
Enhancing the Resolution of Satellite Ocean Data Using Discretized Satellite Gridding Neural Networks


Abstract
1. Introduction
2. Data and Methods
2.1. Data: SST/SSS/SLA/ADT
2.1.1. Data: SST Data of AVHRR
2.1.2. Data: SSS Data of SMOS
2.1.3. Data: SLA Data of CMEMS
2.1.4. Data: ADT Data of CMEMS
2.1.5. Data: EN4.2.2
2.1.6. Data: HYCOM
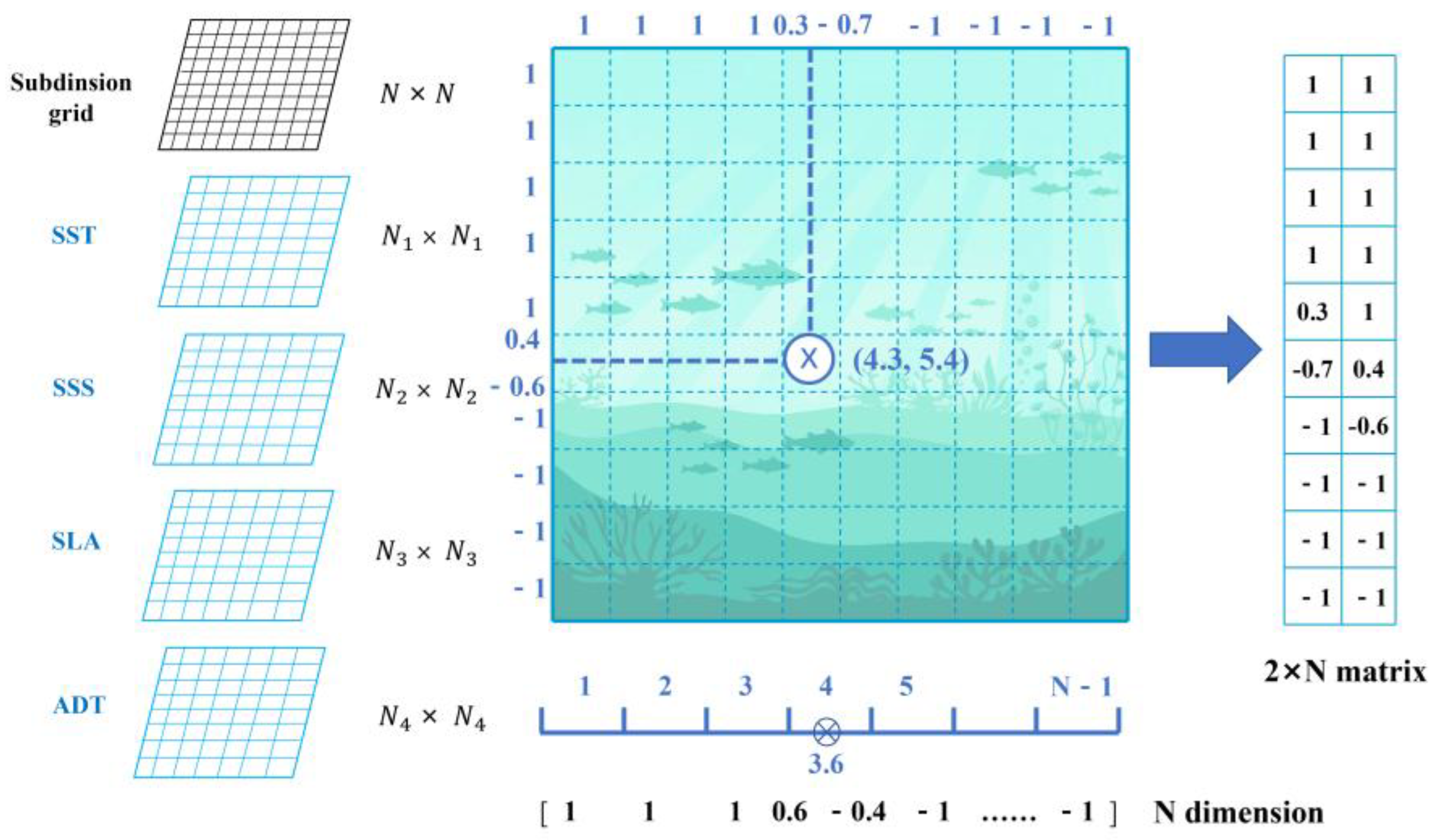
2.2. Discretization Method
2.3. Neural Network Construction
2.3.1. Network Architecture
2.3.2. Weight Decay
2.3.3. Design of Loss Function and Data Testing Criteria
3. Results
3.1. Effectiveness of Satellite Global Data Reconstruction
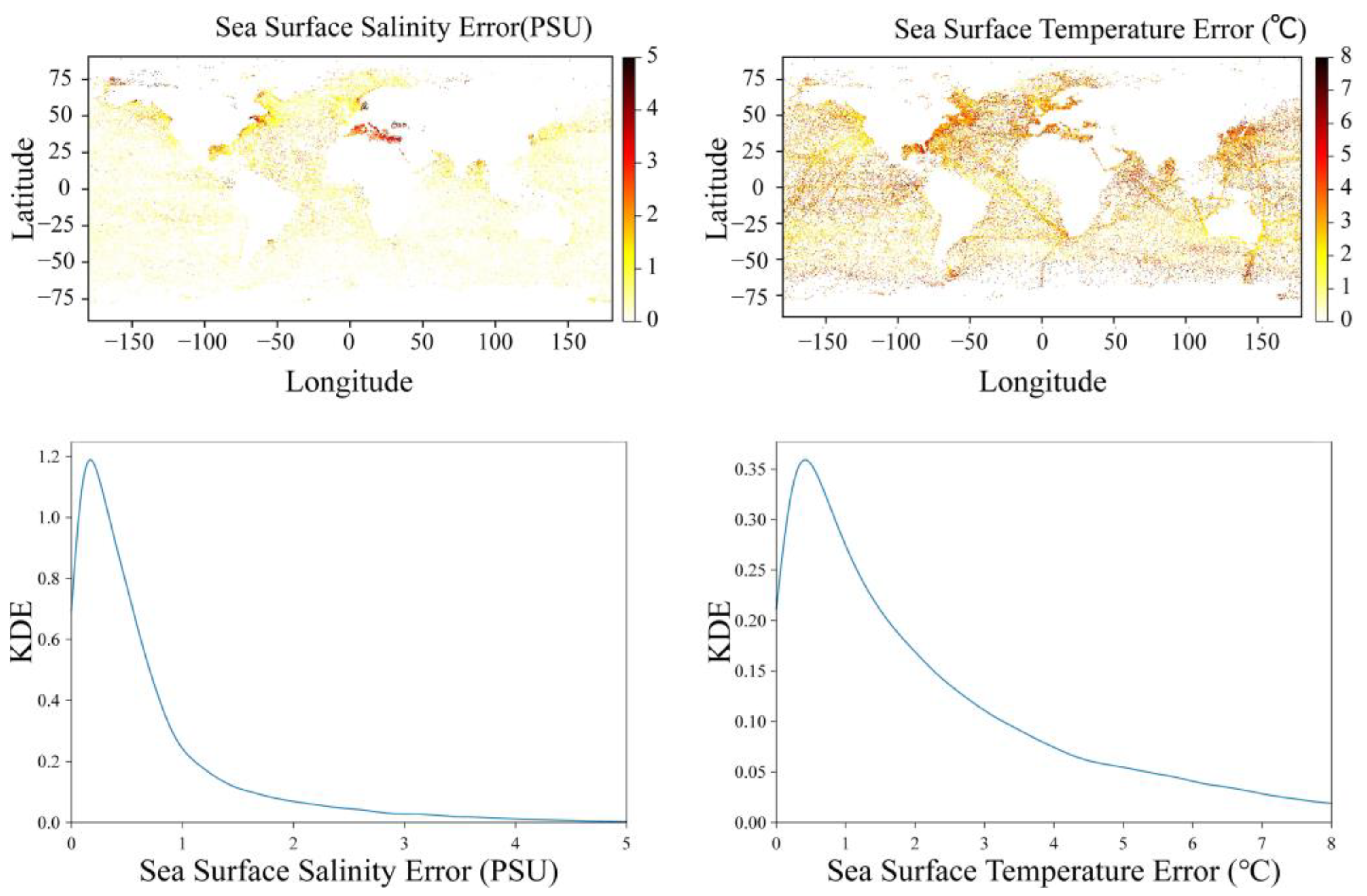
3.2. Error Analysis
3.3. Regional Analysis
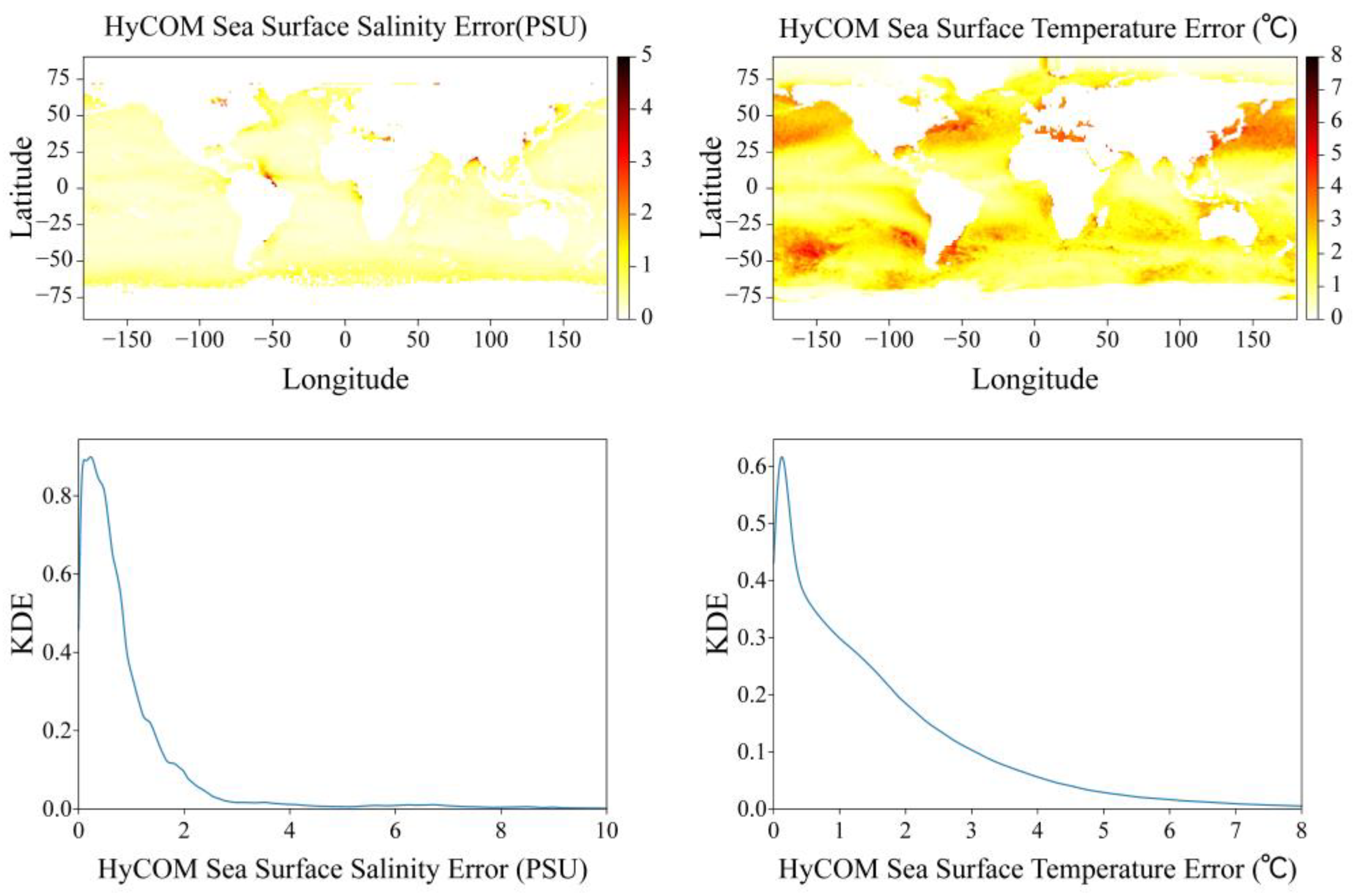
4. Comparison with HYCOM
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A
- Input:
- lon: longitudelat: latitudelon_min: minimum longitude of area of concernlon_max: maximum longitude of area of concernlat_min: minimum latitude of area of concernlat_max: maximum latitude of area of concernscale: scaling factor for grid discretizationnum_lon_grid: number of longitude grid pointsnum_lat_grid: number of latitude grid points
- Output:
- grid_disc: matrix tensor of grid-based weights
- Pseudocode:
- coord_features = num_lon_grid * num_lat_gridcoord_range = tensor([lon_min, lon_max, lat_min, lat_max]) * scaleleft, right, bottom, top = coord_rangex_range = right − left + 1y_range = top − bottom + 1x = lon * scaley = lat * scalex_min_idx = floor(x − left)y_min_idx = floor(y − bottom)x_max_idx = x_min_idx + 1y_max_idx = y_min_idx + 1x_max_w = (x − left) − x_min_idxy_max_w = (y − bottom) − y_min_idxx_min_w = 1 − x_max_wy_min_w = 1 − y_max_wx_min_y_min_idx = y_min_idx * x_range + x_min_idxx_max_y_min_idx = y_min_idx * x_range + x_max_idxx_min_y_max_idx = y_max_idx * x_range + x_min_idxx_max_y_max_idx = y_max_idx * x_range + x_max_idxidx_list = [x_min_y_min_idx, x_max_y_min_idx, x_min_y_max_idx, x_max_y_max_idx]weight_list = [y_min_w * x_min_w, y_min_w * x_max_w, y_max_w * x_min_w, y_max_w * x_max_w]grid_disc = zeros(coord_features)for idx, weight in zip(idx_list, weight_list): grid_disc[idx] = weight
References
- Zhao, Q.; Yu, L.; Du, Z.; Peng, D.; Hao, P.; Zhang, Y.; Gong, P. An overview of the applications of earth observation satellite data: Impacts and Future Trends. Remote Sens. 2022, 14, 1863. [Google Scholar] [CrossRef]
- Ban, Y.; Gong, P.; Giri, C. Global land cover mapping using earth observation satellite data: Recent progresses and challenges. ISPRS J. Photogramm. Remote Sens. 2015, 103, 1–6. [Google Scholar] [CrossRef]
- Kuenzer, C.; Ottinger, M.; Wegmann, M.; Guo, H.; Wang, C.; Zhang, J.; Dech, S.; Wikelski, M. Earth observation satellite sensors for biodiversity monitoring: Potentials and bottlenecks. Int. J. Remote Sens. 2014, 35, 6599–6647. [Google Scholar] [CrossRef]
- Anderson, K.; Ryan, B.; Sonntag, W.; Kavvada, A.; Friedl, L. Earth observation in service of the 2030 Agenda for sustainable development. Geo-Spatial Inf. Sci. 2017, 20, 77–96. [Google Scholar] [CrossRef]
- De Grave, C.; Verrelst, J.; Morcillo-Pallarés, P.; Pipia, L.; Rivera-Caicedo, J.P.; Amin, E.; Moreno, J. Quantifying vegetation biophysical variables from the Sentinel-3/FLEX tandem mission: Evaluation of the synergy of OLCI and FLORIS data sources. Remote Sens. Environ. 2020, 251, 112101. [Google Scholar] [CrossRef]
- Notti, D.; Giordan, D.; Caló, F.; Pepe, A.; Zucca, F.; Galve, J.P. Potential and limitations of open satellite data for flood mapping. Remote Sens. 2018, 10, 1673. [Google Scholar] [CrossRef]
- Wang, S.; Jing, Z.; Wu, L.; Cai, W.; Chang, P.; Wang, H.; Yang, H. El Niño/Southern Oscillation inhibited by submesoscale ocean eddies. Nat. Geosci. 2022, 15, 112–117. [Google Scholar] [CrossRef]
- Høyer, J.L.; She, J. Optimal interpolation of sea surface temperature for the North Sea and Baltic Sea. J. Mar. Syst. 2007, 65, 176–189. [Google Scholar] [CrossRef]
- Gunes, H.; Rist, U. Spatial resolution enhancement/smoothing of stereo–particle-image-velocimetry data using proper-orthogonal-decomposition–based and Kriging interpolation methods. Phys. Fluids A 2007, 19, 064101. [Google Scholar] [CrossRef]
- Liu, X.; Wang, M. Gap filling of missing data for VIIRS global ocean color products using the DINEOF method. IEEE Trans. Geosci. Remote Sens. 2018, 56, 4464–4476. [Google Scholar] [CrossRef]
- Miles, T.N.; He, R. Temporal and spatial variability of Chl-a and SST on the South Atlantic Bight: Revisiting with cloud-free reconstructions of MODIS satellite imagery. Cont. Shelf Res. 2010, 30, 1951–1962. [Google Scholar] [CrossRef]
- Jouini, M.; Lévy, M.; Crépon, M.; Thiria, S. Reconstruction of satellite chlorophyll images under heavy cloud coverage using a neural classification method. Remote Sens. Environ. 2013, 131, 232–246. [Google Scholar] [CrossRef]
- Krasnopolsky, V.; Nadiga, S.; Mehra, A.; Bayler, E.; Behringer, D. Neural networks technique for filling gaps in satellite measurements: Application to ocean color observations. Comput. Intell. Neurosci. 2016, 2016, 6156513. [Google Scholar] [CrossRef]
- Maimaitijiang, M.; Ghulam, A.; Sidike, P.; Hartling, S.; Maimaitiyiming, M.; Peterson, K.; Shavers, E.; Fishman, J.; Peterson, J.; Kadam, S.; et al. Unmanned Aerial System (uas)-based phenotyping of soybean using multi-sensor data fusion and Extreme Learning Machine. ISPRS J. Photogramm. Remote Sens. 2017, 134, 43–58. [Google Scholar] [CrossRef]
- Ouala, S.; Fablet, R.; Herzet, C.; Chapron, B.; Pascual, A.; Collard, F.; Gaultier, L. Neural network based Kalman filters for the Spatio-temporal interpolation of satellite-derived sea surface temperature. Remote Sens. 2018, 10, 1864. [Google Scholar] [CrossRef]
- Goly, A.; Teegavarapu, R.S.; Mondal, A. Development and evaluation of statistical downscaling models for monthly precipitation. Earth Interact. 2014, 18, 1–28. [Google Scholar] [CrossRef]
- Sachindra, D.A.; Ahmed, K.; Rashid, M.M.; Shahid, S.; Perera, B.J.C. Statistical downscaling of precipitation using machine learning techniques. Atmos. Res. 2018, 212, 240–258. [Google Scholar] [CrossRef]
- Jiang, Y.; Yang, K.; Shao, C.; Zhou, X.; Zhao, L.; Chen, Y.; Wu, H. A downscaling approach for constructing high-resolution precipitation dataset over the Tibetan Plateau from ERA5 reanalysis. Atmos. Res. 2021, 256, 105574. [Google Scholar] [CrossRef]
- Dalla Mura, M.; Prasad, S.; Pacifici, F.; Gamba, P.; Chanussot, J.; Benediktsson, J.A. Challenges and opportunities of multimodality and data fusion in remote sensing. Proc. IEEE 2015, 103, 1585–1601. [Google Scholar] [CrossRef]
- Schmitt, M.; Zhu, X.X. Data Fusion and remote sensing: An ever-growing relationship. IEEE Geosci. Remote Sens. Mag. 2016, 4, 6–23. [Google Scholar] [CrossRef]
- Abdikan, S.; Balik Sanli, F.; Sunar, F.; Ehlers, M. A comparative data-fusion analysis of multi-sensor satellite images. Int. J. Digit. Earth 2012, 7, 671–687. [Google Scholar] [CrossRef]
- Smilde, A.K.; Måge, I.; Næs, T.; Hankemeier, T.; Lips, M.A.; Kiers, H.A.; Acar, E.; Bro, R. Common and distinct components in data fusion. J. Chemom. 2017, 31, e2900. [Google Scholar] [CrossRef]
- Park, H.; Kim, K.; Lee, D.k. Prediction of severe drought area based on Random Forest: Using satellite image and topography data. Water 2019, 11, 705. [Google Scholar] [CrossRef]
- Mountrakis, G.; Im, J.; Ogole, C. Support vector machines in remote sensing: A Review. ISPRS J. Photogramm. Remote Sens. 2011, 66, 247–259. [Google Scholar] [CrossRef]
- Huang, X.; Wen, D.; Xie, J.; Zhang, L. Quality assessment of Panchromatic and multispectral image fusion for the ZY-3 satellite: From an information extraction perspective. IEEE Geosci. Remote Sens. Lett. 2014, 11, 753–757. [Google Scholar] [CrossRef]
- Cracknell, M.J.; Reading, A.M. Geological mapping using remote sensing data: A comparison of five machine learning algorithms, their response to variations in the spatial distribution of training data and the use of explicit spatial information. Comput. Geosci. 2014, 63, 22–33. [Google Scholar] [CrossRef]
- Wang, C.; Wang, H. Cascaded feature fusion with multi-level self-attention mechanism for object detection. Pattern Recognit. 2023, 138, 109377. [Google Scholar] [CrossRef]
- Minnett, P.J.; Alvera-Azcarate, A.; Chin, T.M.; Corlett, G.K.; Gentemann, C.L.; Karagali, I.; Li, X.; Marsouin, A.; Marullo, S.; Maturi, E.; et al. Half a century of satellite remote sensing of sea-surface temperature. Remote Sens. Environ. 2019, 233, 111366. [Google Scholar] [CrossRef]
- Mignot, J.; de Boyer Montégut, C.; Lazar, A.; Cravatte, S. Control of salinity on the mixed layer depth in the world ocean: 2. Tropical areas. J. Geophys. Res. Oceans 2007, 112. [Google Scholar] [CrossRef]
- Nardelli, B.B.; Verbrugge, G.N.; Cotroneo, Y.; Zambianchi, E.; Iudicone, D. Southern ocean mixed-layer seasonal and interannual variations from combined satellite and In Situ data. J. Geophys. Res. Oceans 2017, 122, 10042–10060. [Google Scholar] [CrossRef]
- Reynolds, R.W.; Smith, T.M.; Liu, C.; Chelton, D.B.; Casey, K.S.; Schlax, M.G. Daily high-resolution-blended analyses for sea surface temperature. J. Clim. 2007, 20, 5473–5496. [Google Scholar] [CrossRef]
- NCAR. SST Data: NOAA High-Resolution (0.25 × 0.25) Blended Analysis of Daily SST and Ice, OISSTv2. Climate Data Guide. Available online: https://climatedataguide.ucar.edu/climate-data/sst-data-noaa-high-resolution-025x025-blended-analysis-daily-sst-and-ice-oisstv2 (accessed on 14 August 2024).
- Boutin, J.; Reul, N.; Koehler, J.; Martin, A.; Catany, R.; Guimbard, S.; Rouffi, F.; Vergely, J.L.; Arias, M.; Chakroun, M.; et al. Satellite-based sea surface salinity designed for ocean and climate studies. J. Geophys. Res. Oceans 2021, 126, e2021JC017676. [Google Scholar] [CrossRef]
- Srokosz, M.; Banks, C. Salinity from space. Weather 2018, 74, 3–8. [Google Scholar] [CrossRef]
- Banks, C.J.; Calafat, F.M.; Shaw, A.G.P.; Snaith, H.M.; Gommenginger, C.P.; Bouffard, J. A new daily quarter degree sea level anomaly product from CryoSat-2 for ocean science and applications. Sci. Data 2023, 10, 477. [Google Scholar] [CrossRef]
- Amos, C.M.; Castelao, R.M. Influence of the El Niño-Southern Oscillation on SST fronts along the west coasts of North and South America. J. Geophys. Res. Oceans 2022, 127, e2022JC018479. [Google Scholar] [CrossRef]
- Bingham, R.J.; Haines, K.; Hughes, C.W. Calculating the ocean’s mean dynamic topography from a mean sea surface and a geoid. J. Atmos. Ocean. Technol. 2007, 25, 1808–1822. [Google Scholar] [CrossRef]
- Atkinson, C.P.; Rayner, N.A.; Kennedy, J.J.; Good, S.A. An integrated database of ocean temperature and salinity observations. J. Geophys. Res. Oceans 2014, 119, 7139–7163. [Google Scholar] [CrossRef]
- Chassignet, E.P.; Hurlburt, H.E.; Smedstad, O.M.; Halliwell, G.R.; Hogan, P.J.; Wallcraft, A.J.; Baraille, R.; Bleck, R. The HYCOM (Hybrid Coordinate Ocean Model) data assimilative system. J. Mar. Syst. 2007, 65, 60–83. [Google Scholar] [CrossRef]
- Dash, R.; Paramguru, R.L.; Dash, R. Comparative analysis of supervised and unsupervised discretization techniques. Int. J. Adv. Sci. Technol. 2011, 2, 29–37. [Google Scholar]
- Garcia, S.; Luengo, J.; Sáez, J.A.; Lopez, V.; Herrera, F. A survey of discretization techniques: Taxonomy and empirical analysis in supervised learning. IEEE Trans. Knowl. Data Eng. 2012, 25, 734–750. [Google Scholar] [CrossRef]
- Müller, T.; Evans, A.; Schied, C.; Keller, A. Instant neural graphics primitives with a multiresolution hash encoding. ACM Trans. Graphics (TOG) 2022, 41, 102. [Google Scholar] [CrossRef]
- Pargent, F.; Pfisterer, F.; Thomas, J.; Bischl, B. Regularized target encoding outperforms traditional methods in supervised machine learning with high cardinality features. Comput. Stat. 2022, 37, 2671–2692. [Google Scholar] [CrossRef]
- Yang, P.; Jing, Z.; Sun, B.; Wu, L.; Qiu, B.; Chang, P.; Ramachandran, S. On the upper-ocean vertical eddy heat transport in the Kuroshio extension. Part I: Variability and dynamics. J. Phys. Oceanogr. 2021, 51, 229–246. [Google Scholar] [CrossRef]
- Sang, Y.; Qi, H.; Li, K.; Jin, Y.; Yan, D.; Gao, S. An effective discretization method for disposing high-dimensional data. Inf. Sci. 2014, 270, 73–91. [Google Scholar] [CrossRef]
- Franc, V.; Fikar, O.; Bartos, K.; Sofka, M. Learning data discretization via convex optimization. Mach. Learn. 2018, 107, 333–355. [Google Scholar] [CrossRef]
- Spencer, C.J.; Yakymchuk, C.; Ghaznavi, M. Visualizing data distributions with kernel density estimation and reduced chi-squared statistic. Geosci. Front. 2017, 8, 1246–1252. [Google Scholar] [CrossRef]
- Jung, S.; Yoo, C.; Im, J. High-Resolution Seamless Daily Sea Surface Temperature Based on Satellite Data Fusion and Machine Learning over Kuroshio Extension. Remote Sens. 2022, 14, 575. [Google Scholar] [CrossRef]
- Kumar, C.; Podestá, G.; Kilpatrick, K.; Minnett, P. A machine learning approach to estimating the error in satellite sea surface temperature retrievals. Remote Sens. Environ. 2021, 255, 112227. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data Name | Data Source | Resolution | Description |
|---|---|---|---|
| SST | AVHRR | 1/4° | Satellite remote sensing |
| SSS | SMOS | 1/4° | Satellite remote sensing |
| SLA | AVISO | 1/4° | Satellite remote sensing |
| ADT | AVISO | 1/4° | Satellite remote sensing |
| EN 4.2.2 | MOHC | scatter | In situ observation |
| HYCOM | GODAE | 1/12° | Ocean model data |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, S.; Jia, W.; Wang, Q.; Zhang, W.; Wang, H. Enhancing the Resolution of Satellite Ocean Data Using Discretized Satellite Gridding Neural Networks. Remote Sens. 2024, 16, 3020. https://doi.org/10.3390/rs16163020
Liu S, Jia W, Wang Q, Zhang W, Wang H. Enhancing the Resolution of Satellite Ocean Data Using Discretized Satellite Gridding Neural Networks. Remote Sensing. 2024; 16(16):3020. https://doi.org/10.3390/rs16163020
Chicago/Turabian StyleLiu, Shirong, Wentao Jia, Qianyun Wang, Weimin Zhang, and Huizan Wang. 2024. "Enhancing the Resolution of Satellite Ocean Data Using Discretized Satellite Gridding Neural Networks" Remote Sensing 16, no. 16: 3020. https://doi.org/10.3390/rs16163020
APA StyleLiu, S., Jia, W., Wang, Q., Zhang, W., & Wang, H. (2024). Enhancing the Resolution of Satellite Ocean Data Using Discretized Satellite Gridding Neural Networks. Remote Sensing, 16(16), 3020. https://doi.org/10.3390/rs16163020