1. Introduction
Remote sensing (RS) has been widely proven to be advantageous for various environmental mapping tasks [
1,
2,
3,
4,
5]. Regardless of the RS data used for mapping, there are several challenges that can prevent the generation of accurate maps of land cover types of interest. Among these challenges, one is collecting sufficient training samples for a classification model. This is particularly true for classifiers that require large amounts of training data and/or if fieldwork is required in difficult-to-access sites. This challenge has been intensified lately due to COVID-19 restrictions worldwide. A second challenge is that suitable RS data for a study area may not be available; e.g., high spatial resolution (HSR) or cloud-free imagery. UAVs can be beneficial for overcoming both of these challenges due to their high flexibility (e.g., ability to quickly acquire imagery in study sites where other suitable RS data are not available), but planning UAV flights and processing UAV images over wide areas can be time and cost-prohibitive (although they are usually more efficient than acquiring traditional field data). A third challenge is that satellite/UAV images are subject to both spatial and temporal illumination variations (caused by variations in atmospheric conditions, sensor views, solar incidence angle, etc.) that may cause radiometric variations in image pixel values, especially in shortwave bands (e.g., Blue). Without accounting for illumination variations, the performance of classification models can be substantially degraded in unseen/test images. The main reason for this accuracy degradation is that the model learned from the distribution of the source image, which has now shifted in a given target image, meaning that it can no longer perform on the target image as well as it did on the source image on which it was trained. Such image-to-image variations are also found in images acquired by the same sensor unless appropriate normalizations and/or atmospheric corrections are performed.
In general, illumination variations in different scenes (including those acquired over the same area but different times) are a function of topography, the bidirectional reflectance distribution function (BRDF), and atmospheric effects. Accounting for these variables helps to balance radiometric variations in different images, thus making them consistent for different downstream tasks. In the case of raw images, one way of performing such corrections is through absolute radiometric correction to the surface reflectance, which consists of converting raw digital numbers to top-of-atmosphere (TOA) reflectance and then applying an atmospheric correction approach to derive ground-level surface reflectance. Relative radiometric correction (or normalization) is another way of harmonizing images that can be applied to cross-sensor images. Normalizing images to RS surface reflectance (SR) images (such as Landsat or Sentinel-2 images) [
6,
7,
8] or to ground-measured SR [
9] is a popular approach to harmonizing different sources of RS images. Maas and Rajan [
6] proposed a normalization approach (called scatter-plot matching (SPM)) based on invariant features in the scatter plot of pixel values in the red and near-infrared (NIR) bands. The authors reported the successful application of their approach for normalizing Landsat-7 images to Landsat-5 images and for normalizing to SR, although this approach only considers the red and NIR bands. Abuelgasim and Leblanc [
7] developed a workflow to generate Leaf Area Index (LAI) products (with an emphasis on northern parts of Canada). In this regard, the authors employed different sources of RS imagery (including Landsat, AVHRR, and SPOT VGT). To normalize Landsat-7 and Landsat-5 images to AVHRR and SPOT VGT images, the authors trained a Theil–Sen regression model using all the common pixels in a pair of images (i.e., the reference and target images) through improving the efficiency of the original approach to be able to process much more common pixels. In a study by Macander [
8], a solution was developed to normalize 2 m Pleiades satellite imagery to Landsat-8 SR imagery. The authors aimed to match the blue, green, red, and NIR bands to the same bands of a Landsat-8 SR composite (a 5 year summertime composite). For this purpose, they first masked out pixels with highly dynamic reflectance. Then, a linear regression was established between the Landsat-8 composite and the aggregated 30 m Pleiades satellite imagery. Finally, the trained linear model was applied directly to the 2 m Pleiades satellite imagery to obtain a high-resolution SR product. Rather than calibrating images based on an SR image, Staben, et al. [
9] calibrated WorldView-2 (WV2) images to ground SR measurements. For this, the authors used a quadratic equation to convert TOA spectral radiance in WV2 imagery to average field spectra for different target features (e.g., grass, water, sand, etc.). The experiments in that study showed that there was an acceptable level of discrepancies between the ground-truth averaged field spectra and the calibrated bands of the WV2 image, with the NIR band resulting in the largest variance among the other bands.
Although these normalization techniques have proven to be useful for making different non-atmospherically corrected images consistent with atmospherically corrected images, they should be done separately for each image (mainly through non-linear regression modeling). Such approaches are advantageous to harmonize images that have different characteristics (e.g., different acquisition frequencies). However, due to surface illumination variations (depending on sun angle) and varying atmospheric conditions, this does not guarantee seamless scene-to-scene spectral consistency [
8].
Another way of harmonizing images is based on classic approaches such as histogram matching (HM) [
10]. HM is an efficient, context-unaware technique that is widely used to transform the histogram of a given image to match a specific histogram (e.g., the histogram of another image) [
10]. Although this approach is efficient and easy to apply, it does not take into account contextual and textural information. Moreover, HM-based methods do not result in reasonable normalizations when the histogram of the target image is very different from that of the source image [
11]. All the approaches described above intuitively aim to adapt a source domain to a target domain, which in the literature is known as the adaptation of data distributions, a subfield of Domain Adaptation (DA) [
12]. The emergence of Deep Learning (DL) has opened new insights into how DA can significantly improve the performance of models on target images. DA has several variants, but they can be mainly grouped into two classes: Supervised DA (SDA) and Unsupervised DA (UDA) [
13]. DL-based DA approaches have also been successfully employed in RS applications, mainly for urban mapping [
14].
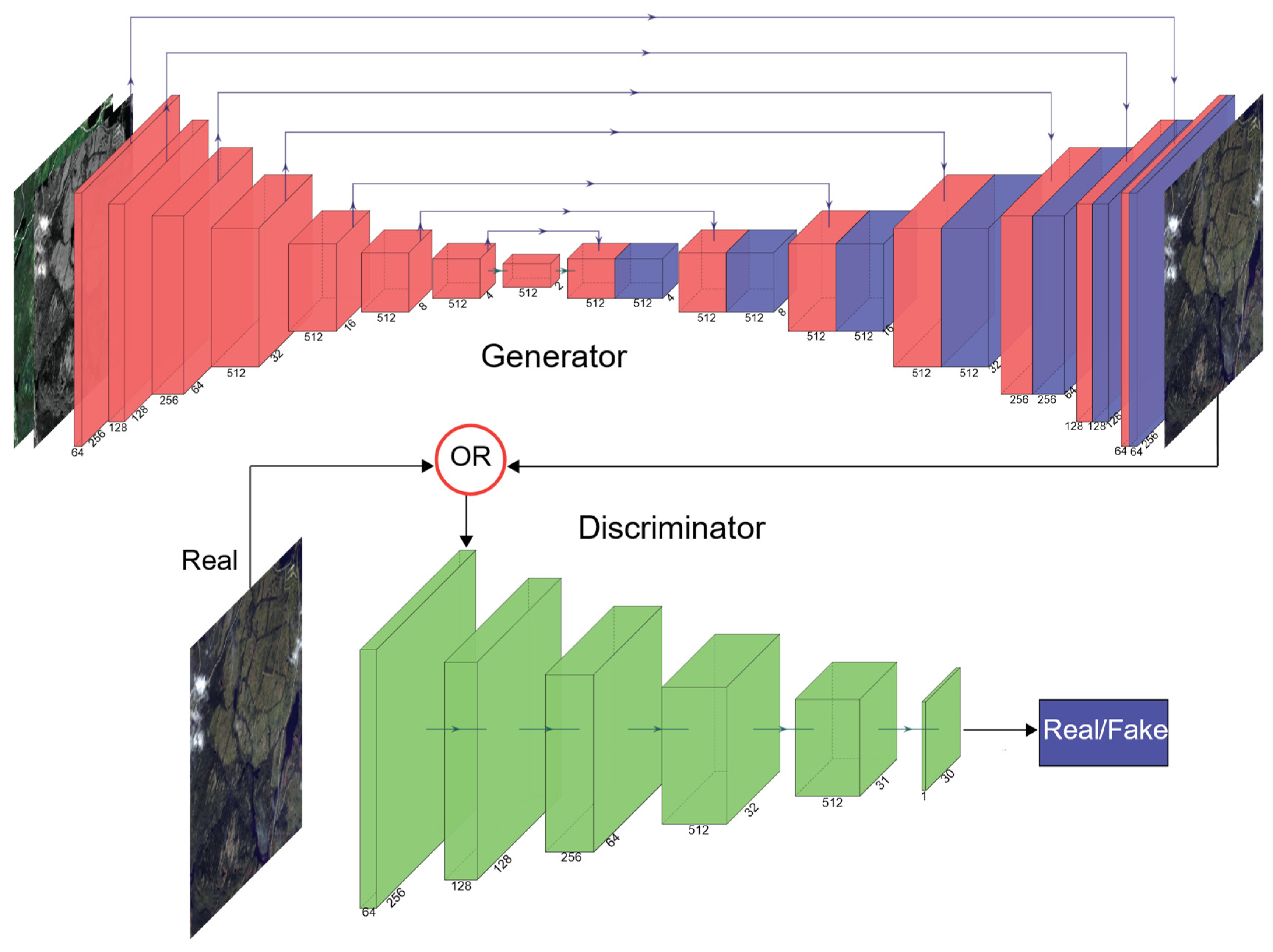
In this study, the main focus is not on normalizing images to surface reflectance, but rather on harmonizing different images regardless of their preprocessing level (e.g., radiometrically corrected, TOA reflectance, surface reflectance), which is a case of UDA. Considering this general-purpose direction, orthogonal to the majority of research in the context of environmental RS, we investigated an extreme case that has not been well studied in environmental RS mapping. The central question addressed in this study is that, if we assume that a classifier (either a DL model or a conventional one, or either a pixel- or object based) has already been trained on a single HRS image of one area (in our case, WV2 imagery), and if we do not have access to any of the target images of other areas during model training, to what degree is it possible to apply the same model, without any further training or collections of new samples whatsoever, to unseen target images and still obtain reasonable accuracy? This is a special, extreme case of UDA (or as we call it in this paper, image normalization). In recent years, Generative Adversarial Networks (GANs) [
15] have been used for several applications (e.g., DA, super-resolution, image fusion, semantic segmentation, etc.) in the context of RS [
16,
17,
18]. Given the potential of GANs in different vision tasks, cGANs based on Pix2Pix [
19] were adopted as the base of image normalization in this study.
3. Experimental Design
To evaluate the potential of image normalization based on cGANs, we conducted an experimental test for caribou lichen cover mapping. Caribou are known as ecologically important animals, but due to multiple factors ranging from climate change to hunting and disease, global caribou populations have been declining in recent decades, and they are now on the International Union for the Conservation of Nature’s (IUCN) red list of threatened species [
26]. Land cover change in caribou habitats is a major factor affecting resource availabilities, and it is driven by both indirect impacts of anthropogenic activities (e.g., climate change causing vegetation changes) as well as direct impacts (e.g., deforestation or forest degradation) [
27]. When land cover changes occur, it may cause caribou herds to change their distributions and migration patterns when foraging for food [
28]. Thus, for caribou conservation efforts, it is important to monitor and analyze the resources on which caribou are highly dependent, such as lichen, which is the main source of winter food of caribou [
29,
30]. Caribou lichens are generally bright-colored and could be challenging to detect in the case of illumination variations between a source image and target images, especially where there are other non-lichen bright features. To evaluate cGANs for image normalization for the lichen mapping task, we used WV2 images with a spatial resolution of 2 m for the multi-spectral bands and of 50 cm for the panchromatic band. Since WV2 images were subject to different atmospheric variations, it would also be reasonable to consider other sources of data/images that are less affected by atmospheric changes and lighting variations accordingly. A helpful option is to use atmospherically corrected images as auxiliary information to help cGANs to learn more stable features when normalizing target images. As explained in the next section, we also tested the potential of using both WV2 images and Sentinel-2 surface reflectance (SR) images for normalization.
3.1. Dataset
Five radiometrically corrected WV2 scenes with eight spectral bands from different parts of Canada were chosen for this study (
Figure 2). The radiometric correction on raw data was performed by the vendor to mitigate image artifacts (appearing as streaks and banding in the raw images) through including a dark offset subtraction and a non-uniformity correction including detector-to-detector relative gain. The Manic-5 image covers a 405 km
2 area located south of the Manicouagan Reservoir, Québec, Canada around the Manic-5 dam. This area consists of boreal forest (black spruce dominated) and open lichen woodlands, or forests with lichen. There are many waterbodies and water courses. The Fire Lake image covers a 294 km
2 area located around the Fire Lake Iron Mine in Québec, Canada. This area is comprised of dense boreal forests (black spruce dominated) with a great proportion of open lichen woodlands and/or forests with lichen. The Labrador image was acquired over 273 km
2 located east of Labrador City, Labrador, Canada. This area is comprised of dense boreal forests (black spruce dominated) with open lichen woodlands and/or forests with lichen. There are also a significant number of water features (bodies and courses) in this area. The Churchill Falls image covers a 397 km
2 area located west of Churchill Falls, Labrador, Canada. This area is comprised of dense boreal forests (black spruce dominated), open lichen woodlands and/or forests with lichen. The Nakina image covers a 261 km
2 area located east of the township of Nakina, Ontario, Canada. This area is comprised of dense boreal forests with very sparse, small lichen patches. Like the other images, this image covers several water bodies.
We chose the image acquired over Manic-5 area as our source image from which the training data were collected and used to train the models on this study. The reason for choosing this image as our source image was that we conducted fieldwork within an area covered by this image. The other four images were used for testing the efficacy of the pipeline applied. We attempted to choose target images from our database that were different from our source image in terms of illumination as much as possible. In all the images except the Labrador image, there were clouds or haze that caused a shift in the distribution of data. Of the four target images, the Nakina image had the least lichen cover. The Fire Lake image was used as a complementary target image to visually evaluate some of the important sources of errors that were observed mainly in this image. Along with WV2 images, we also used Sentinel-2 SR images in this paper. We used the Sentinel-2 Level-2 A product, which is geometrically and atmospherically corrected from the TOA product through an atmospheric correction using a set of look-up tables based on libRadtran [
31]. We chose six bands (B2-5, B8, B11) of 10 m Sentinel-2 SR cloud-free median composites (within the time periods close to the acquisition years of the WV2 images) and downloaded them from Google Earth Engine.
3.2. Training and Test Data
To train the cGANs, we used 5564 image patches with a size of 256 × 256 pixels. No specific preprocessing was performed on the images before inputting them into the models. In order to test the framework applied in this study, we clipped some sample parts of the Labrador, Churchill Falls, and Nakina images. A total of 14 regions in these three target images were clipped for testing purposes. From each of these 14 test image clips, through visual interpretation (with assistance from experts familiar with the areas), we randomly sampled at least 500 pixels (
Table 1), given the extent of each clip. We attempted to equalize the number of lichen and background samples. Overall, 14,074 test pixels were collected from these three target images.
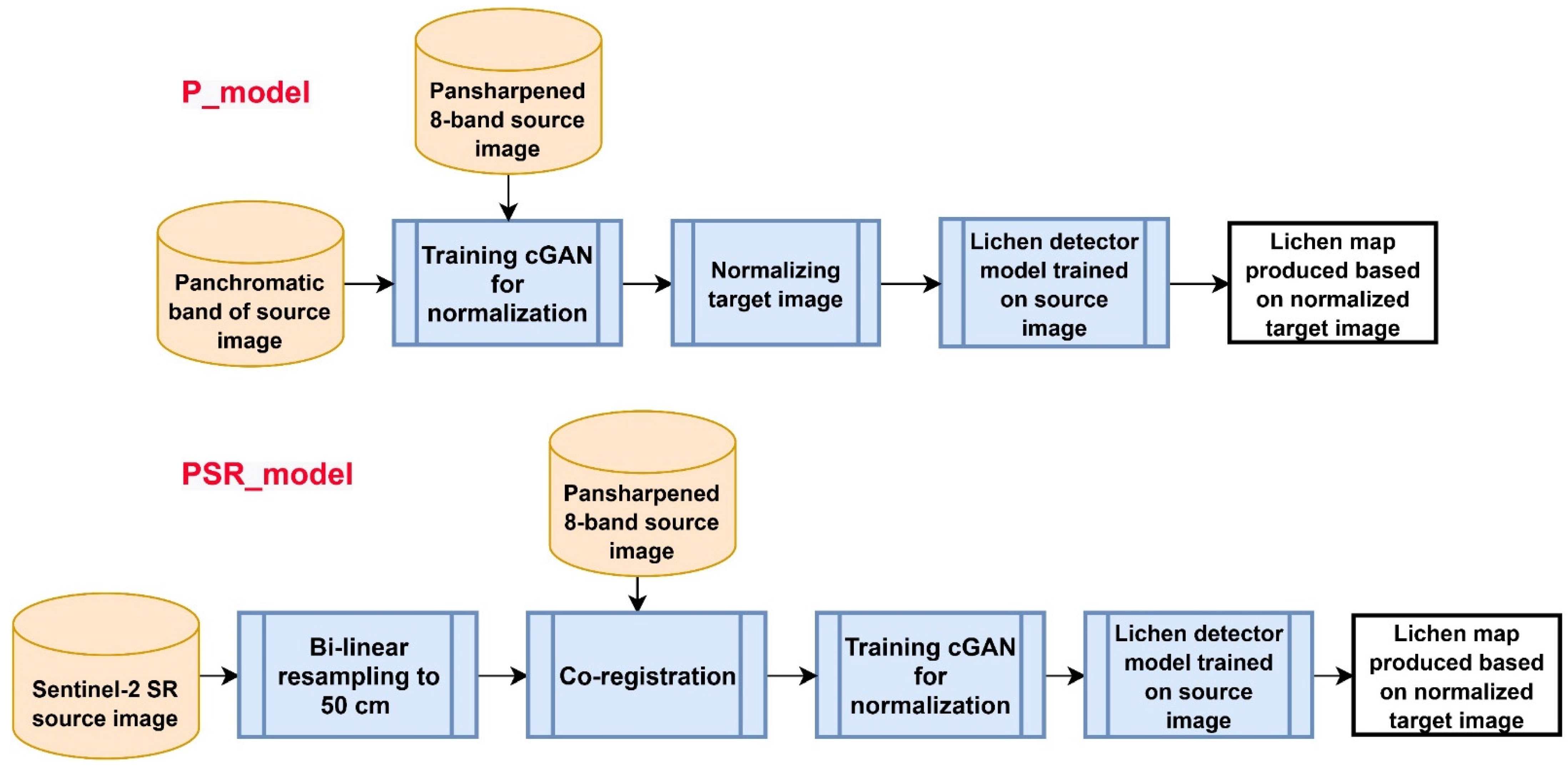
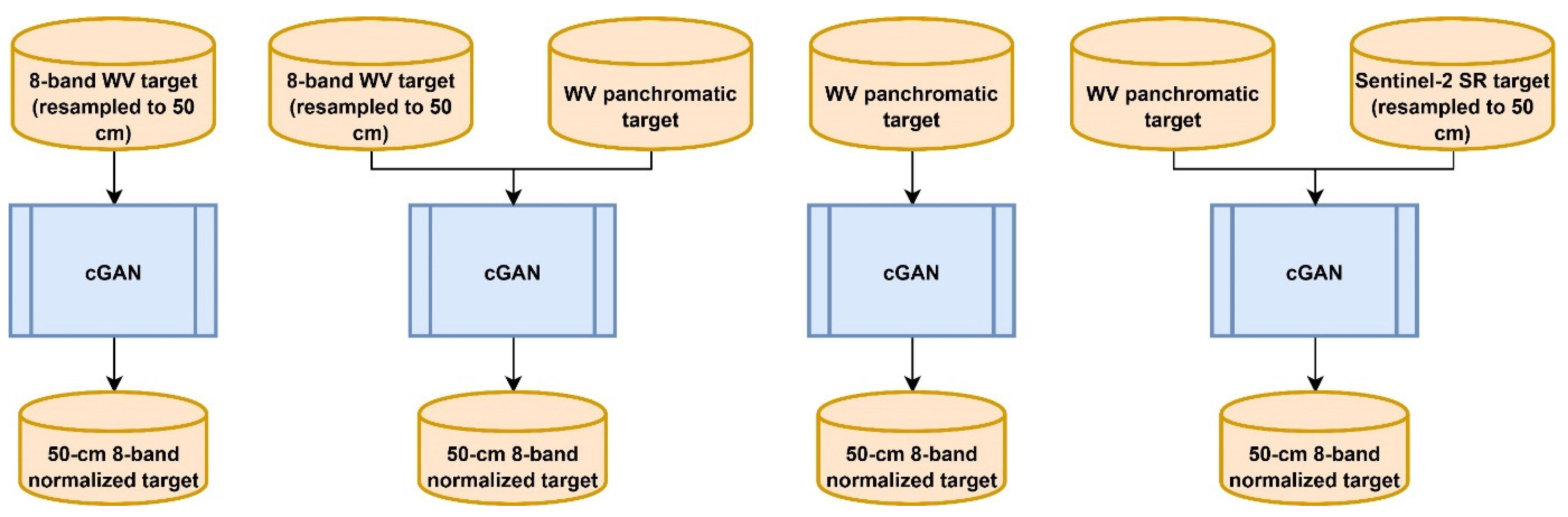
3.3. Normalization Scenarios
Different normalization scenarios were considered in this study based on either WV2 images or a combination of WV2 and auxiliary images. In fact, since WV2 images alone may not be sufficient to reach high-fidelity normalized target images (and accurate lichen mapping accordingly), we also used an auxiliary RS image, namely Sentinel-2 SR imagery, in this study. Given this, the goal was to normalize target WV2 images to a source eight-band pansharpened image with a spatial resolution of 50 cm. This means that the output of the normalization methods should be 50 cm to correspond to the source image. Using these two data sets, we considered four scenarios (
Figure 3) for normalization as follows:
- 1.
Normalization based on the 2 m resolution WV2 multi-spectral bands (resampled to 50 cm);
- 2.
Normalization based on the WV2 panchromatic band concatenated/stacked with the 2 m multi-spectral bands (resampled to 50 cm);
- 3.
Normalization based on the WV2 panchromatic band alone;
- 4.
Normalization based on the WV2 panchromatic band concatenated/stacked with the Sentinel-2 SR imagery (resampled to 50 cm).
The scenarios 1, 3, and 4 can be considered as a special case of pan-sharpening where the spatial information comes from a target image but the spectral information comes from the source image. We performed two steps of experiments to evaluate the quality of image normalization using these scenarios. In the first step, we ruled out the scenarios that did not lead to realistic-looking results. In the second step, we used the approaches found practical in the first step to perform the main comprehensive quantitative tests on different target images.
3.3.1. Scenario 1: Normalization Based on 2 m Multi-Spectral Bands (Resampled to 50 cm)
One way of normalizing a target image to a source image is to follow a pseudo-super-resolution approach, in which the multi-spectral bands (in the case of WV2, with a spatial resolution of 2 m, which must be resampled to 50 cm to be processable by the model) are used as input to the cGAN. However, the difference here is that the goal now is to generate not only a higher-resolution image (with a spatial resolution of 50 cm), but also an image that has a similar spectral distribution to that of the source image. It should be noted that all the resampling to 50 cm was performed using a bi-linear technique before training the GANs.
3.3.2. Scenario 2: Normalization Based on the Panchromatic Band Concatenated/Stacked with 2 m Multi-Spectral Bands (Resampled to 50 cm)
The second way is to improve the spatial fidelity of the generated normalized image by incorporating higher-resolution information into the model without the use of a specialized super-resolution model. One such piece of information could be the panchromatic band, which has a much broader bandwidth than the individual multi-spectral or pansharpened data. In addition to its higher spatial resolution information, it can be hypothesized that this band alone has less variance than the multi-spectral bands combined under different atmospheric conditions. When adding the panchromatic band to the process, the model would learn high-resolution spatial information from the panchromatic band, and the spectral information from the multi-spectral bands. This scenario can be considered as a special type of pansharpening, except that in this case, the goal is to pansharpen a target image so that it not only has a higher spatial resolution, but also its spectral distribution is similar to that of the source image.
3.3.3. Scenario 3: Normalizing Based Only on the Panchromatic Band
The additional variance of multi-spectral bands among different scenes could degrade the performance of normalization in the second scenario. Since a panchromatic band is a high-resolution squeezed representation of the visible multi-spectral bands, it could also be tempting to experiment with the potential of using only this band without including the corresponding multi-spectral bands (to reduce the unwanted variance among different scenes) to analyze if normalization can also be properly conducted based only on this single band.
3.3.4. Scenario 4: Normalization Based on the Panchromatic Band Concatenated/Stacked with the Sentinel-2 Surface Reflectance Imagery (Resampled to 50 cm)
Theoretically, not including multi-spectral information in the third scenario has some downsides. For example, the model may not be able to learn sufficient features from the panchromatic band. On the other hand, the main shortcoming of the first and second scenarios is that the multi-spectral information can introduce higher spectral variance under different atmospheric conditions than the panchromatic band alone can. In this respect, based on the aforementioned factors, another way of approaching this problem is to use RS products that are atmospherically corrected. These can be SR products such as Sentinel-2 SR imagery. Despite having a much coarser resolution, it is hypothesized that combining the panchromatic band of the test image with the Sentinel-2 SR imagery can further improve normalization results by constraining the model to be less affected by abrupt atmosphere-driven changes in the panchromatic image. In this regard, the high-resolution information comes from the panchromatic band of the test image, and some invariant high-level spectral information comes from the corresponding Sentinel-2 SR image. To use SR imagery with the corresponding WV2 imagery, we first resampled the SR imagery to 50 cm using the bilinear technique and then co-registered the SR imagery to the WV2 using the AROSICS tool [
32]. One of the main challenges in this scenario was the presence of clouds in the source image. There were two main problems in this respect. First, since we also used cloud-free Sentinel-2 imagery, the corresponding WV2 clips should also be cloud and haze-free as much as possible to prevent data conflict. The second problem was that if we only used cloud-free areas, the model did not learn cloud features (which could be spectrally similar to bright lichen cover) that might also be present in target images. Given these two problems, we also included a few cloud- and haze-contaminated areas.
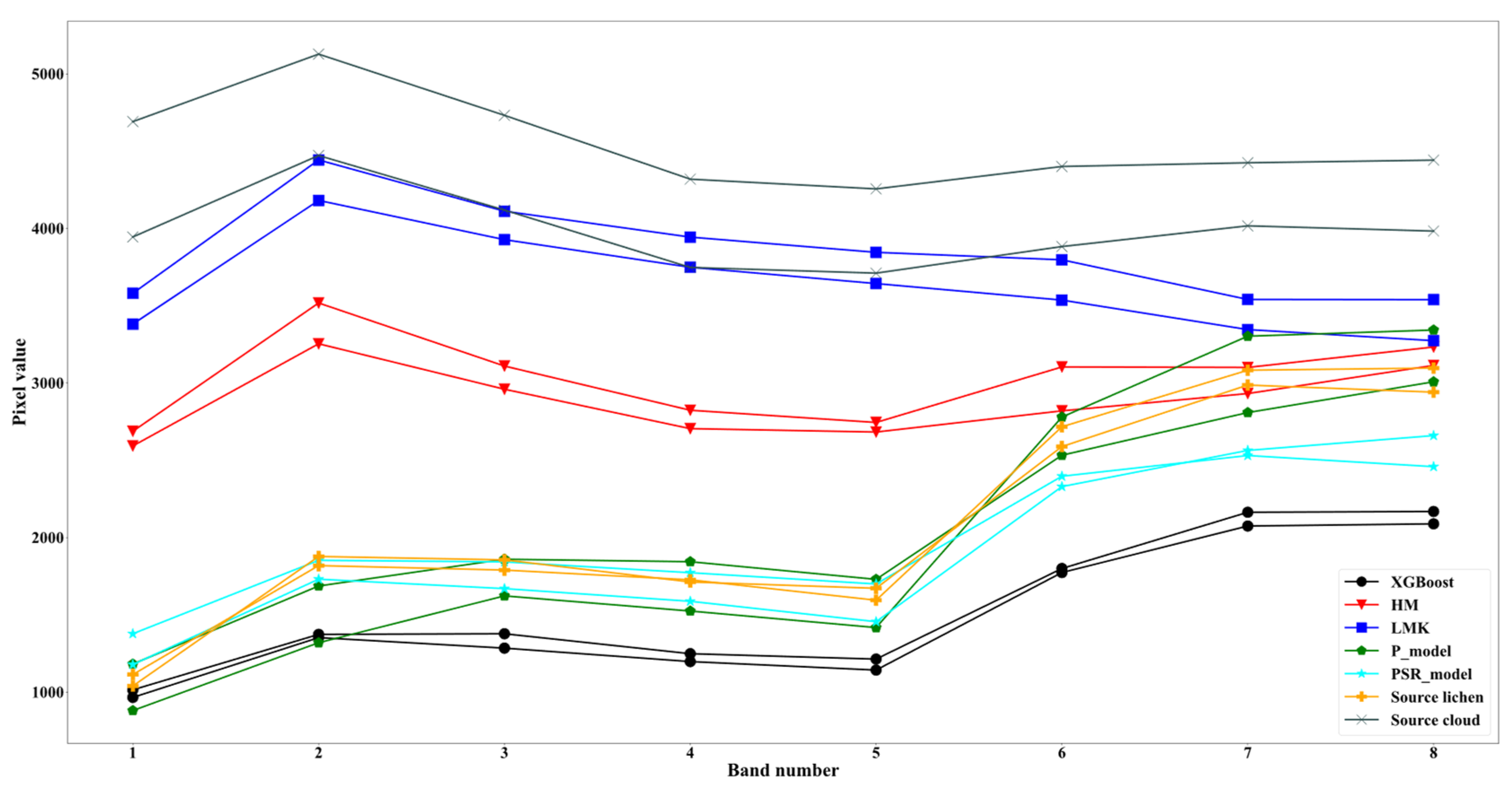
3.4. Comparison of cGANs with Other Normalization Methods
For comparison, we used histogram matching (HM), the linear Monge–Kantorovitch (LMK) technique [
33], and pixel-wise normalization using the XGBoost model. HM is a lightweight approach for normalizing a pair of images with different lighting conditions. The main goal of HM is to match the histogram of a given (test) image to that of a reference (source) image to make the two images similar to each other in terms of lighting conditions, so subsequent image processing analyses are not negatively affected by lighting variations. More technically, HM modifies the cumulative distribution function of a (test) image based on that of a reference image. LMK is a linear color transferring approach that can also be used for the normalization of a pair of images. The objective of LMK is to minimize color displacement through Monge’s optimal transportation problem. This minimization has a closed form, unique solution (Equation (8)) that can be derived using the covariance matrices of the reference and a given (target) image.
where
and
are the covariance matrix of the target and reference images, respectively. The third approach we adopted for comparison was a conventional regression modeling approach using the extreme gradient boosting (XGBoost) algorithm, which is a more efficient version of gradient boosting machines. For this model, the number of trees, maximum depth of the model, and gamma were set using a random grid-search approach.
3.5. Lichen Detector Model
To detect lichen cover, we used the same model presented in [
34], which is a semi-supervised learning (SSL) approach based on a U-Net++ model [
35]. To train this model, we used a single UAV-derived lichen map (generated with a DL-GEOBIA approach [
25,
36]). From the WV2 image corresponding to this map, we then extracted 52 non-overlapping 64-by-64 image patches. A total of 37 image patches were used for training and the rest for validation. To improve the training process, we extracted 75% overlapping image patches from neighboring training image patches as a form of data augmentation. As described in [
34], we did not apply any other type of training-time data augmentation for two main reasons: (1) to evaluate the pure performance of the spectral transferring (i.e., normalization) without being affected by the lichen detector generalization tricks; and (2) to hold the constraint regarding being unaware of the amount of illumination variations in target images. As reported in [
34], although the lichen detector had an overall accuracy of >85%, it failed to properly distinguish lichens from clouds (which could be spectrally similar to bright lichens) as the training data did not contain any cloud samples. Rather than including cloud data in the training set to improve the performance of the lichen detector, we used a separate cloud detector model. The use of a separate model for cloud detection helped us to better analyze the results; that is, since clouds were abundant over the source image, the spectral similarities of bright lichens and clouds may cause lichen patches to take on the spectral characteristics of clouds in the normalized images. This issue can occur if the cGAN fails to distinguish clouds and lichens from each other properly. This problem can be more exacerbated in HM techniques as they are context unaware. Given these two factors, using a separate cloud detector would better evaluate the fidelity of the normalized images. To train the cloud detector, we extracted 280 image patches of 64 × 64 pixels containing clouds. For the background class, we used the data used to train the lichen detector [
34]. We used 60% of the data for training, 20% for validation, and the remaining 20% for testing. The cloud detector model had the same architecture as the lichen detector model with the same training configurations.
5. Conclusions
In this paper, we evaluated a popular GAN-based framework for normalizing HRS images (in this study, WV2 imagery) to mitigate illumination variations that can significantly degrade classification accuracy. In this regard, we trained cGANs (based on Pix2Pix) using two types of data: (1) normalizing based only on the WV2 panchromatic band; and (2) normalizing based on the WV2 panchromatic band stacked with the corresponding Sentinel-2 SR imagery. To test the potential of this approach, we considered a caribou lichen mapping task. Overall, we found that normalizing based on the two cGAN approaches achieved higher accuracies compared with the other approaches, including histogram matching and regression modeling (XGBoost). Our results also indicated that the stacked panchromatic band and the corresponding Sentinel-2 SR bands led to more accurate normalizations (and lichen detections accordingly) than using the WV2 panchromatic band alone. One of the main reasons that the addition of the SR bands resulted in better accuracies was that although the WV2 panchromatic band was less variable than the multi-spectral bands, it was still subject to sudden scene-to-scene variations (caused by different atmospheric conditions such as the presence of clouds and cloud shadows) in different areas, degrading the quality of the normalized images. The addition of the SR image further constrained the cGAN to be less affected by such variations found in the WV2 panchromatic band. In other words, incorporating atmospherically corrected auxiliary data (in this case, Sentinel-2 SR imagery) into the normalization process helped to minimize the atmosphere-driven scene-to-scene variations by which the WV2 panchromatic band is still affected. Applying the lichen detector model to the normalized target images showed a significant accuracy improvement in the results compared to applying the same model on the original pansharpened versions of the target images. Despite the promising results presented in this study, it is still crucial to invest more in training more accurate models on the source image rather than attempting to further improve the quality of the spectral transferring models. More precisely, if a lichen detector model fails to correctly classify some specific background pixels, and if the same background land cover types are also present in target images, it is not surprising that the lichen detector again fails to classify such pixels correctly regardless of the quality of the normalization. One of the most important limitations of this framework is that if the spectral signature of the lichen species of interest changes based on a different landscape, this approach may fail to detect that species, especially if it is no longer a bright-colored feature. So, we currently recommend this approach for ecologically similar lichen cover mapping at a regional scale where training data are scarce in target images covering study areas of interest. Another limitation is that there might be temporal inconsistency between a WV2 image and an SR image. In cases where there are land surface changes, this form of inconsistency may affect the resulting normalized images.


 ,
, 











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}