1. Introduction
Synthetic Aperture Radar (SAR) is a ground-based observation system that utilizes the continuous movement of radar antennas on a flying platform to simulate a long antenna, thus achieving high-resolution imaging. SAR observes the Earth’s surface all-day and all-weather, possessing strong penetration capabilities and capable of acquiring high-quality image information [
1,
2,
3]. Therefore, SAR is applied in various fields, such as soil detection, disaster monitoring, environmental surveillance, and military reconnaissance, where it offers unique advantages that are difficult to replace with other remote sensing methods. Airport aircraft, as typical targets, have wide applications in both military and civilian domains. Hence, aircraft object detection in SAR images has become one of the current research hotspots.
Traditional SAR image object-detection methods primarily rely on manual extraction of target scattering features and the CFAR algorithm [
4]. Manual extraction of target features relies mainly on previous object detection experience and expert analysis. When the target background becomes complex, manual feature extraction becomes difficult. This results in a significantly reduced accuracy and a lack of robustness in detection. CFAR is a common object-detection algorithm in radar systems, which adaptively estimates the statistical characteristics of complex background noise to obtain target echoes, thus achieving object detection. Considering the non-uniformity of the background, several researchers have explored the statistical characteristics of target echoes and background clutter, proposing many improved algorithms for CFAR, such as CA-CFAR [
5], SO-CFAR [
6], VI-CFAR [
7], OS-CFAR [
8], etc. CA-CFAR and SO-CFAR are both mean-type CFAR detectors, which take the average of the sampled power of target echoes within the reference window as an estimate of the background clutter power. CA-CFAR minimizes the missed alarm rate of SAR image object detection to the greatest extent, but it does not adequately tackle the challenge of multi-target occlusion. SO-CFAR enhances the ability to detect multiple targets; however, a significant drawback is the high false alarm rate observed in the edge regions of background clutter. VI-CFAR adjusts the threshold and window size according to the actual situation, improving the precision of object detection and reducing the false alarm rate, but it requires more computational resources. OS-CFAR sorts the sampling data in ascending order within the reference window and selects the k-th value as the background clutter power, further improving the model’s accuracy in multi-object detection, but still suffers from a high false alarm rate in the edge regions of background clutter.
In recent years, as SAR imaging technology advances, SAR images have increased in scale, and the information in the images has become more complex. This poses higher demands on the detection performance of targets in SAR images, and traditional detection methods struggle to satisfy the practical application requirements for both detection accuracy and speed. SAR imaging technology exhibits different polarization modes and illumination angles under different working modes, and targets in SAR images often exhibit different aspect angles. At this point, conventional SAR image object-detection methods have difficulty efficiently and accurately completing detection, and their generalization ability is also insufficient. As a result, there have been many SAR image object-detection methods involving deep learning. Deep learning leverages the greater feature extraction capability of the convolutional neural network (CNN) to better utilize the correlation characteristics of scattering points in SAR images. It has unique advantages in detection accuracy. Detection methods based on deep learning are classified into two main categories: one-stage and two-stage methods. Two-stage methods initially employ a Region Proposal Network (RPN) to propose several regions of interest (RoI) where targets may exist and then further refine these regions for object detection and recognition. Classic models of such a method include Fast R-CNN [
9], Faster R-CNN [
10], Cascade R-CNN [
11], etc. Jiao et al. [
12] constructed a ship detection model utilizing Faster R-CNN and validated its effectiveness in multi-scale ship detection in SAR images. The one-stage method infers target bounding boxes and performs classification directly based on the target features extracted by CNNs, saving a significant amount of computational resources and time. Common one-stage methods include RetinaNet [
13], SSD [
14], YOLOv7 [
15], CornetNet [
16], etc. Zhou et al. [
17] designed a lightweight network inspired by YOLO, which adopts small convolutions to extract image features and adds bidirectional dense connection modules to reduce network complexity. This approach achieves high-precision detection of SAR image targets with less memory and computational cost.
Considering the influence of complex background clutter, the precision of the object detection of the above-mentioned deep learning models is affected by SAR images. Wang et al. [
18] conducted a rapid candidate target search using the saliency region method, followed by precise detection using a CNN. He et al. [
19] addressed the scattering mechanism of SAR images and constructed a multi-layer parallel network using deep features and component information to reduce the false alarms of aircraft detection. Guo et al. [
20] combined an Attention Pyramid Network (APN) with Scatter Information Enhancement (SIE) for aircraft detection within SAR images under complex backgrounds and dense target arrangements. However, aircraft detection within SAR images remains challenging because of SAR’s complex imaging mechanism. Aircraft within SAR images are represented by a series of scattering points with large fluctuations in intensity, making targets prone to being divided into multiple discrete components. Moreover, there are many irrelevant devices around land aircraft, which also appear as multiple strong scattering points in SAR images, leading to confusion with aircraft and increasing the difficulty of detection. The scattering characteristics of different categories of aircraft are relatively similar, and under different imaging angles, targets of the same category also exhibit different scattering characteristics, resulting in large intra-class differences, making the recognition task of aircraft difficult. Furthermore, most of the previous research has focused solely on object detection, without the classification of aircraft.
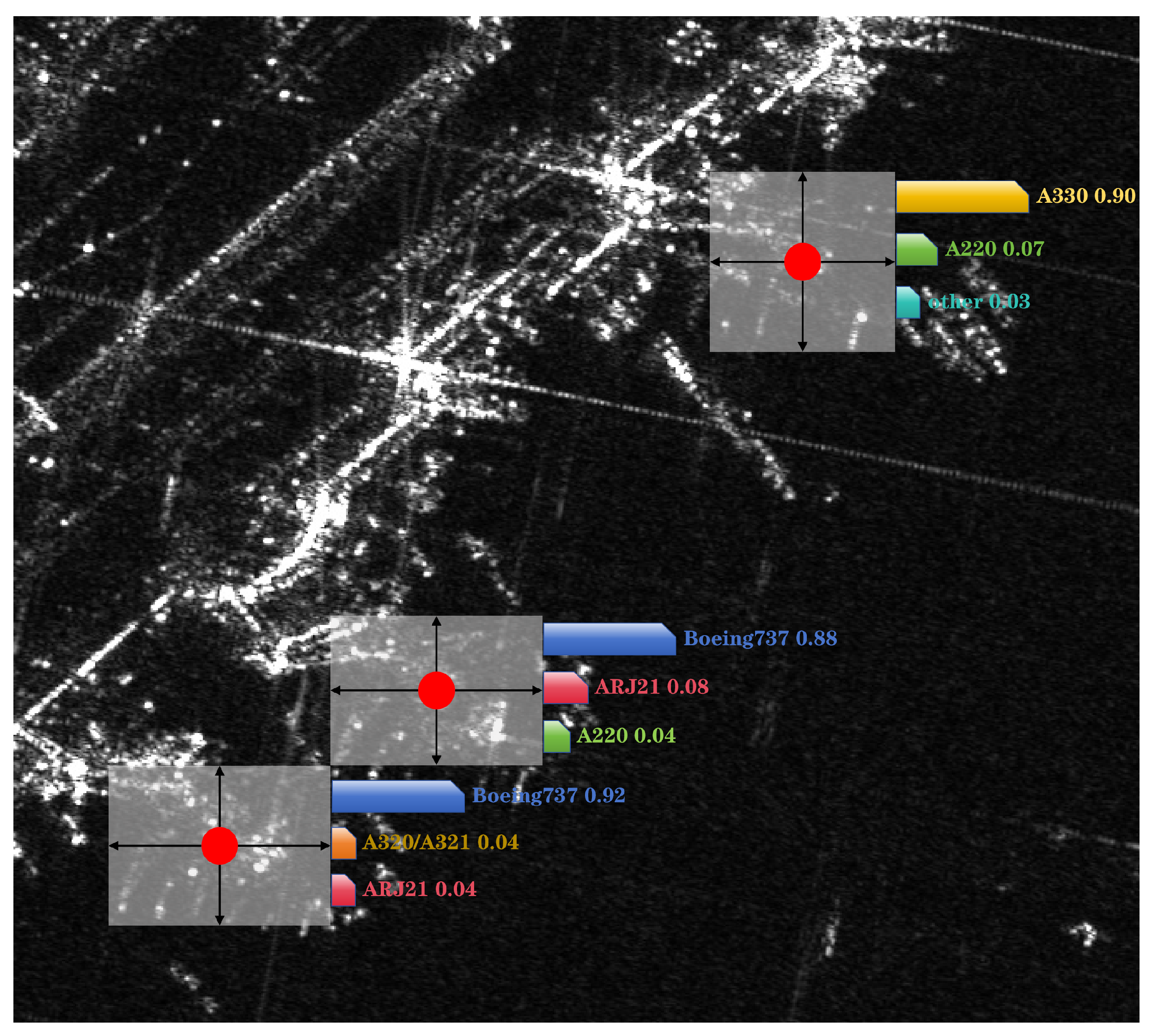
To address the challenges mentioned above, the paper proposes a scattering-point-intensity-adaptive detection and recognition network (SADRN) to enhance the performance of integrated detection and recognition for aircraft targets amidst complex backgrounds and multi-scale cases. Considering the small aircraft targets in SAR images, directly predicting rectangular detection boxes for these targets is difficult and prone to missed alarms. The model predicts the target center instead of the rectangular detection box. Simultaneously, it constructs a Self-adaptive Bell-shaped Kernel (SBK), which constructs a bell-shaped two-dimensional distribution centered on the target center, making the detection “threshold” for the target decrease from the center towards the periphery, reducing the missed alarms of weak scattering points at the edges of the target. Since aircraft targets in SAR images exhibit multi-scale characteristics, the paper proposes the full-aggregation DLA-34 backbone network (FADLA-34) to aggregate the multi-scale feature maps from different network stages, reducing missed alarms on small targets. The backbone network finally outputs three feature maps: the different categories’ heatmap of the target center, the offset map of the target center, and the size map of the object-detection boxes. Meanwhile, to minimize interference from complex backgrounds on aircraft detection, we embedded the Convolutional Block Attention Module (CBAM) [
21] into the FADLA-34 backbone network, which assigns weights to the feature map generated by each convolutional block from the channel dimension and spatial dimension, measuring the contribution of different regions to detection and recognition. In the channel dimension, it utilizes different features extracted from different channels to more sufficiently describe aircraft. In the spatial dimension, it enhances the distinction between target regions and the background, suppressing clutter interference from complex backgrounds. To achieve the integrated detection and recognition of the network, we constructed a multi-task head, which utilizes three feature maps output by the backbone network. The recognition result is the category of the heatmap with the highest pixel value at the center of the target, while the other two feature maps are used to generate the detection box of the target. The concept of integrated detection and recognition is illustrated in
Figure 1.
The following are the summarized contributions we have made in this work:
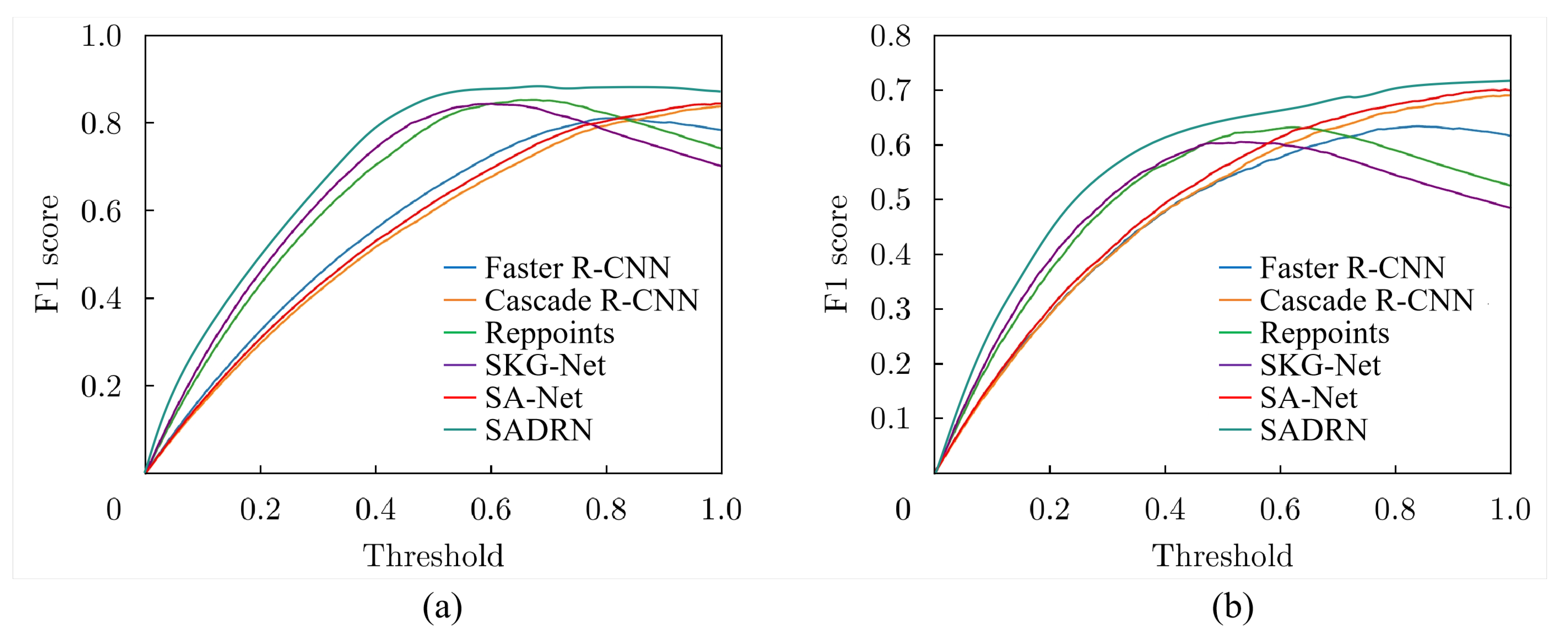
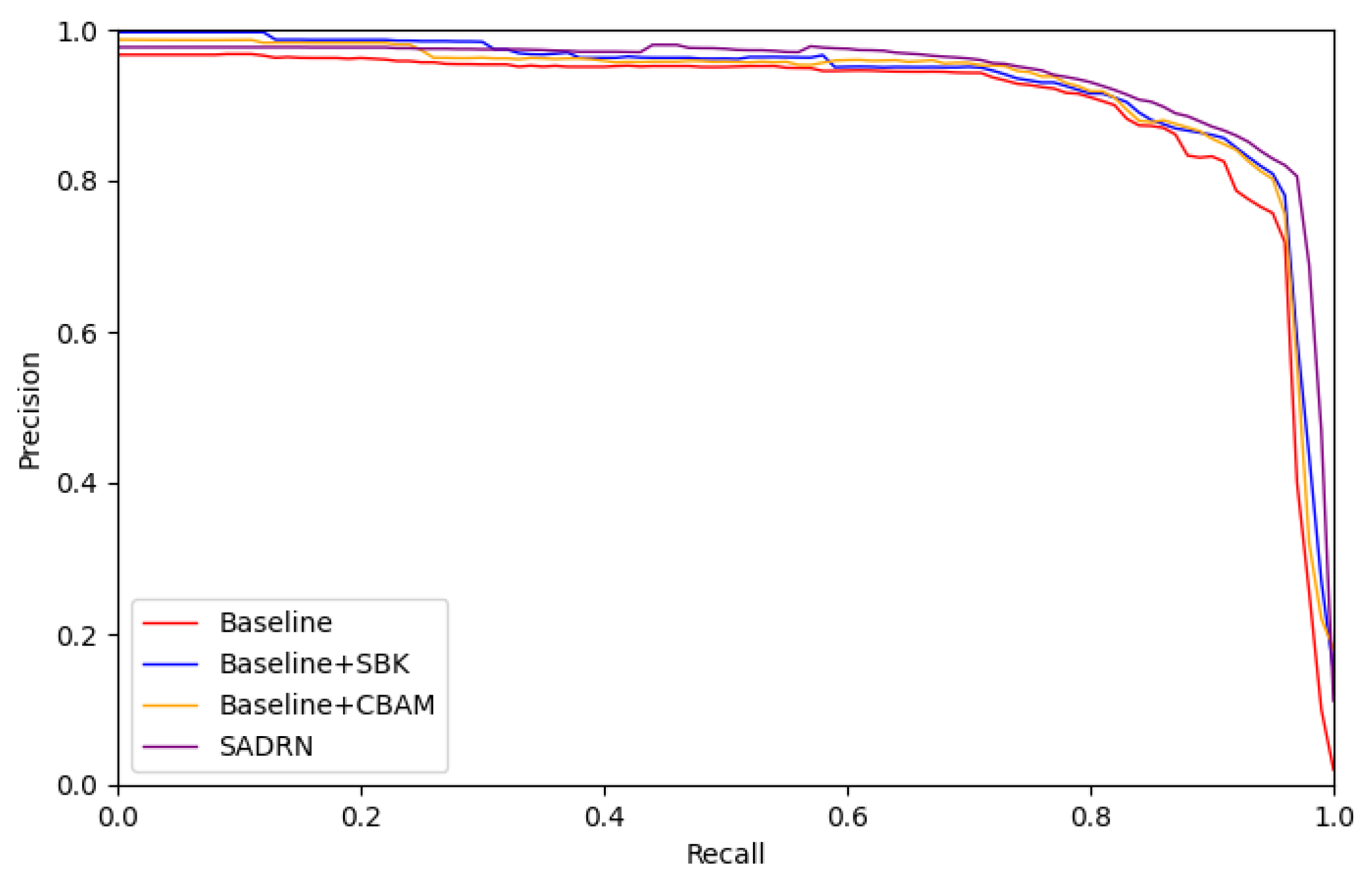
(1) The proposed SADRN enhances the detection capability of multi-scale targets by predicting the target center instead of the bounding box. Additionally, we constructed a Self-adaptive Bell-shaped Kernel (SBK), which constructs a bell-shaped two-dimensional distribution centered on the target center, making the equivalent detection “threshold” for the target decrease from the center towards the periphery, reducing the missed alarms of weak scattering points at the target edges. The detection and recognition performance of the SADRN on the high-resolution SAR aircraft detection and recognition dataset (SAR-AIRcraft-1.0) outperforms current mainstream networks.
(2) We introduce the full-aggregation DLA-34 backbone network (FADLA-34) to address the challenges in detection and recognition caused by the characteristics of aircraft in SAR images. DLA-34 aggregates the multi-scale feature maps across different network stages, reducing the missed alarms for small aircraft targets in SAR images. Meanwhile, CBAM is embedded in the backbone network, considering the attention to the channel dimension and the spatial dimension. The channel attention module utilizes different features extracted from different channels to sufficiently describe aircraft targets in SAR images. The spatial attention module strengthens the difference between the target regions and background in SAR images to minimize interference from complex background clutter on object detection.
(3) We utilized the multi-task head to realize the integration of detection and recognition, which utilizes three feature maps output by the backbone network: the different categories’ heatmap of the target center, the offset map of the target center, and the size map of the object-detection boxes. The recognition result is the category of the heatmap with the highest pixel value at the center of the target, while the other two feature maps are used for generating the detection box of the target.
2. Related Work
2.1. CNN-Based Object Detection
The CNN has strong feature-extraction capabilities on images and has been widely used in recent years in the field of computer vision. Today, CNN-based object-detection methods have surpassed traditional detection methods and become the mainstream approach for object detection. Now, CNN-based object-detection methods are primarily divided into two categories, namely two-stage and one-stage detectors.
Two-stage detectors initially utilize the RPN to perform feature extraction on images and generate RoIs, then classify and post-process these RoIs. The main focus of this method is on how to improve the capabilities of feature extraction of the RPN on images to improve the correct probability of generating RoIs, thus enhancing the accuracy of object detection. These methods build upon RoIs, mainly represented by the series of algorithms known as R-CNNs: Fast R-CNN [
9], Faster R-CNN [
10], Cascade R-CNN [
11], etc. The R-CNN was the first to apply the CNN to the domain of object detection, exhibiting excellent detection performance, with CNN-extracted deep features replacing traditional features such as HOG and SIFT. Fast R-CNN advances upon R-CNN by introducing the RoI pooling layer, which converts multi-scale RoIs into feature maps of the same scale, significantly increasing detection speed. Faster R-CNN [
10] abandons selective search methods and conventional sliding windows, generating RoIs directly using the RPN, greatly improving the speed of RoI generation and, thus, enhancing detection performance. Cascade R-CNN [
11] designs multiple cascaded R-CNNs, using progressively increased IoU thresholds to train each detector, effectively enhancing the detection performance of the network.
One-stage detectors predict target classification and position directly based on features extracted by the CNN, generating final prediction results in a single detection step without the need to generate RoIs. Therefore, compared to two-stage detectors, they have faster detection speeds. However, the accuracy may decrease when detecting small targets because two-stage detectors perform fine-grained processing on each region after generating the RoIs, thereby achieving more accurate object detection. Typical one-stage detectors include the SSD [
14] and RetinaNet [
13]. The SSD [
14] detects targets using multi-scale feature maps, making it highly adaptable to targets of different scales. RetinaNet [
13] first proposed the Focal loss function, reducing the impact of extremely imbalanced positive and negative sample ratios on the accuracy of one-stage detectors.
2.2. CNN-Based SAR Image Aircraft Detection
Due to advancements in deep learning and SAR image resolution, the CNN has found successful applications in SAR image object detection. However, owing to the special imaging mechanism of SAR, aircraft targets are typically composed of scattering points with large fluctuations in intensity. This often leads to missed alarms of weak scattering points.
However, the SSD [
14] and RetinaNet [
13] mentioned above are both anchor-based detectors, where anchors are predefined detection boxes for targets using sliding windows. Currently, many anchor-free detectors have emerged, eliminating the need to preset a large number of anchors through sliding windows, further improving the model’s detection speed. CornerNet [
16] is an anchor-free network proposed in recent years, using the bottom-right and the top-left corners of the object-detection box to jointly represent the detection box.
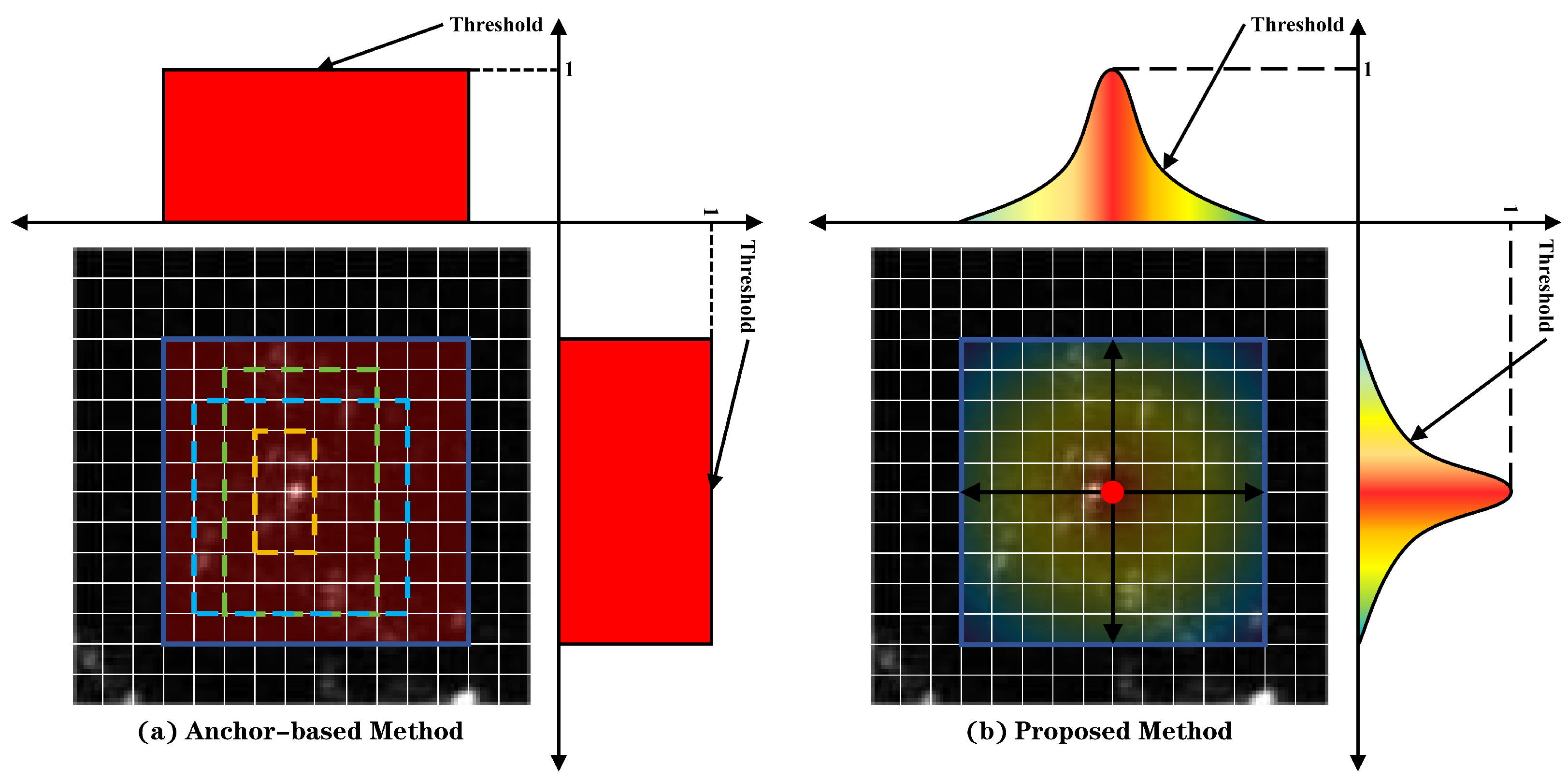
To reduce the missed alarms of target’s weak scattering points, we introduce an anchor-free target detector, which transforms delineating the object-detection box into locating the center on the target. Since the targets on the SAR images are mostly discrete scattering points, most anchors generated by anchor-based detectors frame only one scattering point of the target, thus wasting computational costs and reducing the accuracy of detection. Our method first detects the center of the target and then predicts the target size, allowing it to determine the target area at a more granular level. These advantages make it suitable for detecting aircraft in SAR images. When anchor-based detection methods preset anchors, if the predicted value of a pixel is 1, then the point is determined to be within the anchor area, and if the predicted value is 0, it is determined as the background. This determination method is too strict for weak scattering points within the target, causing missed alarms of weak scattering points, ultimately leading to inaccurate positioning of the target area. To avoid this situation, we constructed a bell-shaped two-dimensional distribution centered on the target center, which is determined by the statistical characteristics of the scattering points. This causes the equivalent detection “threshold” for scattering points to decrease from the center towards the periphery, reducing the missed alarms of weak scattering points at the target edges. The differences between the method we propose and the standard anchor-based detector are illustrated in
Figure 2.
Moreover, targets are often multi-scale and blurry and are heavily influenced by background interference, making object detection in SAR images using the CNN still a challenging problem. To improve the accuracy of SAR image object detection, the attention module is embedded into CNNs, which allows CNNs to autonomously learn and selectively focus on feature extraction in the target regions of SAR images, reducing interference from background clutter on object detection, thereby improving the model’s effectiveness and generalization capability.
In the aspect of aircraft detection within SAR images, Zhao et al. [
22] developed a novel pyramid attention expansion network. The network simultaneously embeds multi-branch dilated convolution modules (MBDCMs) and CBAM, refining redundant information to highlight important features of aircraft. Huang et al. [
23] integrated an efficient channel attention module into YOLO5s, effectively suppressing irrelevant background information while enhancing the speed and accuracy of the network. This integration endows the model with robust anti-interference capabilities. Zhao et al. [
24] proposed the attentional feature refinement and alignment network (AFRAN) by adding the attention feature fusion module (AFFM) to fully integrate high-level semantic features and low-level texture features of aircraft. Kang et al. [
25] proposed the scattering feature relationship network (SFR-Net), which not only integrates contextual feature attention, but also expands the receptive field to facilitate capturing global information. This enhancement leads to improved target localization accuracy. Lin et al. [
26] integrated a weakly supervised deformable convolution module (WSDCM) and CBAM, accurately locating aircraft spots while effectively suppressing interference.
To tackle the detection challenges arising from complex background clutter and the multi-scale characteristic of targets, we introduce a backbone network, aggregating information from multi-scale feature maps to reduce missed alarms for small targets. Additionally, it embeds CBAM to enhance attention on target regions, which assigns weights to the feature map generated by each convolutional block from the channel dimension and the spatial dimension, measuring the contribution from different regions to detection and recognition.
Furthermore, previous studies on SAR image aircraft object detection primarily focused on locating rectangular detection boxes for aircraft targets, but neglected target classification. Performing detection and recognition tasks simultaneously causes their interference with each other, resulting in a decline in the performance of both tasks. Given this, we constructed a multi-task head to achieve integrated detection and recognition, which makes the model exhibit excellent performance.
3. Methods
Due to the special imaging mechanism of SAR images, aircraft targets are typically composed of scattering points with large intensity variations, making the detection prone to missed alarms of weak scattering points. Aircraft targets in SAR images exhibit multi-scale characteristics, which can lead to missed alarms of small targets. The clutter from complex backgrounds often affects object detection, then reduces detection accuracy. Furthermore, previous SAR image target detectors only focused on locating targets, lacking the ability of target classification. To address these issues in SAR image aircraft object detection, we propose the SADRN architecture, simultaneously possessing excellent multi-task capabilities.
3.1. Scattering-Point-Intensity-Adaptive Detection and Recognition Network
The overall architecture of the network structure we propose, SADRN, is illustrated in
Figure 3. It consists of four modules: the full-aggregation DLA-34 (FADLA-34) backbone, Self-adaptive Bell-shaped Kernel (SBK), Convolutional Block Attention Module (CBAM), and multi-task head. In SAR images, aircraft targets exhibit multi-scale characteristics, often leading to missed alarms of small targets. Therefore, to improve the model’s detection accuracy for multi-scale targets, we constructed the FADLA-34 backbone. The input of FADLA-34 is SAR images
, and its output consists of three feature maps, the heatmap of the target center
, the offset map of the target center
, and the size map of the object-detection boxes
, where
W and
H denote the size of the input SAR image,
C denotes the number of aircraft categories, and
R denotes the downsampling stride, typically set to 4 by default. The three feature maps are utilized by the multi-task head for integrated detection and recognition. FADLA-34 integrates information from different scale feature maps at various stages of the network. To mitigate interference from background clutter, CBAM is embedded within the FADLA-34 backbone network. CBAM calculates the weights for the channel dimension and the spatial dimension of the input feature maps through pooling and other operations. The input feature maps are then sequentially multiplied by the channel weights and spatial weights to obtain processed feature maps. These processed feature maps enhance attention on the target area. In SAR images, the significant intensity variations of the target scattering points often result in false alarms. The SBK maps a bell-shaped two-dimensional distribution around each target center in the heatmap’s ground truth
. The heatmap’s ground truth
Y processed by the SBK is then used to train the heatmap. Since the pixel values at the edges of the bell-shaped distribution are relatively low, it reduces the detection “threshold” for weak scattering points at the edges of the target, enabling the model to better locate the target area. The multi-task head is utilized to achieve integrated detection and recognition. For the same target, among the heatmap of different categories, the multi-task head selects the heatmap with the highest pixel value at the target center. The category to which this heatmap belongs is considered as the model’s recognition result. Meanwhile, the multi-task head utilizes the offset map and size map to generate the detection box for the target.
3.2. The Design of Loss Function
The FADLA-34 backbone predicts the target center heatmap , target center offset map , and detection box size map .
Let
represent the collection of the predicted center heatmap for each class. When the prediction result
, this indicates that the point at coordinates
in the heatmap of category
c is detected as the target center, while
indicates that the point is detected as background. Let the ground truth heatmap of the target center be denoted as
Y. Next, an SBK is mapped around each target center of
Y. The processed ground truth
Y is used to train the heatmap. The loss function for the heatmap adopts the Focal loss [
13], denoted as
in Equation (
1):
where
and
denote the hyper-parameters of the Focal loss. In the experiments,
and
.
N denotes the number of target centers in SAR image
I.
By minimizing the loss function , at the true center , where , the predicted value will approach 1 during training. Conversely, at the non-center, where , the predicted value will gradually approach 0.
represents the predicted offset of the center. In inference, due to the downsampling performed by the backbone network, there will be accuracy errors when the predicted center points are remapped to the original image. Therefore, each center point requires additional offset
. In SAR images
I, the coordinate
denotes the center of target
k. After downsampling by the backbone, the corresponding coordinate is obtained as
, where
and
.
represents the ground truth used for training the offset of the center. All categories
c share the same offset map
. The L1 loss is adopted as the loss function for the offset of the center, denoted as
in Equation (
2):
where
denotes the predicted offset for the center of target
k and
N denotes the number of target centers in SAR image
I.
By minimizing the loss function , the predicted offset approaches the true offset during training.
represents the predicted size of the object-detection boxes, which uses
and
to, respectively, represent the predicted width and height of the detection boxes. Let
denote the detection box of target
k. The size of target
k is denoted as
.
represents the ground truth used for training the size of the detection boxes. All categories
c share the same size map
. The loss function for the size of targets uses the L1 loss, denoted as
in Equation (
3):
where
denotes the predicted size of the target
k and
N denotes the number of target centers in SAR image
I.
By minimize the loss function , the predicted size of the detection box approaches the true size during training.
The overall loss function for the SADRN network can be described by Equation (
4):
where
and
are used to balance the influence of each loss function on the experiment. We set these to the default as
and
.
3.3. Multi-Scale Aircraft-Detection and -Recognition Model
Addressing the multi-scale characteristic of aircraft targets in SAR images, we propose that the FADLA-34 backbone network consists of DLA-34 [
27] and the Deformable Convolution Network (DCN) [
28]. The structure of FADLA-34 is shown in
Figure 4. DLA-34, serving as an image-classification network, possesses the ability of hierarchical skip connections to aggregate the feature maps of different sizes to improve the adaptability to multi-scale targets of the network in SAR images. Meanwhile, deformable convolution is utilized in the fusion of feature maps. Unlike regular convolution operations, deformable convolution can adaptively extract effective features within the target region, enabling the model to better accommodate the irregular shape of aircraft in SAR images. When SAR image
is input in the backbone network, FADLA-34 first employs the DLA-34 network to extract multi-scale feature maps from different network stages, followed by the DCN to upsample and aggregate these feature maps to the same scale. FADLA-34 ultimately outputs
, which contains three feature maps: heatmap
, offset map
, and size map
. The size of these feature maps is four-times smaller than the input SAR image
I.
3.3.1. DLA-34
DLA-34 [
27] is divided into six levels from Level 0 to Level 5, with connections between different levels through Iterative Deep Aggregation (IDA) and Hierarchical Deep Aggregation (HDA), and the downsample stride for each level is 2. The operations between Level 0 and Level 1 are the same, where the input feature map undergoes convolution once, followed by downsampling, and then, outputs the feature map. The operations in the remaining levels are more complex, involving convolution, the aggregation node, and embedded CBAM. We will introduce CBAM in the following subsection.
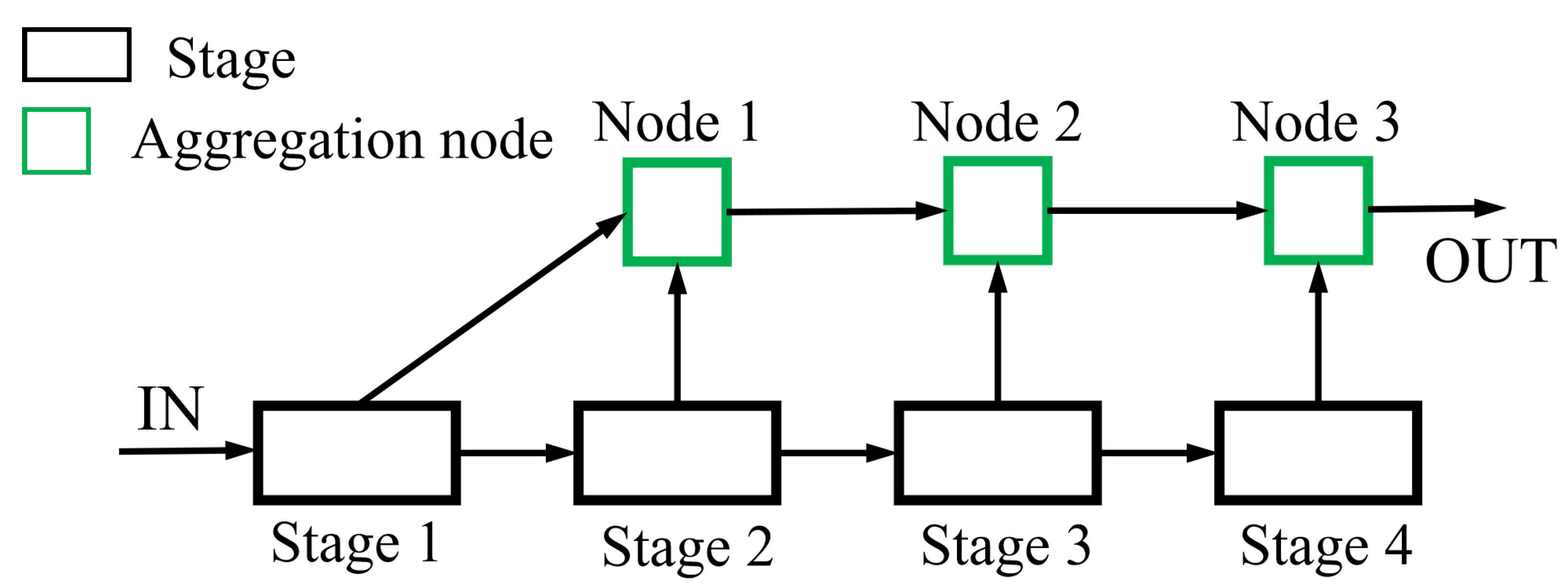
In DLA-34, we utilize aggregation nodes to merge feature maps from different layers or blocks into a single feature output, which is illustrated in
Figure 5. The aggregation node chooses a
convolution followed by batch normalization and, finally, activates the feature map by the sigmoid nonlinear function.
The IDA iteratively aggregates subsequent network stages starting from the shallowest network stage, allowing shallow feature information to propagate to the subsequent stages. The structure of the IDA is shown in
Figure 6.
The HDA focuses on the connections between blocks within a network stage. Using a tree-like structure, the HDA integrates features output by blocks within each stage multiple times. The structure shown in
Figure 7 is an HDA with a depth of 3. The HDA function is defined by the following Equation (
5):
where
denotes the HDA structure with depth
n and
R and
L denote the child nodes in the HDA structure, as defined in Equations (
6) and (
7).
where
B denotes the convolution block.
3.3.2. Deformable Convolution Network
The DCN [
28] extracts four multi-scale feature maps (L2 to L5) output by each level of the DLA-34 network. These feature maps are sequentially upsampled and fused into one feature map for output. In the DCN, deformable convolution is used instead of standard convolution.
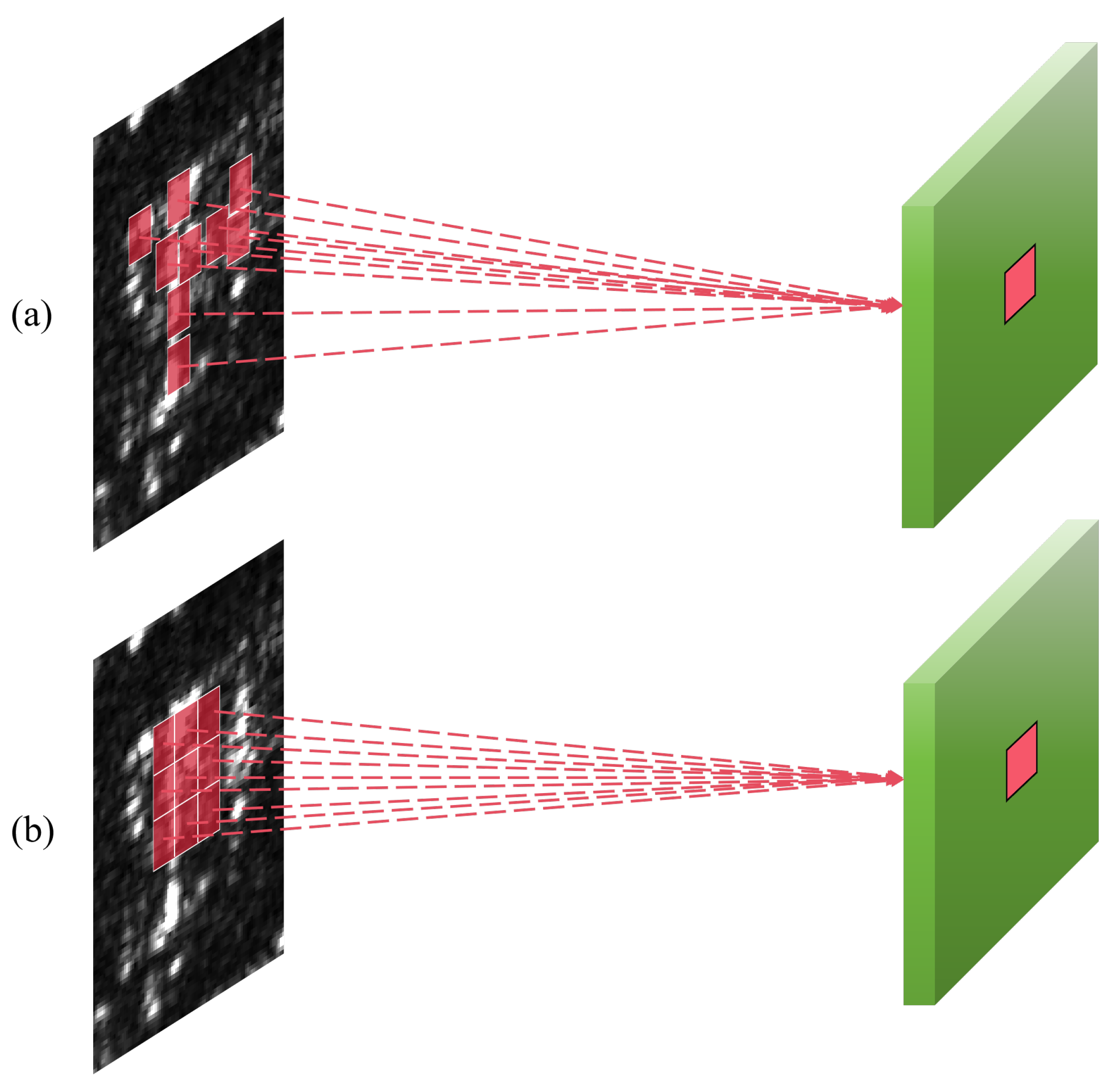
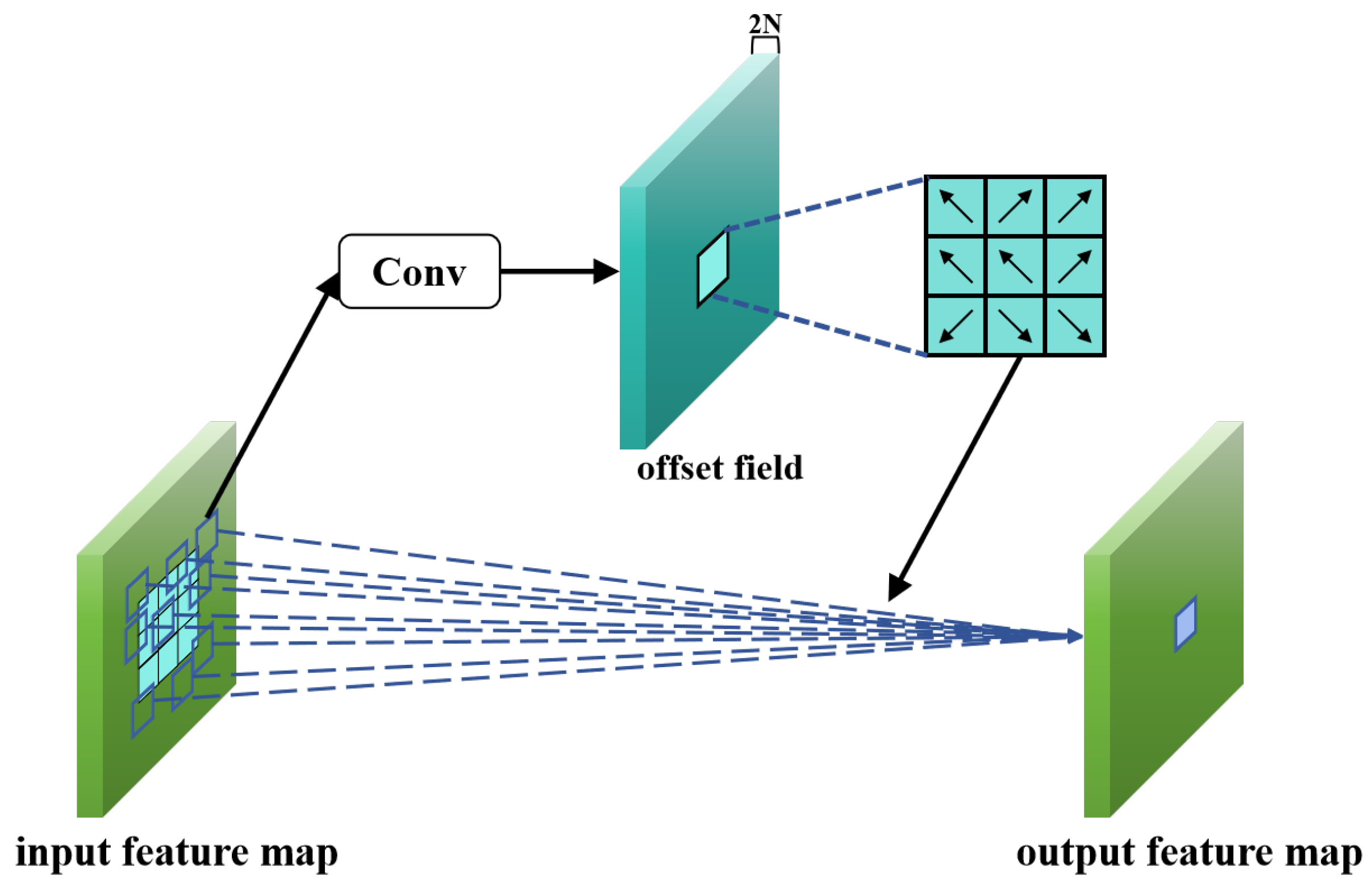
When the shape of a target varies significantly, standard convolution operations struggle to adapt due to their small receptive fields, which increases the difficulty of feature extraction. Deformable convolution adds a learnable offset to each pixel point in the receptive field. These offsets are generated through a standard convolution operation. The spatial dimension of the offset field aligns with the input feature map, and the channel dimension is
, where
N represents the number of pixels contained in the receptive field of the convolution kernel. The resulting receptive field is no longer a traditional square, but rather matches the shape of the target. The difference in receptive fields between the deformable convolution and standard convolution is illustrated in
Figure 8. First, we assume that the grid
Z defines all coordinates of the pixels in the
convolution kernel in the following Equation (
8).
When performing the standard convolution operation with this kernel at coordinate
on the feature map
x, the convolution output is as shown in Equation (
9).
where
y denotes the output feature map,
denotes the enumeration of the coordinates in
Z, and
denotes the weight at coordinates
on the convolution kernel.
In deformable convolution, the receptive field is no longer confined to a square. Compared to standard convolution, an offset
is added at each coordinate of input feature map
x, where
. The deformable convolution output is shown in Equation (
10):
The
deformable convolution is shown in
Figure 9; the input feature map first generates an offset field with
channels by convolution. Each pixel contains two offset values, one for the horizontal direction and one for the vertical direction. These offset values are then applied to each coordinate of the input feature map
x.
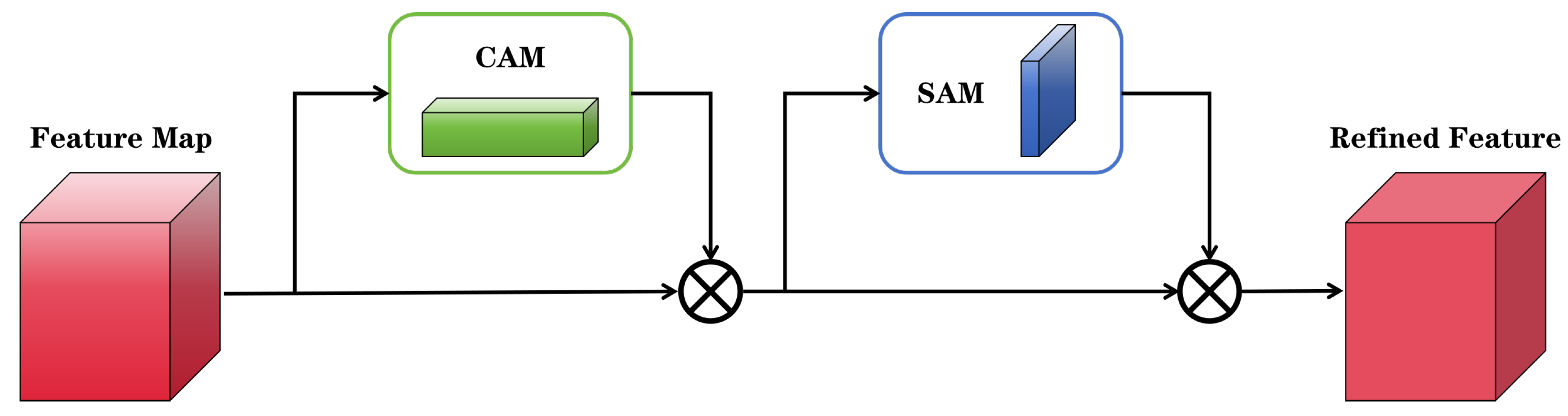
3.4. Attention Module
CBAM [
21] comprises two components: the Channel Attention Module (CAM) and Spatial Attention Module (SAM). CAM exploits different features extracted by different channels to provide a sufficient description of the target, enabling the network to concentrate more on feature information in the target area. SAM utilizes the differences between the target region and background clutter within SAR images to reduce complex background interference on object detection.
Figure 10 shows the overall framework of CBAM.
CAM and SAM calculate the input feature map through pooling and other steps, obtaining weights for the channel dimension and the spatial dimension. Next, the input feature map is multiplied by the channel weights and spatial weights sequentially to produce the output feature map. The output feature map strengthens the attention on the target area.
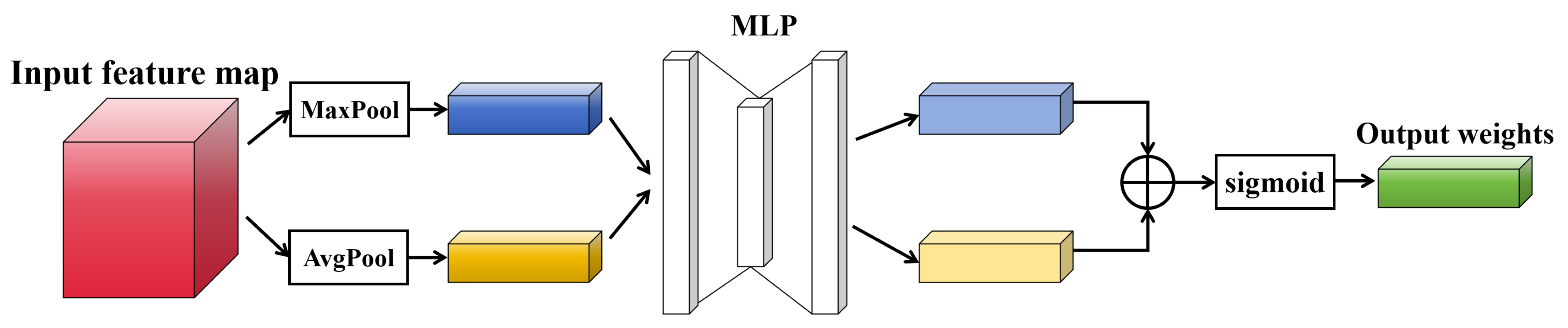
The framework of CAM is illustrated in
Figure 11. Firstly, the input feature map undergoes separate max pooling (MaxPool) and average pooling (AvgPool) operations in the spatial dimension, obtaining two types of weights for the channel dimension. Then, the two weights pass through the multi-layer perceptron (MLP) layer for nonlinear feature transformation, followed by summation. The output weights for each channel are activated using the sigmoid function. These weights are then used to multiply with the input features to achieve CAM. The output feature map serves as the input feature for the subsequent SAM. The output weights of CAM are represented in Equation (
11).
where
F represents the input feature map of CAM,
represents the AvgPool layer,
represents the MaxPool layer,
represents the multi-layer perceptron layer,
represents the sigmoid activation function, and
represents the output weights of CAM.
The framework of SAM is illustrated in
Figure 12. The feature map output by CAM serves as the input to SAM. The feature map undergoes MaxPool and AvgPool separately along the channel dimension, obtaining two types of weights for the spatial dimension. Subsequently, these two types of spatial weights are concatenated and undergo a standard convolution with a filter kernel size of
to obtain the output weights. The output weights are activated using the sigmoid function. These weights are then used to multiply with the input features to achieve SAM. The output feature map serves as the final output of CBAM. The output weights of SAM are represented in Equation (
12).
where
represents the input feature map of SAM,
represents convolution with a filter kernel size of
, and
represents the output weights of SAM.
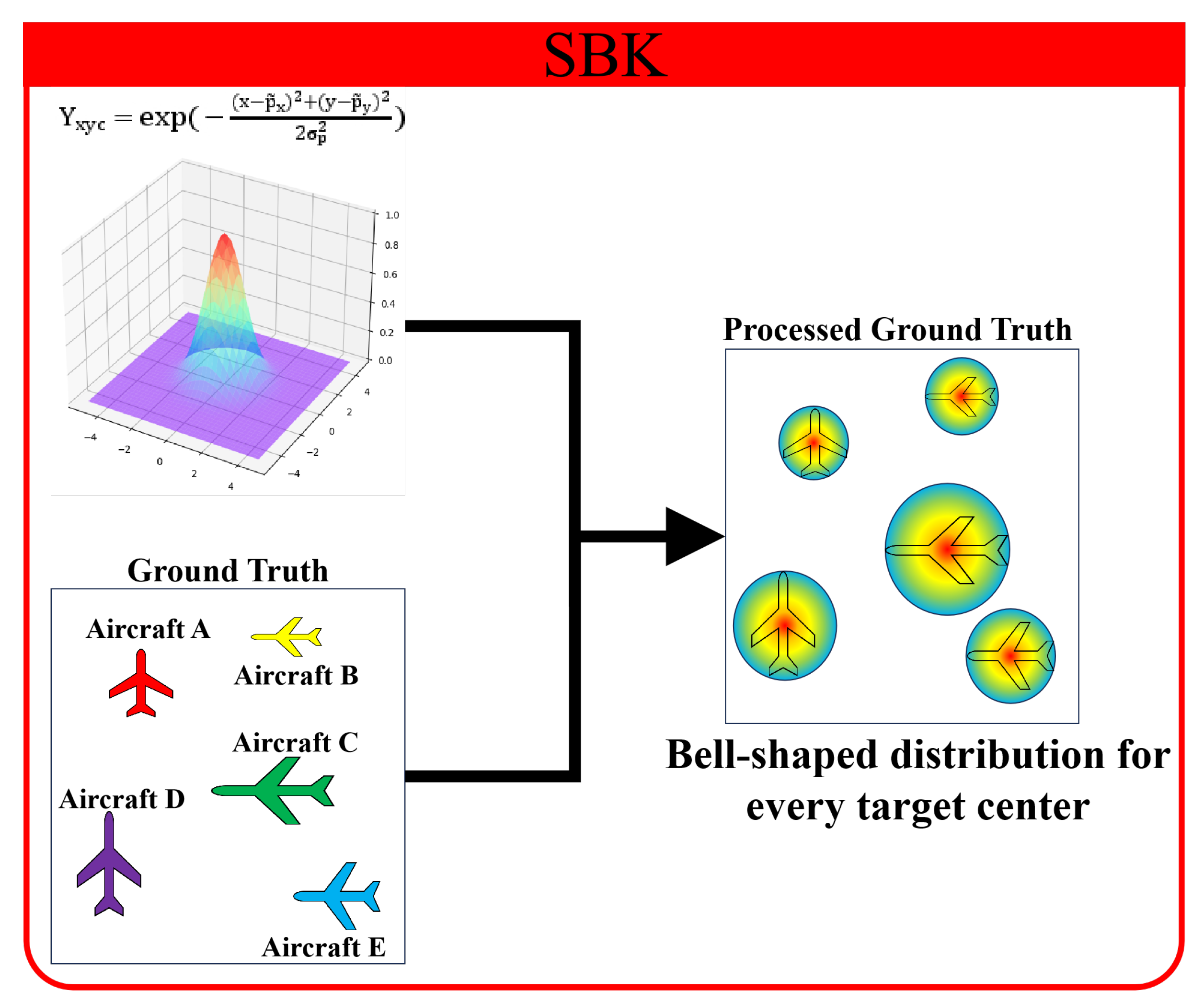
3.5. Self-Adaptive Bell-Shaped Kernel
In typical models, object detection is achieved by having the model identify whether each pixel is part of the target region. If a pixel’s predicted value is 1, the pixel is classified as belonging to the target region; if the predicted value is 0, the pixel is classified as the background. In SAR images, the scattering points forming aircraft targets have large fluctuations in intensity. When using typical models for object detection in SAR images, the weak scattering point components at the edges of targets are prone to being misclassified as the background. This causes the detection boxes obtained by typical models to usually fail to fully enclose the targets, significantly reducing the IoU values with the ground truth. Object detection models typically consider predictions successful when the IoU between the detection box and the ground truth is greater than 0.5. However, when the models miss too many edge weak scattering points, the IoU of the target drops below 0.5, leading to an excessive number of missed alarms for aircraft targets.
The SBK maps the two-dimensional bell-shaped distribution determined by the statistical characteristics of scattering points to each target center in the heatmap’s ground truth. This ensures that the equivalent “threshold” for the detection of scattering points decreases from the center to the surroundings. We utilized the processed ground truth to train the model to predict the heatmap. At this point, the predictable values of weak scattering points at the edges of targets are no longer just the “strict” 0 and 1, reducing the problem of inaccurate target area localization caused by the model’s failure to detect weak scattering points.
Among the various two-dimensional bell-shaped distributions, we chose the representative two-dimensional Gaussian distribution as an example, then mapped the Gaussian distribution to each target center in the ground truth, as illustrated in
Figure 13. The self-adaptive two-dimensional Gaussian distribution is represented in Equation (
13):
where
denotes the value of pixel
in ground truth
,
denotes the coordinate of the target center in the ground truth, and
denotes the adaptive parameter used to adjust the size of the Gaussian distribution.
As shown in
Figure 13, in the processed heatmap’s ground truth
Y, the pixel value
around the target center in the heatmap for the target category channel changes. During the training stage, the pixel value
in
Y is introduced into the loss function
in Equation (
1). Specifically, the addition of the term
reduces the loss value for weak scattering points at the edges of targets. This finally reduces the model’s equivalent detection “threshold” for weak scattering points during the testing stage.
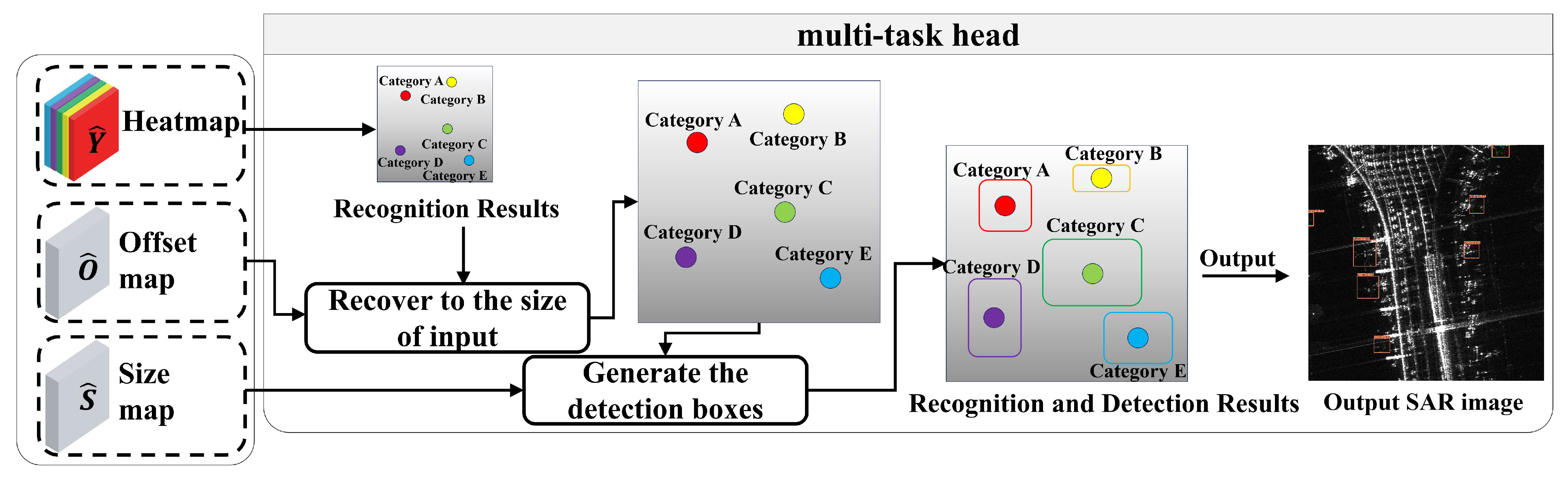
3.6. Integrated Detection and Recognition Head
The multi-task head utilizes three feature maps predicted by the backbone network, heatmap
, offset map
, and size map
, to accomplish integrated detection and recognition of aircraft, as illustrated in
Figure 14. The head can derive the coordinates of the center for each target from
and compare the predicted values of the target center at the same position across different channels. The channel corresponding to the maximum predicted value indicates the class of the target. Since the backbone network performs downsampling of the feature maps with a stride of 4, when the feature maps are resized to the original image size, there are precision errors in the center coordinates. The predicted center offsets help restore the center coordinates to the coordinates of the original image. The head generates object-detection boxes based on the predicted sizes corresponding to each target center in
, thus completing the integration of detection and recognition.










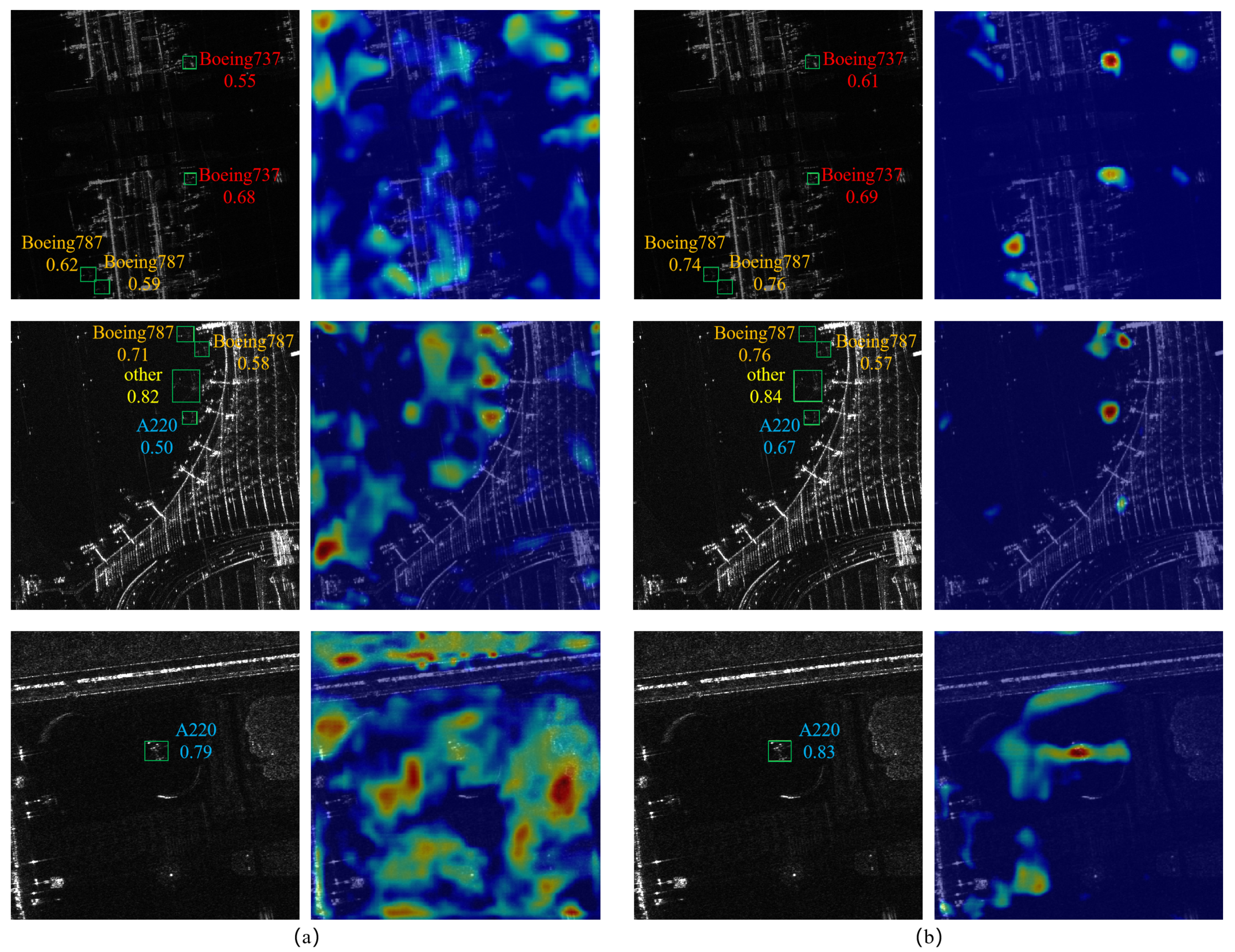

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}