PreciPatch: A Dictionary-based Precipitation Downscaling Method

 , ,
, ,  ,
,
Abstract
1. Introduction
2. Methodology
2.1. Precipitation Downscaling Based on Dictionary Learning
2.1.1. Dictionary Learning for Super-Resolution
2.1.2. Dynamic Dictionary Learning
2.1.3. Downscaling Workflow
- Select a GCM precipitation product that needs to be downscaled.
- Select a downscaling scale ratio or a desired spatial resolution. Let denote the scaling factor, .
- Select an existing gridded precipitation dataset (observation and bias-corrected data are preferred) that has a native spatial resolution match or close to the desired output spatial resolution . The temporal resolution should also be matched on the same level (e.g., hourly, 6-hourly, daily, etc.).
- Upscale to the spatial resolution level that matches or is close to the GCM precipitation product (a widely used method is to aggregate grids as averages from the higher resolution [30]).
- Use the upscaled output and as inputs to construct the patch dictionary.
- Use the GCM precipitation product as input and perform a similarity search on the constructed dictionary to find an estimated high-resolution patch for each grid.
- Align each high-resolution patch to form a weight mask for the high-resolution precipitation field.
- Use the weight mask as a basis, and the original GCM product as the rain rate constraint to produce the downscaled output.
2.2. High-Resolution Dictionary Construction
2.2.1. Recording the Spatial Difference
2.2.2. The Dictionary Construction Algorithm
2.3. A Dynamic Time Warping (DTW) Based Similarity Search
2.4. Generate the High-Resolution Weight Mask Through a Double-Layer DTW Similarity Fuzzy Search Algorithm
2.5. Patch Dictionary Classification and Loose Index
2.5.1. Dictionary Classification Algorithm
2.5.2. Loose Index Algorithm for Sub-Dictionaries
2.5.3. Updated Similarity Search Based on Dictionary Classification and Loose Index
3. Implementation and Results
3.1. Synthetic Experiments
3.1.1. Study Areas
3.1.2. Dataset
3.1.3. Downscaling Methods
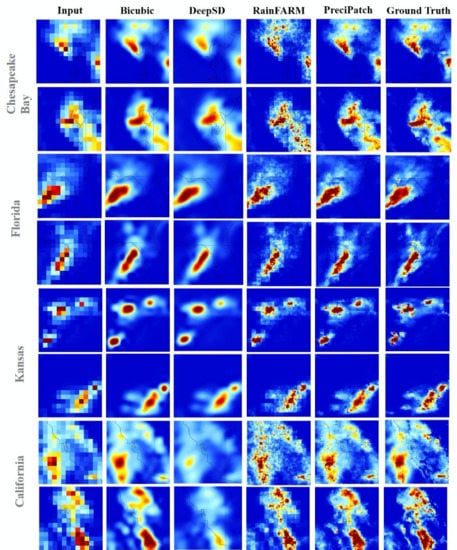
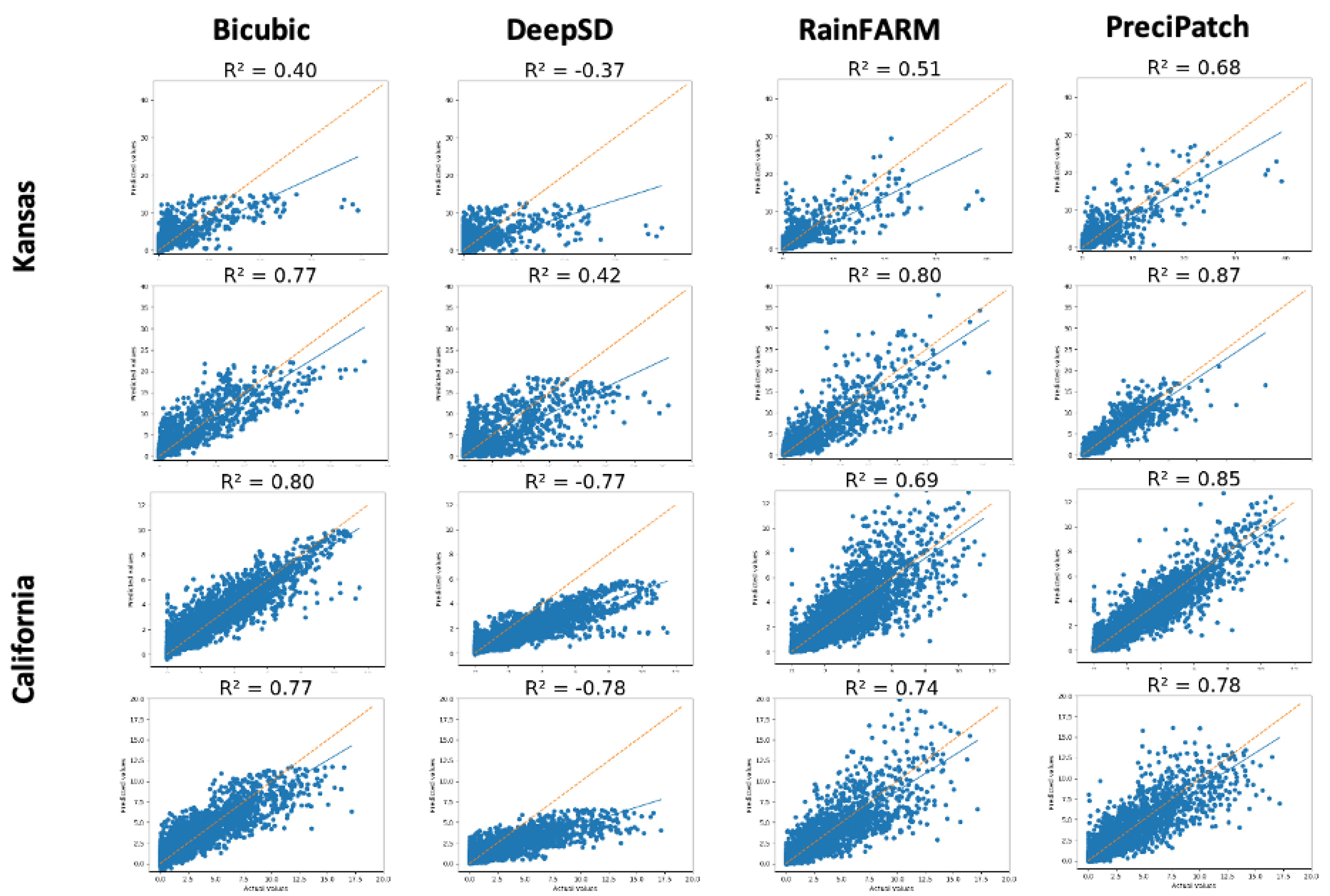
3.2. Results
3.3. Validation and Evaluation
3.4. Discussion
- Full-field generation instead of area limited generation or fixed size.
- Precipitation fields as target production instead of station networks (e.g., single or multiple), providing continuous information in 2D space.
- Precipitation field distribution simulated closer to precipitation observation
- Data independence in production (available for downscaling future predictions).
- Hourly precipitation downscaling to precipitation fields (downscaling short-duration precipitation events) instead of a daily average or seasonal downscaling used in other research.
- Using the prior knowledge learned in one data set and successfully applied to another related data set.
- The rainfall amount is consistent with large-scale vs. rainfall inconsistency in others.
4. Conclusions
- This method does not require additional data as predictors to produce downscaled results, and it could be used for downscaling future estimations from GCMs.
- This downscaling method has the potential to aid climate models like WRF by providing higher resolution inputs.
- The downscaled results from this method could be used to force mountain glacier models for local impact studies, where the complete absence of climate monitoring activities within the regions of interest presents a data challenge.
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Sheehan, M.C.; Fox, M.A.; Kaye, C.; Resnick, B. Integrating health into local climate response: Lessons from the US CDC Climate-Ready States and cities initiative. Environ. Health Perspect. 2017, 125, 094501. [Google Scholar] [CrossRef]
- Fatichi, S.; Ivanov, V.Y.; Caporali, E. Assessment of a stochastic downscaling methodology in generating an ensemble of hourly future climate time series. Clim. Dyn. 2013, 40, 1841–1861. [Google Scholar] [CrossRef]
- Yang, C.; Yu, M.; Li, Y.; Hu, F.; Jiang, Y.; Liu, Q.; Sha, D.; Xu, M.; Gu, J. Big Earth data analytics: A survey. Big Earth Data 2019, 3, 83–107. [Google Scholar] [CrossRef]
- Climate.gov, n.d. Climate Models|NOAA Climate.gov. Available online: https://www.climate.gov/maps-data/primer/climate-models (accessed on 24 August 2019).
- Benestad, R. Downscaling Climate Information. Oxford Research Encyclopedia of Climate Science. 2016. Available online: https://oxfordre.com/climatescience/view/10.1093/acrefore/9780190228620.001.0001/acrefore-9780190228620-e-27 (accessed on 24 August 2019).
- Giorgi, F.; Mearns, L.O. Approaches to regional climate change simulation: A review. Rev. Geophys 1991, 29, 1–2. [Google Scholar] [CrossRef]
- Arritt, R.W.; Rummukainen, M. Challenges in regional-scale climate modeling. Bull. Am. Meteorol. Soc. 2011, 92, 365–368. [Google Scholar] [CrossRef]
- Walton, D.B.; Sun, F.; Hall, A.; Capps, S. A hybrid dynamical–statistical downscaling technique. Part I: Development and validation of the technique. J. Clim. 2015, 28, 4597–4617. [Google Scholar] [CrossRef]
- Wilby, R.L. Statistical downscaling of daily precipitation using daily airflow and seasonal teleconnection indices. Clim. Res. 1998, 10, 163–178. [Google Scholar] [CrossRef]
- Maraun, D.; Wetterhall, F.; Ireson, A.M.; Chandler, R.E.; Kendon, E.J.; Widmann, M.; Brienen, S.; Rust, H.W.; Sauter, T.; Themeßl, M.; et al. Precipitation downscaling under climate change: Recent developments to bridge the gap between dynamical models and the end user. Rev. Geophys. 2010, 48. [Google Scholar] [CrossRef]
- Xu, C.Y. Climate change and hydrologic models: A review of existing gaps and recent research developments. Water Resour. Manag. 1999, 13, 369–382. [Google Scholar] [CrossRef]
- Bronstert, A.; Kolokotronis, V.; Schwandt, D.; Straub, H. Comparison and evaluation of regional climate scenarios for hydrological impact analysis: General scheme and application example. Int. J. Climatol. A J. R. Meteorol. Soc. 2007, 27, 1579–1594. [Google Scholar] [CrossRef]
- Rau, M.; He, Y.; Goodess, C.; Bárdossy, A. Statistical downscaling to project extreme hourly precipitation over the United Kingdom. Int. J. Climatol. 2019, 40, 1805–1823. [Google Scholar] [CrossRef]
- Kundzewicz, Z.W.; Mata, L.J.; Arnell, N.W.; Doll, P.; Kabat, P.; Jimenez, B.; Miller, K.; Oki, T.; Zekai, S.; Shiklomanov, I. Freshwater Resources and Their Management; Parry, M.L., Canziani, O.F., Palutikof, J.P., van der Linden, P.J., Hanson, C.E., Eds.; Climate Change 2007: Impacts, Adaptation and Vulnerability. Contribution of Working Group II to the Fourth Assessment Report of the Intergovernmental Panel on Climate Change; Cambridge University Press: Cambridge, UK, 2007; pp. 173–210. ISBN 9780521880091. [Google Scholar]
- Vrac, M.; Naveau, P. Stochastic downscaling of precipitation: From dry events to heavy rainfalls. Water Resour. Res. 2007, 43, 7. [Google Scholar] [CrossRef]
- Vandal, T.J. Statistical Downscaling of Global Climate Models with Image Super-resolution and Uncertainty Quantification. Ph.D Thesis, Northeastern University, Boston, MA, USA, 2018. [Google Scholar]
- Lenderink, G.; Van Meijgaard, E. Increase in hourly precipitation extremes beyond expectations from temperature changes. Nat. Geosci. 2008, 1, 511. [Google Scholar] [CrossRef]
- Wilks, D.S. Use of stochastic weather generators for precipitation downscaling. Wiley Interdiscip. Rev. Clim. Chang. 2010, 1, 898–907. [Google Scholar]
- Wilby, R.L.; Wigley, T.M.L. Downscaling general circulation model output: A review of methods and limitations. Prog. Phys. Geogr. 1997, 21, 530–548. [Google Scholar] [CrossRef]
- Wilby, R.L.; Charles, S.P.; Zorita, E.; Timbal, B.; Whetton, P.; Mearns, L.O. Guidelines for use of climate scenarios developed from statistical downscaling methods. In Supporting Material of the Intergovernmental Panel on Climate Change; DDC of IPCC TGCIA: Geneva, Switzerland, 2004. [Google Scholar]
- Fowler, H.J.; Blenkinsop, S.; Tebaldi, C. Linking climate change modelling to impacts studies: Recent advances in downscaling techniques for hydrological modelling. Int. J. Climatol. A J. R. Meteorol. Soc. 2007, 27, 1547–1578. [Google Scholar] [CrossRef]
- Tang, J.; Niu, X.; Wang, S.; Gao, H.; Wang, X.; Wu, J. Statistical downscaling and dynamical downscaling of regional climate in China: Present climate evaluations and future climate projections. J. Geophys. Res. Atmos. 2016, 121, 2110–2129. [Google Scholar] [CrossRef]
- Wang, Y.Q.; Leung, L.R.; McGregor, J.L.; Lee, D.K.; Wang, W.C.; Ding, Y.H.; Kimura, F. Regional climate modeling: Progress, challenges, and prospects. J. Meteorol. Soc. Jpn. 2004, 82, 1599–1628. [Google Scholar] [CrossRef]
- Chen, J.; Brissette, F.P.; Leconte, R. Coupling statistical and dynamical methods for spatial downscaling of precipitation. Clim. Chang. 2012, 114, 509–526. [Google Scholar] [CrossRef]
- Jarosch, A.H.; Anslow, F.S.; Clarke, G.K. High-resolution precipitation and temperature downscaling for glacier models. Clim. Dyn. 2012, 38, 391–409. [Google Scholar] [CrossRef]
- Chen, J.; Chen, H.; Guo, S. Multi-site precipitation downscaling using a stochastic weather generator. Clim. Dyn. 2018, 50, 1975–1992. [Google Scholar] [CrossRef]
- Liu, Q.; Li, Y.; Yu, M.; Chiu, L.S.; Hao, X.; Duffy, D.Q.; Yang, C. Daytime Rainy Cloud Detection and Convective Precipitation Delineation Based on a Deep Neural Network Method Using GOES-R ABI Images. Remote Sens. 2019, 11, 2555. [Google Scholar] [CrossRef]
- Rebora, N.; Ferraris, L.; von Hardenberg, J.; Provenzale, A. RainFARM: Rainfall downscaling by a filtered autoregressive model. J. Hydrometeorol. 2006, 7, 724–738. [Google Scholar] [CrossRef]
- Posadas, A.; Duffaut Espinosa, L.A.; Yarlequé, C.; Carbajal, M.; Heidinger, H.; Carvalho, L.; Jones, C.; Quiroz, R. Spatial random downscaling of rainfall signals in Andean heterogeneous terrain. Nonlinear Process. Geophys. 2015, 22, 383–402. [Google Scholar] [CrossRef][Green Version]
- Terzago, S.; Palazzi, E.; Hardenberg, J.V. Stochastic downscaling of precipitation in complex orography: A simple method to reproduce a realistic fine-scale climatology. Nat. Hazards Earth Syst. Sci. 2018, 18, 2825–2840. [Google Scholar] [CrossRef]
- He, X.; Chaney, N.W.; Schleiss, M.; Sheffield, J. Spatial downscaling of precipitation using adaptable random forests. Water Resour. Res. 2016, 52, 8217–8237. [Google Scholar] [CrossRef]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Learning a deep convolutional network for image super-resolution. In Proceedings of the European conference on computer vision, Zurich, Switzerland, 6–12 September 2014; pp. 184–199. [Google Scholar]
- Kim, J.; Kwon Lee, J.; Mu Lee, K. Accurate image super-resolution using very deep convolutional networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1646–1654. [Google Scholar]
- Zhang, Y.; Li, K.; Li, K.; Wang, L.; Zhong, B.; Fu, Y. Image super-resolution using very deep residual channel attention networks. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 286–301. [Google Scholar]
- Ebtehaj, A.M.; Foufoula-Georgiou, E.; Lerman, G. Sparse regularization for precipitation downscaling. J. Geophys. Res. Atmos. 2012, 117. [Google Scholar] [CrossRef]
- Vandal, T.; Kodra, E.; Ganguly, S.; Michaelis, A.; Nemani, R.; Ganguly, R.A. Deepsd: Generating high resolution climate change projections through single image super-resolution. In Proceedings of the 23rd Acm Sigkdd International Conference on Knowledge Discovery and Data Mining, ACM, Halifax, NS, Canada, 13–17 August 2017; pp. 1663–1672. [Google Scholar]
- Freeman, W.T.; Jones, T.R.; Pasztor, E.C. Example-based super-resolution. IEEE Comput. Graph. Appl. 2002, 22, 56–65. [Google Scholar] [CrossRef]
- Itakura, F. Minimum prediction residual principle applied to speech recognition. IEEE Trans. Acoust. Speech Signal Process. 1975, 23, 67–72. [Google Scholar] [CrossRef]
- Keogh, E.; Ratanamahatana, C.A. Exact indexing of dynamic time warping. Knowl. Inf. Syst. 2005, 7, 358–386. [Google Scholar] [CrossRef]
- Tan, C.W.; Webb, G.I.; Petitjean, F. Indexing and classifying gigabytes of time series under time warping. In Proceedings of the 2017 SIAM international Conference on Data Mining. Society for Industrial and Applied Mathematics, Houston, TX, USA, 27–29 April 2017; pp. 282–290. [Google Scholar]
- Yu, M.; Bambacus, M.; Cervone, G.; Clarke, K.; Duffy, D.; Huang, Q.; Li, J.; Li, W.; Li, Z.; Liu, Q.; et al. Spatiotemporal event detection: A review. Int. J. Digit. Earth 2020. [Google Scholar] [CrossRef]
- Yang, C.; Clarke, K.; Shekhar, S.; Tao, C.V. Big Spatiotemporal Data Analytics: A research and innovation frontier. Int. J. Geogr. Inf. Sci. 2019, 1–14. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name: Create the Diff Array |
|---|
| Input: Array , a non-empty array with size Output: , the Diff array of with size 12 Procedure: (1) is defined as: (2) Return |
| Name: Construction of the High-Resolution Dictionary |
|---|
| Definition: is the scaling factor, is one-time slice from a gridded precipitation dataset is the aggregated (upscaled) result from using area average based on the scaling factor Input: Output: , the patch dictionary consists of the low-resolution patch set , high-resolution patch set , and spatial difference set (defined in Table 1) Procedure: (1) For () do { For () do { New Array , Array , Array For () do { For () do { } } Appending as the last element of Appending as the last element of Appending as the last element of } } (2) Return as the integration of sets |
| Name: DTW Distance of Two Data Series with Equal Length (n) |
| Input: Output: Procedure: (1) Construct an n-by-n matrix where the element of the matrix contains the distance between the two points and , (i.e. ). (2) A warping path W is a contiguous set of matrix elements that defines a mapping between A and B. The element of W is defined as, therefore, W is subject to several constrains:
(3) The DTW path is the path that minimizes the warping cost: (4) Define the cumulative distance as the distance found in the current cell and the minimum of the cumulative distances of the adjacent elements: (5) (6) Return |
| Name: Similarity Fuzzy Search Based on a Double-layer DTW Distance |
|---|
| Input: , , is the scaling factor , is the patch dictionary with size for each set is the low-resolution dataset Output: is the downscaled weight mask Procedure: (1) For () do { For () do { New Array , Array , New Array , Array For () do { For () do { } } Let Let Let For each do { If () then { } Else if () then { } Else if () then { } Else {Continue} } } } (2) Return |
| Name: Produce Downscaled Results from a Weighted Mask and Constrains |
|---|
| Input: , , is the scaling factor is the low-resolution dataset is the downscaled weight mask Output: is the downscaled precipitation field from Procedure: (1) For () do { For () do { } } (2) Return |
| Name: Build up Classification |
|---|
| Input: , is the patch dictionary with size for each set Output: The classification code of an element in for an element Procedure: (1) Let (2) For each do { If () then {} Else if () then {} Else if () then {} Else {print (NaN)} } (3) Return |
| Name: Build up a Loose Index for the Sub-dictionary |
|---|
| Input: , is the sub-dictionary under a classification code with size for each set Output: Index set with size Procedure: (1) For each do { Appending as the last element of } (2) Return |
| Name: Using the Classification and Index to Search |
|---|
| Input: , , is the scaling factor , , is the minimum number of patches will be examined Fully classified patch dictionary , for each sub-class with code , the indexed sub-dictionary is with size , for A non-empty array , and its Diff array Output: The similarity fuzzy search results: , Procedure: (1) Find code for and locate the sub-dictionary (2) Calculate for and (3) Calculate absolute differences between and each element in (4) Sort based on the absolute differences in ascending order (5) Find threshold as , if (, then { (6) For each do { If () then { Let Let Let For each do { If () then { } Else if () then { } Else if () then { } Else {Continue} } } Else {Continue} } (7) Return , |
| mm/hour | Bicubic | DeepSD | RainFARM | PreciPatch |
|---|---|---|---|---|
| Average Bias per grid | 0.03 | 0.12 | 4.3 × 10−9 | 0.003 |
| Average R² | 0.18 | -0.16 | 0.29 | 0.42 |
| Average (+) R² | 0.44 | 0.3 | 0.47 | 0.57 |
| RMSE | 0.45 | 0.61 | 0.49 | 0.42 |
| Mean Absolute Error | 0.13 | 0.28 | 0.13 | 0.1 |
| Maximum Absolute Error | 7.75 | 7.95 | 4.2 | 3.87 |
| STDV Absolute Error | 0.2 | 0.27 | 0.09 | 0.07 |
| Bicubic | DeepSD | RainFARM | PreciPatch | |
|---|---|---|---|---|
| Training time | N/A | ~1 hour for 3 months of data (national coverage) | N/A | ~200 hours for 300 Million patches (national coverage) |
| Applicability to different areas? | Direct apply, no training is needed | Additional training is needed if the area is different or the input size is different | Direct apply, no training is needed | Direct apply, no need for additional training |
| Computing time | < 0.001 sec per grid point | ~0.005 sec per grid point | ~0.005 sec per grid point | ~2 sec per grid point per process |
| Overall downscaling performance | Baseline | Not good—close to the baseline | Rainfall clusters are not well simulated | Best |
| Holds rainfall consistency with large-scale input? | No | No | Yes | Yes |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, M.; Liu, Q.; Sha, D.; Yu, M.; Duffy, D.Q.; Putman, W.M.; Carroll, M.; Lee, T.; Yang, C. PreciPatch: A Dictionary-based Precipitation Downscaling Method. Remote Sens. 2020, 12, 1030. https://doi.org/10.3390/rs12061030
Xu M, Liu Q, Sha D, Yu M, Duffy DQ, Putman WM, Carroll M, Lee T, Yang C. PreciPatch: A Dictionary-based Precipitation Downscaling Method. Remote Sensing. 2020; 12(6):1030. https://doi.org/10.3390/rs12061030
Chicago/Turabian StyleXu, Mengchao, Qian Liu, Dexuan Sha, Manzhu Yu, Daniel Q. Duffy, William M Putman, Mark Carroll, Tsengdar Lee, and Chaowei Yang. 2020. "PreciPatch: A Dictionary-based Precipitation Downscaling Method" Remote Sensing 12, no. 6: 1030. https://doi.org/10.3390/rs12061030
APA StyleXu, M., Liu, Q., Sha, D., Yu, M., Duffy, D. Q., Putman, W. M., Carroll, M., Lee, T., & Yang, C. (2020). PreciPatch: A Dictionary-based Precipitation Downscaling Method. Remote Sensing, 12(6), 1030. https://doi.org/10.3390/rs12061030