
Stochastic Remote Sensing Event Classification over Adaptive Posture Estimation via Multifused Data and Deep Belief Network



Abstract
1. Introduction
- We contribute a robust method for the detection of nineteen human body parts over complex human movement; challenging events and human postures can be detected and estimated more accurately.
- For more accurate results in adaptive posture estimation and classification, we designed a skeletal pseudo-2D stick model that enables the detection of nineteen human body parts.
- In the multifused data, we extracted sense-aware features which include energy, moveable body parts, skeleton zigzag features, angular geometric features and 3D Cartesian features. Using these extracted features, we can classify stochastic remote sensing events in multiple human-based videos more accurately.
- For data optimization, a hierarchical optimization model is implemented to reduce computational cost and to optimize data, and charged system search optimization is implemented over-extracted features. A deep belief network is applied for multiple human-based video stochastic remote sensing event classification.
2. Related Work
3. Proposed System Methodology
3.1. Preprocessing Stage
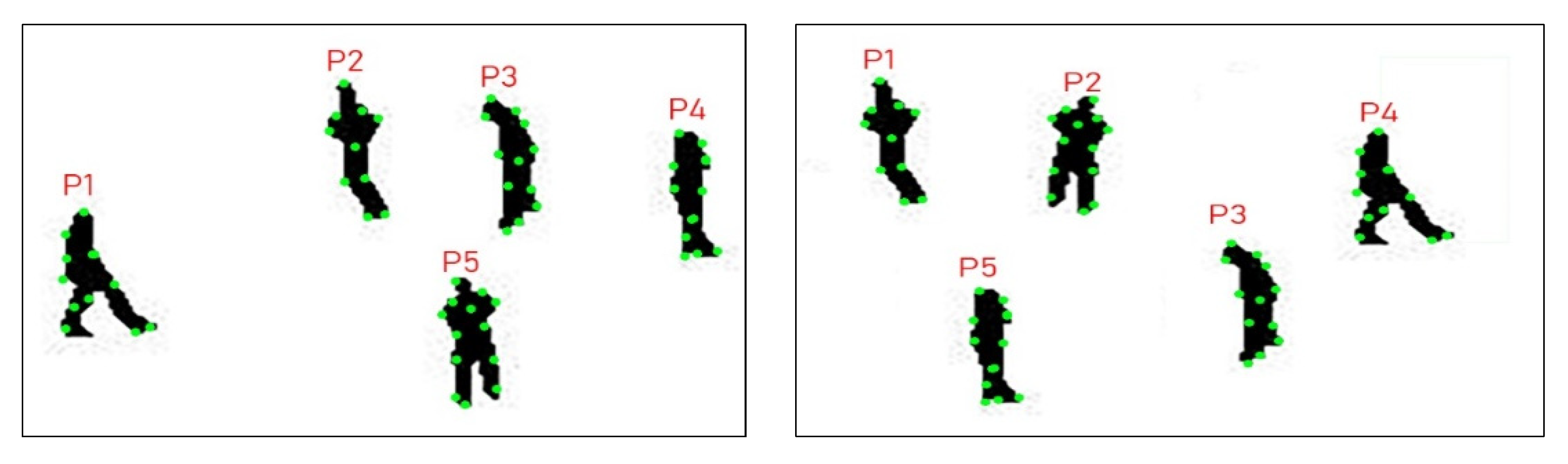
3.2. Posture Estimation: Body Part Detection
| Algorithm 1. Human body key point detection. |
| Input: HES: Extracted full human silhouette |
| Output: 19 body parts as head, shoulders, neck, wrists, elbows, hands, torso, hips, ankle, knees and foot. HFS = Full human silhouette, HSh = human shape, Hs = height, Ws = width, Ls = left, Rs = right, Ish = head, Isn = neck |
| Repeat |
| For i = 1 to N do |
| Search (HFS) |
| Ish = Human_head; |
| S_Up = UpperPoint (Ish) |
| S_ehp = Human _End_Head_point (Ish) |
| S_Mp = mid (Hs,Ws)/2 |
| S_Fp = Bottom(HFS)& search(Ls, Rs) |
| S_Knp = mid(S_Mp, S_ Fp) |
| S_Hnp = S_ehp & S_Up & search(Ls, Rs) |
| S_Shp = search(Ish, Ish) & search(Rs, Ls) |
| S_Elp = mid(S_Hnp, S_Shp) |
| S_Wrp = mid (S_Hnp, S_Elp)/2 |
| S_Hip = S_Mp &search(Rs,Ls) |
| S_Anp = mid (S_Knp, S_Fp)/4 |
| End |
| Until complete human silhouette searched. |
| return 19 body parts as head, shoulders, neck, wrists, elbows, hands, torso, hips, ankles, knees and foot. HFS = Full human silhouette, HSh = human shape, Hs = height, Ws = width, Ls = left, Rs = right, Ish = head, Isn = neck |
3.3. Posture Estimation: Pseudo-2D Stick Model
| Algorithm 2. Pseudo-2D stick model. |
| Input: Human body key point and 2D stick model |
| Output: Pseudo-2D stick graph (kp1, kp2, kp3, …, kpn) |
| Dkp = Detection of human body key points, Cdp = Connection of detected points, Ss = Sticks scaling, Sg = 2D skeleton graph, Vi = Volumetric information, Kk = kinematic dependency and key points tracing, Ei = edges information, Dof = Degree of freedom, GL = Global and local coordinates, Sc = Skeleton Graph Cartesian product |
| % initiating Pseudo-2D Stick Graph % |
| Pseudo-2D Stick Graph ← [] |
| P2DSG_Size ← Get P2DSG_Size () |
| % loop on extracted human silhouettes% |
| For I = 1:K |
| P2DSG_interactions ← GetP2DSG_interactions |
| %Extracting Dkp, Cdp, Ss, Sg, Vi, Kk, Ei, Dof, GL, Sc% |
| Detection of body key points ← Dkp(P2DSG_interactions) |
| Connection of detected points ← Cdp(P2DSG_interactions) |
| Sticks scaling ← Ss(P2DSG_interactions) |
| 2D skeleton graph ← Sg(P2DSG_interactions) |
| Volumetric information ← Vi(P2DSG_interactions) |
| Kinematics dependency ← Kk(P2DSG_interactions) |
| Edges information ← Ei(P2DSG_interactions) |
| Degree of freedom ← Dof(P2DSG_interactions) |
| Global and Local coordinates ← GL(P2DSG_interactions) |
| Skeleton Graph Cartesian product ← Sc(P2DSG_interactions) |
| Pseudo-2D Stick Graph ← Get P2DSG |
| Pseudo-2D Stick Graph.append (P2DSG) |
| End |
| Pseudo-2D Stick Graph ← Normalize (Pseudo-2D Stick Graph) |
| return Pseudo-2D Stick Graph (kp1, kp2, kp3, …, kpn) |
3.4. Multifused Data
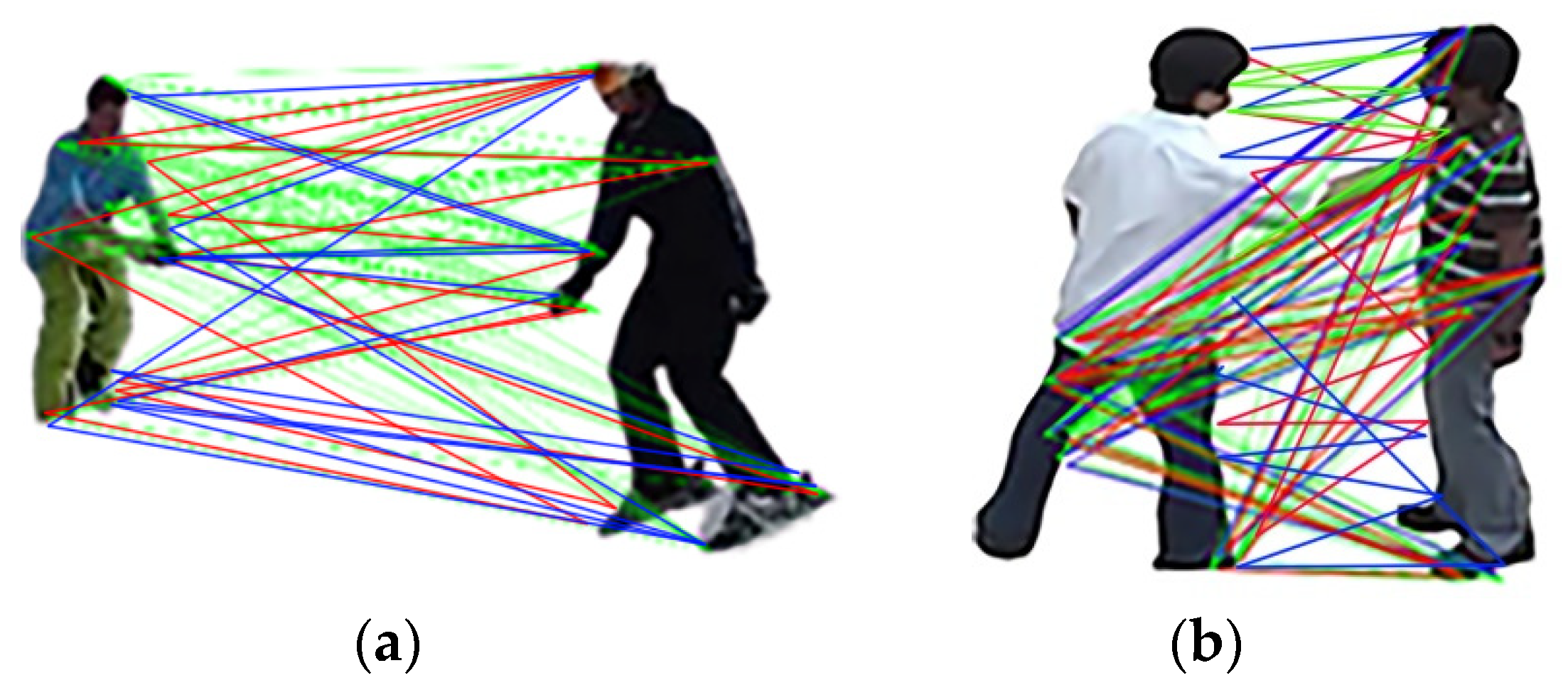
3.4.1. Skeleton Zigzag Feature
3.4.2. Angular Geometric Feature
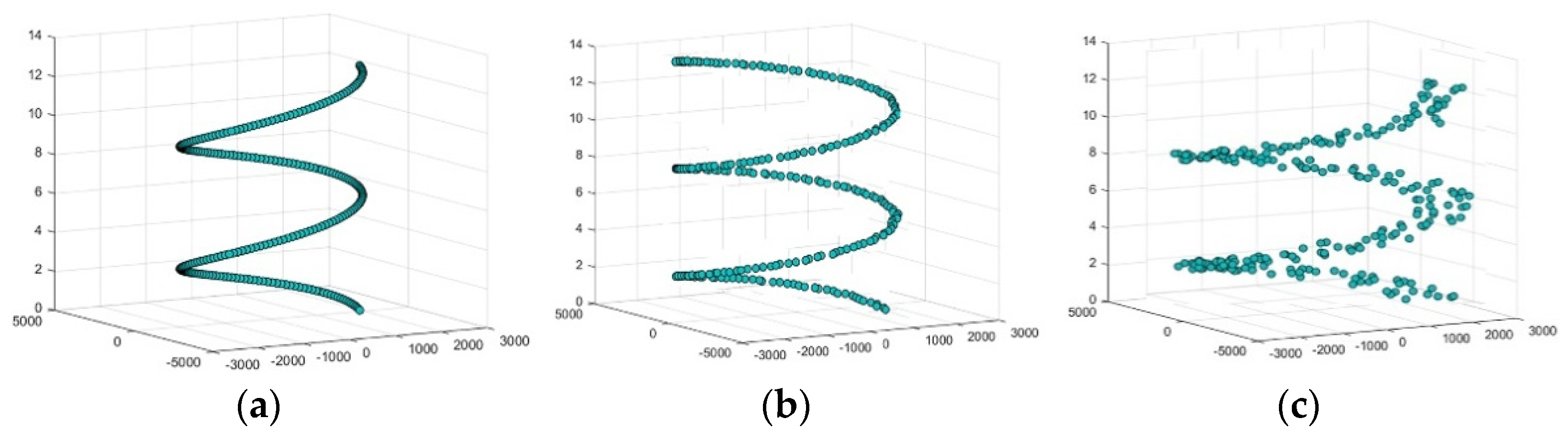
3.4.3. 3D Cartesian View Feature
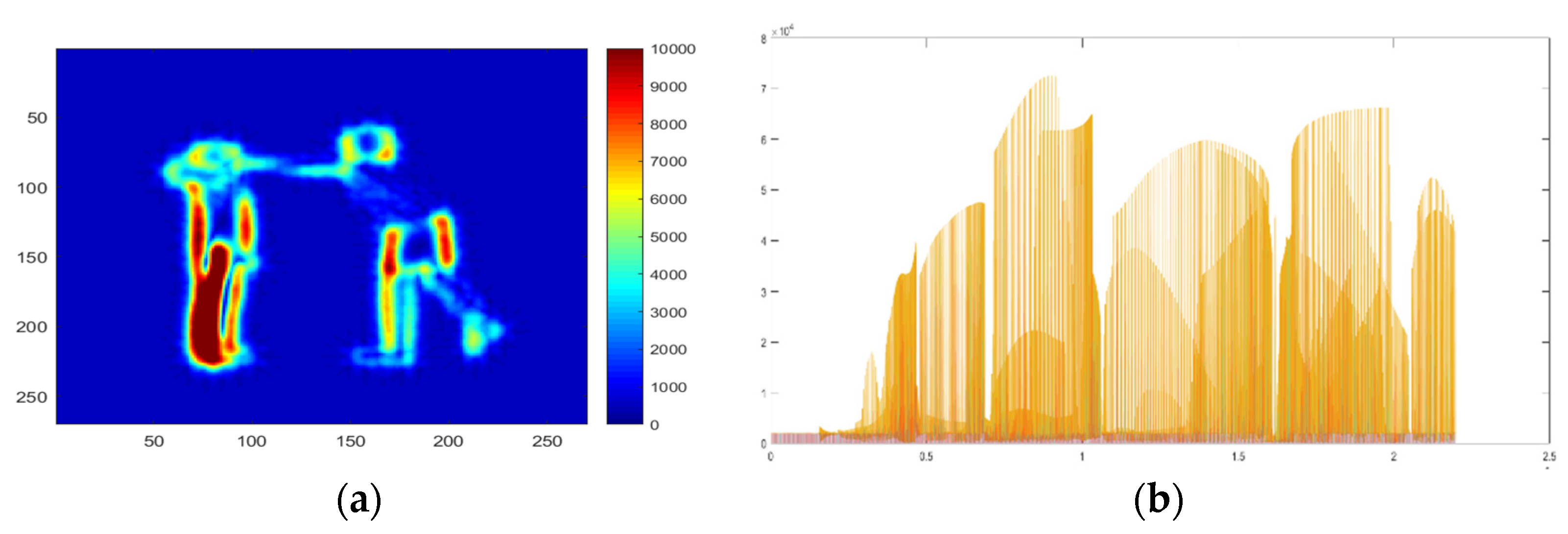
3.4.4. Energy Feature
3.4.5. Moveable Body Parts Feature
| Algorithm 3. Multifused data. |
| Input: N: Extracted human silhouettes frames of RGB images |
| Output: sense –aware feature vectors(sf1, sf2, sf3, …, sfn) |
| % initiating feature vector for stochastic remote sensing event classification % |
| sense-awarefeature_vectors ← [] |
| F_vectorsize ← GetVectorsize () |
| % loop on extracted human silhouettes frames % |
| For i = 1:K |
| F_vectors_ interactions ← Get_F_vectors(interactions) |
| % extracting energy features, moveable human body parts, Smoothing gradient 3D Cartesian view, key points angle features, human skeleton features% |
| Energy Features ←ExtractEnergyFeatures(F_vectors_ interactions) |
| MoveableHumanBodyparts←ExtractMoveableHumanbodyparts(F_vectors_ interactions) |
| Smoothing Gradient 3D Cartesian View ← ExtractSmoothingGradient3DCartesianView(F_vectors_ interactions) |
| Key point angle ← ExtractKeyPointAngle(F_vectors_ interactions) |
| Human skeleton features← ExtractHumanSkeletonFeatures(F_vectors_ interactions) |
| Feature-vectors ← GetFeaturevector |
| Context-aware Feature-vectors.append (F_vectors) |
| End |
| Sense-aware Feature-vectors ← Normalize (sense-awarefeature_vectors) |
| return sense –aware feature vectors(sf1,sf2,sf3,…,sfn) |
3.5. Feature Optimization: Charged System Search Algorithm
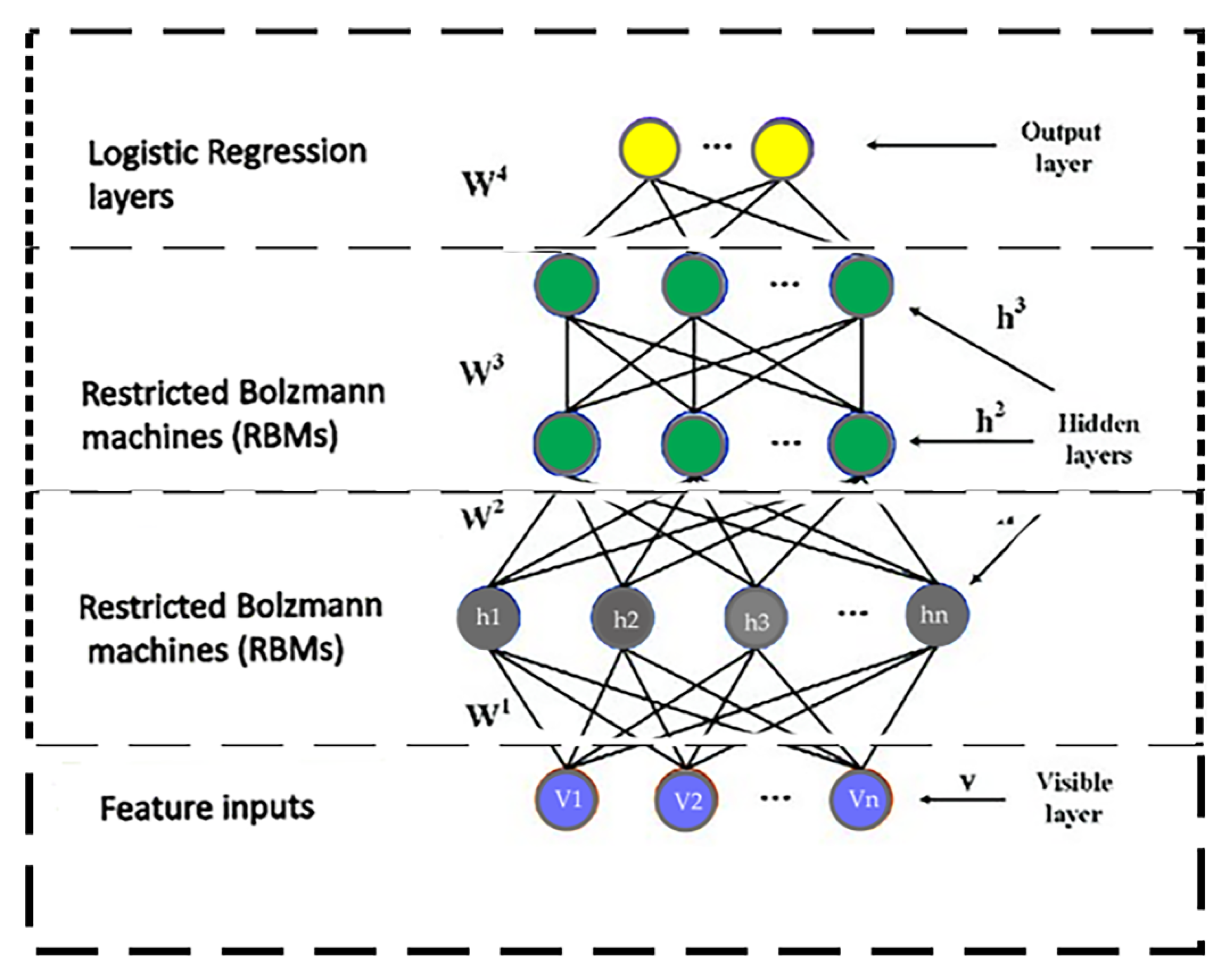
3.6. Event Classification Engine: Deep Belief Network
4. Experimental Results
4.1. Datasets Description
4.2. Experiment I: Body Part Detection Accuracies
4.3. Experiment II: Event Classification Accuracies
4.4. Experiment III: Comparison with Other Classification Algorithms
4.5. Experimentation IV: Qualitative Analysis and Comparison of our Proposed System with State-of-the-Art Techniques
4.6. Experimentation V: Comparison of our Proposed System with State-of-the-Art Techniques
5. Discussion
6. Conclusions
6.1. Theoretical Implications
6.2. Research Limitations
Author Contributions
Funding
Conflicts of Interest
References
- Tahir, S.B.U.D.; Jalal, A.; Kim, K. Wearable Inertial Sensors for Daily Activity Analysis Based on Adam Optimization and the Maximum Entropy Markov Model. Entropy 2020, 22, 579. [Google Scholar] [CrossRef] [PubMed]
- Tahir, S.B.U.D.; Jalal, A.; Batool, M. Wearable Sensors for Activity Analysis using SMO-based Random Forest over Smart home and Sports Datasets. In Proceedings of the 2020 3rd International Conference on Advancements in Computational Sciences (ICACS), Lahore, Pakistan, 17–19 February 2020; 2020; pp. 1–6. [Google Scholar]
- Susan, S.; Agrawal, P.; Mittal, M.; Bansal, S. New shape descriptor in the context of edge continuity. CAAI Trans. Intell. Technol. 2019, 4, 101–109. [Google Scholar] [CrossRef]
- Rehman, M.A.U.; Raza, H.; Akhter, I. Security Enhancement of Hill Cipher by Using Non-Square Matrix Approach. In Proceedings of the 4th international conference on knowledge and innovation in Engineering, Science and Technology, Berlin, Germany, 21–23 December 2018. [Google Scholar]
- Tingting, Y.; Junqian, W.; Lintai, W.; Yong, X. Three-stage network for age estimation. CAAI Trans. Intell. Technol. 2019, 4, 122–126. [Google Scholar] [CrossRef]
- Wiens, T. Engine speed reduction for hydraulic machinery using predictive algorithms. Int. J. Hydromech. 2019, 2, 16. [Google Scholar] [CrossRef]
- Shokri, M.; Tavakoli, K. A review on the artificial neural network approach to analysis and prediction of seismic damage in infrastructure. Int. J. Hydromech. 2019, 2, 178. [Google Scholar] [CrossRef]
- Jalal, A.; Sarif, N.; Kim, J.T.; Kim, T.-S. Human Activity Recognition via Recognized Body Parts of Human Depth Silhouettes for Residents Monitoring Services at Smart Home. Indoor Built Environ. 2012, 22, 271–279. [Google Scholar] [CrossRef]
- Jalal, A.; Uddin, Z.; Kim, T.-S. Depth video-based human activity recognition system using translation and scaling invariant features for life logging at smart home. IEEE Trans. Consum. Electron. 2012, 58, 863–871. [Google Scholar] [CrossRef]
- Jalal, A.; Kim, Y.; Kim, D. Ridge body parts features for human pose estimation and recognition from RGB-D video data. In Proceedings of the Fifth International Conference on Computing, Communications and Networking Technologies (ICCCNT), Hefei, China, 11–14 July 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 1–6. [Google Scholar]
- Jalal, A.; Kamal, S.; Kim, D. A Depth Video Sensor-Based Life-Logging Human Activity Recognition System for Elderly Care in Smart Indoor Environments. Sensors 2014, 14, 11735–11759. [Google Scholar] [CrossRef]
- Akhter, I. Automated Posture Analysis of Gait Event Detection via a Hierarchical Optimization Algorithm and Pseudo 2D Stick-Model. Ph.D. Thesis, Air University, Islamabad, Pakistan, December 2020. [Google Scholar]
- Jalal, A.; Nadeem, A.; Bobasu, S. Human Body Parts Estimation and Detection for Physical Sports Movements. In Proceedings of the 2019 2nd International Conference on Communication, Computing and Digital systems (C-CODE), Islamabad, Pakistan, 6–7 March 2019; pp. 104–109. [Google Scholar]
- Mahmood, M.; Jalal, A.; Kim, K. WHITE STAG model: Wise human interaction tracking and estimation (WHITE) using spatio-temporal and angular-geometric (STAG) descriptors. Multimed. Tools Appl. 2020, 79, 6919–6950. [Google Scholar] [CrossRef]
- Quaid, M.A.K.; Jalal, A. Wearable sensors based human behavioral pattern recognition using statistical features and reweighted genetic algorithm. Multimed. Tools Appl. 2020, 79, 6061–6083. [Google Scholar] [CrossRef]
- Nadeem, A.; Jalal, A.; Kim, K. Human Actions Tracking and Recognition Based on Body Parts Detection via Artificial Neural Network. In Proceedings of the 3rd International Conference on Advancements in Computational Sciences (ICACS 2020), Lahore, Pakistan, 17–19 February 2020; pp. 1–6. [Google Scholar]
- Ahmed, A.; Jalal, A.; Kim, K. A Novel Statistical Method for Scene Classification Based on Multi-Object Categorization and Logistic Regression. Sensors 2020, 20, 3871. [Google Scholar] [CrossRef] [PubMed]
- Jalal, A.; Mahmood, M. Students’ behavior mining in e-learning environment using cognitive processes with information technologies. Educ. Inf. Technol. 2019, 24, 2797–2821. [Google Scholar] [CrossRef]
- Gochoo, M.; Tan, T.-H.; Huang, S.-C.; Batjargal, T.; Hsieh, J.-W.; Alnajjar, F.S.; Chen, Y.-F. Novel IoT-based privacy-preserving yoga posture recognition system using low-resolution infrared sensors and deep learning. IEEE Internet Things J. 2019, 6, 7192–7200. [Google Scholar] [CrossRef]
- Gochoo, M.; Tan, T.-H.; Liu, S.-H.; Jean, F.-R.; Alnajjar, F.S.; Huang, S.-C. Unobtrusive Activity Recognition of Elderly People Living Alone Using Anonymous Binary Sensors and DCNN. IEEE J. Biomed. Heal. Informatics 2018, 23, 1. [Google Scholar] [CrossRef] [PubMed]
- Lee, M.W.; Nevatia, R. Body Part Detection for Human Pose Estimation and Tracking. In Proceedings of the 2007 IEEE Workshop on Motion and Video Computing (WMVC’07), Austin, TX, USA, 23–24 February 2007; p. 23. [Google Scholar]
- Aggarwal, J.; Cai, Q. Human Motion Analysis: A Review. Comput. Vis. Image Underst. 1999, 73, 428–440. [Google Scholar] [CrossRef]
- Wang, L.; Hu, W.; Tan, T. Recent developments in human motion analysis. Pattern Recognit. 2003, 36, 585–601. [Google Scholar] [CrossRef]
- Liu, J.; Luo, J.; Shah, M. Recognizing realistic actions from videos “in the Wild”. In Proceedings of the 2009 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, CVPR Workshops 2009, Miami Beach, FL, USA, 20–25 June 2009. [Google Scholar]
- Khan, M.A.; Javed, K.; Khan, S.A.; Saba, T.; Habib, U.; Khan, J.A.; Abbasi, A.A. Human action recognition using fusion of multiview and deep features: An application to video surveillance. Multimedia Tools Appl. 2020, 1–27. [Google Scholar] [CrossRef]
- Zou, Y.; Shi, Y.; Shi, D.; Wang, Y.; Liang, Y.; Tian, Y. Adaptation-Oriented Feature Projection for One-shot Action Recognition. IEEE Trans. Multimedia 2020, 1. [Google Scholar] [CrossRef]
- Franco, A.; Magnani, A.; Maio, D. A multimodal approach for human activity recognition based on skeleton and RGB data. Pattern Recognit. Lett. 2020, 131, 293–299. [Google Scholar] [CrossRef]
- Ullah, A.; Muhammad, K.; Haq, I.U.; Baik, S.W. Action recognition using optimized deep autoencoder and CNN for surveillance data streams of non-stationary environments. Futur. Gener. Comput. Syst. 2019, 96, 386–397. [Google Scholar] [CrossRef]
- Jalal, A.; Kamal, S.; Kim, D.-S. Detecting Complex 3D Human Motions with Body Model Low-Rank Representation for Real-Time Smart Activity Monitoring System. KSII Trans. Internet Inf. Syst. 2018, 12, 1189–1204. [Google Scholar] [CrossRef]
- Jalal, A.; Mahmood, M.; Hasan, A.S. Multi-features descriptors for Human Activity Tracking and Recognition in Indoor-Outdoor Environments. In Proceedings of the 2019 16th International Bhurban Conference on Applied Sciences and Technology (IBCAST), Islamabad, Pakistan, 8–12 January 2019; pp. 371–376. [Google Scholar]
- van der Kruk, E.; Reijne, M.M. Accuracy of human motion capture systems for sport applications; state-of-the-art review. Eur. J. Sport Sci. 2018, 18, 806–819. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Mori, G. Multiple Tree Models for Occlusion and Spatial Constraints in Human Pose Estimation. In European Conference on Computer Vision; the Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer International Publishing: Berlin/Heidelberg, Germany, 2008; Volume 5304, pp. 710–724. [Google Scholar]
- Amft, O.O.; Tröster, G. Recognition of dietary activity events using on-body sensors. Artif. Intell. Med. 2008, 42, 121–136. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Du, B.; Shen, Y.; Wu, K.; Zhao, G.; Sun, J.; Wen, H. EV-Gait: Event-Based Robust Gait Recognition Using Dynamic Vision Sensors. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 6351–6360. [Google Scholar]
- Jiang, Y.-G.; Dai, Q.; Mei, T.; Rui, Y.; Chang, S.-F.; Chang, S.-F. Super Fast Event Recognition in Internet Videos. IEEE Trans. Multimedia 2015, 17, 1. [Google Scholar] [CrossRef]
- Li, A.; Miao, Z.; Cen, Y.; Zhang, X.-P.; Zhang, L.; Chen, S. Abnormal event detection in surveillance videos based on low-rank and compact coefficient dictionary learning. Pattern Recognit. 2020, 108, 107355. [Google Scholar] [CrossRef]
- Einfalt, M.; Dampeyrou, C.; Zecha, D.; Lienhart, R. Frame-Level Event Detection in Athletics Videos with Pose-Based Convolutional Sequence Networks. In Proceedings of the 2nd International Workshop on Multimedia Content Analysis in Sports—MMSports’19; Association for Computing Machinery (ACM): New York, NY, USA, 2019; pp. 42–50. [Google Scholar]
- Yu, J.; Lei, A.; Hu, Y. Soccer Video Event Detection Based on Deep Learning. In Proceedings of the Constructive Side-Channel Analysis and Secure Design; Springer International Publishing: Berlin/Heidelberg, Germany, 2018; pp. 377–389. [Google Scholar]
- Franklin, R.J.; Mohana; Dabbagol, V. Anomaly Detection in Videos for Video Surveillance Applications using Neural Networks. In Proceedings of the 2020 Fourth International Conference on Inventive Systems and Control (ICISC), Coimbatore, India, 8–10 January 2020; pp. 632–637. [Google Scholar]
- Lohithashva, B.; Aradhya, V.M.; Guru, D. Violent Video Event Detection Based on Integrated LBP and GLCM Texture Features. Rev. d’intelligence Artif. 2020, 34, 179–187. [Google Scholar] [CrossRef]
- Feng, Q.; Gao, C.; Wang, L.; Zhao, Y.; Song, T.; Li, Q. Spatio-temporal fall event detection in complex scenes using attention guided LSTM. Pattern Recognit. Lett. 2020, 130, 242–249. [Google Scholar] [CrossRef]
- Khan, M.H.; Zöller, M.; Farid, M.S.; Grzegorzek, M. Marker-Based Movement Analysis of Human Body Parts in Therapeutic Procedure. Sensors 2020, 20, 3312. [Google Scholar] [CrossRef] [PubMed]
- Esfahani, M.I.M.; Zobeiri, O.; Moshiri, B.; Narimani, R.; Mehravar, M.; Rashedi, E.; Parnianpour, M. Trunk Motion System (TMS) Using Printed Body Worn Sensor (BWS) via Data Fusion Approach. Sensors 2017, 17, 112. [Google Scholar] [CrossRef]
- Golestani, N.; Moghaddam, M. Human activity recognition using magnetic induction-based motion signals and deep recurrent neural networks. Nat. Commun. 2020, 11, 1–11. [Google Scholar] [CrossRef]
- Kaveh, A.; Talatahari, S. A novel heuristic optimization method: Charged system search. Acta Mech. 2010, 213, 267–289. [Google Scholar] [CrossRef]
- Chen, Y.; Zhao, X.; Jia, X. Spectral–Spatial Classification of Hyperspectral Data Based on Deep Belief Network. IEEE J. Sel. Top. Appl. Earth Obs. Remote. Sens. 2015, 8, 2381–2392. [Google Scholar] [CrossRef]
- Jalal, A.; Kamal, S.; Kim, D. Depth silhouettes context: A new robust feature for human tracking and activity recognition based on embedded HMMs. In Proceedings of the 2015 12th International Conference on Ubiquitous Robots and Ambient Intelligence (URAI), Goyang City, Korea, 28–30 October 2015; pp. 294–299. [Google Scholar]
- Li, H.; Lu, H.; Lin, Z.L.; Shen, X.; Price, B.L. Inner and Inter Label Propagation: Salient Object Detection in the Wild. IEEE Trans. Image Process. 2015, 24, 3176–3186. [Google Scholar] [CrossRef] [PubMed]
- Moschini, D.; Fusiello, A. Tracking Human Motion with Multiple Cameras Using an Articulated Model. In Computer Graphics Collaboration Techniques and Applications; Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer International Publishing: Berlin/Heidelberg, Germany, 2009; Volume 5496, pp. 1–12. [Google Scholar]
- Jalal, A.; Akhtar, I.; Kim, K. Human Posture Estimation and Sustainable Events Classification via Pseudo-2D Stick Model and K-ary Tree Hashing. Sustainability 2020, 12, 9814. [Google Scholar] [CrossRef]
- Niebles, J.C.; Chen, C.-W.; Fei-Fei, L. Modeling Temporal Structure of Decomposable Motion Segments for Activity Classification. In Proceedings of the Constructive Side-Channel Analysis and Secure Design; Springer International Publishing: Berlin/Heidelberg, Germany, 2010; pp. 392–405. [Google Scholar]
- Safdarnejad, S.M.; Liu, X.; Udpa, L.; Andrus, B.; Wood, J.; Craven, D. Sports Videos in the Wild (SVW): A video dataset for sports analysis. In Proceedings of the 2015 11th IEEE International Conference and Workshops on Automatic Face and Gesture Recognition (FG), Ljubljana, Slovenia, 4–8 May 2015; Volume 1, pp. 1–7. [Google Scholar]
- Wang, L.; Zhang, Y.; Feng, J. On the Euclidean distance of images. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 1334–1339. [Google Scholar] [CrossRef] [PubMed]
- Akhter, I.; Jalal, A.; Kim, K. Pose Estimation and Detection for Event Recognition using Sense-Aware Features and Ada-boost Classifier. In Proceedings of the 18th International Bhurban Conference on Applied Sciences and Technology (IBCAST), Islamabad, Pakistan, 12–16 January 2021. [Google Scholar]
- Hong, S.; Kim, M. A Framework for Human Body Parts Detection in RGB-D Image. J. Korea Multimedia Soc. 2016, 19, 1927–1935. [Google Scholar] [CrossRef][Green Version]
- Chen, X.; Yuille, A. Articulated pose estimation by a graphical model with image dependent pairwise relations. arXiv 2014, arXiv:1407.3399. [Google Scholar]
- Mahmood, M.; Jalal, A.; Sidduqi, M.A. Robust Spatio-Temporal Features for Human Interaction Recognition Via Artificial Neural Network. In Proceedings of the 2018 International Conference on Frontiers of Information Technology (FIT), Islamabad, Pakistan, 17–19 December 2018; pp. 218–223. [Google Scholar]
- Dorin, C.; Hurwitz, B. Automatic body part measurement of dressed humans using single rgb-d camera. In Proceedings of the 2016 CHI Conference Extended Abstracts on Human Factors in Computing Systems, San Jose, CA, USA, 7–12 May 2016; pp. 3042–3048. [Google Scholar]
- Zhang, D.; Shah, M. Human pose estimation in videos. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 2012–2020. [Google Scholar]
- Amer, M.R.; Todorovic, S. Sum Product Networks for Activity Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 800–813. [Google Scholar] [CrossRef] [PubMed]
- Gomathi, S.; Santhanam, T. Application of Rectangular Feature for Detection of Parts of Human Body. Adv. Comput. Sci. Technol. 2018, 11, 43–55. [Google Scholar]
- Li, Y.; Liu, S.G. Temporal-coherency-aware human pose estimation in video via pre-trained res-net and flow-CNN. In Proceedings of the International Conference on Computer Animation and Social Agents (CASA), Seoul, Korea, 22–24 May 2017; pp. 150–159. [Google Scholar]
- Kong, Y.; Liang, W.; Dong, Z.; Jia, Y. Recognising human interaction from videos by a discriminative model. IET Comput. Vis. 2014, 8, 277–286. [Google Scholar] [CrossRef]
- Rodriguez, C.; Fernando, B.; Li, H. Action Anticipation by Predicting Future Dynamic Images. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Xing, D.; Wang, X.; Lu, H. Action Recognition Using Hybrid Feature Descriptor and VLAD Video Encoding. In Asian Conference on Computer Vision; Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer International Publishing: Berlin/Heidelberg, Germany, 2015; Volume 9008, pp. 99–112. [Google Scholar]
- Chattopadhyay, C.; Das, S. Supervised framework for automatic recognition and retrieval of interaction: A framework for classification and retrieving videos with similar human interactions. IET Comput. Vis. 2016, 10, 220–227. [Google Scholar] [CrossRef]
- Sun, S.; Kuang, Z.; Sheng, L.; Ouyang, W.; Zhang, W. Optical Flow Guided Feature: A Fast and Robust Motion Representation for Video Action Recognition. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1390–1399. [Google Scholar]
- Rachmadi, R.F.; Uchimura, K.; Koutaki, G. Combined convolutional neural network for event recognition. In Proceedings of the Korea-Japan Joint Workshop on Frontiers of Computer Vision, Takayama, Japan, 17–19 February 2016; pp. 85–90. [Google Scholar]
- Zhang, L.; Xiang, X. Video event classification based on two-stage neural network. Multimedia Tools Appl. 2020, 79, 21471–21486. [Google Scholar] [CrossRef]
- Wang, H.; Oneata, D.; Verbeek, J.; Schmid, C. A Robust and Efficient Video Representation for Action Recognition. Int. J. Comput. Vis. 2016, 119, 219–238. [Google Scholar] [CrossRef]
- Nadeem, A.; Jalal, A.; Kim, K. Accurate Physical Activity Recognition using Multidimensional Features and Markov Model for Smart Health Fitness. Symmetry 2020, 12, 1766. [Google Scholar] [CrossRef]
- Zhu, Y.; Zhou, K.; Wang, M.; Zhao, Y.; Zhao, Z. A comprehensive solution for detecting events in complex surveillance videos. Multimedia Tools Appl. 2018, 78, 817–838. [Google Scholar] [CrossRef]
- Park, E.; Han, X.; Berg, T.L.; Berg, A.C. Combining multiple sources of knowledge in deep CNNs for action recognition. In Proceedings of the 2016 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Placid, NY, USA, 7–10 March 2016. [Google Scholar]
- Jain, M.; Jegou, H.; Bouthemy, P. Better Exploiting Motion for Better Action Recognition. In Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013. [Google Scholar]























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Main Contributions |
|---|---|
| Lee et al. [21] | They developed a state-of-the-art hierarchical method in which human body part identification is used for critical silhouette monitoring. Additionally, they introduced region comparison features for optimal data values and to obtain rich information. |
| Aggarwal et al. [22] | They designed a robust scheme, for human body part motion analysis, using multiple cameras that track the human body parts, and for human identification. They also developed a 2D–3D projection for human body joints. |
| Wang et al. [23] | They explained a framework to analyze human behavior. For this, they used the identification of humans, human activity identification and human tracking approaches. |
| Liu, J et al. [24] | They proposed a robust random forest based technique for human body part training, using temporal features, static and motion features. They estimated various human actions in videos and images. |
| Khan and M. A [25] | They suggested an automated process using multiview features, vertical and horizontal gradient features. They used Deep Neural Network (DNN) fusion to identify human actions. A pre-trained Convolutional Neural Network CNN-VGG19 model is adopted to achieve DNN-based feature techniques. |
| Zou and Shi [26] | They explained an automated system, Adaptation-Oriented Features (AOF), with one-shot action identification for the estimation of human actions. The system pertains to every class, and for output, they combine AOF parameters. |
| Franco and Magnani [27] | They designed a multilayer structure for intensive human skeleton information, via RGB images. They extracted Histogram of Oriented (HOG) descriptor features for human action recognition. |
| Ullah and Muhammad [28] | They describe a unified Convolutional Neural Network (CNN)-based approach for real-time data communication and data streams. For data extraction from non-monitoring devices, they used visual sensors. To monitor the human action, temporal features along with deep autoencoder and deep features are estimated via the Convolutional Neural Network (CNN) model. |
| Jalal, A et al. [29] | They proposed a novel technique to identify daily human activities in a smart home environment via depth-based daily routine functionality. They also defined the AR method for the estimation of human activities. |
| Jalal, A et al. [30] | They explained a robust system using a marker-based system in which many body markers are attached to the human body at various strategic points. With the help of extracted synthetic contexts and the multiactors platform, they identify human activity. |
| Kruk and Reijne [31] | They developed a unified model to estimate vibrant human motion in sports event via body marker sensors. The main contribution is the estimation of the kinematics of human body joints, acceleration, velocity and the reconstruction of the human pose to compute human events in sports datasets. |
| Wang and Mori [32] | They proposed a novel technique for event recognition, via spatial relations and human body pose. Tree-based features are described using the kinematics information of connected human body parts. |
| Amft and Troster [33] | They developed a robust framework via a Hidden Markov approach. Time-continuous based features using body marker sensors event recognition is achieved. |
| Wang et al. [34] | They designed a new systematic approach to estimate the consistency of human motion with the help of a human tracking approach. A Deep Neural Network (DNN) is used for event recognition. |
| Jaing et al. [35] | They introduced a multilayered feature method for the estimation of human motion and movements. For event recognition in dynamic scenes, they used a late average mixture algorithm. |
| Li, et al. [36] | They proposed an innovative method for event recognition via joint optimization, optical flow and a histogram of the obtained optical flow. With the help of the norm optimization method, body joint reconstruction and a Low-rank and Compact Coefficient Dictionary Learning (LRCCDL) approach, they achieved accurate event identification. |
| Einfalt et al. [37] | They designed a unified method for the event recognition of an athlete in motion, using task classification, extraction of chronological 2D posture features and a convolutional sequence network. They recognized a sports event precisely. |
| Yu et al. [38] | They explain a heuristic framework that can detect events in a distinct interchange from soccer competition videos. This is achieved with the help of the replay identification approac to discover maximum context features for gratifying spectator requirements and constructing replay story clips. |
| Franklin et al. [39] | They proposed a robust deep learning mechanism for abnormal and normal event detection. Segmentation, classification and graph-based approaches were used to obtain the results. Using deep learning methods, they found normal and abnormal features for event interval utilization. |
| Lohithashva et al. [40] | They designed an innovative mixture features descriptor approach for intense event recognition via the Gray Level Co-occurrence Matrix (GLCM) and the Local Binary Pattern (LBP). They used extracted features with machine learning supervised classification systems for event identification. |
| Feng et al. [41] | They proposed a directed Long Short Term Memory (LSTM) method using a Convolutional Neural Network (CCN)-based model to extract deep features’ temporal positions in composite videos. The state-of-the-art YOLO v3 model is used for human identification and a guided Long Short Term Memory (LSTM)-based framework is adopted for event recognition. |
| Khan et al. [42] | They developed a body-marker sensor-based technique for home-based patient management. Body-marker sensors utilizing a color indication scheme are attached to the joints of the human body to record data of the patients. |
| Esfahani et al. [43] | For sports events, human motion observation body-marker instruments were used to develop a low computational process-based Trunk Motion Method (TMM) with Body-worn Sensors (BWS). In this approach, 12 removable sensors were utilized to calculate trunk 3D motions. |
| Golestani et al. [44] | They proposed a robust wireless framework to identify physical human actions. They tracked human actions with a magnetic induction cable; body-marker sensors were associated with human body joints. To achieve improved accuracy, the laboratory estimation function and Deep Recurrent Neural Network (RNN) were used. |
| Body Key Points | Distance | UT (%) | Distance | Olympic Sports (%) | Distance | SVW (%) |
|---|---|---|---|---|---|---|
| HP | 10.2 | 90 | 10 | 87 | 9 | 89 |
| NP | 9.8 | 85 | 11 | 83 | 10.1 | 86 |
| RSP | 10.5 | 80 | 11.1 | 81 | 12.1 | 83 |
| REP | 10.1 | 82 | 10.7 | 81 | 12.9 | 84 |
| RWP | 8.3 | 77 | 10.5 | 80 | 13 | 79 |
| RHP | 11.8 | 83 | 12 | 79 | 11 | 81 |
| LSP | 12.1 | 81 | 12.9 | 78 | 12 | 83 |
| LEP | 11 | 79 | 11 | 80 | 10 | 75 |
| LWP | 12.1 | 76 | 10 | 81 | 13.1 | 80 |
| LHP | 10.4 | 81 | 13 | 80 | 12.8 | 79 |
| MP | 11.1 | 90 | 14 | 89 | 12.9 | 87 |
| RHP | 12.9 | 77 | 13.9 | 80 | 11.1 | 83 |
| LHP | 11.1 | 80 | 10.1 | 75 | 10.8 | 80 |
| LKP | 11.2 | 93 | 11.8 | 90 | 9.3 | 94 |
| RKP | 10.9 | 90 | 12.3 | 87 | 12.7 | 89 |
| RAP | 11.5 | 81 | 12.7 | 80 | 12.6 | 79 |
| LAP | 11.2 | 78 | 13.1 | 79 | 13 | 78 |
| LFP | 12.3 | 95 | 11 | 94 | 11.1 | 92 |
| RFP | 10.5 | 90 | 9.3 | 93 | 10.8 | 91 |
| Mean Accuracy Rate | 83.57 | 83.00 | 83.78 | |||
| Body Parts | Person1 | Person2 | Person3 | Person4 | Person5 |
|---|---|---|---|---|---|
| HP | ✓ | ✓ | ✓ | ✓ | ✓ |
| NP | ✓ | ✓ | ✓ | ✓ | ✓ |
| RSP | ✓ | ✕ | ✓ | ✕ | ✕ |
| REP | ✕ | ✓ | ✓ | ✓ | ✓ |
| RWP | ✓ | ✕ | ✓ | ✕ | ✓ |
| RHP | ✓ | ✓ | ✕ | ✓ | ✓ |
| LSP | ✕ | ✓ | ✕ | ✓ | ✕ |
| LEP | ✓ | ✕ | ✓ | ✓ | ✕ |
| LWP | ✓ | ✓ | ✓ | ✓ | ✓ |
| LHP | ✕ | ✕ | ✓ | ✕ | ✕ |
| MP | ✓ | ✓ | ✓ | ✓ | ✓ |
| RHP | ✓ | ✓ | ✕ | ✕ | ✓ |
| LHP | ✓ | ✓ | ✓ | ✓ | ✕ |
| LKP | ✕ | ✓ | ✓ | ✕ | ✓ |
| RKP | ✓ | ✕ | ✕ | ✓ | ✕ |
| RAP | ✓ | ✓ | ✓ | ✓ | ✓ |
| LAP | ✕ | ✓ | ✕ | ✓ | ✕ |
| LFP | ✓ | ✓ | ✓ | ✓ | ✓ |
| RFP | ✓ | ✓ | ✓ | ✓ | ✓ |
| Accuracy | 73.1% | 73.6% | 73.7% | 73.8% | 63.1% |
| Mean accuracy = 71.41% | |||||
| Sequence No (Frames = 25) | Actual Track | Successful | Failure | Accuracy |
|---|---|---|---|---|
| 6 | 4 | 4 | 0 | 100 |
| 12 | 4 | 4 | 0 | 100 |
| 18 | 5 | 5 | 0 | 100 |
| 24 | 6 | 5 | 1 | 87.33 |
| 30 | 6 | 5 | 1 | 83.43 |
| Mean Accuracy = 94.15 | ||||
| Event Classes | Artificial Neural Network | Adaboost | Deep Belief Network | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Events | Precision | Recall | F-1 Measure | Precision | Recall | F-1 Measure | Precision | Recall | F-1 Measure |
| HS | 0.727 | 0.800 | 0.762 | 0.778 | 0.875 | 0.824 | 0.833 | 1.000 | 0.909 |
| HG | 0.875 | 0.875 | 0.875 | 1.000 | 0.875 | 0.933 | 1.000 | 0.900 | 0.947 |
| KI | 0.889 | 0.727 | 0.800 | 0.889 | 0.889 | 0.889 | 1.000 | 1.000 | 1.000 |
| PT | 0.700 | 0.875 | 0.778 | 0.875 | 0.875 | 0.875 | 0.900 | 0.900 | 0.900 |
| PN | 0.700 | 0.778 | 0.737 | 0.875 | 0.778 | 0.824 | 0.900 | 0.900 | 0.900 |
| PS | 0.727 | 0.727 | 0.727 | 0.875 | 0.778 | 0.824 | 0.889 | 0.800 | 0.842 |
| Mean | 0.770 | 0.797 | 0.780 | 0.882 | 0.845 | 0.861 | 0.920 | 0.917 | 0.916 |
| Event Classes | Artificial Neural Network | Adaboost | Deep Belief Network | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Events | Precision | Recall | F-1 Measure | Precision | Recall | F-1 Measure | Precision | Recall | F-1 Measure |
| BG | 0.538 | 0.636 | 0.583 | 0.600 | 0.750 | 0.667 | 1.000 | 0.900 | 0.947 |
| DW | 0.692 | 0.750 | 0.720 | 0.636 | 0.636 | 0.636 | 0.889 | 0.800 | 0.842 |
| DM | 0.700 | 0.583 | 0.636 | 0.750 | 0.750 | 0.750 | 1.000 | 1.000 | 1.000 |
| HW | 0.636 | 0.636 | 0.636 | 0.636 | 0.636 | 0.636 | 0.900 | 0.900 | 0.900 |
| JW | 0.727 | 0.889 | 0.800 | 0.889 | 0.889 | 0.889 | 0.900 | 0.900 | 0.900 |
| LP | 0.778 | 0.636 | 0.700 | 0.800 | 0.667 | 0.727 | 0.909 | 1.000 | 0.952 |
| PT | 0.615 | 0.800 | 0.696 | 0.778 | 0.778 | 0.778 | 0.900 | 1.000 | 0.947 |
| ST | 0.563 | 0.750 | 0.643 | 0.563 | 0.750 | 0.643 | 1.000 | 0.800 | 0.889 |
| SH | 0.875 | 0.700 | 0.778 | 1.000 | 0.778 | 0.875 | 0.909 | 1.000 | 0.952 |
| BR | 0.583 | 0.700 | 0.636 | 0.778 | 0.778 | 0.778 | 0.909 | 1.000 | 0.952 |
| TP | 0.750 | 0.750 | 0.750 | 0.700 | 0.700 | 0.700 | 1.000 | 1.000 | 1.000 |
| VT | 0.750 | 0.667 | 0.706 | 0.733 | 0.636 | 0.681 | 1.000 | 1.000 | 1.000 |
| Mean | 0.684 | 0.708 | 0.690 | 0.739 | 0.729 | 0.730 | 0.943 | 0.942 | 0.940 |
| Event Classes | Artificial Neural Network | Adaboost | Deep Belief Network | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Events | Precision | Recall | F-1 Measure | Precision | Recall | F-1 Measure | Precision | Recall | F-1 Measure |
| AR | 0.636 | 0.778 | 0.700 | 0.778 | 0.778 | 0.778 | 0.889 | 0.800 | 0.842 |
| BB | 0.667 | 0.727 | 0.696 | 0.700 | 0.700 | 0.700 | 0.900 | 0.900 | 0.900 |
| Bt | 0.667 | 0.727 | 0.696 | 0.615 | 0.727 | 0.667 | 0.900 | 0.900 | 0.900 |
| BM | 0.727 | 0.727 | 0.727 | 0.800 | 0.615 | 0.696 | 0.900 | 0.900 | 0.900 |
| BW | 0.692 | 0.750 | 0.720 | 0.750 | 0.750 | 0.750 | 0.909 | 1.000 | 0.952 |
| CD | 0.538 | 0.583 | 0.560 | 0.533 | 0.727 | 0.615 | 0.667 | 0.800 | 0.727 |
| FB | 0.700 | 0.700 | 0.700 | 0.750 | 0.692 | 0.720 | 0.889 | 0.800 | 0.842 |
| GL | 0.800 | 0.615 | 0.696 | 0.700 | 0.778 | 0.737 | 0.900 | 0.900 | 0.900 |
| HJ | 0.636 | 0.700 | 0.667 | 0.583 | 0.636 | 0.609 | 0.800 | 0.800 | 0.800 |
| HK | 0.800 | 0.889 | 0.842 | 0.889 | 0.889 | 0.889 | 1.000 | 1.000 | 1.000 |
| HR | 0.889 | 0.533 | 0.667 | 0.800 | 0.800 | 0.800 | 0.909 | 1.000 | 0.952 |
| JV | 0.800 | 0.727 | 0.762 | 1.000 | 0.727 | 0.842 | 1.000 | 1.000 | 1.000 |
| LI | 0.636 | 0.778 | 0.700 | 0.538 | 0.636 | 0.583 | 0.800 | 0.800 | 0.800 |
| PT | 0.875 | 0.700 | 0.778 | 0.875 | 0.700 | 0.778 | 0.889 | 0.800 | 0.842 |
| RW | 0.727 | 0.889 | 0.800 | 0.778 | 0.778 | 0.778 | 0.900 | 0.900 | 0.900 |
| ST | 0.778 | 0.700 | 0.737 | 0.778 | 0.700 | 0.737 | 0.900 | 0.900 | 0.900 |
| SK | 0.500 | 0.500 | 0.500 | 1.000 | 0.778 | 0.875 | 1.000 | 0.900 | 0.947 |
| TN | 0.615 | 0.615 | 0.615 | 0.600 | 0.818 | 0.692 | 0.909 | 1.000 | 0.952 |
| VL | 0.778 | 0.875 | 0.824 | 0.875 | 0.700 | 0.778 | 1.000 | 0.900 | 0.947 |
| Mean | 0.709 | 0.711 | 0.704 | 0.755 | 0.733 | 0.738 | 0.851 | 0.853 | 0.851 |
| Proposed by | Body Part Detection Accuracy (%) | Proposed by | Human Posture Estimation Mean Accuracy (%) | Proposed by | Event Classification Mean Accuracy (%) |
|---|---|---|---|---|---|
| S. Hong, et al. [55] | 76.60 | Chen et al. [56] | 95.0 | Mahmood et al. [57] | 83.50 |
| C. Dorin et al. [58] | 81.90 | Zhang et al. [59] | 96.0 | Amer, M.R. et al. [60] | 82.40 |
| S. Gomathi et al. [61] | 82.71 | Li et al. [62] | 98.0 | Zhu, Y [63] | 83.10 |
| Proposed | 83.78 | Proposed | 98.3 | Proposed | 92.50 |
| Methods | UT-Interaction (%) | Methods | Olympic Sports (%) | Methods | Sports Videos in the Wild (%) |
|---|---|---|---|---|---|
| C. Rodriguez et al. [64] | 71.80 | Zhang.L et al. [69] | 59.10 | S. Sun et al. [67] | 74.20 |
| Xing et al. [65] | 85.67 | Sun. S et al. [67] | 74.20 | Reza. F et al. [68] | 82.30 |
| Chiranjoy. Cet et al. [66] | 89.25 | Wang. H et al. [70] | 89.60 | A. Nadeem et al. [71] | 89.09 |
| Wang. H et al. [70] | 89.10 | A. Nadeem et al. [71] | 88.26 | Zhu, Y [72] | 83.10 |
| Mahmood et al. [57] | 83.50 | E. Park et al. [73] | 89.10 | --- | --- |
| Amer, M.R. et al. [60] | 82.40 | M. Jain et a [74] | 83.20 | --- | --- |
| Kong, Y. et al. [63] | 85.00 | --- | --- | --- | --- |
| Proposed method | 91.67 | 92.50 | 89.47 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gochoo, M.; Akhter, I.; Jalal, A.; Kim, K. Stochastic Remote Sensing Event Classification over Adaptive Posture Estimation via Multifused Data and Deep Belief Network. Remote Sens. 2021, 13, 912. https://doi.org/10.3390/rs13050912
Gochoo M, Akhter I, Jalal A, Kim K. Stochastic Remote Sensing Event Classification over Adaptive Posture Estimation via Multifused Data and Deep Belief Network. Remote Sensing. 2021; 13(5):912. https://doi.org/10.3390/rs13050912
Chicago/Turabian StyleGochoo, Munkhjargal, Israr Akhter, Ahmad Jalal, and Kibum Kim. 2021. "Stochastic Remote Sensing Event Classification over Adaptive Posture Estimation via Multifused Data and Deep Belief Network" Remote Sensing 13, no. 5: 912. https://doi.org/10.3390/rs13050912
APA StyleGochoo, M., Akhter, I., Jalal, A., & Kim, K. (2021). Stochastic Remote Sensing Event Classification over Adaptive Posture Estimation via Multifused Data and Deep Belief Network. Remote Sensing, 13(5), 912. https://doi.org/10.3390/rs13050912