
Construction and Application of a Knowledge Graph

 ,
,  ,
,  and
and {kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. The Theoretical Basis for the Construction of Knowledge Graphs
2.1. Design of Disciplinary Knowledge Graph Mode in the Field of Surveying and Remote Sensing
2.2. The Data Layer of the Knowledge Graph in the Field of Surveying and Remote Sensing
2.2.1. Data Layer Relational Structure Design
2.2.2. Data Layer Construction
3. Construction of Knowledge Graphs
3.1. Data Acquisition and Storage
3.1.1. Data Acquisition
- (1)
- Data processing. First, the original corpus will be loaded. The natural language processing (NLP) tag is added. A set of candidate relationships and the sparse feature representation of each candidate relationship are extracted.
- (2)
- Remote supervision of data and rules, and then various strategies will be used to supervise the data set so that we can use machine learning to learn the weight of the mode.
- (3)
- Learning and inference: mode specification. Then, the advanced configuration of the mode will be specified.
- (4)
- Error analysis and debugging. Finally, we will show how to use DeepDive’s tags, error analysis and debugging tools.
- (1)
- Experiment preparation (preparation before knowledge extraction). First, DeepDive stores the involved input, intermediate and output data in a relational database. DeepDive supports many databases, such as Postgres, Greenplum and MySQL. The database used in this experiment is Postgres.
- (2)
- Data processing. This part is divided into four steps: ① Loading the original input data. First, we convert the target data into an electronic text format. Only the two fields of document id and document content are reserved. We store the cleaned data in a comma-separated values (CSV) format file. Then import the original text data into the associated database. We set the data format of the document storage in the app. ddlog file. There are two text fields in the articles table, articles (id text, content text). Then, we put the compressed file of the original data into the specified input folder and run the “DeepDive compile” command. Then, we execute the “DeepDive do articles” command, which imports the original data into the articles table of the associated database. At this time, we can query the imported raw data by executing the query command. ② Adding NLP markups. We use the CoreNLP natural language processing system to add annotations to the original data. The steps of NLP are: first, the input original article is divided into sentences. The sentence is divided into words, and the part-of-speech tags, standard forms, dependency analysis and entity recognition tags of the words in the sentence are obtained. After NLP, some commonly used entities (person names, place names, etc.) can be marked. It is also necessary to ensure further entity identification of the data processed by NLP. The input are the data in the sentences table. The output are the marked data. Finally, we import the final marked data into the sentences_new table in the database. ③ Extracting candidate relation mentions. DeepDive proposes corresponding input and output interfaces, allowing users to design their entity or relationship extractors. Generally speaking, the SQL(Structured Query Language) statement is used as the input interface to extract data from the database; The output is the corresponding table in the database. We perform entity extraction on the data after entity recognition, and then establish the corresponding database table structure. ④ Extracting features for each candidate. First, we extract the feature description and store the feature in the func_feature table. The purpose is to use certain attributes or characteristics to represent each candidate pair. There is a library DDlib that can automatically generate features in DeepDive, which defines features that are not dependent on the domain. There are also many dictionaries in the DDlib library. These dictionaries contain words related to the correct classification of descriptions and relationships and are usually combined with domains and specific applications. We declare the extract_func_features function in app.ddlog. The input of this function includes the information of the two entities in the entity_mention table and the NLP results in the sentence where the two entities are located. The output is the two entities and their characteristics.
- (3)
- Distant supervision with data and rules. We will use remote supervision to provide noisy label sets for candidate relationships to train machine learning models. Generally speaking, we divide the description method into two basic categories: mapping from secondary data for distant supervision and using heuristic rules for distant supervision [17]. However, we will use a simple majority voting method to solve the problem of multiple labels in each example. This method can be implemented in ddlog. In this method, first, we sum the labels (all −1, 0, or 1). Then, we simply threshold and add these labels to the decision variable table has_spouse. In addition, we also need to make sure that all the spouse candidates who are not marked with rules are not included in this table. Once again, we execute all the above.
- (4)
- Learning and inference: model specification. We need to specify the actual model that DeepDive will perform learning and inference. DeepDive will learn the parameters of the model (the weights of features and the potential connections between variables). Then we perform statistical inferences on the learned model to determine that the probability of each variable of interest is true. ① Specifying prediction variables. In our experiment, we have a variable to predict the mention of each spouse candidate. In other words, we want DeepDive to predict the value of a Boolean variable for each mentioned spouse candidate to indicate whether the value is correct. DeepDive cannot only predict the value of these variables but also predict the marginal probability, that is, DeepDive’s confidence in each prediction. ② Specifying features. We need to define the following: each has_spouse variable will be connected to the elements of the corresponding spouse_candidate row; We hope that DeepDive understands the weights of these elements from the data we remotely monitor; those weights of the element should be the same for the specific function of all instances. ③ Specifying connections between variables. We can use learning weights or given weights to specify the dependencies between predictors. In the experiment, we specify two such rules, which have fixed (given) weights. First, we define the asymmetric connection, that is, if the model considers that a person mentions p1 and another person mentions p2 as a spouse relationship in the sentence, then it should also consider the opposite. The model should be strongly biased towards everyone mentioning a sign of marriage. Instead, we use negative weights for this operation. ④ Finally, we want to perform learning and inference using the specified model. This will build a model based on the data in the database, learn the weights, infer the expected or marginal probabilities of the variables in the model and then load it back into the database. In this way, we can see the probability of the has_spouse variable inferred by DeepDive.
- (5)
- Error analysis and debugging. To accurately analyze the experimental results, we first declare a score or a user-defined query sentence and define the part of the labeled data used for training. DeepDive uses this score to estimate the accuracy of the experiment. We declare these definitions in deepdive.conf and define deepdive.calibration.holdout_fraction as 0.25. The test set is 75% of the labeled data, and the test set is used to verify the correctness of the experimental results. Approximately 1400 labeled data and approximately 1000 data were used for testing. The graph on the left in Figure 4 is the correct rate graph. Under ideal conditions, the red curve should be close to the blue calibration line. However, this is not the case. It may be caused by the sparseness and noise of the training data of the test data. The middle graph in Figure 4 is the predicted number graph of the test set. The forecasted quantity map usually presents a “U” shape. The graph on the right in Figure 4 is the predicted probability quantity graph of the entire data set. Among them, the prediction data falling in the 0.5–0.6 probability interval indicates that there are still some hidden types of instances, and the features of DeepDive are insufficient for these instances. The predicted data whose probability does not fall at (0, 0.1) or (0.9, 1.0) are the data to be extracted. An important indicator to improve the quality of the system is to re-speculate the above data and attribute it to the probability interval (0, 0.1) or (0.9, 1.0).
3.1.2. Data Storage
3.2. Ontology Construction and Storage
3.2.1. Ontology Construction
3.2.2. Ontology Storage
3.3. Ontology and Database Mapping
3.4. Query and Reasoning
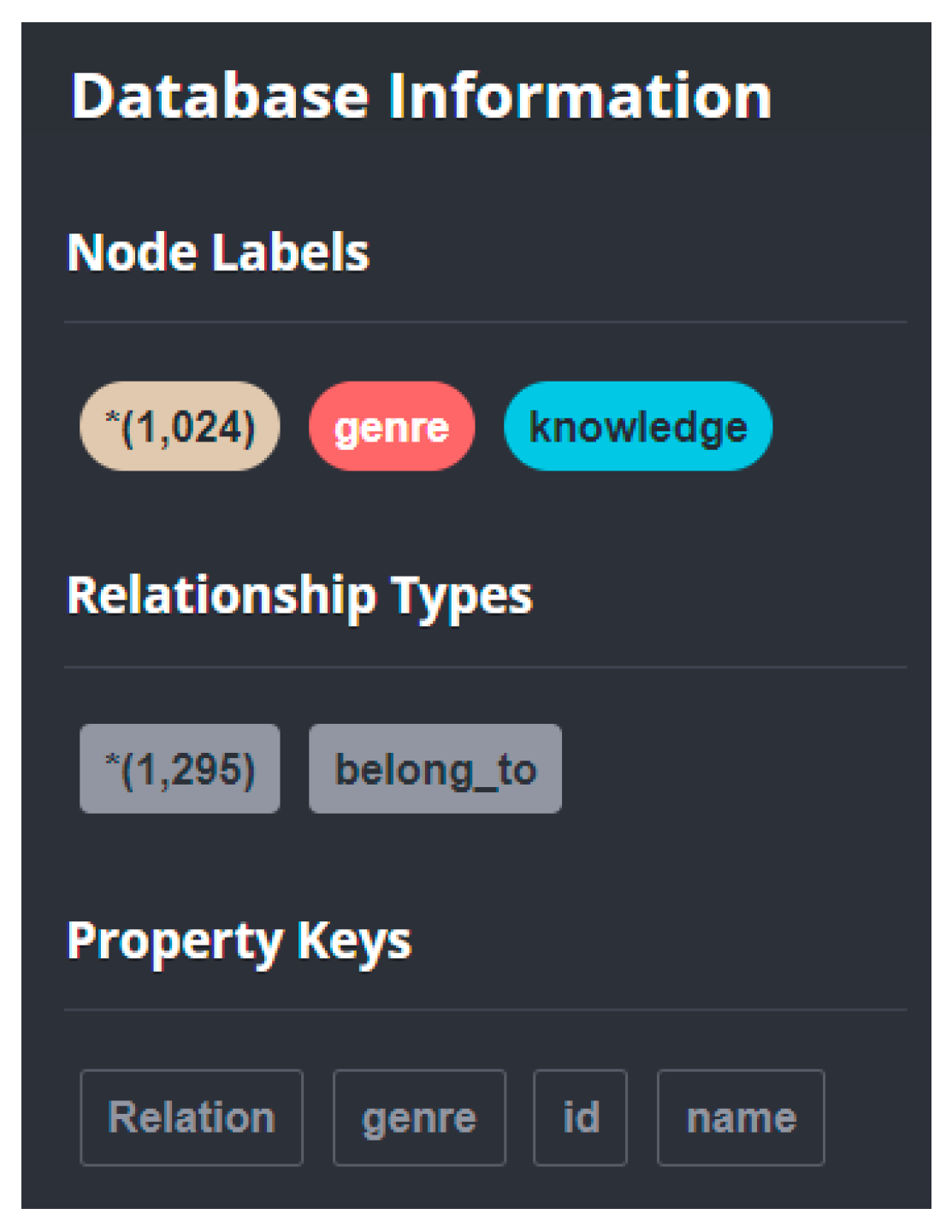
3.5. Visualizing the Knowledge Graph on Neo4j
| Code 1 Entity Data Imported Based on Cypher Language |
| LOAD CSV WITH HEADERS FROM “file:///knowledge.csv” AS line MERGE (k:knowledge{id:line.knowledge_id, name:line.knowledge_name, genre:line.knowledge_genre}) |
| Code 2 Relational Data Imported Based on Cypher Language |
| LOAD CSV WITH HEADERS FROM “file:///knowledge_to_genre.csv” AS line MATCH (from:knowledge{id:line.knowledge_id}),(to:genre{id:line.genre_id}) MERGE (from)-[r:belong_to{Relation:line.knowledge_to_genre}]-(to) |
4. Application Analysis of the Knowledge Graph
4.1. Domain Relevance Analysis
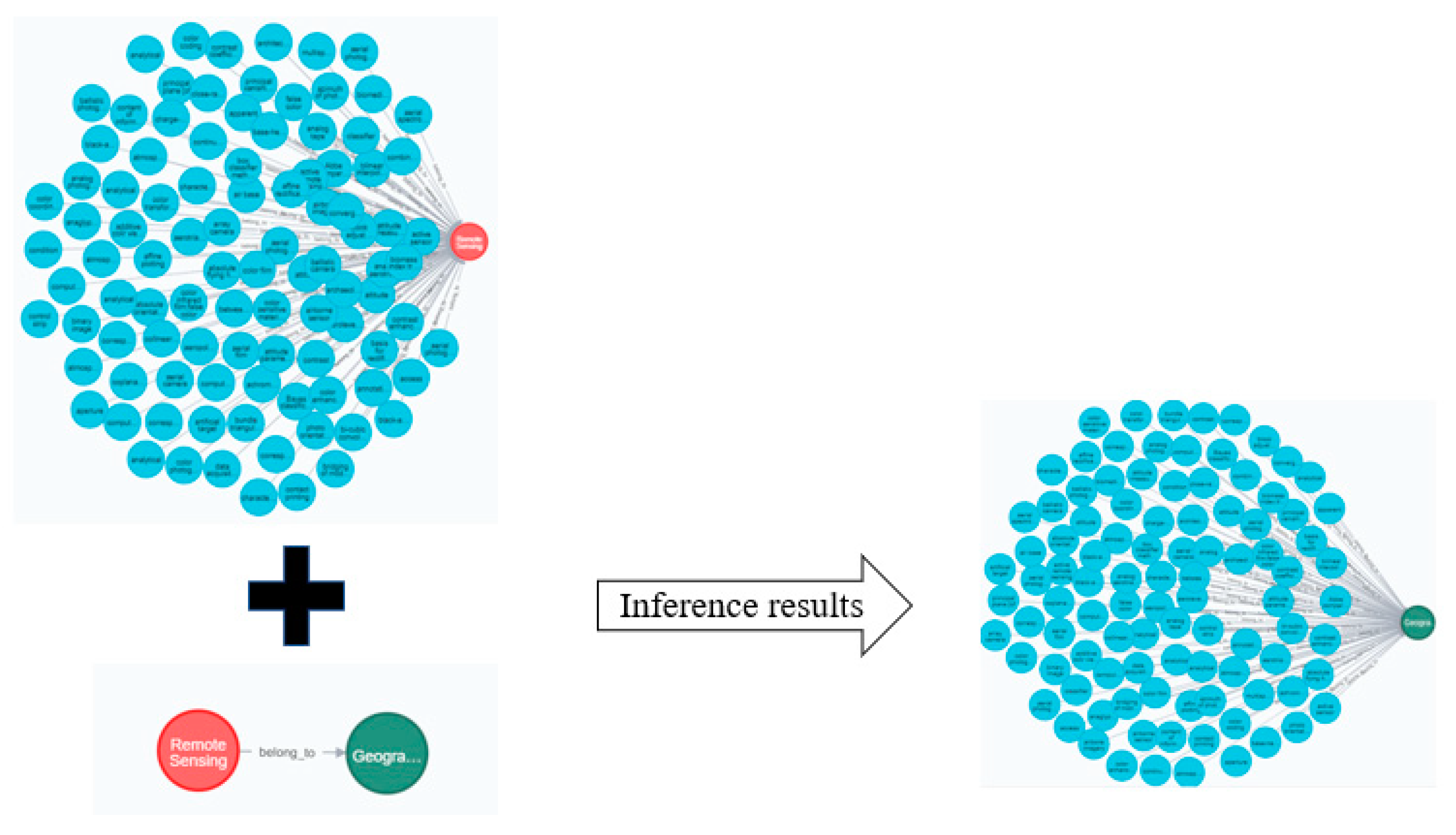
4.2. Knowledge Reasoning in the Field of Surveying and Remote Sensing
| Code 3 Inference Rules Based on SPARQL Language |
| @prefix: http://www.kbdemo.com#. @prefix owl: http://www.w3.org/2002/07/owl#. @prefix rdf: http://www.w3.org/1999/02/22-rdf-syntax-ns#. @prefix xsd: XML Schema. @prefix rdfs: http://www.w3.org/2000/02/rdf-schema#. [rule:(?k:belong_to ?g)(?g:hasname ?n)(?n:genre_name ‘Remote Sensing’)-(?k rdf:type:Geography)] [ruleInverse:(?k:belong_to ?g)-(?g:hasKnowledge ?k)] |
5. Summary and Prospect
- (1)
- To quickly obtain effective data from massive amounts of heterogeneous, decentralized, and dynamically updated data. This article proposes a method for constructing a subject knowledge graph in the field of surveying and remote sensing.
- (2)
- To verify the application value of the knowledge graph in the field of surveying and remote sensing. This article verifies its functions from the query, visualization and reasoning of the knowledge graph.
- (1)
- The connection between the mode layer and the data layer. The knowledge graph in the field of surveying and remote sensing is mainly divided into two parts: mode level construction and a data layer. The mode level is the foundation of the data layer. Through the factual expression of the ontology library standard data layer, ontology is the conceptual template of a structured knowledge base. The data layer is composed of a series of knowledge entities or concepts. Knowledge is stored in units of facts. The data layer expresses knowledge in the form of triples (entity 1-relation-entity 2) or (entity-attribute-attribute value). Realizing the association between ontology and data at two levels is a major challenge in constructing a knowledge graph. This article uses the D2RQ tool to realize mapping from ontology to the database. The D2RQ tool converts the structured data of the relational database into data in RDF format. This mapping also provides the ability to view existing relational data that exist in the RDF data model, which is represented by mapping the structure selected by the customer and the target vocabulary. The R2RML mapping itself is an RDF graph and is recorded in Turtle syntax. R2RML supports different types of mapping implementation. The processor can provide virtual SPARQL endpoints on the mapped relational data, or generate RDF dumps, provide a link data interface.
- (2)
- Application and practice of the domain knowledge graph. This article gives an example of the application of integrating the knowledge graph in the field of surveying and remote sensing into the smart campus platform. The knowledge visualization application of the domain knowledge graph on the smart campus platform can assist teachers and students in selecting courses. The domain knowledge graph is applied to knowledge reasoning on the smart campus platform, which can help teachers and students discover and reason about new knowledge, as well as new relationships between knowledge.
- (1)
- The discovery of new rules of surveying and remote sensing: The continuous increase in surveying and remote-sensing data and the continuous improvement of digital management and utilization technology have provided great convenience for scientific researchers to carry out research work. The surveying and remote-sensing knowledge graph provides support for the insight and discovery of regular knowledge of surveying and remote-sensing resources by associating a large amount of surveying and remote sensing knowledge into a network structure. Researchers can discover various knowledge and rules hidden behind the development process through the analysis of surveying and remote-sensing data to provide relevant scientific research personnel and scientific research policy makers with scientific research directions and a policy-making basis.
- (2)
- Application of machine learning methods in the analysis of knowledge graphs in the field of surveying and remote sensing: From the development process of the combination of machine learning and knowledge graphs (the knowledge graph as a complex network; traditional machine learning methods to conduct graph mining and analysis on the knowledge graph; further application of deep learning methods and graph neural network methods in knowledge graphs), the value and function of the knowledge graphs have been further embodied. The surveying and remote-sensing domain knowledge graph is a special domain knowledge graph, and the analysis method in the general knowledge graph is used to mine and analyse the graph, but it cannot make full use of the structure and characteristics of the surveying and remote-sensing domain knowledge graph. For the specific structural features and entity attributes in the knowledge graph of surveying and remote sensing, it is necessary to design specific machine learning methods or deep neural network structures. At the same time, for different application scenarios, different objective functions are usually designed to learn the parameters of the algorithm. Therefore, the study of machine learning and deep learning mining methods for the knowledge graph in the field of surveying and remote sensing is helpful to the further analysis and application of the knowledge graph in the field of surveying and remote sensing.
- (3)
- Construction of the service platform of the knowledge graph in the field of surveying and remote sensing: In the construction of the knowledge graph in the field of surveying and remote sensing, the work efficiency is affected due to the problem of scattered tools. The next research plan is to build a knowledge graph service platform in the field of surveying and remote sensing to realize the integration of tools and services. At the data source level, it integrates all kinds of open and available data in the field of surveying and remote sensing, as well as data unique to each demand side. Through the provided functions of surveying and remote sensing data acquisition, data storage, ontology construction, graph construction and update, a knowledge graph of the field of surveying and remote sensing that can be updated in time can be constructed. In terms of services, through the provision of knowledge service algorithms and models such as knowledge queries, knowledge visualization, and knowledge reasoning, a service platform provides targeted knowledge services for different roles.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Li, W.; Xiao, Y.W.; Wang, W. People Entity Recognition Based on Chinese Knowledge Graph. Comput. Eng. 2017, 43, 225–231,240. [Google Scholar] [CrossRef]
- Liu, Q.; Li, Y.; Duan, H.; Liu, Y.; Qin, Z. Knowledge Graph Construction Techniques. J. Comput. Res. Dev. 2016, 53, 582–600. [Google Scholar] [CrossRef]
- Cao, Q.; Zhao, Y. The Technical Realization Process and Related Applications of Knowledge Graph. Inf. Stud. Theory Appl. 2015, 12, 127–132. [Google Scholar] [CrossRef]
- Xu, Z.; Sheng, Y.; He, L.; Wang, Y. Review on Knowledge Graph Techniques. J. Univ. Electron. Sci. Technol. China 2016, 45, 589–606. [Google Scholar] [CrossRef]
- Wang, Z.; Xiong, C.; Zhang, L.; Xia, G. Accurate Annotation of Remote Sensing Images via Active Spectral Clustering with Little Expert Knowledge. Remote Sens. 2015, 7, 15014–15045. [Google Scholar] [CrossRef] [Green Version]
- Xie, R.; Luo, Z.; Wang, Y.; Chen, W. Key Techniques for Establishing Domain Specific Large Scale Knowledge Graph of Remote Sensing Satellite. Radio Eng. 2017, 47, 1–6. [Google Scholar] [CrossRef]
- Jiang, B.; Wan, G.; Xu, J. Geographic Knowledge Graph Building Extracted from Multi-sourced Heterogeneous Data. Acta Geod. et Cartogr. Sin. 2018, 47, 1051–1061. [Google Scholar] [CrossRef]
- Lu, F.; Yu, L.; Qiu, P. On Geographic Knowledge graph. J. Geo Inf. Sci. 2017, 19, 723–734. [Google Scholar] [CrossRef]
- Zhu, L.J. Research on Information Resource Management Model Based on Domain Knowledge in World Wide Web Environment. Ph.D. Thesis, China Agricultural University, Beijing, China, 1 June 2004. [Google Scholar]
- Wang, L.; Wang, J.; Xu, N.; Deng, Y. Knowledge Graph-based Metro Engineering Accidents Knowledge Modeling and Analysis. J. Civil. Eng. Manag. 2019, 36, 109–114,122. [Google Scholar] [CrossRef]
- Wei, T.; Wang, J. Construction of Knowledge Graph based on Non-classification Relation Extraction Technology. Ind. Technol. Innov. 2020, 37, 27–32. [Google Scholar] [CrossRef]
- He, L. Research on Key Techniques of Entity Attribute Extraction for Unstructured Text. Master’s Thesis, Harbin University of Science and Technology, Harbin, China, 1 June 2020. [Google Scholar]
- Sun, J.B. Principles and Applications of Remote Sensing, 3rd ed.; Whuhan University Press: Whuhan, China, 2009; pp. 23–126. [Google Scholar]
- Kong, X.Y.; Guo, J.; Liu, Z. Founding of Geodesy, 4th ed.; Whuhan University Press: Wuhan, China, 2005; pp. 56–89. [Google Scholar]
- Vyas, A.; Kadakia, U.; Jat, P. Extraction of Professional Details from Web-URLs using DeepDive. Procedia Comput. Sci. 2018, 132, 1602–1610. [Google Scholar] [CrossRef]
- Ma, H.B. Research on Construction and Application of Knowledge Graph of Enterprise Related Information for Risk Control. Master’s Thesis, Beijing University of Technology, Beijing, China, 30 May 2019; pp. 25–27. [Google Scholar]
- Abad, A.; Moschitti, A. Distant supervision for relation extraction using tree kernels. Appl. Clay Sci. 2015, 115, 108–114. [Google Scholar] [CrossRef]
- Mallory, E.; Zhang, C.; Christopher, R.; Altman, R. Large-scale extraction of gene interactions from full-text literature using DeepDive. Bioinformatics 2016, 1, 106–113. [Google Scholar] [CrossRef] [Green Version]
- John, H.; Gennari, J.; Musen, M.; Fergerson, R. The Evolution of Protégé: An Environment for Knowledge-Based Systems Development. Int. J. Hum. Comput. Stud. 2003, 58, 89–123. [Google Scholar] [CrossRef]
- Zhang, R. Research and Analysis Based on Semantics of Rice Domain Knowledge Expression. Master’s Thesis, Hunan Agricultural University, Hunan, China, 8 May 2007. [Google Scholar]
- Arenas, M.; Ugarte, M. Designing a Query Language for RDF. ACM Trans. Database Syst. 2017, 42, 21.1–21.46. [Google Scholar] [CrossRef]
- Gan, J.; Xia, Y.; Xu, T.; Zhang, X. Extension of Web Ontology Language OWL in Knowledge Representation. J. Yunnan Norm. Univ. 2005, 25, 9–14. [Google Scholar] [CrossRef]
- Duan, X.; Wang, L.; Wang, S. A Preliminary Study on the Application of Knowledge Graphs in Professional Fields. Electron. World 2020, 4. [Google Scholar] [CrossRef]
- Liu, J. Research on the Construction and Application of Knowledge Graph in Tourism Domain. Master’s Thesis, Zhejiang University, Hangzhou, China, 1 June 2019. [Google Scholar]
- Ye, S. Research on the Construction and Query Method of Knowledge Graph in Coalmine Based on Neo4j. Master’s Thesis, China University of Mining and Technology, Xuzhou, China, 30 May 2019. [Google Scholar]
- Zhou, W. The Construction and Application of Knowledge Graph Incorporating Causal Events. Master’s Thesis, East China Normal University, Shanghai, China, 23 May 2019. [Google Scholar]
- Yang, X.; Yang, M.; Yang, D.; Huang, Y. Research on Knowledge Fusion Triplets Storage Structure Based on Jena System. Value Eng. 2018, 8, 134–137. [Google Scholar] [CrossRef]
- Zhao, K.; Wang, H.; Shi, N.; Sa, Z.; Xu, X. Study and Implementation on Knowledge Graph of Guizhi Decoction Associated Formulas Based on Neo4j. World Chin. Med. 2019, 14, 2636–2646. [Google Scholar] [CrossRef]
- Zhang, Z. Research on the Parsing of Graph Database Query Language Cypher. Master’s Thesis, Huazhong University of Science and Technology, Wuhan, China, 8 May 2018. [Google Scholar]
- Zhou, Z.; Xue, D.; Xin, X.; Yang, L. A Construction Method of Scientific Knowledge Graph Based on the Degree of Inter-disciplinary Association. In Proceedings of the 2011 Fall Academic Conference of Chinese Physical Society, Hangzhou, China, 15 September 2011. [Google Scholar]
- Chen, B.; Li, G.; Zhang, J.; Li, J. Framework design of SWRL-based Reasoning Mechanism. Comput. Eng. Des. 2010, 31, 847–849,853. [Google Scholar] [CrossRef]
- Wang, W.G. Knowledge Graph Reasoning: Modern Methods and Applications. Big Data Res. 2021, 1, 1–24. Available online: https://kns.cnki.net/kcms/detail/10.1321.G2.20210331.1811.0O4.html (accessed on 9 May 2021).












Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hao, X.; Ji, Z.; Li, X.; Yin, L.; Liu, L.; Sun, M.; Liu, Q.; Yang, R. Construction and Application of a Knowledge Graph. Remote Sens. 2021, 13, 2511. https://doi.org/10.3390/rs13132511
Hao X, Ji Z, Li X, Yin L, Liu L, Sun M, Liu Q, Yang R. Construction and Application of a Knowledge Graph. Remote Sensing. 2021; 13(13):2511. https://doi.org/10.3390/rs13132511
Chicago/Turabian StyleHao, Xuejie, Zheng Ji, Xiuhong Li, Lizeyan Yin, Lu Liu, Meiying Sun, Qiang Liu, and Rongjin Yang. 2021. "Construction and Application of a Knowledge Graph" Remote Sensing 13, no. 13: 2511. https://doi.org/10.3390/rs13132511
APA StyleHao, X., Ji, Z., Li, X., Yin, L., Liu, L., Sun, M., Liu, Q., & Yang, R. (2021). Construction and Application of a Knowledge Graph. Remote Sensing, 13(13), 2511. https://doi.org/10.3390/rs13132511