
Unsupervised Multistep Deformable Registration of Remote Sensing Imagery Based on Deep Learning

 ,
,  and
and
Abstract
1. Introduction
2. Materials and Methods
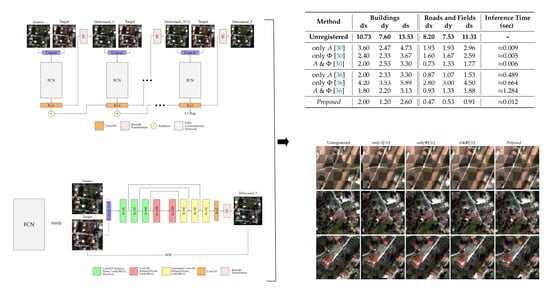
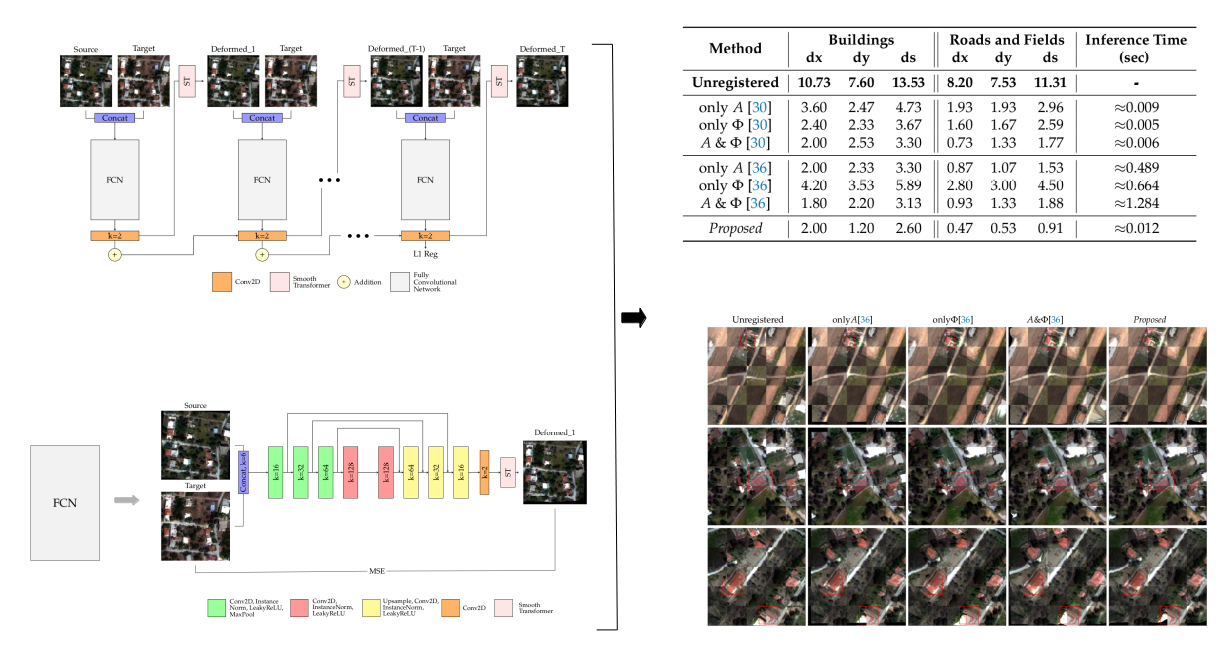
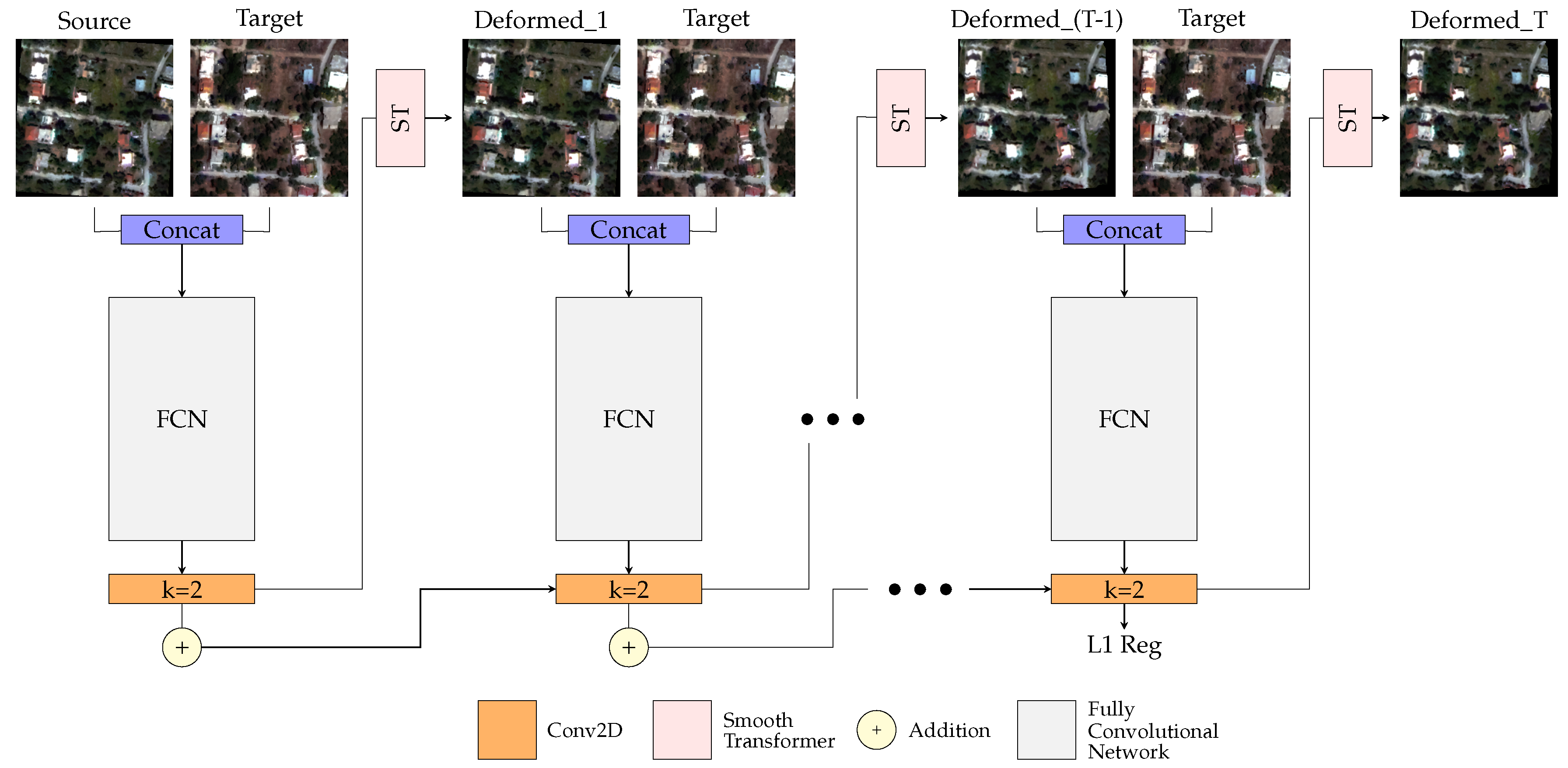
2.1. Multistep Deformable Registration Network
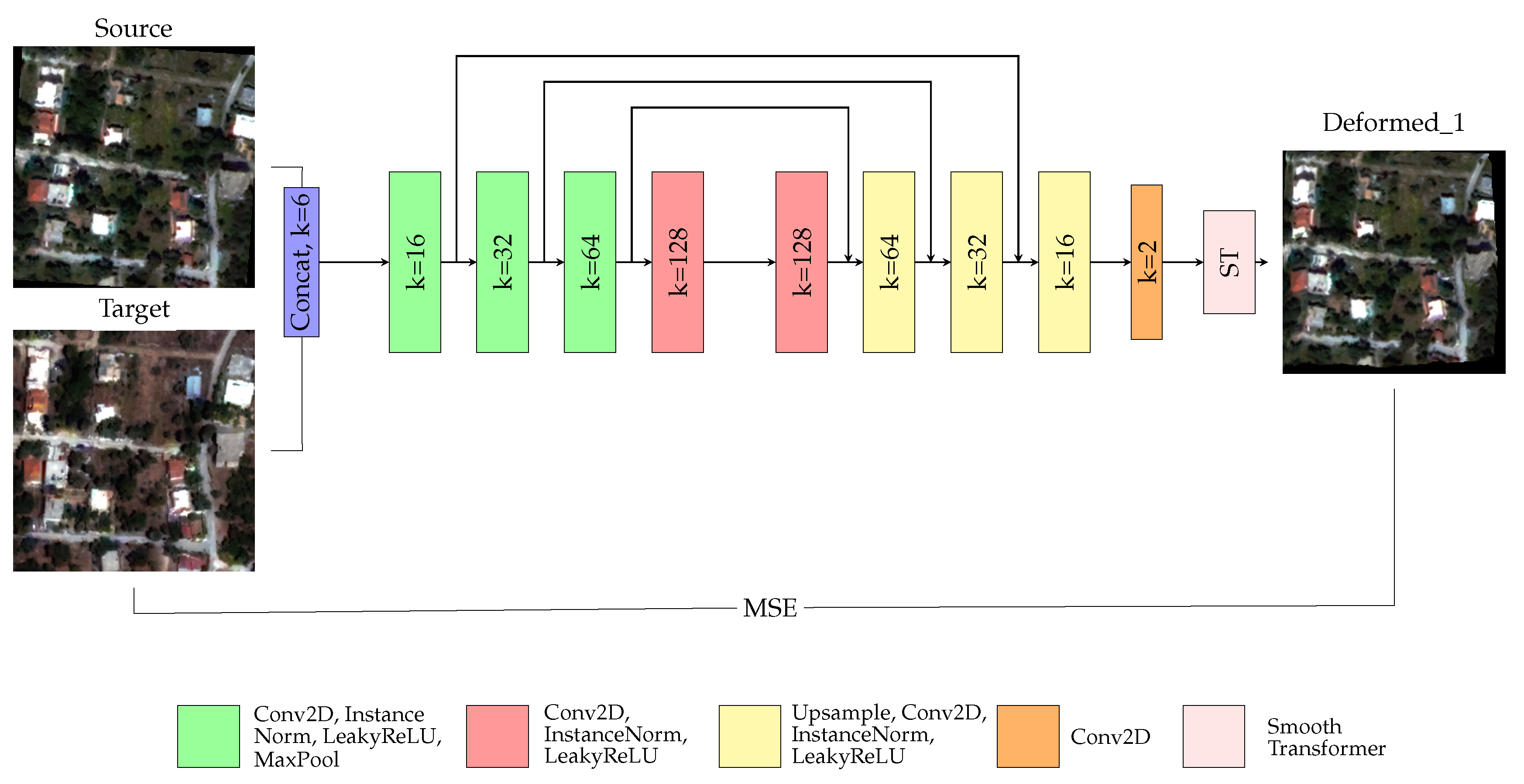
2.2. Network Architecture
3. Experimental Results
3.1. Datasets
3.1.1. Attica VHR
3.1.2. ISPRS Ikonos
3.2. Optimization
3.3. Ablation Study
3.4. Quantitative and Qualitative Evaluation
3.4.1. Attica VHR Dataset
3.4.2. ISPRS Ikonos Dataset
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Vakalopoulou, M.; Karantzalos, K. Automatic Descriptor-Based Co-Registration of Frame Hyperspectral Data. Remote Sens. 2014, 6, 3409–3426. [Google Scholar] [CrossRef]
- Wu, J.; Chang, C.; Tsai, H.Y.; Liu, M.C. Co-registration between multisource remote-sensing images. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. ISPRS Arch. 2012, 39, 439–442. [Google Scholar] [CrossRef]
- Li, Z.; Leung, H. Contour-based multisensor image registration with rigid transformation. In Proceedings of the 2007 10th International Conference on Information Fusion, Quebec, QC, Canada, 9–12 July 2007; pp. 1–7. [Google Scholar]
- Sotiras, A.; Davatzikos, C.; Paragios, N. Deformable Medical Image Registration: A Survey. IEEE Trans. Med. Imaging 2013, 32, 1153–1190. [Google Scholar] [CrossRef]
- Karantzalos, K.; Sotiras, A.; Paragios, N. Efficient and automated multimodal satellite data registration through MRFs and linear programming. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition Workshops, Columbus, OH, USA, 23–28 June 2014; pp. 335–342. [Google Scholar]
- Marcos, D.; Hamid, R.; Tuia, D. Geospatial correspondences for multimodal registration. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 5091–5100. [Google Scholar]
- Hui, L.; Manjunath, B.S.; Mitra, S.K. A contour-based approach to multisensor image registration. IEEE Trans. Image Process. 1995, 4, 320–334. [Google Scholar] [CrossRef]
- Vakalopoulou, M.; Karantzalos, K.; Komodakis, N.; Paragios, N. Graph-Based Registration, Change Detection, and Classification in Very High Resolution Multitemporal Remote Sensing Data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 9, 2940–2951. [Google Scholar] [CrossRef]
- Bowen, F.; Hu, J.; Du, E.Y. A Multistage Approach for Image Registration. IEEE Trans. Cybern. 2016, 46, 2119–2131. [Google Scholar] [CrossRef]
- Feng, R.; Du, Q.; Li, X.; Shen, H. Robust registration for remote sensing images by combining and localizing feature- and area-based methods. ISPRS J. Photogramm. Remote Sens. 2019, 151, 15–26. [Google Scholar] [CrossRef]
- Hong, G.; Zhang, Y. Combination of feature-based and area-based image registration technique for high resolution remote sensing image. In Proceedings of the 2007 IEEE International Geoscience and Remote Sensing Symposium, Barcelona, Spain, 23–28 July 2007; pp. 377–380. [Google Scholar]
- Shen, Z.; Han, X.; Xu, Z.; Niethammer, M. Networks for joint affine and non-parametric image registration. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 4219–4228. [Google Scholar]
- Mok, T.; Chung, A.C.S. Fast symmetric diffeomorphic image registration with convolutional neural networks. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 4643–4652. [Google Scholar]
- Mahapatra, D.; Ge, Z. Combining Transfer Learning and Segmentation Information with GANs for Training Data Independent Image Registration. arXiv 2019, arXiv:abs/1903.10139. [Google Scholar]
- Estienne, T.; Vakalopoulou, M.; Christodoulidis, S.; Battistela, E.; Lerousseau, M.; Carre, A.; Klausner, G.; Sun, R.; Robert, C.; Mougiakakou, S.; et al. U-ReSNet: Ultimate coupling of registration and segmentation with deep nets. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Shenzhen, China, 13–17 October 2019; Springer: Berlin/Heidelberg, Germany, 2019; pp. 310–319. [Google Scholar]
- Moigne, J.L.; Netanyahu, N.S.; Eastman, R.D. Image Registration for Remote Sensing; Cambridge University Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Dawn, S.; Saxena, V.; Sharma, B.D. Remote sensing image registration techniques: A survey. In Proceedings of the International Conference on Image and Signal Processing (ICISP), Trois-Rivières, QC, Canada, 30 June–2 July 2010. [Google Scholar]
- Wang, S.; Dou, Q.; Liang, X.; Ning, M.; Yanhe, G.; Jiao, L. A deep learning framework for remote sensing image registration. ISPRS J. Photogramm. Remote Sens. 2018, 145, 148–164. [Google Scholar] [CrossRef]
- Yang, Z.; Dan, T.; Yang, Y. Multi-Temporal Remote Sensing Image Registration Using Deep Convolutional Features. IEEE Access 2018, 6, 38544–38555. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2015, arXiv:abs/1409.1556. [Google Scholar]
- Ma, W.; Zhang, J.; Wu, Y.; Jiao, L.; Zhu, H.; Zhao, W. A Novel Two-Step Registration Method for Remote Sensing Images Based on Deep and Local Features. IEEE Trans. Geosci. Remote Sens. 2019, 57, 4834–4843. [Google Scholar] [CrossRef]
- He, H.; Chen, M.; Chen, T.; Li, D. Matching of Remote Sensing Images with Complex Background Variations via Siamese Convolutional Neural Network. Remote Sens. 2018, 10, 355. [Google Scholar] [CrossRef]
- Hughes, L.H.; Marcos, D.; Lobry, S.; Tuia, D.; Schmitt, M. A deep learning framework for matching of SAR and optical imagery. ISPRS J. Photogramm. Remote Sens. 2020, 169, 166–179. [Google Scholar] [CrossRef]
- Merkle, N.; Auer, S.; Müller, R.; Reinartz, P. Exploring the Potential of Conditional Adversarial Networks for Optical and SAR Image Matching. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 1811–1820. [Google Scholar] [CrossRef]
- Li, L.; Han, L.; Ding, M.; Liu, Z.; Cao, H. Remote sensing image registration based on deep learning regression model. IEEE Geosci. Remote Sens. Lett. 2020. [Google Scholar] [CrossRef]
- Huang, G.; Liu, Z.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2261–2269. [Google Scholar]
- Zampieri, A.; Charpiat, G.; Girard, N.; Tarabalka, Y. Multimodal image alignment through a multiscale chain of neural networks with application to remote sensing. In Proceedings of the 2018 European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Girard, N.; Charpiat, G.; Tarabalka, Y. Aligning and updating cadaster maps with aerial images by multi-task, multi-resolution deep learning. In Proceedings of the 2018 Asian Conference on Computer Vision (ACCV), Perth, Australia, 2–6 December 2018. [Google Scholar]
- Christodoulidis, S.; Sahasrabudhe, M.; Vakalopoulou, M.; Chassagnon, G.; Revel, M.P.; Mougiakakou, S.; Paragios, N. Linear and deformable image registration with 3d convolutional neural networks. In Proceedings of the 2018 Medical Image Computing and Computer Assisted Intervention (MICCAI), Granada, Spain, 16–20 September 2018. [Google Scholar]
- Vakalopoulou, M.; Christodoulidis, S.; Sahasrabudhe, M.; Mougiakakou, S.; Paragios, N. Image registration of satellite imagery with deep convolutional neural networks. In Proceedings of the IGARSS 2019–2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019. [Google Scholar] [CrossRef]
- Jaderberg, M.; Simonyan, K.; Zisserman, A.; Kavukcuoglu, K. Spatial transformer networks. In Proceedings of the 2015 Neural Information Processing Systems (NIPS), Montreal, QC, Canada, 7–12 December 2015. [Google Scholar]
- Shu, Z.; Sahasrabudhe, M.; Güler, R.A.; Samaras, D.; Paragios, N.; Kokkinos, I. Deforming autoencoders: Unsupervised disentangling of shape and appearance. In Proceedings of the 2018 European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Balakrishnan, G.; Zhao, A.; Sabuncu, M.; Guttag, J.; Dalca, A.V. VoxelMorph: A Learning Framework for Deformable Medical Image Registration. IEEE Trans. Med. Imaging 2019, 38, 1788–1800. [Google Scholar] [CrossRef]
- Zhang, J.; Zareapoor, M.; He, X.; Shen, D.; Feng, D.; Yang, J. Mutual information based multi-modal remote sensing image registration using adaptive feature weight. Remote Sens. Lett. 2018, 9, 646–655. [Google Scholar] [CrossRef]
- Paszke, A.; Gross, S.; Chintala, S.; Chanan, G.; Yang, E.; DeVito, Z.; Lin, Z.; Desmaison, A.; Antiga, L.; Lerer, A. Automatic differentiation in PyTorch. In Proceedings of the NIPS Autodiff Workshop, Long Beach, CA, USA, 9 December 2017. [Google Scholar]
- Joshi, S.; Davis, B.; Jomier, M.; Gerig, G. Unbiased diffeomorphic atlas construction for computational anatomy. NeuroImage 2004, 23, s151–s160. [Google Scholar] [CrossRef]
- Yushkevich, P.; Pluta, J.; Wang, H.; Wisse, L.; Wolk, D. Fast Automatic Segmentation of Hippocampal Subfields and Medial Temporal Lobe Subregions in 3 Tesla and 7 Tesla T2-Weighted Mri. Alzheimer’s Dement. 2016, 12, 126–127. [Google Scholar] [CrossRef]
- Ye, Z.; Kang, J.; Yao, J.; Song, W.; Liu, S.; Luo, X.; Xu, Y.; Tong, X. Robust Fine Registration of Multisensor Remote Sensing Images Based on Enhanced Subpixel Phase Correlation. Sensors 2020, 20, 4338. [Google Scholar] [CrossRef] [PubMed]
- Keller, Y.; Averbuch, A. Multisensor image registration via implicit similarity. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 794–801. [Google Scholar] [CrossRef] [PubMed]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Buildings | Roads and Fields | Training Timeper Epoch (sec) | ||||
|---|---|---|---|---|---|---|---|
| dx | dy | ds | dx | dy | ds | ||
| Unregistered | 10.73 | 7.60 | 13.53 | 8.20 | 7.53 | 11.31 | - |
| () | 2.40 | 2.33 | 3.67 | 1.60 | 1.67 | 2.59 | ≈22 |
| () | 3.07 | 0.60 | 3.40 | 0.80 | 1.20 | 1.75 | ≈28 |
| () | 2.00 | 1.20 | 2.60 | 0.47 | 0.53 | 0.91 | ≈34 |
| () | 2.13 | 1.00 | 2.55 | 0.20 | 0.80 | 0.90 | ≈44 |
| () | 1.27 | 1.27 | 2.07 | 0.33 | 0.33 | 0.59 | ≈56 |
| Method | Buildings | Roads and Fields | Inference Time (sec) | ||||
|---|---|---|---|---|---|---|---|
| dx | dy | ds | dx | dy | ds | ||
| Unregistered | 10.73 | 7.60 | 13.53 | 8.20 | 7.53 | 11.31 | - |
| only A [30] | 3.60 | 2.47 | 4.73 | 1.93 | 1.93 | 2.96 | ≈0.009 |
| only [30] | 2.40 | 2.33 | 3.67 | 1.60 | 1.67 | 2.59 | ≈0.005 |
| A & Φ [30] | 2.00 | 2.53 | 3.30 | 0.73 | 1.33 | 1.77 | ≈0.006 |
| only A [36] | 2.00 | 2.33 | 3.30 | 0.87 | 1.07 | 1.53 | ≈0.489 |
| only [36] | 4.20 | 3.53 | 5.89 | 2.80 | 3.00 | 4.50 | ≈0.664 |
| A & Φ [36] | 1.80 | 2.20 | 3.13 | 0.93 | 1.33 | 1.88 | ≈1.284 |
| Proposed | 2.00 | 1.20 | 2.60 | 0.47 | 0.53 | 0.91 | ≈0.012 |
| Method | Buildings | Roads and Fields | Inference Time (sec) | ||||
|---|---|---|---|---|---|---|---|
| dx | dy | ds | dx | dy | ds | ||
| Unregistered | 2.93 | 9.60 | 10.09 | 2.47 | 9.13 | 9.53 | - |
| only A [30] | 1.07 | 3.93 | 4.13 | 0.93 | 2.33 | 2.65 | ≈0.006 |
| only [30] | 0.60 | 1.87 | 2.08 | 0.53 | 1.87 | 2.09 | ≈0.004 |
| A & Φ [30] | 0.27 | 1.53 | 1.64 | 0.40 | 1.80 | 1.89 | ≈0.005 |
| only A [36] | 0.60 | 1.47 | 1.75 | 0.40 | 1.60 | 1.76 | ≈0.378 |
| only [36] | 2.06 | 3.20 | 3.95 | 1.87 | 4.00 | 4.65 | ≈0.583 |
| A & Φ [36] | 0.53 | 1.27 | 1.55 | 0.87 | 1.20 | 1.73 | ≈1.102 |
| Proposed | 0.20 | 1.20 | 1.32 | 0.40 | 0.93 | 1.22 | ≈0.011 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Papadomanolaki, M.; Christodoulidis, S.; Karantzalos, K.; Vakalopoulou, M. Unsupervised Multistep Deformable Registration of Remote Sensing Imagery Based on Deep Learning. Remote Sens. 2021, 13, 1294. https://doi.org/10.3390/rs13071294
Papadomanolaki M, Christodoulidis S, Karantzalos K, Vakalopoulou M. Unsupervised Multistep Deformable Registration of Remote Sensing Imagery Based on Deep Learning. Remote Sensing. 2021; 13(7):1294. https://doi.org/10.3390/rs13071294
Chicago/Turabian StylePapadomanolaki, Maria, Stergios Christodoulidis, Konstantinos Karantzalos, and Maria Vakalopoulou. 2021. "Unsupervised Multistep Deformable Registration of Remote Sensing Imagery Based on Deep Learning" Remote Sensing 13, no. 7: 1294. https://doi.org/10.3390/rs13071294
APA StylePapadomanolaki, M., Christodoulidis, S., Karantzalos, K., & Vakalopoulou, M. (2021). Unsupervised Multistep Deformable Registration of Remote Sensing Imagery Based on Deep Learning. Remote Sensing, 13(7), 1294. https://doi.org/10.3390/rs13071294