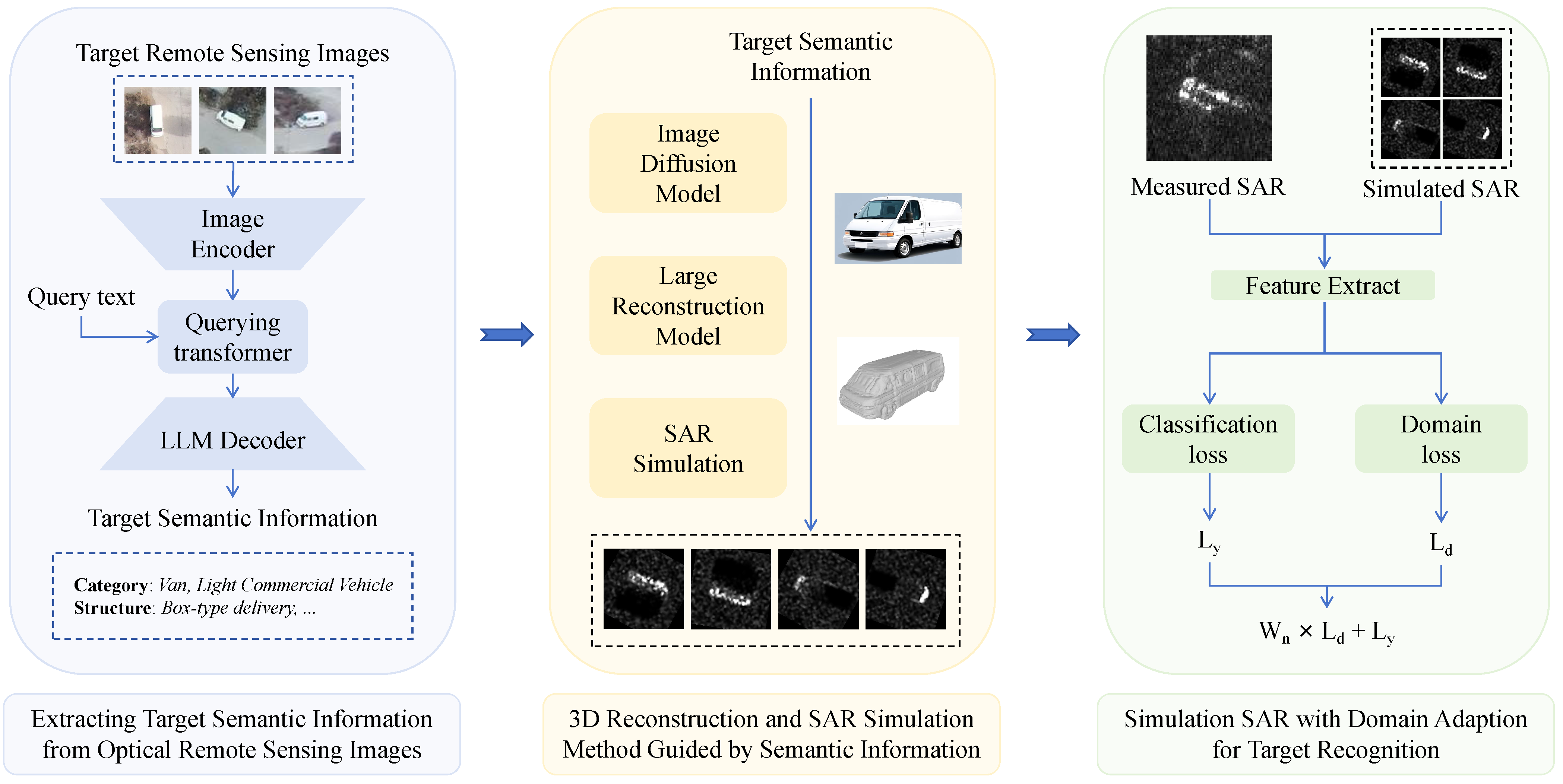
As illustrated in
Figure 1, this paper primarily extracts semantic information from optical RSIs, including key features such as target category and structure. Following the acquisition of the semantic information of the target, it is input into the diffusion generative model to obtain a 3D model of the target, which is then utilized for SAR simulation. Concurrently, in order to compensate for the domain shift between the simulated SAR and measured SAR, domain adaptation methods are employed to achieve target recognition under ZSL conditions. Consequently, the content of this chapter primarily concerns the extraction of semantic information from optical RSIs, 3D reconstruction and SAR simulation guided by semantic information, and simulation SAR with domain adaptation for SAR target recognition.
3.1. Extracting Target Semantic Information from Optical Remote Sensing Image
Semantic information, which includes key features such as target categories and structures, can be used to generate 3D models that include key features of the target. This part outlines the process for obtaining semantic information from optical RSIs.
As shown in
Figure 2, in order to extract the semantic information for target recognition from optical RSIs, we used the image captioning method based on VLP and thus could control the output with prompts. A query transformer (Query) structure inspired by BLIP was used to bridge the gap between the visual and language models [
45]. The visual model we used is pre-trained ViT-B as the image encoder, and
as the initialization parameter for Query [
21,
46]. Next, we trained the Query on the civilian vehicles’ optical RSI dataset we self-built. To preserve the understanding and generation capabilities of the large model, the VLP model was frozen. The Query component was the only trainable element, acting as a lightweight querying transformer. The self-built civilian vehicle optical RSI dataset was the image description dataset used in this paper for four types of civilian vehicle targets, with each target comprising over 100 images and corresponding target descriptions for each type of target. This dataset was used to train Query. Further details on the dataset can be found in the DATASET AND SETTING section.
In the image processing stage, we first resized the input image to 384 × 384 pixels and then used ViT-B to encode it to obtain the feature vectors of the image. In the text processing stage, the prompt text “The vehicle in this photo is” was used, and
was employed to convert the prompt text and text annotations into 768-dimensional text vectors. Subsequently, the text vector and image feature vector were input into the language model. The loss function utilized was the cross-entropy loss, which can be expressed as
where
represents the loss function,
y represents the actual caption,
represents the caption generated by the model, and
N represents the length of the caption.
In order to minimize the loss function, the Adam W optimizer was employed for parameter updates. Pre-trained visual and language models were utilized to process image and text information, with fine-tuning to fit specific remote sensing datasets. A self-built dataset was employed to train Query, with the prior knowledge of large models successfully utilized to process remote sensing images of civilian vehicle targets and generate descriptive text containing target features. The semantic information of the target is presented in descriptive form, including the target category and optical structure features.
3.2. 3D Reconstruction and SAR Simulation Method Guided by Semantic Information
After obtaining target semantic information including target category and optical structure features, it is necessary to convert it into a 3D model for simulation. In SAR simulation, key target features such as machine guns and barrels, which are optical structure features, have a significant impact on SAR images. The existing methods of text diffusion into 3D models are unable to accurately control key features [
30,
31,
34]. In order to effectively preserve and control the key features of the target, optical reconstruction of the target is introduced as an intermediate step, thereby effectively achieving the preservation of key features of the target in the 3D model.
As shown in
Figure 3, the key feature description of the target is first obtained and it is provided as input to the diffusion generation model, achieving optical reconstruction through this step. This paper uses a stable diffusion (SD) model [
39], which can generate images containing key features such as target category, structure, and posture based on input prompts. Subsequently, optical reconstructed images containing key features of the target are input into the LRM for 3D model construction. Finally, using SBR technology, SAR simulation is performed on the constructed 3D model to generate SAR simulation images containing key features of the target.
Taking the T72 machine gun as an example, it can be seen from the
Figure 3 and
Figure 4 that the key features of the target have a significant impact on the simulated image. As indicated by the red circle, when the 3D model has a machine gun, the SAR simulation image obtained clearly has an additional strong scattering center compared to the SAR simulation image without a machine gun, which has a significant impact on target recognition. Therefore, it is necessary to control the key feature of the target.
In order to effectively control the output of the SD using prompt words, we used low-rank adaptation (LoRA) as an efficient fine-tuning method [
48]. LoRA achieves efficiency by introducing low-rank matrices to approximate updates to model weights, thereby drastically reducing the parameter count and accelerating training. The weight matrix of a particular layer in the original model is denoted as
,
d signifies the dimensional, and LoRA eschews direct modification of
W. Instead, it employs two low-rank matrices,
and
, with
, to construct a correction term
. Consequently, the adjusted weight matrix can be expressed as
where
represents a scalar factor that governs the intensity of the LoRA adjustment. After fine-tuning the generated diffusion model through LoRA, a reconstructed image of the target was obtained, which needed to be converted into a 3D model.
LRM incorporates a pre-trained visual transformer, DINO, to encode image features [
49], and then projects this onto a 3D triplane representation through an image-to-triplane transformer decoder [
50]. This decoder employs cross-attention to map 2D features into 3D space and uses self-attention to model inter-token relationships within the structured triplane, enhancing spatial coherence. The decoder’s output is reshaped and upsampled to yield triplane feature maps, which, when decoded via an MLP, generate color and density values for volumetric rendering, thereby reconstructing the 3D model.
This paper uses TripoSR [
34] to convert images into 3D models. The process can be abstracted as follows:
After obtaining the target 3D model, we use SBR for SAR simulation [
51]. The SBR method is a ray tracing-based technique widely used for analyzing and predicting electromagnetic wave scattering characteristics in complex scenes. The SBR method for simulation involves emitting rays from the radar to represent electromagnetic wave propagation paths, ensuring coverage of the entire scene. When these rays encounter a target object’s surface, their reflection directions are computed based on the surface’s electromagnetic properties and the angle of incidence, with reflection and transmission coefficients factored in. The rays then undergo multiple reflections between objects until their intensity diminishes or they exit the scene, enhancing the accuracy of electromagnetic scattering simulations for complex surfaces.
The physical optics (PO) method is often combined with the SBR method to enhance simulation accuracy. The PO method is based on near-field and far-field approximations of electromagnetic waves and computes electromagnetic scattering from the target surface through integration. The mathematical description of the SBR/PO hybrid method is as follows.
First, define the incident wave vector
and the surface normal vector
of the target object. When the ray hits the surface, the angle of incidence
with respect to the normal vector is given by
and then, the reflected wave vector
can be expressed as
During each reflection, the reflection coefficient
and the transmission coefficient
of the electromagnetic wave are given by the Fresnel equations:
where
and
are the refractive indices of the media, and
is the angle of transmission. Using these formulas, the iterative calculation of the rays’ multiple reflections on the target object’s surface generates simulation SAR images.
Based on target 3D reconstruction and SAR simulation methods, we have achieved 3D model reconstruction and SAR simulation images guided by key features. As shown in
Figure 3, when we control the presence or absence of the “machine gun” during the simulation process, this change can be clearly observed from the optical reconstructed image. Specifically, if the key feature of the machine gun is not included in the input, the generated T72 reconstructed image will not show the machine gun. On the contrary, when this feature is included in the input, details of the machine gun will appear in the corresponding optical reconstruction image. This change is also intuitively reflected in the final 3D reconstruction model.
3.3. Simulation SAR with Domain Adaption for Target Recognition
Maintaining complete consistency in imaging conditions between simulations and actual measurements is nearly impossible for target SAR images. At the same time, there are inevitable errors between the actual models of the 3D model obtained in this paper, leading to the gap between the simulated and real domains. We propose a target recognition method based on joint domain loss and classification loss by dynamic weight to achieve cross-domain SAR target recognition.
We use labeled data in the source domain for supervised learning and obtain the classification loss through a classification task. Then, we use unlabeled data in the source and target domains to evaluate the feature distribution gap between them and obtain the domain loss. As shown in
Figure 5, after obtaining the classification loss
and domain loss
, they are combined to jointly optimize the feature extractor of the network. The formula can be abstracted as
where
is a constant.
is unlabeled data from the source domain,
is unlabeled data from the target domain, and
is a function that distinguishes the distance between
and
.
However, constant
cannot dynamically reflect the changes in classification loss
and domain loss
as training progresses. Given the shortcomings of the fixed weight strategy mentioned above, we introduce dynamic weight instead of
for domain loss
, which dynamically adjusts with increasing training batches and can more accurately match the training process, improving the overall performance of unsupervised domain adaptation. The dynamic weight
can be abstracted as
herein, the subscript
n signifies the epoch within the training process, with
representing the weight parameter at the epoch
n.
is the initial value assigned to the weight. This formulation introduces a dynamic mechanism that adjusts the weight
W in accordance with the progression of training epochs, thus dynamically adjusting the impact of domain loss
on the training process.
We employed several methods, such as BNM (Batch Nuclear-norm Maximization) [
52], Deep CORAL (Correlation Alignment) [
53], and DANN (Domain Adversarial Neural Networks) [
54] as the distance function. From the experimental results, it has been proven that this dynamic weighting can enhance the network’s recognition and domain adaptation capabilities, thereby improving its cross-domain SAR target recognition performance.
The framework proposed in this paper mainly includes the SAR simulation part and the ZSL target recognition part. The following formula is a summary of the SAR simulation section.
After extracting the target semantic information from the optical remote sensing images using the image captioning method, the key features of the target are transformed into optical reconstructed images, thereby achieving controllable 3D modeling of key features. The SBR method is employed for the simulation of SAR data with a target 3D model. A domain adaptation method based on dynamic weights is employed to minimize the domain shift between the simulated SAR and measured SAR data, thereby achieving transductive ZSL target recognition.




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}