; Sun, N. RT3D: Real-Time 3-D Vehicle Detection in LiDAR Point Cloud for Autonomous Driving. IEEE Robot. Autom. Lett. 2018, 3, 3434–3440. [Google Scholar] [CrossRef]
- Khanh, T.T.; Hoang Hai, T.; Nguyen, V.; Nguyen, T.D.T.; Thien Thu, N.; Huh, E.-N. The Practice of Cloud-Based Navigation System for Indoor Robot. In Proceedings of the 2020 14th International Conference on Ubiquitous Information Management and Communication (IMCOM), Taichung, Taiwan, 3–5 January 2020; pp. 1–4. [Google Scholar]
- Yu, S.-L.; Westfechtel, T.; Hamada, R.; Ohno, K.; Tadokoro, S. Vehicle Detection and Localization on Bird’s Eye View Elevation Images Using Convolutional Neural Network. In Proceedings of the 2017 IEEE International Symposium on Safety, Security and Rescue Robotics (SSRR), Shanghai, China, 11–13 October 2017; pp. 102–109. [Google Scholar]
- Engelcke, M.; Rao, D.; Wang, D.Z.; Tong, C.H.; Posner, I. Vote3Deep: Fast Object Detection in 3D Point Clouds Using Efficient Convolutional Neural Networks. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 1355–1361. [Google Scholar]
- Leibe, B.; Leonardis, A.; Schiele, B. Robust Object Detection with Interleaved Categorization and Segmentation. Int. J. Comput. Vis. 2008, 77, 259–289. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015; Navab, N., Hornegger, J., Wells, W.M., Frangi, A.F., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2015; Volume 9351, pp. 234–241. ISBN 978-3-319-24573-7. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Computer Vision—ECCV 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2016; Volume 9905, pp. 21–37. ISBN 978-3-319-46447-3. [Google Scholar]
- Zhou, Y.; Tuzel, O. VoxelNet: End-to-End Learning for Point Cloud Based 3D Object Detection. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4490–4499. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Beltran, J.; Guindel, C.; Moreno, F.M.; Cruzado, D.; Garcia, F.; De La Escalera, A. BirdNet: A 3D Object Detection Framework from LiDAR Information. In Proceedings of the 2018 21st International Conference on Intelligent Transportation Systems (ITSC), Maui, HI, USA, 4–7 November 2018; pp. 3517–3523. [Google Scholar]
- Simon, M.; Milz, S.; Amende, K.; Gross, H.-M. Complex-YOLO: An Euler-Region-Proposal for Real-Time 3D Object Detection on Point Clouds. In Computer Vision—ECCV 2018 Workshops; Leal-Taixé, L., Roth, S., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2019; Volume 11129, pp. 197–209. ISBN 978-3-030-11008-6. [Google Scholar]
- Qi, C.R.; Liu, W.; Wu, C.; Su, H.; Guibas, L.J. Frustum pointnets for 3d object detection from rgb-d data. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 918–927. [Google Scholar]
- Liang, M.; Yang, B.; Wang, S.; Urtasun, R. Deep Continuous Fusion for Multi-Sensor 3D Object Detection. In Computer Vision—ECCV 2018; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2018; Volume 11220, pp. 663–678. ISBN 978-3-030-01269-4. [Google Scholar]
- Mohapatra, S.; Yogamani, S.; Gotzig, H.; Milz, S.; Mader, P. BEVDetNet: Bird’s Eye View LiDAR Point Cloud Based Real-Time 3D Object Detection for Autonomous Driving. In Proceedings of the 2021 IEEE International Intelligent Transportation Systems Conference (ITSC), Indianapolis, IN, USA, 19–22 September 2021; pp. 2809–2815. [Google Scholar]
- He, K.; Gkioxari, G.; Dollar, P.; Girshick, R. Mask R-CNN. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Graham, B.; Engelcke, M.; Maaten, L.V.D. 3D Semantic Segmentation with Submanifold Sparse Convolutional Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 9224–9232. [Google Scholar]
- Dai, X.; Li, M.; Zhai, P.; Tong, S.; Gao, X.; Huang, S.; Zhu, Z.; You, C.; Ma, Y. Revisiting Sparse Convolutional Model for Visual Recognition. arXiv 2022, arXiv:2210.12945. [Google Scholar]
- Chen, X.; Ma, H.; Wan, J.; Li, B.; Xia, T. Multi-View 3D Object Detection Network for Autonomous Driving. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6526–6534. [Google Scholar]
- Charles, R.Q.; Su, H.; Kaichun, M.; Guibas, L.J. PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; IEEE: Honolulu, HI, USA, 2017; pp. 77–85. [Google Scholar]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5099–5108. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Vora, S.; Lang, A.H.; Helou, B.; Beijbom, O. PointPainting: Sequential Fusion for 3D Object Detection. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 4603–4611. [Google Scholar]
- Shi, S.; Wang, X.; Li, H. PointRCNN: 3D Object Proposal Generation and Detection From Point Cloud. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 770–779. [Google Scholar]
- Yang, B.; Luo, W.; Urtasun, R. PIXOR: Real-Time 3D Object Detection from Point Clouds. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7652–7660. [Google Scholar]
- Yan, Y.; Mao, Y.; Li, B. SECOND: Sparsely Embedded Convolutional Detection. Sensors 2018, 18, 3337. [Google Scholar] [CrossRef] [PubMed]
- Yang, Z.; Sun, Y.; Liu, S.; Jia, J. 3DSSD: Point-Based 3D Single Stage Object Detector. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 11037–11045. [Google Scholar]
- Qi, C.R.; Litany, O.; He, K.; Guibas, L. Deep Hough Voting for 3D Object Detection in Point Clouds. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9276–9285. [Google Scholar]
- Shi, S.; Wang, Z.; Shi, J.; Wang, X.; Li, H. From Points to Parts: 3D Object Detection from Point Cloud with Part-Aware and Part-Aggregation Network. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 2647–2664. [Google Scholar] [CrossRef] [PubMed]
- Qi, C.R.; Chen, X.; Litany, O.; Guibas, L.J. ImVoteNet: Boosting 3D Object Detection in Point Clouds With Image Votes. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 4403–4412. [Google Scholar]
- Dettmers, T.; Minervini, P.; Stenetorp, P.; Riedel, S. Convolutional 2D Knowledge Graph Embeddings. In Proceedings of the AAAI’18: AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar] [CrossRef]
- Zheng, W.; Tang, W.; Chen, S.; Jiang, L.; Fu, C.-W. CIA-SSD: Confident IoU-Aware Single-Stage Object Detector From Point Cloud. AAAI 2021, 35, 3555–3562. [Google Scholar] [CrossRef]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A simple framework for contrastive learning of visual representations. In Proceedings of the 37th International Conference on Machine Learning, Virtual, 13–18 July 2020; pp. 1597–1607. [Google Scholar]
- Khosla, P.; Teterwak, P.; Wang, C.; Sarna, A.; Tian, Y.; Isola, P.; Maschinot, A.; Liu, C.; Krishnan, D. Supervised contrastive learning. Adv. Neural Inf. Process. Syst. 2020, 33, 18661–18673. [Google Scholar]
- Yuan, W.; Khot, T.; Held, D.; Mertz, C.; Hebert, M. Pcn: Point completion network. In Proceedings of the 2018 International Conference on 3D Vision (3DV), Verona, Italy, 5–8 September 2018; pp. 728–737. [Google Scholar]
- Geiger, A.; Lenz, P.; Urtasun, R. Are We Ready for Autonomous Driving? The KITTI Vision Benchmark Suite. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar]
- Everingham, M.; Eslami, S.M.A.; Van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes Challenge: A Retrospective. Int. J. Comput. Vis. 2015, 111, 98–136. [Google Scholar] [CrossRef]
- Lang, A.H.; Vora, S.; Caesar, H.; Zhou, L.; Yang, J.; Beijbom, O. PointPillars: Fast Encoders for Object Detection From Point Clouds. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 12689–12697. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hardware environment | CPU | Intel Xeon (R) CPU E5-2678 @ |
| 2.50 GHz × 48 | ||
| GPU | NVIDIA GeForce GTX 1080 8 GB | |
| Software environment | OS | Linux Ubuntu 18.04.5 LTS |
| Language | Python 3.7.4 | |
| Platform | Pytorch 1.7.0 | |
| 3D detection platform | OpenPCDet 0.5.2 | |
| CUDA | CUDA 10.1 |
| Method | Car AP@ | Pedestrian AP@ | Cyclist AP@ | ||||||
|---|---|---|---|---|---|---|---|---|---|
| 0.7 | 0.7 | 0.7 | 0.5 | 0.5 | 0.5 | 0.5 | 0.5 | 0.5 | |
| CaDDN [12] | 27.78 | 21.38 | 18.62 | 15.45 | 13.02 | 11.88 | 10.85 | 9.76 | 0.09 |
| VoxelNet [10] | 82.47 | 70.11 | 65.73 | 49.48 | 43.69 | 42.50 | 68.22 | 53.36 | 50.37 |
| PointPillar [40] | 86.74 | 77.21 | 74.47 | 55.32 | 48.80 | 44.50 | 79.21 | 61.90 | 58.15 |
| SECOND [28] | 90.05 | 80.70 | 77.91 | 55.82 | 51.13 | 46.43 | 82.78 | 65.17 | 61.08 |
| PointRCNN [26] | 88.78 | 75.51 | 72.93 | 69.40 | 60.25 | 52.78 | 90.27 | 70.25 | 65.75 |
| Part- [31] | 91.50 | 82.07 | 79.88 | 66.12 | 59.04 | 53.31 | 89.91 | 73.50 | 69.28 |
| Ours | 91.74 | 82.22 | 79.82 | 71.84 | 64.82 | 59.16 | 92.18 | 74.78 | 70.73 |
| Method | Easy | Moderate | Hard | Avg. |
|---|---|---|---|---|
| CaDDN [12] | 18.02 | 14.72 | 13.20 | 15.31 |
| VoxelNet [10] | 66.72 | 66.72 | 52.53 | 58.33 |
| PointPillar [40] | 73.75 | 62.64 | 59.04 | 65.14 |
| SECOND [28] | 76.22 | 65.66 | 61.81 | 67.90 |
| PointRCNN [26] | 82.82 | 68.67 | 63.82 | 71.77 |
| Part- [31] | 82.51 | 71.54 | 67.49 | 73.85 |
| Ours | 85.25 | 73.94 | 69.90 | 76.37 |
| Method | Easy | Moderate | Hard | Avg. |
|---|---|---|---|---|
| None | 82.51 | 71.54 | 67.49 | 73.85 |
| SCL | 83.15 | 72.09 | 68.22 | 74.49 |
| PCN | 83.61 | 72.34 | 68.39 | 74.78 |
| PCN + SCL | 84.09 | 72.78 | 69.11 | 75.32 |
| PCN + SCL + SSFA | 85.25 | 73.94 | 69.90 | 76.37 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Y.; Ou, Z.; Liu, G.; Yang, Z.; Chen, Y.; Shang, R.; Jiao, L. Three-Dimensional Point Cloud Object Detection Based on Feature Fusion and Enhancement. Remote Sens. 2024, 16, 1045. https://doi.org/10.3390/rs16061045
Li Y, Ou Z, Liu G, Yang Z, Chen Y, Shang R, Jiao L. Three-Dimensional Point Cloud Object Detection Based on Feature Fusion and Enhancement. Remote Sensing. 2024; 16(6):1045. https://doi.org/10.3390/rs16061045
Chicago/Turabian StyleLi, Yangyang, Zejun Ou, Guangyuan Liu, Zichen Yang, Yanqiao Chen, Ronghua Shang, and Licheng Jiao. 2024. "Three-Dimensional Point Cloud Object Detection Based on Feature Fusion and Enhancement" Remote Sensing 16, no. 6: 1045. https://doi.org/10.3390/rs16061045
APA StyleLi, Y., Ou, Z., Liu, G., Yang, Z., Chen, Y., Shang, R., & Jiao, L. (2024). Three-Dimensional Point Cloud Object Detection Based on Feature Fusion and Enhancement. Remote Sensing, 16(6), 1045. https://doi.org/10.3390/rs16061045