1. Introduction
As one of the most hazardous natural disasters, earthquakes have typical characteristics significantly different from other natural disasters, such as an instantaneous burst, unpredictability, destructiveness, complex mechanism, difficult defense, broad social impact, and quasi-periodic frequency. With the significant expansion of city population and rapid urbanization, earthquakes have undeniably become the main threat to buildings and other infrastructure in earthquake-prone areas [
1]. According to the statistics of official departments, most of the casualties and economic losses after an earthquake are closely related to the destruction of buildings. Therefore, damage assessment of buildings plays a critical role in seismic damage surveys and emergency management of urban areas after an earthquake disaster. Scientists have conducted many investigations on earthquake occurrence mechanisms and disaster impacts for accurate disaster prevention and reduction.
Generally, the damage assessment of urban buildings after an earthquake needs two steps: object location and damage identification. Among those evaluation methods, the dynamic-response-based structural health monitoring method cannot conduct a comprehensive evaluation using signals collected by a limited number of sensors (e.g., an acceleration sensor), and the on-site ground survey, depending on the seismic experts or structural engineers, is mainly used to evaluate damage status [
2]. Such a method needs to check the buildings one by one, making it challenging to overcome the limitations of accessible space and ineffective use of time. The assessment results greatly rely on the subjective judgment of surveyors, leading to the inevitable difficulty of guaranteeing detection stability due to the limited available information from manual visual observation (e.g., upper views and features of the buildings). Blind zones are also challenging to approach after an earthquake, given the possibity of secondary disasters. Therefore, highly accurate and rapid seismic damage assessment of urban buildings is increasingly demanded for the emergent response, effective searching, and quick rescue after an earthquake.
Comparatively, remote sensing, as a nearly emergent technology, has unique advantages, including a lack of contact, low cost, large-scale coverage, and fast response. Research communities have reported their attempts to use remote sensing data (e.g., optical or synthetic aperture radar (SAR) data)) for automatic seismic damage assessment and other fields [
3,
4,
5,
6]. The remote sensing method prioritizes earthquake damage assessment of buildings, and provides a much faster, more economical, and more compressive assessment than manual assessment. SAR data have become an all-weather information source for disaster assessment because of their strong penetration ability to disturbances, such as heavy clouds and rain [
7,
8,
9,
10]. Generally, most disaster assessments using SAR data are based on multi-source or multi-temporal data, which requires complex image registration and other necessary processes. To overcome these challenges, some researchers prefer satellite optical images [
11]. Compared to SAR data, optical images are much easier to access and to process for extraction of the characteristic information of seismic damage. At present, building earthquake damage assessment based on satellite remote sensing (SRS) optical images mainly includes visual interpretation and change detection. These processes primarily rely on the graphical comparison pre- and post-earthquake, which shows unexpected limitations (e.g., it is challenging to obtain pre-images in less developed areas, and the assessment accuracy depends on technical expertise) and low efficiency [
3,
12].
Artificial intelligence (AI) has made explosive breakthroughs in recent years [
13]. Essential methods of AI collection, machine learning (ML) and computer vision (CV) are mainly promoted by end-to-end learning through the use of artificial neural network (ANN) and CNN approaches. This supplies a new option that utilizes computers to process data and enables computers to analyze and interpret it. In recent years, many efficient algorithms have been created to promote the application of ML and CV methods in structural health monitoring [
14,
15,
16,
17,
18,
19,
20,
21,
22,
23]. These methods effectively reduce or eliminate the dependence on professional measuring equipment, expensive sensors, and the subjective experience of inspectors. AI/CV techniques can overcome the above shortcomings with high efficiency, stability, and robustness. Additionally, these techniques, merging with unmanned aerial vehicles and robotics, can assist humans to access the hard-to-inspect places and ensure safety. Therefore, AI/CV techniques are more suitable for rapid damage assessment of wide-area post-earthquake buildings [
24,
25]. Benefiting from the consistent improvements of remote sensing and AI technology, CV methods have been gradually developed for structural damage assessment, which mainly includes image classification, object detection, and semantic segmentation.
Fundamentally, single-stage object detectors, such as YOLO [
26,
27,
28,
29], and single-shot multibox detectors (SSDs) [
30] omit the process for obtaining the proposal region and transforming the object detection task for location and classification into a regression problem. However, they present unsatisfactory adaptability for SRS data (e.g., low accuracy, either false or missing detection) because of apparently different characteristics rather than natural images, such as limited vertical view information, small and dense objects, complex environmental background, and illumination variation. However, their advantages, including high precision, small volume, and fast operation speed, are advisable for the rapid disaster assessment of urban buildings after an earthquake based on SRS optical images. Moreover, as seismic damage classification of urban buildings greatly depends on footprint information, the accuracy of building positioning directly affects the result of earthquake damage assessment. In most earthquake on-sites, it is challenging to realize ‘one-step’ damage assessment by the data-driven deep learning methods owing to the lack of high-quality annotation datasets [
31]. Under the actual scenarios of investigated urban areas, most of the buildings in the SAR images are in normal condition, while only a few are damaged (which are actually concerned by post-earthquake disaster assessment). Therefore, it causes an imbalanced problem for damage severity classification, which is also a common problem in the field of structural health monitoring for civil engineering. It makes machine learning difficult because the model would be misguided by the overwhelming majority of normal samples and have limited recognition ability of damaged samples. Therefore, it is significant to investigate the problem caused by imbalanced data.
To solve the above-mentioned issues of currently reported methods, this study proposed a modified You Only Look Once (YOLOv4) object detection module and a support vector machine (SVM) derived classification module for building location and damage assessment. Specifically, the objectives of the paper are as follows:
- (1)
This paper aims to develop a novel method for rapid and accurate wide-area post-earthquake building location and damage assessment using SRS optical images.
- (2)
To detect tiny-sized and densely distributed buildings, the YOLOv4 model is improved to achieve a much higher precision.
- (3)
To classify the damage severity of imbalanced buildings, images features of gray level co-occurrence matrix (GLCM) that can effectively distinguish different damage severities are extracted and utilized in SVM classification.
The remainder of this article is organized as follows.
Section 2 focuses on the related work of damage assessment of post-earthquake buildings in SRS optical images using CV methods.
Section 3 exhibits the dataset and experiment details.
Section 4 introduces the overall framework of the proposed method.
Section 5 describes the first module of building location and discusses the results.
Section 6 explains the second module of post-earthquake damage classification and illustrates the results.
Section 7 concludes the article.
2. Related Work
Research communities have introduced CV into building location and damage classification based on SRS optical images. Ci et al. [
32] proposed a new CNN combined with ordinal regression, making full use of historical accumulated data. The results showed 77.39% accuracy of four classifications and 93.95% accuracy of two classifications for the 2014 Ludian earthquake. Duarte et al. [
33] adopted SRS images with different resolutions from satellites and airborne platforms to achieve better accuracy in the damage classification of buildings by integrating multiscale information. Maggiori et al. [
34] addressed the issue of imperfect training data through a two-step training approach and developed an end-to-end CNN framework for building pixel classification of large-scale SRS images. The approach was initialized on a large amount of possibly inaccurate reference data (from the online map platform) and then refined on a small amount of manual, accurately labeled data. Adriano et al. [
35] realized the four-pixel-level classification of building damage with more accuracy than 90% after combining SRS optical data and SAR data. Liu et al. [
36] demonstrated a layered framework for building detection based on a deep learning model. By learning building features at multiscale and different spatial resolutions, the mean average precision (
mAP) of this model for building detection in SRS images was 0.57. To solve the gap between the axial detection box of conventional objects and the actual azimuth variation, Chen et al. [
37] introduced directional anchors and additional dimensions, which achieved a
mAP of 0.93 for object detection of buildings. Etten et al. [
38] addressed a suitable model named You Only Look Twice for processing large-scale SRS images by modifying the You Look Only Once v2 (YOLOv2) structure with finer-grained features and a denser final grid, which achieved an F1-score of 0.61 for building detection. Ma et al. [
39] replaced the Darknet53 in YOLOv3 with the Shufflenetv2 and adopted GIoU as the loss function. The results on SRS images with a resolution of 0.5 m for the Yushu and Wenchuan earthquakes showed that the modified model could detect collapsed buildings with a
mAP of 90.89%.
There is a need for accurate and efficient machine learning models that assess building damage from SRS optical images. The xBD database [
40] is a public, large-scale dataset of satellite imagery for post-disaster change detection and building damage assessment. It covers a diverse set of disasters and geographical locations with over 800,000 building annotations across over 45,000 km
2 of imagery. Furthermore, Gupta et al. [
39] created a baseline model. The localization baseline model achieved an
IoU of 0.97 and 0.66 for “background” and “building,” respectively. The classification baseline model achieved an
F1-score of 0.663, 0.143, 0.009, and 0.466 for no damage, minor damage, major damage, and destroyed building classes, respectively.
Many researchers [
40,
41,
42,
43] began to use the xBD dataset as benchmark dataset for automated building damage assessment studies. Shao et al. [
41] reported a new end-to-end remote sensing pixel-classification CNN to classify each pixel of a post-disaster image as an undamaged building, damaged building, or background. During the training, both pre- and post-disaster images were used as inputs to increase semantic information, while the dice loss and focal loss functions were combined to optimize the model for solving the imbalance problem. The model achieved an
F1-score (a comprehensive index) of 0.83 in the xBD database with multiple types of disasters. Bai et al. [
42] developed a new benchmark model called pyramid pooling module semi-Siamese network (PPM-SSNet), by adding residual blocks with dilated convolution and squeeze-and-excitation blocks into the network and compressing incentive to improve the detection accuracy. Results achieved a
F1 score of 0.90, 0.41, 0.65, and 0.70 for four damage types, respectively.
It can be found that the common idea underlying these methods is to train a CNN in a pixel-level semantic segmentation approach [
32,
33,
34,
35,
36,
37,
38,
39,
40,
41,
42,
43]. For adjacent buildings or buildings with occlusion views, these methods cannot distinguish the geometric range of each independent building after the earthquake. Moreover, due to the influence of imbalanced data on model training, they generally exhibit lower accuracies for damaged samples. Therefore, it is significant to fully consider these characteristics of unbalanced, tiny-sized, and densely distributed buildings and develop an appropriate building recognition and damage assessment method.
3. Preparation of Urban Earthquake Dataset
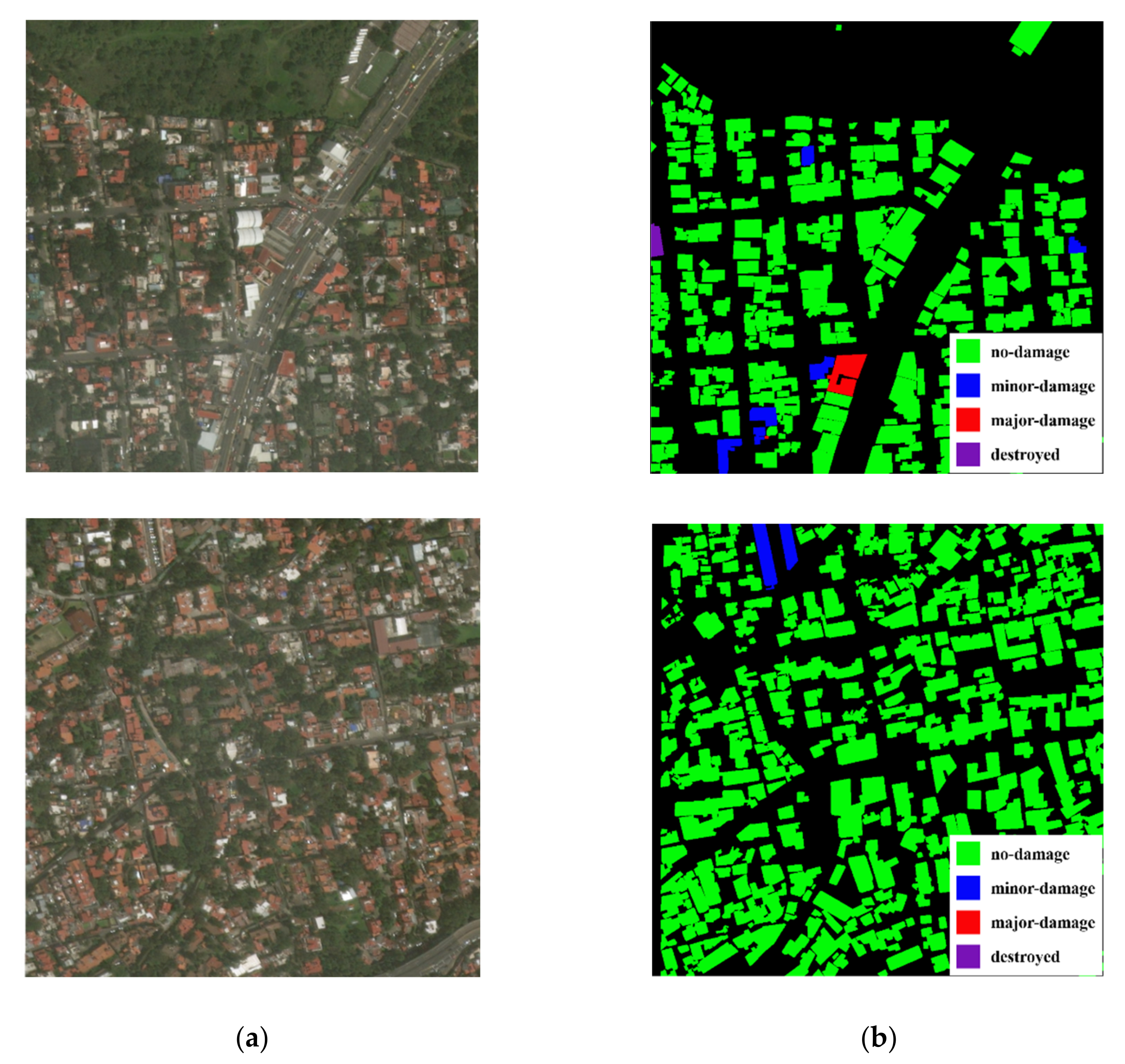
The 2017 Mexico City earthquake data from the xBD database [
40] was adopted in this study. To conduct the large-scale post-earthquake damage assessment, 386 pre- and post-earthquake SRS images with a resolution of 1024 × 1024 pixels and a ground sampling distance of 0.8 m were selected. According to the joint damage rating established by the European macroseismic scale (EMS-98), the building damage was divided into four categories. Representative images are shown in
Figure 1a, and the corresponding labels for the polygon location and damage categories of urban buildings are shown in
Figure 1b. Green, blue, red, and purple represent no damage, minor damage, major damage, and destroyed, respectively.
Table 1 shows the detailed descriptions of the damage categories and numbers of buildings in 193 post-earthquake SRS images. As illustrated in
Figure 1 and
Table 1, the selected dataset presented quite different characteristics than the natural images. For detection objects, buildings in satellite images showed a tiny observable size, dense distribution, and imbalanced damage types.
Furthermore, the number of buildings corresponding to the four damage categories was highly imbalanced; buildings with no damage far outnumbered those in the other three categories. Internal and facade information of buildings were also unable to assess post-earthquake damage other than directly viewed roofs comprehensively. In addition, the available SRS images mainly presented a unified resolution and single hue. Thus, the optimization of detector and classifier should be taken to make up for the shortage caused by the above-summarized data imperfection.
3.1. Data Preparation for Tiny Dense Object Detection of Post-Earthquake Buildings
A total of 386 pre- and post-earthquake images from the 2017 Mexico City earthquake dataset were collected for object detection of the post-earthquake buildings. The pre-earthquake images were regarded as data augmentation to increase the diversity of training sample space, while the corresponding damage was labeled as no damage. Moreover, reported studies have shown that the usage of both pre- and post-disaster images facilitates build location and damage classification after the earthquake [
31,
41].
Figure 2 shows the ground-truth bounding boxes of tiny, dense buildings in an SRS image using original polygon annotations of buildings. The minimal rectangular box surrounding each building was determined by the minimum and maximum coordinates of the polygon.
Considering the memory limit of the Graphics Processing Unit (GPU), the input size of the sub-images was adjusted as 608 × 608 pixels. A sliding window of 608 × 608 pixels with an overlap of 96 in width and height was used to generate patches from the original image of 1024 × 1024 pixels. Edge pixels were padded with pixel intensities of zero, and the 15% overlap area ensured that all regions would be analyzed. This strategy was also conducive to data augmentation by introducing translation to the edge images. Consequently, a total of 13,896 patches were obtained, among which 80% of the data was used for training, and the remaining 20% was used for testing. Statistical analysis showed that the modified dataset contained 1,317,237 buildings, while 95 buildings were included per patch on average.
As shown in
Figure 3, the distribution histogram of building size (the square root of width × height) in the dataset showed that the number of object sizes ranged from pixels of 0–16, 16–32, 32–48, 48–64, 64–80, 80–96, and 96–608 are 13.24, 40.94, 25.97, 11.17, 4.60, 1.91, and 2.17%, respectively. According to the MS COCO dataset [
44], the object scales could be divided into three typical types: the small object (<32 pixels), the medium object (32–96 pixels), and the large object (>96 pixels). The statistical results showed that more than half of building objects (54.18%) in this selected dataset were of the small-object type. Moreover, extremely tiny objects (<16 pixels) took up a proportion of 13%, making them more challenging to detect than normal small parts.
3.2. Data Preparation for Classification of Highly Imbalanced Damage
In general, SRS images can cover a vast area in a vertical view but little spatial information. For instance, when the ground floor of the building completely collapses with the superstructure remaining intact, it is difficult to identify such a damage status using satellite images. Therefore, most reported studies have only divided the buildings into two categories: not collapsed and collapsed [
32,
39,
45]. In this study, buildings were first cropped to rectangular regions separately from the original image. They were then divided into two damage levels containing four different damage levels: no damage or minor damage (Class 1), and major damage or destroyed (Class 2). Class 1 defines reusable buildings after an earthquake, while Class 2 implies that the building is too severely damaged to reuse. All of the 57 major damage and destroyed buildings in
Table 1 were classified as Class 2. Then, a dataset of no-damage and minor-damage buildings, with the same numbers of 57 as Class 1, was randomly selected. These 114 candidates constructed the dataset to train the SVM classifier for building damage classification. The training and testing sets included 70% and 30%, i.e., 40 and 17 samples for the two categories, respectively.
Figure 4 visually depicts the examples for post-earthquake building damage classification. It shows that Class 1 (no damage and minor damage) had clear and intact geometric configurations. In contrast, the major damage and destroyed buildings in Class 2 had poor geometric integrity, vague edges, and scattered rubbles around them. Thus, different damage statuses could be distinguished from the irregular and disordered texture features using these images.
4. Framework
Considering the unique characteristics (tiny size, dense distribution, imbalanced information, and multiscale features) of SRS optical images for urban regions after earthquake disasters, we proposed a machine-learning-derived two-stage method enabling exact building location and rapid seismic damage assessment. In detail, the model was designed to collaboratively realize the detection and classification depending on two hybrid functional modules as a modified YOLOv4 and a support vector machine (SVM). The two-stage detection of YOLOv4 enables the precise detection and location of tiny dense buildings in SRS images, while the supervised-learning-based SVM offers a way for rapid classification using texture features of seismic damages. The schematic illustration and workflow of the proposed framework are shown in
Figure 5. The proposed method consists of three modules, including data preparation, detection for buildings after an earthquake, and classification for buildings of post-earthquake damage:
The 2017 Mexico City earthquake dataset from the xBD database was selected, including SRS images for pre- and post-earthquake buildings and classification labels of damage intensities for building instances. A more detailed description is offered in
Section 3.
- (2)
Precise detection for tiny-sized and densely distributed buildings after an earthquake
To adapt the precise detection of tiny-sized and densely distributed buildings after urban earthquake utilizing SRS optical images, the YOLOv4 model was relevantly optimized by constructing a more efficient network, optimizing the hyperparameters, and selecting the more appropriate anchor boxes. After that, a well-trained YOLOv4 model was obtained for the precise location of buildings. The details of implementation can be found in
Section 5.
- (3)
Rapid classification for urban buildings with highly imbalanced information on post-earthquake damage
Six texture features with a single building in each detected bounding box were extracted by a gray level co-occurrence matrix (GLCM). Among them, three (i.e., the angular second moment, dissimilarity, and inverse difference moment) were validated as effective characteristics to support the following SVM that derived the binary classification of damage intensity (i.e., destroyed/major damage and minor damage/no damage). The detailed discussion is set out in
Section 6.
The workflow is shown in the right part of
Figure 5. After the SRS optical images of post-earthquake buildings in urban areas are input to the modified YOLOv4 model, rectangular bounding boxes are generated for the buildings. Consequently, each image patch inside the generated bounding box is used to obtain the GLCM features and then utilized as the input of the well-trained SVM classification model. Finally, the damage level is classified for each building inside the SRS image.
6. SVM-Derived Damage Classification
6.1. SVM Algorithm
As a classic machine learning algorithm [
54], SVM can achieve the best tradeoff between model complexity and learning performance to obtain the best generalization ability based on limited data information. This algorithm is suitable to process classification problems of high dimensionality, nonlinearity, and small sample size. It has advantages that are different from other methods, such as a complete mathematical theory, simple structure, and time savings. Theoretically, the SVM enables data classification into two categories by searching an optimal linear classification hyperplane [
54,
55].
Equation (14) defines the original optimization problem:
where
represents the input vectors;
is the label;
is the weight vector of the classification surface; and
C is the penalty coefficient, which is used to control the balance of error
(slack variable). SVM is to find an optimal classification hyperplane
, where
can map
to a higher-dimensional space, and
b is the bias.
Then, the final decision function can be obtained by using the Lagrange optimization method and duality principle:
where
is a Lagrangian multiplier for each sample,
is a kernel function that can transform the nonlinearity into linear divisibility in high-dimensionality feature space, and then construct the optimal separating hyperplane in the high dimensional space to achieve the data separation. The radius basis function (RBF) kernel is most widely used for multi-classification tasks because it can realize nonlinear mapping and has fewer parameters and numerical difficulties. The RBF kernel is defined as
.
6.2. GLCM Texture Feature Extraction
Previous reports have demonstrated that the texture features of post-earthquake images play a vital role in damage recognition. Compared with the undamaged images, the damaged region presents uneven textures and particular patterns. These unique characteristics can be utilized for feature extraction to classify the damage status [
56,
57,
58,
59,
60,
61]. The gray level co-occurrence matrix (GLCM) describes gray-scale image texture features by investigating spatial correlation characteristics, the most widely used and effective statistical analysis method for image textures [
62]. The method first uses the spatial correlation of gray level texture to calculate the GLCM according to the direction and distance of the image pixel. The meaningful statistics from the calculated GLCM are then extracted to use as the texture features of an image. The GLCM-based texture features are extracted by the following steps.
In this study, the original RGB image was primarily converted to a 256-level gray-scale image and then evenly quantized to a 16-level gray-scale image.
The matrix order of GLCM was then determined by the gray level of the image, with the value of each element being calculated by the following equation:
where
denotes the occurrence times of a pair of pixel gray values of
i and
j, with a pixel distance of
and a direction of
in the image, where
i,
j = 0, 1, 2, …,
L − 1, and
L is the gray level.
is set to 1, and
is set to 4 directions, including 0, 45°, 90°, 135° in this study.
After that, six statistical indices based on the GLCM were calculated in different
and
, including the angular second moment, contrast, correlation, entropy, dissimilarity, and inverse different moment (abbreviated to
asm,
con,
cor,
ent,
dis, and
idm, respectively), which were calculated by Equations. (17)–(22) [
62], respectively.
- 2.
Contrast (con) describes the clarity of the texture and the depth of the groove.
- 3.
Correlation (cor) is used to determine the main orientation of the texture.
- 4.
Entropy (ent) represents the complexity of the texture.
- 5.
Dissimilarity (dis) is similar to contrast (con), but with a linear increase.
- 6.
Inverse different moment (idm) defines the regularity of the texture.
For each calculated statistic of GLCM with = 1 and different directions ( = 0, 45°, 90°, 135°), the mean value and standard deviation were taken as the features of the GLCM of the image.
6.3. Classification Experiment
To investigate the effectiveness of each eigenvalue in classification, the performance of a single statistic and different statistical combinations were studied. For the eigenvalue of the input SVM model, it was linearly normalized to [−1, 1] by its minimum and maximum values. The RBF kernel with
equaling the number of eigenvalues was selected. The public parameter penalty coefficient
C was set to 1 in the SVM model.
Table 10 shows the detailed experimental settings for SVM-based classification. There were a total of 6 categories, and 1–6 statistical features were extracted from the six statistics, respectively, and labeled as C61-C66.
The classification accuracy is used as the evaluation metric for SVM-based damage assessment, as shown in Equation (23):
where
N(
correct predicted) and
N(
total) represent the numbers of correct predicted and total samples.
Then, 114 samples were used in the classification study, with the percentage of the test set being 30%. Our different experiments were all tested on the testing set with 34 samples (both Class 1 and Class 2 have 17 samples).
Figure 11 and
Table 11 give the test results under different experimental settings. In category C61, the single statistic feature of
idm,
asm, and
dis (C61-4, C61-1, and C61-5) used as the input eigenvalues of SVM could achieve better classification accuracy for damage condition assessment, which was 91.2, 73.5, and 73.5%, respectively. When selecting two statistical features (category C62),
idm combined with
asm and
dis (C62-3, C62-13) could obtain better performance (94.1%).
In comparison, when the three statistical features of asm, dis, and idm were selected (C63-13), an overall optimal classification accuracy of 97.1% was achieved, among which the correct classification in the test set was 33/34. It is worth mentioning that, under the same category of C64, C65, or C66, the experimental settings with the optimal performance (C64-9, C64-12, C65-1, and C66-1) all contained these three statistics, but additional statistical information might produce redundancy and lead to performance degradation. This indicates that it is necessary to comprehensively consider texture features and select the most effective eigenvalues for information fusion. The three statistical indexes (asm, dis, and idm) can competently reflect the critical texture features in SRS images after the earthquake disaster, including the degree of regularity, geometric shape, and clarity of buildings. Therefore, the combined method of modified YOLOv4 and SVM offers a practical approach for the seismic damage assessment of urban buildings.
6.4. Test Results
Figure 12 and
Table 12 show some representative damage classification results of post-earthquake buildings identified by the modified YOLOv4 model. The present locations in the subfigures are randomly selected from the images including different damage levels. The left and right columns in
Figure 12 visualize the actual and predicted locations of the post-earthquake buildings with two damage levels in SRS images. Results demonstrate that target buildings with dense distribution, small size, and at the edge of the image can be correctly classified. All post-earthquake buildings of Class 2 were correctly classified (examples 2, 3, 4), and only one target among the four post-earthquake images was misclassified (example 1), reaching a correct accuracy of 87.5%. Limited by the quality and resolution of the SRS images and the slight deviations in the positioning of the post-earthquake building, a few buildings of Class 1 were identified as Class 2. Actually, in the earthquake damage assessment task using SRS images, the priority is given to identifying buildings with high levels of damage. The subsequent refined evaluation is normally conducted through near-field acquisition platforms such as unmanned aerial vehicles.
The proposed method includes two hybrid modules, fully considering the characteristics of damaged buildings in SRS optical images. The modified YOLOv4 object detection module is employed to detect the tiny-sized and densely distributed post-earthquake buildings, and the SVM-based classification module is devoted to classifying urban buildings with highly imbalanced damage severity. The proposed method decomposes the accurate and rapid post-earthquake assessment task into the above two modules and applies suitable DL and ML models (modified YOLOv4 object detection and SVM classification, respectively) to the subtasks with high precision.
The above discussions further verify the effectiveness of the proposed two-stage method for post-earthquake damage assessment. The seismic damage assessment capacity enables rapid judgment and emergency decision-making for post-disaster evaluation in wide-area urban regions.
7. Conclusions
This study highlighted a machine-learning-based two-stage method combining YOLOv4 and SVM, which was created to realize precise identification and rapid classification of tiny dense objects and highly imbalanced data for post-earthquake building localization and damage assessment of SRS images. The investigated dataset originated from 386 pre-earthquake/post-earthquake remote sensing images of the 2017 Mexico City earthquake, with a resolution of 1024 × 1024. The main conclusions follow.
Through systematic optimizations of the YOLOv4 model on network structure (backbone, neck, and head), the training hyperparameters (i.e., the size of the input image, batch parameters, number of iterations, learning rate strategy, and weight decay), and anchor boxes, the features of SRS images at multiscale were effectively extracted and fused for precise building localization.
Subsequently, three statistical indexes of the angular second moment, dissimilarity, and inverse difference moment of the gray level co-occurrence matrix were validated for their effectiveness in characterizing texture features of SRS images for damage classification (e.g., no damage or minor damage, and major damage or destroyed) by the SVM model.
The results indicate that the assessment accuracies for object detection and damage classification of post-earthquake buildings can reach as high as 95.7 and 97.1%, respectively. Moreover, the test results show that good detection capacity can be achieved under more complex conditions, including buildings on the image boundary, dense buildings, and tree-occluded buildings.
The main implications of this study are two-fold: (1) For the research aspect, the modified YOLOv4 model can be further applied for other tiny-sized and densely distributed object detection tasks in addition to building detection in SRS images. The proposed SVM model based on GLCM features can also be applied in other imbalanced classification problems. (2) For the application aspect, the proposed method combining modified YOLOv4 object detection and SVM classification models holds promising potential for rapid and accurate wide-area post-earthquake building location and damage assessment. The proposed method has been verified on the Mexico City earthquake in 2017 using SRS optical images from the xBD database.
In this study, satellite remote sensing optical images were utilized for rapid and accurate wide-area post-earthquake building damage assessment, which could only provide the roof information of buildings. Therefore, we did not pay much attention to the different types of buildings. However, one of our ongoing studies is conducting a fine-grained assessment of individual buildings using near-field images from unmanned aerial vehicles with more detailed information on damage, components, and building types concerned.



 ,
, 















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}