
AMFuse: Add–Multiply-Based Cross-Modal Fusion Network for Multi-Spectral Semantic Segmentation


Abstract
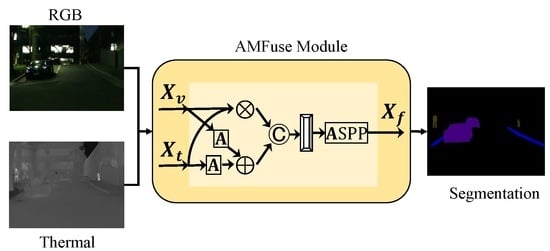
:
1. Introduction
- We propose the AMFuse modules, focusing on both the cross-modal complementary features and common features to take advantage of all the information from both modalities.
- By incorporating the proposed AMFuse modules into the ResNet-based UNet-style framework, we can achieve superior performance for RGBT multi-spectral semantic segmentation and salient object detection.
2. Related Work
2.1. Semantic Segmentation of Natural Images
2.2. Multi-Spectral Image Analysis
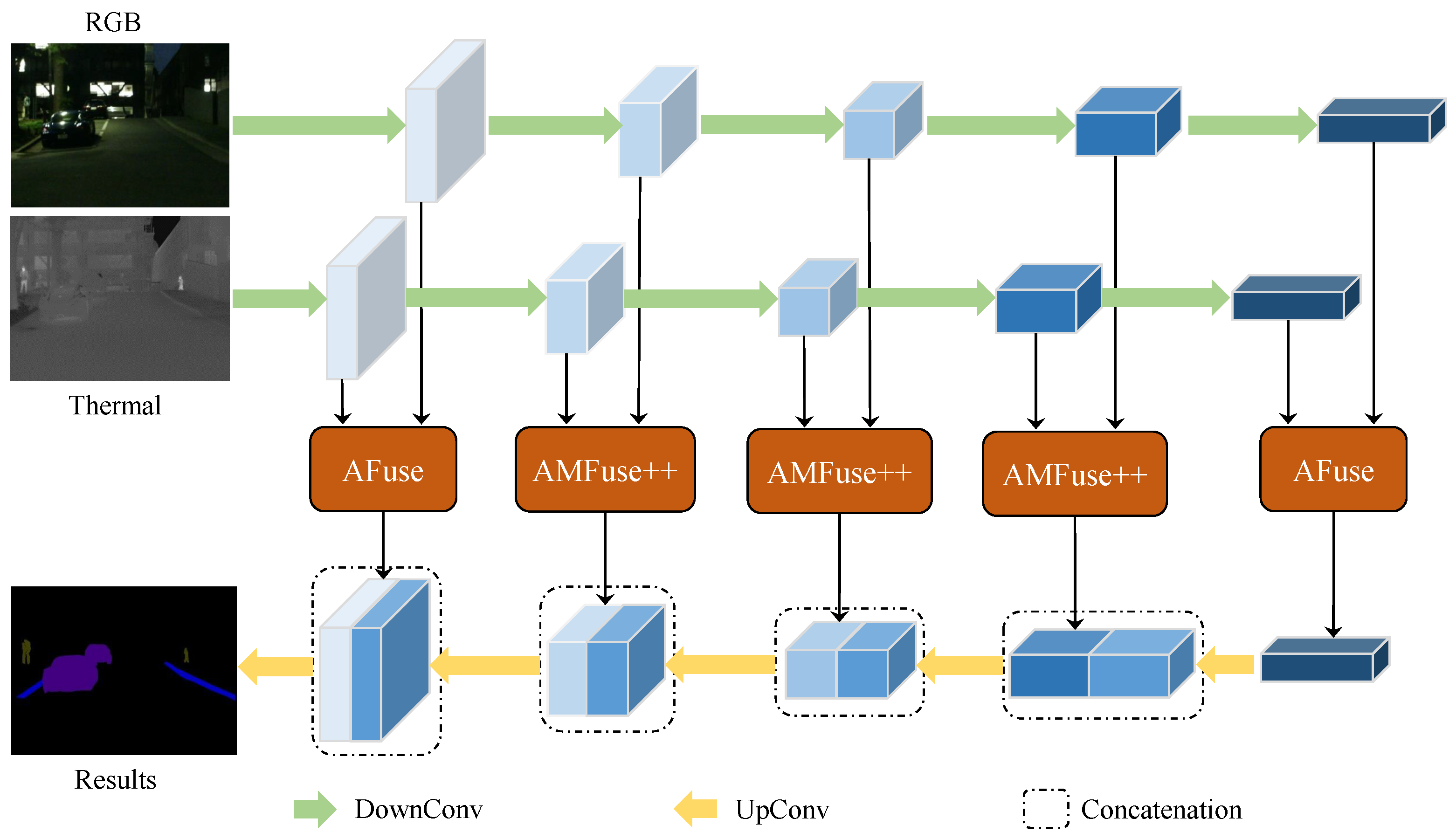
3. Method
3.1. Encoder–Decoder
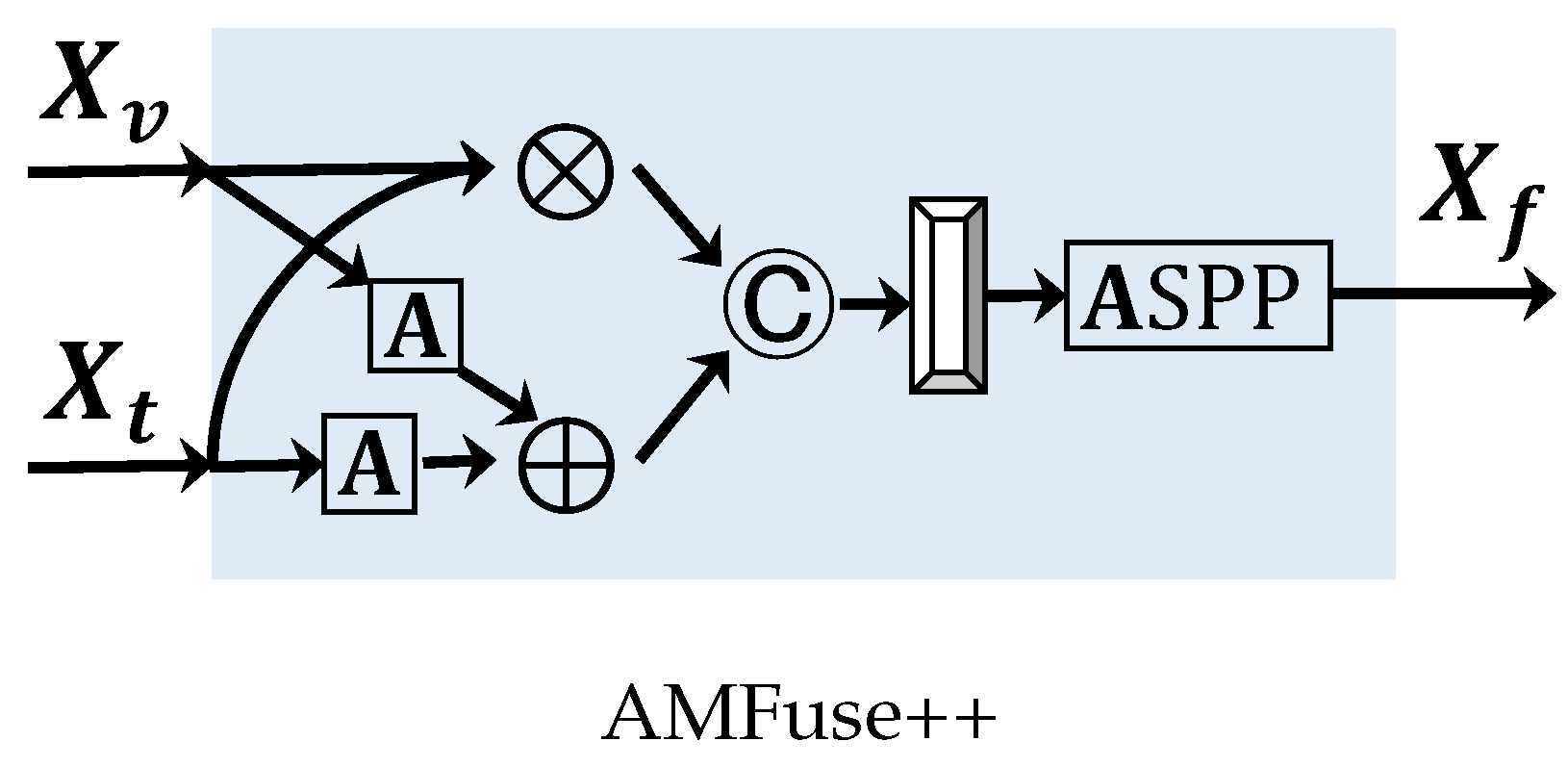
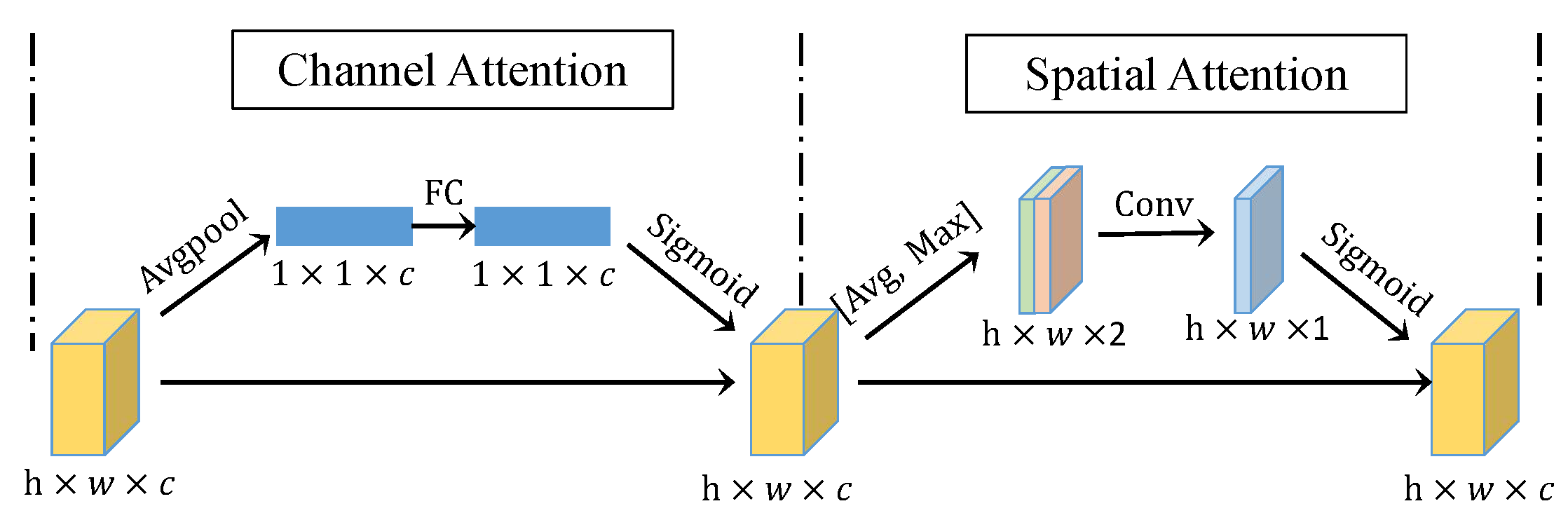
3.2. AMFuse Module
- The cross-modal complementary information. There are some objects only can be sensed by one camera. For example, as shown in Figure 1, during the nighttime one pedestrian only appears in the thermal image (red rectangle), while one car only has indistinct appearance in the RGB image (green rectangle). Methods to fuse these two feature maps to take advantage of those complementary information existing in only one modality is a key problem.
- The cross-modal common information. There are some objects can be sensed by two cameras, which should also be well processed during fusion to enhance them instead of weakening one against the other.
3.3. Loss Function
4. Results
4.1. Experimental Settings
4.2. Comparisons to State-of-the-Art
4.2.1. The Overall Performance
- In general, our proposed AMFuse serial methods perform much better compared to those existing semantic segmentation methods in terms of both mAcc and mIoU metrics.
- Compared to the state-of-the-art method (RTFNet [13]) for RGB–thermal multi-spectral semantic segmentation, our proposed AMFuse methods obtain superior performance. When compared to AMFuse-18 to RTFNet-152: mACC (64.1 vs. 63.1), mIoU (53.1 vs. 53.2), AMFuse-18 performs a little better. However, our method only utilizes resnet-18 as backbone of encoders, while RTFNet utilizes resnet-152 with much more parameters. It demonstrates the effectiveness of our proposed AMFuse module for fusing the RGB and thermal information.
- By comparing the AMFuse methods with different backbones, we can see that AMFuse-50 performs better than both AMFuse-18 and AMFuse-152. However, when modifying the AMFuse++ module by adding a convolution layer for the multiplication operation, AMFuse-152* outperforms AMFuse-50 and AMFuse-152. We conjecture the reason is that the convolution can refine the common information extracted by the multiplication operation from the multi-spectral data.
- The results for different classes are with very big differences in terms of Acc and IoU values, which is caused by the extremely unbalanced distribution of classes in the dataset [12]. In general, for each class the less the number of pixels is, the worse the result is. Especially for Guardrail class, the results may be 0.0, since Guardrail class occupies the fewest pixels, resulting in insufficient training for it. Moreover, there are only 4 images containing Guardrail class among 393 images in the testing dataset.
4.2.2. Daytime and Nighttime Results
4.2.3. Qualitative Demonstrations
5. Discussion
5.1. Ablation Study
5.1.1. The Effectiveness of ResNet as Backbone of Encoder
5.1.2. The Effectiveness of Mixing AFuse and AMFuse++ Modules
5.1.3. The Effectiveness of Attention and ASPP Modules
5.1.4. The Effectiveness of AMFuse Serial Modules
- When fusing the RGB and thermal information with only one operation (addition (AFuse) or multiplication (MFuse)), MFuse performs much worse than AFuse. It is intuitively reasonable, since we argue that the addition operation could focus on the cross-modal complementary components while the multiplication operation could concentrate on the cross-modal common components. Those cross-modal complementary information existing in the RGB and thermal features would dominate the multi-spectral semantic segmentation task. The detail results for each class are listed in Table 7, and some sample qualitative demonstrations are shown in Figure 9.
- When fusing the RGB and thermal information simultaneously with addition and multiplication operation (AMFuse with addition operation and AMFuse+ with concatenation operation), the performance is greatly improved. It demonstrates effectiveness of our method to address the cross-modal complementary information and cross-modal common information simultaneously. AMFuse+ slightly outperforms AMFuse, indicating that compared to the addition operation, the concatenation operation maybe could give more freedoms for feature refining with multiple channels.
- Based on AMFuse+, AMFuse++ can achieve large improvements in terms of the mIoU metric. It demonstrates the effectiveness of incorporating the attention and ASPP modules for enhancing the multi-scale context information, especially for those small objects, as shown in Figure 8.
- AMFuse++* performs worse than AMFuse++, denoting that applying the attention module to both the addition and multiplication branches is worse compared with the one only applying to addition branch. The reason may be that the common information simultaneously existed in two modalities is sensitive to multiplication operation, which is easy distorted by the attention operation separately performed on two modalities.
- Compared to AFuse, MFuse, AMFuse and AMFuse+ methods, AMFuse++ introducing attention and ASPP modules are with more additional parameters and FLOPs. However, AMFuse++ achieved large improvements in terms of the mIoU metric.
5.2. Application to RGBT-Salient Object Detection
5.2.1. Dataset
5.2.2. Experimental Setup
5.2.3. Comparison Results
- The three traditional methods perform much worse than those deep learning based methods, demonstrating the effectiveness of deep learning for feature extraction.
- For the two RGBD SOD methods, DMRA [49] and S2MA [50], they performs poor on the RGBT SOD dataset. The reason maybe lie in the nature of RGBD and RGBT SOD tasks. In RGBD SOD task, the depth channel is always adopted as auxiliary information, while in RGBT SOD task, the RGB and thermal modalities are with equivalent importance for extracting the complementary and common information.
- Our AMFuse serial methods perform well against the existing RGBT SOD methods under the above 5 metrics, which all focus on the fusion of RGB and thermal information. The superiority of our methods demonstrates the effectiveness of the proposed AMFuse modules for fusing the RGB and thermal information.
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Chen, B.; Xia, M.; Huang, J. MFANet: A Multi-Level Feature Aggregation Network for Semantic Segmentation of Land Cover. Remote Sens. 2021, 13, 731. [Google Scholar] [CrossRef]
- Chen, F.; Liu, H.; Zeng, Z.; Zhou, X.; Tan, X. BES-Net: Boundary Enhancing Semantic Context Network for High-Resolution Image Semantic Segmentation. Remote Sens. 2022, 14, 1638. [Google Scholar] [CrossRef]
- Liu, L.; Cao, J.; Liu, M.; Guo, Y.; Chen, Q.; Tan, M. Dynamic Extension Nets for Few-shot Semantic Segmentation. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020. [Google Scholar]
- Zhang, T.; Lin, G.; Cai, J.; Shen, T.; Shen, C.; Kot, A.C. Decoupled Spatial Neural Attention for Weakly Supervised Semantic Segmentation. IEEE Trans. Multimed. 2019, 21, 2930–2941. [Google Scholar] [CrossRef] [Green Version]
- Gu, Z.; Zhou, S.; Niu, L.; Zhao, Z.; Zhang, L. Context-aware Feature Generation For Zero-shot Semantic Segmentation. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ding, L.; Wang, Y.; Laganière, R.; Huang, D.; Fu, S. Convolutional neural networks for multispectral pedestrian detection. Signal Process. Image Commun. 2020, 82, 115764. [Google Scholar] [CrossRef]
- Zhang, L.; Zhu, X.; Chen, X.; Yang, X.; Lei, Z.; Liu, Z. Weakly Aligned Cross-Modal Learning for Multispectral Pedestrian Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 5126–5136. [Google Scholar]
- Liu, H.; Tan, X.; Zhou, X. Parameter Sharing Exploration and Hetero-center Triplet Loss for Visible-Thermal Person Re-Identification. IEEE Trans. Multimed. 2020, 23, 4414–4425. [Google Scholar] [CrossRef]
- Liu, H.; Chai, Y.; Tan, X.; Li, D.; Zhou, X. Strong but Simple Baseline with Dual-Granularity Triplet Loss for Visible-Thermal Person Re-Identification. IEEE Signal Process. Lett. 2021, 28, 653–657. [Google Scholar] [CrossRef]
- Minaee, S.; Boykov, Y.; Porikli, F.; Plaza, A.; Kehtarnavaz, N.; Terzopoulos, D. Image Segmentation Using Deep Learning: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 3523–3542. [Google Scholar] [CrossRef]
- Ha, Q.; Watanabe, K.; Karasawa, T.; Ushiku, Y.; Harada, T. MFNet: Towards real-time semantic segmentation for autonomous vehicles with multi-spectral scenes. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems, Vancouver, BC, Canada, 24–28 September 2017; pp. 5108–5115. [Google Scholar]
- Sun, Y.; Zuo, W.; Liu, M. RTFNet: RGB-Thermal Fusion Network for Semantic Segmentation of Urban Scenes. IEEE Robot. Autom. Lett. 2019, 4, 2576–2583. [Google Scholar] [CrossRef]
- Xu, J.; Lu, K.; Wang, H. Attention fusion network for multi-spectral semantic segmentation. Pattern Recognit. Lett. 2021, 146, 179–184. [Google Scholar] [CrossRef]
- Cao, Y.; Guan, D.; Huang, W.; Yang, J.; Cao, Y.; Qiao, Y. Pedestrian detection with unsupervised multispectral feature learning using deep neural networks. Inf. Fusion 2019, 46, 206–217. [Google Scholar] [CrossRef]
- Wolpert, A.; Teutsch, M.; Sarfraz, M.S.; Stiefelhagen, R. Anchor-free Small-scale Multispectral Pedestrian Detection. arXiv 2020, arXiv:2008.08418. [Google Scholar]
- Wagner, J.; Fischer, V.; Herman, S.; Behnke, S. Multispectral Pedestrian Detection using Deep Fusion Convolutional Neural Networks. In Proceedings of the European Symposium on Artificial Neural Networks, Bruges, Belgium, 27–29 April 2016. [Google Scholar]
- Song, H.; Liu, Z.; Du, H.; Sun, G.; Meur, O.L.; Ren, T. Depth-Aware Salient Object Detection and Segmentation via Multiscale Discriminative Saliency Fusion and Bootstrap Learning. IEEE Trans. Image Process. 2017, 26, 4204–4216. [Google Scholar] [CrossRef] [PubMed]
- König, D.; Adam, M.; Jarvers, C.; Layher, G.; Neumann, H.; Teutsch, M. Fully Convolutional Region Proposal Networks for Multispectral Person Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 243–250. [Google Scholar]
- Fu, K.; Fan, D.P.; Ji, G.P.; Zhao, Q. JL-DCF: Joint Learning and Densely-Cooperative Fusion Framework for RGB-D Salient Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 3049–3059. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Shelhamer, E.; Long, J.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 640–651. [Google Scholar] [CrossRef] [PubMed]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.E.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Fu, J.; Liu, J.; Wang, Y.; Lu, H. Stacked Deconvolutional Network for Semantic Segmentation. IEEE Trans. Image Process. 2019. [Google Scholar] [CrossRef]
- Milletari, F.; Navab, N.; Ahmadi, S.A. V-Net: Fully Convolutional Neural Networks for Volumetric Medical Image Segmentation. In Proceedings of the Fourth International Conference on 3D Vision, Stanford, CA, USA, 25–28 October 2016; pp. 565–571. [Google Scholar]
- Everingham, M.; Eslami, S.M.A.; Gool, L.V.; Williams, C.K.I.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes Challenge: A Retrospective. Int. J. Comput. Vis. 2014, 111, 98–136. [Google Scholar] [CrossRef]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The Cityscapes Dataset for Semantic Urban Scene Understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3213–3223. [Google Scholar]
- Cao, Y.; Xu, J.; Lin, S.; Wei, F.; Hu, H. Gcnet: Non-local networks meet squeeze-excitation networks and beyond. In Proceedings of the Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Seoul, Korea, 27–28 October 2019. [Google Scholar]
- Xie, E.; Wang, W.; Yu, Z.; Anandkumar, A.; Alvarez, J.M.; Luo, P. SegFormer: Simple and efficient design for semantic segmentation with transformers. Adv. Neural Inf. Process. Syst. 2021, 34, 12077–12090. [Google Scholar]
- Zheng, S.; Lu, J.; Zhao, H.; Zhu, X.; Luo, Z.; Wang, Y.; Fu, Y.; Feng, J.; Xiang, T.; Torr, P.H.; et al. Rethinking semantic segmentation from a sequence-to-sequence perspective with transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 6881–6890. [Google Scholar]
- Liu, H.; Cheng, J.; Wang, W.; Su, Y.; Bai, H. Enhancing the discriminative feature learning for visible-thermal cross-modality person re-identification. Neurocomputing 2020, 398, 11–19. [Google Scholar] [CrossRef] [Green Version]
- Zhu, H.; Tan, R.J.; Han, L.; Fan, H.; Wang, Z.; Du, B.; Liu, S.; Liu, Q. DSSM: A Deep Neural Network with Spectrum Separable Module for Multi-Spectral Remote Sensing Image Segmentation. Remote Sens. 2022, 14, 818. [Google Scholar] [CrossRef]
- Wang, G.; Li, C.; Ma, Y.; Zheng, A.; Tang, J.; Luo, B. RGB-T saliency detection benchmark: Dataset, baselines, analysis and a novel approach. In Proceedings of the Chinese Conference on Image and Graphics Technologies; Springer: Berlin/Heidelberg, Germany, 2018; pp. 359–369. [Google Scholar]
- Tu, Z.; Ma, Y.; Li, Z.; Li, C.; Xu, J.; Liu, Y. RGBT salient object detection: A large-scale dataset and benchmark. arXiv 2020, arXiv:2007.03262. [Google Scholar] [CrossRef]
- Tu, Z.; Li, Z.; Li, C.; Lang, Y.; Tang, J. Multi-interactive siamese decoder for RGBT salient object detection. arXiv 2020, arXiv:2005.02315. [Google Scholar]
- Wang, X.; Li, S.; Chen, C.; Fang, Y.; Hao, A.; Qin, H. Data-Level Recombination and Lightweight Fusion Scheme for RGB-D Salient Object Detection. IEEE Trans. Image Process. 2021, 30, 458–471. [Google Scholar] [CrossRef] [PubMed]
- Jin, W.; Xu, J.; Han, Q.; Zhang, Y.; Cheng, M.M. CDNet: Complementary Depth Network for RGB-D Salient Object Detection. IEEE Trans. Image Process. 2021, 30, 3376–3390. [Google Scholar] [CrossRef] [PubMed]
- Hazirbas, C.; Ma, L.; Domokos, C.; Cremers, D. FuseNet: Incorporating Depth into Semantic Segmentation via Fusion-Based CNN Architecture. In Proceedings of the Asian Conference on Computer Vision, Taipei, Taiwan, 20–24 November 2016. [Google Scholar]
- Romera, E.; Álvarez, J.M.; Bergasa, L.M.; Arroyo, R. ERFNet: Efficient Residual Factorized ConvNet for Real-Time Semantic Segmentation. IEEE Trans. Intell. Transp. Syst. 2018, 19, 263–272. [Google Scholar] [CrossRef]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid Scene Parsing Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6230–6239. [Google Scholar]
- Wang, P.; Chen, P.; Yuan, Y.; Liu, D.; Huang, Z.; Hou, X.; Cottrell, G. Understanding Convolution for Semantic Segmentation. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision, Lake Tahoe, NV, USA, 12–15 March 2018; pp. 1451–1460. [Google Scholar]
- Tu, Z.; Xia, T.; Li, C.; Wang, X.; Ma, Y.; Tang, J. RGB-T image saliency detection via collaborative graph learning. IEEE Trans. Multimed. 2019, 22, 160–173. [Google Scholar] [CrossRef] [Green Version]
- Tu, Z.; Xia, T.; Li, C.; Lu, Y.; Tang, J. M3S-NIR: Multi-modal multi-scale noise-insensitive ranking for RGB-T saliency detection. In Proceedings of the 2019 IEEE Conference on Multimedia Information Processing and Retrieval (MIPR), San Jose, CA, USA, 28–30 March 2019; pp. 141–146. [Google Scholar]
- Piao, Y.; Ji, W.; Li, J.; Zhang, M.; Lu, H. Depth-induced multi-scale recurrent attention network for saliency detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 7254–7263. [Google Scholar]
- Liu, N.; Zhang, N.; Han, J. Learning selective self-mutual attention for RGB-D saliency detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 13756–13765. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Car | Pedestrian | Bike | Curve | Car Stop | Guardrail | Color Cone | Bump | mAcc | mIoU | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Acc | IoU | Acc | IoU | Acc | IoU | Acc | IoU | Acc | IoU | Acc | IoU | Acc | IoU | Acc | IoU | |||
| ERFNet [44] | 78.8 | 667.1 | 62.9 | 56.2 | 41.6 | 34.3 | 39.4 | 30.6 | 12.6 | 9.4 | 0.0 | 0.0 | 0.1 | 0.1 | 33.0 | 30.5 | 40.8 | 36.1 |
| PSPNet [45] | 81.0 | 74.8 | 69.2 | 61.3 | 63.8 | 50.2 | 44.7 | 38.4 | 18.1 | 15.8 | 0.0 | 0.0 | 36.4 | 33.2 | 49.0 | 44.4 | 51.3 | 46.1 |
| SegNet [27] | 67.5 | 65.3 | 60.3 | 55.7 | 61.0 | 51.1 | 46.3 | 38.4 | 10.4 | 10.0 | 0.0 | 0.0 | 41.9 | 12.0 | 55.3 | 51.5 | 49.1 | 42.3 |
| DUC-HDC [46] | 91.5 | 84.8 | 76.4 | 68.8 | 66.7 | 54.6 | 54.7 | 41.9 | 30.9 | 19.2 | 12.3 | 4.4 | 40.2 | 34.3 | 61.5 | 45.1 | 59.3 | 50.1 |
| FuseNet [43] | 81.0 | 75.6 | 75.2 | 66.3 | 64.5 | 51.9 | 51.0 | 37.8 | 17.4 | 15.0 | 0.0 | 0.0 | 31.1 | 21.4 | 51.9 | 45.0 | 52.4 | 45.6 |
| MFNet [12] | 77.2 | 65.9 | 67.0 | 58.9 | 53.9 | 42.9 | 36.2 | 29.9 | 12.5 | 9.9 | 0.1 | 0.0 | 30.3 | 25.2 | 30.0 | 27.7 | 45.1 | 39.7 |
| RTFNet-50 [13] | 91.3 | 86.3 | 78.2 | 67.8 | 71.5 | 58.2 | 59.8 | 43.7 | 32.1 | 24.3 | 13.4 | 3.6 | 40.4 | 26.0 | 73.5 | 57.2 | 62.2 | 51.7 |
| RTFNet-152 [13] | 93.0 | 87.4 | 79.3 | 70.3 | 76.8 | 62.7 | 60.7 | 45.3 | 38.5 | 29.8 | 0.0 | 0.0 | 45.5 | 29.1 | 74.7 | 55.7 | 63.1 | 53.2 |
| AFNet [14] | 91.2 | 86.0 | 76.3 | 67.4 | 72.8 | 62.0 | 49.8 | 43.0 | 35.3 | 28.9 | 24.5 | 4.6 | 50.1 | 44.9 | 61.0 | 56.6 | 62.2 | 54.6 |
| AMFuse-18 (ours) | 90.2 | 84.2 | 81.9 | 70.7 | 76.1 | 60.9 | 58.0 | 42.6 | 34.3 | 26.5 | 20.7 | 3.0 | 53.4 | 43.4 | 62.8 | 48.9 | 64.1 | 53.1 |
| AMFuse-50 (ours) | 91.0 | 86.7 | 82.9 | 72.7 | 75.3 | 61.5 | 61.2 | 46.2 | 37.8 | 29.2 | 22.3 | 4.2 | 53.3 | 46.7 | 64.6 | 54.0 | 65.3 | 55.5 |
| AMFuse-152 (ours) | 94.2 | 88.7 | 82.8 | 72.6 | 78.3 | 63.9 | 57.2 | 45.0 | 31.1 | 25.7 | 11.7 | 1.5 | 57.1 | 48.7 | 71.9 | 52.4 | 64.8 | 55.2 |
| AMFuse-152 * (ours) | 94.2 | 88.7 | 83.1 | 73.0 | 78.6 | 63.1 | 58.4 | 46.5 | 38.9 | 30.1 | 18.0 | 2.9 | 55.3 | 46.9 | 76.3 | 56.7 | 66.9 | 56.2 |
| Methods | Daytime | Nighttime | ||
|---|---|---|---|---|
| mAcc | mIoU | mAcc | mIoU | |
| ERFNet [44] | 37.5 | 32.5 | 39.3 | 34.5 |
| PSPNet [45] | 42.6 | 37.8 | 49.7 | 45.2 |
| SegNet [27] | 39.9 | 34.6 | 47.4 | 41.7 |
| DUC-HDC [46] | 56.7 | 44.3 | 55.0 | 49.4 |
| FuseNet [43] | 49.5 | 41.0 | 48.9 | 43.9 |
| MFNet [12] | 42.6 | 36.1 | 41.4 | 36.8 |
| RTFNet-50 [13] | 57.3 | 44.4 | 59.4 | 52.0 |
| RTFNet-152 [13] | 60.0 | 45.8 | 60.7 | 54.8 |
| AFNet [14] | 54.5 | 48.1 | 60.2 | 53.8 |
| AMFuse-18 (ours) | 58.2 | 46.2 | 61.5 | 53.1 |
| AMFuse-50 (ours) | 60.6 | 49.0 | 61.7 | 54.5 |
| AMFuse-152 (ours) | 60.7 | 48.2 | 61.7 | 55.0 |
| AMFuse-152 * (ours) | 61.3 | 48.9 | 63.6 | 55.8 |
| Methods | mAcc | mIoU |
|---|---|---|
| UNet (4c) | 46.7 | 41.2 |
| UNet + AFuse | 47.1 | 41.4 |
| ResNet-18 (4c) | 59.3 | 50.6 |
| ResNet-18 + AFuse | 61.9 | 52.4 |
| ResNet-18 (RGB) | 62.3 | 49.2 |
| ResNet-18 (Thermal) | 57.3 | 46.0 |
| Method | Pos1 | Pos2 | Pos3 | Pos4 | Pos5 | Backbone | mAcc | mIoU |
|---|---|---|---|---|---|---|---|---|
| ① | AFuse | AFuse | AFuse | AFuse | AFuse | ResNet-18 | 61.9 | 52.4 |
| ResNet-50 | 64.5 | 53.2 | ||||||
| ② | AMFuse | AMFuse++ | AMFuse++ | AMFuse++ | AMFuse | ResNet-18 | 62.2 | 52.0 |
| ResNet-50 | 64.5 | 54.6 | ||||||
| ③ | AMFuse+ | AMFuse++ | AMFuse++ | AMFuse++ | AMFuse+ | ResNet-18 | 62.0 | 51.6 |
| ResNet-50 | 64.7 | 54.9 | ||||||
| ④ | AMFuse++ | AMFuse++ | AMFuse++ | AMFuse++ | AMFuse++ | ResNet-18 | 61.1 | 52.3 |
| ResNet-50 | 65.1 | 54.8 | ||||||
| ⑤ | AFuse | AMFuse++ | AMFuse++ | AMFuse++ | AFuse | ResNet-18 | 64.1 | 53.1 |
| ResNet-50 | 65.3 | 55.5 |
| Methods | mAcc | mIoU |
|---|---|---|
| Baseline (ResNet-18 + AFuse) | 61.9 | 52.4 |
| Baseline + Atten | 61.4 | 52.7 |
| Baseline + ASPP | 62.5 | 51.2 |
| Baseline + Atten + ASPP | 63.4 | 53.1 |
| Methods | mAcc (%) | mIoU (%) | Para (M) | FLOPs (G) |
|---|---|---|---|---|
| ResNet-50 + AFuse | 64.5 | 53.2 | 109.3 | 67.1 |
| ResNet-50 + MFuse | 62.9 | 52.5 | 109.3 | 67.1 |
| ResNet-50 + AMFuse | 65.1 | 54.3 | 109.3 | 67.1 |
| ResNet-50 + AMFuse+ | 65.3 | 54.5 | 120.4 | 69.9 |
| ResNet-50 + AMFuse++ | 65.3 | 55.5 | 149.5 | 96.3 |
| ResNet-50 + AMFuse++ * | 64.6 | 53.7 | 149.5 | 96.3 |
| Methods | Car | Pedestrian | Bike | Curve | Car Stop | Guardrail | Color Cone | Bump | mAcc | mIoU | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Acc | IoU | Acc | IoU | Acc | IoU | Acc | IoU | Acc | IoU | Acc | IoU | Acc | IoU | Acc | IoU | |||
| MFuse | 89.2 | 83.5 | 79.8 | 70.8 | 75.1 | 60.2 | 56.2 | 41.5 | 33.3 | 24.5 | 24.1 | 3.3 | 50.2 | 44.3 | 59.9 | 46.2 | 62.9 | 52.5 |
| AFuse | 90.6 | 84.2 | 79.2 | 70.6 | 73.9 | 60.3 | 56.0 | 41.5 | 38.9 | 28.0 | 24.5 | 5.1 | 55.1 | 46.1 | 63.6 | 47.4 | 64.5 | 53.2 |
| AMFuse | 90.2 | 84.9 | 81.7 | 71.6 | 75.1 | 60.6 | 57.1 | 42.0 | 39.0 | 28.0 | 27.3 | 5.1 | 55.8 | 49.9 | 61.4 | 49.5 | 65.1 | 54.3 |
| Methods | Em | Sm | Fm | MAE | wF |
|---|---|---|---|---|---|
| MTMR [38] | 0.795 | 0.680 | 0.595 | 0.114 | 0.397 |
| M3S-NIR [48] | 0.780 | 0.652 | 0.575 | 0.168 | 0.327 |
| SDGL [47] | 0.824 | 0.750 | 0.672 | 0.089 | 0.559 |
| DMRA [49] | 0.696 | 0.672 | 0.562 | 0.195 | 0.532 |
| S2MA [50] | 0.869 | 0.855 | 0.751 | 0.055 | 0.734 |
| ADF [39] | 0.891 | 0.864 | 0.778 | 0.048 | 0.722 |
| SiamDecoder [40] | 0.897 | 0.868 | 0.801 | 0.043 | 0.763 |
| AMFuse-18 (ours) | 0.893 | 0.852 | 0.785 | 0.043 | 0.753 |
| AMFuse-50 (ours) | 0.903 | 0.867 | 0.802 | 0.039 | 0.784 |
| AMFuse-152 * (ours) | 0.918 | 0.872 | 0.823 | 0.039 | 0.751 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, H.; Chen, F.; Zeng, Z.; Tan, X. AMFuse: Add–Multiply-Based Cross-Modal Fusion Network for Multi-Spectral Semantic Segmentation. Remote Sens. 2022, 14, 3368. https://doi.org/10.3390/rs14143368
Liu H, Chen F, Zeng Z, Tan X. AMFuse: Add–Multiply-Based Cross-Modal Fusion Network for Multi-Spectral Semantic Segmentation. Remote Sensing. 2022; 14(14):3368. https://doi.org/10.3390/rs14143368
Chicago/Turabian StyleLiu, Haijun, Fenglei Chen, Zhihong Zeng, and Xiaoheng Tan. 2022. "AMFuse: Add–Multiply-Based Cross-Modal Fusion Network for Multi-Spectral Semantic Segmentation" Remote Sensing 14, no. 14: 3368. https://doi.org/10.3390/rs14143368
APA StyleLiu, H., Chen, F., Zeng, Z., & Tan, X. (2022). AMFuse: Add–Multiply-Based Cross-Modal Fusion Network for Multi-Spectral Semantic Segmentation. Remote Sensing, 14(14), 3368. https://doi.org/10.3390/rs14143368