1. Introduction
The development of remote sensing techniques increases the sensory ability of humans to their living environment without the limitations of space and time. Remote sensing sensors can be installed in satellites or airplanes to obtain multi-scale observation data of the Earth’s surface to satisfy the different requirements of some applications. Identifying changes in our living environment using remote sensing data is a necessary task for humans. With the rise of artificial intelligence, change detection in remote sensing images is becoming the most common technology, surpassing human detection. Monitoring the development of urban areas is currently the biggest application area of change detection, by which unapproved construction projects, changes in land use and development trends of urban areas can be obtained. In [
1], the authors propose the use of a classification method combined with spectral indices of some common landcovers to identify trends in urban growth. In [
2], the authors propose the use of the landcover classification method to achieve the three levels of urban change detection, namely, pixel level, grid level and city block level. The assessment of post-disaster damage is also a significant application of change detection. As with earthquakes, floods and debris flow, disasters can evoke a huge change in landscapes. The change detection technique could quickly and precisely find changes in a landscape to provide powerful support for relief workers [
3,
4]. In addition, the change detection technique can also be applied in environmental monitoring, such for oil spills in the ocean and industrial pollution. In [
5], the authors provide a review of change detection methods in ecosystem monitoring. Although multiple change detection methods have been tested and applied in many real applications, a long research period is still required for wide and credible applications of change detection in realistic situations.
There are many intrinsic factors that disturb the application of change detection methods to real problems. Although we know that the aim of change detection is the quantitative analysis and determination of surface changes from remote sensing images over multiple distinct periods, this research direction is not an easy subject due to inherent problems with remote sensing images. First, remote sensing images contain too many classes of landcover, and there is significant similarity between classes and diversity in the same class. Second, remote sensing images obtained from different remote sensors may be distinct due to the interference of the sensing system or imaging environment. Furthermore, the presentation of the same landcover, such as vegetation, varies with the seasons. The above reasons make it difficult to distinguish real changed landcovers from unchanged landcovers.
In recent decades, many researchers have proposed change detection methods to push the technological development of this domain via different technical routes. Due to the variety of change detection methods, there are many different criteria of group change detection methods [
6,
7,
8,
9]. In [
9], according to the research element, change detection methods can be segmented into pixel- and object-based methods. Pixel-based methods are classical change detection methods, where each pixel is treated as a basic analysis unit. There are abundant pixel-based methods, such as unsupervised direct comparison methods [
10], transformation methods [
11,
12,
13,
14], classification-based methods [
15,
16] and machine learning-based methods [
17,
18,
19]. Pixel-based methods usually suffer from noise effects, leading to isolated changed results, and the deficiency of contextual information gives rise to many challenges in pixel-based methods for very high resolution (VHR) imagery [
9,
20,
21]. Object-based methods first divide the remote sensing images into a group of objects as the analysis unit for the next processing step, which can deal with the above problems of pixel-based methods to a certain degree [
22,
23]. Object-based methods can be divided into post-classification comparison methods [
24,
25] and multitemporal images object analysis methods [
26,
27], which also suffer from problems such as the effect of segmentation/classification results and the limitation of object representation features [
28]. Aiming to overcome the weaknesses of pixel- and object-based methods, several hybrid methods are proposed [
29,
30,
31].
As the proposed method is a pixel-based method, here, we focus on pixel-based methods. The processing of change detection should be divided into four common procedures, namely, preprocessing, feature learning, the generation of different maps and the generation of binary change detection maps. The change detection results can be obtained by using change vector analysis (CVA) [
32,
33], fuzzy c-means Clustering [
34] or Markov Random Field [
35,
36], etc. Among the above procedures, feature learning has been the focus of more research than other methods. The goal of feature learning in change detection is to find an appropriate feature representation space in which the difference between changed pixel pairs and unchanged pixel pairs is more obvious than in the original feature space. Transformation methods, such as principal component analysis (PCA) [
13], independent component analysis (ICA) [
37] and multivariate alteration detection (MAD) [
38], have been successfully applied for change detection. However, these methods are too simple for real change detection requirements. In [
39], slow feature analysis (SFA) can suppress the difference in unchanged pixels by finding the most temporally invariant component. Additionally, dictionary learning and sparse representation are also applied to construct the final feature space [
40].
Recently, the neural network has become the most important research topic in the information technology domain and has achieved remarkable effectiveness in machine vision [
41,
42,
43]. In fact, neural network-based change detection methods also have proliferated in recent years [
44,
45,
46,
47], and the growth trend is obvious [
8]. Unsupervised neural network-based change detection methods aim to reduce the distance between two temporal images’ feature spaces by using a neural network to learn new feature spaces [
44,
45,
46,
47,
48,
49,
50]. Considering the power of label information for change detection, many unsupervised methods introduce some pseudo-label information obtained by pre-classification methods into the feature learning network, to improve the discriminant ability of the new feature space [
45,
46,
49,
50].
Although unsupervised methods cannot consider the data annotation problem, the obtained change detection results are difficult to use in real applications, where too many unconcerned change types are detected.
In contrast to unsupervised methods, supervised neural network-based methods utilize label information to improve the final classification, which only focuses on distinguishing specific change types from a whole scene. For this kind of method, change detection is mainly treated as a pixel classification problem or semantic segmentation problem. In [
51], a new GAN architecture based on W-Net is constructed to generate a change detection map directly from an input image pair. The combination of the spatial characteristics of convolutional networks and temporal characteristics of recurrent networks could improve the efficiency of high-level features for change detection [
52,
53,
54]. The Siamese network structure is usually considered as the basic network structure to extract high-level features of temporal images [
54,
55,
56]. In addition, the attentional mechanism [
57] is also introduced to the neural network to improve its performance. In [
58], authors combined the convolutional neural network with the CBAM attention mechanism to improve the performance of feature learning for SAR image change detection. In [
59], based on the Unet++ framework, an up-sampling attention unit replaced the original up-sampling unit to enhance the guidance of attention in both the spatial space and channel space. However, these methods simply add an attentional block into the network similarly to common operations and do not generate a deep chemical reaction between the attentional mechanism and change detection.
In this paper, the attention-guided Siamese fusion network is proposed for the change detection of remote sensing images. Although the Siamese network structure can extract high-level features of two temporal images, respectively, which could preserve the feature integrality of each image, it ignores the importance of information interaction between those two feature flows during the feature learning process. However, verified by our experiments, this information interaction of feature flows can improve the final performance. Therefore, here, we dexterously combine an attention mechanism with our basic Siamese network, which not only places more focus on important features, but also realizes the information interaction of two feature flows. The innovations of our work can be summarized as three points.
- (1)
The attention information fusion module (AIFM) is proposed. In contrast to common operations, which directly insert an attention block into a neural network to guide the feature learning process, ALFM utilizes an attention block as an information bridge of two feature learning networks to realize their information fusion.
- (2)
Based on the ALFM structure and ResNet32, the attention-guided Siamese fusion network is constructed. The integration of multiple ALFMs can extend the influence of ALFM into a whole feature learning process and fuse the information of two feature learning network branches comprehensively and thoroughly.
- (3)
We apply the attention-guided Siamese fusion network (Atten-SiamNet) to the change detection problem and experimentally validate the performance of the Atten-SiamNet-based change detection method.
The following contents are organized as follows. The second section provides a detailed theoretical introduction of the proposed method. The third section shows the experiments designed to verify the availability and superiority of the proposed method. The final section is a conclusion of this work.
2. The Proposed Method
In the proposed change detection framework, two different temporal images for a certain area are discussed to detect the changes between them, which are denoted as I_1 and I_2, with the size as H × W. To train the fusion network, some pixels are labeled as changed or unchanged to construct the training sample set, such as , where and represent the row- and column-coordinates of the i-th training sample, respectively, and is the label; 0 denotes an unchanged pixel, and 1 denotes a changed pixel. The rest of the pixels of the image pair are treated as the testing set for the fusion network. After the training and testing processes, the probability of each index being a changed pixel is obtained, which can also be denoted as a different map. The final change detection result can be easily achieved by using a simple method to split the different map into a changed pixel set and an unchanged pixel set, such as threshold segmentation.
Many abbreviations are used in this section to make the description more concise. Therefore, an abbreviations list is shown in
Table 1 with their full descriptions.
2.1. Basic Siamese Fusion Network
ResNet is a classical network for classification, which demonstrates significant performance in many visual applications [
60]. The most representative ResNet networks are ResNet50 and ResNet101, which involve a mass of parameters. Compared to the natural scene, the remote sensing scene is simpler, and the labeled samples are limited. Therefore, in our research work, one simple ResNet (ResNet32) structure was selected as the basic network framework. The specific structure of ResNet32 is shown in
Table 2.
When the change detection problem is treated as a pixel classification problem, the simplest scheme is to treat the concatenation of the patch pair of the center pixel in the temporal images as the input, and the probability of being a changed pixel or an unchanged pixel as the output of the network. Here, ResNet32 was used as the network of feature learning and classification, of which a simple schematic diagram is shown in
Figure 1. This change detection method is denoted as ResNet-CD.
In ResNet-CD, the information of two temporal images is fused before feature extraction processing, which is the common operation of data-level fusion. Based on this fusion, the following feature learning procedure is primitive, where the intrinsic difference is not considered. As we know, information fusion can be divided into three levels, namely, data-level fusion, feature-level fusion and decision-level fusion [
61]. For change detection, decision-level fusion is not possible as there is only one output of two input images. Therefore, feature-level fusion is another selectable method, which could also conduct feature extraction for two input images and fuse their high-level features.
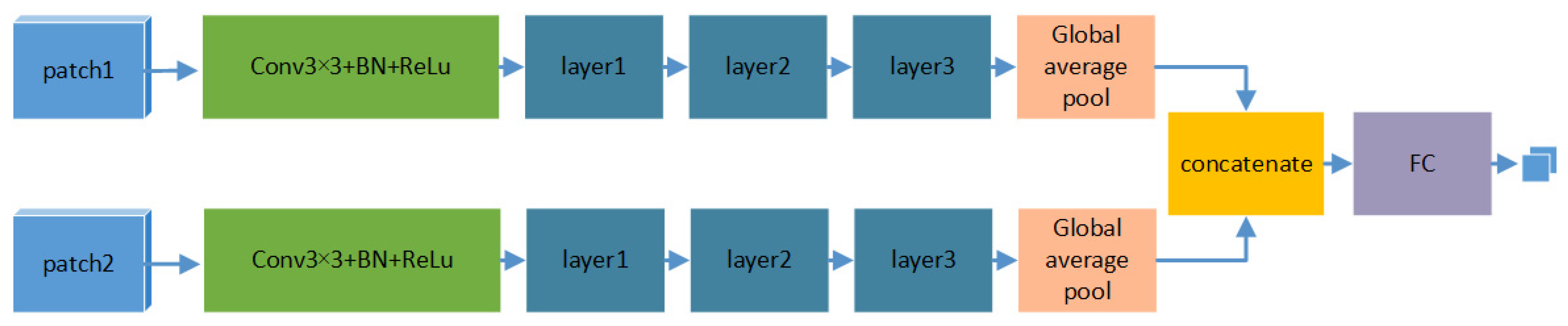
The Siamese network structure is selected to satisfy the requirement of feature-level fusion in change detection. Different temporal images complete feature extraction from different network branches. After obtaining the high-level features, they are combined to import into a full connection layer, which maps features to two-dimensional output, indicating the probability of being changed or unchanged. The final change detection map is obtained by using the segmentation of the changed probability map. The basic Siamese fusion network for change detection is also built on the ResNet32, which is denoted as Siam-ResNet-CD. The structure schematic diagram of Siam-ResNet-CD is shown in
Figure 2. The structures of these two network branches are consistent. The parameters of one branch are updated during the back-propagation processing, and another branch simply copies the parameters from that branch without any computation. In this situation, the network is symmetrical. There is another situation where the structure of the network is symmetrical, but the values of the parameters are not the same, and two branches are updated during back-propagation processing, which is called the Pseudo-Siamese network. In the experiment, we verified that the efficiency of the Siamese network was close to that of the Pseudo-Siamese network but had a lower computation cost. Therefore, in the proposed attention-guided Siamese fusion network, the real Siamese network is chosen as a basic network framework.
2.2. The Attention-Guided Siamese Fusion Network (Atten-SiamNet)
In Siam-ResNet-CD, although high-level features of two image patches from different temporal images are extracted to form the Siamese network, it is obvious that the two branches are totally isolated without any information interaction between them. In other words, the intrinsic differences of two temporal images are considered, but the correlation between them is not considered in Siam-ResNet-CD. The temporal images are different observations of an identical region; there must be a large amount of shared relevant information. Therefore, the correlation should not be ignored during feature learning processing.
Here, the attention mechanism is chosen to realize the interaction of two feature learning branches based on their correlation, and conducts information fusion throughout the whole feature learning process, not just the final step. The attentional mechanism has been widely used in deep learning to improve the final performance [
59]. Through parameter learning, the attention block could adaptively compute the importance of feature channels to guide the learning processing to pay more attention to channels or positions with high importance scores. Aiming to realize the interaction, an attention block is inserted into Siam-ResNet-CD in an unfamiliar way to improve the final performance. The attention information fusion module is the key procedure, where feature flows influence each other, and more important features receive more attention during learning processing.
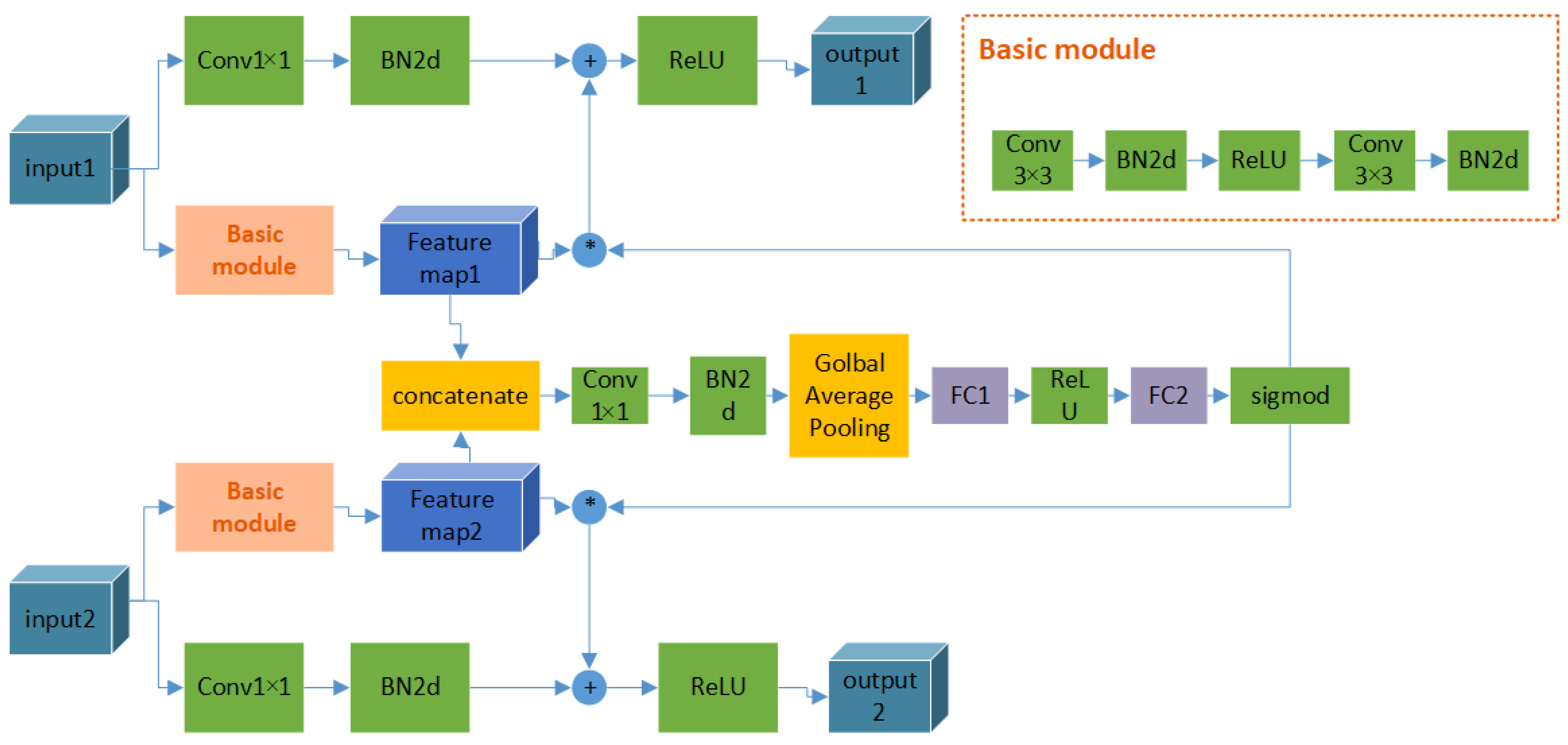
2.2.1. Attention Information Fusion Module (AIFM)
The attention information fusion module is constructed as an information bridge of two feature learning branches. The features obtained by two branches are inputted into one attention mechanism network. Then, the computation of the importance score of feature channels is the information fusion of two branches as the full connection layer maps whole features into a new space adaptively. Therefore, the final importance scores are not obtained from two feature branches in isolation; they are the information fusion results from two feature flows. This is why we denoted it as the attention information fusion module.
In this module, there are two inputs and two outputs, where the inputs are the feature blocks from the front feature extraction layer of two branches and the outputs are the inputs of the next feature extraction layer of two branches. The structure of the attention fusion block is related to the SE attention mechanism [
62], which is well known and applied in computer vision. In
Figure 3, the schematic diagram of the attention information fusion module is shown. This module is constructed on the basic residual module; two inputs obtained new feature maps through the basic module independently, these new feature maps are imported into the attention block. The concatenation first fuses the feature maps together, and two full connection layers combine two branch feature maps. Finally, through the Sigmod activation function, a vector in the range from 0 to 1 can be obtained, of which one element measures the importance of one feature map. These feature maps are multiplied by the vector, in which one feature map corresponds to one element. Then, the feature maps with more importance would be more valuable than other maps.
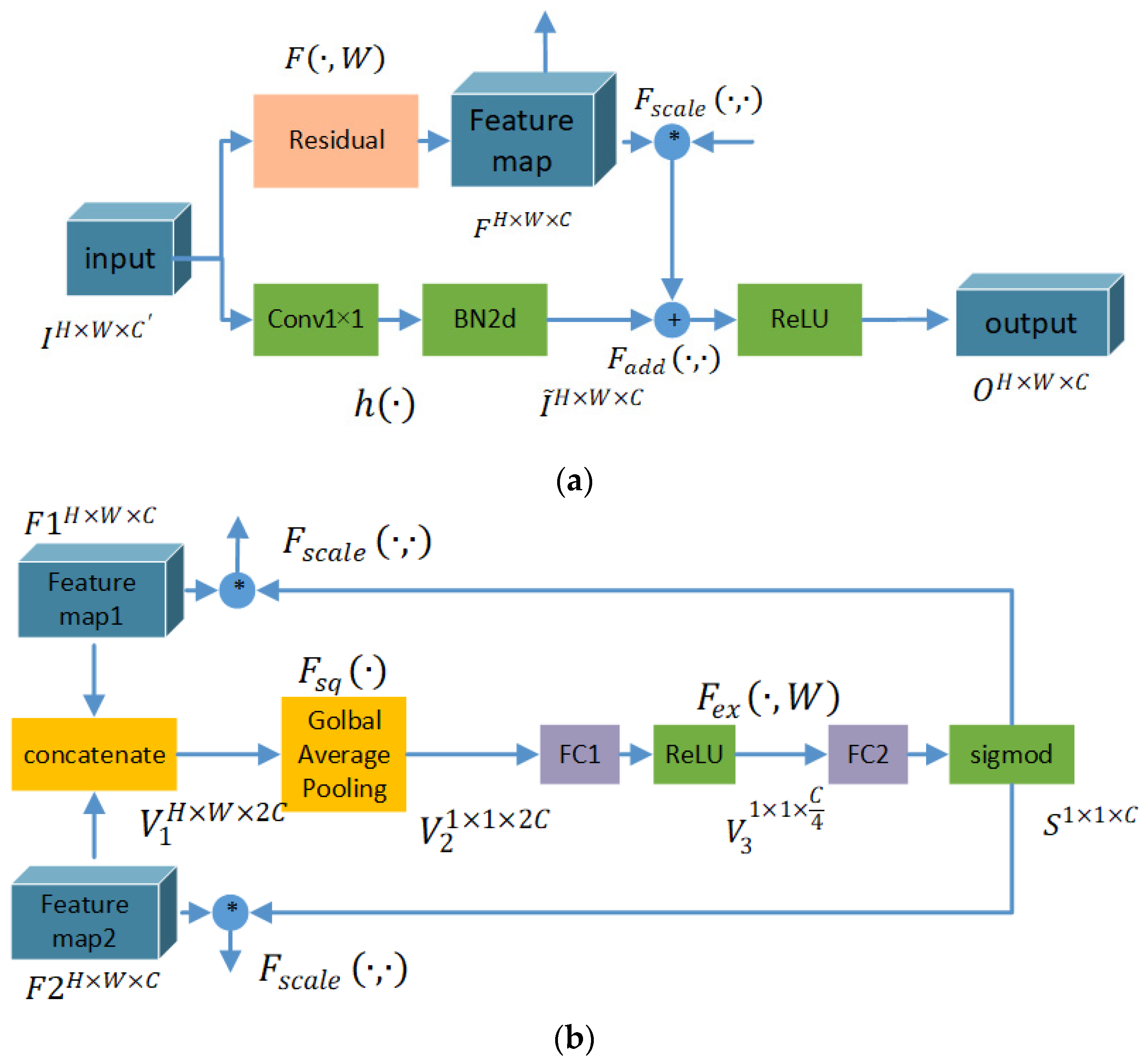
For a better understanding of this module, it can be divided into two parts, namely, the common residual part, shown in
Figure 4a, and the attention fusion part, shown in
Figure 4b. The common residual part assures the basic feature learning performance of each branch. As the traditional residual module, the feature map (
) is entered into a convolutional residual neural network and mapped into an output feature map (
). In the attention fusion part, the feature maps obtained by the convolutional neural network (
) of the Siamese branch in the same layer, such as
and
, are entered and concatenated as whole feature maps (
). Then,
is squeezed into one sequence of 2C length through global average pooling. Furthermore, the excitation processing contains two full connection layers, of which the mapping function is denoted as
. Through this processing, the connection of two branches is constructed and shrinks the length of the sequence from 2C to C. The output of excitation processing (
) fuses the information of the Siamese branches and displays the importance of the feature channel for the final task as a weight vector. The weights of each channel are fed back into the branches, respectively, to enhance the influence of the important channel and reduce the influence of the less important channel for the following feature extraction processing. The parameters of
are adaptively learned from the training data, which reflect the information interaction of whole 2C channels. Through the attention information fusion module, the information interaction of two branches and the import of the attention mechanism are both completed.
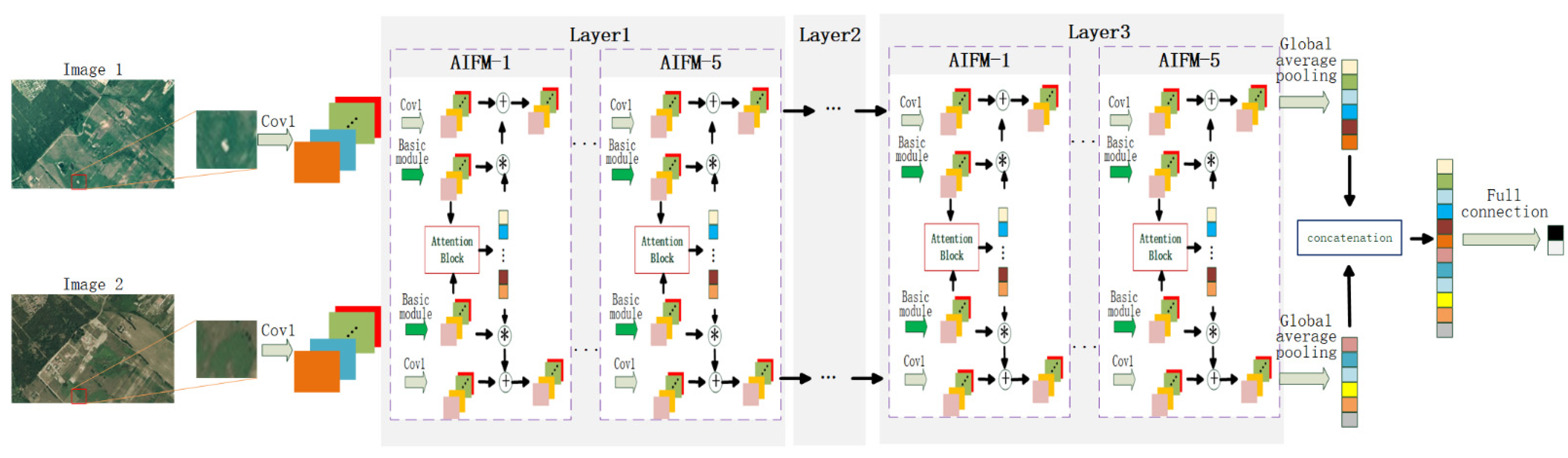
2.2.2. Network Architecture of Atten-SiamNet-CD
Attention-guided Siamese fusion network-based change detection (Atten-SiamNet-CD) is a high-order version of Siam-ResNet-CD, as introduced clearly in
Section 2.1. ResNet32 is also a basic network framework like Siam-ResNet-CD. Multiple AIFMs are integrated into the middle network part (Layer1, Layer2 and Layer3) of Siam-ResNet-CD. In ResNet 32, each layer contains 5 residual modules. In Atten-SiamNet-CD, five residual modules are replaced by five attention information fusion modules, as shown in
Figure 5. Aiming to reduce the size of the feature map, the stride of the convolutional layer of Block 2 and Block 3 is set to 2, by which the output feature maps are reduced to one half of their original size.
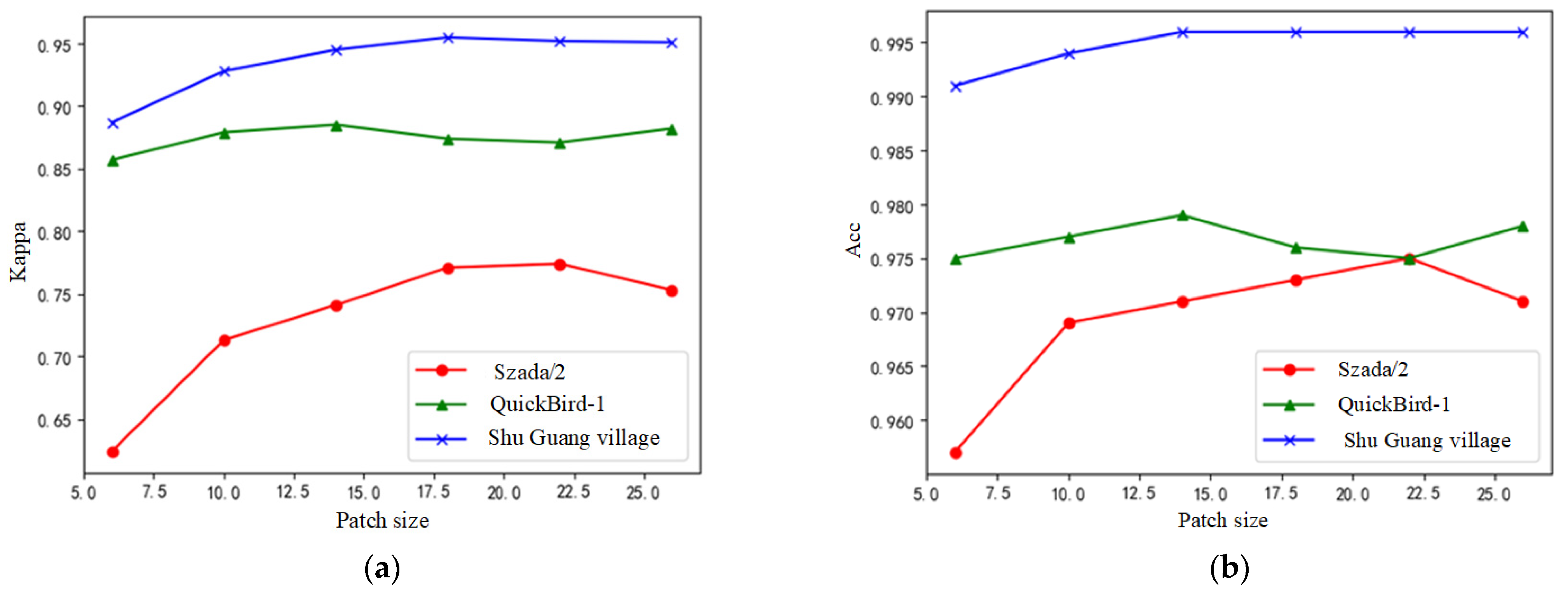
Like other pixel-level change detection methods [
18,
19,
20], the image patch (k × k) around the center pixel is sampled as the original feature of the center pixel. Compared with the signal pixel, image patches contain more structural information on the scene, which is beneficial for change detection. As shown in
Figure 5, image patches of a certain pixel in two temporal images are inputted into the network in pairs. After the attention-guided Siamese fusion network, high-level features are extracted and mapped into the final labels, which indicates if the pixel pairs are changed or unchanged. One-hot encoding is used here, and the cross-entropy loss is used to measure the distance of the label and predicted label, and guide the learning processing. Training data are sampled from labeled data containing some changed pixels and unchanged pixels.
Two temporal remote sensing images are predicted through the trained attention-guided Siamese fusion network. The result can be represented as a tensor, . The value of this tensor denotes the difference in the pixel pairs, where is the probability of pixel pairs being changed and is the probability of pixel pairs being unchanged. Furthermore, and are complementary, of which the sum is 1. Therefore, only is used as the difference map in the following processing. Aiming to verify the feature learning performance of the attention-guided Siamese fusion network, the simple threshold segmentation method is used to obtain the final change detection results. These pixels, of which the difference values are larger than the threshold, are defined as changed pixels, and others are unchanged pixels. The threshold is set to be 0.6 based on multiple experiments.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}