
Semantic-Edge-Supervised Single-Stage Detector for Oriented Object Detection in Remote Sensing Imagery


Abstract
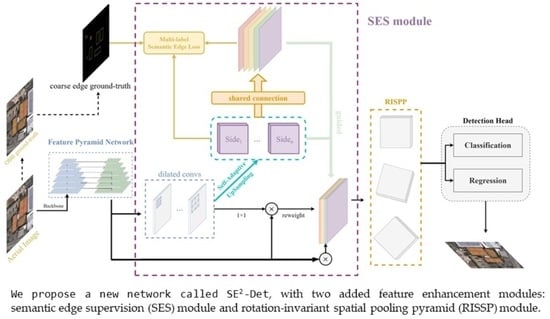
:
1. Introduction
- We creatively introduce semantic edge detection technology into oriented object detection and propose a semantic-edge-supervision feature enhancement network (S-Det) based on the core ideas in its field. This module guides the network in a strong supervision form in the channel, space, and pyramid level dimensions. It also effectively solves the problems of complex background and lack of context regression clues in remote sensing object detection.
- In order to more effectively and comprehensively extract the rotation-invariant features of remote sensing targets in any direction, we propose a rotation-invariant spatial pooling pyramid (RISPP) and achieve remarkable results.
2. Material and Methods
2.1. Related Work
2.1.1. Generic Object Detection
2.1.2. Arbitrary-Oriented Object Detection in Aerial Images
2.1.3. Semantic Edge Detection
2.2. Methods
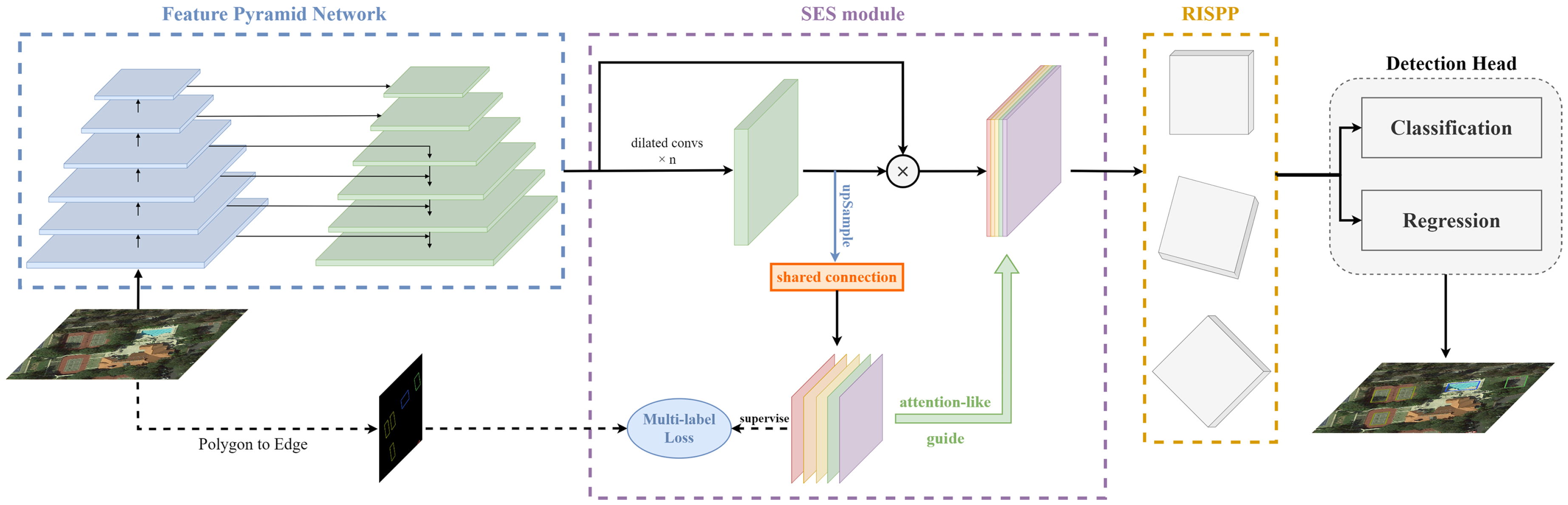
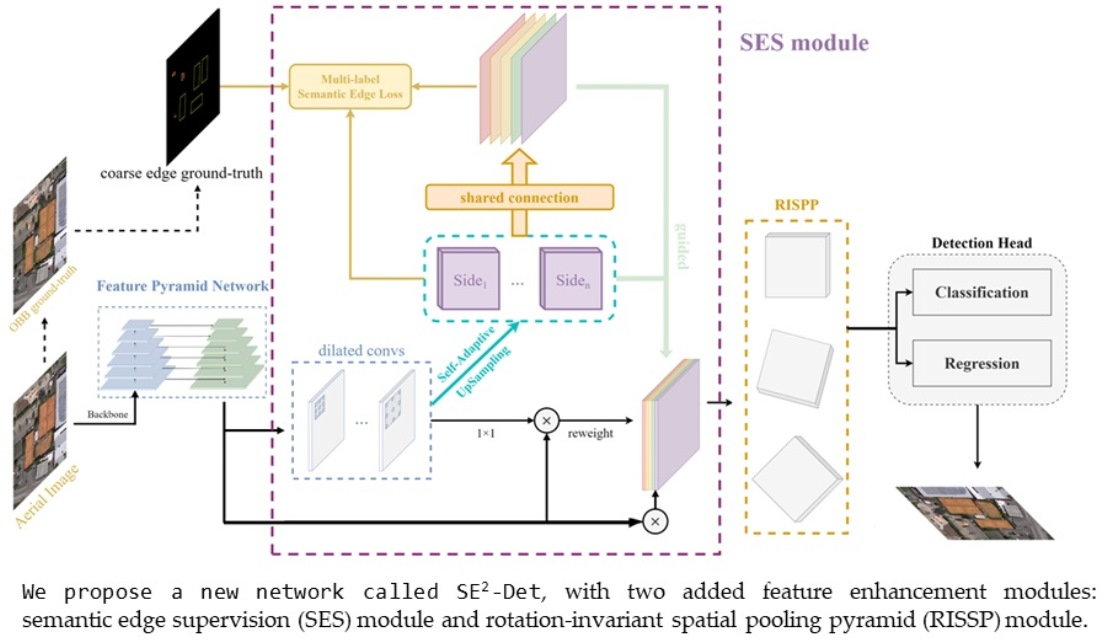
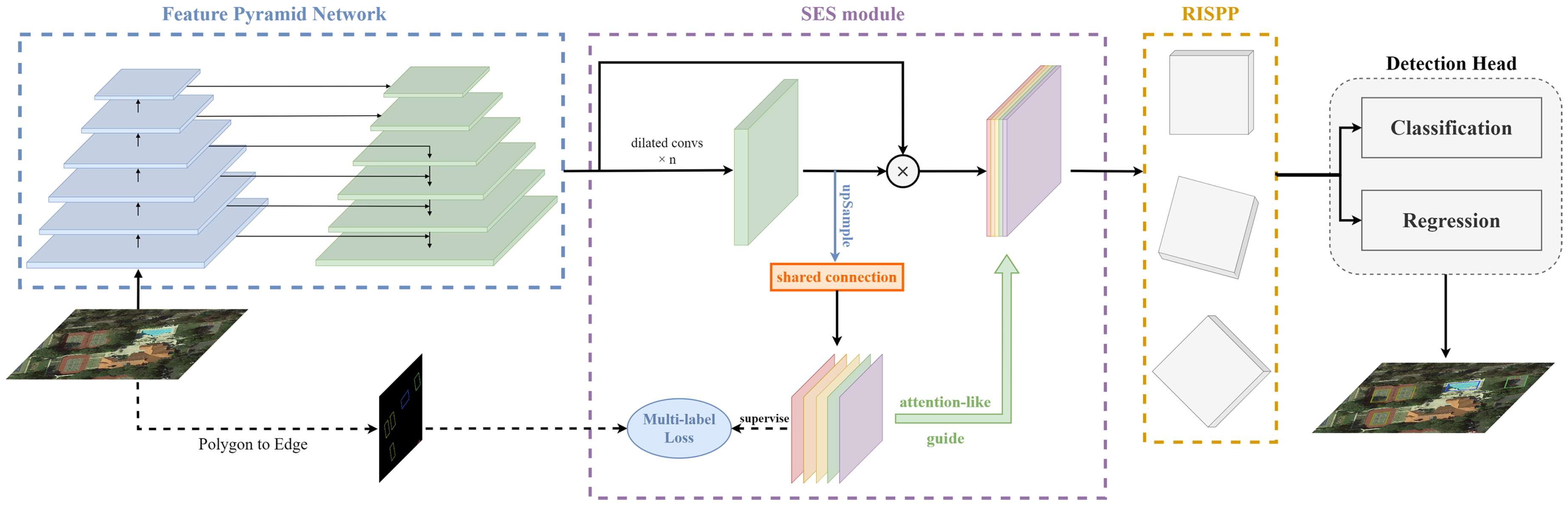
2.2.1. Overall Pipeline
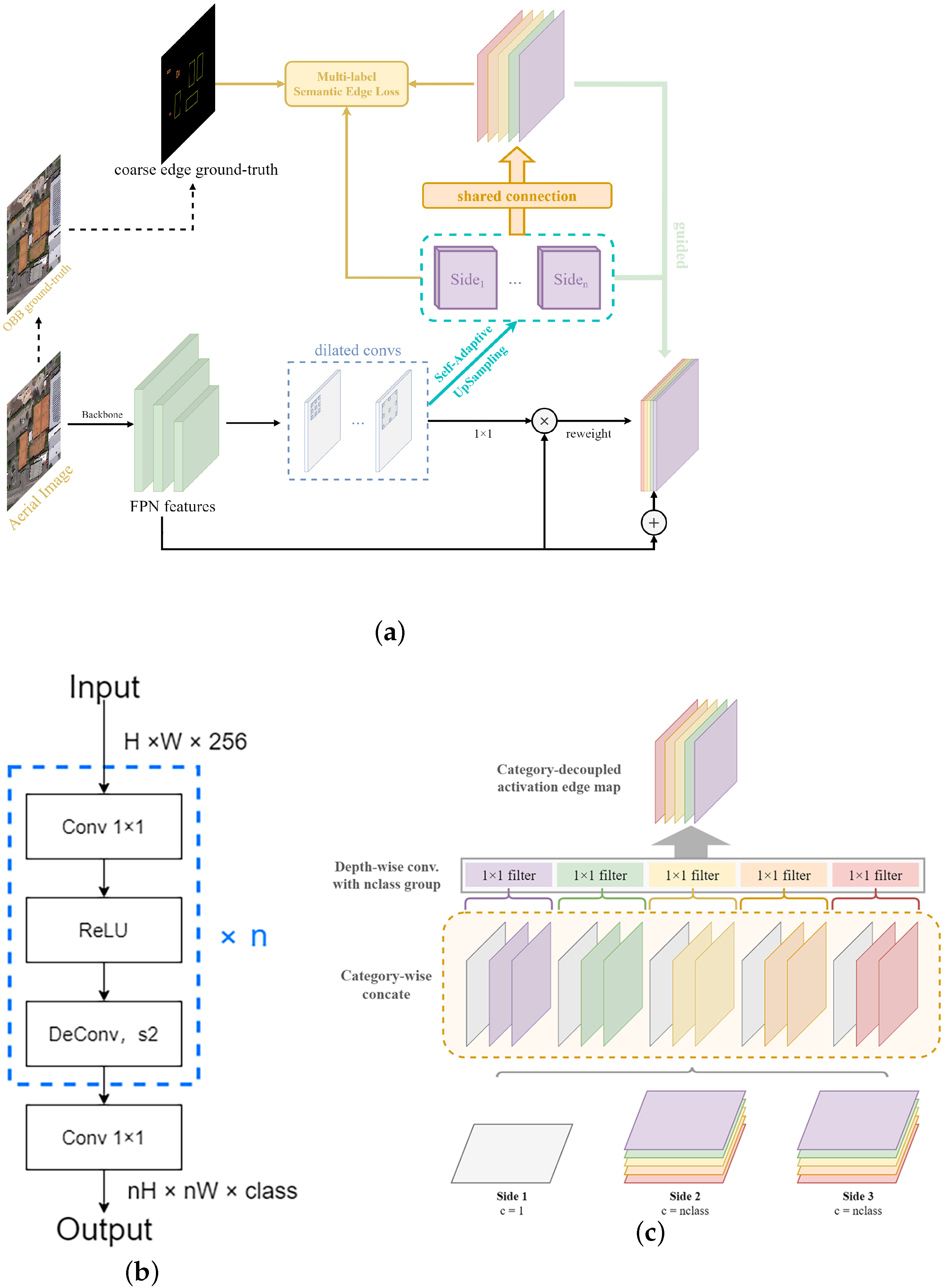
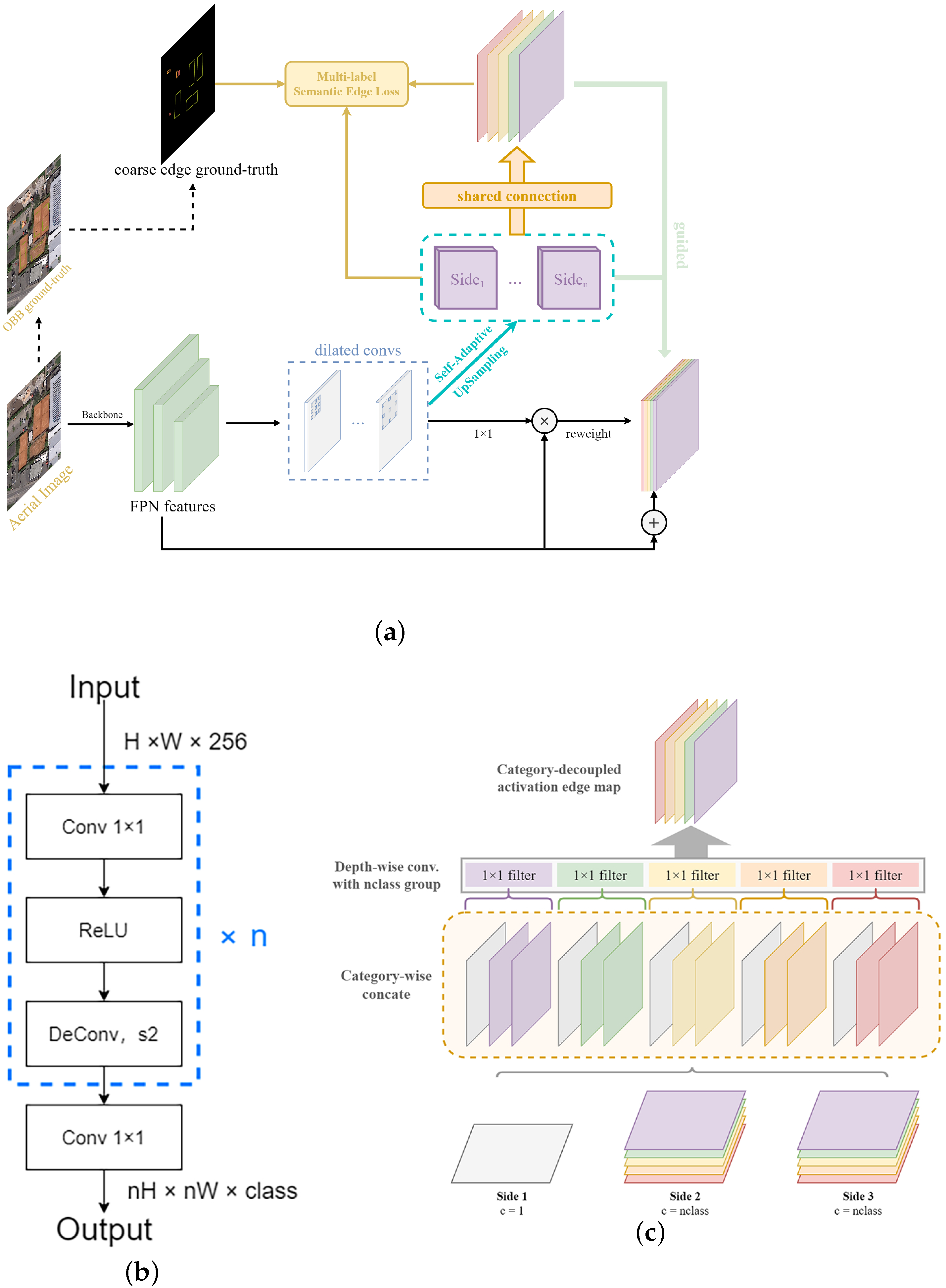
2.2.2. Semantic Edge Supervision for Contextual Feature Enhancement
- (i)
- It is challenging to capture the target’s global features and only focus on the critical local features of the target while ignoring the significant target edge and context features, which is very unfavorable for regression, especially those remote sensing targets with high aspect ratios, as shown in the second row of the first column of Figure 3;
- (ii)
- The network invariably pays attention to the apparent boundaries in the image, but it is worth noting that these boundaries are often the background, thus causing a lot of redundant background interference, as shown in the second row of the second column of Figure 3;
- (iii)
- It is challenging to pay attention to small targets in complex backgrounds. Due to the lack of targeted attention, a large amount of background noise drowns out the small targets, as shown in the third column of the second row of Figure 3.
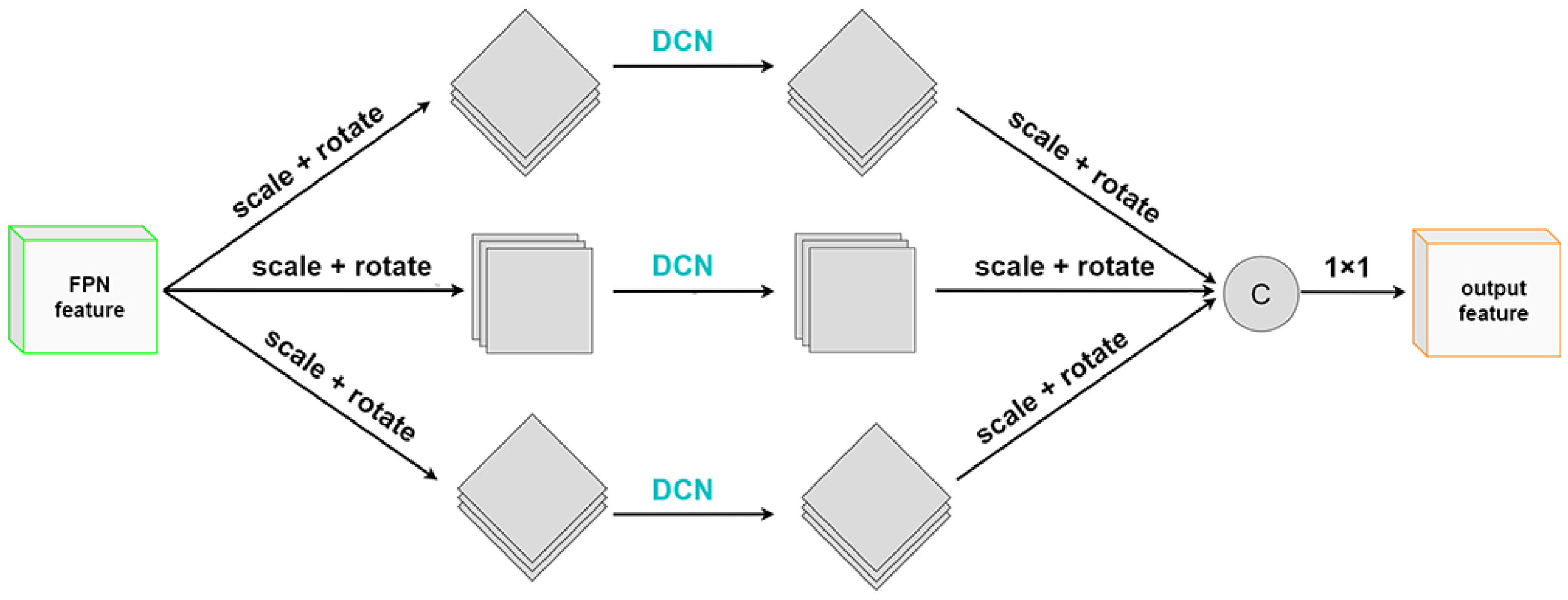
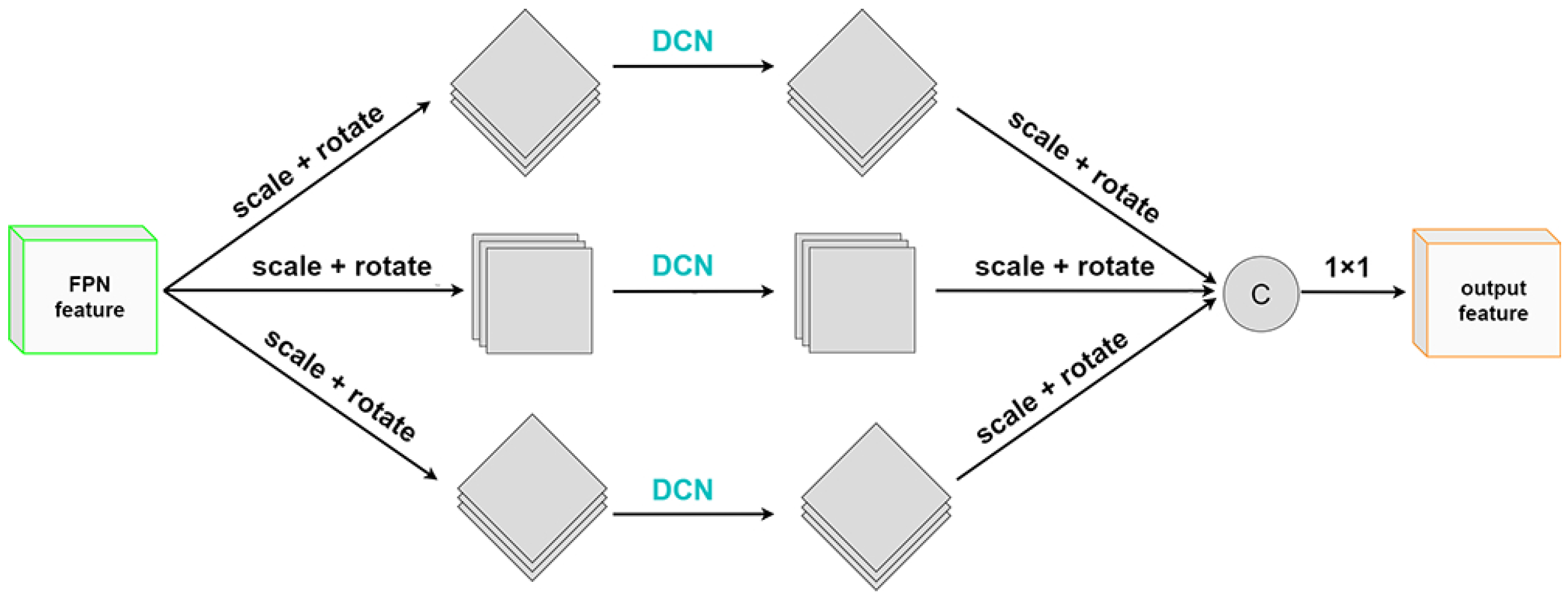
2.2.3. Rotation-Invariant Spatial Pooling Pyramid for Feature Enhancement of Arbitrary-Orientated Target
- (i)
- The offset learning in deformable convolution can better extract the representative features of targets in any direction and has better feature extraction ability for targets with large aspect ratios and different shapes;
- (ii)
- Because of padding, the oriented feature map has obvious boundaries, bringing additional background noise to the ordinary convolution operation. The use of deformable convolution can alleviate this problem.
2.2.4. Multi-Task Loss Function
3. Results
3.1. Datasets
3.2. Main Results
3.2.1. Evaluation of Different Components
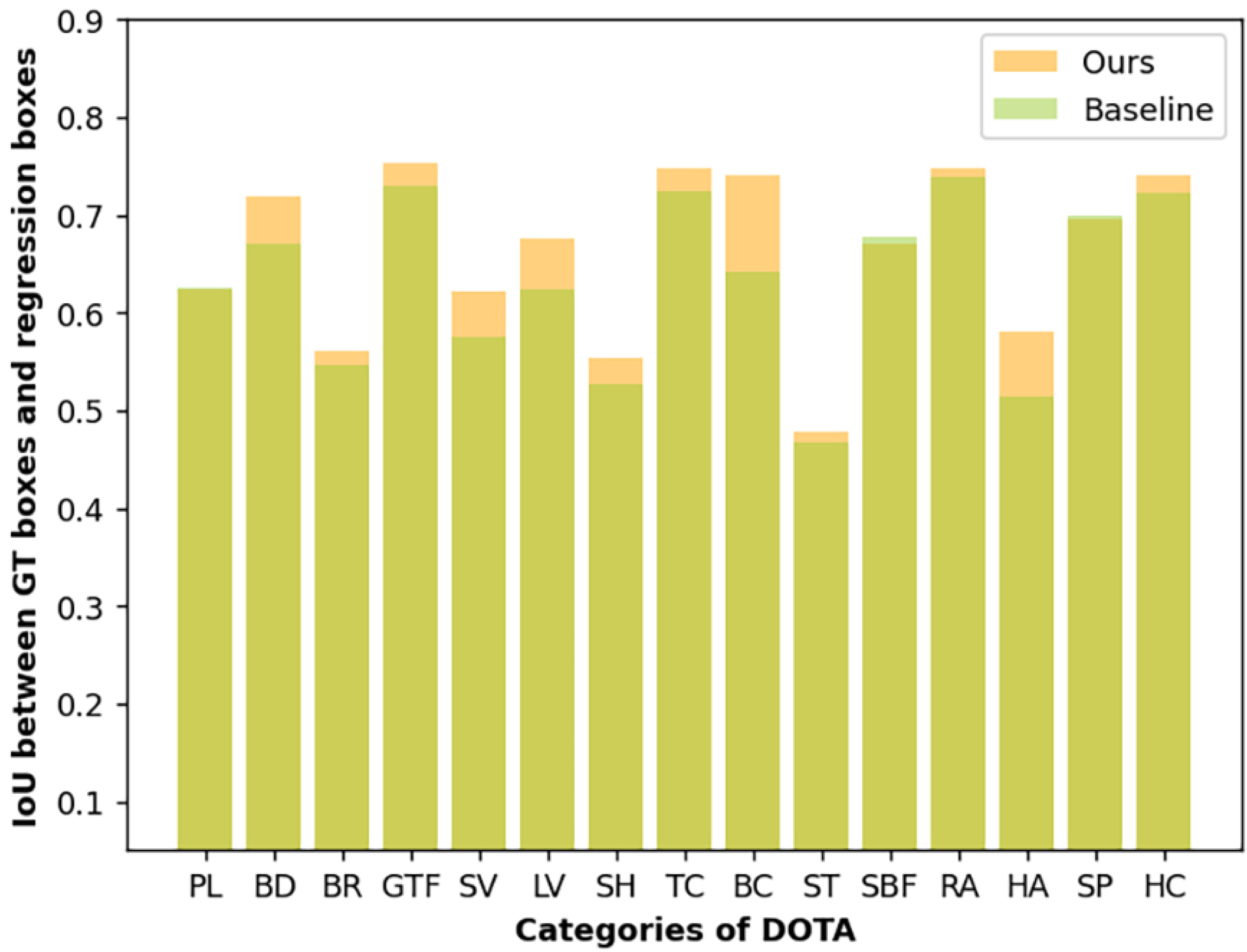
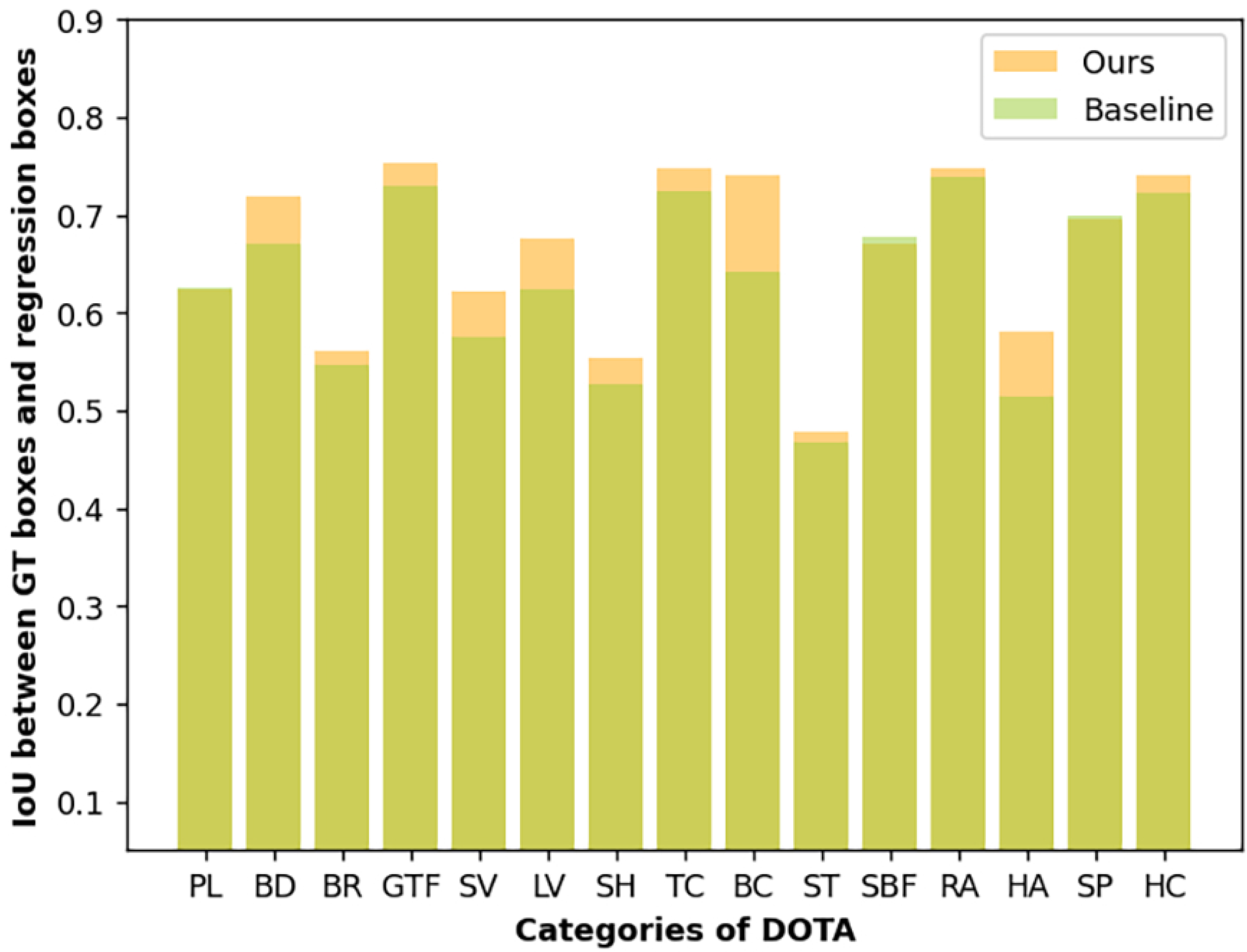
3.2.2. Evaluation of Semantic Edge Supervision
3.2.3. Evaluation of RISPP
3.2.4. Results on DOTA
3.2.5. Results on UCAS-AOD
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Boston, MA, USA, 7–12 June 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade R-CNN: Delving Into High Quality Object Detection. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6154–6162. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. FCOS: Fully Convolutional One-Stage Object Detection. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 9626–9635. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 318–327. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the Computer Vision—ECCV, Amsterdam, The Netherlands, 11–14 October 2016; Lecture Notes in Computer Science. Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer International Publishing: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Yang, X.; Yan, J.; Feng, Z.; He, T. R3Det: Refined Single-Stage Detector with Feature Refinement for Rotating Object. Proc. AAAI Conf. Artif. Intell. 2021, 35, 3163–3171. [Google Scholar]
- Han, J.; Ding, J.; Li, J.; Xia, G.S. Align Deep Features for Oriented Object Detection. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5602511. [Google Scholar] [CrossRef]
- Yang, X.; Yang, J.; Yan, J.; Zhang, Y.; Zhang, T.; Guo, Z.; Sun, X.; Fu, K. SCRDet: Towards More Robust Detection for Small, Cluttered and Rotated Objects. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 8231–8240. [Google Scholar]
- Yang, X.; Yan, J.; Liao, W.; Yang, X.; Tang, J.; He, T. SCRDet++: Detecting Small, Cluttered and Rotated Objects via Instance-Level Feature Denoising and Rotation Loss Smoothing. IEEE Trans. Pattern Anal. Mach. Intell. 2022, early access. [Google Scholar] [CrossRef]
- Ming, Q.; Miao, L.; Zhou, Z.; Song, J.; Yang, X. Sparse Label Assignment for Oriented Object Detection in Aerial Images. Remote Sens. 2021, 13, 2664. [Google Scholar] [CrossRef]
- Ming, Q.; Zhou, Z.; Miao, L.; Zhang, H.; Li, L. Dynamic Anchor Learning for Arbitrary-Oriented Object Detection. Proc. AAAI Conf. Artif. Intell. 2021, 35, 2355–2363. [Google Scholar]
- Yang, X.; Yan, J.; Ming, Q.; Wang, W.; Zhang, X.; Tian, Q. Rethinking Rotated Object Detection with Gaussian Wasserstein Distance Loss. In Proceedings of the 38th International Conference on Machine Learning, PMLR, Virtual, 18–24 July 2021; pp. 11830–11841. [Google Scholar]
- Yang, X.; Yang, X.; Yang, J.; Ming, Q.; Wang, W.; Tian, Q.; Yan, J. Learning High-Precision Bounding Box for Rotated Object Detection via Kullback-Leibler Divergence. In Proceedings of the Advances in Neural Information Processing Systems, Virtual, 6–14 December 2021; Curran Associates, Inc.: Red Hook, NY, USA, 2021; Volume 34, pp. 18381–18394. [Google Scholar]
- Ming, Q.; Miao, L.; Zhou, Z.; Dong, Y. CFC-Net: A Critical Feature Capturing Network for Arbitrary-Oriented Object Detection in Remote-Sensing Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5605814. [Google Scholar] [CrossRef]
- Han, J.; Ding, J.; Xue, N.; Xia, G.S. ReDet: A Rotation-Equivariant Detector for Aerial Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 2786–2795. [Google Scholar]
- Li, Y.; Huang, Q.; Pei, X.; Chen, Y.; Jiao, L.; Shang, R. Cross-Layer Attention Network for Small Object Detection in Remote Sensing Imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 2148–2161. [Google Scholar] [CrossRef]
- Cheng, G.; Han, J.; Zhou, P.; Xu, D. Learning Rotation-Invariant and Fisher Discriminative Convolutional Neural Networks for Object Detection. IEEE Trans. Image Process. 2019, 28, 265–278. [Google Scholar] [CrossRef]
- Yu, Z.; Feng, C.; Liu, M.Y.; Ramalingam, S. CASENet: Deep Category-Aware Semantic Edge Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1761–1770. [Google Scholar]
- Hao, X.; Shan, C.; Xu, Y.; Sun, S.; Xie, L. An Attention-based Neural Network Approach for Single Channel Speech Enhancement. In Proceedings of the ICASSP 2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 6895–6899. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate Attention for Efficient Mobile Network Design. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13713–13722. [Google Scholar]
- Jiang, B.; Luo, R.; Mao, J.; Xiao, T.; Jiang, Y. Acquisition of Localization Confidence for Accurate Object Detection. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 784–799. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Xia, G.S.; Bai, X.; Ding, J.; Zhu, Z.; Belongie, S.; Luo, J.; Datcu, M.; Pelillo, M.; Zhang, L. DOTA: A Large-Scale Dataset for Object Detection in Aerial Images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3974–3983. [Google Scholar]
- Zhu, H.; Chen, X.; Dai, W.; Fu, K.; Ye, Q.; Jiao, J. Orientation robust object detection in aerial images using deep convolutional neural network. In Proceedings of the 2015 IEEE International Conference on Image Processing (ICIP), Quebec City, QC, Canada, 27–30 September 2015; pp. 3735–3739. [Google Scholar]
- Zhou, Y.; Ye, Q.; Qiu, Q.; Jiao, J. Oriented Response Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 519–528. [Google Scholar]
- Kittler, J. On the accuracy of the Sobel edge detector. Image Vis. Comput. 1983, 1, 37–42. [Google Scholar] [CrossRef]
- Canny, J. A Computational Approach to Edge Detection. IEEE Trans. Pattern Anal. Mach. Intell. 1986, PAMI-8, 679–698. [Google Scholar] [CrossRef]
- Hu, Y.; Chen, Y.; Li, X.; Feng, J. Dynamic feature fusion for semantic edge detection. In Proceedings of the 28th International Joint Conference on Artificial Intelligence, (IJCAI’19), Macao, China, 10–16 August 2019; AAAI Press: Macao, China, 2019; pp. 782–788. [Google Scholar]
- Takikawa, T.; Acuna, D.; Jampani, V.; Fidler, S. Gated-SCNN: Gated Shape CNNs for Semantic Segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 5229–5238. [Google Scholar]
- Zhen, M.; Wang, J.; Zhou, L.; Li, S.; Shen, T.; Shang, J.; Fang, T.; Quan, L. Joint Semantic Segmentation and Boundary Detection Using Iterative Pyramid Contexts. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 13666–13675. [Google Scholar]
- Zhao, J.X.; Liu, J.J.; Fan, D.P.; Cao, Y.; Yang, J.; Cheng, M.M. EGNet: Edge Guidance Network for Salient Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 8779–8788. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Lin, T.Y.; DollÃąr, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar]
- Sun, Y.; Ye, J. FEDet: Feature Enhancement Single Shot Detector. In Proceedings of the 2019 IEEE SmartWorld, Ubiquitous Intelligence & Computing, Advanced & Trusted Computing, Scalable Computing & Communications, Cloud & Big Data Computing, Internet of People and Smart City Innovation (SmartWorld/SCALCOM/UIC/ATC/CBDCom/IOP/SCI), Leicester, UK, 19–23 August 2019; pp. 843–850. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st International Conference on Neural Information Processing Systems, NIPS’17. Long Beach, CA, USA, 4–9 December 2017; Curran Associates Inc.: Red Hook, NY, USA, 2017; pp. 6000–6010. [Google Scholar]
- Song, G.; Liu, Y.; Wang, X. Revisiting the Sibling Head in Object Detector. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 11560–11569. [Google Scholar]
- Zhang, X.; Wan, F.; Liu, C.; Ji, X.; Ye, Q. Learning to Match Anchors for Visual Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 3096–3109. [Google Scholar] [CrossRef] [PubMed]
- Xie, S.; Tu, Z. Holistically-Nested Edge Detection. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1395–1403. [Google Scholar]
- Acuna, D.; Kar, A.; Fidler, S. Devil Is in the Edges: Learning Semantic Boundaries From Noisy Annotations. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 11067–11075. [Google Scholar]
- Yu, Z.; Liu, W.; Zou, Y.; Feng, C.; Ramalingam, S.; Kumar, B.V.K.V.; Kautz, J. Simultaneous Edge Alignment and Learning. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 388–404. [Google Scholar]
- Odena, A.; Dumoulin, V.; Olah, C. Deconvolution and Checkerboard Artifacts. Distill 2016, 1, e3. [Google Scholar] [CrossRef]
- Weiler, M.; Cesa, G. General E(2)-equivariant steerable CNNs. In Proceedings of the 33rd International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; Number 1286. Curran Associates Inc.: Red Hook, NY, USA, 2019; pp. 14357–14368. [Google Scholar]
- Dai, J.; Qi, H.; Xiong, Y.; Li, Y.; Zhang, G.; Hu, H.; Wei, Y. Deformable Convolutional Networks. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 764–773. [Google Scholar]
- Liu, Y.; Cheng, M.M.; Fan, D.P.; Zhang, L.; Bian, J.W.; Tao, D. Semantic Edge Detection with Diverse Deep Supervision. Int. J. Comput. Vis. 2022, 130, 179–198. [Google Scholar] [CrossRef]
- Azimi, S.M.; Vig, E.; Bahmanyar, R.; KÃűrner, M.; Reinartz, P. Towards Multi-class Object Detection in Unconstrained Remote Sensing Imagery. In Proceedings of the Computer Vision—ACCV, Perth, Australia, 2–6 December 2018; Springer: Cham, Switzerland, 2019; pp. 150–165. [Google Scholar]
- Ding, J.; Xue, N.; Long, Y.; Xia, G.S.; Lu, Q. Learning RoI Transformer for Oriented Object Detection in Aerial Images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 2849–2858. [Google Scholar]
- Li, C.; Xu, C.; Cui, Z.; Wang, D.; Zhang, T.; Yang, J. Feature-Attentioned Object Detection in Remote Sensing Imagery. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 3886–3890. [Google Scholar]
- Xu, Y.; Fu, M.; Wang, Q.; Wang, Y.; Chen, K.; Xia, G.S.; Bai, X. Gliding Vertex on the Horizontal Bounding Box for Multi-Oriented Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 1452–1459. [Google Scholar] [CrossRef] [Green Version]
- Wang, J.; Ding, J.; Guo, H.; Cheng, W.; Pan, T.; Yang, W. Mask OBB: A Semantic Attention-Based Mask Oriented Bounding Box Representation for Multi-Category Object Detection in Aerial Images. Remote Sens. 2019, 11, 2930. [Google Scholar] [CrossRef] [Green Version]
- Fu, K.; Chang, Z.; Zhang, Y.; Xu, G.; Zhang, K.; Sun, X. Rotation-aware and multi-scale convolutional neural network for object detection in remote sensing images. ISPRS J. Photogramm. Remote Sens. 2020, 161, 294–308. [Google Scholar] [CrossRef]
- Wang, J.; Yang, W.; Li, H.C.; Zhang, H.; Xia, G.S. Learning Center Probability Map for Detecting Objects in Aerial Images. IEEE Trans. Geosci. Remote Sens. 2021, 59, 4307–4323. [Google Scholar] [CrossRef]
- Chen, Z.; Chen, K.; Lin, W.; See, J.; Yu, H.; Ke, Y.; Yang, C. PIoU Loss: Towards Accurate Oriented Object Detection in Complex Environments. In Proceedings of the Computer Vision—ECCV, Glasgow, UK, 23–28 August 2020; Springer: Cham, Switzerland, 2020; pp. 195–211. [Google Scholar]
- Zhou, L.; Wei, H.; Li, H.; Zhao, W.; Zhang, Y.; Zhang, Y. Arbitrary-Oriented Object Detection in Remote Sensing Images Based on Polar Coordinates. IEEE Access 2020, 8, 223373–223384. [Google Scholar] [CrossRef]
- Xiao, Z.; Wang, K.; Wan, Q.; Tan, X.; Xu, C.; Xia, F. A2S-Det: Efficiency Anchor Matching in Aerial Image Oriented Object Detection. Remote Sens. 2021, 13, 73. [Google Scholar] [CrossRef]
- Wei, H.; Zhang, Y.; Chang, Z.; Li, H.; Wang, H.; Sun, X. Oriented objects as pairs of middle lines. ISPRS J. Photogramm. Remote Sens. 2020, 169, 268–279. [Google Scholar] [CrossRef]
- Pan, X.; Ren, Y.; Sheng, K.; Dong, W.; Yuan, H.; Guo, X.; Ma, C.; Xu, C. Dynamic Refinement Network for Oriented and Densely Packed Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11207–11216. [Google Scholar]
- Yi, J.; Wu, P.; Liu, B.; Huang, Q.; Qu, H.; Metaxas, D. Oriented Object Detection in Aerial Images with Box Boundary-Aware Vectors. In Proceedings of the 2021 IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 3–8 January 2021; pp. 2149–2158. [Google Scholar]
- Zhang, S.; Chi, C.; Yao, Y.; Lei, Z.; Li, S.Z. Bridging the Gap Between Anchor-Based and Anchor-Free Detection via Adaptive Training Sample Selection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 9759–9768. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | SES | RISPP | BR | GTF | LV | BC | ST | SBF | RA | HA | SP | mAP | FPS |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Baseline | - | - | 37.9 | 64.8 | 67.5 | 60.2 | 60.3 | 49.0 | 62.9 | 58.4 | 50.8 | 63.49 | 18.2 |
| Ours | × | ✓ | 39.4 | 63.4 | 68.2 | 61.8 | 63.8 | 50.7 | 62.9 | 60.0 | 52.5 | 63.68 | 7.9 |
| ✓ | × | 41.1 | 69.0 | 69.0 | 63.2 | 63.7 | 52.9 | 67.0 | 60.2 | 54.4 | 65.42 | 14.1 | |
| ✓ | ✓ | 41.7 | 68.4 | 69.8 | 63.3 | 64.5 | 53.2 | 66.4 | 61.1 | 54.5 | 65.95 | 6.0 |
| Sides’ Channel | Shared Connection | mAP |
|---|---|---|
| − | − | 63.49 |
| 1, 1 | × | 64.30(+0.81) |
| 15, 15 | × | 64.43(+0.13) |
| 15, 15 | ✓ | 64.94(+0.51) |
| Supervision Strategy | Sides’ Channel | SAU | mAP | FPS |
|---|---|---|---|---|
| Deep | 1, 15, 15 | × | 64.60 | 14.1 |
| Side3, Fuse | 1, 15, 15 | × | 64.82 | 14.4 |
| Side3, Fuse | 15, 15 | × | 64.61 | 16.8 |
| Side3, Fuse | 1, 15, 15 | ✓ | 65.21 | 13.6 |
| Dilated Conv | SES | Decoder | mAP | FPS |
|---|---|---|---|---|
| − | − | − | 63.49 | 18.2 |
| × | ✓ | raw | 64.82 (+1.33) | 14.4 |
| ASPP{6, 8, 16} | ✓ | raw | 64.55 | 12.4 |
| 2,2,2,4 | ✓ | raw | 64.99 | 13.2 |
| 1,2,5 | ✓ | raw | 65.42 (+0.6) | 14.1 |
| 1,2,5 | ✓ | SAU | 65.52 (+0.1) | 12.8 |
| Conv. Type | BR | GTF | BC | HA | SP | mAP | FPS |
|---|---|---|---|---|---|---|---|
| 37.6 | 63.3 | 56.8 | 56.6 | 50.6 | 63.07 | 8.5 | |
| 38.6 | 61.9 | 61.6 | 59.3 | 52.1 | 63.64 | 8.3 | |
| , deformable | 39.4 | 63.4 | 61.8 | 60.0 | 52.5 | 63.68 | 7.9 |
| Methods | Backbone | PL | BD | BR | GTF | SV | LV | SH | TC | BC | ST | SBF | RA | HA | SP | HC | mAP |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Two-Stage: | |||||||||||||||||
| ICN [50] | R-101 | 81.40 | 74.30 | 47.70 | 70.30 | 64.90 | 67.80 | 70.00 | 90.80 | 79.10 | 78.20 | 53.60 | 62.90 | 67.00 | 64.20 | 50.20 | 68.20 |
| RoI-Trans. [51] | R-101 | 88.64 | 78.52 | 43.44 | 75.92 | 68.81 | 73.68 | 83.59 | 90.74 | 77.27 | 81.46 | 58.39 | 53.54 | 62.83 | 58.93 | 47.67 | 69.56 |
| SCRDet [12] | R-101 | 89.98 | 80.65 | 52.09 | 68.36 | 68.36 | 60.32 | 72.41 | 90.85 | 87.94 | 86.86 | 65.02 | 66.68 | 66.25 | 68.24 | 65.21 | 72.61 |
| FADet [52] | R-101 | 90.21 | 79.58 | 45.49 | 76.41 | 73.18 | 68.27 | 79.56 | 90.83 | 83.40 | 84.68 | 53.40 | 65.42 | 74.17 | 69.69 | 64.86 | 73.28 |
| Gliding Vertex [53] | R-101 | 89.64 | 85.00 | 52.26 | 77.34 | 73.01 | 73.14 | 86.82 | 90.74 | 79.02 | 86.81 | 59.55 | 70.91 | 72.94 | 70.86 | 57.32 | 75.02 |
| Mask OBB [54] | RX-101 | 89.56 | 85.95 | 54.21 | 72.90 | 76.52 | 74.16 | 85.63 | 89.85 | 83.81 | 86.48 | 54.89 | 69.64 | 73.94 | 69.06 | 63.32 | 75.33 |
| FFA [55] | R-101 | 90.1 | 82.7 | 54.2 | 75.2 | 71.0 | 79.9 | 83.5 | 90.7 | 83.9 | 84.6 | 61.2 | 68.0 | 70.7 | 76.0 | 63.7 | 75.7 |
| CenterMap OBB [56] | R-101 | 89.83 | 84.41 | 54.60 | 70.25 | 77.66 | 78.32 | 87.19 | 90.66 | 84.89 | 85.27 | 56.46 | 69.23 | 74.13 | 71.56 | 66.06 | 76.03 |
| Single-stage: | |||||||||||||||||
| PIoU [57] | DLA-34 | 80.9 | 69.7 | 24.1 | 60.2 | 38.3 | 64.4 | 64.8 | 90.9 | 77.2 | 70.4 | 46.5 | 37.1 | 57.1 | 61.9 | 64.0 | 60.5 |
| P-RSDet [58] | R-101 | 89.02 | 73.65 | 47.33 | 72.03 | 70.58 | 73.71 | 72.76 | 90.82 | 80.12 | 81.32 | 59.45 | 57.87 | 60.79 | 65.21 | 52.59 | 69.82 |
| A2S-Det [59] | R-101 | 89.59 | 77.89 | 46.37 | 56.47 | 75.86 | 74.83 | 86.07 | 90.58 | 81.09 | 83.71 | 50.21 | 60.94 | 65.29 | 69.77 | 50.93 | 70.64 |
| O2-DNet [60] | H-104 | 89.31 | 82.14 | 47.33 | 61.21 | 71.32 | 74.03 | 78.62 | 90.76 | 82.23 | 81.36 | 60.93 | 60.17 | 58.21 | 66.98 | 61.03 | 71.04 |
| DAL [15] | R-101 | 88.61 | 79.69 | 46.27 | 70.37 | 65.89 | 76.10 | 78.53 | 90.84 | 79.98 | 78.41 | 58.71 | 62.02 | 69.23 | 71.32 | 60.65 | 71.78 |
| DRN [61] | H-104 | 89.71 | 82.34 | 47.22 | 64.10 | 76.22 | 74.43 | 85.84 | 90.57 | 86.18 | 84.89 | 57.65 | 61.93 | 69.30 | 69.63 | 58.48 | 73.23 |
| BBAVector [62] | R-101 | 88.35 | 79.96 | 50.69 | 62.18 | 78.43 | 78.98 | 87.94 | 90.85 | 83.58 | 84.35 | 54.13 | 60.24 | 65.22 | 64.28 | 55.70 | 72.32 |
| CFC-Net [18] | R-50 | 89.08 | 80.41 | 52.41 | 70.02 | 76.28 | 78.11 | 87.21 | 90.89 | 84.47 | 85.64 | 60.51 | 61.52 | 67.82 | 68.02 | 50.09 | 73.50 |
| SLA [14] | R-50 | 88.33 | 84.67 | 48.78 | 73.34 | 77.47 | 77.82 | 86.53 | 90.72 | 86.98 | 86.43 | 58.86 | 68.27 | 74.10 | 73.09 | 69.30 | 76.36 |
| S-Det(Ours) | R-101 | 89.31 | 85.67 | 50.53 | 72.82 | 79.99 | 73.96 | 85.85 | 90.69 | 84.73 | 83.23 | 64.84 | 67.83 | 72.56 | 76.59 | 67.85 | 76.42 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cao, D.; Zhu, C.; Hu, X.; Zhou, R. Semantic-Edge-Supervised Single-Stage Detector for Oriented Object Detection in Remote Sensing Imagery. Remote Sens. 2022, 14, 3637. https://doi.org/10.3390/rs14153637
Cao D, Zhu C, Hu X, Zhou R. Semantic-Edge-Supervised Single-Stage Detector for Oriented Object Detection in Remote Sensing Imagery. Remote Sensing. 2022; 14(15):3637. https://doi.org/10.3390/rs14153637
Chicago/Turabian StyleCao, Dujuan, Changming Zhu, Xinxin Hu, and Rigui Zhou. 2022. "Semantic-Edge-Supervised Single-Stage Detector for Oriented Object Detection in Remote Sensing Imagery" Remote Sensing 14, no. 15: 3637. https://doi.org/10.3390/rs14153637
APA StyleCao, D., Zhu, C., Hu, X., & Zhou, R. (2022). Semantic-Edge-Supervised Single-Stage Detector for Oriented Object Detection in Remote Sensing Imagery. Remote Sensing, 14(15), 3637. https://doi.org/10.3390/rs14153637