1. Introduction
In recent years, high-resolution remote sensing (HRRS) images have become more accessible with the development of satellite and remote sensing technologies, which provide detailed information on the land surface. Therefore, many remote sensing image tasks are also developing rapidly, such as semantic segmentation [
1,
2], object detection [
3] and scene classification. Remote sensing image semantic segmentation has been widely used in various applications, such as natural resource protection, change detection [
4] and other applications [
5,
6]. Objects in high-resolution remote sensing images have rich details, such as geometry and structure, which bring more challenges to land use classification. The scene classification of optical remote sensing images can be divided into two categories, namely, methods based on artificially designed features and methods based on deep features. The hand-crafted features used for optical remote sensing image scene classification can be broadly classified into three categories, namely, spectral features, texture features, and structural features. Commonly used spectral features include image gray value, gray value mean, and gray value variance. Literature [
7] directly uses image gray value as a classification feature, while literature [
8,
9] takes gray mean and variance as classification features. Local Binary Pattern (LBP) and Gray Level Co-occurrence Matrix (GLCM) are typical texture features. Scale-invariant feature transform (SIFT) is an effective structural feature [
8,
9,
10], in addition to the line segment [
11], wavelet transform [
9] and Gabor transform [
12]. However, the methods of hand-crafted features have the limitations of poor data adaptability and low feature utilization. The effectiveness of deep learning in remote sensing images has recently received a lot of attention. Methods based on fusing deep features [
13,
14,
15] increase the information content of the features by fusing one or more CNN features from different layers and improve the classification performance. Cheng et al. [
14] proposed the bag of convolutional features for optical remote sensing image scene classification based on the idea of the BoVW model. Xu et al. [
16] proposed a GLDBS model to learn global and local information from the original image and the key location. A two-stream feature aggregation deep neural network (TFADNN) [
17] was developed to obtain reasonable descriptions of HSR images, which contains the stream of discriminative features and the stream of general features. Xu et al. [
18] developed a deep feature aggregation framework driven by graph convolutional network (DFAGCN), and it employs a pretrained CNN to obtain multilayer features and utilizes a graph convolutional network-based model to reveal patch-to-patch correlations between the feature maps. Bi et al. [
19] presented a local semantic enhanced ConvNet(LSE-Net) and a context-aware class peak response(CACPR) measurement to mimic the top-down human vision perception. Li et al. [
20] designed a discriminative learning of adaptive match network (DLA-MatchNet) for few-shot remote sensing scene images, and it employs the channel attention and spatial attention modules to learn discriminative feature representation. Deng et al. [
21] propoed a joint network combined CNNs and vision transformer(CTNet), and a joint loss function is designed to optimize the network.
The framework of the deep network can be divided into three parts: feature extraction module, quantization module, and optimization strategy. The quantization module mainly includes spatial quantization, amplitude quantization, and evaluation quantization. A typical spatial quantization is pooling, which can reduce the number of parameters and mitigate the impact of overfitting problems. Some activation functions, such as sigmoid and ReLU [
22], are examples of amplitude quantization. It maps real values to a specific range in a nonlinear manner. Evaluation quantization is used to output data in a desirable form, such as softmax. A large number of optimization strategies, such as stochastic gradient descent (SGD) and Adam [
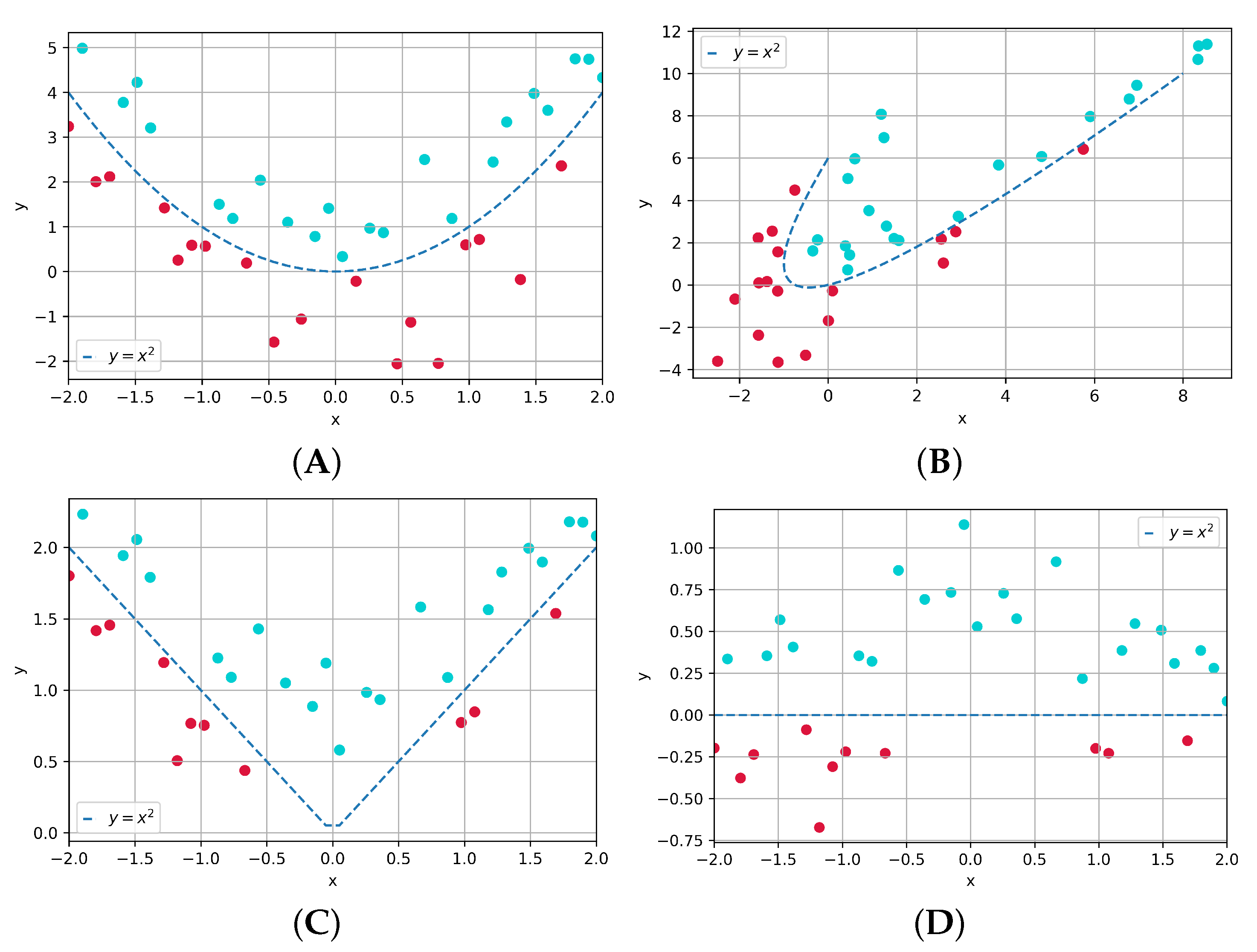
23], have been proposed to speed up network convergence and improve the stability of training. Convolutional neural networks greatly reduce the number of parameters by sharing convolutional kernels, and multiple convolutional kernels can extract different types of features. The convolution kernel slides over the feature map and performs cross-correlation operations with the corresponding regions on the feature map, so the convolution is linear. We can discuss neural networks and classification from the perspective of spatial transformations. Classification can be seen as performing certain spatial transformations on the data, changing the distribution of the data so that eventually a hyperplane can be found to separate the different classes of data. However, the data characterization capability of a linear transformation is limited. Subfigure A in
Figure 1 shows the original data distribution, the second subfigure shows the distribution of the data after linear transformation, the subfigure C and subfigure D are the distribution of the data after nonlinear transformation. It’s obvious that the nonlinear transformation makes the data more separable. Therefore, it is necessary to add an activation function after the convolution layer, which acts as a nonlinear transform. A simple and effective activation function is the Rectified Linear Unit (ReLU). To make the data more separable, it is necessary to deepen the network to enhance its transformation capabilities. The pooling layer reduces the dimensionality of the representation and prevents overfitting. The fully connected layer can map the feature space to the label space, where some evaluation quantization is utilized to achieve better classification.
A manifold is a general term for geometric objects, including curves and surfaces of various dimensions. According to the manifold hypothesis, data in high-dimensional space exist on or near a low-dimensional manifold, which determines the invariance of the data, and the coordinates on the manifold correspond to the core variables of the data. From the perspective of manifold, the classification algorithm aims to separate a bunch of manifolds. The purpose of manifold learning is to determine the internal mapping between the original high-dimensional data and the actual low-dimensional manifold structure. As long as we can learn the manifolds correctly, we can accomplish a complete knowledge of the data and thus derive the nature of the whole data from the partial sample rules. Thus, manifold learning can be seen as a method of dimensionality reduction. Traditional manifold learning can be divided into global learning methods and local learning methods. Global manifold methods consider the structural relationships between all data pairs as equally important for the determination of manifold embeddings and attempt to maintain the global structure of the original space in the low-dimensional manifold space. Typical global methods include multidimensional scaling (MDS) [
24] and Isometric feature mapping (ISOMAP) [
25]. The local manifold method considers that the key to manifold embedding is the structure information of the local region, so the focus of manifold learning is on the accurate modeling of the local structure, which reduces the computational effort to some extent. Locally linear embedding (LLE) [
26] is a typical local method. It assumes that a manifold can be considered as a linear Euclidean space in its local neighborhood, and the local geometric description of the original data space is also valid in the low-dimensional manifold space. Other local methods include Laplacian eigenmaps (LE) [
27]. Manifold learning is a nonlinear transformation, so it has a natural superiority over convolution in space transformation.
Convolutional neural networks cannot handle input data samples that reside on Riemannian manifolds, such as the manifolds of symmetric positive definite (SPD) matrices and the Grassmannian, so some work has focused on deep neural networks with points on the manifold as input. In [
28], the authors propose a two-layer deep manifold network called GrNet, containing three innovative blocks. The input data of GrNet are points located on the Grassmann manifolds. In [
29], a deep network architecture for input data residing on the manifold of symmetric positive definite matrices is introduced. In [
30] the weighted Fréchet mean (wFM) [
31] is used as an analog of convolution operation of manifold-valued data. However, the convexity constraint for wFM limits the value range of wFM, resulting in the limitation of the generalization ability of the model.
Although convolutional neural networks and deep manifold networks are both data-based, there are differences between them. In addition to the input data format, the size of the network also varies greatly. The convolution is a linear transformation, which leads to a relatively weak data characterization ability. Therefore, convolutional neural networks are stacked by many layers to achieve better performance. However, the computation of curved manifolds lies in non-Euclidean space, which has a more powerful characterization than convolution due to its nonlinearity. Consequently, manifold networks can have relatively excellent performance with fewer layers than convolutional neural networks.
In some practical scenarios, such as satellites, drones, and micro-robots, huge deep networks are not feasible. A smaller model has a smaller number of parameters but inevitably leads to a decrease in accuracy. Common approaches to model compression include pruning, quantization, hand-designed networks, and knowledge distillation. Manifold networks are small in size and can be used for the deployment of resource-limited devices. However, its generalization ability is not as good as large convolutional neural networks. Therefore, we propose to transfer the knowledge learned from convolutional neural networks to manifold networks using knowledge distillation. Most of the existing knowledge distillation methods are used between convolutional neural networks and thus will fail to overcome the drawbacks of convolution. On the other hand, current manifold networks are not mature enough to stack many layers like convolutional neural networks, so there is still a performance gap compared with convolutional neural networks. The CNNs can learn knowledge from large amounts of data, while the curve manifold learning has a better characterization of the nature of the data. Therefore, we expect to combine the advantages of deep learning and manifold learning through knowledge distillation.
To the above problems, this paper proposes a knowledge distillation-based method to train the Grassmann manifold network for remote sensing scene classification. The deep convolutional neural networks are used to guide the training process of shallow manifold networks, thus enabling the small manifold networks to acquire knowledge learned from large amounts of data. In the meantime, the size of the final network is small due to the effective characterization of the curve manifold.
Our contributions in this paper are as follows:
- 1
Through knowledge distillation, deep convolutional neural networks are allowed to train shallow manifold networks to seek better classification mappings at a smaller network size. In this way, the shallow manifold network learns information from a large amount of data while maintaining its excellent data characterization capability.
- 2
We first realize the flow and transmission of information between the manifold network and convolutional neural network. Since the input data of the two networks are located in different spaces, convolutional neural networks and manifold networks are inherently incompatible. For the first time, we have broken down the isolation between them, enabling the flow of information between the two networks and providing direction for communication between the other networks.
- 3
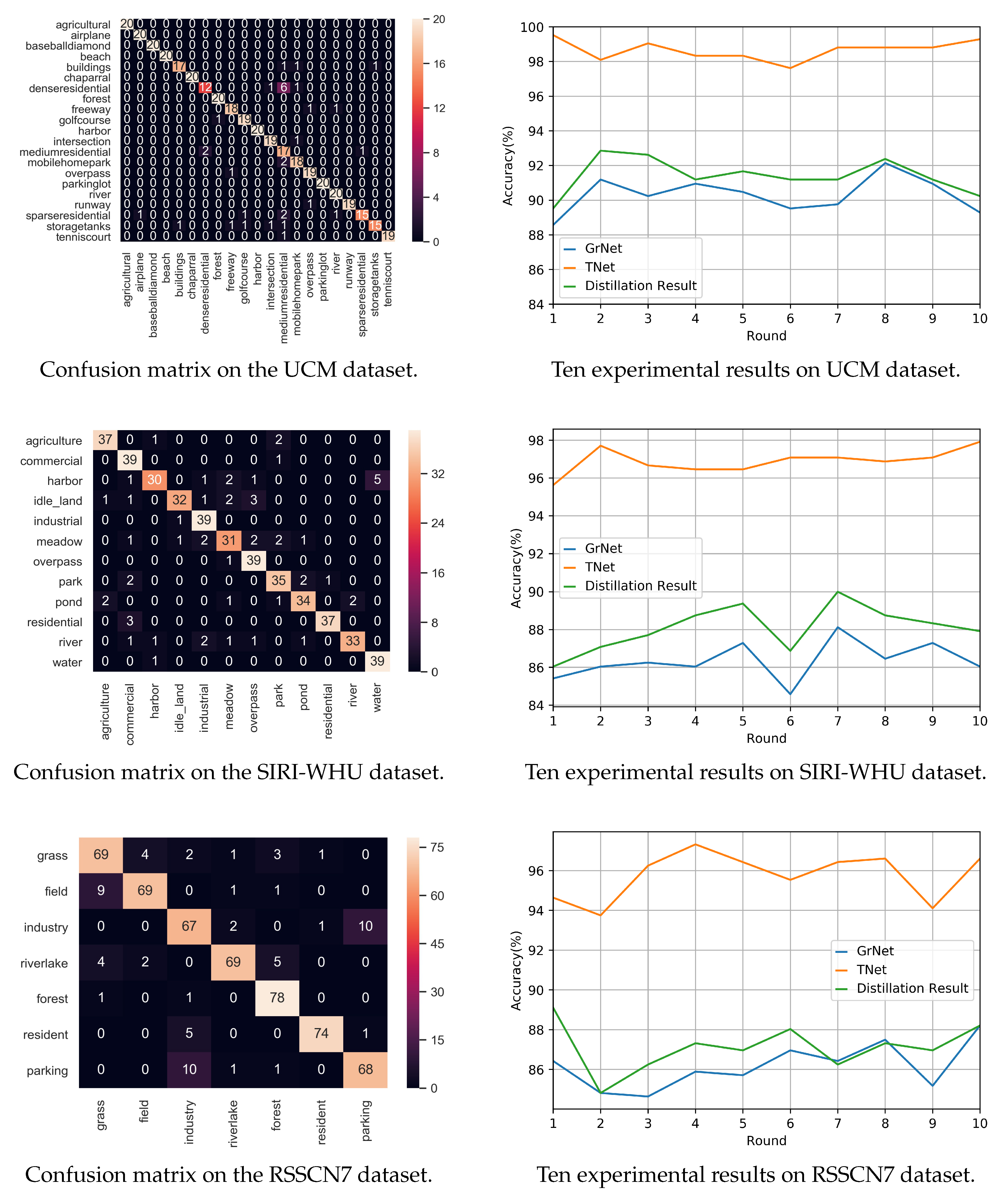
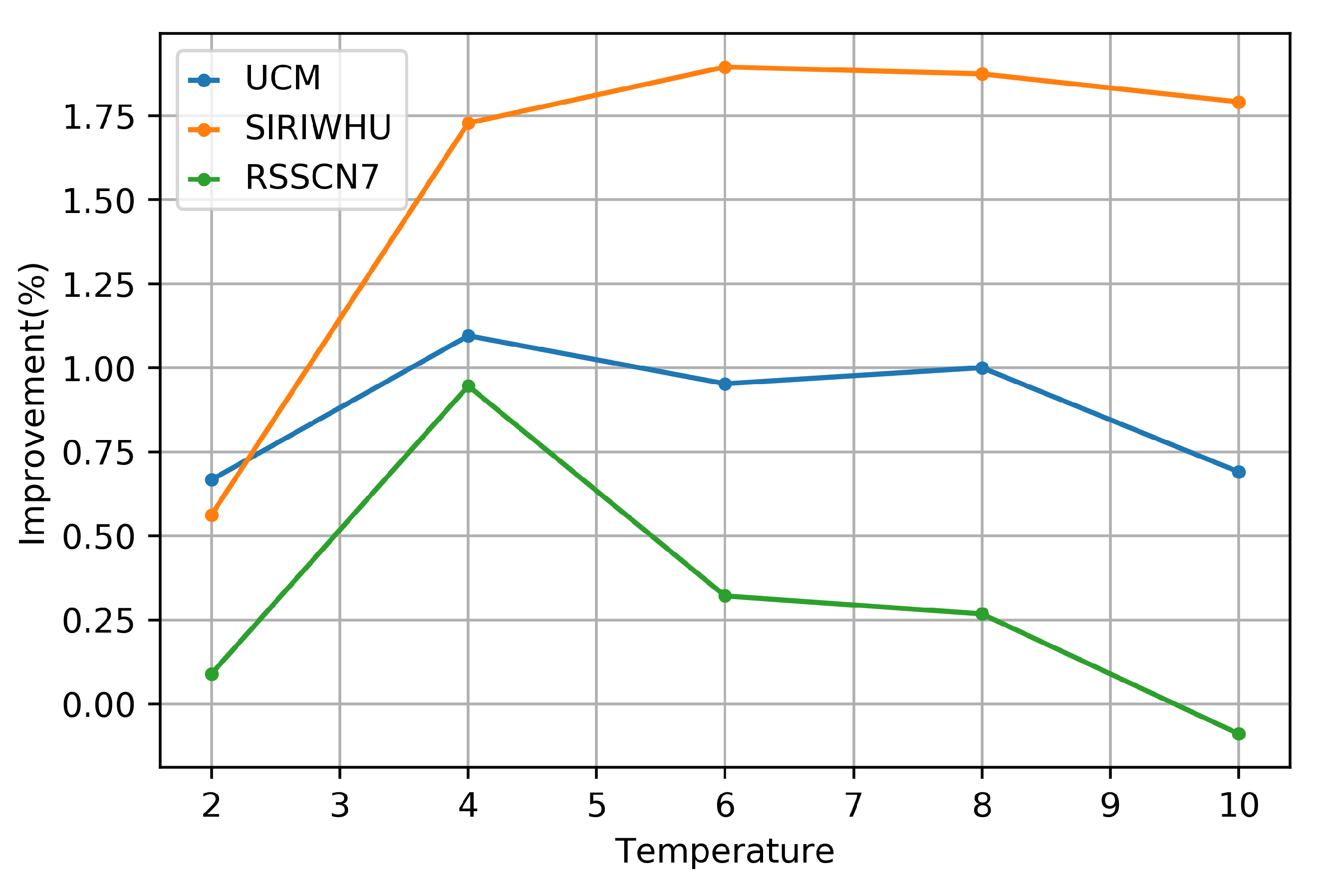
Experiments are carried out on three common standard datasets, namely UC Merced Land Use, SIRI-WHU, and RSSCN7 datasets. The accuracy of each dataset can be effectively improved, and the effectiveness of our method is verified.
The content of this paper is arranged as follows:
Section 2 begins with a brief review of Grassmann networks and knowledge distillation, followed by a detailed description of our methodology. The experimental results and analysis are described in
Section 3. In
Section 4, we discuss the experimental results and the influence of the parameters on the experiment. Finally, the conclusion of this paper is given in
Section 5.
2. Materials and Methods
In this section, a brief introduction to Grassman Network (GrNet) and knowledge distillation is given first. Then we will describe the proposed method in detail.
2.1. Grassmann Network (GrNet)
GrNet [
28] is a Grassmann manifold network. The input of GrNet is Grassmannian data, which lies on the Grassmann manifold. A Grassmann manifold
is a compact Riemannian manifold, which is the set of all
q-dimensional linear subspaces of
that can be spanned by an orthonormal basis matrix
. Therefore we have:
where
is the identity matrix of size
. The operations in Euclidean space are no longer feasible in Non-Euclidean space, so Riemannian calculations [
32] and matrix backpropagation [
33] on Grassmannian data are adopted to train the manifold network.
Features are extracted from successive frames of the face video and then processed so that they form a linear subspace [
34,
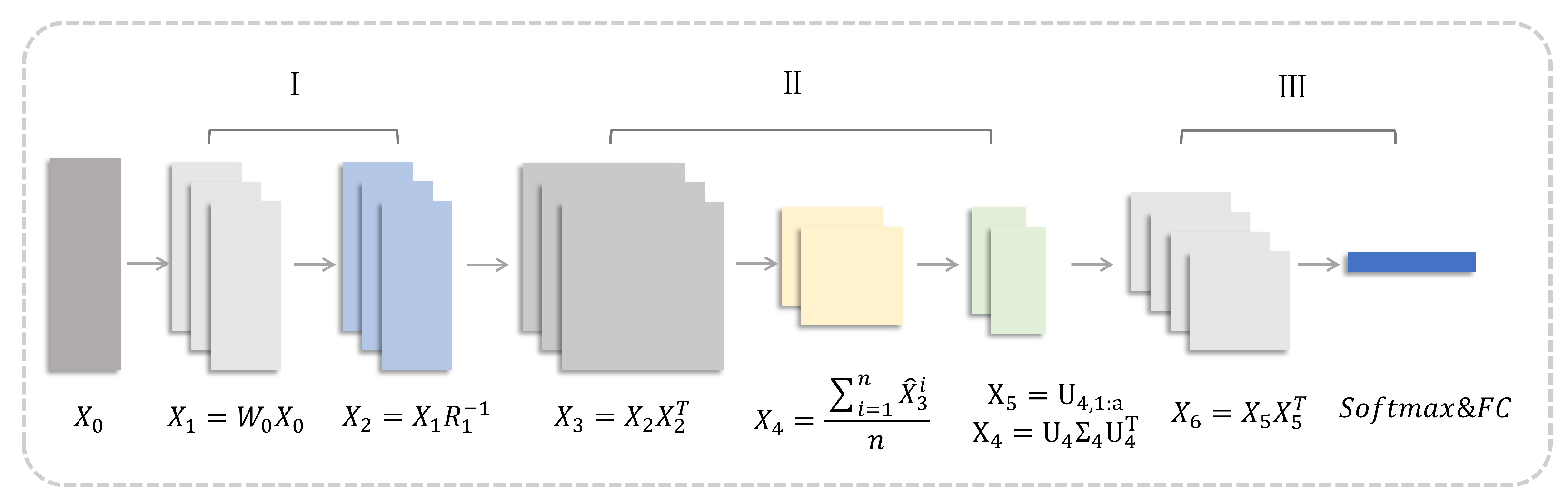
35], which is the Grassmannian manifold data. The Projection block consists of full rank mapping (FRMap) layers and re-orthonormalization (ReOrth) layers, which transform the input Grassmannian manifold data into a more discriminative and compact Grassmannian representation for better classification. The Pooling block is composed of projection mapping (ProjMap) layers, projection pooling (ProjPooling) layers, and orthonormal mapping (OrthMap) layers, which serves to reduce the computational effort and avoid overfitting. The Output block contains the ProjMap layer, fully connected layer, and softmax layer.
Figure 2 is an illustration of the structure of GrNet.
Table 1 lists the mapping functions of each layer in GrNet and the corresponding layers between the convolutional neural network and GrNet.
2.2. Knowledge Distillation
In a classification problem, the model maps the input features to a point in the label space, and in deep neural networks, this is mostly achieved by a fully connected layer. If all samples of a class are mapped to the same point in the label space, information about intra-class variance and inter-class distances will be lost. Furthermore, although incorrect labels have different probability distributions, they are ignored when the true labels are selected. Hinton et al. [
36] proposed the knowledge distillation that can distill the knowledge in an ensemble into a small model by using “soft targets”. The soft targets are the probabilities of different classes in the cumbersome models that can provide more information than the traditional ground truth (also known as hard target). The soft targets obtained from the large size teacher network (TNet) are applied to train the small size student network (SNet) through knowledge distillation to preserve the probability distribution between different incorrect labels. Therefore, the SNet imitates the training process of the TNet through knowledge distillation to adjust the network weights and achieves better performance than by training SNet only.
The softmax layer can convert the logit,
, into the probability of
class,
, as the following way:
The knowledge distillation introduces a temperature parameter,
t, to the softmax layer, which controls probability distribution between different classes. The probability differences between classes tend to be smaller with higher temperatures. As the temperature tends to infinity, the probability of each class tends to be equal. Through the adjustment of parameter
t, the mapping curve of the softmax layer is smoother. The soft target
is computed as below:
Obviously, when t is equal to 1, the soft target equals . Instead of letting fit to hard target only, the knowledge distillation enables the student networks to get the knowledge that the teacher networks have already obtained by narrowing the difference between the soft targets of A and B. From a teaching perspective, a hard target is like a standard answer and a soft target is like the teacher’s experience. With the help of the teacher, students can acquire knowledge faster and better. As a result, the small network can obtain higher accuracy by using both soft targets and hard targets.
At present, there are two ideas for knowledge distillation. One is to perform knowledge distillation at the output end of the network, which is also called goal-driven knowledge distillation. The classic example of this is the distillation framework in [
36], and another extension to it is ProjectionNet [
37]. The other is to perform knowledge distillation in the middle layer of the network, which is also called feature matching knowledge distillation. FitNets [
38] defines the hint layer and guided layer in the middle layer of TNet and SNet, respectively. The guided layer learns from the hint layer by adding a mean square loss between them in training. In [
39], the authors use the attention maps of the middle layers of TNet and SNet to calculate the loss. Similar to this is the use of Gram matrices rather than the attention maps in [
40]. Heo et al. [
41] propose a new designed margin ReLU activation and a new distillation feature position. Other recent methods of knowledge distillation include [
42,
43,
44,
45], etc.
To sum up, the key of knowledge distillation is to break up the original supervision information compressed to one point, which is a simple way to make up for the insufficient supervision signal of the classification problem. It increases the prior knowledge obtained through soft targets, reduces the search space of the network, so as to obtain better generalization ability and accelerate the convergence speed of the network.
2.3. Overview of the Proposed Method
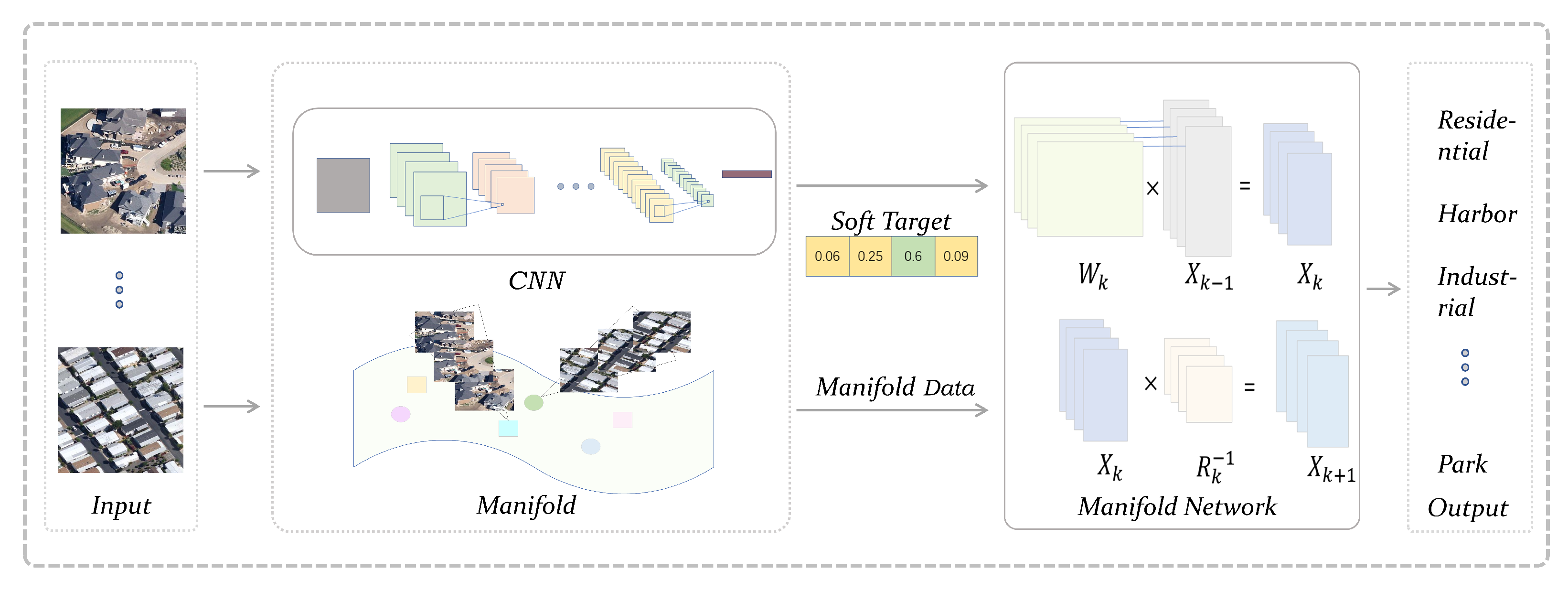
Figure 3 illustrates the way that our proposed method works. Our method consists of two flows. One is the training of traditional convolutional neural networks, and the other is the processing of the manifold network.
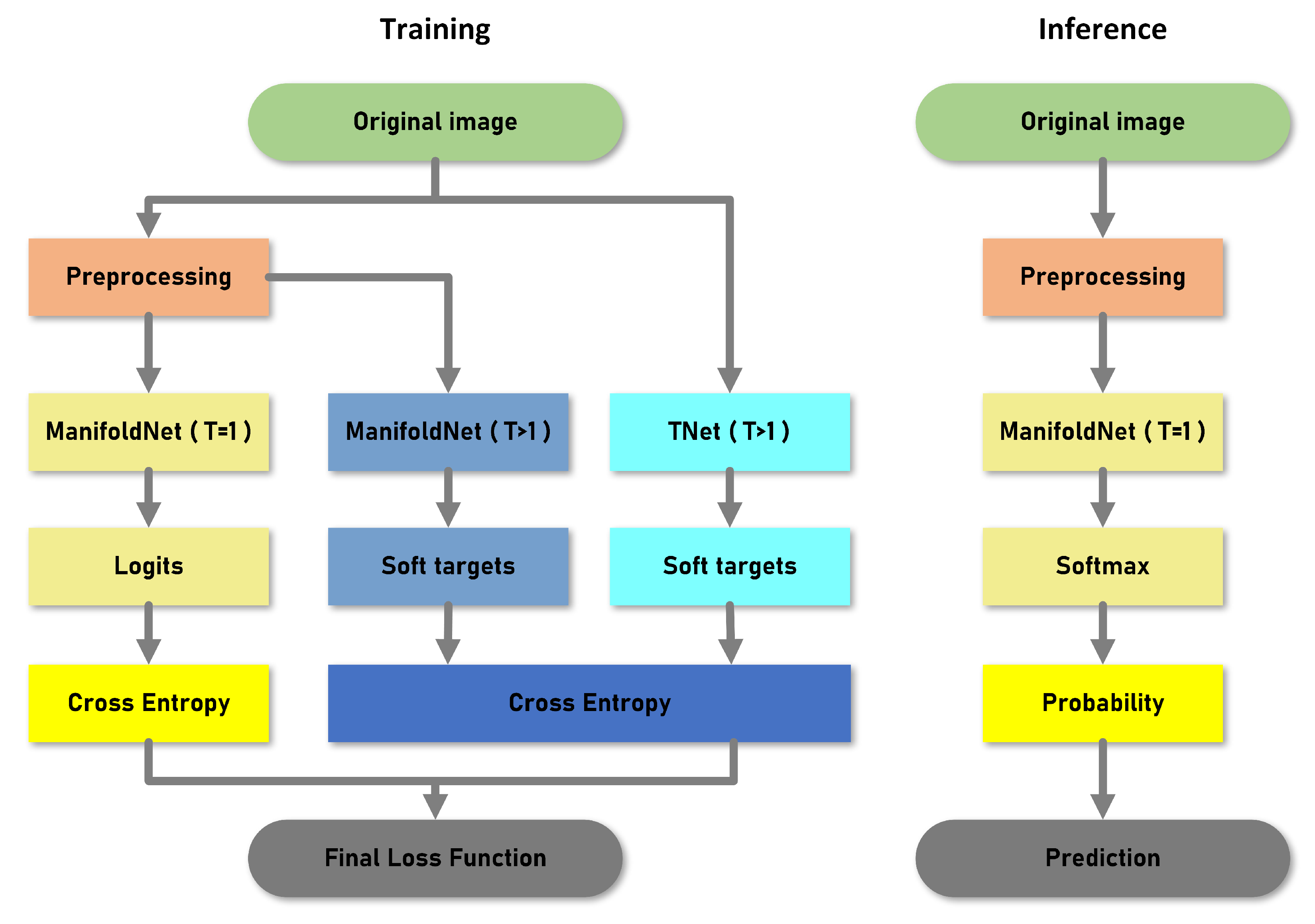
The remote sensing images are fed into the convolutional neural network which is called the teacher network first. The teacher network can get knowledge from a mass of data and store the knowledge in the soft targets that we use later. The input images require preprocessing because the manifold network has a special input format. In this paper, an effective approach is proposed to transform the original remote sensing images into the points in the Grassmann manifold, which is the input space of the manifold network. Then the manifold data is fed into the manifold network. Both soft targets and hard targets are used as supervisory information for training the manifold network. Finally, the resulting model can converge faster and predict more accurately than the model trained without knowledge distillation.
2.4. Training Manifold Network by Knowledge Distillation
Knowledge distillation can transfer the learning ability of a large network to a small network. The condition for distillation is that the partial structure of the student network (SNet) corresponds functionally to that of the teacher network (TNet). However, the manifold networks are structurally incompatible with the convolutional neural networks, leading to the difficulty of distillation between them. The output layers of the two networks are both fully connected layers, hence we choose to distill the knowledge on the top of networks.
First, the teacher network is trained with the original image as input, at which time
t is equal to 1. The trained teacher network is cumbersome, but it has a good generalization of data. Then
t is changed to be greater than 1 and we can obtain a soft target for each original image, which contains more information about the input image. In the meantime, the original images are transformed into Grassmannian data. The approach of transformation will be introduced later. Then we input the Grassmannian data into the student network. During training, the student network has two softmax layers with different temperatures, one with
t equal to 1 and the other with
t greater than 1. Therefore, the network has two outputs, a soft target and a hard target, and correspondingly two loss functions. We write the expression for soft target and hard target in the form of a vector as follows:
where
is the column vector of logit,
is transposition of vector,
is column vector with all elements of 1,
and
are soft target and hard target respectively. Then we substitute the logit
with specific network structures as follows:
where
represents the preprocessing of the input data, the
and
represent the manifold networks and convolutional neural networks respectively,
x is the original input, and the superscripts
S and
T refer to student networks and teacher networks respectively.
The first loss function is the standard cross entropy between the soft targets of two networks, as follows:
where
and
are the soft targets of the teacher network and student network respectively,
is the standard cross entropy.
Another loss function is the standard cross entropy between the ground truth and hard target, as follows:
where the
is hard target of the student network.
These two loss functions form the final loss function through a weighting coefficient
. As a result, the student network can learn weights by the ground truth, and meanwhile, the knowledge learned from the teacher networks can correct the learning direction and improve the accuracy of the small model. The effect of the true labels and the teacher network on the final training results can be controlled by the
. The final loss function
is formulated as follows:
The convolution is a linear operation, so the activation function is used to add nonlinear fitting capability. The convolutional neural network is very deep to obtain good data generalization ability, leading to the cumbersome model. However, the manifold network is defined in the non-Euclidean space, including its inputs and internal operations. The nonlinearity of the operations on the curve manifold leads to better spatial transformation capability and data fitting ability, meaning that the manifold network can achieve better results with fewer layers. With the help of knowledge distillation, we further enhance the performance of the manifold network by transferring the information in the soft targets of the cumbersome model.
Data Preprocessing
We choose GrNet as the manifold network in this paper. The GrNet is designed for Grassmannian data, so the images must be preprocessed before they are fed into the network. In face video recognition, a series of consecutive frames are sampled from the video, and the human face is extracted from the original video frame by using some face extraction algorithm. Therefore, these human face frames have similar patterns. A fixed number of images can be modeled as a linear subspace by extracting features from images, putting them together and then orthogonalizing them. However, there is a difference between human face videos and remote sensing scene images. The face images that belong to a person are very similar because they are consecutive frames extracted from the video. However, there may be a big difference for remote sensing scene images in a category. In general, for classification problems, our task is to label each image rather than classify a group of images into a category. Therefore, the above method is no longer applicable. In this paper, we propose a new method to represent a single image as a linear subspace as follows:
- (1)
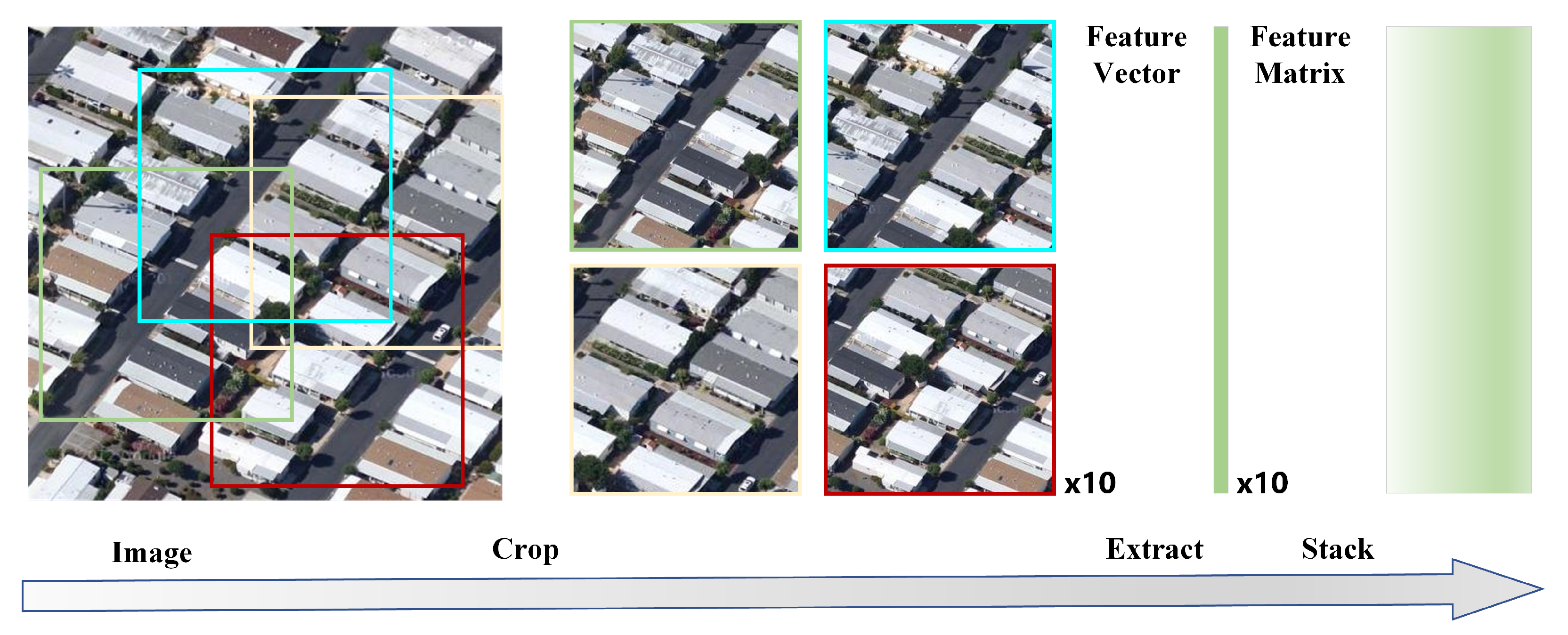
Crop and Stack. An image is randomly cut into
m subgraphs first. Then we extract a feature of fixed dimension for each subgraph. The
m feature vectors are stacked to form a feature matrix. This process is shown in
Figure 4. In this paper, the feature extraction method is the neural network. In our experiment, we set the dimension of the feature to 512 and
m to 10. As a result, each image can generate a feature matrix whose shape is
.
- (2)
Divide the datasets. To ensure that the overall distribution of the training sets and test sets is consistent, each category in the datasets is divided into training sets and test sets in a fixed proportion.
- (3)
PCA dimensionality reduction. Firstly, PCA dimension reduction is carried out on the training data, and the eigenvectors corresponding to k features with the largest eigenvalues are selected to form the eigenmatrix P. Then the eigenmatrix P obtained from the training set is used to reduce the dimension of the data of the training set and the test set. The dimension is reduced to 400 in our experiment, so the shape of the feature matrix becomes .
- (4)
Generate linear subspace. The feature matrix obtained in (3) is transformed into the orthogonal matrix by singular value decomposition(SVD). An orthogonal matrix is a linear subspace that is a point in the Grassmann manifold and also the input to GrNet.
2.5. The Flow of Proposed Method
The entire algorithm flowchart is shown in
Figure 5. First, input the original optical remote sensing images into a trained teacher network with a distillation temperature greater than 1 to get the soft targets. At meanwhile, each image is preprocessed as mentioned above to generate the manifold data. The processed data is entered into the manifold network which has two softmax layers. The first softmax layer with a temperature greater than 1 outputs the soft targets, which calculates the cross-entropy loss with the above soft targets. The second softmax layer with temperature equals 1 outputs logits, and the cross-entropy loss between the ground truth and these hard targets is computed. The final loss function is composed of these two losses and we train the network with a backpropagation algorithm. At inference, the processed images are input into the manifold network with the temperature equals 1, and the prediction results are output according to the obtained probability of each class.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}