
Dynamic Convolution Self-Attention Network for Land-Cover Classification in VHR Remote-Sensing Images

 , , ,
, , ,
Abstract

1. Introduction
- We design a lightweight dynamic convolution module, which combines dynamic convolution with self-attention to extract more useful feature information at a lower cost and avoid the negative impact of redundant features on classification results.
- We design a ladder-shaped context information aggregation module, which can effectively expand the receptive field, fully integrate the multi-scale context information of different resolution feature maps, and effectively solve the problems of fuzzy target contour and large-scale changes in the remote-sensing image scene.
- We propose a full-scale multi-modal feature fusion strategy to maximize the effective fusion of high-level and low-level features, to obtain more accurate location and boundary information.
2. Related Work
2.1. Lightweight Network for Land-Cover Classification
2.2. Feature Fusion for Land-Cover Classification
3. Proposed Method
3.1. Overview
3.2. Lightweight Dynamic Convolution Module
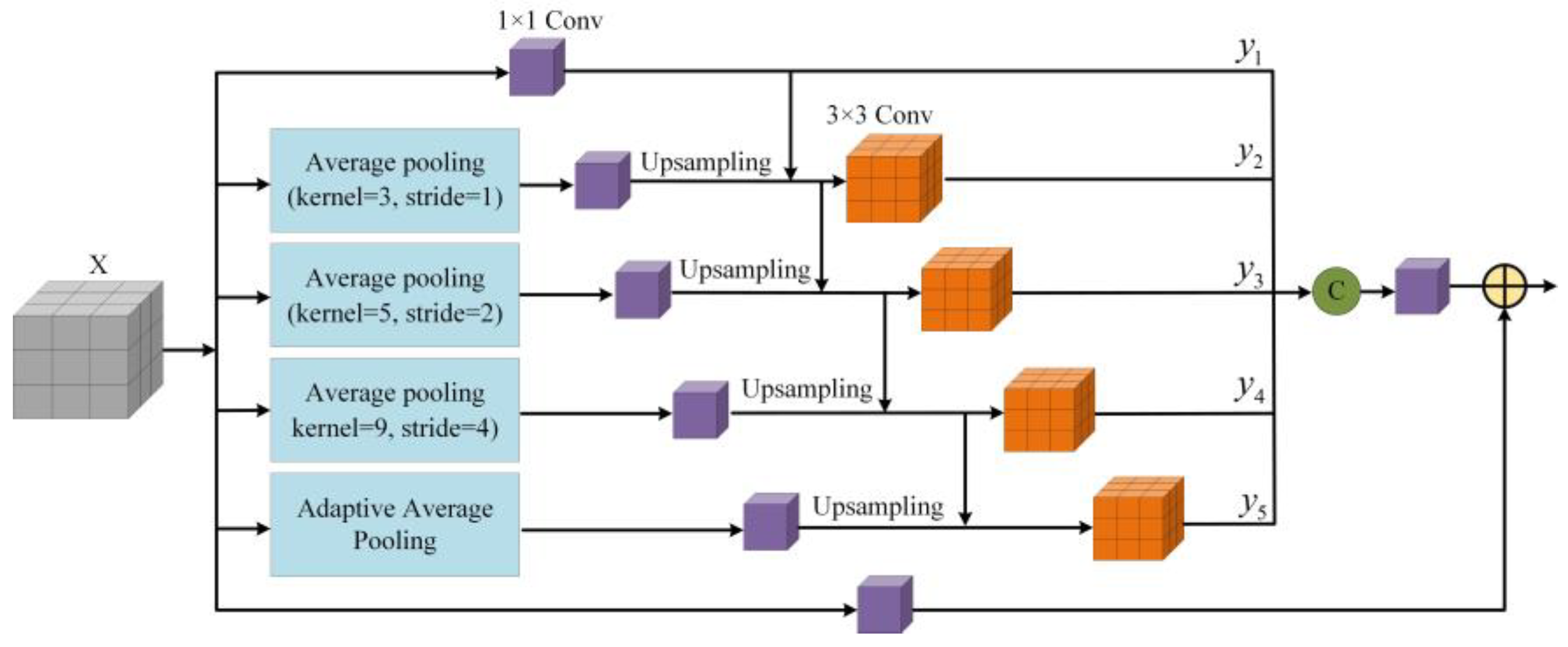
3.3. Context Information Aggregation Module
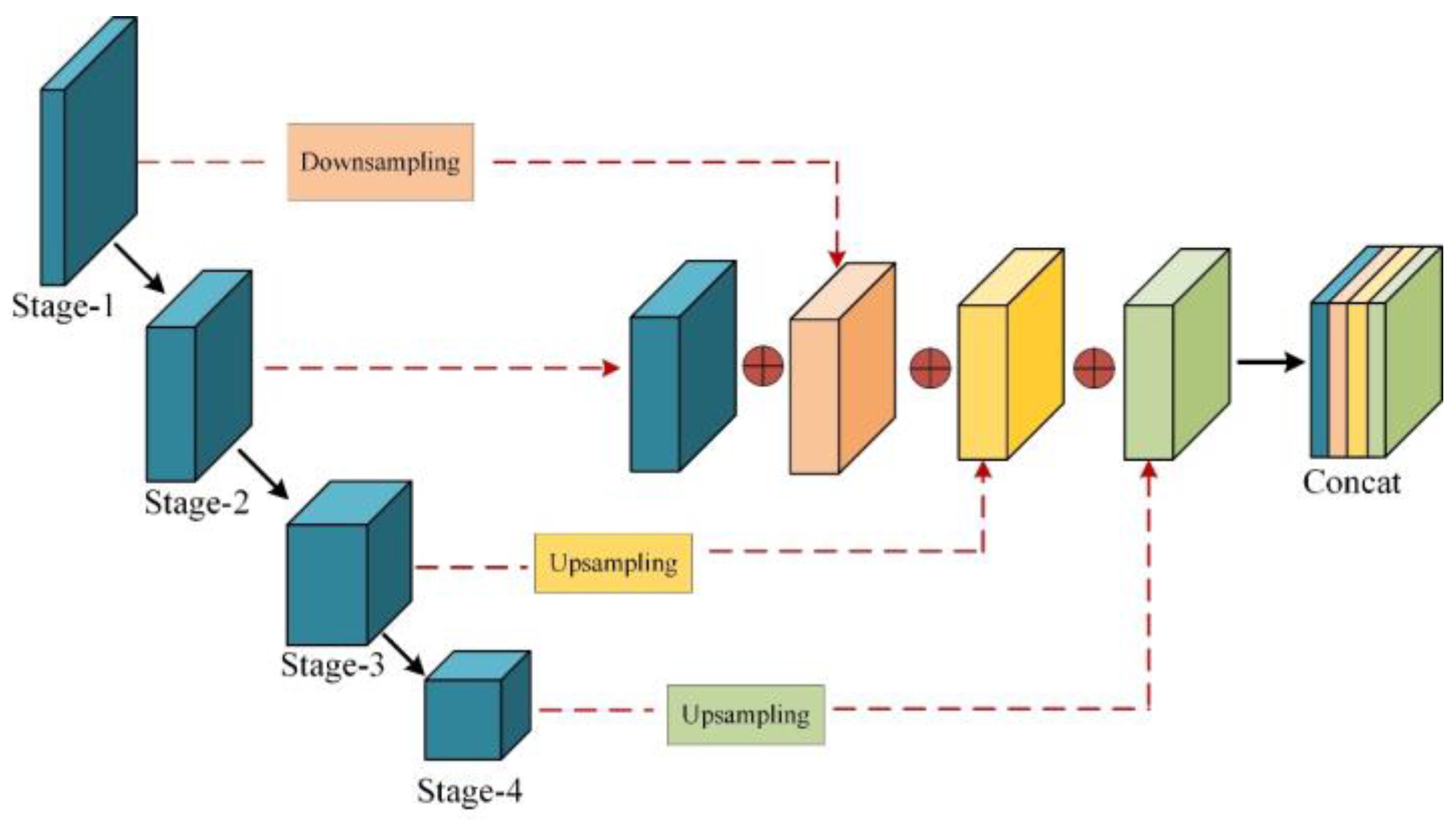
3.4. Full-Scale Feature Interaction Strategy
4. Experimental Results and Analysis
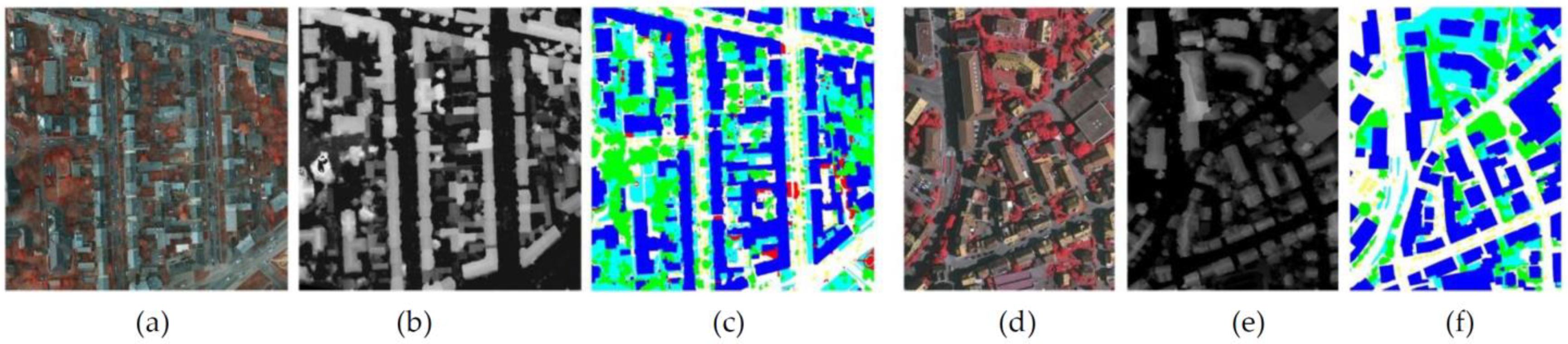
4.1. Datasets Description
4.2. Training Details
4.3. Metrics
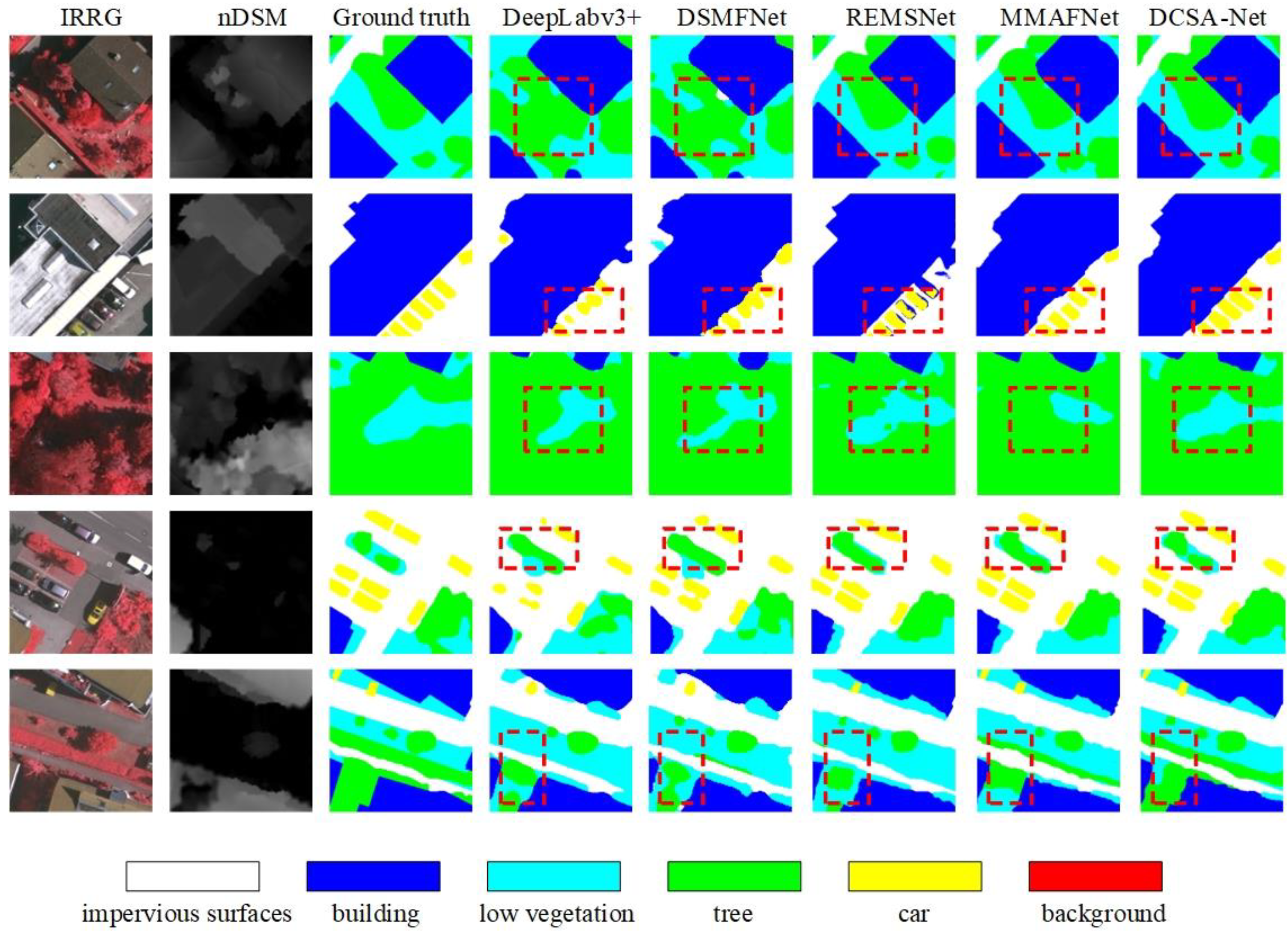
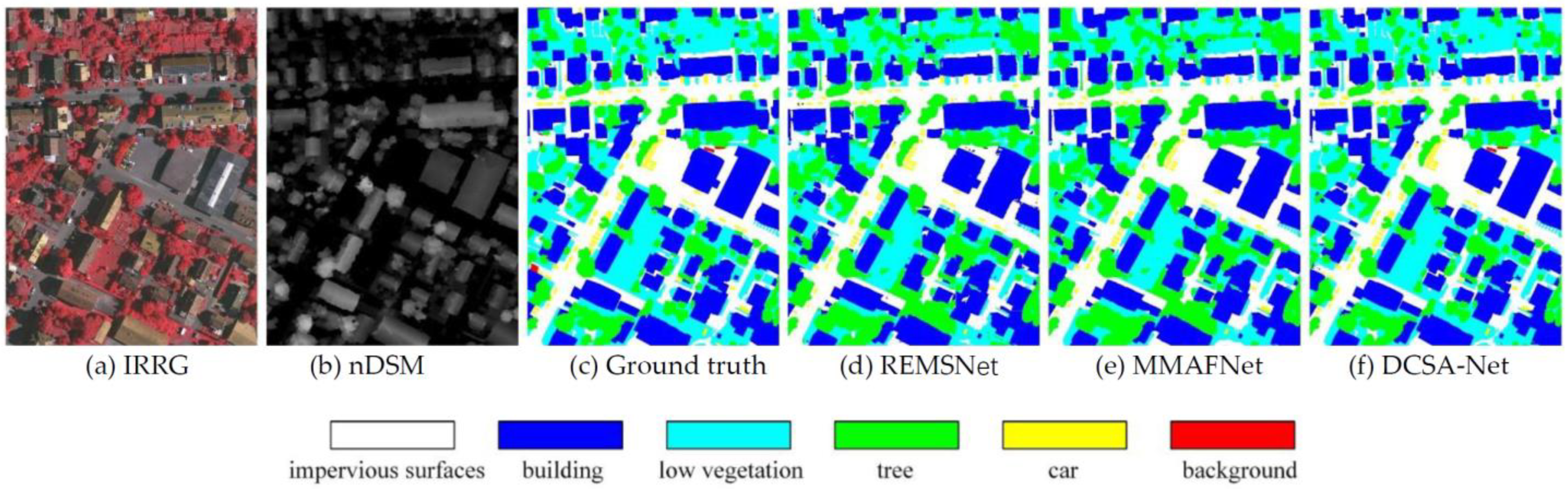
4.4. Results and Analysis
4.5. Model Complexity
4.6. Ablation Studies
5. Discussion
5.1. Discussion on the Effectiveness of the LDCM
5.2. Discussion on the Optimal Selection of Key Parameters in the CIAM
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Lv, Z.; Liu, T.; Benediktsson, J.A.; Falco, N. Land Cover Change Detection Techniques: Very-high-resolution optical images: A review. IEEE Geosci. Remote Sens. Mag. 2022, 10, 44–63. [Google Scholar] [CrossRef]
- Lei, T.; Wang, J.; Ning, H.; Wang, X.; Xue, D.; Wang, Q.; Nandi, A.K. Difference Enhancement and Spatial–Spectral Nonlocal Network for Change Detection in VHR Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–13. [Google Scholar] [CrossRef]
- Li, H.; Li, Y.; Zhang, G.; Liu, R.; Huang, H.; Zhu, Q.; Tao, C. Global and Local Contrastive Self-Supervised Learning for Semantic Segmentation of HR Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–14. [Google Scholar] [CrossRef]
- Troya-Galvis, A.; Gançarski, P.; Berti-Equille, L. Remote sensing image analysis by aggregation of segmentation-classification collaborative agents. Pattern Recognit. 2018, 73, 259–274. [Google Scholar] [CrossRef]
- Zanotta, D.C.; Zortea, M.; Ferreira, M.P. A supervised approach for simultaneous segmentation and classification of remote sensing images. ISPRS J. Photogramm. Remote Sens. 2018, 142, 162–173. [Google Scholar] [CrossRef]
- Lei, T.; Jia, X.; Zhang, Y.; Liu, S.; Meng, H.; Nandi, A.K. Superpixel-Based Fast Fuzzy C-Means Clustering for Color Image Segmentation. IEEE Trans. Fuzzy Syst. 2019, 27, 1753–1766. [Google Scholar] [CrossRef]
- Yu, H.; Gao, L.; Li, J.; Li, S.S.; Zhang, B.; Benediktsson, J.A. Spectral-Spatial Hyperspectral Image Classification Using Subspace-Based Support Vector Machines and Adaptive Markov Random Fields. Remote Sens. 2016, 8, 355. [Google Scholar] [CrossRef]
- Dong, L.; Du, H.; Mao, F.; Han, N.; Li, X.; Zhou, G.; Zhu, D.; Zheng, J.; Zhang, M.; Xing, L.; et al. Very High Resolution Remote Sensing Imagery Classification Using a Fusion of Random Forest and Deep Learning Technique—Subtropical Area for Example. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 13, 113–128. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet Classification with Deep Convolutional Neural Networks. Proc. Adv. Neural Inf. Process. Syst 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Long, J.L.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI), Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid Scene Parsing Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 22–25 July 2017; pp. 2881–2890. [Google Scholar]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef]
- Zhang, X.X.; Chen, T. Segmentation of High Spatial Resolution Remote Sensing Image based on U-Net Convolutional Net-works. In Proceedings of the IGARSS 2020—2020 IEEE International Geoscience and Remote Sensing Symposium, Wikoloa, HI, USA, 26 September 2020–2 October 2020; pp. 2571–2574. [Google Scholar]
- Mustafa, N.; Zhao, J.P.; Liu, Z.Y.; Zhang, Z.H.; Yu, W.X. Iron ORE Region Segmentation Using High-Resolution Remote Sensing Images Based on Res-U-Net. In Proceedings of the IGARSS 2020—2020 IEEE International Geoscience and Remote Sensing Symposium, Wikoloa, HI, USA, 26 September 2020–2 October 2020; pp. 2563–2566. [Google Scholar]
- Niu, Z.; Liu, W.; Zhao, J.; Jiang, G. DeepLab-Based Spatial Feature Extraction for Hyperspectral Image Classification. IEEE Geosci. Remote Sens. Lett. 2019, 16, 251–255. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E.H. Squeeze-and-excitation Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 42, 2011–2023. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Vedaldi, A. Gather-excite: Exploiting Feature Context in Convolutional Neural Networks. In Proceedings of the 32nd International Conference on Neural Information Processing Systems, Red Hook, NY, USA, 3–8 December 2018; pp. 9423–9433. [Google Scholar]
- Cao, Y.; Xu, J.; Lin, S.; Wei, F.; Hu, H. Gcnet: Non-local networks meet squeeze-excitation networks and beyond. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Seoul, Korea, 27–28 October 2019; pp. 1971–1980. [Google Scholar]
- Fu, J.; Liu, J.; Tian, H.J.; Li, Y.; Bao, Y.J.; Fang, Z.W.; Lu, H.Q. Dual Attention Network for Scene Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 3141–3149. [Google Scholar]
- Woo, S.; Park, J.C.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Li, H.; Qiu, K.; Chen, L.; Mei, X.; Hong, L.; Tao, C. SCAttNet: Semantic Segmentation Network with Spatial and Channel Attention Mechanism for High-Resolution Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2021, 18, 905–909. [Google Scholar] [CrossRef]
- Zhang, C.; Jiang, W.S.; Zhang, Y.; Wang, W.; Zhao, Q.; Wang, C.J. Transformer and CNN Hybrid Deep Neural Network for Semantic Segmentation of Very-High-Resolution Remote Sensing Imagery. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–20. [Google Scholar] [CrossRef]
- Lv, P.; Wu, W.; Zhong, Y.; Du, F.; Zhang, L. SCViT: A Spatial-Channel Feature Preserving Vision Transformer for Remote Sensing Image Scene Classification. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–12. [Google Scholar] [CrossRef]
- Iandola, F.N.; Han, S.; Matthew, W.M.; Ashraf, K.; William, J.D.; Keutzer, K. SqueezeNet: AlexNet-level Accuracy with 50x Fewer Parameters and <0.5 MB Model Size. arXiv 2016, arXiv:1602.07360. preprint. [Google Scholar]
- Romera, E.; Alvarez, J.M.; Bergasa, L.M.; Arroyo, R. ERFNet: Efficient Residual Factorized ConvNet for Real-Time Semantic Segmentation. IEEE Trans. Intell. Transp. Syst. 2017, 19, 263–272. [Google Scholar] [CrossRef]
- Howard, A.G.; Zhu, M.L.; Chen, B.; Kalenichenko, D.; Wang, W.J.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. preprint. [Google Scholar]
- Lv, L.; Guo, Y.; Bao, T.; Fu, C.; Huo, H.; Fang, T. MFALNet: A Multiscale Feature Aggregation Lightweight Network for Semantic Segmentation of High-Resolution Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2021, 18, 2172–2176. [Google Scholar] [CrossRef]
- Zhang, X.Y.; Zhou, X.Y.; Lin, M.X.; Sun, J. ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices. In Proceedings of the IEEE conference on computer vision and pattern recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6848–6856. [Google Scholar]
- Qiao, S.; Dong, X.-M.; Peng, J.; Sun, W. LiteSCANet: An Efficient Lightweight Network Based on Spectral and Channel-Wise Attention for Hyperspectral Image Classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 11655–11668. [Google Scholar] [CrossRef]
- Han, K.; Wang, Y.H.; Tian, Q.; Guo, J.Y.; Xu, C.J.; Xu, C. GhostNet: More Features from Cheap Operations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 1580–1589. [Google Scholar]
- Paoletti, M.E.; Haut, J.M.; Pereira, N.S.; Plaza, J.; Plaza, A. Ghostnet for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2021, 59, 10378–10393. [Google Scholar] [CrossRef]
- Cao, Z.; Fu, K.; Lu, X.; Diao, W.; Sun, H.; Yan, M.; Yu, H.; Sun, X. End-to-End DSM Fusion Networks for Semantic Segmentation in High-Resolution Aerial Images. IEEE Geosci. Remote Sens. Lett. 2019, 16, 1766–1770. [Google Scholar] [CrossRef]
- Peng, C.; Li, Y.; Jiao, L.; Chen, Y.; Shang, R. Densely Based Multi-Scale and Multi-Modal Fully Convolutional Networks for High-Resolution Remote-Sensing Image Semantic Segmentation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 2612–2626. [Google Scholar] [CrossRef]
- Ferrari, L.; Dell’Acqua, F.; Zhang, P.; Du, P. Integrating EfficientNet into an HAFNet Structure for Building Mapping in High-Resolution Optical Earth Observation Data. Remote Sens. 2021, 13, 4361. [Google Scholar] [CrossRef]
- Li, R.; Zheng, S.; Zhang, C.; Duan, C.; Su, J.; Wang, L.; Atkinson, P.M. Multiattention Network for Semantic Segmentation of Fine-Resolution Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–13. [Google Scholar] [CrossRef]
- Zhang, Y.J.; Chen, Y.L.; Ma, Q.J.; He, C.T.; Cheng, J. Dual Lightweight Network with Attention and Feature Fusion for Semantic Segmentation of High-Resolution Remote Sensing Images. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium IGARSS, Brussels, Belgium, 11–16 July 2021; pp. 2755–2758. [Google Scholar]
- Liu, Q.; Xiao, L.; Yang, J.; Wei, Z. Multilevel Superpixel Structured Graph U-Nets for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–15. [Google Scholar] [CrossRef]
- Zhou, Z.W.; Rahman Siddiquee, M.M.; Tajbakhsh, N.; Liang, J.M. UNet++: A Nested U-Net Architecture for Medical Image Segmentation. In Proceedings of the Deep learning in medical image analysis and multimodal learning for clinical decision support, Granada, Spain, 20 September 2018; pp. 3–11. [Google Scholar]
- Wang, Y.; Sun, Z.; Zhao, W. Encoder- and Decoder-Based Networks Using Multiscale Feature Fusion and Nonlocal Block for Remote Sensing Image Semantic Segmentation. IEEE Geosci. Remote Sens. Lett. 2021, 18, 1159–1163. [Google Scholar] [CrossRef]
- Xu, Q.; Yuan, X.; Ouyang, C.; Zeng, Y. Attention-Based Pyramid Network for Segmentation and Classification of High-Resolution and Hyperspectral Remote Sensing Images. Remote Sens. 2020, 12, 3501. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Shroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Tian, Q.; Zhao, Y.; Li, Y.; Chen, J.; Chen, X.; Qin, K. Multiscale Building Extraction with Refined Attention Pyramid Networks. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Liu, C.; Zeng, D.; Wu, H.; Wang, Y.; Jia, S.; Xin, L. Urban Land Cover Classification of High-Resolution Aerial Imagery Using a Relation-Enhanced Multiscale Convolutional Network. Remote Sens. 2020, 12, 311. [Google Scholar] [CrossRef]
- Lei, T.; Li, L.; Lv, Z.; Zhu, M.; Du, X.; Nandi, A.K. Multi-Modality and Multi-Scale Attention Fusion Network for Land Cover Classification from VHR Remote Sensing Images. Remote Sens. 2021, 13, 3771. [Google Scholar] [CrossRef]
- Shang, R.; Zhang, J.; Jiao, L.; Li, Y.; Marturi, N.; Stolkin, R. Multi-scale Adaptive Feature Fusion Network for Semantic Segmentation in Remote Sensing Images. Remote Sens. 2020, 12, 872. [Google Scholar] [CrossRef]
- Nie, J.; Wang, C.; Yu, S.; Shi, J.; Lv, X.; Wei, Z. MIGN: Multiscale Image Generation Network for Remote Sensing Image Semantic Segmentation. IEEE Trans. Multimedia 2022, 1–14. [Google Scholar] [CrossRef]
- Gao, S.-H.; Cheng, M.-M.; Zhao, K.; Zhang, X.-Y.; Yang, M.-H.; Torr, P.H. Res2Net: A New Multi-Scale Backbone Architecture. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 652–662. [Google Scholar] [CrossRef]
- Gerke, M.; Rottensteiner, F.; Wegner, J.D.; Sohn, G. ISPRS Semantic Labeling Contest. In Proceedings of the Photogrammetric Computer Vision (PCV), Zurich, Switzerland, 5–7 September 2014. [Google Scholar]
- ISPRS Potsdam 2D Semantic Labeling Dataset. Available online: http://www2.isprs.org/commissions/comm3/wg4/2d-sem-labelpotsdam.html (accessed on 30 January 2021).
- ISPRS Vaihingen 2D Semantic Labeling Dataset. Available online: http://www2.isprs.org/commissions/comm3/wg4/2d-semlabel-vaihingen.html (accessed on 30 January 2021).
- He, K.M.; Zhang, X.Y.; Ren, S.Q.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Li, F.F. ImageNet: A Large-Scale Hierarchical Image Database. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Miami (CVPR), Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Huang, B.; Zhao, B.; Song, Y. Urban land-use mapping using a deep convolutional neural network with high spatial resolution multispectral remote sensing imagery. Remote Sens. Environ. 2018, 214, 73–86. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Imp. Surf. | Building | Low veg. | Tree | Car | Mean F1 | OA | mIoU |
|---|---|---|---|---|---|---|---|---|
| Deeplab v3+ [43] | 89.88 | 93.78 | 83.23 | 81.66 | 93.50 | 88.41 | 87.72 | 79.35 |
| MANet [47] | 91.33 | 95.91 | 85.88 | 87.01 | 91.46 | 90.32 | 89.19 | 81.42 |
| DSMFNet [34] | 93.03 | 95.75 | 86.33 | 86.46 | 94.88 | 91.29 | 90.36 | 82.47 |
| DP-DCN [35] | 92.53 | 95.36 | 87.21 | 86.32 | 95.42 | 91.37 | 90.45 | 82.55 |
| REMSNet [45] | 93.48 | 96.17 | 87.52 | 87.97 | 95.03 | 92.03 | 90.79 | 83.56 |
| MMAFNet [46] | 93.61 | 96.26 | 87.87 | 88.65 | 95.32 | 92.34 | 91.04 | 84.03 |
| DCSA-Net | 93.69 | 96.34 | 88.05 | 88.87 | 95.63 | 92.52 | 91.25 | 84.24 |
| Methods | Imp. Surf. | Building | Low veg. | Tree | Car | Mean F1 | OA | mIoU |
|---|---|---|---|---|---|---|---|---|
| Deeplab v3+ [43] | 87.67 | 93.95 | 79.17 | 86.26 | 80.34 | 85.48 | 87.22 | 75.44 |
| MANet [47] | 90.12 | 94.08 | 81.01 | 87.21 | 81.16 | 86.72 | 88.17 | 76.79 |
| DP-DCN [35] | 91.47 | 94.55 | 80.13 | 88.02 | 80.25 | 86.89 | 89.32 | 77.09 |
| DSMFNet [34] | 91.47 | 95.08 | 82.11 | 88.61 | 81.01 | 87.66 | 89.80 | 77.76 |
| REMSNet [45] | 92.01 | 95.67 | 82.35 | 89.73 | 81.26 | 88.20 | 90.08 | 78.16 |
| MMAFNet [46] | 92.06 | 96.12 | 82.71 | 90.01 | 82.13 | 88.61 | 90.27 | 78.65 |
| DCSA-Net | 92.11 | 96.19 | 83.04 | 90.31 | 82.39 | 88.81 | 90.58 | 78.93 |
| Methods | GFLOPs (GB) | Params (M) | Mean F1 | OA |
|---|---|---|---|---|
| DeepLab v3+ [43] | 89 | 47 | 85.48 | 87.22 |
| MANet [47] | 63 | 85 | 86.72 | 88.17 |
| DP-DCN [35] | 25 | 28.5 | 86.89 | 89.32 |
| DSMFNet [34] | 53 | 52 | 87.66 | 89.80 |
| MMAFNet [46] | 69 | 93 | 88.61 | 90.27 |
| DCSA-Net | 21 | 27 | 88.81 | 90.58 |
| Method | Imp. Surf. | Building | Low veg. | Tree | Car | Mean F1 | OA |
|---|---|---|---|---|---|---|---|
| Res50 | 86.94 | 89.67 | 75.83 | 84.42 | 77.40 | 82.85 | 84.98 |
| Res50+LDCM | 88.23 | 93.81 | 78.36 | 86.99 | 80.31 | 85.54 | 87.42 |
| Res50+CIAM | 88.17 | 92.22 | 77.80 | 85.88 | 79.06 | 84.63 | 86.58 |
| Res50+FF | 89.81 | 94.04 | 79.15 | 87.36 | 81.49 | 86.37 | 87.98 |
| Res50+LDCM+CIAM | 89.03 | 93.90 | 78.76 | 87.21 | 80.95 | 85.97 | 87.86 |
| Res50+LDCM+FF | 91.57 | 95.62 | 81.94 | 89.22 | 81.53 | 87.98 | 89.85 |
| Res50+CIAM+FF | 90.68 | 94.97 | 81.18 | 88.48 | 81.46 | 87.35 | 89.19 |
| DCSA-Net | 92.11 | 96.19 | 83.04 | 90.31 | 82.39 | 88.81 | 90.58 |
| Method | Imp. Surf. | Building | Low veg. | Tree | Car | Mean F1 | OA |
|---|---|---|---|---|---|---|---|
| CIAM(3,5,7) | 92.01 | 96.11 | 82.64 | 90.21 | 82.28 | 88.65 | 90.47 |
| CIAM(3,7,11) | 92.08 | 96.16 | 82.98 | 90.26 | 82.33 | 88.76 | 90.55 |
| CIAM(3,5,11) | 92.10 | 96.16 | 83.00 | 90.29 | 82.37 | 88.78 | 90.56 |
| CIAM(3,5,9) DCSA-Net | 92.11 | 96.19 | 83.04 | 90.31 | 82.39 | 88.81 | 90.58 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, X.; Zhang, Y.; Lei, T.; Wang, Y.; Zhai, Y.; Nandi, A.K. Dynamic Convolution Self-Attention Network for Land-Cover Classification in VHR Remote-Sensing Images. Remote Sens. 2022, 14, 4941. https://doi.org/10.3390/rs14194941
Wang X, Zhang Y, Lei T, Wang Y, Zhai Y, Nandi AK. Dynamic Convolution Self-Attention Network for Land-Cover Classification in VHR Remote-Sensing Images. Remote Sensing. 2022; 14(19):4941. https://doi.org/10.3390/rs14194941
Chicago/Turabian StyleWang, Xuan, Yue Zhang, Tao Lei, Yingbo Wang, Yujie Zhai, and Asoke K. Nandi. 2022. "Dynamic Convolution Self-Attention Network for Land-Cover Classification in VHR Remote-Sensing Images" Remote Sensing 14, no. 19: 4941. https://doi.org/10.3390/rs14194941
APA StyleWang, X., Zhang, Y., Lei, T., Wang, Y., Zhai, Y., & Nandi, A. K. (2022). Dynamic Convolution Self-Attention Network for Land-Cover Classification in VHR Remote-Sensing Images. Remote Sensing, 14(19), 4941. https://doi.org/10.3390/rs14194941