
Global Context Relation-Guided Feature Aggregation Network for Salient Object Detection in Optical Remote Sensing Images

Abstract
1. Introduction
- We design a global context relation learning module to capture the scattered distribution of salient objects in remote sensing images. In order to exploit the high-level semantic information as well as the low-level appearance details, we propose a global context relation-guided feature aggregation module to refine the initial saliency score map in a progressive manner.
- Instead of using traditional binary cross entropy as training loss, which treats all pixels equally, we embed a weighted binary cross entropy to capture local surrounding information of different pixels, which can ensure that the pixels located in hard areas such as edges and holes can be assigned with larger weight.
2. Materials
Datasets
3. Methods
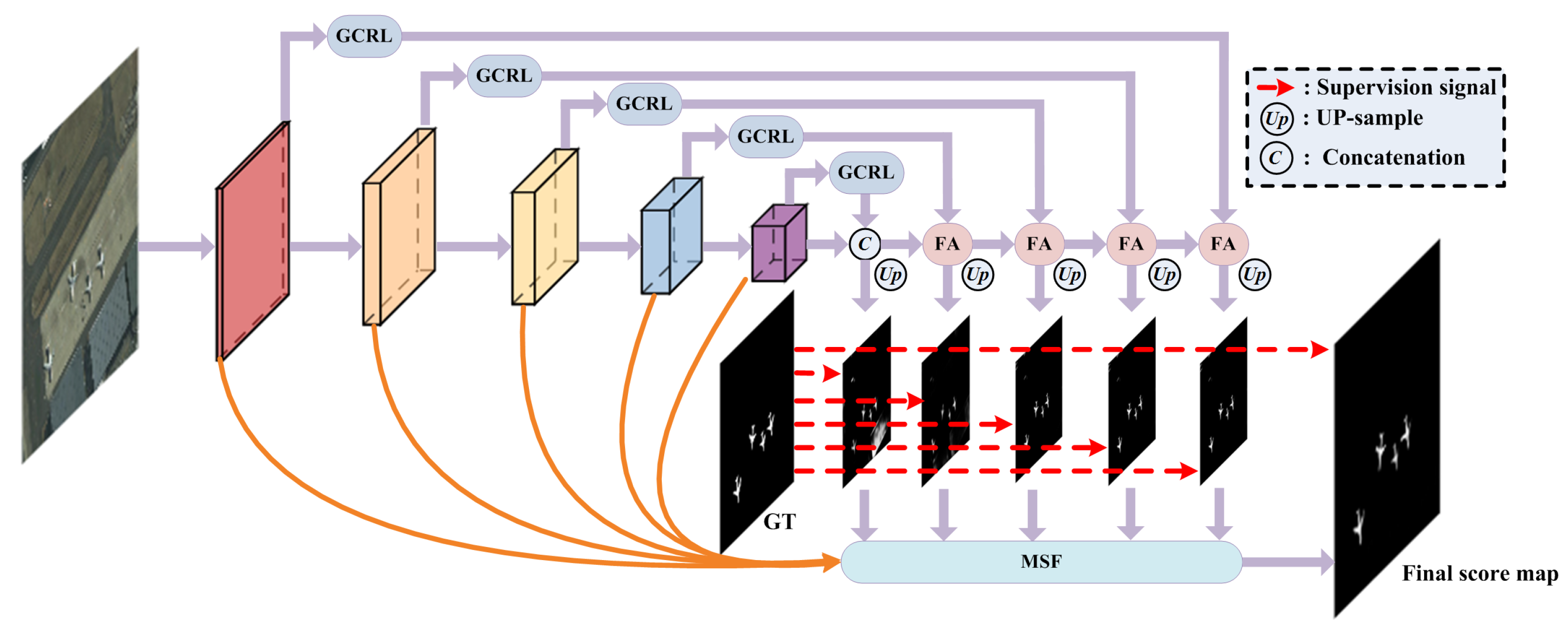
3.1. Overview
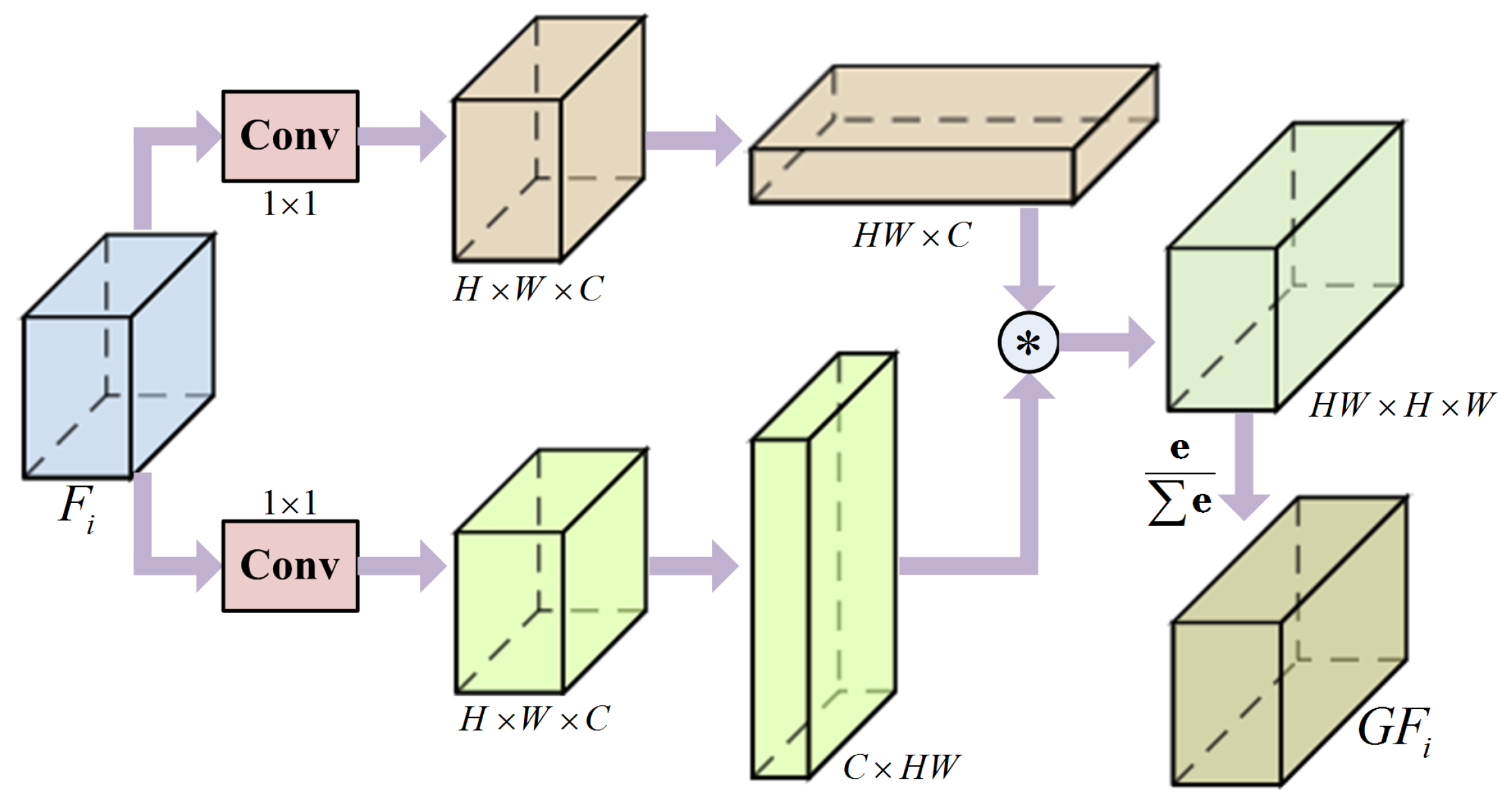
3.2. Global Context Relation Learning Module (GCRL)
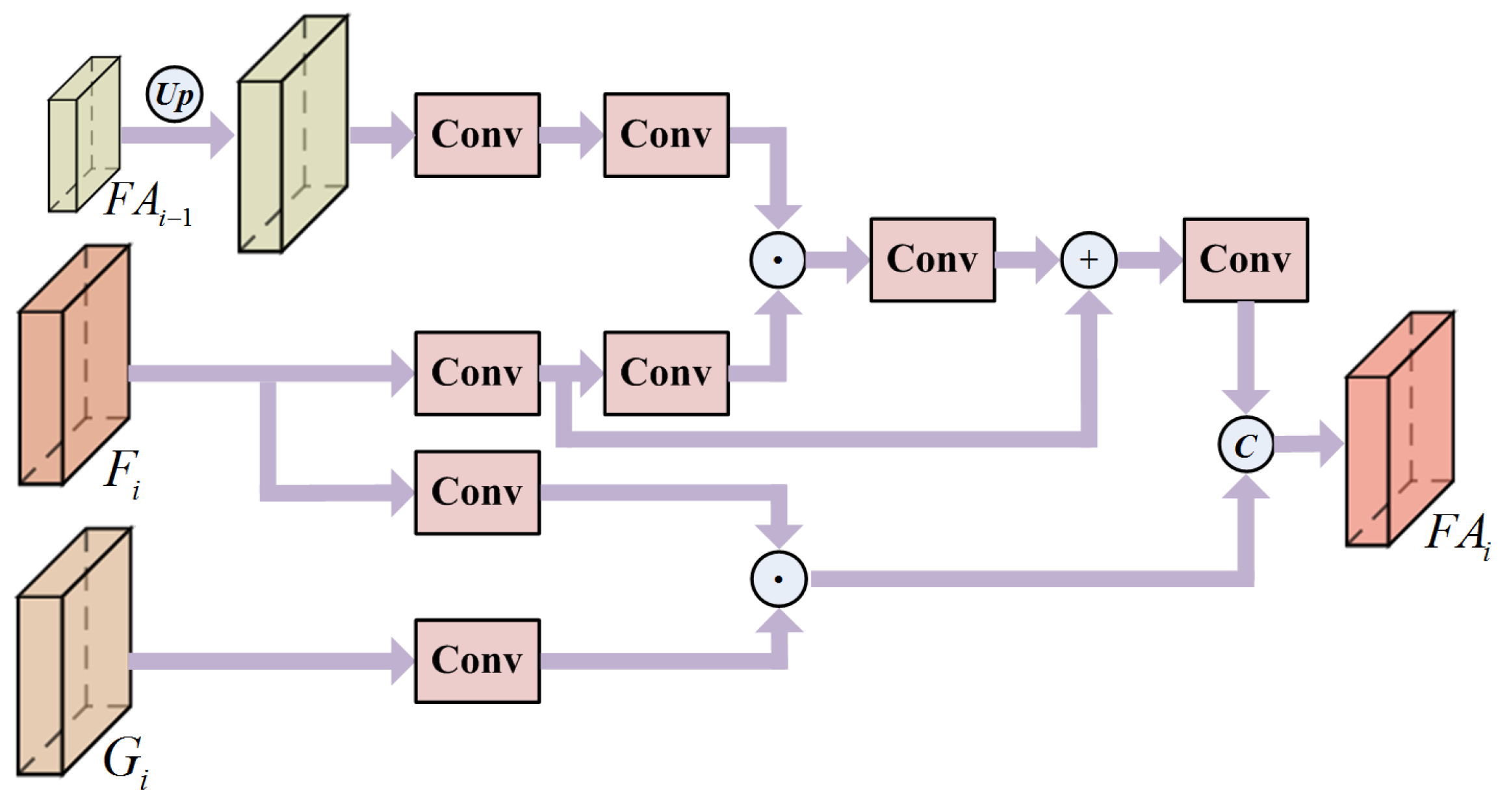
3.3. Feature Aggregation Module (FA)
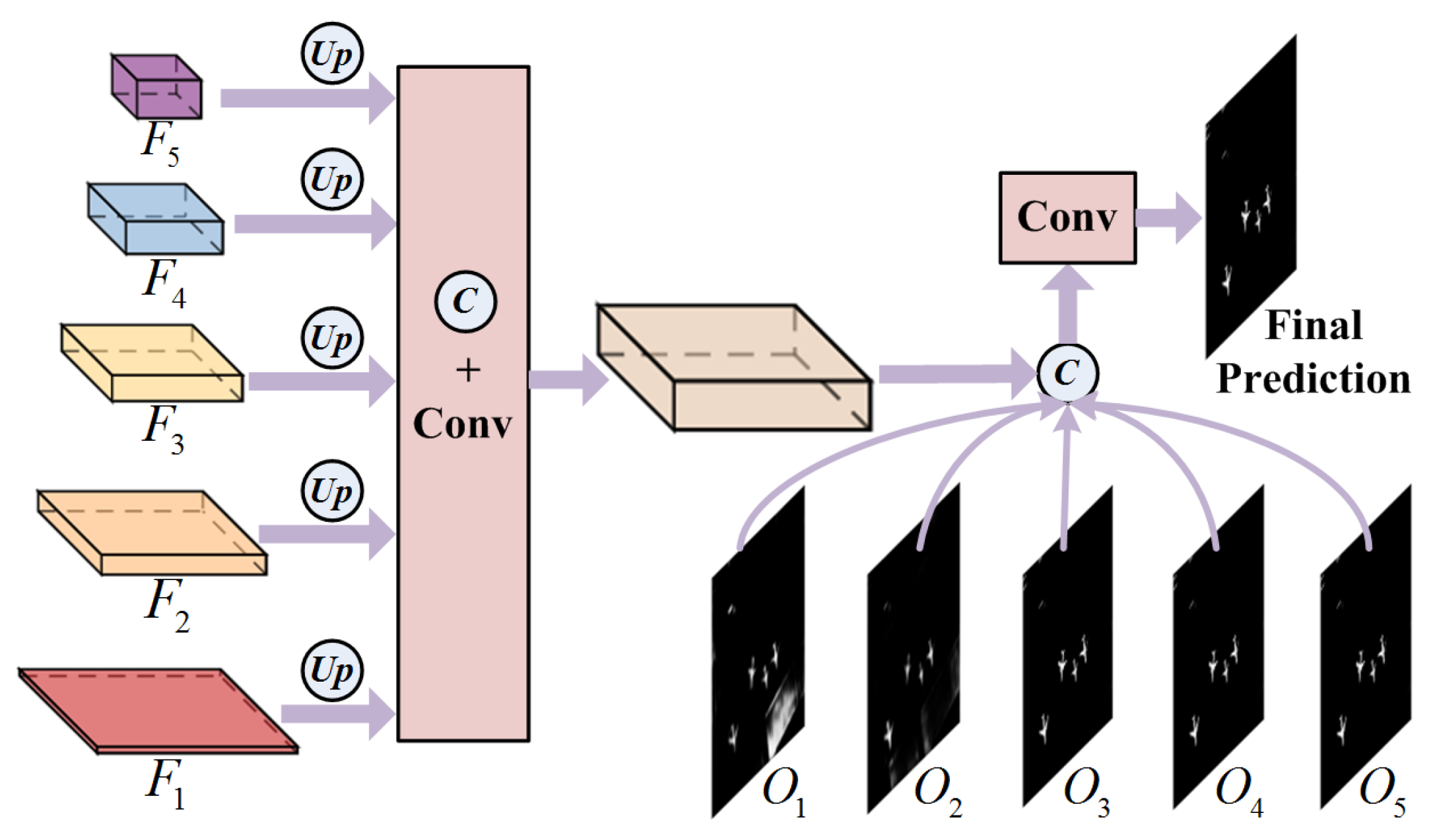
3.4. Multi-Scale Fusion Module (MSF)
3.5. Local Surrounding Aware Loss
3.6. Model Training and Testing
4. Results
4.1. Evaluation Metrics
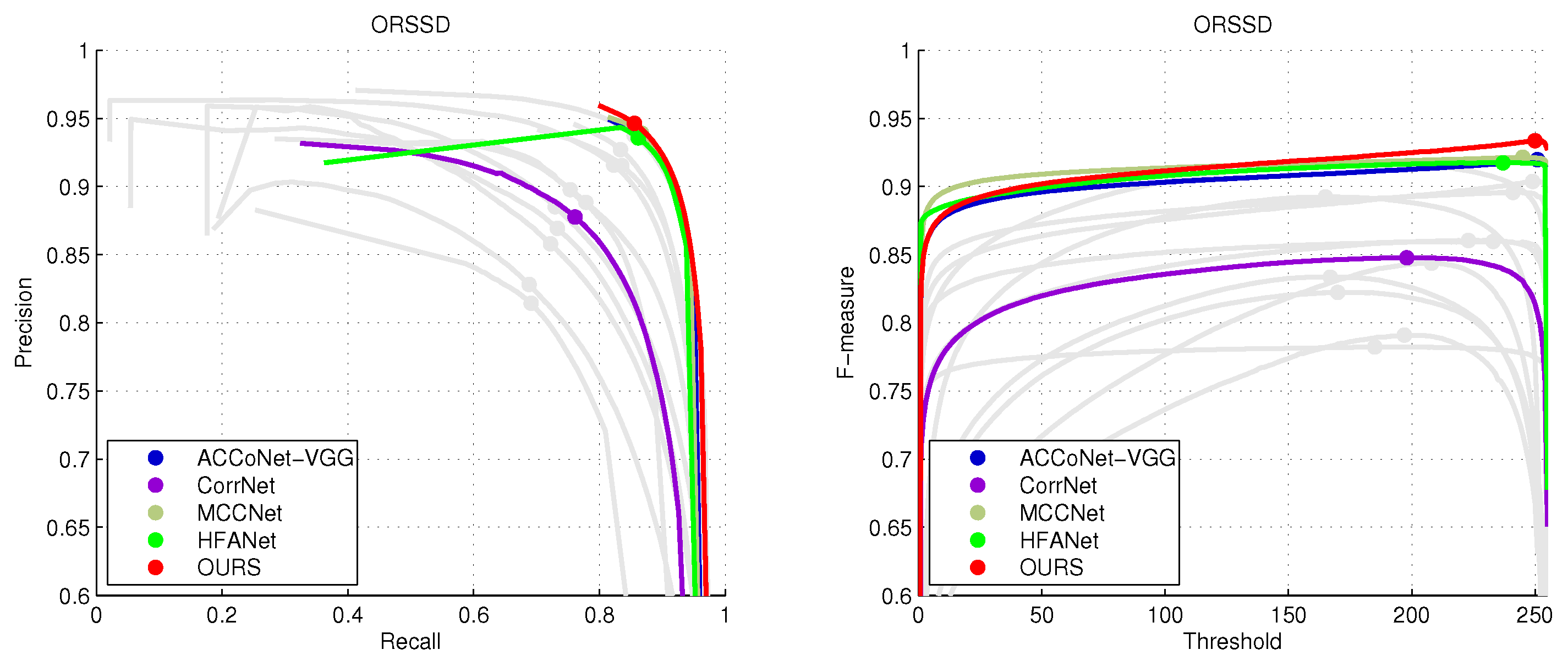
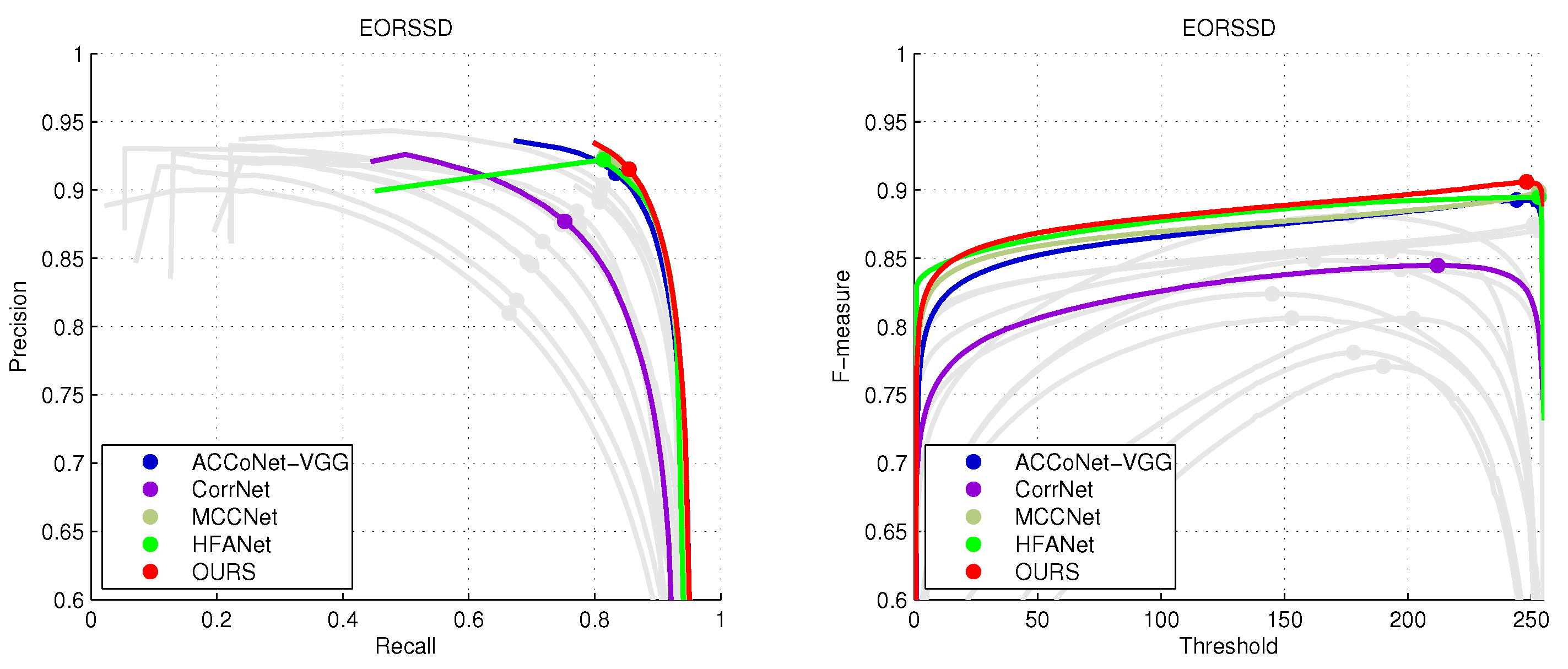
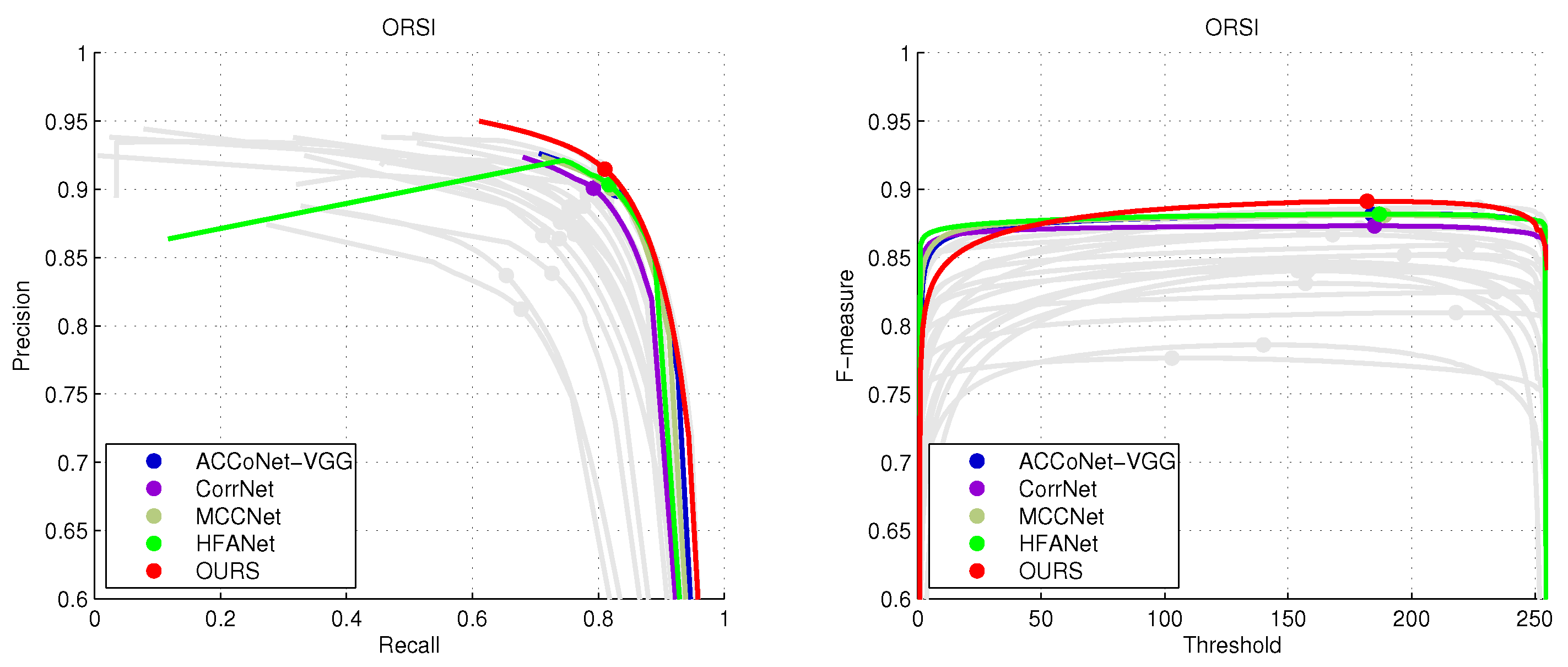
4.2. Comparison with State-of-the-Art Methods
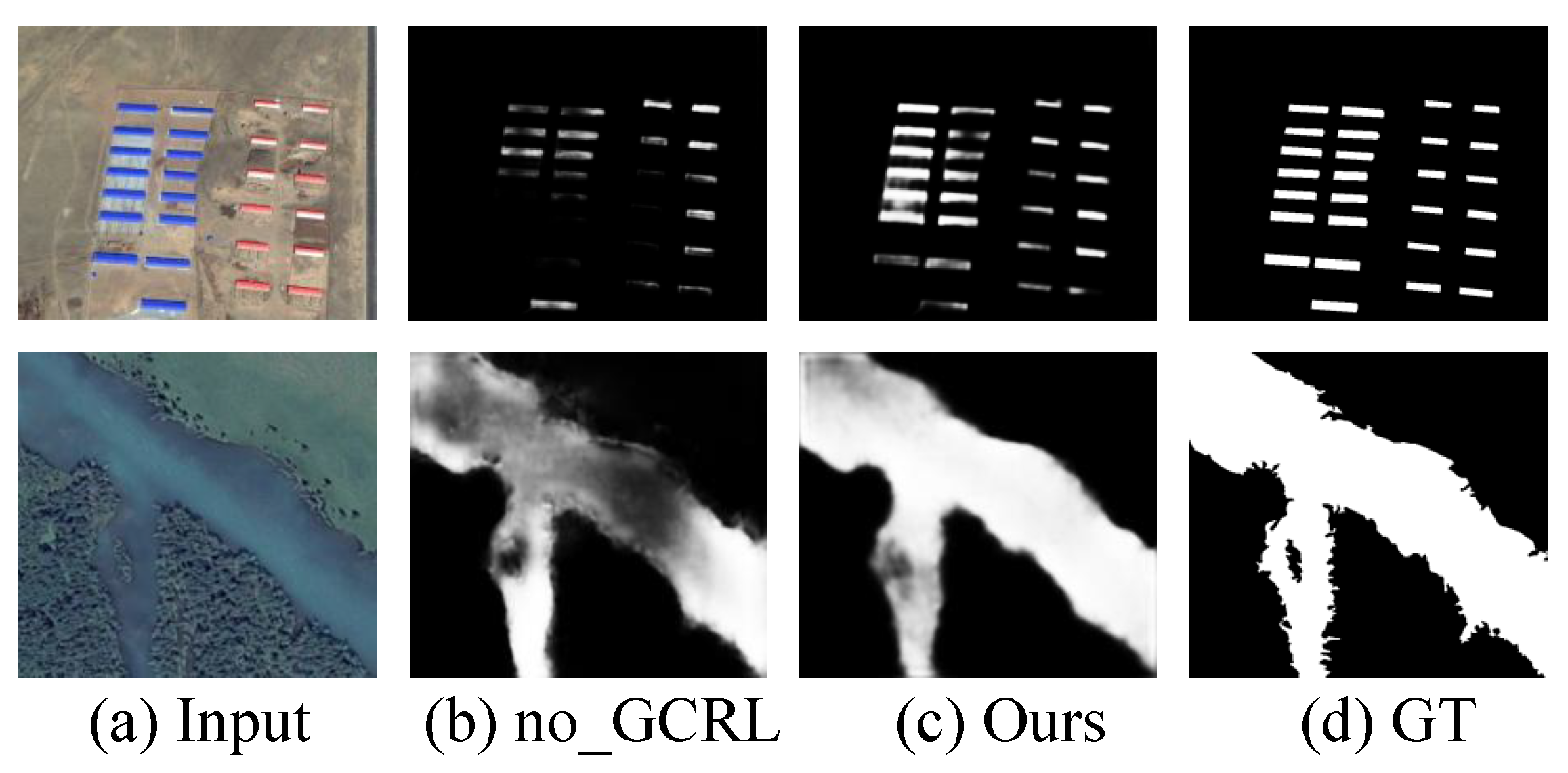
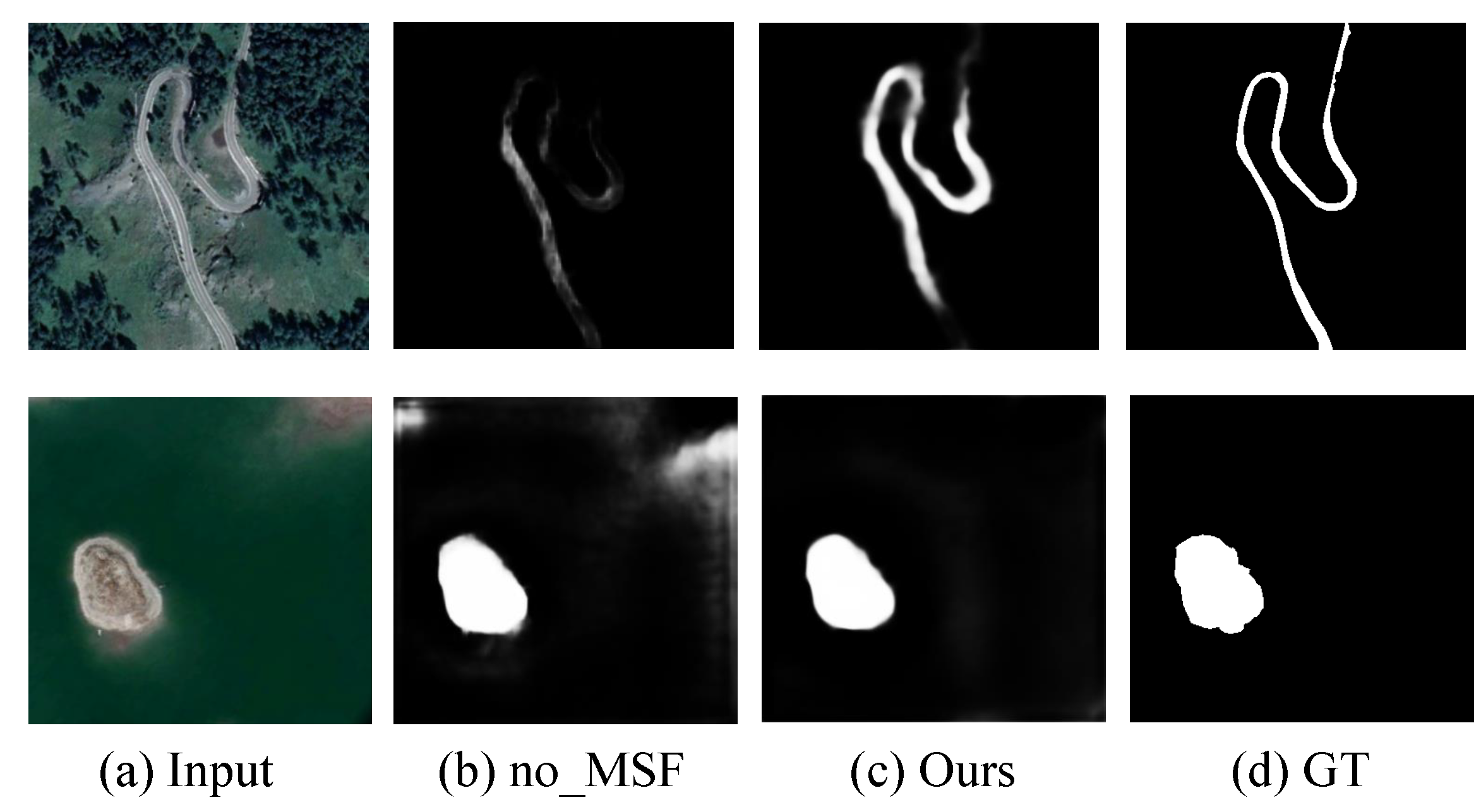
4.3. Ablation Analysis
4.4. Running Efficiency Comparison
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zhang, Z.; Davaasuren, D.; Wu, C.; Goldstein, J.A.; Gernand, A.D.; Wang, J.Z. Multi-region Saliency-aware Learning for Cross-domain Placenta Image Segmentation. Pattern Recognit. Lett. 2020, 140, 165–171. [Google Scholar] [CrossRef] [PubMed]
- Wang, W.; Shen, J.; Yang, R.; Porikli, F. Saliency-aware video object segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 20–33. [Google Scholar] [CrossRef] [PubMed]
- Battiato, S.; Farinella, G.M.; Puglisi, G.; Ravi, D. Saliency-based selection of gradient vector flow paths for content aware image resizing. IEEE Trans. Image Process. 2014, 23, 2081–2095. [Google Scholar] [CrossRef] [PubMed]
- Cho, D.; Park, J.; Oh, T.H.; Tai, Y.W.; So Kweon, I. Weakly-and self-supervised learning for content-aware deep image retargeting. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4558–4567. [Google Scholar]
- Zhang, L.; Shen, Y.; Li, H. VSI: A visual saliency-induced index for perceptual image quality assessment. IEEE Trans. Image Process. 2014, 23, 4270–4281. [Google Scholar] [CrossRef] [PubMed]
- Oszust, M. No-Reference quality assessment of noisy images with local features and visual saliency models. Inf. Sci. 2019, 482, 334–349. [Google Scholar] [CrossRef]
- Liu, L.; Ouyang, W.; Wang, X.; Fieguth, P.; Chen, J.; Liu, X.; Pietikäinen, M. Deep learning for generic object detection: A survey. Int. J. Comput. Vis. 2020, 128, 261–318. [Google Scholar] [CrossRef]
- Pang, Y.; Zhao, X.; Zhang, L.; Lu, H. Multi-Scale Interactive Network for Salient Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 9413–9422. [Google Scholar]
- Zhang, L.; Wu, J.; Wang, T.; Borji, A.; Wei, G.; Lu, H. A Multistage Refinement Network for Salient Object Detection. IEEE Trans. Image Process. 2020, 29, 3534–3545. [Google Scholar] [CrossRef]
- Zhou, S.; Wang, J.; Zhang, J.; Wang, L.; Huang, D.; Du, S.; Zheng, N. Hierarchical U-Shape Attention Network for Salient Object Detection. IEEE Trans. Image Process. 2020, 29, 8417–8428. [Google Scholar] [CrossRef]
- Zhang, J.; Yu, X.; Li, A.; Song, P.; Liu, B.; Dai, Y. Weakly-Supervised Salient Object Detection via Scribble Annotations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 12546–12555. [Google Scholar]
- Wei, J.; Wang, S.; Wu, Z.; Su, C.; Huang, Q.; Tian, Q. Label Decoupling Framework for Salient Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 13025–13034. [Google Scholar]
- Fu, K.; Fan, D.P.; Ji, G.P.; Zhao, Q. Jl-dcf: Joint learning and densely-cooperative fusion framework for rgb-d salient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 3052–3062. [Google Scholar]
- Piao, Y.; Rong, Z.; Zhang, M.; Ren, W.; Lu, H. A2dele: Adaptive and Attentive Depth Distiller for Efficient RGB-D Salient Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 9060–9069. [Google Scholar]
- He, X.; Tang, C.; Liu, X.; Zhang, W.; Sun, K.; Xu, J. Object detection in hyperspectral image via unified spectral-spatial feature aggregation. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5521213. [Google Scholar] [CrossRef]
- Tang, C.; Wang, J.; Zheng, X.; Liu, X.; Xie, W.; Li, X.; Zhu, X. Spatial and spectral structure preserved self-representation for unsupervised hyperspectral band selection. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5531413. [Google Scholar] [CrossRef]
- Li, G.; Bai, Z.; Liu, Z.; Zhang, X.; Ling, H. Salient object detection in optical remote sensing images driven by transformer. IEEE Trans. Image Process. 2023, 32, 5257–5269. [Google Scholar] [CrossRef] [PubMed]
- Yan, R.; Yan, L.; Geng, G.; Cao, Y.; Zhou, P.; Meng, Y. ASNet: Adaptive Semantic Network Based on Transformer-CNN for Salient Object Detection in Optical Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5608716. [Google Scholar] [CrossRef]
- Zhang, Q.; Cong, R.; Li, C.; Cheng, M.M.; Fang, Y.; Cao, X.; Zhao, Y.; Kwong, S. Dense Attention Fluid Network for Salient Object Detection in Optical Remote Sensing Images. IEEE Trans. Image Process. 2020, 30, 1305–1317. [Google Scholar] [CrossRef] [PubMed]
- Li, G.; Liu, Z.; Lin, W.; Ling, H. Multi-content complementation network for salient object detection in optical remote sensing images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5614513. [Google Scholar] [CrossRef]
- Tu, Z.; Wang, C.; Li, C.; Fan, M.; Zhao, H.; Luo, B. ORSI salient object detection via multiscale joint region and boundary model. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5607913. [Google Scholar] [CrossRef]
- Cong, R.; Zhang, Y.; Fang, L.; Li, J.; Zhao, Y.; Kwong, S. RRNet: Relational reasoning network with parallel multiscale attention for salient object detection in optical remote sensing images. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5613311. [Google Scholar] [CrossRef]
- Zhou, X.; Shen, K.; Weng, L.; Cong, R.; Zheng, B.; Zhang, J.; Yan, C. Edge-guided recurrent positioning network for salient object detection in optical remote sensing images. IEEE Trans. Cybern. 2023, 53, 539–552. [Google Scholar] [CrossRef] [PubMed]
- GongyangLi, Z.; Bai, Z.; Lin, W.; Ling, H. Lightweight salient object detection in optical remote sensing images via feature correlation. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5617712. [Google Scholar]
- Wang, Z.; Guo, J.; Zhang, C.; Wang, B. Multiscale feature enhancement network for salient object detection in optical remote sensing images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5634819. [Google Scholar] [CrossRef]
- Li, G.; Liu, Z.; Zhang, X.; Lin, W. Lightweight salient object detection in optical remote-sensing images via semantic matching and edge alignment. IEEE Trans. Geosci. Remote Sens. 2023, 60, 5617712. [Google Scholar] [CrossRef]
- Li, G.; Liu, Z.; Zeng, D.; Lin, W.; Ling, H. Adjacent context coordination network for salient object detection in optical remote sensing images. IEEE Trans. Cybern. 2023, 53, 526–538. [Google Scholar] [CrossRef]
- Cheng, M.M.; Mitra, N.J.; Huang, X.; Torr, P.H.; Hu, S.M. Global contrast based salient region detection. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 37, 569–582. [Google Scholar] [CrossRef]
- Wang, J.; Tang, C.; Zheng, X.; Liu, X.; Zhang, W.; Zhu, E.; Zhu, X. Fast approximated multiple kernel k-means. IEEE Trans. Knowl. Data Eng. 2023, 1–10. [Google Scholar] [CrossRef]
- Wang, J.; Tang, C.; Wan, Z.; Zhang, W.; Sun, K.; Zomaya, A.Y. Efficient and effective one-step multiview clustering. IEEE Trans. Neural Netw. Learn. Syst. 2023, 1–12. [Google Scholar] [CrossRef]
- Chen, S.; Zheng, L.; Hu, X.; Zhou, P. Discriminative saliency propagation with sink points. Pattern Recognit. 2016, 60, 2–12. [Google Scholar] [CrossRef]
- Zhu, W.; Liang, S.; Wei, Y.; Sun, J. Saliency optimization from robust background detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 2814–2821. [Google Scholar]
- Yang, C.; Zhang, L.; Lu, H.; Ruan, X.; Yang, M.H. Saliency detection via graph-based manifold ranking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 3166–3173. [Google Scholar]
- Zhang, P.; Wang, D.; Lu, H.; Wang, H.; Xiang, R. Amulet: Aggregating Multi-level Convolutional Features for Salient Object Detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 202–211. [Google Scholar]
- Hu, X.; Zhu, L.; Qin, J.; Fu, C.W.; Heng, P.A. Recurrently Aggregating Deep Features for Salient Object Detection. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; pp. 6943–6950. [Google Scholar]
- Chen, S.; Tan, X.; Wang, B.; Hu, X. Reverse Attention for Salient Object Detection. In Proceedings of the ECCV, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Zhang, X.; Wang, T.; Qi, J.; Lu, H.; Wang, G. Progressive Attention Guided Recurrent Network for Salient Object Detection. In Proceedings of the CVPR, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Wang, T.; Zhang, L.; Wang, S.; Lu, H.; Yang, G.; Ruan, X.; Borji, A. Detect Globally, Refine Locally: A Novel Approach to Saliency Detection. In Proceedings of the CVPR, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Chen, H.; Li, Y. Progressively complementarity-aware fusion network for RGB-D salient object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3051–3060. [Google Scholar]
- Liu, N.; Zhang, N.; Han, J. Learning Selective Self-Mutual Attention for RGB-D Saliency Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 13756–13765. [Google Scholar]
- Fan, D.P.; Lin, Z.; Zhang, Z.; Zhu, M.; Cheng, M.M. Rethinking RGB-D Salient Object Detection: Models, Data Sets, and Large-Scale Benchmarks. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 2075–2089. [Google Scholar] [CrossRef]
- Li, C.; Cong, R.; Kwong, S.; Hou, J.; Fu, H.; Zhu, G.; Zhang, D.; Huang, Q. ASIF-Net: Attention steered interweave fusion network for RGB-D salient object detection. IEEE Trans. Cybern. 2020, 32, 2075–2089. [Google Scholar] [CrossRef]
- Wang, L.; Lu, H.; Wang, Y.; Feng, M.; Wang, D.; Yin, B.; Ruan, X. Learning to detect salient objects with image-level supervision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 136–145. [Google Scholar]
- Zhang, L.; Zhang, J.; Lin, Z.; Lu, H.; He, Y. Capsal: Leveraging captioning to boost semantics for salient object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 6024–6033. [Google Scholar]
- Zeng, Y.; Zhuge, Y.; Lu, H.; Zhang, L.; Qian, M.; Yu, Y. Multi-source weak supervision for saliency detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 6074–6083. [Google Scholar]
- Tang, C.; Liu, X.; Zheng, X.; Li, W.; Xiong, J.; Wang, L.; Zomaya, A.Y.; Longo, A. DeFusionNET: Defocus blur detection via recurrently fusing and refining discriminative multi-scale deep features. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 44, 955–968. [Google Scholar] [CrossRef]
- Zhao, D.; Wang, J.; Shi, J.; Jiang, Z. Sparsity-guided saliency detection for remote sensing images. J. Appl. Remote Sens. 2015, 9, 095055. [Google Scholar] [CrossRef]
- Li, E.; Xu, S.; Meng, W.; Zhang, X. Building extraction from remotely sensed images by integrating saliency cue. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 10, 906–919. [Google Scholar] [CrossRef]
- Li, T.; Zhang, J.; Lu, X.; Zhang, Y. SDBD: A hierarchical region-of-interest detection approach in large-scale remote sensing image. IEEE Geosci. Remote Sens. Lett. 2017, 14, 699–703. [Google Scholar] [CrossRef]
- Zhang, Q.; Zhang, L.; Shi, W.; Liu, Y. Airport extraction via complementary saliency analysis and saliency-oriented active contour model. IEEE Geosci. Remote Sens. Lett. 2018, 15, 1085–1089. [Google Scholar] [CrossRef]
- Li, C.; Cong, R.; Hou, J.; Zhang, S.; Qian, Y.; Kwong, S. Nested network with two-stream pyramid for salient object detection in optical remote sensing images. IEEE Trans. Geosci. Remote Sens. 2019, 57, 9156–9166. [Google Scholar] [CrossRef]
- Li, C.; Cong, R.; Guo, C.; Li, H.; Zhang, C.; Zheng, F.; Zhao, Y. A parallel down-up fusion network for salient object detection in optical remote sensing images. Neurocomputing 2020, 415, 411–420. [Google Scholar] [CrossRef]
- Huang, K.; Li, N.; Huang, J.; Tian, C. Exploiting Memory-based Cross-Image Contexts for Salient Object Detection in Optical Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5614615. [Google Scholar] [CrossRef]
- Zhao, R.; Zheng, P.; Zhang, C.; Wang, L. Progressive Complementation Network with Semantics and Details for Salient Object Detection in Optical Remote Sensing Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 8626–8641. [Google Scholar] [CrossRef]
- Quan, Y.; Xu, H.; Wang, R.; Guan, Q.; Zheng, J. ORSI Salient Object Detection via Progressive Semantic Flow and Uncertainty-aware Refinement. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5608013. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K. Aggregated residual transformations for deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1492–1500. [Google Scholar]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7794–7803. [Google Scholar]
- Lin, C.Y.; Chiu, Y.C.; Ng, H.F.; Shih, T.K.; Lin, K.H. Global-and-local context network for semantic segmentation of street view images. Sensors 2020, 20, 2907. [Google Scholar] [CrossRef]
- Cheng, M.M.; Fan, D.P. Structure-measure: A new way to evaluate foreground maps. Int. J. Comput. Vis. 2021, 129, 2622–2638. [Google Scholar] [CrossRef]
- Achanta, R.; Hemami, S.; Estrada, F.; Susstrunk, S. Frequency-tuned salient region detection. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 1597–1604. [Google Scholar]
- Fan, D.P.; Gong, C.; Cao, Y.; Ren, B.; Cheng, M.M.; Borji, A. Enhanced-alignment measure for binary foreground map evaluation. In Proceedings of the 27th International Joint Conference on Artificial Intelligence, Stockholm, Sweden, 13–19 July 2018; pp. 698–704. [Google Scholar]
- Deng, Z.; Hu, X.; Zhu, L.; Xu, X.; Qin, J.; Han, G.; Heng, P.A. R3net: Recurrent residual refinement network for saliency detection. In Proceedings of the 27th International Joint Conference on Artificial Intelligence, Stockholm, Sweden, 13–19 July 2018; pp. 684–690. [Google Scholar]
- Liu, N.; Han, J.; Yang, M.H. Picanet: Learning pixel-wise contextual attention for saliency detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3089–3098. [Google Scholar]
- Liu, J.J.; Hou, Q.; Cheng, M.M.; Feng, J.; Jiang, J. A simple pooling-based design for real-time salient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3917–3926. [Google Scholar]
- Zhao, J.X.; Liu, J.J.; Fan, D.P.; Cao, Y.; Yang, J.; Cheng, M.M. EGNet: Edge guidance network for salient object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 8779–8788. [Google Scholar]
- Qin, X.; Zhang, Z.; Huang, C.; Gao, C.; Dehghan, M.; Jagersand, M. Basnet: Boundary-aware salient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 7479–7489. [Google Scholar]
- Wu, Z.; Su, L.; Huang, Q. Cascaded partial decoder for fast and accurate salient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3907–3916. [Google Scholar]
- Chen, S.; Tan, X.; Wang, B.; Lu, H.; Hu, X.; Fu, Y. Reverse attention-based residual network for salient object detection. IEEE Trans. Image Process. 2020, 29, 3763–3776. [Google Scholar] [CrossRef]
- Gao, S.H.; Tan, Y.Q.; Cheng, M.M.; Lu, C.; Chen, Y.; Yan, S. Highly efficient salient object detection with 100k parameters. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 702–721. [Google Scholar]
- Liu, Y.; Zhang, X.Y.; Bian, J.W.; Zhang, L.; Cheng, M.M. SAMNet: Stereoscopically attentive multi-scale network for lightweight salient object detection. IEEE Trans. Image Process. 2021, 30, 3804–3814. [Google Scholar] [CrossRef]
- Liu, Y.; Gu, Y.C.; Zhang, X.Y.; Wang, W.; Cheng, M.M. Lightweight salient object detection via hierarchical visual perception learning. IEEE Trans. Cybern. 2020, 51, 4439–4449. [Google Scholar] [CrossRef]
- Tu, Z.; Ma, Y.; Li, C.; Tang, J.; Luo, B. Edge-guided non-local fully convolutional network for salient object detection. IEEE Trans. Circuits Syst. Video Technol. 2020, 31, 582–593. [Google Scholar] [CrossRef]
- Li, J.; Pan, Z.; Liu, Q.; Wang, Z. Stacked U-shape network with channel-wise attention for salient object detection. IEEE Trans. Multimed. 2020, 23, 1397–1409. [Google Scholar] [CrossRef]
- Xu, B.; Liang, H.; Liang, R.; Chen, P. Locate globally, segment locally: A progressive architecture with knowledge review network for salient object detection. Proc. Aaai Conf. Artif. Intell. 2021, 35, 3004–3012. [Google Scholar] [CrossRef]
- Liu, N.; Zhang, N.; Wan, K.; Shao, L.; Han, J. Visual saliency transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 4722–4732. [Google Scholar]
- Liu, Y.; Zhang, D.; Liu, N.; Xu, S.; Han, J. Disentangled capsule routing for fast part-object relational saliency. IEEE Trans. Image Process. 2022, 31, 6719–6732. [Google Scholar] [CrossRef]
- Fang, C.; Tian, H.; Zhang, D.; Zhang, Q.; Han, J.; Han, J. Densely nested top-down flows for salient object detection. Sci. China Inf. Sci. 2022, 65, 182103. [Google Scholar] [CrossRef]
- Zhuge, M.; Fan, D.P.; Liu, N.; Zhang, D.; Xu, D.; Shao, L. Salient object detection via integrity learning. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 3738–3752. [Google Scholar] [CrossRef]
- Wang, Q.; Liu, Y.; Xiong, Z.; Yuan, Y. Hybrid feature aligned network for salient object detection in optical remote sensing imagery. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5624915. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | ORSSD | EORSSD | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Salient object detection methods for natural images | ||||||||||||||||
| R3Net18 [63] | 0.8141 | 0.7456 | 0.7383 | 0.7379 | 0.8913 | 0.8681 | 0.8887 | 0.0399 | 0.8192 | 0.7516 | 0.6320 | 0.4180 | 0.9500 | 0.8307 | 0.6476 | 0.0171 |
| PiCANet18 [64] | 0.8124 | 0.7489 | 0.7410 | 0.7391 | 0.8988 | 0.8752 | 0.8902 | 0.0323 | 0.8204 | 0.7544 | 0.6364 | 0.4297 | 0.9501 | 0.8351 | 0.6517 | 0.0155 |
| PoolNet19 [65] | 0.8403 | 0.7706 | 0.6999 | 0.6166 | 0.9343 | 0.8650 | 0.8124 | 0.0358 | 0.8217 | 0.7575 | 0.6432 | 0.4627 | 0.9318 | 0.8215 | 0.6851 | 0.0210 |
| EGNet19 [66] | 0.8721 | 0.8332 | 0.7500 | 0.6452 | 0.9731 | 0.9013 | 0.8226 | 0.0216 | 0.8601 | 0.7880 | 0.6967 | 0.5379 | 0.9570 | 0.8775 | 0.7566 | 0.0110 |
| BASNet19 [67] | 0.8716 | 0.8357 | 0.7621 | 0.6558 | 0.9766 | 0.9083 | 0.8317 | 0.0204 | 0.8751 | 0.7916 | 0.7018 | 0.5417 | 0.9581 | 0.8797 | 0.7662 | 0.0111 |
| CPD19 [68] | 0.8955 | 0.8524 | 0.8243 | 0.7717 | 0.9439 | 0.9208 | 0.9211 | 0.0186 | 0.8873 | 0.8094 | 0.7661 | 0.6637 | 0.9391 | 0.8978 | 0.8664 | 0.0110 |
| RAS20 [69] | 0.8961 | 0.8634 | 0.8250 | 0.7761 | 0.9491 | 0.9220 | 0.9271 | 0.0176 | 0.8864 | 0.8123 | 0.7679 | 0.6685 | 0.9412 | 0.8994 | 0.8681 | 0.0112 |
| CSNet20 [70] | 0.8910 | 0.8790 | 0.8285 | 0.7615 | 0.9628 | 0.9171 | 0.9068 | 0.0186 | 0.8364 | 0.8341 | 0.7656 | 0.6319 | 0.9535 | 0.8929 | 0.8339 | 0.0169 |
| SAMNet21 [71] | 0.8761 | 0.8137 | 0.7531 | 0.6843 | 0.9478 | 0.8818 | 0.8656 | 0.0217 | 0.8622 | 0.7813 | 0.7214 | 0.6114 | 0.9421 | 0.8700 | 0.8284 | 0.0132 |
| HVPNet21 [72] | 0.8610 | 0.7938 | 0.7396 | 0.6726 | 0.9320 | 0.8717 | 0.8471 | 0.0225 | 0.8734 | 0.8036 | 0.7377 | 0.6202 | 0.9482 | 0.8721 | 0.8270 | 0.0110 |
| ENFNet20 [73] | 0.8604 | 0.7894 | 0.7301 | 0.6674 | 0.9217 | 0.8641 | 0.8362 | 0.0231 | 0.8654 | 0.7932 | 0.7267 | 0.6163 | 0.9383 | 0.8645 | 0.8147 | 0.0123 |
| SUCA21 [74] | 0.8989 | 0.8484 | 0.8237 | 0.7748 | 0.9584 | 0.9400 | 0.9194 | 0.0145 | 0.8988 | 0.8229 | 0.7949 | 0.7260 | 0.9520 | 0.9277 | 0.9082 | 0.0097 |
| PA-KRN21 [75] | 0.9239 | 0.8890 | 0.8727 | 0.8548 | 0.9680 | 0.9620 | 0.9579 | 0.0139 | 0.9192 | 0.8639 | 0.8358 | 0.7993 | 0.9616 | 0.9536 | 0.9416 | 0.0104 |
| VST21 [76] | 0.9365 | 0.9095 | 0.8817 | 0.8262 | 0.9810 | 0.9621 | 0.9466 | 0.0094 | 0.9208 | 0.8716 | 0.8263 | 0.7089 | 0.9743 | 0.9442 | 0.8941 | 0.0067 |
| DPORTNet-VGG22 [77] | 0.8827 | 0.8309 | 0.8184 | 0.7970 | 0.9214 | 0.9139 | 0.9083 | 0.0220 | 0.8960 | 0.8363 | 0.7937 | 0.7545 | 0.9423 | 0.9116 | 0.9150 | 0.0150 |
| DNTD -Res22 [78] | 0.8698 | 0.8231 | 0.8020 | 0.7645 | 0.9286 | 0.9086 | 0.9081 | 0.0217 | 0.8957 | 0.8189 | 0.7962 | 0.7288 | 0.9378 | 0.9225 | 0.9047 | 0.0113 |
| ICON-PVT23 [79] | 0.9256 | 0.8939 | 0.8671 | 0.8444 | 0.9704 | 0.9637 | 0.9554 | 0.0116 | 0.9185 | 0.8622 | 0.8371 | 0.8065 | 0.9687 | 0.9619 | 0.9497 | 0.0073 |
| Salient object detection methods for optical remote sensing images | ||||||||||||||||
| EMFINetVGG22 [25] | 0.9366 | 0.9002 | 0.8857 | 0.8616 | 0.9737 | 0.9672 | 0.9663 | 0.0110 | 0.9291 | 0.8720 | 0.8486 | 0.7984 | 0.9712 | 0.9605 | 0.9501 | 0.0084 |
| ERPNetVGG22 [23] | 0.9254 | 0.8975 | 0.8745 | 0.8357 | 0.9710 | 0.9565 | 0.9520 | 0.0135 | 0.9210 | 0.8633 | 0.8304 | 0.7554 | 0.9603 | 0.9402 | 0.9228 | 0.0089 |
| CorrNet22 [24] | 0.9380 | 0.9128 | 0.9001 | 0.8875 | 0.9790 | 0.9745 | 0.9720 | 0.0098 | 0.9289 | 0.8778 | 0.8621 | 0.8310 | 0.9696 | 0.9647 | 0.9594 | 0.0084 |
| MCCNet22 [20] | 0.9437 | 0.9155 | 0.9054 | 0.8957 | 0.9800 | 0.9758 | 0.9735 | 0.0087 | 0.9327 | 0.8904 | 0.8604 | 0.8137 | 0.9755 | 0.9685 | 0.9538 | 0.0066 |
| HFANet22 [80] | 0.9399 | 0.9112 | 0.8981 | 0.8819 | 0.9770 | 0.9712 | 0.9722 | 0.0092 | 0.9380 | 0.8876 | 0.8681 | 0.8365 | 0.9740 | 0.9679 | 0.9644 | 0.0070 |
| MJRBMVGG23 [21] | 0.9204 | 0.8842 | 0.8567 | 0.8022 | 0.9622 | 0.9414 | 0.9327 | 0.0163 | 0.9197 | 0.8657 | 0.8238 | 0.7066 | 0.9646 | 0.9350 | 0.8897 | 0.0099 |
| ACCoNet-VGG23 [27] | 0.9437 | 0.9149 | 0.8971 | 0.8806 | 0.9796 | 0.9754 | 0.9721 | 0.0088 | 0.9290 | 0.8837 | 0.8552 | 0.7969 | 0.9727 | 0.9653 | 0.9450 | 0.0074 |
| OURS | 0.9440 | 0.9170 | 0.9073 | 0.8990 | 0.9801 | 0.9762 | 0.9758 | 0.0084 | 0.9346 | 0.8923 | 0.8710 | 0.8448 | 0.9688 | 0.9738 | 0.9697 | 0.0069 |
| Methods | ORSI-4199 | |||||||
|---|---|---|---|---|---|---|---|---|
| Salient object detection methods for natural images | ||||||||
| R3Net18 [63] | 0.8142 | 0.7847 | 0.7790 | 0.7776 | 0.8880 | 0.8722 | 0.8645 | 0.0401 |
| PiCANet18 [64] | 0.8145 | 0.7920 | 0.7792 | 0.7786 | 0.8894 | 0.8891 | 0.8674 | 0.0421 |
| PoolNet19 [65] | 0.8271 | 0.8010 | 0.7779 | 0.7382 | 0.8964 | 0.8676 | 0.8531 | 0.0541 |
| EGNet19 [66] | 0.8464 | 0.8267 | 0.8041 | 0.7650 | 0.9161 | 0.8947 | 0.8620 | 0.0440 |
| BASNet19 [67] | 0.8341 | 0.8157 | 0.8042 | 0.7810 | 0.9069 | 0.8881 | 0.8882 | 0.0454 |
| CPD19 [68] | 0.8476 | 0.8305 | 0.8169 | 0.7960 | 0.9168 | 0.9025 | 0.8883 | 0.0409 |
| RAS20 [69] | 0.7753 | 0.7343 | 0.7141 | 0.7017 | 0.8481 | 0.8133 | 0.8308 | 0.0671 |
| CSNet20 [70] | 0.8241 | 0.8124 | 0.7674 | 0.7162 | 0.9096 | 0.8586 | 0.8447 | 0.0524 |
| SAMNet21 [71] | 0.8409 | 0.8249 | 0.8029 | 0.7744 | 0.9186 | 0.8938 | 0.8781 | 0.0432 |
| HVPNet21 [72] | 0.8471 | 0.8295 | 0.8041 | 0.7652 | 0.9201 | 0.8956 | 0.8687 | 0.0419 |
| ENFNet20 [73] | 0.7766 | 0.7285 | 0.7177 | 0.7271 | 0.8370 | 0.8107 | 0.8235 | 0.0608 |
| SUCA21 [74] | 0.8794 | 0.8692 | 0.8590 | 0.8415 | 0.9438 | 0.9356 | 0.9186 | 0.0304 |
| PA-KRN21 [75] | 0.8491 | 0.8415 | 0.8324 | 0.8200 | 0.9280 | 0.9168 | 0.9063 | 0.0382 |
| VST21 [76] | 0.8790 | 0.8717 | 0.8524 | 0.7947 | 0.9481 | 0.9348 | 0.8997 | 0.0281 |
| DPORTNet-VGG22 [77] | 0.8094 | 0.7789 | 0.7701 | 0.7554 | 0.8759 | 0.8687 | 0.8628 | 0.0569 |
| DNTD-Res22 [78] | 0.8444 | 0.8310 | 0.8208 | 0.8065 | 0.9158 | 0.9050 | 0.8963 | 0.0425 |
| ICON-PVT23 [79] | 0.8752 | 0.8763 | 0.8664 | 0.8531 | 0.9521 | 0.9438 | 0.9239 | 0.0282 |
| Salient object detection methods for optical remote sensing images | ||||||||
| EMFINetVGG22 [25] | 0.8675 | 0.8584 | 0.8479 | 0.8186 | 0.9340 | 0.9257 | 0.9136 | 0.0330 |
| ERPNetVGG22 [23] | 0.8670 | 0.8553 | 0.8374 | 0.8024 | 0.9290 | 0.9149 | 0.9024 | 0.0357 |
| CorrNet22 [24] | 0.8623 | 0.8560 | 0.8513 | 0.8534 | 0.9330 | 0.9206 | 0.9142 | 0.0366 |
| MCCNet22 [20] | 0.8746 | 0.8690 | 0.8630 | 0.8592 | 0.9413 | 0.9348 | 0.9182 | 0.0316 |
| HFANet22 [80] | 0.8767 | 0.8700 | 0.8624 | 0.8323 | 0.9431 | 0.9336 | 0.9191 | 0.0314 |
| MJRBMVGG23 [21] | 0.8593 | 0.8493 | 0.8309 | 0.7995 | 0.9311 | 0.9102 | 0.8891 | 0.0374 |
| ACCoNet-VGG23 [27] | 0.8775 | 0.8686 | 0.8620 | 0.8581 | 0.9412 | 0.9342 | 0.9167 | 0.0314 |
| OURS | 0.8821 | 0.8834 | 0.8776 | 0.8647 | 0.9542 | 0.9431 | 0.9258 | 0.0266 |
| Methods | ORSSD | |||||||
|---|---|---|---|---|---|---|---|---|
| OURS_noGCRL | 0.9288 | 0.9001 | 0.8862 | 0.8810 | 0.9688 | 0.9523 | 0.9561 | 0.0132 |
| OURS_noMSF | 0.9373 | 0.9079 | 0.9002 | 0.8893 | 0.9758 | 0.9686 | 0.9696 | 0.0120 |
| OURS | 0.9440 | 0.9170 | 0.9073 | 0.8990 | 0.9801 | 0.9762 | 0.9758 | 0.0084 |
| – | EORSSD | |||||||
| OURS_noGCRL | 0.9211 | 0.8775 | 0.8516 | 0.8267 | 0.9579 | 0.9578 | 0.9504 | 0.0081 |
| OURS_noMSF | 0.9276 | 0.8861 | 0.8648 | 0.8364 | 0.9629 | 0.9688 | 0.9602 | 0.0072 |
| OURS | 0.9346 | 0.8923 | 0.8710 | 0.8448 | 0.9688 | 0.9738 | 0.9697 | 0.0069 |
| – | ORSI-4199 | |||||||
| OURS_noGCRL | 0.8676 | 0.8642 | 0.8590 | 0.8396 | 0.9403 | 0.9237 | 0.9113 | 0.0311 |
| OURS_noMSF | 0.8704 | 0.8711 | 0.8668 | 0.8587 | 0.9478 | 0.9406 | 0.9221 | 0.0299 |
| OURS | 0.8821 | 0.8834 | 0.8776 | 0.8647 | 0.9542 | 0.9431 | 0.9258 | 0.0266 |
| Methods | Datasets | |
|---|---|---|
| ORSSD/EORSSD | ORSI-4199 | |
| R3Net18 [63] | 0.512 | 0.228 |
| PiCANet18 [64] | 0.612 | 0.273 |
| PoolNet19 [65] | 0.043 | 0.019 |
| EGNet19 [66] | 0.111 | 0.049 |
| BASNet19 [67] | 0.204 | 0.090 |
| CPD19 [68] | 0.197 | 0.087 |
| RAS20 [69] | 0.107 | 0.048 |
| CSNet20 [70] | 0.026 | 0.012 |
| SAMNet21 [71] | 0.023 | 0.010 |
| HVPNet21 [72] | 0.017 | 0.008 |
| ENFNet20 [73] | 0.027 | 0.012 |
| SUCA21 [74] | 0.018 | 0.008 |
| PA-KRN21 [75] | 0.063 | 0.028 |
| VST21 [76] | 0.051 | 0.023 |
| DPORTNet-VGG22 [77] | 0.012 | 0.006 |
| DNTD-Res22 [78] | 0.157 | 0.069 |
| ICON-PVT23 [79] | 0.028 | 0.012 |
| EMFINetVGG22 [25] | 0.041 | 0.018 |
| ERPNetVGG22 [23] | 0.034 | 0.015 |
| CorrNet22 [24] | 0.021 | 0.009 |
| MCCNet22 [20] | 0.020 | 0.009 |
| HFANet22 [80] | 0.037 | 0.016 |
| MJRBMVGG23 [21] | 0.031 | 0.014 |
| ACCoNet-VGG23 [27] | 0.019 | 0.008 |
| OURS | 0.022 | 0.014 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, J.; Li, C.; Zheng, X.; Liu, X.; Tang, C. Global Context Relation-Guided Feature Aggregation Network for Salient Object Detection in Optical Remote Sensing Images. Remote Sens. 2024, 16, 2978. https://doi.org/10.3390/rs16162978
Li J, Li C, Zheng X, Liu X, Tang C. Global Context Relation-Guided Feature Aggregation Network for Salient Object Detection in Optical Remote Sensing Images. Remote Sensing. 2024; 16(16):2978. https://doi.org/10.3390/rs16162978
Chicago/Turabian StyleLi, Jian, Chuankun Li, Xiao Zheng, Xinwang Liu, and Chang Tang. 2024. "Global Context Relation-Guided Feature Aggregation Network for Salient Object Detection in Optical Remote Sensing Images" Remote Sensing 16, no. 16: 2978. https://doi.org/10.3390/rs16162978
APA StyleLi, J., Li, C., Zheng, X., Liu, X., & Tang, C. (2024). Global Context Relation-Guided Feature Aggregation Network for Salient Object Detection in Optical Remote Sensing Images. Remote Sensing, 16(16), 2978. https://doi.org/10.3390/rs16162978