1. Introduction
With the development of the Earth observation technology, an increasing number of optical satellites are launched for Earth observation missions. Remote sensing images acquired from the optical satellites can serve environment protection [
1], global climate change [
2], hydrology [
3], agriculture [
4], urban development [
5], and military reconnaissance [
6]. However, since 60% earth’s surface is covered by clouds, the acquired optical remote sensing (RS) images are often contaminated by clouds [
7]. In the field of meteorological, cloud information of RS images is useful in weather forecast [
8], while, for earth surface observation missions, cloud coverage degrades the quality of satellite imagery. Therefore, it is important to improve RS images quality through cloud detection.
Over the past few decades, cloud detection from RS imagery has attracted much attention. Many advanced cloud detection technologies have been proposed. In this paper, we broadly categorize these methods into rule-based methods and machine learning-based methods. The rule-based methods are mostly developed from spectral/spatial domain [
9,
10,
11,
12]. These methods distinguish clouds from clear sky pixels by exploiting reflectance variations in visible, shortwave-infrared, and thermal bands. Rule-based methods have obvious flaws, i.e., they strongly depend on particular sensor models and have poor generalization performance. For example, Fmask algorithms [
9,
10,
11] are developed for Sentinel-2 and Landsat 4/5/7/8 satellite images, while the multifeature combined (MFC) method [
12] is developed for GF-1 wide field view (WFV) satellite images only. In addition, machine learning-based cloud detection methods have also attracted much attention due to their powerful data adaptability. The most representative machine learning-based cloud detection methods are maximum likelihood [
13,
14], support vector machine (SVM) [
15,
16], and neural network [
17,
18]. However, these methods heavily rely on hand-crafted features, such as color, texture, and morphological features, to distinguish clouds from clear sky pixels.
Recent years, with the development of deep learning, deep convolutional neural network (DCNN) methods have been rapidly developed and widely used for cloud detection from RS images. For example, U-Net and SegNet variants cloud detection frameworks [
19,
20,
21,
22,
23], and multi-scale/level feature fusion cloud detection frameworks [
24,
25,
26,
27,
28]. In addition, advanced convolutional neural network (CNN) models, such as CDnetV2 [
7] and ACDnet [
29], are developed for cloud detection from RS imagery with cloud–snow coexistence. To achieve real-time and onboard processing, lightweight neural networks, such as [
30,
31,
32], are proposed for pixelwise cloud detection from RS images. However, most of the previous CNN-based cloud detection methods are based on supervised learning frameworks. Although these CNN-based cloud detection methods have achieved impressive performance, they heavily rely on a large number of training data with strong pixel-wise annotations. Some recent cloud detection works, such as unsupervised domain adaptation (UDA) [
33,
34] and domain translation strategy [
35], have begun to explore how to avoid using pixel-wise annotations for cloud detection network training. However, these pixel-wise annotations free methods are not real label-free ones because they rely on other labeled datasets.
Obtaining data label is an expensive and time-consuming task, especially pixel-wise annotation. As illustrated in cityscapes dataset annotation work [
36], it usually takes 1.5 h to label a pixel-wise annotation from a high-resolution urban scene image with pixel size of 1024 × 2048. For a remote sensing image with pixel size of 8 k × 8 k, it may take more hours to label a whole scene RS image according to such experience. Although it is easier to label the cloud pixel-wise samples individually, it may still take three to four hours for a tough case that contains a large number of tiny and thin clouds, which increases the heavy cost of manual labeling undoubtedly. In contrast, unlabeled RS images can be far more easily acquired than labeled ones [
37]. Therefore, it desperately needs to exploit how to utilize a large number of unlabeled data to enhance the performance of cloud detection model.
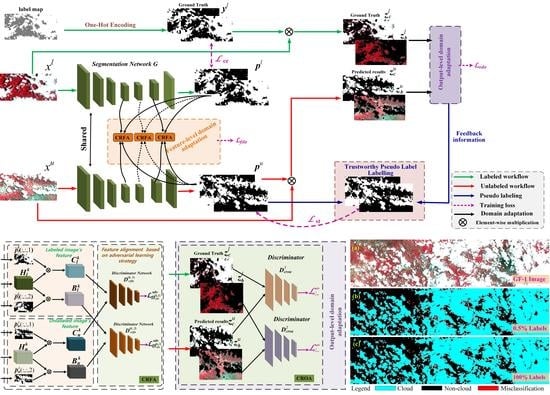
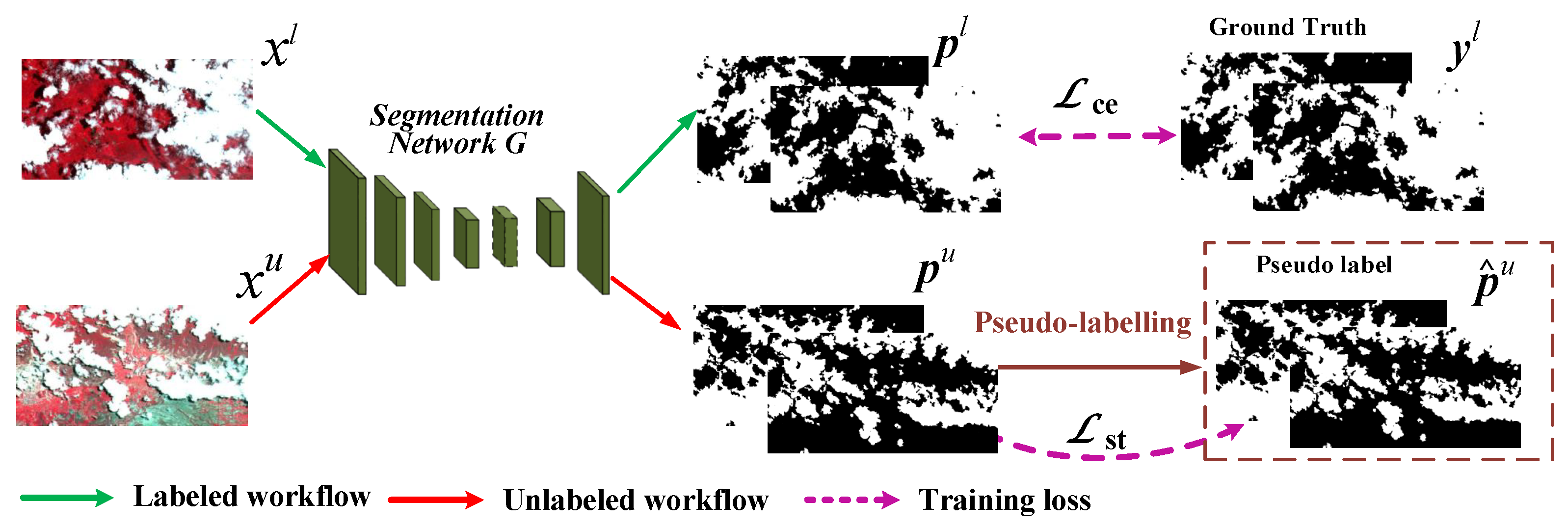
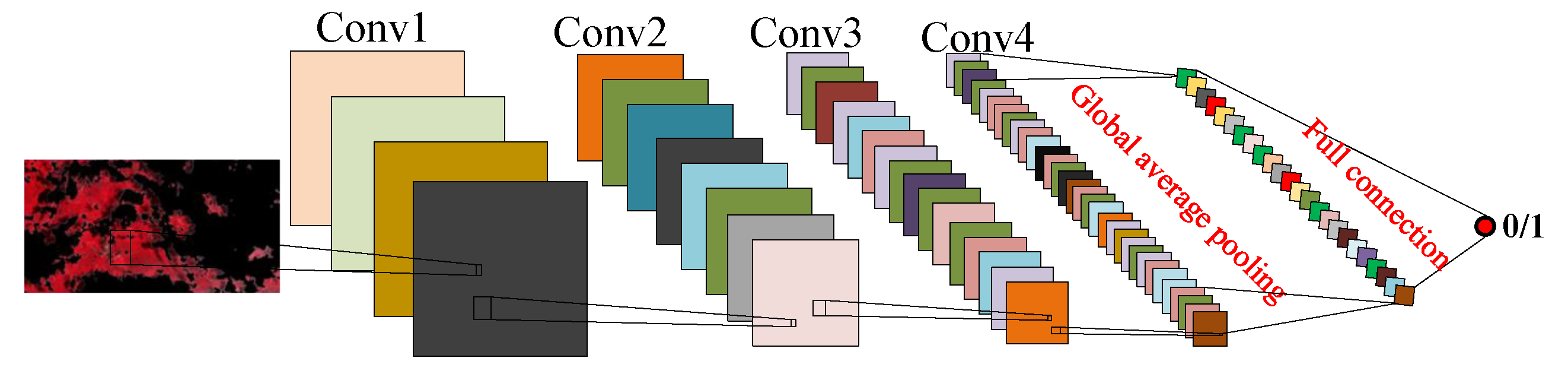
In this paper, we proposed to use a semi-supervised learning (SSL) method [
38,
39] to train a cloud detection network. Because the SSL method is able to reduce the heavy cost of manual dataset labeling. In a semi-supervised segmentation framework, such as DAN [
37] and s4GAN [
40], the segmentation network (cloud detection network) is able to simultaneously take advantage of a large amount of unlabeled samples and a limited number of labeled examples for network’s parameter learning. The core of SSL method is a self-training [
41] strategy, which is able to leverage pseudo-label generated from a large amount of unlabeled samples to supervise the segmentation network training [
42]. This also means that accurate pseudo-label labeling is the key of self-training. Therefore, most advanced SSL methods, such as [
40,
43], focus on improving pseudo-labels of unlabeled samples to improve the performance of the SSL network.
SSL networks developed for tradition natural image segmentation, such as [
38,
39,
40,
43], may not achieve a promising performance for satellite images cloud detection due to RS images are different from traditional camera natural images. In addition, the data drift problem may appear between a limited number of labeled examples and a large number of unlabeled samples due to different cloud shapes and land-cover types on different satellite images. The SSL network trained with labeled samples is difficult to generalize to unlabeled samples due to the data drift problem. During training, the SSL network may produce prediction results with lower certainty when the network input with unlabeled data [
40]. The prediction results of unlabeled samples has shown lower certainty and cannot generate accurate pseudo-labels, which makes self-training unfavorable for providing supervision signals of network training.
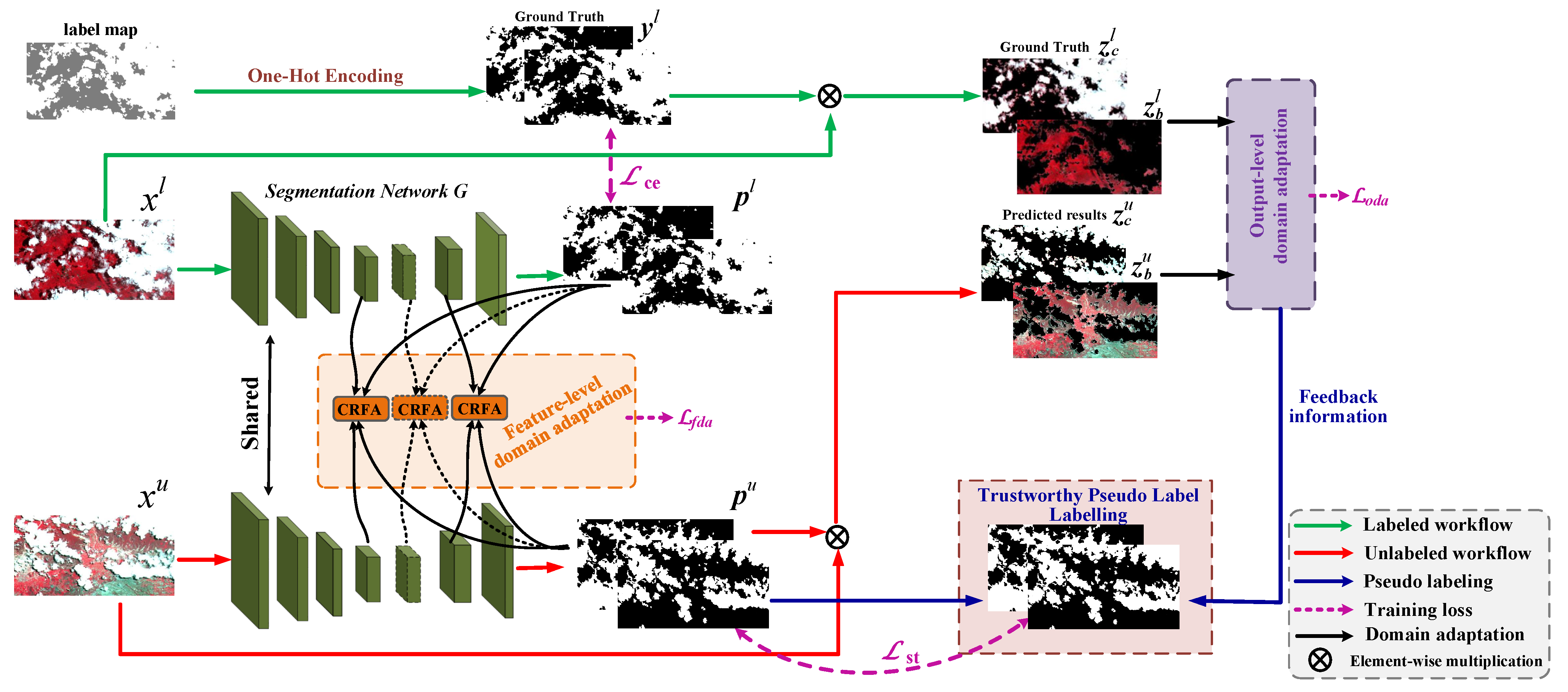
To solve this problem, we take the domain shift problem into account for the SSL framework. In this paper, inspired by unsupervised domain adaptation (UDA) method [
44], we apply domain adaptation at the feature-level [
45] and output-level [
46,
47] in the proposed semi-supervised cloud detection network (SSCDnet) to solve the data drift problem. In this paper, we use two available cloud cover validation datasets, i.e., Landsat-8 OLI (Operational Land Imager) [
48] cloud cover validation dataset (
https://landsat.usgs.gov/landsat-8-cloud-cover-assessment-validation-data, accessed on 24 April 2022) and GF-1 WFV [
12] cloud and cloud shadow cover validation dataset (
http://sendimage.whu.edu.cn/en/mfc-validation-data/, accessed on 24 April 2022), to comprehensively evaluate the proposed SSCDnet. These two datasets have been widely used for evaluating the performance of supervised CNN-based cloud detection methods [
19,
20,
21,
22,
23,
27].
In summary, the main contributions of this work are summarized as follows:
- (i)
We propose a semi-supervised cloud detection framework, named SSCDnet, which learns knowledge from a limited number of pixel-wise labeled examples and a large number of unlabeled samples for cloud detection.
- (ii)
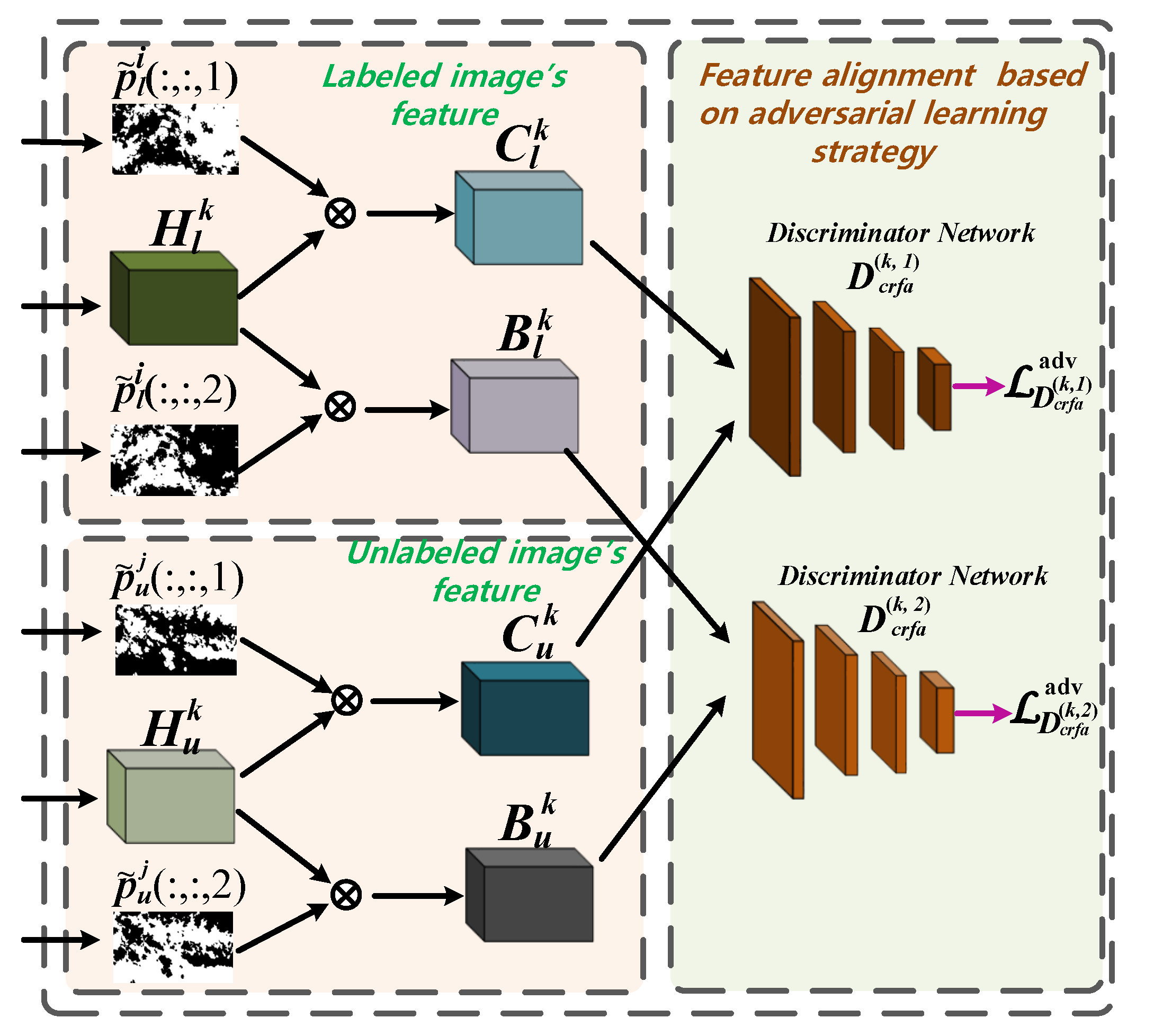
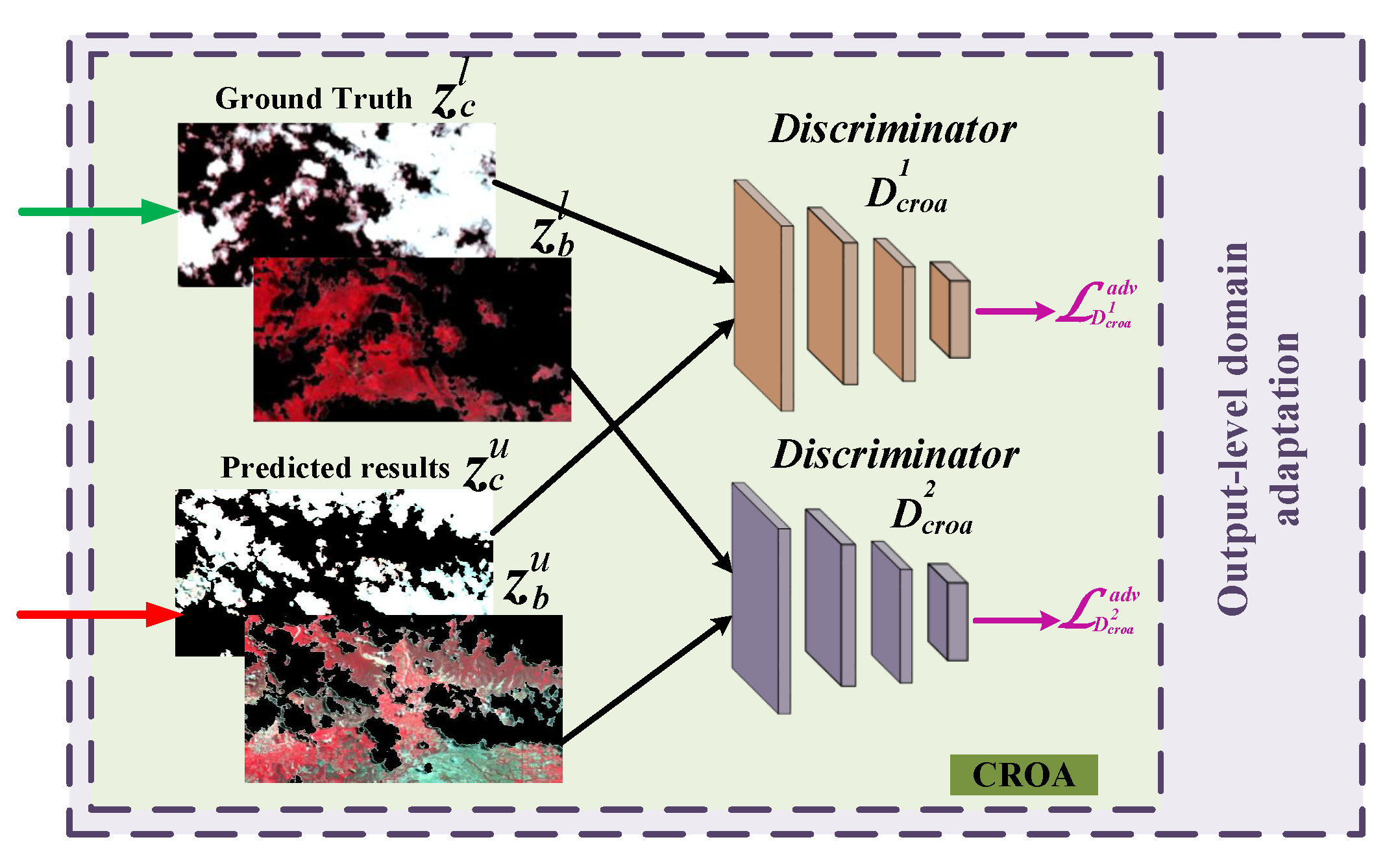
We take the domain shift problem into account between labeled and unlabeled images and propose the feature-level and output-level domain adaptation method to reduce domain distribution gaps.
- (iii)
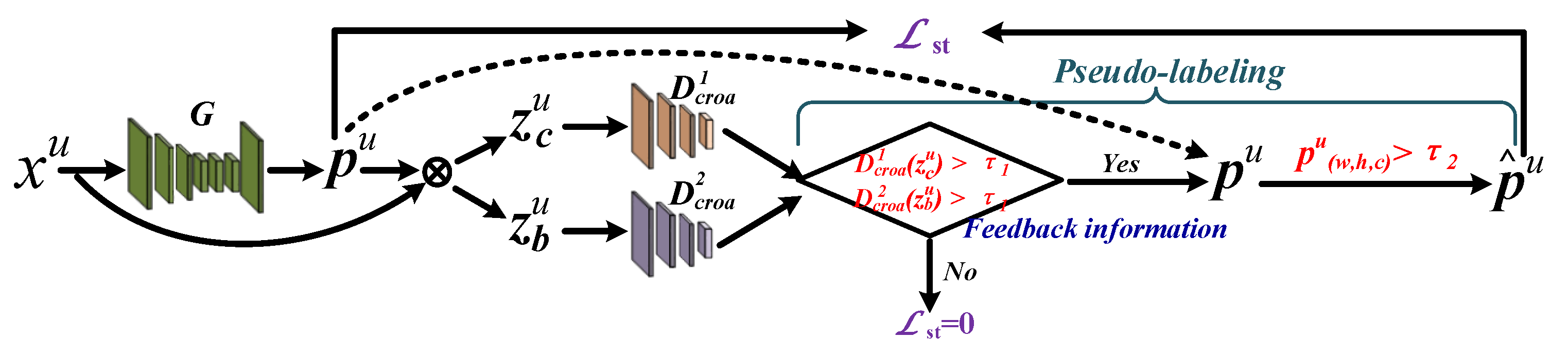
We propose a double threshold pseudo-labeling method to obtain trustworthy pseudo label, which helps to avoid the effects of noise labels for self-training as much as possible and to further enhance the performance of SSCDnet.
This paper is organized as follows: in
Section 2, we present the proposed SSCDnet in detail. Experimental datasets and networks training details are presented in
Section 4. The experimental results and discussions are presented in
Section 4 and
Section 5, respectively, followed by conclusions in
Section 6.
6. Conclusions
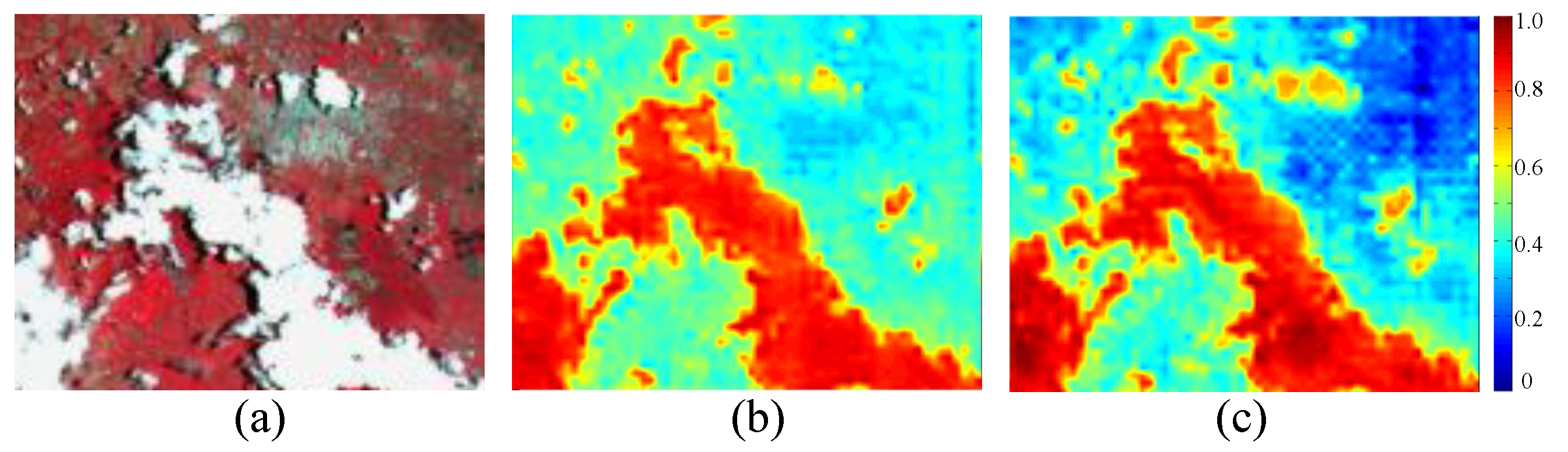
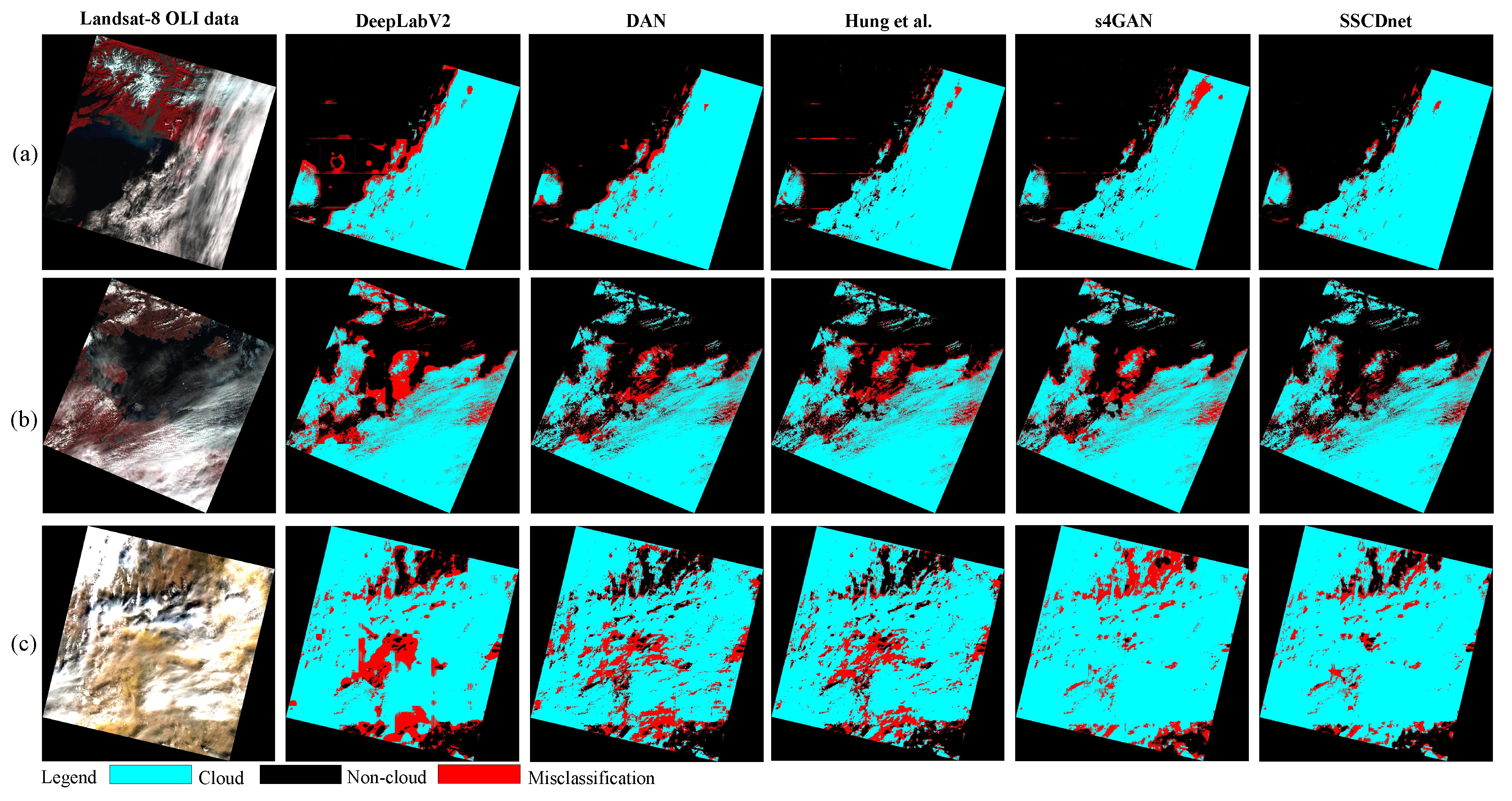
Semi-supervised learning is an effective training strategy, which is able to train a segmentation network by using a limited number of pixel-wise labeled samples and a large number of unlabeled ones. In this paper, we present a semi-supervised cloud detection network, named SSCDnet. Since there are domain distribution gaps between the labeled and unlabeled datasets, we take the domain shift problem into account for the semi-supervised learning framework and propose feature-/output-level domain adaptation strategy to reduce domain distribution gaps, thus improving SSCDnet to generate trustworthy pseudo label for unlabeled data. A high certain pseudo label provides positive supervised signals for segmentation network learning through self-training. Experimental results on GF-1 WFV and Landsat-8 OLI datasets demonstrate that SSCDnet is able to achieve promising performance by using a limited number of labeled samples. It shows great promise for practical application on new satellite RS imagery in the presence of less labeled data available.
Although SSCDnet shows good performance, there is still much room for improvement, such as hyper-parameters setting of loss function and threshold setting of pseudo-labeling. Different cloud detection datasets have different domain distributions. We need to update these parameters to achieve a promising performance on different datasets. In addition, different ground objects have different characteristics, and the performance of SSCDnet on other objects detection also needs to be further evaluated. In our future work, we will further evaluate this method on other cloud detection datasets and other object detection tasks. In addition, SSCDnet performs poorly on cloud boundaries and thin cloud regions, which requires our future efforts to improve it. In our future work, we will also explore how to utilize some auxiliary information, such as land use and land cover (LULC) map, water index map, and vegetation index map, to improve the cloud detection performance.
In general, a semi-supervised learning training strategy provides us with an effective way for cloud detection from RS images in the presence of less labeled data available. In addition, this strategy may provide us a promising way for other object detection tasks such as water, vegetation, and building detection.
In order to promote understanding of the paper’s technology, we released the code of SSCDnet. It is available at:
https://github.com/nkszjx/SSCDnet (accessed on 24 April 2022).







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}












