
Application of Deep Learning for Segmenting Seepages in Levee Systems


 , ,
, ,
Abstract
1. Introduction
- A dataset featuring labeled seepage areas in the images for the semantic segmentation task.
- A proposed architectural design that features a pretrained model as an integrated feature extractor for encoder blocks to improve efficiency and reduce extensive training data needs.
- A proposed controlled transfer learning approach that incorporates a pyramidal pooling channel spatial attention model and Principal Component Analysis (PCA) in a parallel manner, followed by a residual connection for facilitating better information flow between layers.
2. Background
3. Research Gap
4. Enhanced Feature Representation
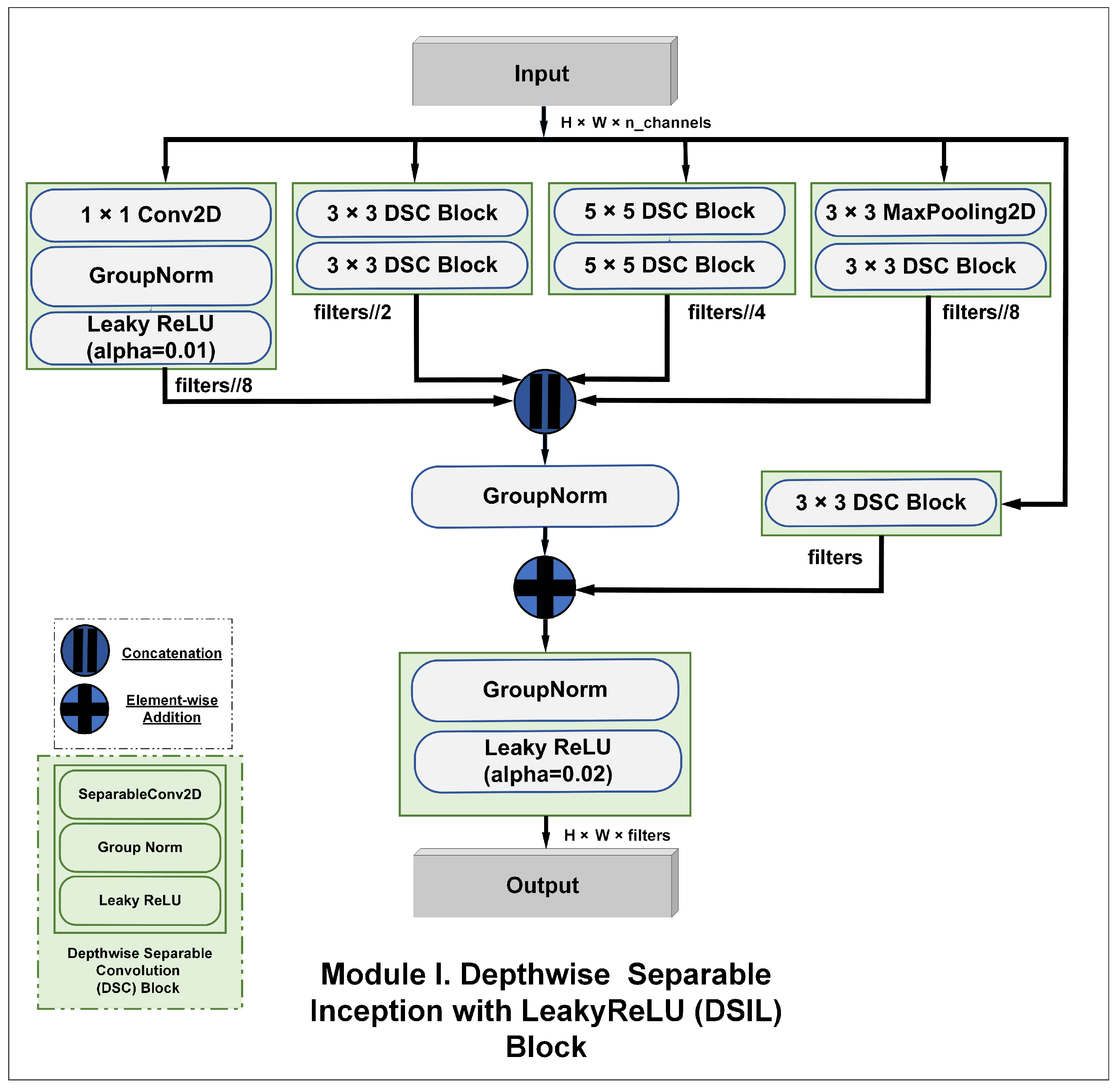
4.1. Residual Depthwise Separable Inception Block
4.2. Attention Modules
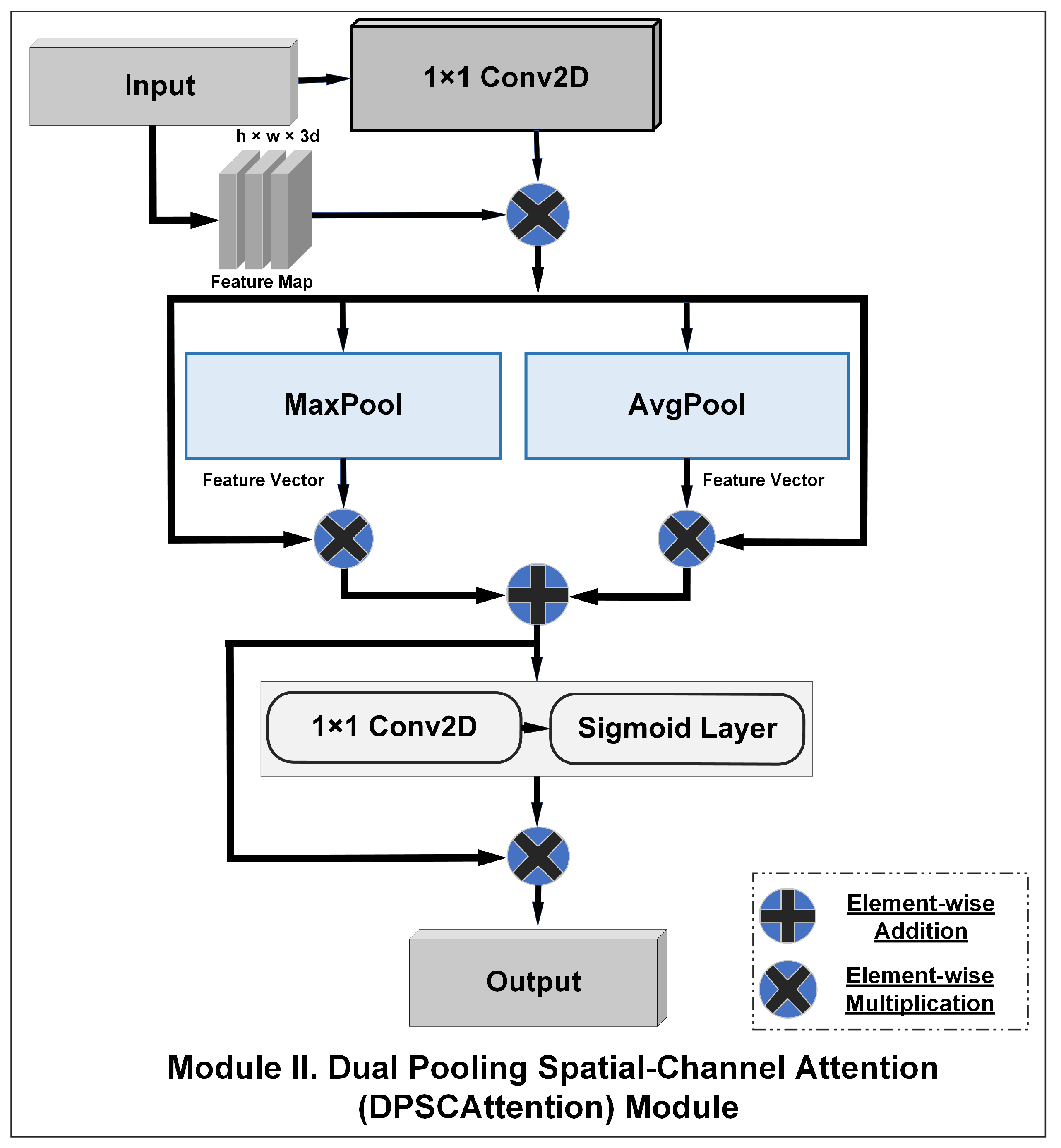
4.2.1. Dual Pooling Spatial-Channel Attention (DPSCA) Module
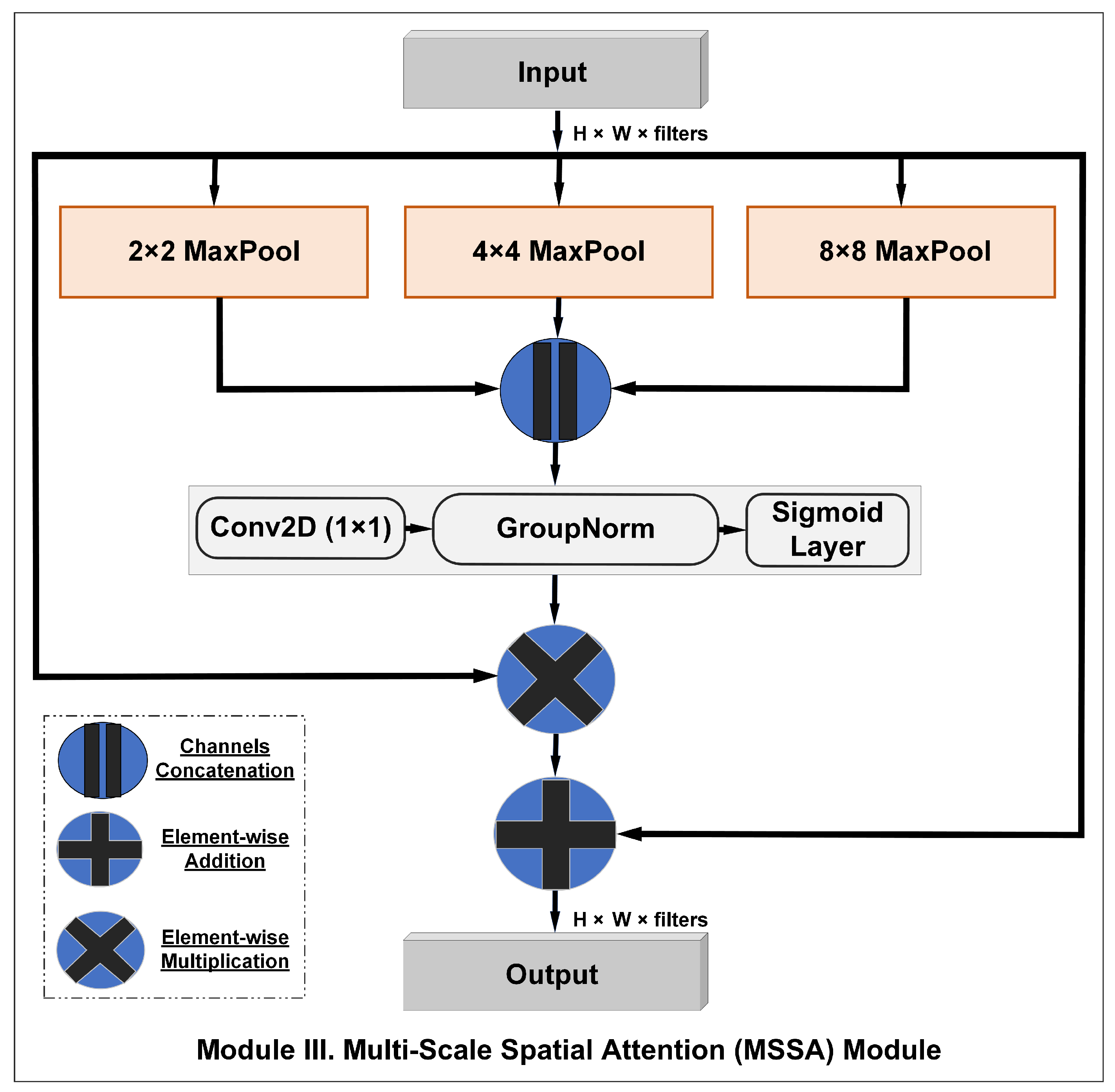
4.2.2. Multi-Scale Spatial Attention (MSSA) Module
4.3. Partial Fine-Tuning
4.4. PCA-Based Domain Adaptation
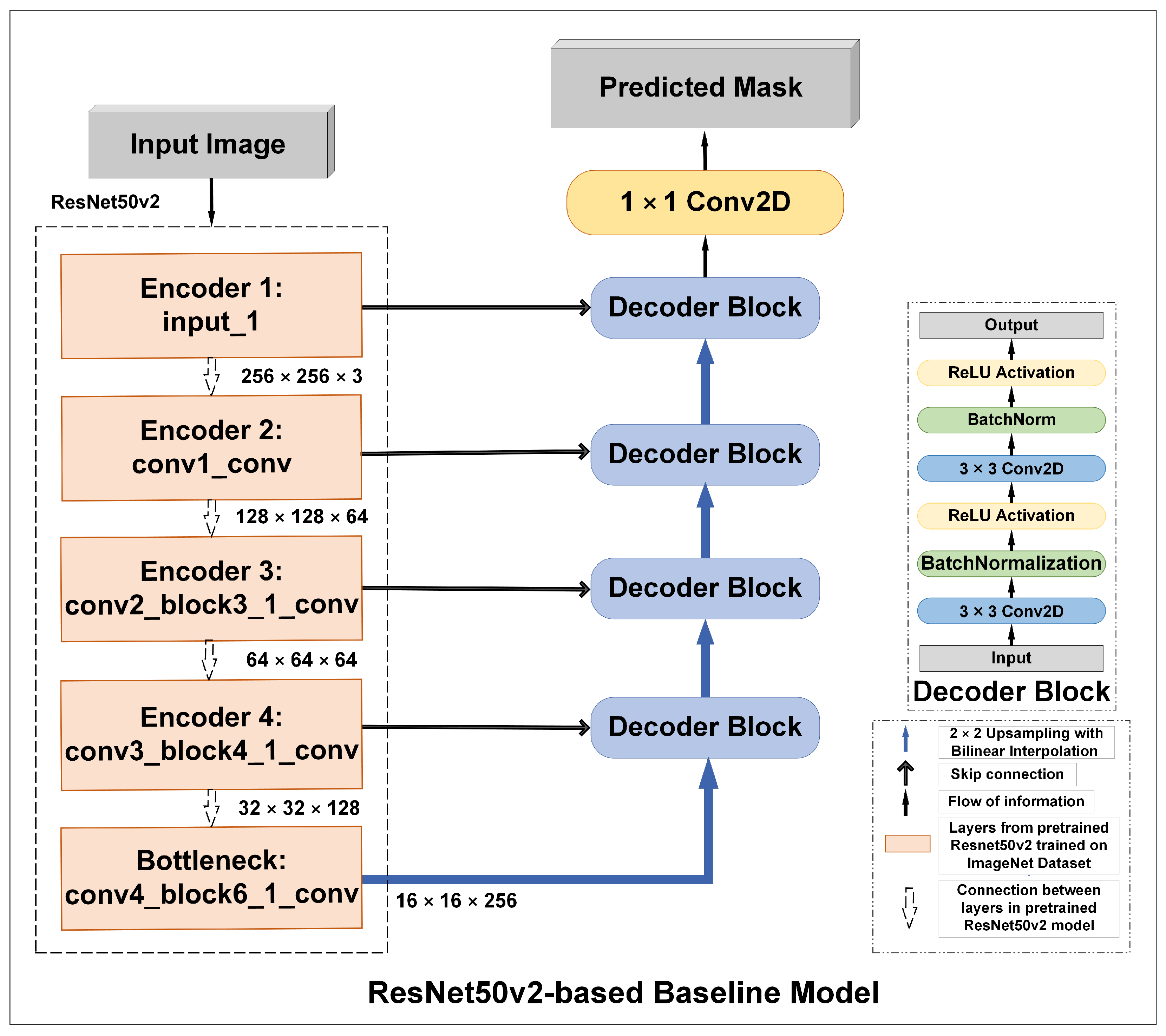
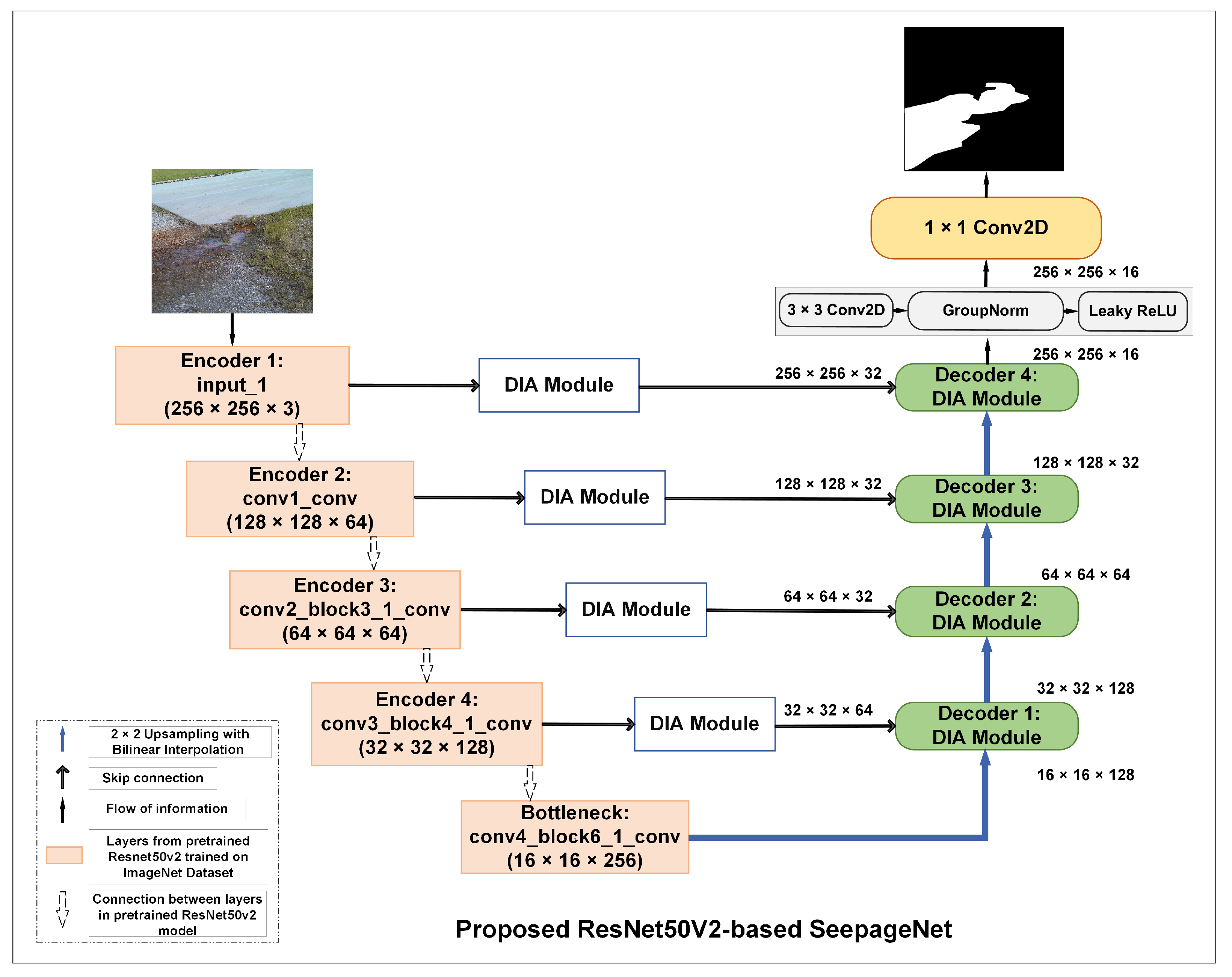
5. SeepageNet: Proposed Architecture
6. Data
6.1. Seepage Dataset
6.2. Data Pre-Processing
7. Selection of State-of-the-Art Models
8. Metrics and Loss Functions
9. Experimental Setup
10. Results and Analysis
10.1. Comparison with State of the Art
10.2. Results of Ablation Study
10.3. Training Workflow Diagram
11. Discussion
Analysis on Negative Samples
12. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| BA | Balanced Accuracy (BA) |
| CNN | Convolutional Neural Network (CNN) |
| DC | Dice Coefficient (DC) |
| DL | Deep Learning (DL) |
| DPSCAttention | Dual Pooling Spatial-Channel Attention (DPSCAttention) |
| DSC | Depthwise Separable Convolution (DSC) |
| GN | Group Normalization (GN) |
| IoU | Intersection over Union (IoU) |
| LLM | Large Language Model (LLM) |
| MaF1 | Macro F1 score (MaF1) |
| MSSA | Multi-Scale Spatial Attention (MSSA) |
| PCA | Principal Component Analysis (PCA) |
| PDIA | PCA-Depthwise Inception Attention (PDIA) |
| TPR | True Positive Rate (TPR) |
| TNR | True Negative Rate (TNR) |
References
- National Research Council. Levees and the National Flood Insurance Program: Improving Policies and Practices; National Academies Press: Washington, DC, USA, 2013. [Google Scholar]
- Leavitt, W.M.; Kiefer, J.J. Infrastructure interdependency and the creation of a normal disaster: The case of Hurricane Katrina and the city of New Orleans. Public Work Manag. Policy 2006, 10, 306–314. [Google Scholar] [CrossRef]
- Federal Emergency Management Agency (FEMA). HIstory of Levees; Federal Emergency Management Agency: Washington, DC, USA, 2020.
- Richards, K.; Doerge, B.; Pabst, M.; Hanneman, D.; O’Leary, T. Evaluation and Monitoring of Seepage and Internal Erosion; Leffel, S., Ed.; FEMA: Washington, DC, USA, 2015.
- Schaefer, J.A.; O’Leary, T.M.; Robbins, B.A. Assessing the implications of sand boils for backward erosion piping risk. In Proceedings of the Geo-Risk 2017, Denver, CO, USA, 4 June 2017; pp. 124–136. [Google Scholar]
- Couvillion, B.R.; Barras, J.A.; Steyer, G.D.; Sleavin, W.; Fischer, M.; Beck, H.; Trahan, N.; Griffin, B.; Heckman, D. Land Area Change in Coastal Louisiana from 1932 to 2010; U.S. Geological Survey: Reston, VA, USA, 2011.
- Haralick, R.M.; Shapiro, L.G. Image segmentation techniques. Comput. Vis. Graph. Image Process. 1985, 29, 100–132. [Google Scholar] [CrossRef]
- Mo, Y.; Wu, Y.; Yang, X.; Liu, F.; Liao, Y. Review the state-of-the-art technologies of semantic segmentation based on deep learning. Neurocomputing 2022, 493, 626–646. [Google Scholar] [CrossRef]
- Feng, D.; Haase-Schütz, C.; Rosenbaum, L.; Hertlein, H.; Gläser, C.; Timm, F.; Wiesbeck, W.; Dietmayer, K. Deep Multi-Modal Object Detection and Semantic Segmentation for Autonomous Driving: Datasets, Methods, and Challenges. IEEE Trans. Intell. Transp. Syst. 2021, 22, 1341–1360. [Google Scholar] [CrossRef]
- Minaee, S.; Boykov, Y.Y.; Porikli, F.; Plaza, A.J.; Kehtarnavaz, N.; Terzopoulos, D. Image segmentation using deep learning: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 3523–3542. [Google Scholar] [CrossRef] [PubMed]
- Ma, L.; Liu, Y.; Zhang, X.; Ye, Y.; Yin, G.; Johnson, B.A. Deep learning in remote sensing applications: A meta-analysis and review. ISPRS J. Photogramm. Remote Sens. 2019, 152, 166–177. [Google Scholar] [CrossRef]
- Cigla, C.; Alatan, A.A. Region-based image segmentation via graph cuts. In Proceedings of the 2008 15th IEEE International Conference on Image Processing, San Diego, CA, USA, 12–15 October 2008; IEEE: Piscataway, NJ, USA, 2008; pp. 2272–2275. [Google Scholar]
- Yu-Qian, Z.; Wei-Hua, G.; Zhen-Cheng, C.; Jing-Tian, T.; Ling-Yun, L. Medical images edge detection based on mathematical morphology. In Proceedings of the 2005 IEEE Engineering in Medicine and Biology 27th Annual Conference, Shanghai, China, 1–4 September 2005; IEEE: Piscataway, NJ, USA, 2006; pp. 6492–6495. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Zhou, Z.; Rahman Siddiquee, M.M.; Tajbakhsh, N.; Liang, J. Unet++: A nested u-net architecture for medical image segmentation. In Proceedings of the Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support: 4th International Workshop, DLMIA 2018, and 8th International Workshop, ML-CDS 2018, Granada, Spain, 20 September 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 3–11. [Google Scholar]
- Milletari, F.; Navab, N.; Ahmadi, S.A. V-net: Fully convolutional neural networks for volumetric medical image segmentation. In Proceedings of the 2016 Fourth International Conference on 3D Vision (3DV), Stanford, CA, USA, 25–28 October 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 565–571. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Oktay, O.; Schlemper, J.; Folgoc, L.L.; Lee, M.; Heinrich, M.; Misawa, K.; Mori, K.; McDonagh, S.; Hammerla, N.Y.; Kainz, B.; et al. Attention u-net: Learning where to look for the pancreas. arXiv 2018, arXiv:1804.03999. [Google Scholar]
- Ibtehaz, N.; Rahman, M.S. MultiResUNet: Rethinking the U-Net architecture for multimodal biomedical image segmentation. Neural Netw. 2020, 121, 74–87. [Google Scholar] [CrossRef]
- Michelazzo, G.; Paris, E.; Solari, L. On the vulnerability of river levees induced by seepage. J. Flood Risk Manag. 2018, 11, S677–S686. [Google Scholar] [CrossRef]
- Simm, J.; Wallis, M.; Smith, P.; Deniaud, Y.; Tourment, R.; Veylon, G.; Durand, E.; McVicker, J.; Hersh-Burdick, R.; Glerum, J. The significance of failure modes in the design and management of levees-a perspective from the International Levee Handbook team. In Proceedings of the 2nd European Conference on Flood Risk Management, FLOODrisk2012, Rotterdam, The Netherlands, 19–23 November 2012. [Google Scholar]
- Sharp, M.; Wallis, M.; Deniaud, F.; Hersch-Burdick, R.; Tourment, R.; Matheu, E.; Seda-Sanabria, Y.; Wersching, S.; Veylon, G.; Durand, E.; et al. The International Levee Handbook; CIRIA: London, UK, 2013. [Google Scholar]
- Mazzoleni, M.; Bacchi, B.; Barontini, S.; Di Baldassarre, G.; Pilotti, M.; Ranzi, R. Flooding hazard mapping in floodplain areas affected by piping breaches in the Po River, Italy. J. Hydrol. Eng. 2014, 19, 717–731. [Google Scholar] [CrossRef]
- Kuchi, A.; Panta, M.; Hoque, M.T.; Abdelguerfi, M.; Flanagin, M.C. A machine learning approach to detecting cracks in levees and floodwalls. Remote Sens. Appl. Soc. Environ. 2021, 22, 100513. [Google Scholar] [CrossRef]
- Panta, M.; Hoque, M.T.; Abdelguerfi, M.; Flanagin, M.C. Pixel-Level Crack Detection in Levee Systems: A Comparative Study. In Proceedings of the IGARSS 2022-2022 IEEE International Geoscience and Remote Sensing Symposium, Kuala Lumpur, Malaysia, 17–22 July 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 3059–3062. [Google Scholar]
- Kuchi, A.; Hoque, M.T.; Abdelguerfi, M.; Flanagin, M.C. Machine learning applications in detecting sand boils from images. Array 2019, 3, 100012. [Google Scholar] [CrossRef]
- Panta, M.; Hoque, M.T.; Abdelguerfi, M.; Flanangin, M.C. IterLUNet: Deep Learning Architecture for Pixel-Wise Crack Detection in Levee Systems. IEEE Access 2023, 11, 12249–12262. [Google Scholar] [CrossRef]
- Alshawi, R.; Hoque, M.T.; Flanagin, M.C. A Depth-Wise Separable U-Net Architecture with Multiscale Filters to Detect Sinkholes. Remote Sens. 2023, 15, 1384. [Google Scholar] [CrossRef]
- Wu, Y.; He, K. Group normalization. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Dubey, A.K.; Jain, V. Comparative study of convolution neural network’s relu and leaky-relu activation functions. In Applications of Computing, Automation and Wireless Systems in Electrical Engineering: Proceedings of MARC 2018; Springer: Berlin/Heidelberg, Germany, 2019; pp. 873–880. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Identity mappings in deep residual networks. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 630–645. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; IEEE: Piscataway, NJ, USA, 2009; pp. 248–255. [Google Scholar]
- Raghu, M.; Zhang, C.; Kleinberg, J.; Bengio, S. Transfusion: Understanding transfer learning for medical imaging. In Proceedings of the Advances in Neural Information Processing Systems 32 (NeurIPS 2019), Vancouver, BC, Canada, 8–14 December 2019; Volume 32. [Google Scholar]
- Panta, M.; Hoque, M.T.; Niles, K.N.; Tom, J.; Abdelguerfi, M.; Falanagin, M. Deep Learning Approach for Accurate Segmentation of Sand Boils in Levee Systems. IEEE Access 2023, 11, 126263–126282. [Google Scholar] [CrossRef]
- Li, H.; Chaudhari, P.; Yang, H.; Lam, M.; Ravichandran, A.; Bhotika, R.; Soatto, S. Rethinking the hyperparameters for fine-tuning. arXiv 2020, arXiv:2002.11770. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; PMLR: Warrington, WA, USA, 2015; pp. 448–456. [Google Scholar]
- Buslaev, A.; Iglovikov, V.I.; Khvedchenya, E.; Parinov, A.; Druzhinin, M.; Kalinin, A.A. Albumentations: Fast and Flexible Image Augmentations. Information 2020, 11, 125. [Google Scholar] [CrossRef]
- Publicly Available Seepage Dataset. Available online: http://cs.uno.edu/~tamjid/Software/seepage_original_images.zip (accessed on 27 April 2024).
- Dutta, A.; Zisserman, A. The VIA annotation software for images, audio and video. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019; pp. 2276–2279. [Google Scholar]
- Fan, R.; Wang, H.; Bocus, M.J.; Liu, M. We learn better road pothole detection: From attention aggregation to adversarial domain adaptation. In Proceedings of the Computer Vision–ECCV 2020 Workshops, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 285–300. [Google Scholar]
- Han, X.; Nguyen, C.; You, S.; Lu, J. Single image water hazard detection using fcn with reflection attention units. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 105–120. [Google Scholar]
- Jadon, S. A survey of loss functions for semantic segmentation. In Proceedings of the 2020 IEEE Conference on Computational Intelligence in Bioinformatics and Computational Biology (CIBCB), Vina del Mar, Chile, 27–29 October 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–7. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1026–1034. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Models | TPs | NTPs | MS (MB) |
|---|---|---|---|
| U-Net | 7,760,097 | 5888 | 91.29 |
| MultiResUNet | 7,238,228 | 24,522 | 80.05 |
| Attention U-Net | 8,903,043 | 9728 | 105.02 |
| U-Net++ | 7,238,228 | 24,522 | 107.99 |
| Baseline | 2,431,681 | 7,456,256 | 58.14 |
| SeepageNet-PCA | 1,302,339 | 7,546,368 | 46.02 |
| SeepageNet-NOPCA | 1,175,315 | 7,456,256 | 47.92 |
| Models | BA (%) | IoU (%) | DC (%) | MaF1 (%) | TPR (%) | TNR (%) |
|---|---|---|---|---|---|---|
| U-Net | 79.1 | 46.2 | 59.9 | 65.7 | 65.8 | 92.5 |
| MultiResUNet | 72.4 | 41.2 | 53.2 | 58.2 | 47.9 | 96.9 |
| Attention U-Net | 78.5 | 50.5 | 63.0 | 68.0 | 61.4 | 95.5 |
| U-Net++ | 80.5 | 48.1 | 61.6 | 68.1 | 71.5 | 89.6 |
| Baseline | 79.8 | 51.7 | 64.9 | 69.8 | 63.7 | 95.9 |
| SeepageNet-PCA | 84.3 | 60.0 | 71.8 | 76.4 | 72.2 | 96.4 |
| Models | BA (%) | IoU (%) | DC (%) | MaF1 (%) | TPR (%) | TNR (%) |
|---|---|---|---|---|---|---|
| Baseline | 79.8 | 51.7 | 64.9 | 69.8 | 63.7 | 95.9 |
| SeepageNet-CBAM | 83.5 | 55.1 | 68.1 | 73.5 | 72.8 | 94.2 |
| SeepageNet-SE | 83.4 | 58.4 | 70.4 | 75.0 | 70.3 | 96.4 |
| SeepageNet-noPCA | 83.6 | 58.2 | 69.9 | 75.1 | 71.5 | 95.8 |
| SeepageNet-PCA | 84.3 | 60.0 | 71.8 | 76.4 | 72.2 | 96.4 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Panta, M.; Thapa, P.J.; Hoque, M.T.; Niles, K.N.; Sloan, S.; Flanagin, M.; Pathak, K.; Abdelguerfi, M. Application of Deep Learning for Segmenting Seepages in Levee Systems. Remote Sens. 2024, 16, 2441. https://doi.org/10.3390/rs16132441
Panta M, Thapa PJ, Hoque MT, Niles KN, Sloan S, Flanagin M, Pathak K, Abdelguerfi M. Application of Deep Learning for Segmenting Seepages in Levee Systems. Remote Sensing. 2024; 16(13):2441. https://doi.org/10.3390/rs16132441
Chicago/Turabian StylePanta, Manisha, Padam Jung Thapa, Md Tamjidul Hoque, Kendall N. Niles, Steve Sloan, Maik Flanagin, Ken Pathak, and Mahdi Abdelguerfi. 2024. "Application of Deep Learning for Segmenting Seepages in Levee Systems" Remote Sensing 16, no. 13: 2441. https://doi.org/10.3390/rs16132441
APA StylePanta, M., Thapa, P. J., Hoque, M. T., Niles, K. N., Sloan, S., Flanagin, M., Pathak, K., & Abdelguerfi, M. (2024). Application of Deep Learning for Segmenting Seepages in Levee Systems. Remote Sensing, 16(13), 2441. https://doi.org/10.3390/rs16132441