1. Introduction
With the continuous advancement of technology, the resolution of remote sensing images has been steadily improving [
1,
2]. Through remote sensing images, we can clearly obtain the texture and spatial features of building and water bodies. The characteristics of water bodies and building contribute to a clearer understanding of urban land planning and water coverage [
3,
4], helping to overcome many challenges related to urban planning, environmental engineering, and natural landscape monitoring [
5,
6]. Therefore, semantic segmentation techniques based on remote sensing images are of great significance for the development of semantic segmentation tasks. Due to the significant differences in the spatial distribution and spectral characteristics of building and water bodies, traditional semantic segmentation models struggle to effectively capture and distinguish the subtle features of these objects. In high-resolution images, the geometric structure of building and the dynamic textures of water bodies pose severe challenges to the feature-extraction and region-segmentation capabilities of segmentation models. Particularly in high-resolution images, the boundaries of these objects are often more blurred, and the scale variations are more pronounced, leading to the need for models to handle more complex spatial information during the feature-extraction and semantic mapping processes. The rapid development of high-resolution remote sensing satellite technology has simultaneously brought significant challenges to the accuracy of land surface classification [
7,
8,
9]. The complex features and background noise in high-resolution images impose higher demands on the robustness and generalization ability of models [
10]. In recent years, with the rapid development of artificial intelligence, a novel and efficient approach has emerged for achieving automatic image segmentation [
11].
Semantic segmentation is primarily employed to generate accurate prediction labels for each pixel in an input image [
12]. Based on the generated labels, the image is classified, and these pixels may originate from objects of different categories. This includes objects with smaller shapes, situated at a distance, or challenging to identify. Effectively classifying these objects has become one of the prominent topics in computer vision and machine learning. Existing deep learning models enhance adaptability to dynamic changes by integrating multiscale features and handling background interference. However, this also introduces new challenges to the design and training methods of these models. Therefore, in the semantic segmentation of high-resolution remote sensing images, how to effectively reduce computational complexity while preserving details and how to improve model robustness when dealing with diverse features have become the current research hotspots and challenges. This not only involves innovation in algorithm design but also challenges existing data-processing and model-training methods, driving the development of remote sensing image-analysis technology towards higher precision and efficiency.
Later, with the fast development of deep learning, an increasing number of researchers applied deep learning to semantic segmentation tasks and proposed many efficient deep learning-based methods for semantic segmentation [
13,
14,
15]. Deep learning methods can learn multi-level semantic information, enabling models to require a deeper understanding of the different features of images [
16,
17,
18].
In 2006, Hinton [
19,
20] was the first to propose a deep learning method, which achieved significant advancements in image-processing tasks, particularly excelling in semantic segmentation tasks. However, some challenges arise when applying certain deep learning methods to datasets involving remote sensing images of building and water: Remote sensing images are complex, often containing noise such as clouds and shadows in addition to building and water features. The instability in image quality can lead to overfitting and underfitting, affecting segmentation accuracy. Remote sensing images typically encompass numerous categories. During training, there may be a bias toward common categories in the dataset, resulting in inaccurate segmentation for rare categories. In semantic segmentation tasks with remote sensing images, spatial information is crucial. The shape and even the quantity of objects in the same image can vary when captured from different angles. Therefore, capturing change information to improve accuracy poses a significant challenge [
21,
22]. It is evident that while simple deep learning methods can enhance accuracy through extensive training and learning of more useful information, they still face substantial challenges when dealing with complex datasets [
23].
During the contemporary period, with the rapid advancement of deep learning, an increasing number of efficient methods for semantic segmentation of remote sensing images have been proposed. Long [
24] and others introduced the Fully Convolutional Network (FCN), which was the first end-to-end Convolutional Neural Network (CNN) structure designed specifically for semantic segmentation. Before the advent of FCN, image features relied on manual extraction followed by pixel classification. These methods not only required multiple stages of processing but also yielded suboptimal results. FCN revolutionized semantic segmentation by implementing an end-to-end process, associating each pixel in the image with its corresponding class. FCN replaced the fully connected layers of CNN with fully convolutional layers, enabling the acceptance of larger images and producing output images of the same size. This simplification of the semantic segmentation process improved segmentation accuracy, driving the advancement of semantic segmentation. Since then, a series of efficient networks for semantic segmentation have been continuously proposed.
However, FCN still lacks attention to global information [
25]. Reference [
26] introduced the DeepLab network, which maintains high image resolution by reducing down-sampling operations. This network incorporates Fully Connected Conditional Random Field (FCCRF) by considering pixel relationships using image labeling, leading to improved segmentation. Subsequently, variations such as DeepLabV2 [
27], DeepLabV3 [
28], and DeepLabV3+ [
17] were proposed based on this model. DeepLabV2 introduced Atrous Spatial Pyramid Pooling (ASPP) to extract and integrate multiscale information. Chen et al., drawing inspiration from methods in references [
18,
29], proposed the DeepLabV3 network. This network eliminates the use of FCCRF and improves ASPP. Building upon this, the DeepLabV3+ network was introduced, adding a decoder module to extract boundary information from features. Additionally, it utilizes depthwise separable convolutions to enhance model performance and reduce parameter count compared to DeepLabV3.
Subsequently, some researchers proposed encoder–decoder-based methods [
30,
31,
32]. Ronneberger et al. [
16] introduced UNet, which strengthens the extraction of spatial semantic information. Similar to FCN, UNet is primarily applied in the semantic segmentation of medical images. Its unique design includes skip connections, connecting feature maps from the encoder and decoder to merge information from different layers, thereby improving segmentation accuracy. The later improvement, UNet++ [
33], enhanced UNet by incorporating short-link skip connections and feature fusion. Badrinarayanan et al. [
34] then introduced SegNet, another encoder–decoder architecture. SegNet is a variant of FCN, and while it shares similarities with UNet, its encoder utilizes the initial 13 layers of the VGG16 convolutional network. Each encoder layer is matched with a corresponding decoder layer. The encoder is utilized to reduce the resolution of feature maps, preserving high-level features, while the decoder restores lower-resolution feature maps to the original resolution. SegNet uses pooling indices instead of traditional weight parameters for upsampling in the decoder stage, minimizing the parameter count and improving memory efficiency. However, SegNet requires extended training time, and optimal results are achieved with demanding parameter settings.
Subsequently, researchers integrated attention mechanisms into networks to enhance segmentation accuracy. Attention-based methods focus more on the features we want to extract, disregarding redundant features [
35,
36,
37], and reducing the impact of noise on feature extraction. Attention mechanisms learn feature weights through forward propagation and backward feedback, extracting features based on these learned weights. Zhao et al. [
38] proposed PSANet, which introduces self-attention mechanisms, allowing each pixel to interact with other pixels in the image, addressing long-range dependencies between pixels. Following this, a series of attention-based networks have been proposed, with CCNet [
39] introducing a crisscross module for extracting global contextual information. BiSeNet [
40] uniquely employs a dual-branch approach for semantic segmentation, dedicated to extracting global contextual information and local details. The feature-fusion module of this network adapts to a multiscale feature pyramid, enabling the segmentation of images with different sizes and resolutions. While BiSeNet is more commonly used in lightweight models, it may perform less optimally in more complex models. Wang et al. [
41] introduced self-attention mechanisms into semantic segmentation tasks, achieving significant results [
42,
43]. The paper proposes a non-local block to obtain long-range spatial dependency information, thereby capturing the global contextual information of the image and effectively improving segmentation accuracy.
To address the challenge of extracting features at different levels, some scholars proposed pyramid structures. By utilizing pyramids with varying scales, this approach extracts features at different hierarchies, obtaining more context information while minimizing performance loss. Zhao et al. [
18] introduced PSPNet (Pyramid Scene Parsing Network), which incorporates the Pyramid Pooling Module (PPM). This module employs dilated convolutions to increase the receptive field. Dilated convolutions do not merely capture more context information but additionally avoid an increase in computational complexity. However, this module does add computational complexity, limiting the applicability of the model. In situations with restricted resources, it may lead to longer training times. Yang et al. [
44] combined DeepLab’s ASPP with DenseNet’s dense connections to create a DenseASPP network. The uniqueness of this network lies in its denser sampling points, allowing for the acquisition of more information.
With the introduction of transformers, semantic segmentation technology has seen significant improvements. Transformers replace the convolutional layers in traditional models by employing self-attention to compute inputs and outputs. Unlike traditional convolutions that rely on local receptive fields, transformers excel in modeling long-range dependencies and capturing global contextual information. Due to their unique attention mechanism, transformers can acquire more comprehensive global information, thereby enhancing their ability to handle more complex scenarios. The introduction of Vision Transformers (ViT) in 2020 [
45] marked the beginning of transformer research in the visual domain. ViT divides images into fixed-size patches and treats each patch as a sequence for processing. Segformer [
46] innovatively combines transformers with a lightweight MLP decoder, achieving efficient segmentation at various resolutions. STT (Sparse Token Transformer) [
47] deepens the interdependence between spatial and channel dimensions through a dual-branch structure, allowing it to capture global context and obtain a global receptive field.
The above-mentioned networks have addressed many challenges in semantic segmentation. However, some limitations still persist, particularly in the segmentation of building and water bodies [
48,
49]. One issue is the neglect of spatial information in many networks. As the network deepens, the image resolution decreases due to increased downsampling, leading to the loss of crucial boundary information and inaccuracies in segmentation [
50]. Therefore, preserving boundary information while deepening the network is a critical challenge for improving semantic segmentation accuracy. Another concern is that many networks focus more on extracting high-level semantic features from deeper layers, overlooking some low-level semantic features, resulting in the omission of basic image features and attributes. Effectively integrating high-level semantic features with low-level semantic features can significantly enhance segmentation accuracy. To address these challenges, this paper introduces a dual-branch semantic segmentation network with spatial complementation information. The network utilizes dual branches to further extract features extracted by deep networks. The module consists of two branches, extracting contextual information and spatial information from the images. While extracting contextual information, this branch reinforces the extraction of spatial information. To mitigate the impact of noise on spatial information, spatial attention is introduced. Finally, to generate feature maps incorporating both high-level and high-resolution features, we combine low-level feature maps with high-level feature maps. Both the deep network and the low-level network pass through a multichannel deep feature-extraction module, controlling the extraction of useful semantic information by measuring the utility of different features. Experiments demonstrate achieving a notable enhancement in the precise extraction of features through the proposed network.
Our work has made the following contributions:
The Context-aware Spatial Feature-Extractor Unit is introduced, composed of two branches dedicated to extracting contextual semantic information and spatial semantic information from images. This module is designed to enhance attention to the relative positional relationships between target objects and their surroundings while considering the relationships between target objects and the surrounding environment. The spatial information branch supplements the partially lost boundary information due to network deepening, thereby addressing the issue of edge blurring in semantic segmentation.
In the Multichannel Deep Feature-Extraction Module of the Context-aware Spatial Feature-Extractor Unit, a spatial attention module has been incorporated. This attention module, instead of focusing more on the target objects, places greater emphasis on the position of the target objects, intensifying attention to the targets and reducing the impact of noise on semantic segmentation accuracy.
Utilizing the Feature-Interaction Module, the contextual semantic information of high-level semantic features is effectively integrated with spatial semantic information. The spatial information is employed to complement the contextual information, resulting in a more comprehensive extraction of features from high-level semantic information.
The Multichannel Deep Feature-Extraction Module is introduced, designed for extracting features at various levels and fusing high-level semantic features with low-level semantic features. This module supplements high-level features with low-level semantic features, controlling information propagation by predicting the usefulness of each pixel. When the information at the current layer is deemed unnecessary, the layer forwards useful information to other layers or receives information from other layers.
2. Methodology
With the continuous enhancement of remote sensing image resolution, the complexity of target objects and background information increases. Spatial information has become a crucial factor affecting the accuracy of semantic segmentation [
51]. In complex spatial scenarios, issues such as misclassification and loss of information may arise, particularly concerning structures and water bodies. To tackle the issue of inaccurate segmentation caused by the loss of spatial information in semantic segmentation, this paper introduces a dual-branch semantic segmentation network with spatial supplementary information. This network effectively extracts spatial semantic information and integrates low-level semantic information with high-level semantic information to enhance segmentation accuracy.
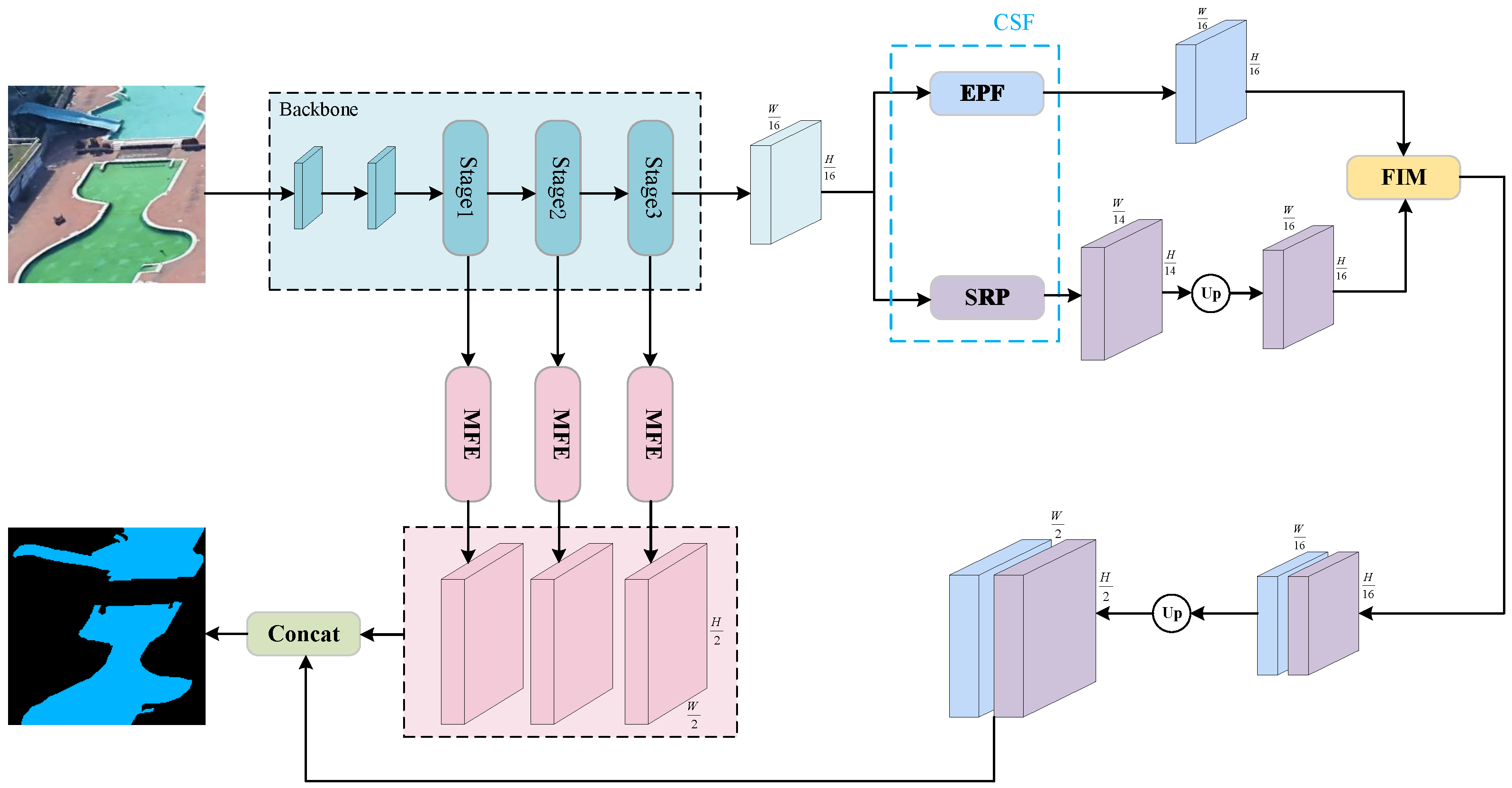
Figure 1 illustrates the overall design of the network. We choose ResNet [
52] as the backbone network for feature extraction at different phases. Subsequently, we employ Context-aware Spatial Feature-Extractor Units to acquire context and spatial information from the images. These feature maps not only contain the semantic information of the target objects but also retain a certain level of spatial resolution. Subsequently, these feature maps are passed to two main branch modules: the spatial information-extraction branch and the contextual information-extraction branch. In the spatial information-extraction branch, context-aware spatial feature-extraction units first capture both contextual and spatial information from the image. This unit primarily focuses on capturing spatial relationships within the image, enhancing attention to critical spatial information through a spatial attention mechanism, while suppressing unnecessary noise. The extracted spatial features are then passed to the feature-interaction module. Meanwhile, the contextual information-extraction branch focuses on capturing global semantic information from the image using the features extracted at different stages of ResNet. The global features within the contextual information are fused with the spatial information through the feature-interaction module. In this process, the feature-interaction module plays a key role, coordinating and combining the features obtained from the two branches to ensure collaboration between global contextual information and local spatial information. Finally, the multi-channel deep feature-extraction module is applied to extract low-level semantic information from the bottom layers of the network. These low-level semantic features are primarily used to supplement the spatiotemporal information previously obtained, thus complementing and enhancing the high-level semantic information. The features obtained from both the low and high levels are then fused to generate the final output feature map. This fusion process ensures that the segmentation results not only possess high-resolution spatial information but also retain comprehensive semantic context, thereby significantly improving segmentation accuracy and robustness.
2.1. Backbone
The backbone network plays a crucial role in semantic segmentation, where an appropriate backbone network can more accurately extract features from images, resulting in enhanced segmentation accuracy. With the success of AlexNet [
53], an increasing number of complex neural networks have gradually come into the public eye. VGG [
54] enhances network performance by increasing its depth, while GoogleNet [
55] executes multiple convolution and pooling operations in parallel, achieving deeper networks with reduced parameters. MobileNet [
56] finds wide applications in mobile and embedded systems, and FCN employs fully convolutional layers to process input images, enabling pixel-level labeling or segmentation. The mentioned networks are currently popular backbone networks that exhibit good performance in semantic segmentation tasks. Deepening the network layers enables the extraction of richer and more intricate features from images, thereby enhancing segmentation accuracy. However, deeper networks may face challenges such as gradient explosions and overfitting. Moreover, increasing parameters with network depth raises computational demands, limiting the network’s applicability. In summary, in this article, we have chosen ResNet50 as the backbone network. The residual network structure of ResNet effectively addresses issues like gradient explosions and overfitting [
57]. The residual structure, depicted in
Figure 2, differs from regular connections by introducing a shortcut mapping that directly connects the input and output. This approach captures the differences between input and output.
The formula for this residual structure is as follows:
where
is the input matrix of the i-th residual module,
is the output of the
residual block.
and
are weight matrices, with
representing ReLU functions.
In this paper, to reduce parameters, we modified the ResNet by removing the last layer; only the first three layers were utilized for semantic feature extraction.
2.2. Context-Aware Spatial Feature-Extractor Unit
Many existing networks have incorporated attention to spatial and contextual information. For example, the PSPNet and DeepLab series focus on contextual information, while Unet and SegNet emphasize spatial information. These networks have shown excellent performance in semantic segmentation tasks. However, the above networks typically focus on either spatial or contextual information. Contextual information is concerned with global semantic details, whereas spatial information focuses on local details. Focusing on only one type of information results in features that are local rather than comprehensive. In contrast, the Context-aware Spatial Feature-Extractor Unit proposed in this paper simultaneously attends to both contextual and spatial information, producing more complete features compared to existing mature networks.
This module consists of two components, the Environmental Perception Feature-Extraction Module and the Spatial Relationship Perception Feature-Extraction Module. The Environmental Perception Feature-Extraction Module extracts contextual information from the image [
58], while the Spatial Relationship Perception Feature-Extraction Module focuses on extracting spatial information. Contextual information primarily addresses the environment in which pixels are located but lacks attention to the relationships between pixels. The proposed network in this paper incorporates a branch for extracting spatial information to complement contextual information, thereby enhancing the overall understanding of the layout and improving the comprehension of contextual information.
2.2.1. Environmental Perception Feature-Extraction Module
This module is primarily crafted for extracting contextual information from images. Contextual information in images refers to the environmental information surrounding the features of interest, specifically the contextual information of pixels. Strengthening the focus on contextual information aids in a more comprehensive understanding of the image, thereby improving segmentation accuracy.
This module obtains multiscale contextual information by using convolutions with different dilation rates. The structure of this module is shown in
Figure 3. Regular convolutions, due to their smaller receptive field, can only capture local features. In this module, we use
convolutions with dilation rates of 6, 12, and 18 to achieve larger receptive fields. Convolutions with different dilation rates focus on different features, thereby helping us obtain more contextual information. Max pooling involves downsampling the input feature map to enlarge the receptive field and gather more contextual information by reducing resolution. Additionally, the module includes a
convolution aimed at reducing the number of channels to decrease computational complexity. Finally, the features obtained from these operations are integrated to produce the ultimate feature map. The feature map obtained through this module contains more contextual information compared to previous ones, effectively improving segmentation accuracy.
The formula for DWconv is shown below:
which
f is the feature map,
x is the input image,
w is the convolution kernel weight,
d is the dilation rate,
i and
j are the coordinates of the output position.
2.2.2. Spatial Relation Perception Feature-Extraction Module
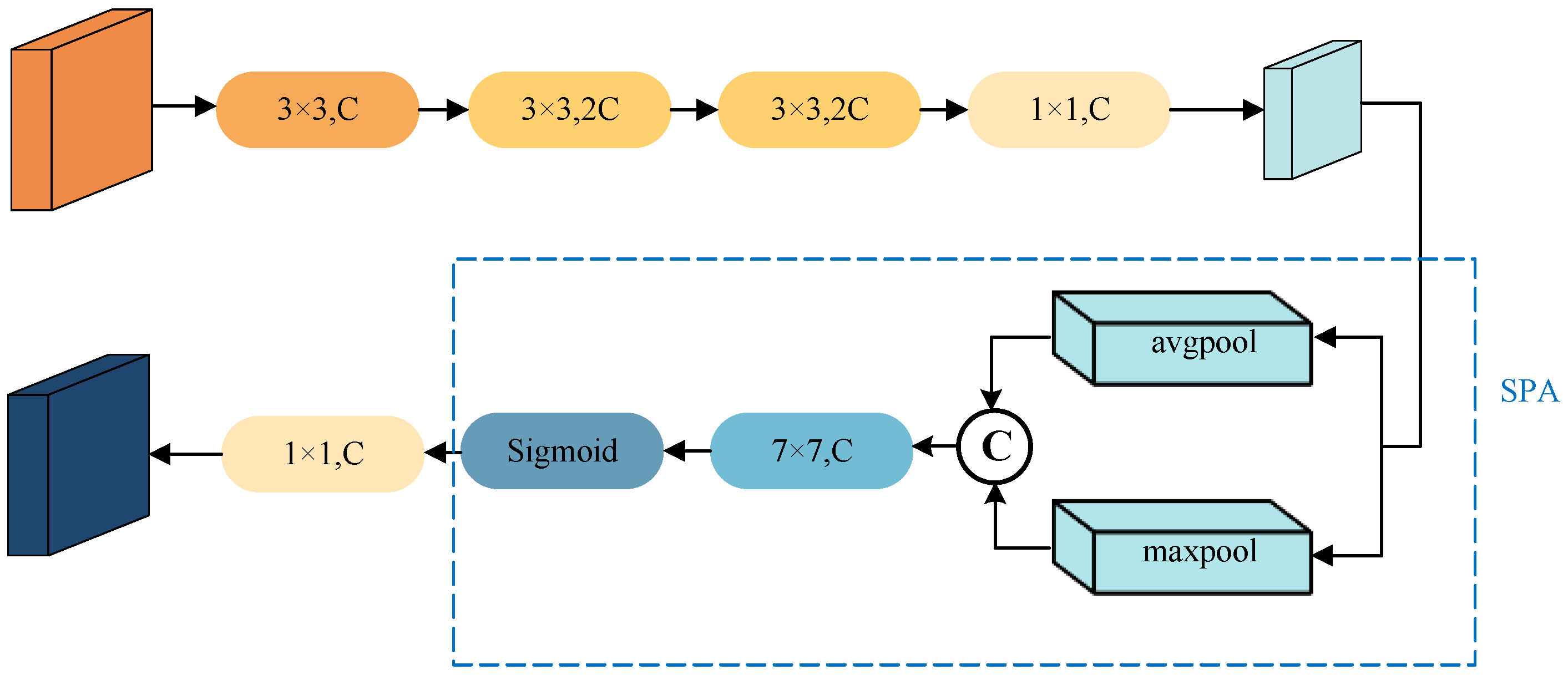
This module is designed to primarily extract spatial information from images. Spatial information in images refers to the spatial position of pixels and their relationships with other pixels. In the previous Environmental Perception Feature-Extraction Module, we neglected the spatial information of features. Therefore, this module is introduced to extract and supplement the missing spatial information. The component comprises two segments: the Spatial Feature-Extraction Component and the Spatial Attention Component.
The Spatial Feature-Extraction Module employs a convolutional neural network to extract features because convolutional networks can automatically learn the features needed for semantic segmentation. This module consists of four convolutional layers, including three
convolutional layers and one
convolutional layer. The first three convolutional layers are mainly used for feature extraction, while the last
convolutional layer is primarily for channel restoration. To obtain more features, we double the number of channels in the second and third
convolutional layers. Increasing the number of channels enhances feature representation capacity, as different channels learn different features, and more channels can capture a more diverse range of features. Nevertheless, the rise in the quantity of channels brings the problem of increased parameters. To tackle this concern, we employ depthwise separable convolutional layers instead of regular convolutional layers, as depthwise separable convolutions have fewer parameters. Finally, a
convolutional layer is applied to restore the quantity of channels to its original size, reducing the extraction of irrelevant information. The model diagram for this module is shown in
Figure 4, where C represents the number of channels.
Depthwise separable convolution consists of depthwise convolution and pointwise convolution. In depthwise convolution, each input has a separate convolutional kernel for each channel, significantly reducing the number of parameters. Depthwise convolution has a very small receptive field for each channel, focusing more on local features of the image, which helps strengthen attention to spatial information and acquire more spatial details. Pointwise convolution is used to obtain local spatial features by performing convolution operations within each channel. Therefore, we replace regular convolutions with depthwise separable convolutions, reducing the number of parameters and providing more attention to the spatial information of features.
Figure 5 illustrates the difference between regular convolution and depthwise separable convolution, demonstrating that regular convolution involves more computations when the number of channels is the same.
In the Spatial Attention Module of the Spatial Feature-Extraction Module, spatial attention is assigned different weights based on the different positions of targets in the input feature map. It focuses on the positions of features by obtaining global features of the input data through average pooling and max pooling. Subsequently, convolutional layers and the sigmoid function are used to generate corresponding weights. The formula for spatial attention is as follows:
where
represents the final attention obtained.
is the input feature map.
is the convolutional layer with a kernel size of
k.
is the sigmoid function.
and
are operations for average pooling and max pooling on the input feature, respectively.
The Spatial Feature-Extraction Module is used for the preliminary extraction of spatial information, and then the spatial attention is incorporated to better comprehend the structure and spatial relationships within the input data. The Spatial Information-Extraction Module, composed of these two modules, can comprehensively extract spatial information that was previously overlooked by the network. This aids in understanding the relative positions and distances between features in the image, as well as grasping the location, size, and shape of features. Ultimately, it enhances our understanding of the image.
2.3. Feature-Interaction Module
In semantic segmentation, both contextual information and spatial information are crucial for effective segmentation. Effectively combining the two can help us understand the relationships between features and grasp the location, size, and shape of features in the image. By focusing on the features themselves and their related content, we can gain a more comprehensive understanding of the features. To address this issue, we propose a Feature-Interaction Module to efficiently integrate the information obtained from the Environmental Perception Feature-Extraction Module and the Spatial Relation Perception Feature-Extraction Module.
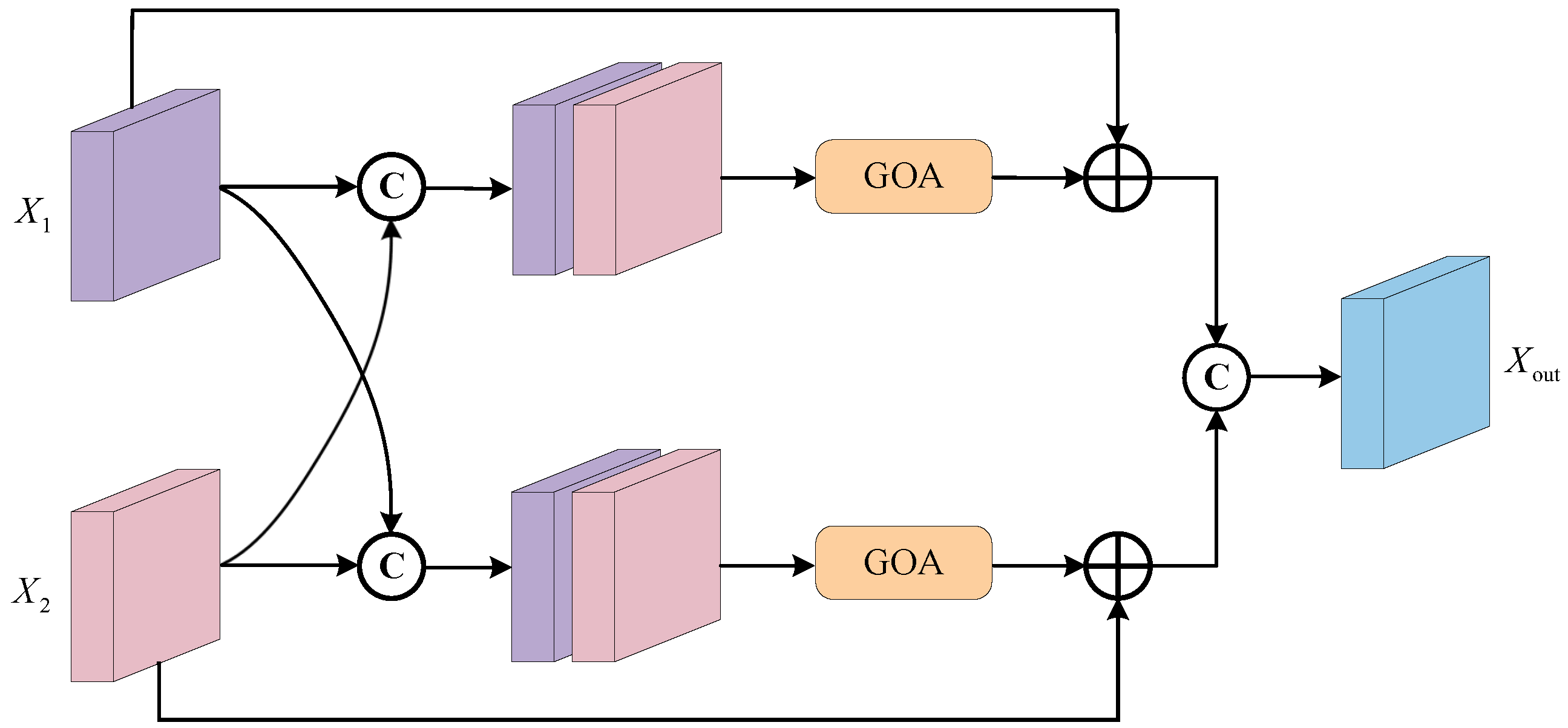
This module is illustrated in
Figure 6. Initially, we cross-fuse the feature maps obtained from the Environmental Perception Feature-Extraction Module and the Spatial Relation Perception Feature-Extraction Module. Each branch’s feature map is passed into the other branch to create a fused map that combines simple semantic and spatial information. Subsequently, the fused maps from both branches are input into the Goal-Oriented Attention Mechanism to obtain a noise-filtered feature map. This attention-filtered feature map is then concatenated with the original feature map through residual connections, effectively improving feature quality and better integrating global and local information to enhance segmentation accuracy. Following this, the feature maps from both branches are fused to obtain the final complete feature-fusion map. The purpose of the two fusion steps is to enhance the model’s representation and generalization capabilities. The introduction of attention during the fusion stages allows the model to selectively emphasize features in different regions or channels adaptively, contributing to a better understanding of various scenes.
The Goal-Oriented Attention Mechanism in this module, as shown in
Figure 7, primarily involves adjusting the feature map effectively using weights. This mechanism aims to make the model focus more on important regions, reducing the impact of noise on segmentation, and thereby enhancing the model’s expressiveness and generalization capability.
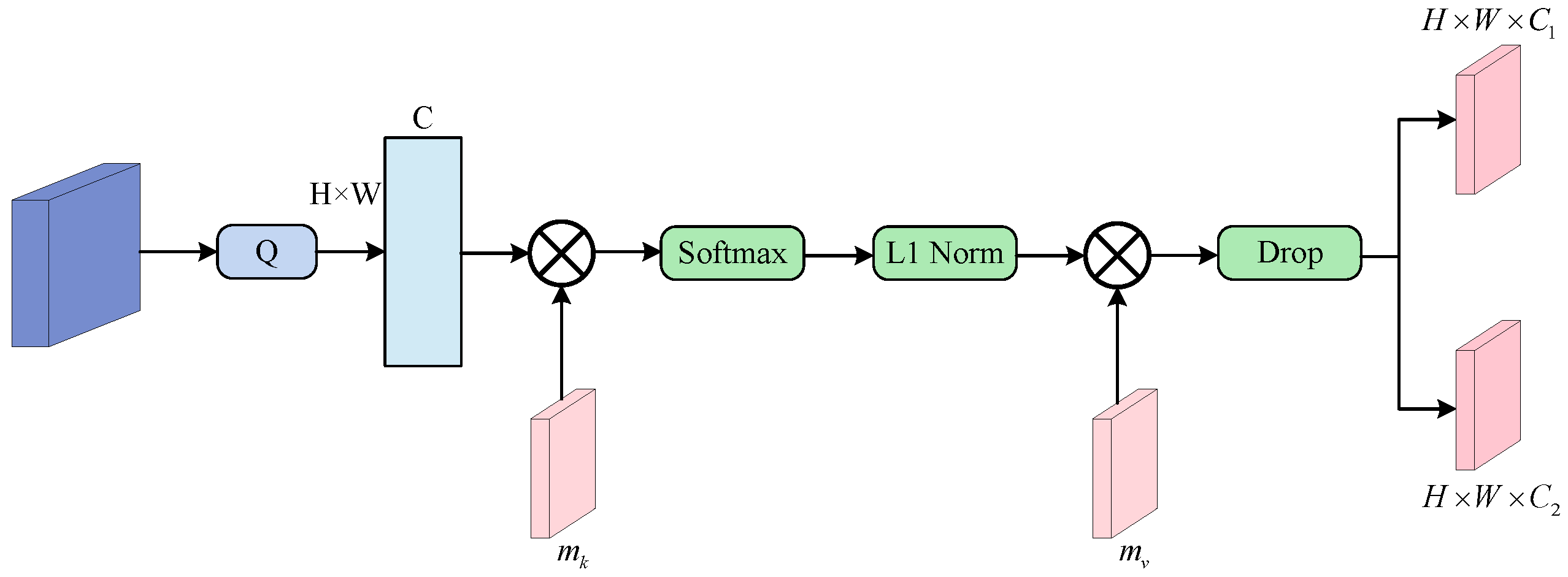
The formula for the Goal-Oriented Attention Mechanism is as follows:
where
is the input feature map,
N is the number of pixels in the image and
d is the dimensionality of the features.
and
are linear layers with 64 nodes. ⊗ represents the dot product.
is the softmax function.
stands for L1 normalization, and
refers to the Dropout layer.
The two linear layers in this section are used to perform linear transformations on the input, along with employing additional linear layers to generate queries, keys, and values. Here, maps the input features to a new space with a dimension of S. This is equivalent to generating queries in the attention mechanism (Query). In addition, maps the output with a dimension of s back to the original feature dimension. This is equivalent to generating values in the attention mechanism (Value). This design ensures a clear method for generating queries and values, which are then applied to compute attention scores. Consequently, it achieves our goal of a weighted combination of input features through attention scores.
The softmax function is defined as:
Softmax primarily involves computing each row of the matrix generated by
. transforming the elements in that row into a probability distribution between 0 and 1, while ensuring that the sum of all elements is within 1. The purpose of applying softmax is to assign a weight to each position [
59], thereby enhancing the network’s attention to specific locations.
After applying softmax, we further use L1 normalization to ensure that the sum of the output probability distribution is 1. The formula for L1 normalization is as follows:
where
is the output of softmax.
is the sum of all current elements. Finally, we use a Dropout layer to prevent overfitting and improve the model’s generalization ability. The formula for Dropout is as follows:
where
represents the elements of the input tensor,
is a Bernoulli distribution, returning 1 with probability
p and 0 with probability
. Here,
p represents the probability of dropout. The spatiotemporal information-aggregation module effectively handles the complex relationships between the feature of the Environmental Perception Feature-Extraction Module and the feature of the Spatial Relation Perception Feature-Extraction Module. This enables the model to better capture multiscale features of the image, enhancing its ability to process details and the overall image. Additionally, we introduced linear layers and softmax functions to learn complex features of the image. Dropout functions are employed to prevent overfitting, enabling the model to concentrate attention on crucial feature parts and enhancing the expressiveness of the network.
2.4. Multichannel Deep Feature-Extraction Module
The final layer of ResNet primarily captures high-level semantic information from the image, obtaining more abstract features such as object shapes and categories. In contrast, the earlier layers of ResNet capture low-level semantic information, including details like edges and textures [
8], as well as local features. While the top feature map contains rich semantic information, its drawback lies in its lower resolution, lacking detailed semantic information. Conversely, the lower-level feature maps can effectively complement the missing parts of high-level semantic information. Therefore, by using low-level semantic features to supplement high-level semantic features, we can obtain a more complete feature map with a resolution restored to that of the original image. This effectively enhances segmentation accuracy.
This module integrates features from the first three layers of ResNet by assigning different parameters to each layer, extracting and fusing shallow network features. Through the analysis of each feature, irrelevant interference is removed, and useful information is fused. In this paper, the sigmoid function is utilized to classify the usefulness of features. When the sigmoid value is closer to 1, it indicates more usefulness and such information is retained. If the sigmoid value is closer to 0, it signifies lower usefulness and other features are used to complement and fuse with this feature. The module is illustrated in
Figure 8.
The formula for this module is as follows:
The formula for this module is as follows. We use this module to extract and fuse features from the first three layers of ResNet. If represents a layer of ResNet, then and represent the remaining two layers of ResNet, primarily used to complement the features of the first layer. We sequentially use the first three layers of ResNet as inputs to assess the importance of the extracted information at each layer. When one layer serves as input , the remaining two layers act as and to complement the features. , and is the sigmoid function, and , , and first undergo a sigmoid function to assign a weight. When approaches 1, approaches 0, indicating the importance of the information in that layer, and there is no need for supplementary information from the other two layers. Conversely, if approaches 0, it indicates that the information in that layer is relatively unimportant, and supplementary information from the other two layers is required. This way, the final features of each layer exclude unimportant information while retaining important information. Finally, the supplemented features are added to the original features to obtain a more complete feature map.
By adding the weighted feature maps to the original feature map, the model is allowed to adaptively choose the degree to which the feature maps are fused. This process preserves the relatively important information in the original feature map while discarding less important information. It utilizes features with stronger semantic information to complement features with weaker semantic information, making better use of information from each layer and achieving accurate image-segmentation tasks. The module can adaptively weight the contributions of the feature maps from the first three layers of ResNet, allowing the network to learn the most useful information. Additionally, this module can dynamically highlighting the significance of each feature map, allowing the network to concentrate attention on critical areas, reducing attention to noise, and enhancing the model’s segmentation precision.
3. Experiment
3.1. Dataset
In this paper, we selected datasets for water bodies and building. Accurately segmenting water bodies and building can provide more technical support for applications such as urban planning, environmental engineering, and natural landscape monitoring. The characteristics of water bodies and building differ significantly. building typically have clear boundaries and geometric shapes, with strong edge information and regular geometric features. Therefore, our focus is more on edge information, shape regularity, and texture details. In contrast, the shape and boundaries of water bodies are variable, and they are more significantly affected by lighting conditions, exhibiting properties like reflection, transparency, or translucency, which are major differences from building. As a result, when segmenting water bodies, it is crucial to better understand color gradients, changes in reflected light, and fluidity characteristics, as well as to incorporate contextual information to focus on global information, accurately distinguishing water bodies from their surrounding environment. It is evident that the key information to focus on during segmentation differs between water bodies and building. building require an emphasis on detail-oriented information, whereas water bodies necessitate a focus on global information. Balancing attention to these different key features poses the greatest challenge to the network proposed in this paper.
3.1.1. Building Dataset
The dataset is derived from Google Earth maps and consists of 300 images with a resolution of
. These images were cropped to
, and after careful inspection and filtering to remove images with a single label, a total of 2000 images were obtained for subsequent experiments. The dataset covers a diverse geographical range, including suburban areas in North America, coastal residential areas in China, and rural parks in Europe, captured from various angles. We applied data augmentation to the images by flipping them horizontally (
), vertically (
), and randomly in orientation (−10 degrees to 10 degrees) after cropping. This enhances the diversity of the data, reduces overfitting, and enhances the model’s capacity for generalization. The dataset is structured as a three-class dataset, with labels for building, water, and background. Subsequently, we split the dataset into training and validation sets with a ratio of 4:6. Partial displays of this dataset are shown in
Figure 9.
In this dataset, accurate segmentation of the model faces some challenges due to various factors. For instance, under poor lighting conditions, building and water bodies may have similar shapes, making it challenging to differentiate them. This scenario effectively tests the model’s representational capabilities. Additionally, shadows from some building and tall trees may obscure building and water bodies, leading to blurry boundaries and segmentation difficulties. This situation serves as a test for the model’s resilience to interference. The dataset’s rich variety of scenes poses a challenge to the model’s detection capabilities.
3.1.2. Water Dataset
The water body dataset is derived from the multispectral remote sensing images of the Chinese HJ-1A (HJ-1B) environmental remote sensing satellite and the multispectral remote sensing satellite Landsat-8 from NASA. The Landsat-8 satellite images consist of 11 bands, and the water body dataset is primarily composed of images from the 4th, 3rd, and 2nd bands. The resolution of Landsat-8 satellite images is 10,000 × 10,000, and the resolution of Google images is
. We cropped them to images with a resolution of
. After cropping, we performed data augmentation, resulting in a total of 8000 images in this dataset. We split the dataset into training and validation sets with a ratio of 4:1. This dataset is a binary classification dataset, where the labels of the images fall into two categories: water and background. The dataset encompasses rich information on water, including various shapes, types, and colors of water, effectively evaluating the model’s generalization ability. Partial displays of this dataset are shown in
Figure 10.
3.2. Experimental Parameter Setting
In the experimental process, we utilized an Intel Core i5-13400F CPU@2.5GHz (Intel Corporation, Santa Clara, CA, USA) NVIDIA RTX4060ti GPU (NVIDIA Corporation, Santa Clara, CA, USA) and NVIDIA RTX4060ti GPU (NVIDIA Corporation, Santa Clara, CA, USA) as the hardware environment, paired with the Windows 10 operating system and the PyTorch deep learning framework. For optimization during experiments, we employed the adaptive learning rate optimization algorithm known as Adam. This algorithm adjusts the learning rate of parameters by computing the first and second-order matrix estimates of the gradients. The advantage of this algorithm lies in its effective combination of the benefits of the momentum method and the RMSProp (Root Mean Square Propagation) algorithm. The formula for the Adam optimization algorithm is as follows:
where
is the updated learning rate.
is the base learning rate.
is the iteration count.
is the total iteration count.
is controls the shape of the learning rate curve. In this paper, we set the base learning rate to 0.001 because in most models, the loss stabilizes after around 200 epochs in this experiment. To prevent overfitting due to too many epochs, we set the total iteration count to 300. We set the power to 0.9. In this experiment, we use BCEWithLogitsLoss as the loss function, and due to GPU memory limitations, we set the batch size to 16. The evaluation metrics in this experiment include pixel accuracy (PA), mean pixel accuracy (MPA), and mean intersection over union (mIoU), with the following formulas:
The variables are represented by
Table 1.
3.3. Backbone Network Comparative Experiment
In this paper, we chose ResNet as the foundational network for our model. We compared three ResNet architectures-ResNet18, ResNet50, and ResNet101—to determine the most effective backbone for our network. ResNet18 has 18 layers, ResNet50 has 50 layers, and ResNet101 has 101 layers.
Table 2 shows our experimental results.
We observe that ResNet18 has the smallest number of parameters, but it has the lowest mIoU, differing significantly from the other two. Therefore, ResNet18 is not selected. ResNet50 and ResNet101 have similar mIoU scores, but ResNet50 has relatively higher accuracy, and its parameter count is only half of ResNet101. Consequently, we choose ResNet50 with 50 layers as the backbone network for our model.
3.4. Ablation Experiments
Ablation Experiments We conducted ablation experiments to assess the impact of each module on overall segmentation performance. We used a modified ResNet50 as the backbone network and sequentially added each module. In this experiment, we primarily used mIoU for model evaluation. The results are presented in the table below. From
Table 3, we can clearly see that incorporating only the Context-aware Spatial Feature-Extraction Unit increased mIoU by
. Adding both the Context-aware Spatial Feature-Extraction Unit and the Feature-Interaction Module resulted in a
increase in mIoU. Further, integrating the Context-aware Spatial Feature-Extraction Unit, the Feature-Interaction Module, and the Multi-Channel Depth Feature-Extraction Module led to a
improvement in mIoU. Finally, incorporating all proposed modules yielded a
enhancement over the backbone network, with mIoU reaching a peak of
. This indicates that all modules used in this paper effectively improved the model’s performance, demonstrating strong performance in semantic segmentation tasks.
To obtain a clearer understanding of the impact of different modules on semantic segmentation tasks, we selected results from several ablation experiments for comparison, as shown in
Figure 11. The backbone network shown in
Figure 11b can only capture rough contours and fails to obtain more detailed semantic information. After incorporating the Context-Aware Spatial Feature extraction shown in
Figure 11c, the model shows a noticeable improvement in attention to contextual semantic information and spatial details. However, the handling of some detailed features still performs suboptimally, and the feature map still contains some noise. Subsequently, with the addition of the Feature-Interaction Module shown in
Figure 11d, noise reduction is achieved by aggregating contextual information and spatial information while introducing attention to handle noise. After incorporating the Multi-Channel Deep Feature-Extraction Module shown in
Figure 11e, the model focuses on the low-level semantic information of the backbone network, resulting in higher resolution and more detailed feature details in the bottom-level semantics. It is evident that the model’s handling of image details is improved. Finally, when all modules are combined to obtain the complete model, from the image, we observe that the network’s processed feature map demonstrates better attention to detail compared to the feature map obtained by the backbone network alone. It simultaneously enhances attention to the surrounding environment of pixels and the relationships between pixels, contributing to a thorough understanding of pixels for classification. Moreover, it effectively handles noise, reducing misclassifications caused by noise. In comparison to the backbone network, the entire network obtains more complete feature maps, leading to a noticeable improvement in segmentation accuracy.
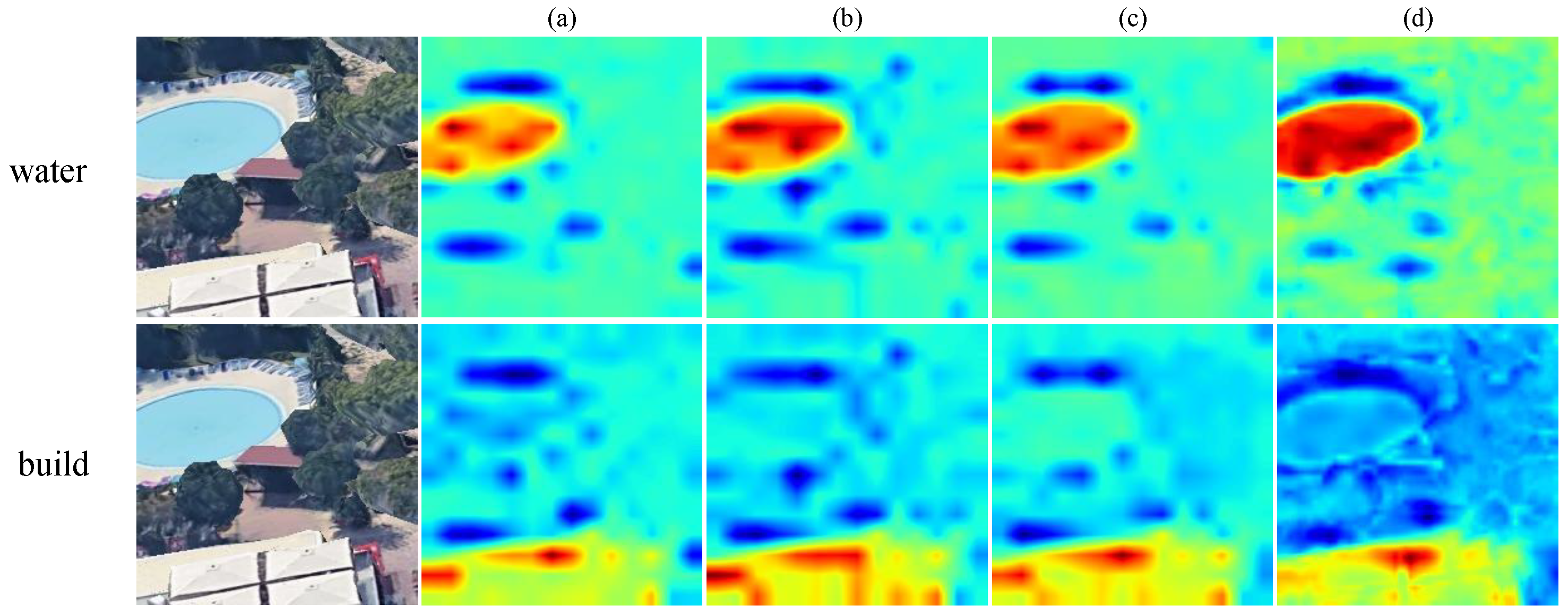
Later, we further compared the heatmaps of the ablation experiments, as shown in
Figure 12. In the heatmap, shades of orange-red represent pixels of primary interest, while yellow and blue indicate secondary pixels. The first row depicts the results for water, and the second row illustrates the results for building. From column
Figure 12a, it can be observed that although the backbone network can roughly capture the areas of building and water bodies, the boundaries are too blurry, and the handling of surrounding noise is poor. After incorporating the Context-Aware Spatial Feature-extraction module shown in
Figure 12b (column), the boundary information of water bodies and building becomes clearer. Subsequently, with the addition of the Feature-Interaction Module
Figure 12c (column), it can be seen that noise within the heatmap is notably diminished, and the model concentrates more on pixels corresponding to building and water bodies. After incorporating the Multi-Channel Deep Feature-Extraction Module, the overall network shows a noticeable improvement in handling image details. The colors for building and water body areas become darker, and the contours become more pronounced, achieving precise segmentation of the image.
3.5. Comparison Experiments Based on the Building Dataset
To assess the efficacy of our model, we performed comparative experiments using the building dataset, comparing it with some popular existing networks. The results demonstrate that our proposed model attains higher accuracy than all existing models, indicating that our SPNet model performs well in land cover segmentation on the dataset.
We selected DeepLabV3+ [
17], Unet [
16], PSPNet [
18], SegNet [
34], DABNet [
60], DDRNet [
61], EDANet [
62], FCN [
24], and DSFNet [
63] for comparison. DDRNet is also a dual-branch network, using a deep dual-resolution branch for semantic segmentation of high-resolution images. While DDRNet is a lightweight network, its accuracy is lower, with PA, MPA, and MIOU being 89.94, 88.96, and 79.15, respectively. UNet, DABNet, PSPNet, SegNet, and FCN focus on spatial information in images. UNet employs an encoder–decoder structure with skip connections in between to preserve spatial information, resulting in PA, MPA, and mIoU of 90.37, 89.67, and 80.89. DABNet incorporates dense attention branches to deepen attention to spatial information, yielding PA, MPA, and mIoU of 90.09, 90.83, and 81.19. SegNet, like UNet, has an encoder–decoder structure, but it uses hierarchical upsampling and downsampling to retain and restore spatial information, with PA, MPA, and mIoU being 87.62, 89.00, and 79.88. FCN uses a fully convolutional structure for dense pixel-level predictions of spatial information, resulting in PA, MPA, and mIoU of 90.55, 89.60, and 81.07. DeepLabV3+ and PSPNet focus on contextual information in images. DeepLabV3+ introduces dilated convolutions to expand the receptive field and proposes Atrous Spatial Pyramid Pooling (ASPP) for multiscale context information fusion, achieving PA, MPA, and mIoU of 90.38, 90.22, and 82.26. PSPNet incorporates a pyramid pooling module to extract information at different scales for multiscale context information, resulting in PA, MPA, and mIoU of 90.63, 91.49, and 82.74. Although DeepLabV3+ and PSPNet demonstrate good segmentation accuracy, this accuracy comes at the expense of computational complexity and parameter count.EDANet and DSFNet aim to improve segmentation accuracy by introducing attention mechanisms. EDANet adds a progressive attention mechanism, with PA, MPA, and mIoU of 89.42, 89.83, and 81.09. DSFNet enhances attention between horizontal directions and positions to boost segmentation accuracy, yielding PA, MPA, and mIoU of 91.03, 91.52, and 83.73.
The proposed SPNet in this paper is a dual-branch network that simultaneously focuses on the contextual information of the image and supplements the spatial information of the features. Additionally, it incorporates processing for low-resolution feature maps, enabling the feature maps to possess excellent spatiotemporal information and detailed local features. The network achieves high performance with PA, MPA, and mIoU reaching 93.54, 93.41, and 87.57, respectively, making it the most accurate among all networks in the comparative experiments.
From
Table 4, we can observe that the computational complexity and parameter count of the proposed SPNet are 11.56 GMac and 39.03 M, respectively. Compared to other semantic segmentation networks, SPNet has a lower computational complexity than the majority of networks. Additionally, it is noteworthy that DeepLabV3+ and PSPNet exhibit better segmentation accuracy; Yet, this level of accuracy is achieved at the cost of heightened computational complexity and an increased number of parameters. In contrast, the proposed SPNet achieves improved segmentation accuracy while simultaneously reducing computational complexity and parameter count.
To obtain a clearer insight into the processing performance of each network, we visualized the segmentation outcomes for six images from the dataset, as depicted in
Figure 13. Each column represents the predicted output of each model, and the last column represents the original labels. From
Figure 13, it’s evident that conventional semantic segmentation networks effectively segment rivers and building, but the results mostly provide a rough outline and shape, losing many details. Additionally, traditional networks may encounter misjudgments in more complex areas. In contrast, the proposed network handles details better, achieving accurate segmentation of building and water bodies. Traditional semantic segmentation networks tend to overlook small areas of water bodies and building, as highlighted by the red circles in
Figure 13. However, our network effectively avoids this issue by incorporating a Multichannel Deep Feature-Extraction Module to handle image details. In cases where building and water bodies are similar to the background, as indicated by the red rectangles in
Figure 13. traditional networks may make misjudgments. We address this by introducing a Spatial Relation Perception Feature-Extraction Module to enhance spatial information processing, effectively distinguishing between the background and building or water bodies, thereby reducing misjudgments. Furthermore, our model exhibits fewer noise artifacts in the predicted images compared to SegNet, as attention mechanisms are incorporated in both the Spatial Relation Perception Feature-Extraction Module and Feature-Interaction Modules, mitigating the impact of noise.
3.6. Comparison Experiments Based on the Water Dataset
In order to test the model’s generalization ability, we conducted a comparative experiment on a water dataset, and the results are shown in
Table 5. At the same time, in the comparative experiments on this dataset, we included STTs (Sparse Token Transformers) for binary classification comparison. This model is a semantic segmentation network based on transformers. In this experiment, the proposed model achieved the highest accuracy, with PA, MPA, and MioU values of 98.8, 98.7, and 96.8, respectively. This experiment demonstrates that SPNet exhibits strong generalization ability.
As shown in
Figure 14, The proposed model outperforms other networks on the water dataset is superior to other networks. In the highlighted regions of the circles, some water areas with similar colors to the background resulted in misjudgments. Among all the compared networks, the effect of SPNet proposed in this paper is the best, with the fewest misjudgments. The dataset also contains many small water areas that are often ignored by networks due to their small size, as indicated by the rectangular marked area in
Figure 14. However, SPNet, introduced in this paper, incorporates a spatial information-extraction module, enhancing the understanding of features regarding their position, size, and shape. This effectively reduces instances of missing information.
5. Discussion
This study primarily utilized two distinct datasets: the land cover dataset and the water dataset. These datasets are entirely different, with the land cover dataset being a three-class classification dataset consisting of villa areas in North America, coastal residential areas in China, and rural parks in Europe. The water dataset, on the other hand, is a binary classification dataset primarily composed of various rivers. The experimental parameters in this study mainly include pixel accuracy (PA), mean pixel accuracy (MPA), and mean intersection over union (mIoU), which are compared to determine model performance. Initially, a comparison was made among ResNet18, ResNet50, and ResNet101, where ResNet50 exhibited the highest accuracy and most suitable parameters. So, we select the ResNet as the backbone. The ablation experiments were conducted to validate the effectiveness of each module. Through these experiments, it was observed that with the addition of each module, the model’s accuracy improved. Specifically, after adding the environment-aware spatial feature-extraction unit, mIoU increased by 1.209 to reach 82.476. Further enhancement was achieved with the incorporation of the information-aggregation module, resulting in an increase of 1.72 to reach 84.196. Finally, integrating the multiscale information-extraction module led to a significant improvement in mIoU by 3.376, reaching 87.572. Subsequently, the effectiveness of each module was further confirmed through experimental visualization. In the comparative experiments on the land cover dataset, the proposed SPNet achieved an accuracy of 87.572, surpassing several mature networks while maintaining a smaller parameter count. This indicates that SPNet effectively improved accuracy without significantly increasing parameter count. Lastly, another comparative experiment was conducted on the water dataset, resulting in an mIoU of 96.8, the highest among all networks. This experiment not only reaffirmed the superior segmentation performance of SPNet but also highlighted its good generalization capabilities.
This study’s findings are of significant importance and value, exerting a positive influence on the development of the semantic segmentation field. Firstly, our experimental results demonstrate that the proposed model excels in segmenting images of specific categories, exhibiting higher accuracy and robustness compared to traditional methods. This offers new methods and insights for addressing image-segmentation issues in practical applications. Secondly, our comparison of different models or parameter settings reveals significant improvements across multiple evaluation metrics, proving the effectiveness and superiority of the proposed model in semantic segmentation tasks. This holds significant implications for advancing the research field, providing strong references and insights for further optimization and improvement of semantic segmentation models. Additionally, our study explores the trends in model performance variations across different scenarios and analyzes the challenges and limitations the model may encounter when handling specific situations. This aids researchers in better understanding the model’s applicability and limitations, offering directions for future research improvements and extensions. Last but not least, in this project, we also conducted research on the current development status and background significance of building and water bodies, which provides valuable reference for subsequent researchers. In summary, the findings of this study hold both theoretical and practical significance, offering valuable insights and inspiration for the development of the semantic segmentation field.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}