
Research on Automatic Identification Method of Terraces on the Loess Plateau Based on Deep Transfer Learning




Abstract
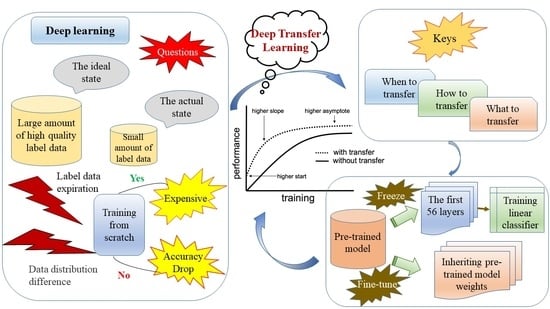
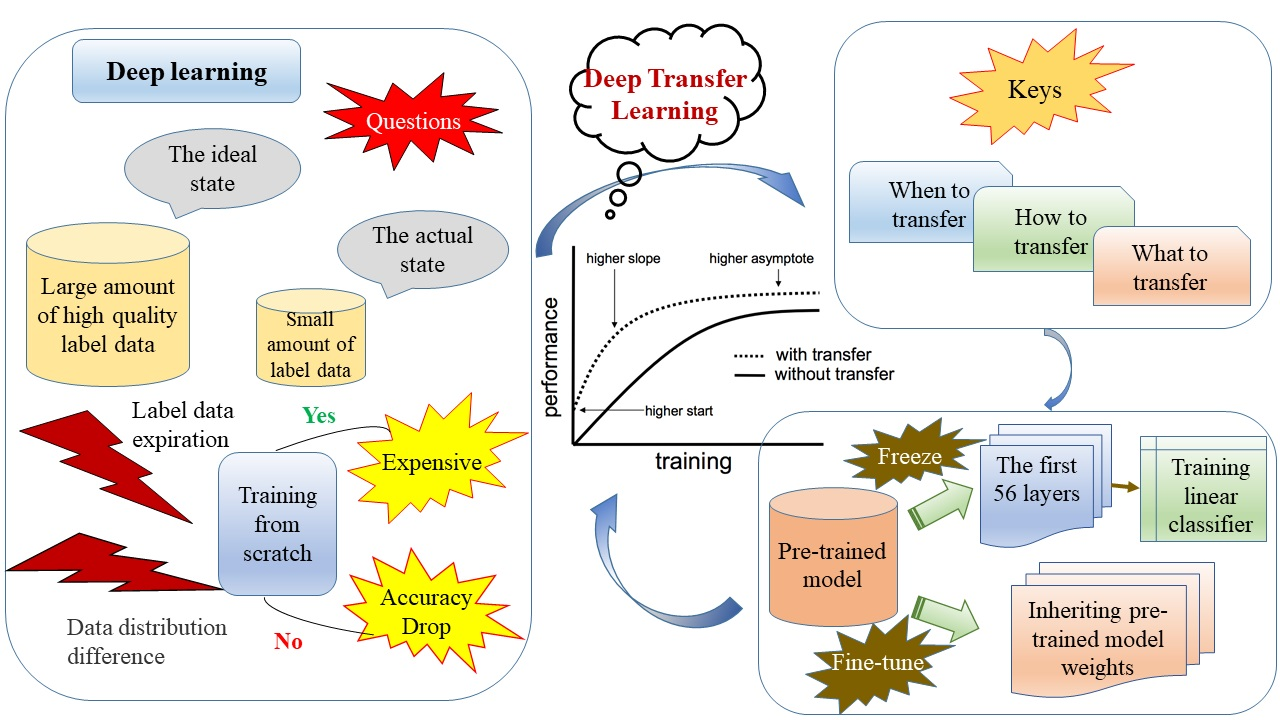
:
1. Introduction
- (1)
- A terrace identification source model adapted to multiple data sources is trained based on the WorldView-1 dataset. This model can be migrated to other types of images for terracing extraction as a pre-trained model.
- (2)
- A deep transfer learning method to extract terraces from high-resolution remote-sensing images is proposed. Based on small sample GF-2 datasets, and compared with deep learning and other transfer learning methods, this method can well achieve high-accuracy extraction of small-sample terrace datasets.
- (3)
- Lastly, a prediction model was established to eliminate the border splicing traces and enrich the image edge information. The accuracy evaluation results show that the model can further improve the terrace identification accuracy.
2. Materials and Methods
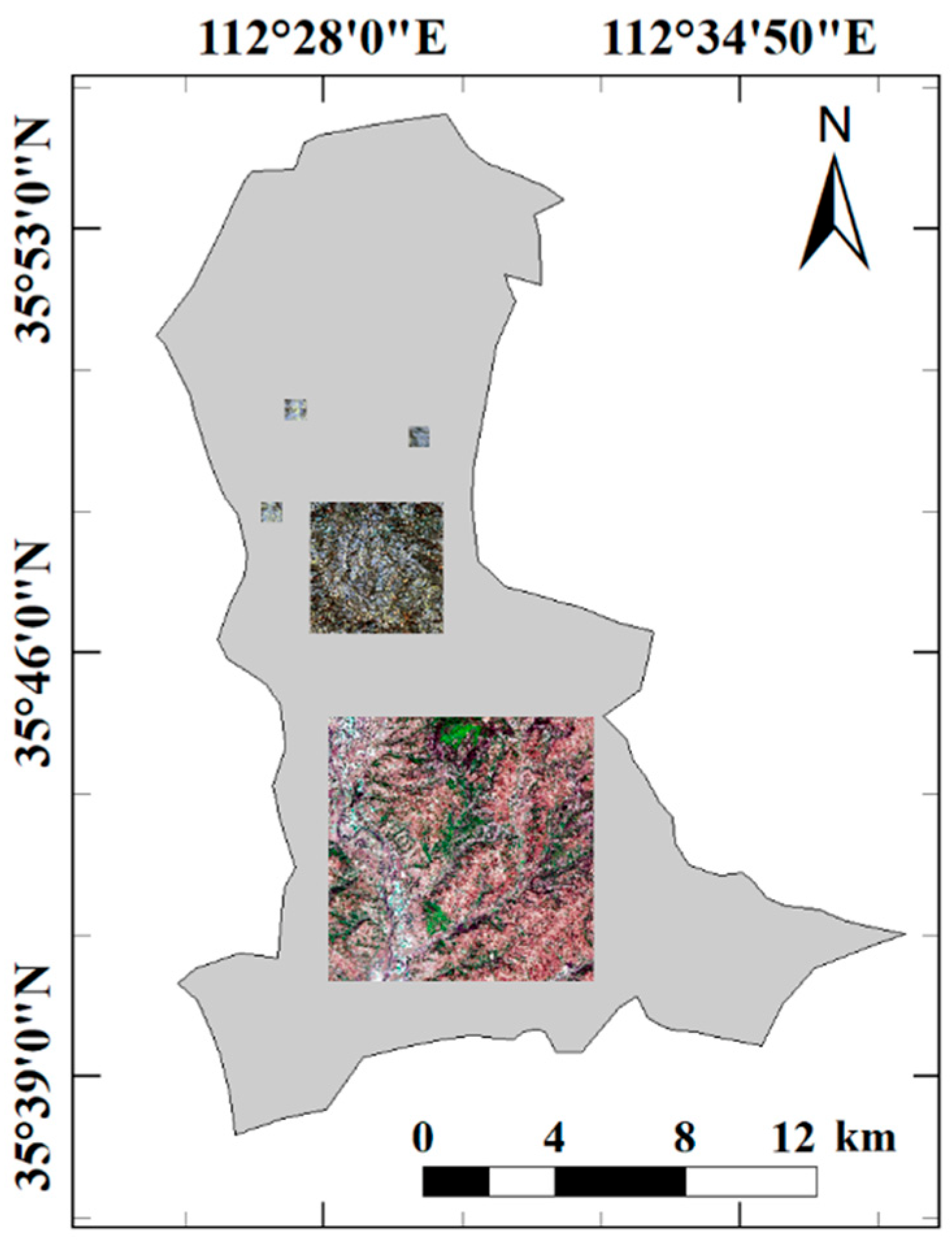
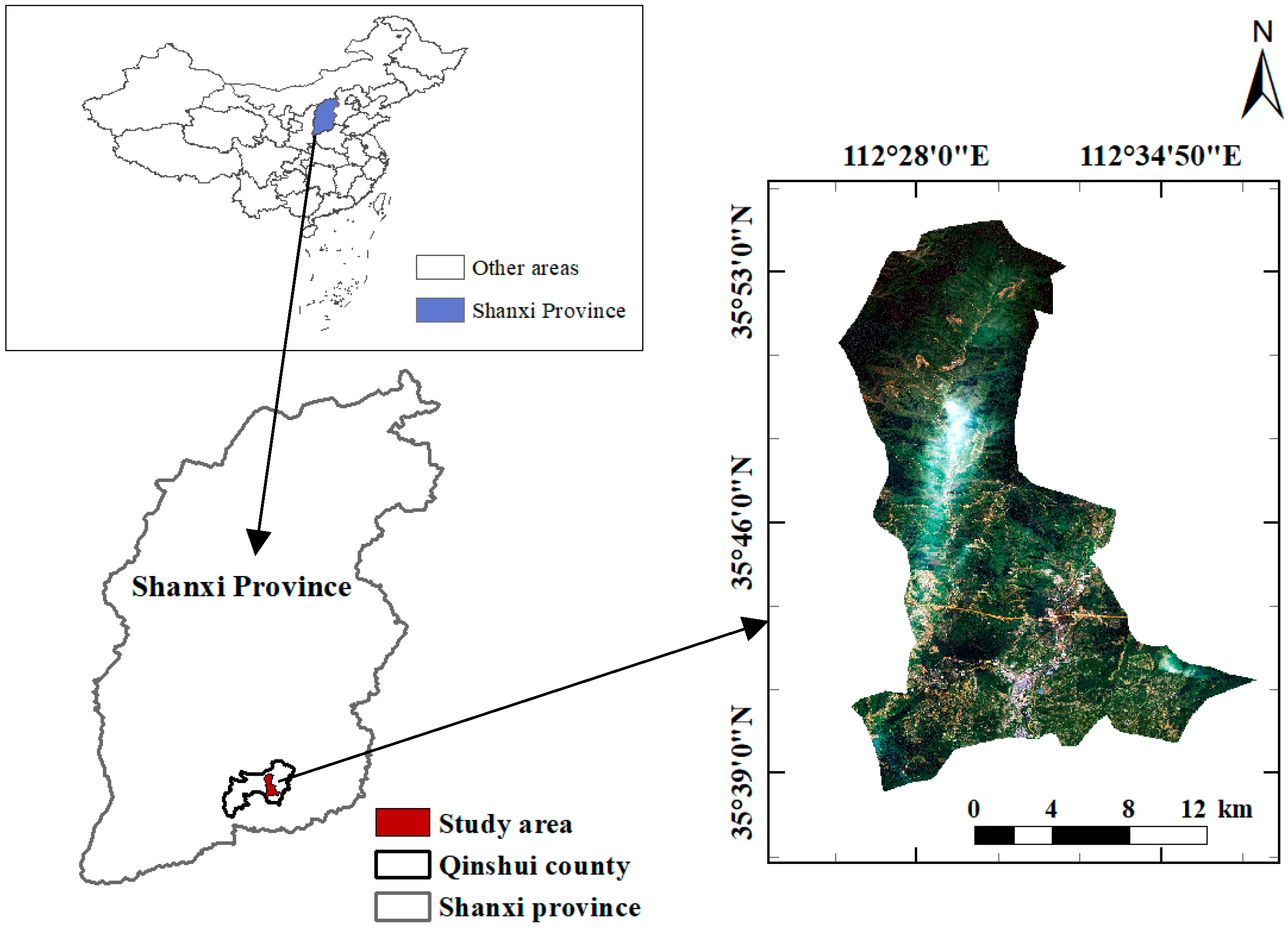
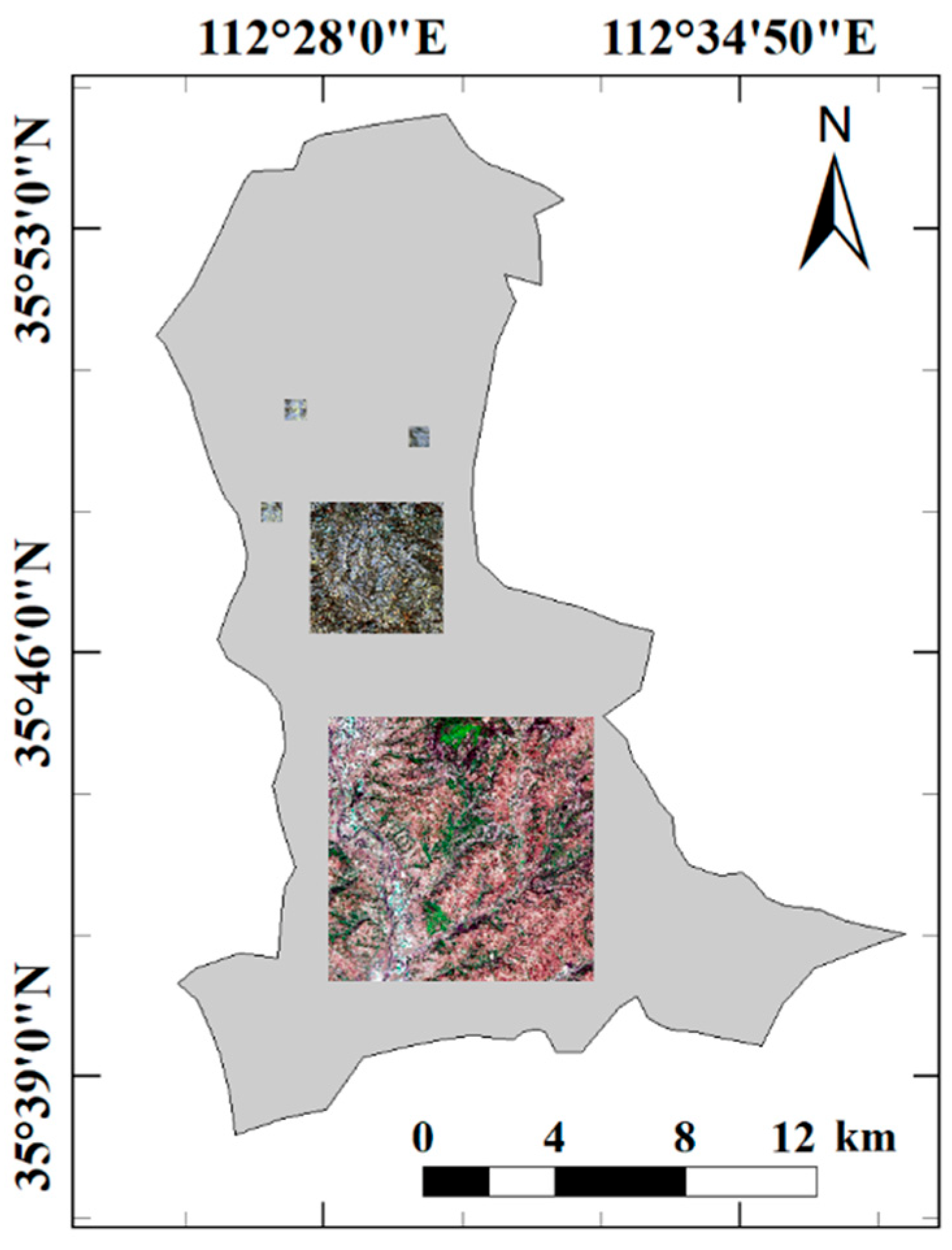
2.1. Study Area Overview
2.2. Data Source
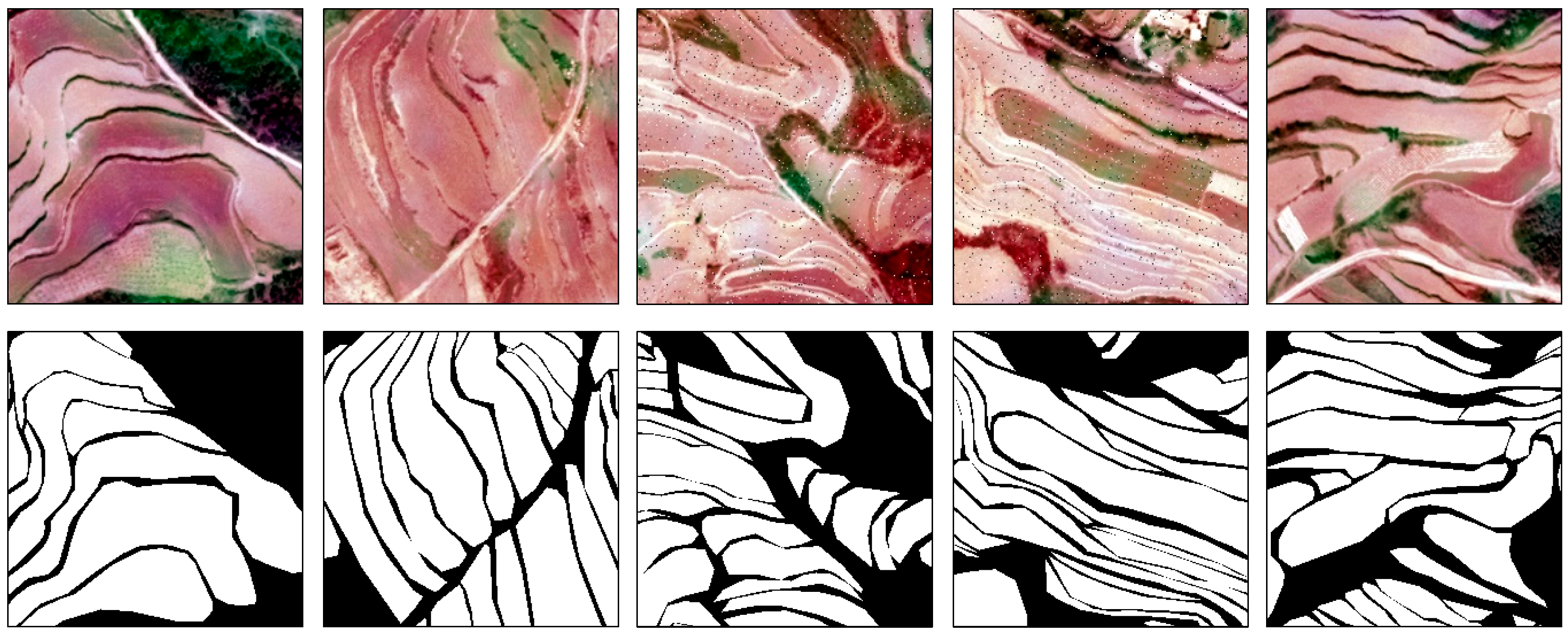
2.3. Data Preprocessing
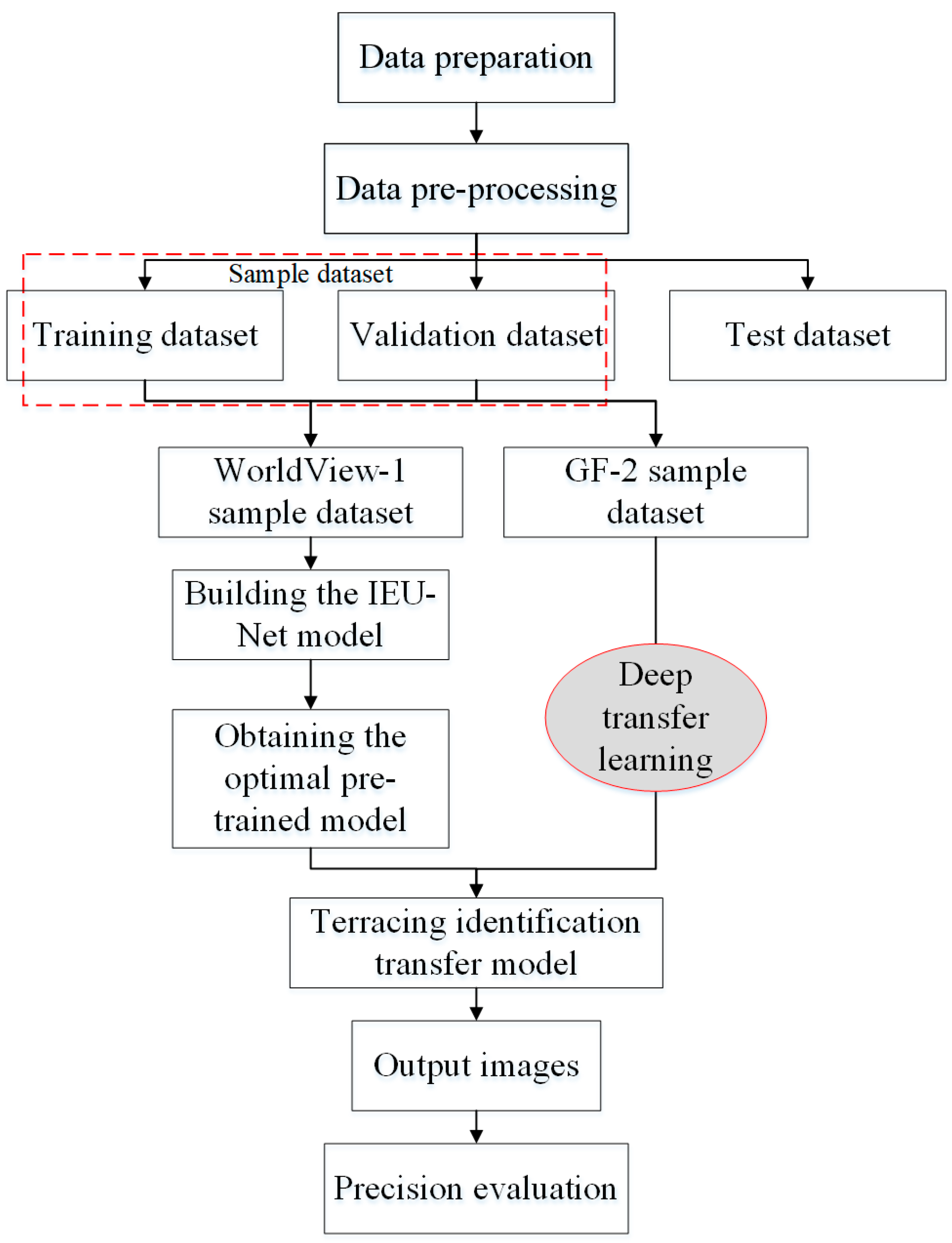
3. Methods
- (1)
- Data preprocessing: The images were preprocessed and used as the basis for manual annotation to obtain true sample labels. The sample dataset of 256 × 256 pixels was generated using the sliding window cropping method, and its format was converted from TIFF to PNG. Lastly, data enhancement was performed, and the enhanced data were divided into training and validation datasets.
- (2)
- Building the IEU-Net model: The IEU-Net model was constructed based on the U-Net model for deep feature extraction of high-resolution remote-sensing data.
- (3)
- Obtaining the optimal pre-training model for terrace identification: The WorldView-1 sample set was inputted into the IEU-Net model for training. After adjusting the parameters, the optimal WorldView-1 terrace recognition model was saved.
- (4)
- Migration of pre-trained models to GF-2 high-precision recognition of small-sample terraces: Pre-trained model weights were loaded, and the model structure was adjusted. The transfer learning model was then constructed according to the experimental requirements. Different finetuning strategies were used to train some or retrain all parameters. The GF-2 sample set was inputted into the new model for training, parameter comparison, and tuning, and the transfer learning model was saved.
- (5)
- Predict and output images: A prediction model was constructed by ignoring the edge prediction method, and the test set was inputted into the model for prediction, elimination of the border splicing traces, and enrichment of the image edge information.
- (6)
- Precision evaluation: The prediction labels of each test area were compared with the true labels. The evaluation indexes of Overall Accuracy (OA), F1 score, and mean intersection-over-union (MIoU) were selected for accuracy evaluation.
3.1. IEU-Net Model
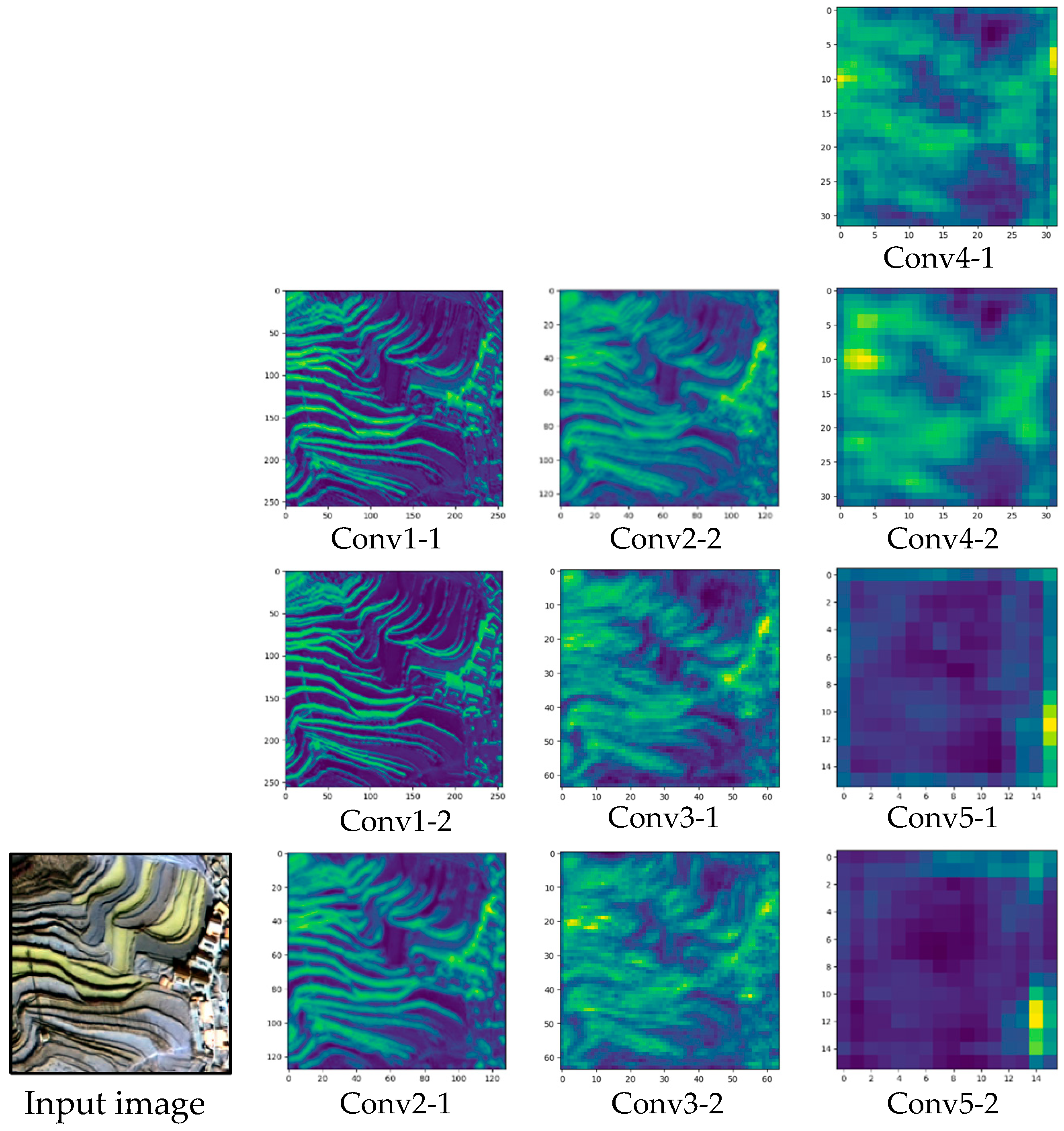
3.1.1. Feature Mapping Visualization
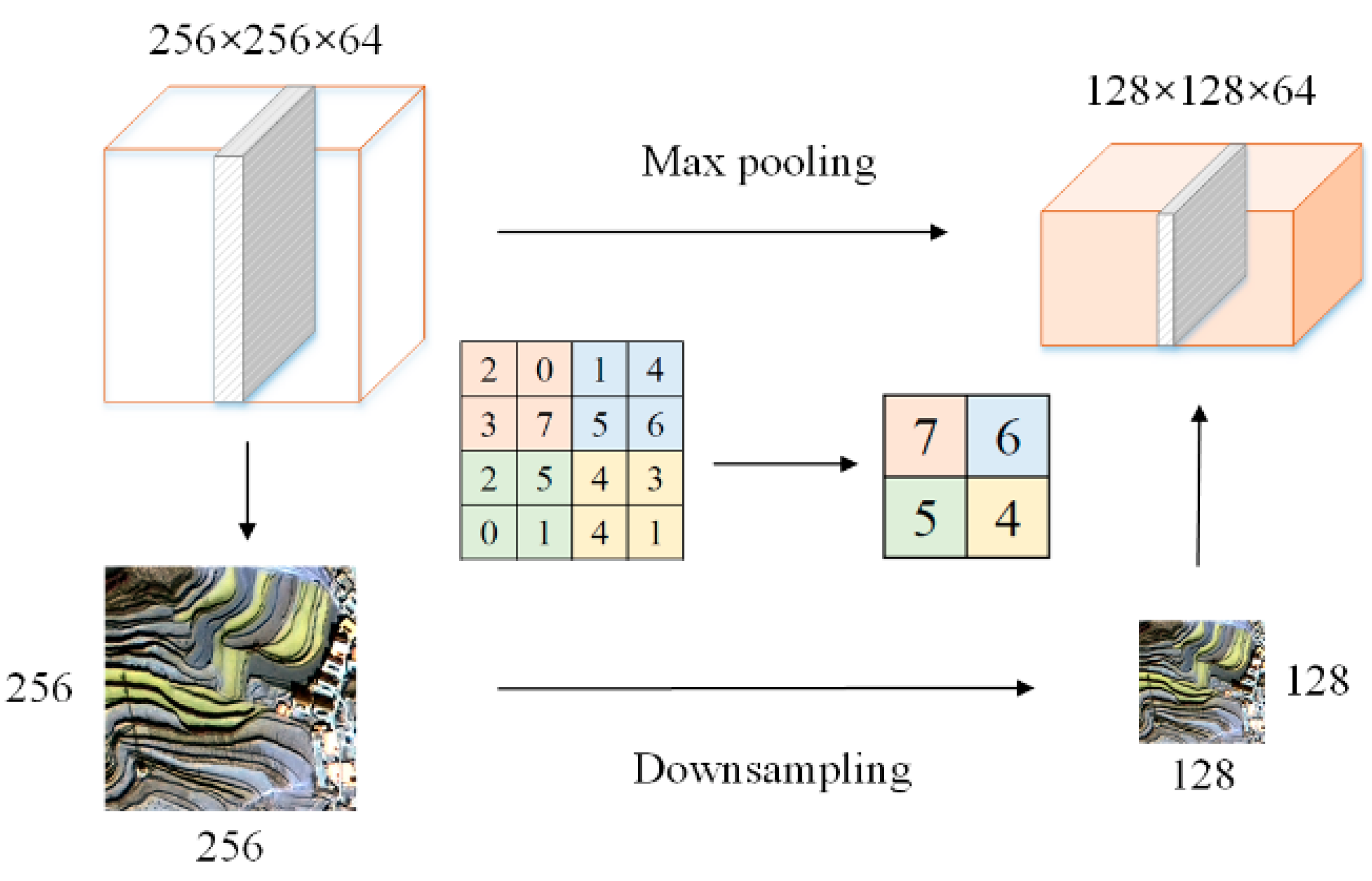
3.1.2. Pooling Operation
3.2. Deep Transfer Learning
- (1)
- Strategy 1: The first 56 layers were used as fixed-invariant feature extractors applied to the new dataset, and a linear classifier was trained based on the new dataset. Since the GF-2 dataset was small, the first 56 layers of the pre-trained model were loaded into the transfer learning model, and its learning rate was set to 0 to freeze the weights and prevent the shallow layers of the model from overfitting the dataset. Essentially, this step fixed the parameters and precluded the weights from being updated during training. The first 56 layers had little to do with specific classification tasks. Therefore, the GF-2 data were used to train only the newly added convolutional layer and the Softmax layer. This method had fewer parameters to train, effectively shortening the training time, but the model training effect was average.
- (2)
- Strategy 2: We loaded all layers of the pre-trained model into the transfer learning model, replaced the classifier in the top layer of the pre-trained model, and retrained it. Next, we initialized the weights of the entire network using the weights of the pre-trained model. The GF-2 dataset was inputted to the transfer learning model, and the weights of the pre-trained network were finetuned by continuing backpropagation with a smaller learning rate based on inherited weights. This method trained identical parameters but saved much time compared to a random initialization network. Moreover, the inherited pre-trained model weights effectively improved the training efficiency, accelerated convergence, improved the model’s generalizability, and obtained good training results.
3.3. Predictive Models
4. Experimental Results and Discussion
4.1. Experimental Platform and Parameter Settings
4.2. Precision Evaluation Metrics
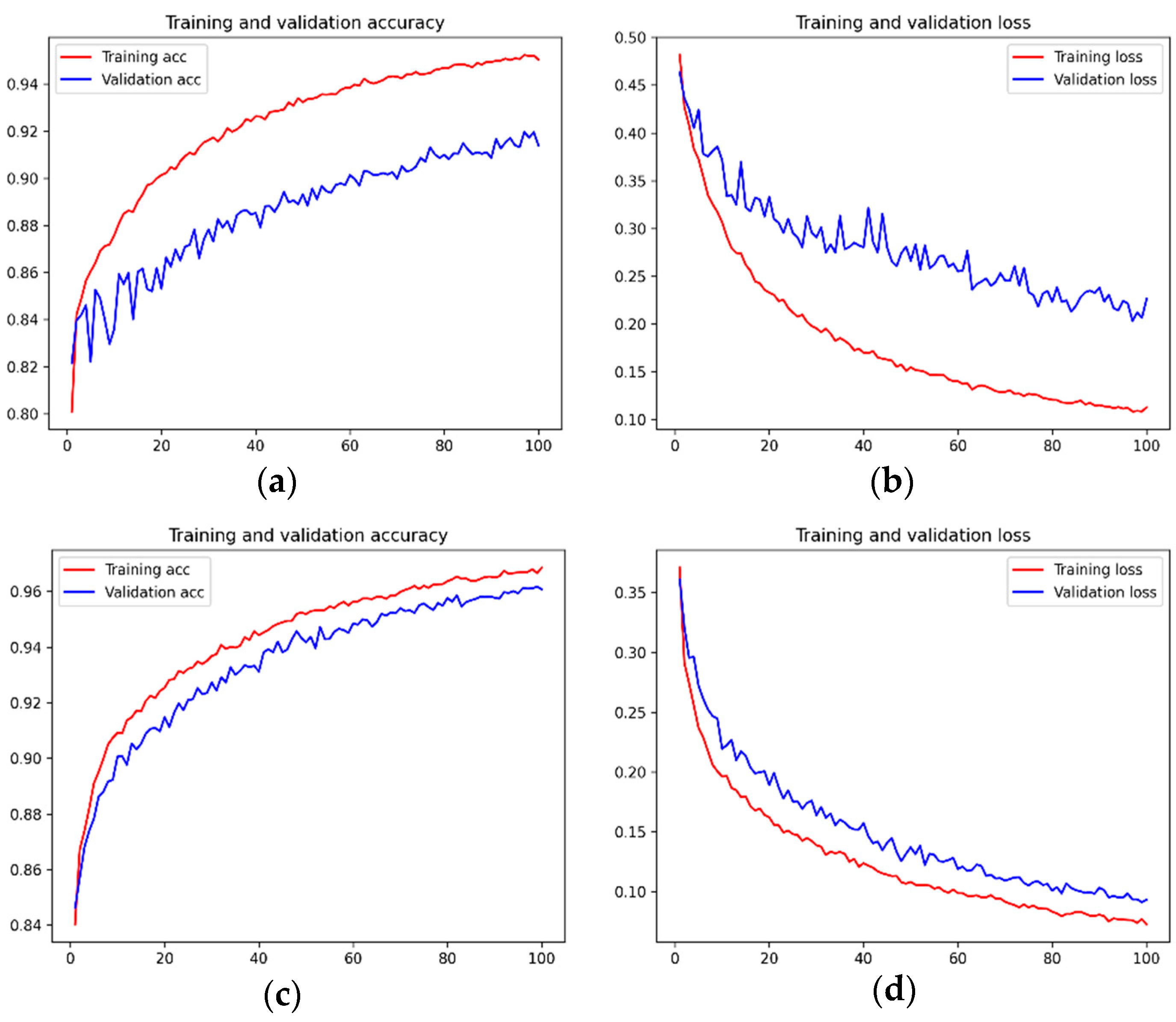
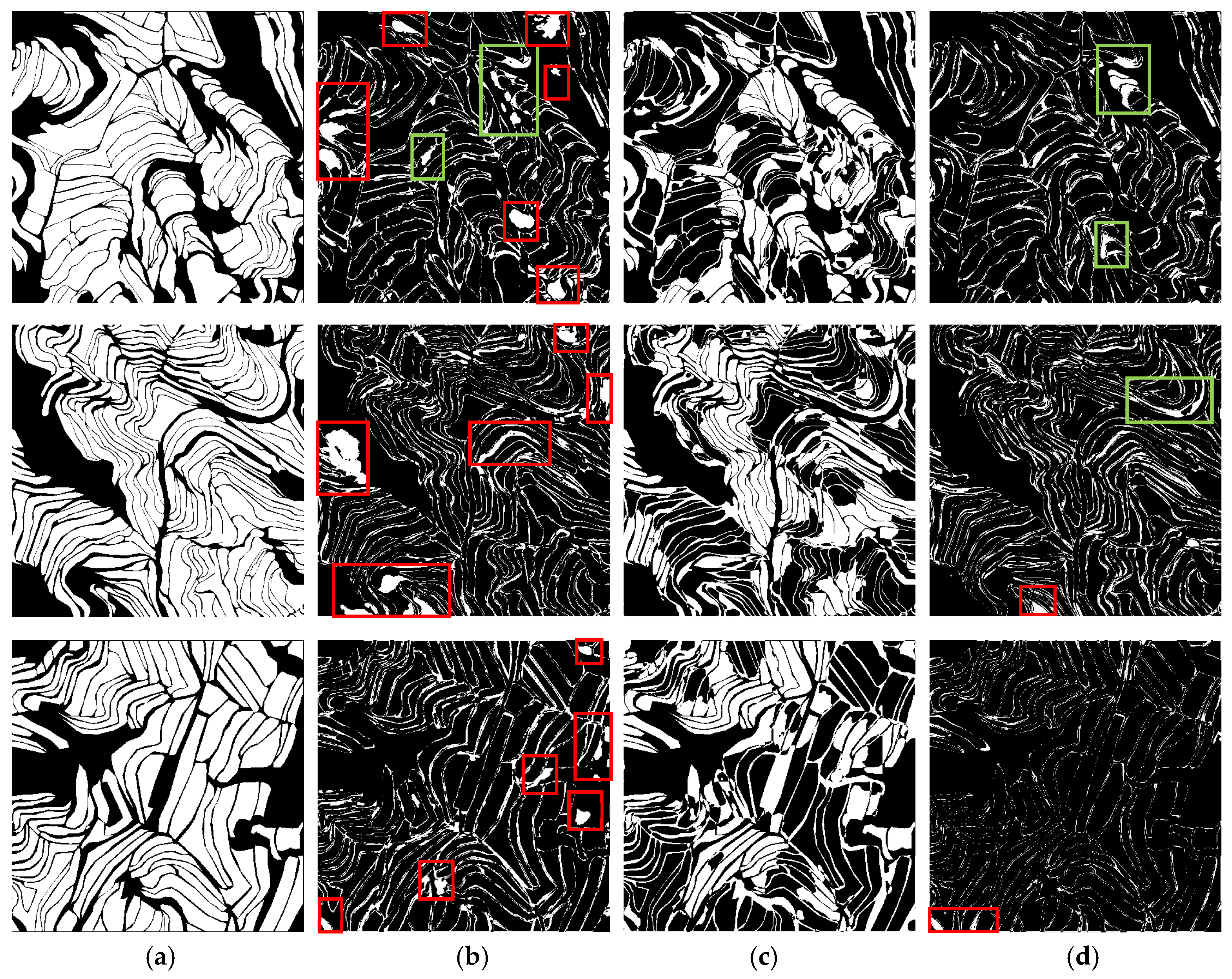
4.3. Results and Analysis
5. Conclusions and Future Research Direction
- (1)
- Topographic characteristics data, such as DEM data, will be combined with high-resolution remote-sensing image data, on which we will use the deep learning method to obtain more accurate terrace extraction results.
- (2)
- A combination of transfer learning feature extraction and high-performance classifiers will be applied to explore whether the accuracy can be further improved, thereby bringing new insights to the field of terrace recognition.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Rashid, M.; Rehman, O.; Alfonso, S.; Kausar, R.; Akram, M. The Effectiveness of Soil and Water Conservation Terrace Structures for Improvement of Crops and Soil Productivity in Rainfed Terraced System. Pakistan J. Agric. Sci. 2016, 53, 241–248. [Google Scholar] [CrossRef]
- Gardner, R.A.M.; Gerrard, A.J. Runoff and Soil Erosion on Cultivated Rainfed Terraces in the Middle Hills of Nepal. Appl. Geogr. 2003, 23, 23–45. [Google Scholar] [CrossRef]
- Capolupo, A.; Kooistra, L.; Boccia, L. A Novel Approach for Detecting Agricultural Terraced Landscapes from Historical and Contemporaneous Photogrammetric Aerial Photos. Int. J. Appl. Earth Obs. Geoinf. 2018, 73, 800–810. [Google Scholar] [CrossRef]
- Zhang, Y.; Shi, M.; Zhao, X.; Wang, X.; Luo, Z.; Zhao, Y. Methods for Automatic Identification and Extraction of Terraces from High Spatial Resolution Satellite Data (China-GF-1). Int. Soil Water Conserv. Res. 2017, 5, 17–25. [Google Scholar] [CrossRef] [Green Version]
- Liu, X.Y.; Yang, S.T.; Wang, F.G.; He, X.Z.; Ma, H.B.; Luo, Y. Analysis on Sediment Yield Reduced by Current Terrace and Shrubs-Herbs-Arbor Vegetation in the Loess Plateau. Shuili Xuebao/J. Hydraul. Eng. 2014, 45, 1293–1300. [Google Scholar] [CrossRef]
- Xiong, L.; Tang, G.; Yang, X.; Li, F. Geomorphology-Oriented Digital Terrain Analysis: Progress and Perspectives. Dili Xuebao/Acta Geogr. Sin. 2021, 76, 595–611. [Google Scholar] [CrossRef]
- Zhao, H.; Fang, X.; Ding, H.; Strobl, J.; Xiong, L.; Na, J.; Tang, G. Extraction of Terraces on the Loess Plateau from High-Resolution Dems and Imagery Utilizing Object-Based Image Analysis. ISPRS Int. J. Geo-Inf. 2017, 6, 157. [Google Scholar] [CrossRef] [Green Version]
- Pijl, A.; Quarella, E.; Vogel, T.A.; D’Agostino, V.; Tarolli, P. Remote Sensing vs. Field-Based Monitoring of Agricultural Terrace Degradation. Int. Soil Water Conserv. Res. 2021, 9, 1–10. [Google Scholar] [CrossRef]
- Martínez-Casasnovas, J.A.; Ramos, M.C.; Cots-Folch, R. Influence of the EU CAP on Terrain Morphology and Vineyard Cultivation in the Priorat Region of NE Spain. Land Use Policy 2010, 27, 11–21. [Google Scholar] [CrossRef]
- Agnoletti, M.; Cargnello, G.; Gardin, L.; Santoro, A.; Bazzoffi, P.; Sansone, L.; Pezza, L.; Belfiore, N. Traditional Landscape and Rural Development: Comparative Study in Three Terraced Areas in Northern, Central and Southern Italy to Evaluate the Efficacy of GAEC Standard 4.4 of Cross Compliance. Ital. J. Agron. 2011, 6, 121–139. [Google Scholar] [CrossRef]
- Zhao, B.Y.; Ma, N.; Yang, J.; Li, Z.H.; Wang, Q.X. Extracting Features of Soil and Water Conservation Measures from Remote Sensing Images of Different Resolution Levels: Accuracy Analysis. Bull. Soil Water Conserv. 2012, 32, 154–157. [Google Scholar] [CrossRef]
- Yu, H.; Liu, Z.-H.; Zhang, X.-P.; Li, R. Extraction of Terraced Field Texture Features Based on Fourier Transformation. Remote Sens. L. Resour. 2008, 20, 39–42. [Google Scholar]
- Zhao, X.; Wang, X.J.; Zhao, Y.; Luo, Z.D.; Xu, Y.L.; Guo, H.; Zhang, Y. A Feasibility Analysis on Methodology of Terraced Extraction Using Fourier Transformation Based on Domestic Hi-Resolution Remote Sensing Image of GF-1 Satellite. Soil Water Conserv. China 2016, 1, 63–65. [Google Scholar] [CrossRef]
- Luo, L.; Li, F.; Dai, Z.; Yang, X.; Liu, W.; Fang, X. Terrace Extraction Based on Remote Sensing Images and Digital Elevation Model in the Loess Plateau, China. Earth Sci. Informatics 2020, 13, 433–446. [Google Scholar] [CrossRef]
- Diaz-Varela, R.A.; Zarco-Tejada, P.J.; Angileri, V.; Loudjani, P. Automatic Identification of Agricultural Terraces through Object-Oriented Analysis of Very High Resolution DSMs and Multispectral Imagery Obtained from an Unmanned Aerial Vehicle. J. Environ. Manag. 2014, 134, 117–126. [Google Scholar] [CrossRef] [PubMed]
- Eckert, S.; Tesfay, S.G.; Hurni, H.; Kohler, T. Identification and Classification of Structural Soil Conservation Measures Based on Very High Resolution Stereo Satellite Data. J. Environ. Manag. 2017, 193, 592–606. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hinton, G.E.; Salakhutdinov, R.R. Reducing the Dimensionality of Data with Neural Networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef] [Green Version]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Hamida, A.B.; Benoit, A.; Lambert, P.; Ben-Amar, C. Deep Learning Approach for Remote Sensing Image Analysis. In Proceedings of the Big Data from Space (BiDS’16), Santa Cruz de Tenerife, Spain, 15–17 March 2016. [Google Scholar]
- Gupta, S.; Dwivedi, R.K.; Kumar, V.; Jain, R.; Jain, S.; Singh, M. Remote Sensing Image Classification Using Deep Learning. In Proceedings of the 2021 10th International Conference on System Modeling and Advancement in Research Trends, SMART 2021, Moradabad, India, 10–11 December 2021. [Google Scholar]
- Cheng, G.; Yang, C.; Yao, X.; Guo, L.; Han, J. When Deep Learning Meets Metric Learning: Remote Sensing Image Scene Classification via Learning Discriminative CNNs. IEEE Trans. Geosci. Remote Sens. 2018, 56, 2811–2821. [Google Scholar] [CrossRef]
- Liu, P.; Choo, K.K.R.; Wang, L.; Huang, F. SVM or Deep Learning? A Comparative Study on Remote Sensing Image Classification. Soft Comput. 2017, 21, 7053–7065. [Google Scholar] [CrossRef]
- Huang, F.; Zhang, J.; Zhou, C.; Wang, Y.; Huang, J.; Zhu, L. A Deep Learning Algorithm Using a Fully Connected Sparse Autoencoder Neural Network for Landslide Susceptibility Prediction. Landslides 2020, 17, 217–229. [Google Scholar] [CrossRef]
- Do, H.T.; Raghavan, V.; Yonezawa, G. Pixel-Based and Object-Based Terrace Extraction Using Feed-Forward Deep Neural Network. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2019, 4, 1–7. [Google Scholar] [CrossRef] [Green Version]
- Zhao, F.; Xiong, L.Y.; Wang, C.; Wang, H.R.; Wei, H.; Tang, G.A. Terraces Mapping by Using Deep Learning Approach from Remote Sensing Images and Digital Elevation Models. Trans. GIS 2021, 25, 2438–3454. [Google Scholar] [CrossRef]
- Cook, D.; Feuz, K.D.; Krishnan, N.C. Transfer Learning for Activity Recognition: A Survey. Knowl. Inf. Syst. 2013, 36, 537–556. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tang, J.; Shu, X.; Li, Z.; Qi, G.J.; Wang, J. Generalized Deep Transfer Networks for Knowledge Propagation in Heterogeneous Domains. ACM Trans. Multimed. Comput. Commun. Appl. 2016, 12, 68. [Google Scholar] [CrossRef]
- Lu, H.; Fu, X.; Liu, C.; Li, L.; He, Y.; Li, N. Cultivated Land Information Extraction in UAV Imagery Based on Deep Convolutional Neural Network and Transfer Learning. J. Mt. Sci. 2017, 14, 731–741. [Google Scholar] [CrossRef]
- Huang, Z.; Pan, Z.; Lei, B. Transfer Learning with Deep Convolutional Neural Network for SAR Target Classification with Limited Labeled Data. Remote Sens. 2017, 9, 907. [Google Scholar] [CrossRef] [Green Version]
- Kaya, A.; Keceli, A.S.; Catal, C.; Yalic, H.Y.; Temucin, H.; Tekinerdogan, B. Analysis of Transfer Learning for Deep Neural Network Based Plant Classification Models. Comput. Electron. Agric. 2019, 158, 20–29. [Google Scholar] [CrossRef]
- Tammina, S. Transfer Learning Using VGG-16 with Deep Convolutional Neural Network for Classifying Images. Int. J. Sci. Res. Publ. 2019, 9, 143–150. [Google Scholar] [CrossRef]
- Porter, C.C.; Morin, P.J.; Howat, I.M.; Niebuhr, S.; Smith, B.E. DEM Extraction from High-Resolution Stereoscopic Worldview 1 & 2 Imagery of Polar Outlet Glaciers. In Proceedings of the Fall Meeting of the American Geophysical Union, San Francisco, CA, USA, 5–9 December 2011. [Google Scholar]
- Li, P.; Yu, H.; Wang, P.; Li, K. Comparison and Analysis of Agricultural Information Extraction Methods Based upon GF2 Satellite Images. Bull. Surv. Mapp. 2017, 1, 48–52. [Google Scholar]
- Qin, Y.; Wu, Y.; Li, B.; Gao, S.; Liu, M.; Zhan, Y. Semantic Segmentation of Building Roof in Dense Urban Environment with Deep Convolutional Neural Network: A Case Study Using GF2 VHR Imagery in China. Sensors 2019, 19, 1164. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In International Conference on Medical Image Computing and Computer-Assisted Intervention; Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Cham, Switzerland, 2015; Volume 9351. [Google Scholar]
- Shelhamer, E.; Long, J.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 640–651. [Google Scholar] [CrossRef] [PubMed]
- Feng, W.; Sui, H.; Huang, W.; Xu, C.; An, K. Water Body Extraction from Very High-Resolution Remote Sensing Imagery Using Deep U-Net and a Superpixel-Based Conditional Random Field Model. IEEE Geosci. Remote Sens. Lett. 2019, 16, 618–622. [Google Scholar] [CrossRef]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A Simple Way to Prevent Neural Networks from Overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. In Proceedings of the 32nd International Conference on Machine Learning, ICML 2015, Lille, France, 6–11 July 2015; Volume 1, pp. 448–456. [Google Scholar]
- Wang, Z.; Zhou, Y.; Wang, S.; Wang, F.; Xu, Z. House Building Extraction from High-Resolution Remote Sensing Images Based on IEU-Net. Yaogan Xuebao/J. Remote Sens. 2021, 25, 2245–2254. [Google Scholar] [CrossRef]
- Glorot, X.; Bordes, A.; Bengio, Y. Deep Sparse Rectifier Neural Networks. In Proceedings of the JMLR Workshop and Conference Proceedings, Lauderdale, FL, USA, 11–13 April 2011; pp. 315–323. [Google Scholar]
- Pan, S.J.; Yang, Q. A Survey on Transfer Learning. IEEE Trans. Knowl. Data Eng. 2010, 22, 1345–1359. [Google Scholar] [CrossRef]
- Keskar, N.S.; Nocedal, J.; Tang, P.T.P.; Mudigere, D.; Smelyanskiy, M. On Large-Batch Training for Deep Learning: Generalization Gap and Sharp Minima. In Proceedings of the 5th International Conference on Learning Representations, ICLR 2017—Conference Track Proceedings, Toulon, France, 24–26 April 2017. [Google Scholar]
- Hoffer, E.; Hubara, I.; Soudry, D. Train Longer, Generalize Better: Closing the Generalization Gap in Large Batch Training of Neural Networks. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 2017. [Google Scholar]
- Smith, S.L.; Kindermans, P.J.; Ying, C.; Le, Q.V. Don’t Decay the Learning Rate, Increase the Batch Size. In Proceedings of the 6th International Conference on Learning Representations, ICLR 2018—Conference Track Proceedings, Vancouver, BC, Canada, 30 April 30–3 May 2018. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Image Type | Band | Spectral Range (μm) | Spatial Resolution (m) |
|---|---|---|---|
| panchromatic image | PAN | 0.40~0.90 | 0.5 1 |
| Image Type | Band | Spectral Range (μm) | Spatial Resolution (m) |
|---|---|---|---|
| panchromatic image | PAN | 0.40~0.90 | 0.8 |
| multispectral image | B1 | 0.45~0.52 | 3.2 |
| B2 | 0.52~0.59 | ||
| B3 | 0.63~0.69 | ||
| B4 | 0.77~0.89 |
| Layer (Number) | Layer (Type) | Output Shape | Parameter No. |
|---|---|---|---|
| 1 | input_1 | (None, 256, 256, 3) | 0 |
| 2 | conv2d | (None, 256, 256, 32) | 896 |
| 3 | batch_normalization | (None, 256, 256, 32) | 128 |
| 4 | conv2d_1 | (None, 256, 256, 32) | 9248 |
| 5 | batch_normalization_1 | (None, 256, 256, 32) | 128 |
| 6 | max_pooling2d | (None, 128, 128, 32) | 0 |
| … | … | … | … |
| … | … | … | … |
| 23 | conv2d_8 | (None, 16, 16, 512) | 1,180,160 |
| 24 | batch_normalization_8 | (None, 16, 16, 512) | 2048 |
| 25 | conv2d_9 | (None, 16, 16, 512) | 2,359,808 |
| 26 | batch_normalization_9 | (None, 16, 16, 512) | 2048 |
| 27 | dropout_1 | (None, 16, 16, 512) | 0 |
| 28 | up_sampling2d | (None, 32, 32, 512) | 0 |
| 29 | conv2d_10 | (None, 32, 32, 512) | 1,049,088 |
| 30 | concatenate | (None, 32, 32, 768) | 0 |
| … | … | … | … |
| … | … | … | … |
| 52 | conv2d_20 | (None, 256, 256, 32) | 18,464 |
| 53 | batch_normalization_16 | (None, 256, 256, 32) | 128 |
| 54 | conv2d_21 | (None, 256, 256, 32) | 9248 |
| 55 | batch_normalization_17 | (None, 256, 256, 32) | 128 |
| 56 | conv2d_22 | (None, 256, 256, 2) | 578 |
| 57 | conv2d_23 | (None, 256, 256, 2) | 6 |
| Epoch | Batch Size | Learning Rate | Optimizer |
|---|---|---|---|
| 100 | 16 | 1 × 10−4 | Adam |
| Prediction Type | Real Type | |
|---|---|---|
| Terraces | Non-Terraced Fields | |
| Terraces | TP (True Positives) | FP (False Positives) |
| Non-terraced fields | FN (False Negatives) | TN (True Negatives) |
| Test area | OA (%) | F1 Score (%) | MIoU (%) | |||
|---|---|---|---|---|---|---|
| Direct Training | Transfer Learning | Direct Training | Transfer Learning | Direct Training | Transfer Learning | |
| 1 | 84.41 | 91.62 | 77.50 | 91.17 | 70.97 | 87.51 |
| 2 | 83.06 | 93.17 | 74.02 | 89.46 | 68.22 | 89.94 |
| 3 | 85.26 | 94.56 | 77.32 | 93.58 | 71.68 | 92.24 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yu, M.; Rui, X.; Xie, W.; Xu, X.; Wei, W. Research on Automatic Identification Method of Terraces on the Loess Plateau Based on Deep Transfer Learning. Remote Sens. 2022, 14, 2446. https://doi.org/10.3390/rs14102446
Yu M, Rui X, Xie W, Xu X, Wei W. Research on Automatic Identification Method of Terraces on the Loess Plateau Based on Deep Transfer Learning. Remote Sensing. 2022; 14(10):2446. https://doi.org/10.3390/rs14102446
Chicago/Turabian StyleYu, Mingge, Xiaoping Rui, Weiyi Xie, Xijie Xu, and Wei Wei. 2022. "Research on Automatic Identification Method of Terraces on the Loess Plateau Based on Deep Transfer Learning" Remote Sensing 14, no. 10: 2446. https://doi.org/10.3390/rs14102446
APA StyleYu, M., Rui, X., Xie, W., Xu, X., & Wei, W. (2022). Research on Automatic Identification Method of Terraces on the Loess Plateau Based on Deep Transfer Learning. Remote Sensing, 14(10), 2446. https://doi.org/10.3390/rs14102446