4.1. Experimental Setup
The experiments are conducted on the following three datasets.
LEVIR-CD. The LEVIR-CD dataset is a large-scale remote sensing image building change detection dataset published by the Learning, Vision and Remote sensing laboratory (LEVIR), which includes 637 pairs of co-registered images of high-resolution remote sensing with a size of
. The bi-temporal images in LEVIR-CD were collected from Google Earth images of 20 different areas in a diverse range of cities in Texas, USA, including Austin, Buda, Kyle, and Dripping Springs. These images were captured from 2002 to 2018, with sufficient consideration of season, illumination, and other factors to aid deep learning algorithms to moderate the effects of non-semantic changes. The dataset includes a wide range of building types such as residential buildings, tall office buildings, and large warehouses, and also incorporates a diversity of building changes such as building extensions, building teardowns, and no changes [
4]. For the convenience of the experiment, the images are cropped to
size to obtain
pairs of bi-temporal images for training, validation, and testing, respectively.
WHU-CD. The WHU-CD dataset captures the reconstruction of buildings in an earthquake-affected area and its subsequent years. It contains the progression of the building from 12,769 to 16,077 in a bi-temporal image with a resolution of 32,507 × 15,354 [
13]. Since this dataset does not provide a pre-divided solution, it is cropped into small patches of
images without overlap and samples random image pairs from them to form the
sets for training, validation, and testing. For the cropped co-registered image patch size less than 256, the padding “0” treatment for it is considered, and the corresponding ground truth is assigned as no change.
DSIFN-CD. The DSIFN-CD dataset is a collection of bi-temporal images from Google Earth of six Chinese cities, including Beijing, Chengdu, Shenzhen, Chongqing, Wuhan, and Xi’an, which contains variations of various objects such as agricultural land, buildings, and water bodies [
18]. The image information of the first five cities is treated as the training and validation sets and the images of Xi’an as the test set, and each of them is
in size and
in number. For experiments, the dataset with size
and 14,400/1360/192 samples is created for training, validation, and testing purpose.
Implementation details. The experiments are implemented using the Pytorch framework and trained on a single NVIDIA TITAN RTX. In the training process, the network is randomly initiated, using some common data augmentation techniques such as flip, rescale, and crop. AdamW is employed as the optimizer, the betas is set to (0.9, 0.999) and the weight decay is employed to 0.01. Moreover, the learning rate is set to 0.001 and linearly decayed from 0 to 200 epochs, while the batch size is set to 16 and the error is computed using Cross-Entropy (CE) loss.
Evaluation Metrics. To effectively evaluate the results of the model training, five normal metrics for evaluation, Precision (
), Recall (
), F1 score, Intersection over Union (
) of the category of change region, and Overall Accuracy (
) are used as the quantitative indices due to the precise classification involved in identifying whether the pixel points belong to the change region or not. The formalization of these measures is as follows:
where
,
,
, and
represent the number of true positive, true negative, false positive, and false negative, respectively. The evaluation metrics in the following experiments are all given in percentage.
4.2. Ablation Studies
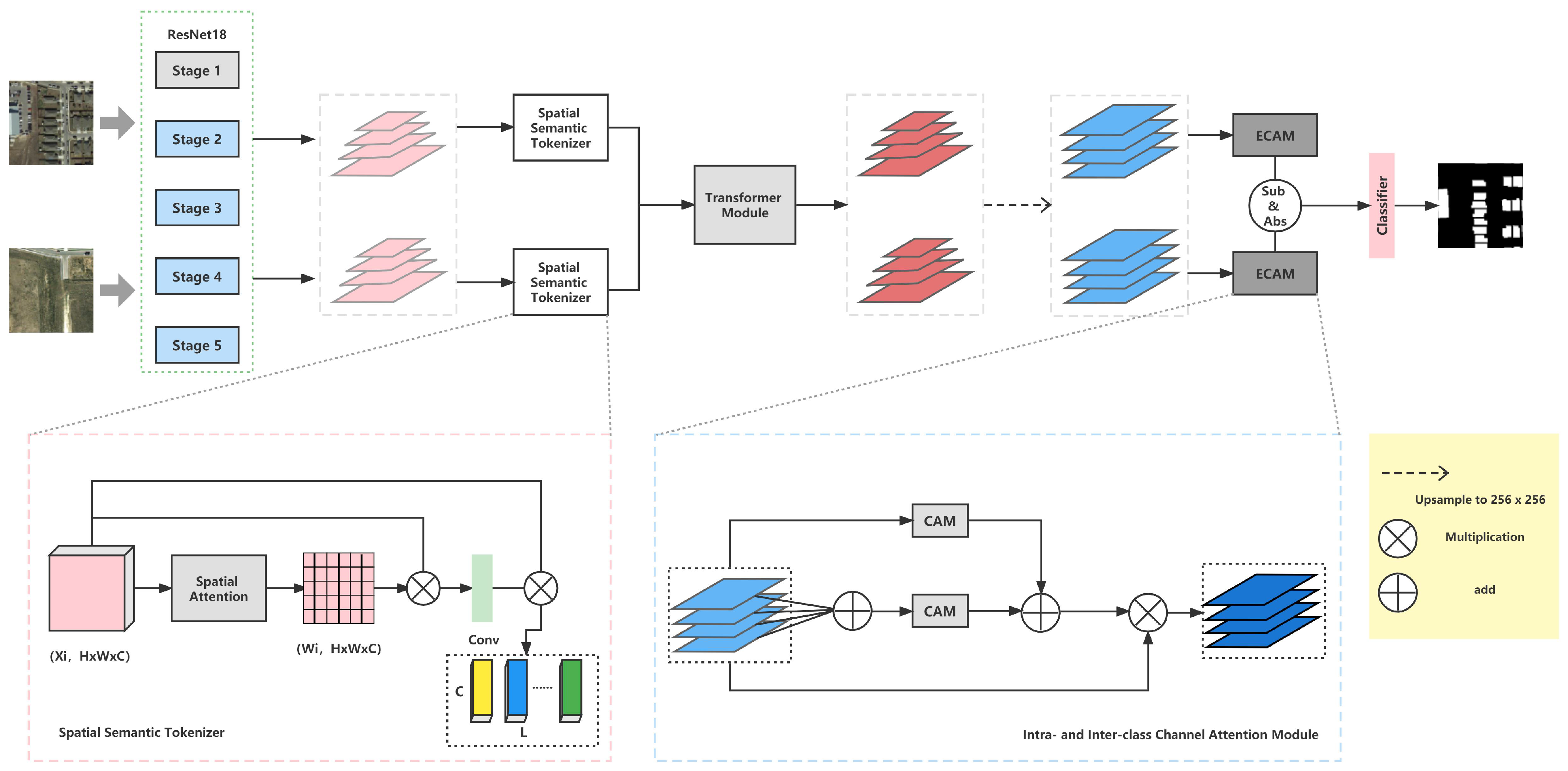
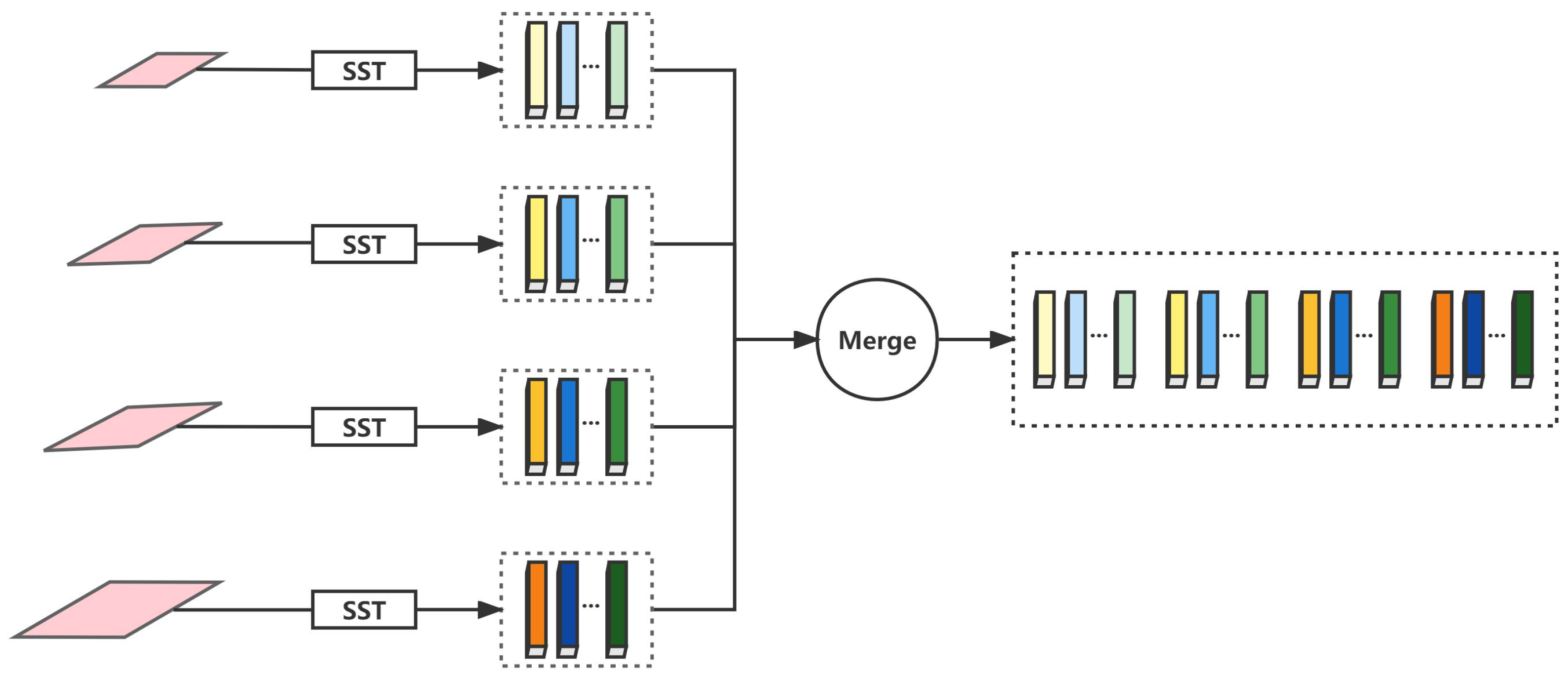
Ablation Studies on MFATNet. The proposed MFATNet integrates Transformer Module (TM), Spatial Semantic Tokenizer (SST), and Intra- and Inter-class Channel Attention Module (IICAM) for remote sensing image change detection. To verify the effectiveness of the mentioned method, the ablation studies are designed.
Base: ResNet18
Proposal1: ResNet18 + TM + Tokenizer (without SST)
Proposal2: ResNet18 + TM + Tokenizer (without SST) + IICAM
Proposal3: ResNet18 + TM + Tokenizer (with SST)
MFATNet: ResNet18 + TM + Tokenizer (with SST) + IICAM
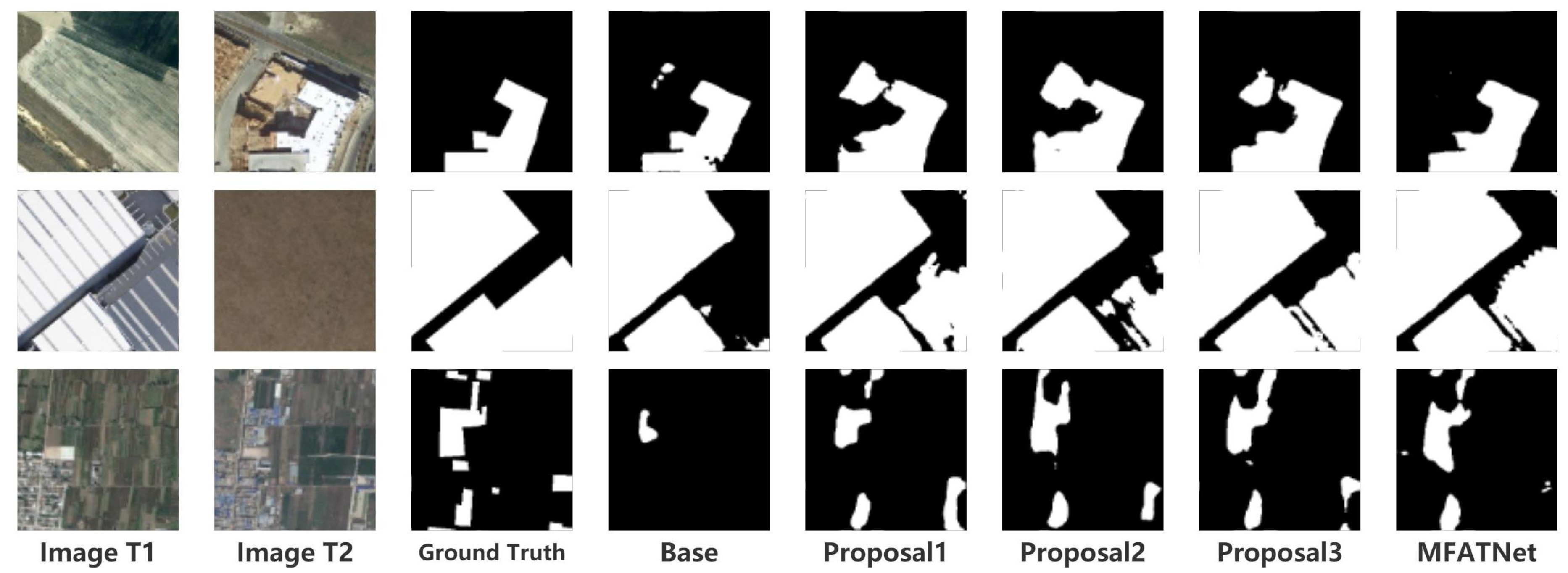
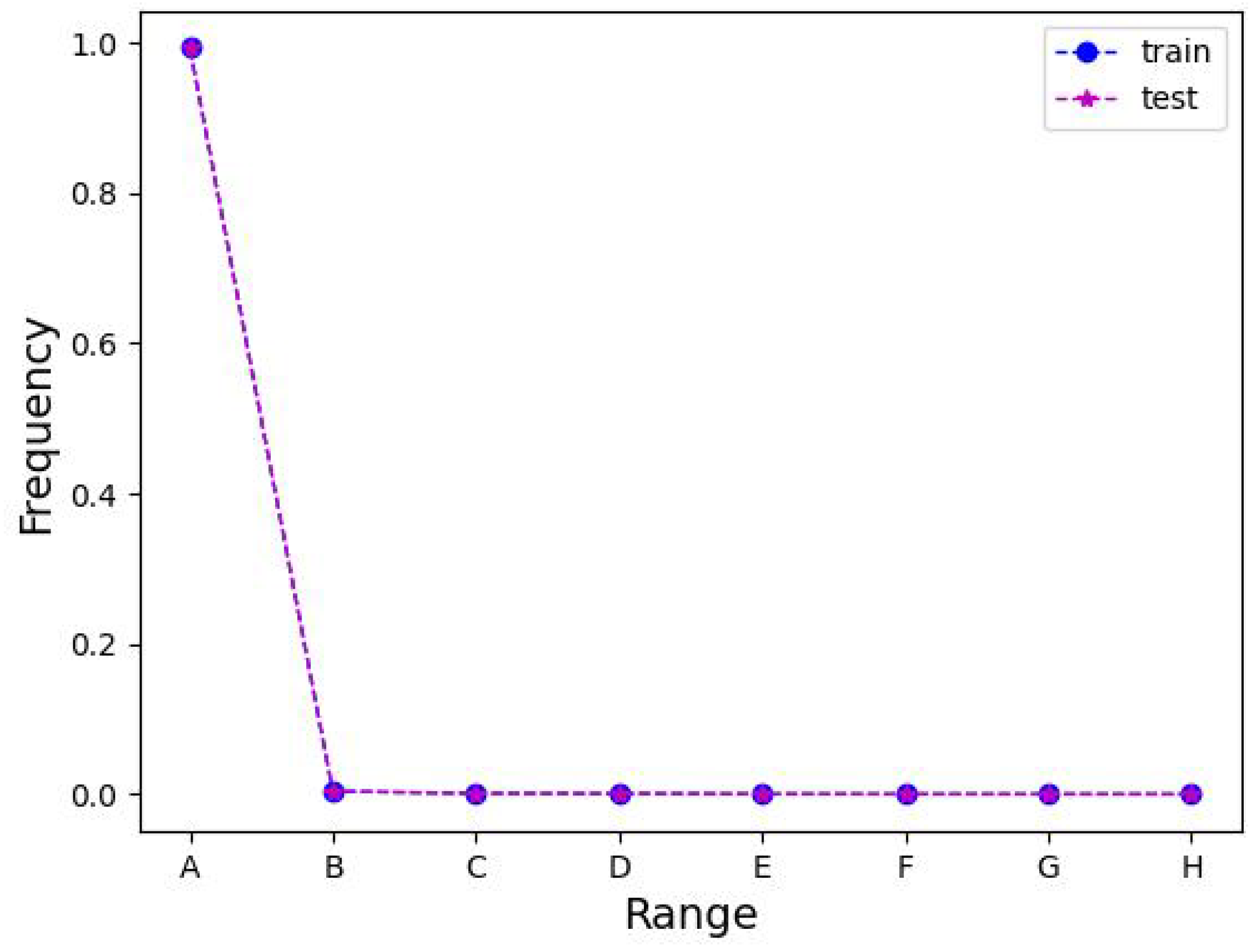
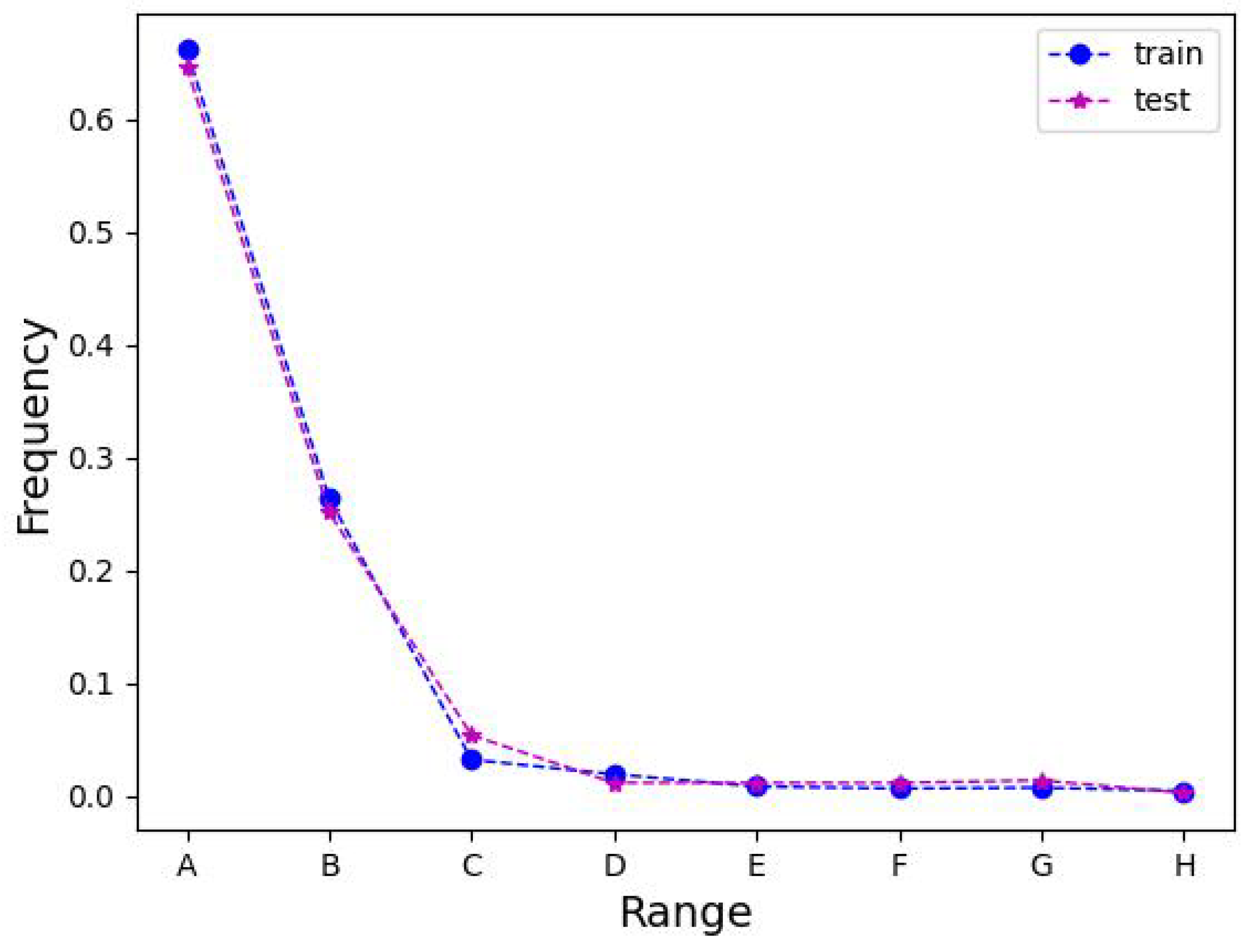
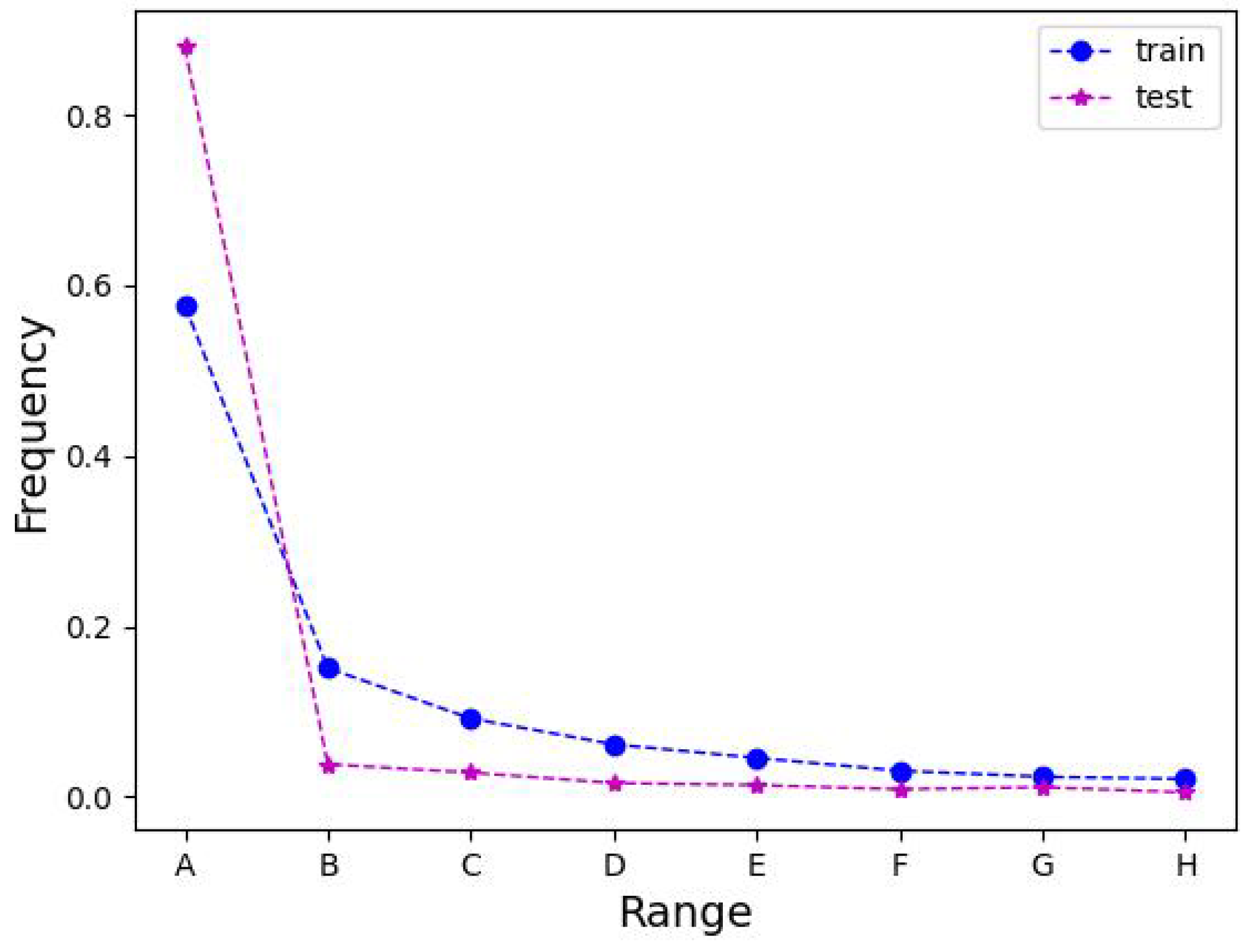
Table 1 illustrates the ablation experiments of MFATNet on three test sets, LEVIR-CD, WHU-CD, and DSIFN-CD. From this, it can be perceived that MFATNet, which integrates the three modules TM, SST, and IICAM achieves the best performance. Compared to the “Base” model, the “Proposal1” model with the TM module inserted is distinctly superior, with
improvement in IoU on the three test sets, respectively. In particular, a surprising performance improvement can be observed on the DSIFN-CD dataset. Given the discussion in
Section 5, such a phenomenon aptly demonstrates the robustness of the multi-scale transformer-based improvements (e.g., TM) in capturing the relationships of different relevant regions. Further, the “Proposal2” model improves the IoU by 0.3/0.64/ 2.54, respectively, compared with the “Proposal1” model, suggesting that the proposed IICAM can better smoothen the localization and semantic gaps in the feature map fusion and select a more discriminative representation. In addition, it can be noticed that the “Proposal3” model improves the IoU by 0.28/1.37/2.29 compared to the “Proposal1” model, indicating that the semantic and spatial correlation-based tokenizer improvement contributes to the performance, providing the transformer structure with better spatial context acquisition.
Figure 7 depicts the schematics of the ablation studies on the LEVIR-CD, WHU-CD, and DSIFN-CD test sets.
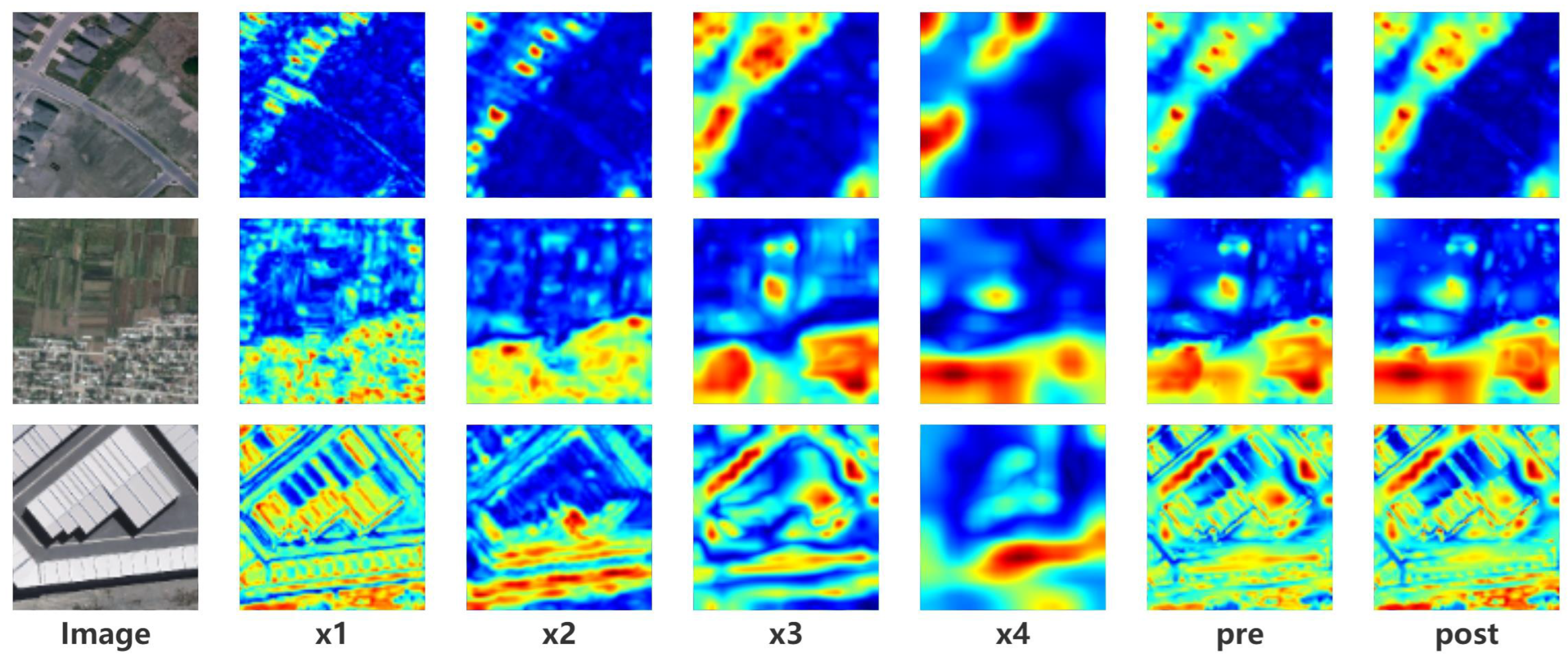
Ablation Studies on IICAM. Once the multi-scale features are extracted by the Convolutional Neural Network feature extractor and the transformer module learns the long-range dependencies, the resulting four feature maps are concatenated and passed through the final classifier to arrive at the change result map. Nevertheless, the four feature maps are subject to the removal of gaps between different channels and the selection of more discriminative representations. Thus, IICAM is introduced. IICAM is re-designed from two CAM modules that select inter-class and intra-class relationships, respectively. As mentioned in
Table 2, the validity of the proposal is demonstrated by comparing the performance of using None, intra- and inter-CAM, and IICAM on Base and Proposal3. Intra-CAM suggests a CAM operation performed after summing the four feature maps along the channel dimension, while the inter-CAM performs a CAM operation after concatenating them along the channel dimension. The IICAM is a combination of both of them, and the experimental record is better than the two independent modules, as anticipated. For a clearer picture of feature fusion and the contribution of the IICAM, the four stages of feature maps, their appearance after fusion, and the introduction of the IICAM, are visualized as
Figure 8.
Parameter analysis on token length. The intuition in designing the Spatial Semantic Tokenizer is to process image signals into compact word tokens as in Natural Language Processing. Thus, the length
L of the token set is considered to be a crucial hyperparameter. As mentioned in
Table 3,
L is set to 2, 4, 8, 16, and 32, and then the experiments are conducted on the three datasets using the Proposal3 method. From the experimental results, the token length of 16 achieves the desired results on the LEVIR-CD and WHU-CD datasets, while it is 4 on the DSIFN-CD dataset. From the previous work [
2,
43],
L of 4 [
2] and 16 [
43] is, respectively, adopted, with a bias toward constructing compact semantic tokens. Since the compact tokens are sufficient to specify the semantic concept of the region of interest, the redundant tokens can be detrimental to the performance of the model [
2]. Meanwhile, the experimental results also illustrate this trend, both too low and too high token lengths perform worse than the intermediate value.
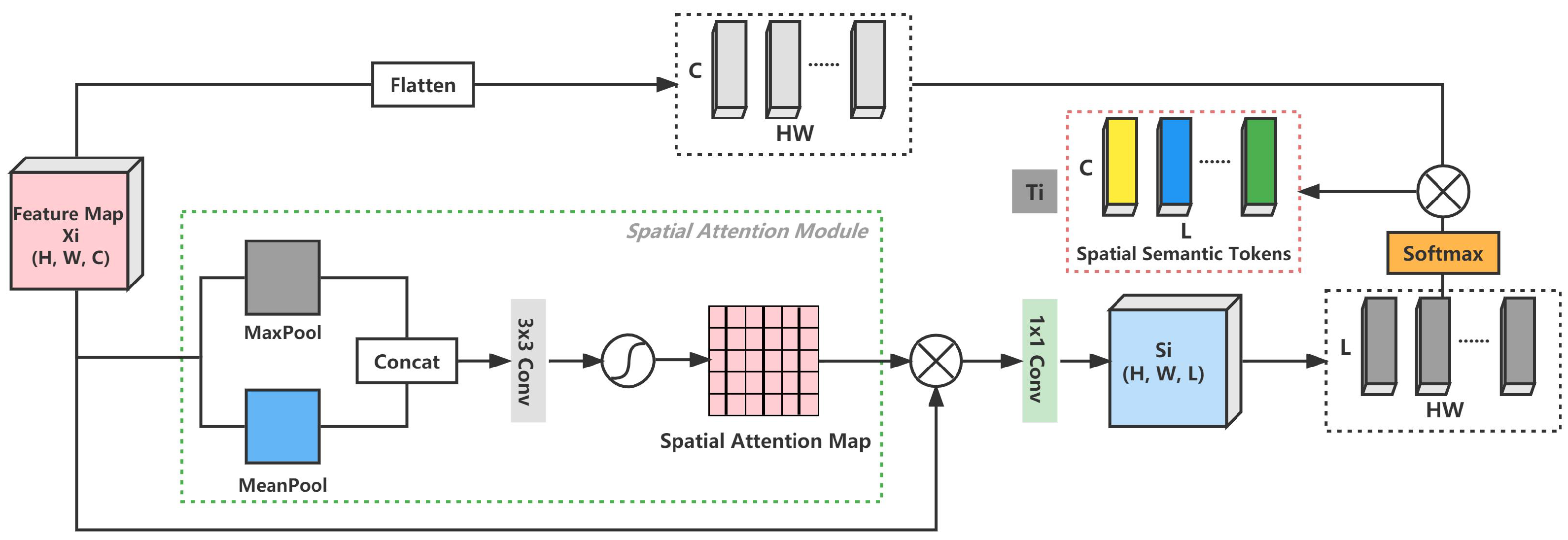
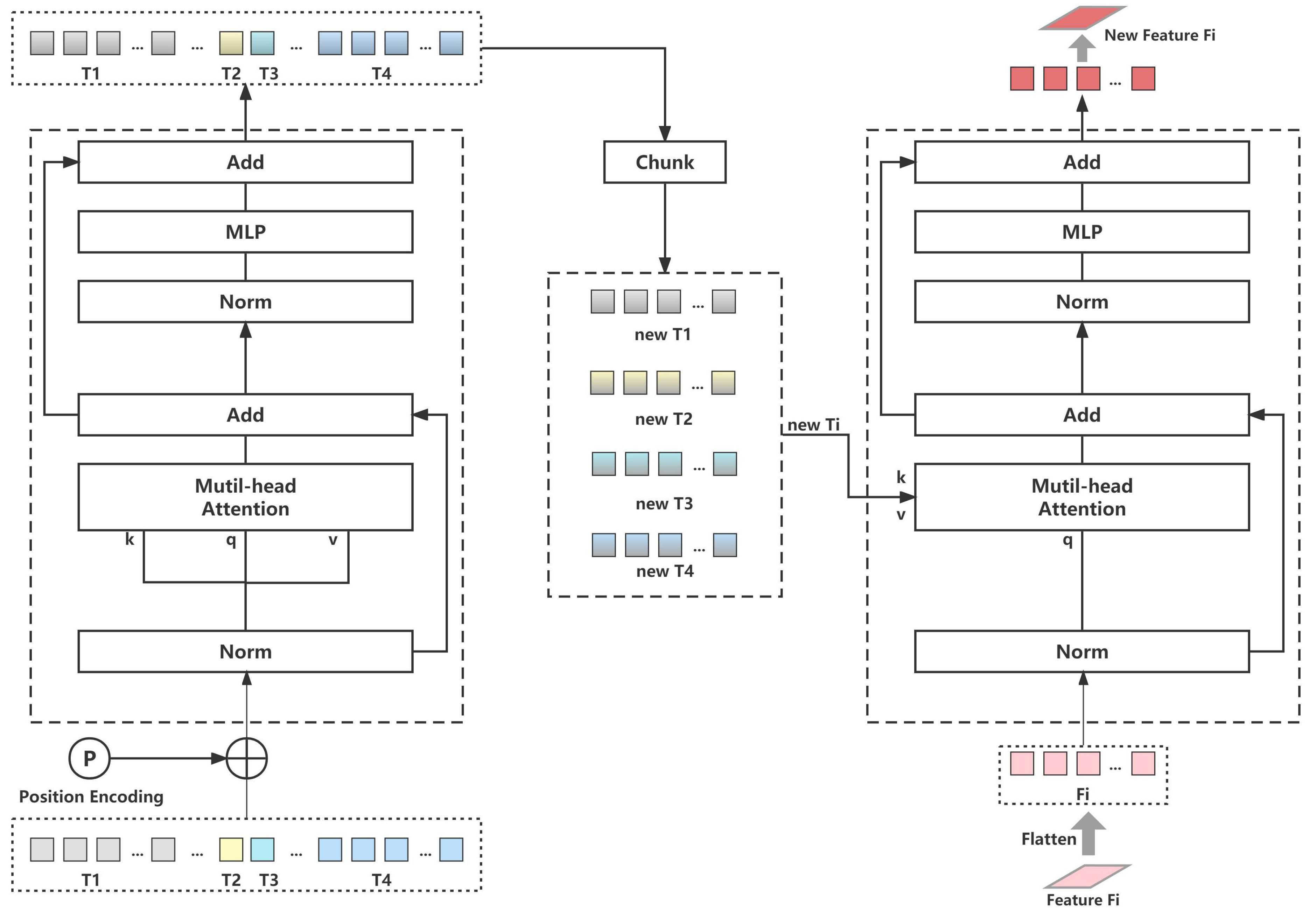
Ablation Studies on SST. When the feature maps from the ResNet18 extractor are obtained, they must be processed into token sets. Moreover, the region of interest must be emphasized on the token. Therefore, SST is proposed based on the Spatial Attention Module. Meanwhile, the following three tokenizer approaches are considered to demonstrate that SST is worthwhile.
Max: Max indicates that an operation must be performed on the feature map and then flattened into a vector, .
Avg: Avg indicates that an operation must first be performed on the feature map and then flattened into a vector, .
ST: Semantic Tokenize (ST) indicates that point-wise convolution must be directly performed on the feature map and then transformed into tokens, without integrating SAM, compared to SST, .
The experimental results on three datasets are reported in
Table 4. It can be concluded that the SST module performs better than the other three methods on the three datasets. It is considered that spatial attention simultaneously incorporates
and
activations, and that
and
are separately designed to explore the behavior of the tokenizer. At the same time, it could also be found that
performs better than the other two methods, and the inference is that
can preserve the overall characteristics to avoid losing more detailed representation. Instead, the proposed SST can work better in constructing compact semantic concepts, which further highlights the spatial criticality and makes the subsequent learning of the multi-scale transformer module more effective.
4.3. Comparison to Other Methods
A comparison of the proposed method is made with other existing excellent methods and the experimental results achieve promising performance. The compared methods are CNN-based methods FCEF [
5], FC-Siam-D [
5], FC-Siam-Conc [
5] and attention-based methods DTCDSCN [
14], STANet [
4], IFNet [
18], SNUNet [
9], and the transformer-based method BiT [
2].
FCEF. An image-level fusion method, which concatenates bi-temporal images by channel dimension before feeding them into an encoder–decoder architecture for convolutional networks.
FC-Siam-D. A feature-level fusion method, variants of the FCEF method, which uses a Siamese network in the feature extraction stage to extract the bi-temporal image features and then computes feature differences for fusing information.
FC-Siam-Conc. A feature-level fusion method, variants of the FCEF method, which uses a Siamese network in the feature extraction stage to extract the bi-temporal image features and then perform feature concatenate for fusing information.
DTCDSCN. An attention-based method, which introduces the auxiliary task of object extractions and dual attention module to a deep Siamese network to improve the discriminative ability of the features.
STANet. An attention-based approach, like DTCDSCN, that integrates the spatial–temporal attention mechanism into a Siamese network to determine stronger features for representation.
IFNet. A deeply supervised image fusion method in which the features are extracted at each stage by applying channel attention and spatial attention to multi-scale bi-temporal features. Deep supervision is also applied to seek results with better performance.
SNUNet. A multi-scale feature fusion method, which uses a Siamese network to fuse bi-temporal features and NestedUNet to obtain multi-scale bi-temporal features and then alleviates the gaps of different scale fusions using the channel attention module.
BIT. A transformer-based method, which uses ResNet18 to extract the feature map of a bi-temporal image, tokenize it, and then feed it into a transformer network structure to capture the long-range dependencies.
In
Table 5,
Table 6 and
Table 7, the results of the comparison experiments on the LEVIR-CD, WHU-CD, and DSIFN-CD test sets are reported, respectively. The proposed method outperforms the other methods in terms of F1 score, IoU, and OA on all three datasets. As shown in
Table 5, on the LEVIR-CD test sets, the proposed method achieved an F1 score of 90.36, IoU of 82.42, and OA of 99.03, corresponding to exceeding the second-best method BiT [
2] by 1.05, 1.74, and 0.11, respectively. The proposed method also achieves competitive performance in the metrics Pre. and Rec. with 91.85 and 88.93, respectively.
Table 6 presents the results for WHU-CD. An 88.31 F1 score, 79.08 IoU, and 99.01 OA are achieved, which are 0.31, 0.5, and 0.02 higher than that of BiT [
2], the second-best method, respectively. As shown in
Table 7, the proposed method performs best on DFISN-CD in all five metrics, while surpassing the second-best method BiT [
2] in F1, IoU, and OA by 18.36, 25.01, and 6.43, respectively. It is worth noting that the proposed CNN feature extractor for MFATNet does not use sophisticated designs such as FPN [
4], dense network structure [
5,
9,
14,
18], and dilated convolution [
2], while the transformer further aggregates multi-scale features compared to the single-scale of BiT [
2].
Meanwhile, it can be observed that the DSIFN-CD dataset produces a striking difference between the proposed method and the second-best method, while the boosting effect is more soothing on the other two datasets. It can also be considered that this condition is attributable to differences in the distribution of the dataset, the details of which are mentioned in
Section 5. To illustrate more graphically the promising outcome of this method compared to the other methods, some of the experimental results are visualized on three datasets, as shown in
Figure 9, where white denotes
, black denotes
, green indicates
, and red denotes
. The holistic visualization exhibits that the proposed method better avoids false positive and false negative (red and green account for less). At the same time, the detection of the change in the region of interest is more consistent with the ground truth in terms of appearance, and the edges of the region are processed in a better way (e.g., LEVIR-CD.a.,b.,c.,d.). It can also be noticed that the proposed method performs appreciably better than the other methods (e.g., WHU-CD.b.,d., and DSIFN-CD.b.,d.) in the face of the detection of large change regions. When large and small change regions are present concurrently, this method is also capable of addressing the two change regions with large differences at the same time (e.g., DSIFN-CD.a.,c., and WHU-CD.c.). Both the above recordings and observations suggest the proposed MFATNet has a promising effect. The visualization results for the detection of large change regions and small change regions expose the prospect of the transformer capturing long-range dependencies for remote sensing image change detection, and the performance improvement brought by the fusion between the more accurate localization information enriched by low-level visual representations and the richer semantic information embedded in high-level visual representations.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}