1. Introduction
With the rapid development of radar and electronic warfare technology, radars’ anti-jamming capability directly determines the radar systems’ detection performance. Digital radio frequency memory (DRFM) [
1] is an important device widely used in radar countermeasures. The coherent jamming signal generated by DRFM can obtain coherent processing gain in the radar receiver and generate false targets. The repeated jamming based on DRFM can be roughly divided into two modes: full-pulse-repeat-back mode and interrupted-sampling-repeating (ISR) mode. Among them, full-pulse-repeat-back jamming usually requires the interception of the complete radar pulse signal to achieve distortion-free sampling and forwarding. A jammer working in ISR mode is called an interrupted sampling repeater jammer, which was proposed by Wang et al. [
2]. Its working method is to sample a segment of the radar transmitted signal and forward it several times, then repeat the process of sampling and forwarding until the end of the pulse. As the jamming signal generated by ISR mode is highly correlated with the transmitted signal, the jamming signal can obtain a large pulse-compression gain. Therefore, the jammer can use relatively low transmission power to achieve the effects of deception jamming and suppression jamming simultaneously, which poses a great threat to the detection ability of radar.
At present, much research has been carried out on improving ISRJ and its application in various radar systems [
3,
4,
5,
6,
7,
8]. Generally, the fake targets generated by ISRJ will be distributed behind the real target, which may cause the jammed radar to identify the real target through the range relationship. Li et al. [
3] proposed an improved method of ISRJ that not only retains all the advantages of the original ISRJ, but also can form a series of fake targets in front of the real targets. In [
4,
6], a new jamming technology of interrupted-sampling and a periodic repeater was presented. The new jamming can make the linear frequency modulated pulse radar obtain many lifelike false targets, of which number, amplitudes, and positions can be adjusted or controlled by changing some parameters of the new jammer. The literature [
5,
7] expounds on the mathematical principles of ISRJ against the linear frequency modulation (LFM) radars. it discusses the characteristics of false targets, including amplitude, spatial distribution, and phase, as well as the vital jamming parameters that determine the characteristics of these false targets. ISRJ has recently been applied in target echo cancellation; Feng et al. [
8] proposed to use the zero-order false target component of ISRJ to cancel a LFM radar target echo. It is an active echo cancellation (AEC) method.
Compared with jamming technology, the research on anti-jamming technology is still insufficient due to military sensitivity. It lacks a relevant theoretical framework and mathematical model, making the task more arduous. Moreover, for ISRJ, the jammer is often installed on the target so that the jamming signal can enter the receiver through the main lobe of the radar antenna to form the main lobe jamming. In addition, ISRJ adopts the intermittent working mode of receiving/transmitting (R/T) time-sharing, which can achieve intra-pulse jamming. Accordingly, traditional radar active anti-jamming methods such as traditional adaptive spatial beamforming, frequency diversity, and frequency agility find it difficult to suppress jamming. Therefore, for ISRJ main lobe jamming, it is urgent to realize jamming suppression from the perspective of passive radar anti-jamming and propose new methods for signal and data processing.
There are few kinds of research on anti-jamming for ISRJ from the signal and data processing level. The existing literature mainly includes two ideas of signal reconstruction and filtering.
Methods of signal reconstruction include reconstruction of the non-jamming echo signal or rebuilding the jamming signal. For example, the literature [
9] extracts the non-interfering target data segment according to the energy difference between the interference signal and the target echo signal. It then reconstructs the target echo signal through compressive sensing theory, thereby realizing the suppression of ISRJ. However, it only works in high jamming-to-signal ratio situations. Reconstructing the jamming signal [
10] estimates the parameters of the jamming signal through time-frequency analysis and deconvolution processing, then generates the jamming signal and uses iterative cancellation to suppress the jamming. The performance of this method primarily depends on the accurate estimation of the jamming signal parameters, and the amount of calculation is large. Since the fractional Fourier transform (FRFT) focuses on the chirp signal, the literature [
11,
12] also studies the method of adaptively reconstructing the signal using compressed sensing in the fractional domain.
The method based on filtering analyzes the distribution characteristics of the jamming and the real signal in different transform domains from the perspective of the signal generation mode of the intermittent sampling jamming and the chirp characteristics of the transmitted signal. Then, according to their distribution differences, specific band-pass filters are designed to achieve jamming suppression. For example, on the time-domain signal, some researchers [
13] define a square modulus of the signal as the energy function. They use it to distinguish the signal interval where the jamming and the target after the mixer are located. Then, normalized Fourier transform is performed on the signal interval without jamming to obtain a band-pass filter. Finally, it is multiplied by the one-dimensional range profile of the original signal to achieve jamming suppression on the range profile. In the time-frequency domain, there is also some energy difference between the jamming and the target. By designing the threshold, we can obtain the two-dimensional distribution interval of the jamming and the target. A band-pass filter in the time-frequency domain [
14,
15] or on the one-dimensional range profile [
16] can also be designed to achieve jamming suppression. The filtering-based algorithm can suppress jamming more effectively than the reconstruction algorithm, but its performance depends on accurately estimating the jamming-free signal interval. Therefore, it performs poorly under a low signal-to-noise ratio and low jamming-signal ratio. In addition, some researchers have tried to use neural networks [
17] to extract the signal interval where the jamming and the target are located. However, since the algorithm only focuses on the signal interval without jamming and completely ignores the target information existing in the signal interval with jamming, the improvement in the jamming suppression capability is limited.
To sum up, the effects of the existing jamming suppression methods are not ideal. Estimating the jamming parameters (such as the sampling time-slice width, the retransmission times, the number of the sampling time slices, etc.) is the key to determining anti-jamming performance. In addition, their effect is susceptible to changes in signal-to-jamming, plus noise, ratio.
In recent years, machine-learning technology represented by deep learning has made great progress. Deep learning is widely used in computer vision, natural language processing and many other fields, and has achieved fruitful results. Suppose the deep-learning method is introduced into radar signal processing, relying on deep-learning models’ ability to perceive and extract subtle features automatically. In that case, it is possible to break through traditional radar anti-jamming technology’s limitations to achieve a more robust and intelligent anti-jamming technology.
The essence of jamming suppression is to separate the target signal from the radar echo. This requirement is similar to the application background of image segmentation and speech noise reduction. Therefore, the research results of deep learning in these fields can provide ideas for the research of this paper. For example, U-Net [
18] is a network structure that is very commonly used in image segmentation and speech denoising [
19]. It can extract and fuse helpful information from multiple feature maps of different scales. Methods such as DC-U-Net [
20], PHASEN [
21], and SNNet [
22] estimate possible noise masks or directly reconstruct the clean time spectrum to achieve speech noise reduction in the time-frequency domain of the speech signal. The WavU network [
23], Conv-TasNet [
24], DPRN [
25], Sepformer [
26], and other methods directly denoise in the time domain. The transformer module [
9] enhances the network’s detection of signal correlations and can capture global features.
Although these deep-learning methods have achieved excellent performance in other fields, there is very little literature [
27,
28] on deep-learning-based radar ISRJ suppression. Accordingly, based on the analysis of ISRJ characteristics, combined with the existing ISRJ suppression methods and deep-learning methods, this paper proposes a multi-level and multi-domain joint anti-jamming deep network (MSMD network) with excellent performance. It suppresses the jamming components and restores the target echo by combining time-frequency domain and time domain features at different stages. The main contributions of this paper are summarized as follows:
We designed an MSMD-net to achieve stable suppression for ISRJ. The network includes three modules: the signal preprocessing module, UT-net, and ResCU-net. These modules perform jamming suppression and target signal reconstruction in multiple transform domains.
Aiming at the problem that the target signal is difficult to detect under a high jamming-to-signal ratio, a shape-matching operator is designed using the transmitted signal as auxiliary knowledge. Then, the time-frequency binary image is preprocessed by limiting filtering.
In the skip connection layer of UT-net, the forget gate mechanism of LSTM [
13] is introduced. We use the forgetting matrix to reduce further the jamming components entering the decoding layer and improve the jamming suppression performance.
A new error-loss function is designed. During the training process, the error loss under the Hilbert transform is added, and the weight of loss is redistributed between samples of different difficulty levels regarding the principle of Focal loss [
29] to balance the network’s learning ability for samples with different degrees of difficulty.
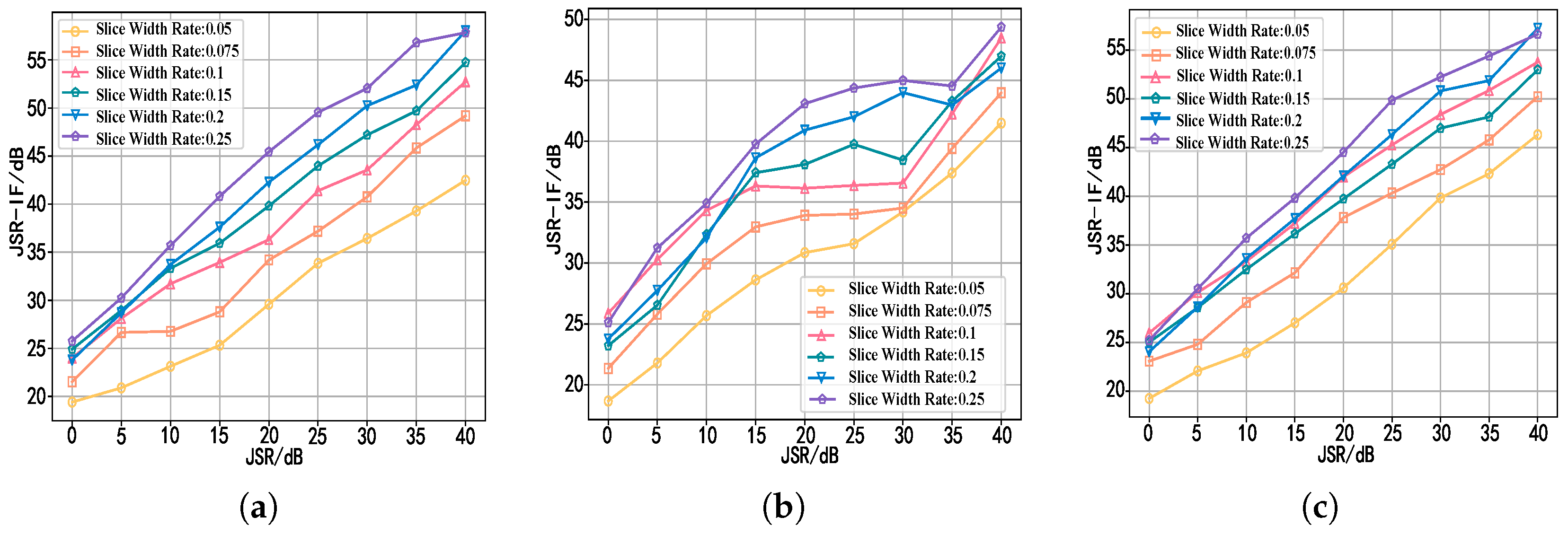
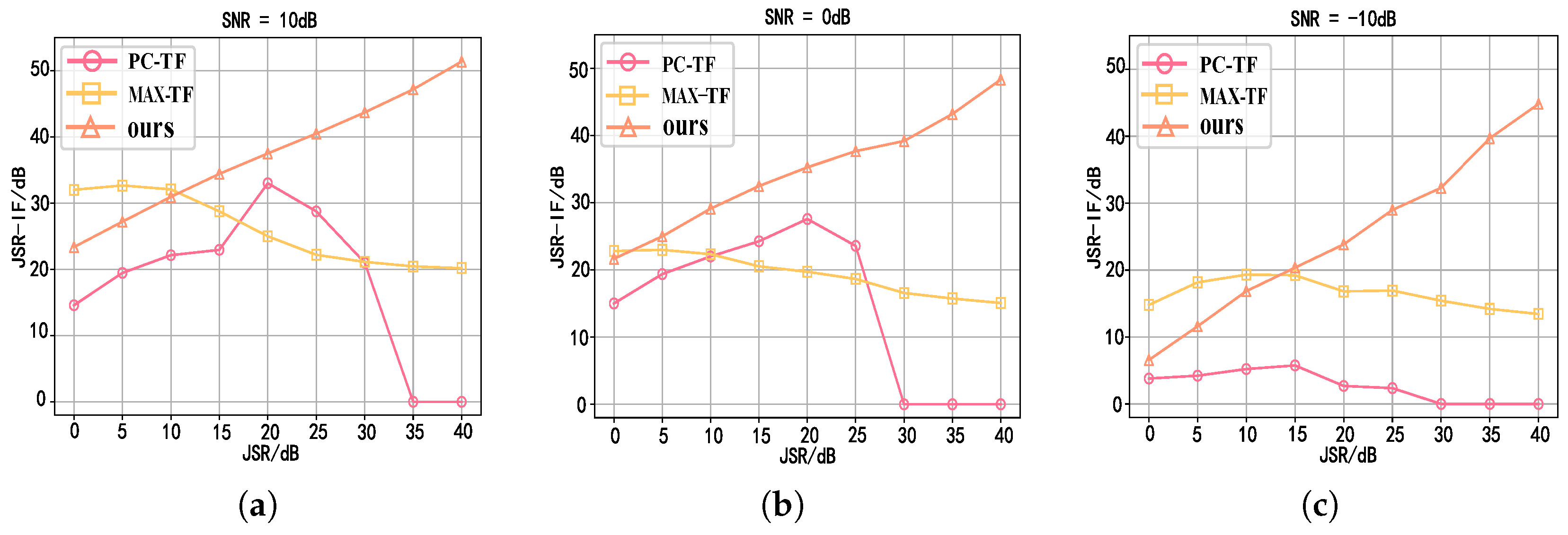
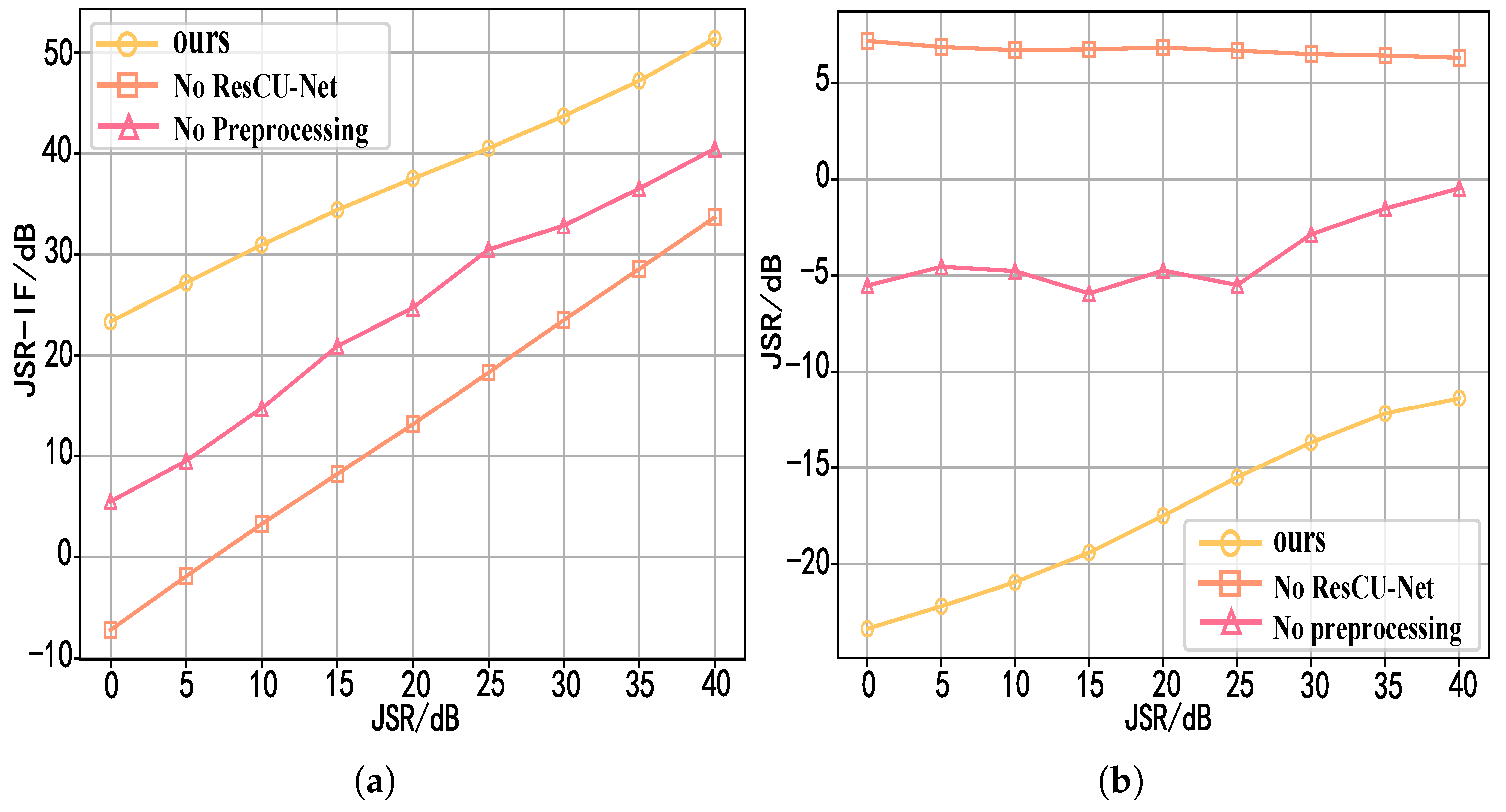
Finally, in the experimental verification stage, the transmission signals with different slopes and bandwidths are used for testing, which verifies the signal recovery capability of the network under various ISRJs. We also demonstrate the effectiveness of each module through ablation experiments. They significantly improved the detection capabilities of radars.
The
Section 2 introduces the signal model of the LFM radar and the working principle of the ISRJ.
Section 3 details the proposed method, including each stage’s framework, preprocessing, network design, and training.
Section 4 describes simulations used to compare the performance of the proposed method with two advanced filtering methods in the published literature. See
Section 5 for conclusions.
2. Signal Model
The LFM signal is the common radar transmitting signal in radar. It has a large width and bandwidth and great target detection advantages. Therefore, this paper mainly studies the problem of ISRJ suppression under the LFM signal.
For the convenience of researching, assume that the true target used in this paper has just one scatter point. The normalized LFM signal emitted by the radar can be expressed as
:
where
denotes carrier frequency;
is a rectangular window function with pulse width
T; and
is the frequency modulation rate, and
B is bandwidth.
Assuming the target is a point target, the target echo signal is expressed as:
where
is a constant, representing the amplitude of the target signal; and
is the time delay from the jammer to radar, where
is the range of target and
c denotes the speed of light.
ISRJ is formed by using DRFM to sample radar signals and then repeat them in sequence intermittently. Its principle is shown in
Figure 1. The gray is the sampling time slice, and the blue is the forwarding time slice. According to different intermittent sampling methods, periodic sampling repeating jamming can be subdivided into jamming with direct repeater (ISDRJ), jamming with repetitive repeater (ISPRJ), and jamming with circular repeater (ISCRJ):
where
N is the number of slices,
is slice width,
M is the number of times each slice is repeated (retransmission times), and
is the interception time interval of two adjacent slices;
is the interception time of the
mth slice, and
is the corresponding delay when the slice is repeated for the
nth time. The calculation formulas are expressed below:
Under self-defense jamming, the jammer and the target are set at the same position and the same speed. Considering other noises, the final echo signal received by the radar can be expressed as:
where
is true target signal;
is jamming, as shown on Equations (
4)–(
6); and
is noise.
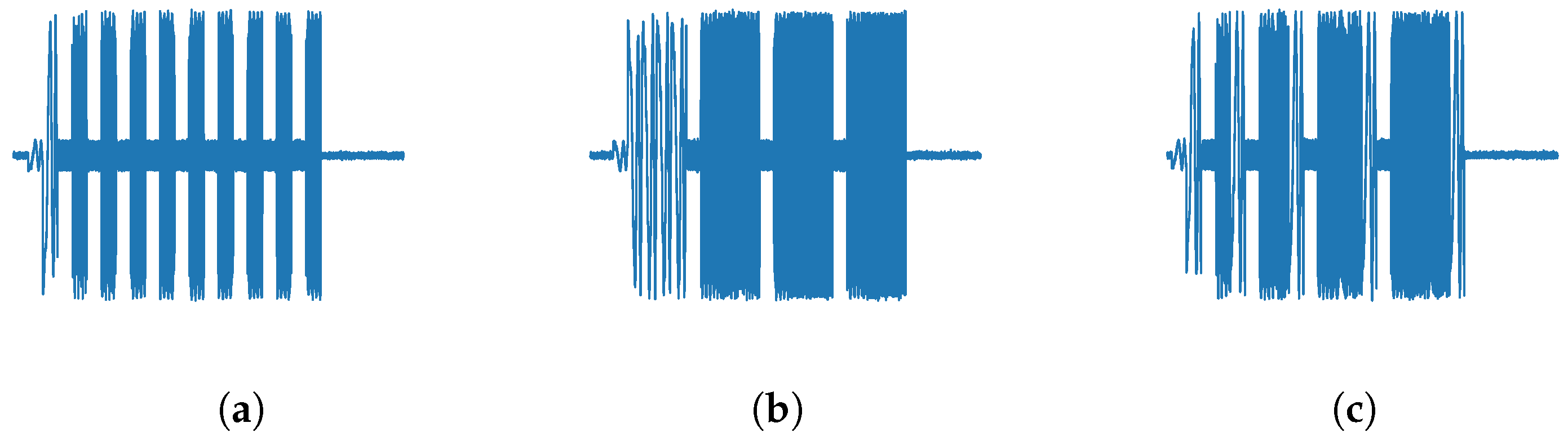
The time-domain signals of radar echo in the three jamming modes are shown in
Figure 2.
We take the short-time Fourier transform (STFT) of the radar echo
to obtain its time-frequency spectrum
. The transformation formula is as in Equation (
9).
The echo time-frequency amplitude spectra under three modes of ISRJ are shown in
Figure 3.
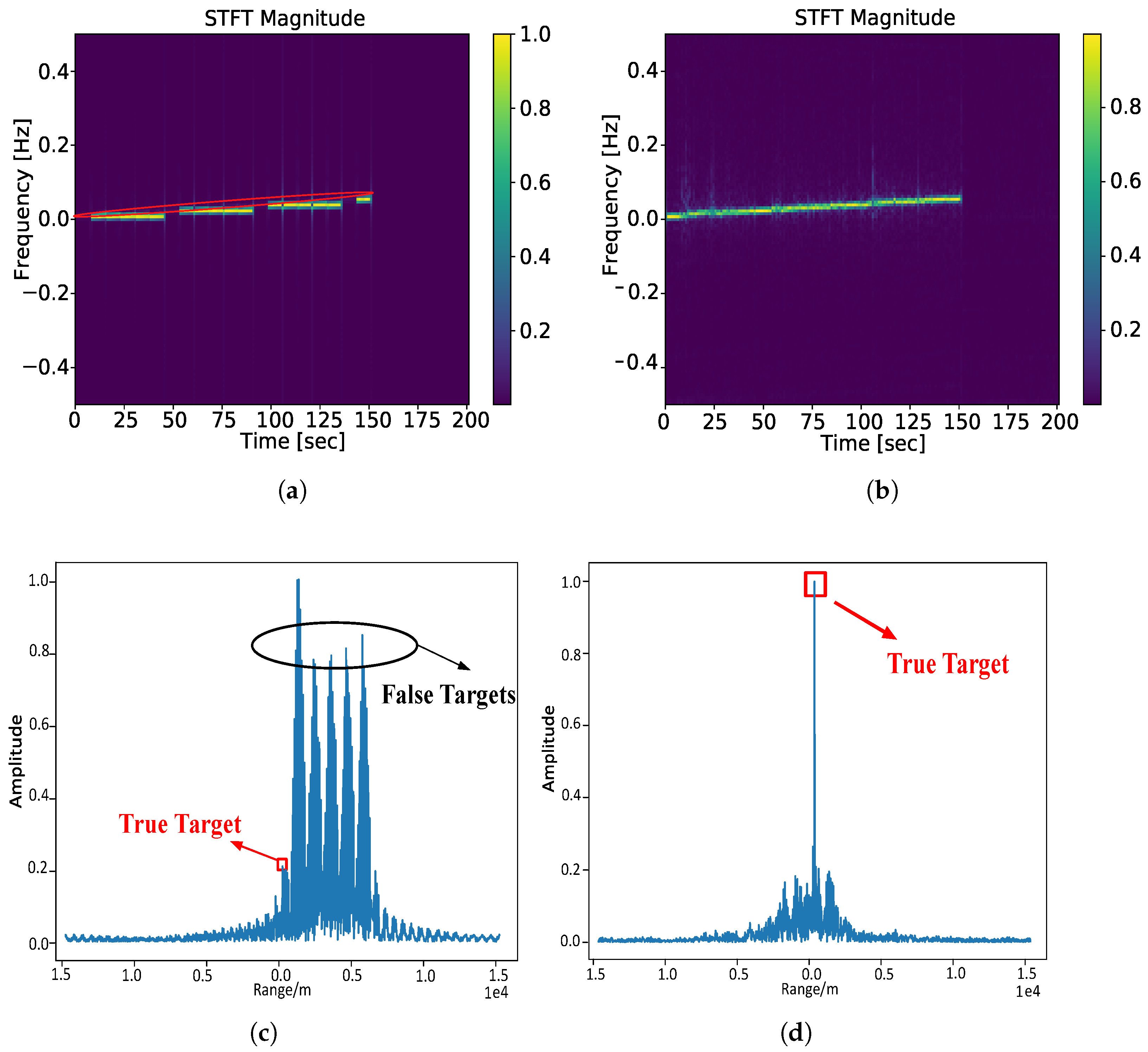
In the time domain shown in
Figure 2, the target and jamming signal overlap for a long time, so it is not easy to separate them directly. In the time-frequency spectrum shown in
Figure 3, the long line segment corresponds to the true target echoes, and the discontinuous short line segment corresponds to the false target echoes. The target and jamming have relatively obvious length and continuity differences in the time-frequency amplitude spectra, so it is more conducive to realizing the separation of the target signal and jamming signal in the time-frequency domain.
3. Method
First, through the analysis of the jamming characteristics in
Section 2, considering that the distribution of jamming and target on the time-frequency spectrum has obvious separable characteristics, we designed a UT-net to initially suppress the jamming on the time-frequency spectrum. The time-domain echo of the target can be obtained by ISTFT operation on the time-frequency spectrum after jamming suppression. However, the jamming suppression processing on the time-frequency spectrum will ignore the phase information of the true echo, so the signal recovered by ISTFT is only a preliminary reconstruction of the echo signal of the target. Therefore, in order to further eliminate the jamming-signal component and restore the detailed information of the target echo, we designed a ResCU-net to further suppress the jamming in the signal time domain. In this multi-stage method, the characteristic information of the target echo is gradually recovered from two different perspectives: the time-frequency domain and the time domain. On the one hand, it has a better jamming suppression effect than the end-to-end network structure; on the other hand, it also increases the interpretability of the model function.
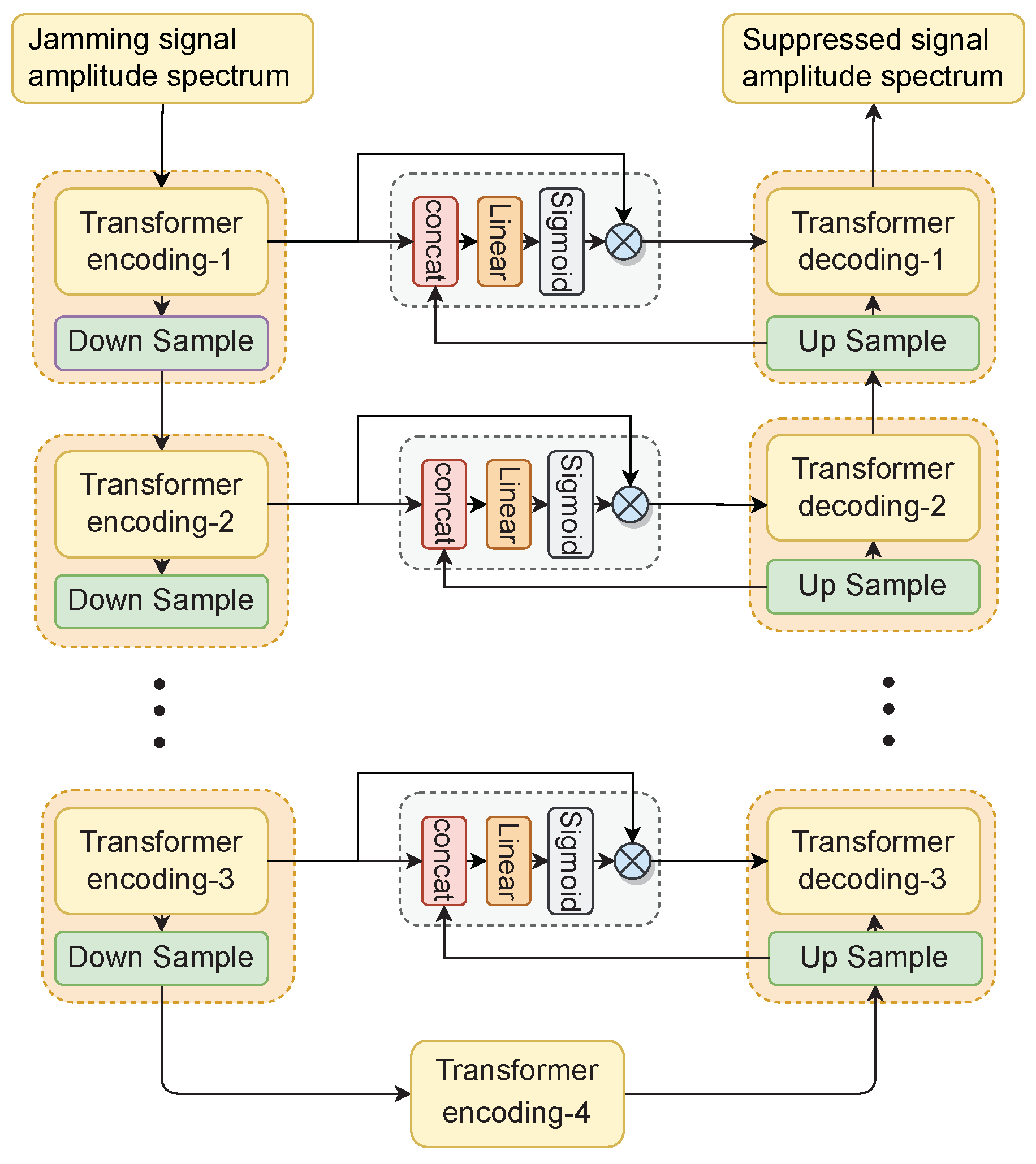
Accordingly, this paper proposes a deep-learning model based on multi-stages and multi-domains (MSMD), which can suppress the jamming signal components in the radar echo and then reconstruct the true echo of the target. The model structure of MSMD-net is shown in
Figure 4, and its processing flow is mainly divided into three stages:
The first stage is the signal preprocessing. The primary purpose is to obtain the normalized amplitude spectrum and phase spectrum from the input signal in the time-frequency domain. Among them, to improve the network’s robustness and enhance its ability to perceive real targets in the case of high JSR, we propose the shape-matching operator to obtain the true target signal strength. Then, we limit and filter the amplitude spectrum to lower the jamming signal strength and reduce the JSR.
In the second stage, the jamming on the time-frequency domain amplitude spectrum is suppressed through UT-Net. UT-net is composed of a U-Net structure with transformer modules, and its input is the normalized amplitude spectrum
, which can be obtained from limiting filtering. Its output is the amplitude spectrum
after suppression. Combining it with the original phase map
for inverse short time Fourier transform (iSTFT), the echo signal
can be initially recovered:
In the third stage, we used the ResCU-net network to repair the details in the signal time domain locally. ResCU-net is composed of Complex-1D-CNN (one-dimensional complex convolution network) combined with the U-Net network. Its input is the preliminary reconstruction signal of the second stage, and the output is the final output signal .
3.1. Preprocessing
In the preprocessing stage, we first needed to carry out complex mixing processing on the signal, and the signal carrier frequency was down converted to zero frequency. Then, we performed short-time Fourier transform on the transmitted signal and the received signal to obtain their time-frequency spectra: and . A 3 dB threshold was used to binarize to obtain a binarized time-frequency spectrum . A shape-matching operator was constructed with the binarized time-frequency spectrum of the transmitted signal as auxiliary information. Secondly, we used the matching operator to convolve the time-frequency spectrum with a sliding window to find a suitable limiting threshold . Finally, we performed limiting filtering on of the received signal and obtained the output of the preprocessing stage: .
Algorithm 1 shows the process of building a shape-matching operator using the transmitted signal. We used the −3 dB threshold to binarize the time-frequency spectrum . Then, the frequency energy width , time energy width , and the transmit signal location in the binarized spectrum were calculated. Finally, we constructed a shape-matching operator .
Algorithm 2 is used to judge whether there is a transmit signal
on the binary spectrum
. The matching operator
slides convolution calculates the matching degree
on
. When there is a matching degree greater than 0.95, it means that the transmit signal exists.
| Algorithm 1: Built shape-matching Operator |
- Input:
Transmit signal: - 1:
Time-Frequency domain amplitude spectrum with STFT: - 2:
3dB energy threshold: - 3:
Binary spectrum: - 4:
Energy peak at each moment: - 5:
Energy peak at each frequency band: - 6:
Frequency energy-width: - 7:
Time energy-width: - 8:
-
Output:
Shape-matching Filtering Operator:
|
| Algorithm 2: Compare-Energe |
-
Input:
Binary spectrum of Echo signal: - 1:
Energe: - 2:
Matching degree threshold: - 3:
Length and width of Filter: - 4:
Fill zeros with w width on the left and right sides of - 5:
- 6:
- 7:
while do - 8:
Matching Energe : - 9:
Matching degree - 10:
if then - 11:
- 12:
return - 13:
end if - 14:
- 15:
end while - 16:
- 17:
return
|
Algorithm 3 shows the main process of limiting filtering. We first used 3 dB to initialize the threshold
to obtain the binarized spectrum of the received signal. On the condition that the matching degree
is greater than 0.95,
was iteratively updated until the condition is satisfied. Finally, the time-frequency spectrum was limiting filtered by the obtained threshold
.
| Algorithm 3: Limiting-filtering |
- Input:
Transmit signal: , Echo signal: - 1:
Build Shape-matching Filtering Operator: - 2:
Time-Frequency domain amplitude spectrum with STFT: - 3:
3dB energy threshold: - 4:
Binary spectrum: - 5:
while Compare-Energe do - 6:
- 7:
- 8:
end while - 9:
- 10:
Limiting-Filtering : - Output:
|
3.2. UT Network
In the analysis in
Section 2, we concluded that the interrupted sampling mechanism of the DRFM jammer will cause the target echo to show a continuous long sloping line on the time-frequency spectrum, while the jamming will show interrupted repeated short sloping lines. Therefore, we first considered using this feature to identify and filter out jamming on the time-frequency spectrum. The traditional methods of jamming suppression are mainly to determine the discontinuous area and repetitive area of the signal by setting the threshold, so as to realize the distinction and suppression of the target and the jamming. However, these methods mostly depend on the experience of experts, and it is easy to fail when the jamming parameters, JSR, and SNR change. Therefore, we designed a UT-net model to automatically realize jamming suppression and target signal restoration on the time-frequency spectrum. The model adopts the U-net architecture with the transformer structure.
U-net uses a self-encoding structure to map signals from high-dimensional signal space to low-dimensional feature space, and then restore from low-dimensional features to high-dimensional signals. This low-dimensional mapping process is the process of extracting the key information of the target and filtering out the jamming information. In the process of restoring from low-dimension to high-dimension, U-net adopts a skip connection mechanism to realize the fusion of multi-scale features, and then better complete signal recovery. Therefore, we used U-net as the basic network architecture to achieve jamming suppression and target echo reconstruction.
However, in the original U-net network, since it adopts the CNN layer in both the encoding layer and the decoding layer, it has a strong ability to capture the local features of the signal, but it is difficult to pay attention to the global shape features of the signal. For interrupted sampling jamming, the jamming is a local copy of the signal. If it only focuses on the local features of the jamming and the target, there will be great similarity between them, which is not conducive to separation. While the true signal is continuous in time, the jamming is discontinuous, so their correlation over the entire time period will be different. In order to enable the network to better pay attention to this relevant feature of the signal globally, we replace the CNN layer in the U-net with the encoder and decoder module of the transformer. The transformer has a stronger modeling ability than CNN, and the self-attention module it contains can model the relationship between all elements well. In addition, the transformer module also uses cross-attention on the decoding layer. Compared with the linear combination in the splicing operation, cross-attention can introduce more nonlinear information, better fuse the lower-layer semantics and cross-layer semantic information, and improve the UT-net network’s ability to reconstruct the target signal.
Therefore, the UT-net with the transformer module added can pay attention to the characteristics of the target signal and the jamming signal at different levels on the time-frequency spectrum, so as to suppress the jamming signal and reconstruct the target signal, accordingly.
The entire process of the UT-net is U-shaped. In
Figure 5, the left part is the encoding—downsampling process, the right part is the decoding—upsampling process and the area in the middle is the skip connection of the feature map. U-net took n maxpool down-sampling layers. After each sampling, the transformer encoding layer extracts information to obtain the feature map. U-net also took n up-sampling layers, which were used to reconstruct the input pixel size. Then, it will go through the transformer decoding layer, which can fix spectrum details. They are shown in Equations (
11) and (
12):
where
is the output of the
nth down-sample layer,
() is the function of the
nth max pooling layer,
() is the output of the
nth decoding layer,
,
() is the function of the
nth up-sampling layer,
() is the function of the skip-connection layer.
represents the
nth encoding layer,
represents the
nth decoding layer.
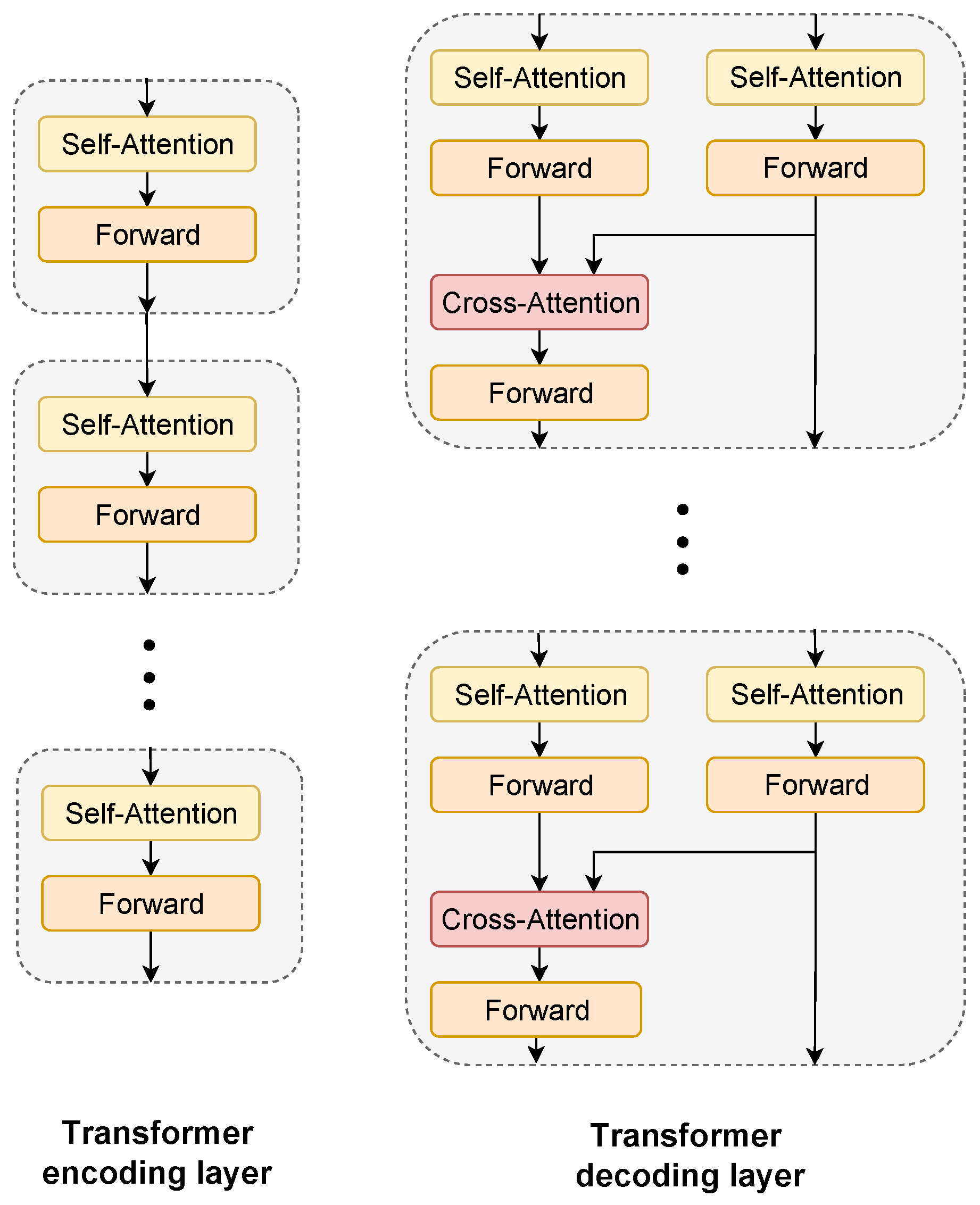
Figure 6 shows the internal structure of the transformer encoding layer and decoding layer. The function of the encoding layer is to extract signal features. In addition, each encoding layer, in
Figure 5, can be composed of multiple encoders with the same structure cascaded. The input to the encoder is normalized magnitude spectrum
or downsampled
. The internal structure of each encoder consists of a self-attention mechanism layer and a forward propagation layer. The decoding layer is also composed of multiple cascaded decoders; its input is the upsampled
and skip-connection layer input. The overall structure of each decoder (see
Figure 5) consists of two self-attention layers and one cross-attention layer. The design of the two self-attention layers mainly balances the input dimension. It ensures that the feature dimension space of the two inputs is the same when calculating the cross attention.
The most critical part of the U-net is the skip connection of the middle area. However, considering that the jamming amplitude is greater than the signal amplitude during the anti-jamming process of the radar signal, there may be still residual jamming in the coding stage. The jamming will be re-transmitted to the subsequent layers by the skip connection, which is not conducive to the decoding layers’ recovery of the signal amplitude.
Therefore, the network should selectively return the information of the encoding layer in the skip connection to reduce the jamming components entering the decoding layer. This paper refers to the design of the forget gate in LSTM [
20]. It uses the full-connect layer and the sigmoid function to design and generate the forgetting matrix so that the skip-connection layer can selectively input the information of the encoding layer into the subsequent decoding layer.
where
() is sigmoid function, and
() is the full-connect layer.
3.3. ResCU Network
We use the time-frequency amplitude spectrum obtained in
Section 3.3 and the original phase spectrum of the received signal to initially recover the target echo signal. Considering that the original phase spectrum is also affected by jamming and noise, the recovered signal still has some jamming. To this end, we continue to use the U-net architecture in the signal time domain to further suppress the jamming component and restore the local details of the signal. Although the transformer module in UT-net can extract global information, it has insufficient ability to obtain local details. Therefore, at this stage, using a CNN layer that can pay more attention to local details and has lower complexity is a better choice. At the same time, considering that the radar echo signal is a complex signal, in order to combine the real-part and imaginary-part features of the signal, at this stage, we chose the complex residual convolution module to replace the transformer to form the ResCU-net structure. Compared with the transformer module in UT-net, the complex residual convolution module of ResCU-net can better pay attention to the local details of the signal in the time domain and improve the recovery accuracy of the true echo. In addition, its residual structure also ensures that it can form a deeper network structure and improve the learning ability of the network.
The overall ResCU-net model structure is similar to the structure described in UT-net. The main difference is that the encoder and decoder of the transformer are replaced with a Complex-1D-CNN [
30], and the pooling layer is no longer used. We chose to use the method of expanding the convolution-kernel step size to achieve dimensionality reduction. The structure of each layer is composed of a residual convolution layer, activation function layer, and batch normalization layer. The number of channels is doubled after each convolution. The upsampling process is the same, but the number of channels is gradually decreased. The skip-connection layer between them is changed to splicing in the channel dimension of the up-sampled signal and then input to the complex-valued convolutional network together.
3.4. Loss Function
The loss value is calculated using the model output signal
and target signal
. The loss function is set as the mean square error function in the time domain (
in Equation (
14)), time-frequency domain (
in Equation (
15)), and Hilbert domain (
in Equation (
16)):
where
N is the length of
,
, and
are the time-frequency domain amplitude maps obtained by short-time Fourier transform of
and
, respectively.
.
() is the Hilbert transform.
The mean square error function on the time domain ensures the consistency of the signal’s energy in the time domain. The mean square error function on the Hilbert domain improves the accuracy of the pulse signal on the rising and falling edges. The square error function ensures the linear representation of the signal on the time-frequency diagram. It provides that the waveform of the recovered signal is consistent with the transmitted signal, which is convenient for subsequent pulse compression processing.
As MSMD-net is a multi-stage network, making each stage’s network model play a corresponding suppression effect is necessary. We designed a loss function for the output of the intermediate stage to calculate the mean square error of the time-frequency amplitude spectrum of the UT-Net network output
and the target signal
, in Equation (
17). It ensures that the UT-net can converge in the direction we expect during training, reducing the difficulty of network training. Finally, the loss function of the whole network can be expressed using Equation (
18).
In addition, during the training process, unlimited random training will lead to a low probability of some extreme hard cases; it will be difficult for the network to learn their characteristics. In the article by He et al. [
29], a new focal loss is proposed to solve the learning problem of hard and easy samples in the image-classification problem. The idea is that, for inaccurately classified samples, the loss remains unchanged. For accurately classified samples, the loss is reduced. Overall, it is equivalent to increasing the weight of hard samples in the loss function. With this idea in mind, this paper proposes focal loss based on regression problems, which is different from the idea of judging difficult samples by relying on probability values in classification problems. We focus more on the regression differences of different samples in a miniBatch. That is, according to the Loss size between each sample, the difficult and easy samples are distinguished, the learning rate of the difficult samples is increased, and the network update direction is more inclined to the direction of the difficult samples. See the formula for the specific implementation.
where
is the loss obtained by each sample in a batch.
is the loss to be updated in this batch.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}