
Multi-Modal Object Detection Method Based on Dual-Branch Asymmetric Attention Backbone and Feature Fusion Pyramid Network






Abstract
1. Introduction
2. Method
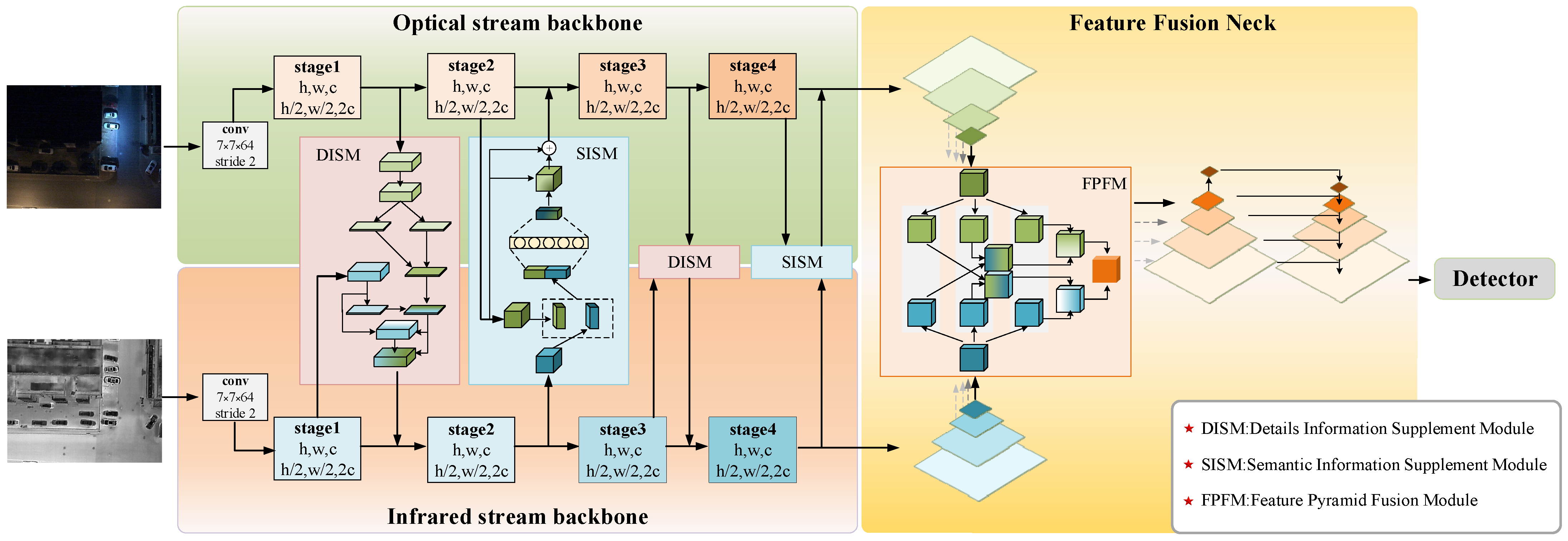
2.1. Overall Network Architecture
| Algorithm 1 The Proposed Detection Method |
| Require: I_rgb: an optical image; I_inf: an infrared image; Ensure: Result: the result of detection Build a dual-branch backbone as B_dual Build feature fusion module as M_f M_f = [M_f1,M_f2,M_f3,M_f4] F_rgbs,F_infs = B_dual(I_rgb,I_inf) F_fusions = [] for i in [0,1,2,3]: F_fusion = M_f[i](F_rgbs[i],F_infs[i]) F_fusions.append(F_fusion) Build a detector as D Result = D(F_fusion) |
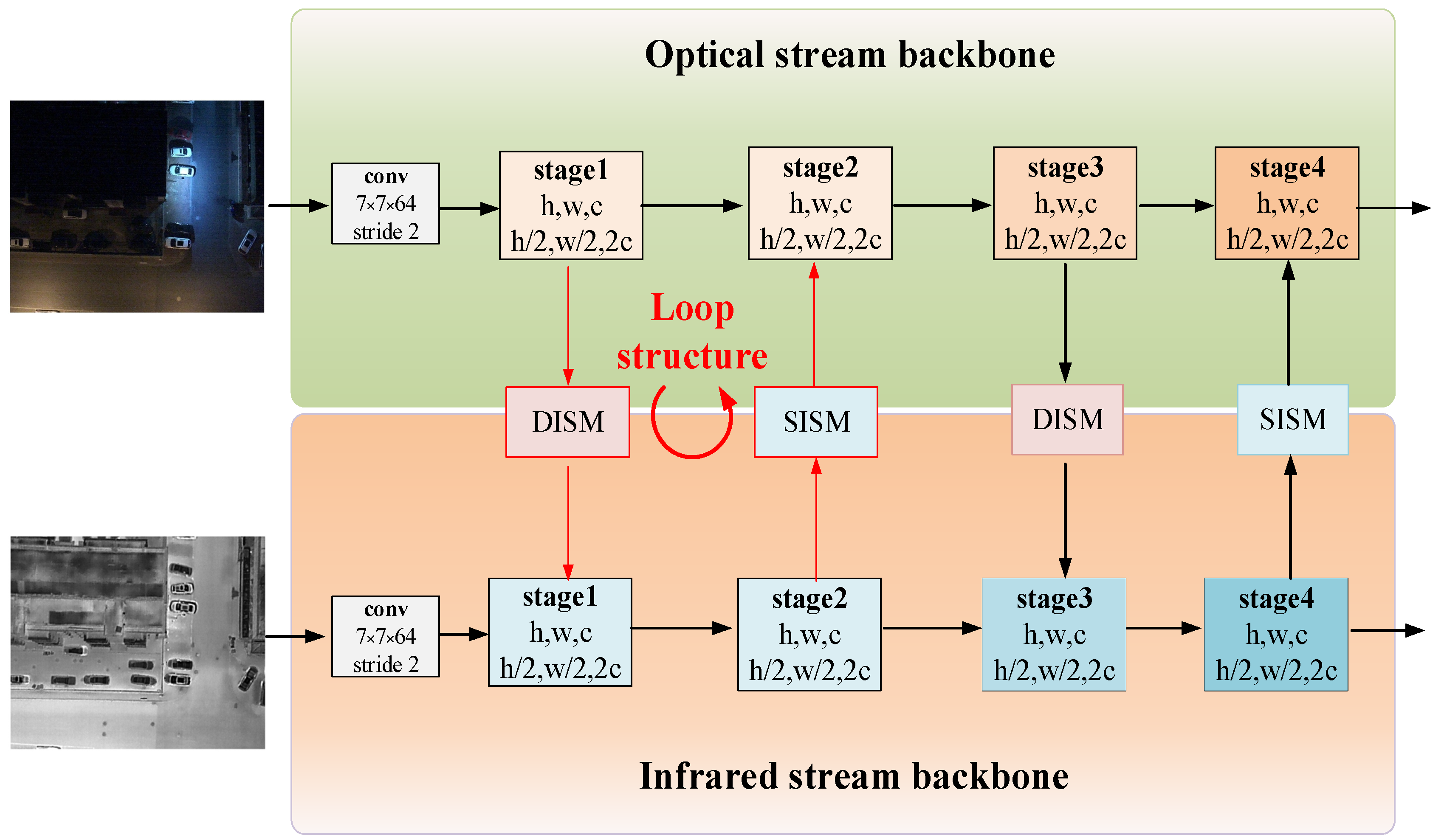
2.2. Dual-Branch Asymmetric Attention Backbone Network
2.2.1. Detail Information Supplement Module
2.2.2. Semantic Information Supplement Module
2.3. Feature Fusion Pyramid Network
3. Results
3.1. Dataset Introduction
3.1.1. FLIR Dataset
3.1.2. DroneVehicle Dataset
3.2. Implementation Details
3.3. Evaluation Metrics
3.4. Analysis of Results
3.4.1. Experiments on the FLIR-Aligned Dataset
- (1)
- Comparison with other state-of-the-art methods
- (2)
- Ablation experiment
3.4.2. Experiments on the DroneVehicle Dataset
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Cerutti-Maori, D.; Klare, J.; Brenner, A.R.; Ender, J.H.G. Wide-Area Traffic Monitoring With the SAR/GMTI System PAMIR. IEEE Trans. Geosci. Remote Sens. 2008, 46, 3019–3030. [Google Scholar] [CrossRef]
- Li, Y.; Zhang, Y.; Huang, X.; Yuille, A.L. Deep networks under scene-level supervision for multi-class geospatial object detection from remote sensing images. ISPRS J. Photogramm. Remote Sens. 2018, 146, 182–196. [Google Scholar] [CrossRef]
- Han, J.; Zhang, D.; Cheng, G.; Guo, L.; Ren, J. Object detection in optical remote sensing images based on weakly supervised learning and high-level feature learning. IEEE Trans. Geosci. Remote Sens. 2015, 53, 3325–3337. [Google Scholar] [CrossRef]
- Li, K.; Wan, G.; Cheng, G.; Meng, L.; Han, J. Object detection in optical remote sensing images: A survey and a new benchmark. ISPRS J. Photogramm. Remote Sens. 2020, 159, 296–307. [Google Scholar] [CrossRef]
- Park, J.; Chen, J.; Cho, Y.K.; Kang, D.Y.; Son, B.J. CNN-Based Person Detection Using Infrared Images for Night-Time Intrusion Warning Systems. Sensors 2019, 20, 34. [Google Scholar] [CrossRef] [PubMed]
- Chen, Y.; Shin, H. Pedestrian Detection at Night in Infrared Images Using an Attention-Guided Encoder-Decoder Convolutional Neural Network. Appl. Sci. 2020, 10, 809. [Google Scholar] [CrossRef]
- Zhou, K.; Chen, L.; Cao, X. Improving Multispectral Pedestrian Detection by Addressing Modality Imbalance Problems. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Wagner, J.; Fischer, V.; Herman, M.; Behnke, S. Multispectral pedestrian detection using deep fusion convolutional neural networks. ESANN 2016, 587, 509–514. [Google Scholar]
- Liu, J.; Zhang, S.; Wang, S.; Metaxas, D.N. Multispectral deep neural networks for pedestrian detection. arXiv 2016, arXiv:1611.02644. [Google Scholar]
- Li, C.; Song, D.; Tong, R.; Tang, M. Illumination-Aware Faster r-Cnn for Robust Multispectral Pedestrian Detection. Pattern Recognit. 2019, 85, 161–171. Available online: https://www.sciencedirect.com/science/article/pii/S0031320318303030 (accessed on 11 August 2023). [CrossRef]
- Zhang, L.; Zhu, X.; Chen, X.; Yang, X.; Lei, Z.; Liu, Z. Weakly aligned cross-modal learning for multispectral pedestrian detection. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 5126–5136. [Google Scholar]
- Meng, S.; Liu, Y. Multimodal Feature Fusion YOLOv5 for RGB-T Object Detection. In Proceedings of the 2022 China Automation Congress (CAC), Xiamen, China, 25–27 November 2022; pp. 2333–2338. [Google Scholar] [CrossRef]
- Hong, D.; Gao, L.; Yokoya, N.; Yao, J.; Chanussot, J.; Du, Q.; Zhang, B. More diverse means better: Multimodal deep learning meets remote-sensing imagery classification. IEEE Trans. Geosci. Remote Sens. 2021, 59, 4340–4354. [Google Scholar] [CrossRef]
- Guan, D.; Cao, Y.; Yang, J.; Cao, Y.; Yang, M.Y. Fusion of Multispectral Data through Illumination-Aware Deep Neural Networks for Pedestrian Detection. Inf. Fusion 2019, 50, 148–157. Available online: https://www.sciencedirect.com/science/article/pii/S1566253517308138 (accessed on 12 August 2023). [CrossRef]
- Li, C.; Song, D.; Tong, R.; Tang, M. Multispectral pedestrian detection via simultaneous detection and segmentation. arXiv 2018, arXiv:1808.04818. [Google Scholar]
- Xie, Y.; Zhang, L.; Yu, X.; Xie, W. YOLO-MS: Multispectral Object Detection via Feature Interaction and Self-Attention Guided Fusion. IEEE Trans. Cogn. Dev. Syst. 2023, 15, 2132–2143. [Google Scholar] [CrossRef]
- Zhang, H.; Fromont, E.; Lefevre, S.; Avignon, B. Guided Attentive Feature Fusion for Multispectral Pedestrian Detection. In Proceedings of the 2021 IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 3–8 January 2021; pp. 72–80. [Google Scholar] [CrossRef]
- Zhang, H.; Wu, C.; Zhang, Z.; Zhu, Y.; Lin, H.; Zhang, Z.; Sun, Y.; He, T.; Mueller, J.; Manmatha, R.; et al. ResNeSt: Split-Attention Networks. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), New Orleans, LA, USA, 19–20 June 2022; pp. 2735–2745. [Google Scholar] [CrossRef]
- Li, X.; Wang, W.; Hu, X.; Yang, J. Selective Kernel Networks. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 510–519. [Google Scholar] [CrossRef]
- Yang, C.; An, Z.; Zhu, H.; Hu, X.; Xu, K.; Li, C.; Diao, B.; Xu, Y. Gated Convolutional Networks with Hybrid Connectivity for Image Classification. arXiv 2019, arXiv:1908.09699. [Google Scholar] [CrossRef]
- Fang, Q.; Han, D.; Wang, Z. Cross-Modality Fusion Transformer for Multispectral Object Detection. arXiv 2021, arXiv:2111.00273. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Zhang, H.; Fromont, E.; Lef, S.; Avignon, B. Multispectral fusion for object detection with cyclic fuse-and-refine blocks. In Proceedings of the 2020 IEEE International Conference on Image Processing (ICIP), Abu Dhabi, United Arab Emirates, 25–28 October 2020; pp. 276–280. [Google Scholar]
- Sun, Y.; Cao, B.; Zhu, P.; Hu, Q. Drone-Based RGB-Infrared Cross-Modality Vehicle Detection Via Uncertainty-Aware Learning. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 6700–6713. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Zhang, H.; Fromont, E.; Lefevre, S.; Avignon, B. Deep Active Learning from Multispectral Data Through Cross-Modality Prediction Inconsistency. In Proceedings of the 2021 IEEE International Conference on Image Processing (ICIP), Anchorage, AK, USA, 19–22 September 2021; pp. 449–453. [Google Scholar] [CrossRef]
- Yu, Y.; Da, F. Phase-Shifting Coder: Predicting Accurate Orientation in Oriented Object Detection. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 13354–13363. [Google Scholar]
- Ding, J.; Xue, N.; Long, Y.; Xia, G.-S.; Lu, Q. Learning RoI Transformer for Oriented Object Detection in Aerial Images. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 2844–2853. [Google Scholar] [CrossRef]
- Wang, Q.; Chi, Y.; Shen, T.; Song, J.; Zhang, Z.; Zhu, Y. Improving RGB-Infrared Object Detection by Reducing Cross-Modality Redundancy. Remote Sens. 2022, 14, 2020. [Google Scholar] [CrossRef]
- Zhang, L.; Liu, Z.; Zhang, S.; Yang, X.; Qiao, H.; Huang, K.; Hussain, A. Crossmodality interactive attention network for multispectral pedestrian detection. Inf. Fusion 2019, 50, 20–29. [Google Scholar] [CrossRef]
- Yuan, M.; Wang, Y.; Wei, X. Translation, Scale and Rotation: Cross-Modal Alignment Meets RGB-Infrared Vehicle Detection. arXiv 2022, arXiv:2209.13801. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Modal | mAP |
|---|---|---|
| Faster RCNN [25] | R/I | 63.60\75.30% |
| HalfwayFusion [23] | R + I | 71.17% |
| MBNet [7] | R + I | 71.30% |
| DALFusion [26] | R + I | 72.11% |
| CFR [23] | R + I | 72.39% |
| GAFF [17] | R + I | 73.80% |
| YOLO-MS [16] | R + I | 75.20% |
| CFT [21] | R + I | 77.63% |
| MFF-YOLOv5 [12] | R + I | 78.20% |
| Baseline | R + I | 68.20% |
| Our method | R + I | 78.73% |
| Method | mAP | FLOPs | MAC | Runtime |
|---|---|---|---|---|
| baseline | 68.21% | 186.98 G | 64.84 M | 0.045 s |
| base + DAAB | 74.82% | 281.42 G | 131.71 M | 0.058 s |
| base + FFPN | 73.50% | 291.99 G | 109.45 M | 0.061 s |
| our | 78.73% | 386.43 G | 176.29 M | 0.068 s |
| Module | Loop Position | mAP | |||
|---|---|---|---|---|---|
| Stage1 | Stage2 | Stage3 | Stage4 | ||
| DISM: D SISM: S | × | × | × | × | 68.20% |
| D | S | × | × | 72.22% | |
| × | × | D | S | 74.21% | |
| D | × | × | S | 73.94% | |
| × | × | × | D, S | 72.15% | |
| D, S | × | × | × | 71.82% | |
| D, S | D, S | D, S | D, S | 73.76% | |
| D | S | D | S | 74.83% | |
| Method | Modal | mAP |
|---|---|---|
| Faster RCNN [25] | R/I | 54.06\60.27% |
| PSC [27] | R/I | 56.23\63.69% |
| RoITransformer [28] | R/I | 61.55\65.47% |
| UA-CMDet [24] | R + I | 64.01% |
| RISNet [29] | R + I | 66.40% |
| Halfway Fusion (OBB) [9] | R + I | 68.19% |
| CIAN(OBB) [30] | R + I | 70.23% |
| AR-CNN(OBB) [11] | R + I | 71.58% |
| TSFADet [31] | R + I | 73.06% |
| Cascade-TSFADet [31] | R + I | 73.90% |
| Our method | R + I | 75.17% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, J.; Su, N.; Zhao, C.; Yan, Y.; Feng, S. Multi-Modal Object Detection Method Based on Dual-Branch Asymmetric Attention Backbone and Feature Fusion Pyramid Network. Remote Sens. 2024, 16, 3904. https://doi.org/10.3390/rs16203904
Wang J, Su N, Zhao C, Yan Y, Feng S. Multi-Modal Object Detection Method Based on Dual-Branch Asymmetric Attention Backbone and Feature Fusion Pyramid Network. Remote Sensing. 2024; 16(20):3904. https://doi.org/10.3390/rs16203904
Chicago/Turabian StyleWang, Jinpeng, Nan Su, Chunhui Zhao, Yiming Yan, and Shou Feng. 2024. "Multi-Modal Object Detection Method Based on Dual-Branch Asymmetric Attention Backbone and Feature Fusion Pyramid Network" Remote Sensing 16, no. 20: 3904. https://doi.org/10.3390/rs16203904
APA StyleWang, J., Su, N., Zhao, C., Yan, Y., & Feng, S. (2024). Multi-Modal Object Detection Method Based on Dual-Branch Asymmetric Attention Backbone and Feature Fusion Pyramid Network. Remote Sensing, 16(20), 3904. https://doi.org/10.3390/rs16203904