
Cross-Dimension Attention Guided Self-Supervised Remote Sensing Single-Image Super-Resolution




Abstract
:1. Introduction
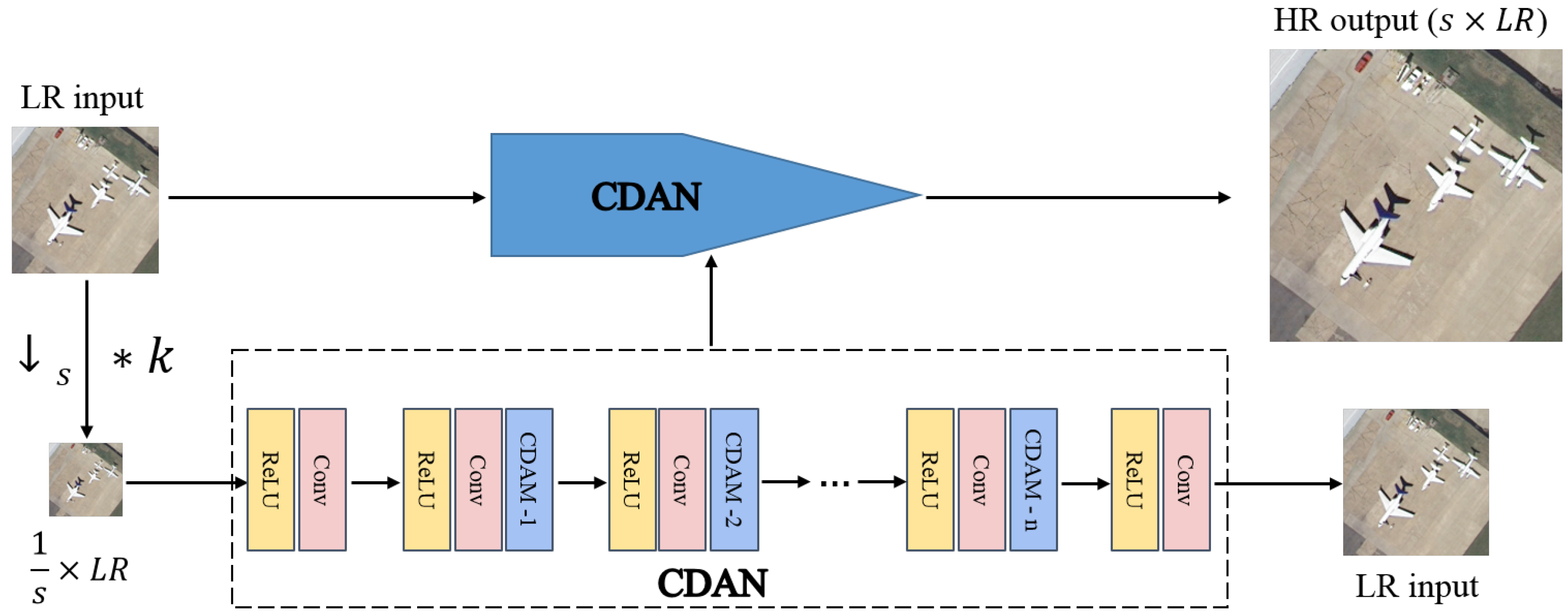
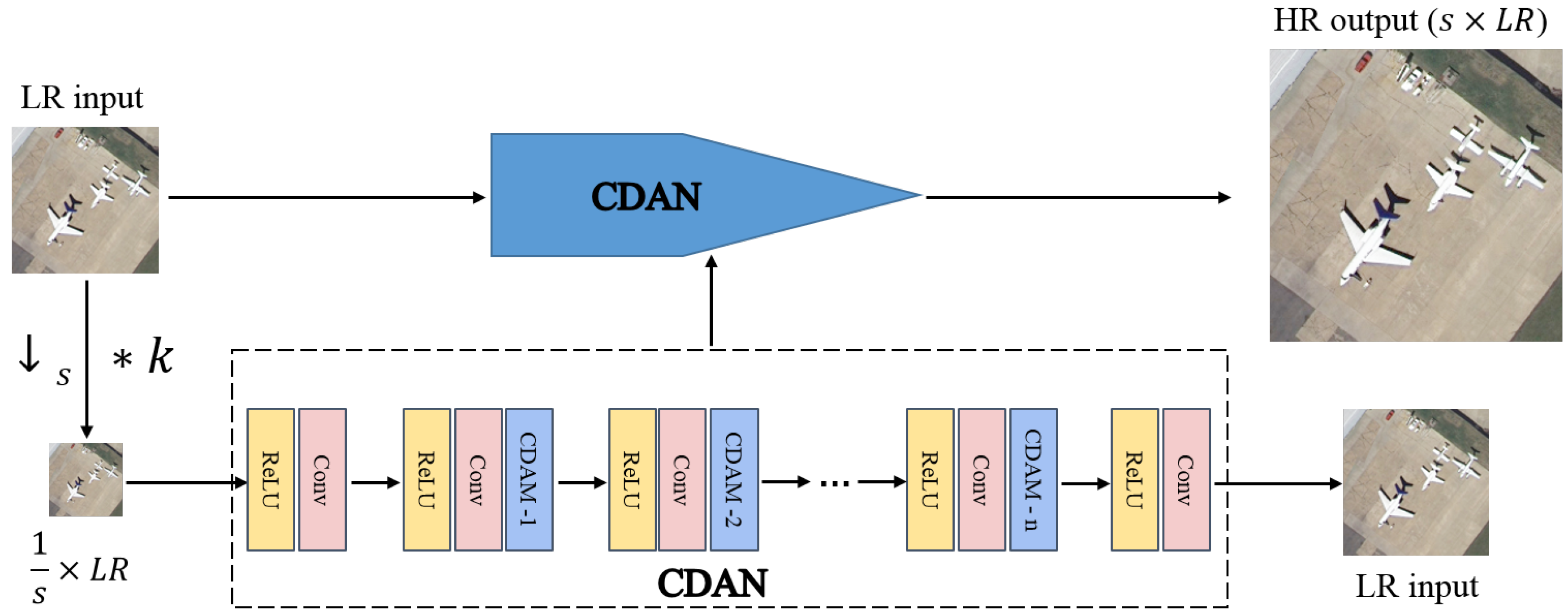
- We introduce a cross-dimension attention guided self-supervised remote sensing single-image super-resolution method (CASSISR). Our CASSISR only needs one image for training. It takes advantage of the reproducibility of the internal information of a single image, does not require prior training in the dataset, and only uses the lower-resolution images extracted from a single input image itself to train the attention guided convolutional network (CDAN), which can better adapt to real remote sensing image super-resolution tasks.
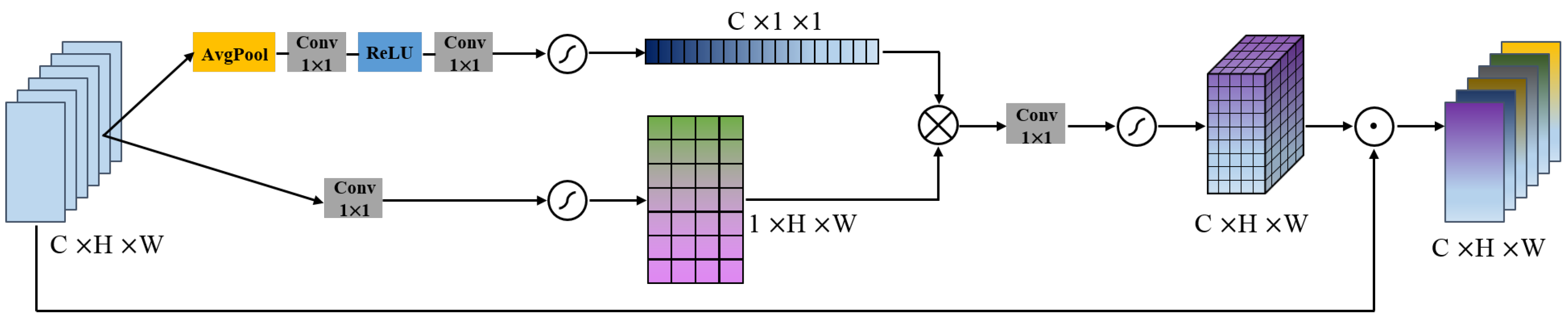
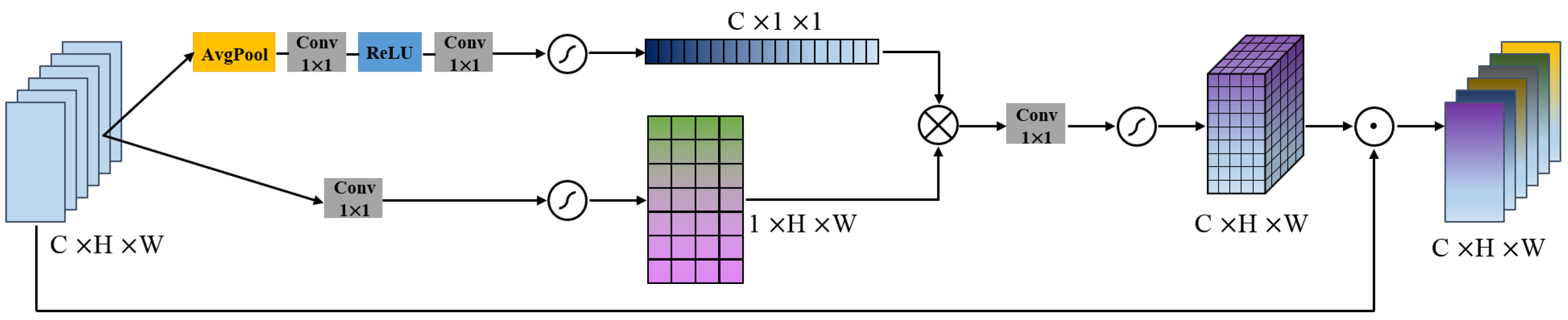
- We propose a cross-dimension attention mechanism module (CDAM). It considers the interaction between the channel dimension and the spatial dimension by modeling the interdependence between the channel and the spatial feature, jointly learning the feature weight of the channel and the spatial, selectively capturing more useful internal duplicate information, improving the learning ability of static CNN.
- We conduct a large number of experiments on the ‘ideal’ remote sensing dataset, ‘non-ideal’ remote sensing dataset, and real-world remote sensing dataset, and compare the experimental results with the SOTA-SR methods. Although there is only one training image for CASSISR, it still obtains more favorable results.
2. Related Work
2.1. CNN-Based SR Method
2.2. Remote Sensing SR Method
2.3. Attention Mechanism
3. Materials and Methods
3.1. Overall Network Overview
3.2. Cross-Dimension Attention Module
3.3. Network Settings and Loss Function
4. Results
4.1. Datasets Construction
4.1.1. ‘Ideal’ Remote Sensing Dataset
4.1.2. ‘Non-Ideal’ Remote Sensing Dataset
4.1.3. Real-World Remote Sensing Dataset
4.2. Experiments on ‘Ideal’ Remote Sensing Dataset
4.3. Experiments on ‘Non-Ideal’ Remote Sensing Dataset
4.3.1. Quantitative Results
4.3.2. Qualitative Results
4.4. Experiments on the Real-World Remote Sensing Dataset
4.5. Ablation Experiment
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| SR | super-resolution |
| HR | high-resolution |
| LR | low-resolution |
| CASSISR | cross-dimension attention guided self-supervised remote sensing single image |
| super-resolution | |
| CDAN | cross-dimension attention network |
| CDAM | cross-dimension attention module |
| CNN | convolutional neural networks |
| ResNet | residual network |
| SOTA | state-of-the-art |
| BN | batch normalization |
References
- Minh-Tan, P.; Aptoula, E.; Lefèvre, S. Feature profiles from attribute filtering for classification of remote sensing images. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2017, 11, 249–256. [Google Scholar]
- Maxwell, A.E.; Warner, T.A.; Fang, F. Implementation of machine-learning classification in remote sensing: An applied review. Int. J. Remote Sens. 2018, 39, 2784–2817. [Google Scholar] [CrossRef] [Green Version]
- Gencer, S.; Cinbis, R.G.; Aksoy, S. Fine-grained object recognition and zero-shot learning in remote sensing imagery. IEEE Trans. Geosci. Remote Sens. 2017, 56, 770–779. [Google Scholar]
- Kong, X.; Huang, Y.; Li, S.; Lin, H.; Benediktsson, J.A. Extended random walker for shadow detection in very high resolution remote sensing images. IEEE Trans. Geosci. Remote Sens. 2017, 56, 867–876. [Google Scholar] [CrossRef]
- Lin, H.; Shi, Z.; Zou, Z. Fully convolutional network with task partitioning for inshore ship detection in optical remote sensing images. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1665–1669. [Google Scholar] [CrossRef]
- Wu, T.; Luo, J.; Fang, J.; Ma, J.; Song, X. Unsupervised object-based change detection via a Weibull mixture model-based binarization for high-resolution remote sensing images. IEEE Geosci. Remote Sens. Lett. 2017, 15, 63–67. [Google Scholar] [CrossRef]
- Liu, Z.; Li, G.; Mercier, G.; He, Y.; Pan, Q. Change detection in heterogenous remote sensing images via homogeneous pixel transformation. IEEE Trans. Image Process. 2017, 27, 1822–1834. [Google Scholar] [CrossRef]
- Zhang, L.; Wu, X. An edge-guided image interpolation algorithm via directional filtering and data fusion. IEEE Trans. Image Process. 2006, 15, 2226–2238. [Google Scholar] [CrossRef] [Green Version]
- Zhang, K.; Gao, X.; Tao, D.; Li, X. Single image super-resolution with non-local means and steering kernel regression. IEEE Trans. Image Process. 2012, 21, 4544–4556. [Google Scholar] [CrossRef]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Learning a deep convolutional network for image super-resolution. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 184–199. [Google Scholar]
- Kim, J.; Lee, J.K.; Lee, K.M. Accurate image super-resolution using very deep convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1646–1654. [Google Scholar]
- Zhang, K.; Zuo, W.; Zhang, L. Learning a single convolutional super-resolution network for multiple degradations. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3262–3271. [Google Scholar]
- Dai, T.; Cai, J.; Zhang, Y.; Xia, S.T.; Zhang, L. Second-order attention network for single image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 11065–11074. [Google Scholar]
- Haris, M.; Shakhnarovich, G.; Ukita, N. Deep back-projection networks for super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1664–1673. [Google Scholar]
- Zhang, Y.; Tian, Y.; Kong, Y.; Zhong, B.; Fu, Y. Residual dense network for image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2472–2481. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Kim, J.; Lee, J.K.; Lee, K.M. Deeply-recursive convolutional network for image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1637–1645. [Google Scholar]
- Lim, B.; Son, S.; Kim, H.; Nah, S.; Lee, K.M. Enhanced deep residual networks for single image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 136–144. [Google Scholar]
- Tai, Y.; Yang, J.; Liu, X. Image super-resolution via deep recursive residual network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3147–3155. [Google Scholar]
- Sajjadi, M.S.; Scholkopf, B.; Hirsch, M. Enhancenet: Single image super-resolution through automated texture synthesis. In Proceedings of the 2017 IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4491–4500. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Zhang, Y.; Li, K.; Li, K.; Wang, L.; Zhong, B.; Fu, Y. Image super-resolution using very deep residual channel attention networks. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 286–301. [Google Scholar]
- Hu, Y.; Li, J.; Huang, Y.; Gao, X. Channel-wise and spatial feature modulation network for single image super-resolution. IEEE Trans. Circuits Syst. Video Technol. 2019, 30, 3911–3927. [Google Scholar] [CrossRef] [Green Version]
- Agustsson, E.; Timofte, R. Ntire 2017 challenge on single image super-resolution: Dataset and study. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 126–135. [Google Scholar]
- Glasner, D.; Bagon, S.; Irani, M. Super-resolution from a single image. In Proceedings of the IEEE International Conference on Computer Vision, Kyoto, Japan, 29 September–2 October 2009; pp. 349–356. [Google Scholar]
- Huang, J.B.; Singh, A.; Ahuja, N. Single image super-resolution from transformed self-exemplars. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 5197–5206. [Google Scholar]
- Michaeli, T.; Irani, M. Nonparametric blind super-resolution. In Proceedings of the 2013 IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 945–952. [Google Scholar]
- Bahat, Y.; Efrat, N.; Irani, M. Non-uniform blind deblurring by reblurring. In Proceedings of the 2017 IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 3286–3294. [Google Scholar]
- Bahat, Y.; Irani, M. Blind dehazing using internal patch recurrence. In Proceedings of the IEEE International Conference on Computer Photography, Evanston, IL, USA, 13–15 May 2016; pp. 1–9. [Google Scholar]
- Shocher, A.; Cohen, N.; Irani, M. “zero-shot” super-resolution using deep internal learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3118–3126. [Google Scholar]
- Xu, X.; Sun, D.; Pan, J.; Zhang, Y.; Pfister, H.; Yang, M.H. Learning to super-resolve blurry face and text images. In Proceedings of the 2017 IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 251–260. [Google Scholar]
- Zhang, X.; Chen, Q.; Ng, R.; Koltun, V. Zoom to learn, learn to zoom. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 3762–3770. [Google Scholar]
- Zontak, M.; Irani, M. Internal statistics of a single natural image. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 20–25 June 2011; pp. 977–984. [Google Scholar]
- Dong, C.; Loy, C.C.; Tang, X. Accelerating the super-resolution convolutional neural network. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 391–407. [Google Scholar]
- Huang, N.; Yang, Y.; Liu, J.; Gu, X.; Cai, H. Single-image super-resolution for remote sensing data using deep residual-learning neural network. In Proceedings of the Springer International Conference on Neural Information Processing, Guangzhou, China, 14–18 November 2017; pp. 622–630. [Google Scholar]
- Lei, S.; Shi, Z.; Zou, Z. Super-Resolution for Remote Sensing Images via Local–Global Combined Network. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1243–1247. [Google Scholar] [CrossRef]
- Xu, W.; Xu, G.; Wang, Y.; Sun, X.; Lin, D.; Wu, Y. Deep memory connected neural network for optical remote sensing image restoration. Remote Sens. 2018, 10, 1893. [Google Scholar] [CrossRef] [Green Version]
- Gu, J.; Sun, X.; Zhang, Y.; Fu, K.; Wang, L. Deep Residual Squeeze and Excitation Network for Remote Sensing Image Super-Resolution. Remote Sens. 2019, 11, 1817. [Google Scholar] [CrossRef] [Green Version]
- Haut, J.M.; Paoletti, M.E.; Fernandez-Beltran, R.; Plaza, J.; Plaza, A.; Li, J. Remote Sensing Single-Image Superresolution Based on a Deep Compendium Model. IEEE Geosci. Remote Sens. Lett. 2019, 16, 1432–1436. [Google Scholar] [CrossRef]
- Jaderberg, M.; Simonyan, K.; Zisserman, A.; Kavukcuoglu, K. Spatial transformer networks. In Proceedings of the Advances in Neural Information Processing Systems 28, Montreal, QC, Canada, 7–12 December 2015; pp. 2017–2025. [Google Scholar]
- Gao, Z.; Xie, J.; Wang, Q.; Li, P. Global second-order pooling convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 3024–3033. [Google Scholar]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Vedaldi, A. Gather-excite: Exploiting feature context in convolutional neural networks. In Proceedings of the NIPS 2018: The 32nd Annual Conference on Neural Information Processing Systems, Montreal, QC, Canada, 3–8 December 2018; pp. 1–11. [Google Scholar]
- Park, J.; Woo, S.; Lee, J.Y.; Kweon, I.S. BAM: Bottleneck Attention Module. In Proceedings of the 2018 British Machine Vision Conference, Newcastle, UK, 3–6 September 2018; pp. 147–163. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2018, arXiv:1412.6980. [Google Scholar]
- Zou, Q.; Ni, L.; Zhang, T.; Wang, Q. Deep learning based feature selection for remote sensing scene classification. IEEE Geosci. Remote Sens. Lett. 2015, 12, 2321–2325. [Google Scholar] [CrossRef]
- Zhao, L.; Tang, P.; Huo, L. Feature significance-based multibag-of-visual-words model for remote sensing image scene classification. J. Appl. Remote Sens. 2016, 10, 035004. [Google Scholar] [CrossRef]
- Sheng, G.; Yang, W.; Xu, T.; Sun, H. High-resolution satellite scene classification using a sparse coding based multiple feature combination. Int. J. Remote Sens. 2012, 33, 2395–2412. [Google Scholar] [CrossRef]
- Yang, Y.; Newsam, S. Bag-of-visual-words and spatial extensions for land-use classification. In Proceedings of the 18th SIGSPATIAL International Conference on Advances in Geographic Information Systems, San Jose, CA, USA, 2–5 November 2010; pp. 270–279. [Google Scholar]
- Xia, G.S.; Hu, J.; Hu, F.; Shi, B.; Bai, X.; Zhong, Y.; Zhang, L. AID: A benchmark data set for performance evaluation of aerial scene classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 3965–3981. [Google Scholar] [CrossRef] [Green Version]
- Cheng, G.; Han, J.; Lu, X. Remote sensing image scene classification: Benchmark and state of the art. Proc. IEEE 2017, 105, 1865–1883. [Google Scholar] [CrossRef] [Green Version]
- Bell-Kligler, S.; Shocher, A.; Irani, M. Blind super-resolution kernel estimation using an internal-gan. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; pp. 284–293. [Google Scholar]
- Daudt, R.C.; Saux, B.L.; Boulch, A.; Gousseau, Y. Urban change detection for multispectral earth observation using convolutional neural networks. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018; pp. 2115–2118. [Google Scholar]
- Mei, Y.; Fan, Y.; Zhou, Y.; Huang, L.; Huang, T.S.; Shi, H. Image Super-Resolution With Cross-Scale Non-Local Attention and Exhaustive Self-Exemplars Mining. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 5690–5699. [Google Scholar]
- Wang, X.; Wu, Y.; Ming, Y.; Lv, H. Remote Sensing Imagery Super Resolution Based on Adaptive Multi-Scale Feature Fusion Network. Remote Sens. 2020, 20, 1142. [Google Scholar] [CrossRef] [Green Version]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Scale | RSSCN7 | RSC11 | WHU-RS19 | UC-Merced | AID | NWPU45 |
|---|---|---|---|---|---|---|---|
| PSNR/SSIM | PSNR/SSIM | PSNR/SSIM | PSNR/SSIM | PSNR/SSIM | PSNR/SSIM | ||
| Bicubic | / | / | / | / | / | / | |
| SRCNN [10] | / | / | / | / | / | / | |
| FSRCNN [35] | / | / | / | / | / | / | |
| EDSR [18] | / | / | / | / | / | / | |
| SRMD [12] | / | / | / | / | / | / | |
| RDN [15] | / | / | / | / | / | / | |
| RCAN [23] | / | / | / | / | / | / | |
| SAN [13] | / | / | / | / | / | / | |
| CS-NL [54] | / | / | / | / | / | / | |
| LGCNet [37] | / | / | / | / | / | / | |
| DMCN [38] | / | / | / | / | / | / | |
| DRSEN [39] | / | / | / | / | / | / | |
| DCM [40] | / | / | / | / | / | / | |
| AMFFN [55] | / | / | / | / | / | / | |
| CASSISR(Our) | / | / | / | / | / | / | |
| Bicubic | / | / | / | / | / | / | |
| SRCNN [10] | / | / | / | / | / | / | |
| FSRCNN [35] | / | / | / | / | / | / | |
| EDSR [18] | / | / | / | / | / | / | |
| SRMD [12] | / | / | / | / | / | / | |
| RDN [15] | / | / | / | / | / | / | |
| RCAN [23] | / | / | / | / | / | / | |
| SAN [13] | / | / | / | / | / | / | |
| CS-NL [54] | / | / | / | / | / | / | |
| LGCNet [37] | / | / | / | / | / | / | |
| DMCN [38] | / | / | / | / | / | / | |
| DRSEN [39] | / | / | / | / | / | / | |
| DCM [40] | / | / | / | / | / | / | |
| AMFFN [55] | / | / | / | / | / | / | |
| CASSISR(Our) | / | / | / | / | / | / |
| Method | Scale | RSSCN7-Blur | RSC11-Blur | WHU-RS19-Blur | UC-Merced-Blur | AID-Blur | NWPU45-Blur |
|---|---|---|---|---|---|---|---|
| PSNR/SSIM | PSNR/SSIM | PSNR/SSIM | PSNR/SSIM | PSNR/SSIM | PSNR/SSIM | ||
| Bicubic | / | / | / | / | / | / | |
| SRCNN [10] | / | / | / | / | / | / | |
| FSRCNN [35] | / | / | / | / | / | / | |
| EDSR [18] | / | / | / | / | / | / | |
| SRMD [12] | / | / | / | / | / | / | |
| RDN [15] | / | / | / | / | / | / | |
| RCAN [23] | / | / | / | / | / | / | |
| SAN [13] | / | / | / | / | / | / | |
| CS-NL [54] | / | / | / | / | / | / | |
| CASSISR(Our) | / | / | / | / | / | / | |
| Bicubic | / | / | / | / | / | / | |
| SRCNN [10] | / | / | / | / | / | / | |
| FSRCNN [35] | / | / | / | / | / | / | |
| EDSR [18] | / | / | / | / | / | / | |
| SRMD [12] | / | / | / | / | / | / | |
| RDN [15] | / | / | / | / | / | / | |
| RCAN [23] | / | / | / | / | / | / | |
| SAN [13] | / | / | / | / | / | / | |
| CS-NL [54] | / | / | / | / | / | / | |
| CASSISR(Our) | / | / | / | / | / | / |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jiang, W.; Zhao, L.; Wang, Y.; Liu, W.; Liu, B. Cross-Dimension Attention Guided Self-Supervised Remote Sensing Single-Image Super-Resolution. Remote Sens. 2021, 13, 3835. https://doi.org/10.3390/rs13193835
Jiang W, Zhao L, Wang Y, Liu W, Liu B. Cross-Dimension Attention Guided Self-Supervised Remote Sensing Single-Image Super-Resolution. Remote Sensing. 2021; 13(19):3835. https://doi.org/10.3390/rs13193835
Chicago/Turabian StyleJiang, Wenzong, Lifei Zhao, Yanjiang Wang, Weifeng Liu, and Baodi Liu. 2021. "Cross-Dimension Attention Guided Self-Supervised Remote Sensing Single-Image Super-Resolution" Remote Sensing 13, no. 19: 3835. https://doi.org/10.3390/rs13193835
APA StyleJiang, W., Zhao, L., Wang, Y., Liu, W., & Liu, B. (2021). Cross-Dimension Attention Guided Self-Supervised Remote Sensing Single-Image Super-Resolution. Remote Sensing, 13(19), 3835. https://doi.org/10.3390/rs13193835