
Automatic Defect Detection of Pavement Diseases

Abstract
1. Introduction
- (1)
- Deformable convolution and new feature pyramids are used to address irregular variations in defect shape and scale respectively.
- (2)
- Improved loss functions can improve detection accuracy.
- (3)
2. Materials
2.1. Traditional Detection Methods
2.2. Deep Learning Methods
2.3. Modern Object Detectors
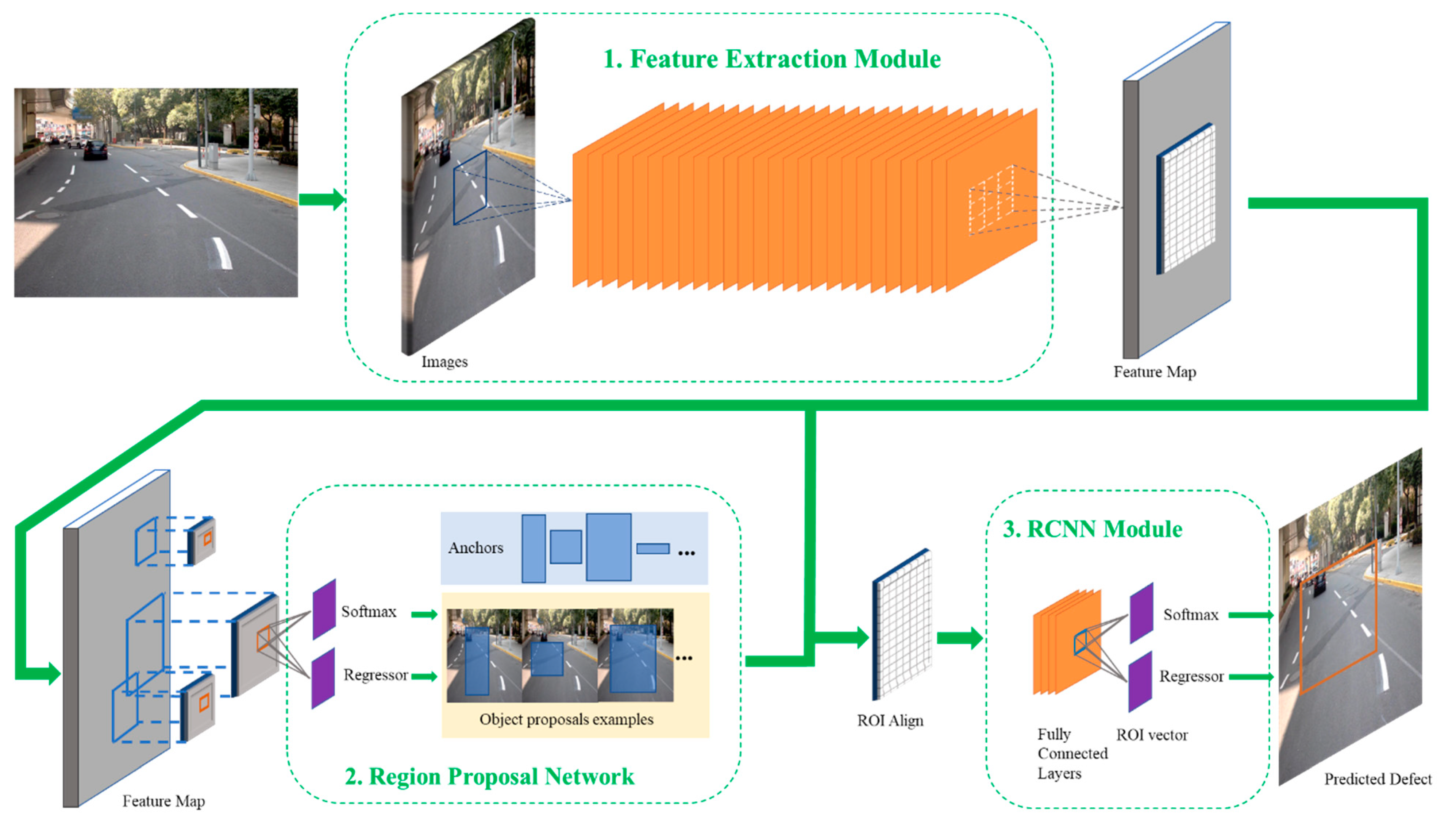
2.4. Faster RCNN
- (1)
- Module for feature extraction. The feature map of the image is first extracted using a set of basic conv + relu + pooling layers. This feature map is then shared for subsequent RPN layers and fully connected layers.
- (2)
- The RPN network is actually divided into two lines, one is used to obtain the positive and negative classification by softmax classification anchors, and the other is used to calculate the bounding box regression offset relative to anchors to obtain the accurate proposal. It is equivalent to completing the function of target positioning.
- (3)
- The RCNN module (i.e., Roi Align and classification network. In order to avoid the mis-alignment problem caused by the two quantizations in the Roi Pooling operation, Roi Align is used instead of the original Roi Pooling) is used to classify the candidate detection boxes. And after the RPN, the coordinates of the candidate box are fine-tuned again to output the detection results.
2.5. FPN
3. Methods
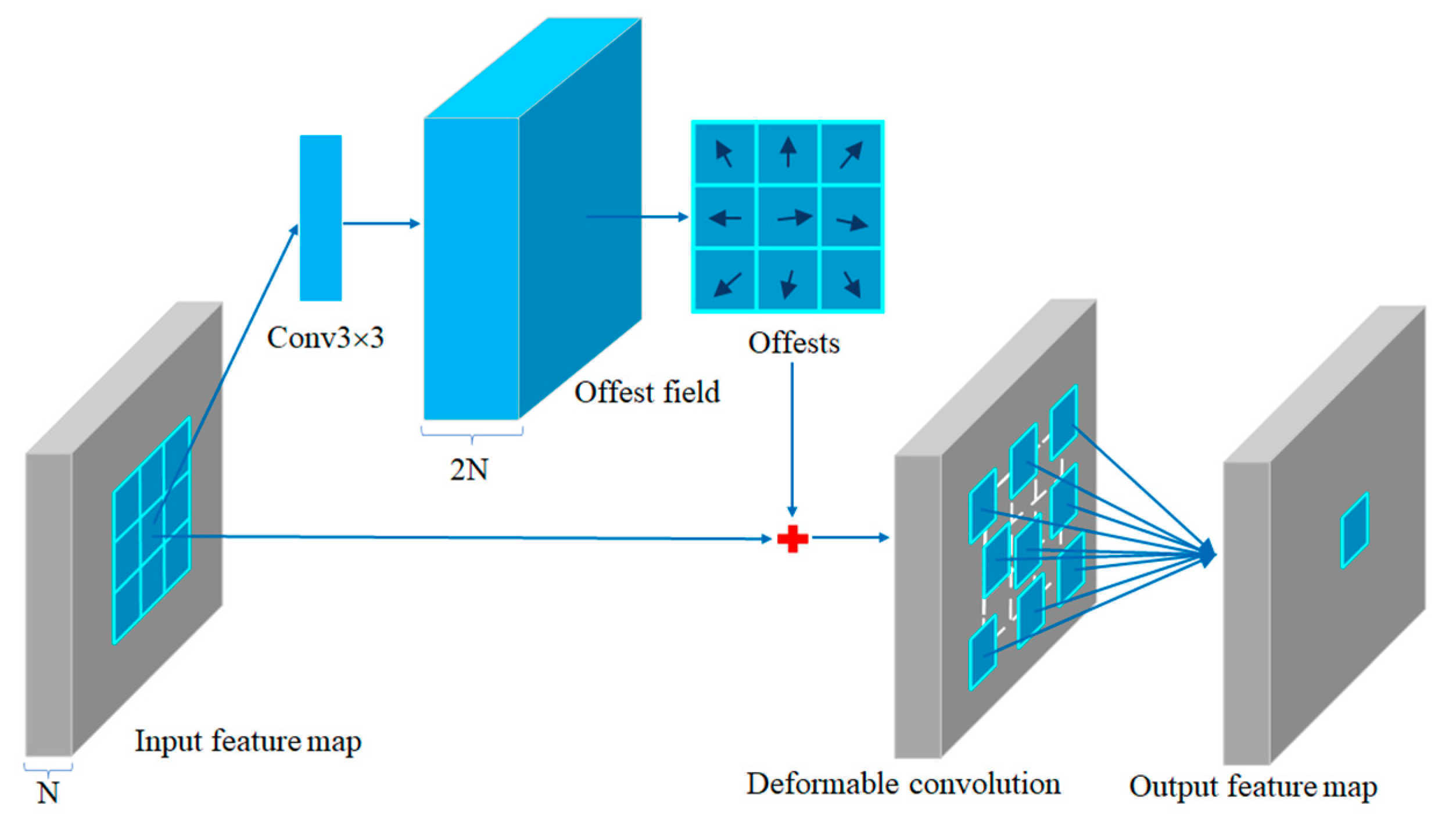
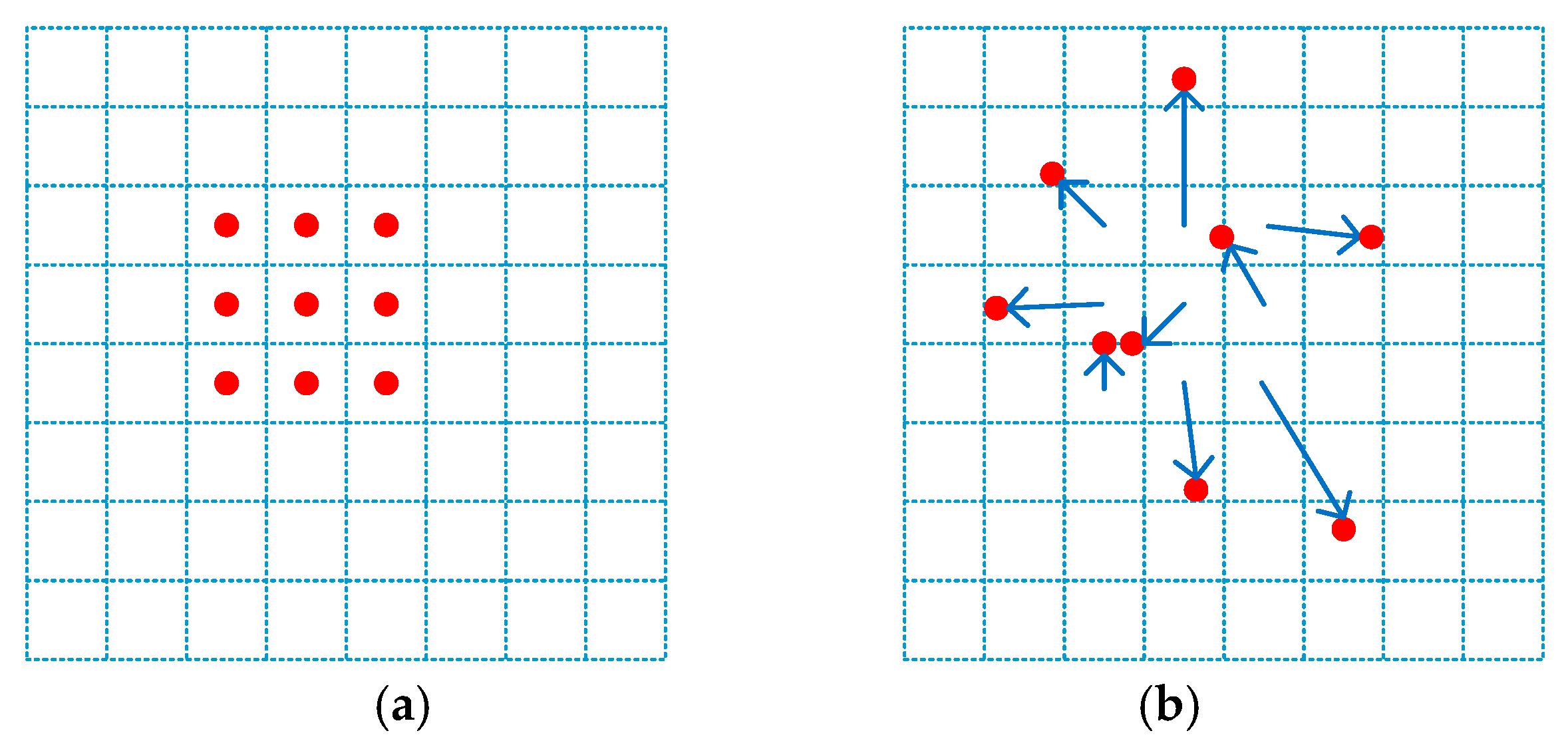
3.1. Deformable Convolution
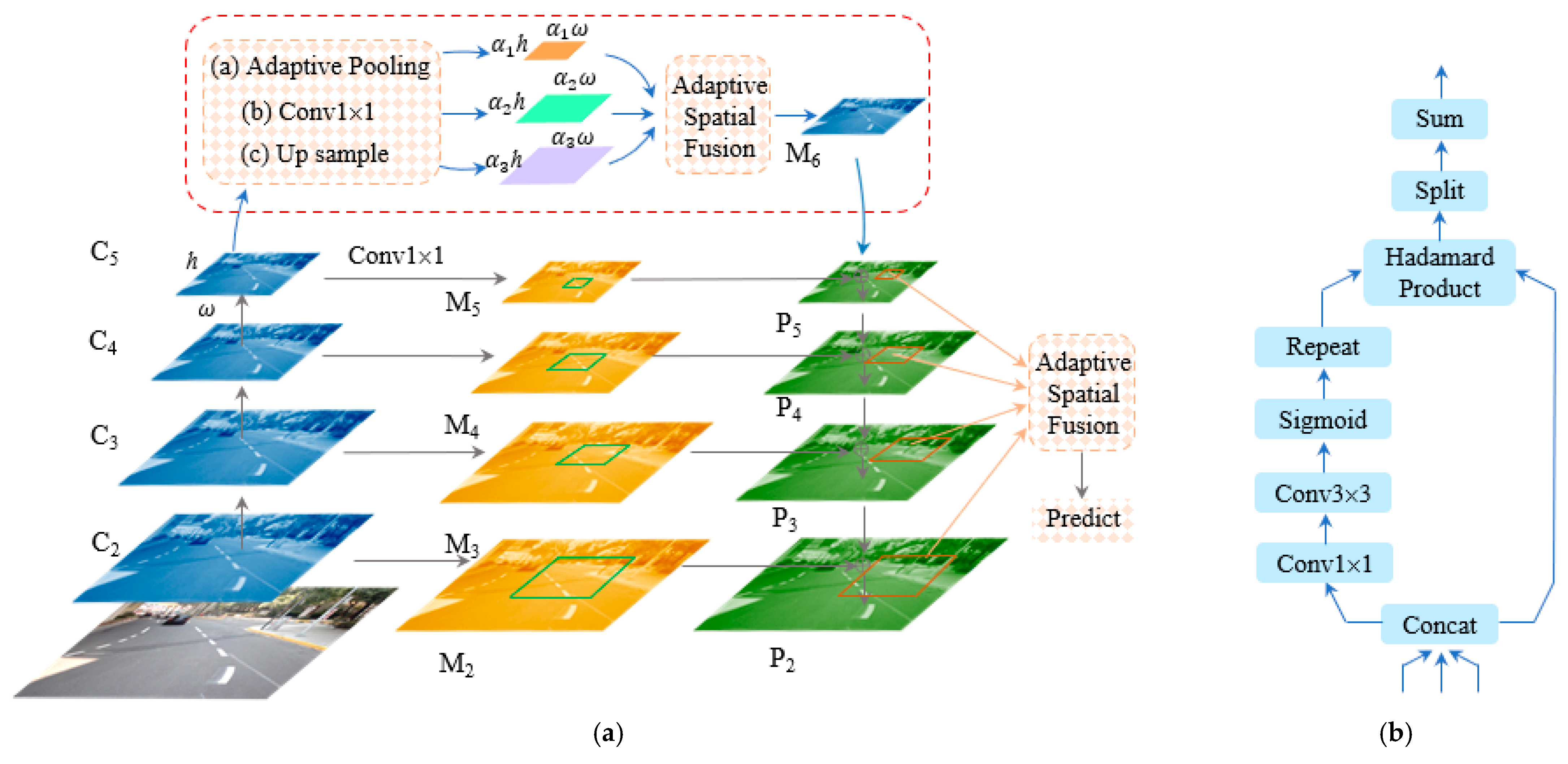
3.2. Aug Feature Pyramid Module
- (1)
- First, a feature pyramid {P2, P3, P4, P5} is constructed based on the multi-scale features {C2, C3, C4, C5} obtained from the backbone, and detectors and classifiers, i.e., RPN Head and RCNN, are added to each feature before it enters the feature pyramid fusion, as shown in the middle part of Figure 6a, which maps the ROIs generated by RPN onto {M2, M3, M4, M5} and obtains the corresponding feature maps to classify and regress these features. The parameters of these classification and regression heads are shared at different levels, facilitating the supervision of features at different scales.
- (2)
- Using residual branches to inject different spatial contextual information into the original branches to improve the feature representation of M5. Assuming that the size of C5 is S = h × w, we downsample C5 into 3 copies, respectively. Specifically, as shown in Figure 6a. Firstly, sample C5 as α1 × s, α2 × s, and α3 × s respectively by adaptive pooling. Secondly, convolve the results of adaptive pooling into 1 × 1 respectively to bring the feature channel down to 256. Thirdly, upsample the 3 different downsampled results again (scale with C5 to remain consistent at 256) as adaptive spatial fusion input.
- (3)
- The next step is adaptive spatial fusion and the final generation of a spatial weight for each feature. This is shown in Figure 6b, where the α1 × s, α2 × s and α3 × s are concat, and finally, the contextual features are fused into M6 using the weights. After generating M6, it is summed with M5 and fused with other lower-level features in turn by propagation. After fusion, 3 × 3 convolution is performed on each feature vector to build the feature pyramid {P2, P3, P4, P5}.
3.3. Sample Weighted Loss Function Module
4. Experiments and Results
4.1. Dataset
4.2. Evaluation Metrics
4.3. Experimental Details
4.4. Experimental Results
4.5. Ablation Experiments
4.6. Comparison with Other Object Detection Algorithms
- (1)
- In the first group, compared with some advanced algorithms, including one-stage and two-stage detectors, our method map reaches 41.1%, which is better than the above methods by 3.4–7.6%.
- (2)
- In the second group, the FPN is added to the detectors to create a multi-level detector, which is extensively employed in object detection and has the potential to considerably increase the detectors’ performance. Our technique incorporates an enhanced FPN, which improves detector performance by 2.4–8% mAP over the method with FPN (Remove FCOS and Libra RCNN with poor results). Moreover, our method is higher in AP50 and improved in AP75, showing good classification and positioning performance, and improving target detection performance in different sizes.
- (3)
- In the third group, our method’s robustness is demonstrated. Several FPN-adding technologies have been chosen to upgrade their backbone to the stronger ResNet-101. Our method’s mAP was elevated by 17.8%, which is 5.4–27.4% mAP greater than the SOTA detector. The discrepancy between our solution and the other SOTA solutions is the same as prior to the backbone update.
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Tang, Y.; Zhu, M.; Chen, Z.; Wu, C.; Chen, B.; Li, C.; Li, L. Seismic performance evaluation of recycled aggregate concrete-filled steel tubular columns with field strain detected via a novel mark-free vision method. Structures 2022, 37, 426–441. [Google Scholar] [CrossRef]
- Yu, S.N.; Jang, J.H.; Han, C.S. Auto inspection system using a mobile robot for detecting concrete cracks in a tunnel. Autom. Constr. 2007, 16, 255–261. [Google Scholar] [CrossRef]
- Zhang, W.; Zhang, Z.; Qi, D.; Liu, Y. Automatic crack detection and classification method for subway tunnel safety monitoring. Sensors 2014, 14, 19307–19328. [Google Scholar] [CrossRef]
- Fukuda, Y.; Feng, M.Q.; Narita, Y.; Kaneko, S.; Tanaka, T. Vision based displacement sensor for monitoring dynamic response using robust object search algorithm. Sensors 2013, 13, 4725–4732. [Google Scholar] [CrossRef]
- Miao, X.; Wang, J.; Wang, Z.; Sui, Q.; Gao, Y.; Jiang, P. Automatic Recognition of Highway Tunnel Defects Based on an Improved U-Net Model. Sensors 2019, 19, 11413–11423. [Google Scholar] [CrossRef]
- Abdel-Qader, I.; Abudayyeh, O.; Kelly, M.E. Analysis of edge detection techniques for crack identification in bridges. J. Comput. Civ. Eng. 2003, 17, 255–263. [Google Scholar] [CrossRef]
- Tanaka, N.; Uematsu, K. A crack detection method in road surface images using morphology. Proc. MVA 1998, 98, 17–19. [Google Scholar]
- Iyer, S.; Sinha, S.K. Segmentation of pipe images for crack detection in buried sewers. Comput.-Aided Civ. Infrastruct. Eng. 2006, 21, 395–410. [Google Scholar] [CrossRef]
- Burges, C.J.C. A tutorial on support vector machines for pattern recognition. Data Min. Knowl. Discov. 1998, 2, 121–167. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Lattanzi, D.; Miller, G.R. Robust automated concrete damage detection algorithms for field applications. J. Comput. Civ. Eng. 2012, 28, 253–262. [Google Scholar] [CrossRef]
- Cord, A.; Chambon, S. Automatic road defect detection by textural pattern recognition based on AdaBoost. Comput.-Aided Civ. Infrastruct. Eng. 2012, 27, 244–259. [Google Scholar] [CrossRef]
- Dawood, T.; Zhu, Z.; Zayed, T. Machine vision-based model for spalling detection and quantification in subway networks. Automat. Construct 2017, 81, 149–160. [Google Scholar]
- Yeum, C.M.; Dyke, S.J. Vision-based automated crack detection for bridge inspection. Comput.-Aided Civ. Infrastruct. Eng. 2015, 30, 759–770. [Google Scholar] [CrossRef]
- Rafiei, M.H.; Adeli, H. A novel unsupervised deep learning model for global and local health condition assessment of structures. Eng. Stuctures 2018, 156, 598–607. [Google Scholar] [CrossRef]
- Rafiei, M.H.; Khushefati, W.H.; Demirboga, R.; Adeli, H. Supervised deep restricted Boltzmann machine for estimation of concrete. ACI Mater. J. 2017, 114, 237–244. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single shot multibox detector. In Proceedings of the 14th Europeon Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Suh, G.; Cha, Y.J. Deep faster R-CNN based automated detection and localization of multiple types of damage. In Proceedings of the Sensors and Smart Structures Technologies for Civil, Mechanical, and Aerospace Systems, Online, 27 April–8 May 2020; SPIE: Bellingham, WA, USA, 2018; Volume 10598, p. 105980T. [Google Scholar] [CrossRef]
- Dai, J.; Qi, H.; Xiong, Y. Deformable Convolutional Networks. In Proceedings of the 16th IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 764–773. [Google Scholar]
- Zhu, X.; Hu, H.; Lin, S.; Dai, J. Deformable ConvNets V2: More Deformable, Better Results. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 9300–9308. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the 30th IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Cai, Z.W.; Vasconcelos, N. Cascade R-CNN: Delving into high quality object detection. In Proceedings of the 31st IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 6154–6162. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 99, 2999–3007. [Google Scholar] [CrossRef]
- Tian, Z.; Shen, C.; Chen, H.; He, T. FCOS: Fully convolutional one-stage object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 9626–9635. [Google Scholar]
- Zhang, S.; Chi, C.; Yao, Y.; Lei, Z.; Li, S.Z. Bridging the gap between anchor-based and anchor-free detection via adaptive training sample selection. In Proceedings of the 33rd IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 9756–9765. [Google Scholar]
- Pang, J.; Chen, K.; Shi, J.; Feng, H.; Ouyang, W.; Lin, D. Libra R-CNN: Towards balanced learning for object detection. In Proceedings of the 32nd IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 821–830. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. Available online: http://arxiv.org/abs/1804.02767 (accessed on 7 August 2022).
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollar, P.; Zitnick, C.L. Microsoft COCO: Common objects in context. In Proceedings of the 13th European Conference on Computer Vision (ECCV), Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Chen, B.; Zhang, X.; Wang, R.; Li, Z.; Deng, W. Detect concrete cracks based on OTSU algorithm with differential image. J. Eng. 2019, 23, 9088–9091. [Google Scholar] [CrossRef]
- Quan, Y.; Sun, J.; Zhang, Y.; Zhang, H. The Method of the Road Surface Crack Detection by the Improved Otsu Threshold. In Proceedings of the 2019 IEEE International Conference on Mechatronics and Automation (ICMA), Tianjin, China, 4–7 August 2019; pp. 1615–1620. [Google Scholar]
- Liu, X.; Xue, F.; Teng, L. Surface defect detection based on gradient LBP. In Proceedings of the 2018 IEEE 3rd International Conference on Image, Vision and Computing (ICIVC), Chongqing, China, 27–29 June 2018; pp. 133–137. [Google Scholar]
- Gunawan, G.; Nurdiyanto, H.; Sriadhi, S.; Fauzi, A.; Usman, A.; Fadlina, F.; Dafitri, H.; Simarmata, J.; Siahaan, A.; Rahim, R. Mobile Application Detection of Road Damage using Canny Algorithm. J. Phys. Conf. Ser. 2018, 1019, 012035. [Google Scholar] [CrossRef]
- Meng, F.; Qi, Z.; Chen, Z.; Wang, B.; Shi, Y. Token based crack detection. J. Intell. Fuzzy Syst. 2020, 38, 3501–3513. [Google Scholar] [CrossRef]
- Medina, R.; Llamas, J.; Zalama, E.; Gómez-García-Bermejo, J. Enhanced automatic detection of road surface cracks by combining 2D/3D image processing techniques. In Proceedings of the 2014 IEEE International Conference on Image Processing (ICIP), Paris, France, 27–30 October 2014; pp. 778–782. [Google Scholar]
- Chanda, S.; Bu, G.; Guan, H.; Jo, J.; Pal, U.; Loo, Y.; Blumenstein, M. Automatic bridge crack detecton—A texture analysisbased approach. In Proceedings of the Artificial Neural Networks in Pattern Recognition, Montreal, QC, Canada, 6–8 October 2014; pp. 193–203. [Google Scholar]
- Quintana, M.; Torres, J.; Menendez, J.M. A simplified computer vision system for road surface inspection and maintenance. IEEE Trans. Intell. Transp. Syst. 2016, 17, 608–619. [Google Scholar] [CrossRef]
- Oliveira, H.; Correia, P.L. Road surface crack detection: Improved segmentation with pixel-based refinement. In Proceedings of the 2017 25th European Signal Processing Conference (EUSIPCO), Kos, Greece, 28 August–2 September 2017; pp. 2026–2030. [Google Scholar]
- Oliveira, H.; Correia, P.L. Automatic road crack detection and characterization. IEEE Trans. Intell. Transp. Syst. 2013, 14, 155–168. [Google Scholar] [CrossRef]
- Shi, Y.; Cui, L.; Qi, Z.; Meng, F.; Chen, Z. Automatic road crack detection using random structured forests. IEEE Trans. Intell. Transp. Syst. 2016, 17, 3434–3445. [Google Scholar] [CrossRef]
- Pan, Y.; Zhang, X.; Sun, M.; Zhao, Q. Object-based and supervised detection of potholes and cracks from the pavement images acquired by UAV. ISPRS—Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2017, 42, 209–217. [Google Scholar] [CrossRef]
- Hadjidemetriou, G.M.; Vela, P.A.; Christodoulou, S.E. Automated pavement patch detection and quantification using support vector machines. J. Comput. Civ. Eng. 2018, 32, 04017073. [Google Scholar] [CrossRef]
- Pan, Y.; Zhang, X.; Cervone, G.; Yang, L. Detection of asphalt pavement potholes and cracks based on the unmanned aerial vehicle multispectral imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 3701–3712. [Google Scholar] [CrossRef]
- Ai, D.; Jiang, G.; Kei, L.S.; Li, C. Automatic pixel-level pavement crack detection using information of multi-scale neighborhoods. IEEE Access 2018, 6, 24452–24463. [Google Scholar] [CrossRef]
- Hoang, N.D. Automatic detection of asphalt pavement raveling using image texture based feature extraction and stochastic gradient descent logistic regression. Autom. Constr. 2019, 105, 102843. [Google Scholar] [CrossRef]
- Zhang, L.; Yang, F.; Zhang, Y.; Zhu, Y.J. Road crack detection using deep convolutional neural network. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 3708–3712. [Google Scholar]
- Gopalakrishnan, K.; Khaitan, S.K.; Choudhary, A.; Agrawal, A. Deep convolutional neural networks with transfer learning for computer vision-based data-driven pavement distress detection. Constr. Build. Mater. 2017, 157, 322–330. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. Available online: http://arxiv.org/abs/1409.1556 (accessed on 7 August 2022).
- Li, B.; Wang, K.C.; Zhang, A.; Yang, E.; Wang, G. Automatic classification of pavement crack using deep convolutional neural network. Int. J. Pavement Eng. 2020, 21, 457–463. [Google Scholar] [CrossRef]
- Du, Y.; Pan, N.; Xu, Z.; Deng, F.; Shen, Y.; Kang, H. Pavement distress detection and classification based on YOLO network. Int. J. Pavement Eng. 2020, 22, 1659–1672. [Google Scholar] [CrossRef]
- Ibragimov, E.; Lee, H.J.; Lee, J.J.; Kim, N. Automated pavement distress detection using region based convolutional neural networks. Int. J. Pavement Eng. 2020, 23, 1981–1992. [Google Scholar] [CrossRef]
- Cha, Y.J.; Choi, W.; Büyüköztürk, O. Deep learning-based crack damage detection using convolutional neural networks. Comput.-Aided Civ. Infrastruct. Eng. 2017, 32, 361–378. [Google Scholar] [CrossRef]
- Chen, F.C.; Jahanshahi, M.R. NB-CNN: Deep learning-based crack detection using convolutional neural network and Naïve Bayes data fusion. IEEE Trans. Ind. Electron. 2017, 65, 4392–4400. [Google Scholar] [CrossRef]
- Zhang, A.; Wang, K.C.P.; Fei, Y. Automated pixel-level pavement crack detection on 3D asphalt surfaces with a recurrent neural network. Comput.-Aided Civ. Infrastruct. Eng. 2019, 34, 213–229. [Google Scholar] [CrossRef]
- Vishwakarma, R.; Vennelakanti, R. Cnn model & tuning for global road damage detection. In Proceedings of the 2020 IEEE International Conference on Big Data (Big Data), Atlanta, GA, USA, 10–13 December 2020; pp. 5609–5615. [Google Scholar]
- Li, S.; Zhao, X.; Zhou, G. Automatic pixel-level multiple damage detection of concrete structure using fully convolutional network. Comput.-Aided Civ. Infrastruct. Eng. 2019, 34, 616–634. [Google Scholar] [CrossRef]
- Zhang, J.; Lu, C.; Wang, J. Concrete cracks detection based on FCN with dilated convolution. Appl. Sci. 2019, 9, 2686. [Google Scholar] [CrossRef]
- Jung, W.M.; Naveed, F.; Hu, B. Exploitation of deep learning in the automatic detection of cracks on paved roads. Geomatica 2019, 73, 29–44. [Google Scholar] [CrossRef]
- Yang, F.; Zhang, L.; Yu, S. Feature pyramid and hierarchical boosting network for pavement crack detection. IEEE Trans. Intell. Transp. Syst. 2019, 21, 1525–1535. [Google Scholar] [CrossRef]
- Tang, J.; Huang, Z.; Li, L.J. Visual measurement of dam concrete cracks based on U-net and improved thinning algorithm. J. Exp. Mech. 2022, 37, 209–220. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the 27th IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed]
- Lu, X.; Li, B.; Yue, Y.; Li, Q.; Yan, J. Grid R-CNN. In Proceedings of the 32nd IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 7355–7364. [Google Scholar]
- Yu, B.; Tao, D. Anchor cascade for efficient face detection. IEEE Trans. Image Processing 2019, 28, 2490–2501. [Google Scholar] [CrossRef]
- Law, H.; Deng, J. CornerNet: Detecting objects as paired key points. Int. J. Comput. Vis. 2019, 128, 642–656. [Google Scholar] [CrossRef]
- Ghahabi, O.; Hernando, J. Restricted Boltzmann machines for vector representation of speech in speaker recognition. Comput. Speech Lang. 2018, 47, 16–29. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Proceedings of the Neural Information Processing Systems 28 (NIP), Montreal, QC, Canada, 7–12 December 2015; Curran Associates, Inc.: Red Hook, NY, USA, 2015; pp. 91–99. [Google Scholar]
- Guo, C.; Fan, B.; Zhang, Q.; Xiang, S.; Pan, C. AugFPN: Improving Multi-Scale Feature Learning for Object Detection. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Los Alamitos, CA, USA, 13–19 June 2020; pp. 12592–12601. [Google Scholar]
- Cai, Q.; Pan, Y.; Wang, Y.; Liu, J.; Yao, T.; Mei, T. Learning a Unified Sample Weighting Network for Object Detection. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Los Alamitos, CA, USA, 13–19 June 2020; pp. 14161–14170. [Google Scholar]
- Everingham, M.; Gool, L.V.; Williams, C.K.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes Challenge 2012 (voc2012) Results (2012). 2011. Available online: http://www.pascal-network.org/challenges/VOC/voc2011/workshop/index.html (accessed on 7 August 2022).
- Chen, K.; Wang, J.; Pang, J.; Cao, Y.; Xiong, Y.; Li, X.; Sun, S.; Feng, W.; Liu, Z.; Xu, J. Mmdetection: Open mmlab detection toolbox and benchmark. arXiv 2019, arXiv:1906.07155. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Xie, S.; Girshick, R.; Dollar, P.; Tu, Z.; He, K. Aggregated residual transformations for deep neural networks. In Proceedings of the 30th IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5987–5995. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Predicted Category | Defect | Non-Defect | |
|---|---|---|---|
| Actual Category | |||
| Defect | TP | FN | |
| Non-defect | FP | TN | |
| Evaluation Indicators | Significance | Calculation |
|---|---|---|
| Recall (R) | Identify positive samples | |
| Precision (P) | Identify the correct positive sample | |
| Average Precision (AP) | Judge a category | |
| Mean Average Precision (mAP) | Average score of AP across all categories |
| Type | Definition and Description |
|---|---|
| PASCAL-VOC [71] | AP at IoU = 0.5 |
| MS-COCO | AP at IoU = 0.5:0.05:0.95 |
| AP at IoU = 0.75 | |
| APS: AP for small objects: area < 322 | |
| APm: AP for medium objects: 322 < area < 962 | |
| APl: AP for large objects: area > 962 |
| Method | Backbone | Inference Time(s) | mAP | AP50 | AP75 | APs | APm | APl |
|---|---|---|---|---|---|---|---|---|
| Faster RCNN | Resnet-50-FPN | 0.152 | 38.7 | 67.9 | 39.7 | 33.1 | 38.3 | 37.9 |
| Faster RCNN | ResneXt-101-FPN | 0.179 | 64.8 | 90.4 | 69.5 | 56.3 | 65.2 | 63.1 |
| DASNet | Resnet-50-DCNv2 | 0.301 | 41.1 | 63.8 | 45.3 | 34.3 | 44.1 | 52.3 |
| DASNet | ResneXt-101-DCNv2 | 0.361 | 79.5 | 95.1 | 77.7 | 52.1 | 66.9 | 66.3 |
| DCNv2 | AugFPN | SWLF | mAP | AP50 | AP75 | APs | APm | APl | Inference Time(s) |
|---|---|---|---|---|---|---|---|---|---|
| 37.7 | 65.9 | 38.7 | 30.5 | 37.2 | 37.2 | 0.152 | |||
| √ | 39.1 | 67.0 | 40.1 | 12.3 | 34.4 | 39.9 | 0.183 | ||
| √ | 39.8 | 68.1 | 42.7 | 33.7 | 42.1 | 51.0 | 0.191 | ||
| √ | 38.5 | 58.6 | 42.2 | 31.9 | 41.9 | 48.9 | 0.168 | ||
| √ | √ | 39.2 | 69.1 | 43.2 | 28.6 | 43.3 | 51.3 | 0.251 | |
| √ | √ | 38.9 | 67.5 | 43.6 | 30.8 | 42.8 | 51.8 | 0.246 | |
| √ | √ | 39.8 | 68.4 | 44.4 | 34.4 | 42.9 | 50.8 | 0.233 | |
| √ | √ | √ | 41.1 | 73.8 | 46.3 | 34.3 | 44.1 | 52.3 | 0.301 |
| Method | Backbone | mAP | AP50 | AP75 | APs | APm | APl |
|---|---|---|---|---|---|---|---|
| Faster RCNN | Resnet-50 | 37.7 | 65.9 | 38.7 | 30.5 | 37.2 | 37.2 |
| Faster RCNN | Resnet-50-DCNv2 | 39.1 | 67.0 | 40.1 | 12.3 | 34.4 | 39.9 |
| Faster RCNN | Resnet-101 | 41.8 | 69.9 | 44.8 | 30.4 | 41.6 | 40.8 |
| Faster RCNN | Resnet-101-DCNv2 | 53.9 | 84.2 | 60.1 | 35.4 | 56.5 | 52.9 |
| Faster RCNN | ResneXt-101 | 67.1 | 89.4 | 65.5 | 52.1 | 63.4 | 59.9 |
| Faster RCNN | ResneXt-101-DCNv2 | 76.5 | 95.1 | 87.7 | 51.1 | 76.9 | 76.3 |
| Method | Backbone | mAP | AP50 | AP75 | APs | APm | APl |
|---|---|---|---|---|---|---|---|
| Faster RCNN | Resnet-50-FPN | 38.7 | 67.9 | 39.7 | 33.0 | 38.3 | 37.9 |
| Faster RCNN | Resnet-50-AugFPN | 39.8 | 68.1 | 42.7 | 33.9 | 42.1 | 51.0 |
| Faster RCNN | Resnet-101-FPN | 41.8 | 69.9 | 44.8 | 30.4 | 41.6 | 40.8 |
| Faster RCNN | Resnet-101-AugFPN | 43.2 | 76.9 | 48.3 | 35.5 | 44.1 | 52.8 |
| Faster RCNN | ResneXt-101-FPN | 71.8 | 90.4 | 69.5 | 56.3 | 65.2 | 63.1 |
| Faster RCNN | ResneXt-101-AugFPN | 74.5 | 91.1 | 79.9 | 62.0 | 75.3 | 77.3 |
| Method | Backbone | mAP | AP50 | AP75 | APs | APm | APl |
|---|---|---|---|---|---|---|---|
| Faster RCNN | Resnet-50 | 37.7 | 65.9 | 38.7 | 30.5 | 37.2 | 37.2 |
| Faster RCNN-SWLF | Resnet-50 | 38.5 | 58.6 | 42.2 | 31.9 | 41.9 | 48.9 |
| Faster RCNN | Resnet-101 | 41.8 | 69.9 | 44.8 | 30.4 | 41.6 | 40.8 |
| Faster RCNN-SWLF | Resnet-101 | 49.1 | 72.1 | 43.6 | 33.1 | 42.9 | 51.4 |
| Faster RCNN | ResneXt-101 | 67.1 | 89.4 | 65.5 | 52.1 | 63.4 | 59.9 |
| Faster RCNN-SWLF | ResneXt-101 | 71.5 | 91.9 | 72.7 | 54.3 | 63.7 | 62.2 |
| Method | FPN | Backbone | mAP | AP50 | AP75 | APS | APM | APL |
|---|---|---|---|---|---|---|---|---|
| YOLOv3 | Darknet-53 | 35.1 | 74.4 | 28.3 | 12.4 | 29.2 | 36.5 | |
| Faster RCNN | ResNet-50 | 37.7 | 65.9 | 38.7 | 30.5 | 37.2 | 37.2 | |
| Cascade RCNN | ResNet-50 | 33.5 | 60.0 | 34.1 | 12.2 | 31.7 | 33.8 | |
| Grid RCNN Plus | ResNet-50 | 33.6 | 53.1 | 34.3 | 21.9 | 30.0 | 31.3 | |
| Ours | ResNet-50 | 41.1 | 73.8 | 46.3 | 34.3 | 44.1 | 52.3 | |
| RetinaNet | √ | ResNet-50 | 38.6 | 63.3 | 41.9 | 11.2 | 36.2 | 38.3 |
| FCOS | √ | ResNet-50 | 7.6 | 15.2 | 6.8 | - | 6.1 | 8.3 |
| ATSS | √ | ResNet-50 | 33.1 | 56.4 | 34.2 | 9.5 | 29.6 | 33.8 |
| Faster RCNN | √ | ResNet-50 | 38.7 | 67.9 | 39.7 | 33.1 | 38.3 | 37.9 |
| Cascade RCNN | √ | ResNet-50 | 35.5 | 62.1 | 36.3 | 10.1 | 34.6 | 35.1 |
| Libra RCNN | √ | ResNet-50 | 27.1 | 49.8 | 26.7 | 20.0 | 24.4 | 27.4 |
| Grid RCNN Plus | √ | ResNet-50 | 33.9 | 55.2 | 37.3 | 24.0 | 32.3 | 34.4 |
| Ours | ResNet-50 | 41.1 | 73.8 | 46.3 | 34.3 | 44.1 | 52.3 | |
| RetinaNet | √ | ResNet-101 | 53.5 | 82.3 | 60.5 | 8.8 | 55.7 | 60.1 |
| Faster RCNN | √ | ResNet-101 | 41.8 | 69.9 | 44.8 | 30.4 | 41.6 | 40.8 |
| Cascade RCNN | √ | ResNet-101 | 52.1 | 79.2 | 60.4 | 31.0 | 51.0 | 52.2 |
| Libra RCNN | √ | ResNet-101 | 31.8 | 55.3 | 32.6 | 11.4 | 30.6 | 31.0 |
| Grid RCNN Plus | √ | ResNet-101 | 35.4 | 56.3 | 39.0 | 22.3 | 33.3 | 35.0 |
| Ours | ResNet-101 | 58.9 | 84.2 | 68.5 | 35.2 | 58.5 | 59.9 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, L.; Wu, Y.; Luo, X.; Yuan, Y. Automatic Defect Detection of Pavement Diseases. Remote Sens. 2022, 14, 4836. https://doi.org/10.3390/rs14194836
Zhao L, Wu Y, Luo X, Yuan Y. Automatic Defect Detection of Pavement Diseases. Remote Sensing. 2022; 14(19):4836. https://doi.org/10.3390/rs14194836
Chicago/Turabian StyleZhao, Langyue, Yiquan Wu, Xudong Luo, and Yubin Yuan. 2022. "Automatic Defect Detection of Pavement Diseases" Remote Sensing 14, no. 19: 4836. https://doi.org/10.3390/rs14194836
APA StyleZhao, L., Wu, Y., Luo, X., & Yuan, Y. (2022). Automatic Defect Detection of Pavement Diseases. Remote Sensing, 14(19), 4836. https://doi.org/10.3390/rs14194836