
Hyperspectral Image Mixed Noise Removal Using Subspace Representation and Deep CNN Image Prior


Abstract
:1. Introduction
1.1. Related Work
1.2. Contributions
- Instead of estimating the subspace basis and the corresponding coefficients of HSIs jointly and iteratively, we decouple the estimation of the subspace basis and the corresponding coefficients. A new subspace learning method, which works independently from coefficient estimation and is robust to mixed noise, is proposed.
- An image prior extracted from a state-of-the-art neural denoising network, FFDNet, is seamlessly embedded within our HSI mixed noise removal framework, which is a successful combination of the traditional machine learning technique and deep learning technique.
2. Problem Formulation
2.1. Observation Model
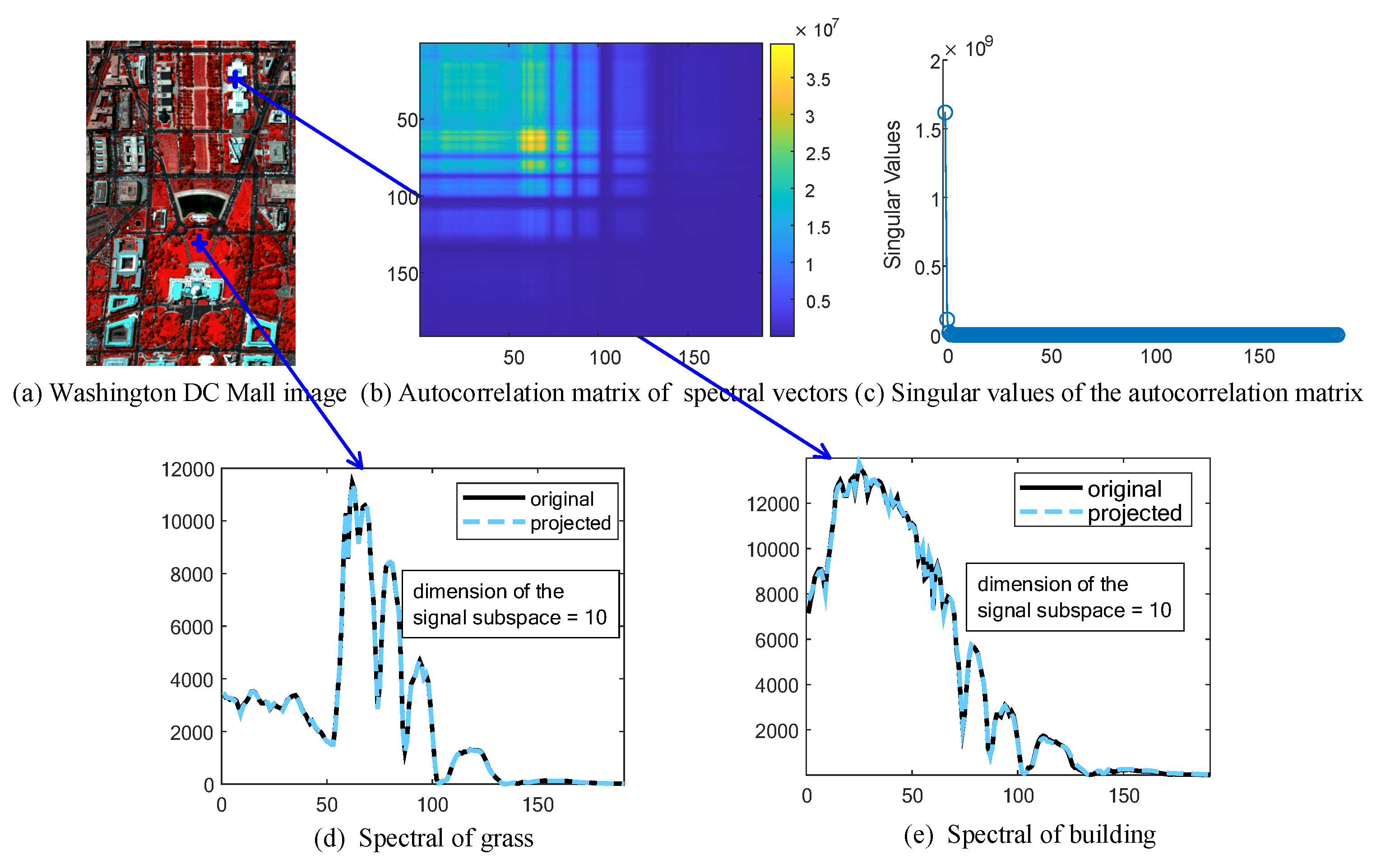
2.2. Subspace Representation of HSIs
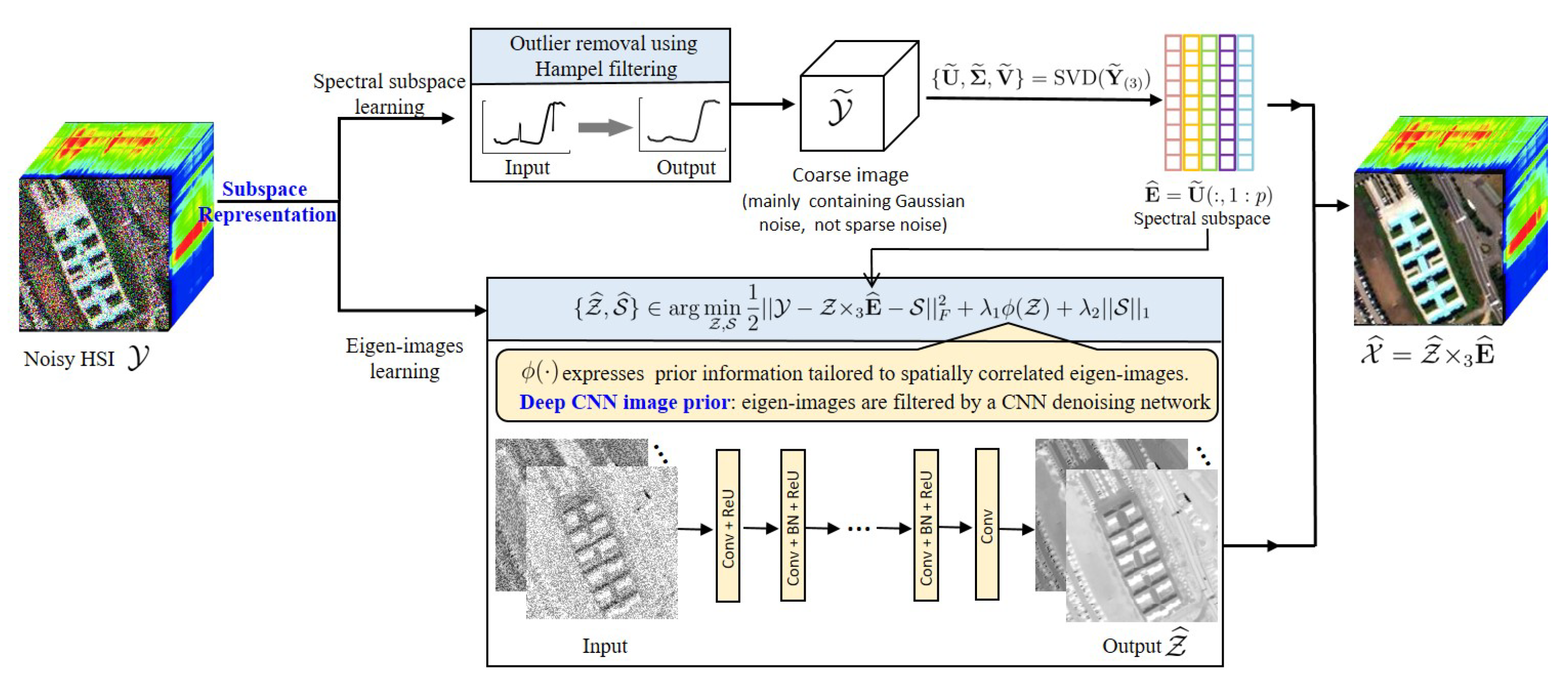
2.3. Subspace Learning against Mixed Noise
2.3.1. Outlier Removal Using Hampel Filtering
2.3.2. Subspace Identification
2.4. Fast Eigenimage Learning
2.4.1. Objective Function
2.4.2. Solver
| Algorithm 1HySuDeep for mixed noise containing i.i.d. Gaussian noise |
|
2.4.3. Plug-and-Play Prior,
2.5. HSI Recovery
3. Model Extension to Non-i.i.d. Gaussian Noise
- Estimate a coarse image, , by removing the sparse noise from observation. A outlier removal step applying Hampel filtering to spectral vectors of the observed image is given in .
- We apply linear regression to each band of the image ; i.e., each band is represented as a linear combination of the remaining bands [37]. That is,where denotes the transpose of the mode-3 unfolding matrix , the subscript means extracting the ith column from a matrix, a matrix with the subscript means the matrix including all columns except ith column, denotes regression coefficients, and denotes regression error.The regression coefficients can be estimated by the least squares method; i.e.,Given , the regression error, , is computed byThe regression errors are taken as a coarse estimate of the Gaussian noise; thus, its covariance matrix, , can be estimated bywhere is a function computing the variance of the elements of the input vector.
| Algorithm 2HySuDeep for mixed noise containing non-i.i.d. Gaussian noise |
4. Experiments with Simulated Images
4.1. Simulation of Noisy Images and Comparisons
4.1.1. Simulation of Noisy Images
4.1.2. Comparisons
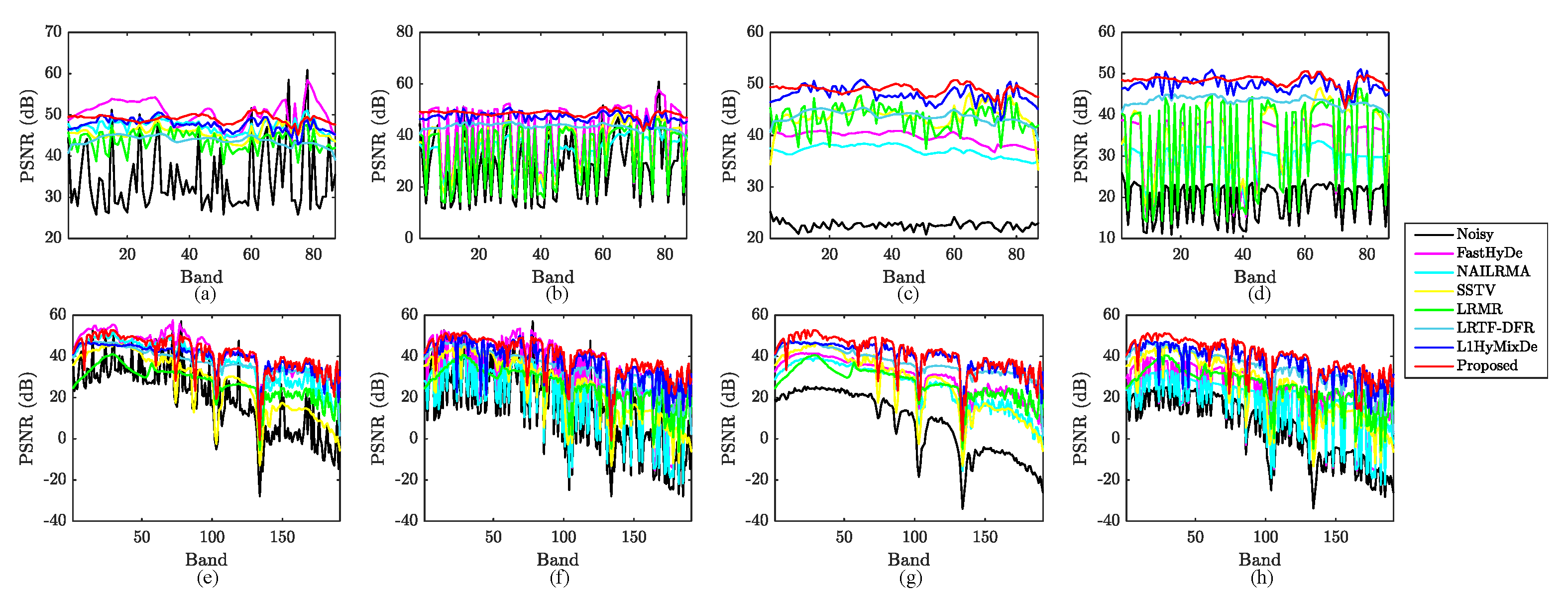
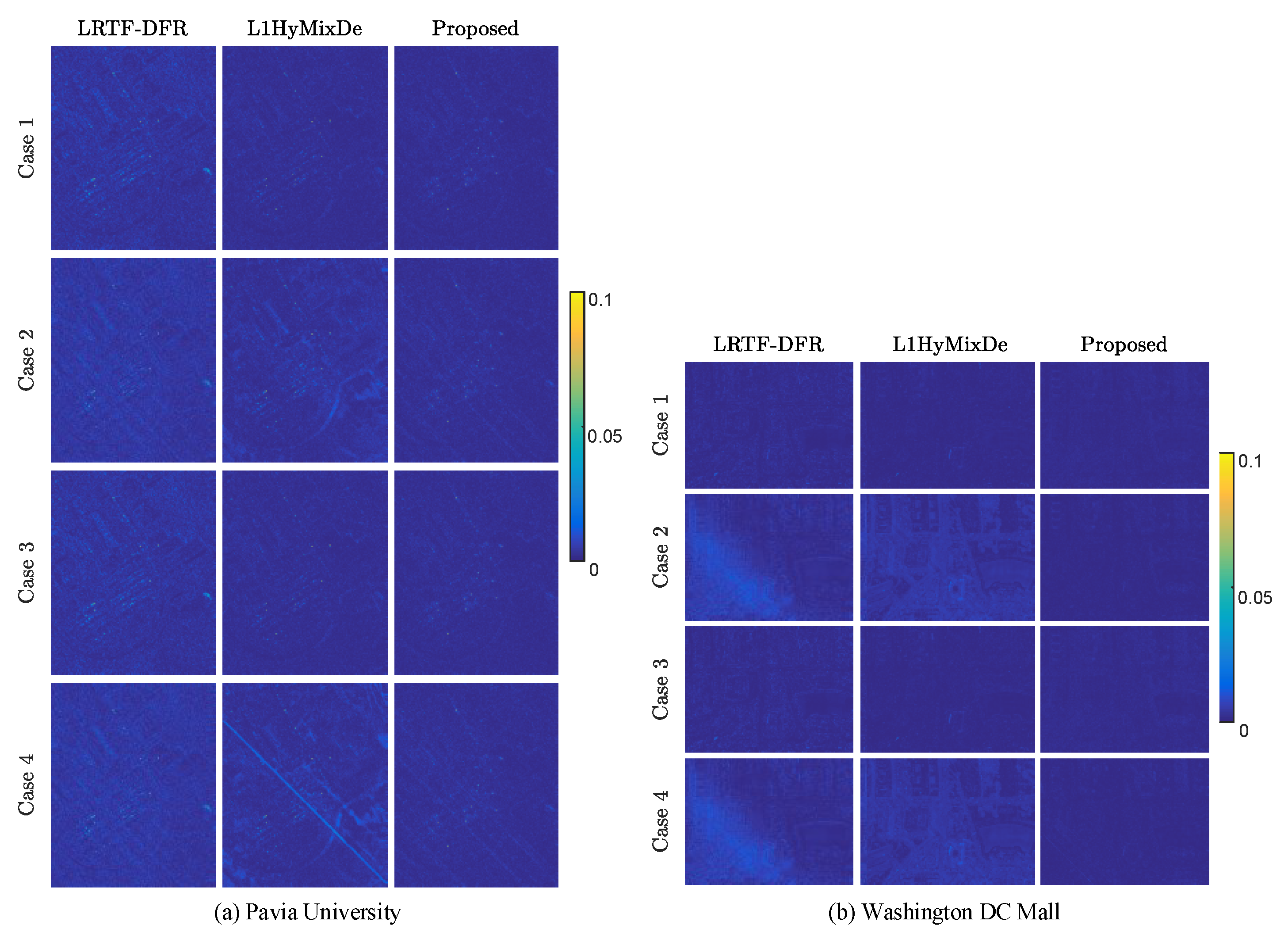
4.2. Mixed Noise Removal
4.3. Subspace Learning against Mixed Noise
4.4. Analysis of Regularization Parameters
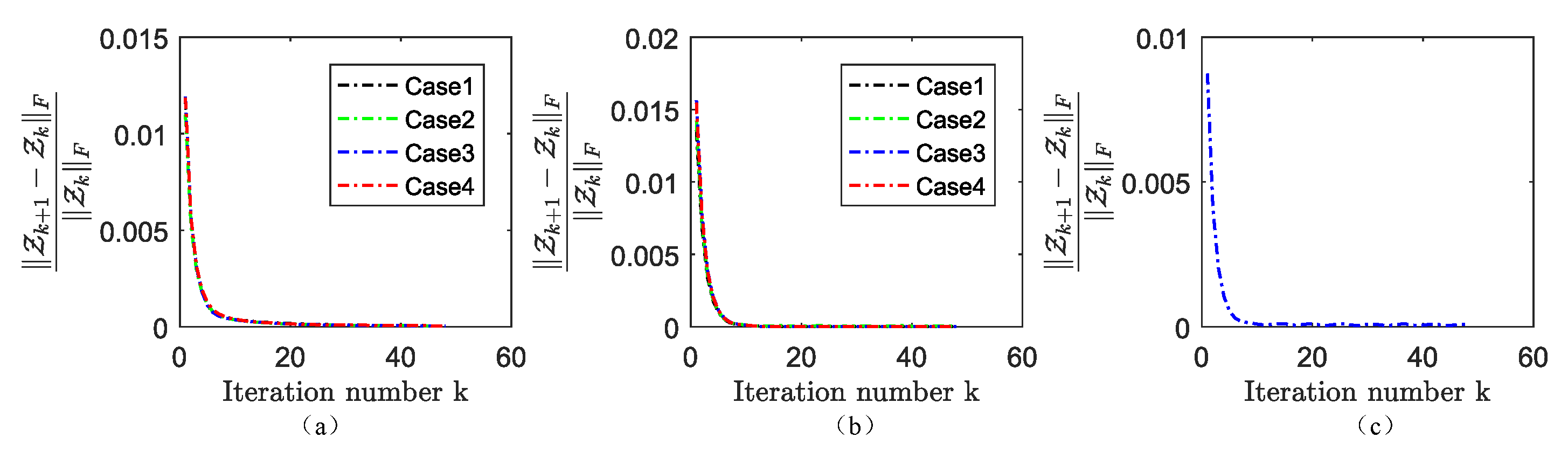
4.5. Numerical Convergence of the HySuDeep
4.6. Application in Hyperspectral Unmixing
5. Experimental Results for Real Images
5.1. Hyperion Cuprite Dataset
5.2. Tiangong-1 Dataset
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Bioucas-Dias, J.; Plaza, A.; Dobigeon, N.; Parente, M.; Du, Q.; Gader, P.; Chanussot, J. Hyperspectral Unmixing Overview: Geometrical, Statistical, and Sparse Regression-Based Approaches. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2012, 5, 354–379. [Google Scholar] [CrossRef] [Green Version]
- Ellis, J.M.; Davis, H.H.; Zamudio, J.A. Exploring for onshore oil seeps with hyperspectral imaging. Oil Gas J. 2001, 99, 49–58. [Google Scholar]
- Lowe, A.; Harrison, N.; French, A.P. Hyperspectral image analysis techniques for the detection and classification of the early onset of plant disease and stress. Plant Methods 2017, 13, 80. [Google Scholar] [CrossRef]
- Abdellatif, M.; Peel, H.; Cohn, A.G.; Fuentes, R. Pavement Crack Detection from Hyperspectral Images Using a Novel Asphalt Crack Index. Remote Sens. 2020, 12, 3084. [Google Scholar] [CrossRef]
- Chang, Y.; Yan, L.; Fang, H.; Liu, H. Simultaneous destriping and denoising for remote sensing images with unidirectional total variation and sparse representation. IEEE Geosci. Remote Sens. Lett. 2013, 11, 1051–1055. [Google Scholar] [CrossRef]
- Xie, Q.; Zhao, Q.; Meng, D.; Xu, Z.; Gu, S.; Zuo, W.; Zhang, L. Multispectral images denoising by intrinsic tensor sparsity regularization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 1692–1700. [Google Scholar]
- Yuan, Q.; Zhang, L.; Shen, H. Hyperspectral image denoising employing a spectral–spatial adaptive total variation model. IEEE Trans. Geosci. Remote Sens. 2012, 50, 3660–3677. [Google Scholar] [CrossRef]
- Zhuang, L.; Bioucas-Dias, J. Fast hyperspectral image denoising and inpainting based on low-rank and sparse representations. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 730–742. [Google Scholar] [CrossRef]
- Zhao, Y.Q.; Yang, J. Hyperspectral image denoising via sparse representation and low-rank constraint. IEEE Trans. Geosci. Remote Sens. 2014, 53, 296–308. [Google Scholar] [CrossRef]
- Jiang, S.; Hao, X. Hybrid Fourier-wavelet image denoising. Electron. Lett. 2007, 43, 1081–1082. [Google Scholar] [CrossRef]
- Rasti, B.; Sveinsson, J.R.; Ulfarsson, M.O.; Benediktsson, J.A. Hyperspectral image denoising using first order spectral roughness penalty in wavelet domain. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2013, 7, 2458–2467. [Google Scholar] [CrossRef]
- Fan, H.; Li, C.; Guo, Y.; Kuang, G.; Ma, J. Spatial-spectral total variation regularized low-rank tensor decomposition for hyperspectral image denoising. IEEE Trans. Geosci. Remote Sens. 2018, 56, 6196–6213. [Google Scholar] [CrossRef]
- Chang, Y.; Yan, L.; Zhong, S. Hyper-laplacian regularized unidirectional low-rank tensor recovery for multispectral image denoising. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA; 2017; pp. 4260–4268. [Google Scholar]
- Xie, T.; Li, S.; Sun, B. Hyperspectral Images Denoising via Nonconvex Regularized Low-Rank and Sparse Matrix Decomposition. IEEE Trans. Image Process. 2020, 29, 44–56. [Google Scholar] [CrossRef]
- Zhang, H.; He, W.; Zhang, L.; Shen, H.; Yuan, Q. Hyperspectral image restoration using low-rank matrix recovery. IEEE Trans. Geosci. Remote Sens. 2013, 52, 4729–4743. [Google Scholar] [CrossRef]
- Wang, M.; Wang, Q.; Chanussot, J.; Li, D. Hyperspectral Image Mixed Noise Removal Based on Multidirectional Low-Rank Modeling and Spatial–Spectral Total Variation. IEEE Trans. Geosci. Remote Sens. 2020, 59, 488–507. [Google Scholar] [CrossRef]
- Zhuang, L.; Fu, X.; Ng, M.K.; Bioucas-Dias, J.M. Hyperspectral Image Denoising Based on Global and Nonlocal Low-Rank Factorizations. IEEE Trans. Geosci. Remote. Sens. 2021. [Google Scholar] [CrossRef]
- He, W.; Yao, Q.; Li, C.; Yokoya, N.; Zhao, Q. Non-Local Meets Global: An Integrated Paradigm for Hyperspectral Denoising. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition; 2019; pp. 6868–6877. [Google Scholar]
- Zhuang, L.; Gao, L.; Zhang, B.; Fu, X.; Bioucas-Dias, J.M. Hyperspectral image denoising and anomaly detection based on low-rank and sparse representations. IEEE Trans. Geosci. Remote. Sens. 2020. [Google Scholar] [CrossRef]
- Lin, J.; Huang, T.Z.; Zhao, X.L.; Jiang, T.X.; Zhuang, L. A Tensor Subspace Representation-Based Method for Hyperspectral Image Denoising. IEEE Trans. Geosci. Remote. Sens. 2020, 59, 7739–7757. [Google Scholar] [CrossRef]
- Zheng, Y.B.; Huang, T.Z.; Zhao, X.L.; Chen, Y.; He, W. Double-factor-regularized low-rank tensor factorization for mixed noise removal in hyperspectral image. IEEE Trans. Geosci. Remote Sens. 2020, 58, 8450–8464. [Google Scholar] [CrossRef]
- Cao, C.; Yu, J.; Zhou, C.; Hu, K.; Xiao, F.; Gao, X. Hyperspectral image denoising via subspace-based nonlocal low-rank and sparse factorization. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 973–988. [Google Scholar] [CrossRef]
- Zhang, K.; Zuo, W.; Chen, Y.; Meng, D.; Zhang, L. Beyond a Gaussian Denoiser: Residual Learning of Deep CNN for Image Denoising. IEEE Trans. Image Process. 2017, 26, 3142–3155. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, K.; Zuo, W.; Zhang, L. FFDNet: Toward a fast and flexible solution for CNN-based image denoising. IEEE Trans. Image Process. 2018, 27, 4608–4622. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Guo, S.; Yan, Z.; Zhang, K.; Zuo, W.; Zhang, L. Toward Convolutional Blind Denoising of Real Photographs. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 1712–1722. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Q.; Yuan, Q.; Li, J.; Liu, X.; Shen, H.; Zhang, L. Hybrid noise removal in hyperspectral imagery with a spatial-spectral gradient network. IEEE Trans. Geosci. Remote Sens. 2019, 57, 7317–7329. [Google Scholar] [CrossRef]
- Chang, Y.; Yan, L.; Fang, H.; Zhong, S.; Liao, W. HSI-DeNet: Hyperspectral Image Restoration via Convolutional Neural Network. IEEE Trans. Geosci. Remote Sens. 2019, 57, 667–682. [Google Scholar] [CrossRef]
- Zhang, Q.; Yuan, Q.; Li, J.; Sun, F.; Zhang, L. Deep spatio-spectral Bayesian posterior for hyperspectral image non-i.i.d. noise removal. ISPRS J. Photogramm. Remote Sens. 2020, 164, 125–137. [Google Scholar] [CrossRef]
- Venkatakrishnan, S.V.; Bouman, C.A.; Wohlberg, B. Plug-and-Play priors for model based reconstruction. In Proceedings of the 2013 IEEE Global Conference on Signal and Information Processing, Austin, TX, USA, 3–5 December 2013; pp. 945–948. [Google Scholar] [CrossRef] [Green Version]
- Chan, S.H.; Wang, X.; Elgendy, O.A. Plug-and-play ADMM for image restoration: Fixed-point convergence and applications. IEEE Trans. Comput. Imaging 2016, 3, 84–98. [Google Scholar] [CrossRef] [Green Version]
- Romano, Y.; Elad, M.; Milanfar, P. The little engine that could: Regularization by denoising (RED). SIAM J. Imaging Sci. 2017, 10, 1804–1844. [Google Scholar] [CrossRef]
- Zhuang, L.; Ng, M.K. Hyperspectral Mixed Noise Removal By ℓ1-Norm-Based Subspace Representation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 1143–1157. [Google Scholar] [CrossRef]
- Simoes, M.; Bioucas-Dias, J.; Almeida, L.B.; Chanussot, J. A convex formulation for hyperspectral image superresolution via subspace-based regularization. IEEE Trans. Geosci. Remote Sens. 2014, 53, 3373–3388. [Google Scholar] [CrossRef] [Green Version]
- Li, J.; Bioucas-Dias, J.M.; Plaza, A. Spectral-Spatial Hyperspectral Image Segmentation Using Subspace Multinomial Logistic Regression and Markov Random Fields. IEEE Trans. Geosci. Remote Sens. 2012, 50, 809–823. [Google Scholar] [CrossRef]
- Gao, L.; Li, J.; Khodadadzadeh, M.; Plaza, A.; Zhang, B.; He, Z.; Yan, H. Subspace-Based Support Vector Machines for Hyperspectral Image Classification. IEEE Geosci. Remote Sens. Lett. 2015, 12, 349–353. [Google Scholar] [CrossRef]
- Zhuang, L.; Lin, C.; Figueiredo, M.A.T.; Bioucas-Dias, J.M. Regularization Parameter Selection in Minimum Volume Hyperspectral Unmixing. IEEE Trans. Geosci. Remote Sens. 2019, 57, 9858–9877. [Google Scholar] [CrossRef]
- Bioucas-Dias, J.M.; Nascimento, J.M.P. Hyperspectral Subspace Identification. IEEE Trans. Geosci. Remote Sens. 2008, 46, 2435–2445. [Google Scholar] [CrossRef] [Green Version]
- Afonso, M.V.; Bioucas-Dias, J.M.; Figueiredo, M.A. An augmented Lagrangian approach to the constrained optimization formulation of imaging inverse problems. IEEE Trans. Image Process. 2010, 20, 681–695. [Google Scholar] [CrossRef] [Green Version]
- Afonso, M.; Bioucas-Dias, J.; Figueiredo, M. Fast image recovery using variable splitting and constrained optimization. IEEE Trans. Image Process. 2010, 19, 2345–2356. [Google Scholar] [CrossRef] [Green Version]
- Eckstein, J.; Bertsekas, D.P. On the Douglas-Rachford splitting method and the proximal point algorithm for maximal monotone operators. Math. Program. 1992, 55, 293–318. [Google Scholar] [CrossRef] [Green Version]
- Combettes, P.; Patric, J.C. Proximal splitting methods in signal processing. In Fixed-Point Algorithms for Inverse Problems in Science and Engineering; Springer: Berlin/Heidelberg, Germany, 2011; pp. 185–212. [Google Scholar]
- Figueiredo, M.A.; Bioucas-Dias, J.M. Restoration of Poissonian images using alternating direction optimization. IEEE Trans. Image Process. 2010, 19, 3133–3145. [Google Scholar] [CrossRef] [Green Version]
- Teodoro, A.M.; Bioucas-Dias, J.M.; Figueiredo, M.A. A convergent image fusion algorithm using scene-adapted Gaussian-mixture-based denoising. IEEE Trans. Image Process. 2018, 28, 451–463. [Google Scholar] [CrossRef]
- Dian, R.; Li, S.; Kang, X. Regularizing hyperspectral and multispectral image fusion by CNN denoiser. IEEE Trans. Neural Networks Learn. Syst. 2021, 32, 1124–1135. [Google Scholar] [CrossRef] [PubMed]
- Gao, L.; Du, Q.; Zhang, B.; Yang, W.; Wu, Y. A comparative study on linear regression-based noise estimation for hyperspectral imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2013, 6, 488–498. [Google Scholar] [CrossRef] [Green Version]
- Bioucas-Dias, J.M.; Plaza, A.; Camps-Valls, G.; Scheunders, P.; Nasrabadi, N.M.; Chanussot, J. Hyperspectral Remote Sensing Data Analysis and Future Challenges. IEEE Geosci. Remote Sens. Mag. 2013, 1, 6–36. [Google Scholar] [CrossRef] [Green Version]
- Altmann, Y.; Pereyra, M.; Bioucas-Dias, J.M. Collaborative sparse regression using spatially correlated supports-application to hyperspectral unmixing. IEEE Trans. Image Process. 2015, 24, 5800–5811. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- He, W.; Zhang, H.; Zhang, L.; Shen, H. Hyperspectral image denoising via noise-adjusted iterative low-rank matrix approximation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 3050–3061. [Google Scholar] [CrossRef]
- Aggarwal, H.K.; Majumdar, A. Hyperspectral image denoising using spatio-spectral total variation. IEEE Geosci. Remote Sens. Lett. 2016, 13, 442–446. [Google Scholar] [CrossRef]
- Chang, Y.; Yan, L.; Wu, T.; Zhong, S. Remote sensing image stripe noise removal: From image decomposition perspective. IEEE Trans. Geosci. Remote Sens. 2016, 54, 7018–7031. [Google Scholar] [CrossRef]
- Golub, G.H.; Reinsch, C. Singular value decomposition and least squares solutions. In Linear Algebra; Springer: Berlin/Heidelberg, Germany, 1971; pp. 134–151. [Google Scholar]
- Wright, J.; Ganesh, A.; Rao, S.; Peng, Y.; Ma, Y. Robust principal component analysis: Exact recovery of corrupted low-rank matrices via convex optimization. Adv. Neural Inf. Process. Syst. 2009, 58, 2080–2088. [Google Scholar]
- Nascimento, J.; Dias, J. Vertex component analysis: A fast algorithm to unmix hyperspectral data. IEEE Trans. Geosci. Remote Sens. 2005, 43, 898–910. [Google Scholar] [CrossRef] [Green Version]
- Bioucas-Dias, J.M.; Figueiredo, M. Alternating direction algorithms for constrained sparse regression: Application to hyperspectral unmixing. In Proceedings of the 2010 2nd Workshop on Hyperspectral Image and Signal Processing: Evolution in Remote Sensing (WHISPERS), Reykjavík, Iceland, 14–16 June 2010; pp. 1–4. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notation | Definition |
|---|---|
| Three-dimensional tensor (calligraphic letter) | |
| Matrix (boldface capital letter) | |
| Vector (boldface lowercase letter) | |
| x | Scalar (italic lowercase letter) |
| Order N | Number of dimensions in a tensor |
| Mode n | nth dimension of a tensor |
| Mode-3 vectors of | -dimensional vectors obtained from by varying the 3rd index while keeping 1st and 2nd indices fixed. |
| Mode-3 slices of | Matrices obtained from by varing every index but the 3rd index. |
| ith mode-3 slice of , a matrix obtained by fixing the mode-3 index of to be i. | |
| Mode-3 unfolding of . A tensor can be unfolded into a matrix by rearranging its mode-3 vectors, which are the column | |
| vectors of . | |
| Tensor matrix multiplication. The mode-3 product of a tensor by a matrix is a tensor | |
| , denoted as , which is corresponding to a matrix multiplication, . | |
| The definition of Frobenius norm of a matrix is extended to a tensor as follows: |
| Cases | Indexes | Noisy | FastHyDe | NAILRMA | SSTV | LRMR | LRTF-DFR | L1HyMixDe | HySuDeep |
|---|---|---|---|---|---|---|---|---|---|
| [8] | [48] | [49] | [15] | [21] | [32] | ||||
| Pavia University data | |||||||||
| Case 1 | MPSNR | 34.29 | 50.50 | 47.25 | 45.73 | 43.72 | 43.77 | 47.62 | 49.08 |
| MSSIM | 0.8221 | 0.9981 | 0.9949 | 0.9929 | 0.9867 | 0.9906 | 0.9971 | 0.9978 | |
| MFSIM | 0.9272 | 0.9991 | 0.9977 | 0.9966 | 0.9945 | 0.9949 | 0.9986 | 0.999 | |
| Time (s) | - | 10 | 185 | 282 | 107 | 141 | 114 | 31 | |
| Case 2 | MPSNR | 27.77 | 40.94 | 32.33 | 35.06 | 33.58 | 43.43 | 47.26 | 48.55 |
| MSSIM | 0.7451 | 0.9087 | 0.9236 | 0.9584 | 0.9176 | 0.9902 | 0.9969 | 0.9975 | |
| MFSIM | 0.8683 | 0.9569 | 0.9519 | 0.9702 | 0.9461 | 0.9948 | 0.9985 | 0.9989 | |
| Time (s) | - | 9 | 182 | 268 | 67 | 141 | 156 | 33 | |
| Case 3 | MPSNR | 22.56 | 39.66 | 37.03 | 43.85 | 43.37 | 43.72 | 47.90 | 48.93 |
| MSSIM | 0.6892 | 0.9781 | 0.9556 | 0.9876 | 0.9858 | 0.9905 | 0.9971 | 0.9977 | |
| MFSIM | 0.8780 | 0.9870 | 0.9799 | 0.9948 | 0.9942 | 0.9948 | 0.9986 | 0.999 | |
| Time (s) | - | 9 | 123 | 250 | 87 | 141 | 112 | 32 | |
| Case 4 | MPSNR | 19.29 | 31.83 | 28.20 | 33.59 | 33.64 | 43.32 | 47.43 | 48.31 |
| MSSIM | 0.6258 | 0.8249 | 0.8531 | 0.9463 | 0.9153 | 0.9901 | 0.9968 | 0.9972 | |
| MFSIM | 0.8267 | 0.9103 | 0.9169 | 0.9656 | 0.9455 | 0.9947 | 0.9985 | 0.9987 | |
| Time (s) | - | 10 | 193 | 274 | 89 | 140 | 114 | 38 | |
| Washington DC Mall data | |||||||||
| Case 1 | MPSNR | 19.13 | 42.04 | 37.22 | 26.78 | 27.15 | 36.96 | 39.52 | 41.17 |
| MSSIM | 0.7781 | 0.9985 | 0.9962 | 0.9674 | 0.9710 | 0.9961 | 0.9981 | 0.9983 | |
| MFSIM | 0.8634 | 0.9980 | 0.9931 | 0.9630 | 0.9706 | 0.9959 | 0.9978 | 0.999 | |
| Time (s) | - | 6 | 218 | 228 | 55 | 145 | 40 | 29 | |
| Case 2 | MPSNR | 12.52 | 30.58 | 20.56 | 24.08 | 25.39 | 34.12 | 36.65 | 40.05 |
| MSSIM | 0.6851 | 0.8608 | 0.8440 | 0.9512 | 0.9636 | 0.9909 | 0.9946 | 0.9978 | |
| MFSIM | 0.7973 | 0.9368 | 0.8940 | 0.9547 | 0.9663 | 0.9948 | 0.9956 | 0.9987 | |
| Time (s) | - | 5 | 196 | 234 | 37 | 145 | 64 | 29 | |
| Case 3 | MPSNR | 7.29 | 29.78 | 24.94 | 26.70 | 27.29 | 36.62 | 39.90 | 40.75 |
| MSSIM | 0.6421 | 0.9818 | 0.9642 | 0.9667 | 0.9707 | 0.9959 | 0.9982 | 0.9981 | |
| MFSIM | 0.8052 | 0.9849 | 0.9713 | 0.9625 | 0.9706 | 0.9958 | 0.9978 | 0.9988 | |
| Time (s) | - | 5 | 137 | 229 | 40 | 144 | 42 | 30 | |
| Case 4 | MPSNR | 3.84 | 20.34 | 15.82 | 24.03 | 24.94 | 34.03 | 36.81 | 39.07 |
| MSSIM | 0.5676 | 0.8029 | 0.7958 | 0.9506 | 0.9617 | 0.9910 | 0.9947 | 0.997 | |
| MFSIM | 0.7508 | 0.8886 | 0.8663 | 0.9544 | 0.9649 | 0.9947 | 0.9956 | 0.998 | |
| Time (s) | - | 5 | 178 | 207 | 43 | 144 | 52 | 30 | |
| Noisy | FastHyDe | NAILRMA | SSTV | LRMR | LRTF-DFR | L1HyMixDe | HySuDeep | |
|---|---|---|---|---|---|---|---|---|
| MPSNR | 28.90 | 48.94 | 40.72 | 35.58 | 39.84 | 45.84 | 50.84 | 51.91 |
| MSSIM | 0.7296 | 0.9933 | 0.9843 | 0.9168 | 0.9831 | 0.9932 | 0.9975 | 0.9987 |
| MFSIM | 0.8719 | 0.9961 | 0.9882 | 0.9548 | 0.9830 | 0.9953 | 0.9984 | 0.9989 |
| Time (s) | - | 20 | 587 | 951 | 129 | 572 | 562 | 137 |
| NMSEA | 0.10 | 0.19 | 0.17 | 0.20 | 0.05 | 0.06 | 0.03 | 0.04 |
| NMSES | 0.52 | 0.48 | 0.47 | 0.48 | 0.46 | 0.51 | 0.15 | 0.09 |
| SVD | RPCA | L1HyMixDe | HySime | HySuDeep | ||
|---|---|---|---|---|---|---|
| [51] | [52] | [32] | [37] | |||
| Pavia University data | ||||||
| Case 1 | 0.9994 | 0.9993 | 0.9995 | 1.0000 | 0.9996 | |
| 0.1789 | 0.1816 | 0.1753 | 0.0954 | 0.1500 | ||
| Case 2 | 0.9854 | 0.9868 | 0.9994 | 0.9881 | 0.9996 | |
| 0.2552 | 0.2526 | 0.1599 | 0.2270 | 0.1314 | ||
| Case 3 | 0.9993 | 0.9991 | 0.9995 | 0.9997 | 0.9996 | |
| 0.1095 | 0.1102 | 0.1066 | 0.0909 | 0.1019 | ||
| Case 4 | 0.9855 | 0.9867 | 0.9993 | 0.9869 | 0.9997 | |
| 0.2355 | 0.2338 | 0.1526 | 0.2109 | 0.1271 | ||
| Washington DC Mall data | ||||||
| Case 1 | 0.9998 | 0.9998 | 0.9998 | 1.0000 | 0.9998 | |
| 0.0772 | 0.0775 | 0.0751 | 0.0466 | 0.0630 | ||
| Case 2 | 0.9826 | 0.9838 | 0.9997 | 0.9878 | 0.9997 | |
| 0.2738 | 0.2700 | 0.0978 | 0.2426 | 0.0585 | ||
| Case 3 | 0.9997 | 0.9997 | 0.9998 | 0.9998 | 0.9998 | |
| 0.0483 | 0.0480 | 0.0456 | 0.0406 | 0.0441 | ||
| Case 4 | 0.9825 | 0.9834 | 0.9997 | 0.9868 | 0.9997 | |
| 0.2342 | 0.2321 | 0.0883 | 0.2110 | 0.0600 | ||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhuang, L.; Ng, M.K.; Fu, X. Hyperspectral Image Mixed Noise Removal Using Subspace Representation and Deep CNN Image Prior. Remote Sens. 2021, 13, 4098. https://doi.org/10.3390/rs13204098
Zhuang L, Ng MK, Fu X. Hyperspectral Image Mixed Noise Removal Using Subspace Representation and Deep CNN Image Prior. Remote Sensing. 2021; 13(20):4098. https://doi.org/10.3390/rs13204098
Chicago/Turabian StyleZhuang, Lina, Michael K. Ng, and Xiyou Fu. 2021. "Hyperspectral Image Mixed Noise Removal Using Subspace Representation and Deep CNN Image Prior" Remote Sensing 13, no. 20: 4098. https://doi.org/10.3390/rs13204098
APA StyleZhuang, L., Ng, M. K., & Fu, X. (2021). Hyperspectral Image Mixed Noise Removal Using Subspace Representation and Deep CNN Image Prior. Remote Sensing, 13(20), 4098. https://doi.org/10.3390/rs13204098