1. Introduction
Remote sensing (RS) imagery has been widely used in meteorology, agriculture, the military, and other fields. However, compared to ground images, the quality of RS images is not good even under haze-free conditions due to the light attenuation in the long imaging distance. In addition, RS imagery has a larger field of view than ground imaging, resulting in a non-uniform distribution of haze. Due to the much more complex atmospheric conditions than exists for ground photography, the captured RS images are usually degraded with contrast reduction and detailed information loss. As a result, such degraded images further constrain the advanced applications of RS images, such as ground object segmentation, classification, recognition, tracking, etc. Therefore, RS image dehazing, as an essential image preprocessing step and image quality enhancement technology, has been extensively researched [
1,
2,
3]. According to the dehazing principle, the existing dehazing methods can be roughly divided into two categories: the traditional dehazing method [
4,
5,
6,
7] and the learning-based dehazing method [
8,
9,
10,
11,
12].
Based on the dehazing principles, the traditional image dehazing methods can be categorized into prior-based methods and enhancement-based methods. The prior-based methods use handcrafted hazy image priors for restoration. For example, He et al. [
7] proposed the dark channel prior (DCP), which is simple and effective for image dehazing. However, since the DCP is based on the statistics of outdoor haze-free images, it fails to remove the haze in regions of white objects or the sky. In Zhu’s work [
4], color attenuation prior (CAP) was proposed to recover the depth information in greater detail, but the CAP is inadequate to remove haze thoroughly. Zhao et al. [
6] used a bounded channel difference prior (BCDP) for single image dehazing. The BCDP can effectively suppress the noise amplification in dehazing, but it may result in uneven brightness of blocks in the dehazed image. Therefore, since most dehazing priors are based on the properties of ground images, it is insufficient to use the easily violated hazy image priors when processing hazy RS images with complex features. Besides using image priors to recover the haze-free image, many image enhancement techniques are selected for image dehazing tasks, such as histogram equalization [
13,
14], wavelet transformation [
15], the Retinex method [
16], and homogeneous filtering [
17]. Kim et al. [
18] proposed an optimized contrast enhancement strategy for real-time image dehazing, which can optimally preserve the image information. Wang et al. [
19] demonstrated a linear relationship in the minimum channel between the hazy and the haze-free images, so the input image is dehazed using a linear transformation. Wang et al. [
20] introduced a multi-scale Retinex with color restoration (MSRCR) algorithm to preserve the image’s dynamic range. However, the enhancement-based methods naively improve the RS hazy image’s visual effect without considering the hazy degradation principle, resulting in over-enhancement and undesired artifacts in the dehazed image.
Due to the rapid development of deep neural networks (DNNs), learning-based methods are being increasingly applied to solve the dehazing problem and have achieved remarkable performance in recent years. They can be categorized into two groups: one is model-based dehazing methods that use the convolutional neural network (CNN) to estimate the parameters of the haze imaging model. The other is end-to-end dehazing methods that use CNN or a generative adversarial network (GAN) to recover the haze-free image directly. For model-based dehazing methods, Bie et al. [
21] proposed a Gaussian and physics-guided dehazing network (GPD-Net) by combining the Gaussian process and physical prior knowledge for single RS image dehazing. Li et al. [
8] designed an all-in-one dehazing network (AOD-Net) that reformulates the atmospheric scattering model to generate a clean image directly. By integrating learning-based and prior-based methods, Chen et al. [
22] embedded a patch-map-based DCP into the learning network to efficiently improve the performance of the dehazing network. For end-to-end dehazing methods, Chen et al. [
23] presented a memory-oriented generative adversarial network (MO-GAN) to find the relationship between the RS hazy domain and the RS clear domain in an unpaired learning manner. Motivated by the attention mechanism, Qin et al. [
10] proposed an end-to-end feature fusion attention network (FFA-Net) to restore the haze-free image directly. Using a deep dehazing network based on encoder–decoder architecture, Jiang et al. [
24] eliminated the non-uniform haze of RS hazy images. Engin et al. [
25] proposed an enhanced cycle-GAN to generate visually better haze-free images. In recent years, transformer models have been applied to RS image dehazing tasks due to their outstanding performance in visual tasks. For example, Song et al. [
26] proposed a DehazeFormer, which obtains fabulous quantitative results on various hazy datasets. Dong et al. [
27] proposed a two-branch neural network fused with Transformer and residual attention to recover the fine details of RS hazy images with nonhomogeneous haze.
Although the learning-based methods achieve remarkable performance, they require large-scale datasets with paired hazy–clear images for training. However, for RS images, collecting large-scale datasets with paired real-world hazy images is scarcely feasible. Therefore, most learning-based RS dehazing methods use synthetic RS hazy datasets (RICE [
28], RS-Haze [
26], SateHaze1k [
29], etc.) for network training, which may result in domain-shift issues. To prevent labor-intensive data collection and solve the domain-shift issues caused by synthetic datasets, in recent years, a few zero-shot dehazing methods [
12,
30,
31,
32] have been proposed. Zero-shot dehazing methods use a single hazy image to perform learning and inference. Motivated by the deep image prior (DIP) [
33], Gandelsman et al. [
30] introduced the Double-DIP using coupled DIP networks. However, the dehazed image by Double-DIP may result in noise amplification, especially in the sky region. Li et al. [
31] proposed a zero-shot dehazing (ZID) framework using three joint sub-networks to estimate the atmospheric light, transmission map, and haze-free image. However, the ZID is unstable and can have over-enhancement and color distortion due to the poor loss function design. Through controlled perturbation of Koschmieder’s model, Kar et al. [
32] designed a zero-shot image restoration network model to recover the degraded image (hazy or underwater image). Although Kar’s method achieves good dehazing performance, certain dehazed images may have color distortion. Therefore, the existing zero-shot dehazing approaches cannot effectively tackle the dehazing problem, and few studies on zero-shot RS image dehazing have been proposed.
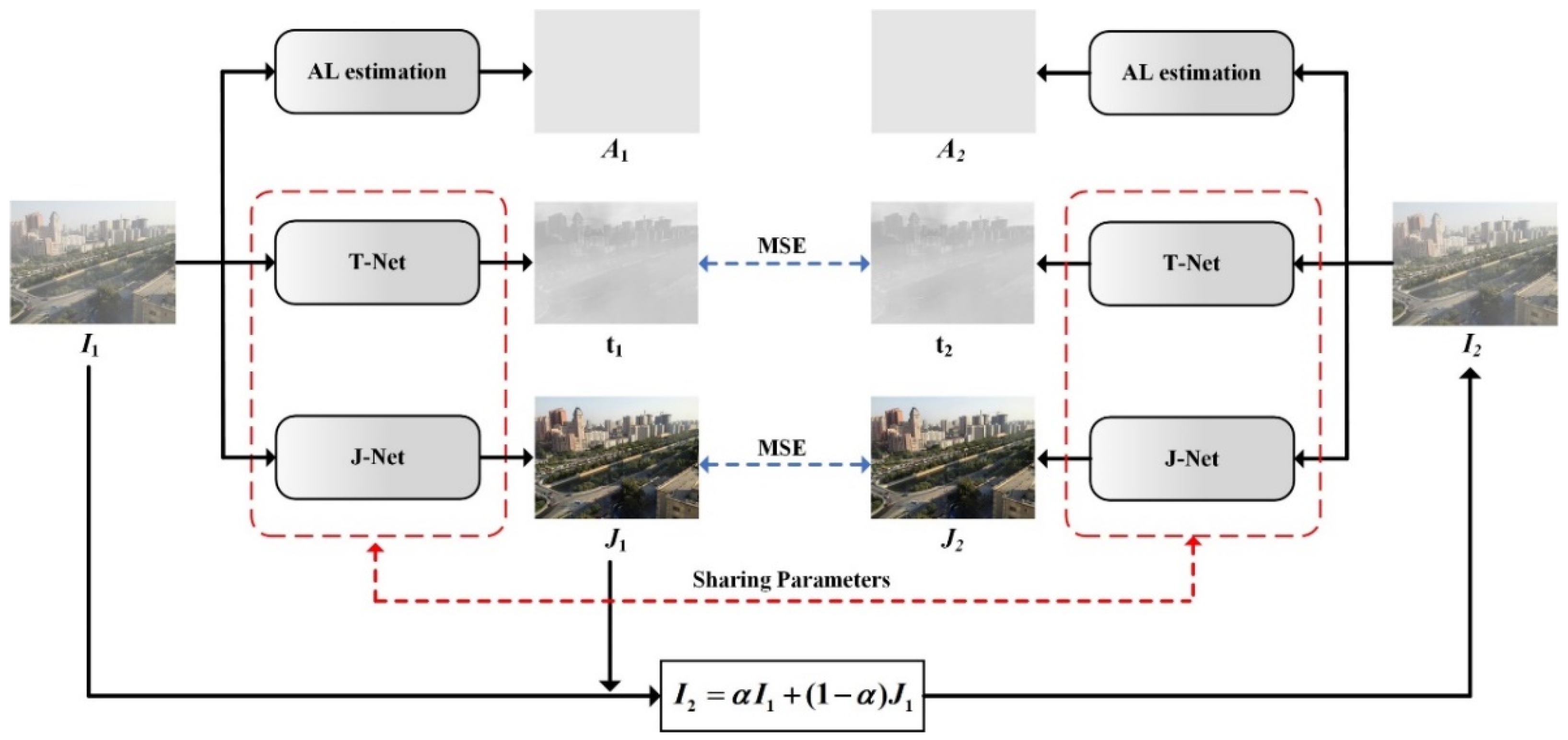
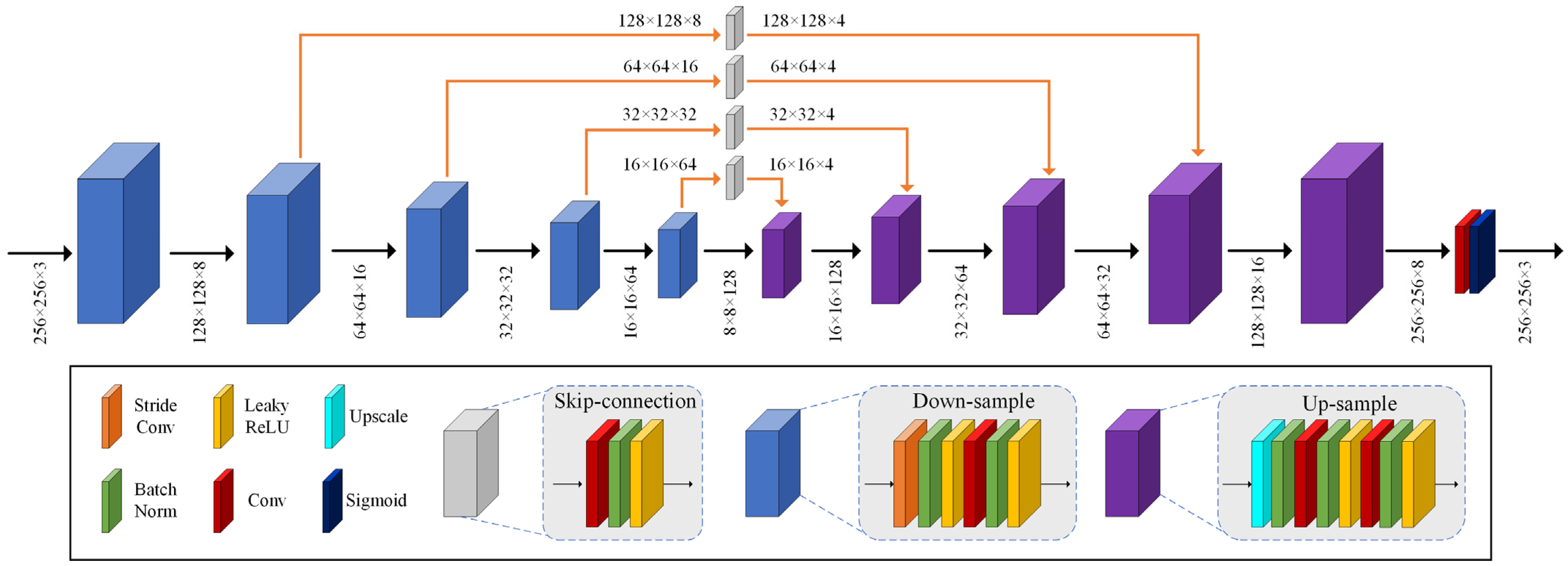
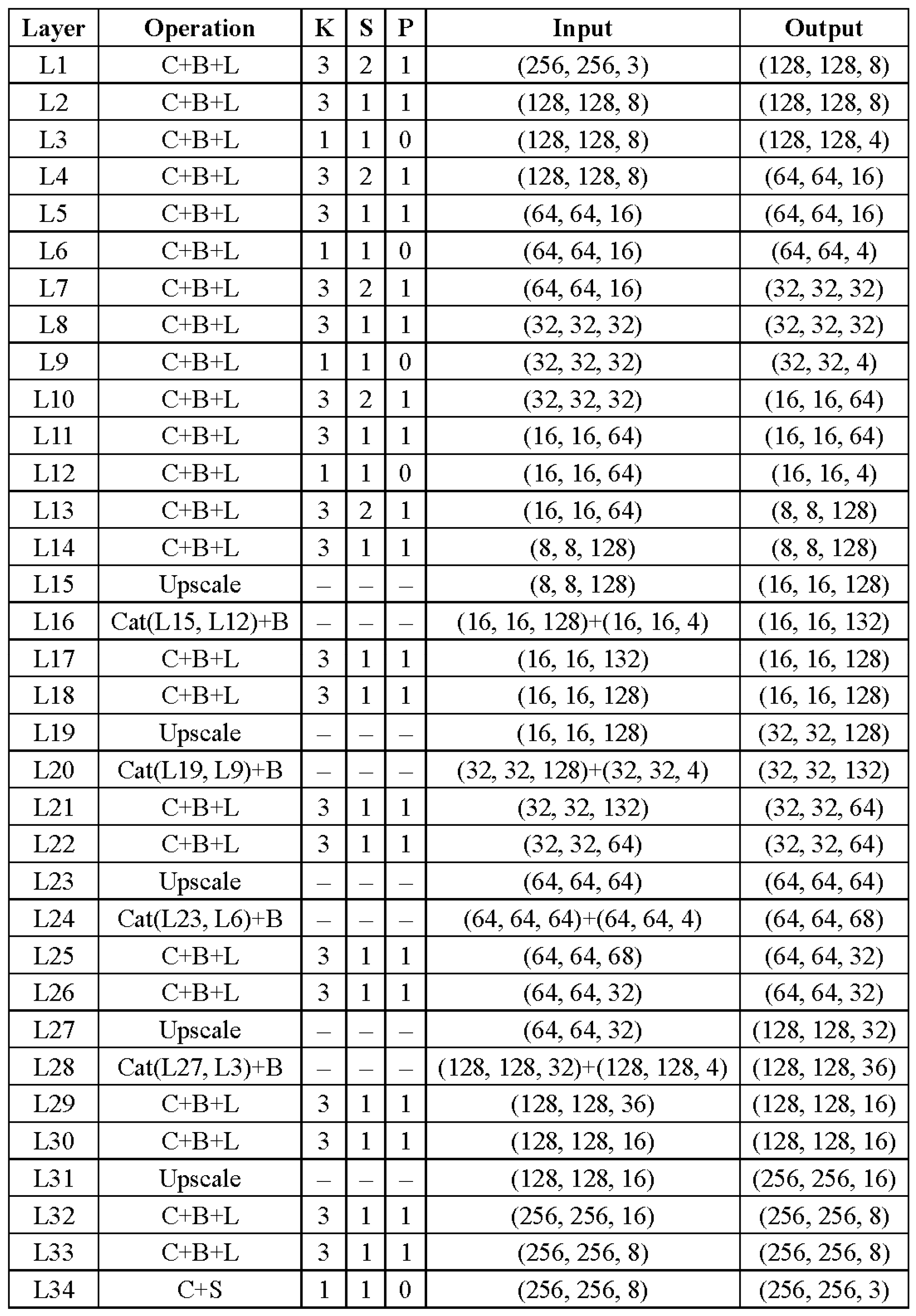
This work proposes a novel re-degradation haze imaging model for zero-shot RS image dehazing. Firstly, we design a dehazing framework consisting of three joint sub-modules: AL estimation, J-Net, and T-Net. The AL estimation module estimates the atmospheric light using a quad-tree hierarchical search algorithm. T-Net and J-Net are two neural networks to infer the transmission map and haze-free image. Thus, the dehazing framework disentangles the hazy input image into three components: the atmospheric light, the transmission map, and the recovered haze-free image. We then generate a re-degraded hazy image by mixing up the hazy input image and the recovered haze-free image. Through the proposed re-degradation haze imaging model, we theoretically demonstrate that the hazy input image and the re-degraded hazy image follow a similar haze imaging model with the same scene radiance, the same atmospheric light, and the transmission maps with known fixed relations. This finding helps us to train the dehazing network in an unsupervised fashion. Concretely, the dehazing network is optimized in a zero-shot manner to generate outputs that satisfy the relationship between the hazy input image and the re-degraded hazy image in the re-degradation haze imaging model. Therefore, given a hazy RS image, the dehazing network directly infers the haze-free image by minimizing a specific loss function. Comprehensive experiments demonstrate the effectiveness of the proposed dehazing method. To summarize, the main contributions of this paper are listed as follows:
(1) Based on layer disentanglement, we design a dehazing framework consisting of three joint sub-modules: AL estimation, J-Net, and T-Net. The AL estimation module estimates the atmospheric light. T-Net and J-Net infer the transmission map and haze-free image, respectively.
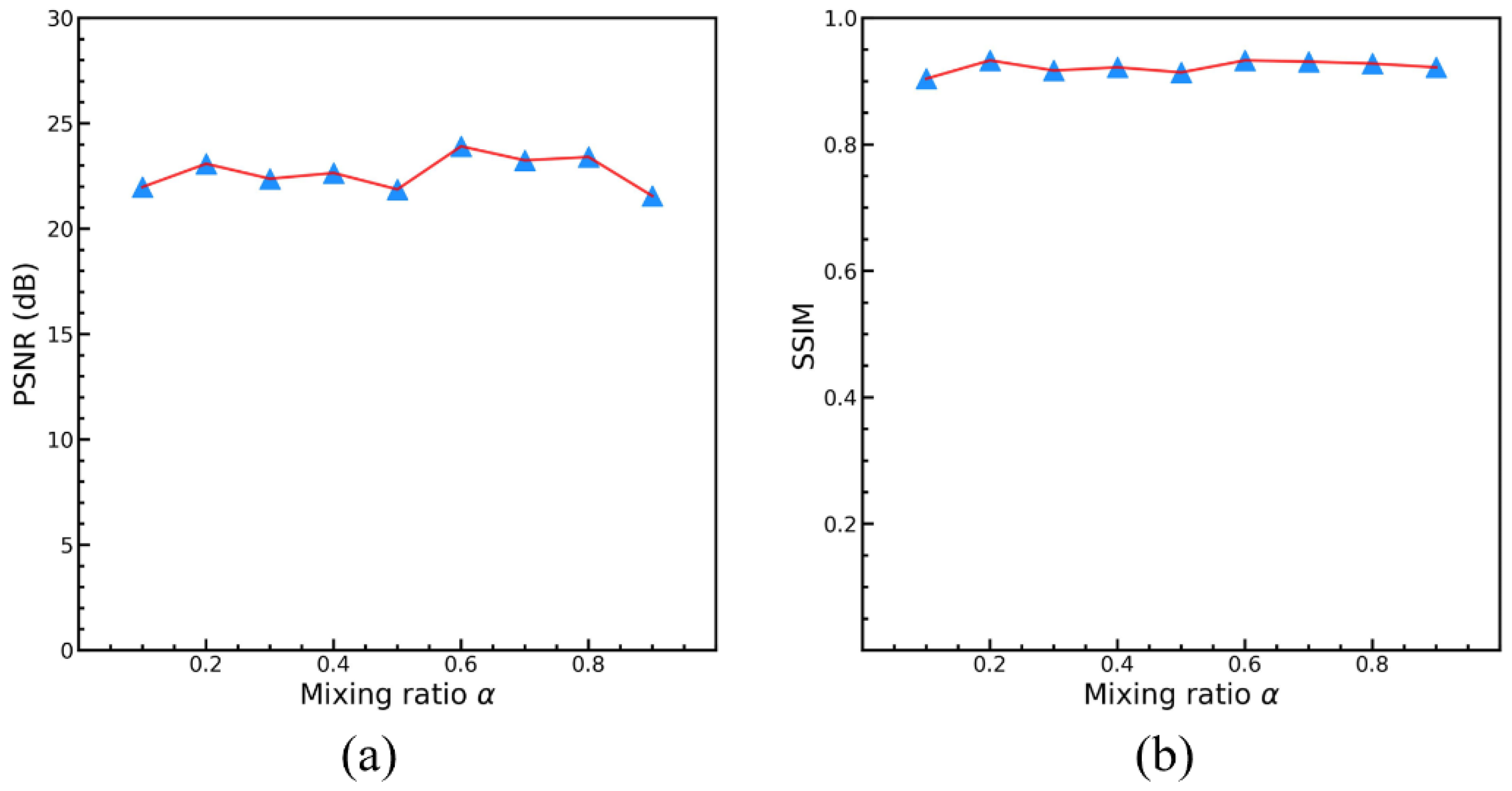
(2) We propose a novel re-degradation haze imaging model to demonstrate the relationship between the hazy input image and the re-degraded hazy image. A re-degradation loss is introduced to train the dehazing network in a zero-shot manner; that is, the dehazing network is optimized using only one hazy RS image.
(3) The proposed network recovers a haze-free image from a single RS image without large training data, hence avoiding labor-intensive data gathering and resolving the domain-shift issue brought on by synthetic datasets.
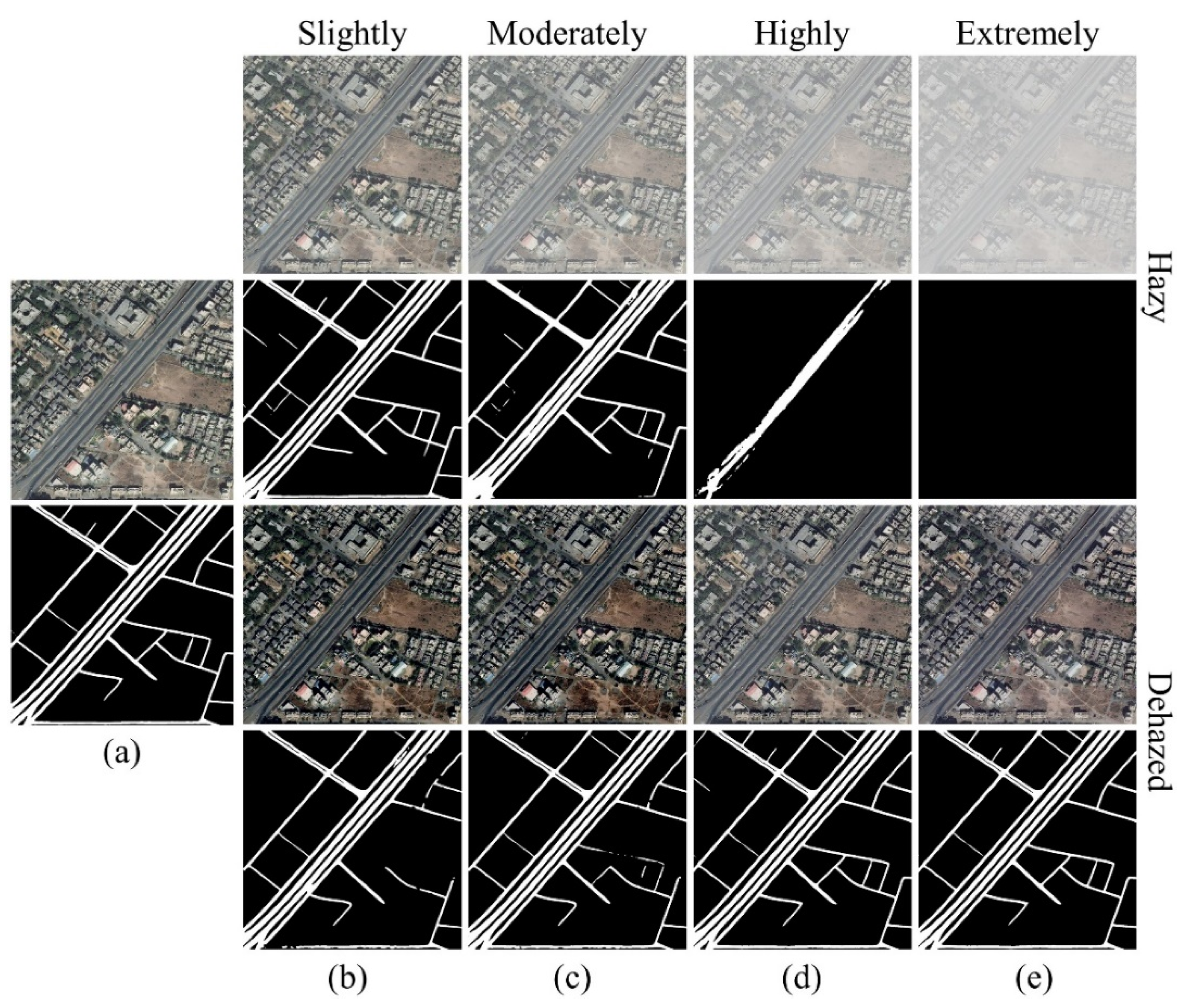
(4) In the experiments, we evaluate uniform RS hazy datasets, non-uniform RS hazy datasets, and real-world RS hazy images. Results show that our method outperforms numerous state-of-the-art (SOTA) dehazing methods in processing RS hazy images with uniform haze or slight/moderate non-uniform haze. In addition, we implement the RS image road extraction task to further demonstrate the effectiveness of our method.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}











