
A Survey on Visual Navigation and Positioning for Autonomous UUVs


Abstract
:1. Introduction
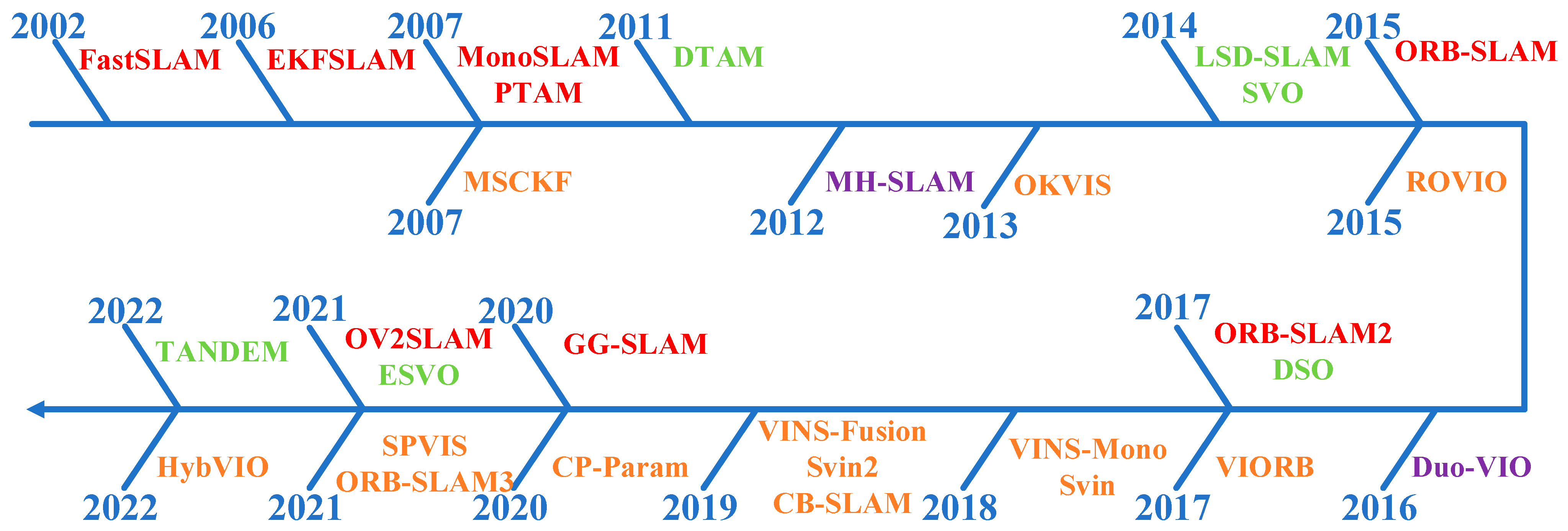
2. Background
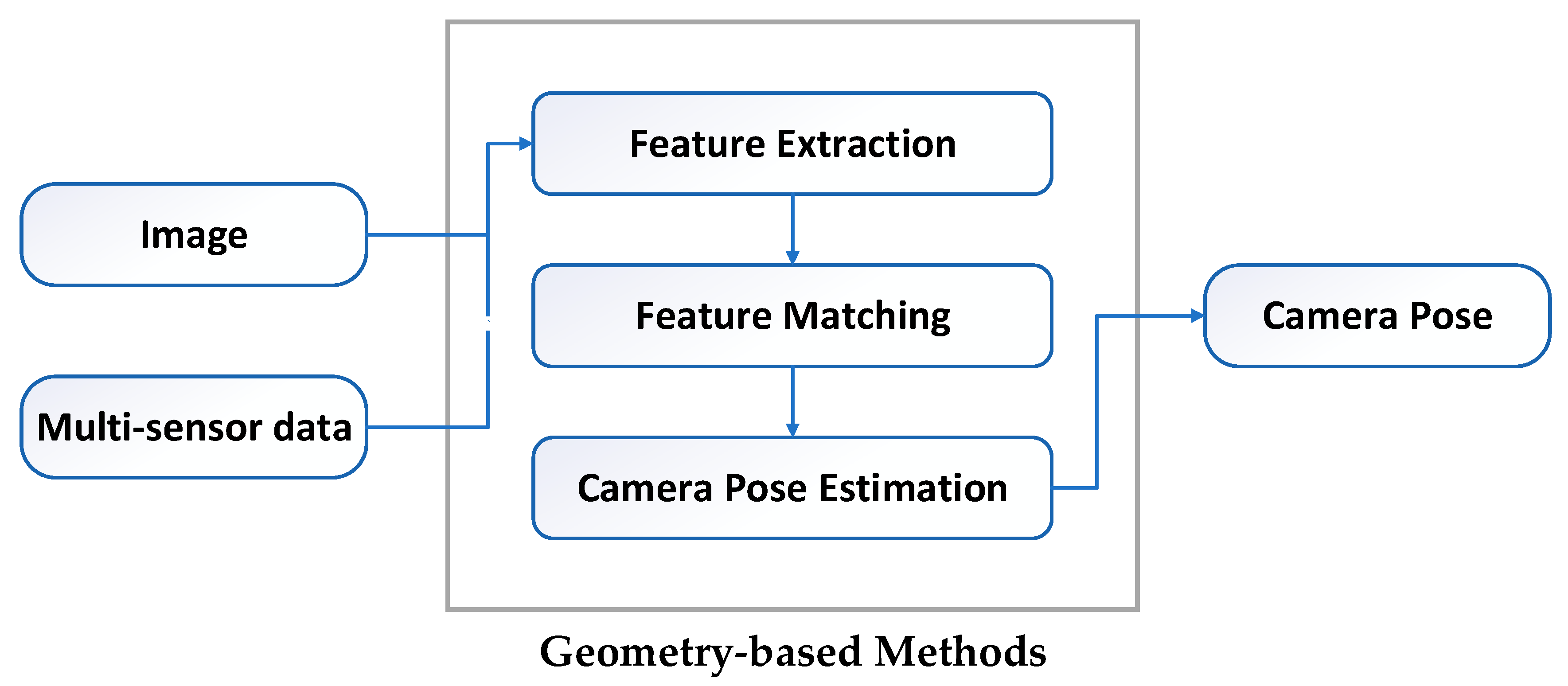
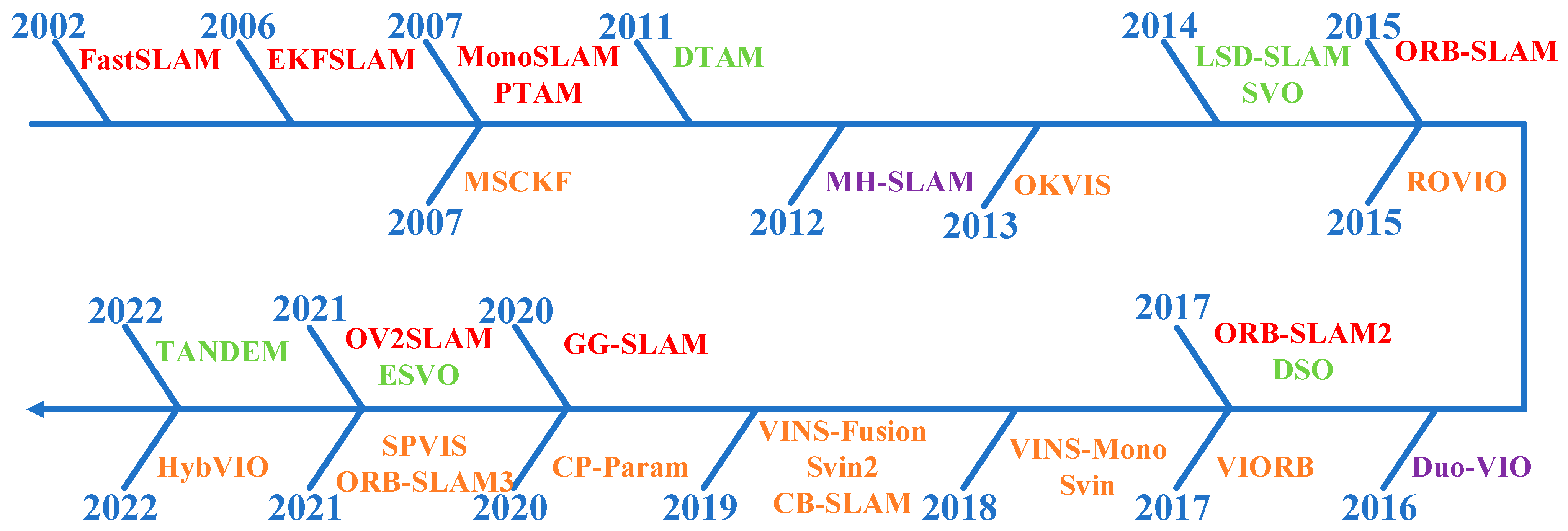
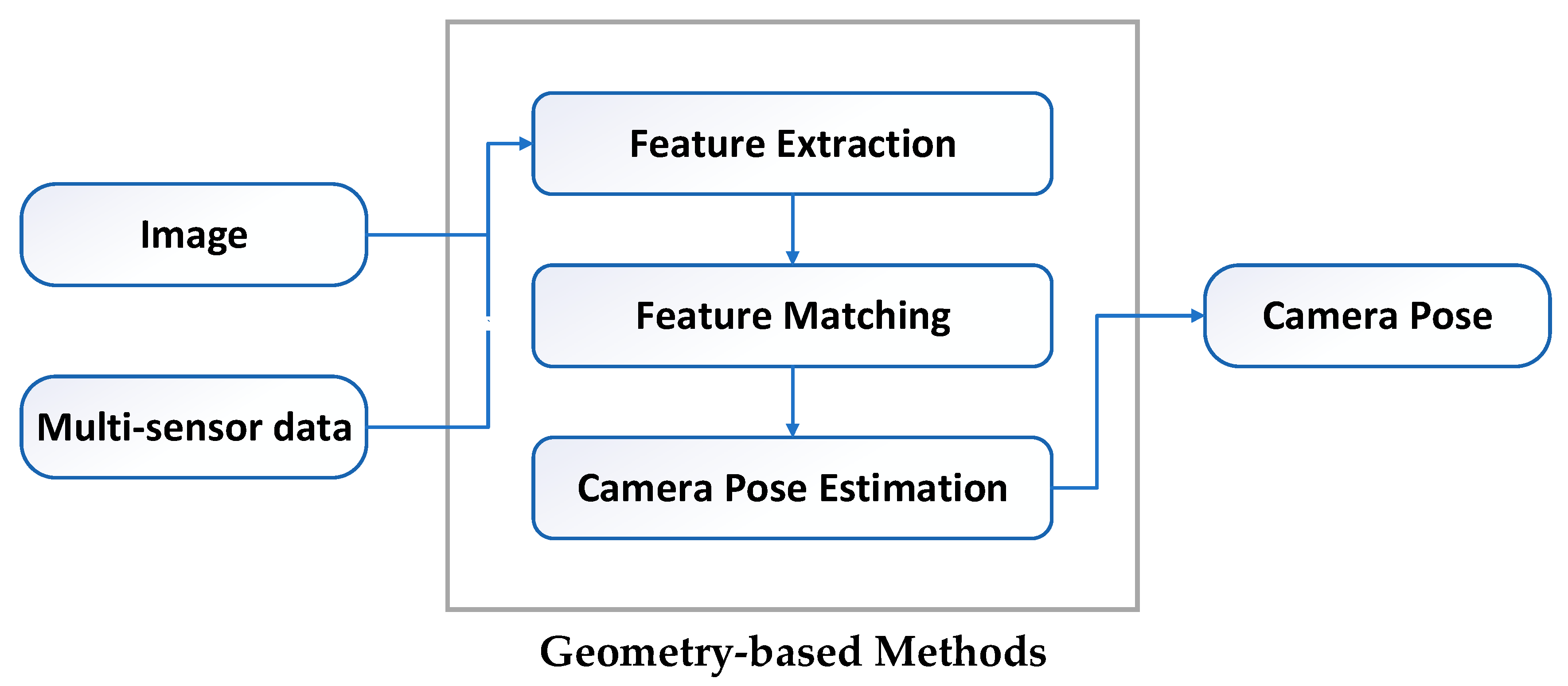
3. Geometry-Based Methods
3.1. Vision-Only Methods
3.2. Vision-Based Multi-Sensor Fusion Methods
3.3. Summary
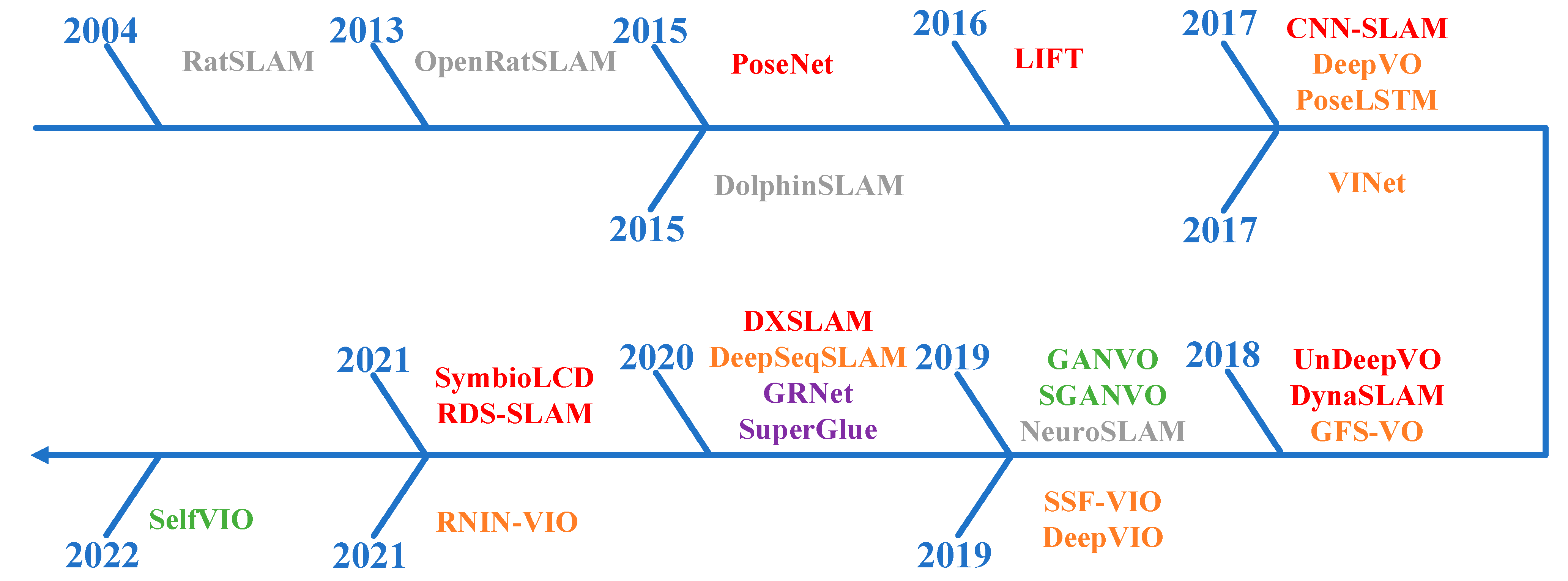
4. Deep Learning-based Methods
4.1. CNN-Based Methods
4.2. RNN-Based Methods
4.3. GAN-Based Methods
4.4. GNN-Based Methods
4.5. SNN-Based Methods
4.6. Summary
5. Experiments and Discussions
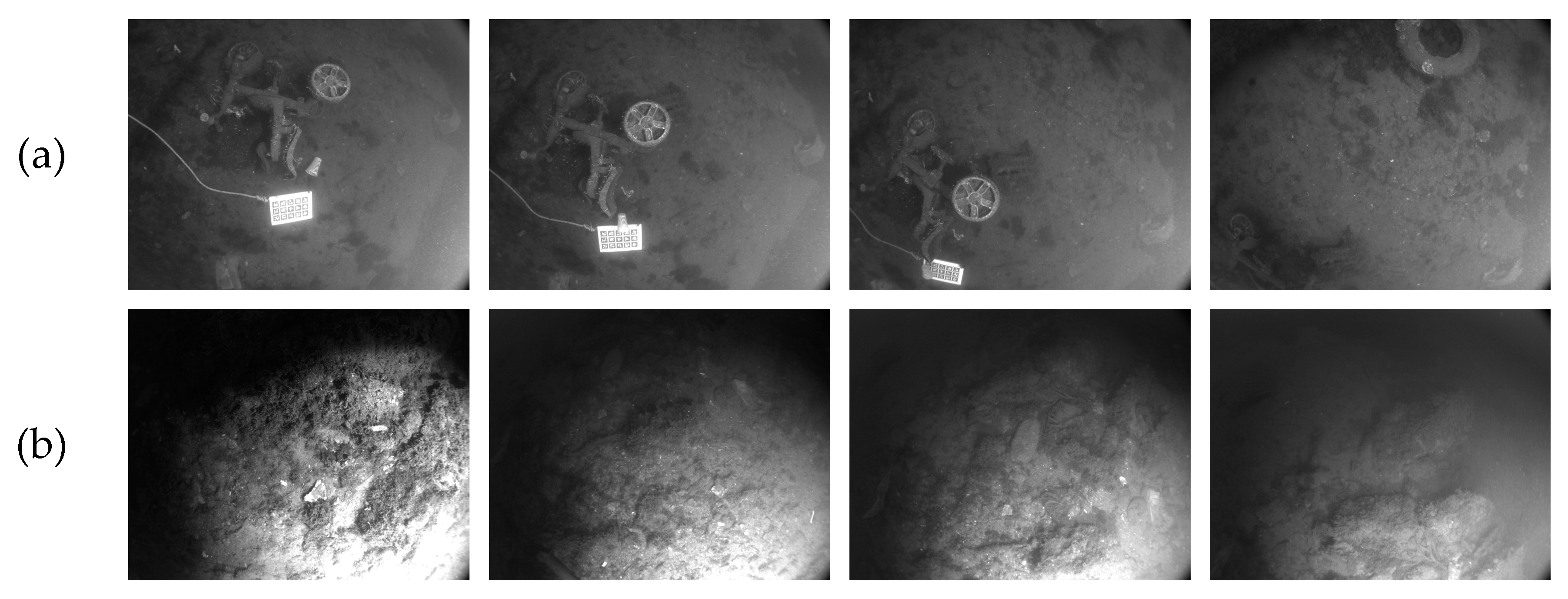
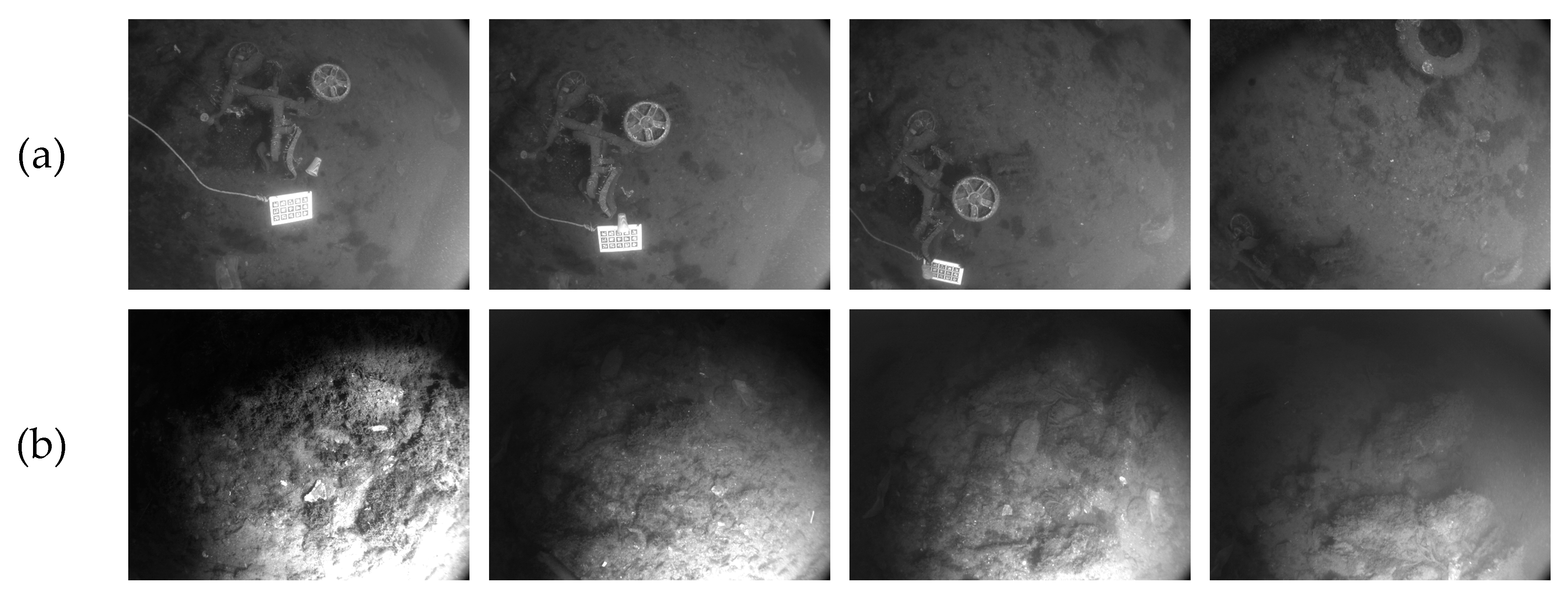
5.1. Dataset
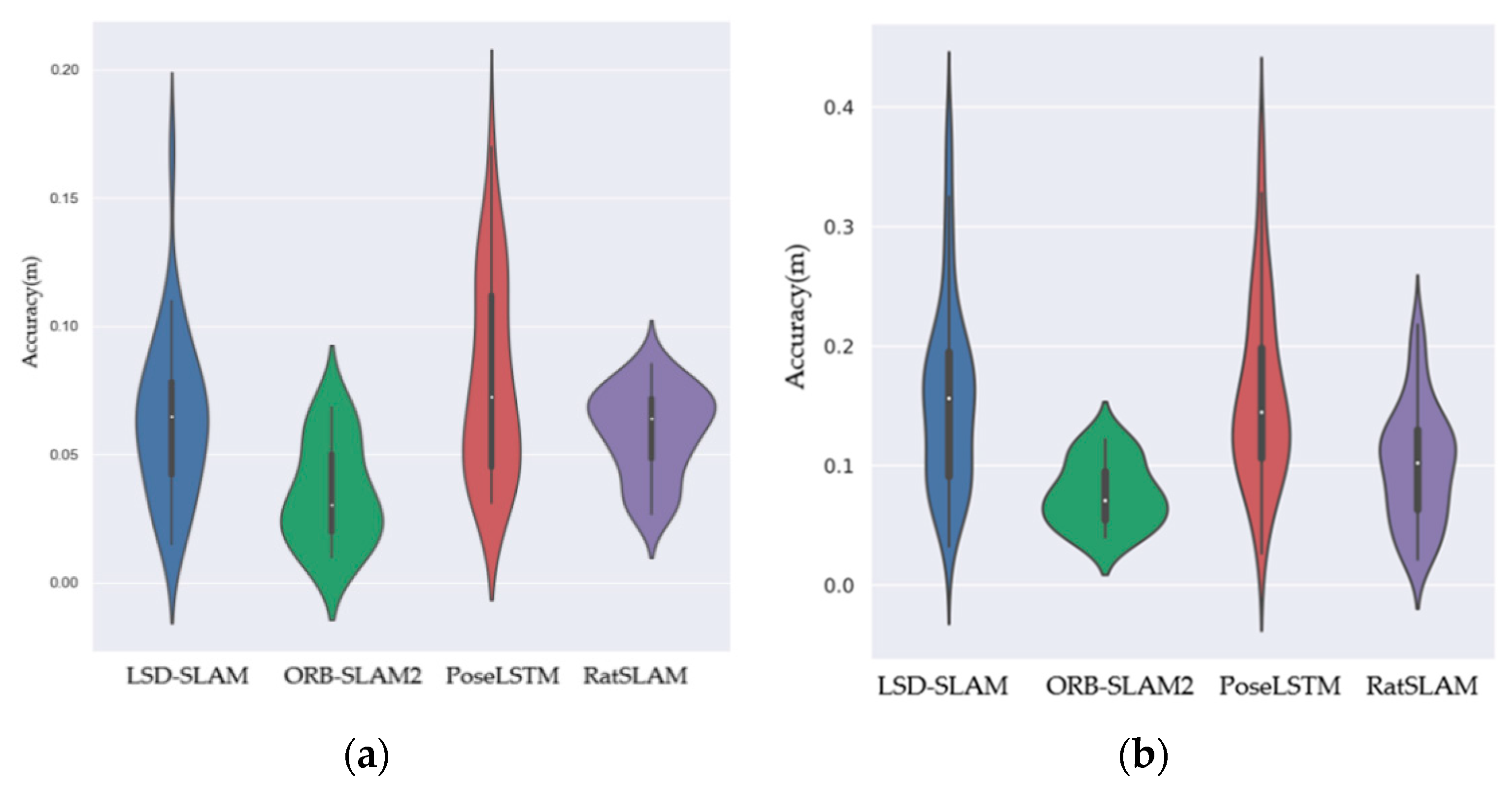
5.2. Experimental Analysis of Vision-Only Methods
5.3. Experimental Analysis of Vision-Inertial Methods
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Khawaja, W.; Semkin, V.; Ratyal, N.; Yaqoob, Q.; Gul, J. Threats from and Countermeasures for Unmanned Aerial and Underwater Vehicles. Sensors 2022, 22, 3896. [Google Scholar] [CrossRef]
- Chemisky, B.; Nocerino, E.; Menna, F.; Nawaf, M.; Drap, P. A Portable Opto-Acoustic Survey Solution for Mapping of Underwater Targets. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2021, 43, 651–658. [Google Scholar] [CrossRef]
- Gilson, C. The Future of Optical Sensors Will Enhance Navigation. Ocean. News Technol. Mag. 2021, 12, 12–13. [Google Scholar]
- Petillot, Y.R.; Antonelli, G.; Casalino, G.; Ferreira, F. Underwater robots: From remotely operated vehicles to intervention-autonomous underwater vehicles. IEEE Robot. Autom. Mag. 2019, 26, 94–101. [Google Scholar] [CrossRef]
- He, Y.; Wang, D.; Ali, Z. A Review of Different Designs and Control Models of Remotely Operated Underwater Vehicle. Meas. Control 2020, 53, 1561–1570. [Google Scholar] [CrossRef]
- Yoerger, D.; Govindarajan, A.; Howland, J.; Llopiz, J.; Wiebe, P.; Curran, M.; Fujii, J.; Gomez-Ibanez, D.; Katija, K.; Robison, B.; et al. A hybrid underwater robot for multidisciplinary investigation of the ocean twilight zone. Sci. Robot. 2021, 6, 1901–1912. [Google Scholar] [CrossRef] [PubMed]
- HROV Nereid Under Ice. Available online: https://www.whoi.edu/what-we-do/explore/underwater-vehicles/hybrid-vehicles/nereid-under-ice/ (accessed on 28 September 2021).
- Vasilijević, A.; Nađ, Đ.; Mandić, F.; Mišković, N.; Vukić, Z. Coordinated navigation of surface and underwater marine robotic vehicles for ocean sampling and environmental monitoring. IEEE/ASME Trans. Mechatron. 2017, 22, 1174–1184. [Google Scholar] [CrossRef]
- Ken Kostel. Terrain Relative Navigation: From Mars to the Deep Sea. Available online: https://oceanexplorer.noaa.gov/okeanos/explorations/ex2102/features/trn/trn.html (accessed on 11 May 2021).
- Sun, K.; Cui, W.; Chen, C. Review of Underwater Sensing Technologies and Applications. Sensors 2021, 21, 7849. [Google Scholar] [CrossRef]
- Burguera, B.A.; Bonin-Font, F. A Trajectory-Based Approach to Multi-Session Underwater Visual SLAM Using Global Image Signatures. J. Mar. Sci. Eng. 2019, 7, 278. [Google Scholar] [CrossRef] [Green Version]
- Wu, Y.; Ta, X.; Xiao, R.; Wei, Y.; Li, D. Survey of Underwater Robot Positioning Navigation. Appl. Ocean Res. 2019, 90, 101845–101860. [Google Scholar] [CrossRef]
- Tan, H.P.; Diamant, R.; Seah, W.K.G.; Waldmeyer, M. A survey of techniques and challenges in underwater localization. Ocean Eng. 2011, 38, 1663–1676. [Google Scholar] [CrossRef] [Green Version]
- Toky, A.; Singh, R.; Das, S. Localization Schemes for Underwater Acoustic Sensor Networks—A Review. Comput. Sci. Rev. 2020, 37, 100241–100259. [Google Scholar] [CrossRef]
- Ran, T.; Yuan, L.; Zhang, J. Scene perception based visual navigation of mobile robot in indoor environment. ISA Trans. 2021, 109, 389–400. [Google Scholar] [CrossRef] [PubMed]
- Zhang, J.; Ila, V.; Kneip, L. Robust visual odometry in underwater environment. In Proceedings of the OCEANS-MTS/IEEE Kobe Techno-Oceans (OTO), Kobe, Japan, 28–31 May 2018. [Google Scholar]
- Nash, J.; Bond, J.; Case, M.; Mccarthy, I.; Teahan, W. Tracking the fine scale movements of fish using autonomous maritime robotics: A systematic state of the art review. Ocean Eng. 2021, 229, 108650–108671. [Google Scholar] [CrossRef]
- Liu, J.; Gong, S.; Guan, W.; Guan, W.; Li, B.; Li, H.; Liu, J. Tracking and Localization based on Multi-angle Vision for Underwater Target. Electronics 2020, 9, 1871. [Google Scholar] [CrossRef]
- Kim, J. Cooperative localization and unknown currents estimation using multiple autonomous underwater vehicles. IEEE Robot. Autom. Lett. 2020, 5, 2365–2371. [Google Scholar] [CrossRef]
- Plum, F.; Labisch, S.; Dirks, J.H. SAUV—A bio-inspired soft-robotic autonomous underwater vehicle. Front. Neurorobot. 2020, 14, 8. [Google Scholar] [CrossRef]
- Lu, Y.; Xue, Z.; Xia, G.S.; Zhang, L. A survey on vision-based UAV navigation. Geo-Spat. Inf. Sci. 2018, 21, 21–32. [Google Scholar] [CrossRef] [Green Version]
- Guilherme, N.D.; Avinash, C.K. Vision for mobile robot navigation: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 237–267. [Google Scholar]
- Nourani-Vatani, N.; Borges, P.V.K.; Roberts, J.M.; Srinivasan, M.V. On the use of optical flow for scene change detection and description. J. Intell. Robot. Syst. 2014, 74, 817–846. [Google Scholar] [CrossRef]
- Zhang, X.; Wang, L.; Su, Y. Visual place recognition: A survey from deep learning perspective. Pattern Recognit. 2021, 113, 107760–107781. [Google Scholar] [CrossRef]
- Cho, D.M.; Tsiotras, P.; Zhang, G.; Marcus, J. Robust feature detection, acquisition and tracking for relative navigation in space with a known target. In Proceedings of the AIAA Guidance, Navigation, and Control (GNC) Conference, Boston, MA, USA, 19–22 August 2013. [Google Scholar]
- Moravec, H.; Elfes, A. High resolution maps from wide angle sonar. In Proceedings of the IEEE International Conference on Robotics and Automation, St. Louis, MO, USA, 25 March 1985. [Google Scholar]
- Thoma, J.; Paudel, D.P.; Chhatkuli, A.; Probst, T.; Gool, L.V. Mapping, localization and path planning for image-based navigation using visual features and map. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Los Angeles, CA, USA, 16–20 June 2019. [Google Scholar]
- Saputra, M.R.U.; Markham, A.; Trigoni, N. Visual SLAM and structure from motion in dynamic environments: A survey. ACM Comput. Surv. (CSUR) 2018, 51, 1–36. [Google Scholar] [CrossRef]
- Yasuda, Y.D.V.; Martins, L.E.G.; Cappabianco, F.A.M. Autonomous visual navigation for mobile robots: A systematic literature review. ACM Comput. Surv. (CSUR) 2020, 53, 1–34. [Google Scholar] [CrossRef] [Green Version]
- Paull, L.; Saeedi, S.; Seto, M.; Li, H. AUV navigation and localization: A review. IEEE J. Ocean. Eng. 2013, 39, 131–149. [Google Scholar] [CrossRef]
- Orpheus Explores the Ocean’s Greatest Depths. Available online: https://www.whoi.edu/multimedia/orpheus-explores-the-oceans-greatest-depths/ (accessed on 18 September 2019).
- Zhou, Z.; Liu, J.; Yu, J. A Survey of Underwater Multi-Robot Systems. IEEE/CAA J. Autom. Sin. 2021, 9, 1–18. [Google Scholar] [CrossRef]
- Qin, J.; Yang, K.; Li, M.; Zhong, J.; Zhang, H. Real-time Positioning and Tracking for Vision-based Unmanned Underwater Vehicles. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2022, 46, 163–168. [Google Scholar] [CrossRef]
- Fuentes-Pacheco, J.; Ruiz-Ascencio, J.; Rendón-Mancha, J.M. Visual simultaneous localization and mapping: A survey. Artif. Intell. Rev. 2015, 43, 55–81. [Google Scholar] [CrossRef]
- Cadena, C.; Carlone, L.; Carrillo, H.; Latif, Y.; Scaramuzza, S.; Neira, J.; Reid, I.; Leonard, J.J. Past, present, and future of simultaneous localization and mapping: Toward the robust-perception age. IEEE Trans. Robot. 2016, 32, 1309–1332. [Google Scholar] [CrossRef] [Green Version]
- Chen, C.; Zhu, H.; Li, M.; You, S. A review of visual-inertial simultaneous localization and mapping from filtering-based and optimization-based perspectives. Robotics 2018, 7, 45. [Google Scholar] [CrossRef] [Green Version]
- Servières, M.; Renaudin, V.; Dupuis, A.; Antigny, N. Visual and visual-inertial SLAM: State of the art, classification, and experimental benchmarking. J. Sens. 2021, 2021, 2054828. [Google Scholar] [CrossRef]
- Macario, B.A.; Michel, M.; Moline, Y.; Corre, G.; Carrel, F. A Comprehensive Survey of Visual SLAM Algorithms. Robotics 2022, 11, 24. [Google Scholar] [CrossRef]
- González-García, J.; Gómez-Espinosa, A.; Cuan-Urquizo, E.; Garcia-Valdovinos, L.G.; Salgado-Jimenez, T.; Cabello, J.A.E. Autonomous underwater vehicles: Localization, navigation, and communication for collaborative missions. Appl. Sci. 2020, 10, 1256. [Google Scholar] [CrossRef] [Green Version]
- Maurelli, F.; Krupiski, S.; Xiang, X.; Petillot, Y. AUV localisation: A review of passive and active techniques. Int. J. Intell. Robot. Appl. 2021, 6, 246–269. [Google Scholar] [CrossRef]
- Watson, S.; Duecker, D.A.; Groves, K. Localisation of unmanned underwater vehicles (UUVs) in complex and confined environments: A review. Sensors 2020, 20, 6203. [Google Scholar] [CrossRef]
- Wirth, S.; Carrasco, P.L.N.; Codina, G.O. Visual odometry for autonomous underwater vehicles. In Proceedings of the MTS/IEEE OCEANS-Bergen, Bergen, Norway, 10–14 June 2013. [Google Scholar]
- Bellavia, F.; Fanfani, M.; Colombo, C. Selective visual odometry for accurate AUV localization. Auton. Robot. 2017, 41, 133–143. [Google Scholar] [CrossRef]
- Choi, J.; Lee, Y.; Kim, T.; Jung, J.; Choi, H. Development of a ROV for visual inspection of harbor structures. In Proceedings of the IEEE Underwater Technology (UT), Busan, Korea, 21–24 February 2017. [Google Scholar]
- Xu, Z.; Haroutunian, M.; Murphy, A.J.; Neasham, J.; Norman, R. An Underwater Visual Navigation Method Based on Multiple ArUco Markers. J. Mar. Sci. Eng. 2021, 9, 1432. [Google Scholar] [CrossRef]
- Li, M.; Qin, J.; Li, D.; Chen, R.; Liao, X.; Guo, B. VNLSTM-PoseNet: A novel deep ConvNet for real-time 6-DOF camera relocalization in urban streets. Geo-Spatial Inf. Sci. 2021, 24, 422–437. [Google Scholar] [CrossRef]
- Ferrera, M.; Moras, J.; Trouvé-Peloux, P.; Creuze, V. Real-time monocular visual odometry for turbid and dynamic underwater environments. Sensors 2019, 19, 687. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Taketomi, T.; Uchiyama, H.; Ikeda, S. Visual SLAM algorithms: A survey from 2010 to 2016. IPSJ Trans. Comput. Vis. Appl. 2017, 9, 16. [Google Scholar] [CrossRef]
- Azzam, R.; Taha, T.; Huang, S.; Zweiri, Y. Feature-based visual simultaneous localization and mapping: A survey. SN Appl. Sci. 2020, 2, 224. [Google Scholar] [CrossRef] [Green Version]
- Bailey, T.; Nieto, J.; Guivant, J.; Stevens, M.; Nebot, E. Consistency of the EKF-SLAM algorithm. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems, Beijing, China, 9–15 October 2006. [Google Scholar]
- Yan, J.; Guorong, L.; Shenghua, L.; Zhou, L. A review on localization and mapping algorithm based on extended kalman filtering. Int. Forum Inf. Technol. Appl. 2009, 2, 435–440. [Google Scholar]
- Davison, A.J.; Reid, I.D.; Molton, N.D.; Stasse, O. MonoSLAM: Real-time single camera SLAM. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 1052–1067. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Stentz, A.; Fox, D.; Montemerlo, M. FastSLAM: A factored solution to the simultaneous localization and mapping problem with unknown data association. In Proceedings of the AAAI National Conference on Artificial Intelligence, Edmonton, AB, Canada, 28 July–1 August 2002. [Google Scholar]
- Klein, G.; Murray, D. Parallel tracking and mapping for small AR workspaces. In Proceedings of the 6th IEEE and ACM International Symposium on Mixed and Augmented Reality, Nara, Japan, 13–16 November 2007. [Google Scholar]
- Mur-Artal, R.; Tardós, J.D. ORB-SLAM2: An open-source SLAM system for monocular, stereo, and RGB-D cameras. IEEE Trans. Robot. 2017, 33, 1255–1262. [Google Scholar] [CrossRef] [Green Version]
- Mur-Artal, R.; Montiel, J.M.M.; Tardos, J.D. ORB-SLAM: A versatile and accurate monocular SLAM system. IEEE Trans. Robot. 2015, 31, 1147–1163. [Google Scholar] [CrossRef] [Green Version]
- Newcombe, R.A.; Lovegrove, S.J.; Davison, A.J. DTAM: Dense tracking and mapping in real-time. In Proceedings of the International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011. [Google Scholar]
- Engel, J.; Schöps, T.; Cremers, D. LSD-SLAM: Large-scale direct monocular SLAM. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014. [Google Scholar]
- Engel, J.; Koltun, V.; Cremers, D. Direct sparse odometry. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 611–625. [Google Scholar] [CrossRef]
- Forster, C.; Pizzoli, M.; Scaramuzza, D. SVO: Fast semi-direct monocular visual odometry. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, China, 31 May–5 June 2014. [Google Scholar]
- Zhao, Y.; Smith, J.S.; Vela, P.A. Good graph to optimize: Cost-effective, budget-aware bundle adjustment in visual SLAM. arXiv 2020, arXiv:2008.10123. [Google Scholar]
- Ferrera, M.; Eudes, A.; Moras, J.; Sanfourche, M.; Besnerais, G.L. OV2SLAM: A Fully Online and Versatile Visual SLAM for Real-Time Applications. IEEE Robot. Autom. Lett. 2021, 6, 1399–1406. [Google Scholar] [CrossRef]
- Zhou, Y.; Gallego, G.; Shen, S. Event-based stereo visual odometry. IEEE Trans. Robot. 2021, 37, 1433–1450. [Google Scholar] [CrossRef]
- Koestler, L.; Yang, N.; Zeller, N.; Cremers, D. TANDEM: Tracking and Dense Mapping in Real-time using Deep Multi-view Stereo. In Proceedings of the Conference on Robot Learning, Auckland, New Zealand, 14–18 December 2022. [Google Scholar]
- Xu, Z.; Haroutunian, M.; Murphy, A.J.; Neasham, J.; Norman, R. An Integrated Visual Odometry System for Underwater Vehicles. IEEE J. Ocean. Eng. 2020, 46, 848–863. [Google Scholar] [CrossRef]
- Jinyu, L.; Bangbang, Y.; Danpeng, C.; Wang, N.; Zhang, G.; Bao, H. Survey and evaluation of monocular visual-inertial SLAM algorithms for augmented reality. Virtual Real. Intell. Hardw. 2019, 1, 386–410. [Google Scholar] [CrossRef]
- Weiss, S.M. Vision Based Navigation for Micro Helicopters. Ph.D. Thesis, ETH Zurich, Zurich, Switzerland, 2012. [Google Scholar]
- Palézieux, N.; Nägeli, T.; Hilliges, O. Duo-VIO: Fast, light-weight, stereo inertial odometry. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Daejeon, Korea, 9–14 October 2016. [Google Scholar]
- Mourikis, A.I.; Roumeliotis, S.I. A Multi-State Constraint Kalman Filter for Vision-aided Inertial Navigation. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Rome, Italy, 10–14 April 2007. [Google Scholar]
- Bloesch, M.; Omari, S.; Hutter, M.; Siegwart, R. Robust visual inertial odometry using a direct EKF-based approach. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–2 October 2015. [Google Scholar]
- Bloesch, M.; Burri, M.; Omari, S.; Hutter, M.; Siegwart, R. Iterated extended Kalman filter based visual-inertial odometry using direct photometric feedback. Int. J. Robot. Res. 2017, 36, 1053–1072. [Google Scholar] [CrossRef] [Green Version]
- Leutenegger, S.; Furgale, P.; Rabaud, V.; Chli, M.; Konolige, K.; Siegwart, R. Keyframe-based visual-inertial SLAM using nonlinear optimization. In Proceedings of the Robotis Science and Systems (RSS), Berlin, Germany, 24–28 June 2013. [Google Scholar]
- Leutenegger, S.; Lynen, S.; Bosse, M.; Siegwart, R.; Furgale, P. Keyframe-based visual–inertial odometry using nonlinear optimization. Int. J. Robot. Res. 2015, 34, 314–334. [Google Scholar] [CrossRef] [Green Version]
- Mur-Artal, R.; Tardós, J.D. Visual-inertial monocular SLAM with map reuse. IEEE Robot. Autom. Lett. 2017, 2, 796–803. [Google Scholar] [CrossRef] [Green Version]
- Qin, T.; Li, P.; Shen, S. VINS-Mono: A robust and versatile monocular visual-inertial state estimator. IEEE Trans. Robot. 2018, 34, 1004–1020. [Google Scholar] [CrossRef] [Green Version]
- Qin, T.; Pan, J.; Cao, S.; Shen, S. A general optimization-based framework for local odometry estimation with multiple sensors. arXiv 2019, arXiv:1901.03638. [Google Scholar]
- Campos, C.; Elvira, R.; Rodríguez, J.J.G.; Montiel, J.M.M.; Tardos, J.D. ORB-SLAM3: An accurate open-source library for visual, visual–inertial, and mul-timap SLAM. IEEE Trans. Robot. 2021, 37, 1874–1890. [Google Scholar] [CrossRef]
- Li, X.; Li, Y.; Örnek, E.P.; Lin, J.; Tombari, F. Co-planar parametrization for stereo-SLAM and visual-inertial odometry. IEEE Robot. Autom. Lett. 2020, 5, 6972–6979. [Google Scholar] [CrossRef]
- Xie, H.; Chen, W.; Wang, J.; Wang, H. Hierarchical quadtree feature optical flow tracking based sparse pose-graph visual-inertial SLAM. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Online, 31 May–15 June 2020. [Google Scholar]
- Seiskari, O.; Rantalankila, P.; Kannala, J.; Ylilammi, J.; Rahtu, E.; Solin, A. HybVIO: Pushing the Limits of Real-time Visual-inertial Odometry. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 4–8 January 2022. [Google Scholar]
- Rahman, S.; Li, A.Q.; Rekleitis, I. Sonar visual inertial SLAM of underwater structures. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018. [Google Scholar]
- Rahman, S.; Li, A.Q.; Rekleitis, I. Svin2: An underwater SLAM system using sonar, visual, inertial, and depth sensor. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 4–8 November 2019. [Google Scholar]
- Rahman, S.; Li, A.Q.; Rekleitis, I. Contour based reconstruction of underwater structures using sonar, visual, inertial, and depth sensor. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 4–8 November 2019. [Google Scholar]
- Cebollada, S.; Payá, L.; Flores, M.; Peidro, A.; Reinoso, O. A state-of-the-art review on mobile robotics tasks using artificial intelligence and visual data. Expert Syst. Appl. 2021, 167, 114195. [Google Scholar] [CrossRef]
- Sartipi, K.; Do, T.; Ke, T.; Vuong, K.; Roumeliotis, S.I. Deep depth estimation from visual-inertial SLAM. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 4 October 2020–24 January 2021. [Google Scholar]
- Duan, C.; Junginger, S.; Huang, J.; Jin, K.; Thurow, K. Deep learning for visual SLAM in transportation robotics: A review. Transp. Saf. Environ. 2019, 1, 177–184. [Google Scholar] [CrossRef]
- Zhao, C.; Sun, Q.; Zhang, C.; Tang, Y.; Qian, F. Monocular depth estimation based on deep learning: An overview. Sci. China Technol. Sci. 2020, 63, 1612–1627. [Google Scholar] [CrossRef]
- Ming, Y.; Meng, X.; Fan, C.; Yu, H. Deep learning for monocular depth estimation: A review. Neurocomputing 2021, 438, 14–33. [Google Scholar] [CrossRef]
- Arshad, S.; Kim, G.W. Role of deep learning in loop closure detection for visual and lidar SLAM: A survey. Sensors 2021, 21, 1243. [Google Scholar] [CrossRef]
- Sualeh, M.; Kim, G.W. Simultaneous localization and mapping in the epoch of semantics: A survey. Int. J. Control. Autom. Syst. 2019, 17, 729–742. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 25–34. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Kendall, A.; Grimes, M.; Cipolla, R. PoseNet: A convolutional network for real-time 6-dof camera relocalization. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Yi, K.M.; Trulls, E.; Lepetit, V.; Fua, P. Lift: Learned invariant feature transform. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016. [Google Scholar]
- Li, D.; Shi, X.; Long, Q.; Liu, S.; Yang, W.; Wang, F.; Wei, Q.; Qiao, F. DXSLAM: A robust and efficient visual SLAM system with deep features. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 4 October 2020–24 January 2021. [Google Scholar]
- Tateno, K.; Tombari, F.; Laina, I.; Navab, N. CNN-SLAM: Real-time dense monocular SLAM with learned depth prediction. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Li, R.; Wang, S.; Long, Z.; Gu, D. UnDeepVo: Monocular visual odometry through unsupervised deep learning. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018. [Google Scholar]
- Kim, J.J.Y.; Urschler, M.; Riddle, P.J.; Wicker, J.S. SymbioLCD: Ensemble-Based Loop Closure Detection using CNN-Extracted Objects and Visual Bag-of-Words. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Prague, Czech Republic, 27 September–1 October 2021. [Google Scholar]
- Bescos, B.; Fácil, J.M.; Civera, J.; Neira, J. DynaSLAM: Tracking, mapping, and inpainting in dynamic scenes. IEEE Robot. Autom. Lett. 2018, 3, 4076–4083. [Google Scholar] [CrossRef] [Green Version]
- Liu, Y.; Miura, J. RDS-SLAM: Real-time dynamic SLAM using semantic segmentation methods. IEEE Access 2021, 9, 23772–23785. [Google Scholar] [CrossRef]
- Yu, Y.; Si, X.; Hu, C.; Zhang, J. A review of recurrent neural networks: LSTM cells and network architectures. Neural Comput. 2019, 31, 1235–1270. [Google Scholar] [CrossRef]
- Shi, X.; Chen, Z.; Wang, H.; Yeung, D.Y.; Wong, W.; Woo, W. Convolutional LSTM network: A machine learning approach for precipitation nowcasting. Adv. Neural Inf. Process. Syst. 2015, 28, 28–37. [Google Scholar]
- Wang, S.; Clark, R.; Wen, H.; Trigoni, N. DeepVo: Towards end-to-end visual odometry with deep recurrent convolutional neural networks. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Marina Bay Sands, Singapore, 29 May–3 June 2017. [Google Scholar]
- Walch, F.; Hazirbas, C.; Leal-Taixe, L.; Sattler, T.; Hilsenbeck, S.; Cremers, D. Image-based localization using LSTMs for structured feature correlation. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Xue, F.; Wang, Q.; Wang, X.; Dong, W.; Wang, J.; Zha, H. Guided feature selection for deep visual odometry. In Proceedings of the Asian Conference on Computer Vision, Perth, Australia, 2–6 December 2018. [Google Scholar]
- Chancán, M.; Milford, M. DeepSeqSLAM: A trainable CNN+ RNN for joint global description and sequence-based place recognition. arXiv 2020, arXiv:2011.08518. [Google Scholar]
- Clark, R.; Wang, S.; Wen, H.; Markham, A.; Trigoni, N. VINet: Visual-inertial odometry as a sequence-to-sequence learning problem. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Chen, C.; Rosa, S.; Miao, Y.; Lu, C.X.; Wu, W.; Markham, A.; Trigoni, N. Selective sensor fusion for neural visual-inertial odometry. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Los Angeles, CA, USA, 16–20 June 2019. [Google Scholar]
- Han, L.; Lin, Y.; Du, G.; Lian, S. DeepVIO: Self-supervised deep learning of monocular visual inertial odometry using 3d geometric constraints. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 4–8 November 2019. [Google Scholar]
- Chen, D.; Wang, N.; Xu, R.; Xie, W.; Bao, H.; Zhang, G. RNIN-VIO: Robust Neural Inertial Navigation Aided Visual-Inertial Odometry in Challenging Scenes. In Proceedings of the IEEE International Symposium on Mixed and Augmented Reality (ISMAR), Bari, Italy, 4–8 October 2021. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. Adv. Neural Inf. Process. Syst. 2014, 27, 27–36. [Google Scholar]
- Almalioglu, Y.; Saputra, M.R.U.; deGusmao, P.P.B.; Markham, A.; Trigoni, N. GanVO: Unsupervised deep monocular visual odometry and depth estimation with generative adversarial networks. In Proceedings of the International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019. [Google Scholar]
- Feng, T.; Gu, D. SGANVO: Unsupervised deep visual odometry and depth estimation with stacked generative adversarial networks. IEEE Robot. Autom. Lett. 2019, 4, 4431–4437. [Google Scholar] [CrossRef] [Green Version]
- Almalioglu, Y.; Turan, M.; Saputra, M.R.U.; Gusmao, P.P.B.; Markham, A.; Trigoni, N. SelfVIO: Self-supervised deep monocular visual-inertial odometry and depth estimation. Neural Netw. arXiv 2019, arXiv:1911.09968. [Google Scholar] [CrossRef] [PubMed]
- Zhou, J.; Cui, G.; Hu, S.; Zhang, Z.; Yang, C.; Liu, Z.; Wang, L.; Li, C.; Sun, M. Graph neural networks: A review of methods and applications. AI Open 2020, 1, 57–81. [Google Scholar] [CrossRef]
- Xue, F.; Wu, X.; Cai, S.; Wang, J. Learning multi-view camera relocalization with graph neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 16–18 June 2020. [Google Scholar]
- Sarlin, P.E.; DeTone, D.; Malisiewicz, T.; Rabinovich, A. SuperGlue: Learning feature matching with graph neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 16–18 June 2020. [Google Scholar]
- Taherkhani, A.; Belatreche, A.; Li, Y.; Cosma, G.; Maguire, L.P.; McGinnity, T.M. A review of learning in biologically plausible spiking neural networks. Neural Netw. 2020, 122, 253–272. [Google Scholar] [CrossRef] [PubMed]
- Milford, M.J.; Wyeth, G.F.; Prasser, D. RatSLAM: A hippocampal model for simultaneous localization and mapping. In Proceedings of the International Conference on Robotics and Automation (ICRA), New Orleans, LA, USA, 26 April–1 May 2004. [Google Scholar]
- Ball, D.; Heath, S.; Wiles, J.; Wyeth, G.; Corke, P.; Milford, M. OpenRatSLAM: An open source brain-based SLAM system. Auton. Robot. 2013, 34, 149–176. [Google Scholar] [CrossRef]
- Silveira, L.; Guth, F.; Drews-Jr, P.; Ballester, P.; Machado, M.; Codevilla, F.; Duarte-Filho, N.; Botelho, S. An open-source bio-inspired solution to underwater SLAM. IFAC-PapersOnLine 2015, 48, 212–217. [Google Scholar] [CrossRef]
- Yu, F.; Shang, J.; Hu, Y.; Milford, M. NeuroSLAM: A brain-inspired SLAM system for 3D environments. Biol. Cybern. 2019, 113, 515–545. [Google Scholar] [CrossRef]
- Qin, J. Visual-Navigation-and-Positioning. Available online: https://github.com/qinjiangying/visual-navigation-and-positioning (accessed on 30 May 2022).
- Ferrera, M.; Creuze, V.; Moras, J.; Trouve-Peloux, P. AQUALOC: An underwater dataset for visual–inertial–pressure localization. Int. J. Robot. Res. 2019, 38, 1549–1559. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | Sequence 1 (m) | Sequence 7 (m) |
|---|---|---|
| LSD-SLAM | 0.07052 | 0.17432 |
| ORB-SLAM2 | 0.03948 | 0.08043 |
| PoseLSTM | 0.08706 | 0.17581 |
| RatSLAM | 0.0611 | 0.11169 |
| Algorithm | Sequence 1 (m) | Sequence 7 (m) |
|---|---|---|
| OKVIS | 0.040636 | 0.11707 |
| ORB-SLAM3 | 0.019821 | 0.02119 |
| VINet | 0.049718 | 0.14946 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qin, J.; Li, M.; Li, D.; Zhong, J.; Yang, K. A Survey on Visual Navigation and Positioning for Autonomous UUVs. Remote Sens. 2022, 14, 3794. https://doi.org/10.3390/rs14153794
Qin J, Li M, Li D, Zhong J, Yang K. A Survey on Visual Navigation and Positioning for Autonomous UUVs. Remote Sensing. 2022; 14(15):3794. https://doi.org/10.3390/rs14153794
Chicago/Turabian StyleQin, Jiangying, Ming Li, Deren Li, Jiageng Zhong, and Ke Yang. 2022. "A Survey on Visual Navigation and Positioning for Autonomous UUVs" Remote Sensing 14, no. 15: 3794. https://doi.org/10.3390/rs14153794
APA StyleQin, J., Li, M., Li, D., Zhong, J., & Yang, K. (2022). A Survey on Visual Navigation and Positioning for Autonomous UUVs. Remote Sensing, 14(15), 3794. https://doi.org/10.3390/rs14153794