
A Multi-Tiered Collaborative Network for Optical Remote Sensing Fine-Grained Ship Detection in Foggy Conditions


Abstract

1. Introduction
- We propose the collaborative network framework, which addresses the shortcomings of traditional models for extracting detailed features in foggy weather conditions with low visibility and degraded image quality. Our framework enhances the feature extraction capability by introducing collaborative block and pixel and channel attention (PCA) modules that focus on relevant target information, thus improving the detection performance under challenging conditions.
- We introduce the collaborative block within the collaborative network framework, which addresses the limitations of traditional models by utilizing a multi-use convolutional kernel to reduce model size and computational complexity without sacrificing accuracy. Additionally, it incorporates a PCA mechanism that allows the network to focus more on target features during image recovery, enhancing overall detection performance.
- The proposed model enables end-to-end ship detection under foggy conditions with improved accuracy and robustness compared to existing models. By focusing on the specific challenges of ship detection in adverse weather conditions, our collaborative network framework directly addresses the shortcomings of prior approaches, making it a highly effective solution for real-world maritime applications.
2. Related Work
2.1. Object Detection
2.2. Exploration of Attention Mechanisms
2.3. Ship Inspection Under Poor Sea Conditions
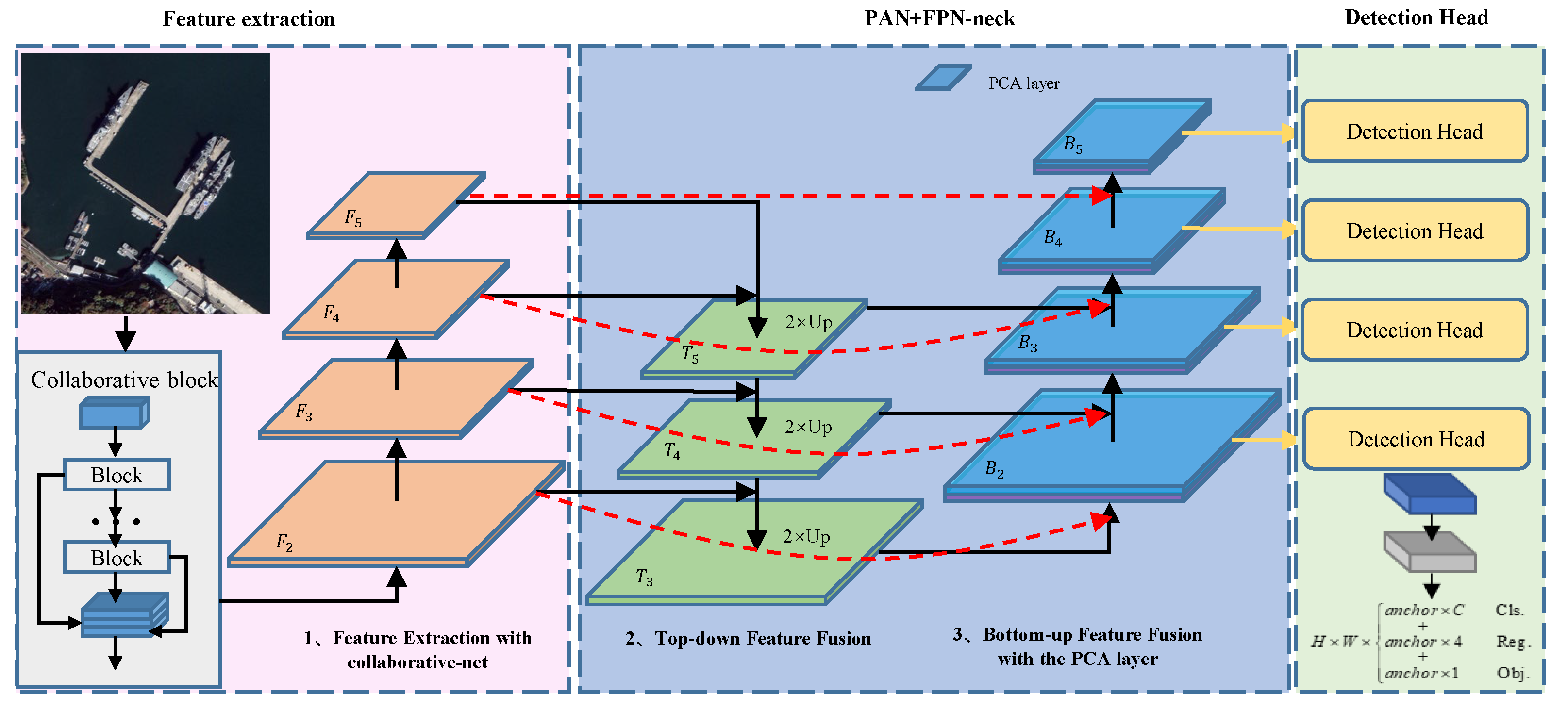
3. Proposed Method
3.1. Network Architecture
3.2. Collaborative Block
3.3. Channel Attention and Pixel Attention
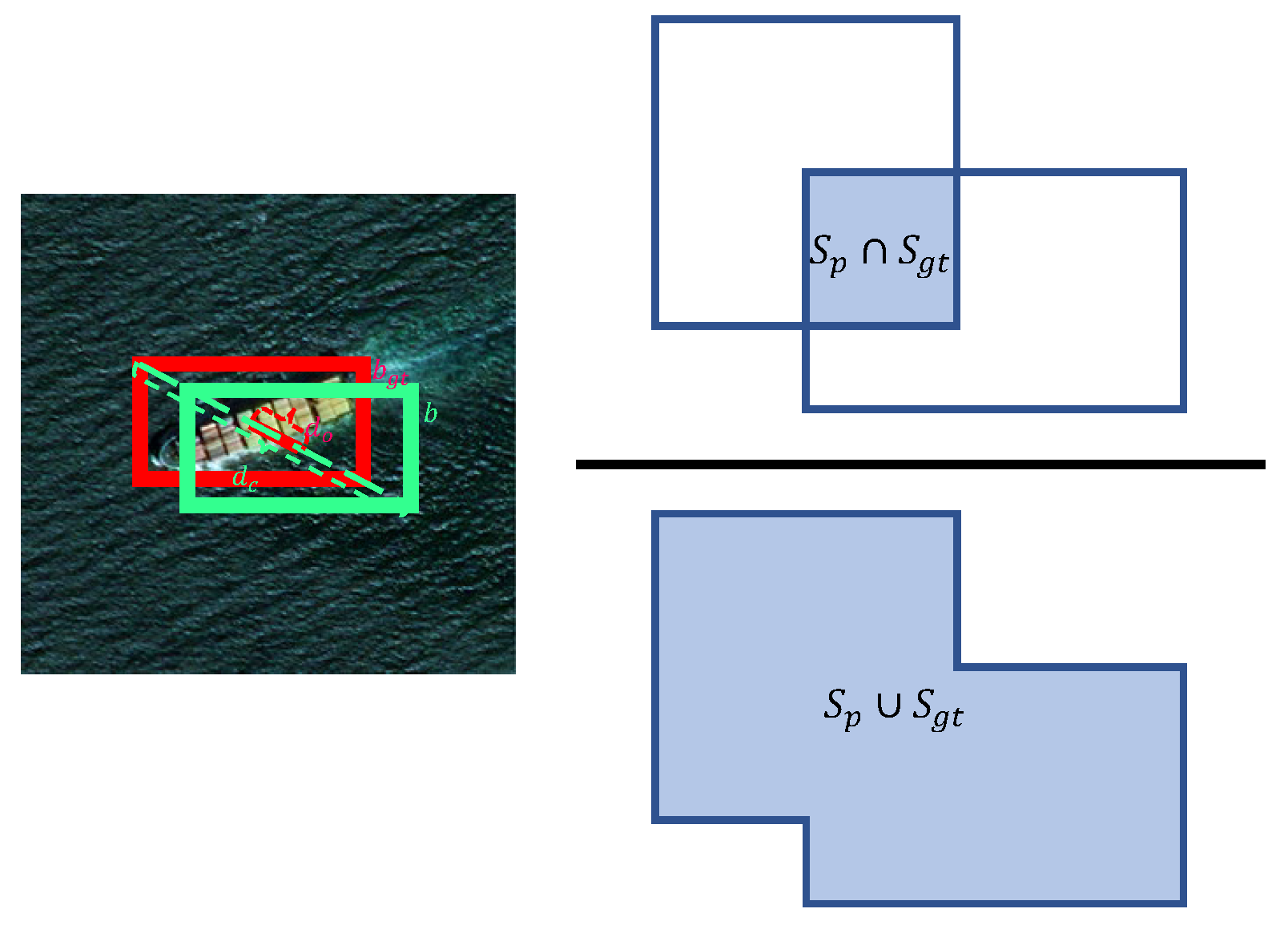
3.4. Loss Function
4. Experimental Procedure
4.1. Datasets
4.2. Evaluation Scheme
5. Results
5.1. Comparative Experiment
5.2. Ablation Experiment
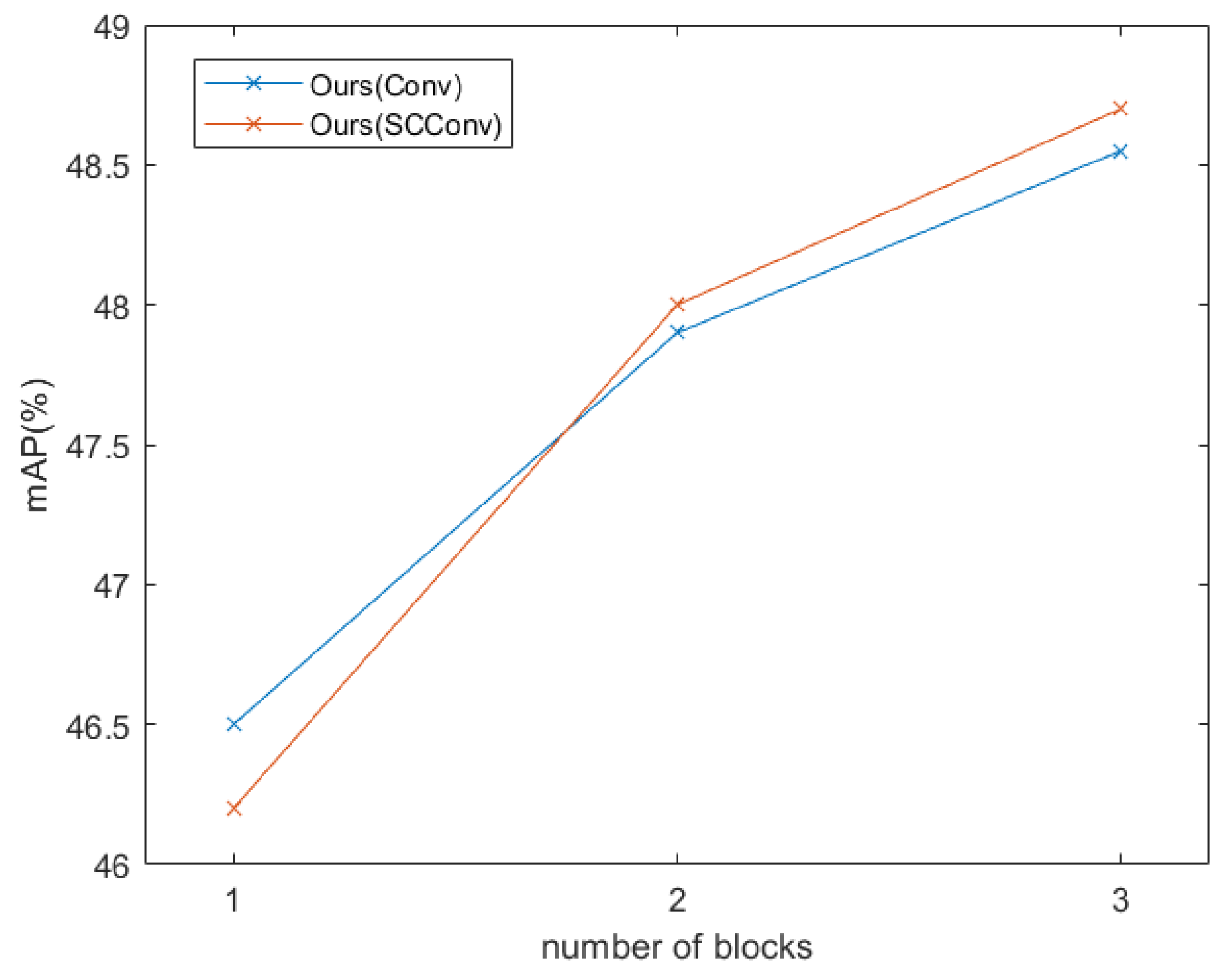
5.2.1. Collaborative Block Component Design
5.2.2. Attention Modules
5.2.3. Overlay of Global Effect
6. Discussion
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A


References
- Zhao, Y.; Chen, D.; Gong, J. A Multi-Feature Fusion-Based Method for Crater Extraction of Airport Runways in Remote-Sensing Images. Remote Sens. 2024, 16, 573. [Google Scholar] [CrossRef]
- Zhang, N.; Wang, Y.; Zhao, F.; Wang, T.; Zhang, K.; Fan, H.; Zhou, D.; Zhang, L.; Yan, S.; Diao, X. Monitoring and Analysis of the Collapse at Xinjing Open-Pit Mine, Inner Mongolia, China, Using Multi-Source Remote Sensing. Remote Sens. 2024, 16, 993. [Google Scholar] [CrossRef]
- Zhou, Y.; Liu, H.; Ma, F.; Pan, Z.; Zhang, F. A sidelobe-aware small ship detection network for synthetic aperture radar imagery. IEEE Trans. Geosci. Remote. Sens. 2023, 61, 1–16. [Google Scholar] [CrossRef]
- Fuentes Reyes, M.; Auer, S.; Merkle, N.; Henry, C.; Schmitt, M. Sar-to-optical image translation based on conditional generative adversarial networks—Optimization, opportunities and limits. Remote Sens. 2019, 11, 2067. [Google Scholar] [CrossRef]
- Melillos, G.; Themistocleous, K.; Danezis, C.; Michaelides, S.; Hadjimitsis, D.G.; Jacobsen, S.; Tings, B. Detecting migrant vessels in the Cyprus region using Sentinel-1 SAR data. In Proceedings of the Counterterrorism, Crime Fighting, Forensics, and Surveillance Technologies IV, Online, 21–25 September 2020; SPIE: Philadelphia, PA, USA, 2020; Volume 11542, pp. 134–144. [Google Scholar]
- Bi, F.; Chen, J.; Zhuang, Y.; Bian, M.; Zhang, Q. A decision mixture model-based method for inshore ship detection using high-resolution remote sensing images. Sensors 2017, 17, 1470. [Google Scholar] [CrossRef] [PubMed]
- Chen, H.; Gao, T.; Chen, W.; Zhang, Y.; Zhao, J. Contour refinement and EG-GHT-based inshore ship detection in optical remote sensing image. IEEE Trans. Geosci. Remote. Sens. 2019, 57, 8458–8478. [Google Scholar] [CrossRef]
- Zhu, Z.; Luo, Y.; Qi, G.; Meng, J.; Li, Y.; Mazur, N. Remote sensing image defogging networks based on dual self-attention boost residual octave convolution. Remote Sens. 2021, 13, 3104. [Google Scholar] [CrossRef]
- Wang, Y.; Dou, Y.; Guo, J.; Yang, Z.; Yang, B.; Sun, Y.; Liu, W. Feasibility Study for an Ice-Based Image Monitoring System for Polar Regions Using Improved Visual Enhancement Algorithms. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 3788–3799. [Google Scholar] [CrossRef]
- Zou, Z.; Shi, Z. Ship detection in spaceborne optical image with SVD networks. IEEE Trans. Geosci. Remote. Sens. 2016, 54, 5832–5845. [Google Scholar] [CrossRef]
- Dong, Y.; Chen, F.; Han, S.; Liu, H. Ship object detection of remote sensing image based on visual attention. Remote Sens. 2021, 13, 3192. [Google Scholar] [CrossRef]
- Tang, J.; Deng, C.; Huang, G.B.; Zhao, B. Compressed-domain ship detection on spaceborne optical image using deep neural network and extreme learning machine. IEEE Trans. Geosci. Remote. Sens. 2014, 53, 1174–1185. [Google Scholar] [CrossRef]
- Zhang, Z.; Wang, C.; Song, J.; Xu, Y. Object tracking based on satellite videos: A literature review. Remote Sens. 2022, 14, 3674. [Google Scholar] [CrossRef]
- Yang, J.; Ma, Y.; Hu, Y.; Jiang, Z.; Zhang, J.; Wan, J.; Li, Z. Decision fusion of deep learning and shallow learning for marine oil spill detection. Remote Sens. 2022, 14, 666. [Google Scholar] [CrossRef]
- Sindagi, V.A.; Oza, P.; Yasarla, R.; Patel, V.M. Prior-based domain adaptive object detection for hazy and rainy conditions. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XIV 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 763–780. [Google Scholar]
- Vaněk, J.; Machlica, L.; Psutka, J. Estimation of single-Gaussian and Gaussian mixture models for pattern recognition. In Proceedings of the Progress in Pattern Recognition, Image Analysis, Computer Vision, and Applications: 18th Iberoamerican Congress, CIARP 2013, Havana, Cuba, 20–23 November 2013; Proceedings, Part I 18. Springer: Berlin/Heidelberg, Germany, 2013; pp. 49–56. [Google Scholar]
- Kim, K.; Chalidabhongse, T.H.; Harwood, D.; Davis, L. Background modeling and subtraction by codebook construction. In Proceedings of the 2004 International Conference on Image Processing, 2004, ICIP’04, Singapore, 24–27 October 2004; IEEE: Piscataway, NJ, USA, 2004; Volume 5, pp. 3061–3064. [Google Scholar]
- Barnich, O.; Van Droogenbroeck, M. ViBe: A powerful technique for background detection and subtraction in video sequences. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, Taipei, Taiwan, 19–24 April 2009; pp. 945–948. [Google Scholar]
- Viola, P.; Jones, M. Rapid object detection using a boosted cascade of simple features. In Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, CVPR 2001, Kauai, HI, USA, 8–14 December 2001; IEEE: Piscataway, NJ, USA, 2001; Volume 1, p. 1. [Google Scholar]
- Viola, P.; Jones, M.J. Robust real-time face detection. Int. J. Comput. Vis. 2004, 57, 137–154. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–26 June 2005; IEEE: Piscataway, NJ, USA, 2005; Volume 1, pp. 886–893. [Google Scholar]
- Felzenszwalb, P.F.; Girshick, R.B.; McAllester, D.; Ramanan, D. Object detection with discriminatively trained part-based models. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 32, 1627–1645. [Google Scholar] [CrossRef]
- Cortes, C. Support-Vector Networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the Computer Vision—ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part I 14. Springer: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- He, K.; Sun, J.; Tang, X. Single image haze removal using dark channel prior. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 33, 2341–2353. [Google Scholar]
- Zhu, Q.; Mai, J.; Shao, L. A fast single image haze removal algorithm using color attenuation prior. IEEE Trans. Image Process. 2015, 24, 3522–3533. [Google Scholar]
- Du, L.; Zhang, R.; Wang, X. Overview of two-stage object detection algorithms. J. Phys. Conf. Ser. 2020, 1544, 012033. [Google Scholar] [CrossRef]
- Chua, L.O.; Roska, T. The CNN paradigm. IEEE Trans. Circuits Syst. Fundam. Theory Appl. 1993, 40, 147–156. [Google Scholar] [CrossRef]
- Zaremba, W. Recurrent neural network regularization. arXiv 2014, arXiv:1409.2329. [Google Scholar]
- Rendle, S.; Gantner, Z.; Freudenthaler, C.; Schmidt-Thieme, L. Fast context-aware recommendations with factorization machines. In Proceedings of the 34th International ACM SIGIR Conference on Research and Development in Information Retrieval, Beijing, China, 24–28 July 2011; pp. 635–644. [Google Scholar]
- Juan, Y.; Zhuang, Y.; Chin, W.S.; Lin, C.J. Field-aware factorization machines for CTR prediction. In Proceedings of the 10th ACM Conference on Recommender Systems, Boston, MA, USA, 15–19 September 2016; pp. 43–50. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the Computer Vision—ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Proceedings, Part V 13. Springer: Berlin/Heidelberg, Germany, 2016; pp. 740–755. [Google Scholar]
- Hoiem, D.; Divvala, S.K.; Hays, J.H. Pascal VOC 2008 challenge. World Lit. Today 2009, 24, 1–4. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; IEEE: Piscataway, NJ, USA, 2009; pp. 248–255. [Google Scholar]
- Hasan, I.; Liao, S.; Li, J.; Akram, S.U.; Shao, L. Generalizable pedestrian detection: The elephant in the room. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 11328–11337. [Google Scholar]
- Redmon, J. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade r-cnn: Delving into high quality object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6154–6162. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Bahdanau, D. Neural machine translation by jointly learning to align and translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Vaswani, A. Attention is all you need. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Lim, J.S.; Astrid, M.; Yoon, H.J.; Lee, S.I. Small object detection using context and attention. In Proceedings of the 2021 International Conference on Artificial Intelligence in Information and Communication (ICAIIC), Jeju Island, Republic of Korea, 13–16 April 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 181–186. [Google Scholar]
- Wang, W.; Zhang, X.; Sun, W.; Huang, M. A novel method of ship detection under cloud interference for optical remote sensing images. Remote Sens. 2022, 14, 3731. [Google Scholar] [CrossRef]
- Weng, J.; Li, G.; Zhao, Y. Detection of abnormal ship trajectory based on the complex polygon. J. Navig. 2022, 75, 966–983. [Google Scholar] [CrossRef]
- Nie, T.; He, B.; Bi, G.; Zhang, Y.; Wang, W. A method of ship detection under complex background. ISPRS Int. J. -Geo-Inf. 2017, 6, 159. [Google Scholar] [CrossRef]
- Wang, R.; You, Y.; Zhang, Y.; Zhou, W.; Liu, J. Ship detection in foggy remote sensing image via scene classification R-CNN. In Proceedings of the 2018 International Conference on Network Infrastructure and Digital Content (IC-NIDC), Guiyang, China, 22–24 August 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 81–85. [Google Scholar]
- Wang, N.; Li, B.; Xu, Q.; Wang, Y. Automatic ship detection in optical remote sensing images based on anomaly detection and SPP-PCANet. Remote Sens. 2018, 11, 47. [Google Scholar] [CrossRef]
- Chen, X.; Wei, C.; Xin, Z.; Zhao, J.; Xian, J. Ship Detection under Low-Visibility Weather Interference via an Ensemble Generative Adversarial Network. J. Mar. Sci. Eng. 2023, 11, 2065. [Google Scholar] [CrossRef]
- Sakaridis, C.; Dai, D.; Van Gool, L. Semantic foggy scene understanding with synthetic data. Int. J. Comput. Vis. 2018, 126, 973–992. [Google Scholar] [CrossRef]
- Li, B.; Ren, W.; Fu, D.; Tao, D.; Feng, D.; Zeng, W.; Wang, Z. Benchmarking single-image dehazing and beyond. IEEE Trans. Image Process. 2018, 28, 492–505. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Z.; Zhang, L.; Wang, Y.; Feng, P.; He, R. ShipRSImageNet: A large-scale fine-grained dataset for ship detection in high-resolution optical remote sensing images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 8458–8472. [Google Scholar] [CrossRef]
- Zhu, C.; He, Y.; Savvides, M. Feature selective anchor-free module for single-shot object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 840–849. [Google Scholar]
- Yang, Z.; Liu, S.; Hu, H.; Wang, L.; Lin, S. Reppoints: Point set representation for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9657–9666. [Google Scholar]
- Chen, Q.; Wang, Y.; Yang, T.; Zhang, X.; Cheng, J.; Sun, J. You only look one-level feature. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2019; pp. 13039–13048. [Google Scholar]
- Li, C.; Li, L.; Geng, Y.; Jiang, H.; Cheng, M.; Zhang, B.; Ke, Z.; Xu, X.; Chu, X. Yolov6 v3. 0: A full-scale reloading. arXiv 2023, arXiv:2301.05586. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient channel attention for deep convolutional neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11534–11542. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | Total | Train | Val | Test |
|---|---|---|---|---|
| Other-Ship | 1696 | 1050 | 297 | 349 |
| Other-Warship | 1455 | 962 | 209 | 284 |
| Submarine | 1017 | 666 | 171 | 180 |
| Aircraft-Carrier | 285 | 196 | 46 | 43 |
| Ticonderoga | 440 | 258 | 77 | 105 |
| Destroyer | 1525 | 940 | 269 | 316 |
| Frigate | 874 | 563 | 105 | 206 |
| Patrol | 154 | 102 | 37 | 15 |
| Landing | 944 | 593 | 150 | 201 |
| Commander | 146 | 88 | 32 | 26 |
| Auxiliary-Ship | 483 | 311 | 83 | 89 |
| Other-Merchant | 252 | 150 | 50 | 52 |
| Container-Ship | 376 | 232 | 72 | 72 |
| RoRo | 170 | 107 | 20 | 43 |
| Cargo | 1082 | 657 | 169 | 256 |
| Barge | 239 | 161 | 22 | 56 |
| Tugboat | 290 | 197 | 46 | 47 |
| Ferry | 309 | 191 | 53 | 65 |
| Yacht | 712 | 501 | 140 | 71 |
| Sailboat | 796 | 325 | 341 | 130 |
| Fishing-Vessel | 606 | 318 | 99 | 189 |
| Oil-Tanker | 204 | 129 | 32 | 43 |
| Hovercraft | 334 | 229 | 31 | 74 |
| Motorboat | 2091 | 1190 | 398 | 503 |
| Dock | 1093 | 744 | 154 | 195 |
| Method | Backbone | mAP(%) |
|---|---|---|
| Faster R-CNN | ResNet50 | 43.4 |
| Faster R-CNN | ResNet101 | 45.3 |
| SSD512 | VGG16 | 42.1 |
| FSAF | ResNet101 | 41.3 |
| RepPoints | ResNet50 | 46.2 |
| YOLOF | ResNet50 | 44.8 |
| YOLOv5s | - | 46.7 |
| YOLOv6s | - | 44.2 |
| YOLOv8n | - | 46.1 |
| Collaborative network (proposed) | - | 48.7 |
| Method | Backbone | Fog | Precision | Recall | mAP(%) |
|---|---|---|---|---|---|
| Faster-R-CNN | ResNet50 | thin | 0.356 | 0.711 | 43.8 |
| medium | 0.392 | 0.645 | 40.7 | ||
| thick | 0.352 | 0.568 | 33.5 | ||
| Faster-R-CNN | ResNet101 | thin | 0.383 | 0.721 | 47.4 |
| medium | 0.418 | 0.667 | 43.8 | ||
| thick | 0.375 | 0.570 | 35.7 | ||
| SSD512 | VGG16 | thin | 0.316 | 0.712 | 42.9 |
| medium | 0.327 | 0.714 | 43.4 | ||
| thick | 0.282 | 0.628 | 36.2 | ||
| FSAF | ResNet101 | thin | 0.314 | 0.683 | 42.1 |
| medium | 0.351 | 0.623 | 39.9 | ||
| thick | 0.317 | 0.512 | 30.5 | ||
| RepPoints | ResNet50 | thin | 0.201 | 0.745 | 45.9 |
| medium | 0.219 | 0.717 | 44.3 | ||
| thick | 0.206 | 0.633 | 36.9 | ||
| YOLOF | ResNet50 | thin | 0.268 | 0.742 | 46.7 |
| medium | 0.279 | 0.720 | 44.9 | ||
| thick | 0.257 | 0.622 | 35.1 | ||
| YOLOv5s | thin | 0.678 | 0.600 | 47.8 | |
| medium | 0.700 | 0.554 | 45.5 | ||
| thick | 0.659 | 0.449 | 37.1 | ||
| YOLOv6s | thin | 0.431 | 0.598 | 45.5 | |
| medium | 0.437 | 0.318 | 33.4 | ||
| thick | 0.332 | 0.279 | 24.5 | ||
| YOLOv8n | thin | 0.630 | 0.512 | 45.1 | |
| medium | 0.592 | 0.529 | 45.4 | ||
| thick | 0.516 | 0.462 | 37.4 | ||
| Collaborative network (proposed) | thin | 0.669 | 0.612 | 49.1 | |
| medium | 0.680 | 0.583 | 47.4 | ||
| thick | 0.653 | 0.514 | 41.3 |
| Method | Block | Precision | Recall | mAP(%) | GFLOPs |
|---|---|---|---|---|---|
| Proposed (Conv) | 1 | 0.682 | 0.551 | 46.5 | 111 |
| Proposed (Conv) | 2 | 0.700 | 0.594 | 47.9 | 172 |
| Proposed (Conv) | 3 | 0.685 | 0.595 | 48.6 | 233 |
| Proposed (SCConv) | 1 | 0.690 | 0.543 | 46.2 | 49.0 |
| Proposed (SCConv) | 2 | 0.685 | 0.538 | 48.0 | 49.6 |
| Proposed (SCConv) | 3 | 0.733 | 0.576 | 48.7 | 50.1 |
| Method | Precision | Recall | mAP(%) |
|---|---|---|---|
| YOLOv5s (baseline) | 0.680 | 0.583 | 46.7 |
| YOLOv5s + SE [61] | 0.669 | 0.585 | 47.1 |
| YOLOv5s + ECA [62] | 0.728 | 0.578 | 47.9 |
| YOLOv5s + CBAM [63] | 0.675 | 0.611 | 48.2 |
| YOLOv5s + PCA (proposed) | 0.733 | 0.576 | 48.7 |
| Method | Precision | Recall | mAP(%) |
|---|---|---|---|
| YOLOv5s (baseline) | 0.680 | 0.583 | 46.7 |
| + collaborative block | 0.640 | 0.560 | 45.3 |
| + 4 attention modules | 0.642 | 0.606 | 47.5 |
| + 4 detection heads | 0.710 | 0.577 | 47.2 |
| + collaborative block + 4 attention modules + 4 detection heads | 0.733 | 0.576 | 48.7 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, W.; Li, L.; Liu, B.; Cao, Y.; Ni, W. A Multi-Tiered Collaborative Network for Optical Remote Sensing Fine-Grained Ship Detection in Foggy Conditions. Remote Sens. 2024, 16, 3968. https://doi.org/10.3390/rs16213968
Zhou W, Li L, Liu B, Cao Y, Ni W. A Multi-Tiered Collaborative Network for Optical Remote Sensing Fine-Grained Ship Detection in Foggy Conditions. Remote Sensing. 2024; 16(21):3968. https://doi.org/10.3390/rs16213968
Chicago/Turabian StyleZhou, Wenbo, Ligang Li, Bo Liu, Yuan Cao, and Wei Ni. 2024. "A Multi-Tiered Collaborative Network for Optical Remote Sensing Fine-Grained Ship Detection in Foggy Conditions" Remote Sensing 16, no. 21: 3968. https://doi.org/10.3390/rs16213968
APA StyleZhou, W., Li, L., Liu, B., Cao, Y., & Ni, W. (2024). A Multi-Tiered Collaborative Network for Optical Remote Sensing Fine-Grained Ship Detection in Foggy Conditions. Remote Sensing, 16(21), 3968. https://doi.org/10.3390/rs16213968