3.1. Overall Process
As shown in
Figure 3, the proposed DDRL-AM consists of three novel components: the network that generates attention images by Grad-CAM, proposed SFT and center loss function. In this section, we will first introduce our novel DDRL-AM framework and then elaborate on each key components of the DDRL-AM framework.
The structure of generating attention maps is shown in the Part 1 of
Figure 3. This part can be illustrated as follows. Firstly, we fine-tune the off-the-shelf ImageNet-trained ResNet-18 [
52]. Then the Grad-CAM algorithm along with the fine-tuned ResNet-18 are used to generate attention maps (
Section 3.2). The Part 2 of
Figure 3 shows two-channel trainable CNN. It consists of feature fusion of different branch structures (
Section 3.3) and integration of two loss function (
Section 3.3). The procedures of the DDRL-AM framework can be explained as follows.
- (1)
Generating attention maps for each image. Firstly, we fine-tune the off-the-shelf ResNet-18 [
42] pretrained on ImageNet on the training dataset of remote sensing images. Then the Grad-CAM algorithm along with the fine-tuned ResNet-18 are used to generate attention maps for each image.
- (2)
Fusing features from the RGB and saliency stream. For each image and attention map, extract features by the fine-tuned CNN and the proposed SFT, respectively. Note that the feature maps output by the CNN and SFT are with the same size. Fuse features from the RGB and saliency stream with multiplicative fusion.
- (3)
Calculating center-based cross entropy loss. Cross-entropy loss and center loss are calculated based on fused features, where center of each class is computed by averaging fused features belonging to this class. Then Cross-entropy loss and center loss are combined to form the center-based cross entropy loss for backpropagation.
Algorithm 1 summarizes the overall process of the DDRL-AM framework. In the first step, each remote sensing image X is put into the fine-tuned CNN and the network returns the attention map
Xam related to each image which is associated with the network’s predictions. In the second step, the original image X is used as a input to the pre-training fine-tuned Resnet-18 network while the attention map
Xam is used as an input to the SFT. The network of the second step returns the probability
P of each test image that belongs to each class. Then the class with the highest probability will be considered as the predicted class of the test image.
| Algorithm 1: DDRL-AM |
| 1: Step 1 Generate attention maps |
| 2: Input: Full Image X; |
| 3:Output: Full Attention Map . |
| 4: The pre-trained ResNet-18 model is fine-tuned on the annotated data. |
| 5: Forward the network for X. |
| 6: The weight coefficients in the Grad-CAM are computed by Equation (1). |
| 7: The gray-scale attention maps can be computed by Equation (2). |
| 8: is upsampled to the full image size . |
| 8: Return. |
| 9: Step 2 Learning an end-to-end CNN |
| 10: Input: Full Attention Map and full image X |
| 11: Output: The probability of each test image P |
| 12: WhileEpoch <= N do |
| 13: Take X, Xam; |
| 14: Fuse features extracted from X and Xam; |
| 15: Calculate center-based cross entropy loss Ltotal from Equation (5); |
| 16: BP(Ltotal) get gradient w.r.t θ; |
| 17: Update θ using ADAM; |
| 18: End while |
| 19: Return The probability of each test image P |
3.2. The Approaches for Generating Attention Maps
It is a highly efficient way of generating saliency maps by the gradient information with Grad-CAM [
53] in the field of attention mechanism. The main idea of the Grad-CAM can be illustrated as follows. It calculates weights of each feature map with global average of gradients. Then feature maps are combined with calculated weights to form the attention maps.
A previous study [
54] has suggested that the deeper convolution layer of CNN is a stronger response to the semantic concept in images will be. A major advantage of Grad-CAM is that it can retain the original network structure, such as convolution layer, average pooling layer, and fully-connected layer. The process of generating attention maps will be specifically described as follows.
In order to obtain the saliency map corresponding to all images including training set, validation set and testing set, the proposed DDRL-AM method constitute backward and forward propagation. Firstly, the pre-trained CNN models are fine-tuned on the training dataset of remote sensing images. The CNN module in
Figure 3a represents a trained convolution network model for remote sensing image classification. Note that we use ResNet [
51] as a backbone classification model because this model has been proved to achieve good scene classification performance. Secondly, the Grad-CAM algorithm is used to generate attention maps for each image by feeding them to the fine-tuned CNN module. The details of Grad-CAM can be illustrated as follows.
First of all, the importance of k-th channel feature map for c-th class
can be calculated based on the last fully-connected layer of fine-tuned CNN module and Equation (1).
where
represents the probability that the images belong to c-th class output by the softmax classifier.
denotes the values of the k-th feature map at location (i, j). Z is the number of all pixels in a feature map.
represents the relative importance coefficient of k-th channel feature map for a land-cover class c, which is important for identifying crucial objects in a scene image.
After obtaining the
, feature maps on the last convolutional layer of fine-tuned CNN models are combined with different weights and Rectified Linear Unit (RELU) function so as to eliminate all negative values in AM and aggregate all feature maps as shown in Equation (2).
where
represents the k-th channel feature map. Note that we need to up-sample the AM (7 × 7) to the size of original image (224 × 224). That is because the feature fusion requires the same dimension of outputs by the RGB stream and saliency stream and the size of original image can make us better predict the important objects. The RELU function can be calculated according to Equation (3).
Figure 4 shows the sketch map of generating attention maps from all feature maps by weighting different channels of feature maps from the last convolutional layer of the fine-tuned ResNet18 model with a RELU function. As can be seen in
Figure 4, the airplanes in airport class are considered as important objects. When training networks, the airplane in airport scenes may be laid with more emphasis, which may decrease the influence of redundant objects on extracting high-level features.
The feature fusion is an effective step in scene understanding task. In this section, we propose a simple and effective two-stream deep fusion architecture for remote scene classification. As shown in
Figure 3(2), the first stream is called original RGB stream, which feeds original RGB images into the network. The second stream is named as saliency stream that applies the attention maps as an input. We designed the SFT network to extract valuable information from grey images.
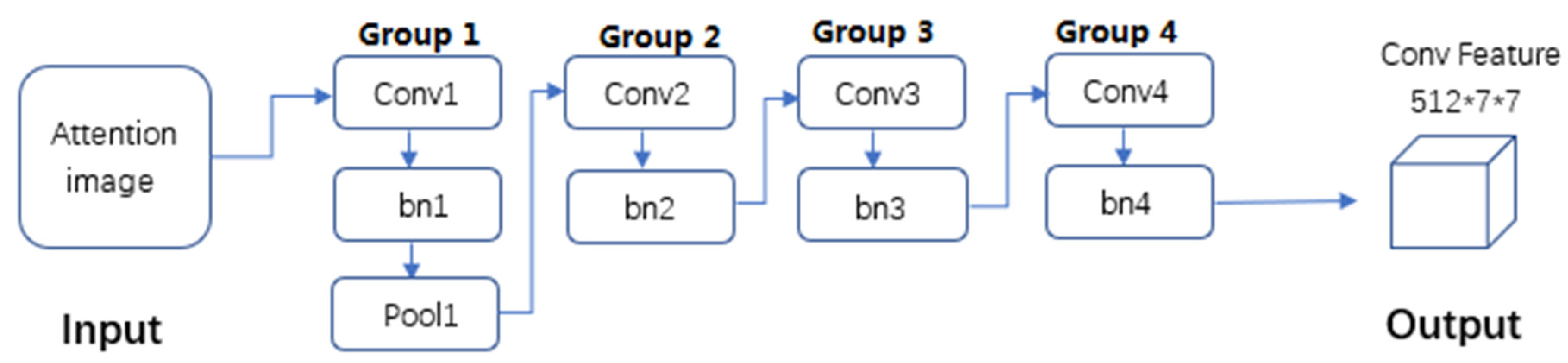
It is noteworthy that the two branches utilize different network structure, respectively, to extract features. The RGB stream is consistent with the ResNet-18 network structure since it has been proven to be effective in scene classification. The proposed SFT is used to extract features for attention maps. The architecture of SFT is presented in
Figure 5 and the specific parameter settings of SFT are shown in
Table 1. Two streams are both with an input of 224 × 224 × 3 and an output of 512 × 7 × 7. SFT contains 4 convolutional layers and 4 batch normalization layers, and one max-pooling layer is only used following the first convolutional layer. The first convolutional layer has 64 filters of size 7 × 7 with a stride of 2 pixels and padding with 3 pixels. The stride and padding of other convolutional layers are set as 2 and 1 pixel, respectively. The second, third, and fourth convolutional layers have 128, 256 and 512 filters with the size of 3 × 3, respectively. The batch normalization layers are consistent with the convolution kernel of the convolutional layer they are connected to. Max-pooling is carried out over a 3 × 3 window with stride 2. The batch normalization layers are aimed to reduce the possibility of overfitting when training the SFT architecture.
We used a spatial feature fusion strategy to fuse feature maps extracted from fine-tuned CNN models and proposed SFT model. In particular, we used multiplicative fusion functions (Equation (4)) for high-dimensional semantic feature fusion.
here, we denote
as the output feature maps of the RGB stream with a size of 512 × 7 × 7. Similarly,
is denoted as the output feature maps of the saliency stream with a size of 512 × 7 × 7. (i, j) is location of (7 × 7) feature maps and d is the channel number which ranges from 1 to 512.
is the feature maps after multiplicative fusion, and its dimension is still 512 × 7 × 7. .× represents the dot product of (7 × 7) feature maps from the RGB and saliency stream in each channel.
The multiplicative fusion can make the fused feature maps contain the sematic information from both the RGB and attention maps by operating dot product of (7 × 7) feature maps from the RGB and saliency stream in each channel. It can increase the discriminative ability of features extracted from scene images.
3.3. The Center-Based Cross Entropy Loss Function
While softmax loss function can help to effectively classify images, it is not enough to classify remote sensing images in a semantic way since feature representations of inner layers are similar for inter-class images. To improve the ability of feature representations to distinguish similar categories, we propose a new learning objective
, which contains softmax loss function
and center loss function
. The formulation of
can be formulated as Equation (5).
As shown in [
12], the scalar λ = 0.5 is used for balancing the two loss functions. The following part elaborates on softmax loss function and center loss functions. The softmax loss function
is widely applied to classification of remote sensing images since it can ensure the convergence speed when the predicted values are close to true labels. The formulation of softmax loss function is shown in Equation (6).
where
represents the features fused by multiplicative fusion for
i-th image whose labels are
denotes the learnt bias and
represents the
j-th column of weights
in the last fully connected layer.
n represents the class number and m is the mini-batch size.
Although the softmax loss function may perform well under some circumstances, it ignores the influence of intra-class diversity on the loss function. Therefore, center loss function is introduced to the softmax loss function. The center loss function was proposed in [
11] to minimize the intra-class variations while keeping the features of inter-class separable. The formulation of center loss function is shown in Equation (7).
where
represents the features fused by multiplicative fusion for i-th image whose labels are
represents centers calculated from features fused by multiplicative fusion belonging to
-th class.
represents the square of L2-norm and m is the batch size of mini-batch.
The formulation of can reduce the influence of intra-class diversity on the loss function while maintaining the discriminative ability of fused features. If we backpropagate the network with the total loss function, the features with the same category will be close and those with diverse classes will be far away, which may decrease the possibility of confusion.

 ,
, 















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}