
Remote Sensing Image Defogging Networks Based on Dual Self-Attention Boost Residual Octave Convolution




Abstract
:
1. Introduction
1.1. Traditional Remote-Sensing Image Defogging Methods
1.2. Deep Learning-Based Image Defogging Methods
- This paper proposes remote sensing image defogging backbone networks based on residual octave convolution. Both high-frequency spatial information and low-frequency image information of a foggy remote sensing image can be extracted simultaneously by residual octave convolution. So, the proposed networks can restore both the details of high-frequency components and structure information of low-frequency components, thereby improving the overall quality of the defogged remote sensing image.
- This paper proposes a dual self-attention mechanism. Due to the unevenly distributed fog/haze and too much detailed information of a foggy remote sensing image, the proposed dual self-attention mechanism can improve the defogging performance and detail retention ability of the proposed networks in thick fog scenes by paying different attention to different details and different thicknesses of fog.
- The SOS boosted module is applied to the feature refinement, so the proposed networks can estimate the remote sensing image information and foggy areas separately, which ensures defogging does not destroy the image details and color information during the network transmission process of image features.
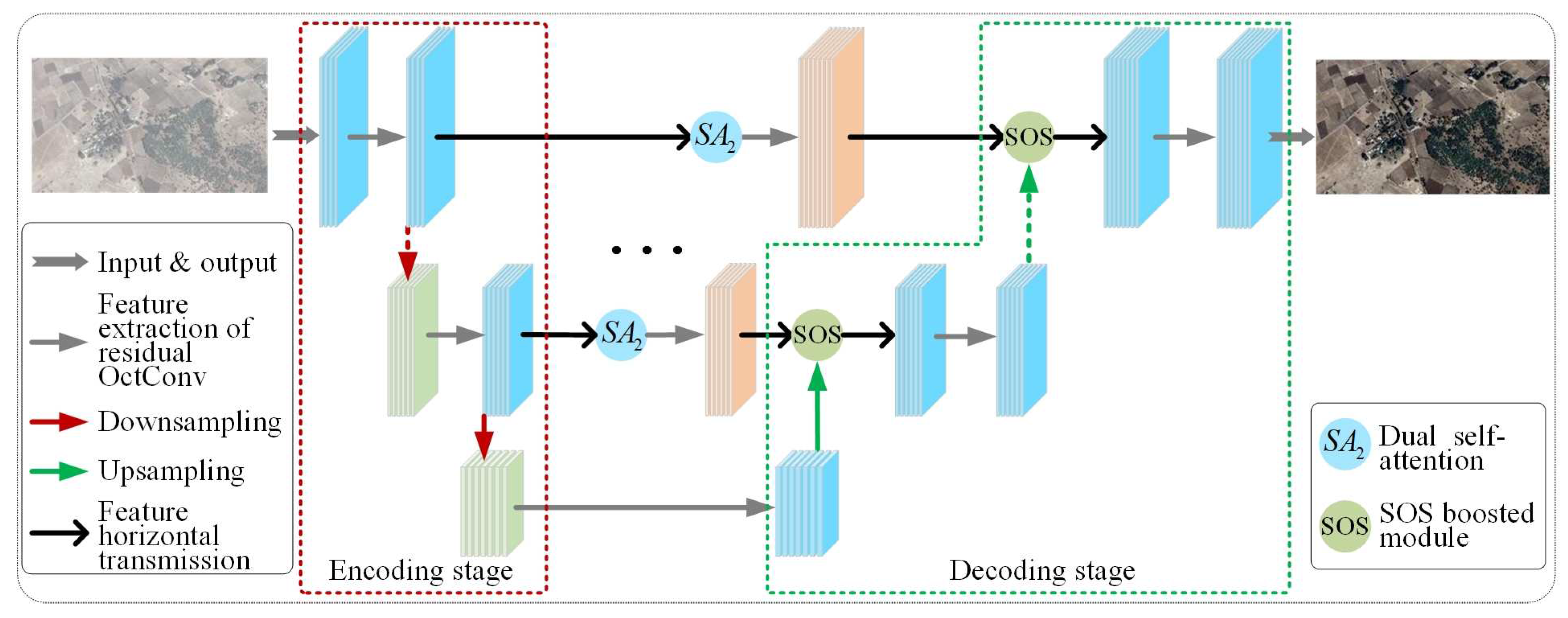
2. Methods
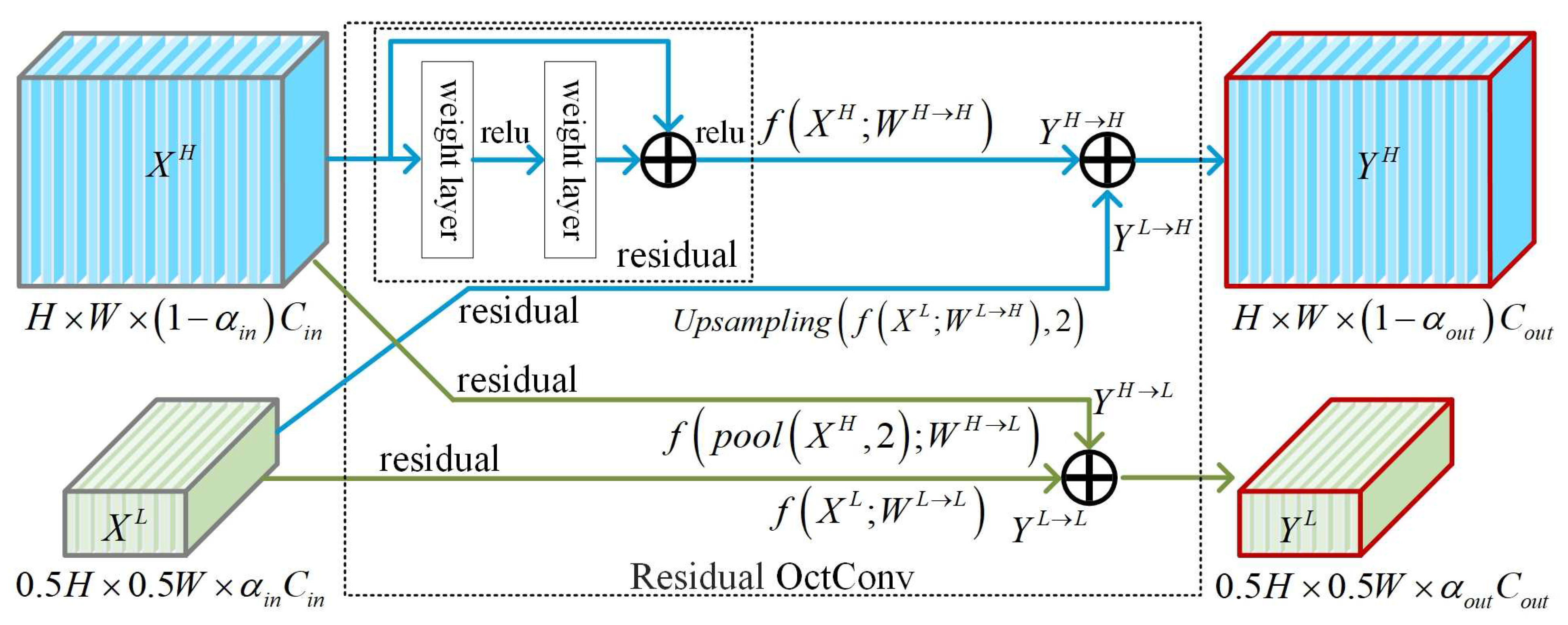
2.1. Feature Map Extraction Based on Residual OctConv
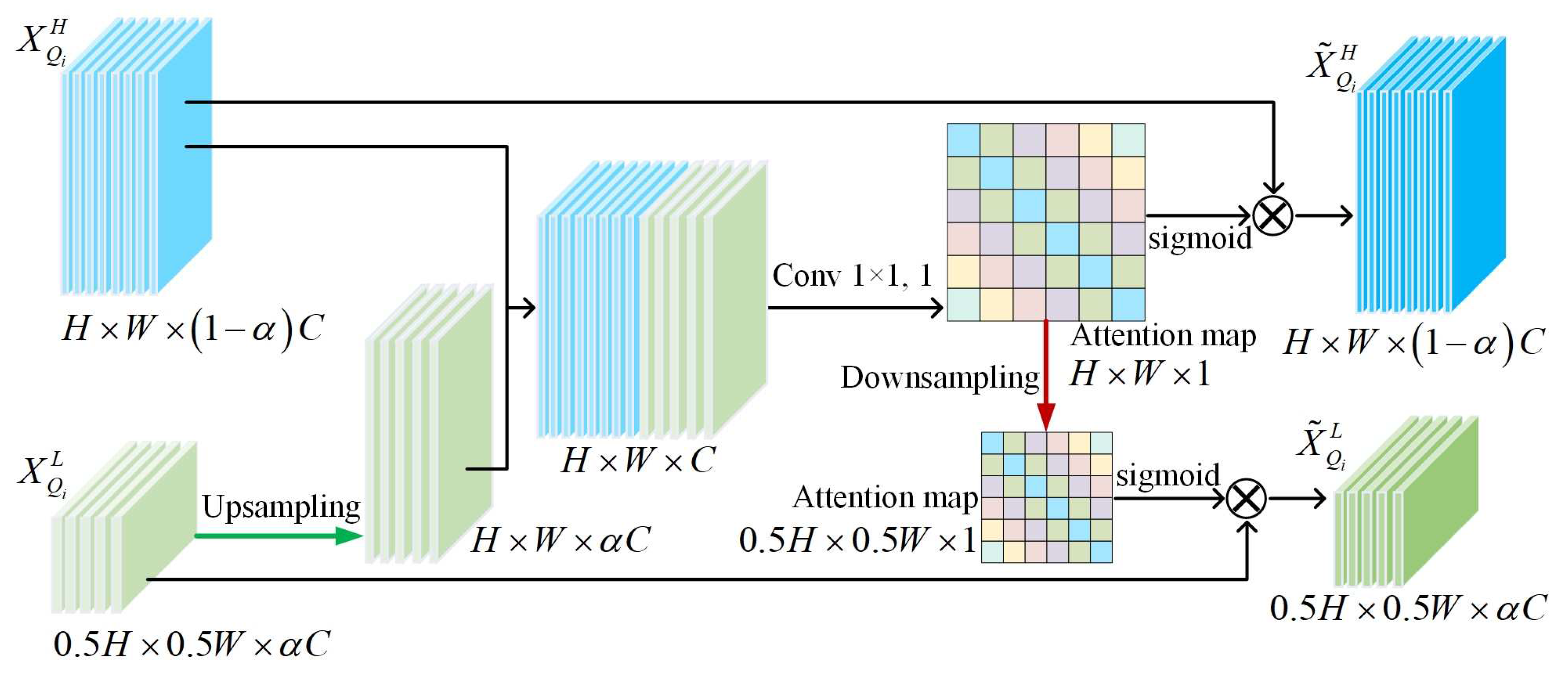
2.2. Feature Enhancement Strategy Based on Dual Self-Attention
2.3. Feature Map Information Fusion Based on SOS Boosted Module
2.4. Usage Comparison of SOS between an Existing Method and the Proposed Method
3. Results
3.1. Experiment Preparations
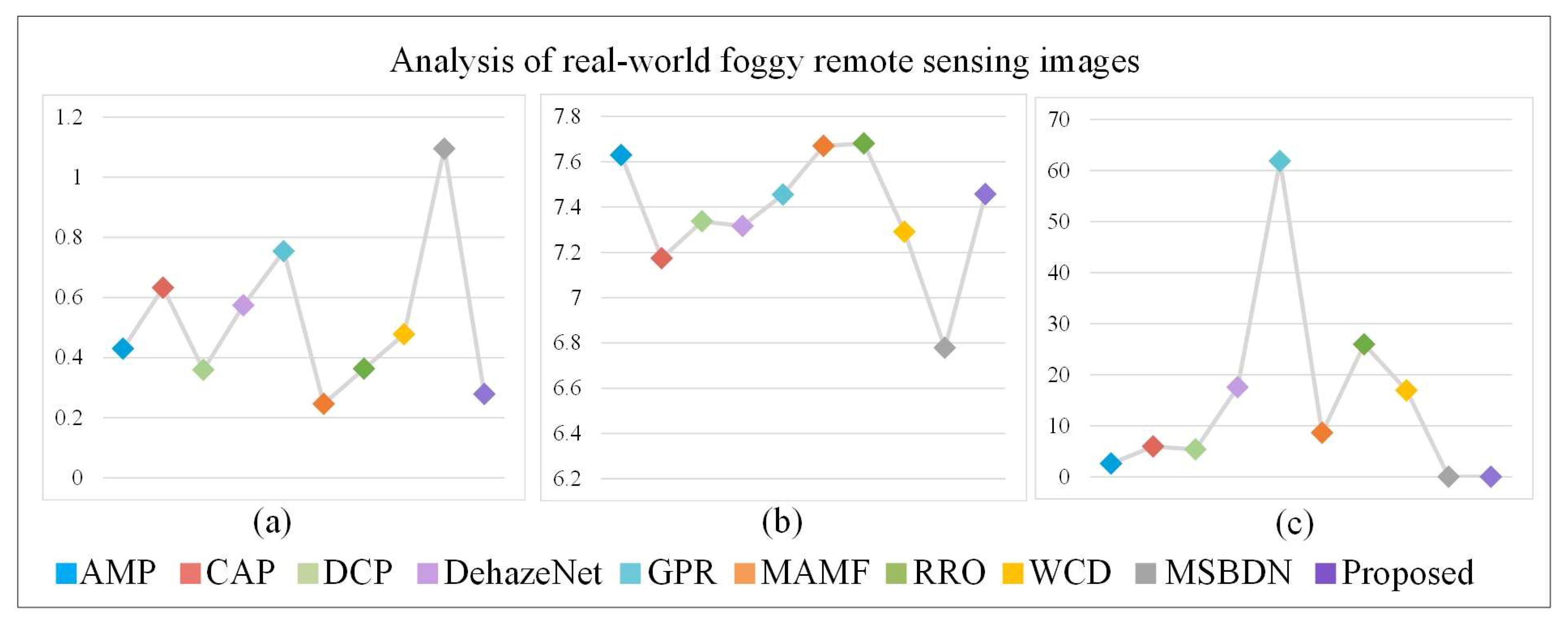
3.2. Results of the Real-World Foggy Remote Sensing Images
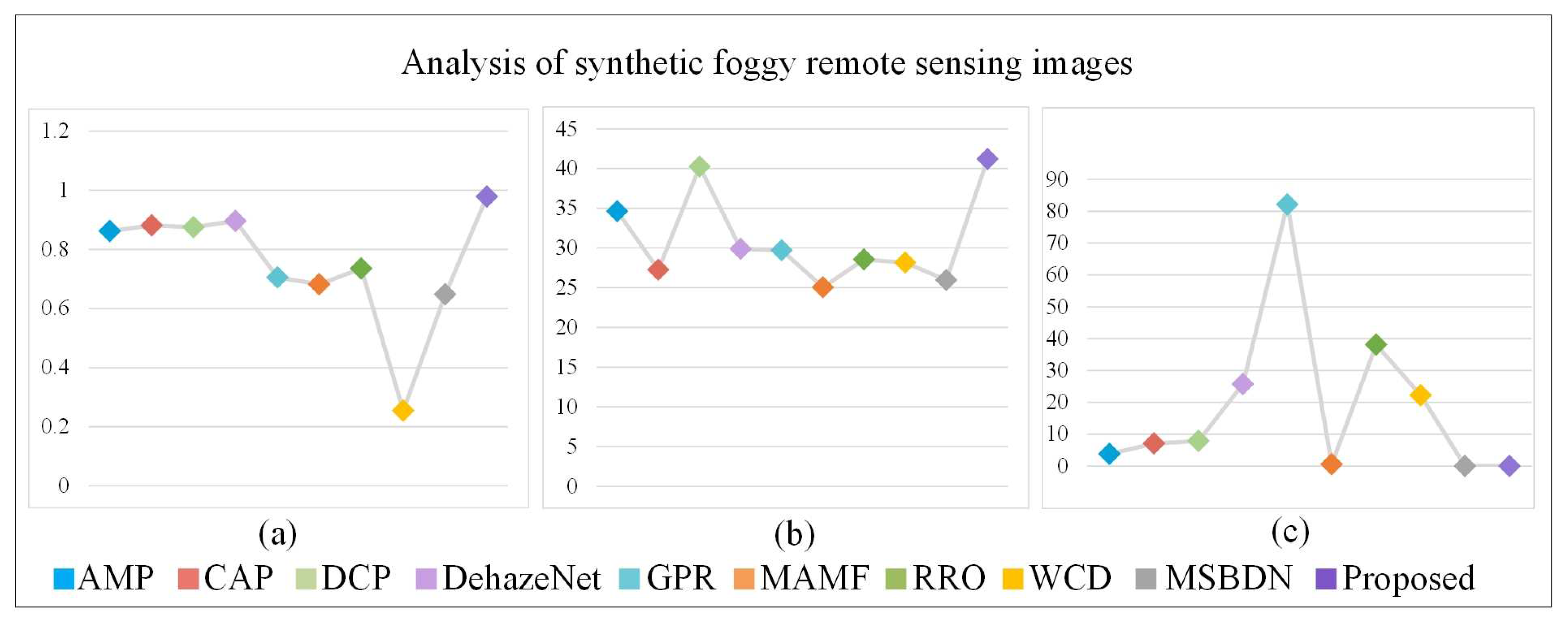
3.3. Results of the Synthetic Foggy Remote Sensing Images
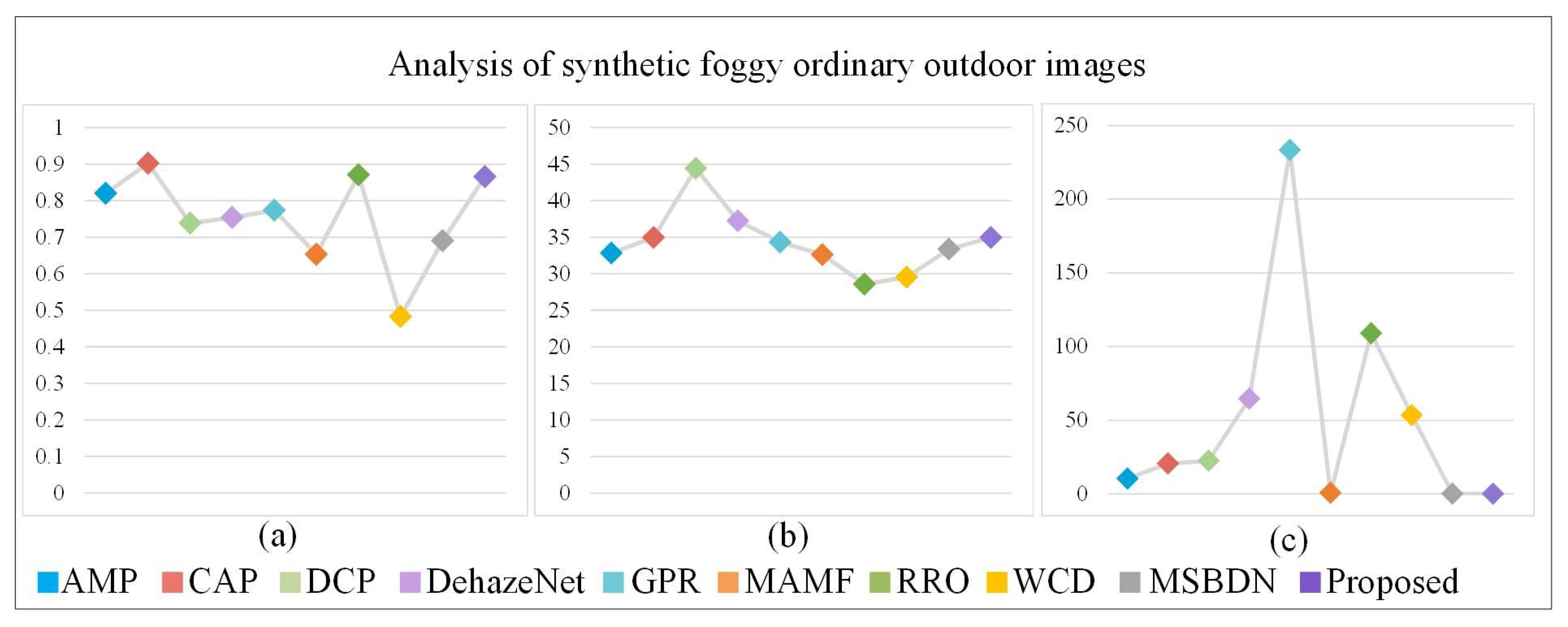
3.4. Results of the Synthetic Foggy Ordinary Outdoor Images
4. Discussion
4.1. Analysis of the Defogged Results of the Real-World Foggy Remote Sensing Images
4.2. Analysis of the Defogged Results of the Synthetic Foggy Remote Sensing Images
4.3. Analysis of the Defogged Results of the Synthetic Foggy Ordinary Outdoor Images
4.4. Ablation Study
4.5. Experiment Results Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Li, Y.; Zhang, Y.; Huang, X.; Ma, J. Learning Source-Invariant Deep Hashing Convolutional Neural Networks for Cross-Source Remote Sensing Image Retrieval. IEEE Trans. Geosci. Remote Sens. 2018, 56, 6521–6536. [Google Scholar] [CrossRef]
- Guo, J.; Ren, H.; Zheng, Y.; Nie, J.; Chen, S.; Sun, Y.; Qin, Q. Identify Urban Area From Remote Sensing Image Using Deep Learning Method. In Proceedings of the IGARSS 2019—2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; pp. 7407–7410. [Google Scholar]
- Zhu, Z.; Wei, H.; Hu, G.; Li, Y.; Qi, G.; Mazur, N. A Novel Fast Single Image Dehazing Algorithm Based on Artificial Multiexposure Image Fusion. IEEE Trans. Instrum. Meas. 2021, 70, 1–23. [Google Scholar]
- Liu, Y.; Chen, X.; Ward, R.K.; Jane Wang, Z. Image Fusion With Convolutional Sparse Representation. IEEE Signal Process. Lett. 2016, 23, 1882–1886. [Google Scholar] [CrossRef]
- Zheng, M.; Qi, G.; Zhu, Z.; Li, Y.; Wei, H.; Liu, Y. Image Dehazing by an Artificial Image Fusion Method Based on Adaptive Structure Decomposition. IEEE Sens. J. 2020, 20, 8062–8072. [Google Scholar] [CrossRef]
- Salazar-Colores, S.; Cruz-Aceves, I.; Ramos-Arreguin, J.M. Single image dehazing using a multilayer perceptron. J. Electron. Imaging 2018, 27, 043022. [Google Scholar] [CrossRef]
- Li, W.; Wei, H.; Qi, G.; Ding, H.; Li, K. A Fast Image Dehazing Algorithm for Highway Tunnel Based on Artificial Multi-exposure Image Fusion. IOP Conf. Ser. Mater. Sci. Eng. 2020, 741, 012038. [Google Scholar] [CrossRef] [Green Version]
- Zhan, J.; Gao, Y.; Liu, X. Measuring the optical scattering characteristics of large particles in visible remote sensing. In Proceedings of the 2017 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Fort Worth, TX, USA, 23–28 July 2017; pp. 4666–4669. [Google Scholar]
- Du, Y.; Guindon, B.; Cihlar, J. Haze detection and removal in high resolution satellite image with wavelet analysis. IEEE Trans. Geosci. Remote Sens. 2002, 40, 210–217. [Google Scholar]
- Shen, H.; Li, H.; Qian, Y.; Zhang, L.; Yuan, Q. An effective thin cloud removal procedure for visible remote sensing images. ISPRS J. Photogramm. Remote Sens. 2014, 96, 224–235. [Google Scholar] [CrossRef]
- Chiang, J.Y.; Chen, Y.C. Underwater Image Enhancement by Wavelength Compensation and Dehazing. IEEE Trans. Image Process. 2012, 21, 1756–1769. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Sun, J.; Tang, X. Single image haze removal using dark channel prior. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Miami, FL, USA, 20–25 June 2009; pp. 1956–1963. [Google Scholar]
- Long, J.; Shi, Z.; Tang, W. Fast haze removal for a single remote sensing image using dark channel prior. In Proceedings of the 2012 International Conference on Computer Vision in Remote Sensing, Xiamen, China, 16–18 December 2012; pp. 132–135. [Google Scholar]
- Xie, F.; Chen, J.; Pan, X.; Jiang, Z. Adaptive Haze Removal for Single Remote Sensing Image. IEEE Access 2018, 6, 67982–67991. [Google Scholar] [CrossRef]
- Zhu, Q.; Mai, J.; Shao, L. A Fast Single Image Haze Removal Algorithm Using Color Attenuation Prior. IEEE Trans. Image Process. 2015, 24, 3522–3533. [Google Scholar] [PubMed] [Green Version]
- Long, J.; Shi, Z.; Tang, W.; Zhang, C. Single Remote Sensing Image Dehazing. IEEE Geosci. Remote Sens. Lett. 2014, 11, 59–63. [Google Scholar] [CrossRef]
- Pan, X.; Xie, F.; Jiang, Z.; Yin, J. Haze Removal for a Single Remote Sensing Image Based on Deformed Haze Imaging Model. IEEE Signal Process. Lett. 2015, 22, 1806–1810. [Google Scholar] [CrossRef]
- Singh, D.; Kumar, V. Dehazing of remote sensing images using fourth-order partial differential equations based trilateral filter. IET Comput. Vis. 2017, 12, 208–219. [Google Scholar] [CrossRef]
- Liu, Q.; Gao, X.; He, L.; Lu, W. Haze removal for a single visible remote sensing image. Signal Process. 2017, 137, 33–43. [Google Scholar] [CrossRef]
- Chen, Y.; Tu, Z.; Ge, L.; Zhang, D.; Chen, R.; Yuan, J. SO-HandNet: Self-Organizing Network for 3D Hand Pose Estimation With Semi-Supervised Learning. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27–28 October 2019; pp. 6960–6969. [Google Scholar]
- Wang, K.; Zheng, M.; Wei, H.; Qi, G.; Li, Y. Multi-Modality Medical Image Fusion Using Convolutional Neural Network and Contrast Pyramid. Sensors 2020, 20, 2169. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tu, Z.; Xie, W.; Dauwels, J.; Li, B.; Yuan, J. Semantic Cues Enhanced Multimodality Multistream CNN for Action Recognition. IEEE Trans. Circuits Syst. Video Technol. 2019, 29, 1423–1437. [Google Scholar] [CrossRef]
- Qi, G.; Wang, H.; Haner, M.; Weng, C.; Chen, S.; Zhu, Z. Convolutional neural network based detection and judgement of environmental obstacle in vehicle operation. CAAI Trans. Intell. Technol. 2019, 4, 80–91. [Google Scholar] [CrossRef]
- Liu, Y.; Chen, X.; Wang, Z.; Wang, Z.J.; Ward, R.K.; Wange, X. Deep learning for pixel-level image fusion: Recent advances and future prospects. Inf. Fusion 2018, 42, 158–173. [Google Scholar]
- Jiang, H.; Lu, N. Multi-scale residual convolutional neural network for haze removal of remote sensing images. Remote Sens. 2018, 10, 945. [Google Scholar] [CrossRef] [Green Version]
- Cai, B.; Xu, X.; Jia, K.; Qing, C.; Tao, D. DehazeNet: An End-to-End System for Single Image Haze Removal. IEEE Trans. Image Process. 2016, 25, 5187–5198. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, H.; Patel, V.M. Densely Connected Pyramid Dehazing Network. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 3194–3203. [Google Scholar]
- Li, B.; Peng, X.; Wang, Z.; Xu, J.; Feng, D. AOD-Net: All-in-One Dehazing Network. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 4780–4788. [Google Scholar]
- Ren, W.; Ma, L.; Zhang, J.; Pan, J.; Cao, X.; Liu, W.; Yang, M.H. Gated Fusion Network for Single Image Dehazing. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 3253–3261. [Google Scholar]
- Chen, D.; He, M.; Fan, Q.; Liao, J.; Zhang, L.; Hou, D.; Yuan, L.; Hua, G. Gated Context Aggregation Network for Image Dehazing and Deraining. In Proceedings of the 2019 IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 7–11 January 2019; pp. 1375–1383. [Google Scholar]
- Engin, D.; Genc, A.; Ekenel, H.K. Cycle-Dehaze: Enhanced CycleGAN for Single Image Dehazing. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018; pp. 938–9388. [Google Scholar]
- Pan, J.; Liu, S.; Sun, D.; Zhang, J.; Liu, Y.; Ren, J.; Li, Z.; Tang, J.; Lu, H.; Tai, Y.W.; et al. Learning Dual Convolutional Neural Networks for Low-Level Vision. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 3070–3079. [Google Scholar]
- Dong, H.; Pan, J.; Xiang, L.; Hu, Z.; Zhang, X.; Wang, F.; Yang, M.H. Multi-Scale Boosted Dehazing Network With Dense Feature Fusion. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 2154–2164. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Chen, Y.; Fan, H.; Xu, B.; Yan, Z.; Kalantidis, Y.; Rohrbach, M.; Shuicheng, Y.; Feng, J. Drop an Octave: Reducing Spatial Redundancy in Convolutional Neural Networks With Octave Convolution. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 3434–3443. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Nayar, S.K.; Narasimhan, S.G. Vision in bad weather. In Proceedings of the Seventh IEEE International Conference on Computer Vision (ICCV), Kerkyra, Greece, 20–27 September 1999; Volume 2, pp. 820–827. [Google Scholar]
- Zhang, Y.; Ding, L.; Sharma, G. HazeRD: An outdoor scene dataset and benchmark for single image dehazing. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 3205–3209. [Google Scholar]
- Fan, X.; Wang, Y.; Tang, X.; Gao, R.; Luo, Z. Two-Layer Gaussian Process Regression With Example Selection for Image Dehazing. IEEE Trans. Circuits Syst. Video Technol. 2017, 27, 2505–2517. [Google Scholar] [CrossRef]
- Cho, Y.; Jeong, J.; Kim, A. Model-Assisted Multiband Fusion for Single Image Enhancement and Applications to Robot Vision. IEEE Robot. Autom. Lett. 2018, 3, 2822–2829. [Google Scholar]
- Shin, J.; Kim, M.; Paik, J.; Lee, S. Radiance-Reflectance Combined Optimization and Structure-Guided l0-Norm for Single Image Dehazing. IEEE Trans. Multimed. 2019, 22, 30–44. [Google Scholar] [CrossRef]
- Wang, Z.; Bovik, A.; Sheikh, H.; Simoncelli, E. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [Green Version]
- Hore, A.; Ziou, D. Image quality metrics: PSNR vs. SSIM. In Proceedings of the International Conference on Pattern Recognition, Istanbul, Turkey, 23–26 August 2010; pp. 2366–2369. [Google Scholar]
- Choi, L.K.; You, J.; Bovik, A.C. Referenceless Prediction of Perceptual Fog Density and Perceptual Image Defogging. IEEE Trans. Image Process. 2015, 24, 3888–3901. [Google Scholar] [CrossRef] [PubMed]
- Qing, C.; Yu, F.; Xu, X.; Huang, W.; Jin, J. Underwater video dehazing based on spatial–temporal information fusion. Multidimens. Syst. Signal Process. 2016, 27, 909–924. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| AMP | CAP | DCP | DehazeNet | GPR | MAMF | RRO | WCD | MSBDN | Proposed | ||
|---|---|---|---|---|---|---|---|---|---|---|---|
| FADE | 0.4300 | 0.6323 | 0.3589(3) | 0.5737 | 0.7538 | 0.2460(1) | 0.3633(4) | 0.4775 | 1.0947 | 0.2783(2) | |
| Entropy | 7.6292(3) | 7.1742 | 7.3370 | 7.3162 | 7.4554 | 7.6697(2) | 7.6810(1) | 7.2907 | 6.7790 | 7.4568(4) | |
| Time(s) | 2.6193(3) | 5.9325 | 5.3533(4) | 17.5564 | 61.8504 | 8.6489 | 25.9441 | 16.9551 | 0.0304(2) | 0.0253(1) |
| AMP | CAP | DCP | DehazeNet | GPR | MAMF | RRO | WCD | MSBDN | Proposed | ||
|---|---|---|---|---|---|---|---|---|---|---|---|
| SSIM | 0.8623 | 0.8817(3) | 0.8751(4) | 0.8960(2) | 0.7052 | 0.6818 | 0.7358 | 0.2546 | 0.6485 | 0.9789(1) | |
| PSNR | 34.6232(3) | 27.2660 | 40.2194(2) | 29.8736(4) | 29.7089 | 25.0630 | 28.5424 | 28.1517 | 25.9687 | 41.1801(1) | |
| Time(s) | 3.8334(4) | 7.0932 | 7.8608 | 25.7578 | 82.0911 | 0.6135(3) | 38.1479 | 22.2366 | 0.0413(1) | 0.0424(2) |
| AMP | CAP | DCP | DehazeNet | GPR | MAMF | RRO | WCD | MSBDN | Proposed | ||
|---|---|---|---|---|---|---|---|---|---|---|---|
| SSIM | 0.8202(4) | 0.9027(1) | 0.7385 | 0.7541 | 0.7737 | 0.6531 | 0.8712(2) | 0.4825 | 0.6901 | 0.8661(3) | |
| PSNR | 32.8200 | 34.9427(4) | 44.4166(1) | 37.2500(2) | 34.3128 | 32.6061 | 28.5646 | 29.5418 | 33.3787 | 34.9675(3) | |
| Time(s) | 10.2798(4) | 20.5646 | 22.4044 | 64.5915 | 233.3549 | 0.7154(3) | 108.9496 | 53.4261 | 0.0333(2) | 0.0315(1) |
| SSIM | PSNR | |
|---|---|---|
| baseline | 0.6220 | 24.0683 |
| baseline + A | 0.9560 | 35.0046 |
| baseline + A + B | 0.9789 | 41.1801 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhu, Z.; Luo, Y.; Qi, G.; Meng, J.; Li, Y.; Mazur, N. Remote Sensing Image Defogging Networks Based on Dual Self-Attention Boost Residual Octave Convolution. Remote Sens. 2021, 13, 3104. https://doi.org/10.3390/rs13163104
Zhu Z, Luo Y, Qi G, Meng J, Li Y, Mazur N. Remote Sensing Image Defogging Networks Based on Dual Self-Attention Boost Residual Octave Convolution. Remote Sensing. 2021; 13(16):3104. https://doi.org/10.3390/rs13163104
Chicago/Turabian StyleZhu, Zhiqin, Yaqin Luo, Guanqiu Qi, Jun Meng, Yong Li, and Neal Mazur. 2021. "Remote Sensing Image Defogging Networks Based on Dual Self-Attention Boost Residual Octave Convolution" Remote Sensing 13, no. 16: 3104. https://doi.org/10.3390/rs13163104
APA StyleZhu, Z., Luo, Y., Qi, G., Meng, J., Li, Y., & Mazur, N. (2021). Remote Sensing Image Defogging Networks Based on Dual Self-Attention Boost Residual Octave Convolution. Remote Sensing, 13(16), 3104. https://doi.org/10.3390/rs13163104