

On Optimizing Hyperspectral Inversion of Soil Copper Content by Kernel Principal Component Analysis


Abstract
:
1. Introduction
2. Materials and Methods
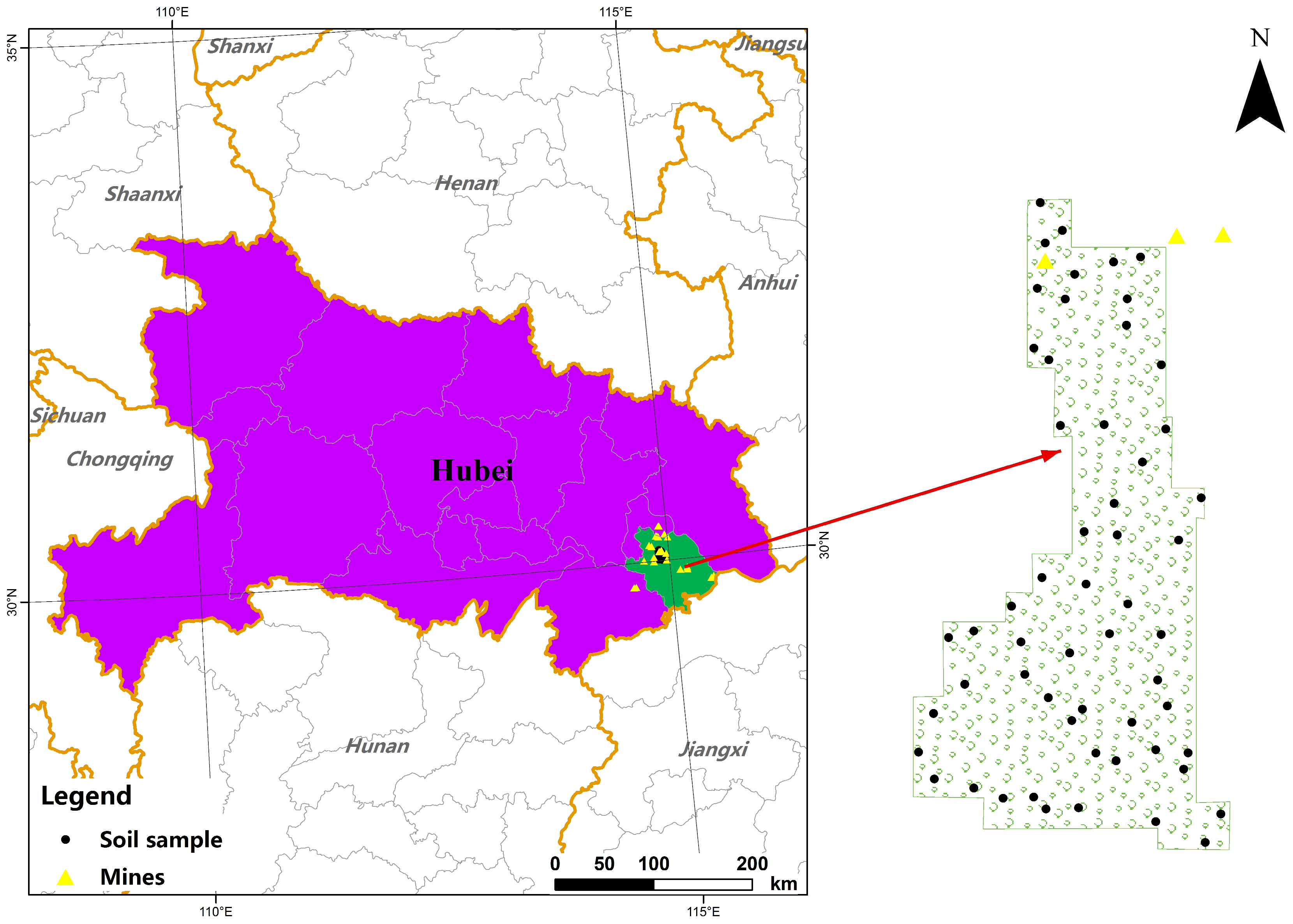
2.1. Study Area and Sampling Points
2.2. Data Determination
2.3. Methodology
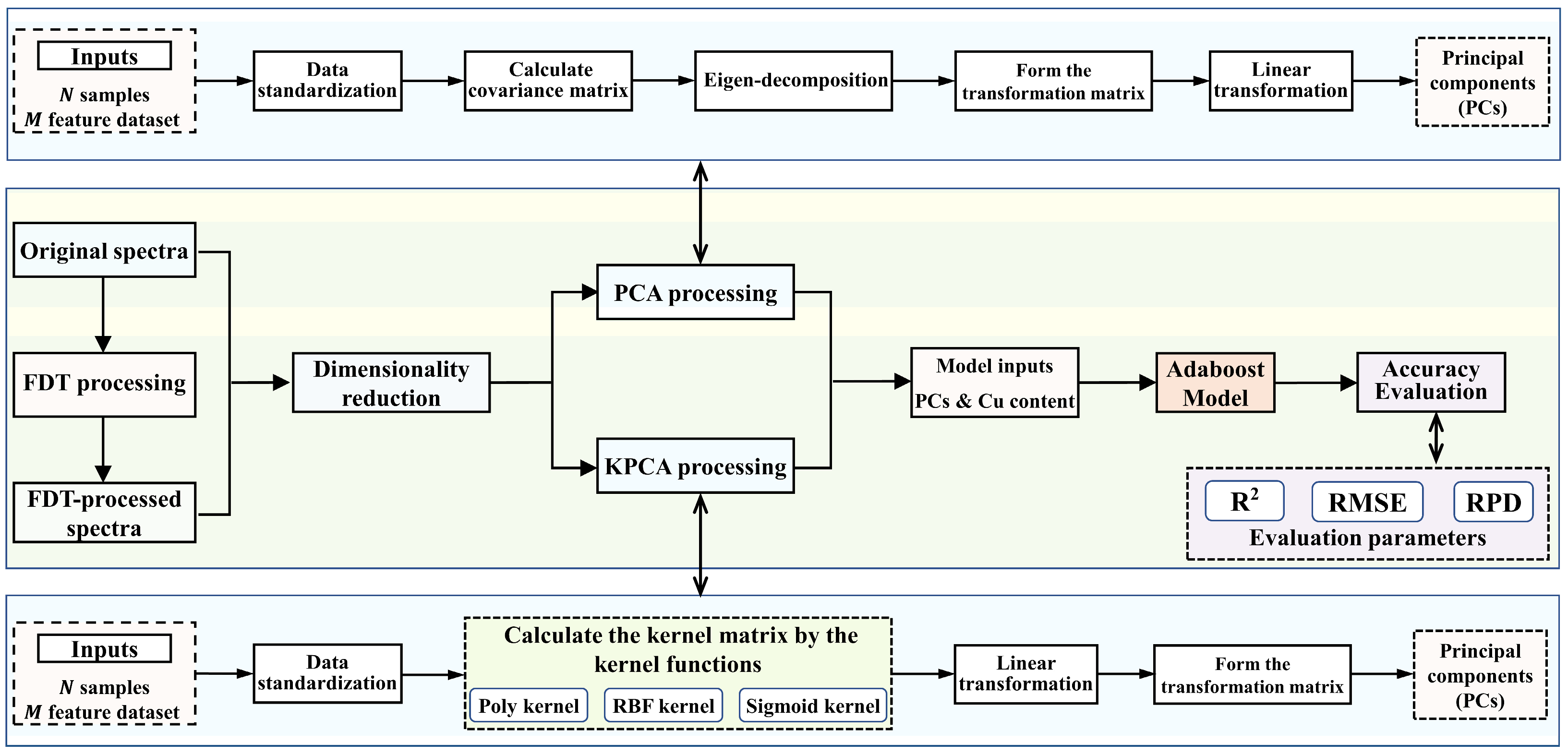
2.3.1. Workflow
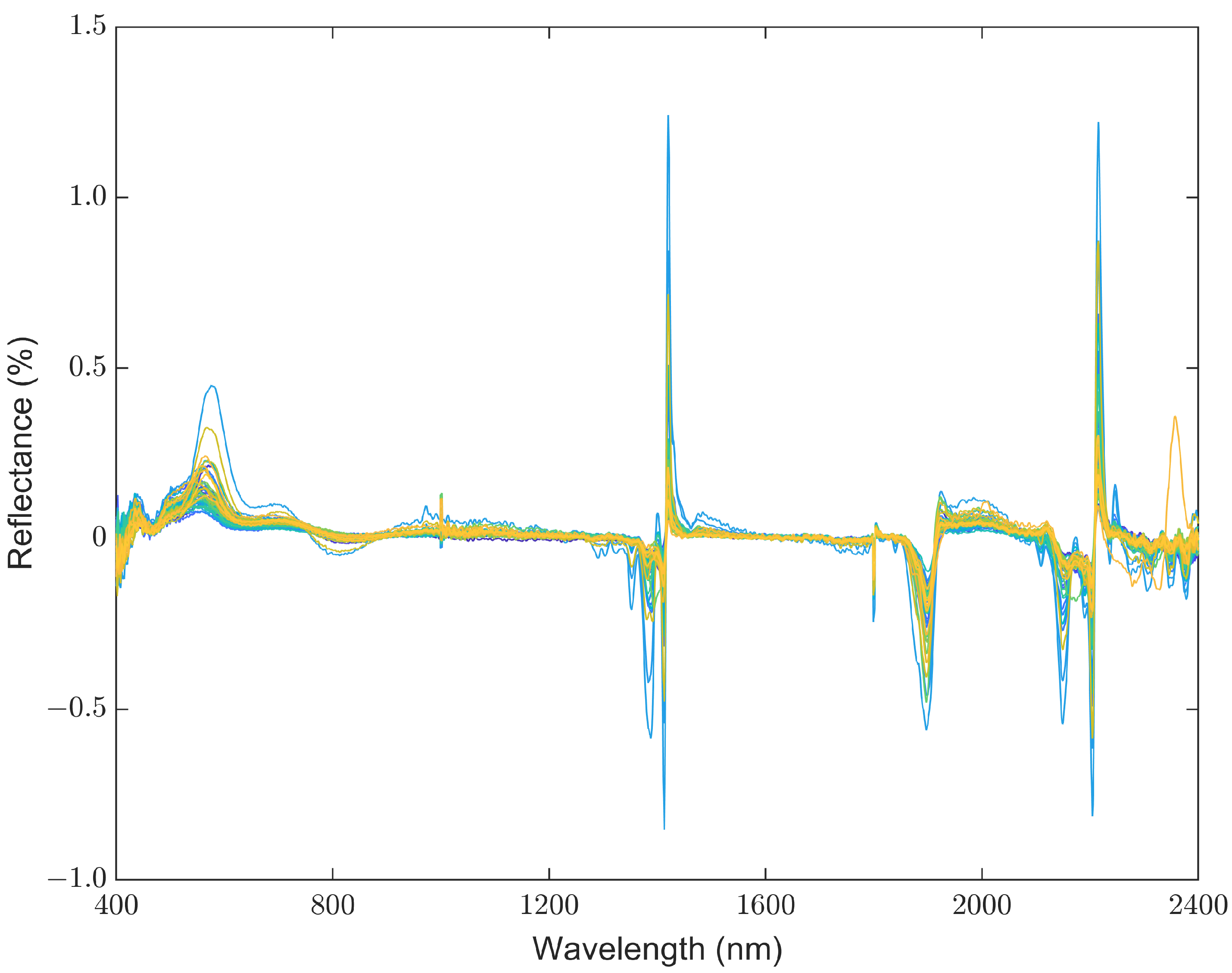
2.3.2. Spectral Pretreatments
2.3.3. Spectral Dimensionality Reduction
2.3.4. Model Construction
| Algorithm 1. The procedure outline for the AdaBoost algorithm |
|
|
|
|
2.3.5. Accuracy Validation
- (1)
- R² is a measure of the proportion of the variance in the dependent variable that is predictable from the independent variable (s). An R² value close to 1 indicates a high goodness of fit, while a value close to 0 suggests a poor fit;
- (2)
- RMSE represents the standard deviation of the prediction residuals and provides a measure of the average magnitude of the errors. A lower RMSE indicates a better model fit;
- (3)
- An RPD value greater than 2.0 indicates an excellent inversion performance. An RPD value between 1.4 and 2.0 suggests the ability to distinguish between high and low values. An RPD value less than 1.4 represents an unsuccessful inversion performance.
3. Results
3.1. Statistic Analysis of Cu Content in Soil
3.2. Inversion Accuracy without Dimensionality Reduction
3.3. Inversion Accuracy with PCA Processing
- (1)
- Cumulative explained variance: The individual and cumulative explained variance of the PCs were first calculated. This process was continued until the cumulative explained variances reached 99.99%, which resulted in a large number of potential PCs;
- (2)
- Iterative model building and evaluation: Starting with the first PC, we incrementally built inversion models using an increasing number of principal components (1 to , where is the number of PCs needed to reach 99.99% cumulative explained variance). For each iteration, we used the current set of PCs as input variables for the Cu inversion model and evaluated the performance using metrics in terms of , PRD, and RMSE;
- (3)
- Optimal selection: By comparing the inversion accuracy across all established inversion models, we determined the number of PCs that resulted in the highest accuracy (lowest RMSE, highest R², or highest RPD) as the optimal choice.
3.4. Inversion Accuracy of KPCA Dimensionality Reduction Methods
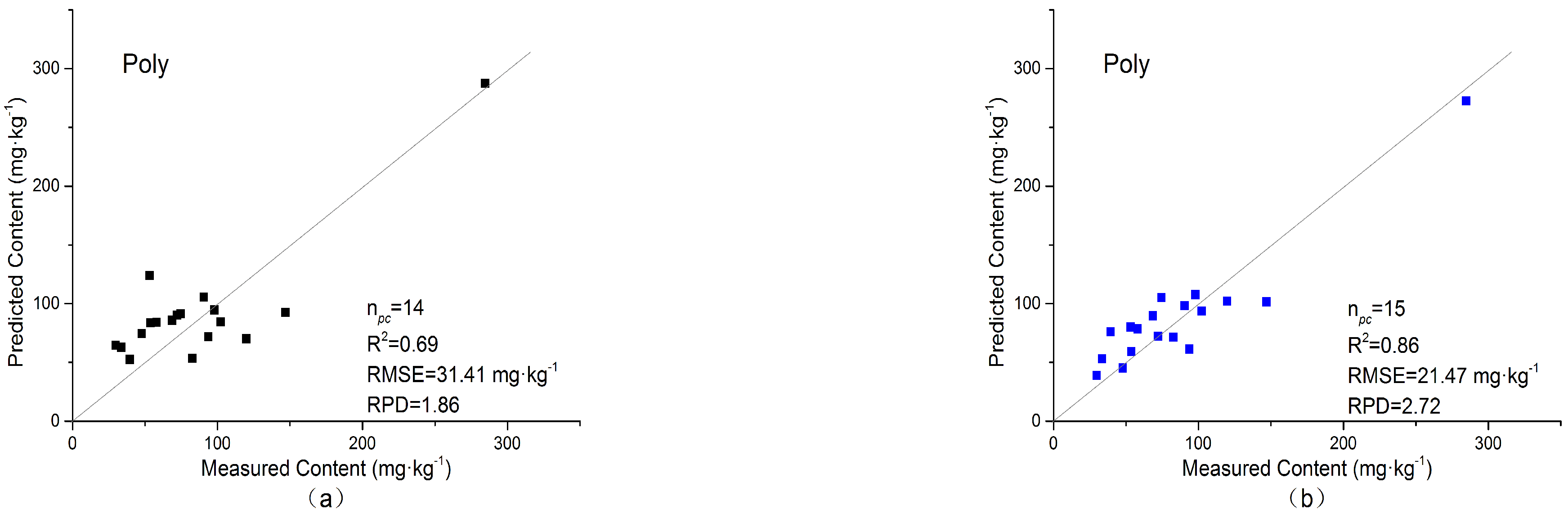
3.4.1. Polynomial Kernel
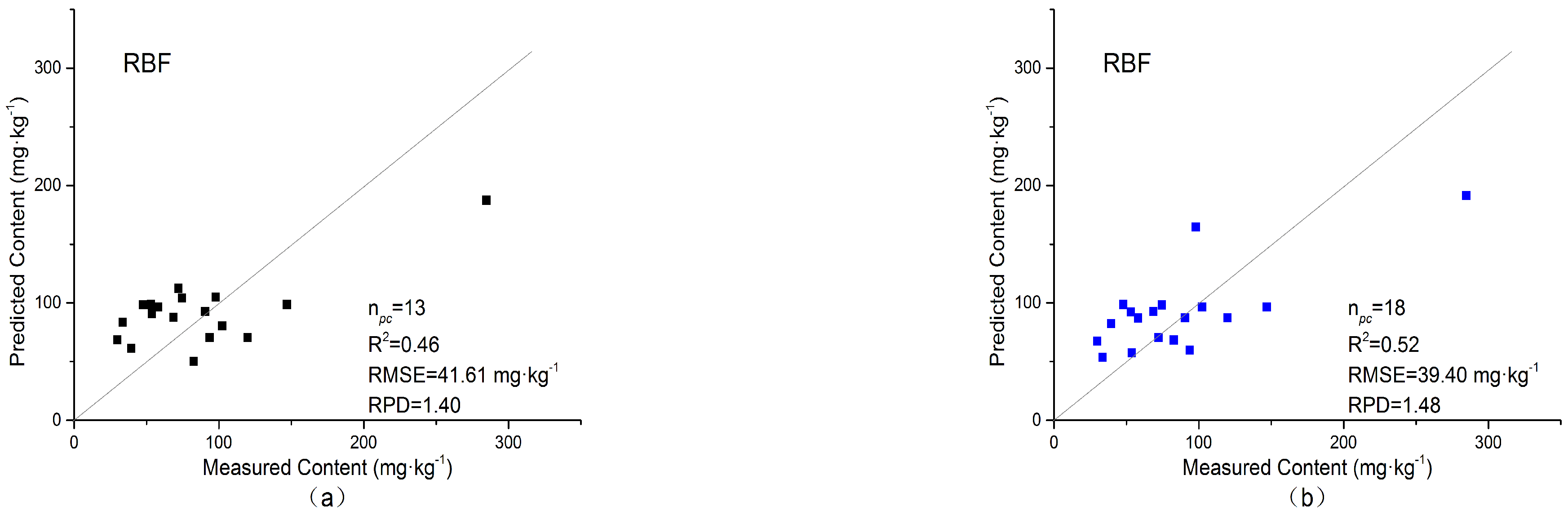
3.4.2. RBF Kernel
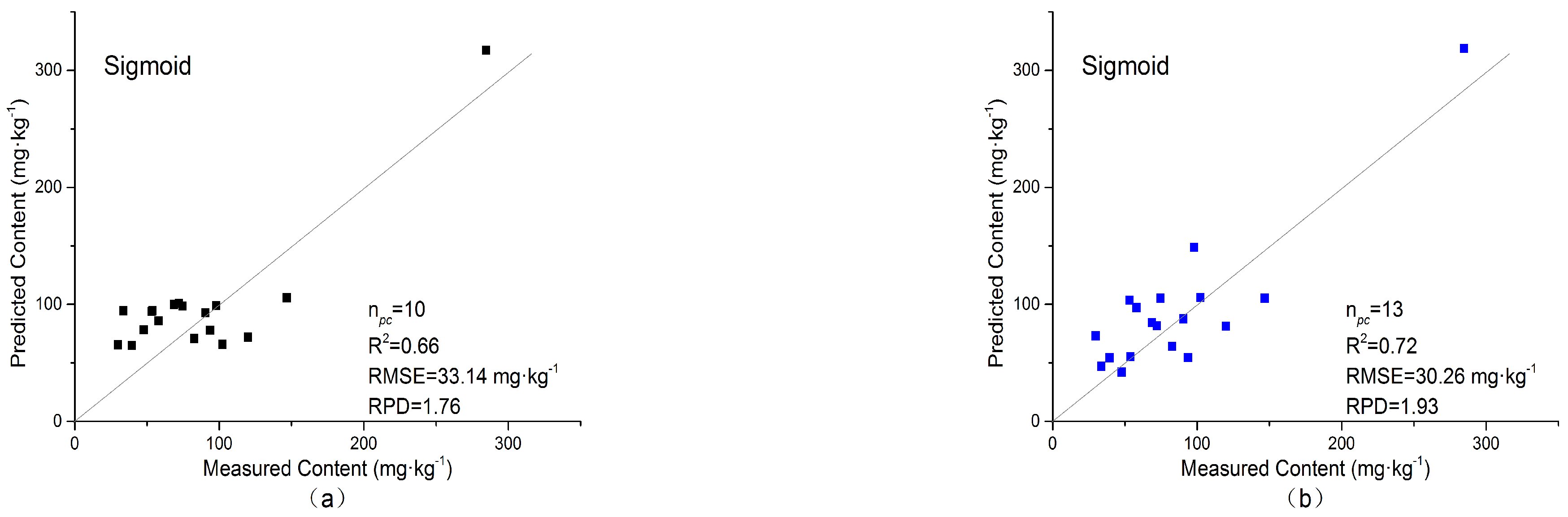
3.4.3. Sigmoid Kernel
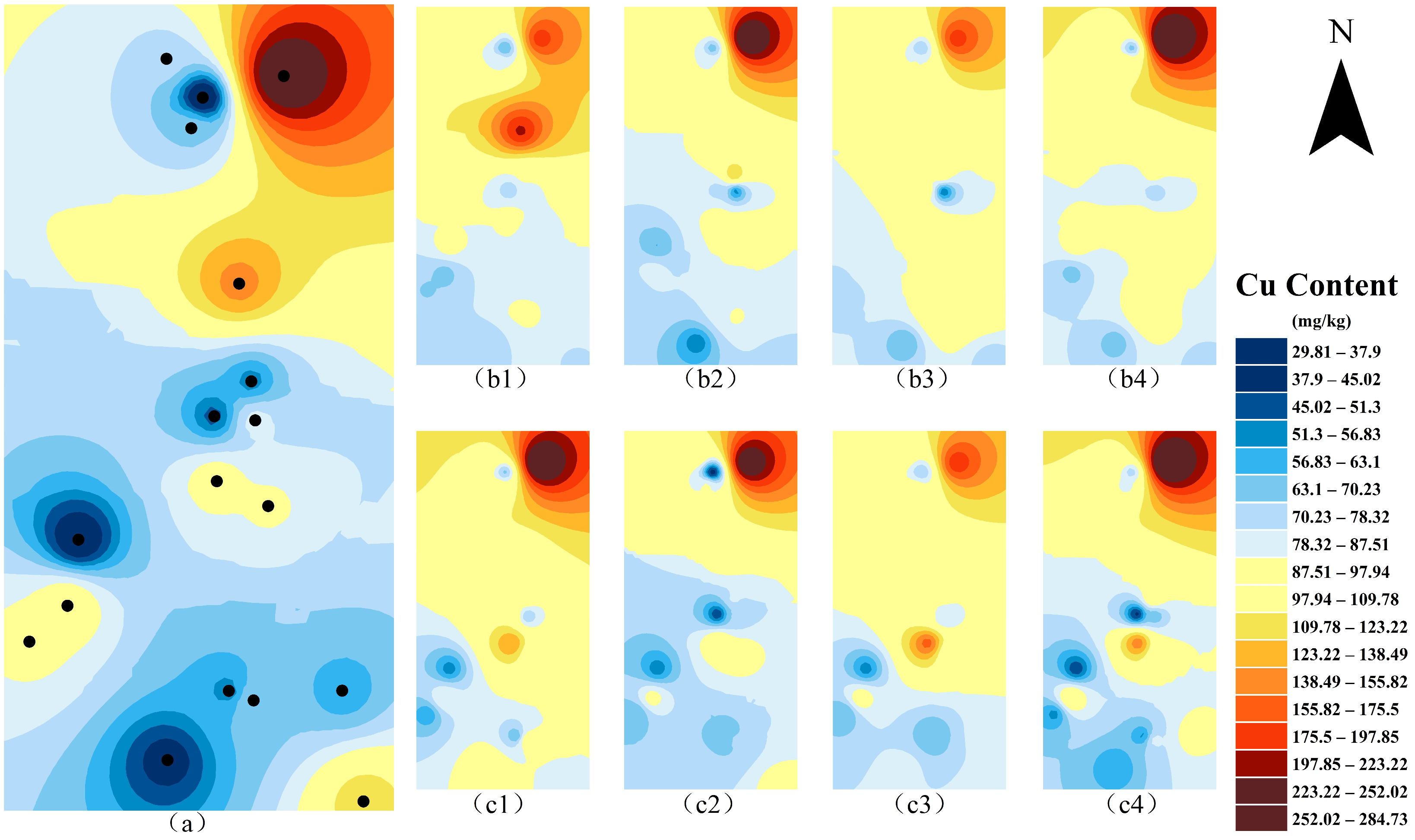
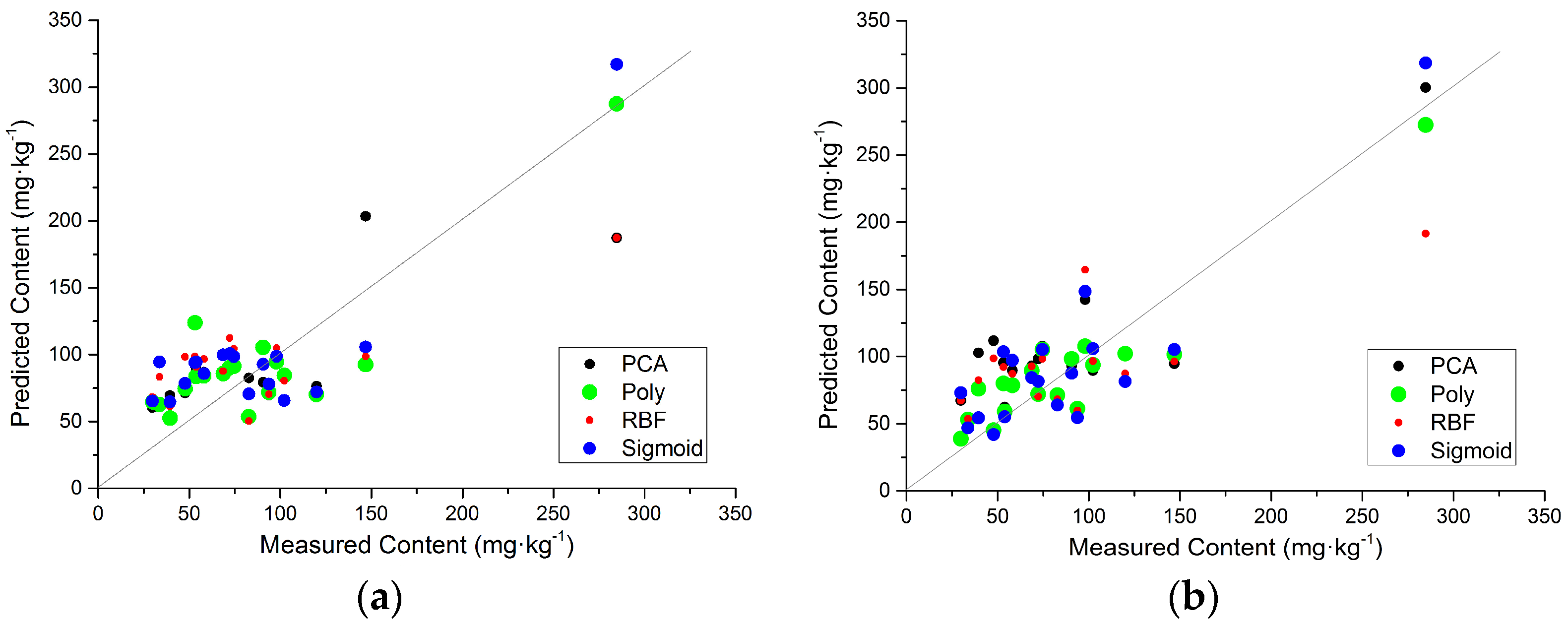
3.5. Spatial Distribution of Soil Cu Contents
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Liu, X.Y.; Bai, Z.K.; Shi, H.D.; Zhou, W.; Liu, X.C. Heavy metal pollution of soils from coal mines in China. Nat. Hazards 2019, 99, 1163–1177. [Google Scholar] [CrossRef]
- Liu, Y.; Du, Q.Y.; Cheng, Z.H.; Chen, J.W.; Lin, Z.J. Generation Model of Optimal Emergency Treatment Technology for Sudden Heavy Metal Pollution Based on Group-G1 Method. Pol. J. Environ. Stud. 2021, 30, 5899–5908. [Google Scholar] [CrossRef]
- Qi, D. Accumulation Effect of Heavy Metal Cadmium by Immobilization Microorganism. Master’s Thesis, Shanxi University, Taiyuan, China, 2010. [Google Scholar]
- Meng, W.; Shanshan, L.I.; Xiaoyue, L.I.; Zhongqiu, Z.; Shibao, C. An overview of current status of copper pollution in soil and remediation efforts in China. Earth Sci. Front. 2018, 25, 305–313. [Google Scholar]
- Rattan, R.K.; Patel, K.P.; Manjaiah, K.M.; Datta, S.P. Micronutrients in Soil, Plant, Animal and Human Health. J. Indian Soc. Soil Sci. 2009, 57, 546–558. [Google Scholar]
- Sun, W.; Zhang, X.; Sun, X.; Sun, Y.; Cen, Y. Predicting nickel concentration in soil using reflectance spectroscopy associated with organic matter and clay minerals. Geoderma 2018, 327, 25–35. [Google Scholar] [CrossRef]
- Khosravi, V.; Doulati Ardejani, F.; Yousefi, S.; Aryafar, A. Monitoring soil lead and zinc contents via combination of spectroscopy with extreme learning machine and other data mining methods. Geoderma 2018, 318, 29–41. [Google Scholar] [CrossRef]
- Wang, J.; Cui, L.; Gao, W.; Shi, T.; Chen, Y.; Gao, Y. Prediction of low heavy metal concentrations in agricultural soils using visible and near-infrared reflectance spectroscopy. Geoderma 2014, 216, 1–9. [Google Scholar] [CrossRef]
- Kemper, T.; Sommer, S. Estimate of heavy metal contamination in soils after a mining accident using reflectance spectroscopy. Environ. Sci. Technol. 2002, 36, 2742. [Google Scholar] [CrossRef]
- Jarmer, T.; Vohland, M.; Lilienthal, H.; Schnug, E. Estimation of some chemical properties of an agricultural soil by spectroradiometric measurements * 1. Pedosphere 2008, 18, 163–170. [Google Scholar] [CrossRef]
- George, K.J.; Kumar, S.; Raj, R.A. Soil organic carbon prediction using visible-near infrared reflectance spectroscopy employing artificial neural network modelling. Curr. Sci. 2020, 119, 377–381. [Google Scholar] [CrossRef]
- Guo, F.; Xu, Z.; Ma, H.; Liu, X.; Tang, S.; Yang, Z.; Zhang, L.; Liu, F.; Peng, M.; Li, K. Estimating chromium concentration in arable soil based on the optimal principal components by hyperspectral data. Ecol. Indic. 2021, 133, 108400. [Google Scholar] [CrossRef]
- Kooistra, L.; Wehrens, R.; Leuven, R.S.E.W.; Buydens, L.M.C. Possibilities of visible-near-infrared spectroscopy for the assessment of soil contamination in river floodplains. Anal. Chim. Acta 2001, 446, 97–105. [Google Scholar] [CrossRef]
- Tsai, F.; Philpot, W. Derivative analysis of hyperspectral data. Remote Sens. Environ. 1998, 66, 41–51. [Google Scholar] [CrossRef]
- Viscarra Rossel, R.A.; Walvoort, D.J.J.; McBratney, A.B.; Janik, L.J.; Skjemstad, J.O. Visible, near infrared, mid infrared or combined diffuse reflectance spectroscopy for simultaneous assessment of various soil properties. Geoderma 2006, 131, 59–75. [Google Scholar] [CrossRef]
- Song, Y.; Li, F.; Yang, Z.; Ayoko, G.; Frost, R.; Ji, J. Diffuse reflectance spectroscopy for monitoring potentially toxic elements in the agricultural soils of Changjiang River Delta, China. Appl. Clay Sci. 2011, 64, 75–83. [Google Scholar] [CrossRef]
- Wang, F.; Gao, J.; Zha, Y. Hyperspectral Sensing of Heavy Metals in Soil and Vegetation: Feasibility and Challenges. ISPRS J. Photogramm. Remote Sens. 2018, 136, 73–84. [Google Scholar] [CrossRef]
- Cui, S.; Zhou, K.; Ding, R.; Cheng, Y.; Jiang, G. Estimation of Soil Copper Content Based on Fractional-Order Derivative Spectroscopy and Spectral Characteristic Band Selection. Spectrochim. Acta Part A Mol. Biomol. Spectrosc. 2022, 275, 121190. [Google Scholar] [CrossRef] [PubMed]
- Fu, Y.; Cheng, Q.; Jing, L.; Ye, B.; Fu, H. Mineral Prospectivity Mapping of Porphyry Copper Deposits Based on Remote Sensing Imagery and Geochemical Data in the Duolong Ore District, Tibet. Remote Sens. 2023, 15, 439. [Google Scholar] [CrossRef]
- Shang, K.; Xiao, C.; Gan, F.; Wei, H.; Wang, C. Estimation of Soil Copper Content in Mining Area Using Zy1-02d Satellite Hyperspectral Data. J. Appl. Remote Sens. 2021, 15, 042607. [Google Scholar] [CrossRef]
- Li, Z.; Ma, Z.; van der Kuijp, T.J.; Yuan, Z.; Huang, L. A Review of Soil Heavy Metal Pollution from Mines in China: Pollution and Health Risk Assessment. Sci. Total Environ. 2014, 468–469, 843–853. [Google Scholar] [CrossRef] [PubMed]
- Hua, H.; Liu, M.; Liu, C.-Q.; Lang, Y.; Xue, H.; Li, S.; La, W.; Han, X.; Ding, H. Differences in the spectral characteristics of dissolved organic matter binding to Cu(II) in wetland soils with moisture gradients. Sci. Total Environ. 2023, 874, 162509. [Google Scholar] [CrossRef] [PubMed]
- Damian, J.M.; da Silva Matos, E.; e Pedreira, B.C.; de Faccio Carvalho, P.C.; Premazzi, L.M.; Williams, S.; Paustian, K.; Cerri, C.E.P. Predicting soil C changes after pasture intensification and diversification in Brazil. Catena 2021, 202, 105238. [Google Scholar] [CrossRef]
- Chen, H.; Teng, Y.; Lu, S.; Wang, Y.; Wang, J. Contamination features and health risk of soil heavy metals in China. Sci. Total Environ. 2015, 512–513, 143–153. [Google Scholar] [CrossRef] [PubMed]
- Cheng, H.; Shen, R.; Chen, Y.; Wan, Q.; Shi, T.; Wang, J.; Wan, Y.; Hong, Y.; Li, X. Estimating heavy metal concentrations in suburban soils with reflectance spectroscopy. Geoderma 2019, 336, 59–67. [Google Scholar] [CrossRef]
- Shen, Q.; Xia, K.; Zhang, S.; Kong, C.; Hu, Q.; Yang, S. Hyperspectral indirect inversion of heavy-metal copper in reclaimed soil of iron ore area. Spectrochim. Acta Part A Mol. Biomol. Spectrosc. 2019, 222, 117191. [Google Scholar] [CrossRef] [PubMed]
- Hong, Y.; Shen, R.; Cheng, H.; Chen, S.; Chen, Y.; Guo, L.; He, J.; Liu, Y.; Yu, L.; Liu, Y. Cadmium concentration estimation in peri-urban agricultural soils: Using reflectance spectroscopy, soil auxiliary information, or a combination of both? Geoderma 2019, 354, 113875. [Google Scholar] [CrossRef]
- Fang, Y.; Hu, Z.; Xu, L.; Wong, A.; Clausi, D.A. Estimation of Iron Concentration in Soil of a Mining Area from Uav-Based Hyperspectral Imagery. In Proceedings of the 2019 10th Workshop on Hyperspectral Imaging and Signal Processing: Evolution in Remote Sensing (WHISPERS), Amsterdam, The Netherlands, 24–26 September 2019. [Google Scholar]
- Cakir, S.; Sita, M. Evaluating the performance of ANN in predicting the concentrations of ambient air pollutants in Nicosia. Atmos. Pollut. Res. 2020, 11, 2327–2334. [Google Scholar] [CrossRef]
- Gao, H.; Huang, D.G.; Liu, W.; Yang, Y.S. Double rule learning in boosting. Int. J. Innov. Comput. Inf. Control 2008, 4, 1411–1420. [Google Scholar]
- Lu, Q.; Wang, S.; Bai, X.; Liu, F.; Wang, M.; Wang, J.; Tian, S. Rapid inversion of heavy metal concentration in karst grain producing areas based on hyperspectral bands associated with soil components. Microchem. J. 2019, 148, 404–411. [Google Scholar] [CrossRef]
- Kumar, B.; Dikshit, O.; Gupta, A.; Singh, M.K. Feature extraction for hyperspectral image classification: A review. Int. J. Remote Sens. 2020, 41, 6248–6287. [Google Scholar] [CrossRef]
- Wei, L.; Yuan, Z.; Zhong, Y.; Yang, L.; Hu, X.; Zhang, Y. An Improved Gradient Boosting Regression Tree Estimation Model for Soil Heavy Metal (Arsenic) Pollution Monitoring Using Hyperspectral Remote Sensing. Appl. Sci. 2019, 9, 1943. [Google Scholar] [CrossRef]
- Chen, T.; Chang, Q.; Clevers, J.G.P.W.; Kooistra, L. Rapid identification of soil cadmium pollution risk at regional scale based on visible and near-infrared spectroscopy. Environ. Pollut. 2015, 206, 217–226. [Google Scholar] [CrossRef]
- Shi, T.; Chen, Y.; Liu, Y.; Wu, G. Visible and near-infrared reflectance spectroscopy—An alternative for monitoring soil contamination by heavy metals. J. Hazard. Mater. 2014, 265, 166–176. [Google Scholar] [CrossRef]
- Xie, H.; Zhao, J.; Wang, Q.; Sui, Y.; Wang, J.; Yang, X.; Zhang, X.; Liang, C. Soil type recognition as improved by genetic algorithm-based variable selection using near infrared spectroscopy and partial least squares discriminant analysis. Sci. Rep. 2015, 5, 10930. [Google Scholar] [CrossRef]
- Shi, T.; Wang, J.; Chen, Y.; Wu, G. Improving the prediction of arsenic contents in agricultural soils by combining the reflectance spectroscopy of soils and rice plants. Int. J. Appl. Earth Obs. Geoinf. 2016, 52, 95–103. [Google Scholar] [CrossRef]
- Mishra, S.P.; Sarkar, U.; Taraphder, S.; Datta, S.; Swain, D.P.; Saikhom, R.; Panda, S.; Laishram, M. Multivariate Statistical Data Analysis- Principal Component Analysis (PCA). Int. J. Livest. Res. 2017, 7, 60–78. [Google Scholar]
- Maduranga, U.; Wijegunarathna, K.; Weerasinghe, S.; Perera, I.; Wickramarachchi, A. Dimensionality Reduction for Cluster Identification in Metagenomics using Autoencoders. In Proceedings of the 2020 20th International Conference on Advances in ICT for Emerging Regions (ICTer), Colombo, Sri Lanka, 4–7 November 2020. [Google Scholar]
- Knadel, M.; Arthur, E.; Weber, P.; Moldrup, P.; Greve, M.H.; Chrysodonta, Z.P.; de Jonge, L.W. Soil Specific Surface Area Determination by Visible Near-Infrared Spectroscopy. Soil Sci. Soc. Am. J. 2018, 82, 1046–1056. [Google Scholar] [CrossRef]
- Deng, X.G.; Zhong, N.; Wang, L. Nonlinear Multimode Industrial Process Fault Detection Using Modified Kernel Principal Component Analysis. IEEE Access 2017, 5, 23121–23132. [Google Scholar] [CrossRef]
- Zhao, Z.G.; Liu, F. On-line nonlinear process monitoring using kernel principal component analysis and neural network. In Advances in Neural Networks—ISNN 2006, Pt 3, Proceedings; Wang, J., Yi, Z., Zurada, J.M., Lu, B.L., Yin, H., Eds.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2006; Volume 3973, pp. 945–950. [Google Scholar]
- Zhu, Y.; Luo, Y.; Chen, J.; Wan, Q. Industrial transformation efficiency and sustainable development of resource-exhausted cities: A case study of Daye City, Hubei province, China. Environ. Dev Sustain. 2023, 1–25. [Google Scholar] [CrossRef]
- Li, C.; Yang, Z.; Yu, T.; Hou, Q.; Wu, T. Study on safe usage of agricultural land in karst and non-karst areas based on soil Cd and prediction of Cd in rice: A case study of Heng County, Guangxi. Ecotoxicol. Environ. Saf. 2021, 208, 111505. [Google Scholar] [CrossRef] [PubMed]
- Li, M.; Xi, X.; Xiao, G.; Cheng, H.; Yang, Z.; Zhou, G.; Ye, J.; Li, Z. National multi-purpose regional geochemical survey in China. J. Geochem. Explor. 2014, 139, 21–30. [Google Scholar] [CrossRef]
- Hong, Y.; Liu, Y.; Chen, Y.; Liu, Y.; Yu, L.; Liu, Y.; Cheng, H. Application of fractional-order derivative in the quantitative estimation of soil organic matter content through visible and near-infrared spectroscopy. Geoderma 2019, 337, 758–769. [Google Scholar] [CrossRef]
- Sun, W.; Zhang, X. Estimating soil zinc concentrations using reflectance spectroscopy. Int. J. Appl. Earth Obs. Geoinf. 2017, 58, 126–133. [Google Scholar] [CrossRef]
- Zhang, X.; Sun, W.; Cen, Y.; Zhang, L.; Wang, N. Predicting cadmium concentration in soils using laboratory and field reflectance spectroscopy. Sci. Total Environ. 2019, 650, 321–334. [Google Scholar] [CrossRef] [PubMed]
- Kariuki, P.C.; Van, D. Determination of Soil Activity from Optical Spectroscopy. 2003. Available online: https://repository.dkut.ac.ke:8080/xmlui/handle/123456789/4824 (accessed on 1 May 2024).
- Merler, S.; Caprile, B.; Furlanello, C. Parallelizing AdaBoost by weights dynamics. Comput. Stat. Data Anal. 2007, 51, 2487–2498. [Google Scholar] [CrossRef]
- Nakamura, M.; Nomiya, H.; Uehara, K. Improvement of boosting algorithm by modifying the weighting rule. Ann. Math. Artif. Intell. 2004, 41, 95–109. [Google Scholar] [CrossRef]
- Saeys, W.; Mouazen, A.; Ramon, H. Potential for Onsite and Online Analysis of Pig Manure using Visible and Near Infrared Reflectance Spectroscopy. Biosyst. Eng. 2005, 91, 393–402. [Google Scholar] [CrossRef]
- Sawut, R.; Kasim, N.; Abliz, A.; Hu, L.; Yalkun, A.; Maihemuti, B.; Qingdong, S. Possibility of optimized indices for the assessment of heavy metal contents in soil around an open pit coal mine area. Int. J. Appl. Earth Obs. Geoinf. 2018, 73, 14–25. [Google Scholar] [CrossRef]
- Chang, C.-W.; Laird, D.; Mausbach, M.; Hurburgh, C. Near-Infrared Reflectance Spectroscopy–Principal Components Regression Analyses of Soil Properties. Soil Sci. Soc. Am. J. 2001, 65, 480–490. [Google Scholar] [CrossRef]
- Chen, C.F.; Zhao, N.; Yue, T.X.; Guo, J.Y. A generalization of inverse distance weighting method via kernel regression and its application to surface modeling. Arab. J. Geosci. 2015, 8, 6623–6633. [Google Scholar] [CrossRef]
- Barbulescu, A.; Bautu, A.; Bautu, E. Optimizing Inverse Distance Weighting with Particle Swarm Optimization. Appl. Sci. 2020, 10, 2054. [Google Scholar] [CrossRef]
- Guo, J.; Zhao, X.W.; Yuan, X.; Li, Y.Y.; Peng, Y. Discriminative unsupervised 2D dimensionality reduction with graph embedding. Multimed. Tools Appl. 2018, 77, 3189–3207. [Google Scholar] [CrossRef]
- Zhang, Z.H.; Guo, F.; Xu, Z.; Yang, X.; Wu, K.Z. On retrieving the chromium and zinc concentrations in the arable soil by the hyperspectral reflectance based on the deep forest. Ecol. Indic. 2022, 144, 109440. [Google Scholar] [CrossRef]
- Guo, F.; Wang, Y.; Lin, D.; Xu, Z. On Optimizing the Principal Component Analysis in the Hyperspectral Inversion of Chromium and Zinc Concentrations by the Deep Forest. IEEE Geosci. Remote Sens. Lett. 2023, 20, 1–5. [Google Scholar] [CrossRef]
- Gu, H.M.; Lin, T.; Wang, X. A preliminary geometric structure simplification for Principal Component Analysis. Neurocomputing 2019, 336, 46–55. [Google Scholar] [CrossRef]
- Chen, H.R.; Li, J.H.; Gao, J.B.; Sun, Y.F.; Hu, Y.L.; Yin, B.C. Maximally Correlated Principal Component Analysis Based on Deep Parameterization Learning. ACM Trans. Knowl. Discov. Data 2019, 13, 39. [Google Scholar] [CrossRef]
- Zhang, X.; Song, Q. A Multi-Label Learning Based Kernel Automatic Recommendation Method for Support Vector Machine. PLoS ONE 2015, 10, e0120455. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Kernel Functions | Polynomial Kernel | RBF Kernel | Sigmoid Kernel |
|---|---|---|---|
| Kernel parameters |
| Soil Cu (mg·kg−1) | Number | Min | Max | Median | Mean | SD 1 | CV 2 |
|---|---|---|---|---|---|---|---|
| Calibration set | 38 | 21.68 | 320.86 | 73.03 | 90.43 | 67.89 | 0.75 |
| Validation set | 18 | 29.81 | 284.73 | 73.38 | 86.10 | 58.36 | 0.68 |
| Whole dataset | 56 | 21.68 | 320.86 | 73.03 | 89.04 | 64.48 | 0.72 |
| Methods | Spectral Type | The Number of Optimal Preserved PCs | Prediction Accuracy | ||
|---|---|---|---|---|---|
| R2 | RMSE (mg·kg−1) | RPD | |||
| Non-dimensionality reduction | Original spectra | - | 0.14 | 55.41 | 1.06 |
| FDT-processed spectra | - | 0.24 | 58.38 | 0.97 | |
| PCA | Original spectra | 13 | 0.53 | 38.89 | 1.50 |
| FDT-processed spectra | 13 | 0.60 | 35.85 | 1.63 | |
| Poly-KPCA | Original spectra | 14 | 0.69 | 31.41 | 1.86 |
| FDT-processed spectra | 15 | 0.86 | 21.47 | 2.72 | |
| RBF-KPCA | Original spectra | 13 | 0.46 | 41.61 | 1.40 |
| FDT-processed spectra | 18 | 0.52 | 39.40 | 1.48 | |
| Sigmoid-KPCA | Original spectra | 10 | 0.66 | 33.14 | 1.76 |
| FDT-processed spectra | 13 | 0.72 | 30.26 | 1.93 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guo, F.; Xu, Z.; Ma, H.; Liu, X.; Gao, L. On Optimizing Hyperspectral Inversion of Soil Copper Content by Kernel Principal Component Analysis. Remote Sens. 2024, 16, 2914. https://doi.org/10.3390/rs16162914
Guo F, Xu Z, Ma H, Liu X, Gao L. On Optimizing Hyperspectral Inversion of Soil Copper Content by Kernel Principal Component Analysis. Remote Sensing. 2024; 16(16):2914. https://doi.org/10.3390/rs16162914
Chicago/Turabian StyleGuo, Fei, Zhen Xu, Honghong Ma, Xiujin Liu, and Lei Gao. 2024. "On Optimizing Hyperspectral Inversion of Soil Copper Content by Kernel Principal Component Analysis" Remote Sensing 16, no. 16: 2914. https://doi.org/10.3390/rs16162914
APA StyleGuo, F., Xu, Z., Ma, H., Liu, X., & Gao, L. (2024). On Optimizing Hyperspectral Inversion of Soil Copper Content by Kernel Principal Component Analysis. Remote Sensing, 16(16), 2914. https://doi.org/10.3390/rs16162914